Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges

 ,
,  ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
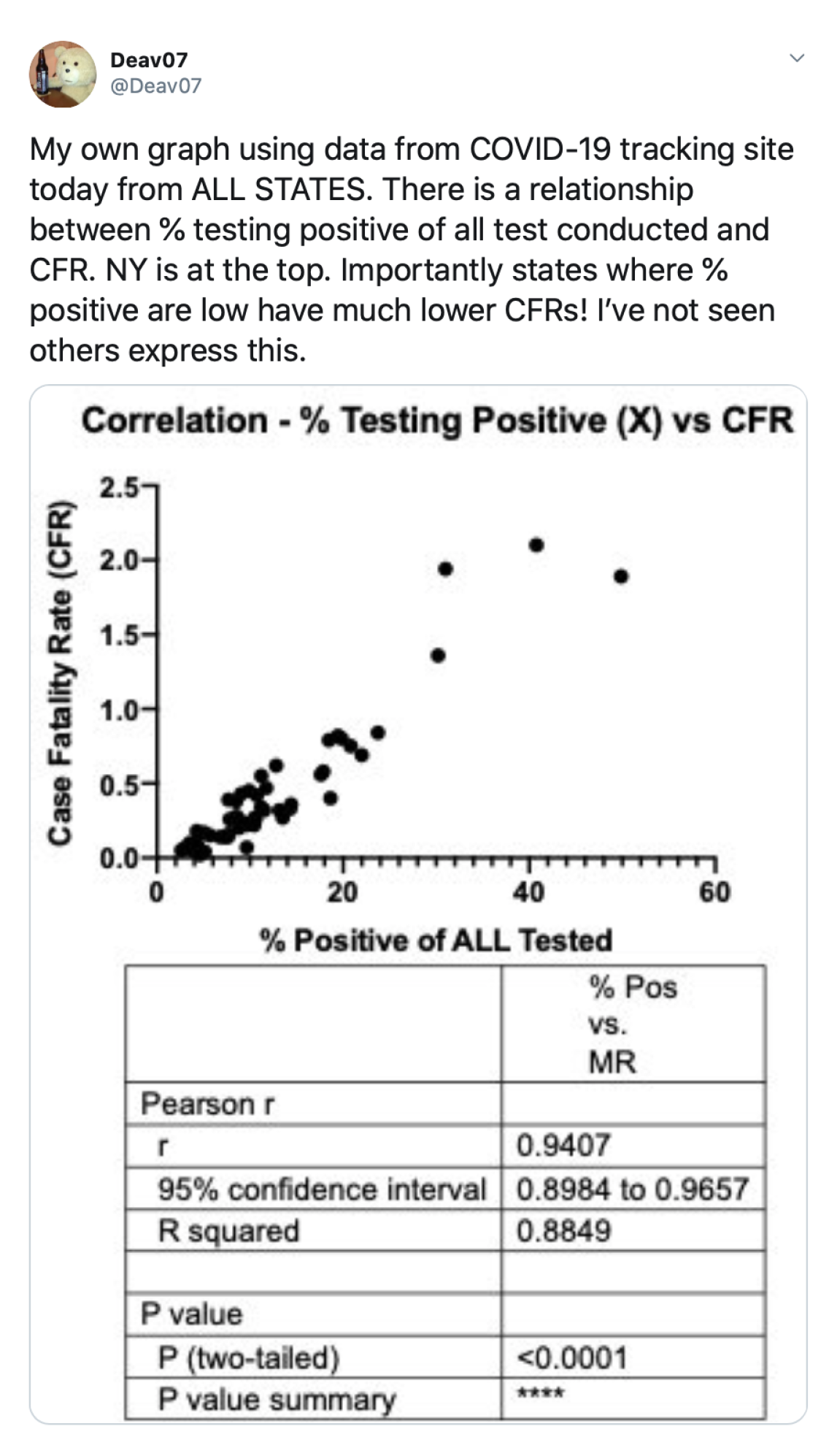{kind=link}
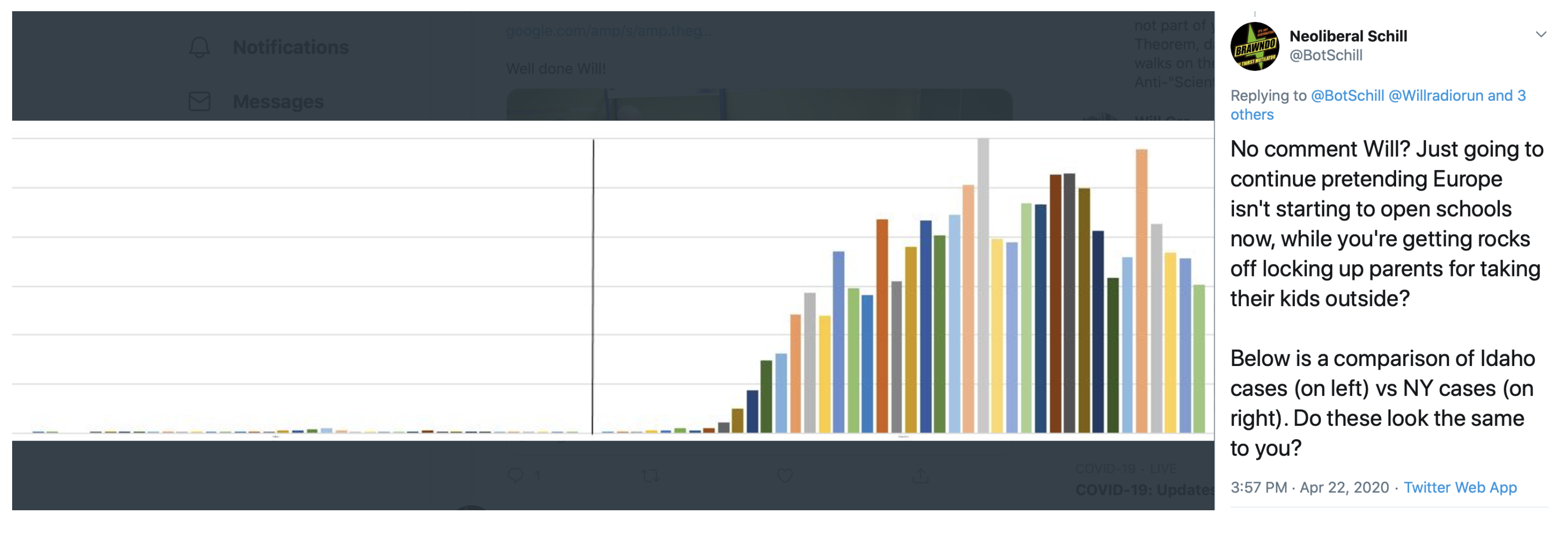{kind=link}
{kind=link}
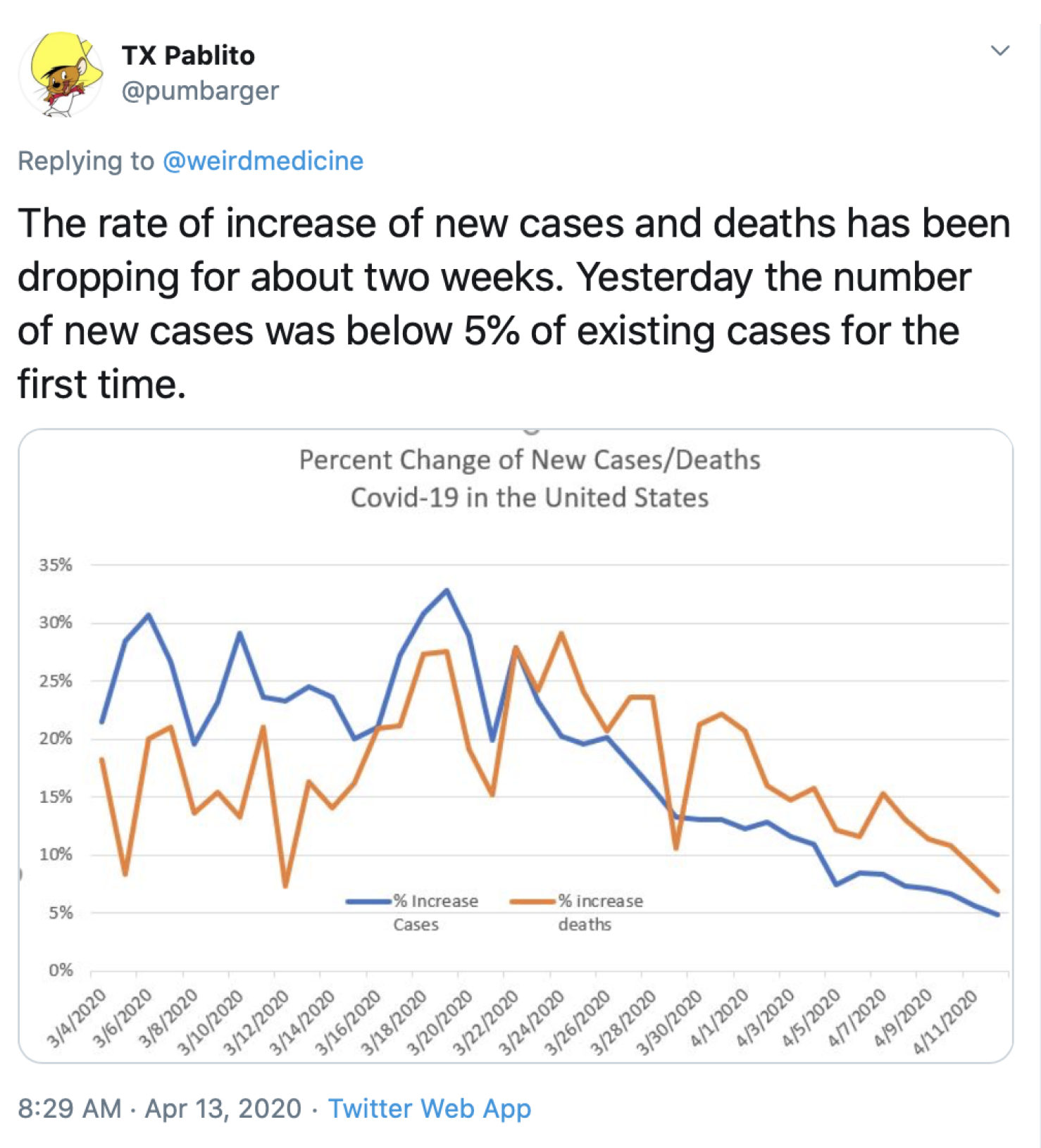{kind=link}
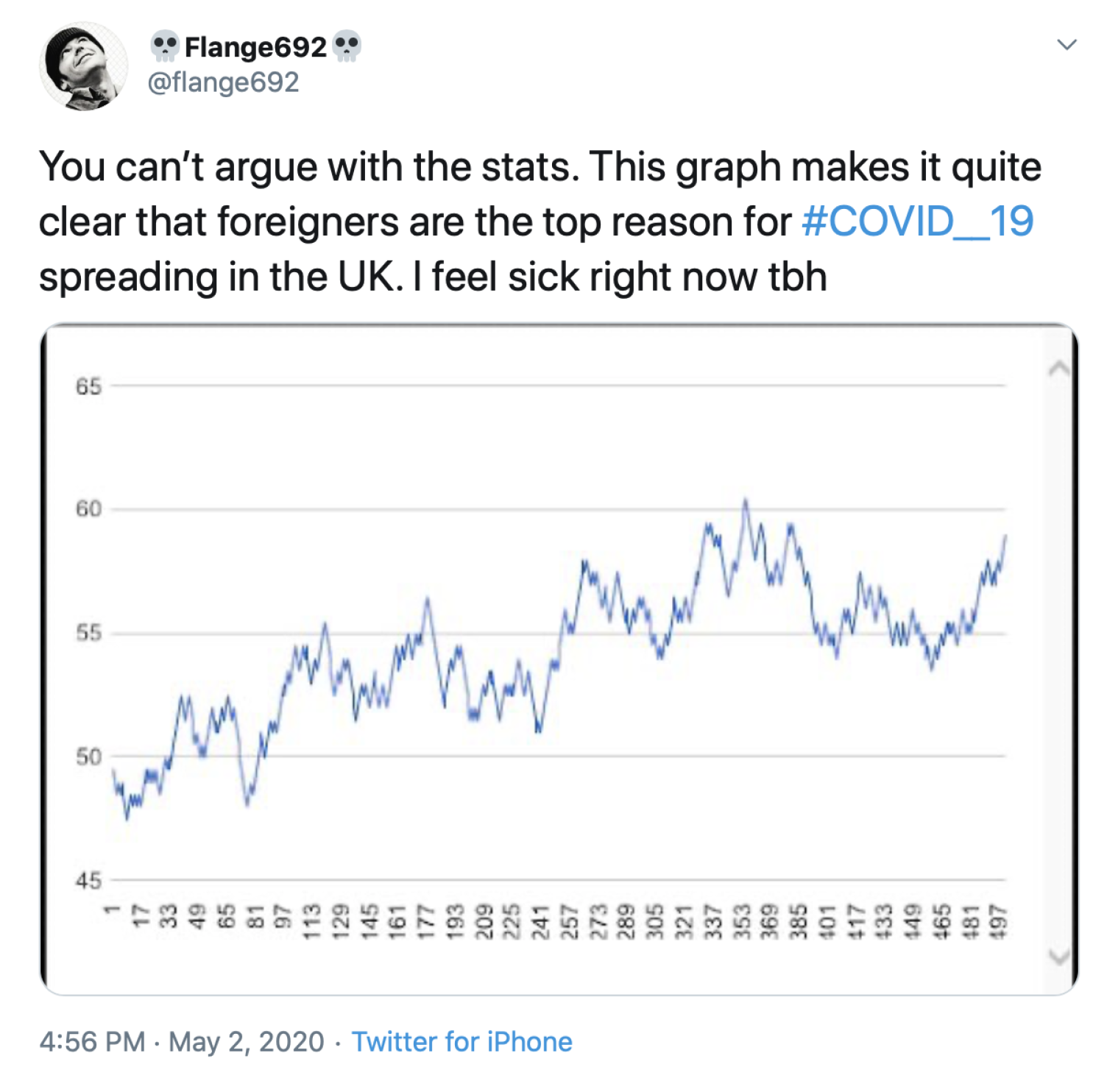{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. Coronavirus on Twitter
2.2. Interpreting Data Visualizations
2.3. Casual Data Visualizations
3. Methodology
3.1. Data Collection
3.2. Research Questions
- (R.Q.1)
- What are people posting?
- (R.Q.2)
- Which do people retweet more—visualizations that are created by individuals or organizations?
- (R.Q.3)
