Improvement of Misleading and Fake News Classification for Flective Languages by Morphological Group Analysis


Abstract
1. Introduction
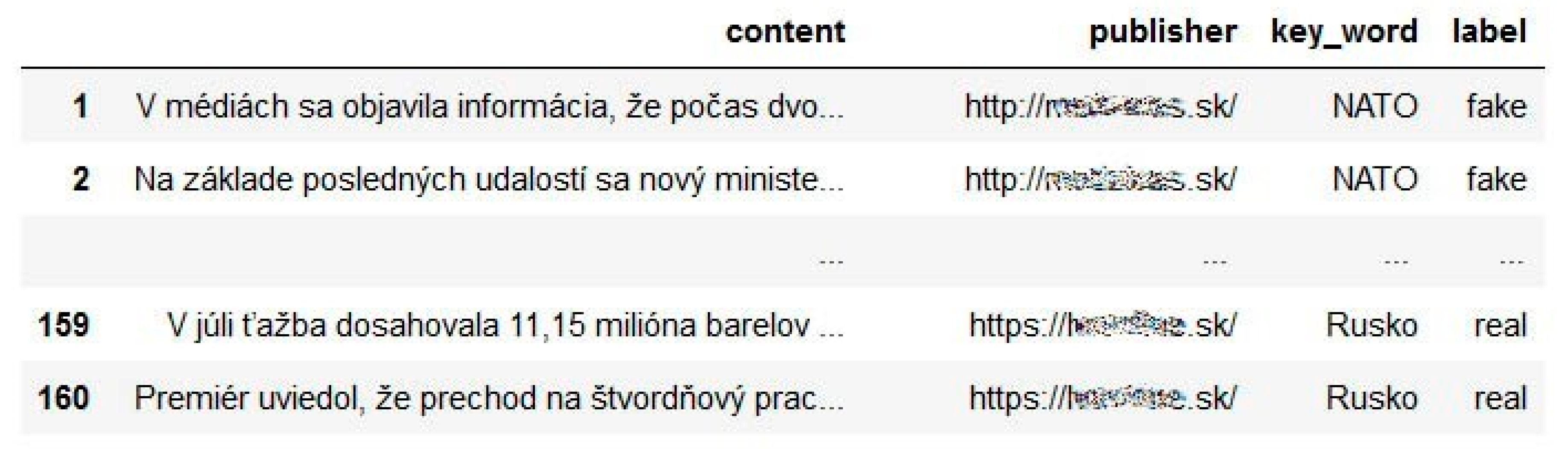
- We create our own datasets from real messages and from fake or misleading content. Datasets are created from messages in Slovak language.
- Datasets are pre-processed by means of the usage of basic techniques for natural language processing.
