
Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Identification of Requirements
- Instagram:
- It has more than 1.5 billion users;
- Instagram ads reach nearly 30% of internet users;
- Instagram is the fourth most popular social network in the world;
- Users aged 25–34 make up the largest cohort of Instagram users;
- 91% of active users say they watch videos on the platform weekly;
- 50% of users have clicked through to a brand’s website after seeing it in Stories;
- 92% of users say they have acted on the spot after seeing a product on Instagram;
- Ads are more likely to reach men and women ages 18–34.
- Facebook:
- The number of active Facebook users is close to 3 billion people, that is, 36% of the world’s population;
- 58.8% of Internet users in the world use Facebook every month;
- About 66% of users connect to the site every day;
- 20% of Facebook users in the world are men between the ages of 25–34;
- Women aged 13–17 are the smallest demographic of Facebook users in the world;
- Facebook is the most used social media platform in the world;
- 66% of Facebook users visit a local business page at least once a week;
- In 2021, a third of Facebook users made purchases on the platform;
- Almost 50% of Facebook users also use Twitter.
- Twitter:
- Users spend, on average, 5.1 h per month on Twitter;
- 22% of Americans use Twitter;
- Twitter will have 76.5 million users in Latin America in 2022;
- 38.5% of Twitter users are between 25 and 34 years old;
- Only 6.6% of Twitter users are 13–17;
- Twitter’s audience is predominantly male: 70.4% of the platform’s demographic identifies with that gender, leaving only a 29.6% female audience on Twitter;
- People spend about 5 h a month browsing Twitter;
- Almost 55% of Twitter users also use TikTok;
- The total number of Twitter users globally is expected to reach 340 million by 2024;
- People spent 6 min a day on Twitter in 2022;
- 52% of users check Twitter daily, 84% check it weekly, and 96% check it monthly;
- Twitter is the social network most frequently used for the generation of political comments and content.
- YouTube:
- People spend, on average, 23.7 h a month on YouTube;
- YouTube is the second most used social media platform in the world, with more than 14 billion total views;
- People spend, on average, 19 min a day on YouTube;
- Around 694,000 h of video is streamed on YouTube every minute of the day;
- Mobile users visit twice as many pages on YouTube than desktop users;
- 70% of viewers bought from a brand after seeing it on YouTube;
- Ads targeted to users by intent (and not by demographics) achieved a 100× higher increase in purchase intent;
- Advertising on YouTube has the potential to reach 2.56 billion users.
2.2. Selection of Tools for Sentiment Analysis
2.3. Method for Sentiment Analysis of Social Networks
- consumerKey<-“XXXXXXXXgEVum0pkpXXXXXXXX”
- consumerSecret<-“XXXXXXXX7oip3jzH5zmaAD2LJ6fw8xpC5MrajfgeXXXXXXXX”
- accessToken<-“XXXXXXXX77787523073-zZUX7Ai9br7mCoCxpCNyPSXXXXXXXX”
- accessSecret<-“XXXXXXXXfVRvMTbUcx2aJyk4whfQYS3coFMhXXXXXXXX”
- option(httr_oauth_cache=TRUE)
- twitter_token<-create_token(consumer_key = consumerkey, consumer_secret = consumerSecret, access_token = accessToken, access_secret = accessSecret)
2.3.1. Downloading of Information
- nt<-500
- until<-Sys.Date()
- since<-“2022-06-05”
- health-1<- search_tweets(“XXXXX XXXXX, health”,n, since = since, until = until)
- economy-1<- search_tweets(“XXXXX XXXXX, economy”,n, since = since, until = until)
- security-1<- search_tweets(“XXXXX XXXXX, security”,n, since = since, until = until)
- education-1<- search_tweets(“XXXXX XXXXX, education”,n, since = since, until = until)
2.3.2. Cleanup of Tweets
- text <- gsub(“@\\w+”, text)
- text <- gsub(“https?://.+”, “”, text)
- text <- gsub(\\d+\\w*\\d*, “”, text)
- text <- gsub(“#\\w+”, “”, text)
- text <- gsub(“[^\x01-\x7F]”, “”, text)
- text <- gsub(“[[:punct:]]”, “”, text)
- text <- gsub(“\n”, “”, text)
- text <- gsub(“^\\s+”, “”, text)
- text <- gsub(“\\s+$”, “”, text)
- text <- gsub(“[ |\t]+”, “”, text)
- text <- gsub(“[[:cntrl:]]”, “”, text)
2.3.3. Sentiment Analysis
- Tweets_token <- unnets_tokens(tbl = tweets,
- output = “word”,
- input = “cleantext”
- Token = “words”)
3. Results
3.1. Identification of the Problem
3.2. Sentiment Processing and Analysis
- Guillermo Lasso, health;
- Guillermo Lasso, economy;
- Guillermo Lasso, security;
- Guillermo Lasso, education.
4. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hussein, D.M.E.-D.M. A survey on sentiment analysis challenges. J. King Saud Univ. Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Dang, N.C.; Moreno-García, M.N.; De La Prieta, F. Sentiment Analysis Based on Deep Learning: A Comparative Study. Electronics 2020, 9, 483. [Google Scholar] [CrossRef] [Green Version]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic reviews in sentiment analysis: A tertiary study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl. -Based Syst. 2021, 266, 107134. [Google Scholar] [CrossRef]
- Hidalgo, O.; Jaimes, R.; Gomez, E.; Lujan-Mora, S. Sentiment Analysis Applied to the Popularity Level of the Ecuadorian Political Leader Rafael Correa. In Proceedings of the 2017 International Conference on Information Systems and Computer Science (INCISCOS), Quito, Ecuador, 23–25 November 2017; Volume 2, pp. 340–346. [Google Scholar]
- Barbaglia, L.; Consoli, S.; Manzan, S. Forecasting with Economic News. J. Bus. Econ. Stat. 2022. [Google Scholar] [CrossRef]
- Kontopoulos, E.; Berberidis, C.; Dergiades, T.; Bassiliades, N. Ontology-based sentiment analysis of twitter posts. Expert Syst. Appl. 2013, 40, 4065–4074. [Google Scholar] [CrossRef]
- Ardia, D.; Bluteau, K.; Borms, S.; Boudt, K. The R Package sentometrics to Compute, Aggregate, and Predict with Textual Sentiment. J. Stat. Softw. 2021, 99, 1–40. [Google Scholar] [CrossRef]
- Silge, J.; Robinson, D. tidytext: Text Mining and Analysis Using Tidy Data Principles in R. J. Open Source Softw. 2016, 1, 37. [Google Scholar] [CrossRef] [Green Version]
- Arun, K.; Srinagesh, A. Multilingual twitter sentiment analysis using machine learning. Int. J. Electr. Comput. Eng. 2020, 10, 5992–6000. [Google Scholar] [CrossRef]
