1. Introduction
With the rapid development of the power industry, the healthy and stable operation of power transformers as key equipment of the power system is crucial to the safe operation of the entire power system. Therefore, it is essential to proactively forecast the operational status of power transformers and promptly implement appropriate measures to address any anomalies [
1]. During the long-term operation of the transformer, the internal insulating oil will deteriorate, causing a small amount of hydrocarbon gas to dissolve in the insulating oil [
2]. Generally speaking, with the extension of the operating time, the dissolved gas content will gradually accumulate, and the hydrocarbon gas is mostly flammable gas, which poses a great threat to the safe operation of the transformer [
3]. Therefore, monitoring the change of dissolved gas content in oil becomes the basis for ensuring the safe and reliable operation of transformers [
4].
In recent years, there has been a growing research focus on the analysis of dissolved gases within transformers. These research methods can be divided into the following categories: dissolved gas prediction method based on the autoregressive integral moving average (ARIMA) model [
5], which is implemented based on mathematical-statistical principles through simple parameter estimation and model selection. However, the model requires a large amount of gas data as a sample and has high requirements for data stability, in addition, the model can only capture linear relationships, and the processing ability of nonlinear relationships is poor. However, in practical applications, sample data is lacking and the data fluctuates greatly, so the model is not suitable for practical engineering applications [
6]. Dissolved gas prediction methods based on the grey model (GM) [
7,
8] only require a small amount of gas data to predict gas content over a period in the future. However, this method requires the original data to have a monotonic tendency to change, and it fails when the data oscillates or steeply rises (dip). In recent years, AI methods have been applied in this area, with back-propagation neural networks (BPNNs) [
9] being one of the most used gas prediction methods, which has strong learning ability and data fitting ability. However, this method requires a large amount of sample data for model training, and the training time is long, which makes it easy to fall into the local optimal solution [
10]. Recurrent neural networks (RNNs) are commonly used in time series data modeling and testing research [
11], and their variants LSTM and GRU are developed on its basis [
12,
13], which can solve the problems of gradient vanishing and gradient explosion existing in the original RNN, and better consider the long-term dependence between data for time series and reduce the impact of information attenuation. However, both RNN and its variant network need to clearly set many time-series feature training data, and have strict requirements for the hidden layer neuron and layer number settings, too few settings make it difficult to achieve the expected results, and too many settings will greatly increase the training time. In the long-term prediction process, errors accumulate and increase prediction errors due to slow network model updates and increased repetitions [
14]. Support vector machines (SVMs) and extreme learning machines (ELMs) are suitable for solving small-sample prediction problems [
15,
16], both of which are robust in processing nonlinear data and can effectively avoid over-fitting problems. Compared with ELM, SVM has more parameters, parameter tuning is more difficult and lacks the ability to capture time series, which is not suitable for modeling long-term time series dependencies. While the above methods have achieved some success in gas forecasting, there are still some shortcomings. On the one hand, when the test data fluctuates sharply, such as steep rises or drops, the network model cannot effectively capture this change process. On the other hand, since the transformer itself operates in a strong magnetic field, the data acquisition and transmission process may be interfered with by noise (pulses). Neural networks lack the ability to handle anomalous data, which may increase prediction errors [
17]. Therefore, how to avoid the impact of data abruptness or oscillation on gas prediction deserves further study.
As an efficient method of data processing, modal decomposition (MD) methods [
18,
19] have been widely used in the field of photovoltaic and wind power prediction. This method can transform the mutation dataset into a smooth dataset in multimodal conditions, effectively reducing the impact of data mutation, but it is rarely used in the prediction of dissolved gas in transformer oil. Riaz et al. used empirical mode decomposition (EMD) technology to extract features from the signal first, and then input the extracted feature signal to SVM for classification processing and finally achieved good classification results [
20]. However, the EMD method has certain shortcomings in extracting signal mutation information, which is prone to modal aliasing, resulting in the inability to completely decompose the noise (mutation) components in the signal [
21]. Variational modal decomposition (VMD) can eliminate modal aliasing [
19], and the frequency characteristics of the decomposed modal components are obvious, the stationarity is high, and the modes are independent of each other, which is conducive to data prediction and processing. The core idea of VMD is to convert the original signal into some non-recursive variational mode calculation process through decomposition, using effective bandwidth iteration and center frequency search to obtain the best decomposition signal [
19]. Like the wind power prediction data set, the dissolved gas content in transformer oil often shows the characteristics of poor regularity and high fluctuation. VMD has high decomposition accuracy when processing complex data and can avoid modal aliasing, but it is necessary to set appropriate balanced iterative mode filtering (BIMF) parameters, penalty factors, and tolerance coefficients. Among them, BIMF parameters have the greatest impact on the decomposition accuracy of the model, when the BIMF value is large, it will lead to excessive decomposition and increase the amount of calculation, and when the BIMF value is too small, it will lead to insufficient extraction of the original data features [
22]. In addition, although the modal signal obtained by VMD decomposition becomes smooth, there is still a sharp fluctuation (nonlinearity), which makes the machine learning model represented by ELM have a predictive risk. As an effective information theory learning criterion, the maximum correntropy criterion (MCC) [
23] of the Gaussian kernel function can capture the high-order statistics of error information, which has potential advantages in dealing with nonlinear problems and suppressing noise (outliers) [
24], and its practicability and effectiveness have been verified in the fields of state estimation and target tracking [
25,
26]. After the above analysis, we need to solve the following problems: First, it is difficult to adjust the parameters of the VMD decomposition method. The second is VMD decomposition, although it decomposes the mutation data into smoothed data in multiple modalities. However, the decomposed data is still a nonlinear fluctuation signal, which is not conducive to the direct use of the machine model.
The contributions of this work are summarized as:
- (1)
The dissolved gas content in power transformer oil is characterized by poor regularity and large fluctuations. The VMD method will be used to handle this complex data, which has high decomposition accuracy and can avoid modal aliasing. However, the use of the VMD method requires setting the appropriate number of decomposition layers K and the penalty factor to obtain the optimal decomposition results. To solve this problem, we can introduce the MPA optimization method to adjust the parameters of VMD, to avoid the increase of prediction error caused by insufficient or excessive mode decomposition;
- (2)
Given the high computational efficiency of ELM, it has great advantages in handling small sample data and un-modeled nonlinear approximation. However, classical ELM is not suitable for unmodeled nonlinear test systems that lack prior information, nor for systems with large fluctuations in data [
27]. To improve the robustness of ELM in processing mutation data, we define a new ExMCC criterion and introduce it into the ELM to develop a novel learning model, which is called ExMCC-ELM;
- (3)
Based on the above IPVMD and ExMCC-ELM, we propose a prediction model for dissolved gas in transformer oil. Firstly, the IPVMD decomposition of the dissolved gas sequence data in oil in the transformer is carried out to obtain an easy-to-process stationary data set, and then the ExMCC-ELM model is established for gas data prediction on the dataset. The simulation results show that the robust prediction method based on IVMD-ExMCC-ELM proposed in this paper can accurately predict the gas content under the condition of uncertain gas content abrupt changes and oscillation laws.
2. Improved VMD
2.1. Variational Mode Decomposition (VMD)
VMD is a signal processing method that aims to decompose complex signals into multiple intrinsic mode functions (IMFs) components. Each component has its own center frequency and limited bandwidth, and the sum of all components should be equal to the input signal. The principle of VMD can be described as follows:
(1) A constrained variational problem is constructed to obtain the decomposition results of the signal, where each component corresponds to an intrinsic mode function.
The constrained variational problem can be formulated as follows:
where
is the set of
k IMF components obtained through VMD decomposition;
is the set of center angular frequencies for each IMF component;
is the unit impulse function;
represents the first-order derivative of the function with respect to time
t;
represents convolution operation.
(2) To solve the constrained variational problem in the VMD method, it can be transformed into an unconstrained variational problem by introducing a quadratic penalty factor
and Lagrange multiplier operator
. Specifically, introducing the quadratic penalty factor
ensures a higher accuracy of signal reconstruction in the presence of Gaussian noise. Introducing the Lagrange multiplier operator
ensures that the constraints are satisfied during the solving process. Based on this, the augmented Lagrange function
can be derived as follows:
To further solve the variational problem mentioned above, the alternating direction method of multipliers (ADMM) can be used. In ADMM, a set of variables (
,
and
) are updated iteratively until convergence is reached to find the saddle point of the augmented Lagrange expression. The corresponding update expressions are as follows:
To obtain the IMF components, the iterative update of variables should be performed until the iteration-stopping condition is satisfied. Once the iteration-stopping condition is met, the iterative updates can be terminated, and the IMF components can be obtained. In general, how to select the optimal K is still an important issue for the performance of the VMD, this work will use a novel optimization method to address this problem.
