1. Introduction
One important activity in the oil industry is to measure well production. By conducting measurements of the oil production, it could show how the well performs compared to the simulation result. Moreover, it plays a significant role in the phase of declining production. By measuring the declining production earlier, petroleum engineers have the capability to deliver appropriate action to respond [
1,
2]. However, such an ideal situation of providing continuous and periodic measurements is not viable to deploy due to economic and technical challenges [
3,
4]. Non-continuous and occasional basis of well production measurement is very common in oilfield operation [
5,
6].
Commonly, well production rate is measured using a test separator for some minutes to hours and then applying certain calculations to represent the whole day production of the well. In more advanced technology, the rate is measured by multiphase flow meters (MPFMs) that are equipped with several sensors, such as an ultrasonic meter that is used for gas rate measurement and a capacitance meter that can measure very high water cut, which is barely possible to acquire using the conventional method [
7,
8]. In many oil fields, a production test is not acquired every day for each well due to the well number limitation of test stations to conduct the test. Therefore, conducting specific tasks such as well performance monitoring will rely on a lagged test that leads to late action when something occurs in the well. Hence, petroleum engineers have difficulty determining declining well production earlier. For a longer production span, some traditional approaches are common to forecast production, including decline curve analysis (DCA), exploration interpolation and the black oil model [
9]. Since those forecasting models need to be tuned with proper parameters and pick the right slope, its main disadvantage is a subjective judgment by the expert who is conducting the analysis [
3]. For shorter-term prediction, many approaches have been proposed using data-driven methodology, such as using thermogravimetric data to predict oil flow rate [
4], inferring flow rate from real-time parameters using diverse neural networks [
10] and many data mining methodologies. Another study involves additional hardware such as extended venturi and the use of a support vector machine (SVM) for the model [
11]. Another experiment was augmented by a lab-scale vertical pipe to obtain differential pressure signals as the inputs to principal component analysis and neural network models [
12].
In the well production forecasting area, the use of artificial intelligence and data mining method have been introduced in the last two decades. The research literature is basically divided into two approaches: non-time series (cross-sectional data) and time series, either univariate or multivariate approaches. Some efforts were intended to improve the prediction by exploiting optimization algorithms such as the imperialist competitive algorithm [
13] and aquila optimizer [
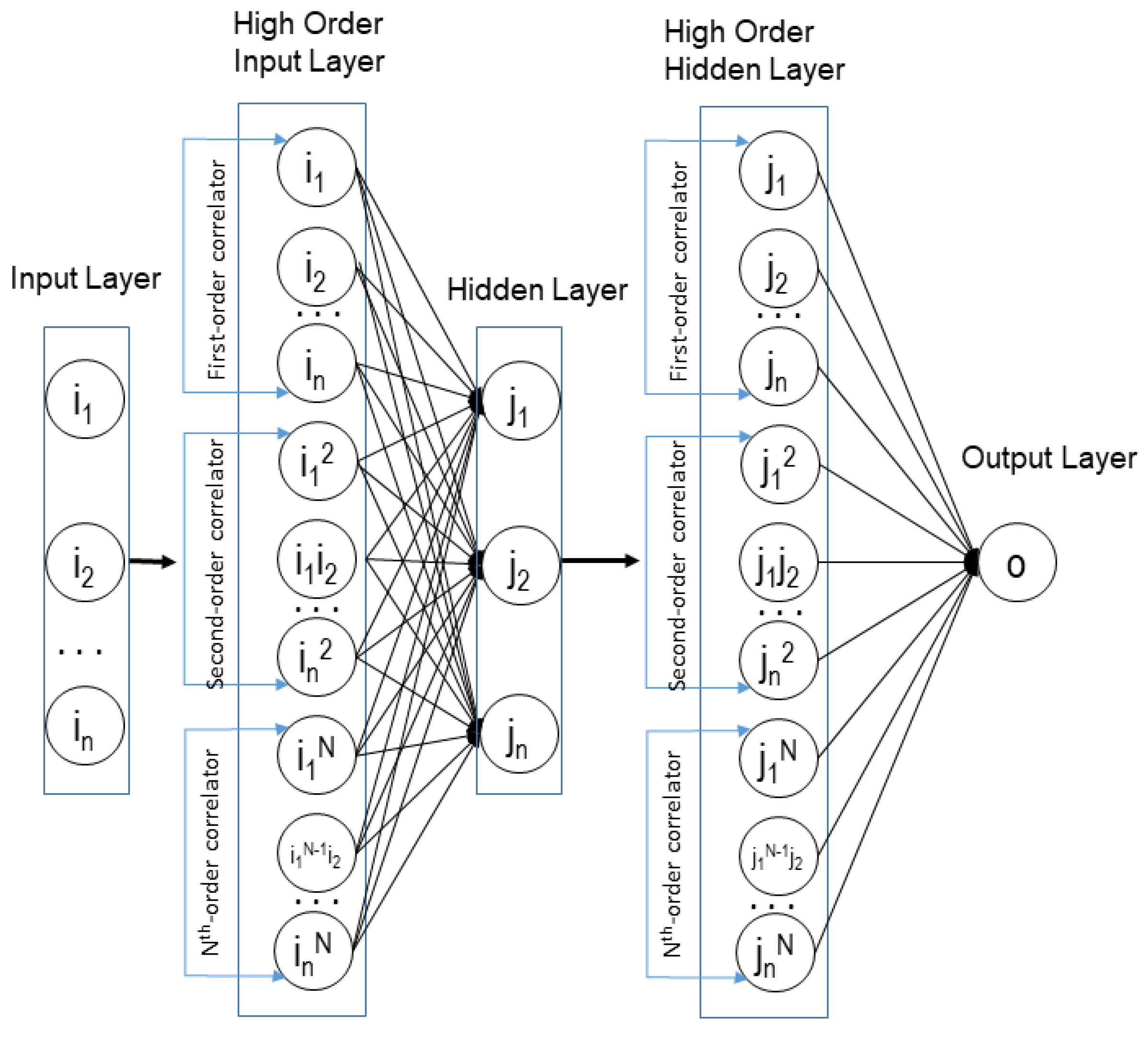
14]. To capture highly non-linear correlation, the higher-order neural network (HONN) has been introduced to forecast cumulative oil production [
