
A Model Based on the Random Forest Algorithm That Predicts the Total Oil–Water Two-Phase Flow Rate in Horizontal Shale Oil Wells


Abstract
:1. Introduction
2. Data Analysis
2.1. Experimental Setup
2.2. Local Flow Velocity Calculation Method
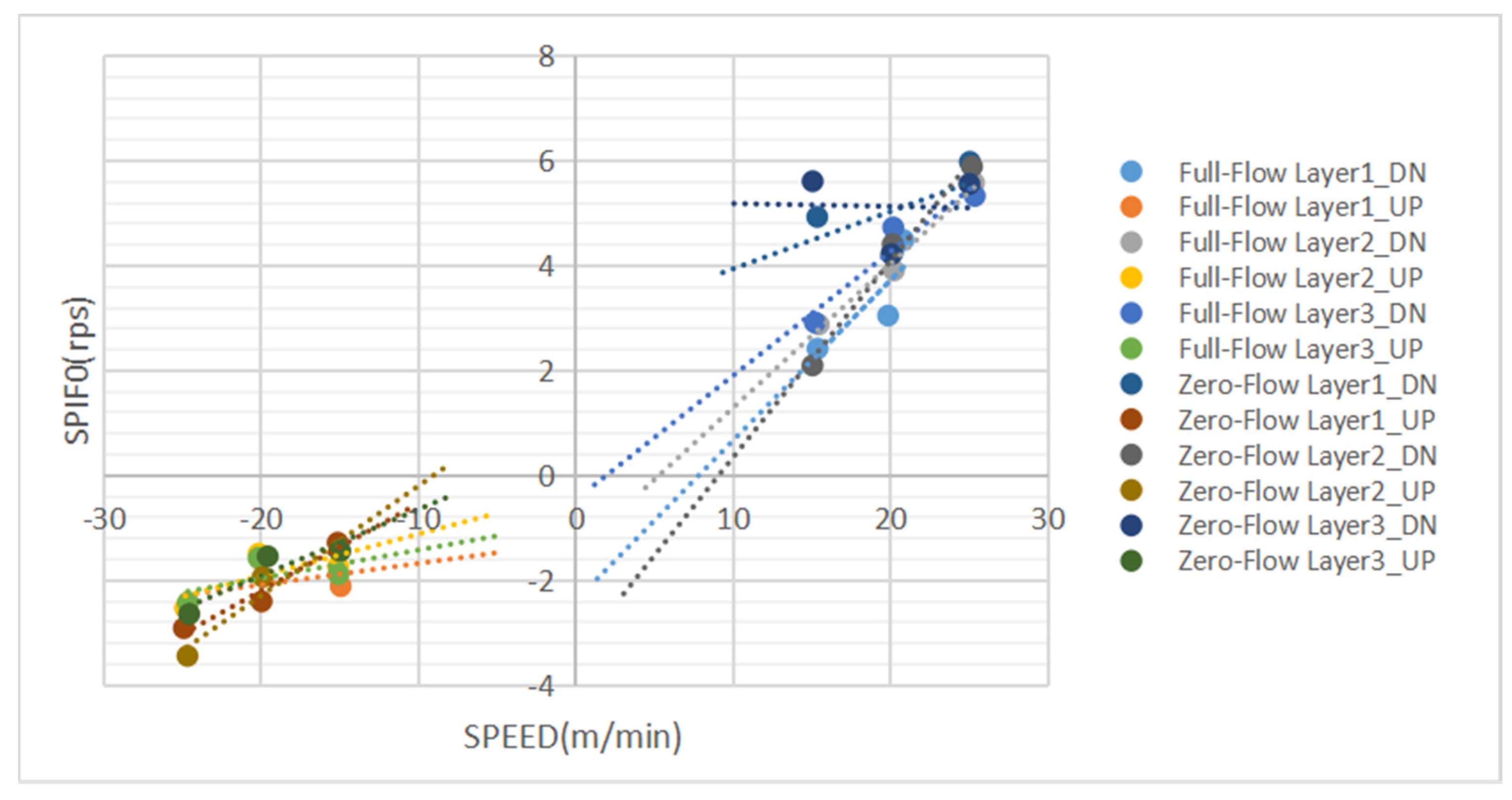
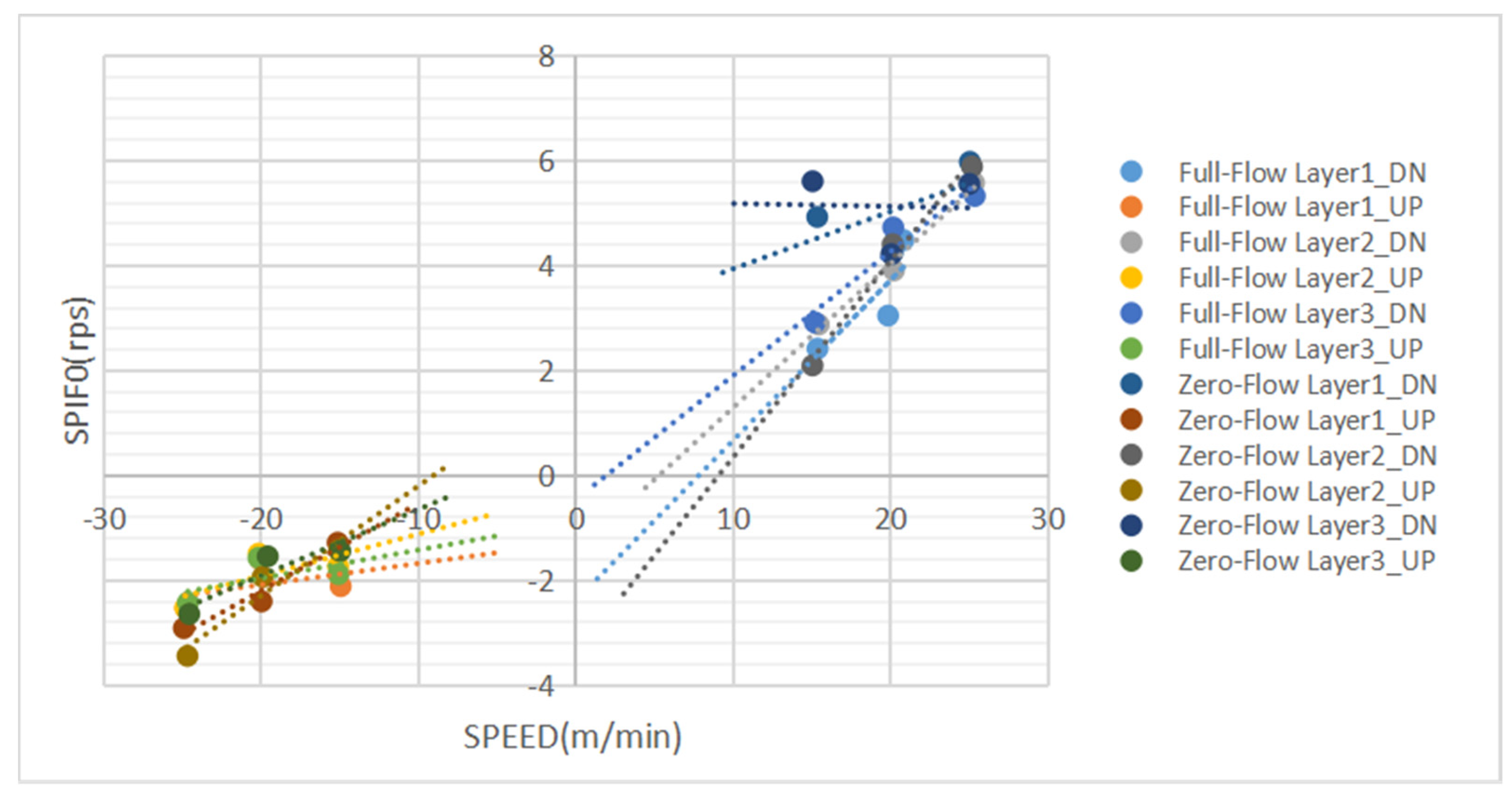
2.3. Analysis of Flow Velocity Influencing Factors
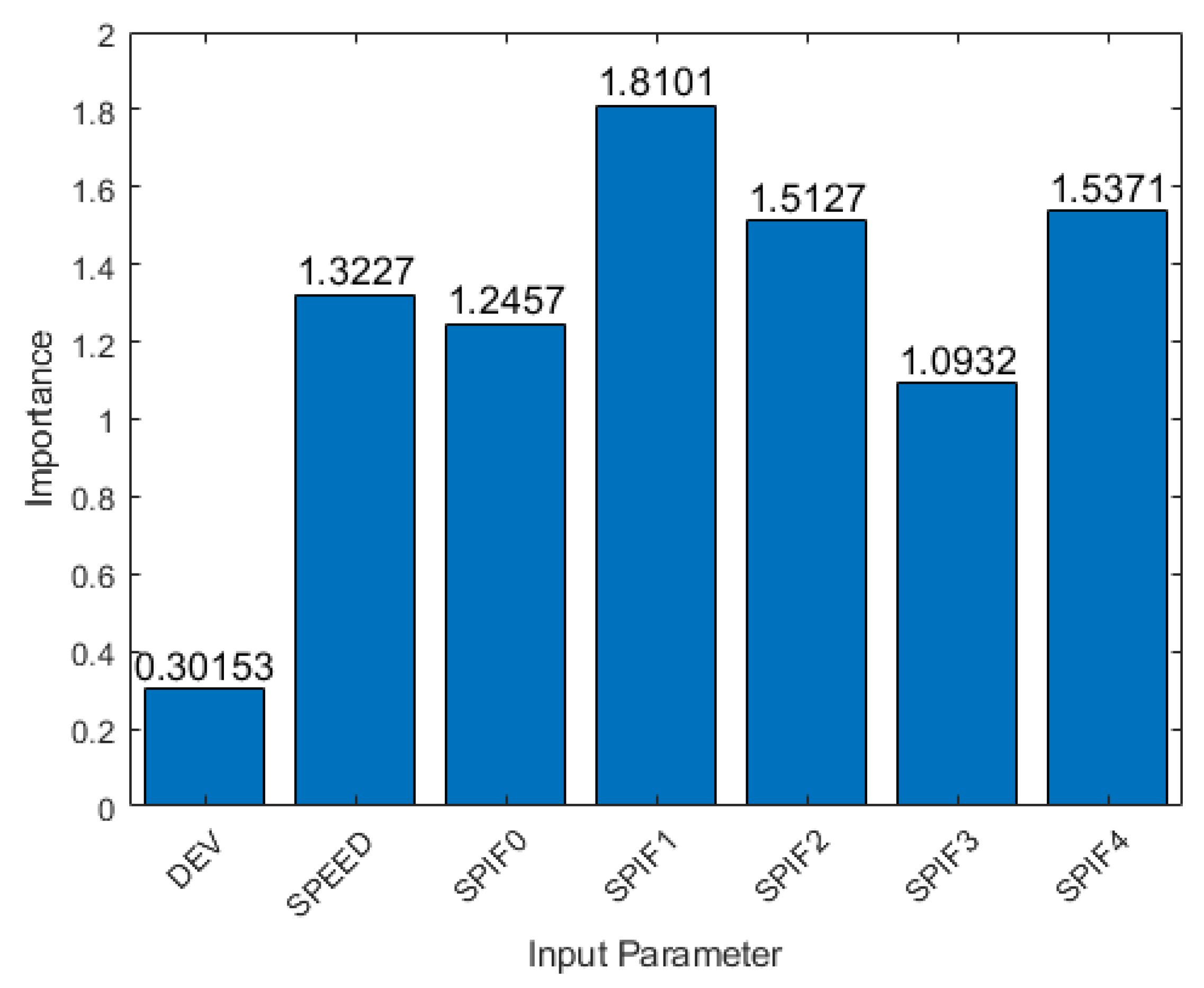