2.2. Marine Predators Algorithm (MPA)
MPA is a new type of meta-heuristic optimization algorithm that is initialized in the same way as most meta-heuristic search algorithms. The initial solution is evenly distributed over the search space on the first test. This approach helps the algorithm better explore the search space to find a better solution.
In the MPA process, optimization is based on different speed ratios of the three stages of the predation-predation cycle. The three-stage prey position update pattern can be described as follows [
28]:
- (1)
When the rate is relatively high, or the prey moves faster than the predator, the following mathematical model can be used to apply the rule:
When
,
where
is a random vector containing a normal distribution based on Brownian motion;
is a constant equal to 0.5;
is the vector of random numbers in [0, 1];
means multiplying by entries;
is the current number of iterations;
is the maximum number of iterations.
- (2)
The following model is applied when the rate ratio is relatively low or when predators and prey move at almost the same speed:
When
, for the first half of the population:
For the second half of the population:
where
is a vector of random numbers based on the Lévy distribution, indicating Lévy motion, while prey updates its position based on the predator’s movement in Lévy motion;
is calculated in the same way as Equation (8).
- (3)
When the low rate is faster than the predator than the moving prey, the following model is applied:
When
,
The product of and simulates the movement of the predator in the Lévy strategy, while increasing the step size at the position simulates the movement of the predator to help update the predator’s position; and is adaptive parameters used to control the predator’s movement step.
- (4)
Vortexes and fish gathering facilities (FADs) also have an impact on the behavior of marine predators, and they are often considered locally optimal solutions in the search space. With this in mind, introducing the FADs effect during the simulation process can avoid falling into the local optimal solution. Therefore, we can mathematically represent the FADs effect:
where
is
the possibility of influencing the optimization process;
is a binary vector containing 0s and 1s;
is a consistent random number in the range [0, 1];
and
are vectors representing the upper and lower bounds of the dimension, respectively; The subscripts
and
are random indexes of the prey matrix.
2.3. MPA-Optimized VMD
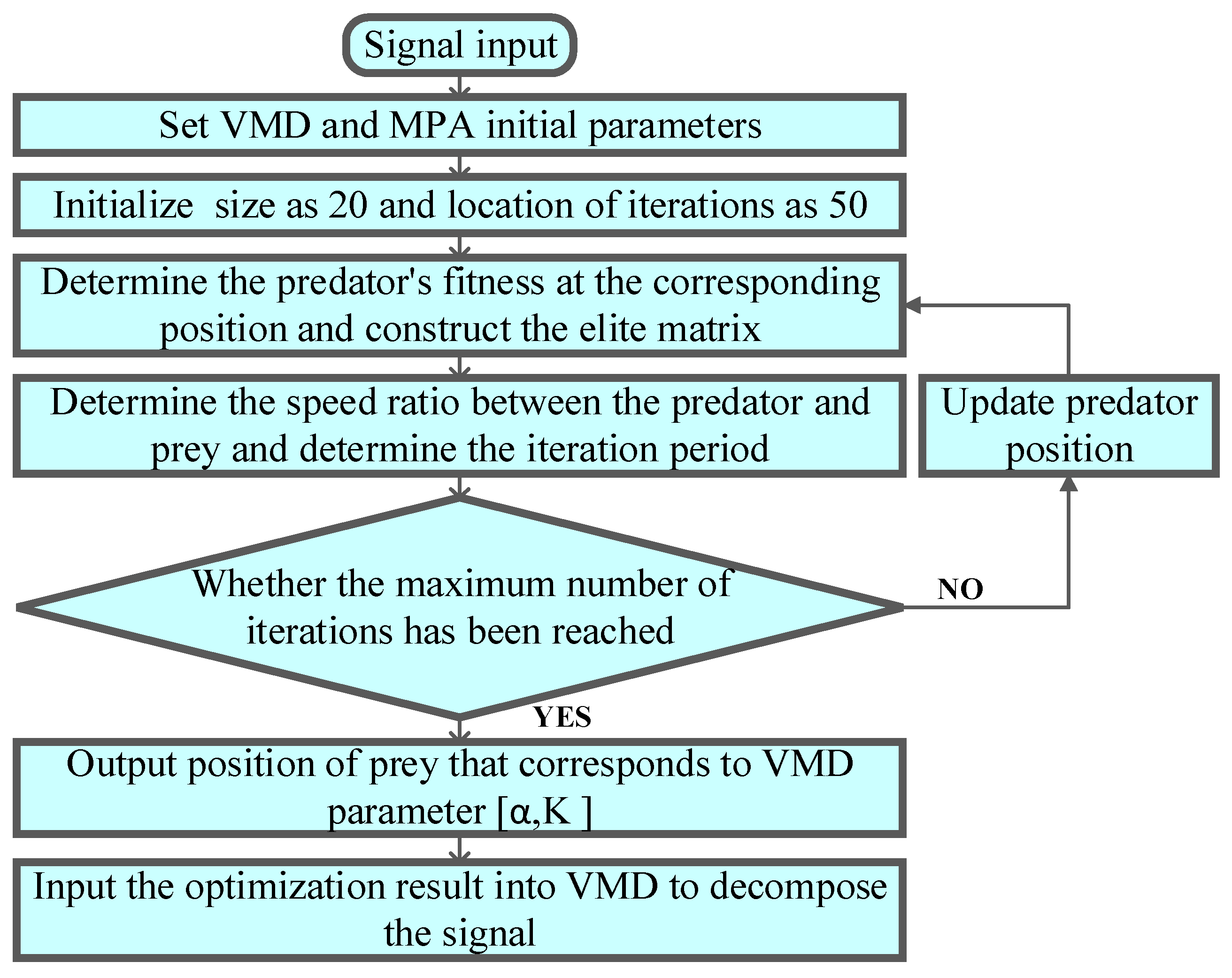
In the process of optimizing VMD parameters using MPA, the selection of the appropriate fitness function plays a crucial role in the optimization results. In this paper, the overall orthogonality index IO of the decomposed IMF is selected as the fitness function for parameter optimization. IO reflects the degree of confusion between the orthogonality and decomposition results of the IMF components, with smaller values indicating better orthogonality. In the MPA algorithm, the prey position parameter corresponds to the value of the variable.
IO can be expressed by the following formula:
where
is the spectral radius of the correlation coefficient matrix between the IMF components, and
is the natural exponential function.
The correlation coefficient matrix between the various IMF components obtained by the IMF decomposition is denoted as
, and the spectral radius
of the correlation coefficient matrix is defined as:
where
denotes the modulus of the eigenvalues of the matrix
.
By selecting IO as the fitness function, the MPA algorithm will minimize the IO value by adjusting the value of the parameter, so as to make the IMF components after VMD decomposition more orthogonal, and the decomposition result more structured and interpretable. The prey position parameter is the parameter that needs to be optimized, and the optimal solution to minimize the fitness function (IO value) is found by constantly updating the value of the prey position parameter, and then the optimal number of decomposition layers K and the penalty parameter α. This can improve the decomposition effect of the VMD algorithm and the accuracy of signal processing. The specific process is as follows [
29]:
- (1)
Set the initial parameters of the VMD and MPA algorithms;
- (2)
Initialize the number of predator populations and the number of iterations in the MPA algorithm. Considering the influence of population size and number of iterations on optimization accuracy and computational efficiency, this paper defines the population size as 20 and the number of iterations as 50;
- (3)
Initialization produces initial prey, and predators build an elite matrix (predator vector). Note that both predators and prey consider themselves search agents because when predators search for prey, the prey is also looking for food. Calculate the fitness value corresponding to that time;
- (4)
The MPA optimization process, as described in
Section 2.2;
- (5)
After updating the predator’s position, the corresponding fitness is calculated and compared to the previous fitness value. Choose the best fitness position as the top predator position;
- (6)
Repeat steps (1–5) until the termination condition is met and output the apex predator position coordinates, which are input into the VMD as the optimal parameters for the decomposition signal.
The flowchart of MPA to optimize VMD is given in
Figure 1.
It should be noted that in situations where the input dataset exhibits weak correlation, managing the IMF components can be challenging. One approach to addressing this issue is to employ advanced feature selection methods and incorporating domain knowledge can further enhance the management of IMF components in such challenging scenarios. Additionally, one can try to use them in combination with other IMF components that are more correlated. By synthesizing multiple IMF components, the accuracy and stability of the predictive model can be improved.
3. Extreme Learning Machine with Extended Maximum Correntropy Criterion
3.1. Extended Maximum Correntropy Criterion
Correntropy is an effective measure of the generalized similarity between two random variables. Given two random variables
, the correntropy can be defined as [
23]:
where
represents the kernel function with kernel width;
is the expectation operator. The Gaussian kernel is usually used as a kernel function in (18), expressed as:
One can see from (17) that the correntropy only contains a second-order moment of error (SOME) with a single kernel width in the exponent part, which may lead to unsuitable performance for complex environments. Therefore, this paper will design a new extended correntropy consisting of two SOME with two different kernel widths in the exponent part, called extended correntropy (ExC), which is defined as:
where
is the parameter that determines the ratio of two kernels;
and
are different kernel widths, and when
or (
), the ExC will degenerate to the original correntropy.
