
TOPCAT: Desktop Exploration of Tabular Data for Astronomy and Beyond


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Source Catalogues
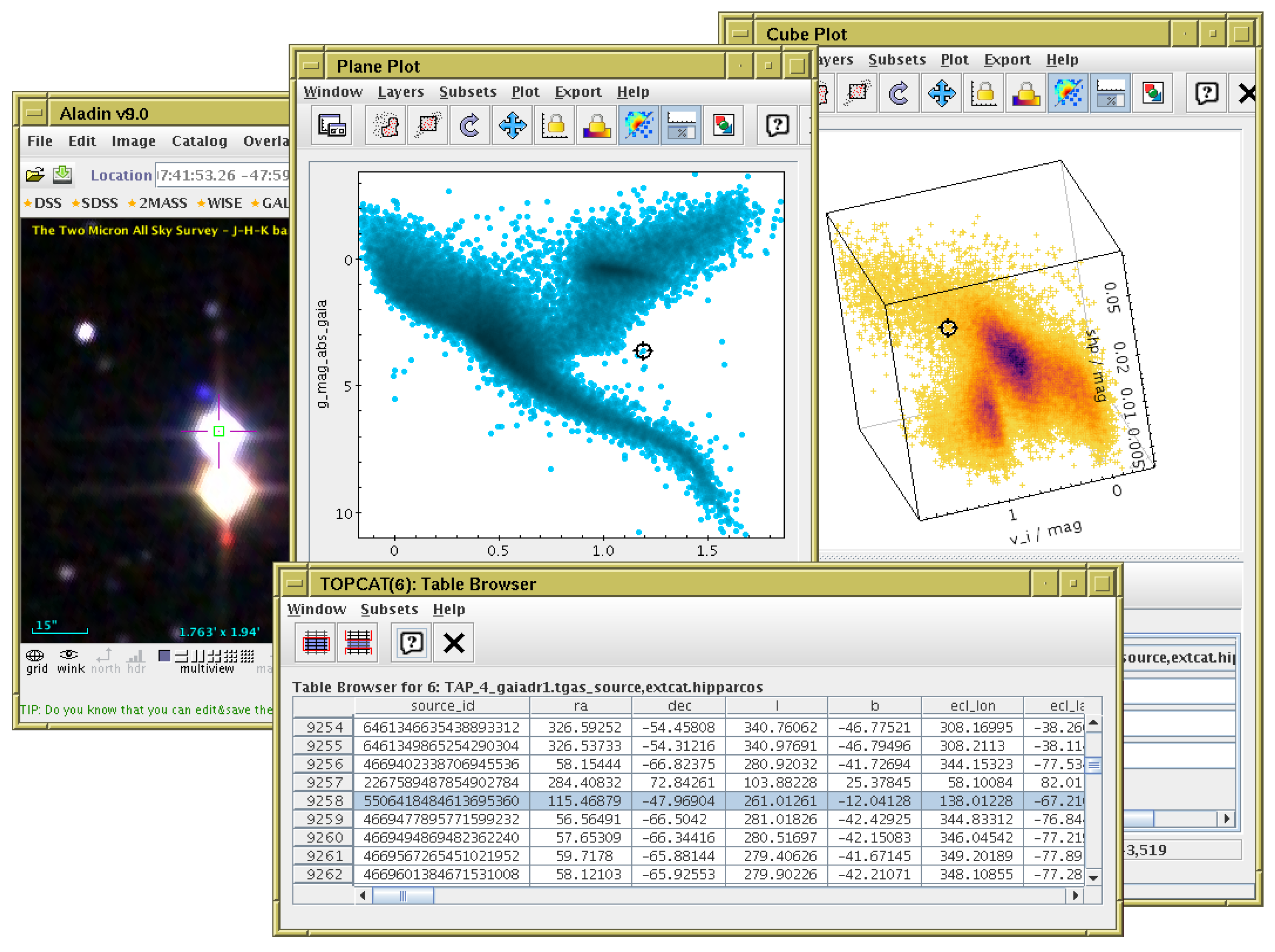
1.2. TOPCAT Application
- the ability to work with large datasets, without any special preparation of the data or prior assumptions about the visualisations required
- provision of many options to explore high-dimensional data, that can be adjusted interactively with rapid visual feedback
- meaningful representation of both high and low density regions of very large point clouds
2. Application Overview
2.1. Data Access
2.2. Usage Model
2.3. Expression Language
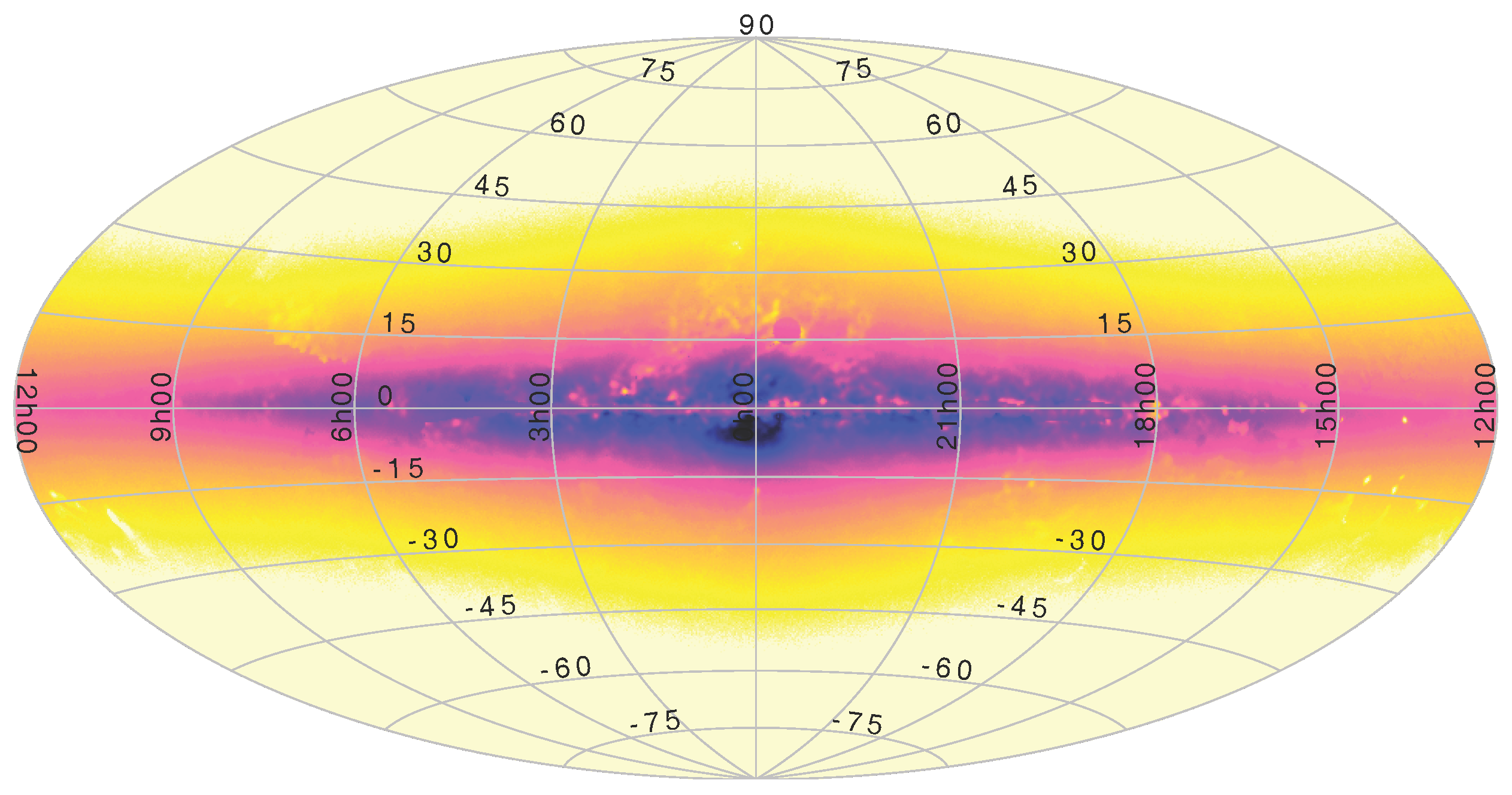
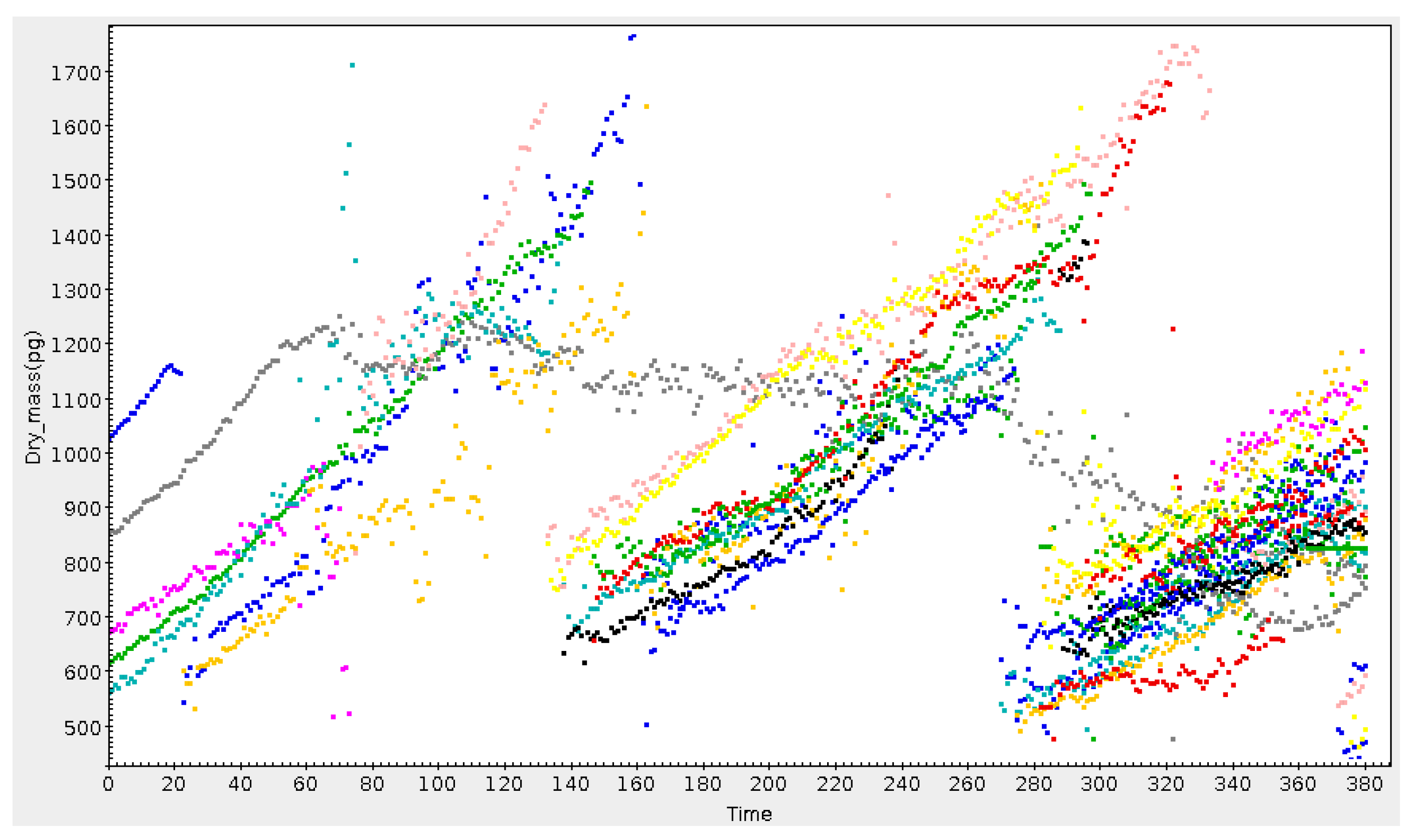
3. Visualising Point Clouds
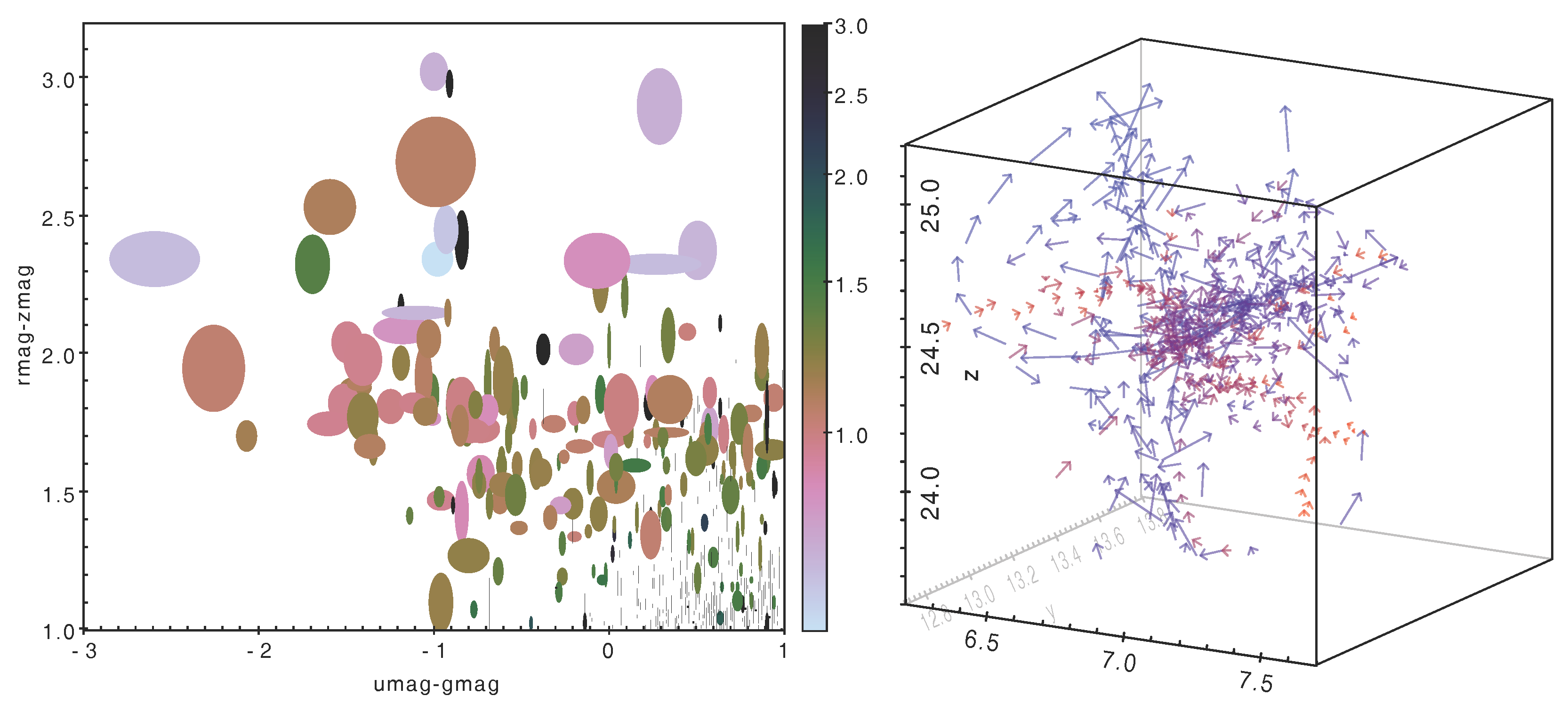
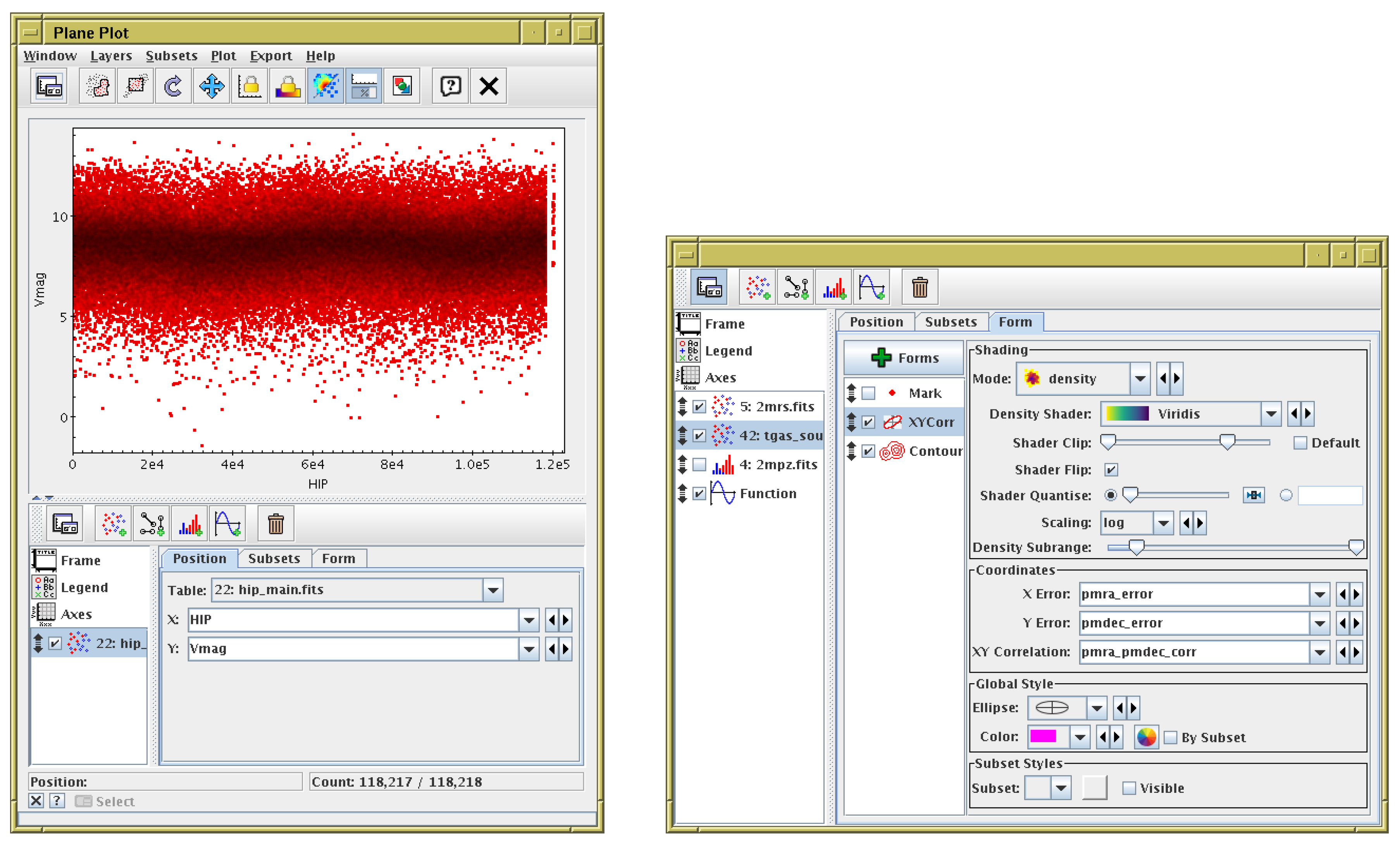
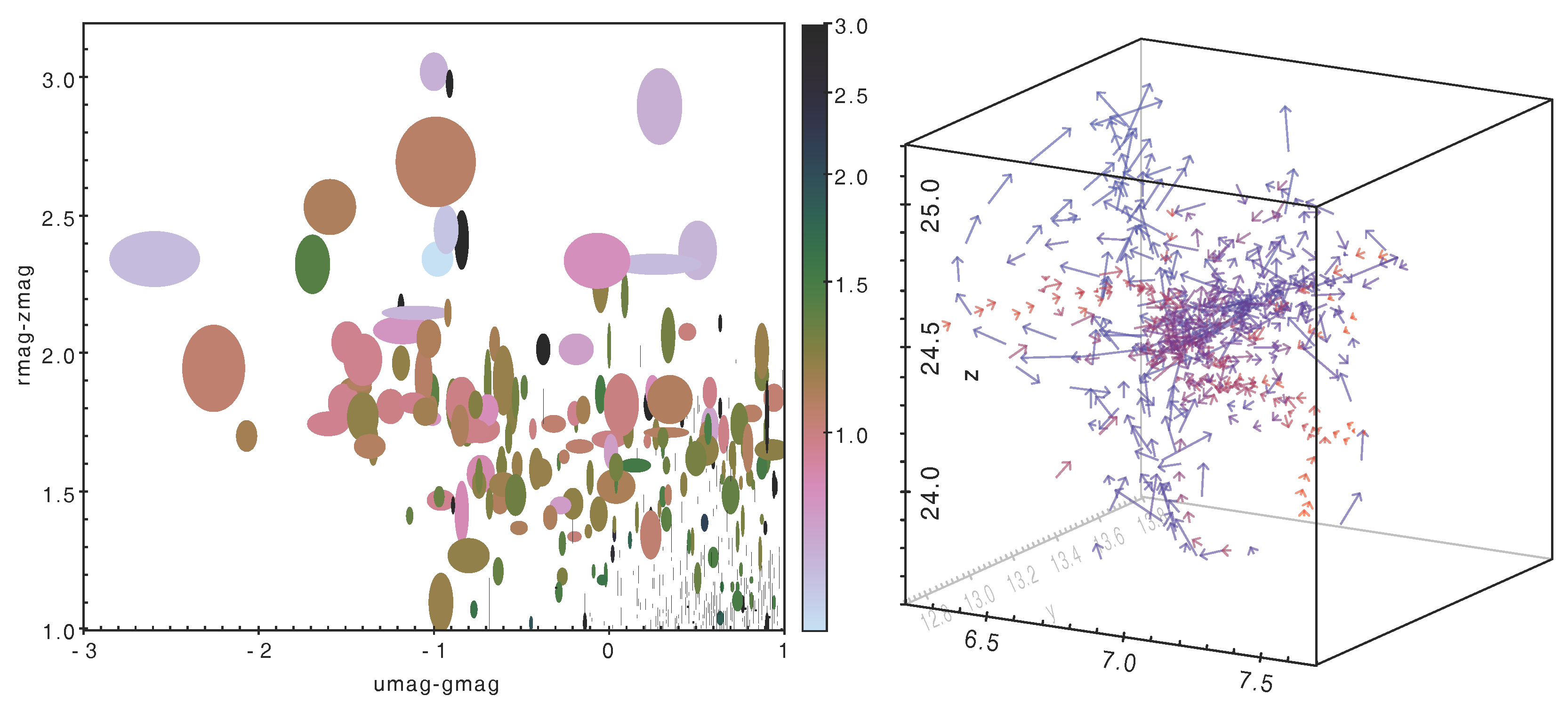
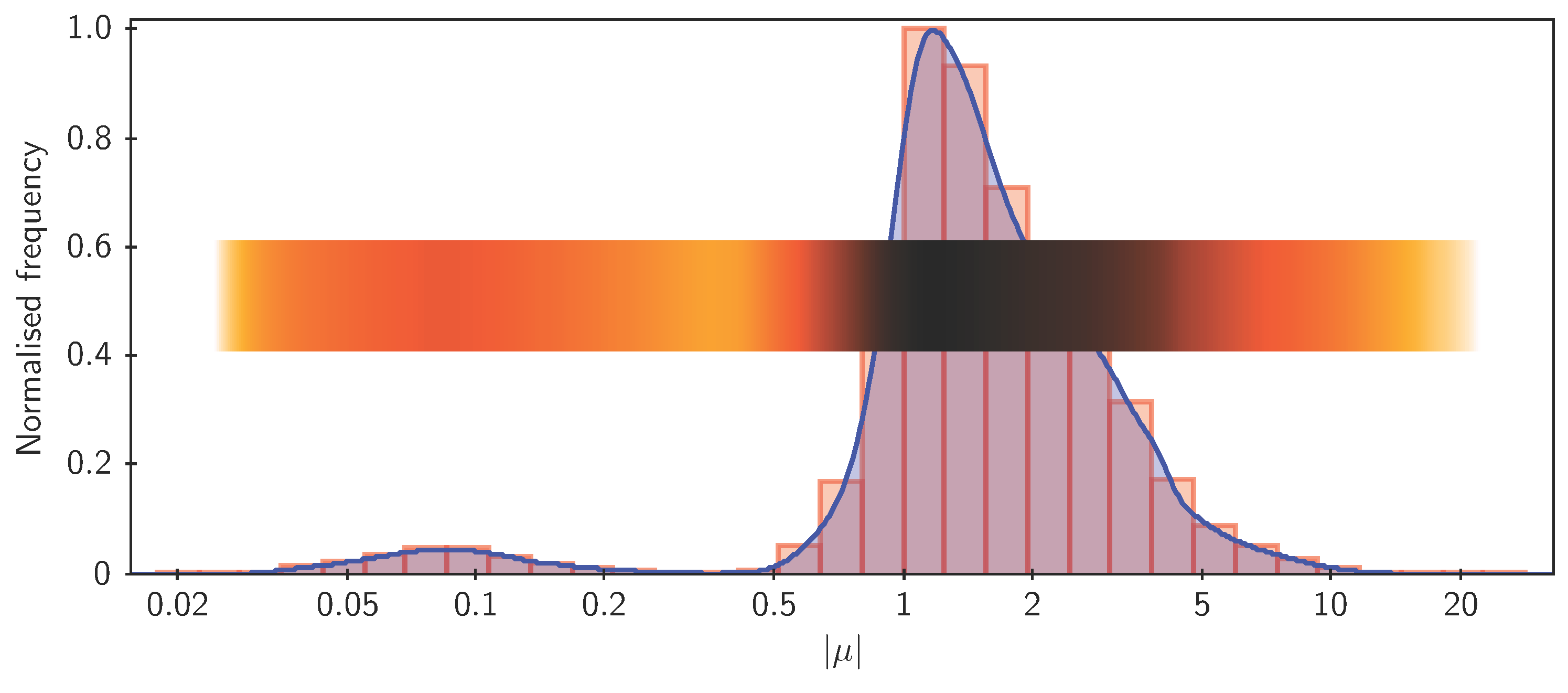
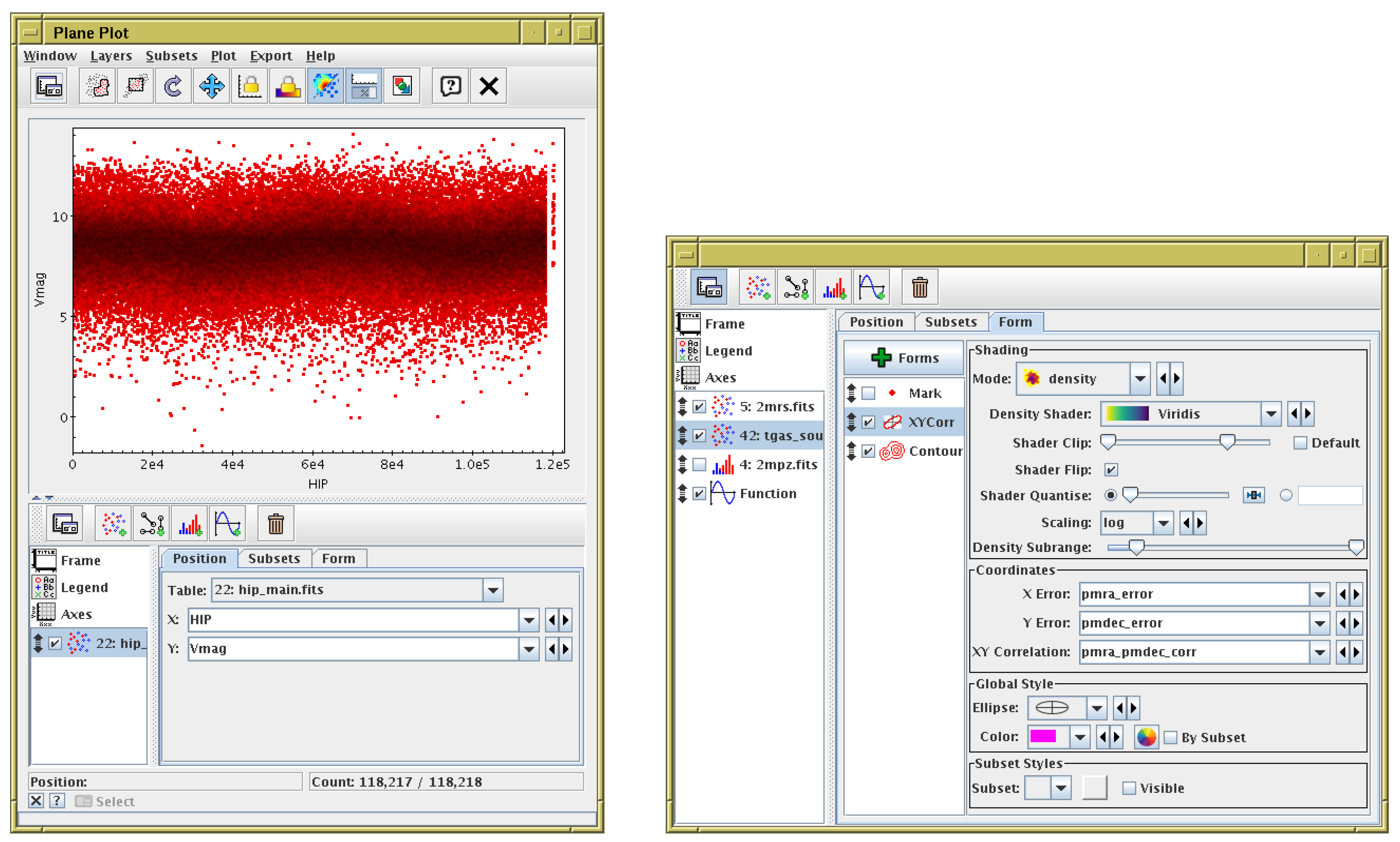
3.1. High-Dimensional Plots
- colour from a selected colour map
- marker size
- X/Y marker extent
- error bars aligned with the axes
- vector with magnitude and orientation
- ellipse primary/secondary radius and orientation