2.4. Characteristic Parameter Analysis
3. Random Forest Algorithm and Model Construction
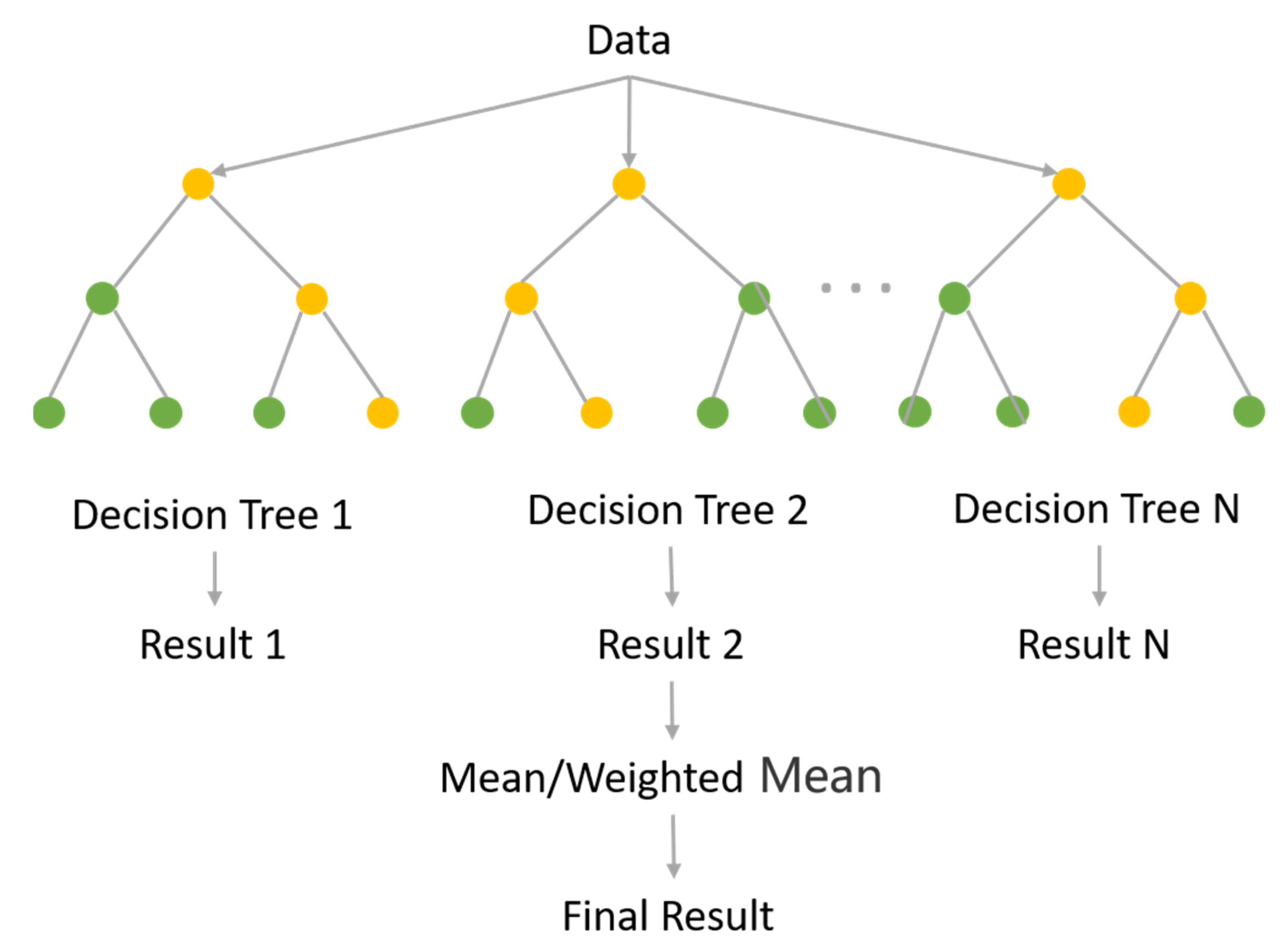
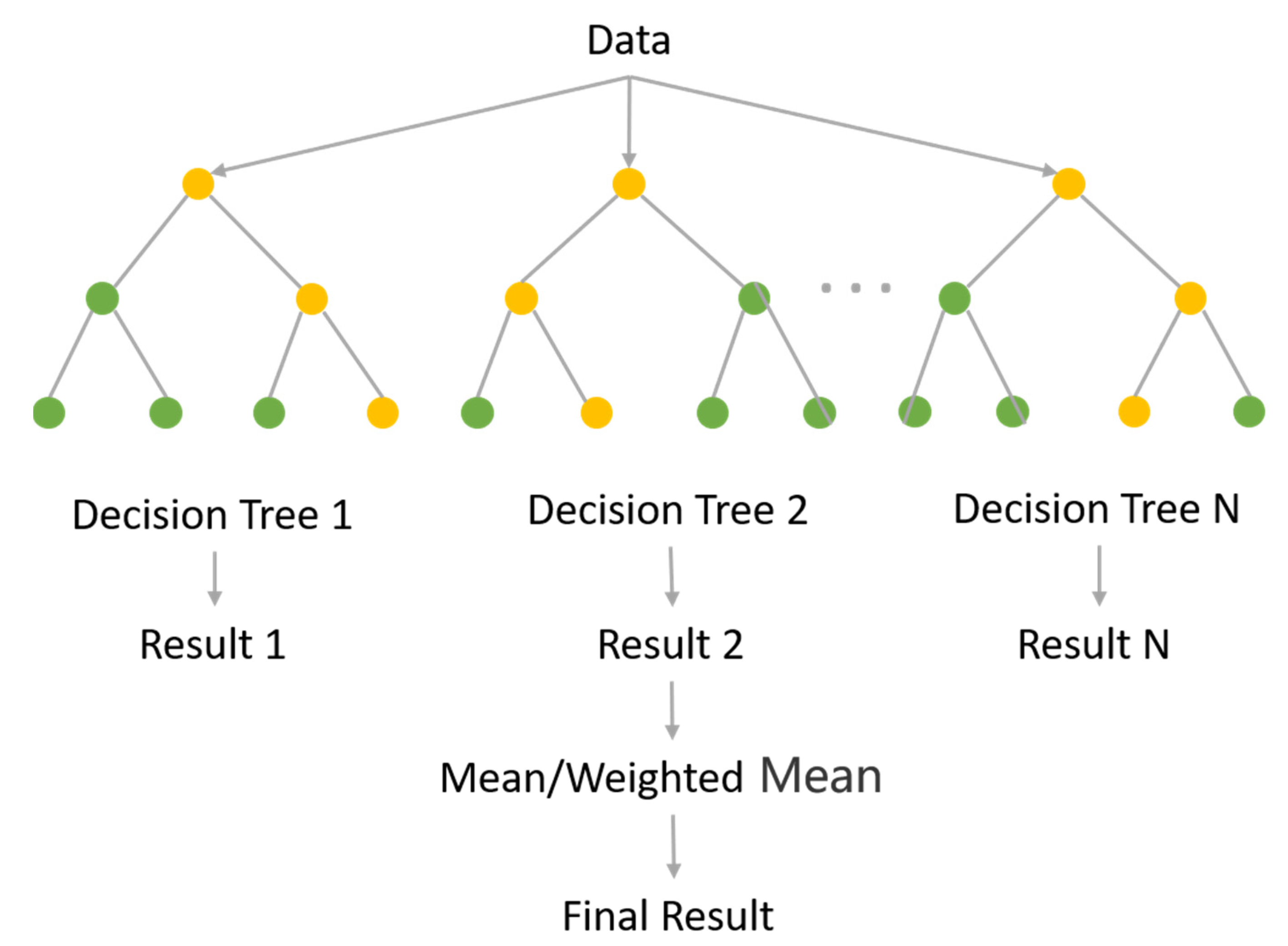
3.1. Principle of Random Forest Algorithm
- (1)
- A finite number of samples may be drawn numerous times, and selecting is performed from the original dataset; the gathered samples are the same size as the original dataset.
