Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation


Abstract
1. Introduction
2. Related Research
2.1. Translation Memories and Fuzzy Matching
2.2. Approaches to TM-MT Integration
2.3. Integrating Fuzzy Matches into NMT through Data Augmentation
2.4. Other Related Research
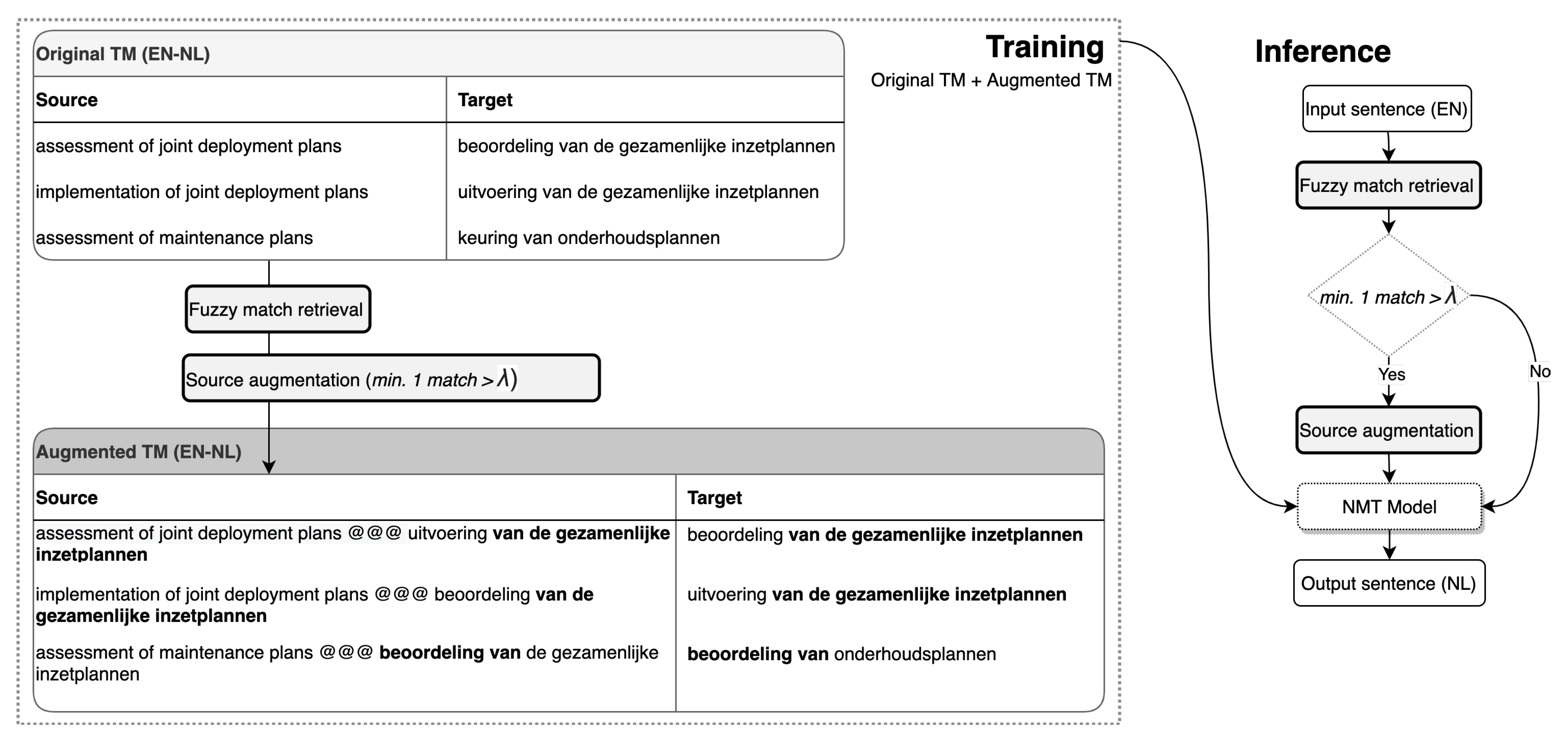
3. Neural Fuzzy Repair: Methodology
3.1. Fuzzy Matching Using Sub-Word Units
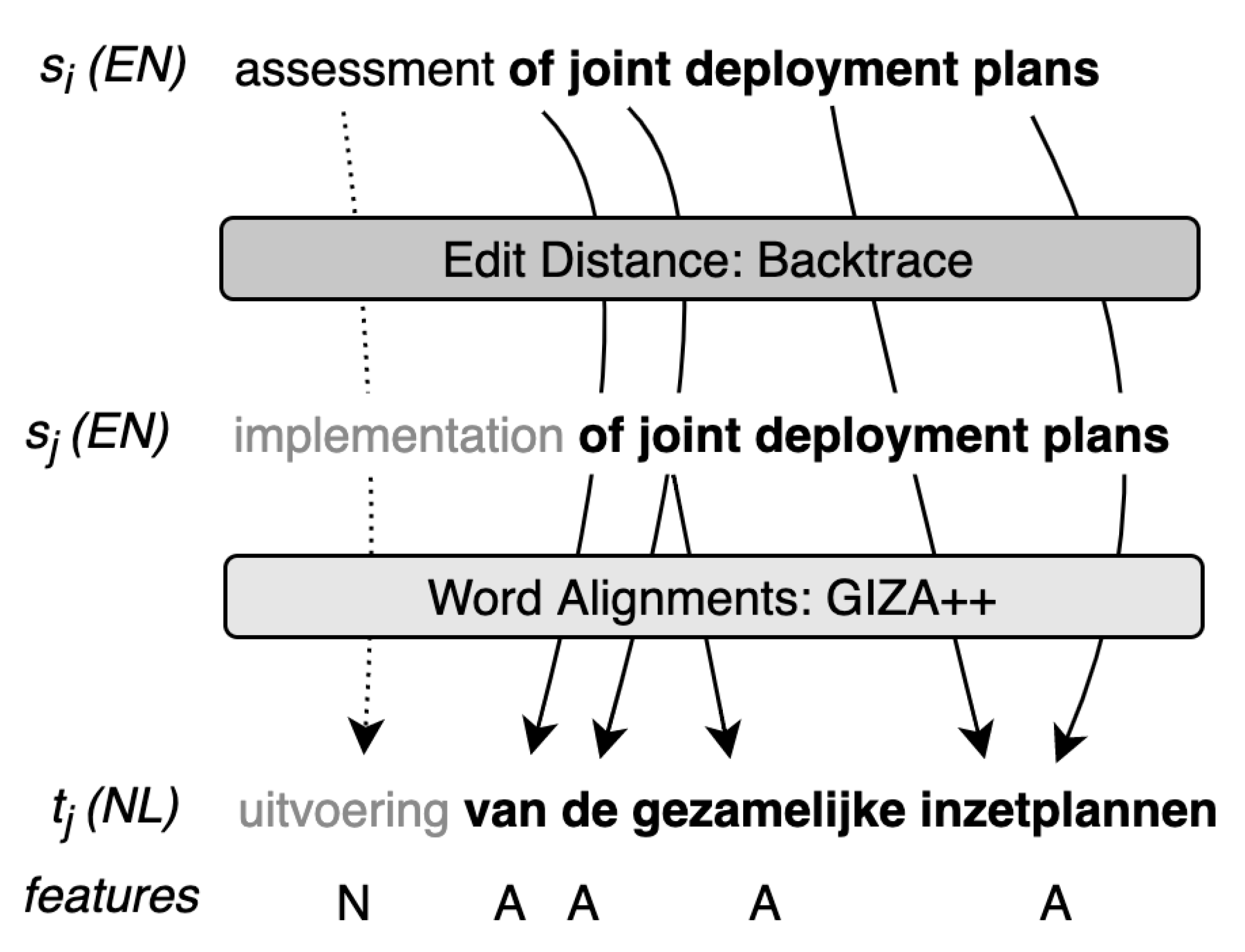
3.2. Marking Relevant Words in Fuzzy Matches
3.3. Maximum Source Coverage
| Algorithm 1: Pseudo-code for . |
 |
4. Experimental Setup
4.1. Data
4.2. Baseline and NFR Models
4.3. Evaluation
5. Results
5.1. Detailed Evaluation for English-Hungarian and Hungarian-English
5.2. Evaluation on Three Additional Language Pairs
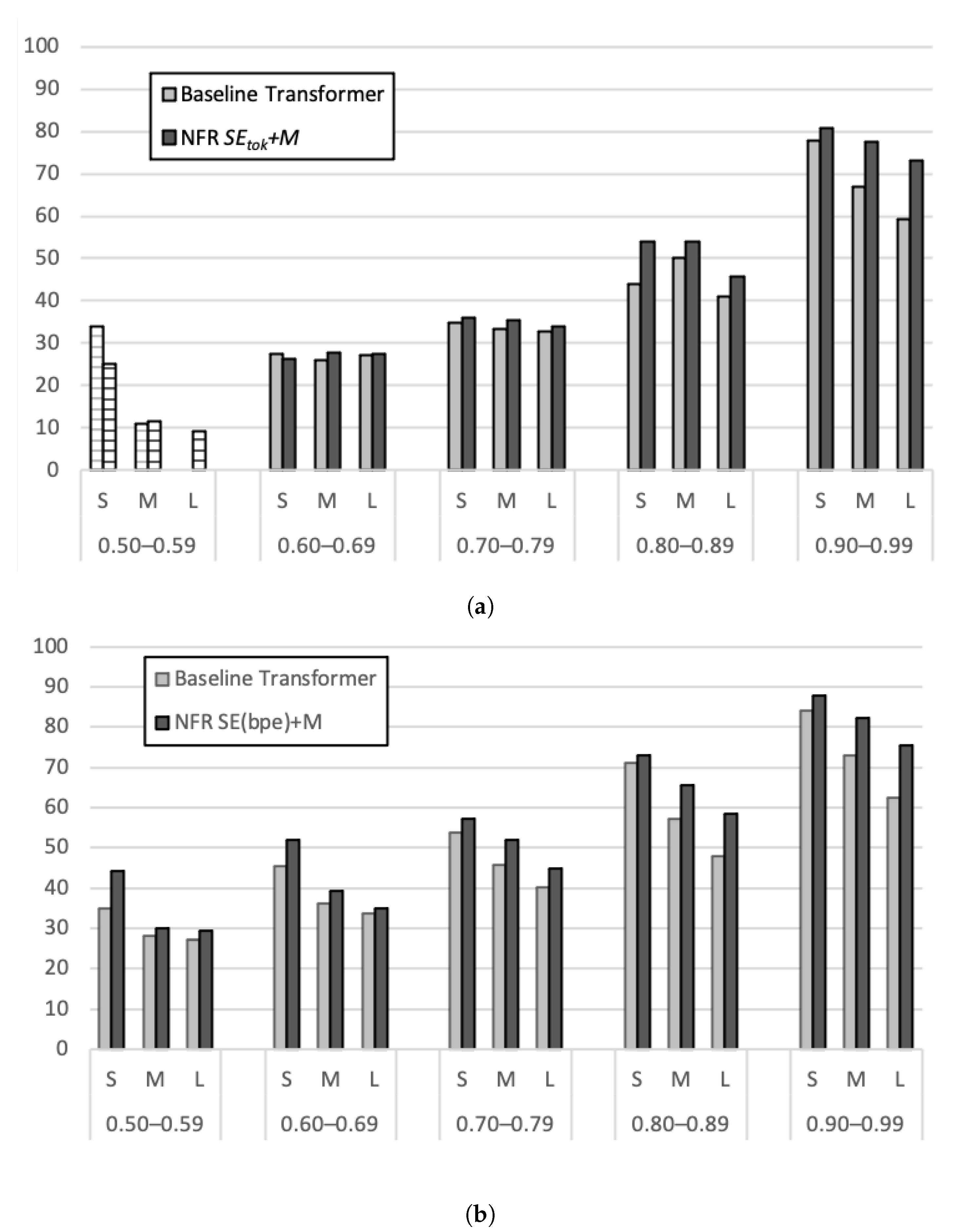
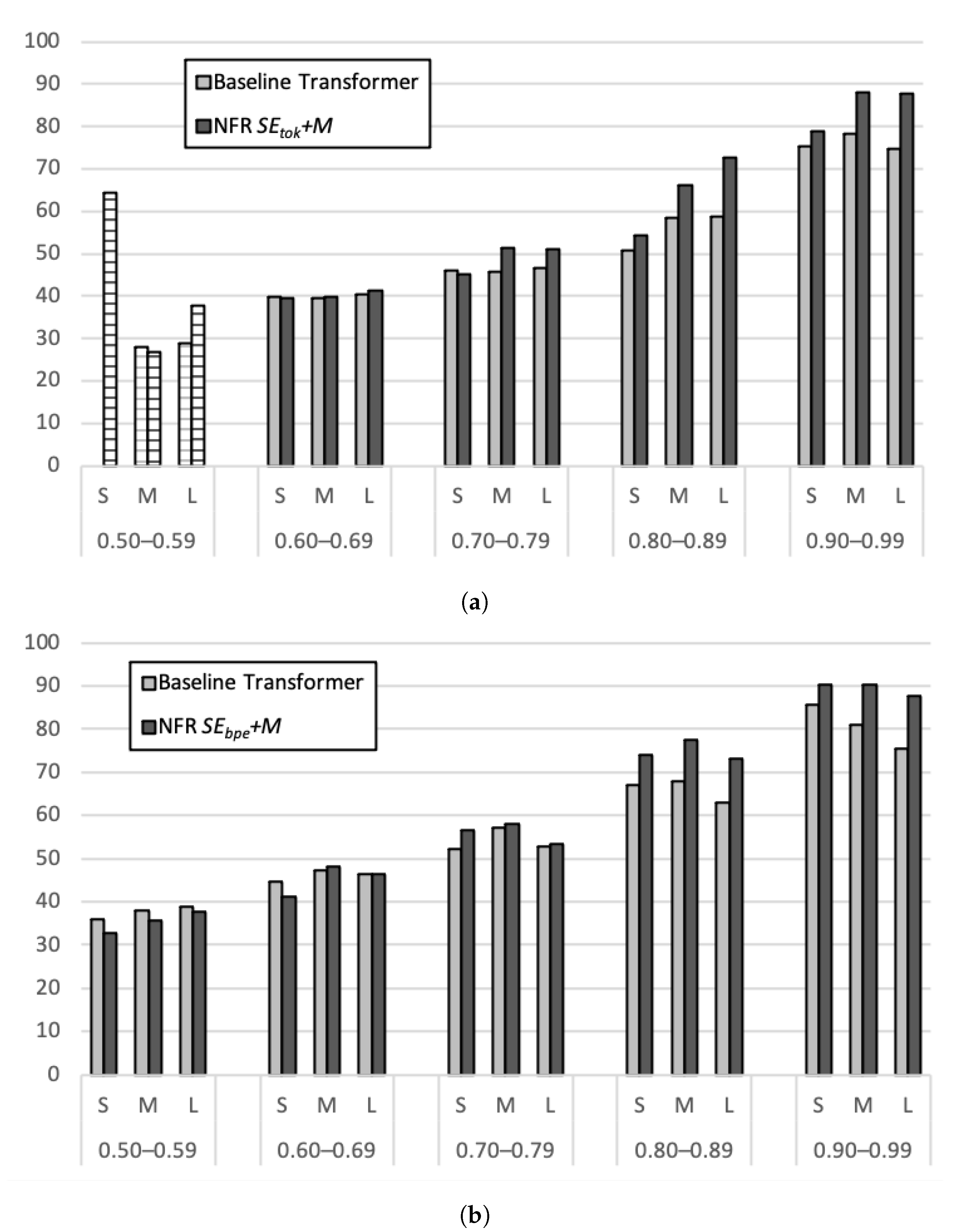
5.3. Impact of Match Score and Sentence Length on Translation Quality
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BLEU | Bilingual Evaluation Understudy |
| BPE | Byte-Pair Encoding |
| CAT | Computer-Assisted Translation |
| ED | Fuzzy Matching using Edit Distance |
| LMVR | Linguistically Motivated Vocabulary Reduction |
| GPU | Graphics Processing Unit |
| NFR | Neural Fuzzy Repair |
| NMT | Neural Machine Translation |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| MT | Machine Translation |
| PBSMT | Phrase-Based Statistical Machine Translation |
| SE | Fuzzy Matching using Sentence Embeddings |
| TER | Translation Edit Rate |
| TM | Translation Memory |
Appendix A. Detailed Information on Data Set Sizes per Language Combination

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Language Combination | Train (M) | Validation | Test | Avg. Length |
|---|---|---|---|---|
| EN-HU | 2.388 | 3000 | 3207 | 22–19.1 |
| HU-EN | 2.388 | 3000 | 3190 | 19.1–22 |
| EN-NL | 2.389 | 3000 | 3207 | 22–22.1 |
| NL-EN | 2.389 | 3000 | 3194 | 22.1–22 |
| EN-FR | 2.373 | 2998 | 3205 | 22.1–26 |
| FR-EN | 2.371 | 2998 | 3205 | 26–22.1 |
| EN-PL | 2.371 | 2998 | 3205 | 22.1–20.3 |
| PL-EN | 2.371 | 2998 | 3205 | 20.3–22.1 |
Appendix B. Hyper-Parameters and Training Details
Appendix B.1. NMT Architecture
| Hyper-Parameter | Value |
|---|---|
| source/target embedding dimension | 512 |
| size of hidden layers | 512 |
| feed-forward layers | 2048 |
| number of heads | 8 |
| number of layers | 6 |
| batch size | 64 sentences |
| gradient accumulation | 2 |
| dropout | 0.1 |
| warm-up steps | 8000 |
| optimizer | Adam |
Appendix B.2. Sent2vec
| Hyper-Parameter | Value |
|---|---|
| embedding dimension | 700 |
| minimum word count | 8 |
| minimum target word count | 20 |
| initial learning rate | 0.2 |
| epochs | 9 |
| subsampling hyper-parameter | |
| bigrams dropped per sentence | 4 |
| number of negatives sampled | 10 |
Appendix B.3. FAISS
Appendix B.4. LMVR
| Hyper-Parameter | Value |
|---|---|
| perplexity threshold | 10 |
| dampening | none |
| minimum shift remainder | 1 |
| length threshold | 5 |
| minimum perplexity length | 1 |
| maximum epochs | 5 |
| lexicon size | 32,000 |
Appendix B.5. GIZA++
Appendix C. Bin Sizes for Comparisons between NFR and Baseline Systems for Different Match Ranges and Sentence Lengths
| +M | +M | |||||
|---|---|---|---|---|---|---|
| Sent. Length | 1–10 | 11–25 | >25 | 1–10 | 11–25 | >25 |
| Match Score | ||||||
| 0.50–0.59 | 5 | 9 | 3 | 81 | 181 | 164 |
| 0.60–0.69 | 41 | 197 | 124 | 104 | 237 | 310 |
| 0.70–0.79 | 101 | 253 | 420 | 122 | 194 | 318 |
| 0.80–0.89 | 147 | 217 | 350 | 136 | 184 | 277 |
