Collecting Labels for Rare Anomalies via Direct Human Feedback—An Industrial Application Study



Abstract
1. Introduction
- Provoking anomalies is still expensive, as retooling the machine for these provocations is time consuming. Furthermore, precious production time is lost as the anomalously processed workpieces cannot be used after the experiment. Thus, annotating data sets with anomaly labels via dedicated measurement campaigns always comes with a trade-off: The higher the amount of labeled data the better the performance of (semi-)supervised anomaly classifiers but also the higher the loss in production time and thus increase in costs. The availability of annotated datasets that also tend to be limited in size and the inherent cost/accuracy trade-off are well-known problems in industrial manufacturing applications and have led to domain-specific approaches optimizing the predictive quality with the given data sets of limited size [1].
- Many anomalies cannot be provoked intentionally, either due to unknown cause–effect relations of these anomalies or due to severe risks of long-term machine part damages.
- If anomalies can be provoked intentionally, the anomalies do not emerge in a natural way. As it is often nontrivial to distinguish between cause and effect in the signal behavior, it is unclear whether the studied abnormal behavior will generalize to real-world anomalies.
- Finally, only anomaly types known in advance can be provoked.
- Can we collect high-quality but low-cost labels for machine tool anomalies from machine operators’ online label feedback to anomalies proposed by a generic unsupervised anomaly detection algorithm?
- Can we develop a sensible and understandable human–machine interface for the online labeling prototype by taking the end users’ (i.e., machine operators’) opinion into account during the design process?
- Can simple anomaly detection models respecting hardware constraints of our embedded labeling prototype yield sensible anomaly propositions?
- How does the reliability of label feedback depend on the type of anomaly, the kind of signal visualization, and the clarity of proposed anomalies (measured in height of anomaly scores)?
- How can we measure reliability of the annotators’ label feedback sensibly without access to ground truth labels for most of the data and with label feedback from only one annotator at a time (i.e., the current operator of the machine tool)?
- We conduct a study exploring how to incorporate domain expert knowledge for online annotation of abnormal rare events in industrial scenarios. To the best of our knowledge, no comparable study exists.
- Other than in the frequent studies on labeling in medical and social applications, we collect labels not via a smartphone-based human–machine interface but via a self-developed visualization and labeling prototype tailor-made for harsh industrial environments.
- We share insights from the process of designing the visualization and labeling interface gathered by exchange with industrial end users (i.e., machine operators).
- We propose measures to judge the quality of anomaly propositions and online label feedback in a scenario where neither ground truth labels are accessible nor comparison of labels of multiple annotators is an option. We evaluate these assumptions on a large corpus (123,942 signals) of real-world industrial data and labels which we collected throughout several weeks.
- Furthermore, we describe which types of anomalies can be labeled reliably with the proposed visualization and labeling prototype and identify influential factors on annotation reliability.
2. Related Work
2.1. Anomaly Detection
- One-dimensional representation: Anomaly detection models rely on the data being given as one-dimensional vectors. These vectors can be given as either raw signals or a transformation of the data to another, one-dimensional representation. Popular transformations are envelope signals [3], wavelet-based representations [4], or other spectral transformations based on singular value decompositions [5].
- Multidimensional representations: These representations emerge when the sensor data are projected to a dual space by extraction of features. When aiming for a generic anomaly detection model, the major challenge is given by the choice of a generic but expressive set of features [6]. Among popular choices are statistical measures and wavelet-based features [7] or filter bank features (e.g., Mel-frequency cepstral coefficient (MFCC) features) [8]. The latter yield similar information to anomaly detection approaches based on time-frequency distributions (TFDs).
- TFD representations: Recently, different powerful deep learning approaches capable of learning the latent representations of the underlying, data-generating process from two-dimensional data have been introduced (with a focus on two-dimensional representations, typically images). Among these, deep generative models like variational autoencoders (VAEs) [9], generative adversial networks (GANs) [10], auto-regressive generative models like PixelRNN/CNN [11], and non-autoregressive flow-based models [12,13,14] supersede earlier autoencoder (AE) approaches [15,16,17] which come with a compressed latent representation of the data but without the possibility of generating samples from the latent representation. It is this ability to sample from the generative process of the data which seems to allow deep generative models to capture details of the data flexibly without any access to labels.
2.1.1. Methods Based on One-Dimensional Representations
2.1.2. Multidimensional Representation-Based Methods
2.1.3. Two-Dimensional Representation-Based Methods
2.2. Label Evaluation
2.2.1. Label Comparison without Knowing a Ground Truth
2.2.2. Online Annotation by Human Users
3. Assumptions
3.1. Assumptions on Measures for Quality of Human Label Feedback
- Assumption 1: We assume reliable online annotations coincide with a low mismatch between anomaly propositions of the anomaly detection model and online annotator feedback (i.e., a high confirmation rate). The amount of confirmed anomalies per class yields information about which types of anomalies can be well identified by the human annotators: We assume frequently labeled anomaly types to be the ones which are identifiable well from the sensor signals visualized with our labeling prototype, as a characteristic signal pattern seems to be observable for the machine operators.
- Furthermore, we assume the confirmation rate of online label feedback to be dependent on anomaly scores and time of proposing signals for annotation.
- -
- Often, anomaly detection models are capable of stating a degree of abnormality of a signal under review compared to the learned normal state. For example, time series models compute distance measures between signals under review and the normal training data (kNN models) or a compressed template of these normal data (NC models) during prediction. These distance measures can be interpreted as anomaly scores. We assume reliable label feedback to coincide with high anomaly scores assigned by the unsupervised anomaly proposing anomaly detection model (Assumption 2a): High anomaly scores are assigned to signals under review clearly deviating from normal behavior. Such clearly deviating signals are more easily identifiable as anomalies and thus assumed to be labeled more reliably.
- -
- Assumption 2b: Additionally, we assume a higher degree of confirmative label feedback for days where visually confirmed anomalies (i.e., due to machine inspection by the operators) are observed. On the other hand, if anomaly propositions for clearly outlying signals are rejected although anomalous machine behavior was confirmed by machine inspection, we assume small reliability of this label feedback.
- For a high mismatch between anomaly proposition and online label feedback, it is hard to decide whether proposition or feedback is more trustworthy. In order to still be able to assess reliability of online label feedback, we introduce a second period of retrospective signal annotation: Signals proposed as anomalous to the machine operators during online annotation are stored for a second review. Multiple annotators are then asked to inspect these signals again retrospectively. Comparison of online label feedback with this second set of retrospective labels allows us to rate the following:
- -
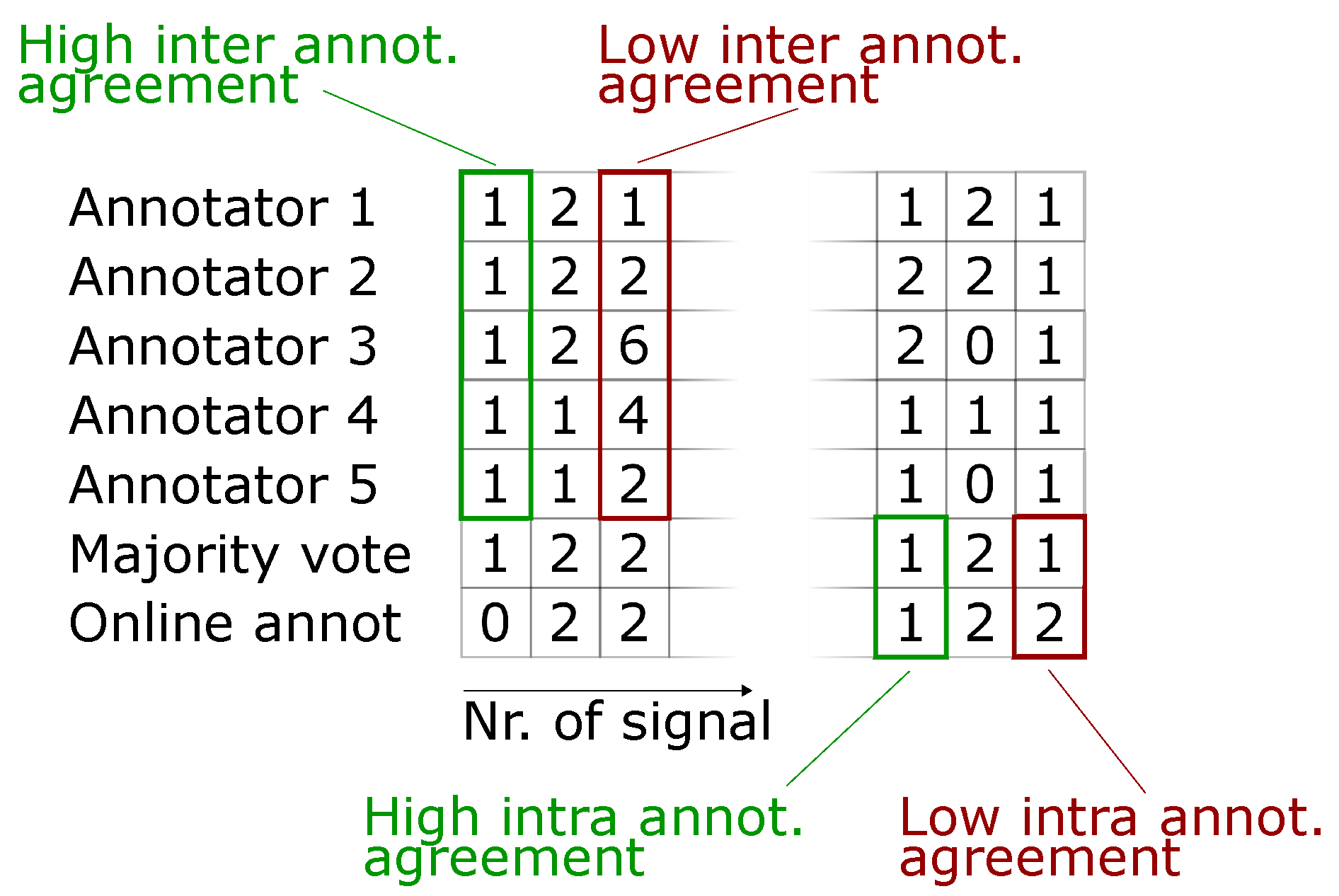
- Inter-annotator agreement (i.e., consistency between retrospective labels of multiple annotators). We assume reliable retrospective labels to coincide with a high inter-annotator agreement (Assumption 3a).
- -
- Intra-annotator agreement (i.e., consistency of annotations between first (online) and second (retrospective) labeling period). In order to make the single online label feedback comparable with multiple retrospective labels, we compute the mode (i.e., majority vote) of the multiple retrospective labels per proposed signal. We assume reliable online label feedback to coincide with a high intra-annotator agreement between online label feedback and these modes (Assumption 3b). A subject-specific annotator agreement cannot be computed, as we do not have access to shift plans (due to local data protection laws).
