

A Novel Framework to Detect Irrelevant Software Requirements Based on MultiPhiLDA as the Topic Model

Abstract
1. Introduction
2. Related Works
3. Noise Detection Framework
3.1. Actor–Action Splitting
| Listing 1. Extracting actors and actions from requirements statement. |
|
3.2. Pre-Processing
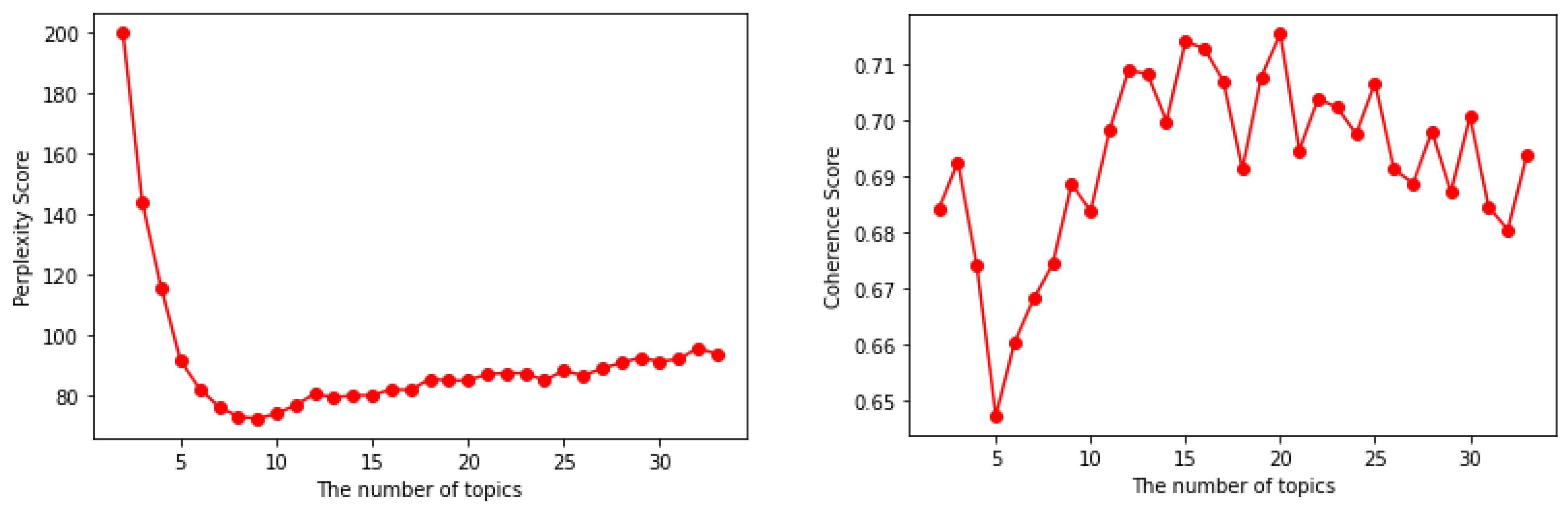
3.3. Optimal Number of Topics and Iterations Estimation
3.4. MultiPhiLDA
| Listing 2. MultiPhiLDA pseudocode. |
|
3.4.1. Separate Topic–Word Distribution for Actor Words and Action Words
3.4.2. Amalgamation of the Topic–Word Distributions
3.5. Identification of Irrelevant Requirements
4. Experimental Setup
4.1. Dataset
4.2. Evaluation Scenarios
5. Result
5.1. Evaluation Scenario 1: Estimate the Optimal Number of Topics and Iterations
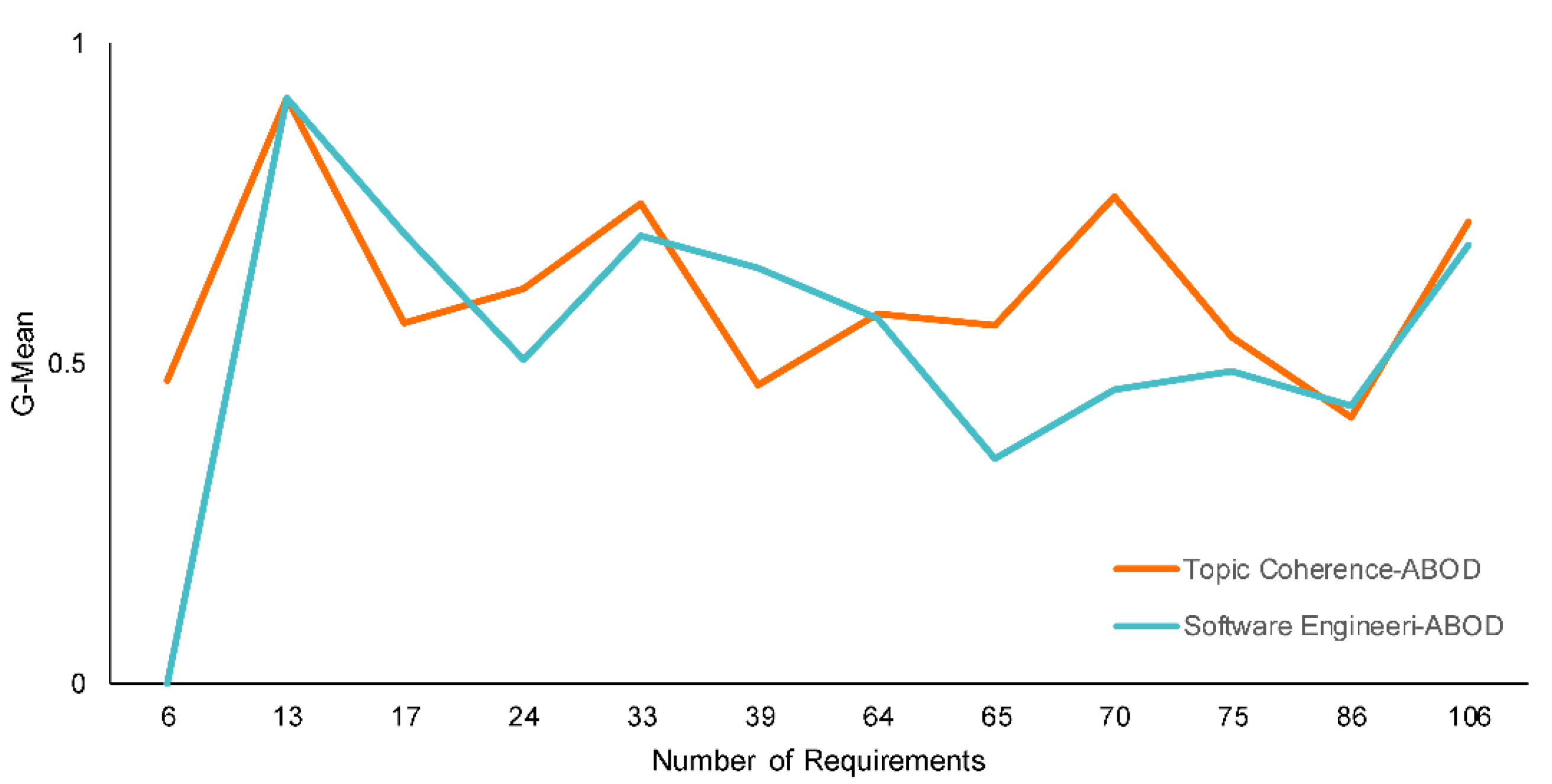
5.2. Evaluation Scenario 2: Sensitivity, Specificity, F1-Score, and G-Mean
5.3. Evaluation Scenario 3: Reliability of the Proposed Framework
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ABOD | Angle-Based Outlier Detection |
| CME-DMM | Collaboratively Modeling and Embedding–Dirichlet Multinomial Mixtures |
| CSTM | Common Semantics Topic Model |
| DT | Decision Tree |
| EBOD | Ensemble-Based Outlier Detection |
| HSLDA | Hierarchically Supervised LDA |
| KNN | k-Nearest Neighbor |
| LDA | Latent Dirichlet Allocation |
| NB | Naïve Bayes |
| NLP | Natural Language Processing |
| PBOD | Percentile-Based Outlier Detection (PBOD) |
| RF | Random Forest (RF) |
| SDLC | Software Development Life Cycle |
| SRS | Software Requirements Specifications |
| SVM | Support Vector Machine |
| VOA | Variance of the Angle |
References
- Iqbal, J.; Ahmad, R.B.; Khan, M.; Fazal-E-Amin; Alyahya, S.; Nasir, M.H.N.; Akhunzada, A.; Shoaib, M. Requirements engineering issues causing software development outsourcing failure. PLoS ONE 2020, 15, e0229785. [Google Scholar] [CrossRef] [PubMed]
- Mandal, A.; Pal, S. Identifying the Reasons for Software Project Failure and Some of their Proposed Remedial through BRIDGE Process Models. Int. J. Comput. Sci. Eng. 2015, 3, 118–126. [Google Scholar]
- del Sagrado, J.; del Águila, I.M. Stability prediction of the software requirements specification. Softw. Qual. J. 2018, 26, 585–605. [Google Scholar] [CrossRef]
