Abstract
Modern companies often rely on integrating an extensive network of suppliers to organize and produce industrial artifacts. Within this process, it is critical to maintain sustainability and flexibility by analyzing and managing information from the supply chain. In particular, there is a continuous demand to automatically analyze and infer information from extensive datasets structured in various forms, such as natural language and domain-specific models. The advancement of Large Language Models (LLM) presents a promising solution to address this challenge. By leveraging prompts that contain the necessary information provided by humans, LLM can generate insightful responses through analysis and reasoning over the provided content. However, the quality of these responses is still affected by the inherent opaqueness of LLM, stemming from their complex architectures, thus weakening their trustworthiness and limiting their applicability across different fields. To address this issue, this work presents a framework to leverage the graph-based LLM to support the analysis of supply chain information by combining the LLM and domain knowledge. Specifically, this work proposes an integration of LLM and domain knowledge to support an analysis of the supply chain as follows: (1) constructing a graph-based knowledge base to describe and model the domain knowledge; (2) creating prompts to support the retrieval of the graph-based models and guide the generation of LLM; (3) generating responses via LLM to support the analysis and reason about information across the supply chain. We demonstrate the proposed framework in the tasks of entity classification, link prediction, and reasoning across entities. Compared to the average performance of the best methods in the comparative studies, the proposed framework achieves a significant improvement of 59%, increasing the ROUGE-1 F1 score from 0.42 to 0.67.
1. Introduction
With globalization and outsourcing trends, modern companies often rely on integrating an extensive network of suppliers to organize and produce industrial artifacts. These extensive supplier networks are often distributed across different regions of the world. Such geographic and operational diversity can present various challenges regarding the sustainability and flexibility of maintaining and managing artifact production [1,2]. To address this issue, there is a continuous demand to analyze and reason about information from suppliers. This process can be supported by technologies and methodologies associated with Industry 4.0 and Industry 5.0 [3,4,5]. For example, the operational data collected from the sensors allocated in different placements supports the analysis of throughput from each supplier [6,7]. In addition, the adoption of Artificial Intelligence (AI)-based methods not only supports the analysis of collected operational data but also facilitates the interpretation of more abstract information, such as natural languages, to analyze information of the supply chain. For example, Deep Learning (DL)-based solutions support the extraction of keywords and analysis of their correlations by analyzing the public documents to identify and integrate information within the network of supply chains through various sources such as nature language descriptions [8].
However, these methods are often specialized for specific tasks and constrained to limited types of data, lacking the flexibility to analyze the heterogeneous information involved in supply chain management. Beyond conventional AI methods that focus on specific types of collected data, the advancement of Large Language Models (LLM) offers a more general solution for processing data in various structures by leveraging their extensive knowledge acquired during training. Therefore, LLM can synthesize features from natural language descriptions and operational data (e.g., time-series data) to analyze the system and its related information. As an example, in [9], LLM can not only facilitate failure mode analysis by combining failure descriptions derived from domain knowledge with collected operational data, but also generate responses that support failure mitigation by analyzing unstructured data and instructions provided in the prompt empowered by its reasoning capabilities. Such capabilities imply promising applications within supply chain networks, which usually involve different suppliers and their corresponding information. For example, the Original Equipment Manufactures (OEM) usually rely on extensive suppliers which provide different raw materials.
However, the extensive and diverse information provided by suppliers and obtained from public sources are typically represented in various unstructured data (e.g., natural language representations), posing challenges for addressing dependencies through multi-level reasoning. The ambiguity and flexibility inherent in heterogeneous natural language representations may compromise the LLM’s effectiveness in capturing the underlying relationships among identified entities. Due to the inherent opaqueness of LLM, the quality of their generated responses can weaken trustworthiness and limit their applicability across various tasks in supply chain management. In particular, hallucination refers to a type of response that is coherent and grammatically correct but factually or semantically incorrect [10]. Although existing approaches, such as Chain-of-Thought (CoT) [11], attempt to enable multi-depth reasoning by modeling dependencies to overcome the issues, they remain insufficient for handling the complex relationships embedded in natural language. The structured data (e.g., graph-based models) supports the analysis of dependencies expressed in natural language. In our work, natural language information can be explicitly structured as meta-models by identifying entities and relationships within the text via corpus [12]. Therefore, such models can alleviate the inherent ambiguity of natural language representations, improving the quality of responses generated by the LLM. However, solely relying on heuristic-based methods to process structured data often lacks the flexibility and generality needed to retrieve information effectively, due to the gap between the proposed questions with unstructured representations and the queries with structured representations required by the knowledge base [13,14].
To alleviate above-mentioned issues caused by LLMs and inflexibility caused by heuristic-based methods, this paper presents a framework to support the analysis of supply chain information by leveraging the domain knowledge for enhancing the performance of LLMs. Specifically, the domain knowledge is formulated as a knowledge base using graph-based data to enhance interaction with the LLM through a Retrieval-Augmented Generation (RAG) process [15]. To further formulate the response from the LLM, this work proposes a methodology to create a prompt for enabling the domain knowledge. As a result, the proposed framework generates responses via LLM to support and reason about information across the supply chain. To this end, we summarize the contributions of this work as follows:
- Proposing a framework that integrates the knowledge base and LLM to support the analysis and reasoning across the graph-based data in the context of supply chain management;
- Constructing graph-based models of the domain knowledge to create the knowledge base to support LLM via proposing different indexing and retrieval solutions;
- Specifying and supporting the various tasks handled by the LLM by formulating the prompts.
The rest of this paper is organized as follows. Section 2 presents the concepts and prior works related to the integration of LLM and domain knowledge to support analysis and reasoning. Section 3 elaborates the methodology of designing the proposed framework. Section 4 evaluates the proposed framework by using a public dataset related to supply chain. To this end, we conduct an error analysis by observing the incorrect responses from the proposed framework along with the comparative methods in Section 5. Section 6 concludes the proposed framework with a discussion.
