Gutenberg Goes Neural: Comparing Features of Dutch Human Translations with Raw Neural Machine Translation Outputs in a Corpus of English Literary Classics




Abstract
1. Introduction
2. Related Research
3. Methodology
3.1. Text Selection
3.2. Error Analysis
3.3. Key Feature Analysis
3.3.1. Lexical Richness
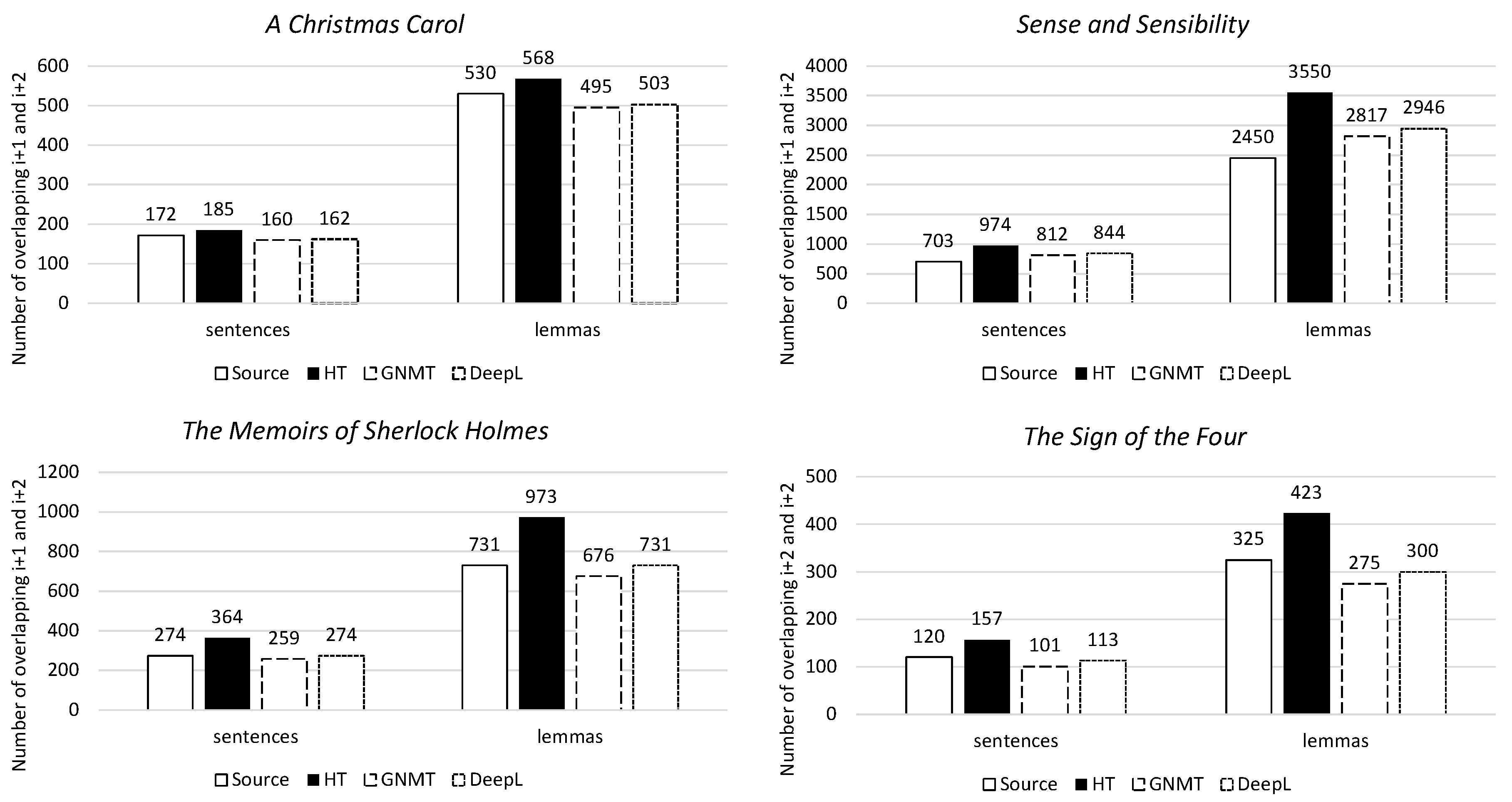
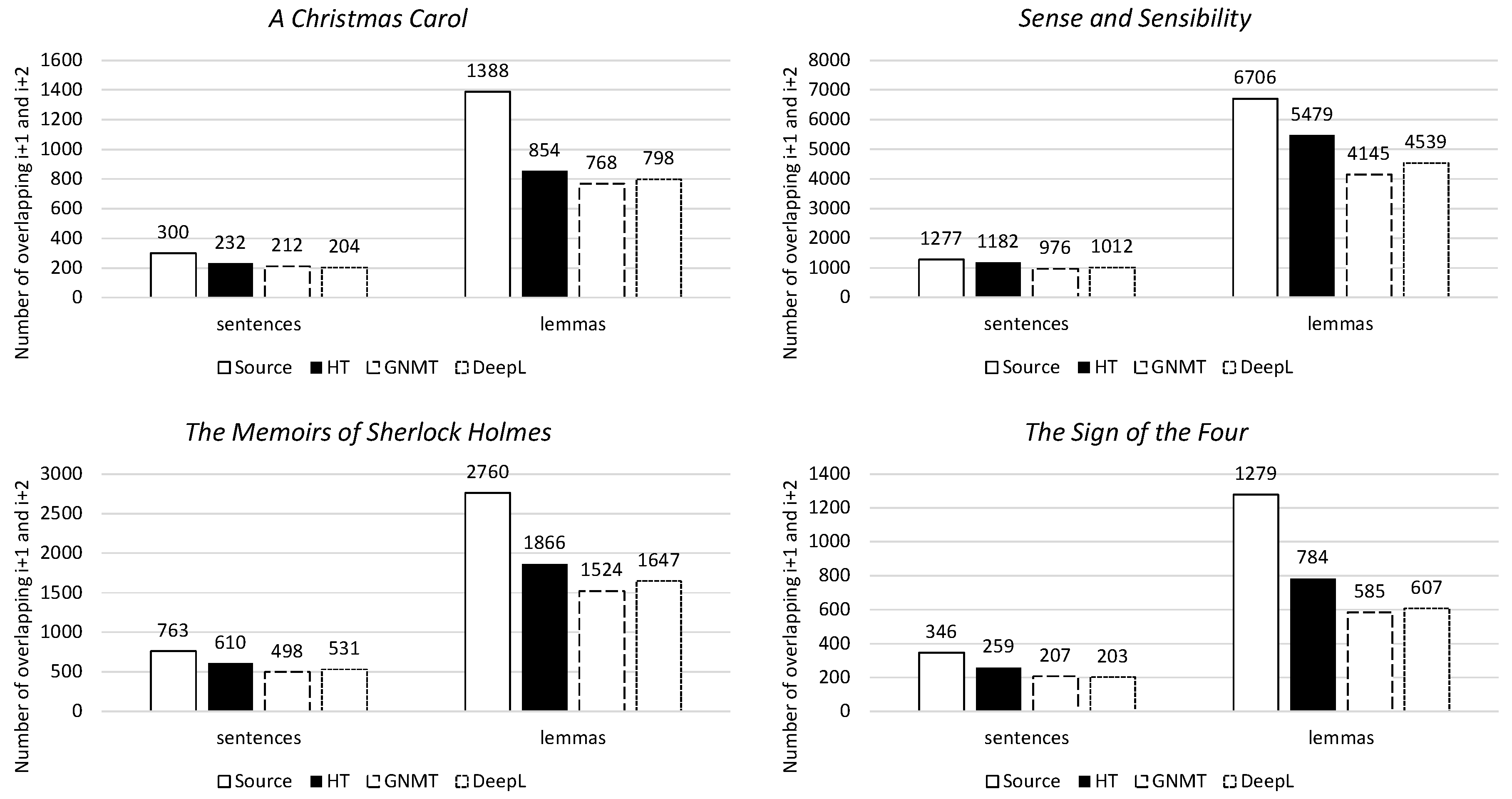
3.3.2. Local Cohesion
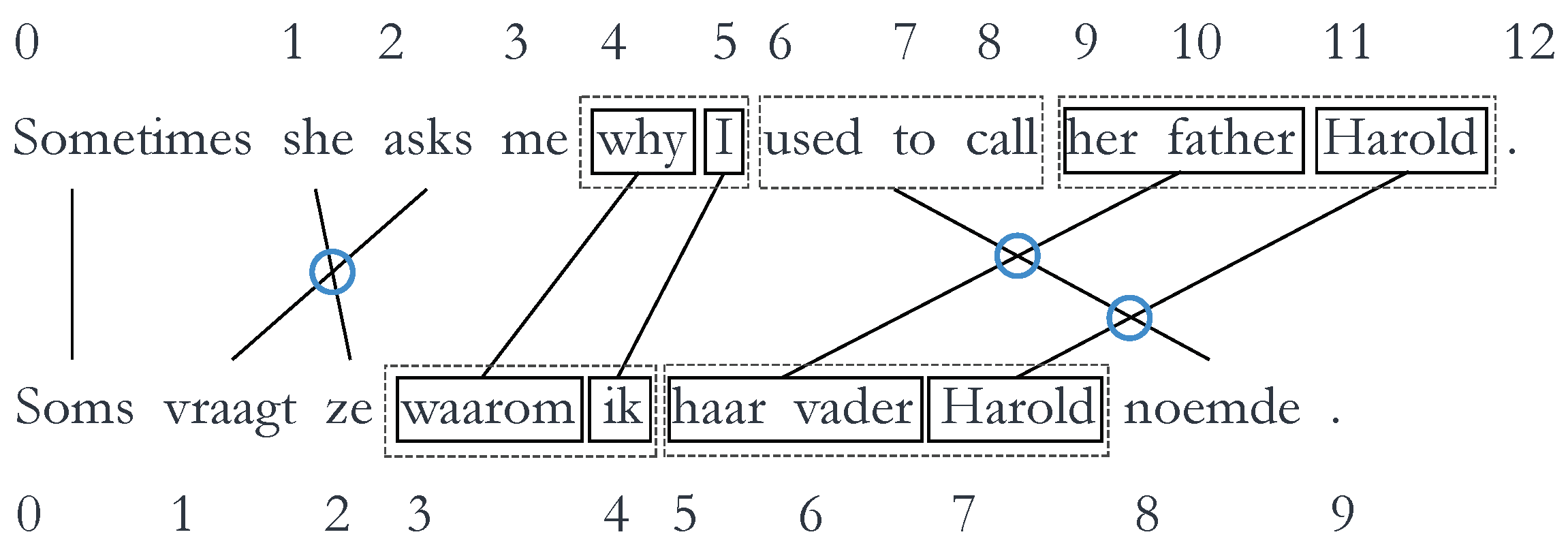
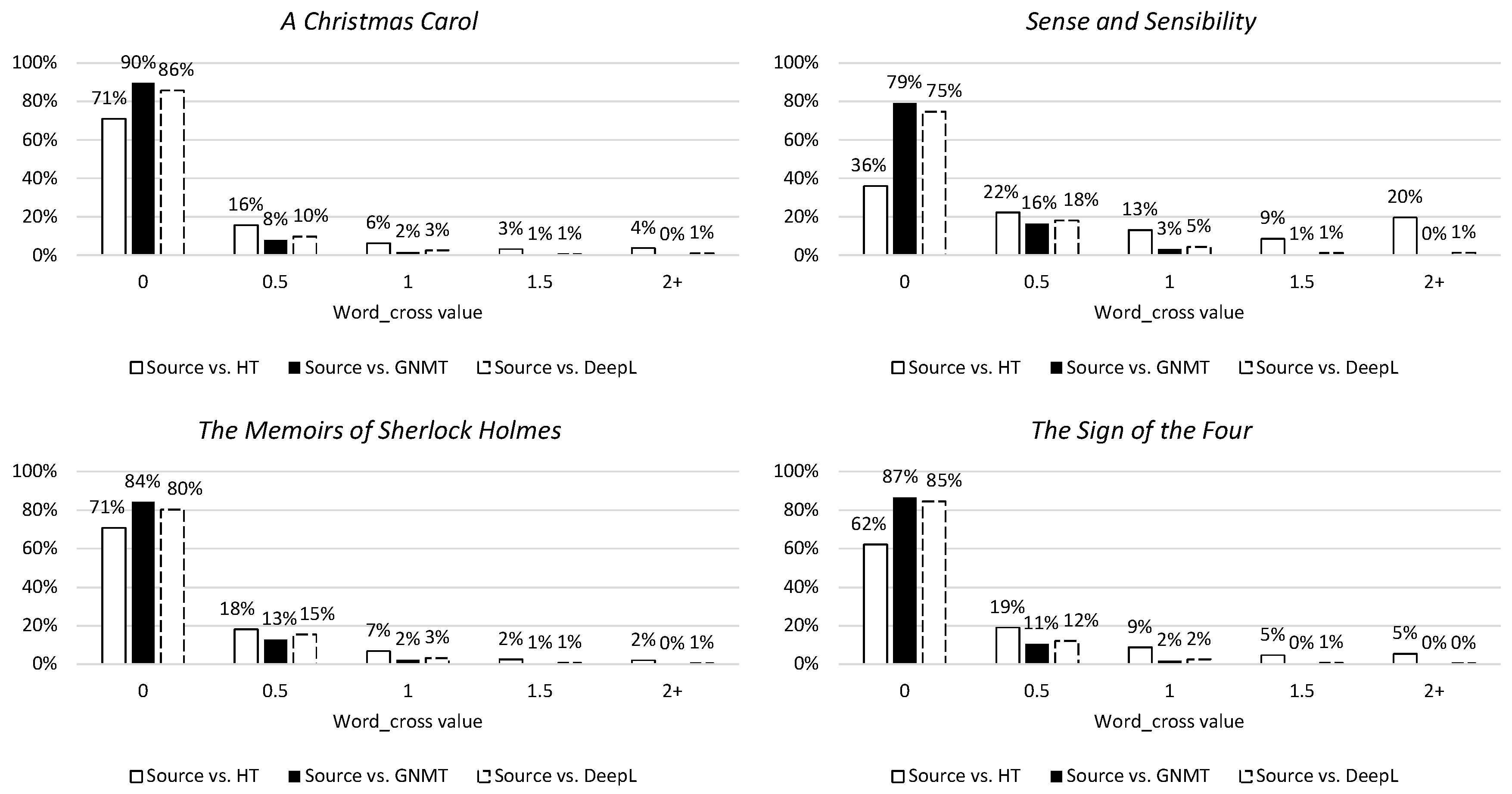
3.3.3. Syntactic Divergence
3.3.4. Stylistic Difference: Burrows’ Delta
“A delta- score […] can be defined as the mean of the absolute differences between the z-scores for a set of word-variables in a given text-group and the z-scores for the same set of word-variables in a target text” [12].