| 0.90–0.99 | 346 | 381 | 606 | 125 | 219 | 412 |
| +M | +M | |||||
|---|---|---|---|---|---|---|
| Sent. Length | 1–10 | 11–25 | >25 | 1–10 | 11–25 | >25 |
| Match Score | ||||||
| 0.50–0.59 | 3 | 5 | 3 | 63 | 230 | 204 |
| 0.60–0.69 | 26 | 197 | 217 | 114 | 269 | 294 |
| 0.70–0.79 | 90 | 375 | 400 | 152 | 202 | 219 |
| 0.80–0.89 | 152 | 237 | 250 | 163 | 202 | 194 |
| 0.90–0.99 | 417 | 428 | 376 | 207 | 297 | 320 |
References
- Koehn, P. Neural Machine Translation; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Chung, J.; Cho, K.; Bengio, Y. A Character-level Decoder without Explicit Segmentation for Neural Machine Translation. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1693–1703. [Google Scholar] [CrossRef]
- Koponen, M. Is machine translation post-editing worth the effort? A survey of research into post-editing and effort. J. Spec. Transl. 2016, 25, 131–148. [Google Scholar]
- Rossi, C.; Chevrot, J.P. Uses and perceptions of Machine Translation at the European Commission. J. Spec. Transl. 2019, 31, 177–200. [Google Scholar]
- Stefaniak, K. Evaluating the usefulness of neural machine translation for the Polish translators in the European Commission. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; European Association for Machine Translation: Lisboa, Portugal, 2020; pp. 263–269. [Google Scholar]
- Macken, L.; Prou, D.; Tezcan, A. Quantifying the effect of machine translation in a high-quality human translation production process. Informatics 2020, 7, 19. [Google Scholar] [CrossRef]
- Läubli, S.; Amrhein, C.; Düggelin, P.; Gonzalez, B.; Zwahlen, A.; Volk, M. Post-editing Productivity with Neural Machine Translation: An Empirical Assessment of Speed and Quality in the Banking and Finance Domain. In Proceedings of the Machine Translation Summit XVII, Dublin, Ireland, 19–23 August 2019; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 267–272. [Google Scholar]
- Sanchez-Torron, M.; Koehn, P. Machine Translation Quality and Post-Editor Productivity. In Proceedings of the Conference of the Association for Machine Translation in the Americas (AMTA) Volume 1: MT Researchers’ Track, Austin, TX, USA, 28 October–1 November 2016; Association for Machine Translation in the Americas (AMTA): Austin, TX, USA, 2016; pp. 16–26. [Google Scholar]
- Christensen, T.P.; Schjoldager, A. Translation-memory (TM) research: What do we know and how do we know it? HERMES J. Lang. Commun. Bus. 2010, 89–101. [Google Scholar] [CrossRef]
- Reinke, U. State of the art in translation memory technology. In Language Technologies for a Multilingual Europe; Rehm, G., Stein, D., Sasaki, F., Witt, A., Eds.; Language Science Press: Berlin, Germany, 2018; Chapter 5; pp. 55–84. [Google Scholar] [CrossRef]
- Seal, T. ALPNET and TSS: The commercial realities of using a computeraided translation system. In Translating and the Computer 13, Proceedings from the Aslib Conference; Aslib: London, UK, 1992; pp. 120–125. [Google Scholar]
- Federico, M.; Cattelan, A.; Trombetti, M. Measuring user productivity in machine translation enhanced Computer Assisted Translation. In Proceedings of the 2012 Conference of the Association for Machine Translation in the Americas, San Diego, CA, USA, 28 October–1 November 2012; AMTA: San Diego, CA, USA, 2012; pp. 44–56. [Google Scholar]
- Simard, M.; Isabelle, P. Phrase-based machine translation in a computer-assisted translation environment. In Proceedings of the MT Summit XII, Ottawa, ON, Canada, 26–30 August 2009; AMTA: Ottawa, ON, Canada, 2009; pp. 120–127. [Google Scholar]
