Abstract
Realistic humanoid robots (RHRs) with embodied artificial intelligence (EAI) have numerous applications in society as the human face is the most natural interface for communication and the human body the most effective form for traversing the manmade areas of the planet. Thus, developing RHRs with high degrees of human-likeness provides a life-like vessel for humans to physically and naturally interact with technology in a manner insurmountable to any other form of non-biological human emulation. This study outlines a human–robot interaction (HRI) experiment employing two automated RHRs with a contrasting appearance and personality. The selective sample group employed in this study is composed of 20 individuals, categorised by age and gender for a diverse statistical analysis. Galvanic skin response, facial expression analysis, and AI analytics permitted cross-analysis of biometric and AI data with participant testimonies to reify the results. This study concludes that younger test subjects preferred HRI with a younger-looking RHR and the more senior age group with an older looking RHR. Moreover, the female test group preferred HRI with an RHR with a younger appearance and male subjects with an older looking RHR. This research is useful for modelling the appearance and personality of RHRs with EAI for specific jobs such as care for the elderly and social companions for the young, isolated, and vulnerable.
1. Introduction
Numerous scholars suggest that emotionally responsive artificial intelligence (EmoAI) in human–robot interaction (HRI) reduces negative perceptual feedback as people feel an affinity towards realistic humanoid robots (RHRs) that can simulate empathy [1,2,3,4,5,6,7,8]. The EmoAI approach is founded on behaviours in human sociology as communication, personality, and comprehension help promote understanding and empathy during human–human interaction [9,10,11,12]. Thus, people empathise more with RHRs than non-anthropomorphic robots as humans feel an innate association with machines that look human, owing to the psychological drive to socialise and form relationships with other humans [13].
In support, RHR Sophia’s ability to discuss its visual and functional limitations with humans helps people empathise with the RHR’s preternatural qualities [14,15]. This design consideration is significant to the progression of RHRs as research in robotic AI has predominantly focused on simulating human cognition and continually neglects the significance of EmoAI in promoting natural HRI, which heightens the potentiality of adverse feedback owing to emotionless robotic AI [16]. Masahiro Mori’s [17] uncanny valley (UV) hypothesis accounts for the negative psychological stimulus propagated by RHRs upon observation, as the more human-like the RHRs appear, the higher the potential for humans to feel repulsed by their appearance.
Quality aesthetics is a foundation for reducing the UV in RHR design [18,19]. However, although the aesthetics approach is a viable first stage for increasing the authenticity of a RHR’s appearance, it neglects the importance of naturalistic functionality and movement. Per the UV, poor functionality supersedes good aesthetical design in the same way that quality aesthetics become secondary to inadequate functionality [20,21]. This condition is significant as RHRs are developed in different configurations. For example, waist up models such as the Robot ‘C’ series by Promo-bot Russia, launched in 2020, are designed as front desk assistants and do not require lower body functions. However, human likeness also applies to other facets of RHR design such as movement. For instance, although Atlas of Boston dynamics bears little aesthetical human resemble, the robot has highly humanlike dexterity and movement. Thus, the term ‘realistic’ is applicable to different factions of RHR engineering outside of appearance, that is, realistic movement, speech, and AI.
Therefore, the consideration of both appearance and functionality is crucial in developing greater human-like RHRs and reducing the UV [22]. However, cultural background influences the UV as observed in many studies conducted by Eastern scholars, which often rate lower levels of the UV than in Western cultures [23,24,25,26,27,28]. Furthermore, many scholars argue that children are less susceptible to the UV as they are naturally more curious and accepting of RHRs than adults owing to a lack of media influence and risk perception [29,30,31,32,33]. Thus, exposing children to RHRs at a young age is a methodology for ethically reducing the UV as it builds a foundation of understanding before media influence [34,35].
Following these findings, developing emotionally responsive RHRs with higher degrees of visual and functional human-likeness has the potentiality to increase affinity and reduce the UV, which may prove essential in enculturating RHRs into society and developing RHRs with higher degrees of human likeness. Nevertheless, little practical research evaluating user preference and the influence of personality and appearance in automated RHRs with embodied artificial intelligence (EAI) exists in HRI. Therefore, this study explores a significant gap in current HRI, EAI, and RHR research and critically investigates this area by outlining the processes utilised in developing EAI personalities for RHRs, substantiated by the results of an HRI experiment measuring the influence of appearance and personality type in HRI.
2. Embodied Artificial Intelligence and Emotional Artificial Intelligence
Until recently, the primary focus of AI research was on creating algorithms that can compute data that humans are incapable of calculating [36]. However, a shift in AI research and development towards emotionally responsive systems with human-like personalities has become a critical factor in developing AI systems that interact naturally with humans [37,38,39]. Thus, EmoAI applications are better suited for situations that involve human communication and sensitivity compared with traditional forms of robotic AI [40,41,42]. For example, EmoAI systems such as ‘Cogito’ monitor emotional cues in the user’s speech during telephone conversations to respond to users naturally and make human–computer interaction (HCI) more engaging [43]. Comparatively, an EmoAI system named ‘Surrportiv’ implements natural language processing (NLP) to converse with users. It adjusts the tonality and empathy of the speech synthesis output to help tackle situations such as user stress and anxiety [44].
A similar EmoAI support system named ‘Butterfly’ utilised in business environments monitors staff stress levels, collaboration, creativity, and confliction between co-workers. The system offers help and guidance to negotiate stressful work situations by sending employees text messages [45]. However, restricting the interactive capabilities of an EAI in HCI to a single stimulus such as speech or text neglects many fundamental communicative processes observed in natural human–human interaction such as facial expressions (FEs), attention, gesturing, and eye contact [46]. Thus, embodying modes of EmoAI in RHRs has the potential to enhance HRI and promote greater naturalistic modes of communication by emulating human emotions.
In support, the humanoid robot ‘Pepper’ recognises and responds to six basic human emotions; joy, sadness, anger, surprise, disgust and fear, using an emotion detection camera system integrated into its AI [47]. The worldwide success of the Pepper robot relies on the system’s ability to communicate and respond to humans with empathy, making the robot feel more approachable and friendly during HRI [48,49,50]. However, Pepper’s appearance is distinctly unnaturalistic, with a plastic shell for skin and immobile eyes and mouth aperture, which reduces the robot’s ability to display human-like emotions, natural skin aesthetics, and FEs [51,52,53,54]. Thus, replicating the naturalistic aesthetics and sensory capabilities of the human skin is essential in HRI. This is outlined in a study testing an artificial skin for tactile interfacing in HRI, which emulates surface changes to touch and temperature to propagate synthetic goosebumps and hair raising [55].
Comparatively, a synthetic skin [56] developed for mobile phones can systematically respond to physical manipulation such as pinching and pulling to determine the emotional state of the user. Unlike the previous example, this prototype has a compatible mobile application that reports on user stress [56]. However, the goal of the robotic skin is for use in HRI to explore the intersection between man and machine with future adaptations to include skin conductance, embedded hair, and temperature recognition features.
Although these prototypes do not currently function with AI, the possibility of configuring the artificial skins with EAI to elicit responses such as changes in speech tonality, pupil dilation, behaviour, temperature, and perspiration is of significant value to RHR design. This approach is essential as it combines a wide range of physical and psychological human responses into one system, proximal to the nervous system. This is highlighted in a report on an RHR named ‘H1’ with tactile skin sensors for enhancing HRI by responding to touch with EmoAI responses [57]. Moreover, developing an EAI personality depends highly on the functionality, sensory abilities, intellectual capacity, and application of the system [58,59]. For instance, chatbot personalities for emergency and rescue situations should be empathetic, but also intellectually efficient in providing quick, logical, and concise instructions to the user [60].
In regard, Gardner’s theory of multiple intelligences suggests that humans have different kinds of intelligence [61]. These include visual–spatial intelligence: people who are good at visualising tasks and spatial judgement. Linguistic-verbal intelligence: people with active reading and writing skills. Logical–mathematical intelligence: individuals who excel at reasoning, recognising patterns, and analysing formulas. Bodily-kinaesthetic intelligence: people with advanced hand-eye coordination and dexterity. Musical intelligence: individuals who think in patterns, rhythms, and sounds. Interpersonal intelligence: people who are good at understanding, relating, and interacting with other people. Intrapersonal intelligence: individuals who can control their emotional states. Finally, naturalistic intelligence: people who are in tune with nature.
However, current modes of robotic AI primarily focus on logical, linguistical, and kinaesthetic intelligence and neglect the implications of interpersonal, musical, naturalistic, and intrapersonal intelligence [62]. This consideration is significant as interpersonal and intrapersonal intelligence are vital in human–human communication as these drives consider how people communicate, control emotions, understand, and empathise with others [63], as shown in Figure 1. The application of Gardener’s multiple-intelligence approach in machine learning (ML), deep learning (DL), statistics, database design, and EAI systems is vital in creating multi-tasking robots with human-like capabilities [64,65,66,67].
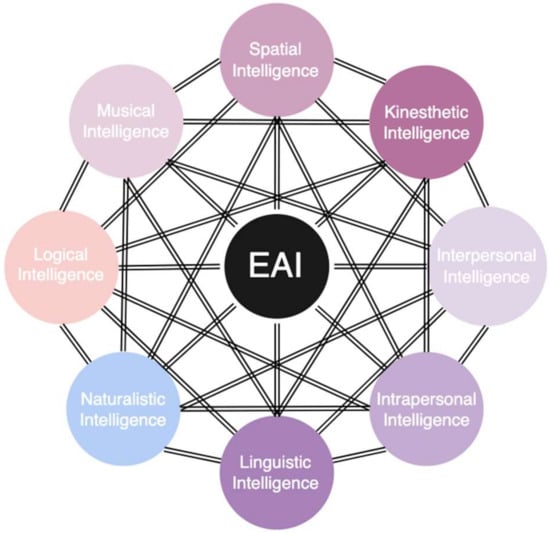
Figure 1.
Gardner’s eight intelligence types’ combinations and application in embodied artificial intelligence (EAI).
Thus, intelligence and personality are intrinsically interlinked, and personality type is a highly influential factor in intellectual capacity [68]. Gardner’s multiple intelligence approach in EAI has a significant impact on the intellectual authenticity of RHRs as human beings have a high level of intuition when examining and testing the abilities of AI systems [69]. Furthermore, EmoAI developed for RHRs is crucial in the effective and naturalistic integration of RHRs into human society [63,70]. This proposition is essential for RHR development as market predictions indicate a substantial rise in the manufacturing, sales, and development of RHRs with EAI over the next five years [71].
2.1. Practical Applications of Humanoid Robots with EAI
Emulating the human body and mind is the most challenging and rewarding endeavour in science, engineering, and technology, as the human being is the highest functioning organism in the known universe [72]. Although the future applications of RHRs with EAI are highly theoretical, emotionally intelligent robots with human-like personalities are gradually emerging in fields such as the following: Vyommitra, 2020: IND [73], space exploration personal assistant; Nadine, 2015: SING [74], social robotics platform; Erica, 2018: JAP [75], HRI research platform, and robotic actress; Robot C, 2020: RUS [76], helpdesk assistant; HAL, 2018: USA [77], for use in pediatric training; Jiang Lilai, 2019: China [78] and Alex, 2019: RUS [79] and Junko Chihira, 2016: JAP [80] are 24 h robotic news reporters; Sophia, 2016: USA [81], social researcher and conference speaker; AI-DA, 2019: UK [82], a robotic artist; BINA 48, 2016: USA [83], a robotic lecturer; Telinoid, 2006: JAP [84], a healthcare assistant for the elderly; CB2, 2006: JAP [85], a robotic child to train young parents for adulthood; Diego San, 2010: USA [86], an RHR to study cognitive development in children; Atlas, 2013: USA [87], search and rescue robot; Affecto, 2010: JAP [88], a child robot to study human sociology; Robocop, 2017: DXB [89], security guard; and Furhat, 2018: SWD [90], personal assistant. However, unlike traditional models of design and programming in robotics, the end goal of RHRs with EAI is to perform multiple tasks in different environments and use common tools, in order to emulate the natural cognitive, emotional, communicative, and physical capabilities of humans [91].
For example, industrial robots have the potential to generate feelings of anxiety in the workplace as they cannot provide the emotional support or understanding of human co-workers [92,93,94]. Therefore, a shift towards emotional industrial robots such as ‘Sawyer’ and ‘Baxter’ that emulate human FEs are reducing the anxiety between workers and machines in factory environments [95]. These ethical factors are crucial in the sociological integration of humans and RHRs as, according to various studies [96,97], assimilation is a critical aspect in human–robot integration because, the fewer the distinctions between humans and machines, the higher the potential for acceptance [98,99].
2.2. AI and Natural Language Processing System Design
The RHRs developed in this study are named Baudi and Euclid, and discussed in press releases [100,101,102]. The RHRs implement Amazon Lex Deep Learning (DL) AI and Amazon Polly speech synthesis (SS) software to converse with people naturally. The personalities and interests of the RHRs reflect their age (appearance and SS) to measure how participants respond to different personality types during HRI. Thus, Baudi’s interests are music, food, and travel, and Euclid’s interests are in art, poetry, and literature. The DL algorithm in amazon Lex permits operators to access Amazon’s large cloud-based databank of information relating to these topics and add additional information to the data sets, depicted in Figure 2. The conversational AI systems function using a series of intents, which are actions the user wants to perform; sample utterances, which are examples of things people may say to convey the intent; slots and containers, which are data banks of information relating to specific words; and topics and fulfilments, providing an appropriate answer/s using the information provided by the user.
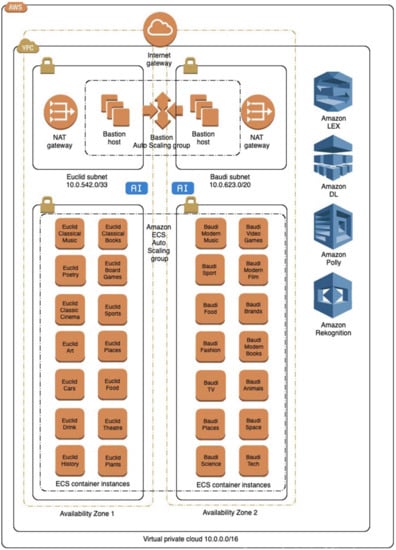
Figure 2.
Euclid and Baudi interests and hobbies cloud data. DL, deep learning; AI, artificial intelligence. Elastic Container Service (ECS), Network Address Translation (NAT).
Moreover, Amazon Lex is a commercial product designed for business, and the UI is mostly inaccessible compared with other open-source AI applications. This configuration makes developing conversational AI for general-purpose communication problematic as the slots defined by the program are mainly for specific types of business such as restaurants, music shops, and book shops. Therefore, mapping together these functions to create a personality depends on selecting and adapting slots and instances, linking them together, and building an EAI personality type and interests around those features. Furthermore, Amazon Lex limits the maximum amount of intents to one hundred questions per chatbot. This limitation is also problematic as it reduces the scope of potential questioning and has a high potential to produce incorrect or repetitive responses. However, this issue is negotiable by increasing the number of slots, sample utterances, and fulfilments per inquiry.
Thus, configuring a separate chatbot for different elements of the robot’s personality, emotions, and interests provides a broader range of interaction during HRI. This approach is crucial in designing an EAI personality as Amazon Lex is restrictive owing to its closed-software status and UI design. However, the quality and accuracy of the DL AI system are highly effective for developing conversational AI for HRI. Furthermore, the Amazon Lex AI system integrates automatic speech recognition (ASR), natural language understanding (NLU), dialogue manager (DM), natural language generation (NLG), and SS into a unified system. These components are of significantly greater quality than many open-source third-party applications and function seamlessly on a cloud-based system, which reduces system delay and system load.