2. Related Work
Given that the proposed framework is related to graph-based LLM and RAG-based techniques, we introduce the background of this work by organizing it into the following sections. Section 2.1 discusses the common taxonomies of graph-based LLMs and current trends in applying LLMs to industrial applications. Section 2.2 presents recent studies and developments of the RAG process to support the integration of LLMs with domain knowledge. In addition, Section 2.3 presents related works that adopt LLMs in supply chain management.
2.1. Overview of Graph-Based LLM
LLM typically refers to a category of DL models with extensive parameters that incorporate various techniques to demonstrate powerful capabilities in solving diverse tasks, including pattern recognition, natural language processing, and automated reasoning through content generation [16]. Specifically, Generative Pre-trained Transformers (GPT) provide a promising solution for generating different representations of data by leveraging a series of pre-trained models trained on extensive and diverse datasets [17]. From the structures of the LLM, they can commonly be categorized into the following types: (1) encoder-only LLMs, such as BERT [18], process the high-dimensional input data and generate their representations, such as probabilistic distributions; (2) encoder–decoder LLMs, such as ChatGPT [19], refer to an LLM able to generate human-understandable data (e.g., nature language and structured data) by analyzing and understanding the corresponding input queries; (3) decoder-only LLMs, such as XLNet [20], are typically used solely to predict subsequent tokens based on the input sequences of tokens. To encourage GPT models to generate specific responses, prompts serve as inputs that guide them by leveraging the knowledge encoded in their training data [21]. In addition, the construction of prompts commonly involves local knowledge to support the LLM in forming responses [22].
Due to the prompts being straightforwardly designed by human users, the responses of LLMs are commonly structured by natural language. Nevertheless, natural language can be inefficient and ambiguous in specific tasks that require precise descriptions of objects and their interactions, primarily due to its unstructured representations [23]. In contrast, structured data such as graph-based and symbolic models depict objects and relationships as nodes and edges, providing clearer and more intuitive representations. Inspired by the fact that LLMs outperform structured models in understanding spatial and temporal relationships within prompts [24], graph-based LLMs reason about graph-based data by analyzing nodes and their relationships. Specifically, a graph-based model typically conveys various types of information at the node level, edge level, and graph level to represent objects, their relationships, and the semantic context by assigning different labels [25]. Therefore, the uses of graph-based LLMs can be categorized as follows [26]. (1) Their use as a predictor refers to the LLMs being used to predict labels across nodes, edges, and graphs. For example, an LLM is used to predict molecular structures, which is typically handled by graph-based models by incorporating prompts that contain domain-specific knowledge [27]. (2) Their use as an encoder refers to the use of an LLM as a pre-trained model to extract spatial and temporal features and generate embeddings within the graph-based models. The generated embeddings can further be used to augment another model that specializes in specific tasks. For example, the LLM is used to encode the graph-based data to enhance an optimized model by generating corresponding explanations [28]. (3) Their use as an aligner refers to the use of an LLM to regularize the latent space generated from another model. Due to the extensive knowledge embedded in the LLM, such an aligner can support knowledge distillation to facilitate the training of another model. As an example of an aligner, the embeddings from graph neural networks are used to align the generations of an LLM to support the analysis of a molecular graph) [29]. (4) Generator refers to the use of an LLM to generate graph-based data or the content embedded within it. Unlike approaches that use LLMs as predictors to classify data through inductive learning, this approach focuses on generating content based on knowledge retrieved by the LLM via deductive learning. For example, an LLM-based framework is used to generate a knowledge graph by synthesizing the queries proposed by users and pre-defined ontology [30].
2.2. Overview of RAG
As mentioned, LLMs can suffer from hallucinations caused by various factors. This issue is particularly evident in specialized domains that involve hierarchical knowledge [12], as such knowledge often constitutes only a small fraction of the LLM’s training data. As a result, the model’s responses may become confused or vague due to irrelevant information from extensive training data. To address this issue, prior works present a RAG process to enhance the accuracy and precision of responses from the LLM by incorporating the domain knowledge base [12,31,32]. Specifically, the main stages of the RAG are shown as follows. (1) Indexing is the process of extracting information from a knowledge base by encoding them; (2) retrieval refers to the retrieval of relevant information within knowledge base by matching the similarity between the data and the information contained in prompts; (3) and generation refers to the use of the LLM generate responses by synthesizing the information of the prompts and retrieval data. Each stage can be further optimized by different methods to improve the efficiency. For example, the embeddings-based methods and semantics analysis can be used in the index stage regarding the specific tasks [33]. The retrieval stage can be further refined by leveraging the granularity of graph-based models, including node-level, edge-level, and graph-level representations [34].
2.3. Applying LLM to Support Analysis of Supply Chain Information
Most current works apply LLMs to support supply chain operations by analyzing collected data to perform the following tasks: (1) Optimization of a human-in-the-loop decision-making process by utilizing the extensive knowledge within LLM to respond different domain-specific answers [35]. Given this task, the LLM performs as an intelligent interactive agent to comprehend the domain knowledge in the context of supply chain management by responding questions from the users. To enable the LLM to capture relevant information involved in the supply chain, ref. [36] utilizes an in-context learning (ICL) approach that integrates domain knowledge into the prompts. (2) Multivariate data analysis by utilizing the generalizable capability of LLM to recognize the underlying patterns across the collected operational data. For example, ref. [37] presents an LLM-based solution to predict the potential risks by analyzing historical operational data. Compared to conventional deep neural network (DNN)-based methods, an LLM implicitly consists of diverse sub-models and a large number of parameters due to its inherent transformer architecture and Mixture-of-Experts (MoE) design, enabling more powerful and generalizable capabilities for analyzing historical data with various structures (e.g., tabular data). (3) Strategic integration of LLMs into automated supply chain systems involves adopting the LLM as middleware to synthesize the operational data over multiple components within the system. The work in [38] presents different solutions by integrating the LLM to the existed systems to support the automated decisions. For example, the LLM enables the analysis of real-time data and generates responses to mitigate side effects of unexpected conditions (e.g., disruptions in pipelines or the supply chain) by operating equipment and adjusting throughput.