In practice, the probability density function of the two random variables is unknown, and the number of samples
is finite. Therefore, the sample mean estimate in Equation (20) is defined as:
where
N represents the number of samples,
and represents the
i-th element of random variables
and
.
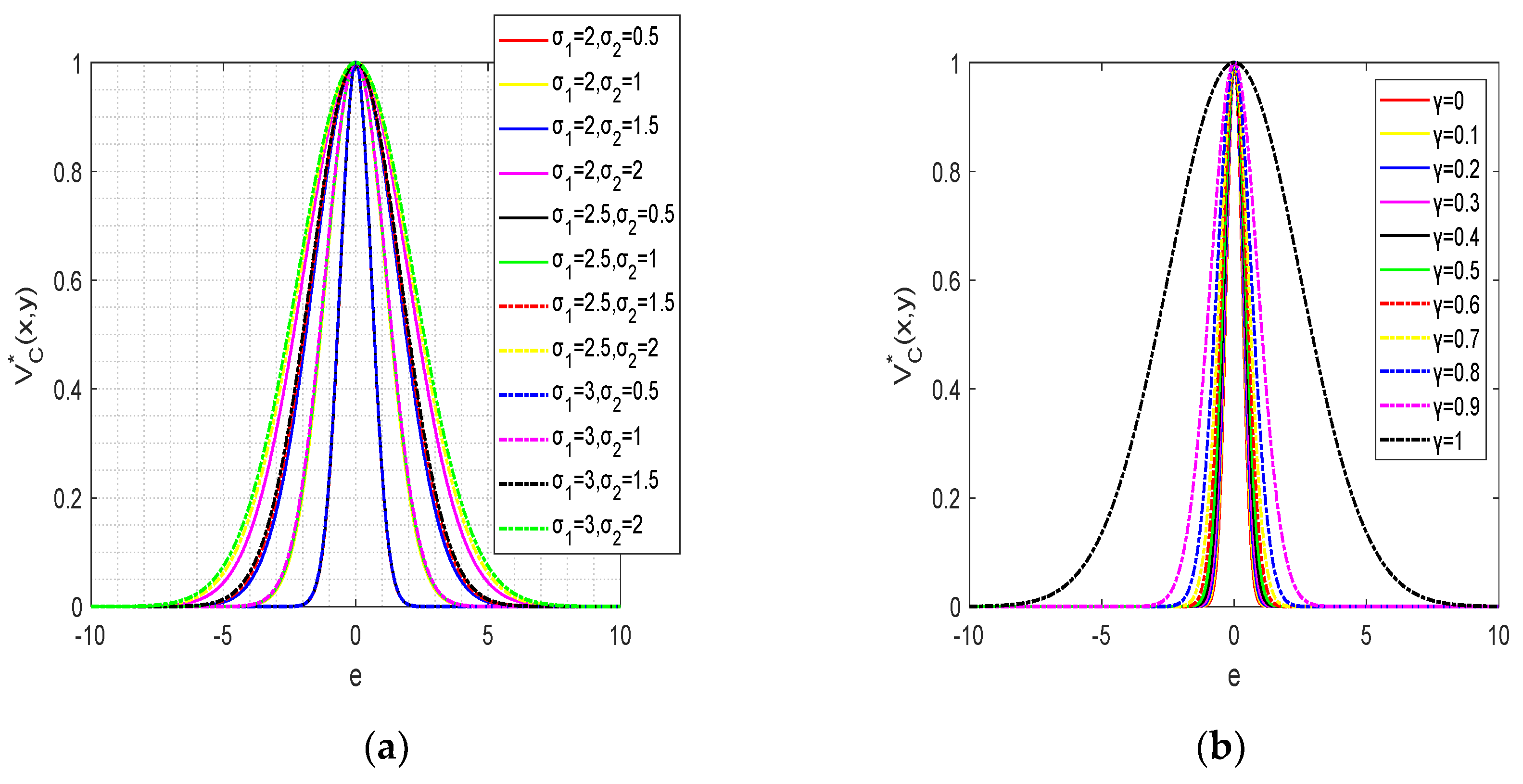
Figure 2 shows the function curve under different parameters, as can be seen from
Figure 2a, when
y is constant and
, the curve gradually becomes flat as
increases. It can be seen from
Figure 2b that when the kernel width value is constant, the function curve tends to be flat with the crease of
, but the overall trend still meets the requirements of convergence and boundedness.
Finally, in conjunction with
Figure 2, we summarize the general properties of ExMCC as follows [
30]:
Property 1: Symmetry, .
Property 2: is positive and bounded, .
Property 3: If , then represents a combined second-order statistic that maps the feature space.
Based on the above properties, we can easily conclude that ExC is an extended form of correntropy. Compared with correntropy, when we select the appropriate free parameters in ExC, it is not only more robust to abnormal data, but also has better convergence speed and stability. Similar to correntropy, the EXC is capable of suppressing the interference of non-Gaussian noise due to its inherent robustness to outliers and its ability to capture higher-order statistical moments beyond the mean and variance. Unlike traditional measures such as the MSE, which are sensitive to outliers and assumptions of Gaussianity, the ExC is based on the probability distribution of the data, allowing it to effectively mitigate the impact of non-Gaussian noise by focusing on the underlying statistical structure of the data rather than solely relying on the second-order statistics. This enables ExC to better capture the true underlying signal in the presence of non-Gaussian noise, making it a valuable tool for robust signal processing. Like the maximum correntropy criterion (MCC), the ExC can also be used as a learning criterion in machine learning fields, which will be denoted as extended MCC (ExMCC) in this work.
3.2. Extreme Learning Machine
An extreme learning machine (ELM) is a single hidden layer feed-forward neural network. The number of hidden layer nodes is usually set artificially, while the input weights and biases are determined randomly. In the process of learning and calculation, the weights and biases are not iteratively calculated, and the optimal solution can be calculated when training data is available. Therefore, compared with traditional feedforward networks such as BP, ELM has more advantages in time series data prediction such as fast training speed, strong generalization ability, fewer hyperparameters, and high accuracy. Recently, ELM has been widely used in the forecasting of time series data, and satisfactory prediction results have been obtained. The calculation procedure of the ELM can be described as follows:
Given a set of sample data
, where
and
represent N-dimensional input and desired output vectors, respectively. Therefore, the hidden layer output of ELM can be expressed as:
where
is the output of the
i-th hidden layer node;
is the weight between the input layer and the hidden layer;
is the hidden layer bias;
is the hidden layer activation function, and in this study, sin is used as the activation function.
Then, we further get the ELM output as:
where
is the output matrix;
is the hidden layer output matrix;
is the weight between the output layer and the hidden layer.
By solving the Moore-Penrose generalized inverse matrix of
, and training the ELM by using the input weights and hidden layer bias, the output weights are obtained:
When employing ELM for time series data forecasting, in certain instances, the weight of the final output of ELM may exhibit significant fluctuations due to substantial changes in forecasted data, consequently leading to poor stability of the forecast results. To address this issue, this paper introduces the ExMCC robust criterion, designed to be impervious to abnormal data, thereby enhancing the robustness of ELM in the presence of abnormal data and effectively mitigating the issue of weight fluctuations caused by abnormal data.
3.3. ELM with ExMCC
In this section, we use ExMCC as a learning criterion for ELM to develop a robust ELM model named ExMCC-ELM, so that when the training data is contaminated, the ELM output can be guaranteed to have a stable optimal weight. The detailed derivation process of ExMCC-ELM is as follows.
Based on the theoretical basis of ExMCC, we rewrite Equation (21) as:
where
represents the desired output;
represents actual output;
,
and represents the
i-th elements of
and
.
The optimal solution of the weight
is obtained using the maximization cost function
. Specifically,
finds the differential with respect to the gradient method and makes it zero.
where
represents the diagonal matrix.