Finally, Amazon Lex is compatible with Amazon Rekognition, ML robotic vision software to enhance the sensory capabilities of the EAI system for RHR design. However, Amazon Rekognition is expensive and difficult to calibrate and is outside of the scope of resources for this study, but may provide a useful enhancement for future studies. Therefore, although Amazon Lex has accessibility issues, the system speed, extensive databases, intuitive DL, cloud-based operating system, highly human-like SS models, and optional machine vision libraries supersede similar conversational AI frameworks such as Googles Dialogflow and IBM Watson.
3. Human–Robot Interaction Experiment
The objective of the HRI experiment is to measure how participants perceive the authenticity, appearance, likeability, and personality of the RHRs. This research is significant to the field of HRI as there is a lack of up-to-date practical study into user preference implementing automated RHRs. The experiment starts with the participant seated in front of a raised table between two RHRs shown in Figure 3 and two computer screens.

Figure 3.
Realistic humanoid robots (RHRs) with EAI ‘Euclid’ and ‘Baudi’ implemented in the human–robot interaction (HRI) experiment.
A galvanic skin response (GSR) electrode is attached to the middle and index finger of the right hand of test subjects to measure skin conductance. The Affdexme facial expression analysis (FEA) system in the eye of Baudi and a webcam in situ to Euclid can detect and track the test subject’s FEs and rate of attention. A second camera system positioned to record the test procedure from a wide-angle is set to monitor the test environment for post-experiment analysis.
The RHRs activate, and the heads and eyes automatically turn towards the participants using the face tracking system developed in Arduino, Microsoft Kinect, and Microsoft Studio. The Pololu microcontrollers activate, and the RHRs start to blink, raise eyebrows, and make subtle cheek movements. The participants press the start button on the handheld controllers and say ‘Hello’ to initiate the AI system. The first stage of the practical HRI experiment divides into four 5-min procedures founded on the evaluation time of the 1950 Turing test, shown in Table 1.

Table 1.
First stage evaluation protocol. AI, artificial intelligence.
The aim of Section 1 and Section 3 of the first stage of the HRI experiment is to assess how the performance of the EAI systems and how participants physiologically and psychologically respond to the RHRs using the biometric sensors. The participants speak to the robots using their voice, and when finished, they press a button on a hand-operated controller to notify the AI system that the conversation has finished and there is a short pause to allow the AI program time to respond.
The manual handheld control system provided greater cohesive data input than implementing time/speech-controlled ASR as stammering, pauses, mumbling, and incomplete sentences had a notable impact on generating incorrect and please repeat responses. This approach is vital in this study as gaining utilisable and concise data are key for assessing and enhancing the EAI personalities.
Section 2 and Section 4 are the gamification elements of the HRI experiment and require the participants to engage with the robots on a much more interactive level. The game implemented in this study is called the animal guessing game and participants are requested to ask the RHRs a series of questions pertaining to the identity of the animal the RHRs are ‘thinking’ of; for example, if Euclid is thinking of a giraffe, the participants may ask the robot questions such as, ‘does it have four legs’, ‘does it live in the sea’, or ‘can it fly’, and the robot responds accordingly with yes or no answers until the participant can correctly identify the animal. Throughout the first stages of the experiment, the correct, incorrect responses, and ‘please repeat’ AI responses are recorded in Amazon Lex statistics; these data are then used to improve the robots’ AI after each interaction.
The second stage of the experiment is a computerised questionnaire in which participants discuss the HRI experience and personal preference and evaluate the appearance, movement, AI, and speech of the robots. During the questionnaire stage, the robots continue to track the head movements of the participant, perform FEs using the Pololu, and speak to participants if requested to aid in answering the questionnaire. This novel interactive evaluation approach permits test subjects to engage with the RHRs while filling in the survey, compared with detaching the participant survey evaluation from the HRI test. Numerous studies across HRI implement mixed methodological approaches to help discern trends in large data sets and support and question participant taxonomies [3,103,104,105].
In accordance, this study employs a mixed methodology approach to data analysis, using both quantitative and qualitative methods. This study implements a GSR system and two camera-based FEA applications to measure the participant’s emotional responsivity on a fluctuating scale during the HRI examination, which exports into graphs and data fields (.CSV, .TXT, and .PDF). These data are quantitative and reinforced using qualitative inquiries of the HRI survey to verify outcomes. The results of quantitative dichotomous questions are statistically analysed by employing Cronbach’s Alpha to examine internal consistency, where lower than 0.60 is unacceptable, between 0.60 and 0.70 is undesirable, between 0.70 and 0.80 is respectable, and >0.90 is excellent [106]. Standard deviation and the margin of error are also factored: 0.0 exact comparison, <1.20 acceptable, and >2.0 unacceptable [107], shown in Supplementary Materials Tables S1–S5.
3.1. Population Sample, Recruitment, and Participant Restrictions
The population sample size for the primary survey is 20 test subjects; based on the 20 human interrogators implemented in Ishiguro’s total Turing test (TTT) [108] for androids, Harnad’s TTT [109], Harnad & Scherzera’s robot Turing test (RTT) [110], and Schweizer’s truly total Turing test (TTTT) [111] for RHRs. The population sample sizes of THT and HTT are incompatible with this study as these approaches do not evaluate appearance, movement, speech, or AI. Similarly, the sample size of the most compatible and recent research [2] proved unsuitable for this study as the experiment neglects AI, robotic vision, tracking, speech synthesis, and biometric data gathering. Although the population sample for this study is relatively small, the 50-question questionnaire and biometric devices collect large sums of data to yield confirmable results. Gay’s [112] estimative sampling formula indicates the number of invitations required to recruit 20 participants, depicted in Equation (1):
20 rr ÷ 10% er = 200 a
Equation (1): Gay’s estimative sampling method: rr—response range (replies needed), er—percentile of estimated responses, a—audience (amount of invitations).
Participants were required to have 20/20 vision or corrected vision to evaluate the authenticity of the RHRs and be aged over 18 years to satisfy the terms of the ethics agreement. Recruitment was open to all individuals of different backgrounds, gender, cultures, abilities, and nationalities. However, the ability to speak fluent English is a condition of this examination for the NLP to function accurately. Per the limitations of the Turing test, a selective recruitment and screening procedure ensured participants had sufficient background knowledge of the field of robotics and AI for effective analysis in mixed method data research [113]. Applications from students and professionals within robotics and AI and engineering were given preference over applicants in lesser-related areas. A short discussion over e-mail regarding the participants’ background, interests, and prior experience of robotics and AI was conducted before acceptance.
3.2. Participants Profiles
Per the ethical requirements for approval, all test subjects were over 18 years of age. The total number of experiments conducted was 21; this is owing to one participant not completing the HRI test because of a strong regional accent, which was unreadable by the NLP system. The subject was made aware of this issue and continued using type-written responses. However, this approach did not generate speech synthesis responses from the RHRs, which is vital for the HRI experiment, as Baudi’s speech synthesis accent is slow and low in tone and Euclid’s intonation is higher with a faster speech rate. Thus, as the test subject was unable to evaluate the RHRs’ speech synthesis during HRI, the results were withdrawn from the dataset.
The number of completed experiments is 20, equivalent to the sample of the TTT and TTTT; this includes GSR, FEA, and a complete HRI questionnaire. Table 2 indicates the background of each test subject, gender, age, and previous experience of those taking part in HRI research. As there are no similar HRI studies that implement two automated RHRs with conversational AI, all data are extracted, grouped, and analysed to a high degree for future research.
Table 2.
Human–robot interaction (HRI) experiment test subject profiles.
The gender ratio for this study is 11 (55%) males and 9 (45%) females; as there is one more male test subject than female, participant responses and results that are examined by gender group require significant differences in outcomes to be considered viable. The age ranges group into two equitable series of 18–27 (10: 50%) and 28–56 (10: 50%) to provide a comparative analysis between a higher and lower age group. However, as there is a greater diverse age range in the 28–56-year-old group, only outcomes with significant differences in results are considered viable. The analysis of the population sample indicated a high percentage of test subjects of Western ethnicities with English as a native language 18 (90%) compared with other ethnic backgrounds with English as a second language (10%). Therefore, ethnic and cultural diversity is an issue in this data set. However, the study was open to people of all cultures and backgrounds, and no preference was given to individuals from specific cultures or ethnicities. Ninety-five percent of participants indicated no previous experience in taking part in HRI experiments.
This result is not surprising per the accessibility to RHRs and the narrow recruitment factors of HRI studies. However, one participant (5%) indicated previous experience in HRI within higher education. All participants underwent a background check, as outlined in the Turing test recruitment procedure. During recruitment, potential participants were asked to disclose their current/previous level of study and background/current experience to establish their expertise in robotics, AI, and relevant fields for eligibility in the HRI experiment.
Thus, 6/20 (30%)—1:PRO (professional), 1:PG (post-grad), 4:UG (undergrad)—participants had previous or current experience in the field of robotics and AI; this percentage is high owing to the related nature of the study and the targeted online recruitment of AI and robotics students and staff members from the university. Further, 5/20 (30%)—2:UG, 3:PG:—subjects had experience in areas relating to computing and AI; this includes computer programming, application design, and AI games programming. Further, 5/20 (25%)—4:PRO, 1:UG—participants had experience in engineering and electronics with knowledge of robotic system design. Morover, 2/20 (10%)—1:PRO, 1:UG—individuals work or study in film and media, with experience in animation and programming.
Two out of twenty (10%)—2:PRO—subjects are professionals in areas relating to human psychology and physiology, to which both participants indicated an interest and personal study of AI. A further 8/20 (40%) of participants are current university students studying undergraduate degrees, 4/20 (20%) of subjects are undertaking postgraduate degrees at either Master’s or Ph.D. Lastly, 8/20 (40%) of candidates are professionals within their field with significant personal and industrial experience in AI, robotics, and related areas, as shown in Table 2.
Questionnaire categories: The RHR and EAI user preference and design questionnaire consist of 10 open-ended questions followed by 15 quantitative questions measured on five-point Likert scales covering the following: likeability, human-likeness, and competence, shown in Table 3, based on previous studies [105,114,115]. The qualitative and quantitative HRI questionnaire results are comparatively analysed against the GSR, FEA, and AI analytic data for a comprehensive cross-analysis of all data fields.
Table 3.
Quantitative HRI survey questions based on previous HRI research [116].
4. HRI Questionnaire
Question 1. Which robot do you think looks most human-like, Baudi or Euclid?
A total of 18/20 (90%) cited Euclid as the more human-like RHR. Of this dataset, 14/18 mentioned that Euclid’s skin appeared more human-like, 3/18 conferred Euclid’s mouth as the most human-like, and 1/18 cited Euclid’s eyes as more aesthetically realistic than Baudi’s. Moreover, 1/20 (5%) of results explained that Baudi’s hair implants made the RHR look human-like. One out of twenty (5%) of test subjects cited Baudi’s skin tone as more human-like than Euclid’s. A key theme in the results of Q1 is the aesthetical quality of the silicone skins, which many test subjects testified as having a significant impact on the RHRs’ visual authenticity. Both silicone skins were commissioned from the same artist to minimise visible irregularities between the RHRs and aesthetical and material quality. Euclid’s skin wrinkles were a recurring theme in participant responses.
RHRs are typically young in appearance and designed without skin imperfections or blemishes [33,100], which is not an accurate representation of the natural tonal variance and ageing of human skin. This aesthetical consideration is significant to RHR design as, although Baudi’s skin is not flawless, the RHR has no skin wrinkles and fewer skin imperfections. Therefore, as Euclid is much older in appearance with a greater range of facial defects, the RHRs’ appearance further blurs the line between human beings and RHRs. More male (M) subjects cited Euclid as humanlike than females (F): F8, M10 and Baudi: F1, M1. There was little difference between the higher and lower age groups, H = ages (18–27) and L = ages (27–56), Euclid: L9, H9 and Baudi: L1, H1.
Question 2. Which robotic voice did you prefer/understand better, Baudi or Euclid?
In total, 13/20 (65%) of test subjects preferred the voice of Baudi. Of that dataset, 8/13 explained that Baudi’s speech was slower and easier to understand than Euclid’s and 5/13 stipulated that Baudi’s accent was easier to understand than Euclid’s. Moreover, 7/20 (35%) cited Euclid’s speech synthesis as the most understandable. Of those results, 3/7 cited the pitch and tone of Euclid’s voice as the most human-sounding. A key theme in the HRI results considered the American accents of the robots, as the speech synthesis program implemented in this study only outputs American accents. This configuration appeared to impact natural speech understanding of non-American listeners. A recurring theme in the test results was the preference of the American accent as 2/20 stated the American accents were off-putting, and 4/20 suggested that they liked the American accents.
However, 4/20 of test subjects explained that the American accents were difficult to understand at times. A higher number of male test subjects preferred the speech synthesis of Baudi owing to the speech rate, depth, and tone: M9, F4 compared with Euclid M2, F5. Age-related statistics indicated that the lower age group preferred the speech synthesis accent of Baudi: L9, H4 compared with Euclid: L1, H6.
Question 3. Did you feel empathy/emotion towards Euclid or Baudi?
Here, 8/20 (40%) explained that they did not feel empathy or emotions towards the RHRs because the appearance, movement, and AI did not feel entirely human. However, out of that dataset, 3/6 advocated that, although they did not feel any emotion, they felt relaxed, happy, and calm during HRI with the RHRs, counter to the UV. Moreover, 5/20 (25%) cited that they felt no emotion or empathy because the robots were just heads without a body, which made them feel inhuman.
This outcome is justifiable with the current configurations of the RHRs as time limitations prohibited the design, development, and production of a robotic body and implementing a still manakin type body was difficult owing to spatial constraints. Further, 5/20 (25%) of test subjects suggested that they felt empathy towards Baudi owing to his unnatural appearance, which resembled human disability. A further 2/5 explained that Baudi’s eyes played a role in instigating an emotional response. Moreover, 2/20 (10%) felt that Euclid’s realistic appearance made them feel awkward and intimidated, which coincides with the UV. However, this sample is not sufficient in size to support the existence of the uncanny valley.
A higher number of female subjects felt an emotional response towards the RHRs compared with male subjects—F6, M1—and a greater number of males indicated no emotional responsivity—F3, M10. Out of that dataset, F5 cited an emotional response when interacting with Baudi and F1, M1 cited an emotional response during HRI with Euclid. Similarly, there was a notable difference in the age-related statistical analysis. L8, H5 cited no emotional response and L2, H5 suggested an emotional interaction. Out of that dataset, L2, H3 mentioned feeling an emotional response when interacting with Baudi and L0, H2 with Euclid.
Question 4. How did you feel when Baudi made eye contact with you?
Here, 8/20 (40%) of test subjects stated that they felt nothing resembling an emotional response when Baudi made eye contact with them. Of this dataset, 5/8 indicated that they did not feel the same way as when making eye contact with other humans. A further 3/8 suggested that the eye contact interaction was not consistent to make it feel like the RHR was looking at them naturally.
Moreover, 12/20 (60%) stated that they felt an emotional response when making eye contact with Baudi, and 7/12 suggested that it felt as if the robot was looking back at them. Of these results, 3/12 cited Baudi’s eye aesthetics as making the eyes appear creepy. Another 2/12 explained that the pupil dilation function made the eyes look humanlike. Gender statistical analysis indicated a higher percentage of female participants felt an emotional response to Baudi’s eyes than male test subjects—F7, M1 compared with no emotional response F2, M10. However, the results of the age-related statistical analysis indicated little correlation between an emotional response L3, H5 and no emotion L7, H5.