- To the words of examined dataset reports two different data preparation approaches are applied:
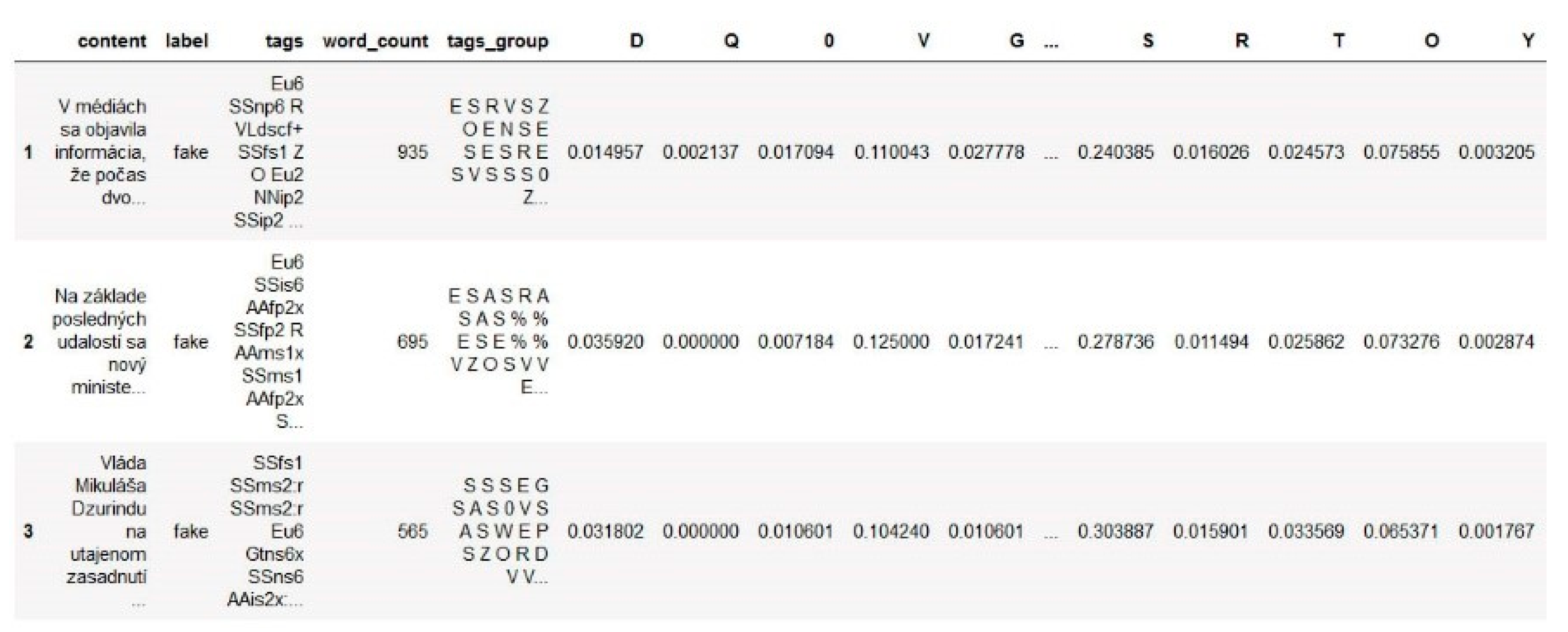
- Approach 1:
- Morphological tags are identified.
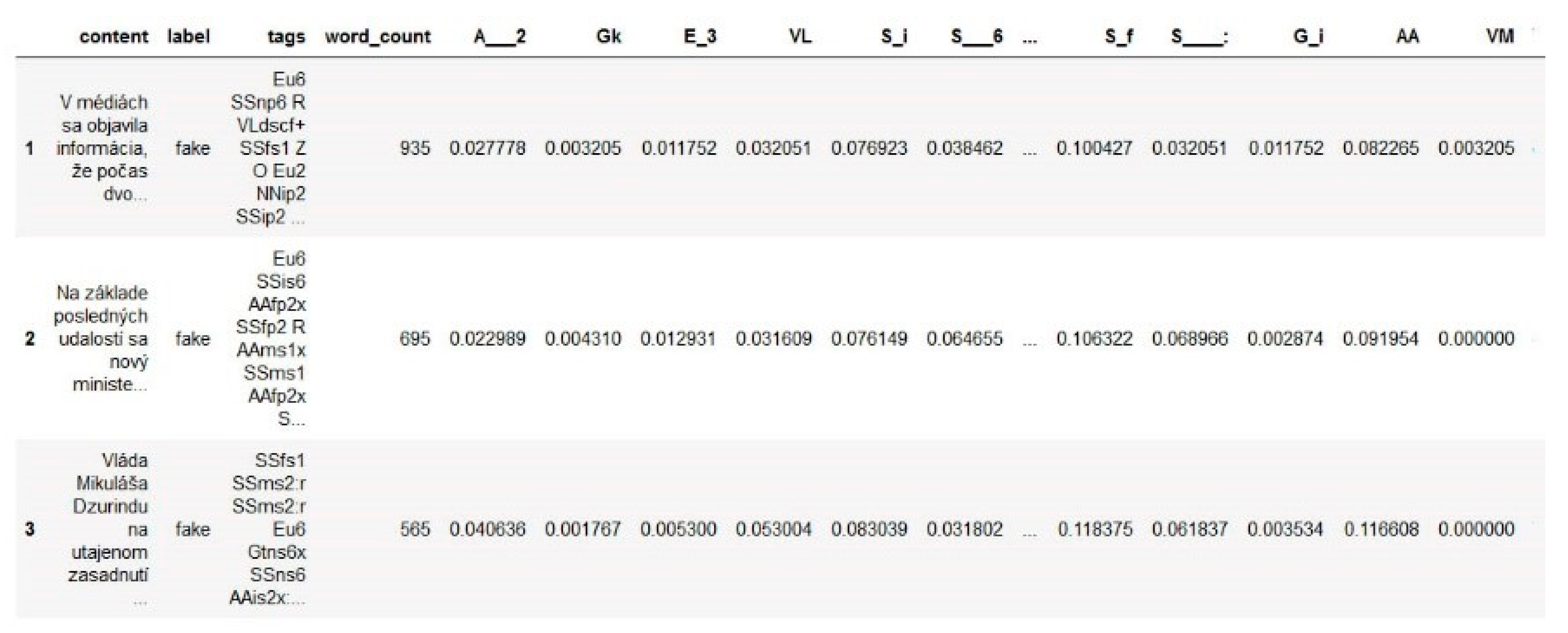
- Approach 2:
- According to our method (described below in our article), new categories are created from morphological tags.
