
Benchmarking Machine Learning Models to Assist in the Prognosis of Tuberculosis

 ,
,  , , , , , and
, , , , , and 
Abstract
1. Introduction
2. Related Works
3. Background
3.1. Feature Selection Techniques
3.2. Machine Learning Models
3.2.1. Logistic Regression (LR)
3.2.2. Linear Discriminant Analysis (LDA)
3.2.3. K-Nearest Neighbors (KNN)
3.2.4. Naive Bayes (NB)
3.2.5. Decision Trees (DT)
3.2.6. Support Vector Machine (SVM)
3.2.7. Gradient Boosting (GB)
3.2.8. Random Forest (RF)
3.2.9. Multilayer Perceptron (MLP)
3.3. Ensemble
3.4. Evaluation Metrics
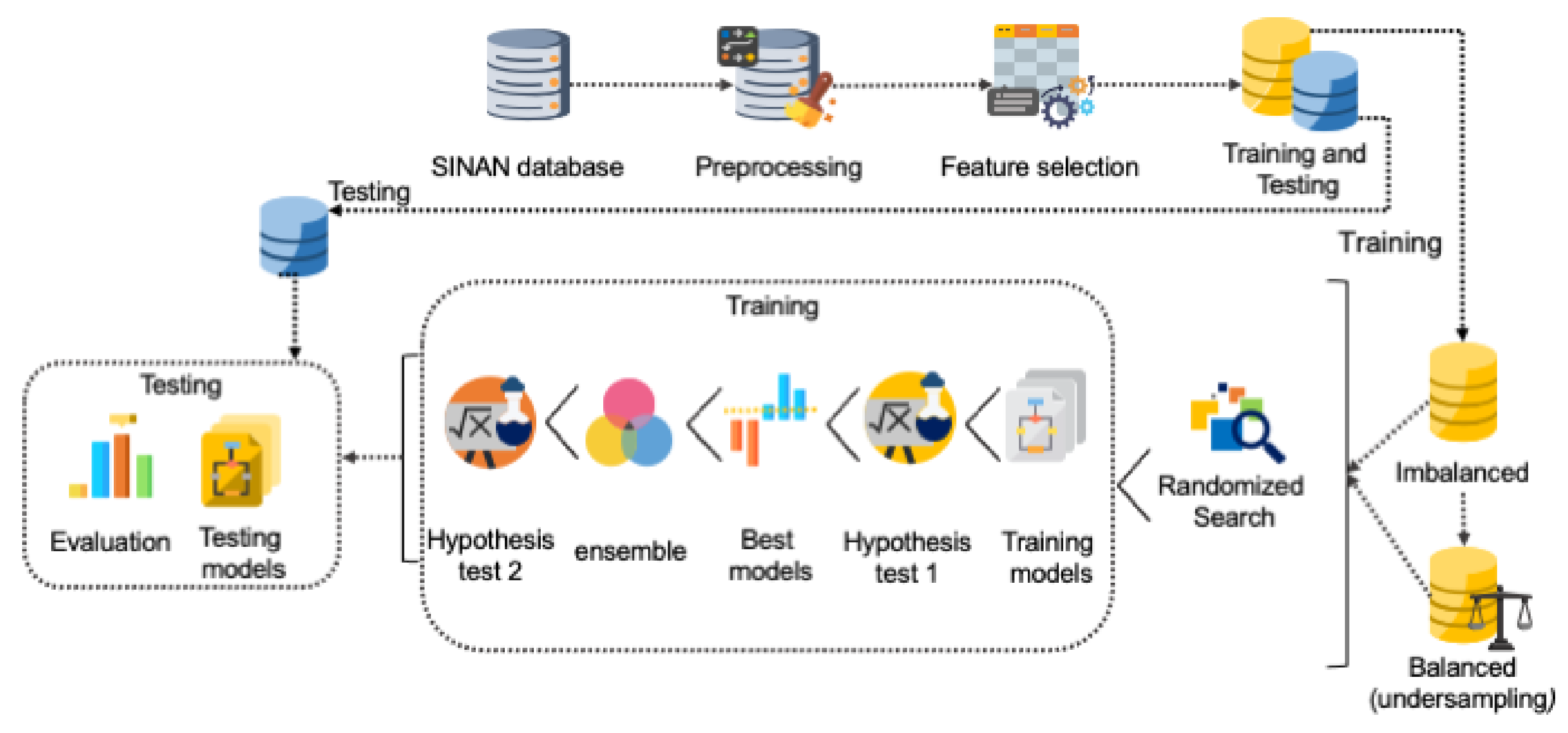
4. Materials and Methods