Question 5. How did you feel when Euclid made eye contact with you?
Here, 13/20 (65%) suggested that they did not feel anything when Euclid made eye contact with them. A further 8/13 argued that making eye contact with Euclid was like looking into the glass eyes of a doll or the eyes of a painting. Moreover, 3/20 suggested that Euclid’s eyes were not real enough to instigate an emotional reaction. Another 2/13 gave no reasoning other than to state that they did not feel anything relating to an emotional response. A further 7/20 (35%) suggested an emotional response to making eye contact with Euclid. Another 4/7 cited that they felt like the robot was looking back at them, or another human was looking at them through a camera. Another 2/7 advocated that Euclid had dead eyes which made them feel unnerved. Finally, 1/7 explained that Euclid maintained constant eye contact with them, which made them feel unsettled. Gender statistical analysis suggested no correlation between male and female test subjects—no emotional response: F5, M8 and emotional response: F4. M3. Similarly, the results of the age-related statistical analysis indicated no discernable relationships between emotional responsivity L6, H7 and no emotion L4, H3.
Question 6. Which robot head do you think moved most naturally, Euclid or Baudi?
Here, 16/20 (80%) of candidates cited Euclid’s head as moving the most naturally. Of this dataset, 9/16 explained that they felt a greater natural interaction when communicating with Euclid compared to Baudi. A further 4/16 stipulated that Euclid exhibited a more extensive range of FEs.
Moreover, 2/16 mentioned Euclid’s mouth as a decisive factor in the RHRs naturalistic movement, and 1/16 of outcomes suggested that Euclid’s head moved more naturally. Another 4/20 (20%) explained that they felt Baudi exhibited a more extensive range of natural movement. A further 3/4 of test subjects advocated that Baudi exhibited a broader range of FEs. Finally, 1/4 suggested that Baudi made consistent eye contact with them.
These outcomes suggest that Euclid functioned with a higher range of movement than Baudi. However, both robots are of the same build and implement the same tracking and face detection applications and operate using a single Kinect system paired between the two robots to minimise interference. Therefore, there should be few distinctions between the functionality of the RHRs apart from the eye and mouth components. Thus, it is probable that the appearance and skin movement of the RHRs influenced how test subjects perceived the movement of the RHRs, as both robots instigate eyebrow raises and cheek raises at random intervals using the Pololu microcontroller. Thus, it is probable that, during individual sessions, one robot expressed a more extensive range of these functions owing to the randomisation of the FEs. This configuration may account for the differences in emotive HRI as the RHRs function differently with a wide range of variables during each session. These outcomes support the findings of the literature review that suggest poor aesthetical quality supersedes quality functionality, and vice versa [20,21]. Gender analysis indicated that more male test subjects cited Euclid’s movement (M10, F6) as more naturalistic than Baudi (F3, M1). However, age-related statistics inferred little discernible difference between the naturalistic movement of Euclid (L8, H8) and Baudi (L2, H2).
Question 7. Which robotic head expressed the greatest range of facial expressions?
Here, 11/20 (55%) advocated that Euclid performed the broadest range of FEs. Another 4/11 suggested that Euclid’s eyebrow raises and cheek lifts were prominent, 2/11 explained that Euclid appeared to respond to questions with FEs, 2/11 argued that Euclid’s skin wrinkles and skin stretching made FEs appear more realistic, and 3/11 stipulated that Euclid portrayed a wider range of emotive FEs than Baudi. A further 8/20 (40%) suggested that Baudi displayed the broadest range of FEs. Another 5/8 argued that Baudi appeared to synchronise FEs with AI responses more coherently. Another 3/8 claimed that Baudi performed the widest range of FEs. Finally, 1/20 (5%) of test subjects advocated that they could not distinguish which RHR displayed the broader range of FEs.
These outcomes suggest that natural skin aesthetics play a significant role in displaying FEs in RHRs. This approach is vital in developing greater human-like RHRs as typical methods in RHR design neglect skin blemishes and wrinkles, as these features do not fit in with the paradigm of cutting-edge technologies. Gender statistical analysis suggested that a greater number of male participants thought Euclid expressed the broadest range of FEs (F2, M9) and F6, M2 stated Baudi displayed the most FEs. F1 unclassified. Age-related analysis indicated that more subjects in the higher age group thought Euclid displayed the most FEs—EL: 3, EH: 8 and BL: 6, BH: 2. L1 unclassified.
These results correspond with existing literature in FE recognition in human psychology. For example, a comprehensive study measuring facial FE recognition [117] discovered that older adults focus on the mouth area for gauging emotive FEs and younger individuals concentrate on the eyes. This consideration is significant as the robotic mouths are greater articulated and expressive than the robotic eyes, per the results of the literature review (practical versus virtual HRI for evaluating the UV). Thus, ‘own age advantage’ may account for test subjects in the higher age group recognising more FEs during HRI, as their attention is on the mouths of the RHRs rather than the eyes.
Question 8. Which AI did you prefer communicating with during the conversation?
Here, 13/20 (65%) preferred to interact with Euclid’s AI. Of this dataset, 4/13 indicated that they felt Euclid had more relatable interests and hobbies than Baudi. Another 7/13 cited that they felt Euclid gave more accurate and fully formed responses than Baudi’s and 2/13 advocated that Euclid’s personality was more engaging than Baudi’s. A further 7/20 (35%) preferred Baudi’s AI system, 3/7 of that dataset cited that Baudi gave more accurate and full responses, and 2/7 stated that they had more in common with the interests of Baudi. Moreover, 2/7 explained that they felt Baudi was the more engaging RHR. During HRI, many individuals attempted to deceive the RHRs into giving incorrect responses by asking questions outside the scope of the AI system. For example, one participant asked Baudi, “How many hairs do you have on your head?”, which produced an incorrect response of “My eyebrows are made of human hair”. Male test subjects: M8, F5 preferred to converse with Euclid, while M3, F4 preferred Baudi, and the higher age group favoured Euclid’s AI and the lower age group preferred Baudi’s AI: EL: 4, EH: 9 and BL: 6, BH:1.
Question 9. Which AI system did you prefer during the guessing game?
Here, 11/20 (55%) preferred Baudi’s conversational AI during the guessing game session. Another 8/11 cited Baudi as the more competent RHR. A further 2/8 of candidates advocated that Baudi had a broader knowledge base, and 1/8 stated that Baudi was more engaging. Moreover, 9/20 (45%) cited that they preferred to interact with Euclid during the guessing game session. Finally, 5/9 argued that Euclid produced more correct answers, 3/9 stated that Euclid had a wider knowledge base, and 1/9 explained that Euclid was more naturalistic during HRI.
As with the previous test, several subjects asked unusual or irrelevant questions to deceive the AI system. Male subjects preferred to interact with Baudi (M8, F3) and females with Euclid (M3, F6). However, there was little notable difference in the age-related factors—Baudi: L5, H6 and Euclid: L5, H4.
Question 10. Did you prefer communicating with an older or younger-looking robot?
Here, 12/20 (60%) preferred to communicate with Euclid. Of this dataset, 5/12 explained that they felt more comfortable interacting with an older looking robot because they felt trust towards an RHR with an aged appearance. Moreover, 2/13 suggested they prefer to interact with an older looking RHR as it was less intimidating than a younger model. A further 3/13 suggested that Euclid reminded them of older relatives, which made HRI less intimidating. Another 2/13 stated that as they felt Euclid looked more humanlike than Baudi, Euclid’s highly realistic appearance made the communication more naturalistic. Another 8/20 (40%) advocated that they prefer to communicate with Baudi, and 5/8 explained that Baudi appeared less threatening because his appearance was softer.
Moreover, 2/8 indicated that they felt Baudi was more engaging than Euclid and 1/8 suggested that, as they interact more with younger people daily, they felt a greater connection with a young-looking RHR. These results indicate that participant outcomes were closely divided between communication with a younger-looking robot and an older looking RHR. This finding is intriguing as it correlates with the age-related statistics, which infers that the higher age group favoured interaction with Euclid (H8, L4) and the lower age group preferred HRI with Baudi (H2, L6). This outcome is vital to this study as the results suggest that younger test subjects felt a greater connection with a younger-looking RHR, and the older age group felt a greater connection with an older looking RHR. Moreover, although Baudi is designed to look younger than Euclid, neither RHR is assigned a specific age, meaning participants were left to decide how old the robots appeared to them. Interestingly, several subjects interpreted the appearance of the RHRs as threatening or intimidating, depending on how old they looked. This result may relate to how young people perceive older adults and older people see younger individuals in society. Gender factors did not influence decision making; F5, M7 preferred to interact with a robot with an elderly appearance and F4, M4 preferred HRI with a younger-looking robot.
4.1. Comparative Analysis of Qualitative and Quantitative Results (All Test Subjects)
Series 1A. Likeability: (Q11, Q14, Q17, Q20, and Q23). On average, Baudi rated 4/5 more likeable than Euclid 1/5. Internal consistency was high in this subset, 0.8 α, indicating high levels of consistency in participant responses. These results confirm the outcomes of Q3, Q6, and Q7 in which candidates cited a more significant emotional response to Baudi during HRI. However, these results contrast with the results of Q10, where test subjects preferred to interact with an older looking RHR (Euclid) over a younger-looking RHR (Baudi). These outcomes collectively conclude that participants found Baudi more likeable than Euclid.
Series 2A. Human-likeness: (Q13, Q15, Q18, Q21, and Q25). Test subjects rated Euclid 4/5 more human-like than Baudi 1/5. Coefficient factors were high in the subset, 0.9 α, suggesting a high level of accuracy in participant outcomes. However, 1/5 (Q15) of test subject outcomes were of an equivalent rating on the five-point Likert scale (3). These results validate the findings of Q1 of the HRI questionnaire, where test subjects cited Euclid as appearing, functioning, and moving more humanlike than Baudi. Therefore, these outcomes collectively conclude that test subjects found Euclid more humanlike than Baudi.
Series 3A. Competency: (Q12, Q16, Q19, Q22, and Q24). Test subjects rated Euclid 3/5 as more competent than Baudi 2/5. However, out of these results, 2/3 (Q19 & Q24) rated equivalent (3) on the five-point Likert scale. Internal consistency was acceptable, 0.7 α, suggesting some variance in the outcomes of participants’ responses. These results collate with the findings of Q6–Q8, which cite Euclid as moving and responding to participants more competently than Baudi. However, these results contrast with the outcomes of Q2 and Q13, which suggested Baudi’s AI functioned with a higher degree of competency during the guessing game session and clarity in speech synthesis during verbal HRI. These results collectively confirm that participants rated Euclid as the more competent RHR during HRI.
4.2. Comparative Analysis of (Q1–14) and (Q21–35) Results (Male & Female)
Series 1B. Likeability: (Q11, Q14, Q17, Q20, and Q23). Male subjects liked Euclid 3/5 more than female subjects 2/5, and 3/5 (Q14 and Q20) equivalent ratings of (3). Female subjects rated Baudi as more likeable 3/5 than male subjects 1/5; coefficient factors were high in this subset, 0.8 α, suggesting high consistency in the results of Series 1B. These results correspond with the results of Q3 as more female test subjects cited feeling an emotional response to Baudi: F5/M0, and Q4–Q5 were female participants stated feeling emotional during eye contact interfacing with Baudi: F7, M1. These results collectively conclude that male subjects preferred Euclid and female test subjects favoured Baudi.
Series 2B. Humanlikeness: (Q13, Q15, Q18, Q21, and Q25). Group analysis of Series 2 indicates that both gender groups rated Euclid as more humanlike (4/5) and females liked Baudi more than male subjects M0/5, F1/5. Internal consistency was high, 0.9 α, in the collective results of Series 2. These outcomes support and validate the findings of Q1, where both gender groups rated Euclid as more humanlike: Euclid: F8, M10 and Baudi: F1, M1. In Q5, both gender groups preferred Euclid’s eye aesthetics: Euclid: F6, M9 and Baudi: F2, M2. In Q6, both gender groups cited Euclid’s eyes as moving the more human-like: Euclid: F5, M7.
Series 3B. Competency: (Q12, Q16, Q19, Q22, and Q24). Male test subjects rated Euclid as more competent: (E: M2/5, F1/5) and (B: M1/5, F1/5); 2/5 of ratings were equivalent [3], Q16 and Q24. Internal consistency was acceptable, 0.7 α, suggesting some level of variance in participant results. These results correlate Q7 in which male test subjects cited Euclid as displaying a broader range of FEs than Baudi: E: F2, M9 and B: F6, M2. Q8 as male test subjects achieved higher accuracy in Euclid’s 5-min topical conversation AI test, ME: 146 (51%), FE: 136 (49%) and MB: 88 (56%), FB: 65 (44%). In Q9, male participants achieved higher accuracy scores in the 5-min guessing game AI test. However, these results contrast with the results of Q2, where more males cited Baudi’s speech synthesis as more understandable than Euclid, (B: M9, F4 and E: M2, F5). These outcomes are difficult to collectively verify owing to the level of variance in results of the gender statistical analysis.
4.3. Comparative Analysis of (Q1–14) and (Q21–35) Results (Age Groups)
Series 1C. Likeability: (Q11, Q14, Q17, Q20, and Q23). The higher age group (18–27) liked Euclid: EL: 1/5, EH: 3/5 and 1/5 (Q20) rating of (3) and the lower age group BL3/5, EH1/5, and 1/5 (Q23) rating of (3). Coefficients were 0.8 α, indicating a high level of consistency in participant outcomes.
These findings correlate with the results of Q3: emotions during HRI (E: L2, H3 and B: L0, H2). Q6–Q7 eye contact interaction, Euclid: L6, H7 and Baudi L3, H5. In Q14, the lower age group preferred HRI with Baudi and the higher age group with Euclid: E: H8, L4 and B: H2, L6. Therefore, these results collectively substantiate and validate the findings that the younger age group preferred HRI with Baudi, and the more mature age group preferred HRI with Euclid.
Series 2C. Humanlikeness: (Q13, Q15, Q18, Q21, and Q25). Euclid rated L4/5 and H 3/5 and Baudi L0/5 H1/5. Coefficient factors were high in the dataset, 0.9 α, suggesting a high level of consistency in participant responses. These results correspond with the outcomes of Q1, where both age groups cited Euclid as the more humanlike RHR: E: L9, H9 and B: L1, H1. In Q4, both age groups suggested Euclid’s eye movement as the more aesthetically realistic: E: H8, L6 and B: H2, L2, L1 unclassified.
However, these results conflict with the results of Q5 as the higher age group preferred the eye movement of Euclid, E: H8, L4 and B: H2, L6. These results collectively conclude that both age groups rated Euclid as the most human-like RHR.
Series 3C. Competency: (Q12, Q16, Q19, Q22, and Q24). The lower age group rated Euclid as more competent 3/5 than the higher age group 2/5, and (3) in Q13, Q16, and Q24 and Baudi rated 2/5 in the higher age group and 1/5 in the lower age group. Internal consistency was acceptable, 0.7 α, suggesting some variance in participant outcomes. These results correlate with Q6 and Q7, where both age groups rated Euclid as moving more naturally in head movement: E: L7, H8 and B: L3, H1 and mouth movement L10, H1. However, these results conflict with Q2 speech synthesis, B: L8, H4 and E: L2, H6. Q11 FEs, EL: 3, EH:7 and BL: 6, BH: 3. Q12 AI topical conversation session EL: 129 (46%), EH: 154 (54%) and BL: 95 (39%), BH: 145 (61%) and Q13 5-min AI guessing game: EH: 369 (54%), EL: 316 (46%). The quantitative questionnaire results of Series 3C conflict with the findings of the qualitative results (Q1–10), making the outcomes of this dataset difficult to cross-analyse and substantiate.