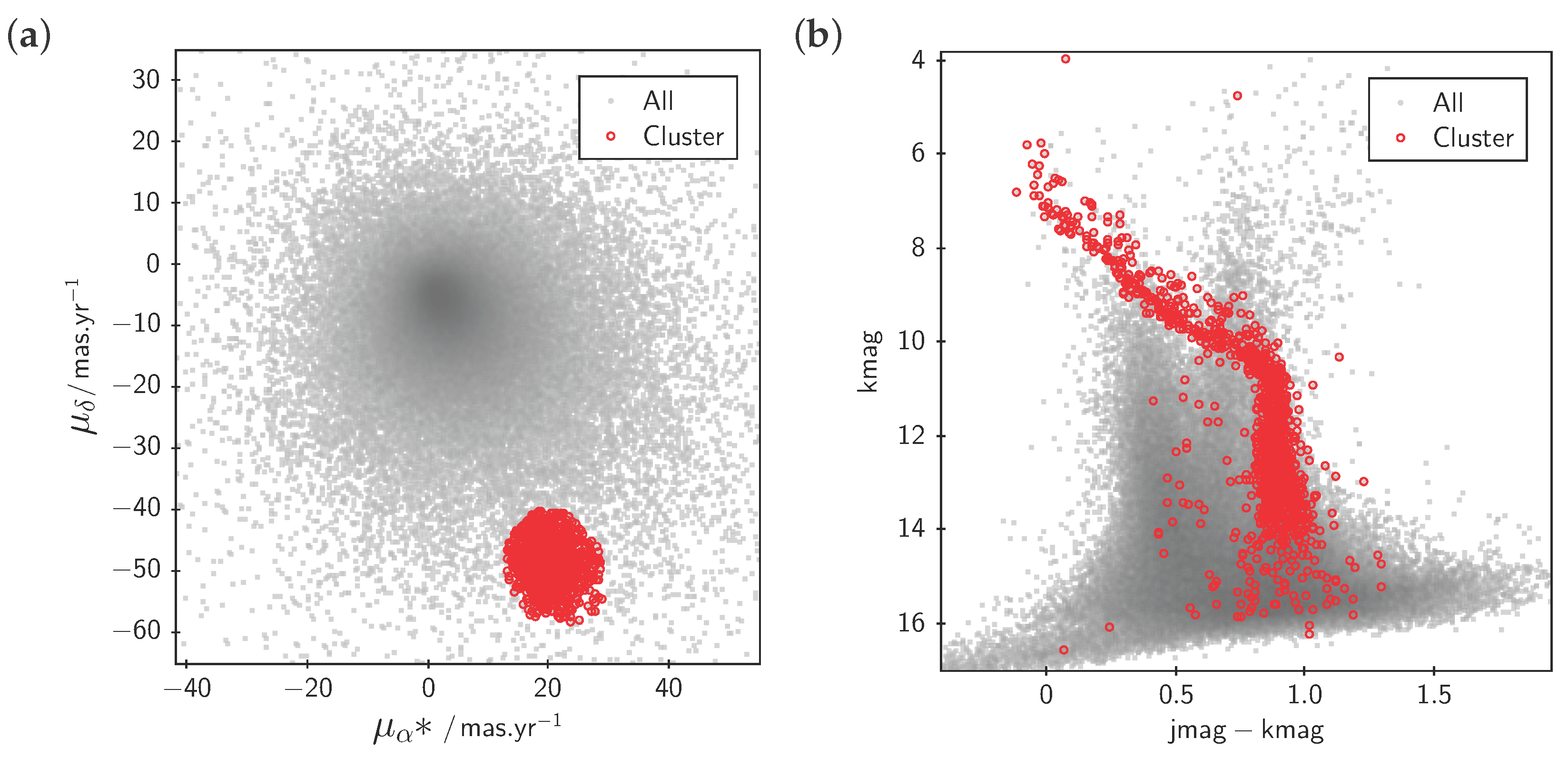
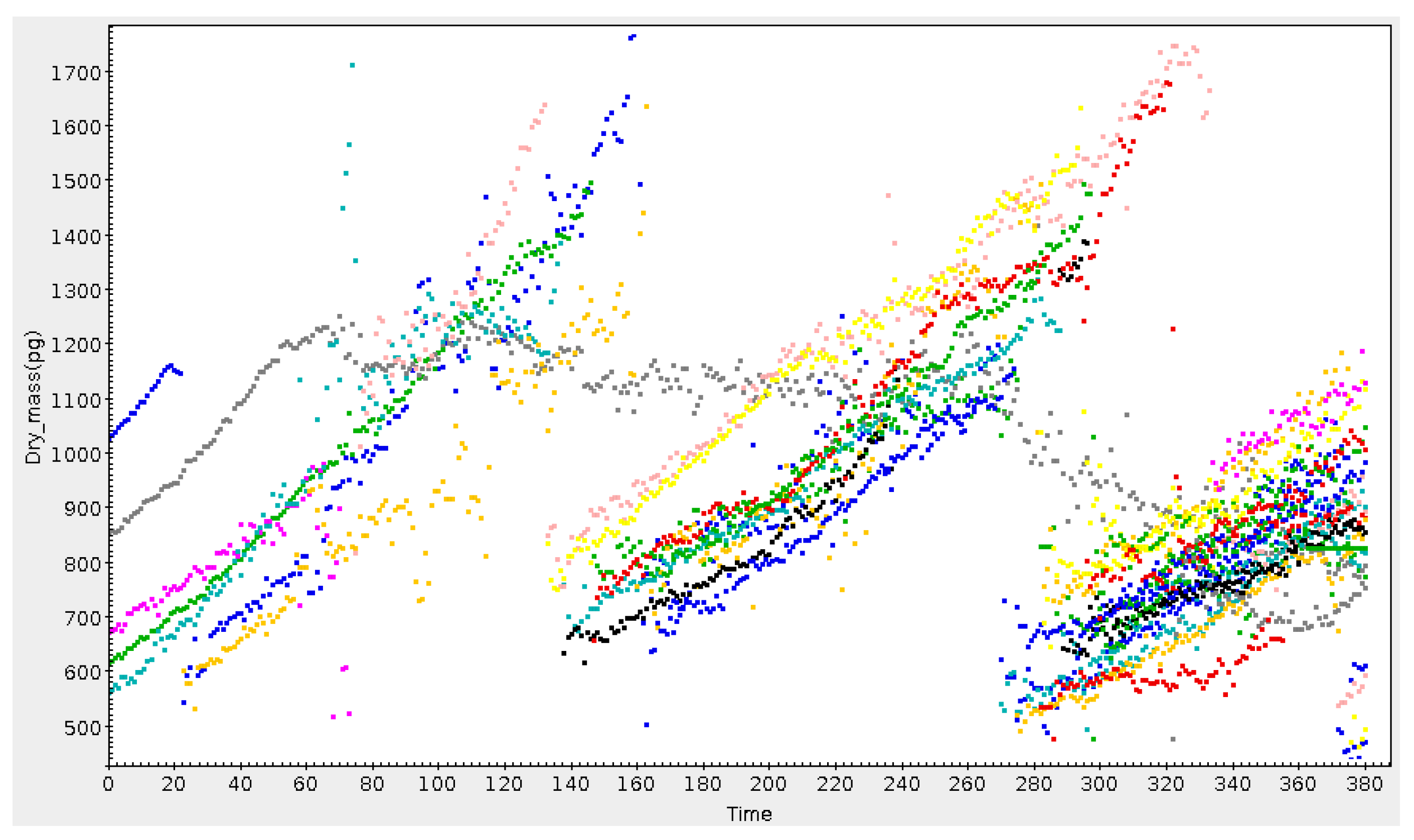
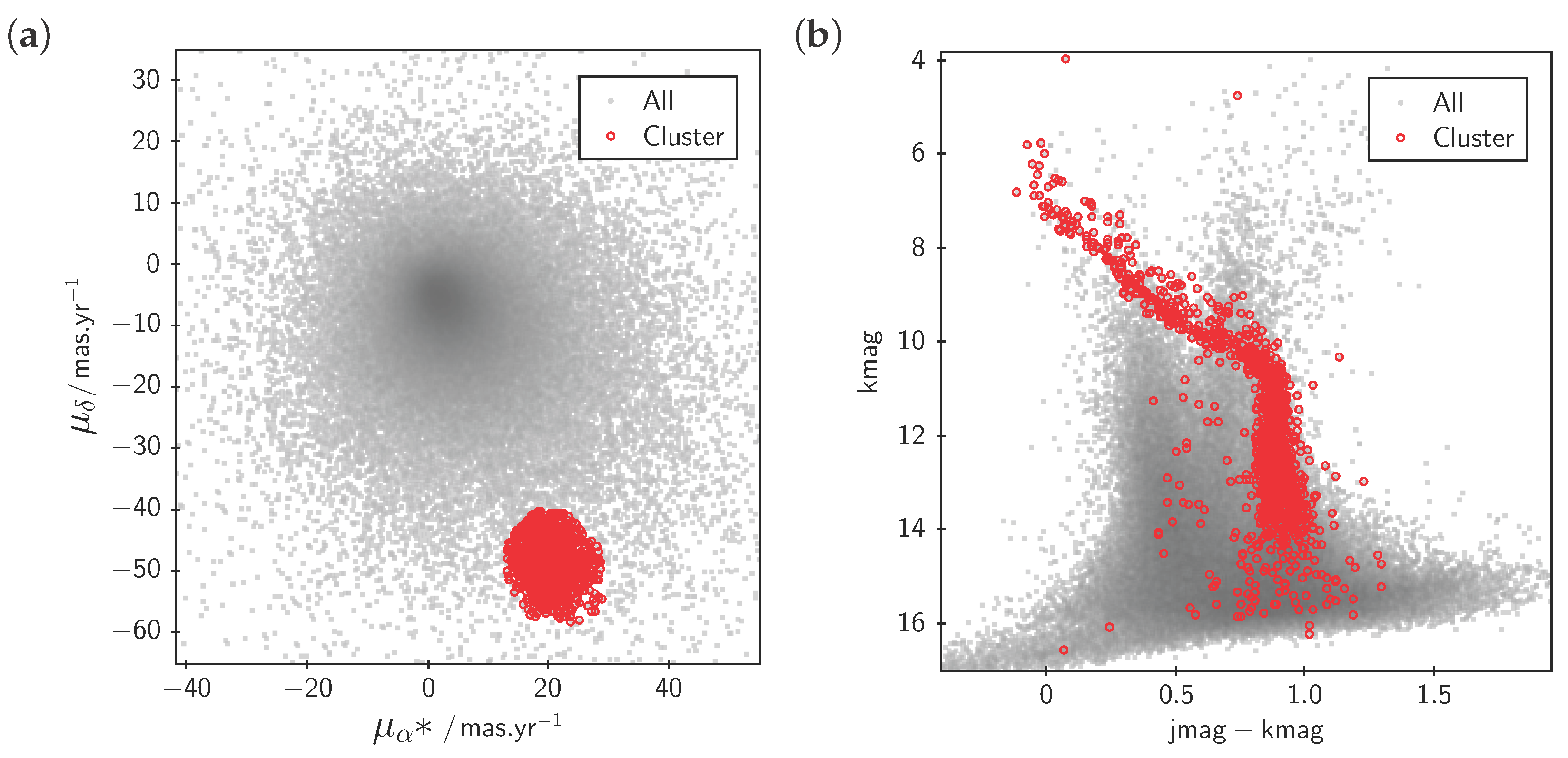
3.2. Subset Selection and Linked Views
3.3. Row Highlighting and Linked Views
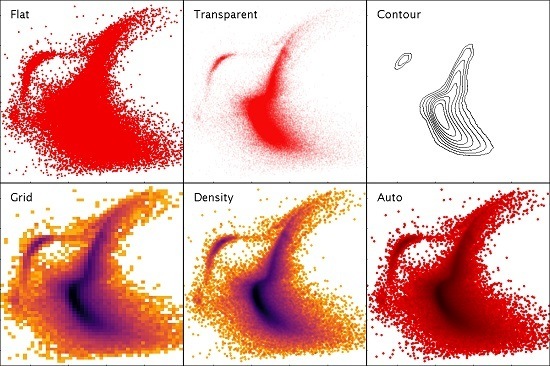
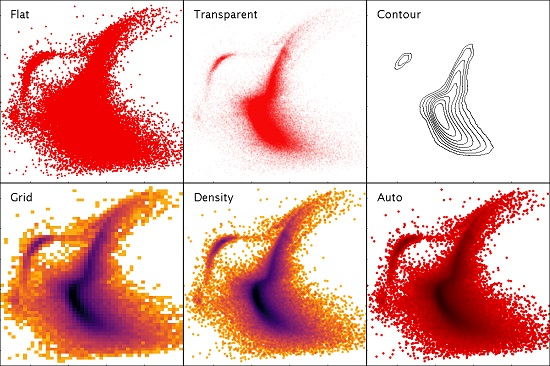
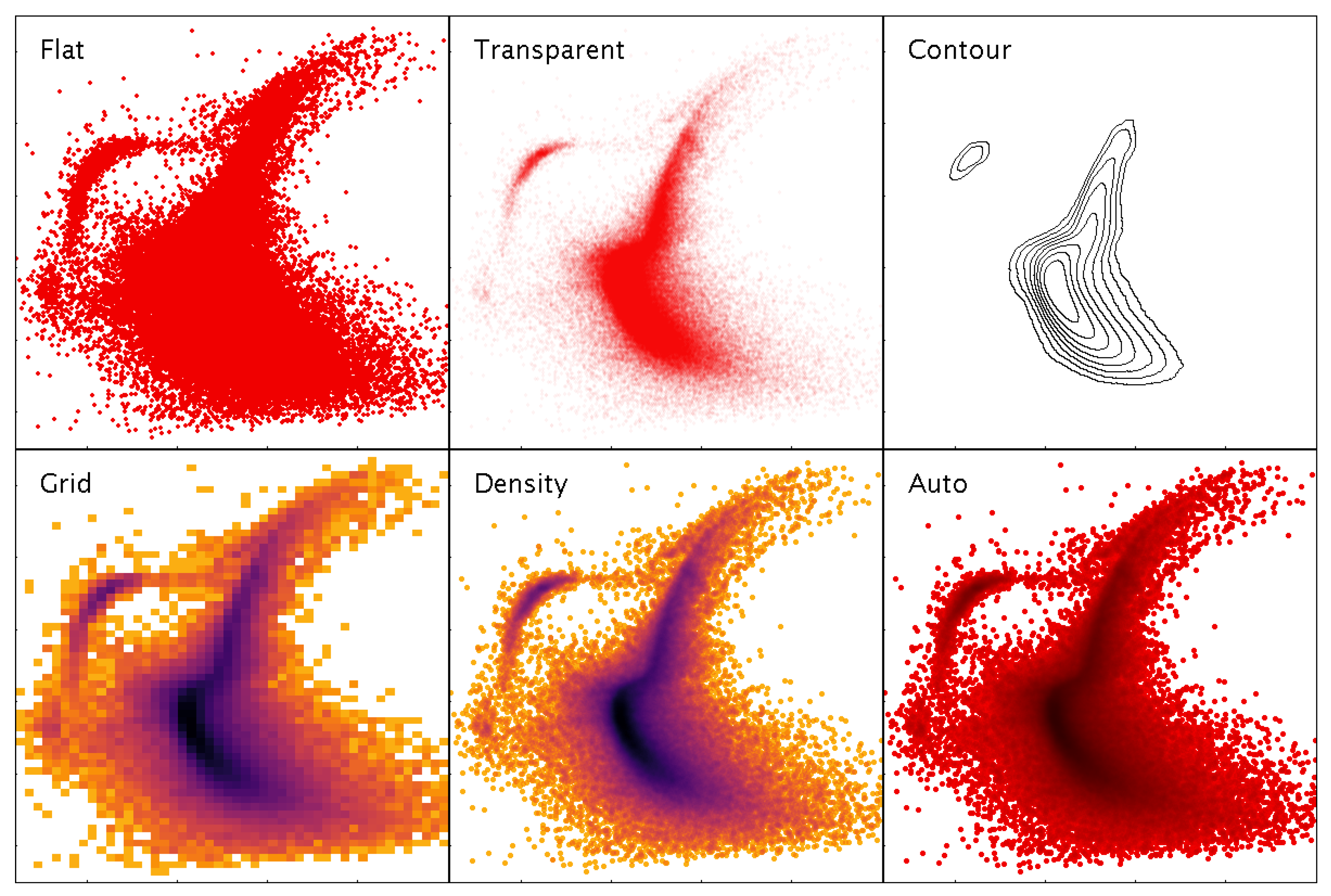
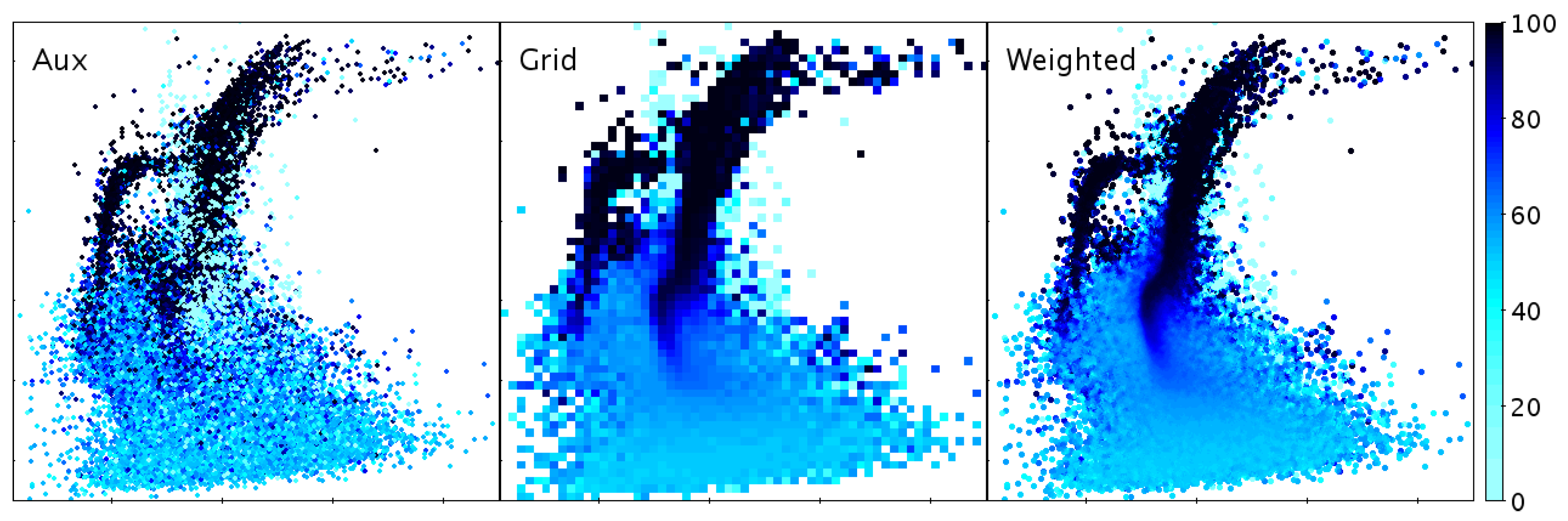
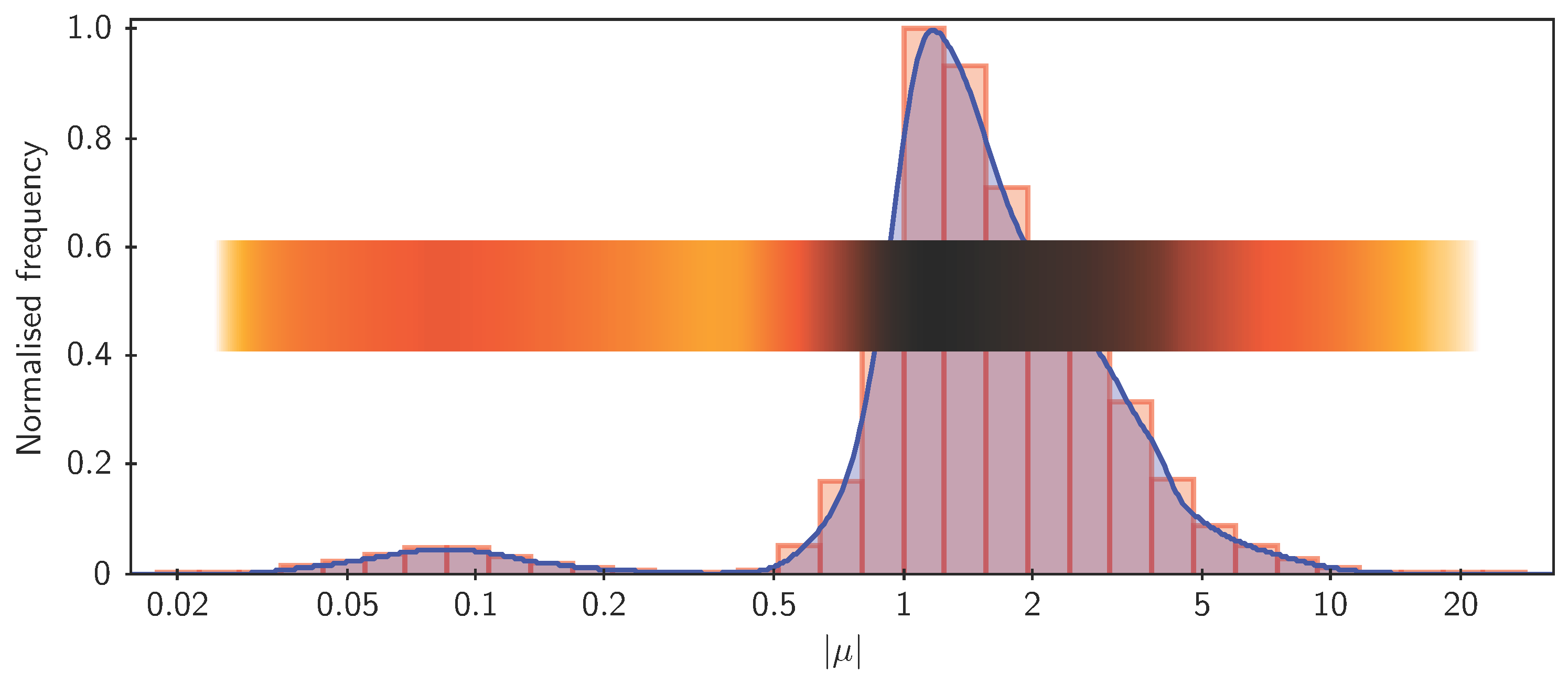
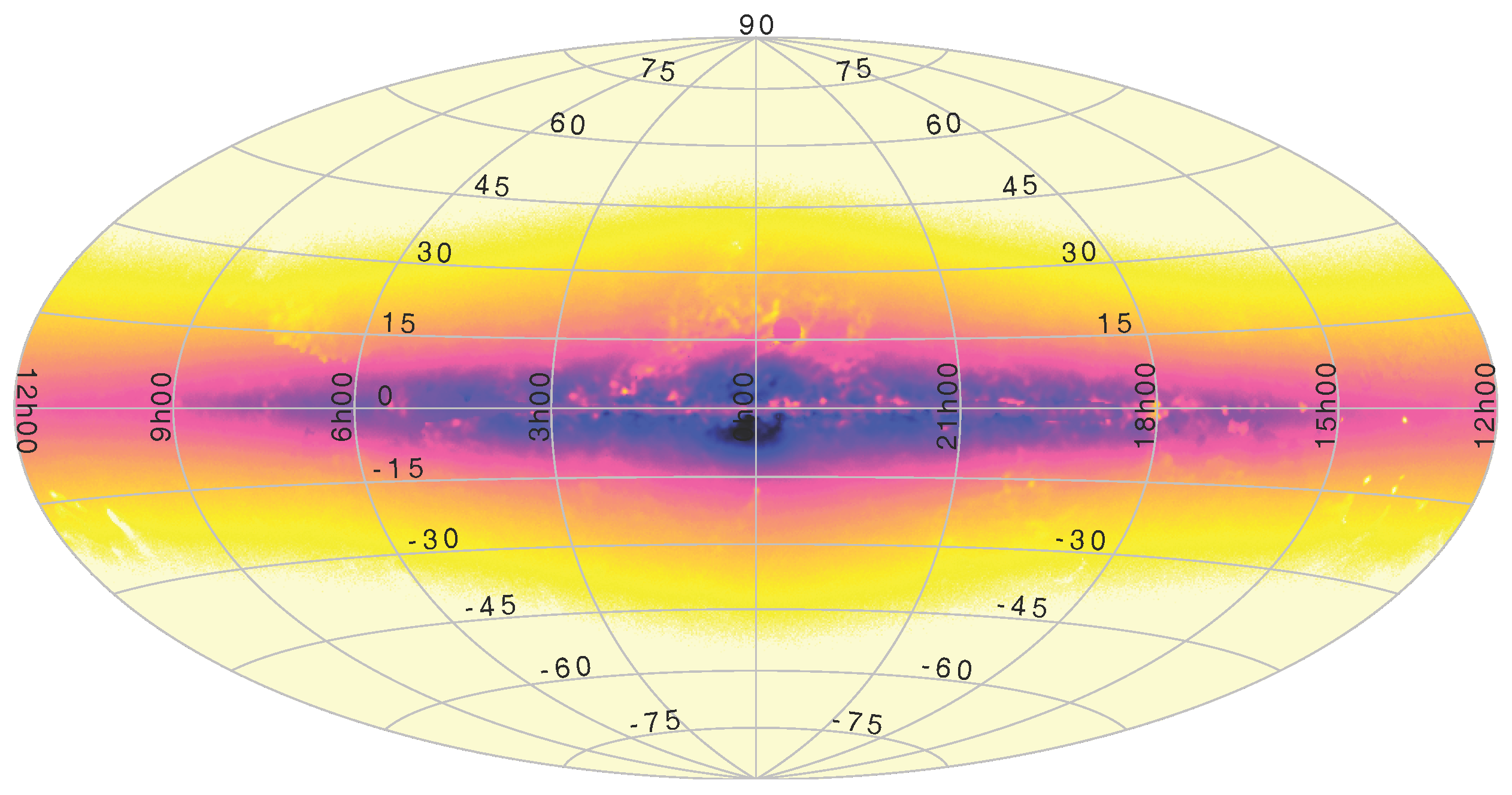
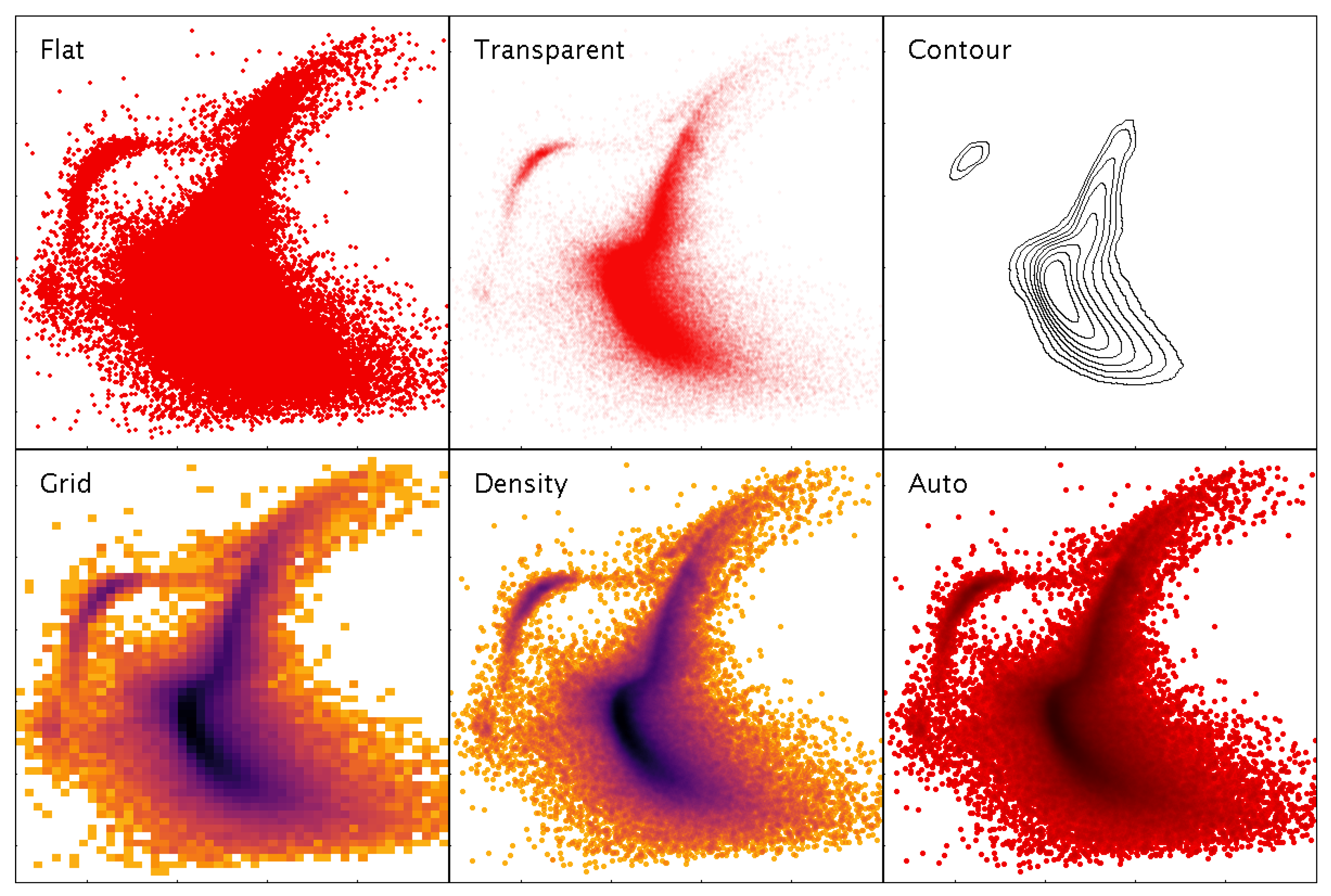
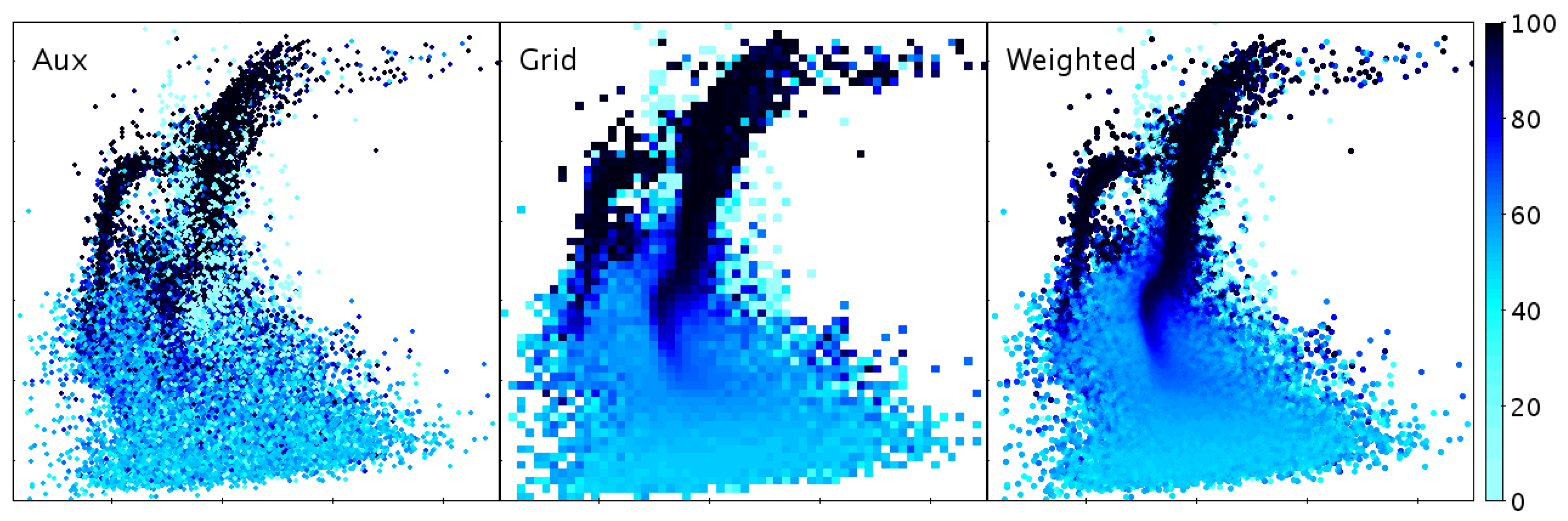
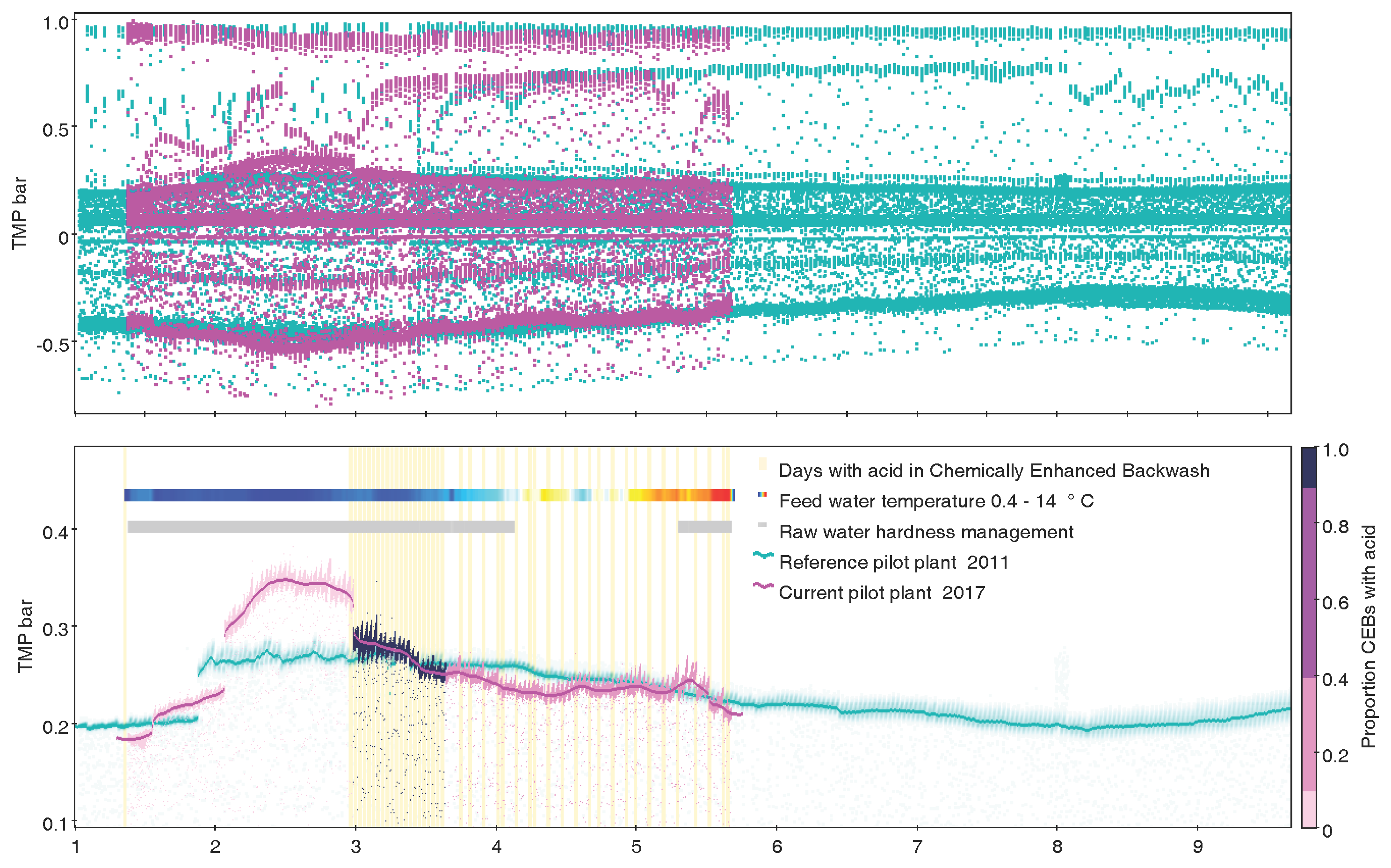
3.4. High-Density Plots
3.5. Navigation
4. Other Plot Types
5. Configuration User Interface
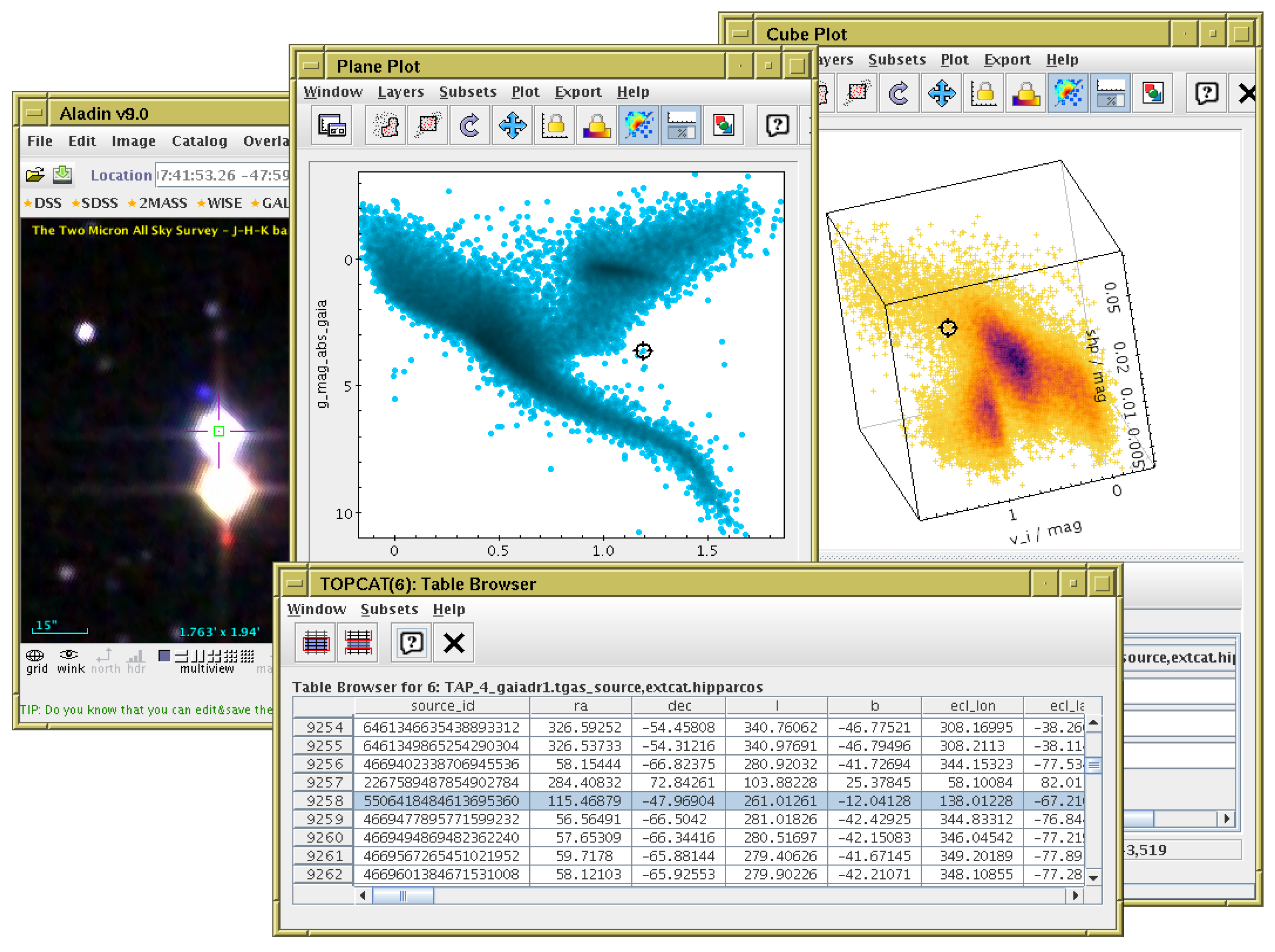
6. Alternative Interfaces
7. Implementation Notes
7.1. Scalability
7.2. Responsive User Interface
7.3. Configuration Option Management
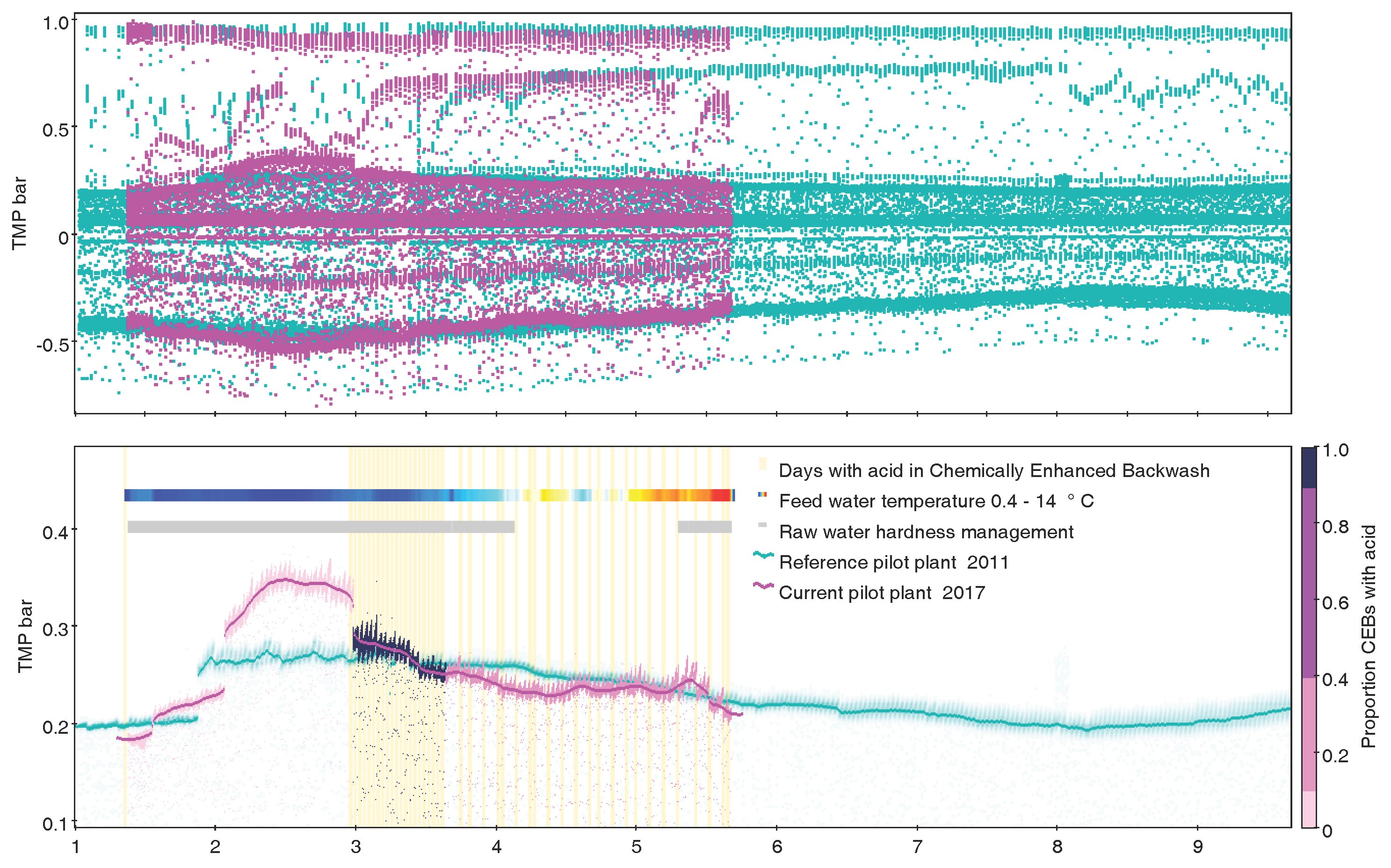
8. Use Beyond Astronomy
9. Software Availability
10. Conclusions
Acknowledgments
Conflicts of Interest
References
- Messier, C. Catalogue des Nébuleuses & des amas d’Étoiles (Catalog of Nebulae and Star Clusters); Technical Report; Memoirs of the Royal Academy of Sciences for 1771: Paris, France, 1781. (In French) [Google Scholar]