5. Results
5.1. Preprocessing and Feature Selection
5.2. Results of the Randomized Search Technique
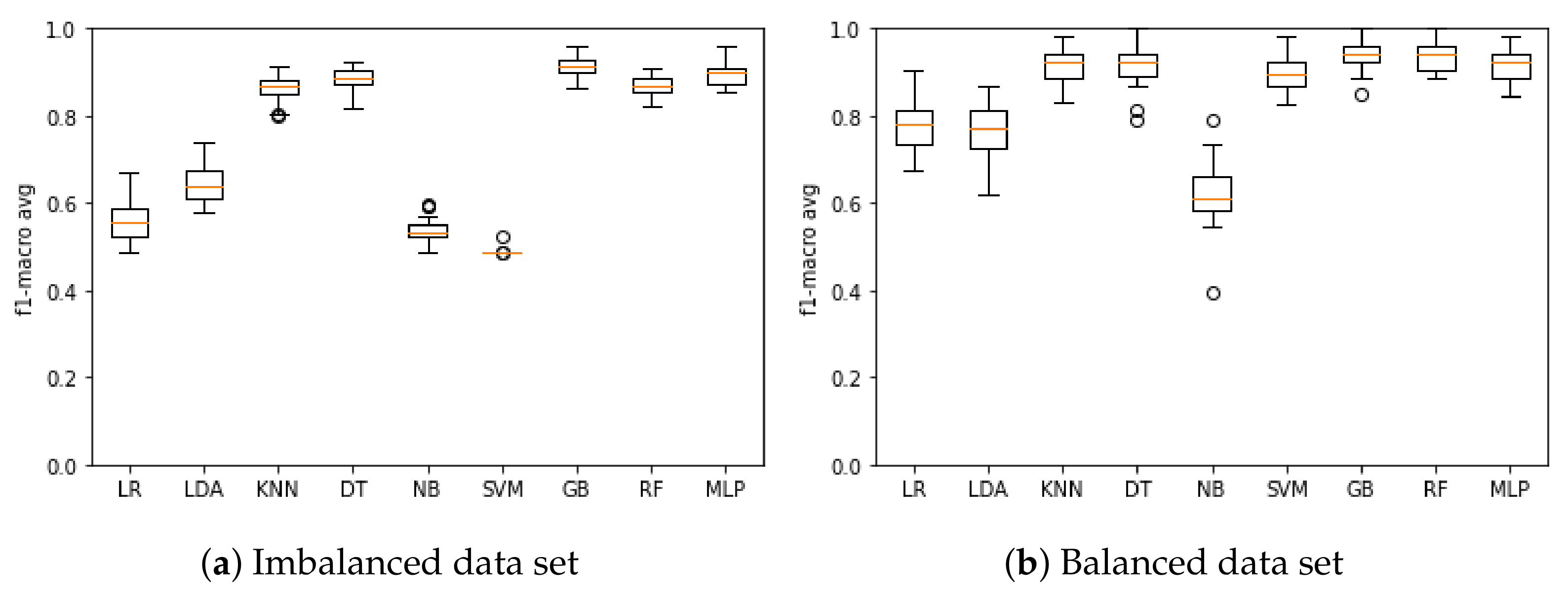
5.3. Model Training and Validation
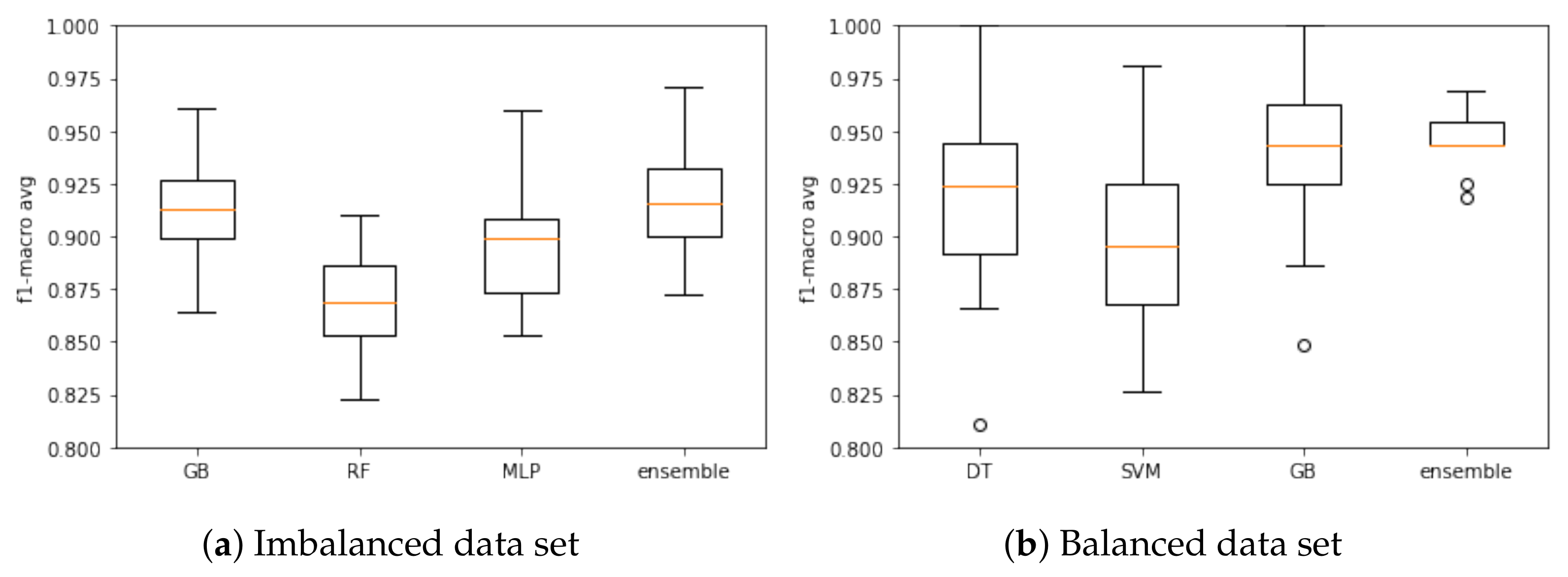
5.4. Testing the Models
5.5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pai, M.; Behr, M.; Dowdy, D.; Dheda, K.; Divangahi, M.; Boehme, C.; Raviglione, M. Tuberculosis. Nat. Rev. Dis. Prim. 2016, 2, 16076. [Google Scholar] [CrossRef]
- WHO. Global Tuberculosis Report 2020. Available online: https://apps.who.int/iris/bitstream/handle/10665/336069/9789240013131-eng.pdf (accessed on 25 January 2021).