- What are the topics that get retweeted the most? Specifically, what is the relationship between the variables in the data visualization and the number of retweets?
- (R.Q.4)
- What challenges may arise from the interpretation of these casual data visualizations?
3.3. Data Analysis
Coding
- Visualization Generation specifies who created the visualization. Specifically, we noticed that some visualizations that people re-tweeted were originally created by organizations (e.g., news media, state agencies), while others were designed and created by individual Twitter users. This was identified through a process of visual inspection or by asking users.
- Source of Data: We looked at how the raw data were obtained, and if they were taken from an online source (e.g., CDC, Johns Hopkins);
- Type of Data: A broad descriptor that we used to initially classify the content of the data visualization;
- Type of Visualization: Whether it was a line graph, bar graph, pie chart, table, scatter plot, flowchart, map, histogram, Venn diagram, or tree-map;
- Title of the Visualization, which was directly taken out of the visualization.
4. Results
4.1. R.Q.1: What Are People Posting?
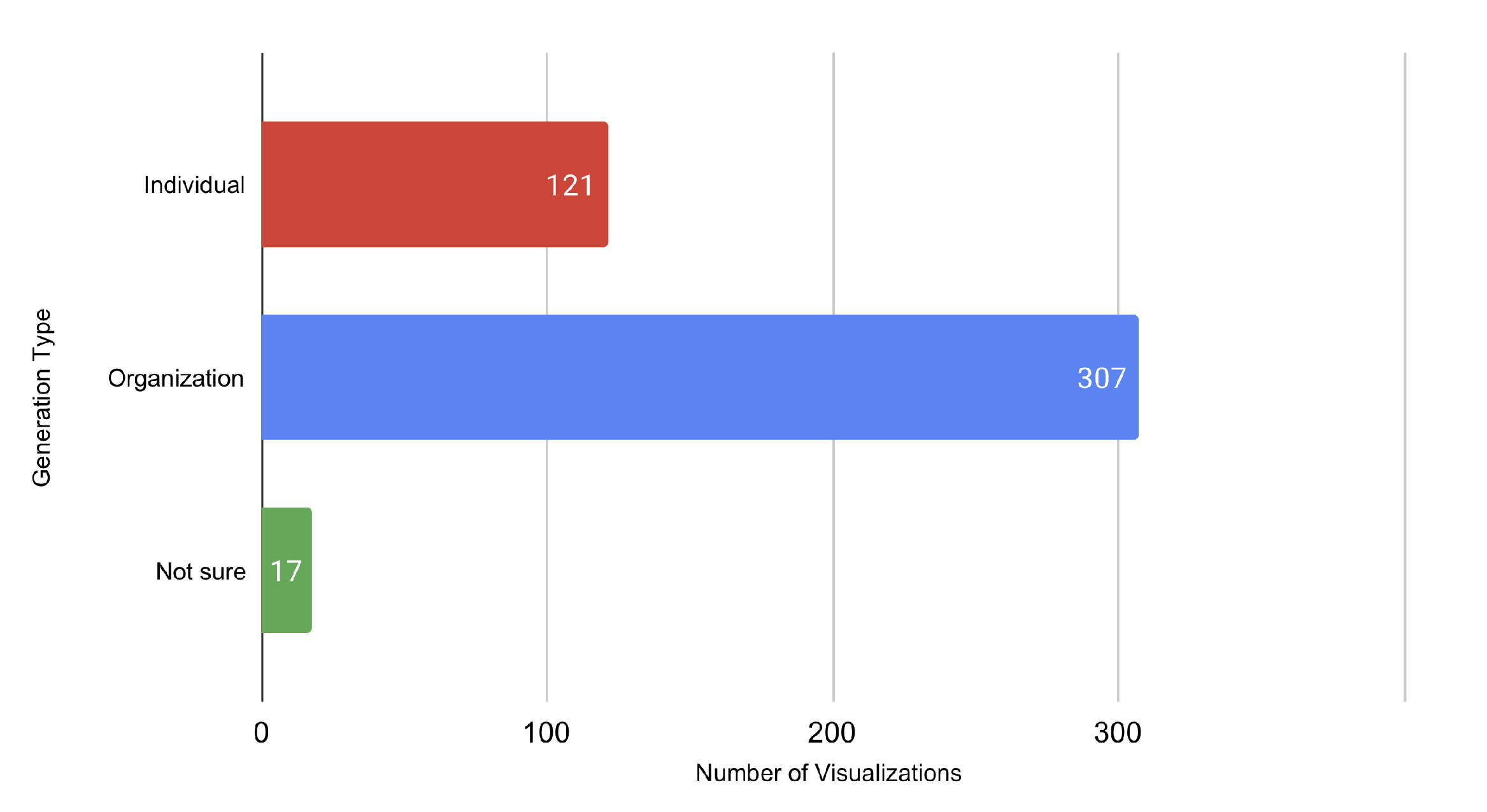
4.1.1. Individuals vs. Organizations
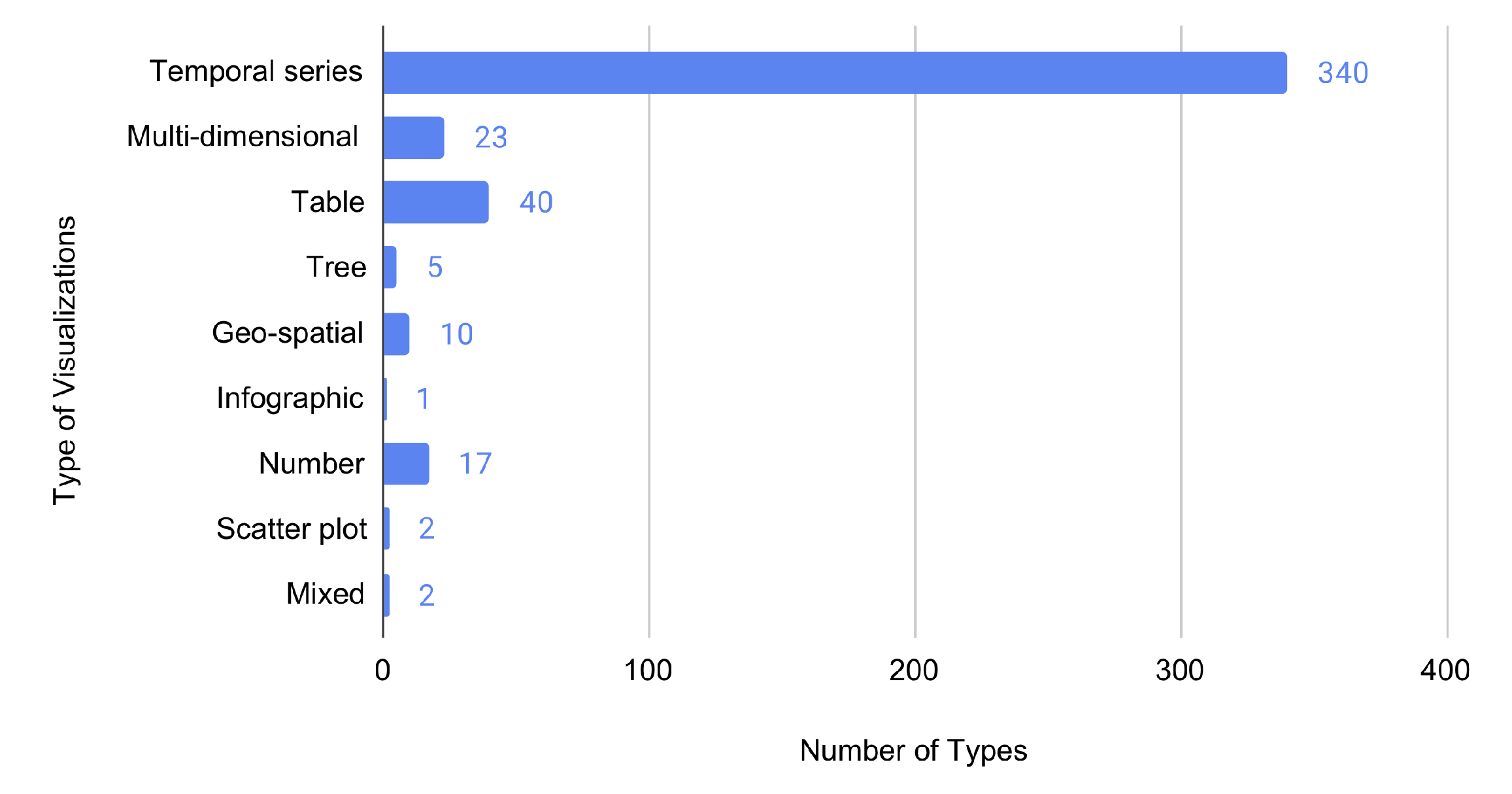
4.1.2. Type of Data Visualization
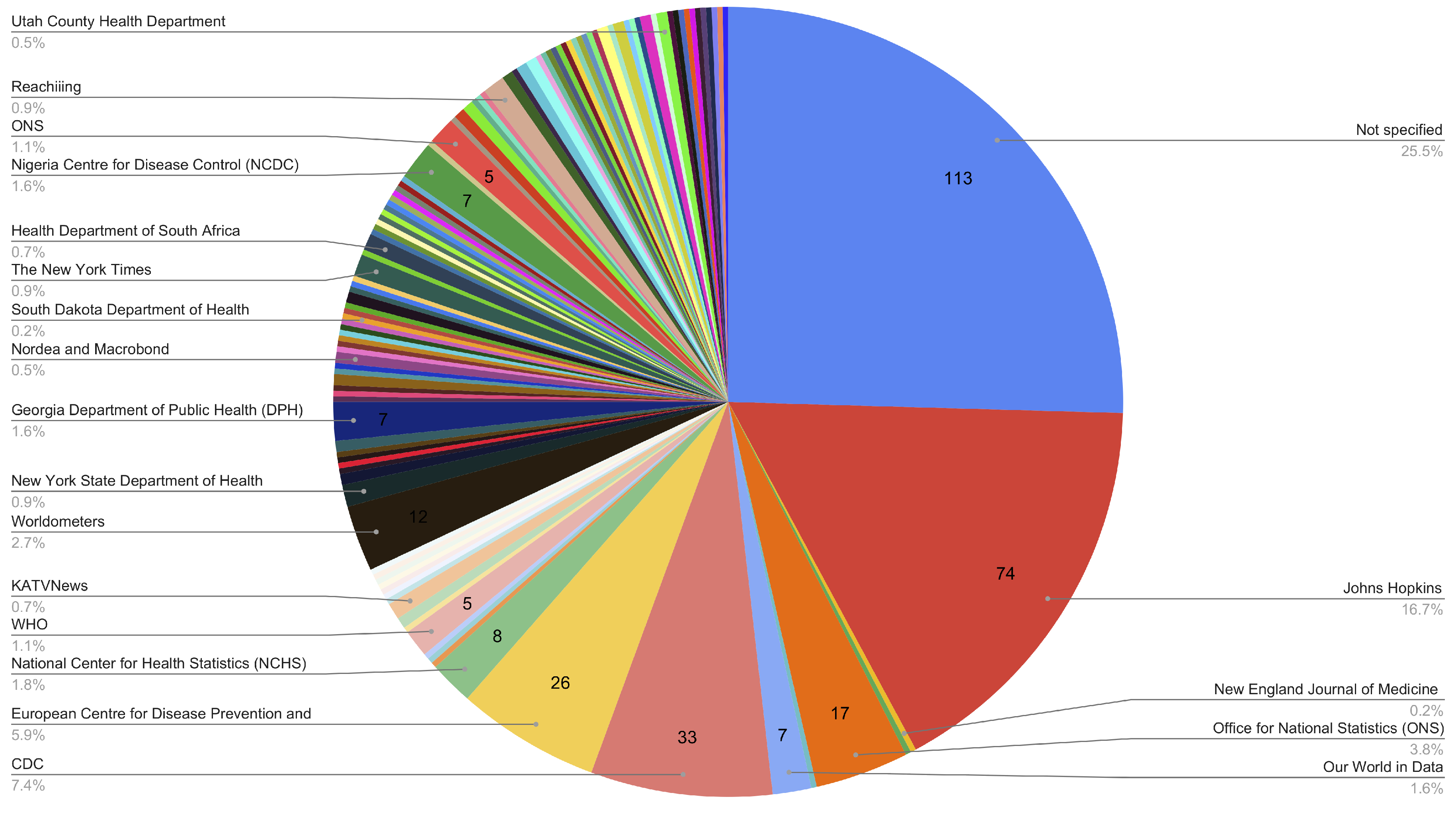
4.1.3. Data Source
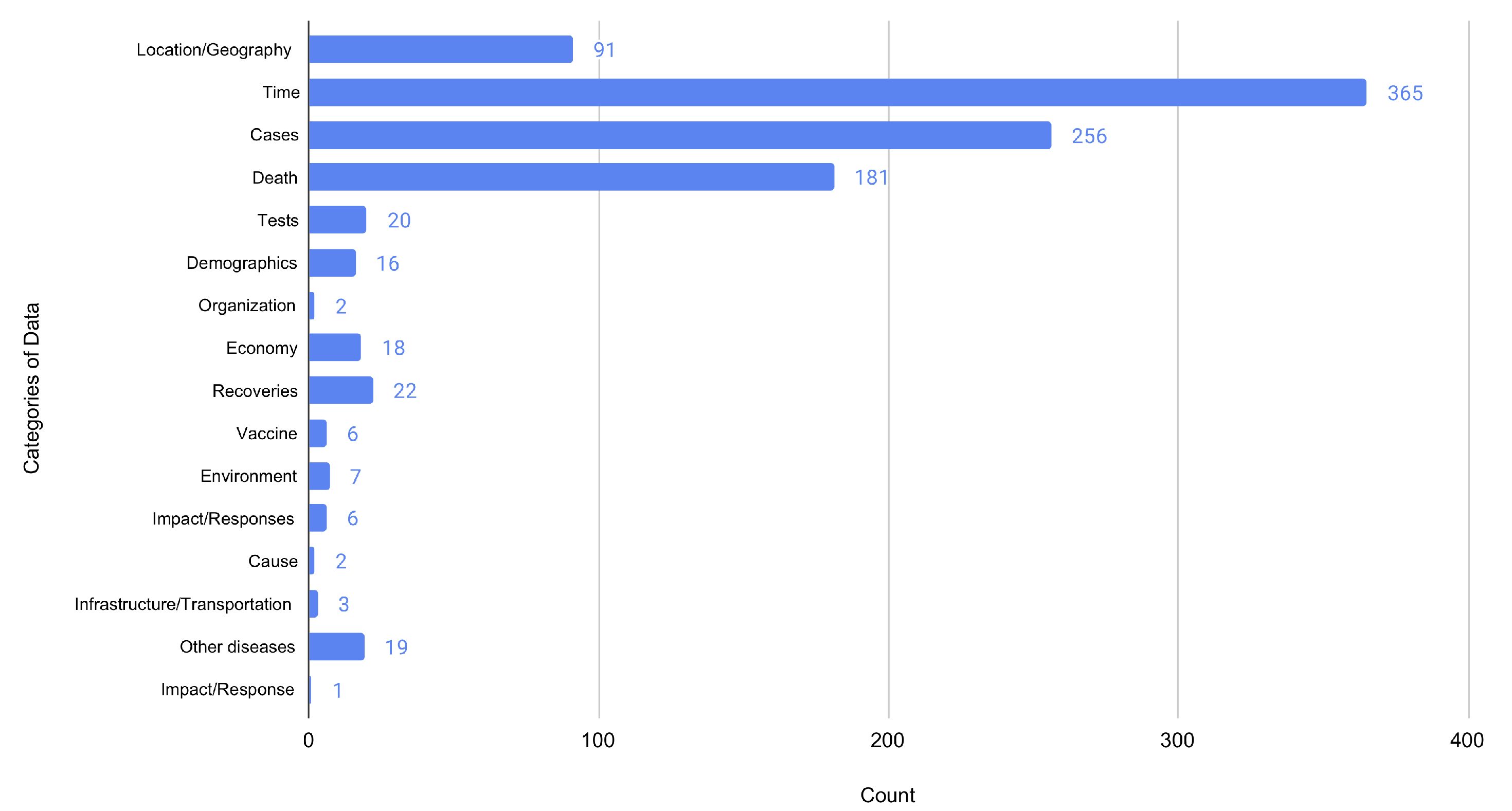
4.1.4. Categories of Data
4.2. (R.Q.2): Do People Retweet More the Visualizations That Are Created by Individuals or Organizations?