4.4. Analysis of FEA and GSR Biometric Data Feeds
The following section examines the FEA and GSR biometric data feed extracted from test subjects during the HRI experiment. The FEA reads the following FEs from 0–100%.
- Rest, 0–100%: this configuration is the default position of the FEA system.
- Frown, 0–100%: the frown function measures negative Fes, which examine the position of the lips, cheeks, and eyebrows.
- Smile, 0–100%: similar to the frown function, the FEA system measures the correlation and position of the lips, cheeks, and eyebrows to determine if and to what extent the test subject expresses a positive facial expression.
- Disengage, 0–100%: this mode engages when the system is unable to track the user.
- Attention, 0–100%: the FEA system measures the frequency of the test subjects eye positions with the camera position to monitor attention rates.
The GSR data combined with the FEA data provide an overview of the type and level of stress experienced by the test subjects at any given state. This combinatory approach permits the verification of positive and negative emotional states in the GSR and FEA data to eliminate interference from other facial movements such as speech, gesturing, and facial tics that may register as a positive or negative facial expression in the FEA application. This method acts as a low pass filtration system and permits greater accurate measurements of frequency, duration, and range of emotive FEs for comparative analysis between the AI results and the findings of the HRI questionnaire.
4.4.1. All Test Subjects: 5-Min Conversation. FEA and GSR Data Analysis
The results of the FEA biometric data analysis indicated that test subjects spent more time in the rested state when interacting with Euclid (Avg 18%). Compared with Baudi (Avg 15%), suggesting participants spent more time in the neutral facial position when interacting with Euclid. Negative FEA data was higher in Euclid’s results (Avg intensity (INTST), 8%, Fq: 228, Avg: 11) compared with Baudi (Avg INTST, 7%, Fq: 213, Av: 11), suggesting subjects experienced greater negative stimulus during HRI with Euclid. Positive FEA results cite a greater positive FE HRI with Baudi (Avg INTST, 10%, Fq: 200, Avg: 10) compared with Euclid (Avg INTST, 9%, Fq: 201, Avg: 10). The attention level was marginally higher in Baudi’s FEA results, Avg: 73% compared with Euclid, Avg: 72%, as shown in Figure 4. However, subjects exhibited more disengaging behaviour with Baudi than Euclid (B: 53. Avg 3, E: 41. Avg 2). The FEA results validate the results of the Series 1A (likeability), Series 2A (Human-likeness), and Series 2A (competency). These outcomes collectively suggest greater humanlike RHRs emit higher levels of the UV.
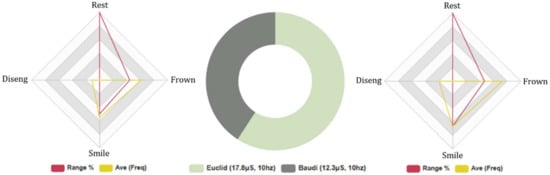
Figure 4.
Five-min topical AI conversation experiment: all test subjects. Biometric data—Left: Euclid facial expression analysis (FEA) results, Right: Baudi FEA results, Middle: Euclid and Baudi galvanic skin response (GSR).
Interestingly, although the FEA results were marginal, the range of internal consistency was low across the data set (0.04 α/0.5 α), suggesting very high levels of variance. Therefore, per the results of the FE data analysis, although test subjects expressed a wide range of FEs during the 5-min AI conversation experiment, these did not significantly change in frequency or intensity between the RHRs. However, the GSR data analysis indicated higher levels of stress during HRI with Euclid: total Avg, 17.8 μS. (Neg stimuli: Avg 5.6 μS/Pos stimuli: Avg 4.2 μS) compared with Baudi: Total Avg, 12.3 μS. (Neg stimuli: Avg 2.1 μS/Pos stimuli: Avg 4.2 μS), suggesting test subjects experienced a greater negative HRI experience with Euclid as cited in the results of Series 1A.
4.4.2. Euclid: Females and Males, 5-Min Conversation. Biometric Data Analysis
The FEA results indicate that male test subjects spent more time in the rested FE state when interfacing with Euclid (M: 20%, F: 16%). Negative FEA data were higher in male subjects, M: (Avg INTST, 9%, Fq: 118, Avg: 11), F: (Avg INTST, 7%, Fq:110, Avg: 12). Comparatively, male subjects displayed greater positive FE than female participants, M: (Avg INTST, 11%, Fq: 125, Avg: 11), F: (Avg INTST, 7%, Fq: 76, Avg: 8). These results suggest that male participants expressed the greatest range and intensity of negative and positive FE. The average attention level was similar in the results of male and female test subjects, M: Avg 73% and F: Avg 72%. However, male subjects exhibited more disengaging behaviour than female subjects, (M: 26. Avg 2, F: 19. Avg 2), suggesting greater accuracy in the results of female subjects, as shown in Figure 5.
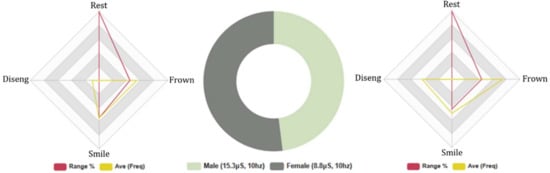
Figure 5.
Euclid: 5-Min topical AI conversation, male/female subjects. Biometric data—Left: male FEA results, Right: female FEA results, Middle: male and female GSR.
Coefficient factors ranged between (0.03 α/0.7 α), indicating a high level of variance in the test results. However, as in the previous set of results, male test subjects expressed similar FE intensities to females, yet FE frequencies were significantly higher in male subjects (M: 429, F: 243), indicating that males engaged with greater emotional FE and HRI with Euclid. Conversely, the GSR biometric data analysis showed that female test subjects exhibited higher levels of stress during HRI with Euclid compared with male participants, F: Total Avg, 19.3 μS. (Neg stimuli: Avg 4.9 μS/Pos stimuli: Avg 4.4 μS) and M: Total Avg, 16.6 μS. (Neg stimuli: Avg 3.2 μS/Pos stimuli: Avg 2.8 μS). The GSR results contradict the FE results; therefore, it is likely that, although female test subjects displayed less FE than males, female subjects responded with higher electrodermal activity ‘stress’. The FEA test results support the outcomes of Series 1B (likeability) and Series 3B (competency), and per the UV, the GSR results support the findings of Series 2B (human-likeness) as both gender groups rated Euclid as humanlike at a rate of (4/5).
4.4.3. All Test Subjects, 5-Min Guessing Game, Biometric Data Analysis
The FEA results suggest that candidates spent more time in a neutral FE state when interacting with Baudi during the 5-min guessing game session (B: 13%, E: 14%). Negative FEA indicates that test subjects experienced higher levels of negative FE intensity when interacting with Euclid. However, negative FE frequencies were more elevated in Baudi’s results, Euclid: (Avg INTST, 10%, Fq: 322, Avg: 16) and Baudi: (Avg INTST, 9%, Fq: 325, Avg: 16), suggesting that, although participants expressed a higher rate of negative FE during HRI with Baudi, negative FE intensity was greater during HRI with Euclid. Positive FEA results indicate higher levels of positive FE during HRI with Baudi, E: (Avg INTST, 7%, Fq: 205, Avg: 10), B: (Avg INTST, 8%, Fq: 197, Avg: 10), suggesting test subjects experienced greater positive FE during HRI with Baudi. The average level of attention was higher during HRI with Baudi, E Avg 71% and B: Avg 74%. However, disengaging behaviour in test subjects was significantly higher in Baudi’s results, but similar on average (E: 20. Avg 2, B: 49. Avg 2), suggesting specific individuals exhibited high levels of disengaging behavior, which was not representative of the whole dataset.
These results correlate with Series 1A (likeability), where subjects cited Baudi positive emotional responses. Internal consistency was low across the dataset ranging between (−0.06 α/0.4 α), indicating a high level of variance in FEA data. On average, GSR results suggest higher levels of positive electrodermal activity during HRI with Baudi and greater negative GSR during HRI with Euclid, which supports the FEA results and the results of Series 2A (human-likeness) and Series 3A (competency) per the UV. Euclid: Total Avg, 10.10 μS. (Neg stimuli: Avg 4.3 μS/Pos stimuli: Avg 2.8 μS) and Baudi: Total Avg, 12.10 μS. (Neg stimuli: Avg 3.1 μS/Pos stimuli: Avg 5.2 μS), depicted in Figure 6.
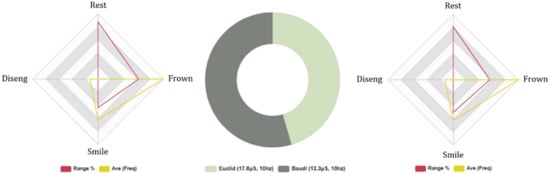
Figure 6.
Five-min AI guessing game experiment: all test subjects. Biometric data comparison—Left: Euclid FEA results, Right: Baudi FEA results, Middle: GSR results.
4.4.4. Baudi: Females and Males, 5-Min Conversation. FEA/GSR Data Analysis
The FEA results cite that female subjects spent more time in the rested FE state during HRI with Baudi (F: 16%, M: 15%). Negative FEA was higher in male subjects, M: (Avg INTST, 7%, Fq: 125, Avg: 11), F: (Avg INTST, 6%, Fq:88, Avg:10), suggesting that, although FE intensity was similar in both gender groups, the frequency of negative FE was significantly higher in male subjects. Comparatively, positive FEA was higher in male participants, M: (Avg INTST, 11%, Fq: 114, Avg: 10), F: (Avg INTST, 8%, Fq: 86, Avg: 10), indicating similar levels of intensity in both gender groups. However, positive and negative FE frequencies were considerably higher in male test subjects compared with female participants. The FEA results suggest that male subjects experienced higher levels of emotive FE during HRI with Baudi than female subjects. The average attention level was higher in the male test group, M: Avg 74% and F: Avg 72% and similar in disengaging behaviour, (M: 29. Avg 3, F: 23. Avg 3), suggesting marginally higher accuracy in the results of female participants. Internal consistency was low in the dataset ranging from (0.02 α/0.7 α), indicating high variability in the FEA test results.
The FEA results correspond with the Series 1B (likeability) and Series 3B (competency), as male subjects rated the RHRs higher than females. However, the FEA data conflict with the outcomes of Series 2B (human-likeness), which cited both gender groups as experiencing similar emotions during HRI. GSR data analysis reinforces the results of the FEA data and questionnaire results, as male subjects discharged higher levels of electrodermal activity than female participants, M: Total Avg, 15.3 μS. (Neg stimuli: Avg 3.6 μS/Pos stimuli: Avg 4.2 μS) and F: Total Avg, 8.8 μS. (Neg stimuli: Avg 2.1 μS/Pos stimuli: Avg 3.5 μS), suggesting that male subjects experienced significantly higher levels of positive and negative emotional stimulus during HRI, depicted in Figure 7.
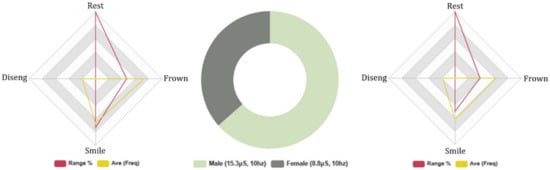
Figure 7.
Baudi: 5-min topical AI conversation, male/female subjects. Biometric bata—Left: male FEA results, Right: female FEA results, Middle: male and female GSR results.
4.4.5. Euclid: Age Groups, 5-Min Conversation. FEA/GSR Data Analysis
The FEA results indicate that the lower age group spent significantly more time in a neutral FE state, L: 21%, H: 15%, during HRI with Euclid. Negative FEA was higher in the lower age group for FE intensity and frequency, L: (Avg INTST, 9%, Fq:118, Avg: 12), H: (Avg INTST, 8%, Fq: 110, Avg: 11). Positive FEA results indicate that both age groups experienced similar positive FE intensities and total frequencies. However, the average positive FE frequency was greater in the higher age group. L: (Avg INTST, 9%, Fq: 94, Avg: 9), H: (Avg INTST, 9%, Fq: 107, Avg: 11).
The average level of attention was higher in the lower age group, L: Avg 73% and H: Avg 71% and the lower age group exhibited higher levels of disengaging behaviour (L: 19. Avg 2, H: 22. Avg 2), suggesting similar levels of accuracy in both gender groups. Coefficients were incredibly low across the dataset, ranging between (−0.05 α/0.6 α), indicating a high level of variance in FEA test results. These outcomes support the findings of Series 1C (likeability), where the higher age group rated a greater positive HRI experience with Euclid. Furthermore, the FEA outcomes verify the results of Series 2C (human-likeness), where the lower age group rated Euclid as more human-like, and Series 3C (Competency), where both age groups cited similar positive and negative emotions during HRI.
The results of the GSR data analysis indicated greater levels of electrodermal activity positive and negative stimuli in the higher age group, L: Total Avg, 22.5 μS. (Neg stimuli: Avg 4.4 μS/Pos stimuli: Avg 5.1 μS) and H: Total Avg, 13.2 μS. (Neg stimuli: Avg 6.2 μS/Pos stimuli: Avg 3.4 μS). The GSR outcomes add validity to the findings of the FEA data analysis as they suggest that the lower age group exhibited greater negative emotions during HRI with Euclid compared with the senior group, as shown in Figure 8.
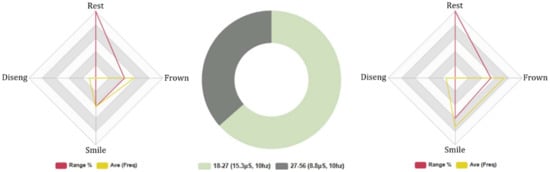
Figure 8.
Euclid: 5-min topical AI conversation age groups. Biometric data—Left: (27–56) FEA results, Right: (18–27) FEA results, Middle: (18–27)/(27–56) GSR.
4.4.6. Baudi: Age Groups, 5-Min Conversation. FEA/GSR Analysis
The FEA results indicate that the lower age group spent more time in a rested FE state (L: 17%, H: 14%). Negative FEA intensity was proximal in both age groups; however, negative FEA frequency was marginally greater in the higher age group, L: (Avg INTST, 7%, Fq: 101, Avg: 10), H: (Avg INTST, 7%, Fq: 112, Avg: 11). These results suggest that the higher age group experienced similar negative emotions during HRI with Baudi. Conversely, positive FEA was significantly greater in the higher age group, H: (Avg INTST, 9%, Fq: 103, Avg: 10), L: (Avg INTST, 8%, Fq: 97, Avg: 10), indicating that the higher age group expressed greater positive emotional HRI with Baudi.
The average attention level was higher in the lower age group, L Avg 73% and H: Avg 71%, and the higher age group exhibited significantly greater disengaging behaviours (H: 33. Avg 3, L: 19. Avg 2). These results suggest greater concentration during HRI and higher accuracy in the results of the lower age group. Coefficient factors were relatively low in the dataset, ranging between (0.2 α/0.6 α), suggesting a high level of variability in the FEA test results. GSR data analysis indicates that, on average, the lower age group exhibited greater electrodermal activity than the higher age group, L: Total Avg, 16.8 μS. (Neg stimuli: Avg 2.4 μS/Pos stimuli: Avg 4.1 μS) and H: Total Avg, 7.9 μS. (Neg stimuli: Avg 3.1 μS/Pos stimuli: Avg 2.5 μS). However, both age groups discharged similar levels of negative electrodermal activity, and the higher age group exhibited greater positive GSR readings, which support the outcomes of the FEA data analysis, as shown in Figure 9. These results collectively support the findings of Series 2C (human-likeness) and Series 3C (competency), as test subjects cited similar ratings and positive and negative emotions during HRI with the RHRs. However, more significantly, these results support the outcome of Series 1C (likeability), which suggests that the lower age group preferred HRI with a younger-looking RHR.