- For a better understanding, different scenarios of inter- and intra-annotator agreement are visualized in Figure 2. Here, retrospective annotators 1 to 5 are shown the signals proposed as anomalous during online annotation (bottom row) for a second review. We can judge inter-annotator agreement from these 5 annotations per proposed signal. The majority vote found from these 5 annotations per signal is depicted in row 6 and allows for comparison of retrospective annotations to the online annotations in row 7. This in turn allows for specifying an intra-annotator agreement, i.e., consistency between both labeling periods for each signal proposed as anomalous.
- Finally, we relate high label reliability to high annotator motivation. Annotator motivation, on the other hand, is estimated by the assumptions stated in the next section.
3.2. Assumptions on Measures for Annotator Motivation
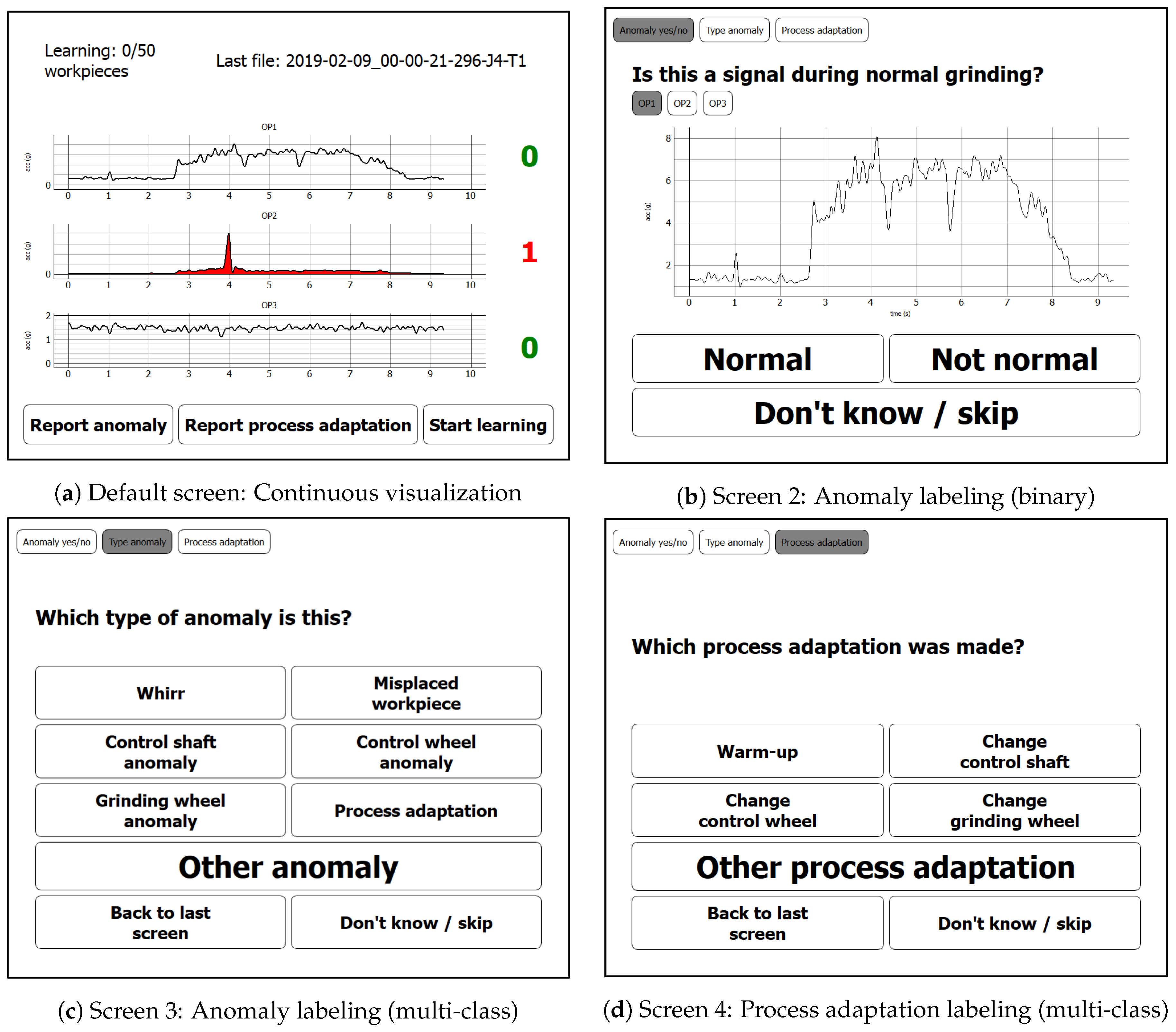
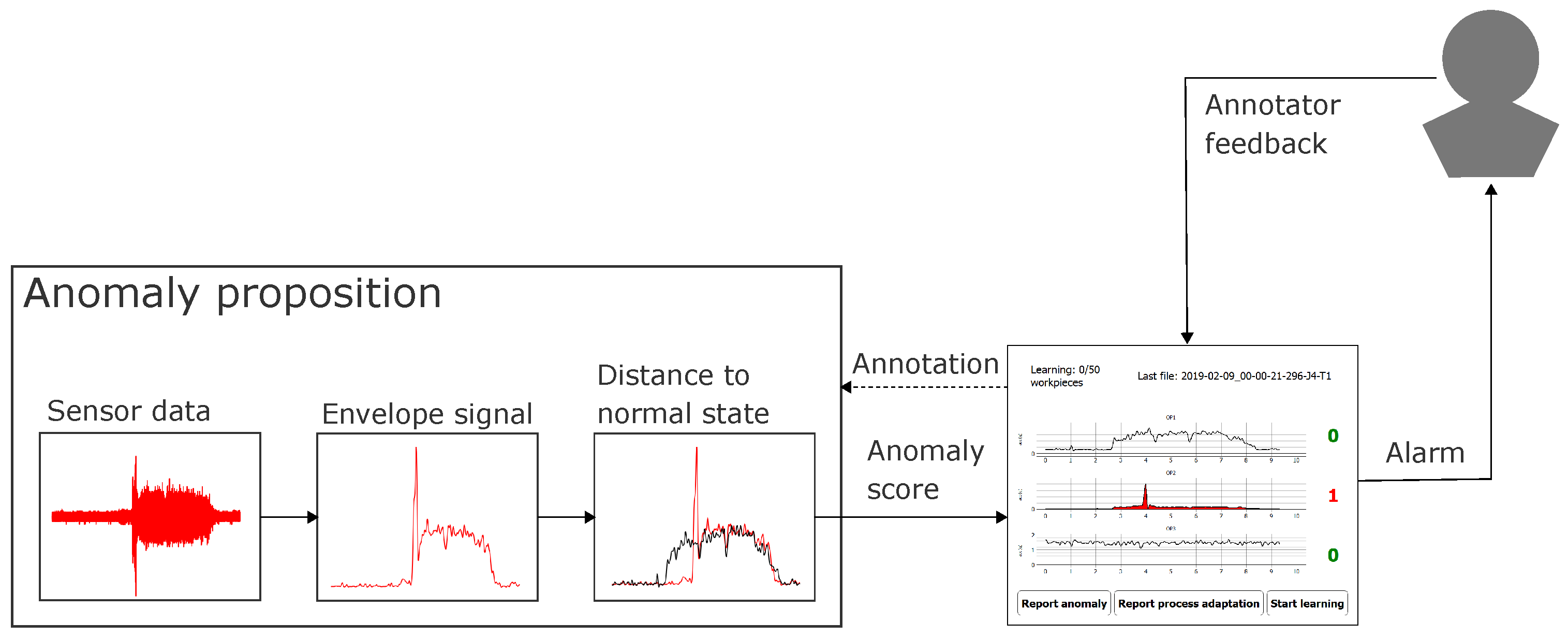
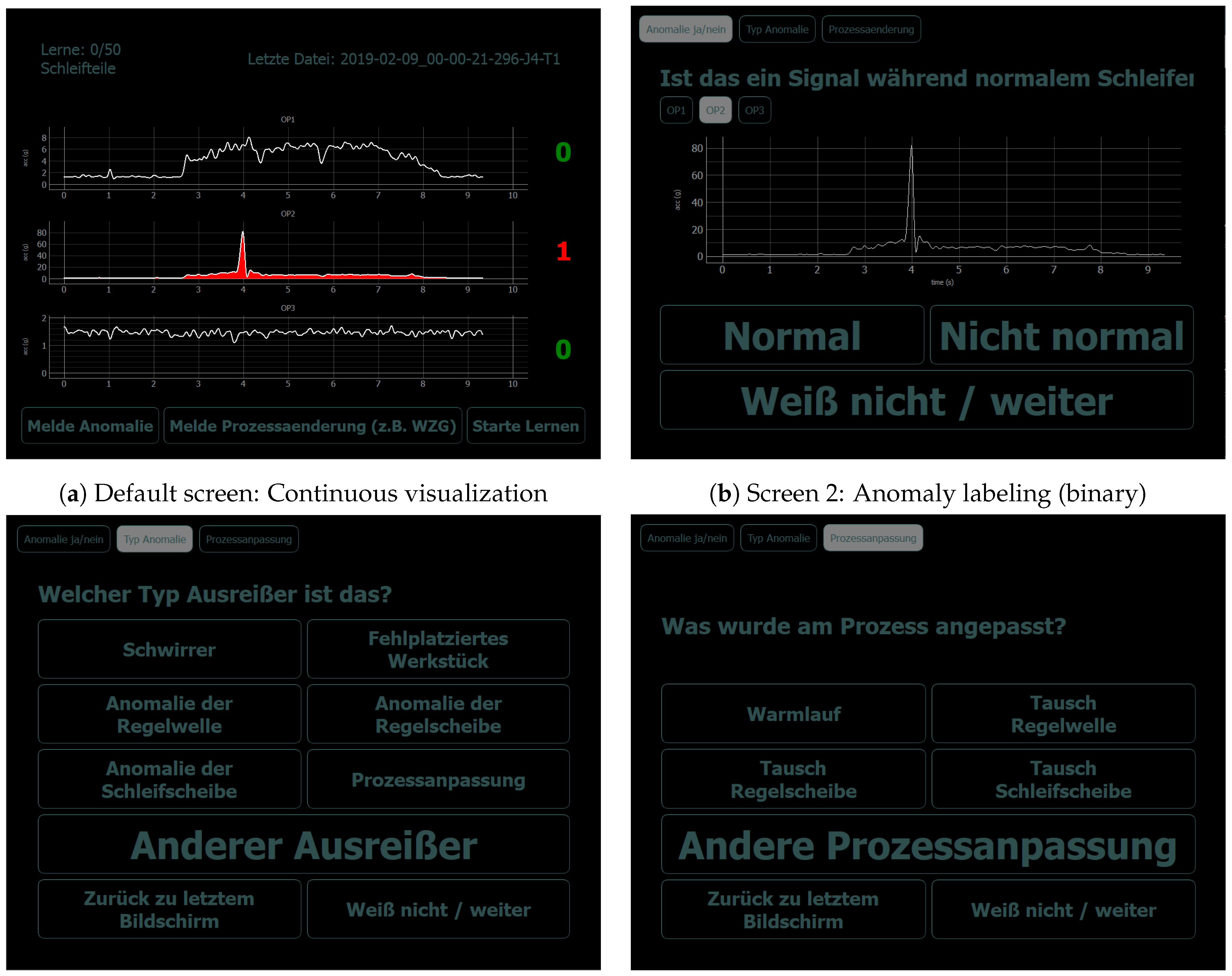
- A high reaction rate during online annotation to labels proposed by the anomaly detection algorithm. This is measured by the ratio of anomaly propositions that the annotator reacted to by either confirming an anomaly or rejecting the proposed label (i.e., by assigning a “Normal” label). Furthermore, an intentional skipping of the current anomaly proposition by pressing the “Don’t know/Skip” button (for specification of uncertainty) on our labeling prototype (cf. Figure 4) is rated as a reaction (Assumption 4a).