- Sánchez-Gijón, P.; Moorkens, J.; Way, A. Post-editing neural machine translation versus translation memory segments. Mach. Transl. 2019, 33, 31–59. [Google Scholar] [CrossRef]
- Baldwin, T. The hare and the tortoise: Speed and accuracy in translation retrieval. Mach. Transl. 2009, 23, 195–240. [Google Scholar] [CrossRef]
- Bloodgood, M.; Strauss, B. Translation Memory Retrieval Methods. In Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 202–210. [Google Scholar] [CrossRef]
- Moorkens, J.; O’Brien, S. Assessing user interface needs of post-editors of machine translation. In Human Issues in Translation Technology: The IATIS Yearbook; Taylor & Francis: Abingdon, UK, 2016; pp. 109–130. [Google Scholar]
- Langlais, P.; Simard, M. Merging example-based and statistical machine translation: An experiment. In Proceedings of the Conference of the Association for Machine Translation in the Americas, Tiburon, CA, USA, 6–12 October 2002; Springer: Tiburon, CA, USA, 2002; pp. 104–113. [Google Scholar]
- Marcu, D. Towards a Unified Approach to Memory- and Statistical-Based Machine Translation. In Proceedings of the 39th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 9–11 July 2001; Association for Computational Linguistics: Toulouse, France, 2001; pp. 386–393. [Google Scholar] [CrossRef]
- Simard, M.; Langlais, P. Sub-sentential exploitation of translation memories. In Proceedings of the Machine Translation Summit VIII, Santiago de Compostela, Spain, 18–22 September 2001; EAMT: Santiago de Compostela, Spain, 2001; Volume 8, pp. 335–339. [Google Scholar]
- Feng, Y.; Zhang, S.; Zhang, A.; Wang, D.; Abel, A. Memory-augmented Neural Machine Translation. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Stroudsburg, PA, USA, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 1390–1399. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Y.; Cho, K.; Li, V.O.K. Search engine guided neural machine translation. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Association for the Advancement of Artificial Intelligence: New Orleans, LA, USA, 2018; pp. 5133–5140. [Google Scholar]
- Zhang, J.; Utiyama, M.; Sumita, E.; Neubig, G.; Nakamura, S. Guiding Neural Machine Translation with Retrieved Translation Pieces. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 1325–1335. [Google Scholar] [CrossRef]
- Bulte, B.; Tezcan, A. Neural Fuzzy Repair: Integrating Fuzzy Matches into Neural Machine Translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1800–1809. [Google Scholar] [CrossRef]
- Xu, J.; Crego, J.; Senellart, J. Boosting Neural Machine Translation with Similar Translations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1580–1590. [Google Scholar] [CrossRef]
- Krollmann, F. Linguistic data banks and the technical translator. Meta 1971, 16, 117–124. [Google Scholar] [CrossRef][Green Version]
- Chatzitheodorou, K. Improving translation memory fuzzy matching by paraphrasing. In Proceedings of the Workshop Natural Language Processing for Translation Memories, Hissar, Bulgaria, 11 September 2015; Association for Computational Linguistics: Hissar, Bulgaria, 2015; pp. 24–30. [Google Scholar]