Although these current works show promising trends for the adoption of LLMs for supporting supply chain management, the quality of the generated results from the LLMs still remains an issue due to the following reasons. (1) Although some of these frameworks [35,36] provide local knowledge via ICL to support LLM in generating responses, this knowledge often fails to offer comprehensive insights into specific domains by synthesizing the semantics across multiple prompt sessions. (2) Most of these methods generate content in the form of natural language, which is a typical unstructured form of data, making it less efficient for further analysis and evaluation of the quality of the generated responses. (3) Some of these methods usually adopt the LLM for a specific task (e.g., classification), requiring more effort to exploit the capability of LLMs in the context of supply chain management. (4) Although these methods support users in proposing various questions related to supply chain management, their prompts need to be further refined to improve the precision of responses generated by the LLM.
To address the above-mentioned issues, this paper proposes a design by leveraging the domain knowledge to enhance responses from LLM via s RAG process. This work adopts a pre-trained LLM model without re-training or fine-tuning, due to their computational and financial cost. Based on this, we design multiple techniques for indexing and retrieval process to support response generation. This paper also proposes the adoption of graph-based models, which is a typical structured data, to support the analysis of supply chain management. Compared to existing work that typically adopts LLM for data classification, we propose a broader range of applications by using LLMs as both predictors and generators. In addition, this paper formulates a set of prompt paradigms to further improve the precision and insights of responses.
3. Proposed Experimental Framework
The workflow of the proposed framework is illustrated in Figure 1, where the main components are highlighted in different colors. Specifically, the modeling of graph-based data, shown as green regions, is elaborated in Section 3.1 to support the construction of a knowledge base. The indexing and retrieving processes, shown as blue regions, are proposed in Section 3.2 and Section 3.3. The pink region presented in Section 3.4 refers to the interface by analyzing the input questions and synthesizing the above components.
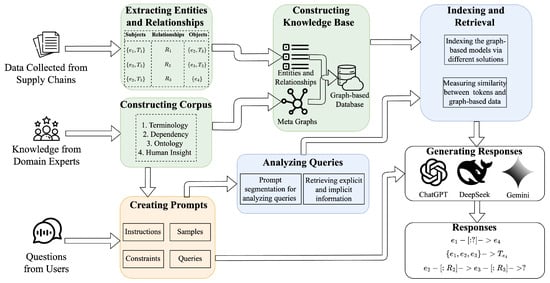
Figure 1.
Overview of the proposed framework.
3.1. Graph-Based Models for Knowledge Construction
As previously mentioned, the information collected from the supply chain is usually unstructured data [6,39,40] which is saved in a plain format (e.g., csv files). This incomplete data could be insufficient to support supply chain management when represented as a graph-based model. To cope with this issue, this work presents the modeling of the supply chain information via domain-specific models [41]. We firstly identify a set of entities from the collected data. Each entity is assigned its name , properties , and values . We further enrich the entities and their interactions elicited from a corpus constructed by domain knowledge [42]. This corpus includes multiple perspectives such as expert insights, terminology, dependencies, and ontology to support the construction of the knowledge base. In particular, the ontology is used to describe the schema of these collected entities and their interactions [43]. Within the ontology, Terminology Box (TBox) defines the stereotypes by labeling the entities within in relation to their corresponding stereotypes. Assertion Box (ABox) specifies the set of relationships to depict the interactions within the entities. Any two entities which exist a relationship are modeled as a triplet . Any relationship obtains a type .
Based on the schema elicited through ontology design, we define a meta-model consisting of a set of unique meta-paths that represent stereotypes and relationships to describe patterns of entities and their interactions. Specifically, a meta-path refers to a unique, limited-length, and acyclic path formed by connecting stereotypes, defined as follows:
where stereotypes and their types of relationships .
By associating the existing meta-model , we construct a meta-graph , where the nodes refer to the stereotypes within the entity set and edges refer to the types of relationships within these stereotypes. The knowledge base formulated in Equation (2) comprises a set of graph-based models that manage the collected data by following the schema of the meta-graph . These models can be adapted to generate outputs tailored to specific requirements for the further use of LLM.
where refers to a set of entities that obtain unique names by removing the duplicate entities within the collected entity set . The term refers to a set of triplets that depict the relationships within entities of .
3.2. Indexing of the Graph-Based Models
While current methods often solely rely on data-driven approaches (e.g., embedding-based techniques) to index information derived from domain knowledge, these approaches can be inefficient and computation can be costly in graph-based models due to the extensive number of entities and their relationships [12,26]. To address these limitations, this work presents multiple solutions to indexing the information within the knowledge base . Specifically, due to the diversity of entities and their stereotypes, this work mainly focuses on node-level indexing methods, which are presented as follows:
Keyword-based methods via corpus: This indexing method typically matches keywords by leveraging solvers that efficiently manage the knowledge base [44]. Specifically, we model the keywords which assist in searching and matching via the heuristic-based methods as follows:
where refers to a set of keywords; any keyword can be the name, alias, or stereotypes of any entity .
Based on the keyword set , a heuristic-based method is adopted to directly search for keywords within prompts, providing a straightforward approach to retrieving relevant information from the knowledge base.
Embedding-based methods via an LLM-based encoder: The embedding-based indexing method provides a more flexible solution compared to the heuristic-based method for matching the keywords. To optimize the efficiency of the embedding-based solution, this work adopts an interface to store the embeddings of each indexing data [44] by extending the keyword set . This interface can be created in advance and support to update graph-based models during runtime. Specifically, we encode node-level data using a pre-trained model . The resulting embeddings are formulated as follows:
where follows the same definition as in Equation (3). refers to the generated embedding regarding the keyword .
Next, the embeddings and their corresponding data are stored in an interface as a look-up table consisting of a set of tuples by merging the set and . Specifically, the look-up table is formulated as follows:
where denotes the look-up table used to support the retrieval of relevant information from the knowledge base. The combination of keyword and embedding-based methods implies the potential use cases as follows. (1) If the input contains typos, this leads to empty results by searching keywords; the embedding-based search then helps it to return valid results. In cases where the typos are highly ambiguous, multiple embeddings may be retrieved, leading to the generation of multiple graph-based data by the LLM. (2) If the input exactly matches the keywords that exist in the corpus, this leads to a simultaneous search in the look-up table. This case implies that these two methods do not have any priority difference. The returned results from two methods are consistent. (3) If the input does not contain any keywords identified in the corpus, the LLM decomposes the input question into tokens by adopting the embeddings presented in Equation (4).