4. Results
4.1. Comparison of Four Novels
4.2. Error Analysis
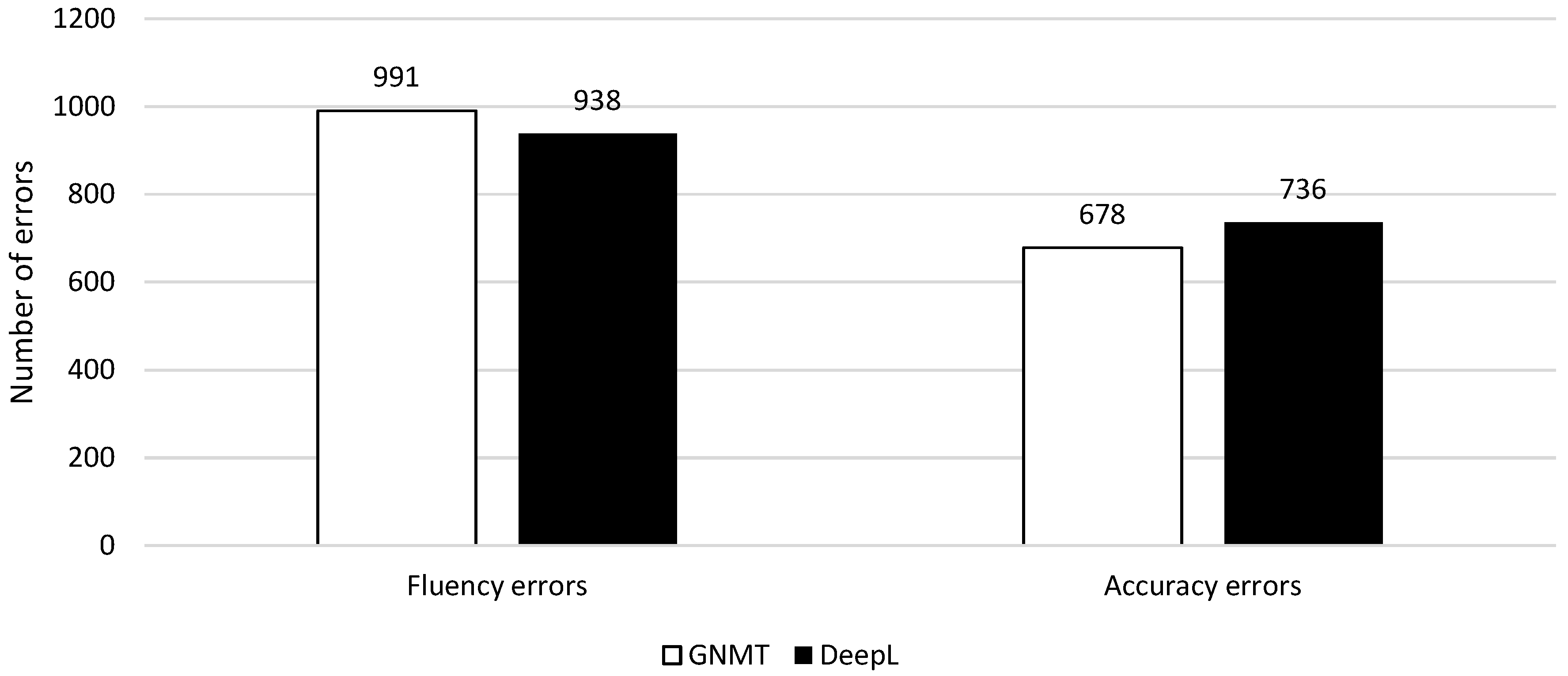
4.2.1. Overall Quality
4.2.2. Error Distribution
4.3. Key Feature Analysis
4.3.1. Lexical Richness
4.3.2. Local Cohesion
4.3.3. Syntactic Divergence
4.3.4. Stylistic Difference
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ASTrED | aligned syntactic tree edit distance |
| DeepL | neural machine translation system of DeepL |
| GNMT | neural machine translation system of Google |
| HT | human translation |
| MASS | mass index |
| MSTTR | mean segmental type-token ratio |
| MT | machine translation |
| NMT | neural machine translation |
| PBMT | phrase-based machine translation |
| SACr | syntactically aware cross |
| ST | source text |
| TT | target text |
| TTR | type-token ratio |
| UD | universal dependencies |
References
- Matusov, E. The Challenges of Using Neural Machine Translation for Literature. In Proceedings of the Qualities of Literary Machine Translation, Dublin, Ireland, 19 August 2019; pp. 10–19. [Google Scholar]
- Voigt, R.; Jurafsky, D. Towards a Literary Machine Translation: The Role of Referential Cohesion. In Proceedings of the NAACL-HLT 2012 Workshop on Computational Linguistics for Literature, Montréal, QB, Canada, 8 June 2012; pp. 18–25. [Google Scholar]
- Toral, A.; Way, A. What Level of Quality Can Neural Machine Translation Attain on Literary Text? In Translation Quality Assessment; Moorkens, J., Castilho, S., Gaspari, F., Doherty, S., Eds.; Springer International Publishing AG: Cham, Switzerland, 2018; pp. 263–287. [Google Scholar]
- Fonteyne, M.; Tezcan, A.; Macken, L. Literary Machine Translation under the Magnifying Glass: Assessing the Quality of an NMT-Translated Detective Novel on Document Level. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 3790–3798. [Google Scholar]
- Tezcan, A.; Daems, J.; Macken, L. When a ‘sport’ is a person and other issues for NMT of novels. In Proceedings of the Qualities of Literary Machine Translation; Hadley, J., Popović, M., Afli, H., Way, A., Eds.; European Association for Machine Translation: Lisbon, Portugal, 2019; pp. 40–49. [Google Scholar]
- Tezcan, A.; Hoste, V.; Macken, L. SCATE taxonomy and corpus of machine translation errors. In Trends in E-Tools and Resources for Translators and Interpreters; Pastor, G.C., Durán-Muñoz, I., Eds.; Approaches to Translation Studies; Brill | Rodopi: Leiden, The Netherlands, 2017; Volume 45, pp. 219–244. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PL, USA, 7–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Hassan, H.; Aue, A.; Chen, C.; Chowdhary, V.; Clark, J.; Federmann, C.; Huang, X.; Junczys-Dowmunt, M.; Lewis, W.; Li, M.; et al. Achieving Human Parity on Automatic Chinese to English News Translation. arXiv 2018, arXiv:1803.05567. [Google Scholar]