- Levenshtein, V. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Vanallemeersch, T.; Vandeghinste, V. Assessing linguistically aware fuzzy matching in translation memories. In Proceedings of the 18th Annual Conference of the European Association for Machine Translation, Antalya, Turkey, 11–13 May 2015; EAMT: Antalya, Turkey, 2015; pp. 153–160. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R.; Micciulla, L.; Makhoul, J. A study of translation edit rate with targeted human annotation. In Proceedings of the 2006 Conference of the Association for Machine Translation in the Americas, Cambridge, MA, USA, 8–12 August 2006; AMTA: Cambridge, MA, USA, 2006; pp. 223–231. [Google Scholar]
- Vanallemeersch, T.; Vandeghinste, V. Improving fuzzy matching through syntactic knowledge. Transl. Comput. 2014, 36, 217–227. [Google Scholar]
- Ranasinghe, T.; Orasan, C.; Mitkov, R. Intelligent Translation Memory Matching and Retrieval with Sentence Encoders. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; European Association for Machine Translation: Lisboa, Portugal, 2020; pp. 175–184. [Google Scholar]
- Steinberger, R.; Eisele, A.; Klocek, S.; Pilos, S.; Schlüter, P. DGT-TM: A freely available Translation Memory in 22 languages. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), Istanbul, Turkey, 23–25 May 2012; European Language Resources Association (ELRA): Istanbul, Turkey, 2012; pp. 454–459. [Google Scholar]
- Bulté, B.; Vanallemeersch, T.; Vandeghinste, V. M3TRA: Integrating TM and MT for professional translators. In Proceedings of the 21st Annual Conference of the European Association for Machine Translation, Alicante, Spain, 28–30 May 2018; EAMT: Alicante, Spain, 2018; pp. 69–78. [Google Scholar]
- Hewavitharana, S.; Vogel, S.; Waibel, A. Augmenting a statistical translation system with a translation memory. In Proceedings of the 10th Annual Conference of the European Association for Machine Translation, Budapest, Hungary, 30–31 May 2005; European Association for Machine Translation: Budapest, Hungary, 2005; pp. 126–132. [Google Scholar]
- Kranias, L.; Samiotou, A. Automatic Translation Memory Fuzzy Match Post-Editing: A Step Beyond Traditional TM/MT Integration. In Proceedings of the Fourth International Conference on Language Resources and Evaluation (LREC’04), Lisbon, Portugal, 26–28 May 2004; European Language Resources Association (ELRA): Lisbon, Portugal, 2004; pp. 331–334. [Google Scholar]
- Ortega, J.E.; Sánchez-Martınez, F.; Forcada, M.L. Fuzzy-match repair using black-box machine translation systems: What can be expected. In Proceedings of the AMTA, Austin, TX, USA, 30 October–3 November 2016; AMTA: Austin, TX, USA, 2016; Volume 1, pp. 27–39. [Google Scholar]
- Ortega, J.; Sánchez-Martínez, F.; Turchi, M.; Negri, M. Improving Translations by Combining Fuzzy-Match Repair with Automatic Post-Editing. In Proceedings of the Machine Translation Summit XVII, Dublin, Ireland, 19–23 August 2019; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 256–266. [Google Scholar]
- Ortega, J.E.; Forcada, M.L.; Sanchez-Martinez, F. Fuzzy-match repair guided by quality estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Carl, M.; Way, A. Recent Advances in Example-Based MACHINE Translation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 21. [Google Scholar]
- Nagao, M. A Framework of a Mechanical Translation Between Japanese and English by Analogy Principle. In Artificial and Human Intelligence; Elithorn, A., Barnerji, R., Eds.; North-Holland: Amsterdam, The Netherlands, 1984; pp. 173–180. [Google Scholar]
- Dandapat, S.; Morrissey, S.; Way, A.; Forcada, M.L. Using example-based MT to support statistical MT when translating homogeneous data in a resource-poor setting. In Proceedings of the 15th Annual Meeting of the European Association for Machine Translation, Leuven, Belgium, 30–31 May 2011; European Association for Machine Translation: Leuven, Belgium, 2011; pp. 201–208. [Google Scholar]