Obviously, Equation (26) is a fixed-point equation
, so the fixed-point iterative method is used to calculate the optimal solution for
. The overall calculation flow of the proposed ExMCC-ELM algorithm is organized in Algorithm 1. In addition, in ExMCC-ELM, it will degenerate into MC-ELM when
or
. Using ExMCC as a learning criterion for ELM can improve ELM robustness by utilizing its ability to model and suppress non-Gaussian noise. Traditional ELM assumes that both input data and noise follow a Gaussian distribution, but in practical applications, non-Gaussian noise such as outliers can often interfere with the data. ExMCC allows for the modeling of non-Gaussian noise. By maximizing the ExC between features and noise, the influence of outliers on the ELM model can be reduced, better adapting to the characteristics of non-Gaussian noise. Therefore, using ExMCC as the learning criterion for ELM can improve ELM robustness in dealing with abnormal data.
| Algorithm 1. ExMCC-ELM model. Initialize ExMCC-ELM: |
Training phase:
Training input:
Training output:
Testing phase:
Testing input: and
Testing output:
1. For to
2. Calculate the error vector , based on the initial :
3. Calculate the diagonal matrix
4. Calculate the output weight
5. Determine whether the loop ends:
6. End For |
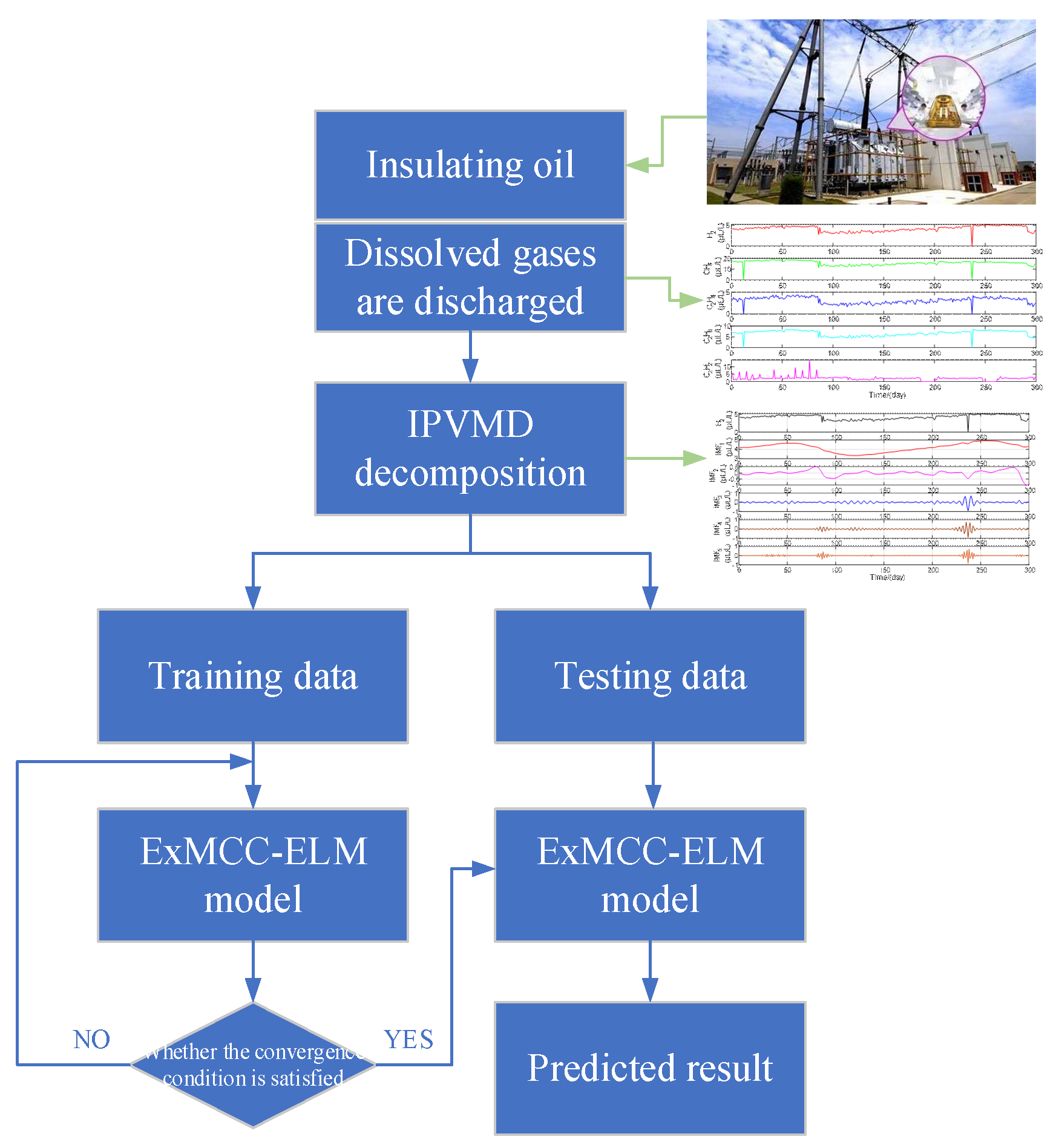
By using the decomposed data obtained from the VMD with MPA optimization developed in
Section 2, one can train the proposed model ExMCC-ELM, and then use the test data to evaluate its prediction capability.
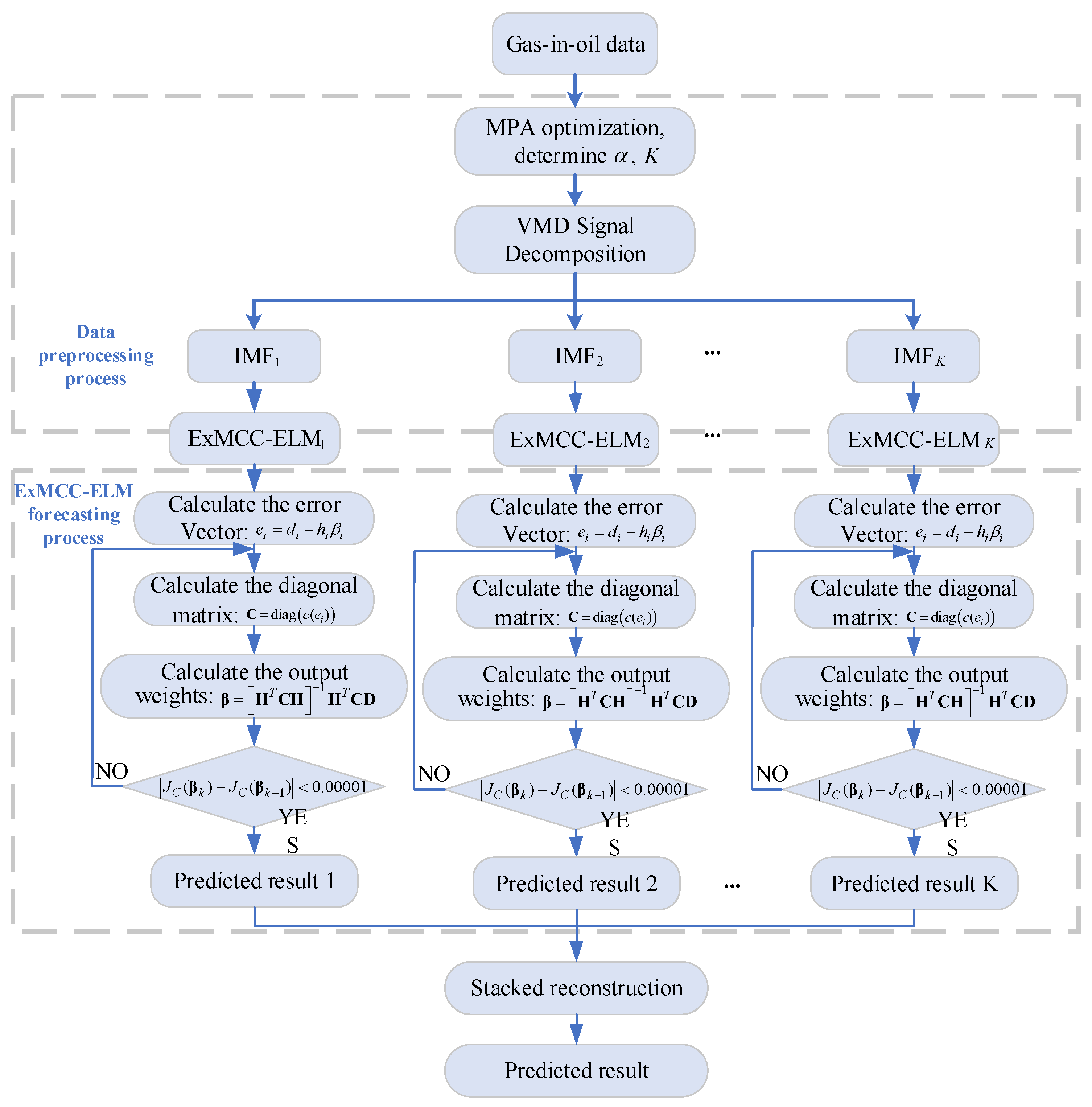
Figure 3 gives a diagram to illustrate the complete prediction process by using the proposed method for dissolved gases forecasting.
4. Gas-in-Oil Prediction Scheme via ExMCC-ELM and IPVMD
4.1. Data Construction
Given the large variety of internal gases in power transformers, the connection between individual gases is not tight and the amount of data is lacking. To solve this problem, this paper uses the method of constructing data pairs to predict various gases.