- Rai, S.; Goyal, S.B.; Kumar, J. Sentiment Analysis of Twitter Data. Int. Res. J. Adv. Sci. Hub 2021, 2, 56–61. [Google Scholar] [CrossRef]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Rong, L.; Song, D.; Zhang, P. A Survey on Multimodal Sentiment Analysis. Moshi Shibie Yu Rengong Zhineng/Pattern Recognit. Artif. Intell. 2020, 33, 3–14. [Google Scholar] [CrossRef]
- Adwan, O.Y.; Al-Tawil, M.; Huneiti, A.; Shahin, R.; Abu Zayed, A.; Al-Dibsi, R. Twitter Sentiment Analysis Approaches: A Survey. Int. J. Emerg. Technol. Learn. 2020, 15, 79–93. [Google Scholar] [CrossRef]
- Vimali, J.S.; Murugan, S. Sentiment Analysis on Twitter Social Media Product Reviews. Indian J. Comput. Sci. Eng. 2021, 12, 551–560. [Google Scholar] [CrossRef]
- Kharde, A.V.; Sonawane, S. Sentiment Analysis of Twitter Data: A Survey of Techniques. Int. J. Comput. Appl. 2016, 139, 5–15. [Google Scholar] [CrossRef]
- Obiedat, R.; Al-Darras, D.; Alzaghoul, E.; Harfoushi, O. Arabic Aspect-Based Sentiment Analysis: A Systematic Literature Review. IEEE Access 2021, 9, 152628–152645. [Google Scholar] [CrossRef]
- Abdullah, N.A.S.; Rusli, N.I.A. Multilingual Sentiment Analysis: A Systematic Literature Review. Pertanika J. Sci. Technol. 2021, 29, 445–470. [Google Scholar] [CrossRef]
- Torres, J.; Baquerizo, G.; Vaca, C.; Pelaez, E. Characterizing Influential Leaders of Ecuador on Twitter Using Computational Intelligence. In Proceedings of the 2016 3rd International Conference on eDemocracy and eGovernment (ICEDEG), Sangolqui, Ecuador, 30 March–1 April 2016. [Google Scholar] [CrossRef]
- Murdaca, A.M.; Oliva, P.; Costa, S. Evaluating the perception of disability and the inclusive education of teachers: The Italian validation of the Sacie-R (Sentiments, Attitudes, and Concerns about Inclusive Education—Revised Scale). Eur. J. Spec. Needs Educ. 2018, 33, 148–156. [Google Scholar] [CrossRef]