- Stoughton, C.; Lupton, R.H.; Bernardi, M.; Blanton, M.R.; Burles, S.; Castander, F.J.; Connolly, A.J.; Eisenstein, D.J.; Frieman, J.A.; Hennessy, G.S.; et al. Sloan Digital Sky Survey: Early Data Release. Astron. J. 2002, 123, 485–548. [Google Scholar] [CrossRef]
- Brown, A.G.A.; Vallenari, A.; Prusti, T.; de Bruijne, J.H.J.; Mignard, F.; Drimmel, R.; Babusiaux, C.; Bailer-Jones, C.A.L.; Bastian, U.; Elteren, A.K.; et al. Gaia Data Release 1. Summary of the astrometric, photometric, and survey properties. Astron. Astrophys. 2016, 595, A2. [Google Scholar]
- Ochsenbein, F.; Taylor, M.; Williams, R.; Davenhall, C.; Demleitner, M.; Durand, D.; Fernique, P.; Giaretta, D.; Hanisch, R.; McGlynn, T.; et al. VOTable Format Definition Version 1.3. IVOA Recommendation 20 September 2013. arXiv, 2013; arXiv:1110.0524. [Google Scholar]
- Hanisch, R.J.; Farris, A.; Greisen, E.W.; Pence, W.D.; Schlesinger, B.M.; Teuben, P.J.; Thompson, R.W.; Warnock, A., III. Definition of the Flexible Image Transport System (FITS). Astron. Astrophys. 2001, 376, 359–380. [Google Scholar] [CrossRef]
- Arviset, C.; Gaudet, S.; IVOA Technical Coordination Group. IVOA Architecture Version 1.0. IVOA Note 23 November 2010. arXiv, 2011; arXiv:1106.0291. [Google Scholar]
