


Multiple Graph Adaptive Regularized Semi-Supervised Nonnegative Matrix Factorization with Sparse Constraint for Data Representation
Abstract
1. Introduction
- This paper proposes the MSNMFSC method, which incorporates the multiple graph adaptive regularization, the limited supervisory information and the sparse constraint into the original NMF model for learning superior low-dimensional data representation.
- The multiplicative update rules of MSNMFSC are derived by solving the optimization problem using the multiplicative update algorithm.
- The convergence of MSNMFSC is analyzed theoretically, and the objective function will monotonically decrease under the update rules of MSNMFSC.
2. Preliminaries
2.1. Notations
2.2. Related Works
2.3. Constraint Propagation Algorithm (CPA)
- Construct the pairwise constraints matrix by Formula (1), compute the Laplacian matrix , in which is the diagonal matrix with and is the input weight matrix;
- Make vertical propagating by repeating until convergence, is the balance parameter;
- Make horizontal propagating by repeating until convergence, is the limit of ;
- Obtain the final propagated pairwise constraints matrix , is the limit of ;
- Calculate the new weight matrix by
3. The Proposed MSNMFSC
3.1. Objective Function
3.2. Solving Optimization Problem
3.2.1. Updating
3.2.2. Updating
3.2.3. Computing the Weight Value
| Algorithm 1: MSNMFSC Algorithm. |
| Input: Data matrix , label information , parameters , p, , and . Output: . |
4. Convergence of MSNMFSC
5. Experiments Results
5.1. Settings for the Experiments
5.2. Clustering Results
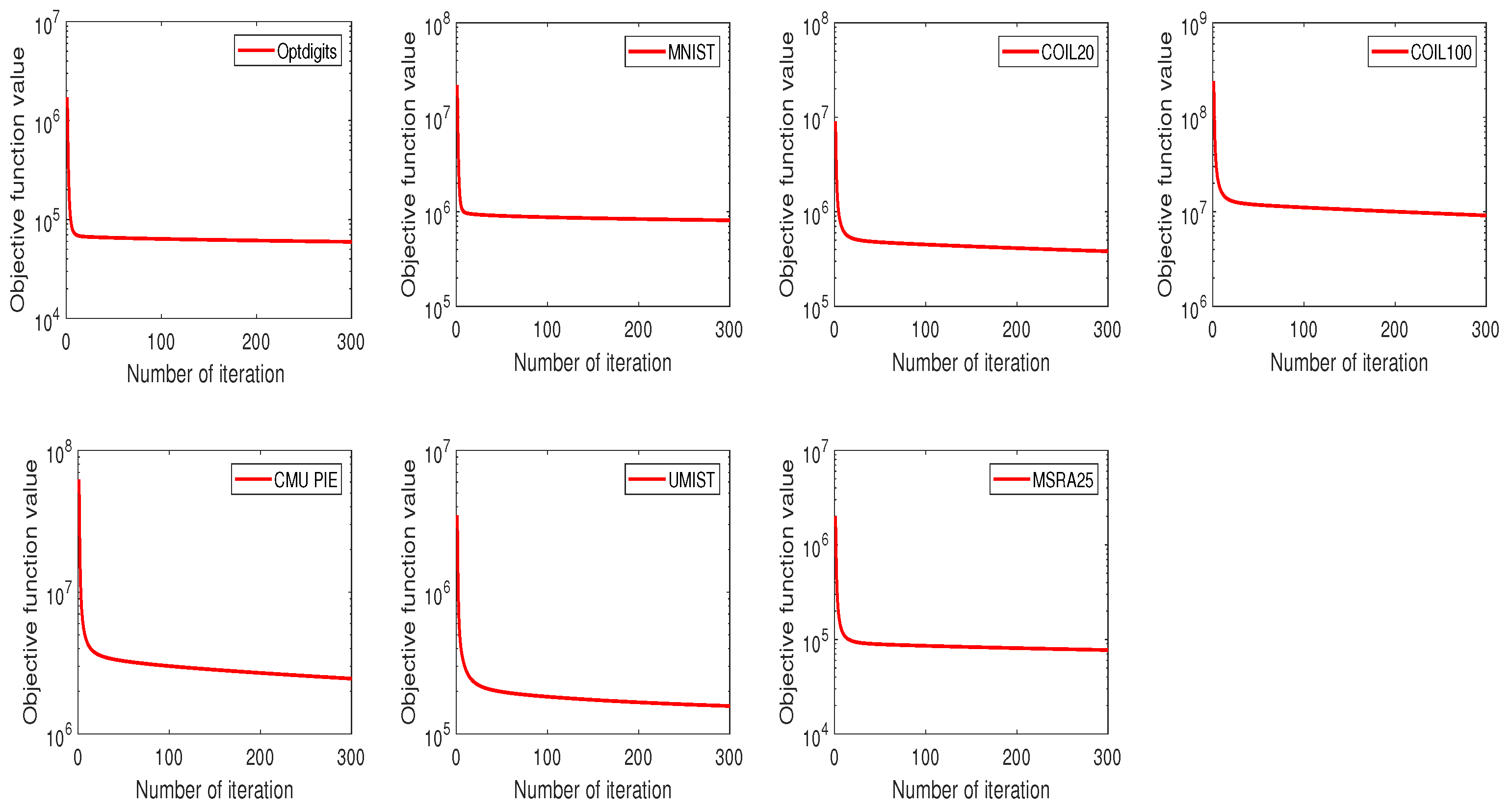
5.3. Convergence
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control. 1980, 25, 164–176. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788. [Google Scholar] [CrossRef] [PubMed]
- Stone, J.V. Independent component analysis: An introduction. Trends Cogn. Sci. 2002, 6, 59–64. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Pang, Y. Deterministic column-based matrix decomposition. IEEE Trans. Knowl. Data Eng. 2009, 22, 145–149. [Google Scholar] [CrossRef]
- Shlens, J. A tutorial on principal component analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; SIAM: Philadelphia, PA, USA, 2020. [Google Scholar]
- Janmaijaya, M.; Shukla, A.K.; Muhuri, P.K.; Abraham, A. Industry 4.0: Latent Dirichlet Allocation and clustering based theme identification of bibliography. Eng. Appl. Artif. Intell. 2021, 103, 104280. [Google Scholar] [CrossRef]
- Pozna, C.; Precup, R.E. Applications of Signatures to Expert Systems Modelling. Acta Polytech. Hung. 2014, 11, 21–39. [Google Scholar]
