Multimodal Hand Gesture Classification for the Human–Car Interaction

 , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
- We propose a deep learning-based framework for the dynamic hand gesture recognition task. In particular, we follow the Natural User Interface paradigm: in this way, a driver could use hand gestures to safely interact with the infotainment system of the car.
- We extend the preliminary work proposed in [20]. Specifically, in this paper we investigate the use of multimodal data with the focus on light-invariant data (i.e., depth and infrared images).
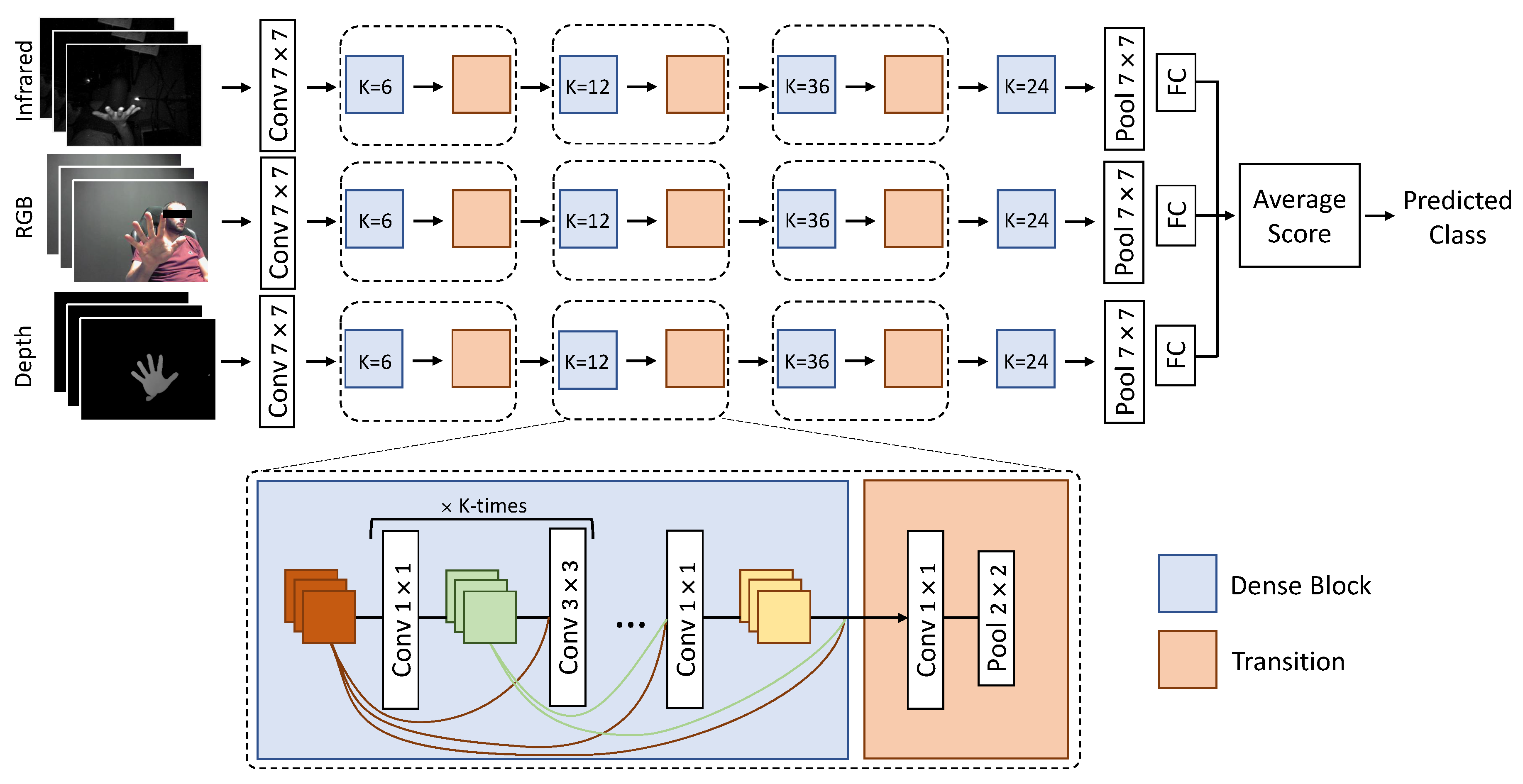
- We propose and analyze the use of a multimodal deep learning-based architectures, as shown in Figure 1. Moreover, we conduct extensive tests about the use of several input data types (single, double and triple) and different training procedures.