- (2)
- Assume that M attribute features make up the sample and that m of those features is chosen at random for node splitting, with m being substantially smaller than M.
- (3)
- Use step (2) to continue splitting the selected nodes until a stopping condition is fulfilled. This stopping condition may be that the maximum depth of the decision tree has been reached or the number of samples in the node is below a threshold etc.
- (4)
- Keep repeating steps (2) and (3) to create a multitude of decision trees that eventually combine to form a random forest.
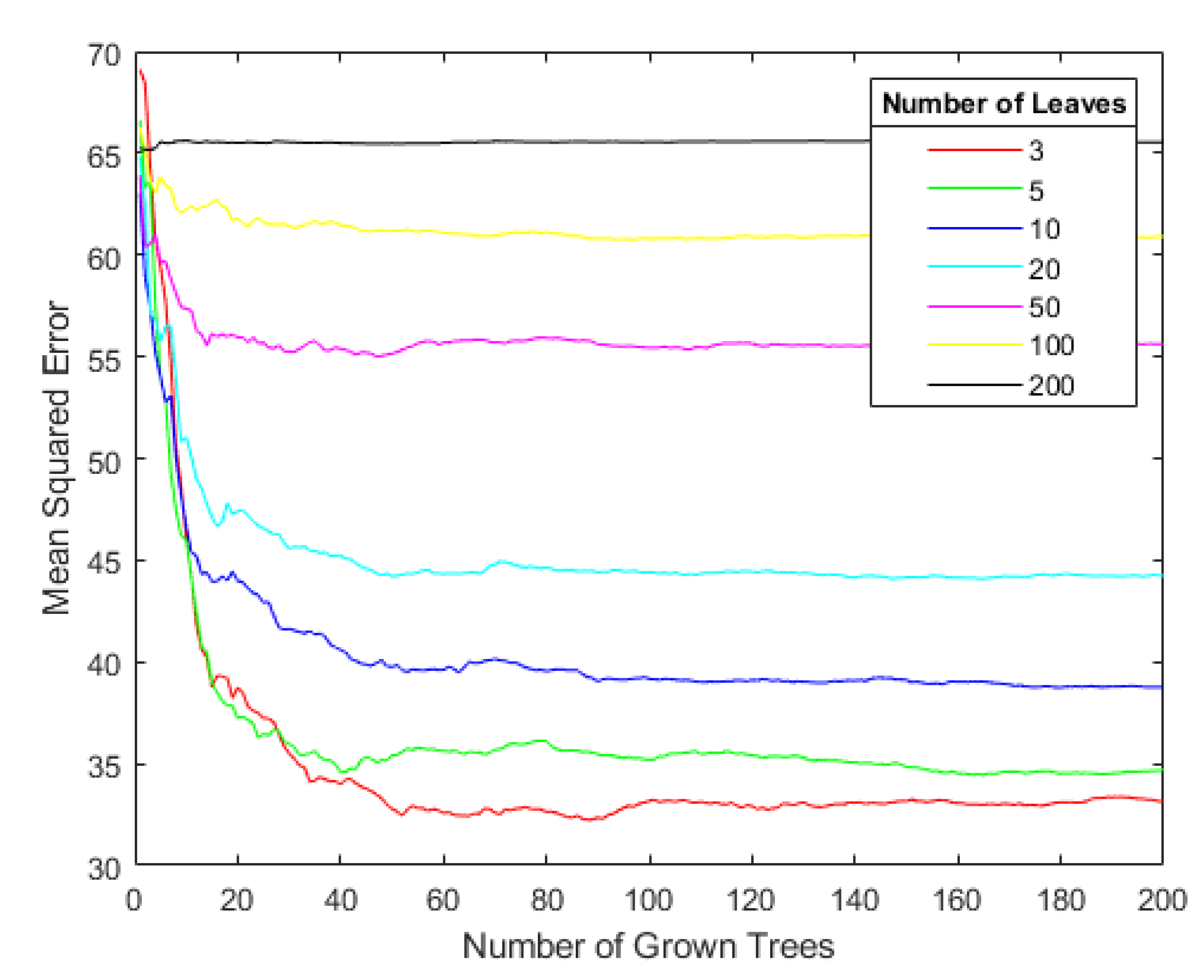
3.2. Model Construction
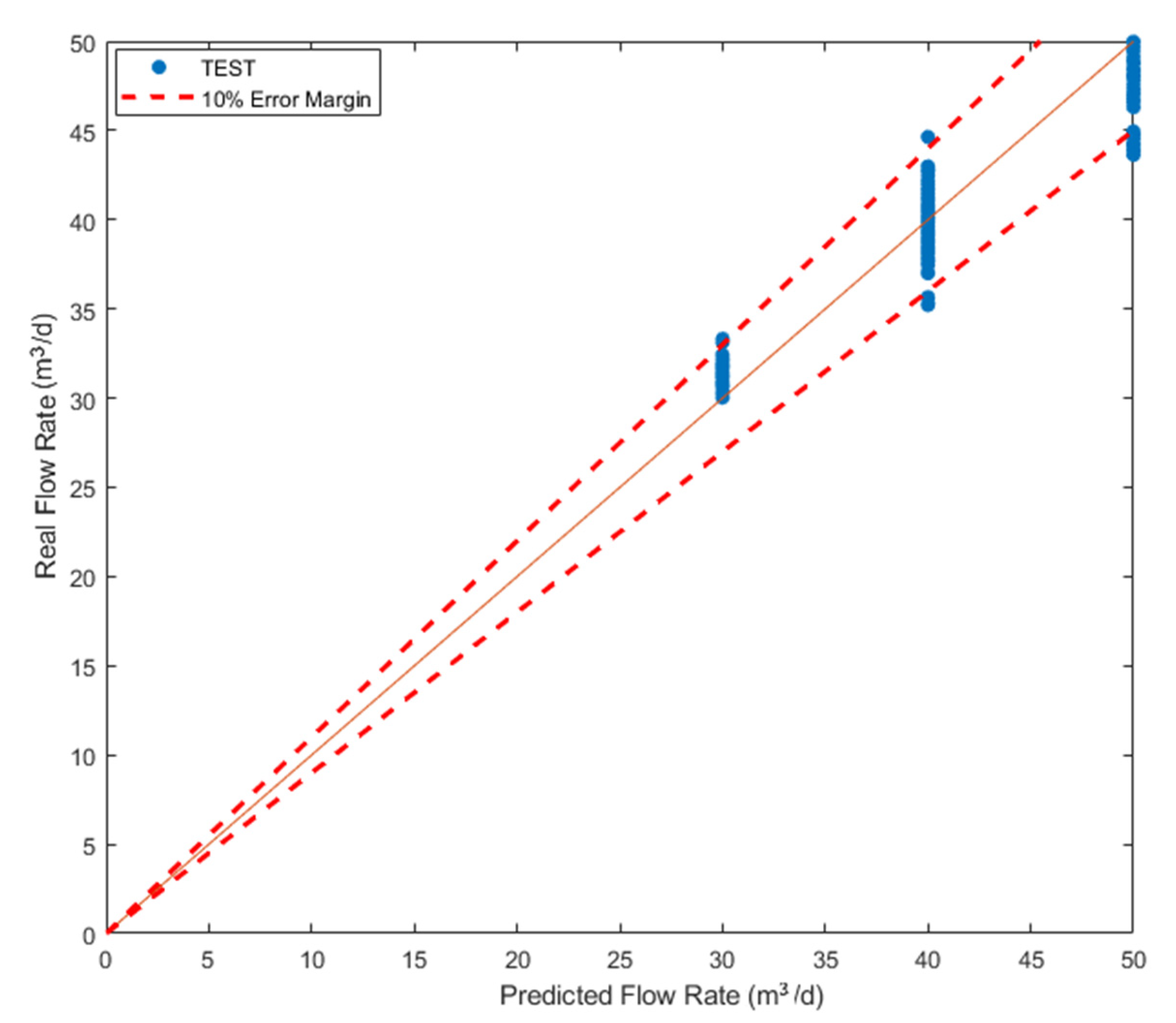
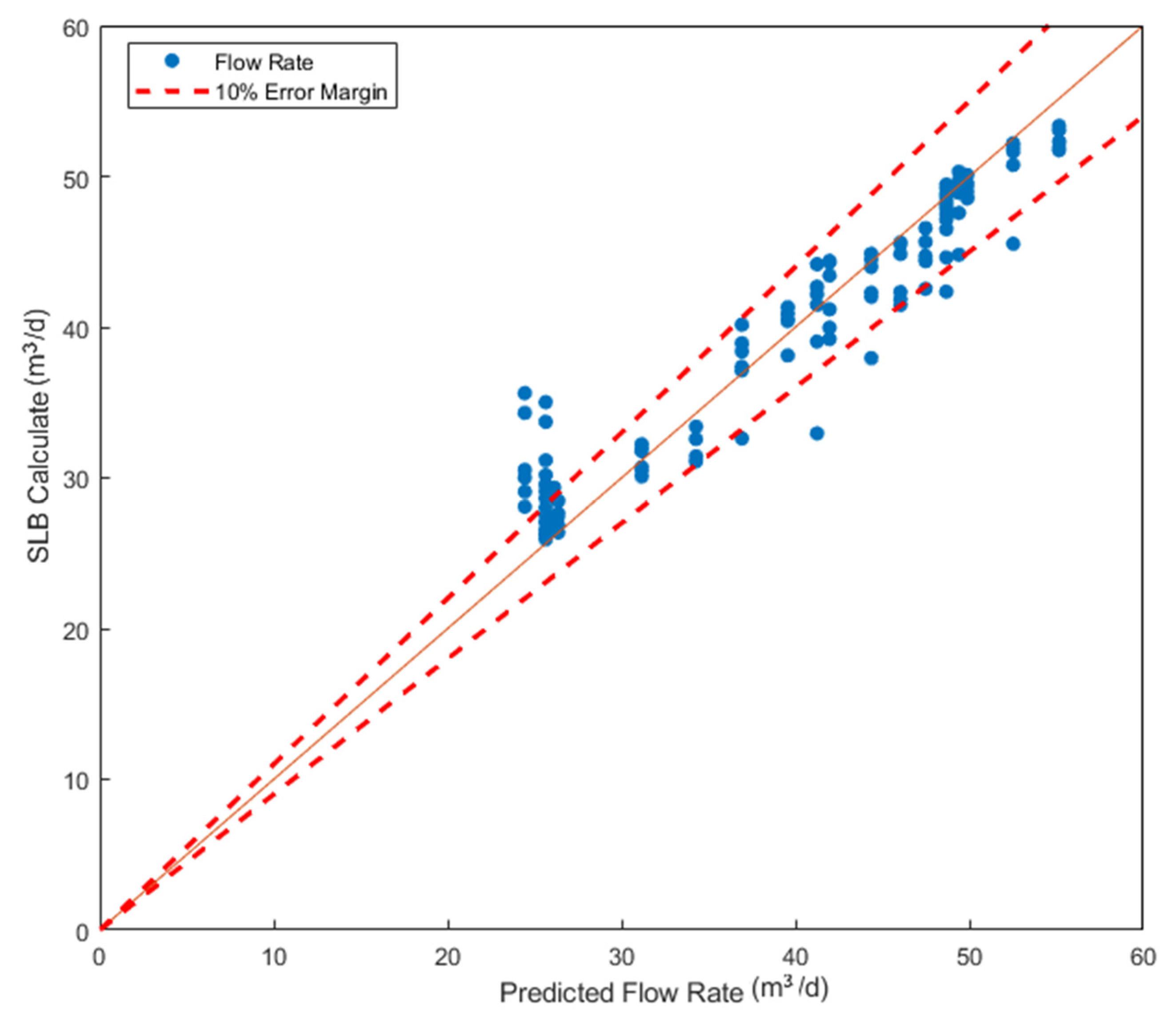
4. Example Verification
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, W.; Bian, C.; Li, Y.; Zhang, J.; He, K.; Liu, W.; Zhang, B.; Lei, Z.; Liu, C.; Zhang, J.; et al. Enrichment factors of movable hydrocarbons in lacustrine shale oil and exploration potential of shale oil in Gulong sag, Songliao Basin, NE China. Pet. Explor. Dev. 2023, 50, 455–467. [Google Scholar] [CrossRef]
- Yuan, S.; Lei, Z.; Li, J.; Yao, Z.; Li, B.; Wang, R.; Liu, Y.; Wang, Q. Key theoretical and technical issues and countermeasures for effective development of Gulong shale oil, Daqing Oilfield, NE China. Pet. Explor. Dev. 2023, 50, 638–650. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, Q.; Lyu, Q.; Xue, Z.; Cao, X.; Liu, Z. Evaluation technology and practice of continental shale oil development in China. Pet. Explor. Dev. 2022, 49, 1098–1109. [Google Scholar] [CrossRef]
- Pang, X.; Li, M.; Li, B.; Wang, T.; Hui, S.; Liu, Y.; Liu, G.; Hu, T.; Xu, T.; Jiang, F.; et al. Main controlling factors and movability evaluation of continental shale oil. Earth-Sci. Rev. 2023, 243, 104472. [Google Scholar] [CrossRef]
