




Intelligent Optimization of Gas Flooding Based on Multi-Objective Approach for Efficient Reservoir Management

 , ,
, ,
Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Description | Advantages | Limitations |
|---|---|---|---|
| Uniform division | Divided by uniform conditions [2] | 1. Simple. 2. Suitable for weakly heterogeneous reservoirs. | 1. Lack of physical basis. 2. Extremely poor applicability in highly heterogeneous reservoirs. |
| Proportional division | Divided by reservoir properties [3] | 1. Considers the actual conditions of the reservoir to a certain extent. 2. Suppresses the risk of water and gas invasion effectively. | 1. Relatively dependent on the accuracy of RNS models. 2. Difficult to determine whether the result is the optimal solution. |
| Divided according to statistical methods [5,6,7] | 1. The main factors of the reservoir could be obtained. 2. The computational complexity is reduced. 3. Can continuously analyze various experimental levels. | 1. Constrained by the calculation speed of RNS. 2. The optimization results rely heavily on the selection of experimental point ranges. | |
| Divided using iterative optimization [21,22,23] | 1. Considers specific objectives, improving the relevance. 2. Obtains unique optimal result of the objective function. | 1. Relatively dependent on the accuracy of RNS models. 2. Only one objective is considered mainly. |
2. Methodology
2.1. Transformer
2.2. MOPSO
3. Case Study
3.1. Basic Information of Target Reservoir
3.2. Multi-Objective Function
3.3. Model Training and Data Preprocessing
3.4. Model Structure and Evaluation Criterion
4. Experimental Results
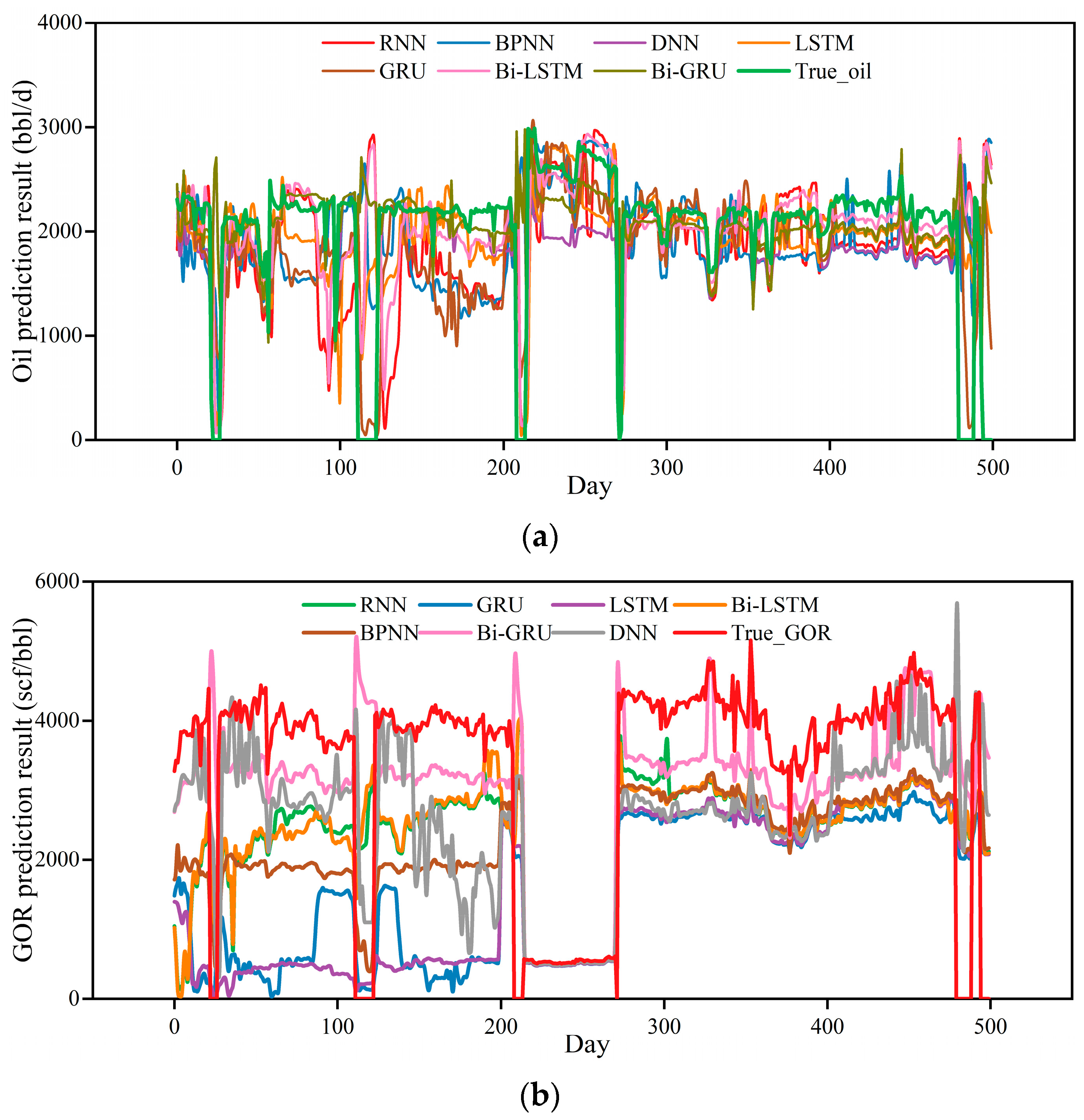
4.1. Performance in Prediction of Production and GOR
4.2. Iteration Result of MOPSO
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khormali, A.; Petrakov, D.G.; Farmanzade, A.R. Prediction and Inhibition of Inorganic Salt Formation under Static and Dynamic Conditions—Effect of Pressure, Temperature, and Mixing Ratio. Int. J. Technol. 2016, 7, 943–951. [Google Scholar] [CrossRef]
- Chen, C.; Li, G.; Reynolds, A.C. Robust Constrained Optimization of Short- and Long-Term Net Present Value for Closed-Loop Reservoir Management. SPE J. 2012, 17, 849–864. [Google Scholar] [CrossRef]
- An, Z.; Zhou, K.; Hou, J.; Wu, D.; Pan, Y. Accelerating Reservoir Production Optimization by Combining Reservoir Engineering Method with Particle Swarm Optimization Algorithm. J. Pet. Sci. Eng. 2022, 208, 109692. [Google Scholar] [CrossRef]
- Gunst, R.F.; Myers, R.H.; Montgomery, D.C. Response Surface Methodology: Process and Product Optimization Using Designed Experiments. Technometrics 1996, 38, 285. [Google Scholar] [CrossRef]