- We test the proposed method on two public datasets, namely Briareo [20] and Nvidia Dynamic Hand Gesture [21] (here also referred as NVGestures). Results in terms of accuracy and confusion matrices confirm the high level of accuracy achieved, enabling the implementation of real-world human–car interaction application. We also report the computational performance.
2. Related Work
2.1. Methods
2.2. Dataset for Hand Gesture Classification
3. Proposed Method
3.1. Model
3.2. Training
3.3. Multimodal Fusion
4. Experimental Evaluation
4.1. Datasets
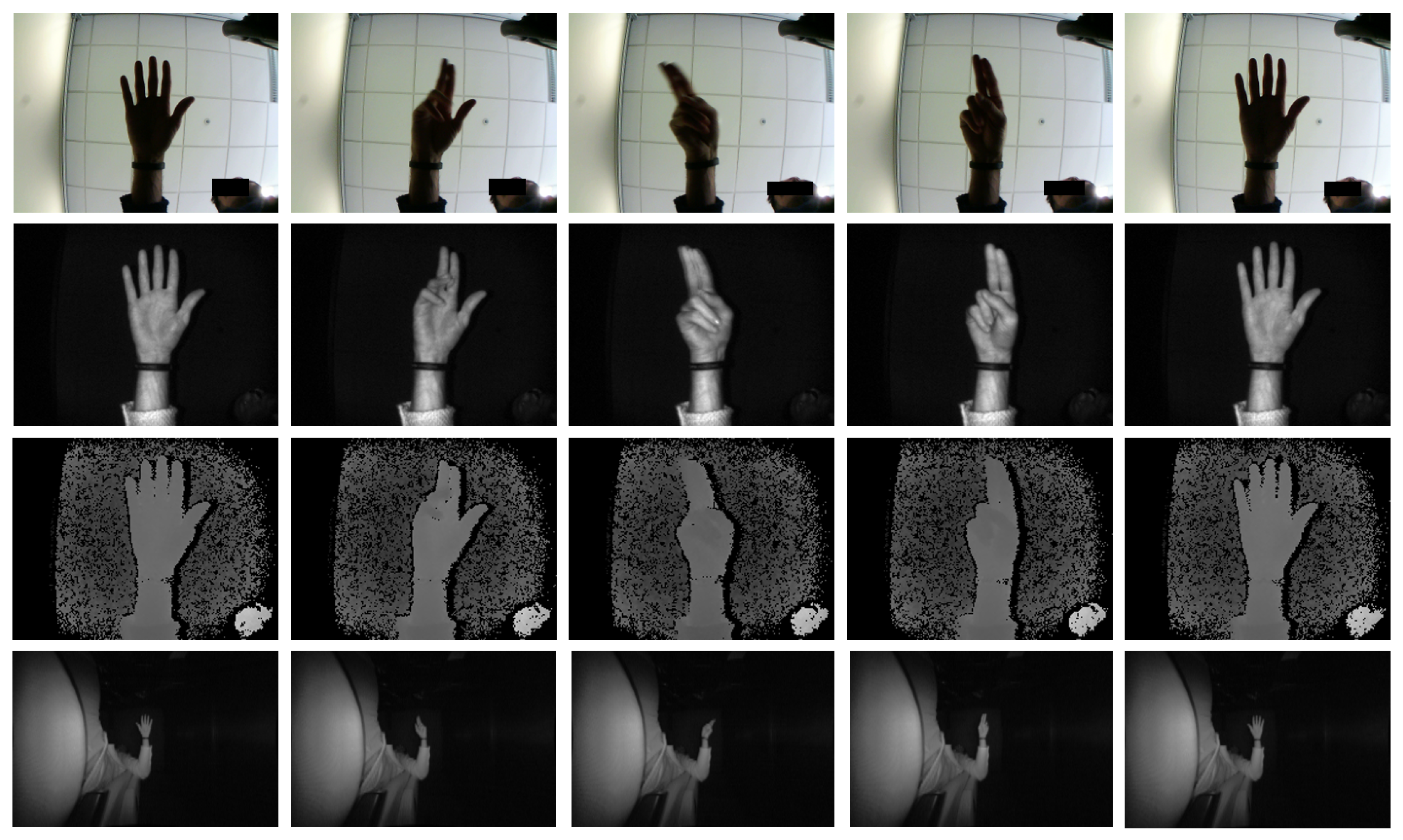
4.1.1. Briareo Dataset
- Pico Flexx (https://pmdtec.com/picofamily/flexx): this is a Time-of-Flight (ToF) depth sensor. As reported in [49], ToF devices assure a better quality with the respect of Structured Light (SL) depth sensors, for instance, reducing the presence of visual artifacts (visually represented as black pixels or missing values). It has a spatial resolution of pixels, acquiring 16-bit depth images. This sensor is suitable for the automotive context due to its very limited form factor (only mm) and weight (8 g), making it easy to be integrated in a car cockpit. Moreover, the acquisition range allows to perform gesture next to the device, a crucial element in an indoor environment like a car. In particular, there are two possible depth resolutions and two possible ranges: 0.5–4 m and 0.1–1 m. During the acquisition, the second one is used. The frame rate for the acquisition is set to 45 frame per seconds.
- Leap Motion (https://www.leapmotion.com): an infrared stereo camera specifically designed for the human–computer interaction. It is suitable for the automotive context due to the high frame rate (up to 200 frame per seconds) and limited size ( mm) and weight (32 g). In addition, the presence of two cameras with a good spatial resolution () is remarkable. A fish-eye lens guarantees a proper acquisition range for in-car applications. These sensors are equipped with a proprietary SDK able to detect the 3D location of hand joints, together with the bone lengths and their orientations, with real-time performance.
- Fist
- Pinch
- Flip
- Phone
- Right swipe
- Left swipe
- Top-down swipe
- Bottom-up swipe
- Thumb up
- Point
- Clockwise rotation
- Counterclockwise rotation
4.1.2. Nvidia Dynamic Hand Gesture Dataset
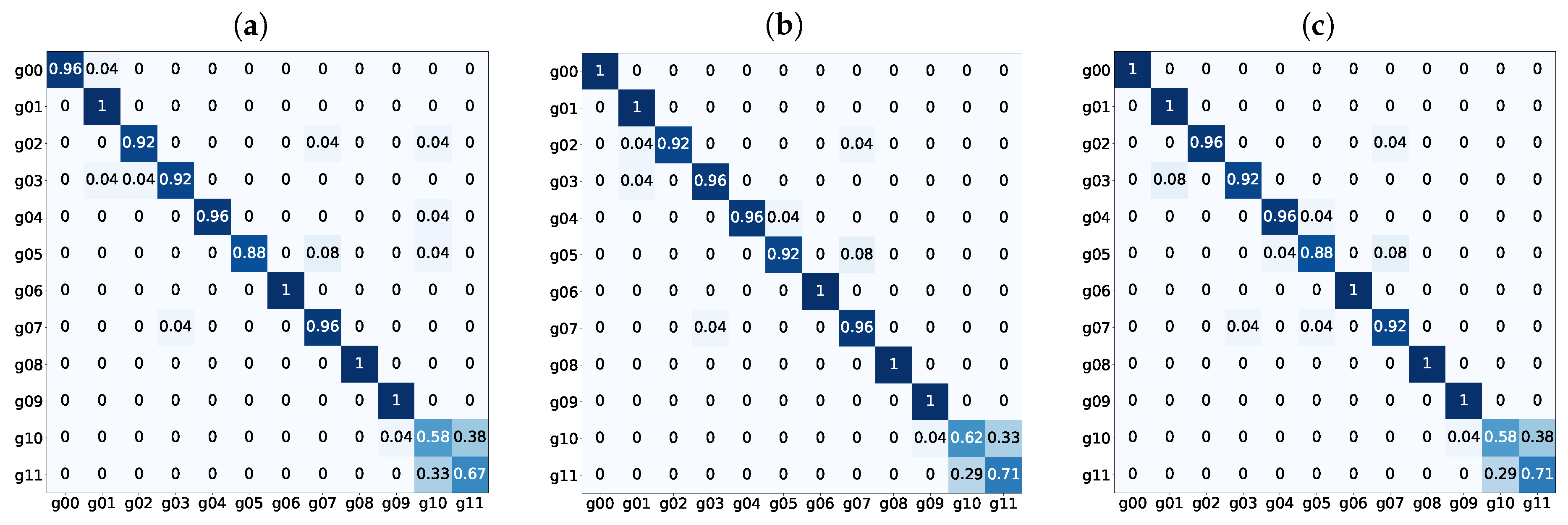
4.2. Experimental Results
4.2.1. Multimodal Fusion Analysis
4.2.2. Computational Performance