- Dowler, P.; Rixon, G.; Tody, D. Table Access Protocol Version 1.0. IVOA Recommendation 27 March 2010. arXiv, 2010; arXiv:astro-ph.IM/1110.0497. [Google Scholar]
- Plante, R.; Williams, R.; Hanisch, R.; Szalay, A. Simple Cone Search Version 1.03. IVOA Recommendation 22 February 2008. arXiv, 2008; arXiv:astro-ph.IM/1110.0498. [Google Scholar]
- Taylor, M.B. TOPCAT & STIL: Starlink Table/VOTable Processing Software. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XIV, Pasadena, CA, USA, 24–27 October 2004; Shopbell, P., Britton, M., Ebert, R., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2005; Volume 347, p. 29. [Google Scholar]
- Taylor, M.B.; Page, C.G. Column-Oriented Table Access Using STIL: Fast Analysis of Very Large Tables. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XVII, London, UK, 23–26 September 2007; Argyle, R.W., Bunclark, P.S., Lewis, J.R., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2008; Volume 394, p. 422. [Google Scholar]
- Moitinho, A.; Krone-Martins, A.; Savietto, H.; Barros, M.; Barata, C.; Falcão, A.J.; Fernandes, T.; Alves, J.; Gomes, M.; Bakker, J.; et al. Gaia Data Release 1: The archive visualisation service. Astron. Astrophys. 2017, in press. [Google Scholar]