- Tuberculosis Profile: Brazil. Available online: https://worldhealthorg.shinyapps.io/tb_profiles?_inputs_&lan=%22EN%22&iso2=%22BR%22 (accessed on 25 September 2020).
- WHO. Country Profiles for 30 High TB Burden Countries. Available online: https://www.who.int/tb/publications/global_report/tb19_Report_country_profiles_15October2019.pdf?ua=1 (accessed on 29 September 2020).
- Ranzani, O.T.; Pescarini, J.M.; Martinez, L.; Garcia-Basteiro, A.L. Increasing tuberculosis burden in Latin America: An alarming trend for global control efforts. BMJ 2021. [Google Scholar] [CrossRef]
- Sistema Único de Saúde (SUS): Estrutura, Princípios e Como Funciona. Available online: https://antigo.saude.gov.br/sistema-unico-de-saude (accessed on 25 January 2021).
- Brasil é único com ‘SUS’ Entre Países Com Mais de 200 Milhões de Habitantes. Available online: https://www1.folha.uol.com.br/cotidiano/2019/10/brasil-e-unico-com-sus-entre-paises-com-mais-de-200-milhoes-de-habitantes.shtml (accessed on 28 January 2021).
- Brazil’s Sistema Único da Saúde (SUS): Caught in the Cross Fire. Available online: https://www.csis.org/blogs/smart-global-health/brazils-sistema-unico-da-saude-sus-caught-cross-fire (accessed on 25 January 2021).
- Hemingway, H. Prognosis research: Why is Dr. Lydgate still waiting? J. Clin. Epidemiol. 2006, 59, 1229–1238. [Google Scholar] [CrossRef]
- Hemingway, H.; Riley, R.D.; Altman, D.G. Ten steps towards improving prognosis research. BMJ 2009, 339, b4184. [Google Scholar] [CrossRef] [PubMed]
- Bora, R.M.; Chaudhari, S.N.; Mene, S.P. A Review of Ensemble Based Classification and Clustering in Machine Learning. Int. J. New Innov. Eng. Technol. 2019, 12, 2319–6319. [Google Scholar]
- García-Gil, D.; Holmberg, J.; García, S.; Xiong, N.; Herrera, F. Smart Data based Ensemble for Imbalanced Big Data Classification. arXiv 2020, arXiv:2001.05759. [Google Scholar]
- Yang, K.; Yu, Z.; Wen, X.; Cao, W.; Chen, C.P.; Wong, H.S.; You, J. Hybrid Classifier Ensemble for Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1387–1400. [Google Scholar] [CrossRef] [PubMed]
- Martins, V.d.O.; de Miranda, C.V. Diagnóstico e Tratamento Medicamentoso Em Casos de Tuberculose Pulmonar: Revisão de Literatura. Rev. Saúde Multidiscip. 2020, 7, 1. [Google Scholar]
- Lakhani, P.; Sundaram, B. Deep learning at chest radiography: Automated classification of pulmonary tuberculosis by using convolutional neural networks. Radiology 2017, 284, 574–582. [Google Scholar] [CrossRef] [PubMed]
- Rajaraman, S.; Candemir, S.; Xue, Z.; Alderson, P.O.; Kohli, M.; Abuya, J.; Thoma, G.R.; Antani, S. A novel stacked generalization of models for improved TB detection in chest radiographs. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 718–721. [Google Scholar]
- Hooda, R.; Sofat, S.; Kaur, S.; Mittal, A.; Meriaudeau, F. Deep-learning: A potential method for tuberculosis detection using chest radiography. In Proceedings of the 2017 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuching, Malaysia, 12–14 September 2017; pp. 497–502. [Google Scholar]
- Sethi, K.; Parmar, V.; Suri, M. Low-Power Hardware-Based Deep-Learning Diagnostics Support Case Study. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar]
- Kant, S.; Srivastava, M.M. Towards automated tuberculosis detection using deep learning. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1250–1253. [Google Scholar]
- Carneiro, G.; Oakden-Rayner, L.; Bradley, A.P.; Nascimento, J.; Palmer, L. Automated 5-year mortality prediction using deep learning and radiomics features from chest computed tomography. In Proceedings of the 2017 IEEE 14th International Symposium on Biomedical Imaging (ISBI 2017), Melbourne, VIC, Australia, 18–21 April 2017; pp. 130–134. [Google Scholar]
- Song, Q.; Zheng, Y.J.; Xue, Y.; Sheng, W.G.; Zhao, M.R. An evolutionary deep neural network for predicting morbidity of gastrointestinal infections by food contamination. Neurocomputing 2017, 226, 16–22. [Google Scholar] [CrossRef]
- Lee, C.K.; Hofer, I.; Gabel, E.; Baldi, P.; Cannesson, M. Development and validation of a deep neural network model for prediction of postoperative in-hospital mortality. Anesthesiol. J. Am. Soc. Anesthesiol. 2018, 129, 649–662. [Google Scholar] [CrossRef] [PubMed]
- Peetluk, L.S.; Ridolfi, F.M.; Rebeiro, P.F.; Liu, D.; Rolla, V.C.; Sterling, T.R. Systematic review of prediction models for pulmonary tuberculosis treatment outcomes in adults. BMJ Open 2021, 11, e044687. [Google Scholar] [CrossRef] [PubMed]
- Abdelbary, B.; Garcia-Viveros, M.; Ramirez-Oropesa, H.; Rahbar, M.; Restrepo, B. Predicting treatment failure, death and drug resistance using a computed risk score among newly diagnosed TB patients in Tamaulipas, Mexico. Epidemiol. Infect. 2017, 145, 3020–3034. [Google Scholar] [CrossRef]
- Aljohaney, A.A. Mortality of patients hospitalized for active tuberculosis in King Abdulaziz University Hospital, Jeddah, Saudi Arabia. Saudi Med. J. 2018, 39, 267. [Google Scholar] [CrossRef] [PubMed]