- Smith, J.; Clark, S. EBMT for SMT: A new EBMT-SMT hybrid. In Proceedings of the 3rd International Workshop on Example-Based Machine Translation, Dublin, Ireland, 12–13 November 2009; European Association for Machine Translation: Dublin, Ireland, 2009; pp. 3–10. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F.; Calixto, I.; Tinsley, J.; Way, A. Is neural machine translation the new state of the art? Prague Bull. Math. Linguist. 2017, 108, 109–120. [Google Scholar] [CrossRef]
- Koehn, P.; Senellart, J. Convergence of Translation Memory and Statistical Machine Translation. In Proceedings of the AMTA Workshop on MT Research and the Translation Industry, Denver, CO, USA, 31 October–4 November 2010; Association for Machine Translation in the Americas: Denver, CO, USA, 2010; pp. 21–31. [Google Scholar]
- Biçici, E.; Dymetman, M. Dynamic translation memory: Using statistical machine translation to improve translation memory fuzzy matches. In Proceedings of the International Conference on Intelligent Text Processing and Computational Linguistics, Haifa, Israel, 17–23 February 2008; Springer: Haifa, Israel, 2008; pp. 454–465. [Google Scholar]
- Li, L.; Escartin, C.P.; Liu, Q. Combining Translation Memories and Syntax-Based SMT: Experiments with Real Industrial Data. In Proceedings of the 19th Annual Conference of the European Association for Machine Translation, Riga, Latvia, 30 May–1 June 2016; European Association for Machine Translation: Riga, Latvia, 2016; pp. 165–177. [Google Scholar]
- Wang, K.; Zong, C.; Su, K.Y. Integrating Translation Memory into Phrase-Based Machine Translation during Decoding. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–9 August 2013; Association for Computational Linguistics: Sofia, Bulgaria, 2013; pp. 11–21. [Google Scholar]
- Cao, Q.; Xiong, D. Encoding Gated Translation Memory into Neural Machine Translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 3042–3047. [Google Scholar] [CrossRef]
- Hokamp, C.; Liu, Q. Lexically Constrained Decoding for Sequence Generation Using Grid Beam Search. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 1535–1546. [Google Scholar] [CrossRef]
- Khandelwal, U.; Fan, A.; Jurafsky, D.; Zettlemoyer, L.; Lewis, M. Nearest neighbor machine translation. arXiv 2020, arXiv:2010.00710. [Google Scholar]
- Hokamp, C. Ensembling Factored Neural Machine Translation Models for Automatic Post-Editing and Quality Estimation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 647–654. [Google Scholar] [CrossRef]
- Dabre, R.; Cromieres, F.; Kurohashi, S. Enabling multi-source neural machine translation by concatenating source sentences in multiple languages. arXiv 2017, arXiv:1702.06135. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 30th Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Neural Information Processing Systems Foundation: Long Beach, CA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised Learning of Sentence Embeddings Using Compositional n-Gram Features. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: New Orleans, LA, USA, 2018; pp. 528–540. [Google Scholar] [CrossRef]
- Dinu, G.; Mathur, P.; Federico, M.; Al-Onaizan, Y. Training Neural Machine Translation to Apply Terminology Constraints. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 3063–3068. [Google Scholar] [CrossRef]