- Jin, X.; Li, G.X.; Meng, S.W.; Wang, X.Q.; Liu, C.; Tao, J.P.; Liu, H. Microscale comprehensive evaluation of continental shale oil recoverability. Pet. Explor. Dev. 2021, 48, 222–232. [Google Scholar] [CrossRef]
- Zhou, X.Y.; Wei, M.X.; Zhang, Y.R.; Li, T.; Xu, S. Reservoir Benefit Classification and Development Countermeasures for Changqing Oilfield. Xinjiang Pet. Geol. 2022, 43, 320–323+340. [Google Scholar]
- Cai, M. Current situation and prospect of main technology of oil production engineering in Daqing Oilfield. Oil Drill. Prod. Technol. 2022, 44, 546–555. [Google Scholar]
- Liu, J.F.; Shi, S.B.; Chen, H. Experimental Research on Oil-Water Flow Imaging in Near-Horizontal Well Using Single-Probe Multi-Position Measurement Fluid Imager. Processes 2022, 10, 1051. [Google Scholar] [CrossRef]
- Andreussi, P.; Pitton, E.; Ciandri, P.; Picciaia, D.; Vignali, A.; Margarone, M.; Scozzari, A. Measurement of liquid film distribution in near-horizontal pipes with an array of wire probes. Flow Meas. Instrum. 2016, 47, 71–82. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, W.; Zhao, J.; Cao, Z.; Xie, R.; Liu, X.; Hu, J. Support-vector-regression-based prediction of water holdup in horizontal oil-water flow by using a bicircular conductance probe array. Flow Meas. Instrum. 2017, 57, 64–72. [Google Scholar] [CrossRef]
- Li, Q.Z.; Liu, J.F.; Gao, F.; Dai, Y.X.; Peng, W.S. Interpretation Method of Oil-Water Two-Phase Flow in Horizontal Well Based on Array Spinner and Array Holdup Tools. Well Logging Technol. 2021, 45, 405–410+430. [Google Scholar]
- Liu, J.F.; Xu, Y.C.; Wu, Q.X. Holdup flow imaging analysis for capacitance and resistance ring array probes. Prog. Geophys. 2018, 33, 2141–2147. [Google Scholar]