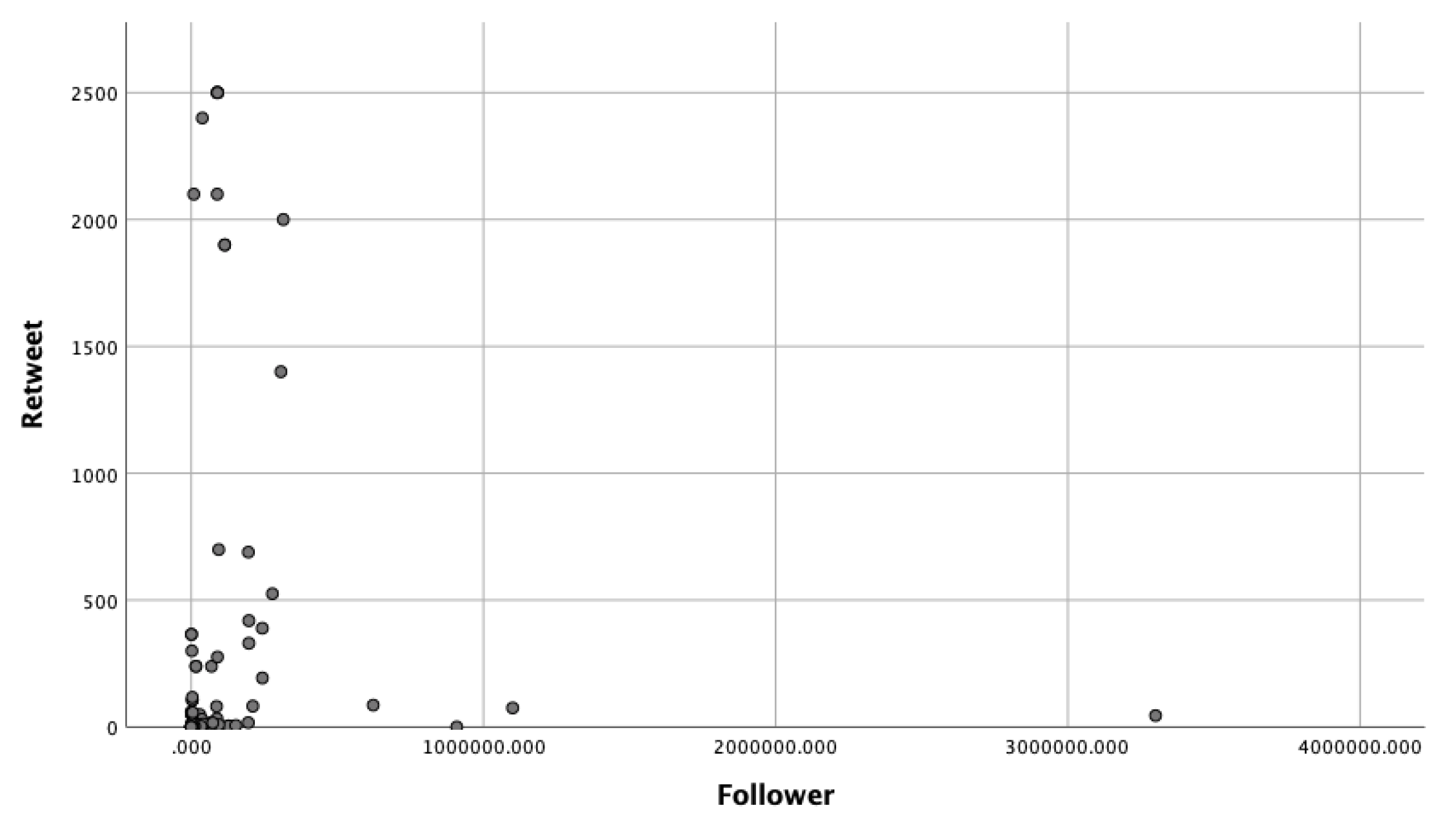
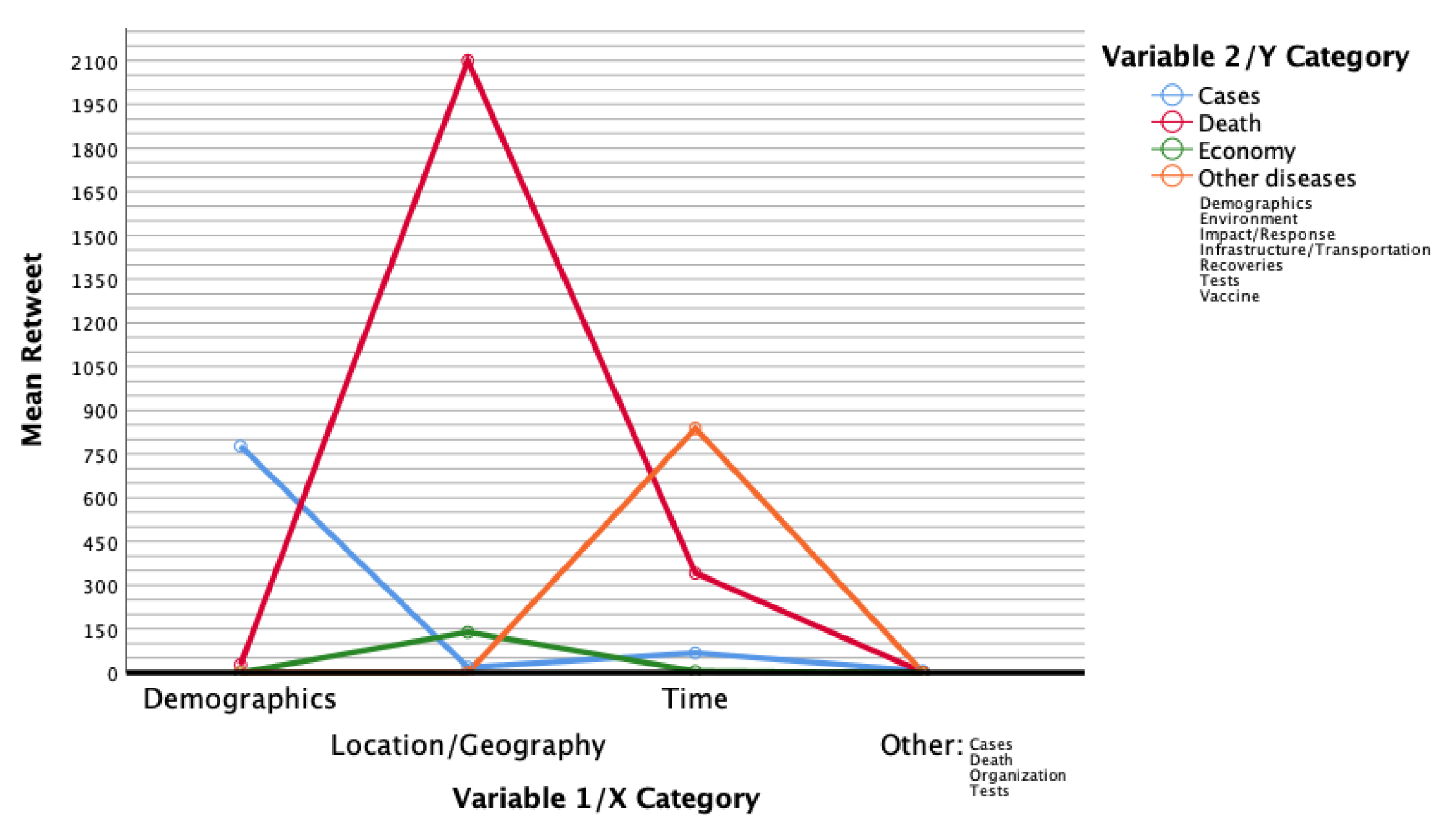
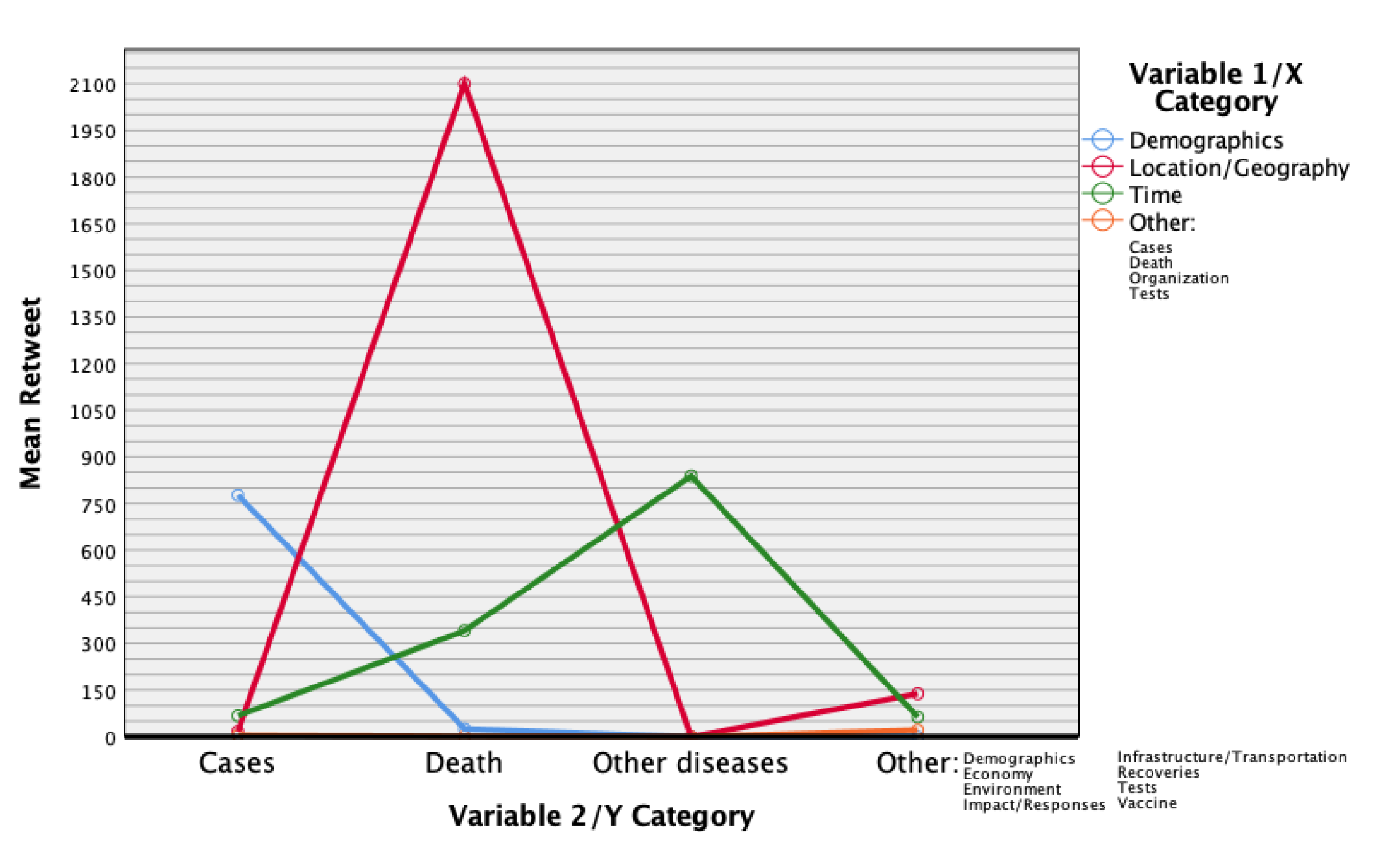
4.3. R.Q.3: What Is the Relationship between Variables and and the Number of Retweets?
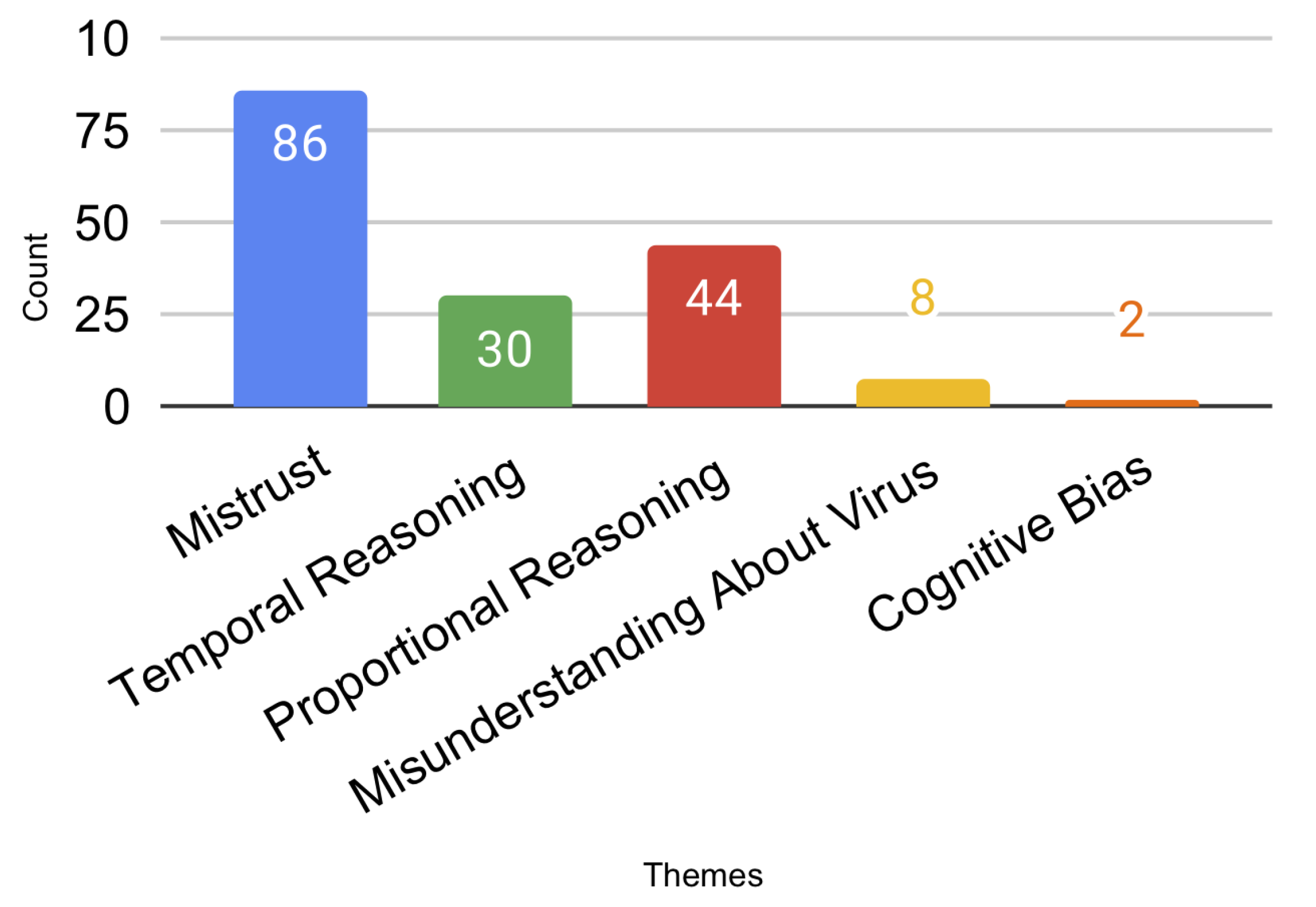
4.4. R.Q.4: What Challenges May Arise from These Casual Visualizations?
- Mistrust: We identified issues related to Mistrust in 86 posts (20% of the dataset). For example, we coded a post as Mistrust if the lack of data source led users to question the reliability of graph/visualization through the open-coding of the post replies.
- Proportional Reasoning: Proportional Reasoning refers to the users’ ability to compare variables of the graph based on ratios or fractions. We identified potential challenges related to the ability of the visualization to facilitate Proportional Reasoning in 44 posts (11% of the dataset).
- Temporal Reasoning: Temporal Reasoning refers to people’s ability to understand change over time. We identified 30 posts that raised issues related to Temporal Reasoning.
- Misunderstanding about Virus: 2% of the issues (eight posts) showed a misunderstanding about the virus among people. For example, some users confused the coronavirus with SARS or the influenza virus.
- Cognitive Bias: We identified 0.51% (two posts) of the posts that may lead users to misinterpret data because of their perception and prior experiences.