- Zhao, Y. R and Data Mining: Examples and Case Studies; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Kumar, A.; Garg, G. Sentiment analysis of multimodal twitter data. Multimed. Tools Appl. 2019, 78, 24103–24119. [Google Scholar] [CrossRef]
- Flores, B.E.H. Processing of the Opinions of a Public Person in Ecuador. RISTI Rev. Iber. Sist. Tecnol. De Inf. 2019, E17, 1094–1102. [Google Scholar]
- Dutta, P.; Lodh, A. Scraping of Social Media Data Using Python-3 and Performing Data Analytics Using Microsoft Power BI. Int. J. Eng. Sci. Res. Technol. 2020, 9, 66–79. [Google Scholar] [CrossRef]
- Toujani, R.; Chaabani, Y.; Dhouioui, Z.; Bouali, H. The Next Generation of Disaster Management and Relief Planning: Immersive Analytics Based Approach. In Communications in Computer and Information Science, Proceedings of the Immersive Learning Research Network, Missoula, MT, USA, 24–29 June 2018; Springer: Cham, Switzerland, 2018; Volume 840, pp. 80–93. [Google Scholar] [CrossRef]
- Scott, T. Power BI vs Tableau: A Data Analytics Duel; TechnologyAdvice: Nashville, TN, USA, 14 September 2019. [Google Scholar]
- Kapenieks, J. A Web-Based Fast and Reliable Text Classification Tool. In Proceedings of the International Scientific Conference, Society, Technology, Solutions, Valmiera, Latvia, 25–26 April 2019; Volume 1. [Google Scholar] [CrossRef]
- Murthy, J.S.; Siddesh, G.M.; Srinivasa, K.G. A Distributed Framework for Real-Time Twitter Sentiment Analysis and Visualization. In Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2018; Volume 709, pp. 55–61. [Google Scholar] [CrossRef]