- Kang, X.; Li, B.; Zhang, J.; Wang, X.; Yu, W. Optimization of the SAGP Process in L Oil-Sand Field with Response Surface Methodology. In Proceedings of the Abu Dhabi International Petroleum Exhibition & Conference, Abu Dhabi, United Arab Emirates, 11–14 November 2019. [Google Scholar]
- Wantawin, M.; Dachanuwattana, S.; Sepehrnoori, K. An Iterative Response-Surface Methodology by Use of High-Degree-Polynomial Proxy Models for Integrated History Matching and Probabilistic Forecasting Applied to Shale-Gas Reservoirs. SPE J. 2017, 22, 2012–2031. [Google Scholar] [CrossRef]
- Wantawin, M.; Sepehrnoori, K. An Iterative Work Flow for History Matching by Use of Design of Experiment, Response-Surface Methodology, and Markov Chain Monte Carlo Algorithm Applied to Tight Oil Reservoirs. SPE J. 2017, 20, 613–626. [Google Scholar] [CrossRef]
- Sarma, P.; Aziz, K.; Durlofsky, L.J. Implementation of Adjoint Solution for Optimal Control of Smart Wells. In Proceedings of the SPE Reservoir Simulation Symposium, The Woodlands, TX, USA, 31 January–2 February 2005; p. SPE-92864-MS. [Google Scholar]
- Mohsin Siraj, M.; Van den Hof, P.M.; Jansen, J.-D. Handling Geological and Economic Uncertainties in Balancing Short-Term and Long-Term Objectives in Waterflooding Optimization. SPE J. 2017, 22, 1313–1325. [Google Scholar] [CrossRef]
- Da Cruz Schaefer, B.; Sampaio, M.A. Efficient Workflow for Optimizing Intelligent Well Completion Using Production Parameters in Real-Time. Oil Gas Sci. Technol. Rev. IFP Energ. Nouv. 2020, 75, 69. [Google Scholar] [CrossRef]
- Zhao, M.; Zhang, K.; Chen, G.; Zhao, X.; Yao, J.; Yao, C.; Zhang, L.; Yang, Y. A Classification-Based Surrogate-Assisted Multiobjective Evolutionary Algorithm for Production Optimization under Geological Uncertainty. SPE J. 2020, 25, 2450–2469. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. Particle Swarm Optimization for Feature Selection in Classification: A Multi-Objective Approach. IEEE Trans. Cybern. 2013, 43, 1656–1671. [Google Scholar] [CrossRef]
- Fu, J.; Wen, X.-H. A Regularized Production-Optimization Method for Improved Reservoir Management. SPE J. 2018, 23, 467–481. [Google Scholar] [CrossRef]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast and Elitist Multiobjective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Yasari, E.; Pishvaie, M.R.; Khorasheh, F.; Salahshoor, K.; Kharrat, R. Application of Multi-Criterion Robust Optimization in Water-Flooding of Oil Reservoir. J. Pet. Sci. Eng. 2013, 109, 1–11. [Google Scholar] [CrossRef]
- Bagherinezhad, A.; Boozarjomehry Bozorgmehry, R.; Pishvaie, M.R. Multi-Criterion Based Well Placement and Control in the Water-Flooding of Naturally Fractured Reservoir. J. Pet. Sci. Eng. 2017, 149, 675–685. [Google Scholar] [CrossRef]
- Wang, L.; Yao, Y.; Wang, K.; Adenutsi, C.D.; Zhao, G.; Lai, F. Data-Driven Multi-Objective Optimization Design Method for Shale Gas Fracturing Parameters. J. Nat. Gas Sci. Eng. 2022, 99, 104420. [Google Scholar] [CrossRef]