- A small reaction latency during online annotation to labels proposed by the anomaly detection algorithm (Assumption 4b).
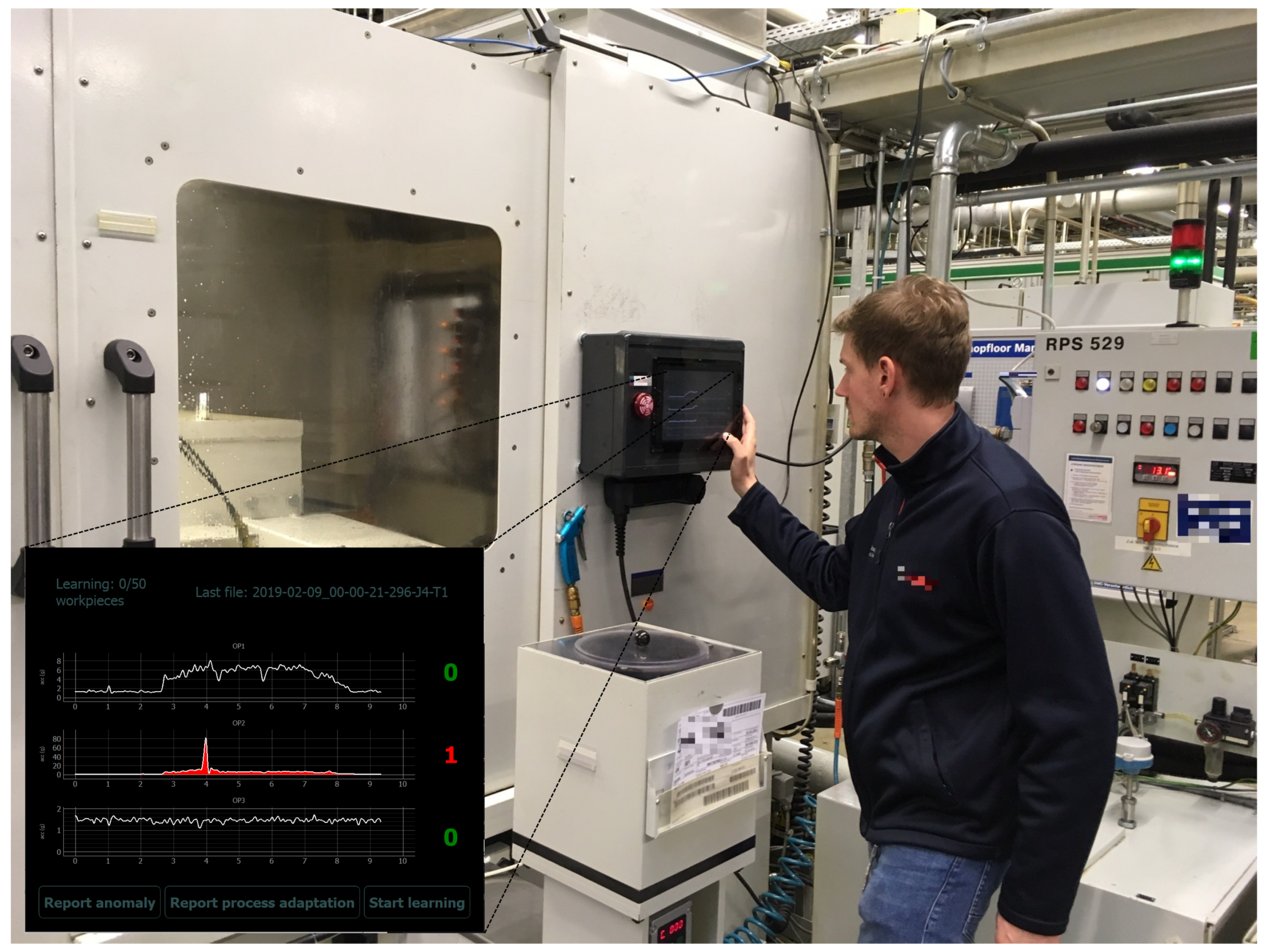
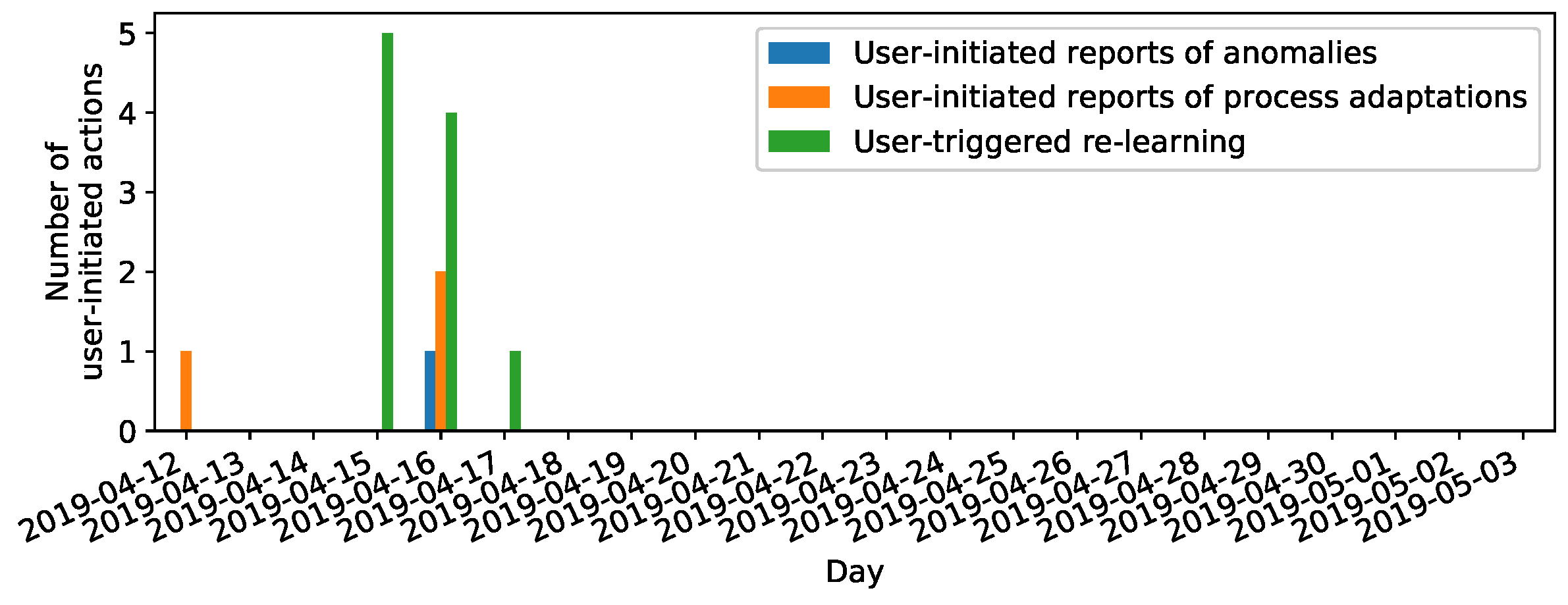
- A high degree of user-initiated actions for days with visually confirmed anomalies, as we assume a higher necessity of process adaptations after confirmed anomalies and higher necessity of reporting anomalies missed by the anomaly detection model at clusters of abnormal machine behavior (Assumption 5). This degree can be measured by the number of clicks of any of the buttons for user-initiated actions on our visualization and labeling prototype (cf. Figure 4a and buttons “Report anomaly”, “Report process adaptation”, and “Start learning”).
4. Measurement Setup
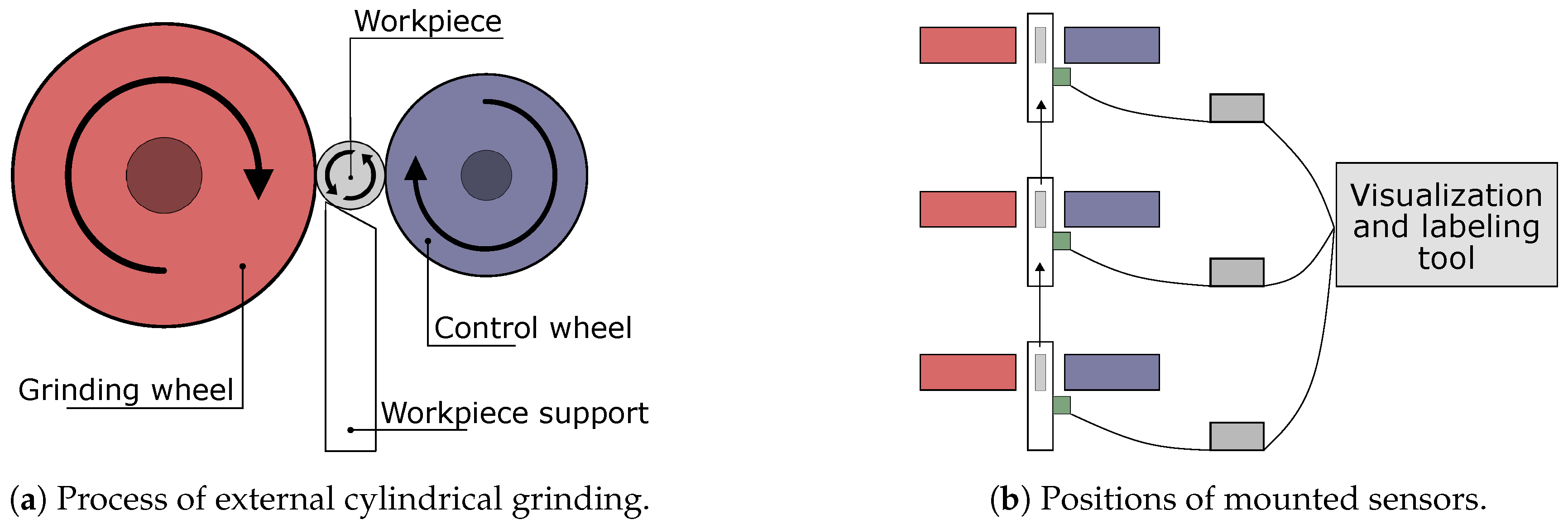
4.1. Centerless External Cylindrical Grinding
4.2. Sensor Specifications
5. Description of the Visualization and Labeling Prototype
5.1. Design Process of The Labeling Prototype
- First, general impressions of the surrounding included its loudness and the necessity of the machine operator to be capable of handling multiple tasks in parallel.