- Dalal, S.; Chhillar, R. Case studies of most common and severe types of software system failure. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 341–347. [Google Scholar]
- Wiegers, K.E.; Beatty, J. Software Requirements, 3rd ed.; Microsoft Press: Washington, DC, USA, 2013; pp. 19–22. [Google Scholar]
- Yanuarifiani, A.P.; Chua, F.F.; Chan, G.Y. An ontology framework for generating requirements specification. Int. J. Adv. Sci. Eng. Inf. Technol. 2020, 10, 1137–1142. [Google Scholar] [CrossRef]
- Zheng, L. Effective information elicit for software quality specification based on ontology. In Proceedings of the IEEE International Conference on Software Engineering and Service Sciences ICSESS, IEEE Computer Society, Beijing, China, 23–25 September 2015; pp. 677–680. [Google Scholar] [CrossRef]
- Meyer, B. On Formalism in Specification. IEEE Softw. 1985, 2, 6–26. [Google Scholar] [CrossRef]
- Fahmi, A.A.; Siahaan, D.O. Algorithms Comparison For Non- Requirements Classification Using The Semantic Feature of Software. IPTEK J. Technol. Sci. 2020, 31, 1–9. [Google Scholar] [CrossRef]
- Manek, P.G.; Siahaan, D. Noise Detection In Software Requirements Specification Document Using Spectral Clustering. JUTI J. Ilm. Teknol. Inf. 2019, 17, 30–37. [Google Scholar] [CrossRef]
- Wang, D.; Su, J.; Yu, H. Feature extraction and analysis of natural language processing for deep learning english language. IEEE Access 2020, 8, 46335–46345. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet allocation (LDA) and topic modeling: Models, applications, a survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, H.; Liu, R.; Ye, Z.; Lin, J. Experimental explorations on short text topic mining between LDA and NMF based Schemes. Knowl.-Based Syst. 2019, 163, 1–13. [Google Scholar] [CrossRef]
- Chen, Y.H.; Li, S.F. Using latent Dirichlet allocation to improve text classification performance of support vector machine. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation, CEC, Vancouver, BC, Canada, 24–29 July 2016; Institute of Electrical and Electronics Engineers Inc.: Hoes Lane Piscataway, NJ, USA, 2016; pp. 1280–1286. [Google Scholar] [CrossRef]
- Schröder, K. Hierarchical Multiclass Topic Modelling with Prior Knowledge. Master’s Thesis, Humboldt—Universität zu Berlin, Berlin, Germany, 2018. [Google Scholar]