- Si, S.; Wang, J.; Zhang, R.; Su, Q.; Xiao, J. Federated Non-negative Matrix Factorization for Short Texts Topic Modeling with Mutual Information. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Seo, H.; Shin, J.; Kim, K.H.; Lim, C.; Bae, J. Driving Risk Assessment Using Non-Negative Matrix Factorization With Driving Behavior Records. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20398–20412. [Google Scholar] [CrossRef]
- Helal, S.; Sarieddeen, H.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M.S. Signal Processing and Machine Learning Techniques for Terahertz Sensing: An overview. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Sun, L.; Lin, Z. Robust nonnegative matrix factorization with local coordinate constraint for image clustering. Eng. Appl. Artif. Intell. 2020, 88, 103354. [Google Scholar] [CrossRef]
- Xing, Z.; Wen, M.; Peng, J.; Feng, J. Discriminative semi-supervised non-negative matrix factorization for data clustering. Eng. Appl. Artif. Intell. 2021, 103, 104289. [Google Scholar] [CrossRef]
- Gillis, N. Nonnegative Matrix Factorization; SIAM: Philadelphia, PA, USA, 2020. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Peng, S.; Ser, W.; Chen, B.; Lin, Z. Robust semi-supervised nonnegative matrix factorization for image clustering. Pattern Recognit. 2021, 111, 107683. [Google Scholar] [CrossRef]
- Sun, J.; Wang, Z.; Sun, F.; Li, H. Sparse dual graph-regularized NMF for image co-clustering. Neurocomputing 2018, 316, 156–165. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Lin, Z. Robust orthogonal nonnegative matrix tri-factorization for data representation. Knowl. Based Syst. 2020, 201, 106054. [Google Scholar] [CrossRef]
- Shang, F.; Jiao, L.; Wang, F. Graph dual regularization non-negative matrix factorization for co-clustering. Pattern Recognit. 2012, 45, 2237–2250. [Google Scholar] [CrossRef]
- Rahiche, A.; Cheriet, M. Variational Bayesian Orthogonal Nonnegative Matrix Factorization Over the Stiefel Manifold. IEEE Trans. Image Process. 2022, 31, 5543–5558. [Google Scholar] [CrossRef]
- Xu, X.; He, P. Manifold Peaks Nonnegative Matrix Factorization. IEEE Trans. Neural Netw. Learn. Syst. 2022. early access. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, G.; Yin, X.; Wang, Y. Robust Graph Regularized Nonnegative Matrix Factorization. IEEE Access 2022, 10, 86962–86978. [Google Scholar] [CrossRef]
- Meng, Y.; Shang, R.; Jiao, L.; Zhang, W.; Yang, S. Dual-graph regularized non-negative matrix factorization with sparse and orthogonal constraints. Eng. Appl. Artif. Intell. 2018, 69, 24–35. [Google Scholar] [CrossRef]
- Wang, J.J.Y.; Bensmail, H.; Gao, X. Multiple graph regularized nonnegative matrix factorization. Pattern Recognit. 2013, 46, 2840–2847. [Google Scholar] [CrossRef]