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| NUI | Natural User Interface |
| SL | Structured Light |
| ToF | Time-of-Flight |
| CNN | Convolutional Neural Network |
| SVM | Support Vector Machine |
| LSTM | Long Short-Term Memory |
| GRU | Gate Recurrent Unit |
| SGD | Stochastic Gradient Descent |
References
- Borghi, G.; Vezzani, R.; Cucchiara, R. Fast gesture recognition with multiple stream discrete HMMs on 3D skeletons. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 997–1002. [Google Scholar]
- Vidakis, N.; Syntychakis, M.; Triantafyllidis, G.; Akoumianakis, D. Multimodal natural user interaction for multiple applications: The gesture—Voice example. In Proceedings of the 2012 International Conference on Telecommunications and Multimedia (TEMU), Chania, Greece, 30 July–1 August 2012; pp. 208–213. [Google Scholar]
- Saba, E.N.; Larson, E.C.; Patel, S.N. Dante vision: In-air and touch gesture sensing for natural surface interaction with combined depth and thermal cameras. In Proceedings of the 2012 IEEE International Conference on Emerging Signal Processing Applications, Las Vegas, NV, USA, 12–14 January 2012; pp. 167–170. [Google Scholar]
- Liu, W. Natural user interface-next mainstream product user interface. In Proceedings of the 2010 IEEE 11th International Conference on Computer-Aided Industrial Design & Conceptual Design 1, Yiwu, China, 17–19 November 2010; Volume 1, pp. 203–205. [Google Scholar]
- Rodríguez, N.D.; Wikström, R.; Lilius, J.; Cuéllar, M.P.; Flores, M.D.C. Understanding movement and interaction: An ontology for Kinect-based 3D depth sensors. In Ubiquitous Computing and Ambient Intelligence. Context-Awareness and Context-Driven Interaction; Springer: Berlin/Heidelberg, Germany, 2013; pp. 254–261. [Google Scholar]
- Boulabiar, M.I.; Burger, T.; Poirier, F.; Coppin, G. A low-cost natural user interaction based on a camera hand-gestures recognizer. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 9–14 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 214–221. [Google Scholar]
- Villaroman, N.; Rowe, D.; Swan, B. Teaching natural user interaction using OpenNI and the Microsoft Kinect sensor. In Proceedings of the 2011 Conference on Information Technology Education, New York, NY, USA, 20–22 October 2011; pp. 227–232. [Google Scholar]
- Marin, G.; Dominio, F.; Zanuttigh, P. Hand gesture recognition with leap motion and kinect devices. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1565–1569. [Google Scholar]