- Cui, S.F.; Liu, J.F.; Li, K. Data Analysis of Two-Phase Flow Simulation Experiment of Array Optical Fiber and Array Resistance Probe. Coatings 2021, 11, 1420. [Google Scholar] [CrossRef]
- Cui, S.F.; Liu, J.F.; Chen, X.L. Experimental Analysis of Gas Holdup Measured by Gas Array Tool in Gas–Water Two Phase of Horizontal Well. Coatings 2021, 11, 343. [Google Scholar] [CrossRef]
- Song, H.; Guo, H.; Guo, S.; Shi, H. Partial phase flow rate measurements for stratified oil-water flow in horizontal wells. Pet. Explor. Dev. 2020, 47, 613–622. [Google Scholar] [CrossRef]
- Cui, S.F. Method of Horizontal Well Array Flow Image Research on Simulation Experiment and Interpretation. Master’s Thesis, Yangtze University, Wuhan, China, 2023. [Google Scholar]
- Liang, H.; Liu, G.; Zou, J.; Bai, J.; Jiang, Y. Research on calculation model of bottom of the well pressure based on machine learning. Future Gener. Comput. Syst. 2021, 124, 80–90. [Google Scholar] [CrossRef]
- Nwanwe, C.C.; Duru, U.I.; Anyadiegwu, C.; Ekejuba, A.I.B. An artificial neural network visible mathematical model for real-time prediction of multiphase flowing bottom-hole pressure in wellbores. Pet. Res. 2022, in press. [Google Scholar] [CrossRef]
- Sami, N.A. Application of machine learning algorithms to predict tubing pressure in intermittent gas lift wells. Pet. Res. 2022, 7, 246–252. [Google Scholar] [CrossRef]
- Liu, J.; Jiang, L.; Chen, Y.; Liu, Z.; Yuan, H.; Wen, Y. Study on prediction model of liquid hold up based on random forest algorithm. Chem. Eng. Sci. 2023, 268, 118383. [Google Scholar] [CrossRef]
- Wahid, M.F.; Tafreshi, R.; Khan, Z.; Retnanto, A. Prediction of pressure gradient for oil-water flow: A comprehensive analysis on the performance of machine learning algorithms. J. Pet. Sci. Eng. 2022, 208, 109265. [Google Scholar] [CrossRef]