- In order to draw the attention of the machine operator to the labeling prototype display while being involved with other tasks, we triggered an alarm flash light and red coloring of proposed abnormal signals. Furthermore, an acoustic alarm signal was activated. This alarm signal had to be rather loud due to the noisy surrounding of the machine.
- To address the expected uncertainty in the operators’ annotation process which occurred due to handling multiple tasks in parallel, we included an opportunity to skip the labeling when uncertain (buttons “Don’t know/skip” on screens in Figure 4). Additionally, we allowed switching between the successive labeling screens manually to review the visualized signals again during the labeling process (buttons “Back to last screen” on screens in Figure 4). Finally, void class buttons (“Other anomaly” and “Other process adaptation”) allowed expressing uncertainty about the class of anomaly/process adaptation or giving a label for an anomaly/process adaptation which was not listed among the label choices.
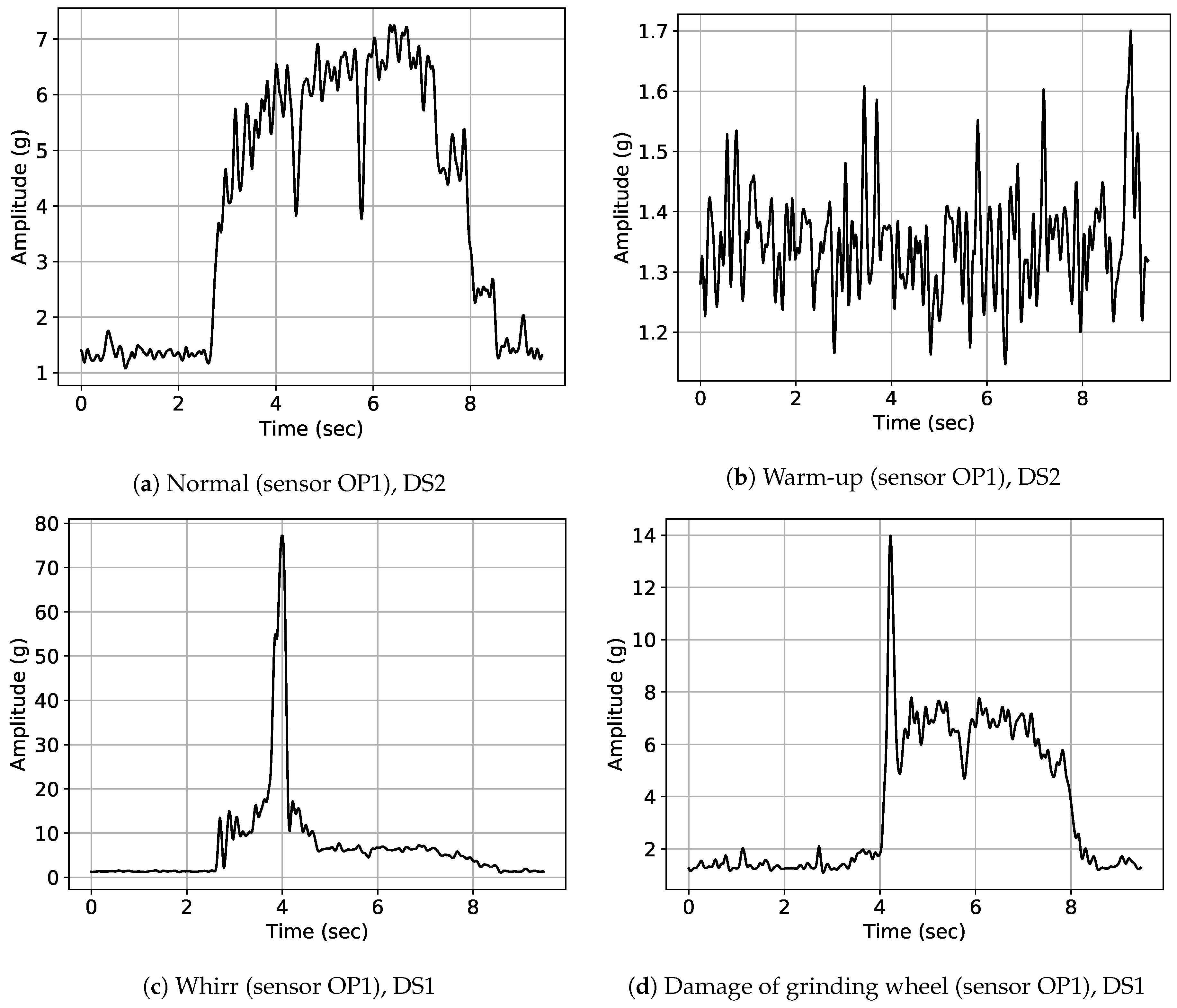
- In order to define an initial version of the labeling prototype screen design, we had a first meeting with the machine adjuster. In this meeting, we proposed and adapted a first version of the labeling prototype design. Additionally, we discussed the most accustomed way for presentation of sensor data: Industrially established solutions typically depict the envelope signals rather than the raw sensor data, TFD representations or feature scores. We thus chose the similar, well-known form of signal representation. Finally, we discussed the most frequent anomaly types and process adaptations to be included as dedicated class label buttons (screens 3 and 4 in Figure 4).
- After implementation of the labeling GUI from the adapted design of the initial meeting, we discussed the user experience of the proposed labeling GUI in a second meeting with the machine adjuster. This involved a live demo of the suggested labeling GUI in order to illustrate the intended use of the labeling prototype and resulted in a second rework of the labeling prototype.
- After this second rework of the labeling prototype, a meeting was arranged including both the machine adjusters and all machine operators. This meeting included a live demo of the labeling prototype directly at the grinding machine targeted in this study and a discussion of the terms chosen for the labeling buttons on screen 3 and 4 depicted in Figure 4. Additionally, an open interview gave the opportunity to discuss other ideas or concerns regarding the design or use of the labeling prototype.
- In order to address remaining uncertainties about the intended use of the labeling prototype after deployment on the demonstrator, we have written a short instruction manual which was attached next to the labeling prototype at the machine.
5.2. Functionality of the Labeling Prototype
6. Experiments
6.1. Selection of a Generic Unsupervised Anomaly Detection Algorithm
6.1.1. Evaluation Data
6.1.2. Anomaly Detection Models and Features