- Boch, T.; Fernique, P. Aladin Lite: Embed your Sky in the Browser. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XXIII, Waikoloa Beach Marriott, HI, USA, 29 September–3 October 2013; Manset, N., Forshay, P., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2014; Volume 485, p. 277. [Google Scholar]
- Carbon, D.F.; Henze, C.; Nelson, B.C. Exploring the SDSS Data Set with Linked Scatter Plots. I. EMP, CEMP, and CV Stars. Astrophys. J. Suppl. 2017, 228, 19. [Google Scholar] [CrossRef]
- Springel, V.; White, S.D.M.; Jenkins, A.; Frenk, C.S.; Yoshida, N.; Gao, L.; Navarro, J.; Thacker, R.; Croton, D.; Helly, J.; et al. Simulations of the formation, evolution and clustering of galaxies and quasars. Nature 2005, 435, 629–636. [Google Scholar] [CrossRef] [PubMed]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Boston, MA, USA, 1977. [Google Scholar]
- Goodman, A.A. Principles of high-dimensional data visualization in astronomy. Astron. Nachr. 2012, 333, 505–514. [Google Scholar] [CrossRef]
- Altmann, M.; Roeser, S.; Demleitner, M.; Bastian, U.; Schilbach, E. Hot Stuff for One Year (HSOY). A 583 million star proper motion catalogue derived from Gaia DR1 and PPMXL. Astron. Astrophys. 2017, 600, L4. [Google Scholar] [CrossRef]