- Bastos, H.N.; Osório, N.S.; Castro, A.G.; Ramos, A.; Carvalho, T.; Meira, L.; Araújo, D.; Almeida, L.; Boaventura, R.; Fragata, P.; et al. A prediction rule to stratify mortality risk of patients with pulmonary tuberculosis. PLoS ONE 2016, 11, e0162797. [Google Scholar] [CrossRef]
- Gupta-Wright, A.; Corbett, E.L.; Wilson, D.; van Oosterhout, J.J.; Dheda, K.; Huerga, H.; Peter, J.; Bonnet, M.; Alufandika-Moyo, M.; Grint, D.; et al. Risk score for predicting mortality including urine lipoarabinomannan detection in hospital inpatients with HIV-associated tuberculosis in sub-Saharan Africa: Derivation and external validation cohort study. PLoS Med. 2019, 16, e1002776. [Google Scholar] [CrossRef]
- Horita, N.; Miyazawa, N.; Yoshiyama, T.; Sato, T.; Yamamoto, M.; Tomaru, K.; Masuda, M.; Tashiro, K.; Sasaki, M.; Morita, S.; et al. Development and validation of a tuberculosis prognostic score for smear-positive in-patients in Japan. Int. J. Tuberc. Lung Dis. 2013, 17, 54–60. [Google Scholar] [CrossRef]
- Koegelenberg, C.F.N.; Balkema, C.A.; Jooste, Y.; Taljaard, J.J.; Irusen, E.M. Validation of a severity-of-illness score in patients with tuberculosis requiring intensive care unit admission. S. Afr. Med. J. 2015, 105, 389–392. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Graviss, E.A. Development and validation of a prognostic score to predict tuberculosis mortality. J. Infect. 2018, 77, 283–290. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Graviss, E.A. Development and validation of a risk score to predict mortality during TB treatment in patients with TB-diabetes comorbidity. BMC Infect. Dis. 2019, 19, 1–8. [Google Scholar] [CrossRef]
- Nguyen, D.T.; Jenkins, H.E.; Graviss, E.A. Prognostic score to predict mortality during TB treatment in TB/HIV co-infected patients. PLoS ONE 2018, 13, e0196022. [Google Scholar] [CrossRef] [PubMed]
- Pefura-Yone, E.W.; Balkissou, A.D.; Poka-Mayap, V.; Fatime-Abaicho, H.K.; Enono-Edende, P.T.; Kengne, A.P. Development and validation of a prognostic score during tuberculosis treatment. BMC Infect. Dis. 2017, 17, 251. [Google Scholar] [CrossRef] [PubMed]
- Podlekareva, D.N.; Grint, D.; Post, F.A.; Mocroft, A.; Panteleev, A.M.; Miller, R.; Miro, J.; Bruyand, M.; Furrer, H.; Riekstina, V.; et al. Health care index score and risk of death following tuberculosis diagnosis in HIV-positive patients. Int. J. Tuberc. Lung Dis. 2013, 17, 198–206. [Google Scholar] [CrossRef]
- Valade, S.; Raskine, L.; Aout, M.; Malissin, I.; Brun, P.; Deye, N.; Baud, F.J.; Megarbane, B. Tuberculosis in the intensive care unit: A retrospective descriptive cohort study with determination of a predictive fatality score. Can. J. Infect. Dis. Med. Microbiol. 2012, 23, 173–178. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Han, W.; Niu, J.; Sun, B.; Dong, W.; Li, G. Prognostic value of serum macrophage migration inhibitory factor levels in pulmonary tuberculosis. Respir. Res. 2019, 20, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Wejse, C.; Gustafson, P.; Nielsen, J.; Gomes, V.F.; Aaby, P.; Andersen, P.L.; Sodemann, M. TBscore: Signs and symptoms from tuberculosis patients in a low-resource setting have predictive value and may be used to assess clinical course. Scand. J. Infect. Dis. 2008, 40, 111–120. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, L.; Pang, X.; Zeng, Y.; Hao, Y.; Wang, Y.; Wu, L.; Gao, G.; Yang, D.; Zhao, H.; et al. A Clinical scoring model to predict mortality in HIV/TB co-infected patients at end stage of AIDS in China: An observational cohort study. Biosci. Trends 2019, 13, 136–144. [Google Scholar] [CrossRef] [PubMed]
- Hussain, O.A.; Junejo, K.N. Predicting treatment outcome of drug-susceptible tuberculosis patients using machine-learning models. Inform. Health Soc. Care 2019, 44, 135–151. [Google Scholar] [CrossRef]
- Killian, J.A.; Wilder, B.; Sharma, A.; Choudhary, V.; Dilkina, B.; Tambe, M. Learning to prescribe interventions for tuberculosis patients using digital adherence data. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2430–2438. [Google Scholar]
- Sauer, C.M.; Sasson, D.; Paik, K.E.; McCague, N.; Celi, L.A.; Sanchez Fernandez, I.; Illigens, B.M. Feature selection and prediction of treatment failure in tuberculosis. PLoS ONE 2018, 13, e0207491. [Google Scholar] [CrossRef]
- Kalhori, S.R.N.; Zeng, X.J. Evaluation and comparison of different machine learning methods to predict outcome of tuberculosis treatment course. J. Intell. Learn. Syst. Appl. 2013, 5, 10. [Google Scholar] [CrossRef][Green Version]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Elsevier: Amsterdam, The Netherlands, 1992; pp. 249–256. [Google Scholar]
- Rocha, E.D.S. DEEPTUB: Plataforma Para PrediçãO De Morte Por Tuberculose Baseado Em Modelos De Deep Learning Utilizando Dados DemográFicos, ClíNicos E Laboratoriais. Dissertação de Mestrado, Universidade de Pernambuco, Recife, PE, Brazil, 2020. [Google Scholar]