- Suri, P.; Roy, N.R. Comparison between LDA & NMF for event-detection from large text stream data. In Proceedings of the 3rd IEEE International Conference on “Computational Intelligence and Communication Technology”, Ghaziabad, India, 9–10 February 2017; Institute of Electrical and Electronics Engineers Inc.: Hoes Lane Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Schubert, M.; Zimek, A. Angle-based outlier detection in high-dimensional data. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 444–452. [Google Scholar] [CrossRef]
- Ouyang, B.; Song, Y.; Li, Y.; Sant, G.; Bauchy, M. EBOD: An ensemble-based outlier detection algorithm for noisy datasets. Knowl.-Based Syst. 2021, 231, 107400. [Google Scholar] [CrossRef]
- Sharma, S.; Kang, D.H.; Montes de Oca, J.R.; Mudgal, A. Machine learning methods for commercial vehicle wait time prediction at a border crossing. Res. Transp. Econ. 2021, 89, 101034. [Google Scholar] [CrossRef]
- Kamara, A.F.; Chen, E.; Liu, Q.; Pan, Z. A hybrid neural network for predicting Days on Market a measure of liquidity in real estate industry. Knowl.-Based Syst. 2020, 208, 106417. [Google Scholar] [CrossRef]
- Darnoto, B.R.P.; Siahaan, D. MultiPhiLDA for Detection Irrelevant Software Requirement Specification. In Proceedings of the 2021 International Conference on Computer Science, Information Technology and Electrical Engineering, Banyuwangi, Indonesia, 27–28 October 2021; pp. 92–97. [Google Scholar] [CrossRef]
- Ambreen, T.; Ikram, N.; Usman, M.; Niazi, M. Empirical research in requirements engineering: Trends and opportunities. Requir. Eng. 2018, 23, 63–95. [Google Scholar] [CrossRef]
- Romano, S.; Scanniello, G.; Fucci, D.; Juristo, N.; Turhan, B. Poster: The effect of noise on requirements comprehension. In Proceedings of the International Conference on Software Engineering, Madrid, Spain, 23–29 September 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 308–309. [Google Scholar] [CrossRef]
- Jørgensen, M.; Grimstad, S. The impact of irrelevant and misleading information on software development effort estimates: A randomized controlled field experiment. IEEE Trans. Softw. Eng. 2011, 37, 695–707. [Google Scholar] [CrossRef]
- Ferrari, A.; Gori, G.; Rosadini, B.; Trotta, I.; Bacherini, S.; Fantechi, A.; Gnesi, S. Detecting requirements defects with NLP patterns: An industrial experience in the railway domain. Empir. Softw. Eng. 2018, 23, 3684–3733. [Google Scholar] [CrossRef]