- The algorithm is not provided with any labels during our live annotation experiments and should thus allow for completely unsupervised learning. Incorporating label feedback for an improved anomaly detection will be part of a follow-up study.
- Due to the embedded nature, the algorithms should allow for fast predictions (due to real-time constraints) and have low memory occupation (embedded system with restricted memory space).
- Frequent process adaptations necessitate either fast relearning or fast transfer learning capabilities of the models in order to retain an appropriate representation of the normal state.
6.1.3. Results
6.1.4. Choice of Unsupervised Anomaly Detection Model for Deployment
- Can online annotations yield reliable signal labels (in comparison to retrospective annotations)?
- Which types of anomalies can a human annotator detect by reviewing sensor signal envelopes (both during online annotation and retrospective annotation)?
- Can human operators identify subtle anomalies proposed by the NC model?
- On which factors does the reliability of label feedback depend?
6.2. Label Evaluation
6.2.1. Assumption 1 (Amount and Distribution of Label Feedback)
6.2.2. Assumption 2a (Dependency of Label Feedback on Anomaly Scores)
6.2.3. Assumption 2b (Dependency of Online Label Feedback on Time)
6.2.4. Assumption 3a (Inter-Annotator Agreement between Multiple Retrospective Annotators)
6.2.5. Assumption 3b (Intra-Annotator Agreement between Online Label Feedback and the Mode of Retrospective Annotations)
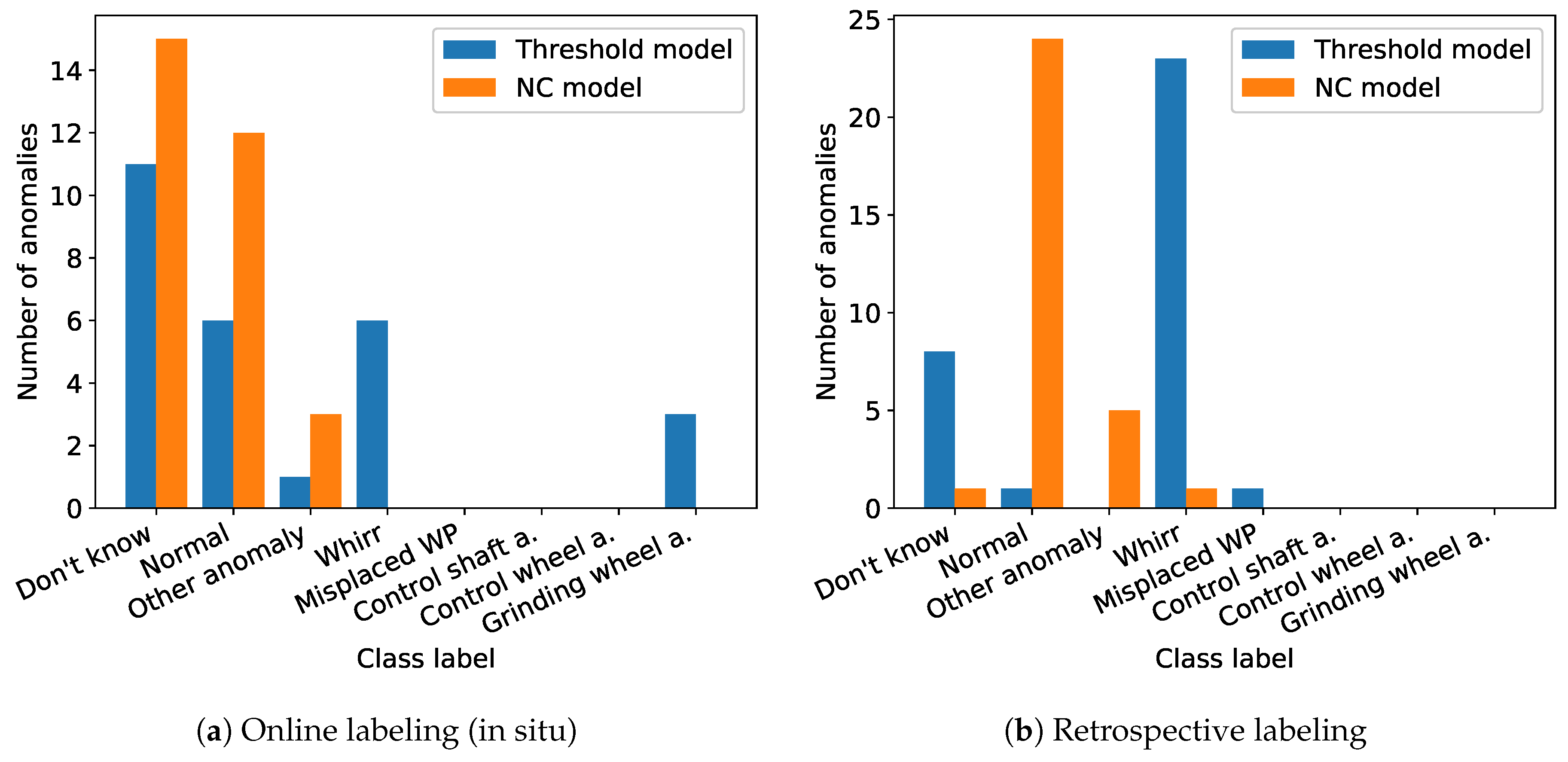
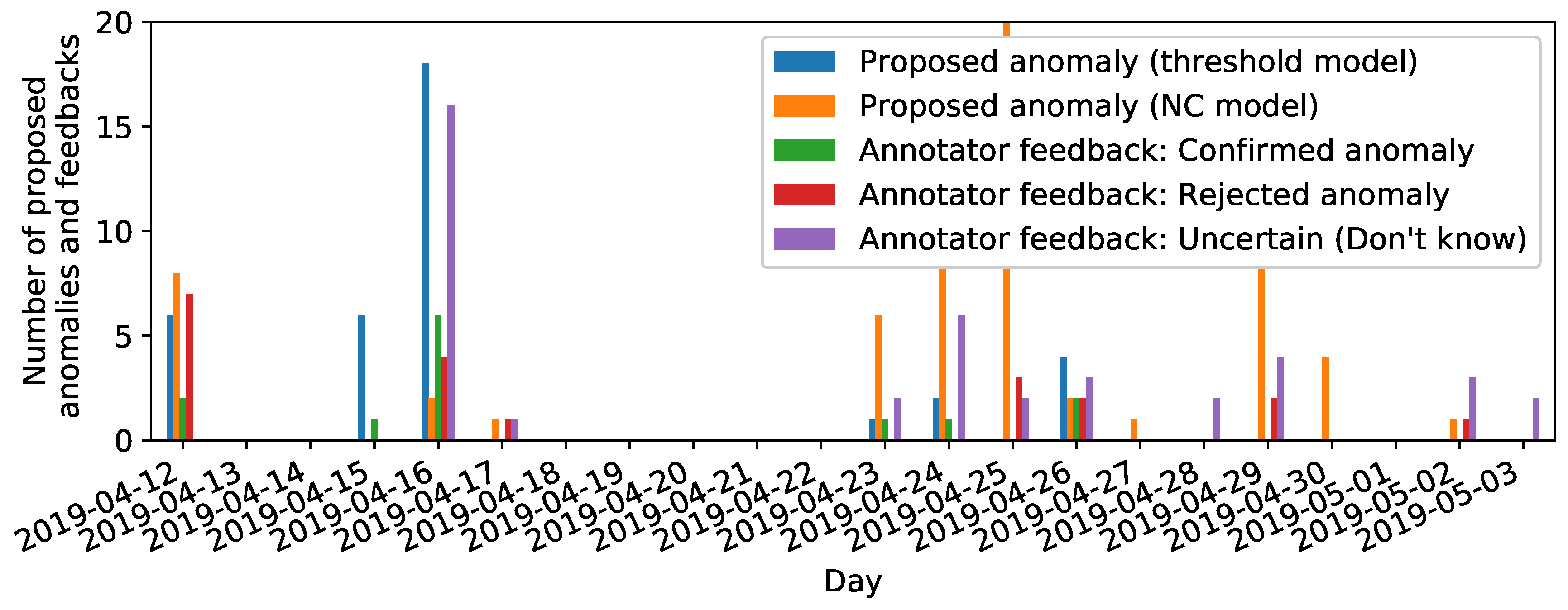
- Dependency of online label feedback on types of anomaly (Assumption 1): Clear anomaly types (whirring workpieces, grinding wheel damages) were more often confirmed and typically proposed by the threshold model, whereas other subtle anomalies were confirmed more seldom in general and typically proposed by the NC model (cf. Figure 7).
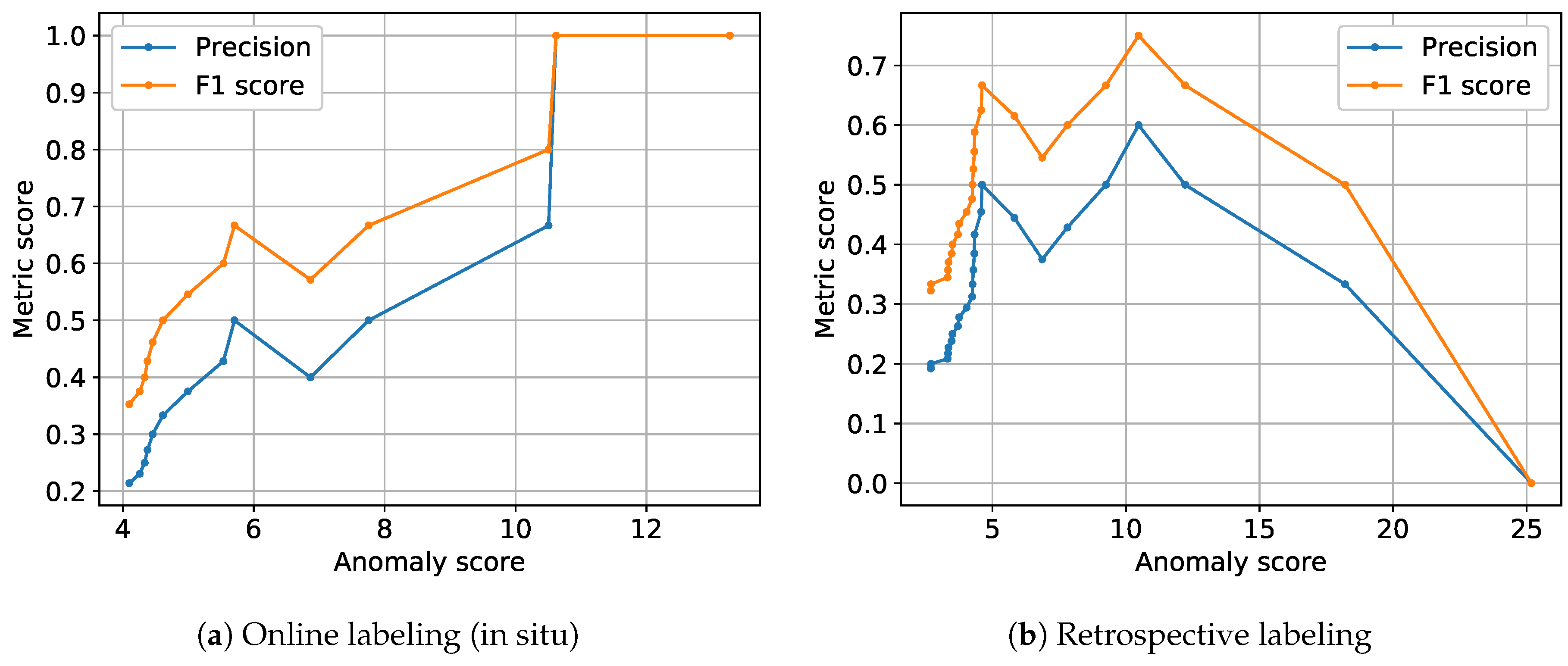
- Dependency of label feedback on height of anomaly scores (Assumption 2a): Higher anomaly scores for anomaly propositions of the NC model resulted in higher precision and F1 scores (cf. Figure 8). We interpret this to be due to clearer signal deviations that were better observable by the human operator, resulting in more certain and thus reliable online label feedback. This dependency was more clearly observable for live annotations than for retrospective annotations.
- Dependency of online label feedback on time (cf. Assumption 2b): High amounts both of anomaly propositions and online label feedback clustered at days of visually confirmed machine damages (cf. Figure 9). This verifies the sensibility of anomaly propositions and reliability of online label feedback at these days. Furthermore, we observed a “calibration” phase of users getting accustomed with the labeling prototype where the labeling behavior of users changed from tending to reject anomaly propositions to reacting with labeling signals as uncertain (“Don’t know”). We interpret this latter finding as increased trust of human annotators in anomaly propositions prompted via the labeling prototype.