- Marcano-Cedeno, A.; Quintanilla-Domínguez, J.; Cortina-Januchs, M.; Andina, D. Feature selection using sequential forward selection and classification applying artificial metaplasticity neural network. In Proceedings of the IECON 2010—36th Annual Conference on IEEE Industrial Electronics Society, Glendale, AZ, USA, 7–10 November 2010; pp. 2845–2850. [Google Scholar]
- Alakuş, T.B.; Türkoğlu, İ. Feature selection with sequential forward selection algorithm from emotion estimation based on EEG signals. Sak. Üniversitesi Fen Bilim. Enstitüsü derg. 2019, 23, 1096–1105. [Google Scholar] [CrossRef]
- Kuchibhotla, S.; Vankayalapati, H.D.; Anne, K.R. An optimal two stage feature selection for speech emotion recognition using acoustic features. Int. J. Speech Technol. 2016, 19, 657–667. [Google Scholar] [CrossRef]
- Varma, M.; Jereesh, A. Identifying predominant clinical and genomic features for glioblastoma multiforme using sequential backward selection. In Proceedings of the 2017 International Conference on Circuit, Power and Computing Technologies (ICCPCT), Kollam, India, 20–21 April 2017; pp. 1–4. [Google Scholar]
- Lingampeta, D.; Yalamanchili, B. Human Emotion Recognition using Acoustic Features with Optimized Feature Selection and Fusion Techniques. In Proceedings of the 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbatore, India, 26–28 February 2020; pp. 221–225. [Google Scholar]
- Das, K.; Behera, R.N. A survey on machine learning: Concept, algorithms and applications. Int. J. Innov. Res. Comput. Commun. Eng. 2017, 5, 1301–1309. [Google Scholar]
- Callahan, A.; Shah, N.H. Machine learning in healthcare. In Key Advances in Clinical Informatics; Elsevier: Amsterdam, The Netherlands, 2017; pp. 279–291. [Google Scholar]
- Bonte, C.; Vercauteren, F. Privacy-preserving logistic regression training. BMC Med. Genom. 2018, 11, 86. [Google Scholar] [CrossRef] [PubMed]
- Menard, S. Applied Logistic Regression Analysis; SAGE: Thousand Oaks, CA, USA, 2002; Volume 106. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Xanthopoulos, P.; Pardalos, P.M.; Trafalis, T.B. Linear discriminant analysis. In Robust Data Mining; Springer: Berlin/Heidelberg, Germany, 2013; pp. 27–33. [Google Scholar]
- Balakrishnama, S.; Ganapathiraju, A. Linear discriminant analysis-a brief tutorial. Inst. Signal Inf. Process. 1998, 18, 1–8. [Google Scholar]
- Basha, S.M.; Rajput, D.S. Survey on Evaluating the Performance of Machine Learning Algorithms: Past Contributions and Future Roadmap. In Deep Learning and Parallel Computing Environment for Bioengineering Systems; Elsevier: Amsterdam, The Netherlands, 2019; pp. 153–164. [Google Scholar]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Talita, A.; Nataza, O.; Rustam, Z. Naïve Bayes Classifier and Particle Swarm Optimization Feature Selection Method for Classifying Intrusion Detection System Dataset. J. Phys. Conf. Ser. IOP Publ. 2021, 1752, 012021. [Google Scholar] [CrossRef]
- Rukmawan, S.; Aszhari, F.; Rustam, Z.; Pandelaki, J. Cerebral Infarction Classification Using the K-Nearest Neighbor and Naive Bayes Classifier. J. Phys. Conf. Ser. 2021, 1752, 012045. [Google Scholar] [CrossRef]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop On Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–6 August 2001; Volume 3, pp. 41–46. [Google Scholar]
- da Silva, L.A.; Peres, S.M.; Boscarioli, C. Introdução à Mineração de Dados: Com Aplicações em R; Elsevier: Brasil, Brazil, 2017. [Google Scholar]
- Bordoloi, D.J.; Tiwari, R. Optimum multi-fault classification of gears with integration of evolutionary and SVM algorithms. Mech. Mach. Theory 2014, 73, 49–60. [Google Scholar] [CrossRef]
- Yao, Y.; Liu, Y.; Yu, Y.; Xu, H.; Lv, W.; Li, Z.; Chen, X. K-SVM: An Effective SVM Algorithm Based on K-means Clustering. JCP 2013, 8, 2632–2639. [Google Scholar] [CrossRef]
- Lu, H.; Karimireddy, S.P.; Ponomareva, N.; Mirrokni, V. Accelerating Gradient Boosting Machines. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Palermo, Italy, 3–5 June 2020; pp. 516–526. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed]
- Gomes, H.M.; Bifet, A.; Read, J.; Barddal, J.P.; Enembreck, F.; Pfharinger, B.; Holmes, G.; Abdessalem, T. Adaptive random forests for evolving data stream classification. Mach. Learn. 2017, 106, 1469–1495. [Google Scholar] [CrossRef]
- Zanaty, E. Support vector machines (SVMs) versus multilayer perception (MLP) in data classification. Egypt. Inform. J. 2012, 13, 177–183. [Google Scholar] [CrossRef]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; CRC Press: Boca Raton, FL, USA, 2012. [Google Scholar]
- Dicionário de Dados-SINAN NET-Versão 5.0. Available online: http://portalsinan.saude.gov.br/images/documentos/Agravos/Tuberculose/DICI_DADOS_NET_Tuberculose_23_07_2020.pdf (accessed on 25 January 2021).