3.3. Retrieval of Information from Knowledge Base
Based on the design of indexing, we propose a retrieval approach that aligns the indexing with the prompts. Retrieval not only involves identifying explicit information mentioned in the prompts, but also requires analyzing and understanding the underlying implications. Specifically, to explicitly identify keywords, we decompose the prompts into a set of tokens for analysis. These tokens support the retrieval of explicit information from the knowledge base by searching in the look-up table defined in Equation (5) via matching the keywords or their encoded embeddings. In addition, we further develop it to retrieve the implicit information related to the explicit information. Specifically, the retrieval of explicit and implicit information is presented as follows:
Retrieving the explicit information: Given that prompts may include tokens present in the corpus, explicit information can be efficiently retrieved by aligning these tokens with corresponding data in the knowledge base. In addition, considering that prompts may contain tokens not present in the corpus (e.g., typos and synonyms), we propose a more flexible solution for knowledge retrieval by introducing a similarity-based method. Specifically, we use the pre-trained model defined in Equation (4) to encode the identified tokens to compare with them in the look-up table as follows:
where refers to the embedding results. The term refers to the identified tokens decomposed from the queries.
Next, a distance-based method is used to measure the similarity by using the distance between and , as follows [45]:
where refers to the distance metrics (e.g., Euclidean distance). refers to the similarity between the embedding of and . If is larger than a pre-defined threshold , the explicit information is retrieved using the look-up table .
Retrieving the implicit information: In addition to retrieving entities by analyzing keywords, implicit information also needs to be considered. In this work, we define implicit information as the entities connected to the retrieved ones through multi-hop search in the knowledge base. Given the diversity of queries within prompts, we assume that the number of hops for retrieving implicit information depends on the syntactic patterns of the queries [30,46]. We propose a heuristic-based method that identifies a set of interrogative words (e.g., what, how) and a set of conjunctive words (e.g., and, with) [46,47] as additional tokens to determine the retrieval of implicit information. Specifically, we present a weighted method that calculates a normalized score based on the combination of identified interrogative and conjunctive words within a query as follows:
where refers to cardinality of a given set. refers to the number of interrogative words within the query . refers to the number of conjunctive words within the query . The amount of implicit information depends on the normalized score .
To this end, we elaborate the retrieval of explicit and implicit information from the knowledge base. We denote this information as .
3.4. Prompt Creation to Support Query Analysis
Although we have briefly mentioned the prompts in previous sections, the detailed design of prompts requires further refinement, as it determines the LLM’s ability to generate clear and precise responses across various types of questions. The prompts usually consist of instructions , samples , and constraints to guide the LLM to generate responses. Specifically, the instructions define the requirements that guide the LLM in generating responses. The samples serve as demonstrations derived from domain knowledge, offering local perspectives that help the LLM follow specific patterns. The constraints are used to limit the responses to a particular domain or scope. Beyond the common elements used to construct prompts, we further specify queries to engage the LLM in the following tasks by retrieving relevant information elaborated in Section 3.3 from the knowledge base:
Entities classification: This task involves the classification of the stereotypes of entities, where these entities and their relationships are given by the queries . We model the classification tasks as follows:
where refers to the classification function from the LLM defined by the instructions. refers to the predicted stereotype of classified by the LLM.
Edge prediction: This task involves predicting the edges within a pair of entities proposed by the queries . Specifically, we model the prediction tasks as follows:
where refers to the prediction function from the LLM defined by the instructions . refers to the predicted types of edges within a pair of entities .
Information generation: To further analyze information across graph-based models, the framework leverages the generative capabilities of the LLM to reason about various entities and their relationships. Compared to the aforementioned entity classification and edge prediction via inductive learning, this task mainly focuses on generating a specific entity via deductive learning. Therefore, we refine the notion of reasoning as the capability to generate features—such as names and properties—by aggregating multiple nodes and edges, based on both explicit and implicit information retrieved from the knowledge base. Specifically, we formulate the queries , including a set of entities and their relationships . Based on these given entities and their relationships, the LLM can generate information (e.g., names) about unknown entities requested by the user. For example, in a two-hop inference scenario, the LLM is used to generate the information of an unknown entity that is connected to two given entities through their respective relationships. Similarly, three-hop inference involves a greater number of connected entities provided by the query and requires the LLM to generate a response that identifies information about a more distantly related unknown entity.
To this end, we formulate the reasoning process as follows:
Here, contains the generated information (e.g., names and properties) of the unknown entity. denotes the generation function of LLM that enables multi-hop reasoning over the known entity set and their corresponding relationships .
As an example shown in Figure 1, the entities and their relationships are extracted from the plain document. Based on the ontology from the domain knowledge, some of these extracted data are endowed with different stereotypes including . However, some information could be not identified by domain knowledge, such as the entity . As mentioned in Section 3.1, the domain knowledge specifies the meta-graphs via defining and merging four meta-paths defined as Equation (1). The knowledge base is constructed by synthesizing the meta-graphs with the extracted entities and their relationships. These data are indexed by the methods presented in Section 3.2. Next, based on the corpus from the domain knowledge, the prompts are enriched by the instructions, samples, and the constraints and queries for different tasks mentioned in Section 3.4. Before the LLM makes the responses, the framework segments the queries as different tokens, which are mentioned in Section 3.3, for retrieving the relevant data via different methods. These data, along with prompts, are fed to the LLM to generate responses. In Figure 1, refers to the edge prediction between and by synthesizing the prompts and collected data via the LLM. Based on the stereotypes of extracted entities and their relationships, the LLM is able to classify the stereotype of the entity , which is not identified in the knowledge base. We also present an example of two-hops reasoning by using the LLM to generate a possible name for an entity connected to through the relationship , given the graph-based triplet retrieved from the knowledge base.