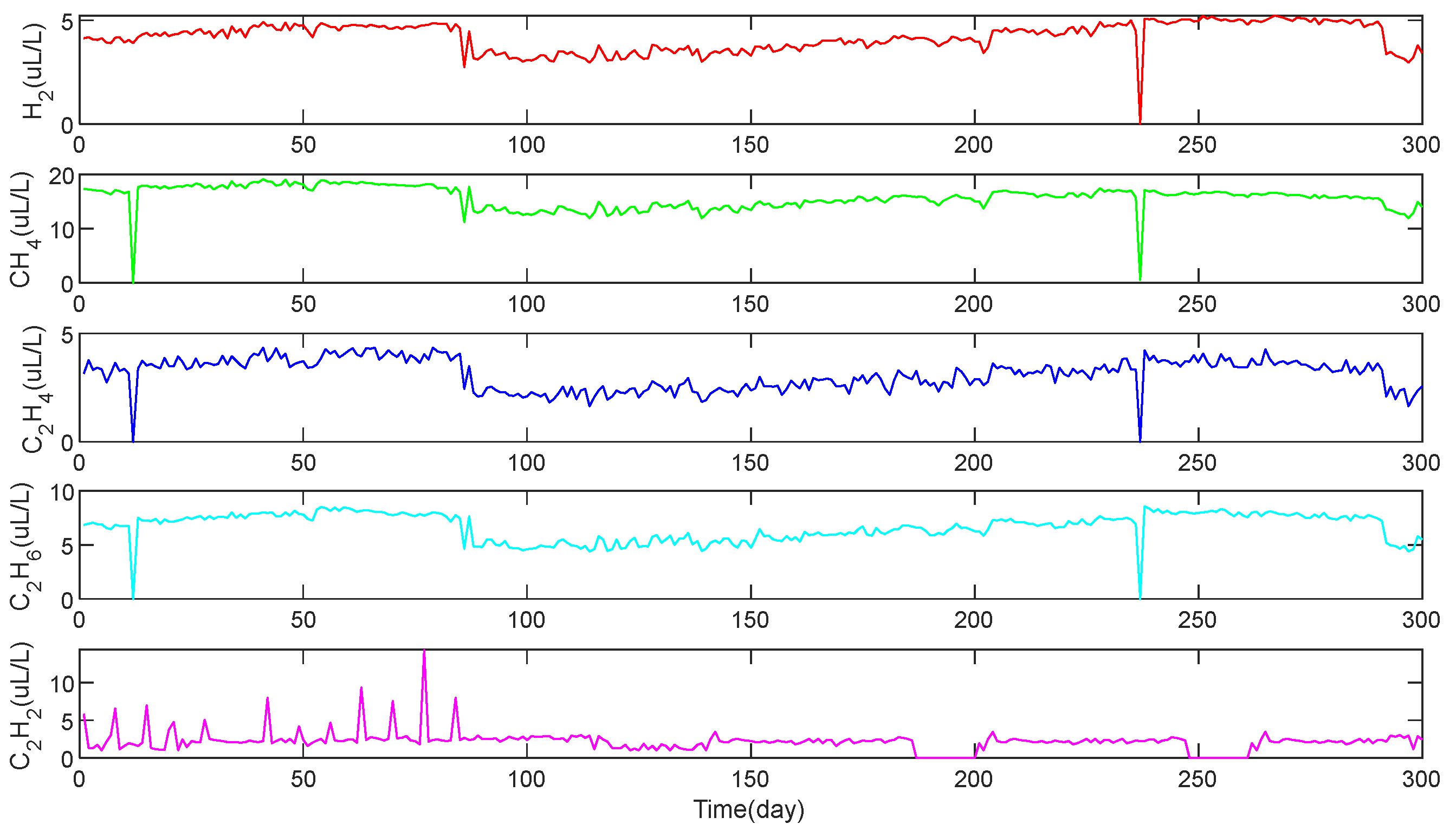
Firstly, the dissolved gas data in the oil
[
31] are used as inputs for IPVMD decomposition, and the decomposition vectors of these five gases were obtained respectively.
The raw dissolved gases in oil data are shown in
Figure 4.
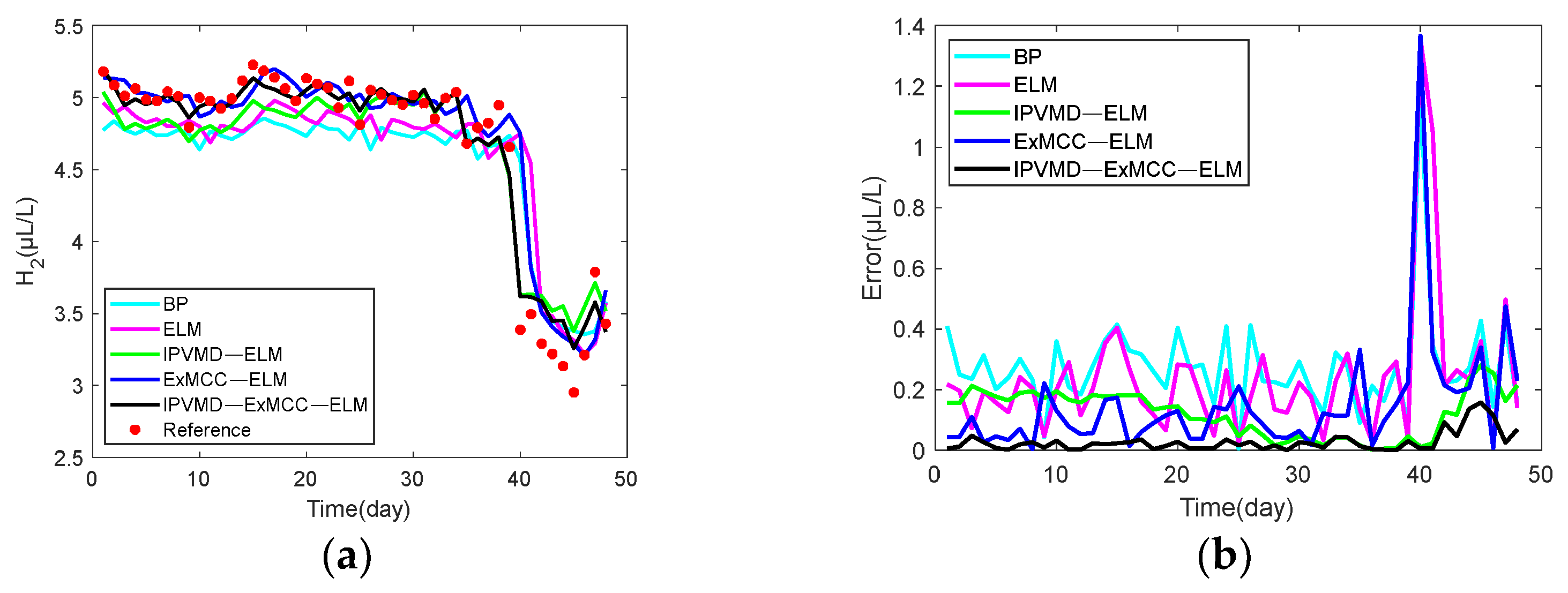
To verify whether IPVMD can efficiently extract the temporal information of the gas content sequence. Taking
gas as an example, the IPVMD method was used to perform modal decomposition of the raw
data.