- Das, I.; Dennis, J.E. A Closer Look at Drawbacks of Minimizing Weighted Sums of Objectives for Pareto Set Generation in Multicriteria Optimization Problems. Struct. Optim. 1997, 14, 63–69. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Lechuga, M.S. MOPSO: A Proposal for Multiple Objective Particle Swarm Optimization. In Proceedings of the 2002 Congress on Evolutionary Computation. CEC′02 (Cat. No.02TH8600), Honolulu, HI, USA, 12–17 May 2002; Volume 6. [Google Scholar] [CrossRef]
- Yasari, E.; Pishvaie, M.R. Pareto-Based Robust Optimization of Water-Flooding Using Multiple Realizations. J. Pet. Sci. Eng. 2015, 132, 18–27. [Google Scholar] [CrossRef]
- Moshir Farahi, M.M.; Ahmadi, M.; Dabir, B. Model-Based Production Optimization under Geological and Economic Uncertainties Using Multi-Objective Particle Swarm Method. Oil Gas Sci. Technol. Rev. IFP Energ. Nouv. 2021, 76, 60. [Google Scholar] [CrossRef]
- Farahi, M.M.M. Model-Based Water-Flooding Optimization Using Multi-Objective Approach for Efficient Reservoir Management. J. Pet. Sci. Eng. 2021, 196, 107988. [Google Scholar] [CrossRef]
- Zhao, H.; Li, Y.; Cui, S.; Shang, G.; Reynolds, A.C.; Guo, Z.; Li, H.A. History Matching and Production Optimization of Water Flooding Based on a Data-Driven Interwell Numerical Simulation Model. J. Nat. Gas Sci. Eng. 2016, 31, 48–66. [Google Scholar] [CrossRef]
- Coello Coello, C.A.; Reyes-Sierra, M. Multi-Objective Particle Swarm Optimizers: A Survey of the State-of-the-Art. Int. J. Comput. Intell. Res. 2006, 2, 287–308. [Google Scholar] [CrossRef]
- Reddy, M.J.; Nagesh Kumar, D. Multi-Objective Particle Swarm Optimization for Generating Optimal Trade-Offs in Reservoir Operation. Hydrol. Process. 2007, 21, 2897–2909. [Google Scholar] [CrossRef]
- Fallah-Mehdipour, E.; Haddad, O.B.; Mariño, M.A. MOPSO Algorithm and Its Application in Multipurpose Multireservoir Operations. J. Hydroinform. 2011, 13, 794–811. [Google Scholar] [CrossRef]
- Zheng, Y.-J.; Ling, H.-F.; Xue, J.-Y.; Chen, S.-Y. Population Classification in Fire Evacuation: A Multiobjective Particle Swarm Optimization Approach. IEEE Trans. Evol. Comput. 2014, 18, 70–81. [Google Scholar] [CrossRef]
- Fu, J.; Wen, X.-H. Model-Based Multiobjective Optimization Methods for Efficient Management of Subsurface Flow. SPE J. 2017, 22, 1984–1998. [Google Scholar] [CrossRef]
- Wang, H. Optimal Well Placement Under Uncertainty Using a Retrospective Optimization Framework. SPE J. 2012, 17, 112–121. [Google Scholar] [CrossRef]
- Desbordes, J.K.; Zhang, K.; Xue, X.; Ma, X.; Luo, Q.; Huang, Z.; Hai, S.; Jun, Y. Dynamic Production Optimization Based on Transfer Learning Algorithms. J. Pet. Sci. Eng. 2022, 208, 109278. [Google Scholar] [CrossRef]