- Badža, M.M.; Barjaktarović, M.Č. Classification of brain tumors from MRI images using a convolutional neural network. Appl. Sci. 2020, 10, 1999. [Google Scholar] [CrossRef]
- Cherifa, M.; Blet, A.; Chambaz, A.; Gayat, E.; Resche-Rigon, M.; Pirracchio, R. Prediction of an acute hypotensive episode during an ICU hospitalization with a super learner machine-learning algorithm. Anesth. Analg. 2020, 130, 1157–1166. [Google Scholar] [CrossRef] [PubMed]
- Song, W.; Jung, S.Y.; Baek, H.; Choi, C.W.; Jung, Y.H.; Yoo, S. A Predictive Model Based on Machine Learning for the Early Detection of Late-Onset Neonatal Sepsis: Development and Observational Study. JMIR Med. Inform. 2020, 8, e15965. [Google Scholar] [CrossRef] [PubMed]
- Eickelberg, G.; Sanchez-Pinto, L.N.; Luo, Y. Predictive modeling of bacterial infections and antibiotic therapy needs in critically ill adults. J. Biomed. Inform. 2020, 109, 103540. [Google Scholar] [CrossRef]
- Ho Thanh Lam, L.; Le, N.H.; Van Tuan, L.; Tran Ban, H.; Nguyen Khanh Hung, T.; Nguyen, N.T.K.; Huu Dang, L.; Le, N.Q.K. Machine learning model for identifying antioxidant proteins using features calculated from primary sequences. Biology 2020, 9, 325. [Google Scholar] [CrossRef]
- Liashchynskyi, P.; Liashchynskyi, P. Grid Search, Random Search, Genetic Algorithm: A Big Comparison for NAS. arXiv 2019, arXiv:1912.06059. [Google Scholar]
- Woolson, R. Wilcoxon signed-rank test. In Wiley Encyclopedia of Clinical Trials; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2007; pp. 1–3. [Google Scholar]
- Le, N.Q.K.; Do, D.T.; Hung, T.N.K.; Lam, L.H.T.; Huynh, T.T.; Nguyen, N.T.K. A computational framework based on ensemble deep neural networks for essential genes identification. Int. J. Mol. Sci. 2020, 21, 9070. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Feature Selection Techniques | ||||
|---|---|---|---|---|
| Model | SFS | SFFS | SBS | SBFS |
| LR | 94.71 (±0.007) | 94.88 (±0.007) | 95.30 (±0.000) | 95.31 (±0.000) |
| LDA | 94.94 (±0.007) | 95.13 (±0.006) | 95.31 (±0.001) | 95.30 (±0.001) |
| KNN | 95.17 (±0.004) | 95.40 (±0.002) | 93.79 (±0.004) | 93.89 (±0.005) |
| DT | 96.00 (±0.002) | 95.99 (±0.002) | 95.71 (±0.001) | 95.70 (±0.001) |
| NB | 94.11 (±0.003) | 94.39 (±0.001) | 90.15 (±0.004) | 90.15 (±0.004) |
| SVM | 95.22 (±0.002) | 95.23 (±0.002) | 94.37 (±0.002) | 94.38 (±0.002) |
| GB | 96.04 (±0.003) | 96.02 (±0.003) | 96.29 (±0.000) | 96.30 (±0.000) |
| RF | 94.63 (±0.006) | 94.84 (±0.006) | 92.69 (±0.005) | 92.74 (±0.005) |
| MLP | 95.51 (±0.004) | 95.55 (±0.003) | 95.70 (±0.000) | 95.72 (±0.000) |
| SBFS | SBS | SFFS | SFS | SFFS | SFFS | SBFS | SFFS | SBFS |
|---|---|---|---|---|---|---|---|---|
| LR | LDA | KNN | DT | NB | SVM | GB | RF | MLP |
| CS_SEXO | CS_SEXO | FORMA | CS_SEXO | CS_SEXO | CS_SEXO | TRATAMENTO | CS_SEXO | RAIOX_TORA |
| CS_RACA | TESTE_TUBE | AGRAVDIABE | CS_RACA | CS_RACA | CS_RACA | AGRAVAIDS | CS_RACA | AGRAVALCOO |
| TRATAMENTO | FORMA | AGRAVDOENC | TRATAMENTO | TRATAMENTO | TRATAMENTO | AGRAVALCOO | TRATAMENTO | BACILOSC_E |
| RAIOX_TORA | AGRAVAIDS | BACILOSC_O | TESTE_TUBE | RAIOX_TORA | AGRAVAIDS | BACILOSC_O | RAIOX_TORA | CULTURA_ES |
| FORMA | AGRAVALCOO | RIFAMPICIN | AGRAVDOENC | TESTE_TUBE | AGRAVALCOO | CULTURA_ES | FORMA | HIV |
| AGRAVDIABE | AGRAVDIABE | ISONIAZIDA | RIFAMPICIN | AGRAVAIDS | AGRAVDIABE | HIV | AGRAVDIABE | RIFAMPICIN |
| BACILOSC_E | AGRAVOUTRA | ETAMBUTOL | ETAMBUTOL | AGRAVALCOO | AGRAVDOENC | ETAMBUTOL | AGRAVDOENC | ISONIAZIDA |
