
Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs

Abstract
:1. Introduction
2. Model Introduction
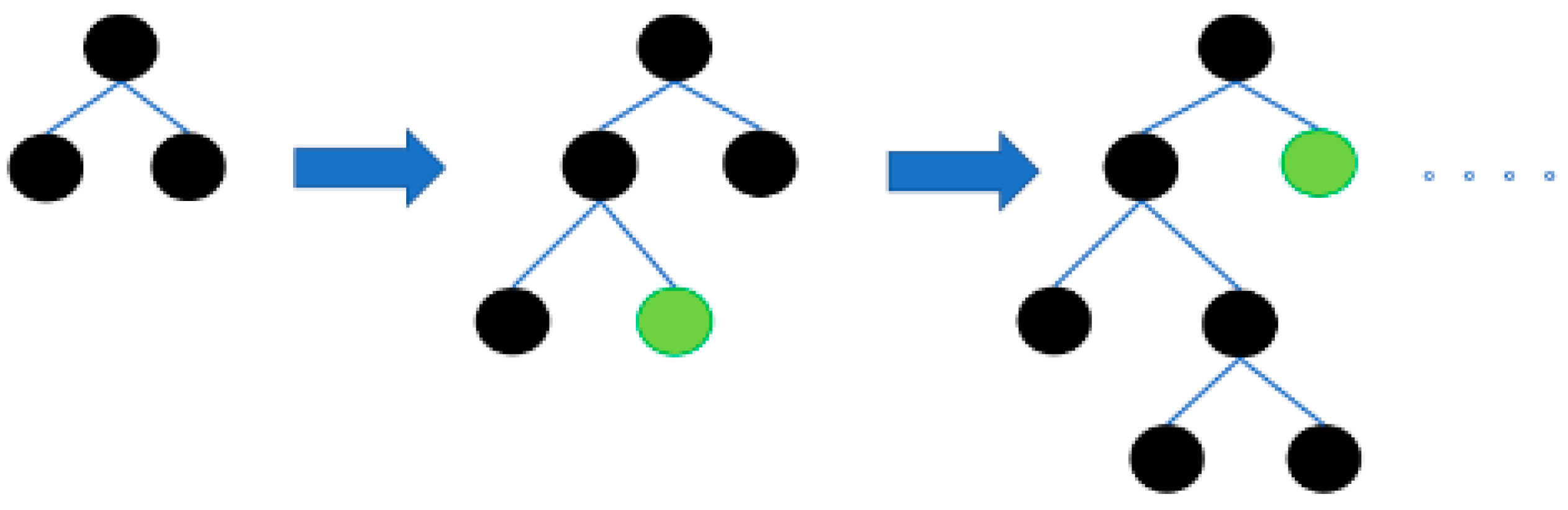
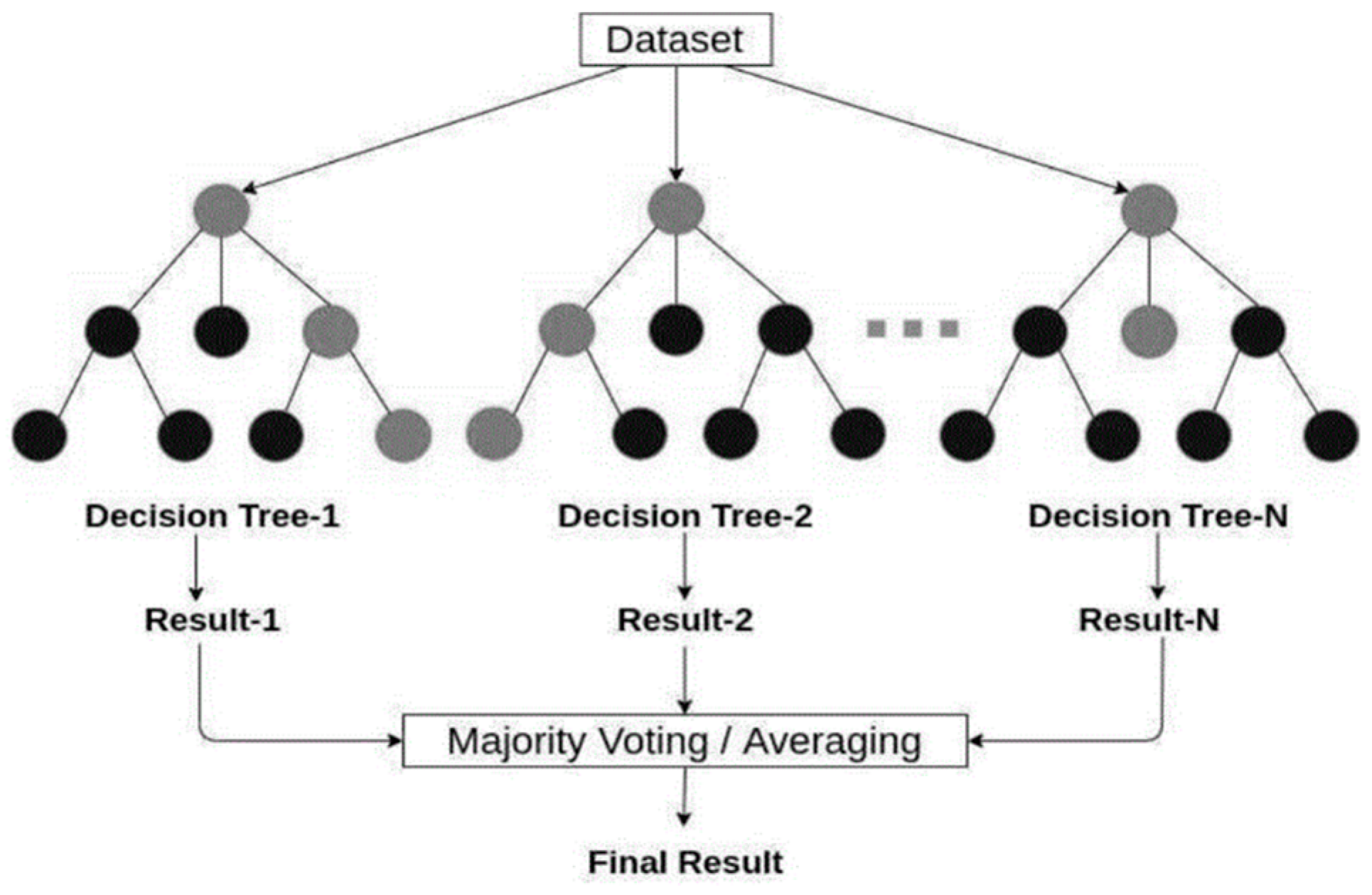
2.1. Random Forest
- (a)
- Randomly select B features as the splitting features for each decision tree, constructing a randomly selected feature subset F;
- (b)
- Obtain a training set Dn of size n from the dataset D using sampling with replacement, where n is the size of D;
- (c)
- Build a decision tree model Tk using the feature subset F and training set Dn;
- (d)
- Repeat steps b and c until T decision trees are obtained.