- Kamalrudin, M.; Ow, L.L.; Sidek, S. Requirements defects techniques in requirements analysis: A review. J. Telecommun. Electron. Comput. Eng. 2018, 10, 47–51. [Google Scholar]
- Rosmadi, N.A.; Ahmad, S.; Abdullah, N. The relevance of software requirement defect management to improve requirements and product quality: A systematic literature review. Adv. Intell. Syst. Comput. 2015, 355, 95–106. [Google Scholar] [CrossRef]
- Alshazly, A.A.; Elfatatry, A.M.; Abougabal, M.S. Detecting defects in software requirements specification. Alex. Eng. J. 2014, 53, 513–527. [Google Scholar] [CrossRef]
- Chari, K.; Agrawal, M. Impact of incorrect and new requirements on waterfall software project outcomes. Empir. Softw. Eng. 2018, 23, 165–185. [Google Scholar] [CrossRef]
- Martínez, A.B.B.; Arias, J.J.P.; Vilas, A.F. Merging requirements views with incompleteness and inconsistency. In Proceedings of the Australian Software Engineering Conference, ASWEC, Brisbane, Australia, 29 March–1 April 2005; pp. 58–67. [Google Scholar] [CrossRef]
- Elgammal, A.; Papazoglou, M.; Krämer, B.; Constantinescu, C. Design for Customization: A New Paradigm for Product-Service System Development. Procedia CIRP 2017, 64, 345–350. [Google Scholar] [CrossRef]
- Özlem, A.; Kurtoǧlu, H.; Biçakçi, M. Incomplete software requirements and assumptions made by software engineers. In Proceedings of the Asia-Pacific Software Engineering Conference, APSEC, Penang, Malaysia, 1–3 December 2009. [Google Scholar] [CrossRef]
- Li, X.; Wang, Y.; Zhang, A.; Li, C.; Chi, J.; Ouyang, J. Filtering out the noise in short text topic modeling. Inf. Sci. 2018, 456, 83–96. [Google Scholar] [CrossRef]
- Liu, Z.; Qin, T.; Chen, K.J.; Li, Y. Collaboratively Modeling and Embedding of Latent Topics for Short Texts. IEEE Access 2020, 8, 99141–99153. [Google Scholar] [CrossRef]
- Vo, D.T.; Ock, C.Y. Learning to classify short text from scientific documents using topic models with various types of knowledge. Expert Syst. Appl. 2015, 42, 1684–1698. [Google Scholar] [CrossRef]
- Albalawi, R.; Yeap, T.H.; Benyoucef, M. Using Topic Modeling Methods for Short-Text Data: A Comparative Analysis. Front. Artif. Intell. 2020, 3, 42. [Google Scholar] [CrossRef]