- Li, Y.; Jia, C.; Song, B.; Li, B.; Zhu, Y.; Qian, Q.; Wei, C. Geological Models Comparison and Selection for Multi-Layered Sandstone Reservoirs. In Proceedings of the SPE Middle East Oil & Gas Show and Conference, Manama, Bahrain, 6–9 March 2017; p. D031S026R005. [Google Scholar]
- Gu, J.; Liu, W.; Zhang, K.; Zhai, L.; Zhang, Y.; Chen, F. Reservoir Production Optimization Based on Surrograte Model and Differential Evolution Algorithm. J. Pet. Sci. Eng. 2021, 205, 108879. [Google Scholar] [CrossRef]
- Alkinani, H.H.; Al-Hameedi, A.T.; Dunn-Norman, S.; Flori, R.E.; Alsaba, M.T.; Amer, A.S. Applications of Artificial Neural Networks in the Petroleum Industry: A Review. In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 18–21 March 2019; p. D032S063R002. [Google Scholar]
- El-Sebakhy, E.A.; Sheltami, T.; Al-Bokhitan, S.Y.; Shaaban, Y.; Raharja, P.D.; Khaeruzzaman, Y. Support Vector Machines Framework for Predicting the PVT Properties of Crude Oil Systems. In Proceedings of the SPE Middle East Oil and Gas Show and Conference, Manama, Bahrain, 11–14 March 2007; p. SPE-105698-MS. [Google Scholar]
- Madasu, S.; Rangarajan, K.P. Deep Recurrent Neural Network DRNN Model for Real-Time Multistage Pumping Data. In Proceedings of the OTC Arctic Technology Conference, Houston, TX, USA, 5–7 November 2018; p. D033S017R005. [Google Scholar]
- Romero Quishpe, A.; Silva Alonso, K.; Alvarez Claramunt, J.I.; Barros, J.L.; Bizzotto, P.; Ferrigno, E.; Martinez, G. Innovative Artificial Intelligence Approach in Vaca Muerta Shale Oil Wells for Real Time Optimization. In Proceedings of the SPE Annual Technical Conference and Exhibition, Calgary, AB, Canada, 30 September–2 October 2019; p. D011S009R002. [Google Scholar]
- Huang, R.; Wei, C.; Li, B.; Xiong, L.; Yang, J.; Wu, S.; Gao, Y.; Liu, S.; Zhang, C.; Lou, Y.; et al. A Data Driven Method to Predict and Restore Missing Well Head Flow Pressure. In Proceedings of the International Petroleum Technology Conference, Riyadh, Saudi Arabia, 21–23 February 2022; p. D032S154R004. [Google Scholar]
- Ahmadi, M.-A.; Bahadori, A. A LSSVM Approach for Determining Well Placement and Conning Phenomena in Horizontal Wells. Fuel 2015, 153, 276–283. [Google Scholar] [CrossRef]
- Nwachukwu, A.; Jeong, H.; Pyrcz, M.; Lake, L.W. Fast Evaluation of Well Placements in Heterogeneous Reservoir Models Using Machine Learning. J. Pet. Sci. Eng. 2018, 163, 463–475. [Google Scholar] [CrossRef]
- Clarkson, C.R.; Williams-Kovacs, J.D.; Qanbari, F.; Behmanesh, H.; Heidari Sureshjani, M. History-Matching and Forecasting Tight/Shale Gas Condensate Wells Using Combined Analytical, Semi-Analytical, and Empirical Methods. J. Nat. Gas Sci. Eng. 2015, 26, 1620–1647. [Google Scholar] [CrossRef]
- Hutahaean, J.; Demyanov, V.; Christie, M. Many-Objective Optimization Algorithm Applied to History Matching. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–8. [Google Scholar]