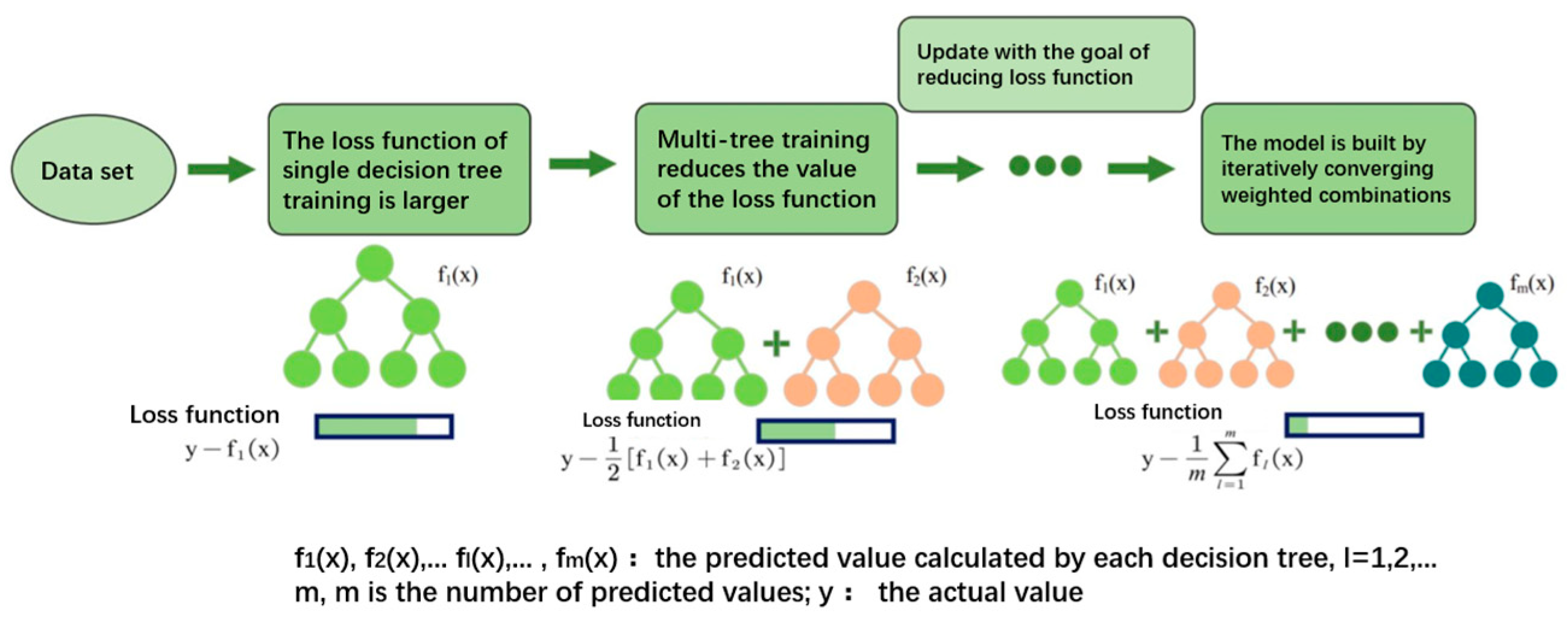
2.2. LightGBM
2.3. CatBoost
3. Classification Prediction
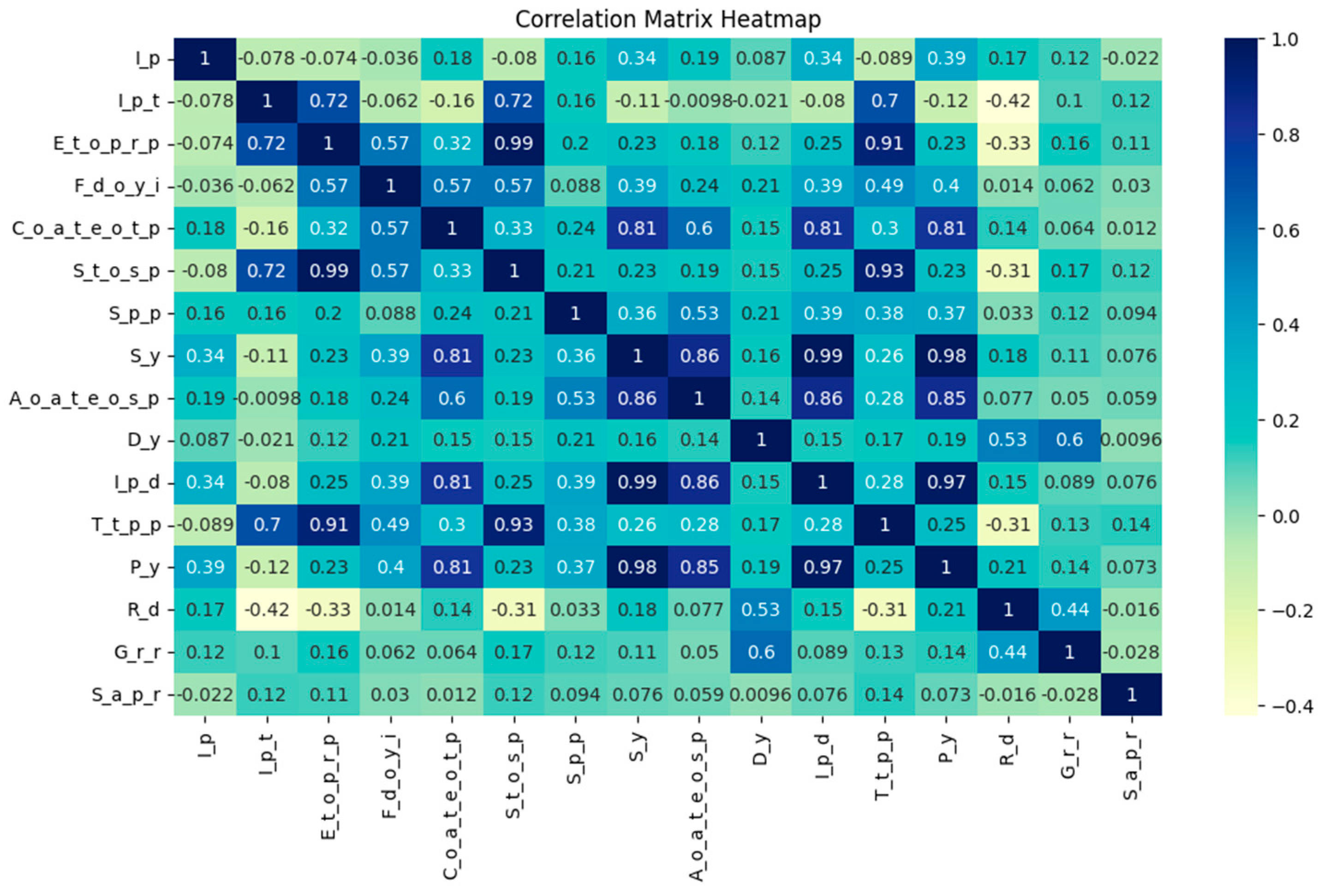
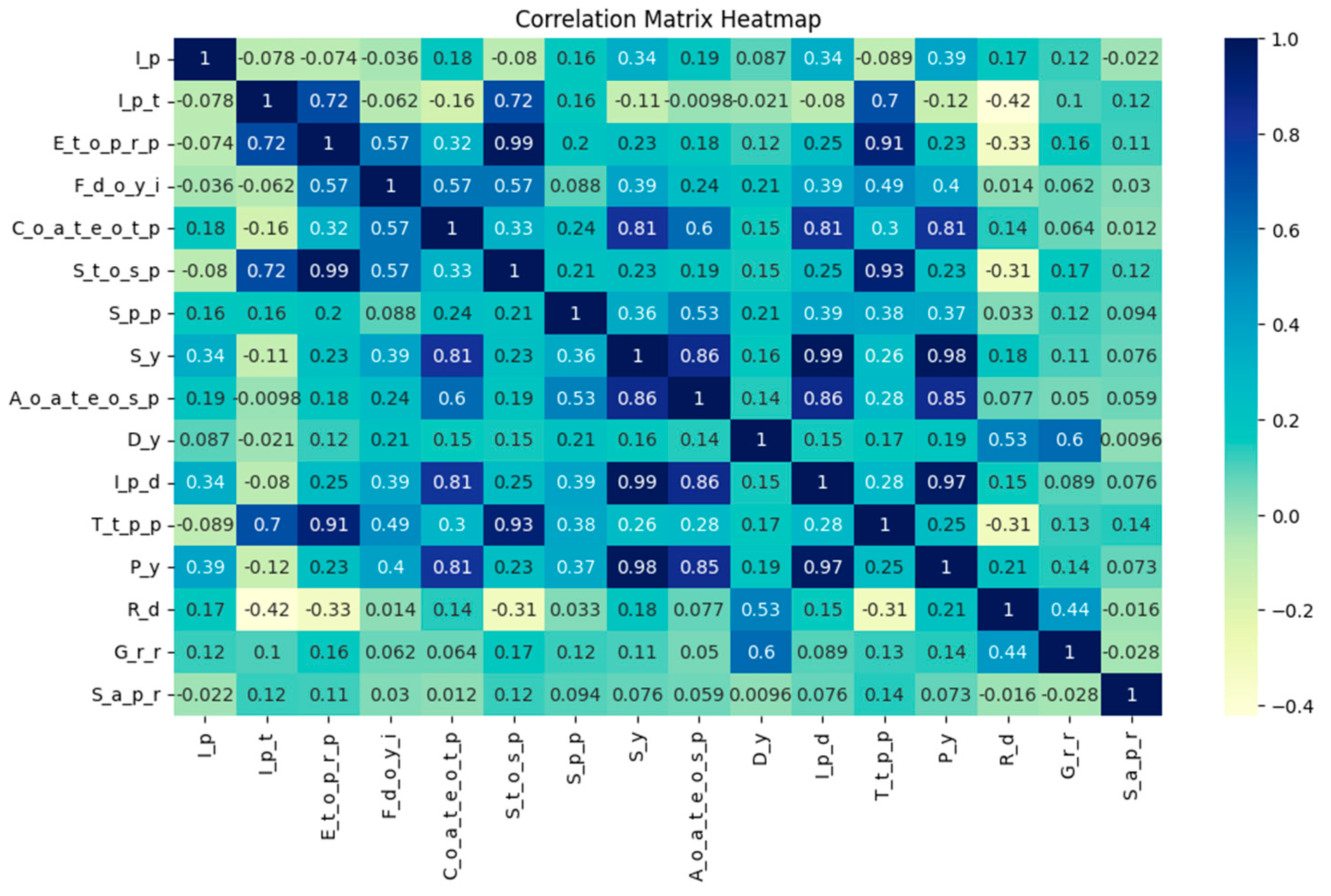
3.1. Dataset Introduction and Feature Selection
3.2. Data Preprocessing
3.3. Model Selection and Implementation