- Dwimarcahyani, D.; Badriyah, T.; Karlita, T. Classification on Category of Public Responses on Television Program Using Naive Bayes Method. In Proceedings of the IES 2019—International Electronics Symposium: The Role of Techno-Intelligence in Creating an Open Energy System Towards Energy Democracy, Surabaya, Indonesia, 27–28 September 2019. [Google Scholar]
- Shahanur Alam, M.; Abdullah-Al-Jubair, M.; Ashikur Rahman, M.; Supti, T.I.; Tabassum, R.; Ara, T.; Weng, N.G. Electronic Opinion Analysis System for Library (E-OASL). In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020. [Google Scholar]
- Abayomi-Alli, A.; Abayomi-Alli, O.; Misra, S.; Fernandez-Sanz, L. Study of the Yahoo-Yahoo Hash-Tag Tweets Using Sentiment Analysis and Opinion Mining Algorithms. Information 2022, 13, 152. [Google Scholar] [CrossRef]
- Jaichandran, R.; Bagath Basha, C.; Shunmuganathan, K.L.; Rajaprakash, S.; Kanagasuba Raja, S. Sentiment Analysis of Movies on Social Media using R Studio. Int. J. Eng. Adv. Technol. 2019, 8, 2171–2175. [Google Scholar] [CrossRef]
- Tiezzi, J.; Tyler, R.; Sharma, S. Lessons Learned: A Case Study in Creating a Data Pipeline Using Twitter’s API. In Proceedings of the 2020 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 24 April 2020. [Google Scholar]
- Villegas-Ch, W.; Luján-Mora, S.; Buenaño-Fernandez, D.; Román-Cañizares, M. Analysis of Web-Based Learning Systems by Data Mining. In Proceedings of the 2017 IEEE Second Ecuador Technical Chapters Meeting (ETCM), Salinas, Ecuador, 16–20 October 2017; pp. 1–5. [Google Scholar]
- Villegas-Ch, W.; García-Ortiz, J.; Sánchez-Viteri, S. Identification of the Factors That Influence University Learning with Low-Code/No-Code Artificial Intelligence Techniques. Electronics 2021, 10, 1192. [Google Scholar] [CrossRef]