4. Experimental Results
This section presents case studies to evaluate the proposed framework. Specifically, we present a detailed workflow by using a public dataset about supply chain management [48,49]. This plain-format dataset includes information on over 7000 manufacturers and their related entities, such as processed materials, areas of operation, and certifications. The data is collected from public documents and online sources.
4.1. Constructing the Graph-Based Knowledge Base
We categorize the entities within the collected data as the following stereotypes by synthesizing domain knowledge: (1) Manufacturers are companies associated with a brand name that handle products. (2) Materials depicts the raw industrial materials (e.g., steel, plastic) that are required by the manufacturers. A manufacturer handles multiple cardinalates of different materials. (3) Services are the capabilities of manufacturers that enable material processing. A manufacturer enables multiple services. In addition, given the hierarchy of the services (e.g., wood processing includes paper and construction materials), we further divide them into different branches, with services able to connect to multiple entities of their branches. (4) Certifications are the credentials and qualifications awarded to companies that meet industry-specific standards and requirements. A manufacturer enables multiple cardinalates of different certifications. (5) Industries denote the sectors of potential clients for products from manufacturers. Based on the dependencies within these different stereotypes, we present the triplets shown in Table 1.

Table 1.
Triplets regarding different stereotypes of entities.
By associating these triplets, we present four meta-paths, which are visualized in Figure 2. We utilize Neo4j, a graph database system, to construct graph-based knowledge base by importing entities along with associated meta-graphs. Cypher query, an SQL-like language designed for Neo4j, supports us in managing and refining the graph structure by merging duplicate entities that share the same names or identification numbers. The consistency of the resulting graph-based models is verified through comparison with the meta-graphs.
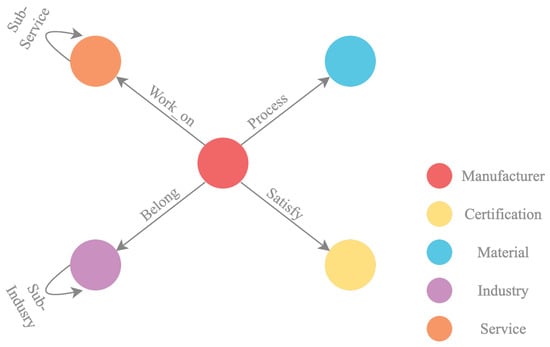
Figure 2.
Meta-graph visualized by Neo4j.
4.2. Indexing and Retrieving Graph-Based Models
By leveraging Neo4j, we can directly search for keywords that exist in the knowledge base. Specifically, we use the stereotypes, their relationships, and names listed in Table 1 as a corpus to support a search within the knowledge base following the method in Section 3.2. Next, we use Gemini [50] as the encoder to generate the embeddings of the graph-based models within the knowledge base. Due to the extensive dimensions of embeddings, we preserve the graph-based models and their corresponding embeddings in a plain-format file as the look-up table formulated in Equation (5). To measure the similarity defined in Equation (7), we use cosine-based distance [51], which is a common metric to evaluate the quality of generated embeddings. We set up the threshold . Candidate retrieved data are identified when their similarity exceeds the predefined threshold. Next, the most relevant information is retrieved by ranking these candidates and selecting the top-matching items.
To determine the number of graph-based models to retrieve, we define a set of interrogative words , including does, what, how, why, which, and where. We also define a set of conjunctive words , comprising in, and, to, for, given, with and that. Although different configurations of the coefficients in Equation (12) are possible, setting and provides an acceptable balance for the normalized score . In addition, we configure the retrieved numbers of relevant information presented in Section 3.3 as an indicator function in Equation (12):
4.3. Creating Prompts for Generating Responses
Due to the design of prompt creation in Section 3.4, the aim of the prompt is to assist the LLM in understanding its role and making the corresponding responses. Based on this idea, we firstly formulate the instructions of prompts as follows:
- You are an expert AI assistant specializing in supply chain management;
- Your task is to give responses based on the retrieved multi-level graph-based models.
Based on the instructions, we specify the generation patterns as semi-structured models, which not only facilitate user interpretation but also support further use in visualization and analysis. Specifically, constraints are formulated as follows:
- The generated responses should follows this format: - (Entity A)-[:Relationship]→(Entity B).
- Based on the generated responses, we need you to provide a detailed reasoning process with human-understandable representation.
- If the retrieved models yield no direct matches for the queries, we need you to infer the possible results based on the known situations.
Next, we present example queries and their expected responses from the LLM by constructing sample pairs as follows:
- User Queries: Which manufacturers work in the material field and satisfy ISO 9001?
- Try to retrieve the entities which obtain manufacturers in the material field from the knowledge base. For example, Entity Name 149401-us.all.biz is working in the material industry, and it satisfies ISO 9001.
- The generated responses should contain all the relationships and entities related to the company 149401-us.all.biz, formulated as follows:(149401-us.all.biz)-[:Certification]→ (ISO9001)(149401-us.all.biz)-[:Process]→ (Woods).
4.4. Performance Evaluation
To evaluate the performance of the proposed framework, we use the following methods as ablation studies. (1) Solely using the LLM involves a framework that adopts the LLM without support from the knowledge base for analyzing the supply chain information [27,37]. (2) Solely using the heuristic-based method involves using a path-based method by searching the keywords within the knowledge base [52]. (3) Using the conventional RAG framework involves using the LLM to generate the responses by adopting embedding retrieval and heuristic retrieval-based methods. Specifically, the former refers to the case in which the LLM generates responses solely based on similarity measurements across embeddings, without considering the retrieval depth of the graph-based models defined in Equation (12). The latter refers to the case in which the LLM generates responses solely based on the exact matching of keywords between the input questions and the corpus, without accounting for the semantic similarity of embeddings defined in Equations (4) and (7). We use Gemini 2.0 as the API to enable the LLM to support the proposed framework.