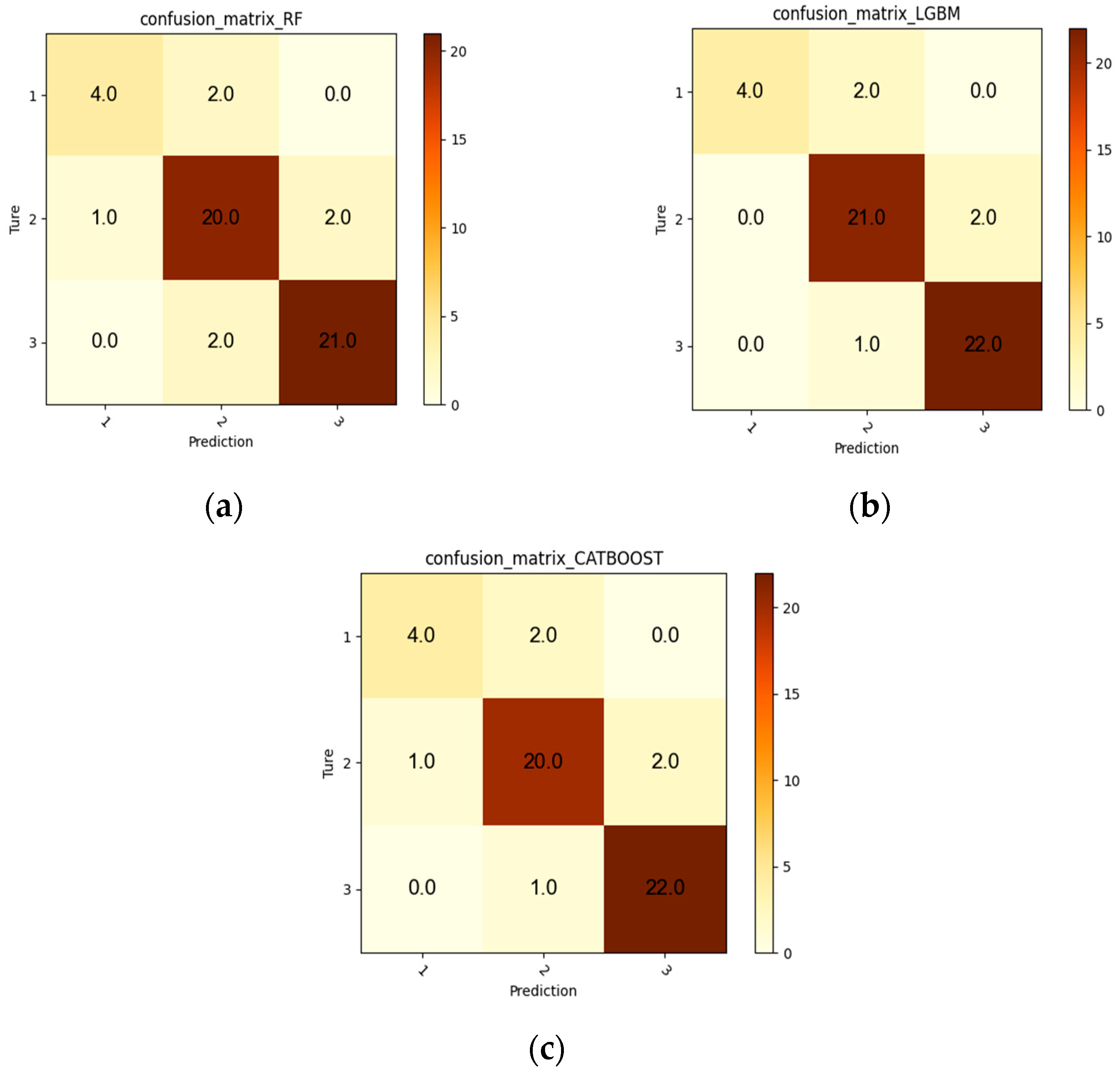
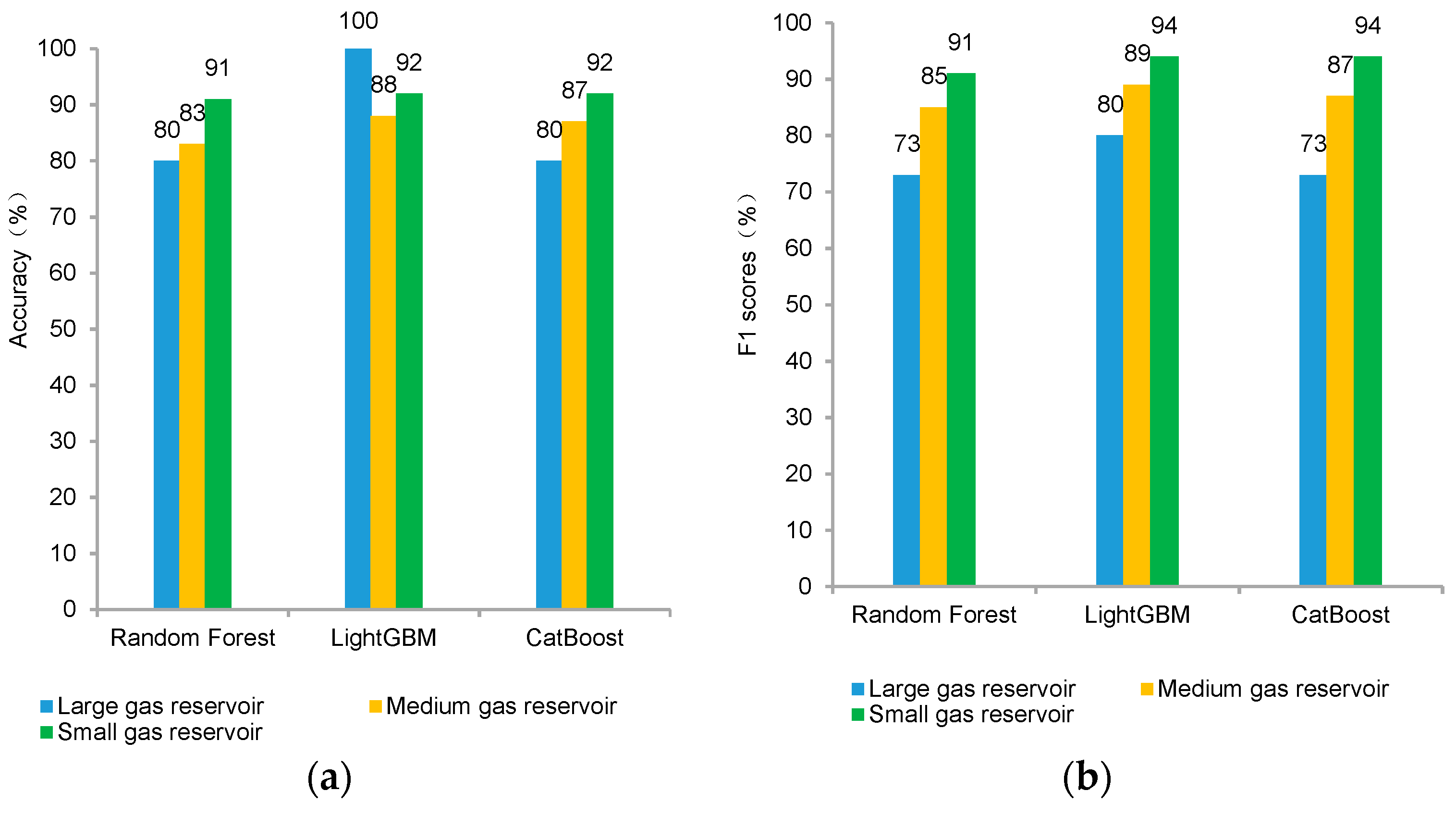
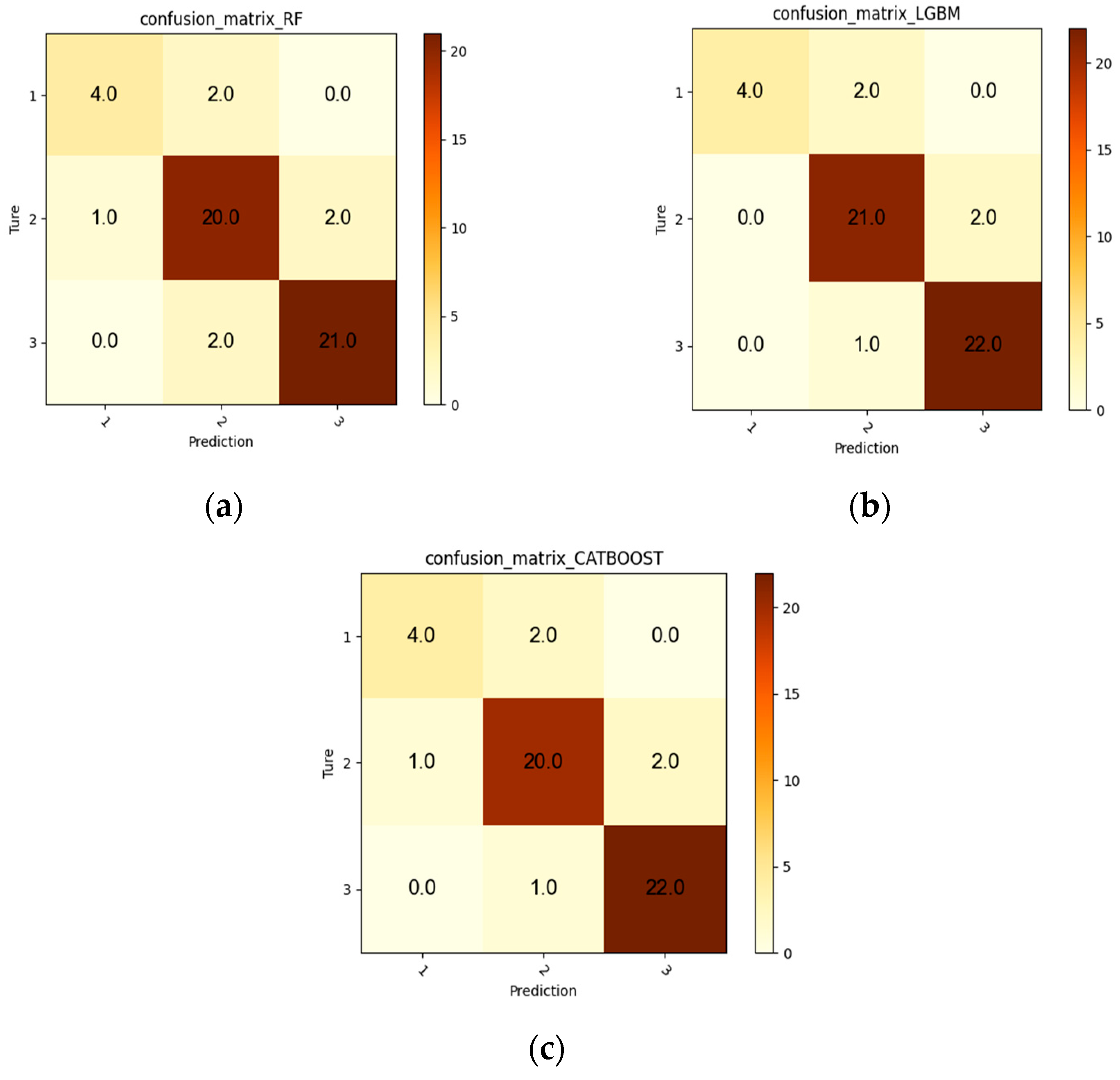
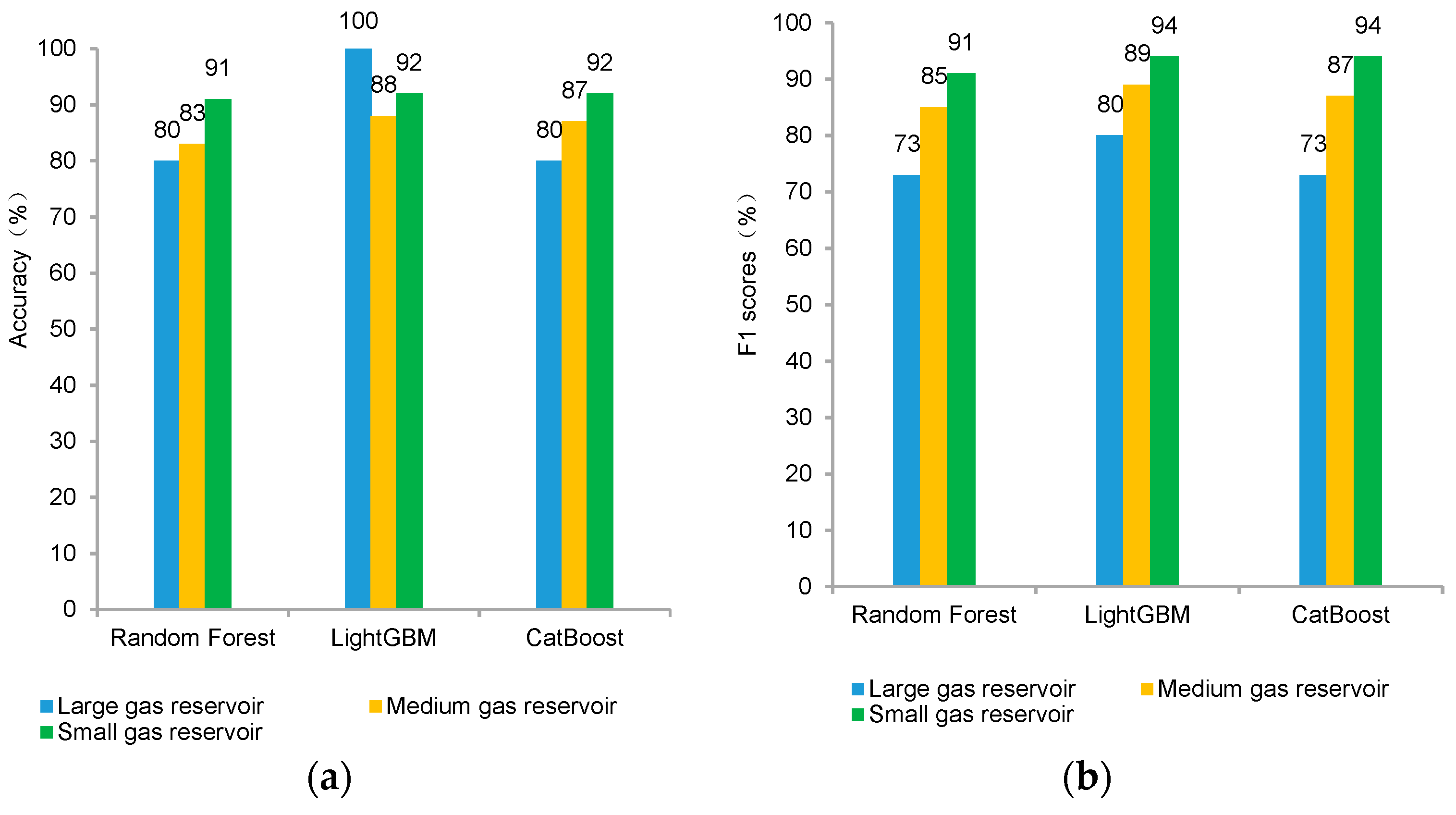
3.4. Comparative Analysis of Classification Models
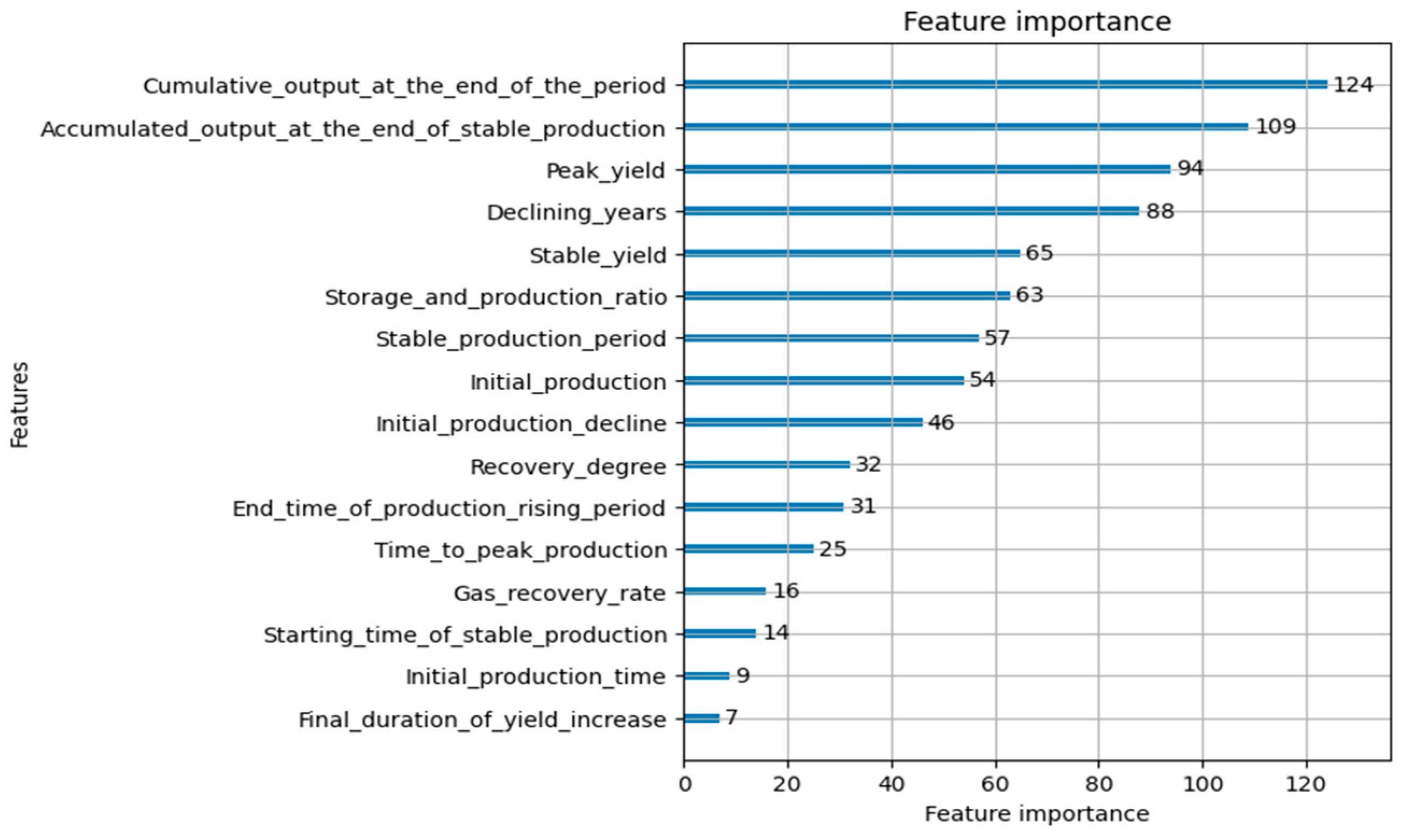
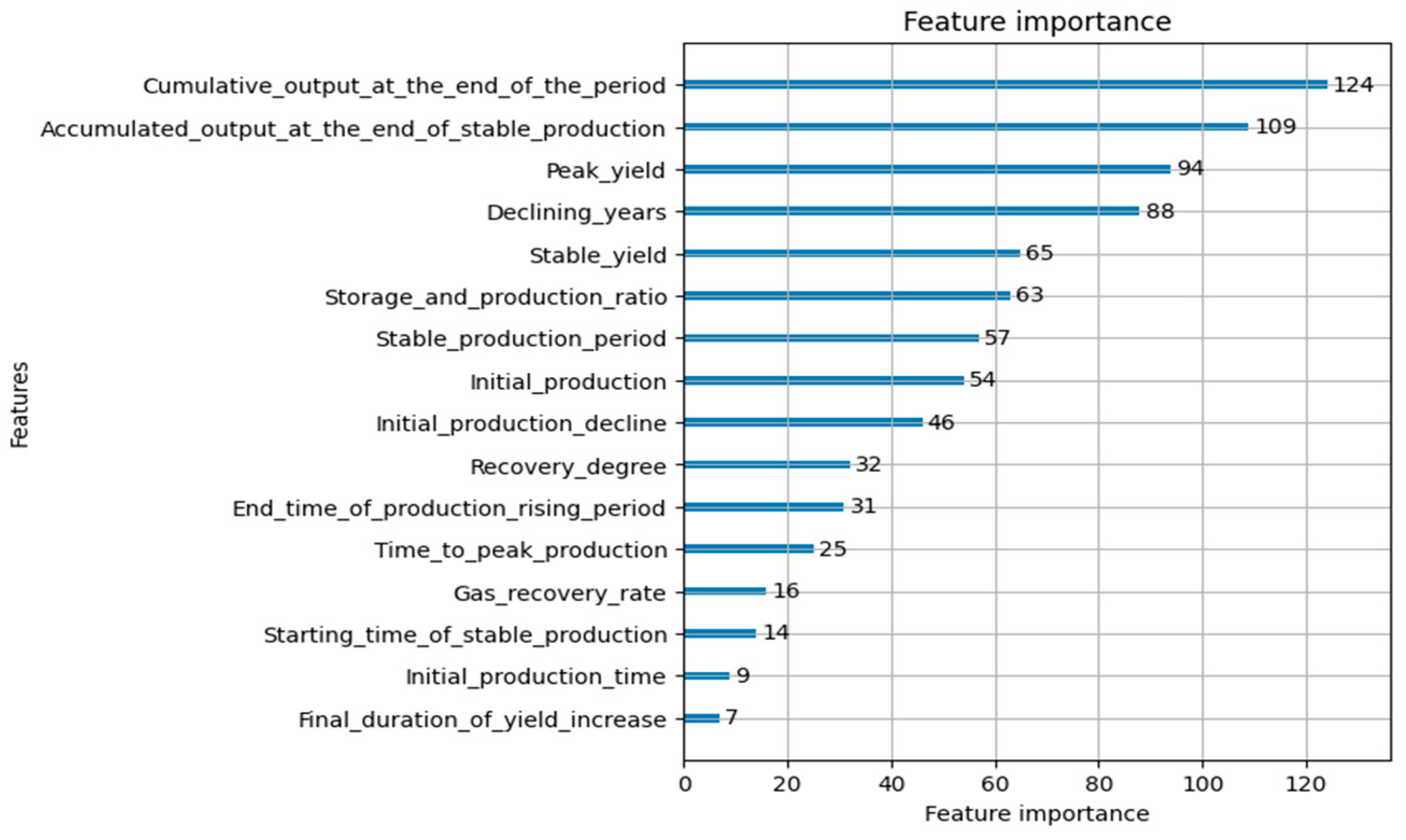