- Shu, Z.; Wu, X.; Fan, H.; Huang, P.; Wu, D.; Hu, C.; Ye, F. Parameter-less auto-weighted multiple graph regularized nonnegative matrix factorization for data representation. Knowl. Based Syst. 2017, 131, 105–112. [Google Scholar] [CrossRef]
- Wang, D.; Gao, X.; Wang, X. Semi-supervised nonnegative matrix factorization via constraint propagation. IEEE Trans. Cybern. 2015, 46, 233–244. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Jia, Y.; Kwong, S.; Hou, J. Pairwise constraint propagation-induced symmetric nonnegative matrix factorization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6348–6361. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Pascual-Montano, A.; Carazo, J.M.; Kochi, K.; Lehmann, D.; Pascual-Marqui, R.D. Nonsmooth nonnegative matrix factorization (nsNMF). IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 403–415. [Google Scholar] [CrossRef]
- Ding, C.; Li, T.; Peng, W.; Park, H. Orthogonal nonnegative matrix t-factorizations for clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 126–135. [Google Scholar]
- Choi, S. Algorithms for orthogonal nonnegative matrix factorization. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1828–1832. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Shi, G.; Liu, J. Graph-based discriminative nonnegative matrix factorization with label information. Neurocomputing 2017, 266, 91–100. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, X.; Peng, S. Multiple graph regularized semi-supervised nonnegative matrix factorization with adaptive weights for clustering. Eng. Appl. Artif. Intell. 2021, 106, 104499. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, Y.; Yan, W.; Xiang, Y.; Xie, S. A fast non-smooth nonnegative matrix factorization for learning sparse representation. IEEE Access 2016, 4, 5161–5168. [Google Scholar] [CrossRef]
- Sun, F.; Xu, M.; Hu, X.; Jiang, X. Graph regularized and sparse nonnegative matrix factorization with hard constraints for data representation. Neurocomputing 2016, 173, 233–244. [Google Scholar] [CrossRef]
- Donoho, D.L.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via L1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef] [PubMed]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Nie, F.; Li, J.; Li, X. Parameter-free auto-weighted multiple graph learning: A framework for multiview clustering and semi-supervised classification. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 1881–1887. [Google Scholar]


{kind=link}
| Dataset | Accuracy (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| LCDNMF | MGNMF | PAMGNMF | GDNMF | SDNMF | CPSNMF | MSNMF | MSNMFSC | |
| Optdigits | 83.95 | 80.56 | 81.32 | 84.18 | 91.66 | 98.21 | 98.39 | 98.52 |
| MNIST | 63.58 | 59.62 | 63.49 | 70.12 | 72.91 | 81.48 | 85.59 | 90.55 |