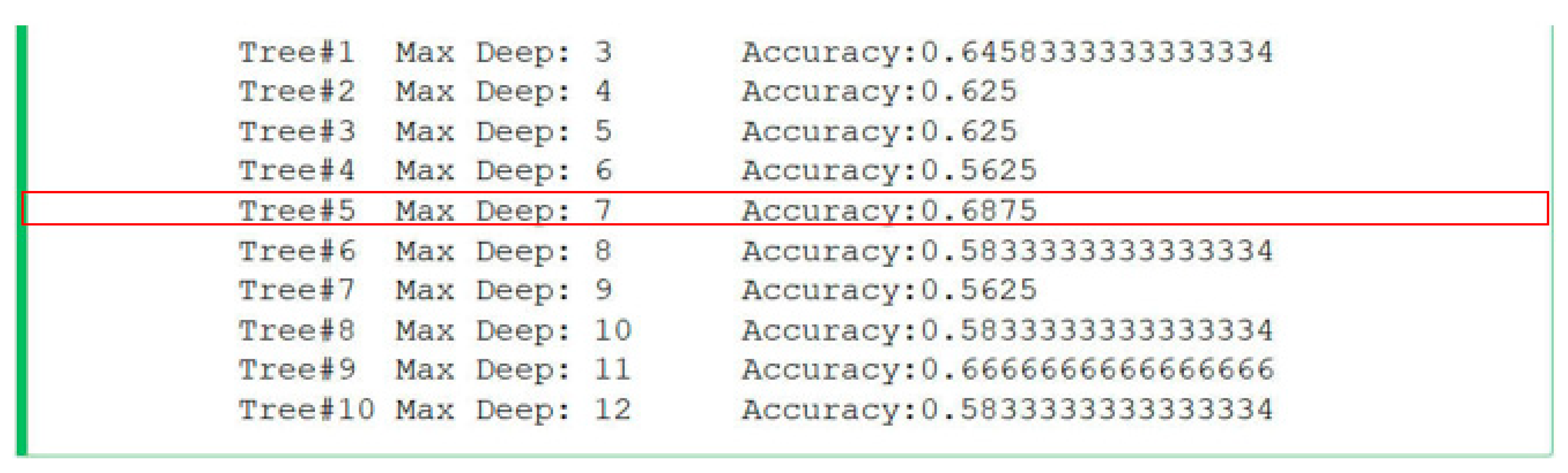
- Decision trees are generated from the preprocessed data (Approaches 1 and 2).
- The basic characteristics of the created decision trees are compared with the evaluation of data preparation method, which provides better results. It is determined which method is more suitable for the Slovak language, as a flective type of language.
2. Related Work
3. Methodology
- Select the best attribute using attribute selection measures (ASM) to split the records.
- Make that attribute a decision node and break the dataset into smaller subsets.
- Start tree building by repeating this process recursively for each child until one of the conditions is matched:
- All tuples belong to the same attribute value.
- There are no more remaining attributes.
- There are no more instances.