3.5. Feature Importance Selection
4. Discussion of Results
5. Case Verification
6. Conclusions
- (1)
- By using representative models such as Random Forest, LightGBM, and CatBoost for prediction and conducting optimization and comparison, it is found that the LightGBM model has the highest accuracy and overall good F1 scores for different categories. This model exhibits the best predictive capability and is more suitable for analyzing the relationship between production characteristics and different reserve sizes of tight reservoirs.
- (2)
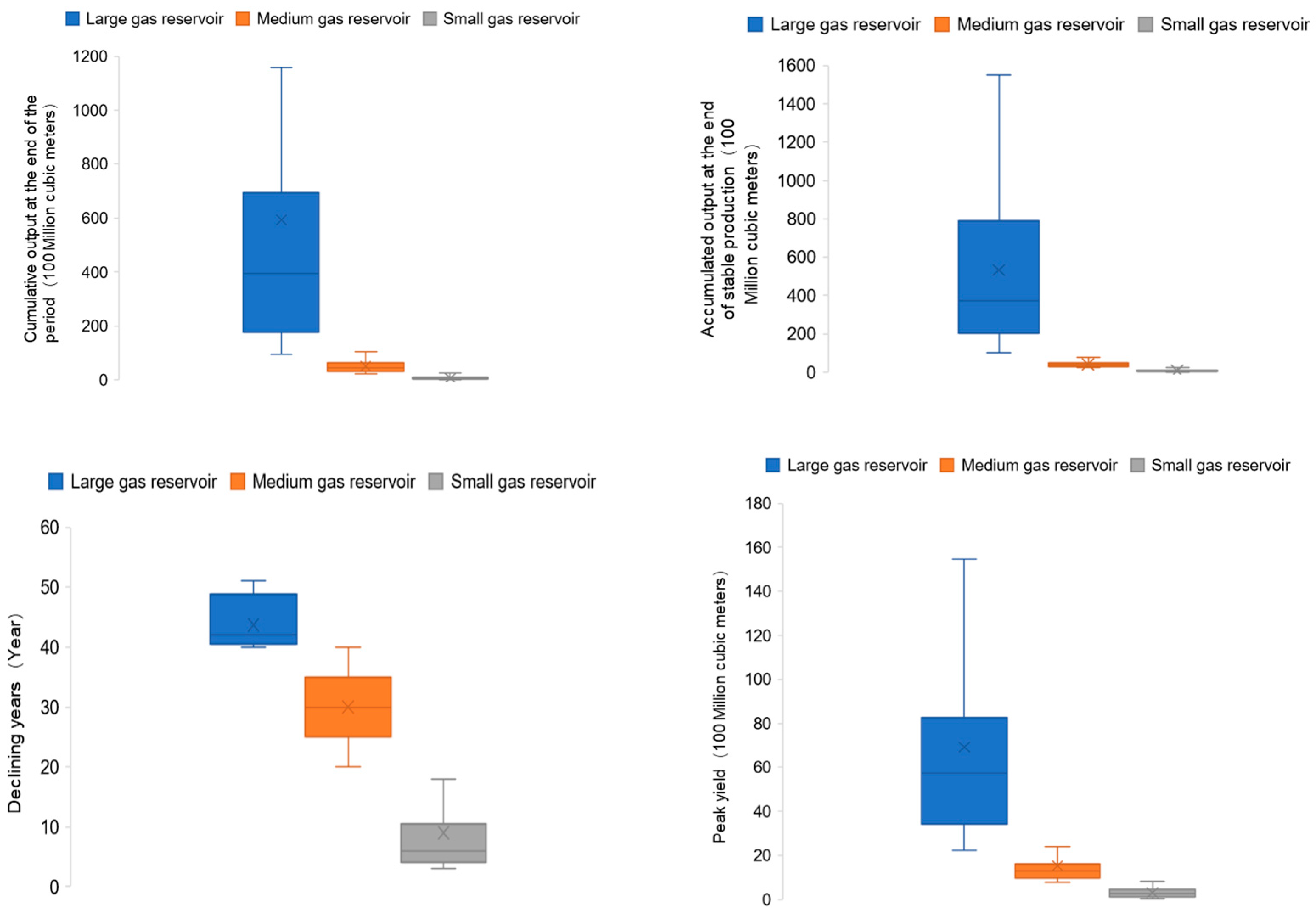
- The LightGBM model selects the top four most important feature indicators, which are Cumulative output at the end of the period, Accumulated output at the end of stable production, Peak yield, and Declining years. These indicators are used to establish production feature judgment rules that match the reserve size of tight reservoirs.