- Mazzini, L.; Franco, A.; Maltoni, D. Gesture Recognition by Leap Motion Controller and LSTM Networks for CAD-oriented Interfaces. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 185–195. [Google Scholar]
- Wilson, F.A.; Stimpson, J.P. Trends in fatalities from distracted driving in the United States, 1999 to 2008. Am. J. Public Health 2010, 100, 2213–2219. [Google Scholar] [CrossRef]
- Dong, Y.; Hu, Z.; Uchimura, K.; Murayama, N. Driver inattention monitoring system for intelligent vehicles: A review. IEEE Trans. Intell. Transp. Syst. 2011, 12, 596–614. [Google Scholar] [CrossRef]
- McKnight, A.J.; McKnight, A.S. The effect of cellular phone use upon driver attention. Accid. Anal. Prev. 1993, 25, 259–265. [Google Scholar] [CrossRef]
- Ranney, T.A.; Garrott, W.R.; Goodman, M.J. NHTSA Driver Distraction Research: Past, Present, and Future; SAE Technical Paper; SAE: Warrendale, PA, USA, 2001. [Google Scholar]
- Borghi, G.; Gasparini, R.; Vezzani, R.; Cucchiara, R. Embedded recurrent network for head pose estimation in car. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017. [Google Scholar]
- Harbluk, J.L.; Noy, Y.I.; Trbovich, P.L.; Eizenman, M. An on-road assessment of cognitive distraction: Impacts on drivers’ visual behavior and braking performance. Accid. Anal. Prev. 2007, 39, 372–379. [Google Scholar] [CrossRef] [PubMed]
- Recarte, M.A.; Nunes, L.M. Mental workload while driving: Effects on visual search, discrimination, and decision making. J. Exp. Psychol. Appl. 2003, 9, 119. [Google Scholar] [CrossRef] [PubMed]
- Young, K.L.; Salmon, P.M. Examining the relationship between driver distraction and driving errors: A discussion of theory, studies and methods. Saf. Sci. 2012, 50, 165–174. [Google Scholar] [CrossRef]
- Sharwood, L.N.; Elkington, J.; Stevenson, M.; Wong, K.K. Investigating the role of fatigue, sleep and sleep disorders in commercial vehicle crashes: A systematic review. J. Australas. Coll. Road Saf. 2011, 22, 24. [Google Scholar]
- Borghi, G.; Frigieri, E.; Vezzani, R.; Cucchiara, R. Hands on the wheel: A dataset for driver hand detection and tracking. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018. [Google Scholar]
- Manganaro, F.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Hand Gestures for the Human-Car Interaction: The Briareo dataset. In Proceedings of the International Conference on Image Analysis and Processing, Trento, Italy, 9–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 560–571. [Google Scholar]