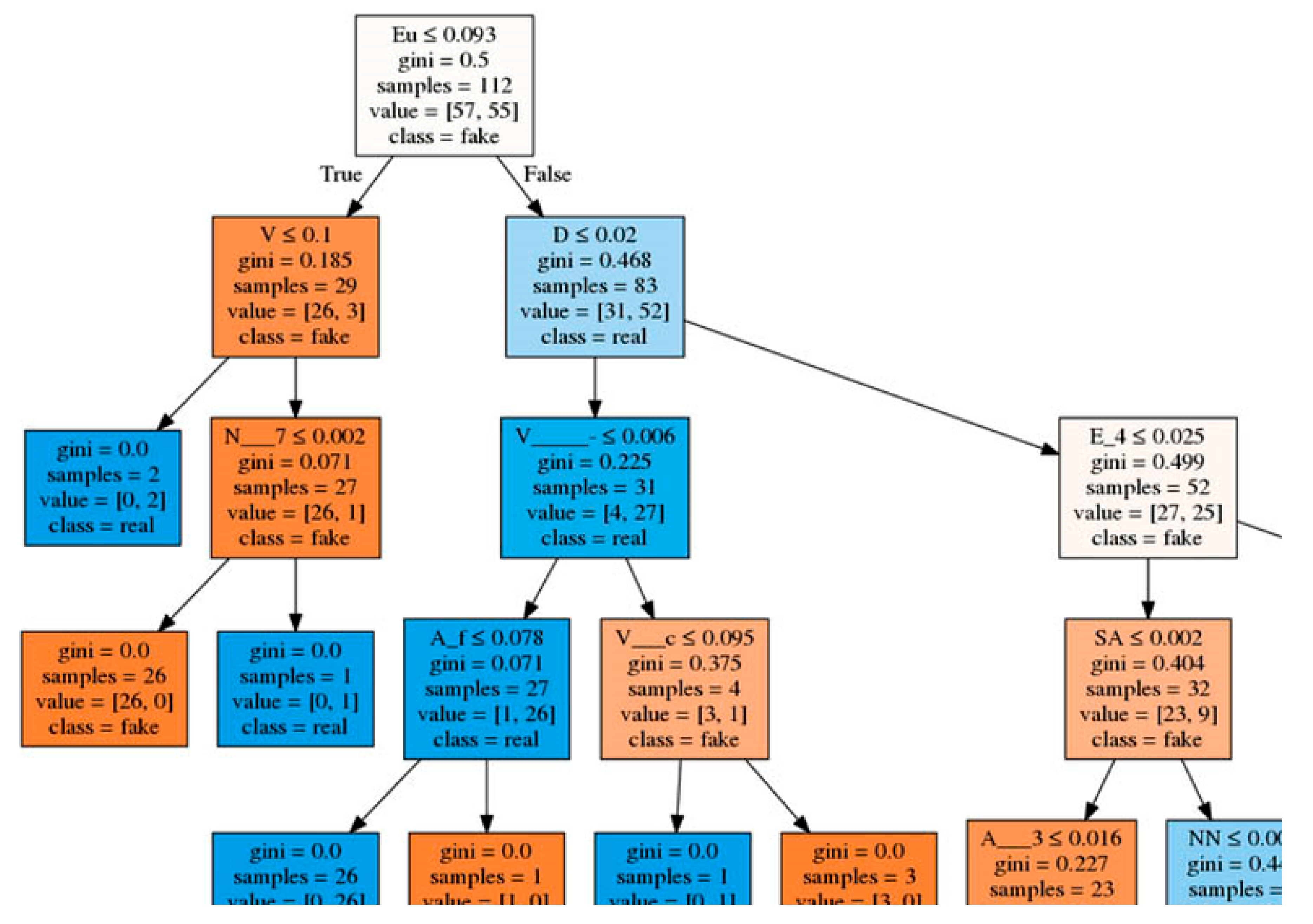
4. Results
5. Discussion
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Guess, A.; Nyhan, B.; Reifler, J. Selective Exposure to Misinformation: Evidence from the Consumption of Fake News during the 2016 U.S. Presidential Campaign. Available online: https://csdp.princeton.edu/publications/selective-exposure-misinformation-evidence-consumption-fake-news-during-2016-us (accessed on 23 December 2019).