| COIL20 | 80.15 | 72.51 | 75.31 | 81.01 | 79.76 | 81.79 | 82.71 | 83.87 |
| COIL100 | 58.93 | 52.19 | 55.31 | 58.16 | 66.41 | 66.22 | 68.45 | 69.26 |
| CMU PIE | 79.83 | 68.51 | 72.26 | 76.03 | 79.43 | 82.18 | 82.91 | 85.71 |
| UMIST | 56.44 | 49.33 | 53.35 | 54.55 | 64.81 | 68.86 | 69.05 | 70.2 |
| MSRA25 | 66.22 | 68.43 | 72.28 | 71.11 | 85.16 | 88.35 | 96.18 | 99.28 |
| Dataset | NMI (%) | |||||||
| LCDNMF | MGNMF | PAMGNMF | GDNMF | SDNMF | CPSNMF | MSNMF | MSNMFSC | |
| Optdigits | 86.78 | 82.29 | 84.59 | 87.18 | 91.13 | 95.55 | 96.01 | 96.19 |
| MNIST | 70.26 | 56.17 | 62.35 | 69.75 | 74.89 | 79.59 | 82.16 | 84.83 |
| COIL20 | 90.01 | 84.17 | 85.29 | 88.98 | 88.66 | 89.21 | 90.25 | 91.08 |
| COIL100 | 81.43 | 76.65 | 77.56 | 79.26 | 84.59 | 85.17 | 85.97 | 86.44 |
| CMU PIE | 89.88 | 80.58 | 84.03 | 88.14 | 90.18 | 91.12 | 91.49 | 91.98 |
| UMIST | 74.91 | 67.61 | 70.93 | 71.11 | 78.46 | 80.12 | 81.31 | 81.76 |
| MSRA25 | 76.23 | 80.33 | 84.19 | 77.29 | 90.55 | 92.33 | 96.79 | 98.5 |
| Dataset | Purity (%) | |||||||
| LCDNMF | MGNMF | PAMGNMF | GDNMF | SDNMF | CPSNMF | MSNMF | MSNMFSC | |
| Optdigits | 94.57 | 91.23 | 92.46 | 94.69 | 97.04 | 98.28 | 98.46 | 98.52 |
| MNIST | 87.93 | 66.56 | 80.86 | 87.81 | 90.81 | 91.57 | 93.08 | 93.56 |
| COIL20 | 90.65 | 83.91 | 85.43 | 90.36 | 92.34 | 89.73 | 92.95 | 92.99 |
| COIL100 | 80.05 | 70.21 | 73.55 | 77.68 | 83.01 | 84.19 | 84.75 | 85.71 |
| CMU PIE | 88.86 | 79.79 | 84.16 | 89.38 | 90.81 | 90.09 | 91.66 | 90.94 |
| UMIST | 74.43 | 66.61 | 71.51 | 73.55 | 80.06 | 79.57 | 81.57 | 79.65 |
| MSRA25 | 74.18 | 79.89 | 84.41 | 87.39 | 93.06 | 98.37 | 98.49 | 99.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Li, L.; Di, J.; Wang, Y.; Zhao, X.; Zhang, J. Multiple Graph Adaptive Regularized Semi-Supervised Nonnegative Matrix Factorization with Sparse Constraint for Data Representation. Processes 2022, 10, 2623. https://doi.org/10.3390/pr10122623
Zhang K, Li L, Di J, Wang Y, Zhao X, Zhang J. Multiple Graph Adaptive Regularized Semi-Supervised Nonnegative Matrix Factorization with Sparse Constraint for Data Representation. Processes. 2022; 10(12):2623. https://doi.org/10.3390/pr10122623
Chicago/Turabian StyleZhang, Kexin, Lingling Li, Jinhong Di, Yi Wang, Xuezhuan Zhao, and Ji Zhang. 2022. "Multiple Graph Adaptive Regularized Semi-Supervised Nonnegative Matrix Factorization with Sparse Constraint for Data Representation" Processes 10, no. 12: 2623. https://doi.org/10.3390/pr10122623
APA StyleZhang, K., Li, L., Di, J., Wang, Y., Zhao, X., & Zhang, J. (2022). Multiple Graph Adaptive Regularized Semi-Supervised Nonnegative Matrix Factorization with Sparse Constraint for Data Representation. Processes, 10(12), 2623. https://doi.org/10.3390/pr10122623