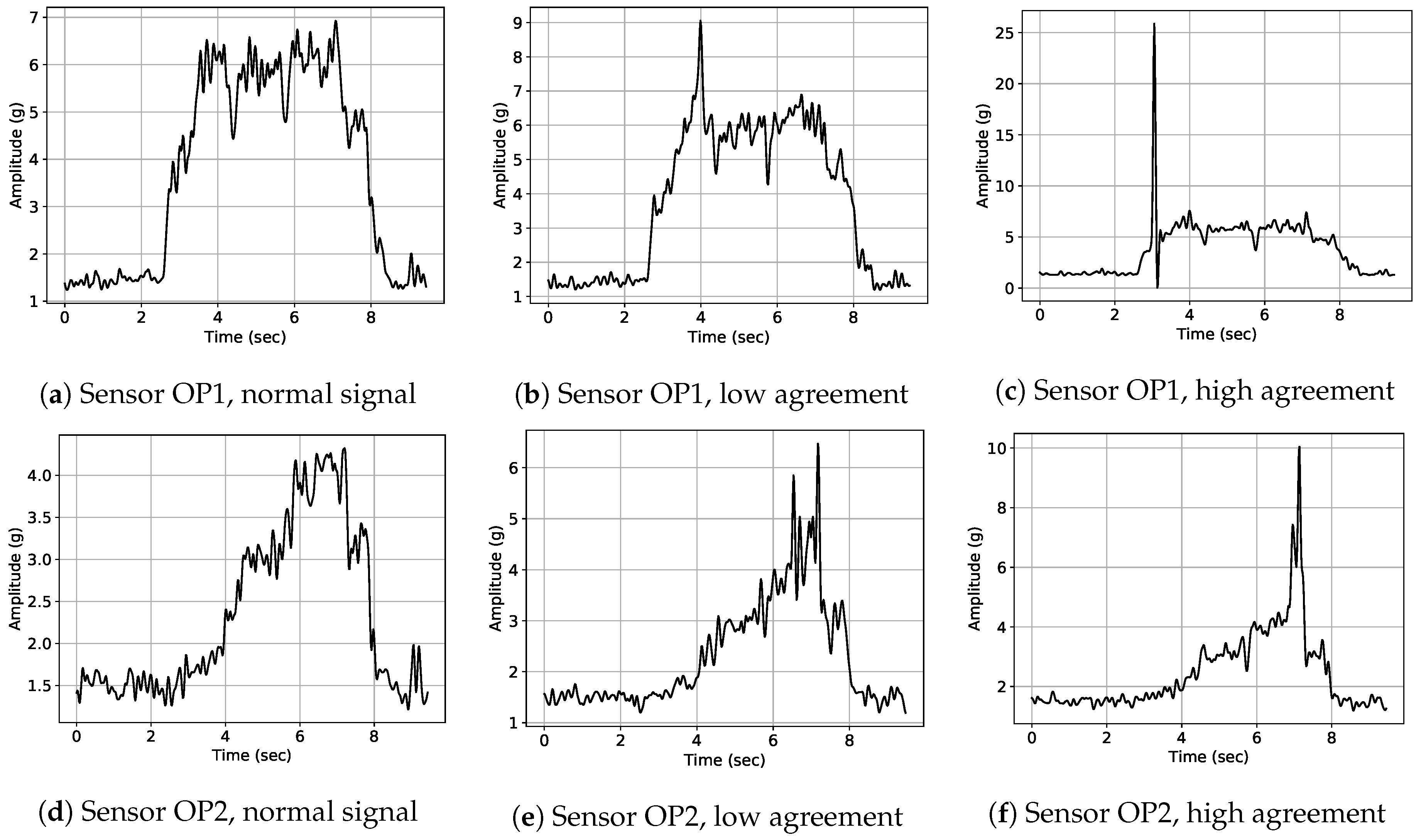
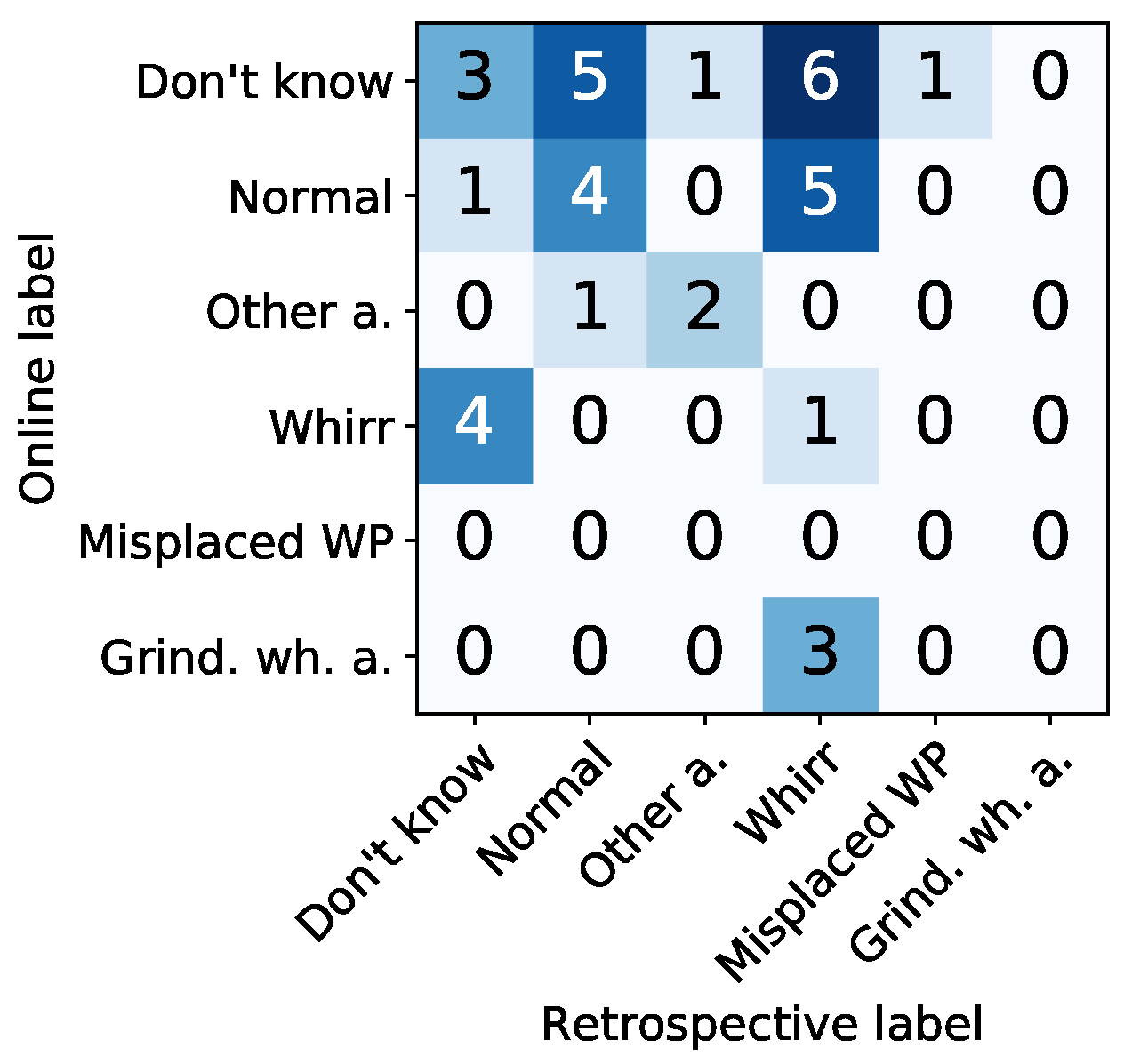
- Reliability of retrospective annotations (Assumption 3a): Retrospective annotations illustrated high inter-annotator agreement especially for the class “Whirr” (cf. Figure 10). This confirms high reliability of retrospective labels especially for this anomaly class. Furthermore, signal examples illustrated in Figure 11 visually confirm that signals with high inter-annotator agreement were clearly identifiable as signal outliers and depict a typical “Whirr” signal pattern. On the other hand, examples with low inter-annotator agreement were characterized by more subtle deviations.
- Reliability of online annotator feedback (cf. Assumption 3b): Similarly, online label feedback showed a high agreement with retrospective labels for the visually clearly identifiable signal deviations of class “Whirr” (cf. Figure 10 and Figure 12). More subtle and uncertain signal outliers were more likely to be labeled an anomaly during retrospective labeling (cf. Figure 7b and Figure 10). We thus interpret this clear type of “Whirr” anomalies to be labeled most reliably during online annotation.
6.2.6. Assumptions 4a and 4b (Reaction Rate and Reaction Latency during Online Label Feedback)
6.2.7. Assumption 5 (Dependency of User-Initiated Actions on Time)
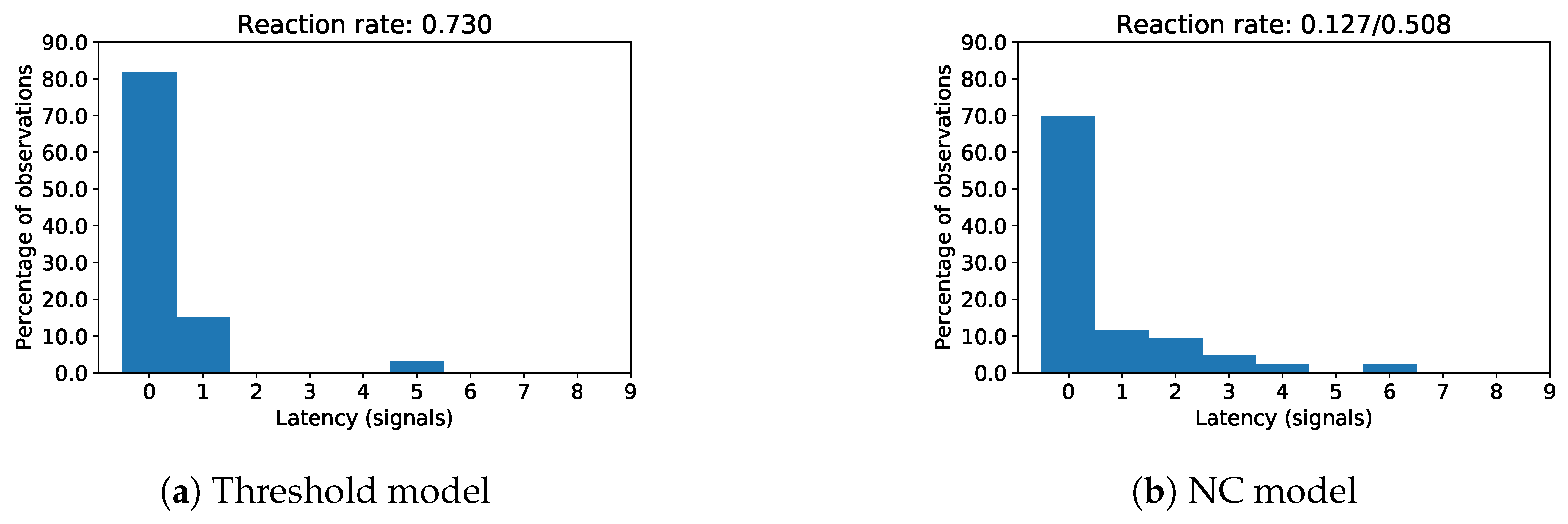
- Relation between user motivation and user reaction latency/rate (Assumptions 4a and 4b): Reaction latencies for online label feedback were small for both anomaly proposing models (Figure 13), which we interpret as a sign of high user motivation. The smaller reaction rate to NC anomaly propositions might be related to the more thorough reviewing of subtle signal deviations which characterized many of the NC anomaly propositions.
- Relation between user motivation and time (Assumption 5): We observed user-initiated actions only during days of visually confirmed machine damages (i.e., grinding wheel damage on April 16th) (Figure 14) and changes of machine parts (i.e., change of grinding wheel on April 16th). We interpret this as a sign of high user motivation to annotate signals.
7. Conclusions
- Other types of signal representation for a better visualization of anomalous signal information (e.g., raw signals, TFDs or feature score trends).
- More advanced anomaly detection models with the ability to cluster anomalies and give feedback about most anomalous signal regions. The former allows prompting potential anomalies together with formerly prompted signals of the same cluster, which in turn raises awareness for subtle but characteristic similar signal deviations and allows operators to gradually build up an internalized characteristic pattern of these more subtle anomalies. The latter allows for local highlighting of anomalous regions in signals visualized on the labeling tool screen (e.g., by local time series distance measures, shapelet approaches or attention-based models). This highlighting of anomalous signal regions also helps operators to learn new characteristic patterns for other anomaly types.
- Semi-supervised and weakly supervised approaches: In order to clarify whether including label feedback for tuning of anomaly detection model hyperparameters allows to better align anomaly propositions with the operator’s concept of what an anomaly is (i.e., reduce the FP rate).