- Yang, S.; Shu, K.; Wang, S.; Gu, R.; Wu, F.; Liu, H. Unsupervised Fake News Detection on Social Media: A Generative Approach. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 5644–5651. [Google Scholar]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Sydell, L. We Tracked Down A Fake-News Creator in the Suburbs. Here’s What We Learned. Available online: https://www.npr.org/sections/alltechconsidered/2016/11/23/503146770/npr-finds-the-head-of-a-covert-fake-news-operation-in-the-suburbs?t=1573633982008 (accessed on 24 December 2019).
- Oksanen, A.; Keipi, T. Young people as victims of crime on the internet: A population-based study in Finland. Vulnerable Child. Youth Stud. 2013, 8, 298–309. [Google Scholar] [CrossRef]
- Kanoh, H. Why do people believe in fake news over the Internet? An understanding from the perspective of existence of the habit of eating and drinking. Procedia Comput. Sci. 2018, 126, 1704–1709. [Google Scholar] [CrossRef]
- Rubin, V.L.; Conroy, N.J.; Chen, Y. Towards News Verification: Deception Detection Methods for News Discourse. In Proceedings of the Hawaii International Conference on System Sciences (HICSS48) Symposium on Rapid Screening Technologies, Deception Detection and Credibility Assessment Symposium, London, ON, Canada, 5–8 January 2015; Western University: London, ON, Canada, 2015; pp. 5–8. [Google Scholar]
- Bachenko, J.; Fitzpatrick, E.; Schonwetter, M. Verification and implementation of language-based deception indicators in civil and criminal narratives. In Proceedings of the 22nd International Conference; Association for Computational Linguistics (ACL), Manchester, UK, 18–22 August 2008; Volume 1, pp. 41–48. [Google Scholar]
- Rubin, V.L.; Conroy, N.J. Challenges in Automated Deception Detection in Computer-Mediated Communication; Wiley: Hoboken, NJ, USA, 2011; Volume 48, pp. 1–4. [Google Scholar]
- Klein, D.O.; Wueller, J.R. Fake news: A legal perspective. J. Internet Law 2017, 20, 6–13. [Google Scholar]
- Gupta, A.; Lamba, H.; Kumaraguru, P.; Joshi, A. Faking sandy: Characterizing and identifying fake images on twitter during hurricane sandy. In Proceedings of the WWW 2013 Companion—Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 729–736. [Google Scholar]
- Zhang, J.; Dong, B.; Yu, P.S. FAKEDETECTOR: Effective Fake News Detection with Deep Diffusive Neural Network; Cornell University: New York, NY, USA, 2018; pp. 1–13. [Google Scholar]
- Ajao, O.; Bhowmik, D.; Zargari, S. Fake News Identification on Twitter with Hybrid CNN and RNN Models. In Proceedings of the 9th International Conference on Computer Systems and Technologies and Workshop for PhD Students in Computing—CompSysTech ’08, Association for Computing Machinery (ACM), Copenhagen, Denmark, 18–20 July 2018; pp. 226–230. [Google Scholar]
- Ozbay, F.A.; Alatas, B. Fake news detection within online social media using supervised artificial intelligence algorithms. Phys. A Stat. Mech. Its Appl. 2019. [Google Scholar] [CrossRef]
- Gravanis, G.; Vakali, A.; Diamantaras, K.; Karadais, P. Behind the cues: A benchmarking study for fake news detection. Expert Syst. Appl. 2019, 128, 201–213. [Google Scholar] [CrossRef]
- Zhang, X.; Ghorbani, A.A. An overview of online fake news: Characterization, detection, and discussion. Inf. Process. Manag. 2019, 57. [Google Scholar] [CrossRef]
- Manzoor, S.I.; Singla, J.; Nikita. Fake news detection using machine learning approaches: A systematic review. In Proceedings of the International Conference on Trends in Electronics and Informatics, ICOEI, Tirunelveli, India, 23–25 April 2019; pp. 230–234. [Google Scholar]