To measure the precision of the responses generated by the LLM, we use the Recall-Oriented Understudy for Gisting Evaluation (ROUGE) by comparing the overlap of individual elements, including the entities and their relationships, between the generated responses and the ground truth [53]. Specifically, we use recall (), precision (), and F1-score (), as formulated in (13), to evaluate the performance of unigram overlap (ROUGE-1) in the context of each node and relationship.
where refers to the intersected elements that co-occur in both the generated response and the ground truth and refers to a set of elements present in the ground truth.
To generate diverse queries for evaluating the performance of the proposed framework, we use a template-based method [54], in which different entities are randomly inserted into predefined templates. Specifically, we present the following templates to address classification, edge prediction, and reasoning across entities:
Template A: Which manufacturer maintains connections with industries through any sub-industries?
Template B: Is the manufacturer capable of processing material?
Template C: Given the services and certifications of a manufacturer, what is its stereotype?
Here, the italicized components in the templates above denote user-customizable elements. Using these templates, we generate 100 queries and collect LLM responses across 100 epochs.
We present an example generated by these methods in Figure 3. Figure 3a illustrates the ground truth relationships between specific industries, their working fields, and certifications. The heuristic-based method, shown in Figure 3c, retrieves entities from the knowledge base and is able to identify a specific industry and its working field. However, it overlooks other similar industries that share the same connections. On the other hand, LLM-based methods using either embedding-based or heuristic-based retrieval shown in Figure 3d,e are often insufficient for retrieving multi-hop entities (e.g., the working field in this case), as these methods lack the ability to capture implicit information. Compared to these methods, the proposed framework, shown in Figure 3b, not only retrieves more similar industry entities but is also capable of retrieving information across multiple depths.
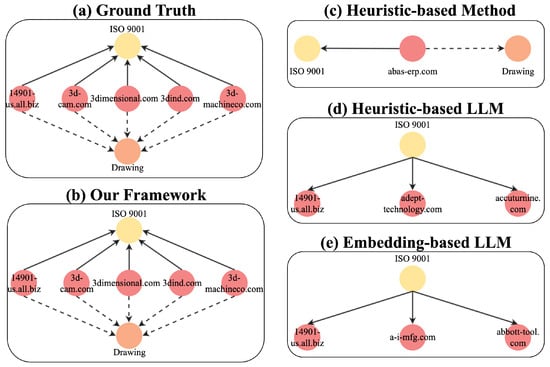
Figure 3.
Visualization of example generated results.
The platform is 11th Generation Intel Core i7 processor, 32 GB of RAM, and an NVIDIA GeForce RTX 3070 GPU. As a result, we present Table 2 to compare the performance of our approach against several baselines, including heuristic-based search, a purely LLM-based framework, and an LLM with the embedding-based retrieval and the heuristic-based retrieval. From the results, we observe that the LLM without RAG exhibits the weakest average performance, as it fails to generate domain-specific responses. Since the heuristic-based search is a path-based method, it can only produce responses when the queries contain information explicitly present in the knowledge base. In comparison to other LLM frameworks with different retrieval methods, the proposed framework demonstrates a significant improvement. We conclude that such an improvement is due to the retrieval of explicit and implicit information to provide additional insights for generating responses.To this end, we present the average performance, including precision, recall, and F1-score, across our framework and the baseline methods. Since the LLM-based solution without RAG can generate responses solely based on its internal knowledge, it shows the poorest performance among all methods. In contrast, the heuristic search produces valuable responses when the input exactly matches the information in the knowledge base; its performance can be compromised when there is a semantic gap between the input question and the stored knowledge. This also implies that the LLM-based solution with heuristic retrieval performs worse than the one using embedding-based retrieval.
Table 2.
Results of comparative studies.
To further evaluate the practical applicability of the proposed framework in real-world scenarios, we evaluate real-time performance during the comparative studies. Specifically, we collect the time elapsed from the completion of each prompt input until the generation of the corresponding LLM response. Next, we present the average time elapse and the Worst-Case Execution Time (WCET) [55] over all the templates within comparative studies in Table 3. From the table, we observe that the LLM-based solution without RAG generates responses more quickly, as it relies solely on its own generative capabilities rather than relevant information from the knowledge base. However, this also results in less precise outcomes. Since LLM-based solutions that rely solely on embeddings do not possess the retrieval depth defined in Equation (12) within the graph-based knowledge base, they tend to perform exhaustive searches to match all possible entities within the graph-based knowledge base, thereby consuming significantly more time. While the heuristic-based RAG specifies retrieval depths, it requires an exact match between the keywords in the input questions and those in the corpus. As a result, when the keywords do not exist in the corpus, the process becomes more time-consuming than the embedding-based method, implying that its WCET is worse than others. The proposed framework is more efficient than LLM-based solutions that rely on embeddings or heuristic retrieval, as it leverages the strengths of both methods while mitigating the drawbacks associated with exact matching in heuristic retrieval and exhaustive searching in embedding-based retrieval.
Table 3.
Results of real-time performance.
5. Error Analysis and Discussion
To further analyze the performance of the proposed framework and the baseline methods, particularly those adopting RAG-based techniques, we present the observed failure modes as follows:
- Factual hallucination refers to responses in which the LLM follows the schema defined in the prompts but produces disinformation that violates factual accuracy. We observe this type of error commonly existed in LLM adopting embedding-based retrieval. For example, although the manufacturer actually meets the ISO 9001 standard, the LLM incorrectly states that it meets the ISO 14001 standard, as these two standards have closely related embeddings.
- Faithfulness hallucination refers to responses in which the LLM fails to provide valid answers. We observe this type of error frequently in LLMs that adopt heuristic-based retrieval, particularly when the model cannot retrieve relevant information from the knowledge base. For example, when an input prompt contains keywords that do not exist in the corpus, the LLM is unable to generate valid responses through heuristic-based retrieval and may instead produce incorrect answers (e.g., reproducing examples from few-shot learning in the prompts).