15]. A more recent experiment utilized a univariate and multivariate time series approach using a nonlinear autoregressive neural network with exogenous input (NARX) to forecast oil production in a natural fracture reservoir [
16]. Another approach with a multi-layer multi-valued neural network (MLMVN) was developed for predicting oil production [
17]. This model is based on complex numbers for the input and weight parameters of neural network nodes. The advantage of MLMVN is a derivative-free learning approach which benefits from requiring fewer resources and a faster process [
18]. Another approach uses an ensemble neural network with adaptive simulated annealing to optimize the combining strategy [
10]. Dongyan et al. [
19] proposed ensemble univariate algorithms, namely autoregressive integrated moving average (ARIMA) and long short-term memory (LSTM). The most recent one is the approach using deep long-short term memory (DLSTM) as an extension to the traditional recurrent neural network [
20]; however, this research only focuses on non-stationary time series well production data. An interesting approach was performed by decomposing the production data before inputting it into the model [
21].
Even though the univariate forecasting method is very popular in other topics, such as crude oil price forecasting [
22] and electrical load forecasting [
23], only a few studies focused on the univariate time series prediction of oil flow rate. In a previous study, the multivariate model in certain cases showed better results than the univariate one [
16]; however, multivariate has its own limitation, such as requiring more dependent variables to be collected. All of the literature confirms that oil production is non-linear and needs a special approach to capture such complex behavior [
24]. One of the complex behaviors came from the disturbance factor of oil flow rate measurement noise. According to previous literature, noise reduction is a contributing factor to achieving an excellent univariate forecasting method [
15]. Another gap in previous univariate time series forecasting for oil production is the focus on non-stationary data [
20], which may not cover all the characteristics of well production.
In this study, we propose a novel hybrid model for time series well production forecasting data using a back propagation higher-order neural network (BP-HONN) with first, second and third-order synaptic operation and the decomposition method. The decomposition method utilizes simplifying the trend of input data (signal); thus, the neural network could learn it more accurately. Based on a recent study, as the effect of decomposition, increasing the linearity of time series data could improve accuracy performance [
9]. For the decomposition, empirical mode decomposition (EMD) is being proposed, as it is proven for a non-linear dataset in other research areas [
24,
25]. To evaluate the robustness of the model, the stationary and non-stationary time series data are being used. The actual field dataset was taken from previous literature [
15] and production data from the Sumatra Basin field, Indonesia, a total of 30 wells of production data. In addition, another novel hybrid model is also being introduced as the benchmark. The same dataset will be evaluated with EMD-BP-MLMVN to show the performance comparison of the proposed model.