- Shetty, S.D. Sentiment Analysis, Tweet Analysis and Visualization on Big Data Using Apache Spark and Hadoop. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1099, 012002. [Google Scholar] [CrossRef]
- Lyu, J.C.; Le Han, E.; Luli, G.K. COVID-19 Vaccine–Related Discussion on Twitter: Topic Modeling and Sentiment Analysis. J. Med. Internet Res. 2021, 23, e24435. [Google Scholar] [CrossRef]
- Mu, R.; Zheng, Y.; Zhang, K.; Zhang, Y. Research on Customer Satisfaction Based on Multidimensional Analysis. Int. J. Comput. Intell. Syst. 2021, 14, 605. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef] [Green Version]
- Trivedi, S.K.; Singh, A. Twitter sentiment analysis of app based online food delivery companies. Glob. Knowl. Mem. Commun. 2021, 70, 891–910. [Google Scholar] [CrossRef]
- Eugenio, V.P.A.; Raúl, C.C.A.; Alejandro, P.I.K. Perception and Image: Study through Time Series Analysis. Rev. Venez. De Gerenc. 2020, 25, 327–339. [Google Scholar] [CrossRef]
- Srivastava, A.; Singh, V.; Drall, G.S. Sentiment Analysis of Twitter Data. Int. J. Healthc. Inf. Syst. Inform. 2019, 14, 1–16. [Google Scholar] [CrossRef]
- Smetanin, S. The Applications of Sentiment Analysis for Russian Language Texts: Current Challenges and Future Perspectives. IEEE Access 2020, 8, 110693–110719. [Google Scholar] [CrossRef]
- Mohammad, S. NRC Emotion Lexicon; National Research Council: Ottawa, ON, Canada, 15 July 2015; Volume 2, p. 234. [Google Scholar]
- Consoli, S.; Barbaglia, L.; Manzan, S. Fine-grained, aspect-based sentiment analysis on economic and financial lexicon. Knowl. -Based Syst. 2022, 247, 108781. [Google Scholar] [CrossRef]
- Kumar, A.; Jaiswal, A. Systematic literature review of sentiment analysis on Twitter using soft computing techniques. Concurr. Comput. Pract. Exp. 2020, 32, e5107. [Google Scholar] [CrossRef]