- The omittance of intermediate relationships within multi-depth reasoning refers to responses in which the LLM generates an output which imprecisely merges the multi-depth relationships of graph-based data retrieved from the knowledge base. We observe this type of error frequently in our proposed framework. For example, while the expected output should be [A]–(:r1)–[B]–>(:r2)–>[C], the actual output is [A]–>(:r3)–>[C], where the relationship r3 could be related to the semantics of r1 and r2; nevertheless, the intermediate relationships –(:r1)–[B]–>(:r2) are omitted. We believe this issue may arise because the generated responses contain multi-depth relationships (e.g., one or more hops across entities), which can cause the LLM to become confused about the expected output patterns.
6. Conclusions and Future Work
This paper presents a framework that leverages LLM to support the analysis of supply chain information. To alleviate hallucination of the LLM, we firstly adopt RAG-based techniques by retrieving domain knowledge in the context of supply chain information from the knowledge base. Given the complex and deeply interconnected relationships, as well as the underlying logic, within supply chain data, we use graph-based models to construct the knowledge base by explicitly modeling the identified entities and their relationships. Such models can mitigate the ambiguity commonly encountered in natural language representations. To improve the efficiency of retrieving relevant information from the knowledge base, we propose a hybrid design that combines data-driven and heuristic-based methods to capture both implicit and explicit information. The proposed framework supports multiple tasks, including edge prediction, node classification, and information generation. For comparative studies, we selected several baseline methods that exclude the proposed design components. The results demonstrate that the proposed framework outperforms all baseline methods. In addition, we also analyze the errors observed in the proposed framework for future optimization.
Although the design presents significantly improved performance compared to the baseline methods, future work can be conducted on the following aspects:
- While our framework adopts two different indexing and retrieval methods, these approaches can be further integrated into a unified solution to support the RAG process. This solution can simultaneously support the analysis of keywords and embedding-based data.
- While our framework currently relies solely on the inference and generation capabilities of the LLM, it can be further extended by developing domain-specific DL models through API calls triggered by special tokens. Such integration has the potential to further enhance overall performance.
- While our framework provides initial demonstrations, future work can explore integration with LLM frameworks such as LangChain to support broader industrial applications.
- The real-time performance needs to be further evaluated and optimized by applying pruning techniques to the LLM. Such pruning enables the deployment of our framework on edge devices.
Author Contributions
Conceptualization, P.S., D.C. and R.X.; Methodology, P.S., D.C. and R.X.; Validation, R.X. and P.S.; Formal analysis, P.S. and R.X.; Writing—original draft, P.S.; Writing—review & editing, D.C. and R.X.; Supervision, D.C.; Funding acquisition, D.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by: (1) Project of Basic Science (Natural Science) Research in Jiangsu Province: 25KJA413002 (2) KTH Royal Institute of Technology with the industrial research project ADinSOS: 2019065006.
Data Availability Statement
Dataset available on request from the corresponding author, Dejiu Chen (chendj@kth.se).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dolgui, A.; Ivanov, D.; Sokolov, B. Ripple effect in the supply chain: An analysis and recent literature. Int. J. Prod. Res. 2018, 56, 414–430. [Google Scholar] [CrossRef]
- Zheng, X.; Zhang, L. Risk assessment of supply-chain systems: A probabilistic inference method. Enterp. Inf. Syst. 2020, 14, 858–877. [Google Scholar] [CrossRef]
- Abdirad, M.; Krishnan, K. Industry 4.0 in logistics and supply chain management: A systematic literature review. Eng. Manag. J. 2021, 33, 187–201. [Google Scholar] [CrossRef]
- Maddikunta, P.K.R.; Pham, Q.V.; Prabadevi, B.; Deepa, N.; Dev, K.; Gadekallu, T.R.; Ruby, R.; Liyanage, M. Industry 5.0: A survey on enabling technologies and potential applications. J. Ind. Inf. Integr. 2022, 26, 100257. [Google Scholar] [CrossRef]
- Su, P.; Chen, D. Designing a knowledge-enhanced framework to support supply chain information management. J. Ind. Inf. Integr. 2025, 47, 100874. [Google Scholar] [CrossRef]
- Mishra, D.; Gunasekaran, A.; Papadopoulos, T.; Childe, S.J. Big Data and supply chain management: A review and bibliometric analysis. Ann. Oper. Res. 2018, 270, 313–336. [Google Scholar] [CrossRef]
- Gonzálvez-Gallego, N.; Molina-Castillo, F.J.; Soto-Acosta, P.; Varajao, J.; Trigo, A. Using integrated information systems in supply chain management. Enterp. Inf. Syst. 2015, 9, 210–232. [Google Scholar] [CrossRef]
- Wu, W.; Shen, L.; Zhao, Z.; Li, M.; Huang, G.Q. Industrial IoT and long short-term memory network-enabled genetic indoor-tracking for factory logistics. IEEE Trans. Ind. Inform. 2022, 18, 7537–7548. [Google Scholar] [CrossRef]
- Singla, T.; Anandayuvaraj, D.; Kalu, K.G.; Schorlemmer, T.R.; Davis, J.C. An empirical study on using large language models to analyze software supply chain security failures. In Proceedings of the 2023 Workshop on Software Supply Chain Offensive Research and Ecosystem Defenses, Copenhagen, Denmark, 30 November 2023; pp. 5–15. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2022, New Orleans, LA, USA, 27 November–8 December 2022; NeurIPS Foundation: La Jolla, CA, USA, 2022; Volume 35, pp. 24824–24837. [Google Scholar]
- Peng, B.; Zhu, Y.; Liu, Y.; Bo, X.; Shi, H.; Hong, C.; Zhang, Y.; Tang, S. Graph retrieval-augmented generation: A survey. arXiv 2024, arXiv:2408.08921. [Google Scholar] [CrossRef]
- Wang, Y.; Cheng, Y.; Qi, Q.; Tao, F. IDS-KG: An industrial dataspace-based knowledge graph construction approach for smart maintenance. J. Ind. Inf. Integr. 2024, 38, 100566. [Google Scholar] [CrossRef]
- Su, P.; Xu, R.; Wu, W.; Chen, D. Integrating Large Language Model and Logic Programming for Tracing Renewable Energy Use Across Supply Chain Networks. Appl. Syst. Innov. 2025, 8, 160. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2020, Vancouver, BC, Canada, 6–12 December 2020; NeurIPS Foundation: La Jolla, CA, USA, 2020; Volume 33, pp. 9459–9474. [Google Scholar]
- Wu, T.; He, S.; Liu, J.; Sun, S.; Liu, K.; Han, Q.L.; Tang, Y. A Brief Overview of ChatGPT: The History, Status Quo and Potential Future Development. IEEE/CAA J. Autom. Sin. 2023, 10, 1122–1136. [Google Scholar] [CrossRef]
- Yenduri, G.; Srivastava, G.; Maddikunta, P.K.R.; Jhaveri, R.H.; Wang, W.; Vasilakos, A.V.; Gadekallu, T.R. Generative pre-trained transformer: A comprehensive review on enabling technologies, potential applications, emerging challenges, and future directions. arXiv 2023, arXiv:2305.10435. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 4 November 2025).