- Molchanov, P.; Yang, X.; Gupta, S.; Kim, K.; Tyree, S.; Kautz, J. Online detection and classification of dynamic hand gestures with recurrent 3d convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4207–4215. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Weissmann, J.; Salomon, R. Gesture recognition for virtual reality applications using data gloves and neural networks. In Proceedings of the IJCNN’99, International Joint Conference on Neural Networks, Proceedings (Cat. No. 99CH36339), Washington, DC, USA, 10–16 July 1999; Volume 3, pp. 2043–2046. [Google Scholar]
- Shull, P.B.; Jiang, S.; Zhu, Y.; Zhu, X. Hand gesture recognition and finger angle estimation via wrist-worn modified barometric pressure sensing. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 724–732. [Google Scholar] [CrossRef] [PubMed]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wu, D.; Pigou, L.; Kindermans, P.J.; Le, N.D.H.; Shao, L.; Dambre, J.; Odobez, J.M. Deep dynamic neural networks for multimodal gesture segmentation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1583–1597. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4489–4497. [Google Scholar]
- Molchanov, P.; Gupta, S.; Kim, K.; Kautz, J. Hand gesture recognition with 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Boston, MA, USA, 7–12 June 2015; pp. 1–7. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Graves, A.; Schmidhuber, J. Offline handwriting recognition with multidimensional recurrent neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 545–552. [Google Scholar]
- Ohn-Bar, E.; Trivedi, M.M. Hand gesture recognition in real time for automotive interfaces: A multimodal vision-based approach and evaluations. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2368–2377. [Google Scholar] [CrossRef]
- Miao, Q.; Li, Y.; Ouyang, W.; Ma, Z.; Xu, X.; Shi, W.; Cao, X. Multimodal gesture recognition based on the resc3d network. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 3047–3055. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Boulahia, S.Y.; Anquetil, E.; Multon, F.; Kulpa, R. Dynamic hand gesture recognition based on 3D pattern assembled trajectories. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017. [Google Scholar]