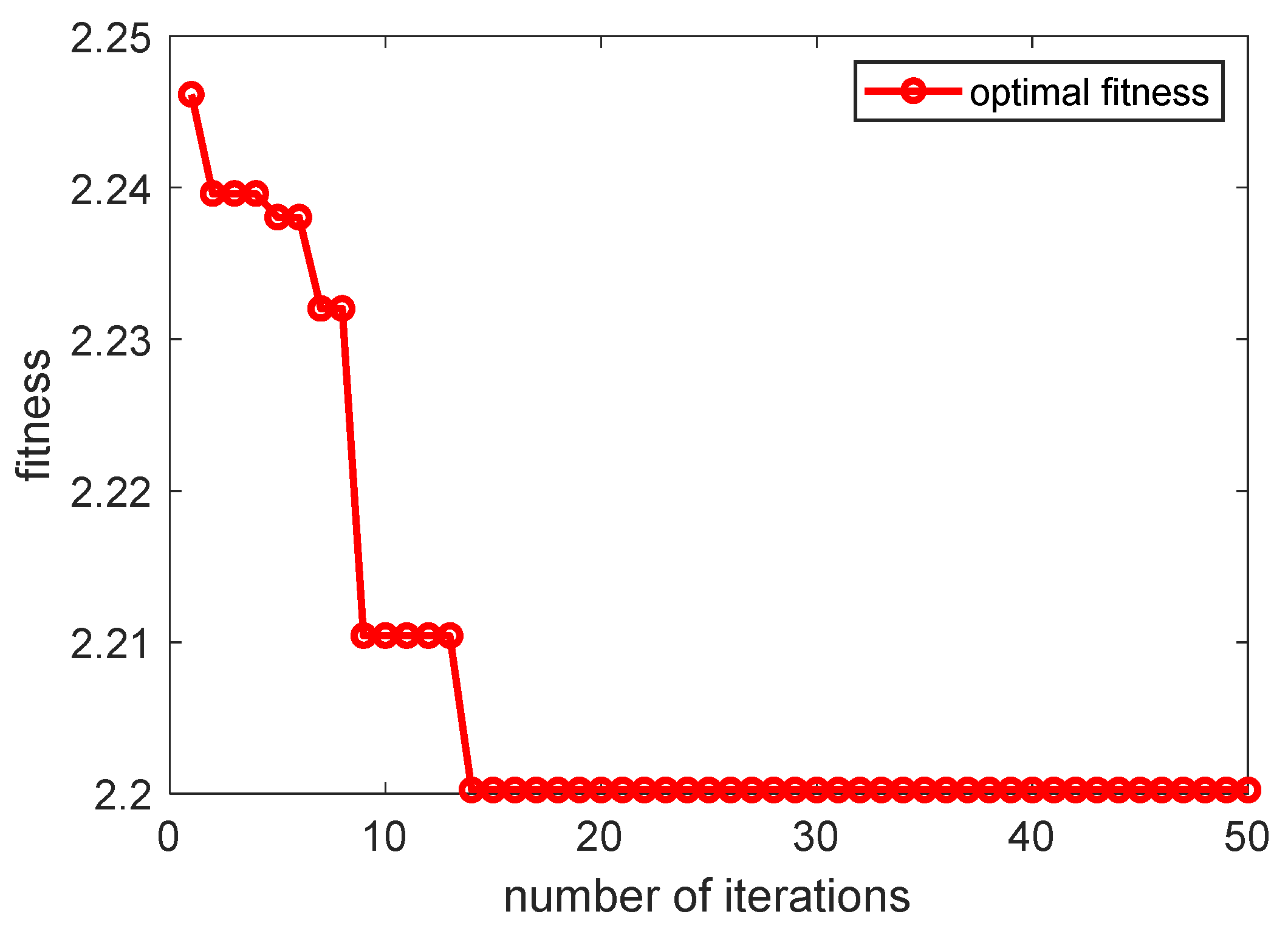
Figure 5 illustrates the convergence curve of the MPA-optimized VMD decomposition
process.
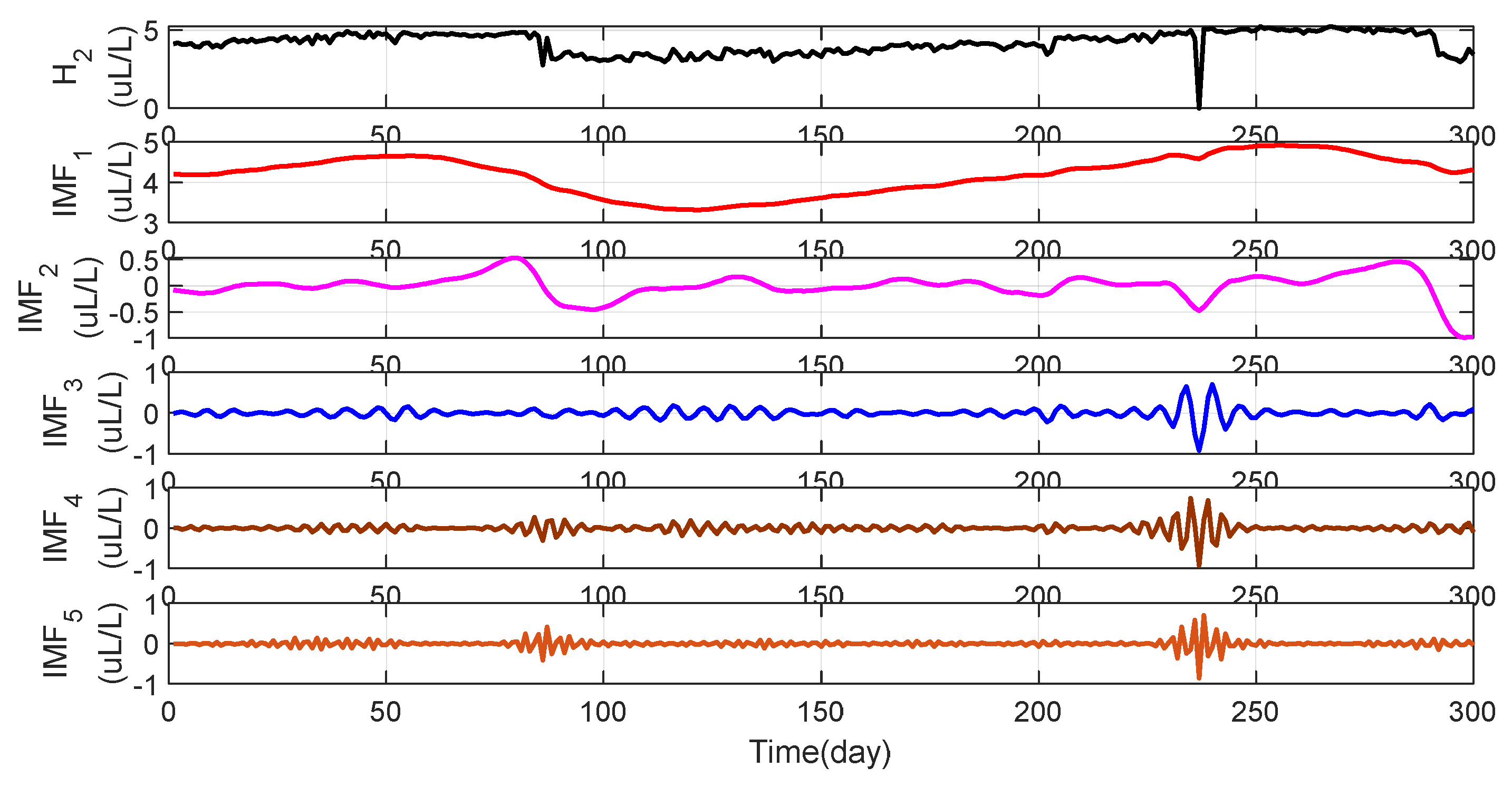
Figure 6 shows the raw data of
and the five-modal data
after IPVMD decomposition and the optimized K is selected as 5 by using the MPA algorithm. It can be seen from