- Guo, H.; Dai, J.; Chen, K. Production Logging Principles and Data Interpretation; Petroleum Industry Press: Beijing, China, 2007; pp. 35–37. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic Parameter | Range | Mean Value | Standard Deviation |
|---|---|---|---|
| SPEED (m/min) | −21.18~−10.18 | −17.73 | 2.64 |
| SPIF0 (rps) | −7.44~−0.41 | −3.24 | 1.01 |
| SPIF1 (rps) | −7.52~0.42 | −4.47 | 1.76 |
| SPIF2 (rps) | −9.02~−1.47 | −4.93 | 1.53 |
| SPIF3 (rps) | −8.53~4.68 | −3.92 | 1.23 |
| SPIF4 (rps) | −5.64~1.67 | 0.22 | 1.38 |
| DEV (°) | 85~90 | 88.21 | 2.40 |
| Mean Squared Error | Decision Coefficient |
|---|---|
| 2.77 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, H.; Liu, J.; Fei, J.; Shi, S. A Model Based on the Random Forest Algorithm That Predicts the Total Oil–Water Two-Phase Flow Rate in Horizontal Shale Oil Wells. Processes 2023, 11, 2346. https://doi.org/10.3390/pr11082346
Zhou H, Liu J, Fei J, Shi S. A Model Based on the Random Forest Algorithm That Predicts the Total Oil–Water Two-Phase Flow Rate in Horizontal Shale Oil Wells. Processes. 2023; 11(8):2346. https://doi.org/10.3390/pr11082346
Chicago/Turabian StyleZhou, Huimin, Junfeng Liu, Jiegao Fei, and Shoubo Shi. 2023. "A Model Based on the Random Forest Algorithm That Predicts the Total Oil–Water Two-Phase Flow Rate in Horizontal Shale Oil Wells" Processes 11, no. 8: 2346. https://doi.org/10.3390/pr11082346
APA StyleZhou, H., Liu, J., Fei, J., & Shi, S. (2023). A Model Based on the Random Forest Algorithm That Predicts the Total Oil–Water Two-Phase Flow Rate in Horizontal Shale Oil Wells. Processes, 11(8), 2346. https://doi.org/10.3390/pr11082346