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AE | autoencoder |
| AUC | area under curve |
| CEC | centerless external cylindrical |
| CNN | convolutional neural network |
| DBA | DTW barycenter averaging |
| DTW | dynamic time warping |
| ED | Euclidean distance |
| FFT | fast Fourier transform |
| FN | false negative |
| FNR | false negative rate |
| FP | false positive |
| FPR | false positive rate |
| GAN | generative adversial network |
| GUI | graphical user interface |
| HMI | human-machine interface |
| kNN | k-nearest neighbors |
| MEMS | microelectromechanical systems |
| MFCC | Mel-frequency cepstral coefficient |
| NC | nearest centroid |
| NMF | nonnegative matrix factorization |
| RNN | recurrent neural network |
| ROC | receiver operating characteristic |
| SDTW | soft-DTW |
| STFT | short-time Fourier transform |
| SVM | support vector machine |
| TFD | time-frequency distribution |
| TSC | time series classification |
| VAE | variational autoencoder |
Appendix A. Original German Version of Screens of Labeling Prototype

References
- Bustillo, A.; Urbikain, G.; Perez, J.M.; Pereira, O.M.; de Lacalle, L.N.L. Smart Optimization of a Friction-Drilling Process Based on Boosting Ensembles. J. Manuf. Syst. 2018, 48, 108–121. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. Acm Comput. Surv. 2009, 41, 15:1–15:58. [Google Scholar] [CrossRef]
- Betea, B.; Dobra, P.; Gherman, M.C.; Tomesc, L. Comparison between envelope detection methods for bearing defects diagnose. Ifac Proc. Vol. 2013, 46, 137–142. [Google Scholar] [CrossRef]
- Sheen, Y.T.; Hung, C.K. Constructing a wavelet-based envelope function for vibration signal analysis. Mech. Syst. Signal Process. 2004, 18, 119–126. [Google Scholar] [CrossRef]
- Liao, Z.; Song, L.; Chen, P.; Guan, Z.; Fang, Z.; Li, K. An Effective Singular Value Selection and Bearing Fault Signal Filtering Diagnosis Method Based on False Nearest Neighbors and Statistical Information Criteria. Sensors 2018, 18, 2235. [Google Scholar] [CrossRef]
- Paparrizos, J.; Gravano, L. k-Shape: Efficient and Accurate Clustering of Time Series. SIGMOD Rec. 2016, 45, 69–76. [Google Scholar] [CrossRef]
- Teti, R.; Jemielniak, K.; O’Donnell, G.; Dornfeld, D. Advanced Monitoring of Machining Operations. Cirp-Ann.-Manuf. Technol. 2010, 59, 607–822. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Zerhouni, N.; Rechak, S. Tool condition monitoring based on mel-frequency cepstral coefficients and support vector regression. In Proceedings of the 5th International Conference on Electrical Engineering, Boumerdes, Algeria, 29–31 October 2017; pp. 1–5. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, 8–13 December 2014; MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Oord, A.V.; Kalchbrenner, N.; Kavukcuoglu, K. Pixel Recurrent Neural Networks. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Dinh, L.; Krueger, D.; Bengio, Y. NICE: Non-linear independent components estimation. arXiv 2014, arXiv:1410.8516. [Google Scholar]
- Dinh, L.; Sohl-Dickstein, J.; Bengio, S. Density Estimation Using Real NVP. arXiv 2016, arXiv:1605.08803. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1x1 Convolutions. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 10215–10224. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Rifai, S.; Vincent, P.; Muller, X.; Glorot, X.; Bengio, Y. Contractive Auto-encoders: Explicit Invariance During Feature Extraction. In Proceedings of the 28th International Conference on International Conference on Machine Learning, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Zong, B.; Song, Q.; Min, M.R.; Cheng, W.; Lumezanu, C.; Cho, D.; Chen, H. Deep autoencoding gaussian mixture model for unsupervised anomaly detection. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Berndt, D.J.; Clifford, J. Using Dynamic Time Warping to Find Patterns in Time Series. In AAAIWS’94, Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 31 July–1 August 1994; AAAI Press: Cambridge, MA, USA, 1994; pp. 359–370. [Google Scholar]
- Cuturi, M.; Blondel, M. Soft-DTW: a Differentiable Loss Function for Time-Series. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A Global Averaging Method for Dynamic Time Warping, with Applications to Clustering. Pattern Recogn. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Xi, X.; Keogh, E.; Shelton, C.; Wei, L.; Ratanamahatana, C.A. Fast Time Series Classification Using Numerosity Reduction. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Bagnall, A.; Lines, J. An Experimental Evaluation of Nearest Neighbour Time Series Classification. arXiv 2014, arXiv:1406.4757. [Google Scholar]
- Wang, X.; Mueen, A.; Ding, H.; Trajcevski, G.; Scheuermann, P.; Keogh, E. Experimental Comparison of Representation Methods and Distance Measures for Time Series Data. Data Min. Knowl. Discov. 2013, 26, 275–309. [Google Scholar] [CrossRef]
- Petitjean, F.; Forestier, G.; Webb, G.I.; Nicholson, A.E.; Chen, Y.; Keogh, E. Faster and More Accurate Classification of Time Series by Exploiting a Novel Dynamic Time Warping Averaging Algorithm. Knowl. Inf. Syst. 2016, 47, 1–26. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Clustering by means of medoids. In Statistical Data Analysis Based on the L1 Norm and Related Methods; Dodge, Y., Ed.; Elsevier: Amsterdam, The Netherlands, 1987; pp. 405–416. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-based Algorithm for Discovering Clusters a Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining; AAAI Press: Cambridge, MA, USA, 1996; pp. 226–231. [Google Scholar]
- Ankerst, M.; Breunig, M.M.; Kriegel, H.P.; Sander, J. OPTICS: Ordering Points to Identify the Clustering Structure. In Proceedings of the 1999 ACM SIGMOD International Conference on Management of Data; ACM: New York, NY, USA, 1999; pp. 49–60. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates. In Advances in Knowledge Discovery and Data Mining; Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G., Eds.; Springer: Berlin, Germany, 2013; pp. 160–172. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Bahadori, M.T.; Kale, D.; Fan, Y.; Liu, Y. Functional Subspace Clustering with Application to Time Series. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Liao, T.W. Clustering of Time Series Data-a Survey. Pattern Recogn. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series Clustering—A Decade Review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long Short Term Memory Networks for Anomaly Detection in Time Series. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A Deep Neural Network for Unsupervised Anomaly Detection and Diagnosis in Multivariate Time Series Data. arXiv 2018, arXiv:1811.08055. [Google Scholar]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications. In Proceedings of the 2018 World Wide Web Conference on World Wide Web, Lyon, France, 23–27 April 2018. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Aggarwal, C.C. Outlier Analysis, 2nd ed.; Springer International Publishing: Berlin, Germany, 2016. [Google Scholar]
- Aggarwal, C.C.; Yu, P.S. An Effective and Efficient Algorithm for High-dimensional Outlier Detection. VLDB J. 2005, 14, 211–221. [Google Scholar] [CrossRef]
- Rousseeuw, P.J.; Driessen, K.V. A fast algorithm for the minimum covariance determinant estimator. Technometrics 1999, 41, 212–223. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Kröger, P.; Zimek, A. Outlier detection techniques. Tutorial at KDD 2010, 10, 1–76. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Tax, D.M.J.; Duin, R.P.W. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Ruff, L.; Vandermeulen, R.; Görnitz, N.; Deecke, L.; Siddiqui, S.A.; Binder, A.; Müller, E.; Kloft, M. Deep One-Class Classification. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Hautamaki, V.; Karkkainen, I.; Franti, P. Outlier Detection Using k-Nearest Neighbour Graph. In Proceedings of the Pattern Recognition, 17th International Conference on (ICPR’04), Cambridge, UK, 26 August 2004. [Google Scholar]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-based Local Outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data; ACM: New York, NY, USA; pp. 93–104.
- Schubert, E.; Zimek, A.; Kriegel, H.P. Local outlier detection reconsidered: a generalized view on locality with applications to spatial, video, and network outlier detection. Data Min. Knowl. Discov. 2014, 28, 190–237. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.C.; Cheung, D.W.L. Enhancing Effectiveness of Outlier Detections for Low Density Patterns. In Proceedings of the 6th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2002; pp. 535–548. [Google Scholar]
- He, Z.; Xu, X.; Deng, S. Discovering Cluster-based Local Outliers. Pattern Recogn. Lett. 2003, 24, 1641–1650. [Google Scholar] [CrossRef]
- Jin, W.; Tung, A.K.H.; Han, J.; Wang, W. Ranking Outliers Using Symmetric Neighborhood Relationship. In Proceedings of the 10th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2006; pp. 577–593. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. LoOP: Local Outlier Probabilities. In Proceedings of the 18th ACM Conference on Information and Knowledge Management; ACM: New York, NY, USA, 2009; pp. 1649–1652. [Google Scholar]
- Zhang, K.; Hutter, M.; Jin, H. A New Local Distance-Based Outlier Detection Approach for Scattered Real-World Data. In Proceedings of the 13th Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining; Springer: Berlin, Germany, 2009; pp. 813–822. [Google Scholar]
- Latecki, L.J.; Lazarevic, A.; Pokrajac, D. Outlier Detection with Kernel Density Functions. In Proceedings of the 5th International Conference on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin, Germany, 2007; pp. 61–75. [Google Scholar]
- Schubert, E.; Zimek, A.; Kriegel, H.P. Generalized outlier detection with flexible kernel density estimates. In Proceedings of the 2014 SIAM International Conference on Data Mining, Philadelphia, PA, USA, 24–26 April 2014. [Google Scholar]
- Aggarwal, C.C. Outlier Ensembles: Position Paper. SIGKDD Explor. Newsl. 2013, 14, 49–58. [Google Scholar] [CrossRef]
- Zimek, A.; Campello, R.J.; Sander, J. Ensembles for Unsupervised Outlier Detection: Challenges and Research Questions a Position Paper. SIGKDD Explor. Newsl. 2014, 15, 11–22. [Google Scholar] [CrossRef]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining; IEEE Computer Society: Washington, DC, USA, 2008; pp. 413–422. [Google Scholar]