- Wagh, R.; Punde, P. Survey on Sentiment Analysis Using Twitter Dataset. In Proceedings of the 2018 2nd International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018. [Google Scholar]
- Ruz, G.A.; Henríquez, P.A.; Mascareño, A. Sentiment analysis of Twitter data during critical events through Bayesian networks classifiers. Future Gener. Comput. Syst. 2020, 106, 92–104. [Google Scholar] [CrossRef]
- Saif, H.; He, Y.; Fernandez, M.; Alani, H. Contextual semantics for sentiment analysis of Twitter. Inf. Process. Manag. 2016, 52, 5–19. [Google Scholar] [CrossRef] [Green Version]
- Alsaeedi, A.; Zubair, M. A Study on Sentiment Analysis Techniques of Twitter Data. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 361–374. [Google Scholar] [CrossRef] [Green Version]
- Giachanou, A.; Crestani, F. Like It or Not: A Survey of Twitter Sentiment Analysis Methods. ACM Comput. Surv. 2016, 49, 1–41. [Google Scholar] [CrossRef]
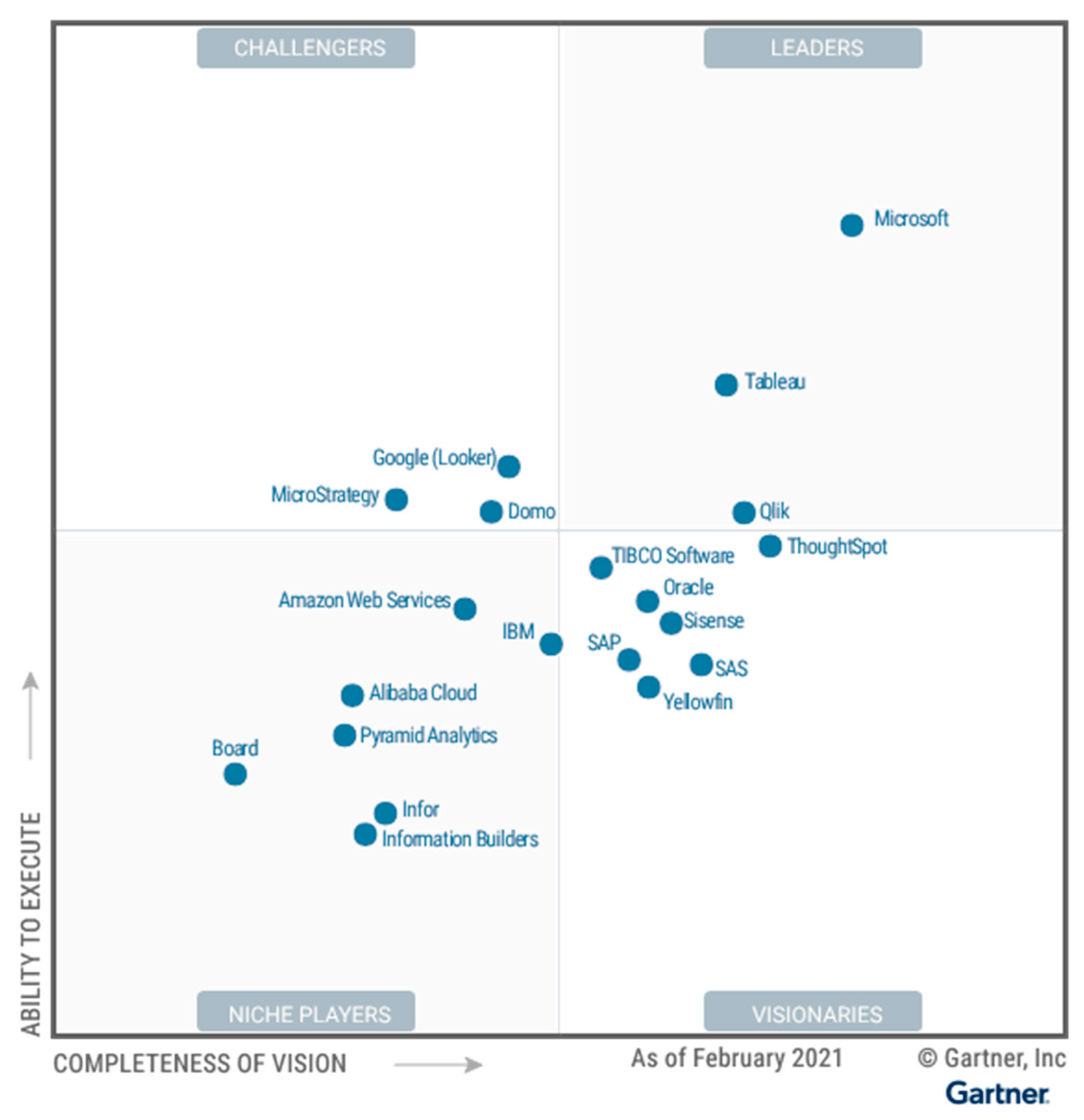






{kind=link}
{kind=link}
{kind=link}
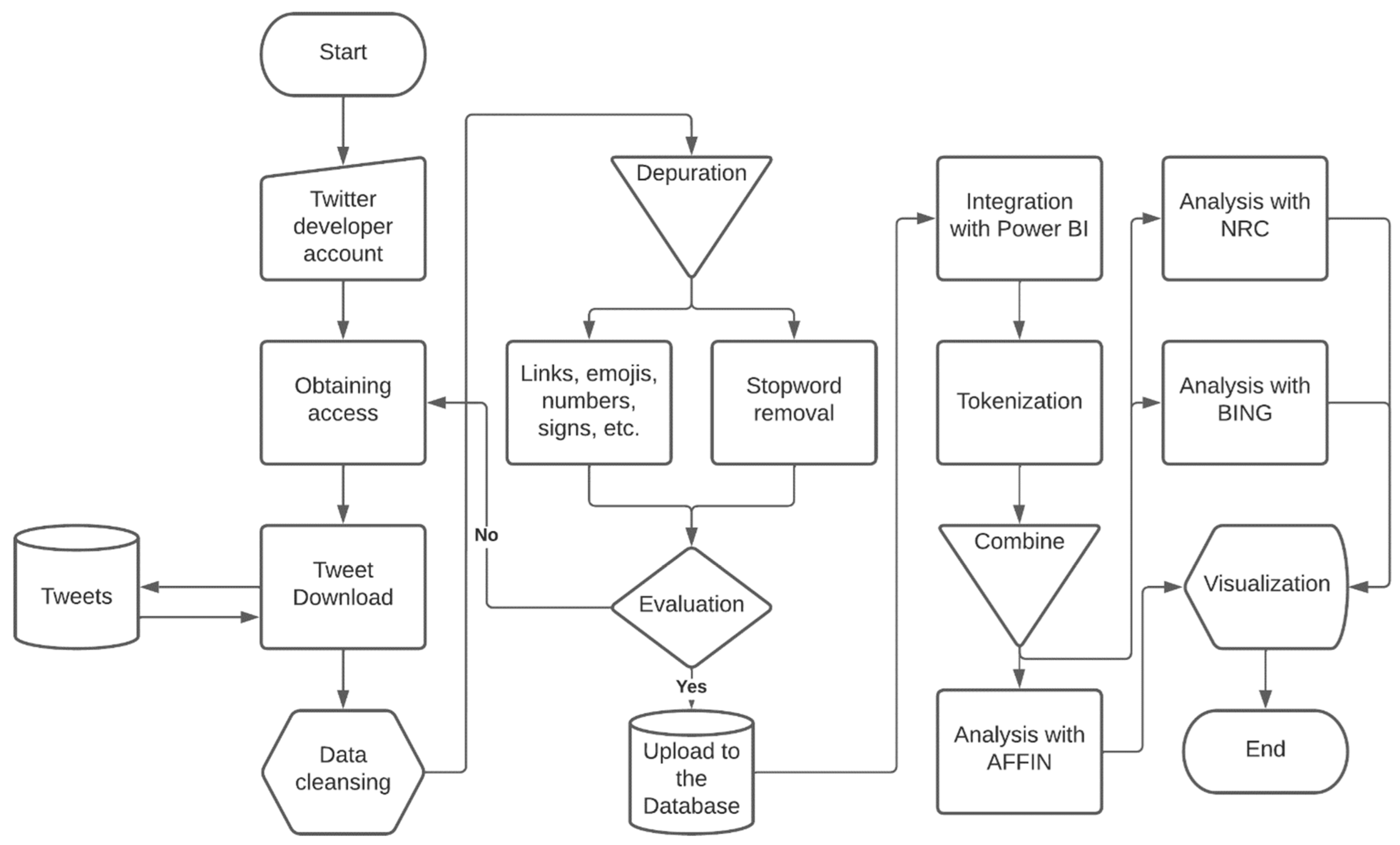{kind=link}
{kind=link}
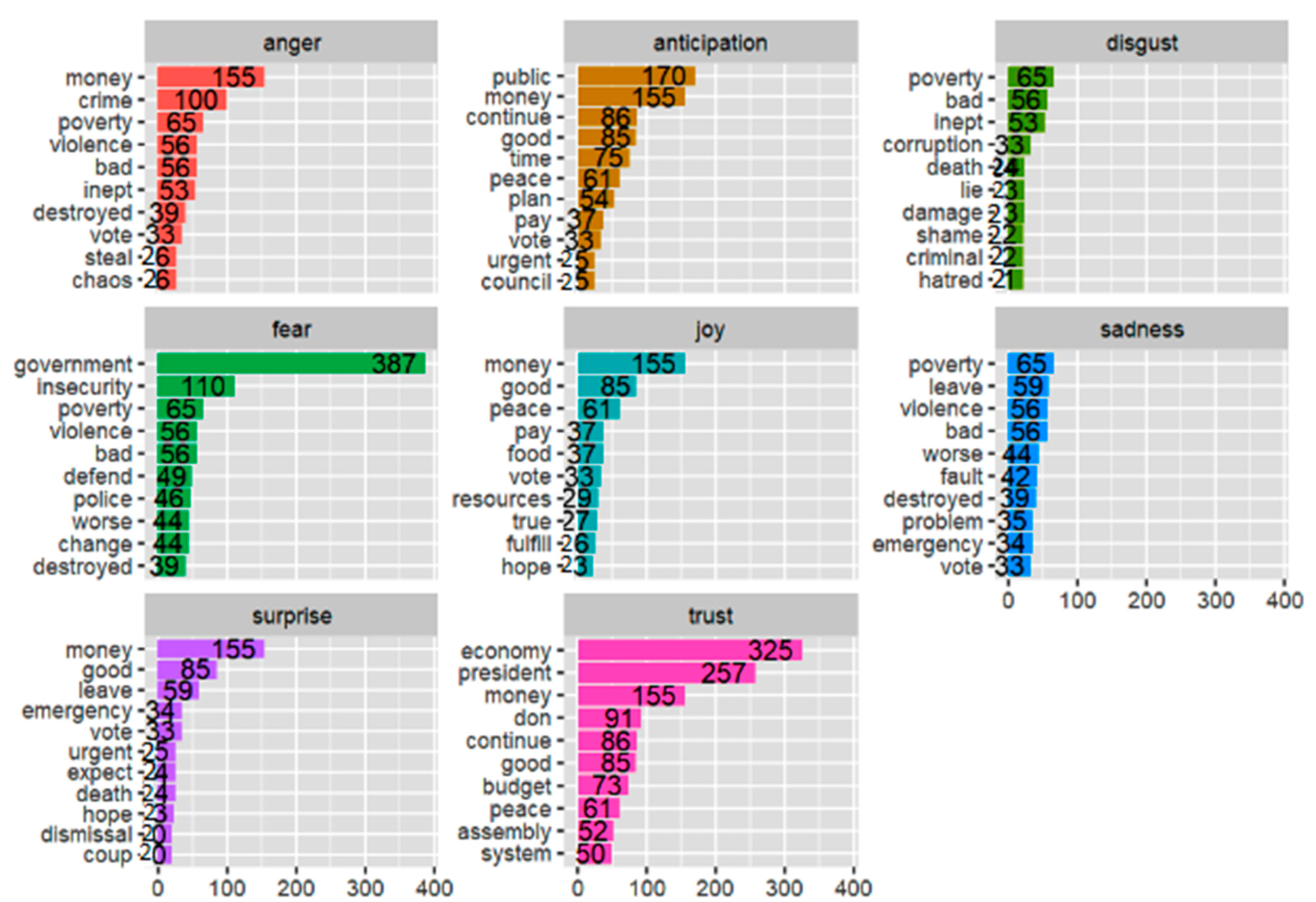{kind=link}
| Power BI | Tableau | Qlik | |
|---|---|---|---|
| Focus | Wide range of analysis workflow capabilities, with a high executive level | Analysis with deep search | Exploring data without employing a long learning curve |
| Connections and data integration | High | Lower than Power BI | High |
| Visualization and type of analysis | Wide | Wide | Improvements to be made |
| Advantage | Easy to use Includes Python- and R-based visualizations, including predictive analytics Low cost, includes free versions | Intuitive and easy to use. Support for Python and R with predictive analytics | Simple for users Scripting for prior data processing Less dependency on IT for system maintenance |