- Bonnarel, F.; Fernique, P.; Bienaymé, O.; Egret, D.; Genova, F.; Louys, M.; Ochsenbein, F.; Wenger, M.; Bartlett, J.G. The ALADIN interactive sky atlas. A reference tool for identification of astronomical sources. Astron. Astrophys. Suppl. 2000, 143, 33–40. [Google Scholar] [CrossRef]
- Taylor, M.B.; Boch, T.; Taylor, J. SAMP, the Simple Application Messaging Protocol: Letting applications talk to each other. Astron. Comput. 2015, 11, 81–90. [Google Scholar] [CrossRef]
- Joye, W.A.; Mandel, E. New Features of SAOImage DS9. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XII, Baltimore, MD, USA, 13–16 October 2002; Payne, H.E., Jedrzejewski, R.I., Hook, R.N., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2003; Volume 295, p. 489. [Google Scholar]
- Robitaille, T.P.; Tollerud, E.J.; Greenfield, P.; Droettboom, M.; Bray, E.; Aldcroft, T.; Davis, M.; Ginsburg, A.; Price-Whelan, A.M.; Kerzendorf, W.E.; et al. Astropy: A community Python package for Astronomy. Astron. Astrophys. 2013, 558, A33. [Google Scholar]
- Bellini, A.; Piotto, G.; Bedin, L.R.; Anderson, J.; Platais, I.; Momany, Y.; Moretti, A.; Milone, A.P.; Ortolani, S. Ground-based CCD astrometry with wide field imagers. III. WFI@2.2m proper-motion catalog of the globular cluster ω Centauri. Astron. Astrophys. 2009, 493, 959–978. [Google Scholar] [CrossRef]
- Taylor, M.B. Visualizing Large Datasets in TOPCAT v4. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XXIII, Waikoloa Beach Marriott, HI, USA, 29 September–3 October 2013; Manset, N., Forshay, P., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2014; Volume 485, p. 257. [Google Scholar]
- Taylor, M.B. STILTS—A Package for Command-Line Processing of Tabular Data. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software and Systems XV, San Lorenzo de El Escorial, Spain, 2–5 October 2005; Gabriel, C., Arviset, C., Ponz, D., Enrique, S., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2006; Volume 351, p. 666. [Google Scholar]
- Taylor, M.B. External Use of TOPCAT’s Plotting Library. In Astronomical Society of the Pacific Conference Series, Proceedings of the Astronomical Data Analysis Software an Systems XXIV (ADASS XXIV), Calgary, AB, Canada, 5–9 October 2014; Taylor, A.R., Rosolowsky, E., Eds.; Astronomical Society of the Pacific: San Francisco, CA, USA, 2015; Volume 495, p. 177. [Google Scholar]