- Lubis, F.F.; Rosmansyah, Y.; Supangkat, S.H. Topic discovery of online course reviews using LDA with leveraging reviews helpfulness. Int. J. Electr. Comput. Eng. 2019, 9, 426–438. [Google Scholar] [CrossRef]
- Bornmann, L.; Leydesdorff, L.; Mutz, R. The use of percentiles and percentile rank classes in the analysis of bibliometric data: Opportunities and limits. J. Inf. 2013, 7, 158–165. [Google Scholar] [CrossRef]
- Siahaan, D. Irrelevant Requirements. 2022. Available online: http://dx.doi.org/10.6084/m9.figshare.19380545.v1 (accessed on 13 June 2022). [CrossRef]
- Tang, J.; Meng, Z.; Nguyen, X.L.; Mel, Q.; Zhang, M. Understanding the limiting factors of topic modeling via posterior contraction analysis. In Proceedings of the 31st International Conference on Machine Learning, International Machine Learning Society (IMLS) 2014, Beijing, China, 21–26 June 2014; pp. 337–345. [Google Scholar]
- Netemeyer, R.G.; Bearden, W.O.; Sharma, S. Scaling Procedures: Issues and Applications, 1st ed.; SAGE: London, UK, 2003; pp. 153–159. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Project Name | #Reqs | #-word | #-verb | #Actor | #Irr |
|---|---|---|---|---|---|---|
| DA-1 | Submit Job | 13 | 6 | 1 | 1 | 1 |
| DA-2 | System Administrator | 17 | 12 | 1 | 4 | 5 |
| DA-3 | Archive Administrator | 39 | 12 | 2 | 4 | 2 |
| DA-4 | SPG Application | 6 | 6 | 1 | 1 | 3 |
| DA-5 | System Administrator Staff | 33 | 40 | 1 | 8 | 3 |
| DA-6 | Software Development | 65 | 17 | 2 | 33 | 5 |
| DA-7 | Display System | 106 | 13 | 2 | 17 | 3 |
| DA-8 | Internet Access | 64 | 18 | 2 | 22 | 7 |
| DA-9 | Meeting Initiator | 33 | 24 | 1 | 7 | 4 |
| DA-10 | Online System | 17 | 15 | 1 | 7 | 2 |
| DA-11 | Library System | 86 | 17 | 2 | 32 | 9 |
| DA-12 | IMSETY System | 70 | 12 | 2 | 13 | 3 |
| DA-13 | Manage Student Information | 24 | 22 | 1 | 9 | 3 |
| DA-14 | PHP Project | 75 | 28 | 1 | 50 | 10 |
| Noise Classifier | Perplexity | Topic Coherence | Software Engineer | Status | |||
|---|---|---|---|---|---|---|---|
| #Topic | # Iteration | #Topic | #Iteration | #Topic | #Iteration | ||
| DA-01 | 5 | 224 | 4 | 273 | 4 | 273 | Not Accepted |
| DA-02 | 15 | 62 | 13 | 493 | 9 | 424 | Not Accepted |
| DA-03 | 10 | 425 | 19 | 490 | 9 | 59 | Not Accepted |
| DA-04 | 5 | 22 | 4 | 323 | 6 | 62 | Not Accepted |