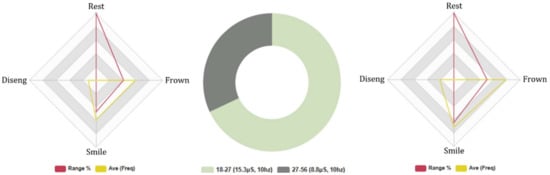
Figure 9.
Baudi: 5-Min topical AI conversation age groups. Biometric data—Left: (18–27) FEA results, Right: (27–56) FEA results, Middle: (18–27, 27–56) GSR.
4.5. FEA/GSR Biometric Data Analysis: 5-Min Guessing Game HRI
4.5.1. Euclid: Females and Males 5-Min Guessing Game, FEA/GSR Analysis
The FEA results indicate that male subjects spent more time in a neutral FE position (M: 14%, F: 13%). Negative FE results were higher in male test subjects, M: (Avg INTST, 11%, Fq: 179, Avg: 16), F: (Avg INTST, 9%, Fq: 143, Avg: 16). Positive FEA was also higher in male candidates (Avg INTST, 8%, Fq: 118, Avg: 11) compared with female participants (Avg INTST, 7%, Fq: 87, Avg: 10), suggesting male test subjects exhibited greater emotive FE during the 5-min guessing game HRI session. The FEA data support the findings of Series 1B (likeability) and 3B (competency), where male subjects cited comparable results. Coefficient factors were low across the dataset, ranging between (0.01 α/0.5 α), indicating a high level of variance in FEA results.
However, male subjects exhibited significantly more disengaging behaviour than female subjects (M: 32. Avg 3, F: 15. Avg 2), suggesting greater accuracy and attention in the results of female subjects. The results of the average attention rate support these outcomes as female participants rated higher levels of concentration than males, M: Avg 71% and F: Avg 72%. GSR data analysis indicated that female test subjects demonstrated higher levels of positive and negative electrodermal activity than male candidates, Males: Total Avg, 9 μS. (Neg stimuli: Avg 3.6 μS/Pos stimuli: Avg 1.5 μS) and Females: Total Avg, 14 μS. (Neg stimuli: Avg 3.1 μS/Pos stimuli: Avg 2.4 μS), as shown in Figure 10. The FEA and GSR results add validity to the results of the 5-min topical conversation session with Euclid, where male subjects expressed greater emotive FE, and female participants expressed greater emotional GSR during HRI. These results support the findings of Series 2B (human-likeness), where both gender groups rated comparable feelings and emotions during HRI.
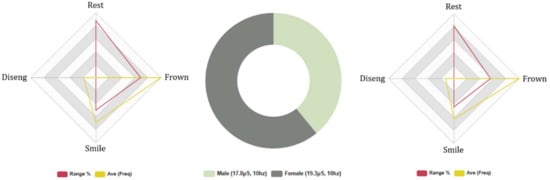
Figure 10.
Euclid: 5-min AI guessing game test: male/female subjects. Biometric data—Left: male FEA results, Right: female FEA results, Middle: male and female GSR.
4.5.2. Baudi: Females and Males, 5-Min Guessing Game, FEA/GSR Analysis
The FEA results indicate that female test subjects registered greater neutral FE states during HRI with Baudi, (M: 12%, F: 13%). The negative FEA outcomes suggested male subjects exhibited greater intensity and frequency of negative FE, M: (Avg INTST, 10%, Fq: 187, Avg: 17). F: (Avg INTST, 8%, Fq: 138, Avg: 15), and both gender groups expressed similar positive FE intensity M: (Avg INTST, 8%, Fq: 109, Avg: 10), F: (Avg INTST, 8%, Fq: 88, Avg: 10). However, positive FE frequencies were higher in the results of male test subjects. The FEA results support the outcomes of Series 1B (likeability) and Series 2B (human-likeness), where male subjects rated Baudi as the less humanlike and competent RHR compared with female candidates—M0/5, F1/5.
Attention levels were higher in female test subjects, M: Avg 72% and F: Avg 76%, and male subjects exhibited greater disengaging behaviours (M: 29. Avg 3, F: 20. Avg 2), suggesting greater immersion and accuracy in the results of female subjects. Internal consistency was low across the dataset, ranging between (0.01 α/0.4 α), indicating high levels of variance in the FEA data. GSR results suggest that female test subjects exhibited higher levels of electrodermal activity than male candidates, M: Total Avg, 8 μS. (Neg stimuli: Avg 2.2 μS/Pos stimuli: Avg 1.9 μS) and F: Total Avg, 16 μS. (Neg stimuli: Avg 4.2 μS/Pos stimuli: Avg 3.9 μS), as highlighted in Figure 11. Interestingly, these results correlate with Baudi’s FEA and GSR results during the 5-min topical conversation session. Therefore, it is highly likely that the male test subjects expressed greater positive and negative emotive FE, and female participants dispersed higher levels of positive and negative electrodermal activity during HRI with Baudi. These outcomes are significant as results cite notable differences between the gender groups in FEA and GSR data, which adds greater validity to the results of Series 3B (competency).
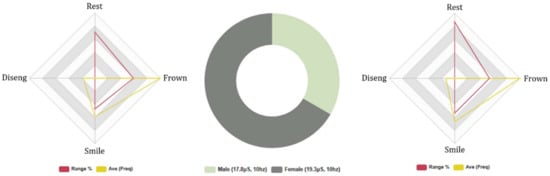
Figure 11.
Baudi: 5-min AI guessing game test: male/female test subjects. Biometric data—Left: male FEA results, Right: female FEA results, Middle: male and female GSR.
4.5.3. Euclid: Age Groups: 5-Min Guessing Game, FEA/GSR Analysis
The FEA results suggest that the lower age group spent more time in a rested FE state (L: 14%, H: 13%). Negative FEA was higher in the lower age group in intensity and frequency, L: (Avg INTST, 11%, Fq: 177, Avg: 18), H: (Avg INTST, 8%, Fq: 145, Avg: 15). Conversely, positive FEA intensity and frequency were greater in the higher age group, L: (Avg INTST, 7%, Fq: 101, Avg: 10), H: (Avg INTST, 8%, Fq: 104, Avg: 10). The negative and positive FEA outcomes parallel with Euclid’s previous FEA results in the 5-min topical conversation session. The FEA results correspond with the findings of Series 1C (likeability), where the higher age group cited having a positive HRI, and Series 2C (human-likeness) and Series 3C (competency), where the higher age group rated Euclid as more humanlike (per the UV).
Internal consistency was low, ranging between (0.01 α/0.5 α), indicating high variability in the FEA data. The average attention rate was greater in the higher age group, L: Avg 69% and H: Avg 73%. However, the higher age group exhibited more disengaging behaviours (L: 29. Avg 3, H: 20. Avg 2). These results suggest higher attention levels in the lower age group and greater distraction in the higher age group. The FEA results contrast with the 5-min topical conversation session AI data. A probable cause for this shift is the parameters of the gamification session, which requires concentration and strategy, compared with the 5-min topical conversation session, which is relaxed and unstructured. GSR readings indicate that the lower age group exerted higher levels of positive electrodermal activity than the higher age group, and negative GSR was higher in the lower age group, H: Total Avg, 15 μS. (Neg stimuli: Avg 3.6 μS/Pos stimuli: Avg 2.3 μS), and L: Total Avg, 8 μS. (Neg stimuli: Avg 2.9 μS/Pos stimuli: Avg 3.9 μS). The GSR results correlate and support the results of the FEA data, as shown in Figure 12.
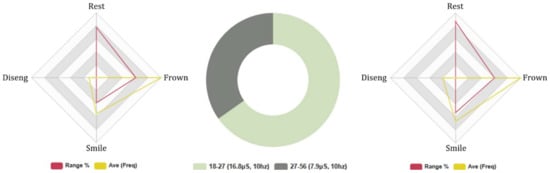
Figure 12.
Euclid: 5-min AI guessing game, age groups (18–27)/(27–56). Biometric data—Left: (18–27) FEA results, Right: (27–56) FEA results, Middle: (18–27)/(27–56) GSR.
4.5.4. Baudi: Age Groups: 5-Min Guessing Game, FEA/GSR Analysis
The FEA results indicate higher levels of resting FE behaviour in the lower age group (L: 12%, H: 13%). Negative FEA intensity was greater in the higher age group, and negative FEA frequency was higher in the lower age group, L: (Avg INTST, 9%, Fq: 164, Avg: 16), H: (Avg INTST, 10%, Fq: 161, Avg: 16). Conversely, positive FEA results indicate that the higher age group expressed greater intensive and frequent FE, L: (Avg INTST, 8%, Fq: 95, Avg: 10), H: (Avg INTST, 9%, Fq: 102, Avg: 10), as illustrated in Figure 13. Coefficient factors were low, ranging between (0.01 α/06. α), indicating high levels of variance in the FEA data. Attention levels were greater in the higher age group, L: Avg 73% and H: Avg 75%, and disengaging behaviour was lower in the higher age group (L: 26. Avg 3, H: 23. Avg 2). The FEA results conflict with the previous FEA results registered during the 5-min topical conversation session, as observed in Euclid’s results. The GSR results indicate that the lower age group exerted significantly higher levels of positive and negative electrodermal activity, H: Total Avg, 18 μS. (Neg stimuli: Avg 4.1 μS/Pos stimuli: Avg 3.3 μS) and L: Total Avg, 6 μS. (Neg stimuli: Avg 1.9 μS/Pos stimuli: Avg 1.1 μS). These outcomes support the findings of Series 1C (likeability) and Series 2C (human-likeness), and conflict with the results of Series 3C (competency), as the lower age group rated Baudi as the more competent RHR.
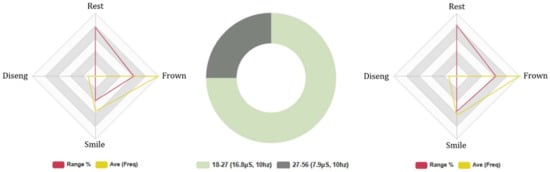
Figure 13.
Baudi: 5-min AI guessing game, age groups (18–27)/(27–56). Biometric data—Left: (18–27) FEA results, Right: (27–56) FEA results, Middle: (18–27)/(27–56) GSR.
However, the lower age group exhibited higher GSR and FEA readings in the gamification session than the topical conversation component. These results suggest the lower age group experienced a greater immersive and visceral HRI during the guessing game session compared with the more mature age group, which exerted higher biometric feedback during the verbal communication component. These outcomes are explored and comparatively analysed against the Amazon Web Services (AWS) AI data in the following section.
4.6. Topical Conversational and Guessing Game AI Data Analysis
The following section examines the results of the 5-min topical conversation and the guessing game AI sessions recorded in AWS during HRI. The results are categorised and cross-analysed with the HRI questionnaire results and FEA and GSR data to validate findings.
4.6.1. Euclid and Baudi: All Test Subjects, Topical Conversational AI Data
Euclid delivered 283/545 (52%) of questions correctly, Figure 14, and Baudi achieved a lower rating of 241/497 (48%), Figure 15. Euclid produced incorrect responses at a rate of 158/545 (28%) and Baudi 153/497 (31%), and Euclid executed the ‘please repeat’ command of 144/545 (20%) compared with Baudi of 105/497 (21%). These results do not tally with the findings of Q8, as subjects cited Euclid as providing more correct responses, E: 7/13, B: 3/7. However, the AI test results support the outcomes of Series 3A, as subjects rated Euclid as the more competent RHR (incorrect and repeat responses), and the FEA and GSR, as subjects rated higher levels of positive biofeedback during HRI with Baudi.
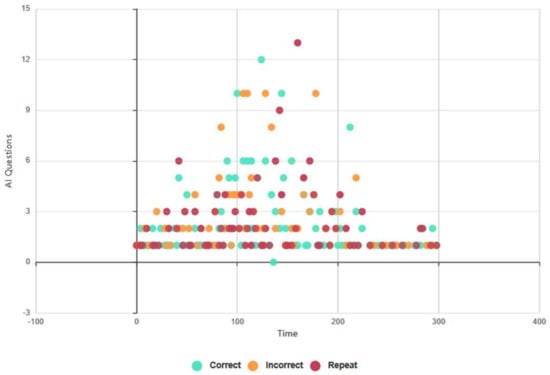
Figure 14.
Euclid: 5-min topical conversation, AI data (all test subjects).
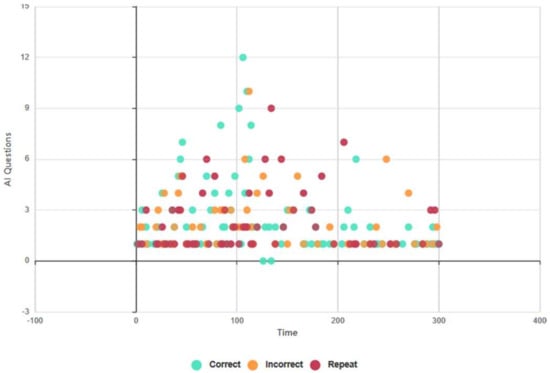
Figure 15.
Baudi: 5-min topical conversation, AI data (all test subjects).
4.6.2. Euclid and Baudi: Males and Females, Topical Conversation AI Data
Male test subjects achieved a greater number of correct AI responses than females during HRI with Euclid, EM: 146 (47%) and EF: 136 (55%), depicted in Figure 16, and similarly with Baudi, BM: 133 (45%) and BF: 108 (54%), Figure 17. The AI test results support the outcomes of Q9 as more male test subjects—M8, F5—preferred to converse with Euclid, and similarly in the results of Baudi (M3, F4), as Euclid achieved greater accuracy (E: 283, B: 241). However, males scored a higher rate of incorrect responses than females—EM: 96 (31%), EF: 62 (25%) and BM: 88 (30%), BF: 65 (32%)—and in instigating the ‘please repeat’ response, EM: 66 (22%), EF: 48 (20%) and BM: 72 (25%), BF: 33 (16%), which suggests male test subjects asked a higher number of questions outside the scope of the AI system. These results support the findings of Series 3B (competency), as male candidates rated Euclid as the more competent RHR, and correlate with the gender-based FEA and GSR biometric data results during the topical conversation session.
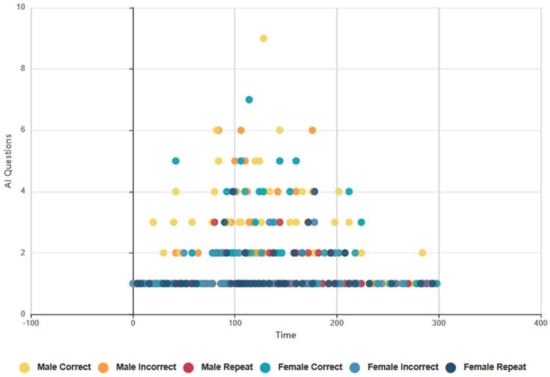
Figure 16.
Euclid: 5-min topical conversation, AI data (males and females).