- Escalera, S.; Baró, X.; Gonzalez, J.; Bautista, M.A.; Madadi, M.; Reyes, M.; Ponce-López, V.; Escalante, H.J.; Shotton, J.; Guyon, I. Chalearn looking at people challenge 2014: Dataset and results. In Proceedings of the Workshop at the ECCV, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 459–473. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8026–8037. [Google Scholar]
- Robbins, H.; Monro, S. A stochastic approximation method. Ann. Math. Stat. 1951, 400–407. [Google Scholar] [CrossRef]
- Kiefer, J.; Wolfowitz, J. Stochastic estimation of the maximum of a regression function. Ann. Math. Stat. 1952, 23, 462–466. [Google Scholar] [CrossRef]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 17–19 June 2013; pp. 1139–1147. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 8778–8788. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Pini, S.; Ahmed, O.B.; Cornia, M.; Baraldi, L.; Cucchiara, R.; Huet, B. Modeling multimodal cues in a deep learning-based framework for emotion recognition in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 536–543. [Google Scholar]
- Gao, Q.; Ogenyi, U.E.; Liu, J.; Ju, Z.; Liu, H. A two-stream CNN framework for American sign language recognition based on multimodal data fusion. In Proceedings of the UK Workshop on Computational Intelligence, Portsmouth, UK, 11–13 September 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 107–118. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Sarbolandi, H.; Lefloch, D.; Kolb, A. Kinect range sensing: Structured-light versus Time-of-Flight Kinect. In Computer Vision and Image Understanding; Elsevier: Amsterdam, The Netherlands, 2015; pp. 1–20. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | # Subjects | # Gestures | Dynamic | 3DJoints | RGB | Depth | Infrared |
|---|---|---|---|---|---|---|---|---|
| Unipd [8] | 2014 | 14 | 10 | ✓ | ✓ | SL | ||
| VIVA [32] | 2014 | 8 | 19 | ✓ | ✓ | SL | ✓ | |
| Nvidia [21] | 2015 | 20 | 25 | ✓ | ✓ | SL | ✓ | |
| LMDHG [36] | 2017 | 21 | 13 | ✓ | ✓ | ✓ | ||
| Turms [19] | 2018 | 7 | - | ✓ | ✓ | |||
| CADGestures [9] | 2019 | 30 | 8 | ✓ | ✓ | ✓ | ||
| Briareo [20] | 2019 | 40 | 12 | ✓ | ✓ | ✓ | ToF | ✓ |
| Block | Definition | Input Size | Output Size |
|---|---|---|---|
| Convolution | conv, stride 2 | rgb: infrared: depth: | |
| Pooling | max pool, stride 2 | ||
| Dense Block (1) | |||
| Transition Block (1) | |||
| Dense Block (2) | |||
| Transition Block (2) | |||
| Dense Block (3) | |||
| Transition Block (3) | |||
| Dense Block (4) | |||
| Pooling | global avg pool | ||
| Classification | C-class fully connected softmax | 2208 | C |