| DA-05 | 18 | 466 | 12 | 286 | 19 | 86 | Not Accepted |
| DA-06 | 23 | 198 | 12 | 473 | 27 | 201 | Not Accepted |
| DA-07 | 9 | 122 | 21 | 203 | 35 | 187 | Accepted |
| DA-08 | 14 | 74 | 20 | 123 | 26 | 400 | Not Accepted |
| DA-09 | 13 | 96 | 18 | 294 | 18 | 294 | Not Accepted |
| DA-10 | 7 | 400 | 6 | 107 | 11 | 239 | Not Accepted |
| DA-11 | 19 | 433 | 30 | 390 | 36 | 132 | Not Accepted |
| DA-12 | 12 | 330 | 9 | 375 | 48 | 430 | Not Accepted |
| DA-13 | 17 | 472 | 10 | 409 | 20 | 500 | Not Accepted |
| DA-14 | 23 | 430 | 39 | 89 | 53 | 320 | Not Accepted |
| Noise Classifier | Sensitivity | Specificity | F1-Score | G-Mean | |
|---|---|---|---|---|---|
| PBOD | Perplexity | 0.28 | 0.81 | 0.54 | 0.47 |
| Topic Coherence | 0.27 | 0.80 | 0.53 | 0.46 | |
| Software Engineer | 0.23 | 0.82 | 0.52 | 0.43 | |
| ABOD | Perplexity | 0.43 | 0.70 | 0.56 | 0.55 |
| Topic Coherence | 0.59 | 0.65 | 0.62 | 0.62 | |
| Software Engineer | 0.60 | 0.56 | 0.58 | 0.58 | |
| Manek and Siahaan [10] | 0.10 | 0.65 | 0.38 | 0.25 | |
| Noise Classifier | Sensitivity | Specificity | AVE | CR | |
|---|---|---|---|---|---|
| PBOD | Perplexity | 0.28 | 0.81 | 0.03 | 0.75 |
| Topic Coherence | 0.27 | 0.80 | 0.03 | 0.77 | |
| Software Engineer | 0.23 | 0.82 | 0.02 | 0.74 | |
| ABOD | Perplexity | 0.43 | 0.70 | 0.04 | 0.85 |
| Topic Coherence | 0.59 | 0.65 | 0.05 | 0.93 | |
| Software Engineer | 0.60 | 0.56 | 0.05 | 0.93 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siahaan, D.; Darnoto, B.R.P. A Novel Framework to Detect Irrelevant Software Requirements Based on MultiPhiLDA as the Topic Model. Informatics 2022, 9, 87. https://doi.org/10.3390/informatics9040087
Siahaan D, Darnoto BRP. A Novel Framework to Detect Irrelevant Software Requirements Based on MultiPhiLDA as the Topic Model. Informatics. 2022; 9(4):87. https://doi.org/10.3390/informatics9040087
Chicago/Turabian StyleSiahaan, Daniel, and Brian Rizqi Paradisiaca Darnoto. 2022. "A Novel Framework to Detect Irrelevant Software Requirements Based on MultiPhiLDA as the Topic Model" Informatics 9, no. 4: 87. https://doi.org/10.3390/informatics9040087
APA StyleSiahaan, D., & Darnoto, B. R. P. (2022). A Novel Framework to Detect Irrelevant Software Requirements Based on MultiPhiLDA as the Topic Model. Informatics, 9(4), 87. https://doi.org/10.3390/informatics9040087