- Gu, J.; Wang, C.; Zhao, J. Levenshtein transformer. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Neural Information Processing Systems Foundation: Vanvouver, BC, Canada, 2019; pp. 11181–11191. [Google Scholar]
- Susanto, R.H.; Chollampatt, S.; Tan, L. Lexically Constrained Neural Machine Translation with Levenshtein Transformer. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3536–3543. [Google Scholar] [CrossRef]
- Alkhouli, T.; Bretschner, G.; Peter, J.T.; Hethnawi, M.; Guta, A.; Ney, H. Alignment-Based Neural Machine Translation. In Proceedings of the First, Conference on Machine Translation, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 54–65. [Google Scholar] [CrossRef]
- Li, Z.; Specia, L. Improving Neural Machine Translation Robustness via Data Augmentation: Beyond Back-Translation. In Proceedings of the 5th Workshop on Noisy User-generated Text, Hong Kong, China, 4 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 328–336. [Google Scholar] [CrossRef]
- Hossain, N.; Ghazvininejad, M.; Zettlemoyer, L. Simple and Effective Retrieve-Edit-Rerank Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 2532–2538. [Google Scholar] [CrossRef]
- Johnson, J.; Douze, M.; Jégou, H. Billion-scale similarity search with GPUs. IEEE Trans. Big Data 2019. [Google Scholar] [CrossRef]
- Artetxe, M.; Schwenk, H. Massively Multilingual Sentence Embeddings for Zero-Shot Cross-Lingual Transfer and Beyond. Transact. Assoc. Comput. Linguist. 2019, 7, 597–610. [Google Scholar] [CrossRef]
- Chaudhary, V.; Tang, Y.; Guzmán, F.; Schwenk, H.; Koehn, P. Low-Resource Corpus Filtering Using Multilingual Sentence Embeddings. In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 1–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 261–266. [Google Scholar] [CrossRef]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 1715–1725. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Ataman, D.; Negri, M.; Turchi, M.; Federico, M. Linguistically motivated vocabulary reduction for neural machine translation from Turkish to English. Prague Bull. Math. Linguist. 2017, 108, 331–342. [Google Scholar] [CrossRef]
- Gage, P. A New Algorithm for Data Compression. C Users J. 1994, 12, 23–38. [Google Scholar]
- Schuster, M.; Nakajima, K. Japanese and Korean voice search. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 5149–5152. [Google Scholar] [CrossRef]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing, 2nd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Och, F.J.; Ney, H. A Systematic Comparison of Various Statistical Alignment Models. Comput. Linguist. 2003, 29, 19–51. [Google Scholar] [CrossRef]
- Dyer, C.; Chahuneau, V.; Smith, N.A. A Simple, Fast, and Effective Reparameterization of IBM Model 2. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 644–648. [Google Scholar]
- Zenkel, T.; Wuebker, J.; DeNero, J. End-to-End Neural Word Alignment Outperforms GIZA++. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1605–1617. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, 23–30 June 2007; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 177–180. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Banerjee, S.; Lavie, A. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; Association for Computational Linguistics: Ann Arbor, MI, USA, 2005; pp. 65–72. [Google Scholar]
- Koehn, P. Statistical Significance Tests for Machine Translation Evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 388–395. [Google Scholar]