- Robin, A.C.; Luri, X.; Reylé, C.; Isasi, Y.; Grux, E.; Blanco-Cuaresma, S.; Arenou, F.; Babusiaux, C.; Belcheva, M.; Drimmel, R.; et al. Gaia Universe model snapshot. A statistical analysis of the expected contents of the Gaia catalogue. Astron. Astrophys. 2012, 543, A100. [Google Scholar] [CrossRef]
- Streicher, O. Debian Astro: An open computing platform for astronomy. arXiv, 2016; arXiv:astro-ph.IM/1611.07203. [Google Scholar]
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taylor, M. TOPCAT: Desktop Exploration of Tabular Data for Astronomy and Beyond. Informatics 2017, 4, 18. https://doi.org/10.3390/informatics4030018
Taylor M. TOPCAT: Desktop Exploration of Tabular Data for Astronomy and Beyond. Informatics. 2017; 4(3):18. https://doi.org/10.3390/informatics4030018
Chicago/Turabian StyleTaylor, Mark. 2017. "TOPCAT: Desktop Exploration of Tabular Data for Astronomy and Beyond" Informatics 4, no. 3: 18. https://doi.org/10.3390/informatics4030018
APA StyleTaylor, M. (2017). TOPCAT: Desktop Exploration of Tabular Data for Astronomy and Beyond. Informatics, 4(3), 18. https://doi.org/10.3390/informatics4030018