- (3)
- The analysis of the relationship between production characteristics and reserves in global tight gas reservoirs can provide valuable references for the formulation of development technology policies, rational production strategies, and production potential evaluation in the production and development of tight gas reservoirs. For example, by analyzing the relationship between production characteristics and reserves in global tight gas reservoirs, the production potential of different reservoirs can be assessed. This helps identify which reservoirs have higher production efficiency and sustainable production levels, thereby guiding the rational allocation of development and production resources. It also helps in formulating appropriate production strategies. Reservoirs with different reserve levels may require different development and production techniques to maximize production and economic benefits. Analyzing the relationship between production characteristics and reserves can guide the selection of suitable well pattern layouts, fracturing parameters, and production control methods, thereby maximizing the production capacity of the reservoir.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jia, A.; Wei, Y.; Guo, Z.; Wang, G.; Meng, D.; Huang, S. Development status and prospects of tight sandstone gas in China. Nat. Gas Ind. 2022, 9, 467–476. [Google Scholar] [CrossRef]
- Jia, A.; Yan, H.; Guo, J.; He, D.; Cheng, L.; Jia, C. Development characteristics of different types of carbonate gas reservoirs. Acta Pet. Sin. 2013, 34, 914–923. [Google Scholar]
- Duna, P.J. Analysis on development characteristics and technical measures of condensate gas reservoir. China Pet. Petrochem. Ind. 2016, 86. [Google Scholar]
- Xu, Z.; Fang, B. Characteristics and development strategies of volcanic gas reservoirs in the Xushen gas field. Nat. Gas Ind. 2010, 30, 1–4. [Google Scholar]
- Luo, X.; Wang, S.; Jing, Z.; Xu, G. A Study on Triassic Shale Gas Reservoir Characteristics from Ordos Basin. In Proceedings of the 2016 5th International Conference on Measurement, Instrumentation and Automation (ICMIA 2016), Shenzhen, China, 17–18 September 2016. [Google Scholar]
- Hui, D.; Hu, Y.; Li, T.; Peng, X.; Li, Q. A typical bottom water reservoir development characteristics and suitable development strategy enlightenment. J. Oil Gas Geol. Oil Recovery 2023, 30, 101–111. [Google Scholar] [CrossRef]
- He, D.; Yan, H.; Yang, C.; Wei, Y.; Zhang, L.; Guo, J.; Luo, W.; Liu, X.; Hu, D.; Xia, Q.; et al. Gas reservoir characteristics and development technical countermeasures of Member 4 of Dengying Formation, Anyue Gas field. Acta Pet. Sin. 2022, 43, 977–988. [Google Scholar]
- Chen, J. Pore structure characteristics and depletion development law of deep high-pressure carbonate gas reservoirs. Spec. Oil Gas Reserv. 2022, 29, 80–87. [Google Scholar]
- Zhou, M.; Xiang, Y.; Zhang, W.; Zhang, N.; Zhang, Y. Development characteristics and technical countermeasures of the bio-reef gas reservoir in Changxing Formation, eastern Sichuan. Nat. Gas Explor. Dev. 2020, 43, 44–51. [Google Scholar]
- Chen, X.; Wang, G. Comprehensive classification method of low permeability reservoir. Pet. Geol. Oilfield Dev. Daqing 2014, 33, 58–61. [Google Scholar]
- Wang, W.; Yuan, X.; Wang, G.; Liao, R. Study on classification and production characteristics of ultra-low permeability reservoirs. Pet. Drill. Technol. 2007, 72–75. [Google Scholar]
- Li, H.; Guo, H.; Guo, H.; Meng, Z.; Tan, F. Research on mining method of complex reservoir logging evaluation data. Acta Pet. Sin. 2009, 30, 542–549. [Google Scholar]
- Wang, L.; Wang, Z.; Tao, G. A new reservoir classification method for tight sandstone gas reservoir. Sci. Technol. Rev. 2011, 29, 47–50. [Google Scholar]
- Liu, Y.; Zhang, X.; Zhang, W.; Guo, W.; Kang, L.; Liu, D.; Gao, J.; Yu, R.; Sun, Y. A Review of Macroscopic Modeling for Shale Gas Production: Gas Flow Mechanisms, Multiscale Transport, and Solution Techniques. Processes 2023, 11, 2766. [Google Scholar] [CrossRef]
- Jia, A.; Yan, H.; Guo, J.; Wei, T.; He, D. Development characteristics and experience of different types of large gas reservoirs in the world. Nat. Gas Ind. 2014, 34, 33–46. [Google Scholar]
- Li, J.; Sheng, W.; Sheng, Z.; Yin, G.; Xia, X. Research on development and Production dynamic characteristics of classified gas reservoirs in DHXH Gas Field. Offshore Oil 2019, 39, 18–22. [Google Scholar]
- Yan, X.; Gu, H.; Xiao, Y.; Ren, H.; Ni, J. XGBoost algorithm in the application of tight sandstone gas reservoir logging interpretation. J. Pet. Geophys. Prospect. 2019, 54, 447–455+241. [Google Scholar] [CrossRef]
- Nie, Y.; Gao, G. Based on Random Forest “Dessert” Classification Method of Shale Gas. Reserv. Eval. Dev. 1–15. Available online: http://kns.cnki.net/kcms/detail/32.1825.te.20230221.1002.002.html (accessed on 6 April 2023).
- Shi, G. Application prospect of data mining in petroleum exploration database. China Pet. Explor. 2009, 14, 60–64+1. [Google Scholar]
- Cheng, Q.; Wang, X.; Wang, S.; Li, Y.; Liu, H.; Li, Z.; Sun, W. Research on a Carbon Emission Prediction Method for Oil Field Transfer Stations Based on an Improved Genetic Algorithm—The Decision Tree Algorithm. Processes 2023, 11, 2738. [Google Scholar] [CrossRef]
- Billah, M.; Islam, A.S.; Mamoon, W.B.; Rahman, M.R. Random forest classifications for landuse mapping to assess rapid flood damage using Sentinel-1 and Sentinel-2 data. Remote Sens. Appl. Soc. Environ. 2023, 30, 100947. [Google Scholar] [CrossRef]
- Li, H.; Cao, Z.; Wu, X.; Zhu, S.; Deng, J.; Zhang, S. Prediction Method of Formation Fracture Pressure Based on LightGBM Algorithm and Its Application. Chin. Test 1–9. Available online: http://kns.cnki.net/kcms/detail/51.1714.TB.20230111.1033.001.html (accessed on 7 April 2023).
- Wu, Y.-h. Optimization of LightGBM-XGBoost Power Load Forecasting Based on Genetic Algorithm. Sci. Technol. Innov. 2023, 71–75. [Google Scholar]
- Xing, C.; Xu, J. LightGBM Mixture Model in the Diagnosis of Breast Cancer. Comput. Eng. Appl. 1–10. Available online: http://kns.cnki.net/kcms/detail/11.2127.TP.20230228.1116.020.html (accessed on 7 April 2023).