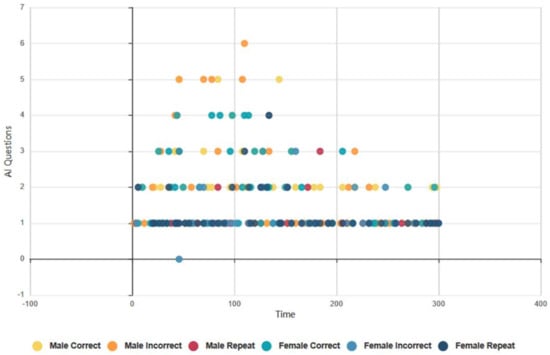
Figure 17.
Baudi: 5-min topical conversation, AI data (males and females).
4.6.3. Euclid and Baudi: Age Groups Topical Conversational AI Data
The higher age group achieved a greater number of correct responses during HRI with Euclid, EL: 129 (47%), EH: 154 (55%); similar results during HRI with Baudi, BL: 95 (39%), BH: 145 (61%); in incorrect answers, EL: 87 (55%), EH: 71 (45%) and BL: 74 (41%), BH: 79 (30%); and in instigating the ‘please repeat’ response, EL: 59 (21%), EH: 55 (20%) and BL: 61 (27%), BH: 44 (16%), suggesting a greater competency in the higher age group, which corresponds with the outcomes of Q8: EL: 4, EH: 9 and BL: 6, BH: 1, shown in Figure 18 and Figure 19. However, the AWS AI findings contradict the results of Series 3C (competency), as the lower age group rated Euclid as the most competent RHR and the lower age group cited Baudi as the more competent RHR. Nevertheless, these outcomes support the findings of the biometric data analysis as the higher age group exhibited greater FEA, GSR, and attention during the topical conversation session.
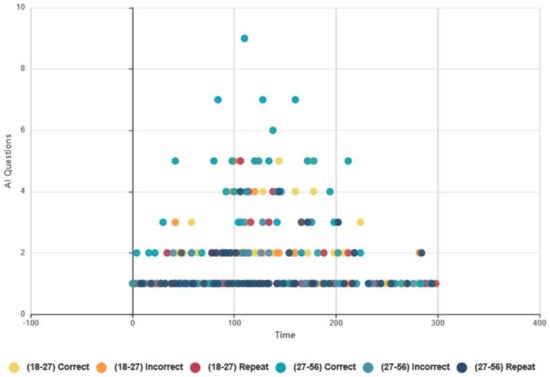
Figure 18.
Euclid: 5-min topical conversation, AI data (age groups).
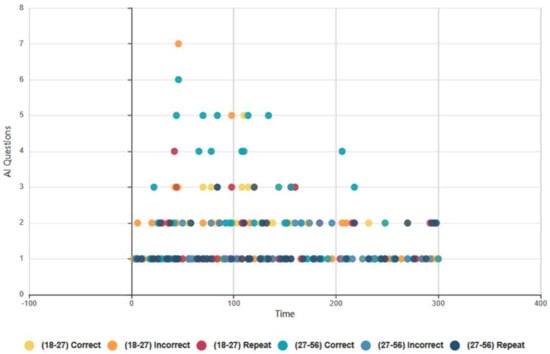
Figure 19.
Baudi: 5-min topical conversation, AI data (age groups).
4.6.4. Euclid and Baudi: All Test Subjects, Guessing Game AI Data
The objective of the AI guessing game was to engage subjects with a greater challenging mode of HRI to examine how the DL AI functioned at a faster rate of processing. The AI results indicate that Baudi achieved a marginally higher accuracy rating than Euclid: B: 705/1235, (57%) and E: 685/1223, (56%). However, Baudi generated a higher sum of incorrect answers than Euclid, B: 257/1235, (21%) and E: 245/1223, (20%), and ‘please repeat’ replies, E: 292 (24%) and B: 273 (22%), as shown in Figure 20 and Figure 21. These results support the findings of Series 3A (competency), as test subjects rated the RHRs as competent, E: 3/5 and B: 2/5 with (2/5 equivalent ratings of 3). Significantly, the results of Q9 (guessing game) conflict with the findings of Series 3A, yet validate the AWS AI data. Thus, Euclid rated as more competent in movement and Baudi in AI interaction during the guessing game session. Furthermore, the biometric data analysis validates the AI results as Baudi rated higher in positive FEA/GSR than Euclid during this session.
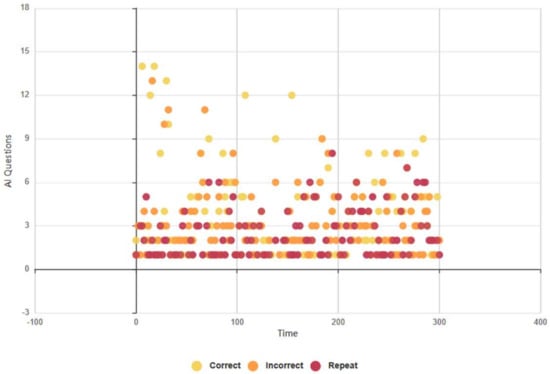
Figure 20.
Euclid: 5-min guessing game results, AI data (all participants).
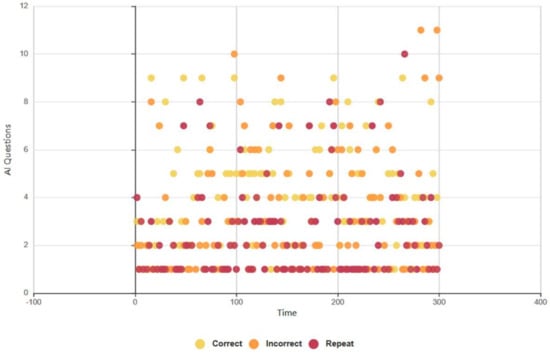
Figure 21.
Baudi: 5-min guessing game results, AI data (all participants).
4.6.5. Euclid and Baudi: Male and Female Subjects Guessing Game AI Data
The AWS AI results indicate a higher number of male subjects achieved correct responses than females: EM: 394 (57%), EF: 291 (55%) and BM: 415 (59%) BF: 290 (54%). However, male candidates incurred a higher sum of incorrect responses than females: EM: 128 (18%), EF: 117 (22%) and BM: 140 (20%), BF: 117 (22%), and similar in the ‘please repeat’ response, EM: 168 (25%), EF: 124 (23%) and BM: 147 (21%), BF: 126 (24%), shown in Figure 22 and Figure 23. These figures are significant as female test subjects asked fewer questions than males FE: 532 (Avg 27), ME: 691 (Avg 35) and FB: 533 (Avg 27), MB: 702 (Avg 35). These AI test scores support the outcomes of Q9, as M8, F3 preferred to interact with Baudi and M3, F6 with Euclid, and validate the outcomes of Series 3B, as male subjects rated Euclid as the more competent RHR. Furthermore, the results of Series 3B (competency) cited high variability in participant responses that parallel with the frequencies of incorrect and ‘please repeat’ responses indicated in AWS AI analytics.
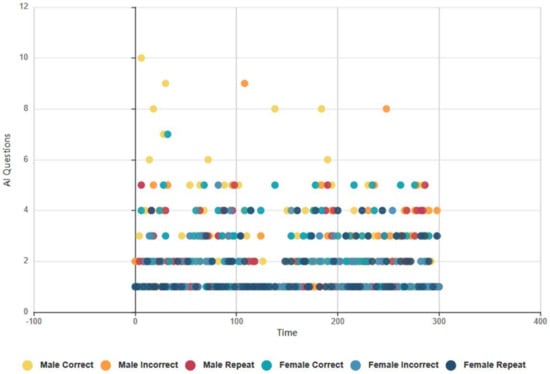
Figure 22.
Euclid: 5-min guessing game, AI data (males and females).
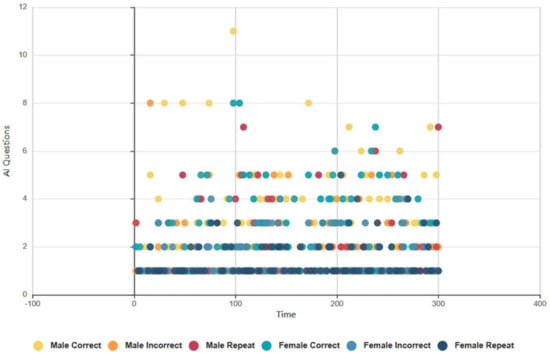
Figure 23.
Baudi: 5-min guessing game, AI data (males and females).
4.6.6. Euclid and Baudi: Age Groups Guessing Game AI Data
The higher age group achieved greater accurate responses during the guessing game session: correct responses: EL: 316 (54%), HE: 369 (61%), BL: 338 (57%), BH: 367 (57%); incorrect responses: EL: 119 (20%), EH: 126 (18%), BL: 126 (21%), BH: 131 (21%); and inciting the ‘please repeat’ response: EL: 151 (26%), EH: 141 (21%), BL: 132 (22%), BH: 141 (22%), shown in Figure 24 and Figure 25. However, there was little statistical difference in the age-related results of Q9—Baudi: L5, H6 and Euclid: L5, H4. These results conflict with the outcomes of Series 3C (competency) owing to the high variance in participant outcomes. However, the biometric data analysis indicated higher levels of positive feedback in the lower age group than in the more senior age group, which collates with the AI response data. Significantly, the level of attention was greater in the higher age group during the guessing game session, which validates the AWS AI data. Nevertheless, these outcomes are problematic to substantiate owing to the high level of variance between the results of the HRI questionnaire, FEA, GSR, and AWS AI data.
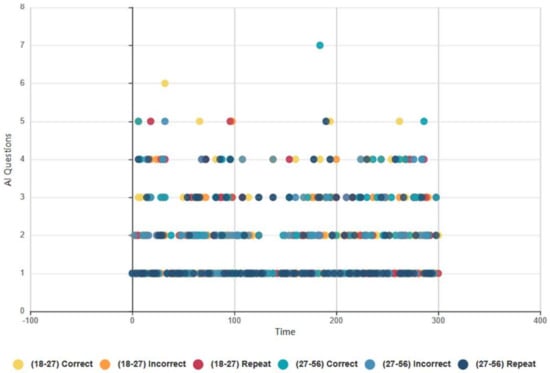
Figure 24.
Euclid: 5-min guessing game, AI data (age groups).
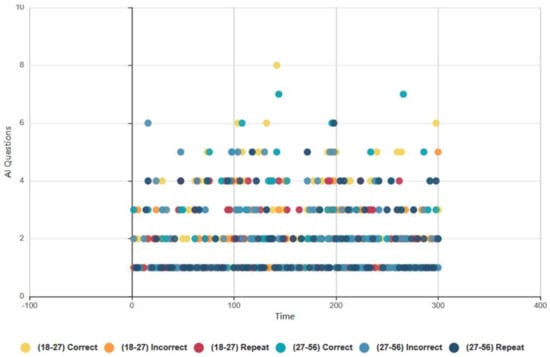
Figure 25.
Baudi: 5-min guessing game, AI data (age groups).
5. Conclusions
The results of this study show that the younger age group preferred HRI with a younger looking RHR and the more senior age group preferred HRI with an older looking RHR, reinforced by the FEA/GSR data. These results provide a strong foundation for the appropriation of age in RHR design in fields such as older looking RHRs in care for the elderly and younger looking RHRs as social companions for the young, vulnerable, and isolated. Furthermore, test subjects stated that they felt greater trust towards an older looking RHR compared with a more youthful RHR, as it reminded them of the trust and care of older relatives. Similarly, the gender-based analysis indicated that male test subjects preferred HRI with Euclid (older in appearance) and females with Baudi (younger in appearance). Although there is little scientific evidence to substantiate the reasoning behind this outcome, it is an interesting finding that requires further study.
Upon review of the AWS AI data, male subjects asked more questions outside the scope of the AI system compared with female test subjects. This anomaly was observed during HRI and identified in the outcomes of the questionnaire when test subjects purposefully attempted to deceive the AI system into giving incorrect responses. Thus, more male subjects prompted the RHRs into giving incorrect responses compared with female participants. This outcome coincides with the FEA data analysis as male subjects expressed significantly greater disengaging behaviours and reduced attention levels than female participants. Thus, it is plausible that, as the RHRs are modelled on the male form, male participants felt a need to test the capacity and abilities of the system more than female subjects. This hypothesis may account for the irregularities between the HRI questionnaire and biometric data results as, in the survey, many male subjects cited feeling no emotions during HRI. However, these outcomes contradicted the FEA data that firmly showed male subjects exerted significantly higher levels of positive and negative FE biometric feedback than females.
Finally, another possible method of evaluating RHRs is to compare two identical systems side by side. This method would reduce influential factors such as different ages and gender and narrow the scope of evaluation to specific variables such as static and dilating pupils. However, creating identical RHRs is incredibly difficult owing to the variability in materiality, aesthetics, and application of hand-made silicone skin onto the underlying exoskeleton. This visual irregularity is observable in the RHR ‘Sophia’, as new generations of the RHR look distinctly different from the first owing to the application and reapplication of the silicone skin.
Nevertheless, as in this study, comparing RHRs with different appearances, genders, and personalities permits the investigation of gender and age in terms of user preference, which yielded highly interesting and intriguing results for modelling user preference in EAI and appearance in future RHR design.
5.1. Employing FEA and GSR to Support Questionnaire Results
The combinatory approach to biometric data gathering, camera feed analysis, and AI analytics provided critical insights into the behaviours and emotions of test subjects not cited in the HRI questionnaire. For example, male participants expressed significantly greater positive and negative emotive FE than females during HRI. Yet, the majority of male subjects cited feeling no emotions in the HRI questionnaire. Similarly, the lower age group expressed greater levels of negative FEA and GSR during the 5-min topical conversation and guessing game AI sessions, which correlates with the results of the AI test data, as the lower age group achieved a lower number of correct answers and a higher number of incorrect and ‘please repeat’ responses during HRI. However, these results conflict with the questionnaire outcomes as there were little discernable differences in participant results, as male subjects stated feeling little to no emotions during HRI. Furthermore, the implementation of the GSR and FEA systems did not restrict the participant’s freedom of movement and accessibility to the RHRs.
This outcome is significant for future HRI studies as these non-invasive methods of biometric data gathering permitted test subjects to interact and communicate with the RHRs naturally without any obstruction or interference from the biometric sensors. Employing a mixed-method biometric data gathering approach permitted a more precise analysis of the data feeds, as high and low levels of FEA were confirmable by the GSR data, and a drop/loss of GSR signal was verifiable with the FEA data and camera feed. This method provided consistent and valid biometric data for analysis, as anomalies in the data feed could be attributed to either incredibly higher or low levels of emotional stimulus or as a result of issues with the connectivity of the biometric systems. Finally, an issue with the GSR and FEA mixed-method approach was the delay in the data processing as the GSR lagged the FEA, which resulted in a time offset of approximately ±5 s between the feeds. However, this issue was negatable by examining the Hz frequencies of the devices to determine the processing rate and electrode sensitivity of the systems to help synchronise the data fields. Moreover, the Esense GSR application provides the precise offset of the stimulus to the biometric readings, in seconds and milliseconds, which also helped precisely align the two datasets for comparative analysis.