5. Discussion
5.1. Mistrust
5.1.1. Visibility of the Data Source
5.1.2. Organizations vs. Individuals
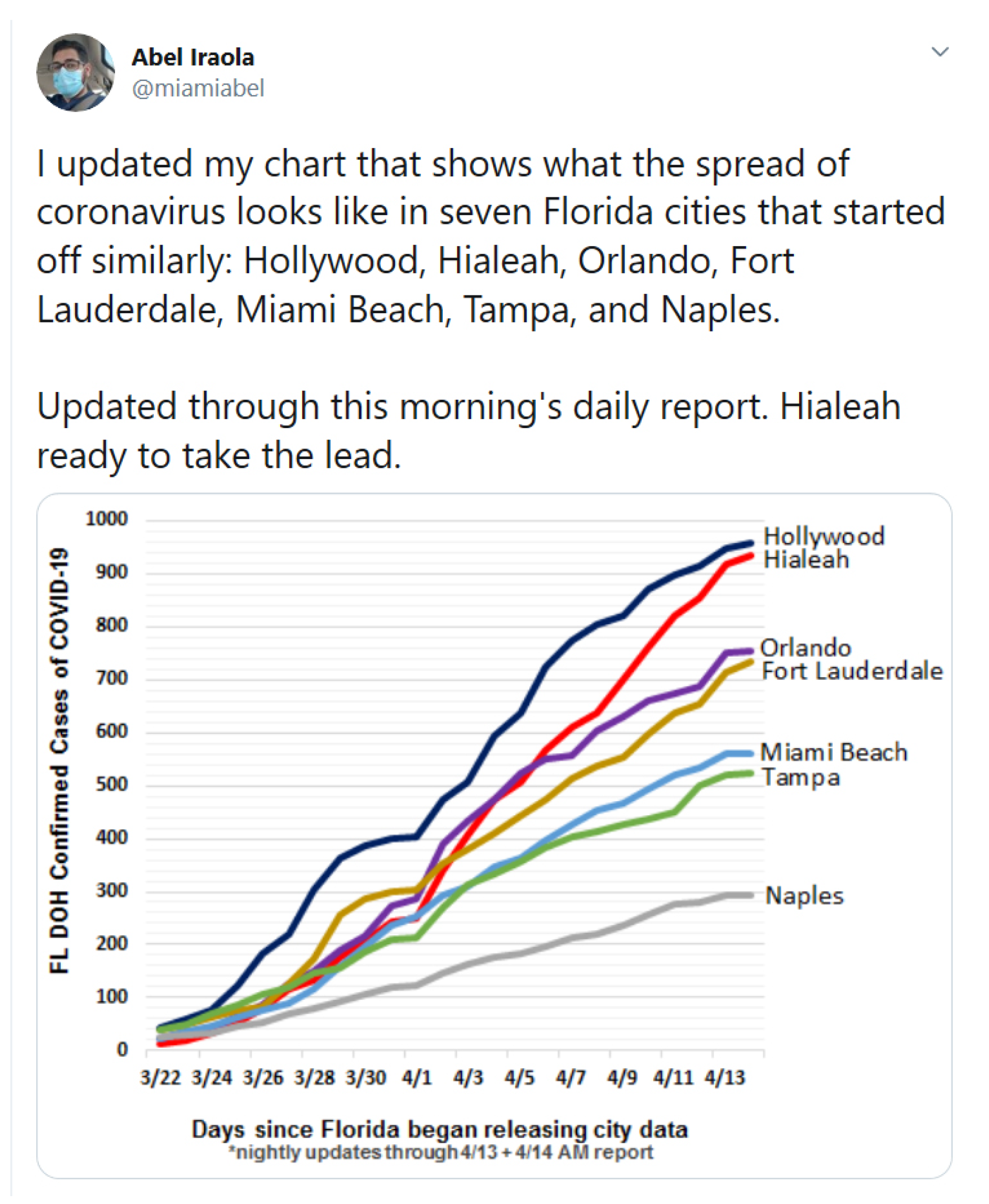
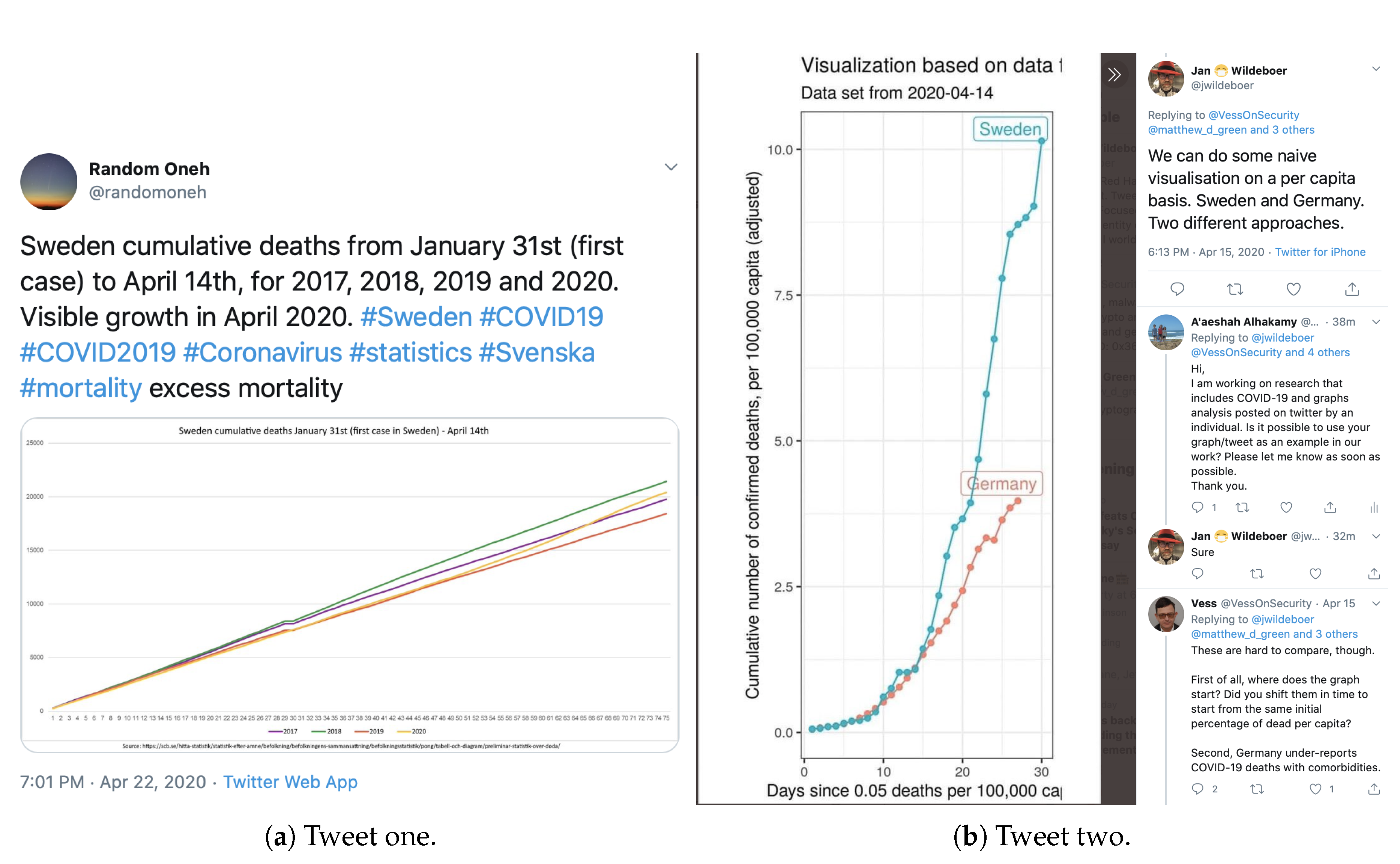
5.1.3. Alternative Interpretation of Similar Data Visualizations
5.2. Proportional Reasoning
5.2.1. Part-Whole Relationship
5.2.2. Stretchers and Shrinkers
5.3. Temporal Reasoning
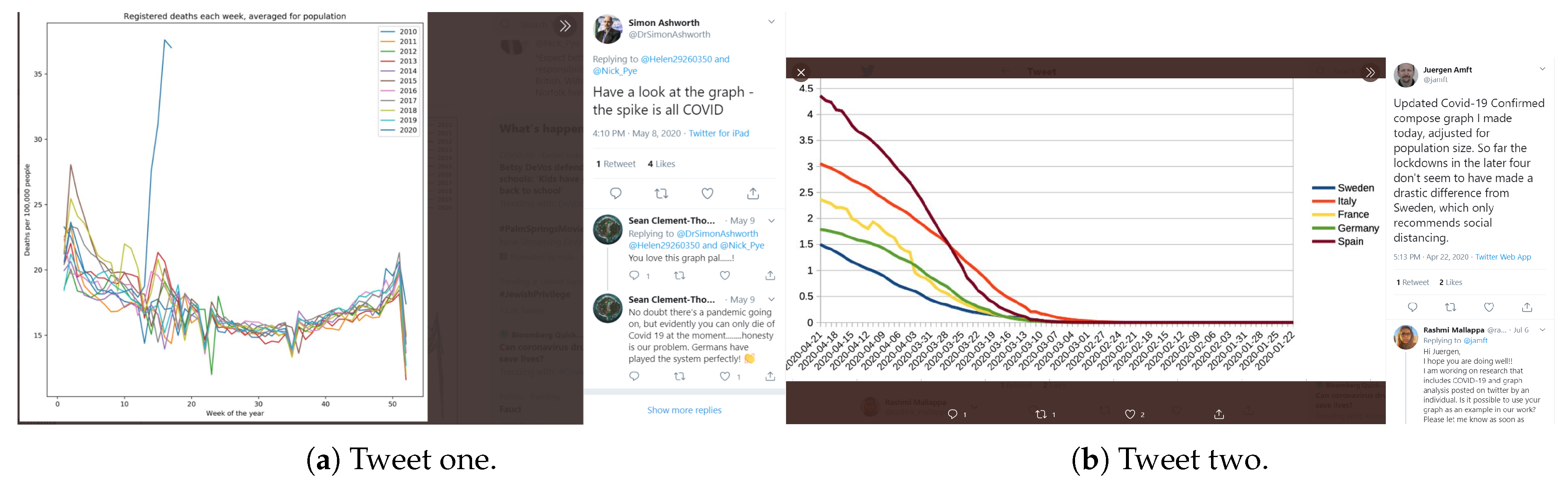
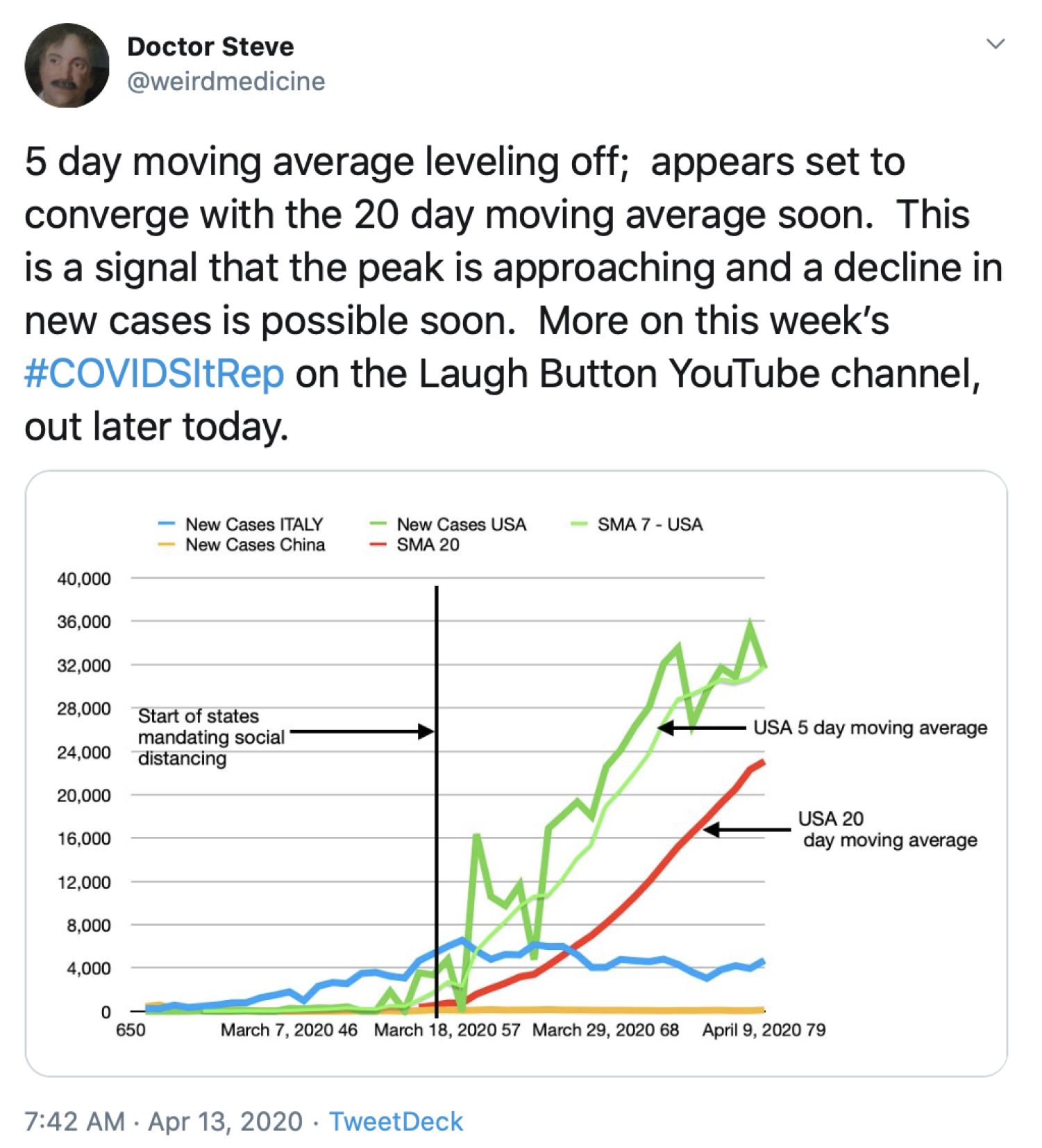
5.3.1. Metrics that Always Increase
5.3.2. Inaccurate Part-Whole Relationships with Data that Refer to Different Points in Time
5.3.3. Out-of-Context Stretchers and Shrinkers
5.4. Cognitive Bias
5.5. Misunderstanding about the Virus
5.6. Additional Recurrent Themes
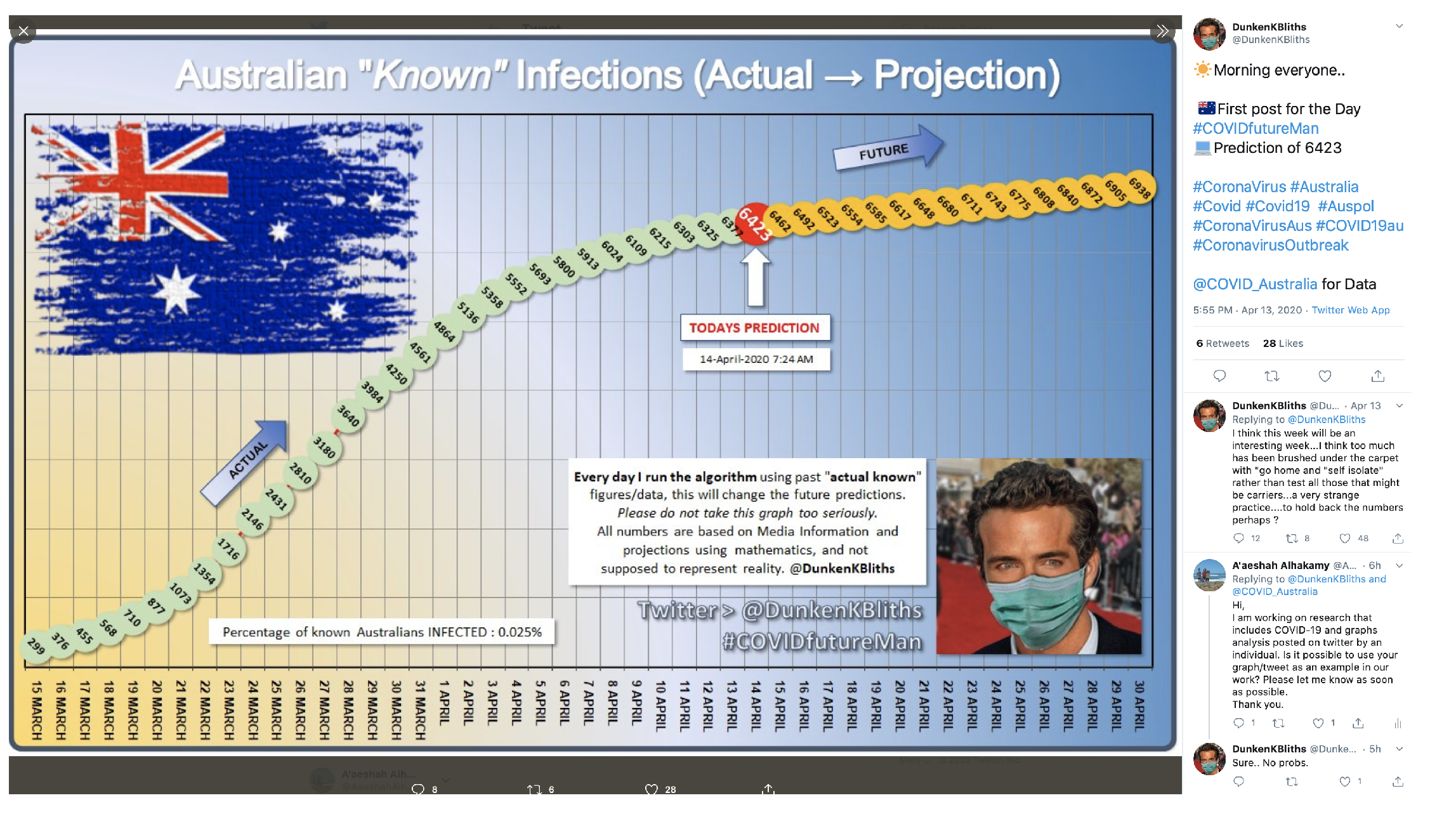
5.6.1. Predictions
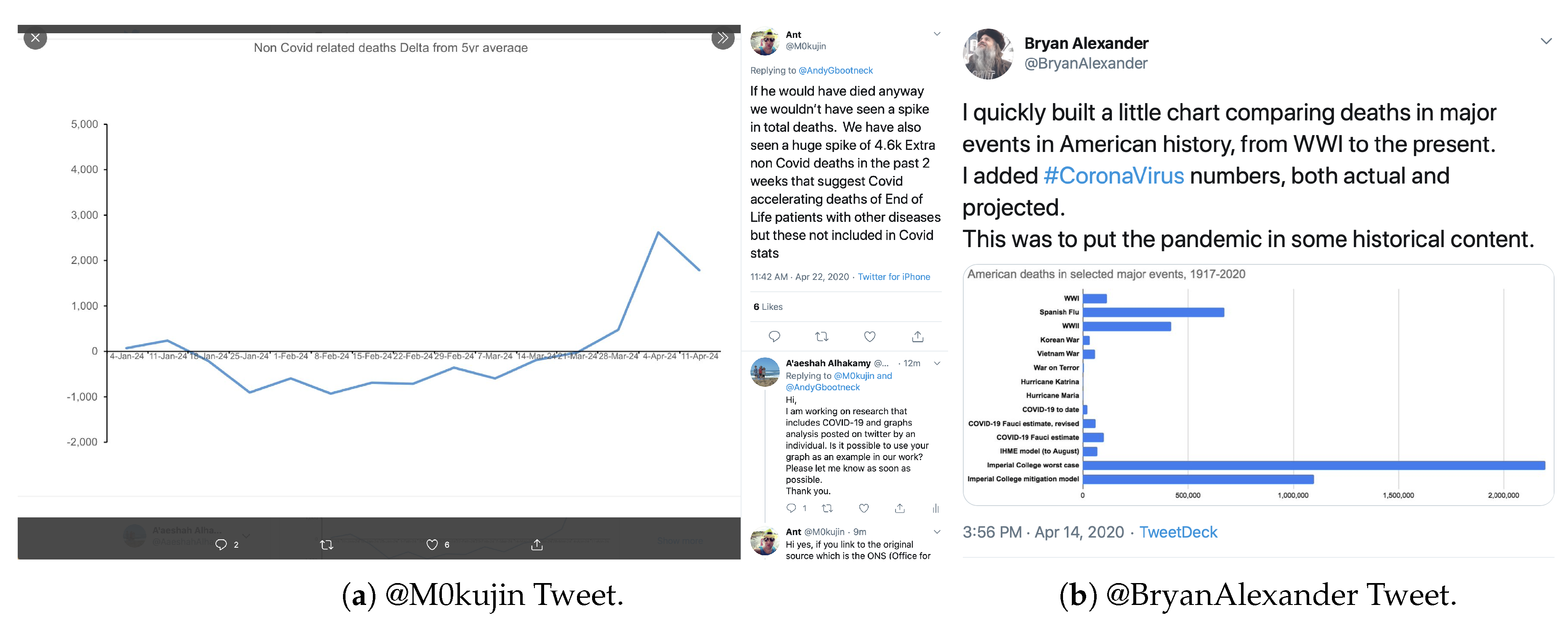
5.6.2. Comparison with Past Epidemics/Pandemics
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| COVID-19 | coronavirus disease of 2019 |
| CWWS | the ability to cope with workplace-related stress |
| MERs | middle eastern respiratory syndrome |
| SARs | severe acute respiratory syndrome |
References
- Pousman, Z.; Stasko, J.; Mateas, M. Casual information visualization: Depictions of data in everyday life. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1145–1152. [Google Scholar] [CrossRef] [PubMed]
- Sprague, D.; Tory, M. Exploring how and why people use visualizations in casual contexts: Modeling user goals and regulated motivations. Inf. Vis. 2012, 11, 106–123. [Google Scholar] [CrossRef]
- Chen, E.; Lerman, K.; Ferrara, E. Covid-19: The first public coronavirus twitter dataset. arXiv 2020, arXiv:2003.07372. [Google Scholar]
- Way, A.; Haque, R.; Xie, G.; Gaspari, F.; Popović, M.; Poncelas, A. Rapid Development of Competitive Translation Engines for Access to Multilingual COVID-19 Information. Informatics 2020, 7, 19. [Google Scholar] [CrossRef]
- Vicari, S.; Murru, M. One Platform, a Thousand Worlds: On Twitter Irony in the Early Response to the COVID-19 Pandemic in Italy. Soc. Med. Soc. 2020, 6. [Google Scholar] [CrossRef]
- Karisani, N.; Karisani, P. Mining Coronavirus (COVID-19) Posts in Social Media. arXiv 2020, arXiv:2004.06778. [Google Scholar]
- Zarei, K.; Farahbakhsh, R.; Crespi, N.; Tyson, G. A first Instagram dataset on COVID-19. arXiv 2020, arXiv:2004.12226. [Google Scholar]
- Lopez, C.E.; Vasu, M.; Gallemore, C. Understanding the perception of COVID-19 policies by mining a multilanguage Twitter dataset. arXiv 2020, arXiv:2003.10359. [Google Scholar]
- Kouzy, R.; Abi Jaoude, J.; Kraitem, A.; El Alam, M.B.; Karam, B.; Adib, E.; Zarka, J.; Traboulsi, C.; Akl, E.W.; Baddour, K. Coronavirus goes viral: Quantifying the COVID-19 misinformation epidemic on Twitter. Cureus 2020, 12, e7255. [Google Scholar] [CrossRef]
- Alshaabi, T.; Minot, J.R.; Arnold, M.V.; Adams, J.L.; Dewhurst, D.R.; Reagan, A.J.; Muhamad, R.; Danforth, C.M.; Dodds, P.S. How the world’s collective attention is being paid to a pandemic: COVID-19 related 1-gram time series for 24 languages on Twitter. arXiv 2020, arXiv:2003.12614. [Google Scholar]
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An “Infodemic”: Leveraging High-Volume Twitter Data to Understand Public Sentiment for the COVID-19 Outbreak. medRxiv 2020. [Google Scholar] [CrossRef]
- Schild, L.; Ling, C.; Blackburn, J.; Stringhini, G.; Zhang, Y.; Zannettou, S. “go eat a bat, chang!”: An early look on the emergence of sinophobic behavior on web communities in the face of covid-19. arXiv 2020, arXiv:2004.04046. [Google Scholar]
- Ferrara, E. What types of COVID-19 conspiracies are populated by Twitter bots? First Monday 2020. [Google Scholar] [CrossRef]