- Parikh, S.B.; Atrey, P.K. Media-Rich Fake News Detection: A Survey. In Proceedings of the 2018 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; pp. 436–441. [Google Scholar]
- Helmstetter, S.; Paulheim, H. Weakly Supervised Learning for Fake News Detection on Twitter. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Barcelona, Spain, 28–31 August 2018; pp. 274–277. [Google Scholar]
- Zhang, C.; Gupta, A.; Kauten, C.; Deokar, A.V.; Qin, X. Detecting fake news for reducing misinformation risks using analytics approaches. Eur. J. Oper. Res. 2019, 279, 1036–1052. [Google Scholar] [CrossRef]
- Bondielli, A.; Marcelloni, F. A Survey on Fake News and Rumour Detection Techniques. Inf. Sci. 2019, 497, 38–55. [Google Scholar] [CrossRef]
- Vedova, M.L.; Della; Tacchini, E.; Moret, S.; Ballarin, G.; Dipierro, M. Content and Social Signals. In Proceedings of the 2018 22nd Conference of Open Innovations Association (FRUCT), Jyvaskyla, Finland, 15–18 May 2018; pp. 272–279. [Google Scholar]
- Gupta, A.; Kumaraguru, P. Credibility ranking of tweets during high impact events. In Proceedings of the 1st Workshop on Human Factors in Hypertext—HUMAN ’18, Baltimore, MA, USA, 9 July 2018; pp. 2–8. [Google Scholar]
- Reasons behind Creating This Initiative—What Are the Criteria for Inclusion in our Database. Available online: https://www.konspiratori.sk/en/why-this-initiative.php#5 (accessed on 23 December 2019).
- Garabík, R.; Simkova, M. Slovak Morphosyntactic Tagset. J. Lang. Model. 2012, 1, 41–63. [Google Scholar] [CrossRef]
- Munk, M.; Munková, D. Detecting errors in machine translation using residuals and metrics of automatic evaluation. J. Intell. Fuzzy Syst. 2018, 34, 3211–3223. [Google Scholar] [CrossRef]
- Munk, M.; Munková, D.; Benko, L. Towards the use of entropy as a measure for the reliability of automatic MT evaluation metrics. J. Intell. Fuzzy Syst. 2018, 34, 3225–3233. [Google Scholar] [CrossRef]
- Schmid, H.; Baroni, M.; Zanchetta, E.; Stein, A. The Enriched TreeTagger System. In Proceedings of the EVALITA 2007 Workshop, Roma, Italy, 10 September 2007. [Google Scholar]
- Schmid, H. Probabilistic Part-of-Speech Tagging Using Decision Trees. In Improvements in Part-of-Speech Tagging with an Application to German; UCL press: London, UK, 1994; pp. 44–49. [Google Scholar]
- Furman, E.; Kye, Y.; Su, J. Computing the Gini index: A note. Econ. Lett. 2019, 185, 108753. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Noun | Pronoun | |||
|---|---|---|---|---|
| Position | Possible Values | Description | Possible Values | Description |
| 1 | S | part of speech tag | P | part of speech tag |
| 2 | SAFU | paradigm | SAFU | paradigm |
| 3 | mifn | gender | mifn | gender |
| 4 | sp | number | sp | number |
| 5 | 1234567 | case | 1234567 | case |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kapusta, J.; Obonya, J. Improvement of Misleading and Fake News Classification for Flective Languages by Morphological Group Analysis. Informatics 2020, 7, 4. https://doi.org/10.3390/informatics7010004
Kapusta J, Obonya J. Improvement of Misleading and Fake News Classification for Flective Languages by Morphological Group Analysis. Informatics. 2020; 7(1):4. https://doi.org/10.3390/informatics7010004
Chicago/Turabian StyleKapusta, Jozef, and Juraj Obonya. 2020. "Improvement of Misleading and Fake News Classification for Flective Languages by Morphological Group Analysis" Informatics 7, no. 1: 4. https://doi.org/10.3390/informatics7010004
APA StyleKapusta, J., & Obonya, J. (2020). Improvement of Misleading and Fake News Classification for Flective Languages by Morphological Group Analysis. Informatics, 7(1), 4. https://doi.org/10.3390/informatics7010004