- Zhang, W.; Feng, Y.; Meng, F.; You, D.; Liu, Q. Bridging the gap between training and inference for neural machine translation. In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4334–4343. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A simple and language independent subword tokenizer and detokenizer for Neural Text Processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–3 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 66–71. [Google Scholar] [CrossRef]
- Hodász, G.; Pohl, G. MetaMorpho TM: A linguistically enriched translation memory. In Proceedings of the International Workshop: Modern Approaches in Translation Technologies, Borovets, Bulgaria, 24 September 2005; Incoma Ltd.: Shoumen, Bulgaria, 2005; pp. 26–30. [Google Scholar]
- Reimers, N.; Gurevych, I. Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4512–4525. [Google Scholar]
- Chatterjee, R.; Negri, M.; Turchi, M.; Blain, F.; Specia, L. Combining Quality Estimation and Automatic Post-editing to Enhance Machine Translation output. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas, Boston, MA, USA, 17–21 March 2018; Association for Machine Translation in the Americas: Boston, MA, USA, 2018; pp. 26–38. [Google Scholar]
- Ding, S.; Xu, H.; Koehn, P. Saliency-driven Word Alignment Interpretation for Neural Machine Translation. In Proceedings of the Fourth Conference on Machine Translation, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1–12. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-source toolkit for neural machine translation. arXiv 2017, arXiv:1701.02810. [Google Scholar]
- Gao, Q.; Vogel, S. Parallel implementations of word alignment tool. In Software Engineering, Testing, and Quality Assurance for Natural Language Processing; Association for Computational Linguistics: Columbus, OH, USA, 2008; pp. 49–57. [Google Scholar]




| Score | ||
|---|---|---|
| a görbületi sugarak közötti eltérések: | ||
| 0.5 | a nemek közötti egyenlőség: | |
| gender equality: | ||
| a görb@@ ületi sugar@@ ak közötti eltérések: | ||
| 0.5 | a tük@@ rö@@ k görb@@ ületi sugar@@ ai közötti eltérések | |
| differences between the radii of curvature of mirrors | ||
| a gör @@b @@ület @@i sugar @@ak köz @@ött @@i eltérés @@ek: | ||
| 0.71 | a tükr @@ök gör @@b @@ület @@i sugar @@ai köz @@ött @@i eltérés @@ek | |
| differences between the radii of curvature of mirrors |
| Match Rank/Type | Score | Best Fuzzy Match Targets |
|---|---|---|
| 2-Best , without Features (Bulté & Tezcan, 2019) | ||
| 0.5 | medical equipment. | |
| 0.5 | to receive medical treatment | |
| Best + Best (Xu et al., 2020) | ||
| 0.5 | medical|A equipment|N .|A | |
| 0.862 | to|E receive|E medical|E treatment|E | |
| 2-best | ||
| 0.862 | to|N receive|N medical|A treatment|N | |
| 0.829 | medical|A equipment|N .|A | |
| Best + | ||
| 0.862 | to|N receive|N medical|A treatment|N | |
| 0.765 | medical|A physics|A expert|N |
| Baseline Systems | Match | Match | Match | NMT | Alignment | Maximum |
|---|---|---|---|---|---|---|
| Threshold | Method | Unit | Unit | Features | Coverage | |
| Baseline Transformer | BPE | |||||
| 0.5 | ED | tok | BPE | − | − | |
| 0.6/0.8 | ED/SE | tok | BPE | +/− | − | |
| 0.5 | ED/SE | tok | BPE | +/− | − | |
| Tested systems | ||||||
| 0.5 | ED | BPE | BPE | − | − | |
| 0.5 | ED | LMVR | LMVR | − | − | |
| 0.5 | SE | tok | BPE | − | − | |
| 0.5 | SE | BPE | BPE | − | − | |
| 0.5 | SE | LMVR | LMVR | − | − | |
| + | 0.5 | SE | tok | BPE | + | − |
| + | 0.5 | SE | BPE | BPE | + | − |
| + | 0.5 | SE | LMVR | LMVR | + | − |
| +M | 0.5 | SE | tok | BPE | + | + |