| Input Data | |||||||
|---|---|---|---|---|---|---|---|
| Single Input | Double Input | Triple Input | |||||
| RGB | ✓ | ✓ | ✓ | ✓ | |||
| Infrared | ✓ | ✓ | ✓ | ✓ | |||
| Depth | ✓ | ✓ | ✓ | ✓ | |||
| Accuracy | 0.833 | 0.861 | 0.903 | 0.864 | 0.920 | 0.895 | 0.909 |
| Gesture | C3D [20] | Ours | ||
|---|---|---|---|---|
| RGB | Depth | Infrared | Depth + Infrared | |
| Fist | 0.542 | 0.708 | 0.750 | 1.000 |
| Pinch | 0.833 | 0.875 | 0.958 | 1.000 |
| Flip-over | 0.792 | 0.750 | 0.875 | 0.917 |
| Telephone call | 0.625 | 0.792 | 1.000 | 0.958 |
| Right swipe | 0.833 | 0.833 | 0.917 | 0.958 |
| Left swipe | 0.833 | 0.917 | 0.792 | 0.917 |
| Top-down swipe | 0.917 | 0.750 | 0.958 | 1.000 |
| Bottom-up swipe | 0.750 | 0.833 | 0.875 | 0.958 |
| Thumb up | 0.917 | 0.625 | 1.000 | 1.000 |
| Point | 0.667 | 0.708 | 1.000 | 1.000 |
| CW Rotation | 0.542 | 0.375 | 0.750 | 0.625 |
| CCW Rotation | 0.417 | 0.958 | 0.635 | 0.708 |
| Overall Accuracy | 0.722 | 0.760 | 0.875 | 0.920 |
| Model | Input Type | |
|---|---|---|
| RGB | Depth | |
| 2D CNN [21] | 0.556 | 0.681 |
| 2D RNN [21] | 0.579 | 0.647 |
| 2D RNN + CTC [21] | 0.656 | 0.691 |
| Ours | 0.520 | 0.761 |
| Input Data | ||||
|---|---|---|---|---|
| Double Input | Triple Input | |||
| RGB | ✓ | ✓ | ✓ | |
| Infrared | ✓ | ✓ | ✓ | |
| Depth | ✓ | ✓ | ✓ | |
| Mid-Fusion | 0.882 | 0.837 | 0.885 | 0.878 |
| Late-Fusion | 0.864 | 0.920 | 0.895 | 0.909 |
| Training Procedures | |||
|---|---|---|---|
| End-to-End | Fine-Tuning | Freezed | |
| Mid-Fusion | 0.722 | 0.774 | 0.878 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. Multimodal Hand Gesture Classification for the Human–Car Interaction. Informatics 2020, 7, 31. https://doi.org/10.3390/informatics7030031
D’Eusanio A, Simoni A, Pini S, Borghi G, Vezzani R, Cucchiara R. Multimodal Hand Gesture Classification for the Human–Car Interaction. Informatics. 2020; 7(3):31. https://doi.org/10.3390/informatics7030031
Chicago/Turabian StyleD’Eusanio, Andrea, Alessandro Simoni, Stefano Pini, Guido Borghi, Roberto Vezzani, and Rita Cucchiara. 2020. "Multimodal Hand Gesture Classification for the Human–Car Interaction" Informatics 7, no. 3: 31. https://doi.org/10.3390/informatics7030031
APA StyleD’Eusanio, A., Simoni, A., Pini, S., Borghi, G., Vezzani, R., & Cucchiara, R. (2020). Multimodal Hand Gesture Classification for the Human–Car Interaction. Informatics, 7(3), 31. https://doi.org/10.3390/informatics7030031