| BACILOSC_O | BACILOSC_E | ESTREPTOMI | PIRAZINAMI | AGRAVOUTRA | BACILOSC_E | PIRAZINAMI | AGRAVOUTRA | ETAMBUTOL |
| RIFAMPICIN | BACILOS_E2 | PIRAZINAMI | OUTRAS | BACILOSC_E | BACILOSC_O | ETIONAMIDA | CULTURA_ES | TRAT_SUPER |
| ETAMBUTOL | BACILOSC_O | ETIONAMIDA | DOENCA_TRA | CULTURA_ES | HIV | BACILOSC_1 | HIV | BACILOSC_1 |
| BACILOSC_1 | CULTURA_ES | OUTRAS | BACILOSC_2 | HIV | BACILOSC_3 | BACILOSC_2 | BACILOSC_1 | BACILOSC_2 |
| BACILOSC_2 | DOENCA_TRA | DOENCA_TRA | BACILOSC_3 | OUTRAS | BACILOSC_4 | BACILOSC_3 | BACILOSC_2 | BACILOSC_4 |
| BACILOSC_3 | BACILOSC_6 | BACILOSC_4 | BACILOSC_4 | DOENCA_TRA | BACILOSC_5 | BACILOSC_5 | BACILOSC_3 | BACILOSC_6 |
| BACILOSC_4 | AGRAVDROGA | BACILOSC_5 | BACILOSC_5 | AGRAVDROGA | BACILOSC_6 | BACILOSC_6 | BACILOSC_6 | TPUNINOT |
| BACILOSC_6 | AGRAVTABAC | BACILOSC_6 | BACILOSC_6 | AGRAVTABAC | TPUNINOT | TPUNINOT | TPUNINOT | AGRAVTABAC |
| DIAS | DIAS | AGRAVDROGA | AGRAVTABAC | DIAS | DIAS | DIAS | DIAS | DIAS |
| IDADE | IDADE | DIAS | DIAS | IDADE | IDADE | IDADE | IDADE | IDADE |
| Model | Parameters | Randomized Search Using Imbalanced Data Set | Randomized Search Using Balanced Data Set |
|---|---|---|---|
| LR | Penalty | none | l1 |
| Solver | newton-cg | liblinear | |
| Multiclass | ovr | auto | |
| LDA | Solver | svd | svd |
| Shrinkage | None | None | |
| Priors | None | None | |
| KNN | Weights | distance | distance |
| Algorithm | ball_ree | ball_ree | |
| Leaf size | 30 | 30 | |
| Metric | minkowski | minkowski | |
| Parameter metric | None | None | |
| Number of jobs: | −1 | −1 | |
| DT | Criterion | entropy | entropy |
| Splitter | best | best | |
| Minimum samples split | 3 | 4 | |
| Minimum samples leaf | 5 | 4 | |
| Maximum features | sqrt | log2 | |
| SVM | Kernel | rbf | rbf |
| Gamma | scale | scale | |
| GB | Loss | exponential | exponential |
| Criterion | friedman_mse | friedman_mse | |
| Number of estimators | 300 | 300 | |
| Minimum samples split | 3 | 3 | |
| Minimum samples leaf | 4 | 4 | |
| Maximum depth | 9 | 9 | |
| Maximum feature | log2 | log2 | |
| RF | Criterion | entropy | entropy |
| Number of estimators | 200 | 200 | |
| Minimum samples split | 2 | 2 | |
| Minimum samples leaf | 1 | 1 | |
| Maximum depth | 6 | 6 | |
| Maximum feature | log2 | log2 | |
| Maximum samples leaf | 4 | 4 | |
| Bootstrap | False | False | |
| OOB Score | False | False | |
| Weight class | balanced | balanced | |
| MLP | Hidden layers | 2 | 2 |
| Neurons in each layer | 20 | 20 | |
| Activation functions | logistic | logistic | |
| Solver | adam | adam | |
| Learning rate | invscaling | invscaling |
| Model | Imbalanced Data Set | Balanced Data Set |
|---|---|---|
| LR | 55.99 (±0.043) | 77.82 (±0.062) |
| LDA | 64.49 (±0.040) | 76.40 (±0.060) |
| KNN | 86.07 (±0.029) | 91.70 (±0.035) |
| DT | 88.37 (±0.027) | 91.93 (±0.047) |
| NB | 53.61 (±0.027) | 62.39 (±0.076) |
| SVM | 48.88 (±0.006) | 89.76 (±0.039) |
| GB | 91.14 (±0.024) | 94.52 (±0.031) |
| RF | 86.89 (±0.021) | 94.08 (±0.031) |
| MLP | 89.67 (±0.025) | 91.88 (±0.034) |
| Ensemble | 91.69 (±0.022) | 94.47 (±0.014) |
| Imbalanced Data Set | ||||
|---|---|---|---|---|
| Metric | GB | RF | MLP | Ensemble |
| Accuracy | 98.47 (±0.000) | 97.05 (±0.000) | 98.11 (±0.000) | 98.57 (±0.000) |
| Precision | 98.90 (±0.000) | 99.58 (±0.000) | 98.80 (±0.001) | 99.02 (±0.000) |
| Sensitivity | 77.12 (±0.008) | 91.50 (±0.001) | 75.05 (±0.021) | 79.67 (±0.003) |
| Specificity | 99.50 (±0.000) | 97.32 (±0.000) | 99.22 (±0.000) | 99.48 (±0.000) |