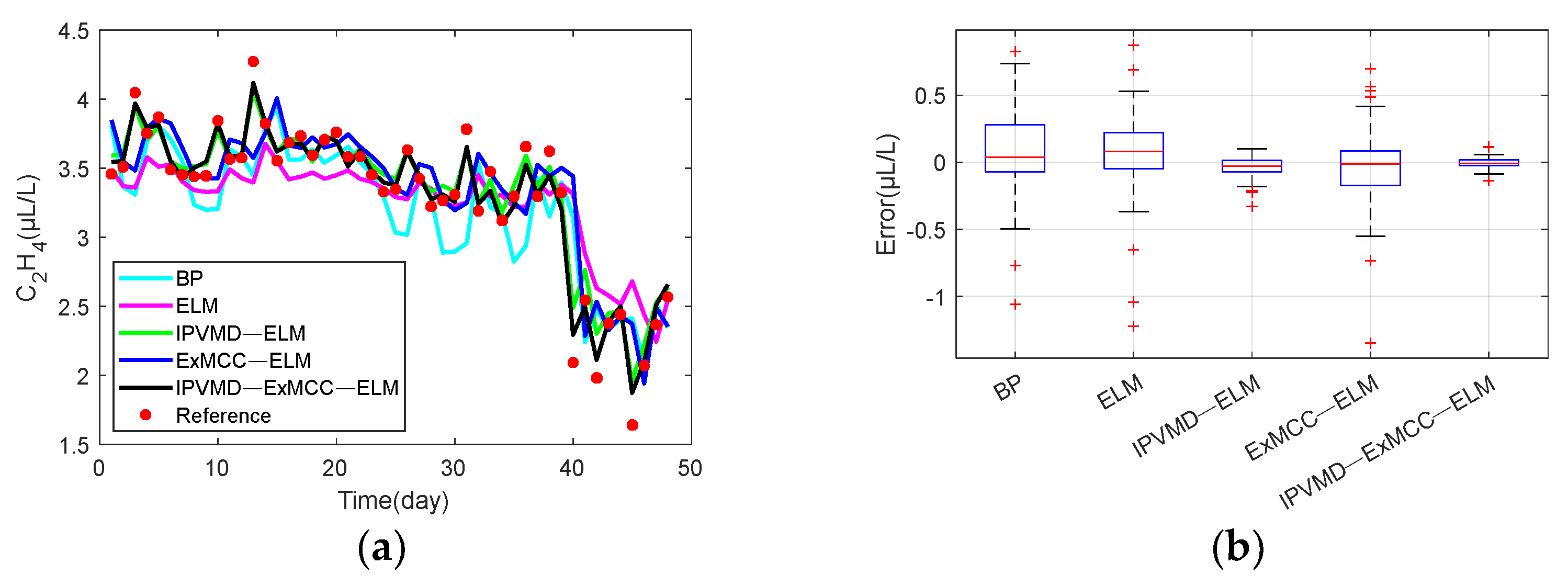
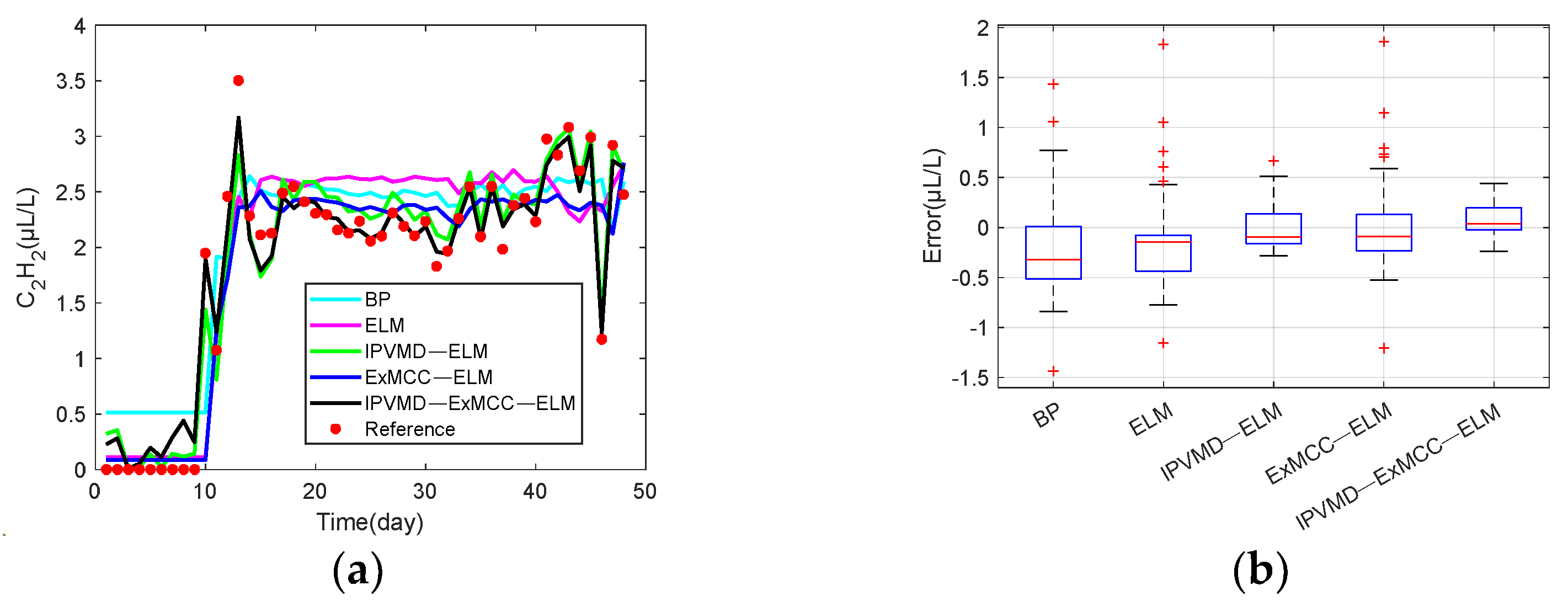
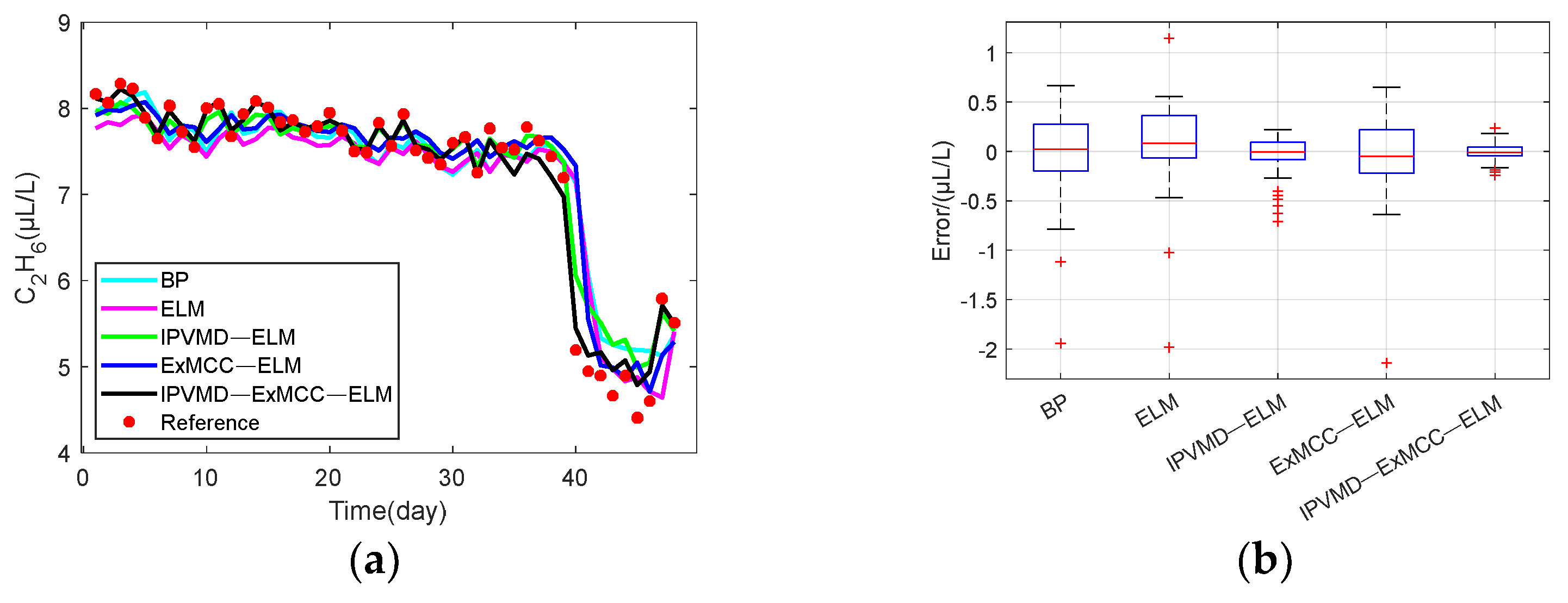
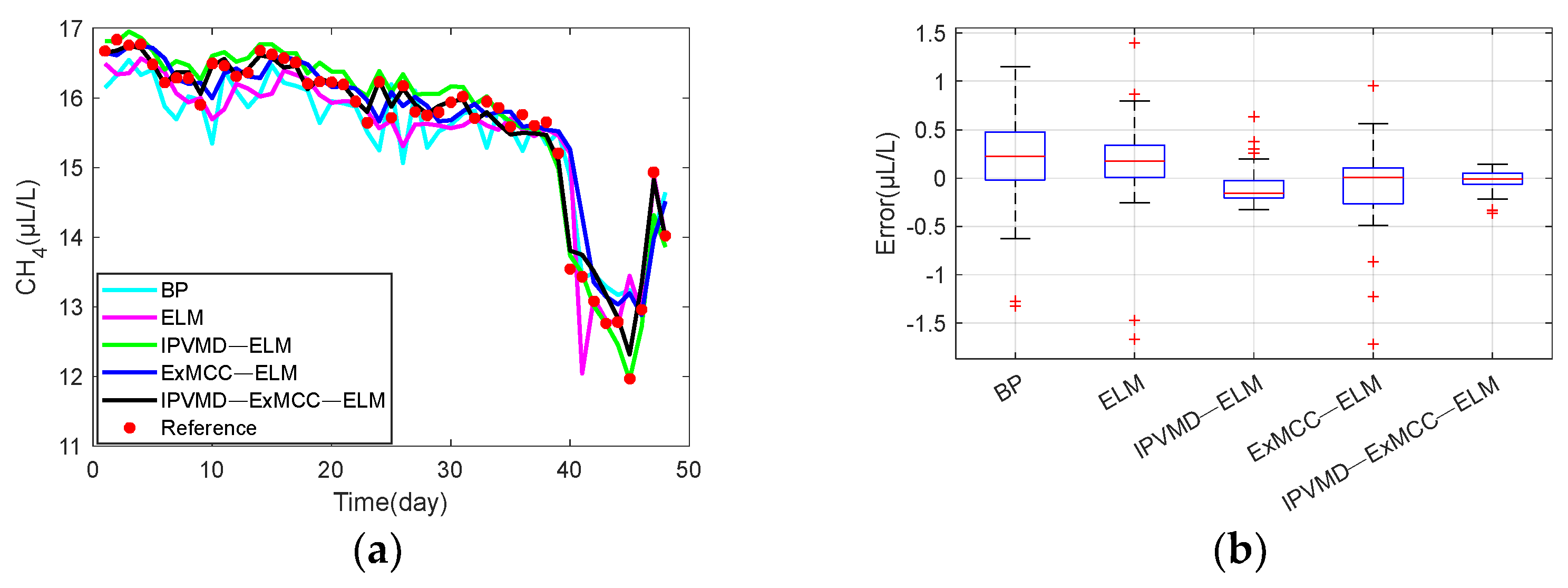
Figure 5 that the original strong fluctuation and irregular data after VMD decomposition become smooth in the five modes, which is helpful for training and testing the data of each modality.