The contributions of this research are:
The introduction of a novel hybrid method incorporating EMD and BP-HONN as the main proposed framework for forecasting short term oil production.
The introduction of a secondary novel hybrid framework utilizing EMD and BP-MLMVN for the same objective.
Providing a 25-well dataset from an actual oilfield consisting of stationary and non-stationary datasets, which is a real representation of business challenges. This dataset will be available for future work by other researchers.
The experiment shows that the proposed method EMD-BP-HONN are significantly better than other benchmark models.
The remainder of this paper explains the oilfield/reservoir description where the dataset is retrieved, the algorithms that are used, the selected performance evaluation and eventually, the framework proposed. The final result will be discussed in the result section alongside the statistical test to evaluate the significant difference among models.
4. Conclusions
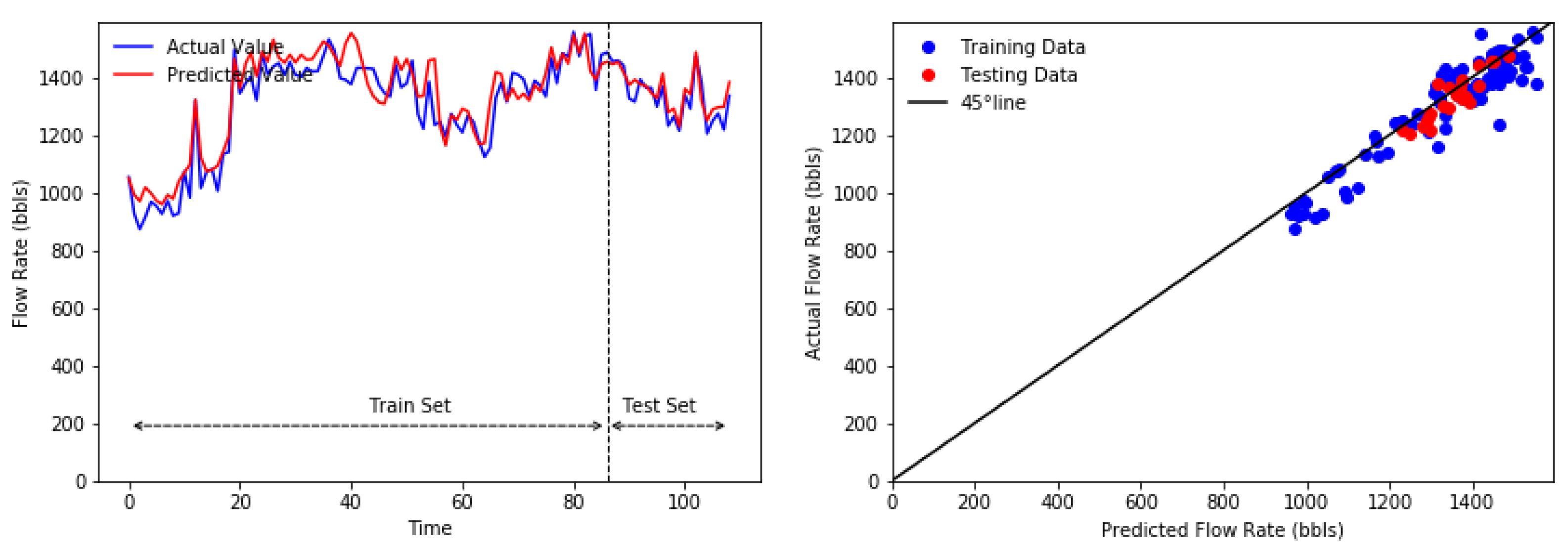
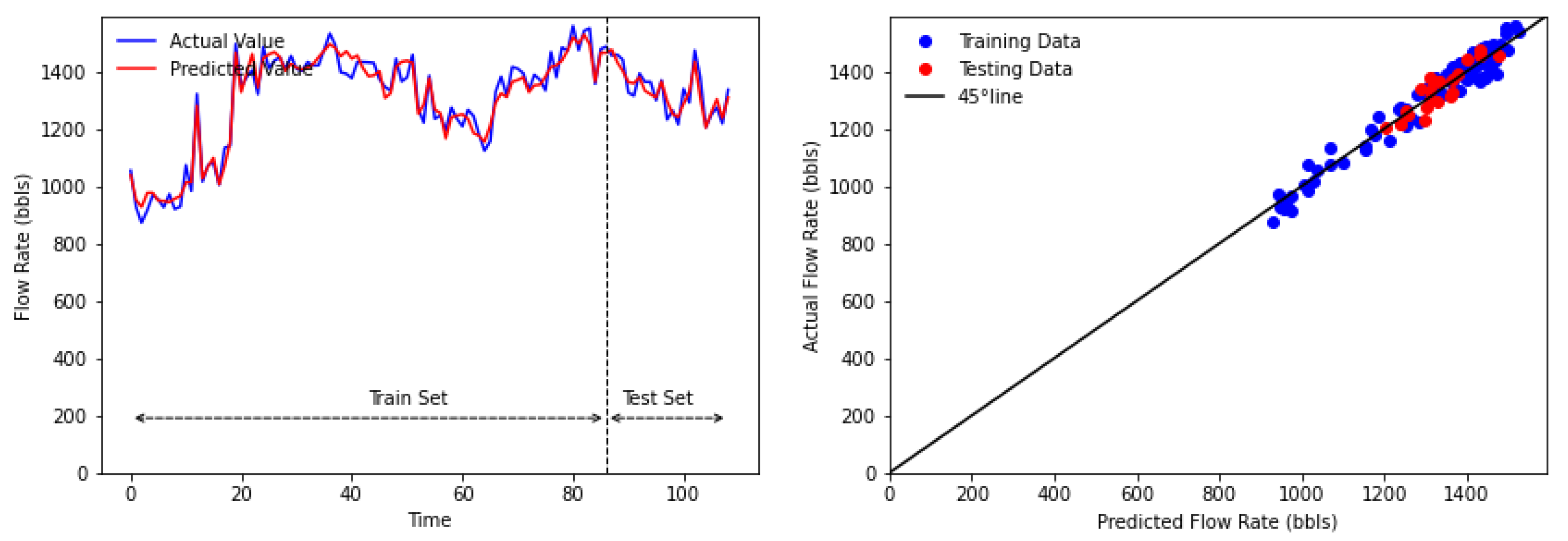
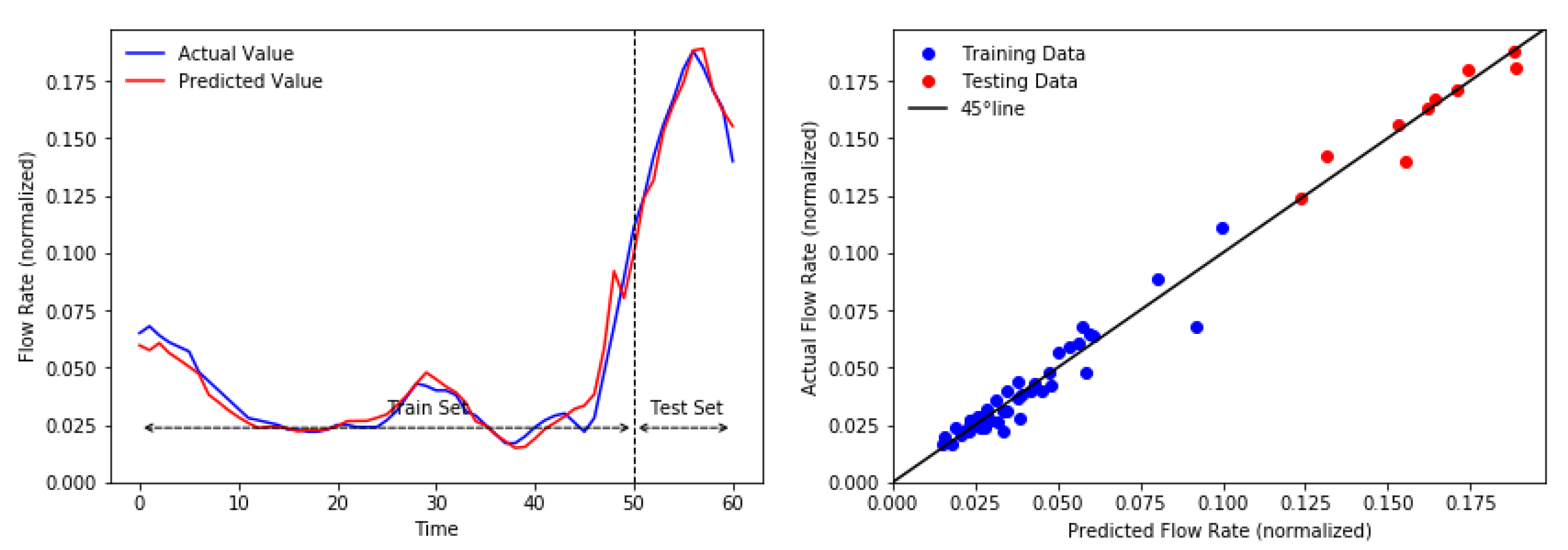
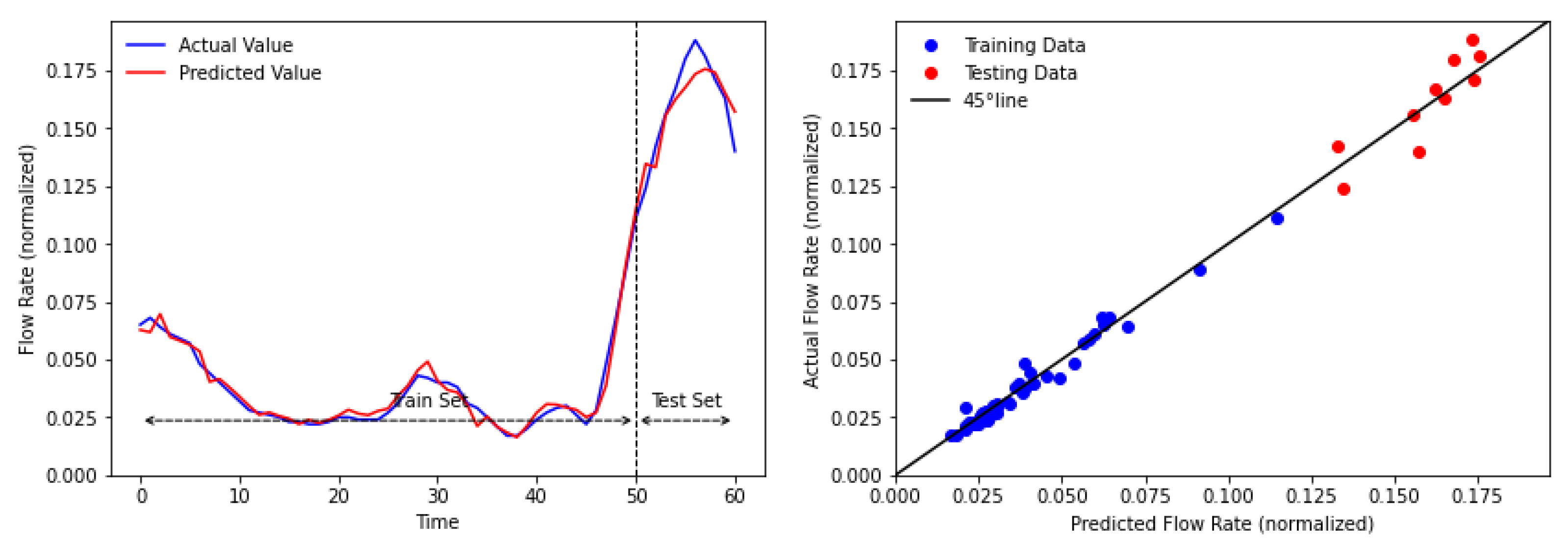
In this study, we introduced a hybrid model of EMD-BP-HONN and EMD-BP-MLMVN for oil flow rate forecasting. The decomposition method of EMD was utilized in the pre-processing stage to make time-series data simpler; thus, it should increase the performance of the forecasting algorithm. The proposed methods were applied to 30 datasets collected from two oilfields, Cambay Basin, India and the Central Sumatra Basin, Indonesia. To compare the performance, time-series forecasting was tested as well. The proposed methods have significant results and outperformed the benchmark models in most datasets. In addition, by implementing the decomposition method prior to base models, the hybrid models were improved significantly in all datasets.
For future works, the hybrid models being proposed, EMD-BP-HONN and EMD-BP-MLMVN, could be improved with a more advanced version of the decomposition method. Selecting the best parameter can also be explored using an optimization algorithm to be able to search global optimum of parameters.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}