- Shterionov, D.; Superbo, R.; Nagle, P.; Casanellas, L.; O’Dowd, T.; Way, A. Human versus automatic quality evaluation of NMT and PBSMT. Mach. Transl. 2018, 32, 217–235. [Google Scholar] [CrossRef]
- Vanmassenhove, E.; Shterionov, D.; Way, A. Lost in Translation: Loss and Decay of Linguistic Richness in Machine Translation. In Proceedings of Machine Translation Summit XVII Volume 1: Research Track; European Association for Machine Translation: Dublin, Ireland, 2019; pp. 222–232. [Google Scholar]
- Cop, U.; Dirix, N.; Drieghe, D.; Duyck, W. Presenting GECO: An eyetracking corpus of monolingual and bilingual sentence reading. Behav. Res. Methods 2017, 49, 602–615. [Google Scholar] [CrossRef] [PubMed]
- Burrows, J. ’Delta’: A Measure of Stylistic Difference and a Guide to Likely Authorship. Lit. Linguist. Comput. 2002, 17, 267–287. [Google Scholar] [CrossRef]
- Van Brussel, L.; Tezcan, A.; Macken, L. A fine-grained error analysis of NMT, PBMT and RBMT output for English-to-Dutch. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation; Calzolari, N., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Hasida, K., Isahara, H., Maegaard, B., Mariani, J., Mazo, H., et al., Eds.; European Language Resources Association (ELRA): Paris, France, 2018; pp. 3799–3804. [Google Scholar]
- Johnson, W. Sudies in Language Behavior. Psychol. Monogr. 1944, 56, 1–15. [Google Scholar] [CrossRef]
- Läubli, S.; Sennrich, R.; Volk, M. Has Machine Translation Achieved Human Parity? A Case for Document-level Evaluation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4791–4796. [Google Scholar]
- Voita, E.; Sennrich, R.; Titov, I. When a Good Translation is Wrong in Context: Context-Aware Machine Translation Improves on Deixis, Ellipsis, and Lexical Cohesion. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 1198–1212. [Google Scholar]
- Werlen, L.M.; Ram, D.; Pappas, N.; Henderson, J. Document-Level Neural Machine Translation with Hierarchical Attention Networks. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2947–2954. [Google Scholar]
- McNamara, D.S.; Graesser, A.C.; McCarthy, P.M.; Cai, Z. Automated Evaluation of Text and Discourse with Coh-Metrix; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar] [CrossRef]