- Ordun, C.; Purushotham, S.; Raff, E. Exploratory analysis of covid-19 tweets using topic modeling, umap, and digraphs. arXiv 2020, arXiv:2005.03082. [Google Scholar]
- Jahanbin, K.; Rahmanian, V. Using Twitter and web news mining to predict COVID-19 outbreak. Asian Pac. J. Trop. Med. 2020, 13. [Google Scholar]
- Cleveland, W.S.; McGill, R. Graphical perception: The visual decoding of quantitative information on graphical displays of data. J. R. Stat. Soc. Ser. A (General) 1987, 150, 192–210. [Google Scholar] [CrossRef]
- Shah, P.; Hoeffner, J. Review of graph comprehension research: Implications for instruction. Educ. Psychol. Rev. 2002, 14, 47–69. [Google Scholar] [CrossRef]
- Ress, S.; Cafaro, F.; Bora, D.; Prasad, D.; Soundarajan, D. Mapping History: Orienting Museum Visitors across Time and Space. J. Comput. Cult. Herit. (JOCCH) 2018, 11, 1–25. [Google Scholar] [CrossRef]
- Szafir, D.A. Modeling color difference for visualization design. IEEE Trans. Vis. Comput. Graph. 2017, 24, 392–401. [Google Scholar] [CrossRef] [PubMed]
- Henry, N.; Fekete, J.D.; McGuffin, M.J. Nodetrix: A hybrid visualization of social networks. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1302–1309. [Google Scholar] [CrossRef]
- Gao, B.; Berendt, B. Circles, posts and privacy in egocentric social networks: An exploratory visualization approach. In Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Niagara Falls, ON, Canada, 25–28 August 2013; pp. 792–796. [Google Scholar]
- Caine, K.; Kisselburgh, L.G.; Lareau, L. Audience visualization influences disclosures in online social networks. In Proceedings of the ACM CHI Conference on Human Factors in Computing Systems Extended Abstracts, Vancouver, BC, Canada, 7–12 May 2011; pp. 1663–1668. [Google Scholar]
- Nagulendra, S.; Vassileva, J. Understanding and controlling the filter bubble through interactive visualization: A user study. In Proceedings of the 25th ACM Conference on Hypertext and Social Media, Santiago, Chile, 1–4 September 2014; pp. 107–115. [Google Scholar]
- Hu, M.; Wongsuphasawat, K.; Stasko, J. Visualizing social media content with sententree. IEEE Trans. Vis. Comput. Graph. 2016, 23, 621–630. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Cao, N.; Wen, Z.; Song, Y.; Lin, Y.R.; Collins, C. # fluxflow: Visual analysis of anomalous information spreading on social media. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1773–1782. [Google Scholar] [PubMed]
- Xu, P.; Wu, Y.; Wei, E.; Peng, T.Q.; Liu, S.; Zhu, J.J.; Qu, H. Visual analysis of topic competition on social media. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2012–2021. [Google Scholar] [PubMed]
- Thom, D.; Krüger, R.; Ertl, T. Can Twitter save lives? A broad-scale study on visual social media analytics for public safety. IEEE Trans. Vis. Comput. Graph. 2015, 22, 1816–1829. [Google Scholar] [CrossRef] [PubMed]
- Isenberg, P.; Zuk, T.; Collins, C.; Carpendale, S. Grounded Evaluation of Information Visualizations. In Proceedings of the 2008 Workshop on BEyond Time and Errors: Novel EvaLuation Methods for Information Visualization (BELIV ’08), Florence, Italy, 5 April 2008; Association for Computing Machinery: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Sandelowski, M. Sample size in qualitative research. Res. Nurs. Health 1995, 18, 179–183. [Google Scholar] [CrossRef] [PubMed]
- Corbin, J.M.; Strauss, A. Grounded theory research: Procedures, canons, and evaluative criteria. Qual. Sociol. 1990, 13, 3–21. [Google Scholar] [CrossRef]