- Aggarwal, C.C.; Sathe, S. Theoretical Foundations and Algorithms for Outlier Ensembles. SIGKDD Explor. Newsl. 2015, 17, 24–47. [Google Scholar] [CrossRef]
- Manzoor, E.; Lamba, H.; Akoglu, L. xStream: Outlier Detection in Feature-Evolving Data Streams. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Zimek, A.; Gaudet, M.; Campello, R.J.; Sander, J. Subsampling for Efficient and Effective Unsupervised Outlier Detection Ensembles. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; ACM: New York, NY, USA, 2013; pp. 428–436. [Google Scholar]
- Wu, K.; Zhang, K.; Fan, W.; Edwards, A.; Yu, P.S. RS-Forest: A Rapid Density Estimator for Streaming Anomaly Detection. In Proceedings of the 2014 IEEE International Conference on Data Mining; IEEE Computer Society: Washington, DC, USA, 2014; pp. 600–609. [Google Scholar]
- Tan, S.C.; Ting, K.M.; Liu, T.F. Fast Anomaly Detection for Streaming Data. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence—Volume Two; AAAI Press: Cambridge, MA, USA, 2011; pp. 1511–1516. [Google Scholar]
- Rayana, S.; Akoglu, L. Less is More: Building Selective Anomaly Ensembles. ACM Trans. Knowl. Discov. Data 2016, 10, 42:1–42:33. [Google Scholar] [CrossRef]
- Rayana, S.; Zhong, W.; Akoglu, L. Sequential Ensemble Learning for Outlier Detection: A Bias-Variance Perspective. In 2016 IEEE 16th International Conference on Data Mining (ICDM); IEEE: New York, NY, USA, 2016; pp. 1167–1172. [Google Scholar]
- Pevny, T. Loda: Lightweight On-line Detector of Anomalies. Mach. Learn. 2016, 102, 275–304. [Google Scholar] [CrossRef]
- Sathe, S.; Aggarwal, C.C. Subspace Outlier Detection in Linear Time with Randomized Hashing. In 2016 IEEE 16th International Conference on Data Mining (ICDM); IEEE: New York, NY, USA, 2016; pp. 459–468. [Google Scholar]
- Zimek, A.; Schubert, E.; Kriegel, H.P. Tutorial i: Outlier detection in high-dimensional data. In 2012 IEEE 12th International Conference on Data Mining (ICDM); IEEE: New York, NY, USA, 2012; Volume 10, pp. xxx–xxxii. [Google Scholar]
- Adams, R.; Marlin, B. Learning Time Series Detection Models from Temporally Imprecise Labels. Proc. Mach. Learn. Res. 2017, 54, 157. [Google Scholar] [PubMed]
- Adams, R.; Marlin, B. Learning Time Series Segmentation Models from Temporally Imprecise Labels. In Proceedings of the 34th Conference on Uncertainty in Artificial Intelligence (UAI), Monterey, CA, USA, 6–10 August 2018. [Google Scholar]
- Siegert, I.; Böck, R.; Wendemuth, A. Inter-rater reliability for emotion annotation in human–computer interaction: Comparison and methodological improvements. J. Multimodal User Interfaces 2014, 8, 17–28. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A Review of Human Activity Recognition Methods. Front. Robot. 2015, 2, 28. [Google Scholar] [CrossRef]
- Minor, B.D. Toward Learning and Mining from Uncertain Time-Series Data for Activity Prediction. In SIGKDD Workshop on Mining and Learning from Time Series (MiLeTS’2015); ACM: New York, NY, USA, 2015. [Google Scholar]
- Cleland, I.; Han, M.; Nugent, C.D.; Lee, H.; McClean, S.I.; Zhang, S.; Lee, S. Evaluation of Prompted Annotation of Activity Data Recorded from a Smart Phone. Sensors 2014, 14, 15861–15879. [Google Scholar] [CrossRef] [PubMed]
- Zenonos, A.; Khan, A.; Kalogridis, G.; Vatsikas, S.; Lewis, T.; Sooriyabandara, M. HealthyOffice: Mood recognition at work using smartphones and wearable sensors. In IEEE International Conference on Pervasive Computing and Communication Workshops (PerCom Workshops); IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Cruciani, F.; Cleland, I.; Nugent, C.D.; McCullagh, P.J.; Synnes, K.; Hallberg, J. Automatic Annotation for Human Activity Recognition in Free Living Using a Smartphone. Sensors 2018, 18, 2203. [Google Scholar] [CrossRef] [PubMed]
- Vaizman, Y.; Ellis, K.; Lanckriet, G.; Weibel, N. ExtraSensory App: Data Collection In-the-Wild with Rich User Interface to Self-Report Behavior. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems; ACM: New York, NY, USA, 2018; pp. 554:1–554:12. [Google Scholar]
- Lewis, D.D.; Gale, W.A. A Sequential Algorithm for Training Text Classifiers. In Proceedings of the 17th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval; Springer: New York, NY, USA, 1994; pp. 3–12. [Google Scholar]
- Gwet, K.L. Handbook of Inter-Rater Reliability: The Definitive Guide to Measuring the Extent of Agreement among Raters, 4th ed.; Advanced Analytics, LLC: Gaithersburg, MD, USA, 2014. [Google Scholar]
- Quadrianto, N.; Smola, A.J.; Caetano, T.S.; Le, Q.V. Estimating Labels from Label Proportions. J. Mach. Learn. Res. 2009, 10, 2349–2374. [Google Scholar]
- Moreno, P.G.; Artés-Rodríguez, A.; Teh, Y.W.; Perez-Cruz, F. Bayesian Nonparametric Crowdsourcing. J. Mach. Learn. Res. 2015, 16, 1607–1627. [Google Scholar]
- Yang, Y.; Zhang, M.; Chen, W.; Zhang, W.; Wang, H.; Zhang, M. Adversarial Learning for Chinese NER From Crowd Annotations. In 32nd AAAI Conference on Artificial Intelligence (AAAI18); AAAI Press: Cambridge, MA, USA, 2018; pp. 1627–1634. [Google Scholar]
- Snow, R.; O’Connor, B.; Jurafsky, D.; Ng, A. Cheap and fast—but is it good? Evaluating non-expert annotations for natural language tasks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 254–263. [Google Scholar]
- Hovy, D.; Berg-Kirkpatrick, T.; Vaswani, A.; Hovy, E. Learning Whom to Trust with MACE. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics (ACL), Atlanta, GA, USA, 9–14 June 2013; pp. 1120–1130. [Google Scholar]
- Passonneau, R.J.; Carpenter, B. The Benefits of a Model of Annotation. Trans. Assoc. Comput. Linguist. 2014, 2, 311–326. [Google Scholar] [CrossRef]
- Plötz, T.; Chen, C.; Hammerla, N.Y.; Abowd, G.D. Automatic Synchronization of Wearable Sensors and Video-Cameras for Ground Truth Annotation—A Practical Approach. In Proceedings of the 2012 16th Annual International Symposium on Wearable Computers (ISWC); IEEE Computer Society: Washington, DC, USA, 2012; pp. 100–103. [Google Scholar]
- Miu, T.; Missier, P.; Plötz, T. Bootstrapping Personalised Human Activity Recognition Models Using Online Active Learning. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing, Liverpool, UK, 26–28 October 2015. [Google Scholar]
- Schröder, M.; Yordanova, K.; Bader, S.; Kirste, T. Tool Support for the Online Annotation of Sensor Data. In Proceedings of the 3rd International Workshop on Sensor-based Activity Recognition and Interaction; ACM: New York, NY, USA, 2016; pp. 9:1–9:7. [Google Scholar]
- Miu, T.; Plötz, T.; Missier, P.; Roggen, D. On Strategies for Budget-based Online Annotation in Human Activity Recognition. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication; ACM: New York, NY, USA, 2014; pp. 767–776. [Google Scholar]
- Gjoreski, H.; Roggen, D. Unsupervised Online Activity Discovery Using Temporal Behaviour Assumption. In Proceedings of the 2017 ACM International Symposium on Wearable Computers; ACM: New York, NY, USA, 2017; pp. 42–49. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Zhao, Y.; Nasrullah, Z.; Li, Z. PyOD: A Python Toolbox for Scalable Outlier Detection. arXiv 2019, arXiv:1901.01588. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | F1 Score | Precision | Recall | Memory [kB] | Training Time [s] | Prediction Time [ms] |
|---|---|---|---|---|---|---|
| 1NN (ED) sup. | 99.85 | 99.85 | 99.85 | 8742 | 0.09 | 1.29 |
| NC (ED) | 99.75 | 99.75 | 99.75 | 23 | 0.05 | 0.05 |
| NC (ED+TI) | 99.80 | 99.80 | 99.80 | 23 | 0.78 | 0.47 |
| NC (DTW) | 99.20 | 99.22 | 99.19 | 21 | 1641.55 | 861.28 |
| NC (SDTW) | 99.30 | 99.30 | 99.30 | 21 | 205.99 | 1016.63 |
| LOF [45] | 52.32 | 88.45 | 47.25 | 170 | 0.05 | 0.03 |
| CBLOF [48] | 53.55 | 88.50 | 48.36 | 12 | 0.94 | 0.01 |
| IF [56] | 55.84 | 88.61 | 50.48 | 78 | 0.14 | 0.03 |
| kNN | 53.11 | 88.48 | 47.96 | 150 | 0.06 | 0.09 |
| MCD [39] | 67.45 | 89.37 | 62.24 | 19 | 0.61 | 0.01 |
| OCSVM [41] | 51.59 | 88.42 | 46.60 | 109 | 0.06 | 0.02 |
| HDBSCAN [28] | 96.26 | 96.61 | 96.47 | 599 | 0.20 | 0.01 |
| LODA [64] | 90.06 | 93.62 | 88.94 | 29 | 0.02 | 0.01 |
| HSTrees [61] | 96.43 | 96.75 | 96.62 | 278 | 6.31 | 5.12 |
| RSForest [60] | 96.15 | 96.31 | 96.31 | 304 | 4.82 | 5.10 |
| RSHash [65] | 95.92 | 96.12 | 96.11 | 1807 | 2.17 | 0.01 |
| xStream [58] | 96.25 | 96.45 | 96.42 | 246,994 | 13.00 | 8.04 |
| Algorithm | F1 Score | Precision | Recall | Memory [kB] | Training Time [s] | Prediction Time [ms] |
|---|---|---|---|---|---|---|
| 1NN (ED) sup. | 100.0 | 100.0 | 100.0 | 9675 | 0.06 | 1.44 |
| NC (ED) | 100.0 | 100.0 | 100.0 | 23 | 0.05 | 0.06 |
| NC (ED+TI) | 100.0 | 100.0 | 100.0 | 23 | 1.11 | 0.62 |
| NC (DTW) | 100.0 | 100.0 | 100.0 | 23 | 1676.78 | 785.73 |
| NC (SDTW) | 100.0 | 100.0 | 100.0 | 23 | 174.61 | 911.29 |
| LOF [45] | 99.41 | 99.60 | 99.32 | 190 | 0.05 | 0.04 |
| CBLOF [48] | 100.0 | 100.0 | 100.0 | 12 | 0.03 | 0.01 |
| IF [56] | 99.79 | 99.82 | 99.77 | 79 | 0.17 | 0.04 |
| kNN | 99.48 | 99.63 | 99.41 | 167 | 0.05 | 0.11 |
| MCD [39] | 99.75 | 99.79 | 99.73 | 20 | 0.66 | 0.01 |
| OCSVM [41] | 99.30 | 99.55 | 99.19 | 101 | 0.06 | 0.02 |
| HDBSCAN [28] | 99.98 | 100.0 | 99.01 | 669 | 0.35 | 0.01 |
| LODA [64] | 99.83 | 99.85 | 99.82 | 29 | 0.03 | 0.01 |
| HSTrees [61] | 99.65 | 99.68 | 99.68 | 278 | 6.75 | 5.08 |
| RSForest [60] | 99.71 | 99.73 | 99.73 | 304 | 4.95 | 5.14 |
| RSHash [65] | 100.0 | 100.0 | 100.0 | 2019 | 2.52 | 0.01 |
| xStream [58] | 99.81 | 99.82 | 99.82 | 224,335 | 15.17 | 9.35 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reich, C.; Mansour, A.; Van Laerhoven, K. Collecting Labels for Rare Anomalies via Direct Human Feedback—An Industrial Application Study. Informatics 2019, 6, 38. https://doi.org/10.3390/informatics6030038
Reich C, Mansour A, Van Laerhoven K. Collecting Labels for Rare Anomalies via Direct Human Feedback—An Industrial Application Study. Informatics. 2019; 6(3):38. https://doi.org/10.3390/informatics6030038
Chicago/Turabian StyleReich, Christian, Ahmad Mansour, and Kristof Van Laerhoven. 2019. "Collecting Labels for Rare Anomalies via Direct Human Feedback—An Industrial Application Study" Informatics 6, no. 3: 38. https://doi.org/10.3390/informatics6030038
APA StyleReich, C., Mansour, A., & Van Laerhoven, K. (2019). Collecting Labels for Rare Anomalies via Direct Human Feedback—An Industrial Application Study. Informatics, 6(3), 38. https://doi.org/10.3390/informatics6030038