- Crossley, S.A.; Kyle, K.; McNamara, D.S. The tool for the automatic analysis of text cohesion (TAACO): Automatic assessment of local, global, and text cohesion. Behav. Res. Methods 2016, 48, 1227–1237. [Google Scholar] [CrossRef]
- Vanroy, B.; Tezcan, A.; Macken, L. Predicting syntactic equivalence between source and target sentences. Comput. Linguist. Neth. J. 2019, 9, 101–116. [Google Scholar]
- Vanroy, B.; De Clercq, O.; Tezcan, A.; Daems, J.; Macken, L. Metrics of syntactic equivalence to assess translation difficulty. In Explorations in Empirical Translation Process Research; Springer International Publishing AG: Cham, Switzerland, 2020; Submitted. [Google Scholar]
- Matthews, P. Syntax. In Cambridge Textbooks in Linguistics; Cambridge University Press: Cambridge, UK, 1981. [Google Scholar]
- Tai, K.C. The tree-to-tree correction problem. J. ACM 1979, 26, 422–433. [Google Scholar] [CrossRef]
- Nivre, J.; De Marneffe, M.C.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1659–1666. [Google Scholar]
- Qi, P.; Zhang, Y.; Zhang, Y.; Bolton, J.; Manning, C.D. Stanza: A Python Natural Language Processing Toolkit for Many Human Languages. In Proceedings of the 58th Annual Meetingof the Association for Computational Linguistics: System Demonstrations, Seattle, WA, USA, 5–10 July 2020; pp. 101–108. [Google Scholar]
- Evert, S.; Proisl, T.; Jannidis, F.; Reger Isabella, P.S.; Schöch, C.; Vitt, T. Understanding and explaining Delta measures for authorship attribution. Digit. Scholarsh. Humanit. 2017, 32, 4–16. [Google Scholar] [CrossRef]
- Proisl, T.; Evert, S.; Jannidis, F.; Schöch, C.; Konle, L.; Pielström, S. Delta vs. N-Gram Tracing: Evaluating the Robustness of Authorship Attribution Methods. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus Phrase-Based Machine Translation Quality: A Case Study. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 257–267. [Google Scholar] [CrossRef]
- Kong, X.; Tu, Z.; Shi, S.; Hovy, E.; Zhang, T. Neural machine translation with adequacy-oriented learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 6618–6625. [Google Scholar]
- Koehn, P.; Knowles, R. Six Challenges for Neural Machine Translation. In Proceedings of the First, Workshop on Neural Machine Translation; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 28–39. [Google Scholar] [CrossRef]
- Baker, M. In Other Words/Mona Baker; Routledge: London, UK; New York, NY, USA, 2001. [Google Scholar]