5.2. Ethical and Broader Issues in RHR Design and Application in Society
The outcomes of this study provided critical data regarding how the test subjects perceive the future of RHRs in society. One key area that test subjects highlighted as a suitable application for RHRs with EAI was the care and support industry, as the RHRs provided useful and entertaining content in a manner proximal to human–human communication. In support, 45% of participants stated that, as the RHRs cannot make personal judgements or become offended, HRI was more relaxed, honest, and free-flowing than human–human communication. This outcome correlates with previous studies [118,119,120] and the results of the HRI age-related statistical analysis, which suggested younger test subjects preferred HRI with a younger-looking RHR and the more mature age group with an older looking RHR. This study covered two key areas of RHR and EAI ethics relating to robot rights and the fallibility of human perception in RHR design. Firstly, 75% of candidates stated that RHRs should be treated as machines, regardless of human-likeness and intelligence. However, this approach is susceptible to a fundamental flaw in human perception, because, if an RHR can authentically emulate a human in a manner proximal to the human condition in real-world conditions, then there is no definitive way of determining if the RHR is human or robot without an internal examination.
Finally, 45% of participants stated that EmoAI would be useful in human society. Interestingly, more male subjects cited applications of emotional AI, which correlates with the outcomes of the FEA data, as male subjects exhibited more emotional stress than females. Thus, it is likely that male subjects felt that they could express emotions freely during HRI compared with recounting them in the HRI questionnaire. Similarly, more subjects in the higher age group cited the use of EmoAI in society. These results interlink with the biometric, AWS AI data analytics, and HRI questionnaire results, as the higher age group exhibited greater levels of positive and negative emotional stimulus during HRI.
Supplementary Materials
The following are available online at https://www.mdpi.com/2227-9709/7/3/28/s1, Table S1: Quanatative Questoinanire Responces (All Test Subjects). Table S2: Quanatative Questoinanire Responces (Male Test Subjects). Table S3: Quanatative Questoinanire Responces (Female Test Subjects). Table S4: Quanatative Questoinanire Responces (Test Subjects Ages 18–27). Table S5: Quanatative Questoinanire Responces (Test Subjects Ages 27–55).
Author Contributions
Investigation, C.S.; Supervision, M.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hanson, D.; Olney, A.; Prilliman, S.; Mathews, E.; Zielke, M.; Hammons, D.; Fernandez, R.; Stephanou, E. Upending the Uncanny Valley. AAAI 2005, 4, 1728–1729. [Google Scholar]
- Nishio, T.; Yoshikawa, Y.; Ogawa, K.; Ishiguro, H. Development of an Effective Information Media Using Two Android Robots. Appl. Sci. 2019, 9, 3442. [Google Scholar] [CrossRef]
- Ishi, T.; Minato, T.; Ishiguro, H. Motion Analysis in Vocalized Surprise Expressions and Motion Generation in Android Robots. IEEE Robot. Autom. Lett. 2017, 2, 1748–1754. [Google Scholar] [CrossRef]
- Goertzel, B. Why We Need Humanoid Robots Instead of Faceless Kiosks. 2019. Available online: https://www.forbes.com/sites/forbestechcouncil/2019/12/27/why-we-need-humanoid-robot s-instead-of-faceless-kiosks/#4dfc88192e21 (accessed on 15 February 2020).
- Todo, T. SEER: Simulative emotional expression robot. In ACM SIGGRAPH 2018 Emerging Technologies; AMC Publishers: New York, NY, USA, 2018; pp. 1–2. [Google Scholar]
- Doering, D.; Glas, H.; Ishiguro, H. Modelling Interaction Structure for Robot Imitation Learning of Human Social Behaviour. IEEE Trans. Hum. Mach. Syst. 2019, 49, 219–231. [Google Scholar] [CrossRef]
- Haque, Z.; Nasir, J. Investigating the Uncanny Valley and human desires for interactive robots. In Proceedings of the 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 15–18 December 2007; pp. 2228–2233. [Google Scholar] [CrossRef]
- Yamazaki, R.; Nishio, S.; Ogawa, K.; Matsumura, K.; Minato, T.; Ishiguro, H.; Fujinami, T.; Nishikawa, M. Promoting Socialization of schoolchildren using a teleoperated Android. Int. J. Hum. Robot. 2013, 10. [Google Scholar] [CrossRef]
- Camble, A.; Frances, J. Talking about Disfigurement. 2018. Available online: https://www.sec-ed.co.uk/best-practice/talking-about-disfigurement-1/ (accessed on 18 April 2020).
- Waskul, D.; Vannini, P. Body/Embodiment: Symbolic Interaction and the Sociology of the Body; Routledge: Abingdon, UK, 2012; pp. 1–297. ISBN 13: 9781317173441. [Google Scholar]
- Whitaker, I.; Shokrollahi, K.; Dickson, W. Burns, Oxford Specialist Handbooks in Surgery; Oxford University Press: Oxford, UK, 2019; ISBN 0191503584. 9780191503580. [Google Scholar]
- Harcourt, D.; Rumsey, N. Psychology and Visible Difference. 2008. Available online: https://thepsychologist.bps.org.uk/volume-21/edition-6/psychology-and-visible-difference (accessed on 13 March 2020).
- Riek, T.; Rabinowitch, B.; Chakrabarti, C.; Robinson, P. How anthropomorphism affects empathy toward robots. In Proceedings of the 2009 4th ACM/IEEE International Conference on Human-Robot Interaction (HRI), La Jolla, CA, USA, 11–14 March 2009; pp. 245–246. [Google Scholar] [CrossRef]
- Kleinman, Z. CES 2018: A Clunky Chat with Sophia, The Robot. 2018. Available online: https://www.bbc.co.uk/news/technology-42616687 (accessed on 19 April 2020).
- Chung, S. Meet Sophia: The Robot Who Laughs, Smiles, and Frowns Just Like Us. 2018. Available online: https://edition.cnn.com/style/article/sophia-robot-artificial-intelligence-smart -creativity/index.html (accessed on 13 March 2020).
- Pessoa, L. Intelligent architectures for robotics: The merging of cognition and emotion. Phys. Life 2019, 31, 157–170. [Google Scholar] [CrossRef] [PubMed]
- Mori, M. The Uncanny Valley. Energy 1970, 33–35. [Google Scholar] [CrossRef]
- Hanson, D. Expanding the aesthetic possibilities for humanoid robots. In Proceedings of the IEEE-RAS international conference on humanoid robots, Tsukuba, Japan, 5–7 December 2015; Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.472.2518&rep=rep1&type=pdf (accessed on 27 March 2019).
- Hanson, D. Exploring the Aesthetic Range for Humanoid Robots. Corpus ID: 17275411. 2006. Available online: https://www.researchgate.net/publication/228356164_Exploring_the_aesthetic_range_for_humanoid_robots. (accessed on 27 March 2019).
- Tromp, J.; Bullock, A.; Steed, A.; Sadagic, A.; Slater, M.; Frécon, E. Small-group behaviour experiments in the COVEN Project. IEEE Comput. Graph. Appl. 1998, 18, 53–63. [Google Scholar] [CrossRef]
- Garau, M.; Weirich, D. The Impact of Avatar Fidelity on Social Interaction in Virtual Environments. Corpus ID: 141182802. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.459.8694&rep=rep1&type=pdf (accessed on 27 March 2019).
- Nass, C.; Isbister, K.; Lee, J. Truth is a beauty: Researching conversational agents. In Embodied Conversational Agents; MIT Press: Cambridge, MA, USA, 2000; pp. 374–402. [Google Scholar]
- Bar-Cohen, Y.; Hanson, D.; Marom, A. Introduction. In The Coming Robot Revolution; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Schoenherr, J.R.; Burleigh, T.J. Uncanny sociocultural categories. Front. Psychol. 2015, 5, 1456. [Google Scholar] [CrossRef]
- Browne, W.; Kawamura, K. Uncanny valley revisited. IEEExplore 2005, 151–157. [Google Scholar] [CrossRef]
- Barthelmess, U.; Furbach, U. Do we need Asimov’s Laws? ArXiv 2013, arXiv:1405.0961. [Google Scholar]
- Vallverdu, J. The Eastern Construction of the Artificial Mind. Enrahonar 2011, 47, 233–253. [Google Scholar] [CrossRef]
- Cheetham, M. Editorial: The Uncanny Valley Hypothesis and beyond. Front. Psychol. 2017, 8, 1738. [Google Scholar] [CrossRef] [PubMed]
- Brink, K.; Wellman, H. Hi, Robot: Adults, Children and The Uncanny Valley. 2017. Available online: https://www.npr.org/sections/13.7/2017/12/16/563075762/hi-robot-adults-children-and-the-uncanny-valley?t=1582650482901 (accessed on 25 February 2020).
- Brink, K.; Gray, K.; Wellman, H. Creepiness Creeps In: Uncanny Valley Feelings Are Acquired in Childhood. Child. Dev. 2017. [Google Scholar] [CrossRef]
- Feng, S.; Wang, X.; Wang, Q.; Fang, J.; Wu, Y.; Yi, L.; Wei, K. The uncanny valley effect in typically developing children and its absence in children with autism spectrum disorders. PLoS ONE 2018, 13, e0206343. [Google Scholar] [CrossRef]
- Maya, M.; Reichling, D.; Lunardini, F.; Geminiani, A.; Antonietti, A.; Ruijten, P.; Levitan, C.; Nave, G.; Manfredi, D.; Bessette-Symons, B.; et al. Uncanny but not confusing: Multisite study of perceptual category confusion in the Uncanny Valley. Comput. Hum. Behav. 2019, 103. [Google Scholar] [CrossRef]
- Lay, S.; Brace, N.; Pike, G.; Pollick, F. Circling around the Uncanny Valley: Design Principles for Research into the Relation Between Human-likeness and Eeriness. I-Perception 2016. [Google Scholar] [CrossRef]
- Tinwell, A.; Sloan, R.J. Children’s perception of uncanny human-like virtual characters. Comput. Hum. Behav. 2014, 36, 286–296. [Google Scholar] [CrossRef]
- Tung, F. Child Perception of Humanoid Robot Appearance and Behavior. Int. J. Hum. -Comput. Interact. 2016, 32, 493–502. [Google Scholar] [CrossRef]
- Towers-Clark, C. Keep the Robot in The Cage—How Effective (And Safe) Are Co-Bots? 2019. Available online: www.forbes.com/sites/charlestowersclark/2019/09/11/keep-the-robot-in-the-cagehow-effective--safe-are-co-bots/#3279006415cc (accessed on 5 April 2020).
- Patel, V.N. An Emotionally Intelligent AI Could Support Astronauts on a Trip to Mars. 2020. Available online: www.technologyreview.com/s/615044/an-emotionally-intelligent-ai-could-support-astronauts-on-a-trip-to-mars/ (accessed on 15 February 2020).
- McDuff, D.; Kapoor, A. Toward Emotionally Intelligent Artificial Intelligence. 2019. Available online: www.microsoft.com/en-us/research/blog/toward-emotionally-intelligent-artificial-intelligence/ (accessed on 21 February 2020).
- Alasaarela, M. The Rise of Emotionally Intelligent AI. 2017. Available online: https://machinelearnings.co/the-rise-of-emotionally-intelligent-ai-fb9a814a630e (accessed on 22 February 2020).
- Dewan, K. The Rise of AI Makes Emotional Intelligence More Important. 2019. Available online: https://www.entrepreneur.com/article/340637 (accessed on 22 February 2020).
- Jarboe, J. What Is Artificial Emotional Intelligence & How Does Emotion AI Work? 2018. Available online: https://www.searchenginejournal.com/what-is-artificial-emotional-intelligence/255769/ (accessed on 22 February 2020).
- Fatemi, F. Why EQ + AI Is A Recipe for Success. 2018. Available online: https://www.forbes.com/sites/falonfatemi/2018/05/30/why-eq-ai-is-a-recipe-for-success/#61 (accessed on 22 February 2020).
- Nordli, B. Cogito, Whose AI Interprets Human Emotions, Adds $20M. 2019. Available online: https://www.builtinboston.com/2019/09/05/cogito-raises-20m-funding (accessed on 21 February 2020).
- Field, H. Technologists Are Creating Artificial Intelligence to Help Us Tap into Our Humanity. Here is How (and Why). 2019. Available online: https://www.entrepre neur.com/article/340207 (accessed on 13 March 2020).
- Lewis, A.; Guzman, L.; Schmidt, T. Automation, Journalism, and Human-Machine Communication: Rethinking Roles and Relationships of Humans and Machines in News. Digit. J. 2019, 7, 409–427. [Google Scholar] [CrossRef]
- Wiltz, C. What is the state of Emotional Artificial Intelligence? Drive World 2019, 12, 234–255. Available online: www.designnews.com/electronics-test/whats-state-emotional-ai/20315341406148 2 (accessed on 23 March 2020).
- Williams, D. The Rise of Emotional Robots. 2018. Available online: https://www.sapiens.org/technology/emotional-intelligence-robots/ (accessed on 19 March 2020).
- Streeter, B. Seriously Successful Results from HSBC Bank’s Branch Robot Rollout. 2019. Available online: https://thefinancialbrand.com/84245/hsbc-banks-branch-robot-pepper-digital-transformation-phygital/ (accessed on 21 March 2020).
- Pandey, A.K.; Gelin, R. A Mass-Produced Sociable Humanoid Robot: Pepper: The First Machine of Its Kind. IEEE Robot. Autom. Mag. 2018. [Google Scholar] [CrossRef]
- Starr, M. Caring Pepper Robot Hits the Market, Sells Out in a Minute. 2015. Available online: https://www.cnet.com/news/caring-pepper-robot-hits-the-market-sells-out-in-a-minute/ (accessed on 21 February 2020).
- Goodman, J. Robotics Roundtable: Should Robots Look Like Humans, or Like Machines? 2018. Available online: https://internetofbusiness.com/should-robots-look-like-humans-or-like-machines/ (accessed on 21 February 2020).
- Simon, M. The Creepy-Cute Robot that Picks Peppers with its Face. 2018. Available online: www.wired.com/story/the-creepy-cute-robot-that-picks-peppers/ (accessed on 22 February 2020).
- Glaser, A. Pepper, the Emotional Robot, Learns How to Feel Like an American. 2016. Available online: www.wired.com/2016/06/pepper-emotional-robot-learns-feel-like-american/ (accessed on 21 February 2020).
- Hawes, N. Pepper the Emotional Robot May Just Make You Angry. 2014. Available online: https://theconversation.com/pepper-the-emotional-robot-may-just-make-you-angry-27655 (accessed on 21 February 2020).
- Hu, M.S.; Maan, Z.N.; Wu, J.C.; Rennert, R.C.; Hong, W.X.; Lai, T.S. Tissue engineering and regenerative repair in wound healing. Ann. Biomed. Eng. 2014, 42, 1494–1507. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Xiang, C.; Conn, R.; Rossiter, J. All-Soft Skin-Like Structures for Robotic Locomotion and Transportation. Soft Robot. 2019. [Google Scholar] [CrossRef] [PubMed]
- Williams, R. Researchers Create a First Autonomous Humanoid Robot with Full-Body Artificial Skin. 2019. Available online: https://inews.co.uk/news/technology/researchers-autonomous-humanoid-robot-artificial-skin-sense-805511 (accessed on 15 February 2020).
- Zilnik, A. Designing a Chatbot’s Personality. 2016. Available online: Chatbotsmagazine.com/designing-a-chatbots-personality-52dcf1f4df7d (accessed on 22 February 2020).
- Pavlus, J. The Next Phase Of UX: Designing Chatbot Personalities. 2016. Available online: https://www.fastcompany.com/3054934/the-next-phase-of-ux-designing-chatbot-personalities. (accessed on 19 March 2020).
- Marr, B. Why AI and Chatbots Need Personality. 2019. Available online: https://www.forbes.com/sites/bernardmarr/2019/08/02/why-ai-and-chatbots-need-personality/#fc7224214f84 (accessed on 23 April 2020).