Then, the limited data sample ), is the number of modes to be decomposed by the VMD, which is determined by the MPA algorithm) is divided into training data and testing data of the ExMCC-ELM model, respectively, where the first 250 points are used as the training set and the last 50 points are used as the testing set. Training and testing use data pairs constructed in the form of input and output, respectively.
4.2. MPAVMD-ExMCC-ELM Model Prediction Process
In this paper, the VMD decomposition method is used to decompose the nonstationary timing signal of dissolved gas in transformer oil and convert it into a stationary signal in multi-mode. Secondly, in the face of the uncertainty of signal decomposition, the IO optimization method is further used to optimize the parameters of VMD, and the most satisfactory signal decomposition results have been obtained. Thirdly, the lack of sample data, strong volatility, and poor regularity are not conducive to the characteristics of network model training and testing. This paper introduces ExMCC optimization criteria in the ELM model to overcome the above shortcomings. In this study, the original gas data was divided into training and testing parts, and the
Step 1: Initialize IPVMD and ExMCC-ELM
The exMCC-ELM model was trained with the first 250 sets of data, the last 50 sets of data were tested, and the gas data involved was included .
The specific steps are as follows:
Step 2: The gas data was decomposed by IPVMD respectively to obtain its decomposition vector . is the number of modes of VMD decomposition, which is determined by the VMD optimization algorithm, and the value may be different for different gases.
Step 3: The obtained decomposition vector is used as the training data and test data of the ExMCC-ELM model respectively, where the first 250 points are used as the training set and the last 50 points are used as the test set. Training and testing use data pairs constructed in the form of input and output, respectively. That is, the input and output of the ExMCC-ELM model training process are: , ; The input and output of the test process are , .
Step 4: The prediction results of each decomposition vector are reconstructed to obtain the prediction results of the raw gas: .
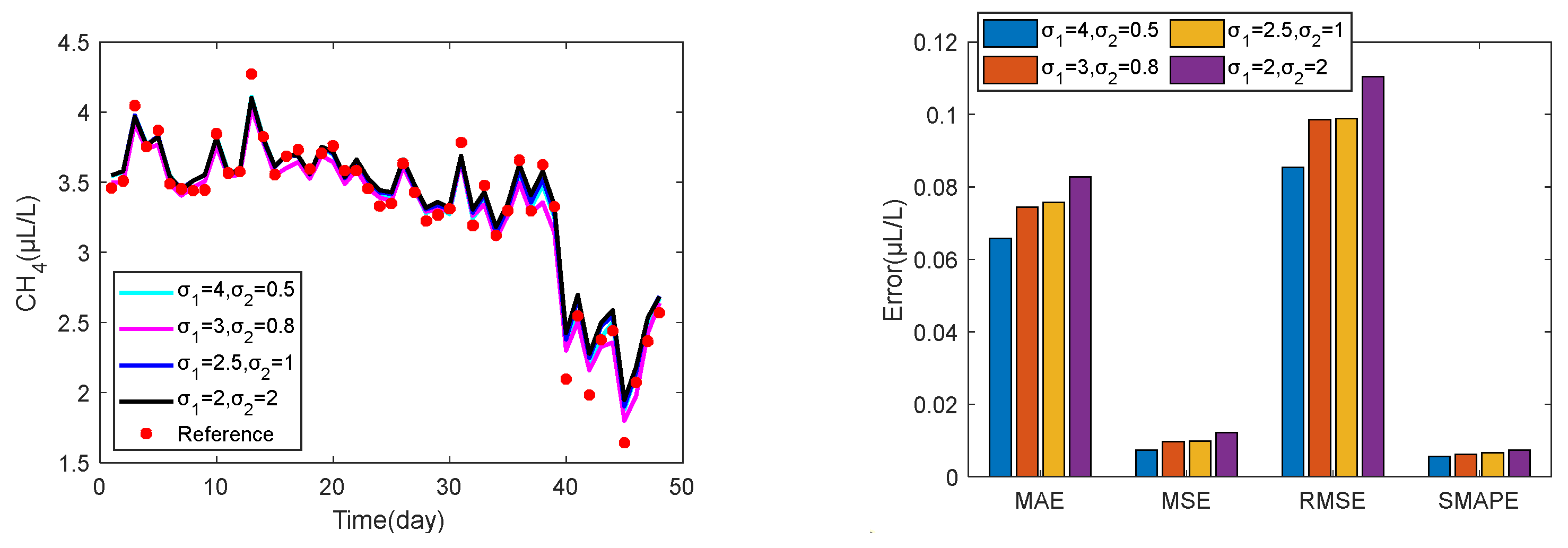
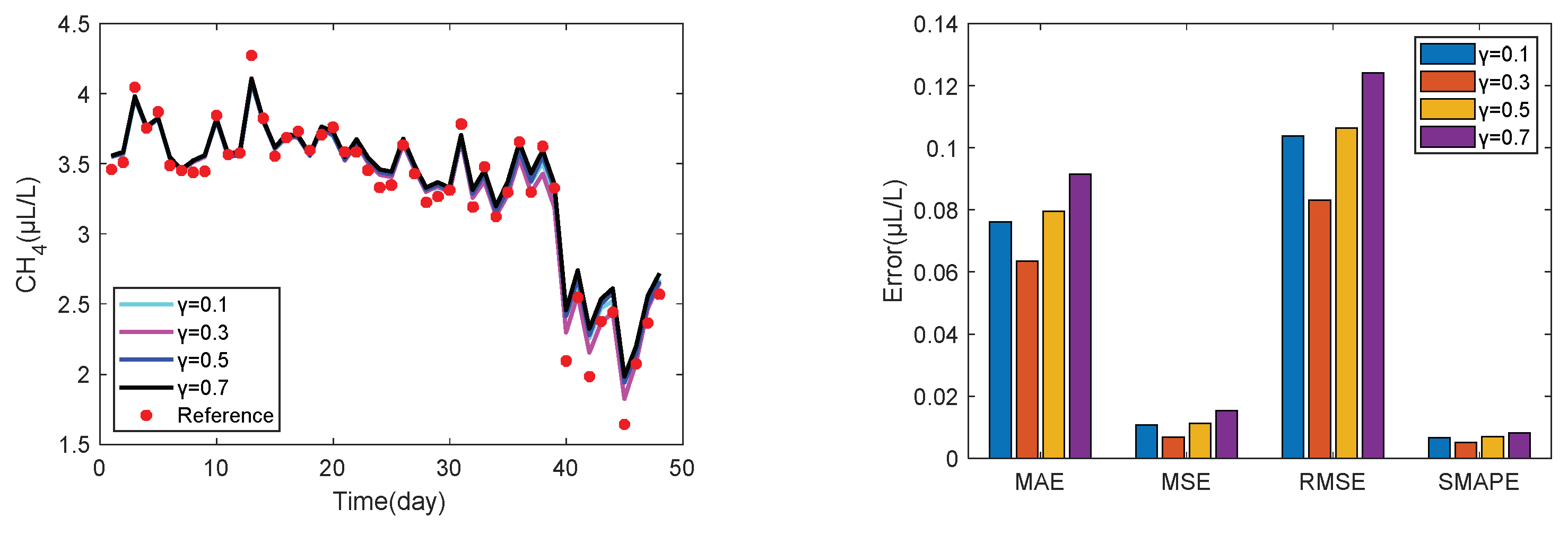
In this paper, the performance of the prediction method is evaluated using mean absolute error (MAE), mean squared error (MSE), root mean square error (RMSE), and symmetric mean absolute percentage error (SMAPE), defined as follows:
where
is the sample size;
is the expected value;
is the actual predicted value.
The structure diagram of the IPVMD-ExMCC-ELM model for predicting dissolved gases in transformer oil can be seen in
Figure 7.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}