- Besacier, L.; Schwartz, L. Automated Translation of a Literary Work: A Pilot Study. In Proceedings of the Fourth Workshop on Computational Linguistics for Literature, Denver, CO, USA, 4 June 2015; pp. 114–122. [Google Scholar] [CrossRef]
- Rybicki, J.; Heydel, M. The stylistics and stylometry of collaborative translation: Woolf’s Night and Day in Polish. Lit. Linguist. Comput. 2013, 28, 708–717. [Google Scholar] [CrossRef]
- Qin, Y.; Zhang, J.; Lu, X. The Gap between NMT and Professional Translation from the Perspective of Discourse. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence, New York, NY, USA, 14–17 March 2019; Volume ICIAI 2019, pp. 50–54. [Google Scholar] [CrossRef]













{kind=link}
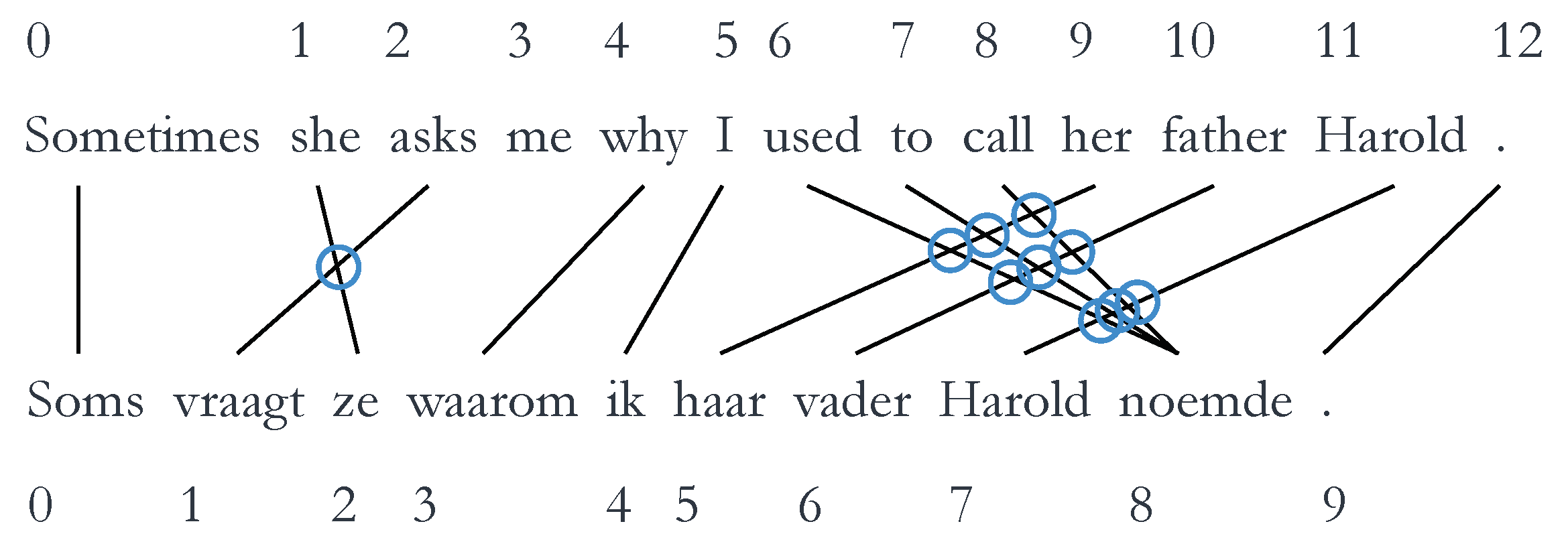{kind=link}
{kind=link}
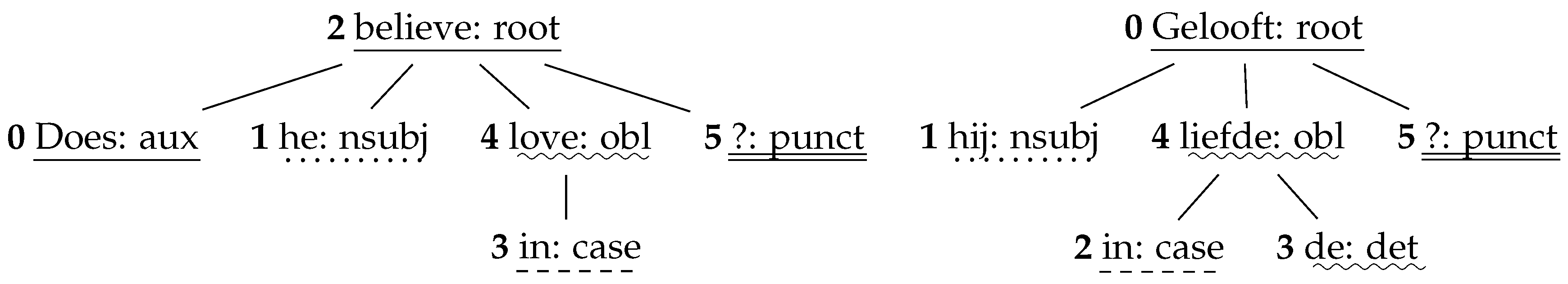{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Novel | Original Data (ST) | Adapted Data (ST) |
|---|---|---|
| A Christmas Carol | 3030 words/190 sentences | 2855 words/185 sentences |
| Sense and Sensibility | 3015 words/117 sentences | 2956 words/116 sentences |
| The Memoirs of SH | 3009 words/141 sentences | 2686 words/131 sentences |
| The Sign of the Four | 3014 words/203 sentences | 2956 words/198 sentences |
| Novel | Original Data (ST) | Adapted Data (ST) |
|---|---|---|
| A Christmas Carol | 35,976 words/1762 sentences | 35,863 words/1748 sentences |
| Sense and Sensibility | 141,591 words/4951 sentences | 141,018 words/4857 sentences |
| The Memoirs of SH | 106,027 words/5352 sentences | 105,706 words/5308 sentences |
| The Sign of the Four | 52,409 words/2850 sentences | 52,284 words/2837 sentences |
| 0+ | 5+ | 10+ | 15+ | 20+ | 25+ | 30+ | 35+ | 40+ | 45+ | Avg. Length | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A Christmas Carol | 102 | 436 | 327 | 215 | 145 | 136 | 86 | 97 | 50 | 154 | 20.517 |
| Sense and Sensibility | 75 | 624 | 745 | 607 | 512 | 482 | 335 | 287 | 244 | 946 | 29.034 |
| The Memoirs of SH | 137 | 924 | 1114 | 845 | 727 | 549 | 378 | 249 | 136 | 249 | 19.914 |
| The Sign of the Four | 66 | 509 | 704 | 499 | 380 | 269 | 169 | 93 | 65 | 83 | 18.429 |
| 29,000 Words; n = 150 | A Christmas Carol | Sense and Sensibility | The Memoirs of SH | The Sign of the Four |
|---|---|---|---|---|
| A Christmas Carol | 0 | 1.395 | 1.139 | 1.182 |
| Sense and Sensibility | 0 | 1.393 | 1.430 | |
| The Memoirs of SH | 0 | 0.628 | ||
| The Sign of the Four | 0 |
| A Christmas Carol | ST | HT | GNMT | DeepL |
|---|---|---|---|---|
| Unique words | 4260 | 5064 | 4799 | 4804 |
| Total words | 35,863 | 33,766 | 34,182 | 35,729 |