| F1-score | 99.20 (±0.000) | 98.43 (±0.000) | 99.01 (±0.000) | 99.25 (±0.000) |
| AUC ROC | 88.31 (±0.004) | 94.41 (±0.000) | 87.13 (±0.010) | 89.57 (±0.001) |
| F1-macro | 90.76 (±0.002) | 86.65 (±0.002) | 89.12 (±0.004) | 91.46 (±0.001) |
| Balanced Data Set | ||||
|---|---|---|---|---|
| Metric | DT | SVM | GB | Ensemble |
| Accuracy | 94.14 (± 0.017) | 95.30 (± 0.000) | 95.97 (± 0.001) | 95.80 (± 0.004) |
| Precision | 99.56 (± 0.001) | 99.17 (± 0.000) | 99.86 (± 0.000) | 99.85 (± 0.000) |
| Sensitivity | 91.54 (± 0.023) | 83.38 (± 0.000) | 97.22 (± 0.001) | 97.12 (± 0.002) |
| Specificity | 94.26 (± 0.018) | 95.88 (± 0.000) | 95.91 (± 0.001) | 95.74 (± 0.004) |
| F1-score | 96.83 (± 0.001) | 97.50 (± 0.000) | 97.84 (± 0.000) | 97.75 (± 0.002) |
| AUC ROC | 92.90 (± 0.016) | 89.63 (± 0.000) | 96.56 (± 0.000) | 96.43 (± 0.002) |
| F1-macro | 78.29 (± 0.039) | 79.76 (± 0.000) | 83.40 (± 0.003) | 82.92 (± 0.011) |
| GB | Predicted class | RF | Predicted class | |||||
| Negative (cured) | Positive (death) | Negative (cured) | Positive (death) | |||||
| True class | Negative (cured) | 6840 | 34 | True class | Negative (cured) | 6696 | 178 | |
| Positive (death) | 71 | 260 | Positive (death) | 28 | 303 | |||
| MLP | Predicted class | Ensemble | Predicted class | |||||
| Negative (cured) | Positive (death) | Negative (cured) | Positive (death) | |||||
| True class | Negative (cured) | 6808 | 66 | True class | Negative (cured) | 6700 | 174 | |
| Positive (death) | 67 | 264 | Positive (death) | 29 | 302 | |||
| DT | Predicted class | SVM | Predicted class | |||||
| Negative (cured) | Positive (death) | Negative (cured) | Positive (death) | |||||
| True class | Negative (cured) | 6257 | 617 | True class | Negative (cured) | 6591 | 283 | |
| Positive (death) | 21 | 310 | Positive (death) | 55 | 276 | |||
| GB | Predicted class | Ensemble | Predicted class | |||||
| Negative (cured) | Positive (death) | Negative (cured) | Positive (death) | |||||
| True class | Negative (cured) | 6596 | 278 | True class | Negative (cured) | 6594 | 280 | |
| Positive (death) | 9 | 322 | Positive (death) | 10 | 321 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lino Ferreira da Silva Barros, M.H.; Oliveira Alves, G.; Morais Florêncio Souza, L.; da Silva Rocha, E.; Lorenzato de Oliveira, J.F.; Lynn, T.; Sampaio, V.; Endo, P.T. Benchmarking Machine Learning Models to Assist in the Prognosis of Tuberculosis. Informatics 2021, 8, 27. https://doi.org/10.3390/informatics8020027
Lino Ferreira da Silva Barros MH, Oliveira Alves G, Morais Florêncio Souza L, da Silva Rocha E, Lorenzato de Oliveira JF, Lynn T, Sampaio V, Endo PT. Benchmarking Machine Learning Models to Assist in the Prognosis of Tuberculosis. Informatics. 2021; 8(2):27. https://doi.org/10.3390/informatics8020027
Chicago/Turabian StyleLino Ferreira da Silva Barros, Maicon Herverton, Geovanne Oliveira Alves, Lubnnia Morais Florêncio Souza, Elisson da Silva Rocha, João Fausto Lorenzato de Oliveira, Theo Lynn, Vanderson Sampaio, and Patricia Takako Endo. 2021. "Benchmarking Machine Learning Models to Assist in the Prognosis of Tuberculosis" Informatics 8, no. 2: 27. https://doi.org/10.3390/informatics8020027
APA StyleLino Ferreira da Silva Barros, M. H., Oliveira Alves, G., Morais Florêncio Souza, L., da Silva Rocha, E., Lorenzato de Oliveira, J. F., Lynn, T., Sampaio, V., & Endo, P. T. (2021). Benchmarking Machine Learning Models to Assist in the Prognosis of Tuberculosis. Informatics, 8(2), 27. https://doi.org/10.3390/informatics8020027