- Gardner, H. Frames of Mind: The Theory of Multiple Intelligences; Basic Books: New York, NY, USA, 1983; pp. 55–78. ISBN 13: 978-0006862901. [Google Scholar]
- Moltzau, A. AI and Nine Forms of Intelligence. 2019. Available online: https://towardsdatascience.com/ai-and-nine-forms-of-intelligence-5cf587547731 (accessed on 21 February 2020).
- Duffy, B.R. Towards Social Intelligence in Autonomous Robotics: A Review. Int. J. Adv. Robot. Syst. 2001. [Google Scholar] [CrossRef]
- Roberts, J.; Dennison, J. The Photobiology of Lutein and Zeaxanthin in the Eye. J. Ophthalmol. 2015. [Google Scholar] [CrossRef] [PubMed]
- Davis, K.; Christodoulou, A.; Seider, S.; Gardner, H. The Theory of Multiple Intelligences. In Cambridge Handbook of Intelligence; Sternberg, R.J., Kaufman, S.B., Eds.; Cambridge University Press: New York, NY, USA, 2011; pp. 485–503. [Google Scholar]
- Tirri, K.; Nokelainen, P.; Komulainen, E. Multiple Intelligences: Can they be measured? Psychological Test and Assessment Modelling. Psychol. Test Assess Modeling 2013, 55, 438–461. [Google Scholar] [CrossRef]
- Núñez-Cárdenas, F.D.; Camacho, J.H.; Tomás-Mariano, V.T.; Redondo, A.M. Application of Data Mining to describe Multiple Intelligences in University Students. IJCOPI 2015, 6, 20–30. [Google Scholar]
- Kretzschmar, K.; Tyroll, H.; Pavarini, G.; Manzini, A.; Singh, I. Can Your Phone Be Your Therapist? Young People’s Ethical Perspectives on the Use of Fully Automated Conversational Agents in Mental Health Support. Biomed. Inform. Insights. 2019. [Google Scholar] [CrossRef]
- Edwards, D. The HeartMath coherence model: Implications and challenges for artificial intelligence and robotics. Ai Soc. 2019, 34, 899–905. [Google Scholar] [CrossRef]
- Maybury, M.T. The mind matters artificial intelligence and its societal implications. IEEE Technol. Soc. Mag. 1990, 9, 7–15. [Google Scholar] [CrossRef]
- Hiren, S. Global Humanoid Robot Market Evolving Industry Trends and Key Insights by 2024. 2019. Available online: http://zmrnewsmagazine.com/18125/global-humanoid-robot-market-evolving-industry-trends-and-key-insights-by-2024/ (accessed on 21 May 2019).
- Zlotowski, J.; Proudfoot, D.; Bartneck, C. More Human Than Human: Does the Uncanny Curve Matter? In Proceedings of the HRI2013, Workshop on Design of Humanlikeness in HRI: From uncanny valley to minimal design, Tokyo, Japan, 3–6 March 2013; pp. 7–13. [Google Scholar]
- Burton, B. Meet Vyommitra, the Legless Female Humanoid Robot India’s Sending to Space. 2020. Available online: https://www.cnet.com/news/meet-vyommitra-the-legless-female-humanoid-robot-indias-sending-to-space/ (accessed on 28 July 2020).
- Ramanathan, M.; Mishra, N.; Thalmann, N.M. Nadine Humanoid Social Robotics Platform. In Lecture Notes in Computer Science; CGI 2019: Advances in Computer Graphics; Gavrilova, M., Chang, J., Thalmann, N., Hitzer, E., Ishikawa, H., Eds.; Springer: Cham, Switzerland, 2019; Volume 11542. [Google Scholar] [CrossRef]
- McCurry, J. Erica, the ‘Most Beautiful and Intelligent’ Android, Leads Japan’s ROBOT Revolution. 2015. Available online: www.theguardian.com/technology/2015/dec/31/erica-the-most-beautiful-and-intelligent-android-ever-leads-japans-robot-revolution (accessed on 28 July 2020).
- Tao, M. Promobot to ‘Mass Produce’ Humanoid Robots. 2019. Available online: https://roboticsandautomationnews.com/2019/11/10/promobot-to-mass-produce-humanoid-robots/26628/ (accessed on 28 July 2020).
- RobotsNu Humanoid Robots for Patient Simulation in Medical Training. 2018. Available online: https://robots.nu/en/newsitem/humanoid-robots-for-patient-simulation (accessed on 28 July 2020).
- Marco, M. This Robot Girl is a Physical Version of Alita. 2019. Available online: https://www.personalrobots.biz/chinas-robot-girl-is-a-physical-version-of-alita/ (accessed on 28 July 2020).
- Malewar, A. A Humanoid Robot Alex Maybe the Futuristic News Anchor. 2019. Available online: https://www.techexplorist.com/humanoid-robot-alex-futuristic-news-anchor/22439/ (accessed on 28 July 2020).
- Muoio, D. Toshiba’s Latest Humanoid Robot Speaks Three Languages and Works in a Mall. 2015. Available online: https://www.businessinsider.com/toshibas-humanoid-robot-junko-chihira-speaks-three-languages-2015-11?r=US&IR=T (accessed on 29 July 2020).
- Greshko, M. Meet Sophia, the Robot That Looks Almost Human. 2018. Available online: https://www.nationalgeographic.com/photography/proof/2018/05/sophia-robot-artificial-intelligence-science/ (accessed on 28 July 2020).
- Block, I. AI robot Ai-Da Presents Her Original Artworks in University of Oxford Exhibition. 2019. Available online: https://www.dezeen.com/2019/06/14/ai-robot-ai-da-artificial-intelligence-art-exhibition/ (accessed on 28 July 2020).
- Harmon, A. Making Friends with a Robot Named Bina48. 2010. Available online: https://www.nytimes.com/2010/07/05/science/05robotside.html (accessed on 28 July 2020).
- Guizzo, E. Telenoid R1: Hiroshi Ishiguro’s Newest and Strangest Android. 2010. Available online: https://spectrum.ieee.org/automaton/robotics/humanoids/telenoid-r1-hiroshi-ishiguro-newest-and-strangest-android (accessed on 28 July 2020).
- Minato, T.; Yoshikawa, Y.; Noda, T.; Ikemoto, S.; Ishiguro, H.; Asada, M. CB2: A child robot with biomimetic body for cognitive developmental robotics. In Proceedings of the 2007 7th IEEE-RAS International Conference on Humanoid Robots, Pittsburgh, PA, USA, 29 November–1 December 2007; IEEE-RAS Humanoids: Pittsburgh, PA, USA, 2007; pp. 557–562. [Google Scholar] [CrossRef]
- Guizzo, E. Robot Baby Diego-San Shows Its Expressive Face on Video. 2013. Available online: https://spectrum.ieee.org/automaton/robotics/humanoids/robot-baby-diego-san (accessed on 20 July 2020).
- Etherington, D. Atlas the Humanoid Robot Shows Off a New and Improved Gymnastics Routine. 2019. Available online: https://techcrunch.com/2019/09/24/atlas-the-humanoid-robot-shows-off-a-new-and-improved-gymnastics-routine/ (accessed on 28 July 2020).
- Sanders, L. Linking Sense of Touch to Facial Movement Inches Robots Toward ‘Feeling’ Pain. 2020. Available online: https://www.sciencenews.org/article/robots-feel-pain-artificial-intelligence (accessed on 28 July 2020).
- Breslin, S. Meet the Terrifying New Robot Cop That’s Patrolling Dubai. 2017. Available online: https://www.forbes.com/sites/susannahbreslin/2017/06/03/robot-cop-dubai/#d6b5c9a6872b (accessed on 28 July 2020).
- Furhat Robotics What’s in a Name? The Story Behind Furhat Robotics. 2019. Available online: https://medium.com/@furhatrobotics/why-the-name-furhat-robotics-af53cd76639c (accessed on 28 July 2020).
- Goodrich, M.; Lee, J.; Kirlik, A. Multitasking and Multi-Robot Management. In The Oxford Handbook of Cognitive Engineering; Oxford University Press: Oxford, UK, 2013; pp. 453–556. [Google Scholar] [CrossRef]
- Hoskins, T. Robot Factories Could Threaten the Jobs of Millions of Garment Workers. 2016. Available online: https://www.theguardian.com/sustainablebusiness/2016/jul/16/robot-factor ies-threaten-jobs-millions-garment-workers-south-east-asia-women (accessed on 19 February 2020).
- Ghose, T. Robots Could Hack Turing Test by Keeping Silent. 2016. Available online: https://www.scientificamerican.com/article/robots-could-hack-turing-test-by-keeping-silent/ (accessed on 25 February 2020).
- Solis, B. Now Hiring: Robots, Please Apply Within. 2019. Available online: www.forbes.com/sites/briansolis/2019/09/17/now-hiring-robots-please-apply-within/ (accessed on 11 February 2020).
- Shell, E.R. AI and Automation Will Replace Most Human Workers Because They Do Not Have to Be Perfect, Just Better Than You. 2018. Available online: www.new sweek.com/2018/11/30/ai-and-automation-will-replace-most-human-workers-because-they-dont-have-be-1225552.html (accessed on 11 February 2020).
- Burkhardt, M. Living in a Robot Society: Perspective of a World-Leading Roboticist. 2019. Available online: //towardsdatascience.com/living-in-a-robot-society-a-perspective-of-a-world-leading-robotocist-51175fb455e3 (accessed on 11 February 2020).
- Yamaguchi, T. Japan’s robotic future. Crit. Asian Stud. 2019, 51, 134–140. [Google Scholar] [CrossRef]
- Chatila, R. Inclusion of Humanoid Robots in Human Society: Ethical Issues. In Humanoid Robotics; Springer: Dordrecht, The Netherlands, 2018. [Google Scholar] [CrossRef]
- Dautenhahn, K. Robots and Us-Useful Roles of Robots in Human Society. In Proceedings of the 2018 ACM/IEEE International Conference on Human-Robot Interaction (HRI ’18); Association for Computing Machinery; New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Mathieson, S.A. Mr Robot: Will Androids Ever be Able to Convince People They Are Human? 2019. Available online: https://www.researchgate.net/publication/341756234_Mr_Robot_Will_androids_ever_be_able_to_convince_people_they_are_human_Guardian_Online (accessed on 19 July 2020).
- The World Economic Forum Can machine’s think? A New Turing Test May Have the Answer. 2019. Available online: www.weforum.org/agenda/2019/08/our-turing-test-for-androids-will-judge-how-lifelike-humanoid-robots-can-be/. (accessed on 14 March 2020).
- Barnfield, N. Face to Face with The Future of AI. Horiz. Mag. Riley Raven. 2020, 8–11. Available online: https://www.staffs.ac.uk/alumni/ horizon-alumni-magazine (accessed on 29 June 2020).
- Yan, J.; Wang, Z.; Yan, Y. Humanoid Robot Head Design Based on Uncanny Valley and FACS. J. Robot. 2014, 2014, 208924. [Google Scholar] [CrossRef]
- Sakamoto, D.; Kanda, T.; Ono, T.; Ishiguro, H.; Hagita, N. Android as a telecommunication medium with a human-like presence. In Proceedings of the 2007 2nd ACM/IEEE International Conference on Human-Robot Interaction (HRI), Arlington, VA, USA, 2–8 March 2007; pp. 193–200. [Google Scholar] [CrossRef]
- Liu, Y.; Shi, L.; Liu, L.; Zhang, Z.; Jinsong, L. Inflated dielectric elastomer actuator for eyeball’s movements: Fabrication, Analysis and Experiments. In Proceedings of the SPIE, San Diego, CA, USA, 10 April 2008; p. 6927. [Google Scholar] [CrossRef]
- Harkness, K.; McKelvie, A. The Measurement of Uncertainty in Caregivers of Patients with Heart Failure. J. Nurs. Meas. 2013, 21, 23. [Google Scholar] [CrossRef] [PubMed]
- Payakpate, J. Knowledge Management Platform for Promoting Sustainable Energy Technologies in Rural Thai Communities. Ph.D. Thesis, Murdoch University, Murdoch, Australia, 2020. [Google Scholar]
- Ishiguro, H. Android science: Toward a new cross-interdisciplinary framework. J. Comput. Sci. 2005, 28, 118–127, Springer, Berlin, Heidelberg; Corpus ID: 6105971. [Google Scholar]
- Harnad, S. The Turing Test Is Not A Trick: Turing Indistinguishability Is A Scientific Criterion. Sigart Bull. 1992, 3, 9–10. [Google Scholar] [CrossRef]
- Harnad, S.; Scherzera, P. First, scale up to the robotic Turing test, then worry about feeling. Artif. Intell. Med. 2008, 44, 83–89. [Google Scholar] [CrossRef]
- Schweizer, P. The Truly Total Turing Test. Minds Mach. 1998, 8, 263–272. [Google Scholar] [CrossRef]
- Gay, L. Educational Research: Competencies for Analysis and Application, 3rd ed.; Merrill Publishing Company: Columbus, OH, USA, 1987; Chapters 2–4; ISBN 13: 978-0675205061. [Google Scholar]
- Palinkas, L.A.; Horwitz, S.M.; Green, C.A.; Wisdom, J.P.; Duan, N.; Hoagwood, K. Purposeful Sampling for Qualitative Data Collection and Analysis in Mixed Method Implementation Research. Adm. Policy Ment. Health Ment. Health Serv. Res. 2015, 42, 533–544. [Google Scholar] [CrossRef]
- Ivaldi, S.; Anzalone, S.; Rousseau, W.; Sigaud, O.; Chetouani, M. Robot initiative in a team learning task increases the rhythm of interaction but not the perceived engagement. Front. Neurorobotics 2014, 8, 5. [Google Scholar] [CrossRef]
- Mavridis, N.; Katsaiti, N.M.; Falasi, A.; Nuaimi, A.; Araifi, H.; Kitbi, A. Opinions and attitudes toward humanoid robots in the Middle East. Ai Soc. 2012, 27, 517–534. [Google Scholar] [CrossRef]
- Ganadas, P.; Henderson, A.; Ji, E. A Research Project in HRI. 2015. Available online: Katrinashaw.com/project/experiment-on-human-robot-deception/ (accessed on 12 March 2019).
- Birmingham, E.; Svärd, J.; Kanan, C.; Fischer, H. Exploring emotional expression recognition in aging adults using the Moving Window Technique. PLoS ONE 2018, 13, e0205341. [Google Scholar] [CrossRef] [PubMed]
- Vaidyam, A.; Torous, J. Chatbots: What Are They and Why Care? 2019. Available online: https://www.psychiatrictimes.com/telepsychiatry/chatbots-what-are-they-and-why-care/page/0/1 (accessed on 11 April 2020).
- Vaidyam, A.N.; Wisniewski, H.; Halamka, J.D.; Kashavan, M.S.; Torous, J.B. Chatbots and Conversational Agents in Mental Health: A Review of the Psychiatric Landscape. J. Psychiatry 2019, 64, 456–464. [Google Scholar] [CrossRef] [PubMed]
- Gardiner, M.; McCue, D.; Negash, L.; Cheng, T.; White, F.; Yinusa-Nyahkoon, S.; Jack, W.; Bickmore, W. Engaging women with an embodied conversational agent to deliver mindfulness and lifestyle recommendations. Patient Educ. Couns. 2017, 100, 1720–1729. [Google Scholar] [CrossRef] [PubMed]

























© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).