| Sense and Sensibility | ST | HT | GNMT | DeepL |
| Unique words | 6334 | 10,090 | 7747 | 8206 |
| Total words | 141,018 | 139,032 | 137,422 | 143,707 |
| The Memoirs of SH | ST | HT | GNMT | DeepL |
| Unique words | 7168 | 9438 | 8771 | 8773 |
| Total words | 105,706 | 99,305 | 99,986 | 103,317 |
| The Sign Of The Four | ST | HT | GNMT | DeepL |
| Unique words | 5399 | 6407 | 6175 | 6238 |
| Total words | 52,284 | 49,646 | 49,277 | 51,236 |
| A Christmas Carol | ST | HT | GNMT | DeepL |
|---|---|---|---|---|
| TTR | 0.119 | 0.150 | 0.140 | 0.134 |
| Mass index | 0.019 | 0.017 | 0.018 | 0.018 |
| MSTTR | 0.648 | 0.682 | 0.663 | 0.648 |
| Sense and Sensibility | ST | HT | GNMT | DeepL |
| TTR | 0.040 | 0.073 | 0.056 | 0.057 |
| Mass index | 0.022 | 0.019 | 0.021 | 0.020 |
| MSTTR | 0.680 | 0.703 | 0.695 | 0.683 |
| The Memoirs of SH | ST | HT | GNMT | DeepL |
| TTR | 0.068 | 0.095 | 0.088 | 0.085 |
| Mass index | 0.020 | 0.018 | 0.018 | 0.019 |
| MSTTR | 0.664 | 0.689 | 0.681 | 0.672 |
| The Sign Of The Four | ST | HT | GNMT | DeepL |
| TTR | 0.103 | 0.129 | 0.125 | 0.122 |
| Mass index | 0.019 | 0.017 | 0.018 | 0.018 |
| MSTTR | 0.670 | 0.700 | 0.686 | 0.676 |
| A Christmas Carol; n = 150 | HT | GNMT | DeepL |
|---|---|---|---|
| HT | 0 | 1.479 | 1.455 |
| GNMT | 0 | 0.889 | |
| DeepL | 0 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Webster, R.; Fonteyne, M.; Tezcan, A.; Macken, L.; Daems, J. Gutenberg Goes Neural: Comparing Features of Dutch Human Translations with Raw Neural Machine Translation Outputs in a Corpus of English Literary Classics. Informatics 2020, 7, 32. https://doi.org/10.3390/informatics7030032
Webster R, Fonteyne M, Tezcan A, Macken L, Daems J. Gutenberg Goes Neural: Comparing Features of Dutch Human Translations with Raw Neural Machine Translation Outputs in a Corpus of English Literary Classics. Informatics. 2020; 7(3):32. https://doi.org/10.3390/informatics7030032
Chicago/Turabian StyleWebster, Rebecca, Margot Fonteyne, Arda Tezcan, Lieve Macken, and Joke Daems. 2020. "Gutenberg Goes Neural: Comparing Features of Dutch Human Translations with Raw Neural Machine Translation Outputs in a Corpus of English Literary Classics" Informatics 7, no. 3: 32. https://doi.org/10.3390/informatics7030032
APA StyleWebster, R., Fonteyne, M., Tezcan, A., Macken, L., & Daems, J. (2020). Gutenberg Goes Neural: Comparing Features of Dutch Human Translations with Raw Neural Machine Translation Outputs in a Corpus of English Literary Classics. Informatics, 7(3), 32. https://doi.org/10.3390/informatics7030032