- Jo, S.; Jeong, H.; Min, B.; Park, C.; Kim, Y.; Kwon, S.; Sun, A. Efficient Deep-Learning-Based History Matching for Fluvial Channel Reservoirs. J. Pet. Sci. Eng. 2022, 208, 109247. [Google Scholar] [CrossRef]
- Lee, K.; Lim, J.; Yoon, D.; Jung, H. Prediction of Shale-Gas Production at Duvernay Formation Using Deep-Learning Algorithm. SPE J. 2019, 24, 2423–2437. [Google Scholar] [CrossRef]
- Li, X.; Ma, X.; Xiao, F.; Wang, F.; Zhang, S. Application of Gated Recurrent Unit (GRU) Neural Network for Smart Batch Production Prediction. Energies 2020, 13, 6121. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-Series Well Performance Prediction Based on Long Short-Term Memory (LSTM) Neural Network Model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Kocoglu, Y.; Gorell, S.; McElroy, P. Application of Bayesian Optimized Deep Bi-LSTM Neural Networks for Production Forecasting of Gas Wells in Unconventional Shale Gas Reservoirs. In Proceedings of the 9th Unconventional Resources Technology Conference, Houston, TX, USA, 26–28 July 2021. [Google Scholar]
- Huang, R.; Wei, C.; Wang, B.; Yang, J.; Xu, X.; Wu, S.; Huang, S. Well Performance Prediction Based on Long Short-Term Memory (LSTM) Neural Network. J. Pet. Sci. Eng. 2022, 208, 109686. [Google Scholar] [CrossRef]
- Li, W.; Wang, L.; Dong, Z.; Wang, R.; Qu, B. Reservoir Production Prediction with Optimized Artificial Neural Network and Time Series Approaches. J. Pet. Sci. Eng. 2022, 215, 110586. [Google Scholar] [CrossRef]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention Based Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. Proc. AAAI Conf. Artif. Intell. 2019, 33, 922–929. [Google Scholar] [CrossRef]
- Bai, J.; Zhu, J.; Song, Y.; Zhao, L.; Hou, Z.; Du, R.; Li, H. A3T-GCN: Attention Temporal Graph Convolutional Network for Traffic Forecasting. ISPRS Int. J. Geo-Inf. 2021, 10, 485. [Google Scholar] [CrossRef]
- Wang, S.; Wang, X.; Wang, S.; Wang, D. Bi-Directional Long Short-Term Memory Method Based on Attention Mechanism and Rolling Update for Short-Term Load Forecasting. Int. J. Electr. Power Energy Syst. 2019, 109, 470–479. [Google Scholar] [CrossRef]
- Liu, Y.; Shan, L.; Yu, D.; Zeng, L.; Yang, M. An Echo State Network with Attention Mechanism for Production Prediction in Reservoirs. J. Pet. Sci. Eng. 2022, 209, 109920. [Google Scholar] [CrossRef]
- Niu, Z.; Yu, Z.; Tang, W.; Wu, Q.; Reformat, M. Wind Power Forecasting Using Attention-Based Gated Recurrent Unit Network. Energy 2020, 196, 117081. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with Deep Learning Models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Ma, X.; Xiao, F.; Xiao, C.; Wang, F.; Zhang, S. Time-Series Production Forecasting Method Based on the Integration of Bidirectional Gated Recurrent Unit (Bi-GRU) Network and Sparrow Search Algorithm (SSA). J. Pet. Sci. Eng. 2022, 208, 109309. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]