| Disadvantages | The project must be uploaded to the cloud to share the visualizations | It additionally requires an ETL (extract, transform, and load) tool For advanced users, there is disapproval of the tool for advanced and sophisticated capabilities, such as embedded BI, metadata management, and data preparation | Needs a lot of RAM |
| Retweet_Location | Economy | Education | Health | Security |
|---|---|---|---|---|
| Guayaquil | 1932 | 238 | 538 | 3481 |
| Quito | 1767 | 138 | 1383 | 2039 |
| Guayaquil, Ecuador | 22 | 1602 | 11 | 981 |
| Sangolquí | 44 | 187 | 1514 | 572 |
| Manta | 176 | 241 | 424 | 953 |
| Quito-Ecuador-Sudamérica | 896 | 539 | 593 | 401 |
| Guayas, Ecuador | 2091 | 477 | 371 | 2091 |
| Cuenca | 984 | 562 | 396 | 1093 |
| Pichincha, Ecuador | 209 | 113 | 102 | 1183 |
| Total | 8121 | 4097 | 5332 | 12,794 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch., W.; Molina, S.; Janón, V.D.; Montalvo, E.; Mera-Navarrete, A. Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R. Informatics 2022, 9, 63. https://doi.org/10.3390/informatics9030063
Villegas-Ch. W, Molina S, Janón VD, Montalvo E, Mera-Navarrete A. Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R. Informatics. 2022; 9(3):63. https://doi.org/10.3390/informatics9030063
Chicago/Turabian StyleVillegas-Ch., William, Sofía Molina, Víctor De Janón, Estevan Montalvo, and Aracely Mera-Navarrete. 2022. "Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R" Informatics 9, no. 3: 63. https://doi.org/10.3390/informatics9030063
APA StyleVillegas-Ch., W., Molina, S., Janón, V. D., Montalvo, E., & Mera-Navarrete, A. (2022). Proposal of a Method for the Analysis of Sentiments in Social Networks with the Use of R. Informatics, 9(3), 63. https://doi.org/10.3390/informatics9030063