| +M | 0.5 | SE | BPE | BPE | + | + |
| +M | 0.5 | SE | LMVR | LMVR | + | + |
| English-Hungarian | Hungarian-English | |||||||
|---|---|---|---|---|---|---|---|---|
| BLEU | TER | MET. | Match% | BLEU | TER | MET. | Match% | |
| Baseline Transformer | 46.78 | 40.01 | 63.51 | - | 57.63 | 30.74 | 44.93 | - |
| 52.22 | 36.44 | 67.17 | 58% | 62.30 | 27.81 | 46.80 | 50% | |
| 52.83 | 35.77 | 67.66 | 65% | 63.20 | 27.35 | 47.15 | 65% | |
| 53.45 | 35.29 | 68.19 | 99% | 64.06 | 26.39 | 47.55 | 99% | |
| 52.27 | 36.54 | 67.15 | 56% | 62.19 | 28.12 | 46.67 | 47% | |
| 50.64 | 38.46 | 65.38 | 55% | 60.53 | 29.05 | 45.79 | 48% | |
| 52.89 | 35.89 | 67.71 | 99% | 64.17 | 26.53 | 47.49 | 99% | |
| 53.11 | 35.79 | 67.86 | 96% | 65.22 | 25.86 | 48.04 | 98% | |
| 51.72 | 36.92 | 66.77 | 99% | 63.43 | 26.89 | 47.04 | 99% | |
| + | 53.52 | 35.27 | 68.26 | 99% | 64.41 | 26.48 | 47.76 | 99% |
| + | 53.63 | 35.16 | 68.34 | 96% | 65.03 | 26.05 | 47.90 | 98% |
| + | 52.09 | 36.28 | 67.06 | 99% | 63.39 | 27.16 | 46.98 | 99% |
| +M | 53.83 | 34.81 | 68.60 | 99% | 65.44 | 25.65 | 48.19 | 99% |
| +M | 53.62 | 35.22 | 68.34 | 96% | 65.75 | 25.40 | 48.28 | 98% |
| +M | 52.34 | 36.17 | 67.22 | 99% | 63.97 | 26.78 | 47.23 | 99% |
| English-Hungarian | Hungarian-English | |||||
|---|---|---|---|---|---|---|
| BLEU | TER | MET. | BLEU | TER | MET. | |
| -M | 53.58 | 35.33 | 68.15 | 64.49 | 26.59 | 47.55 |
| -M | 53.31 | 35.74 | 67.95 | 65.55 | 25.55 | 48.13 |
| Model | English-Dutch | Dutch-English | ||||
|---|---|---|---|---|---|---|
| BLEU | TER | MET. | BLEU | TER | MET. | |
| Baseline Transformer | 56.04 | 32.54 | 73.21 | 61.38 | 27.39 | 46.85 |
| 61.00 | 29.17 | 76.06 | 66.78 | 24.05 | 49.06 | |
| 62.92 | 27.41 | 77.46 | 67.68 | 23.04 | 49.43 | |
| +M | 63.21 | 27.36 | 77.57 | 68.54 *** | 22.67 | 49.76 |
| +M | 63.46 ** | 27.29 | 77.70 | 68.47 ** | 22.69 | 49.82 |
| Model | English-French | French-English | ||||
|---|---|---|---|---|---|---|
| BLEU | TER | MET. | BLEU | TER | MET. | |
| Baseline Transformer | 60.80 | 29.53 | 73.64 | 61.81 | 26.91 | 47.08 |
| 64.41 | 27.18 | 75.93 | 67.01 | 23.44 | 49.26 | |
| 65.76 | 26.06 | 76.90 | 68.04 | 22.82 | 49.68 | |
| +M | 66.45 ** | 25.72 | 77.39 | 68.83 ** | 22.31 | 50.09 |
| +M | 66.69 *** | 25.48 | 77.51 | 69.11 *** | 22.08 | 50.24 |
| Model | English-Polish | Polish-English | ||||
|---|---|---|---|---|---|---|
| BLEU | TER | MET. | BLEU | TER | MET. | |
| Baseline Transformer | 52.13 | 35.77 | 38.24 | 59.16 | 30.24 | 45.48 |
| 56.09 | 33.11 | 40.15 | 63.97 | 27.32 | 47.38 | |
| 57.18 | 32.21 | 40.76 | 66.01 | 25.77 | 48.28 | |
| +M | 58.24 *** | 31.68 | 41.32 | 66.86 ** | 25.21 | 48.67 |
| +M | 58.34 *** | 31.50 | 41.36 | 67.59 *** | 24.55 | 49.05 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tezcan, A.; Bulté, B.; Vanroy, B. Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation. Informatics 2021, 8, 7. https://doi.org/10.3390/informatics8010007
Tezcan A, Bulté B, Vanroy B. Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation. Informatics. 2021; 8(1):7. https://doi.org/10.3390/informatics8010007
Chicago/Turabian StyleTezcan, Arda, Bram Bulté, and Bram Vanroy. 2021. "Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation" Informatics 8, no. 1: 7. https://doi.org/10.3390/informatics8010007
APA StyleTezcan, A., Bulté, B., & Vanroy, B. (2021). Towards a Better Integration of Fuzzy Matches in Neural Machine Translation through Data Augmentation. Informatics, 8(1), 7. https://doi.org/10.3390/informatics8010007