- Saunders, B.; Sim, J.; Kingstone, T.; Baker, S.; Waterfield, J.; Bartlam, B.; Burroughs, H.; Jinks, C. Saturation in qualitative research: Exploring its conceptualization and operationalization. Qual. Quant. 2018, 52, 1893–1907. [Google Scholar] [CrossRef]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the 1996 IEEE Symposium on Visual Languages, Boulder, CO, USA, 3–6 September 1996; pp. 336–343. [Google Scholar]
- Eysenbach, G.; Powell, J.; Kuss, O.; Sa, E.R. Empirical Studies Assessing the Quality of Health Information for Consumers on the World Wide WebA Systematic Review. JAMA 2002, 287, 2691–2700. [Google Scholar] [CrossRef]
- Sillence, E.; Briggs, P.; Fishwick, L.; Harris, P. Trust and Mistrust of Online Health Sites. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’04), Vienna, Austria, 24–29 April 2004; Association for Computing Machinery: New York, NY, USA, 2004; pp. 663–670. [Google Scholar] [CrossRef]
- Wright, V. Proportional reasoning: Some rational thoughts. In Proceedings of the 42nd Annual Conference of the Mathematical Association of Victoria: Celebrating Achievement, Melbourne, Australia, 1–2 December 2005; pp. 363–375. [Google Scholar]
- Inhelder, B.; Piaget, J. The Growth of Logical Thinking from Childhood to Adolescence: An Essay on the Construction of Formal Operational Structures; Routledge: London, UK, 1958; Volume 22. [Google Scholar]
- Karplus, R.; Karplus, E.; Formisano, M.; Paulsen, A.C. A survey of proportional reasoning and control of variables in seven countries. J. Res. Sci. Teach. 1977, 14, 411–417. [Google Scholar] [CrossRef]
- Lamon, S.J. Ratio and proportion: Connecting content and children’s thinking. J. Res. Math. Educ. 1993, 24, 41–61. [Google Scholar] [CrossRef]
- Tourniaire, F.; Pulos, S. Proportional reasoning: A review of the literature. Educ. Stud. Math. 1985, 16, 181–204. [Google Scholar] [CrossRef]
- Parish, L. Facilitating the Development of Proportional Reasoning through Teaching Ratio. In Proceedings of the 33rd Annual Conference of the Mathematics Education Research Group of Australasia, Freemantle, Australia, 3–7 July 2010; pp. 469–476. [Google Scholar]
- Oran, D.P.; Topol, E.J. Prevalence of Asymptomatic SARS-CoV-2 Infection: A Narrative Review. Ann. Intern. Med. 2020, 173, 362–367. [Google Scholar] [CrossRef] [PubMed]
- Haselton, M.G.; Nettle, D.; Murray, D.R. The Evolution of Cognitive Bias. In The Handbook of Evolutionary Psychology; Chapter 41; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 1–20. [Google Scholar] [CrossRef]
- Greifeneder, R.; Bless, H.; Fiedler, K. Social Cognition: How Individuals Construct Social Reality; Psychology Press: Abingdon, UK, 2017. [Google Scholar]
- Culotta, A. Estimating County Health Statistics with Twitter. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI ’14), Toronto, ON, Canada, 26 April–1 May 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1335–1344. [Google Scholar] [CrossRef]





















© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trajkova, M.; Alhakamy, A.; Cafaro, F.; Vedak, S.; Mallappa, R.; Kankara, S.R. Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges. Informatics 2020, 7, 35. https://doi.org/10.3390/informatics7030035
Trajkova M, Alhakamy A, Cafaro F, Vedak S, Mallappa R, Kankara SR. Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges. Informatics. 2020; 7(3):35. https://doi.org/10.3390/informatics7030035
Chicago/Turabian StyleTrajkova, Milka, A’aeshah Alhakamy, Francesco Cafaro, Sanika Vedak, Rashmi Mallappa, and Sreekanth R. Kankara. 2020. "Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges" Informatics 7, no. 3: 35. https://doi.org/10.3390/informatics7030035
APA StyleTrajkova, M., Alhakamy, A., Cafaro, F., Vedak, S., Mallappa, R., & Kankara, S. R. (2020). Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges. Informatics, 7(3), 35. https://doi.org/10.3390/informatics7030035