- Li, H.; Tan, Q.; Zhu, S.; Deng, J.; Yan, K. Pore pressure prediction Method based on CatBoost algorithm and its application in wellbore stability analysis. China Saf. Prod. Sci. Technol. 2023, 19, 136–142. [Google Scholar]
- Bai, G.; Zheng, L. Distribution characteristics of large gas fields in the world. Nat. Gas Geosci. 2007, 90, 161–167. [Google Scholar]
- Jin, Z. Structure and distribution of large and medium-sized oil and gas fields in China. Xinjiang Pet. Geol. 2008, 385–388. [Google Scholar]
- Zou, C.; Guo, J.; Jia, A.; Wei, Y.; Yan, H.; Jia, C.; Tang, H. Connotation of scientific development of large gas fields in China. Nat. Gas Ind. 2020, 7, 533–546. [Google Scholar]
- Li, D.; Xiong, H.; Shi, G.; Niu, M. Data mining pretreatment based on global typical oil and gas field database. Pet. Geol. Oilfield Dev. Daqing 2016, 35, 66–70. [Google Scholar]
- Li, D.; Shi, G. Optimization of common data mining algorithms in oil and gas exploration and development. Acta Pet. Sin. 2018, 39, 240–246. [Google Scholar]
- Shang, Y.; Zhai, S.; Lin, X.; Li, X.; Li, H.; Feng, Q. Dynamic and Dynamic Integration Classification Model of Low Permeability Tight Gas Well Based on XGBoost Algorithm. Spec. Reserv. 1–12. Available online: http://kns.cnki.net/kcms/detail/21.1357.TE.20230607.1001.002.html (accessed on 13 October 2023).
- Jia, Y.; Shi, J.; Li, X.; Chen, H.; Fang, J. Research on classification and evaluation method of low permeability tight gas Wells: A case study of Changqingzizhou gas field. Geol. Explor. 2021, 57, 647–655. [Google Scholar]
- Yuan, B.; Ye, Q.; Zhang, L.; Chen, Z.; Lei, M. Classification method of offshore low permeability gas reservoir based on multiple evaluation parameters. J. Southwest Pet. Univ. Nat. Sci. Ed. 2020, 42, 111–118. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic Variable | Meaning and Unit | |
|---|---|---|
| 1 | Initial production | Production data for the first year of field production (100 Million cubic meters) |
| 2 | Initial production time | Time of initial production of gas field (Year) |
| 3 | End time of production rising period | Point in time when gas field production stopped increasing (Year) |
| 4 | Final duration of yield increase | Total time spent on production upswing (Year) |
| 5 | Cumulative output at the end of the period | Cumulative production at the end of the upswing period (100 Million cubic meters) |
| 6 | Stable production period | Years of stable production period (Year) |
| 7 | Starting time of stable production | The time when the stable yield period begins (Year) |
| 8 | Stable yield | The average annual output during the stable production period (100 Million cubic meters) |
| 9 | Accumulated output at the end of stable production | Cumulative production at the end of a stable period (100 Million cubic meters) |
| 10 | Declining years | The duration of the decline period (Year) |
| 11 | Initial production decline | Production at the beginning of the decline period (100 Million cubic meters) |
| 12 | Peak yield | The maximum lifetime production of a gas field (100 Million cubic meters) |
| 13 | Time to peak production | The time when the field reaches maximum production (Year) |
| 14 | Recovery degree | The degree of production in the gas field (%) |
| 15 | Storage and production ratio | Reserve-production ratio of gas field |
| 16 | Gas recovery rate | Rate of gas production in a gas field (%) |
| 17 | Recoverable reserves | Recoverable reserves of gas fields (100 Million cubic meters) |
| Type | Recoverable Reserves | Number of Original Datasets | Number of Datasets after Balancing |
|---|---|---|---|
| Large gas reservoir | More than 30 billion square meters | 30 | 190 |
| Medium gas reservoir | 5 to 30 billion square meters | 41 | 190 |
| Small gas reservoir | 0–5 billion square meters | 190 | 190 |
| Random Forest | LightGBM | CatBoost |
|---|---|---|
| max_depth = [5, 10, 15, 20, None] max_features = [1, 2, 4] min_samples_leaf = [1, 2, 4] min_samples_split = [2, 5, 10] n_estimators = [10, 100, 200] | feature_fraction = [0.5, 0.8, 1] learning_rate = [0.01, 0.1, 0.3] max_depth = [−1, 3, 5, 8] n_estimators = [20, 40, 100] num_leaves = [16, 32, 64] reg_lambda = [1, 3, 5] | depth = [4, 6, 10] depth = [4, 6, 10] learning_rate = [0.01, 0.1] |
| Random Forest | LightGBM | CatBoost |
|---|---|---|
| Max_depth = 10 max_features = 4 min_samples_leaf = 2 min_samples_split = 10 n_estimators = 10 | feature_fraction = 1 learning_rate = 0.3 max_depth = 3 n_estimators = 100 num_leaves = 16 reg_lambda = 1 | depth = 4 l2_leaf_reg = 4 learning_rate = 0.01 |
| Type | Decision Rule |
|---|---|
| Small gas reservoir | 0.1 ≤ Cumulative_output_at_the_end_of_the_period ≤ 2.5 billion cubic meters, 0.2 ≤ Accumulated_output_at_the_end_of_stable_production ≤ 2.4 billion cubic meters, 0.005 ≤ Peak_yield ≤ 0.8 billion cubic meters, 3 ≤ Declining_years ≤ 20 years |
| Medium gas reservoir | 2.5 ≤ Cumulative_output_at_the_end_of_the_period ≤ 10 billion cubic meters, 2.4 ≤ Accumulated_output_at_the_end_of_stable_production ≤ 7.9 billion cubic meters, 0.8 ≤ Peak_yield ≤ 2.3 billion cubic meters, 20 ≤ Declining_years ≤ 40 years |
| Large gas reservoir | 10 ≤ Cumulative_output_at_the_end_of_the_period ≤ 115.8 billion cubic meters, 7.9 ≤ Accumulated_output_at_the_end_of_stable_production ≤ 154.9 billion cubic meters, 2.3 ≤ Peak_yield ≤ 13.8 billion cubic meters, 40 ≤ Declining_years ≤ 51 years |
| Tight Gas Reservoir | Loma La Lata Area | Travis Peak Tight Gas ALT TX | Aknazar | Churchie Area |
|---|---|---|---|---|
| Cumulative output at the end of the period (100 million square meters) | 780.09 | 52.70 | 11.46 | 1.19 |
| Accumulated output at the end of stable production (100 million square meters) | 455.67 | 30.43 | 14.65 | 2.43 |
| Peak yield (100 million square meters) | 123.47 | 12.19 | 5.06 | 0.67 |
| Declining years (Years) | 40 | 33 | 6 | 7 |
| Recoverable reserves (100 million square meters) | 3117.71 | 192.53 | 42.32 | 18.52 |
| True type | Large gas reservoir | Medium gas reservoir | Small gas reservoir | Small gas reservoir |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, B.; Li, C. Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs. Processes 2023, 11, 3159. https://doi.org/10.3390/pr11113159
Liu B, Li C. Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs. Processes. 2023; 11(11):3159. https://doi.org/10.3390/pr11113159
Chicago/Turabian StyleLiu, Baolei, and Changxuan Li. 2023. "Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs" Processes 11, no. 11: 3159. https://doi.org/10.3390/pr11113159
APA StyleLiu, B., & Li, C. (2023). Mining and Analysis of Production Characteristics Data of Tight Gas Reservoirs. Processes, 11(11), 3159. https://doi.org/10.3390/pr11113159