| Reservoir Physical Property | Value |
|---|---|
| Reservoir thickness | 150–154 ft |
| Initial reservoir pressure | 4425 psi |
| Initial bubble point pressure | 2980 psi |
| Porosity range | 5–25% |
| Permeability range | 1.3–6.3 mD |
| Oil volume coefficient (at bubble point pressure) | 1.44 rb/STB |
| Oil phase compression coefficient (at bubble point pressure) | 15 × 10−6 1/psi |
| Average GIR of I-14 (Mscf/d) | Average GIR of I-40 (Mscf/d) | Average GIR of I-74 (Mscf/d) | Average GIR of I-19 (Mscf/d) | Sum (Mscf/d) |
|---|---|---|---|---|
| 12,804 | 8471 | 12,238 | 12,804 | 46,317 |
| Parameters | Value |
|---|---|
| Epoch | 3000 |
| Batch size | 64 |
| Time step | 16 |
| Learning rate | 0.001 |
| Number of hidden layers | 2 |
| Number of hidden neurons | 60 |
| Optimizer | Adam |
| Loss function | RMSE |
| Activation function | ReLU |
| Parameters | Value |
|---|---|
| Number of particle groups | 300 |
| Iterations | 10,000 |
| Inertia factor | 0.7 |
| Individual confidence factor | 2.0 |
| Group confidence factor | 2.0 |
| Method | RNN | GRU | LSTM | Bi-LSTM | BPNN | Bi-GRU | DNN | Attention | RNS |
|---|---|---|---|---|---|---|---|---|---|
| Time (s) | 960 | 830 | 890 | 970 | 1250 | 1080 | 1320 | 760 | 4600 |
| Method | GIR #1 (Mscf/d) | GIR #2 (Mscf/d) | GIR #3 (Mscf/d) | GIR #4 (Mscf/d) | Sum (Mscf/d) |
|---|---|---|---|---|---|
| Average allocation | 12,500 | 12,500 | 12,500 | 12,500 | 50,000 |
| Reservoir engineering | 4457 | 26,360 | 16,027 | 3154 | 50,000 |
| Pareto result | 8198 | 27,260 | 6662 | 7879 | 50,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, M.; Wei, C.; Zhao, X.; Huang, R.; Li, B.; Yang, J.; Gao, Y.; Liu, S.; Xiong, L. Intelligent Optimization of Gas Flooding Based on Multi-Objective Approach for Efficient Reservoir Management. Processes 2023, 11, 2226. https://doi.org/10.3390/pr11072226
Gao M, Wei C, Zhao X, Huang R, Li B, Yang J, Gao Y, Liu S, Xiong L. Intelligent Optimization of Gas Flooding Based on Multi-Objective Approach for Efficient Reservoir Management. Processes. 2023; 11(7):2226. https://doi.org/10.3390/pr11072226
Chicago/Turabian StyleGao, Meng, Chenji Wei, Xiangguo Zhao, Ruijie Huang, Baozhu Li, Jian Yang, Yan Gao, Shuangshuang Liu, and Lihui Xiong. 2023. "Intelligent Optimization of Gas Flooding Based on Multi-Objective Approach for Efficient Reservoir Management" Processes 11, no. 7: 2226. https://doi.org/10.3390/pr11072226
APA StyleGao, M., Wei, C., Zhao, X., Huang, R., Li, B., Yang, J., Gao, Y., Liu, S., & Xiong, L. (2023). Intelligent Optimization of Gas Flooding Based on Multi-Objective Approach for Efficient Reservoir Management. Processes, 11(7), 2226. https://doi.org/10.3390/pr11072226