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; NeurIPS Foundation: La Jolla, CA, USA, 2019; Volume 32. [Google Scholar]
- Sahoo, P.; Singh, A.K.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv 2024, arXiv:2402.07927. [Google Scholar] [CrossRef]
- Dong, Q.; Li, L.; Dai, D.; Zheng, C.; Ma, J.; Li, R.; Xia, H.; Xu, J.; Wu, Z.; Liu, T.; et al. A survey on in-context learning. arXiv 2022, arXiv:2301.00234. [Google Scholar]
- Shi, F.; Chen, X.; Misra, K.; Scales, N.; Dohan, D.; Chi, E.H.; Schärli, N.; Zhou, D. Large language models can be easily distracted by irrelevant context. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 31210–31227. [Google Scholar]
- Hu, H.; Lu, H.; Zhang, H.; Song, Y.Z.; Lam, W.; Zhang, Y. Chain-of-symbol prompting elicits planning in large langauge models. arXiv 2023, arXiv:2305.10276. [Google Scholar]
- Su, P.; Chen, D. Adopting graph neural networks to analyze human–object interactions for inferring activities of daily living. Sensors 2024, 24, 2567. [Google Scholar] [CrossRef]
- Jin, B.; Liu, G.; Han, C.; Jiang, M.; Ji, H.; Han, J. Large language models on graphs: A comprehensive survey. IEEE Trans. Knowl. Data Eng. 2024, 26, 8622–8642. [Google Scholar] [CrossRef]
- Guo, T.; Guo, K.; Liang, Z.; Guo, Z.; Chawla, N.V.; Wiest, O.; Zhang, X. What indeed can GPT models do in chemistry? A comprehensive benchmark on eight tasks. arXiv 2023, arXiv:2305.18365. [Google Scholar]
- He, X.; Bresson, X.; Laurent, T.; Perold, A.; LeCun, Y.; Hooi, B. Harnessing explanations: Llm-to-lm interpreter for enhanced text-attributed graph representation learning. arXiv 2023, arXiv:2305.19523. [Google Scholar]
- Lacombe, R.; Gaut, A.; He, J.; Lüdeke, D.; Pistunova, K. Extracting molecular properties from natural language with multimodal contrastive learning. arXiv 2023, arXiv:2307.12996. [Google Scholar] [CrossRef]
- Kim, J.; Kwon, Y.; Jo, Y.; Choi, E. KG-GPT: A general framework for reasoning on knowledge graphs using large language models. arXiv 2023, arXiv:2310.11220. [Google Scholar] [CrossRef]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, H.; Wang, H. Retrieval-augmented generation for large language models: A survey. arXiv 2023, arXiv:2312.10997. [Google Scholar]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 17754–17762. [Google Scholar]
- Huang, Y.; Li, Y.; Xu, Y.; Zhang, L.; Gan, R.; Zhang, J.; Wang, L. Mvp-tuning: Multi-view knowledge retrieval with prompt tuning for commonsense reasoning. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 13417–13432. [Google Scholar]
- Mavromatis, C.; Karypis, G. Gnn-rag: Graph neural retrieval for large language model reasoning. arXiv 2024, arXiv:2405.20139. [Google Scholar] [CrossRef]
- Li, B.; Mellou, K.; Zhang, B.; Pathuri, J.; Menache, I. Large language models for supply chain optimization. arXiv 2023, arXiv:2307.03875. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2020, Vancouver, BC, Canada, 6–12 December 2020; NeurIPS Foundation: La Jolla, CA, USA, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Zheng, G.; Almahri, S.; Xu, L.; Minaricova, M.; Brintrup, A. LLMs in Supply Chain Management: Opportunities and Case Study. IFAC-PapersOnLine 2025, 59, 2951–2956. [Google Scholar] [CrossRef]
- Aghaei, R.; Kiaei, A.A.; Boush, M.; Vahidi, J.; Barzegar, Z.; Rofoosheh, M. The Potential of Large Language Models in Supply Chain Management: Advancing Decision-Making, Efficiency, and Innovation. arXiv 2025, arXiv:2501.15411. [Google Scholar] [CrossRef]
- Khan, T.; Emon, M.M.H.; Rahman, M.A. A systematic review on exploring the influence of Industry 4.0 technologies to enhance supply chain visibility and operational efficiency. Rev. Bus. Econ. Stud. 2024, 12, 6–27. [Google Scholar] [CrossRef]
- Han, K. Applying graph neural network to SupplyGraph for supply chain network. arXiv 2024, arXiv:2408.14501. [Google Scholar] [CrossRef]
- Zdravković, M.; Panetto, H.; Trajanović, M.; Aubry, A. An approach for formalising the supply chain operations. Enterp. Inf. Syst. 2011, 5, 401–421. [Google Scholar] [CrossRef]
- Kosasih, E.E.; Margaroli, F.; Gelli, S.; Aziz, A.; Wildgoose, N.; Brintrup, A. Towards knowledge graph reasoning for supply chain risk management using graph neural networks. Int. J. Prod. Res. 2024, 62, 5596–5612. [Google Scholar] [CrossRef]
- Tiddi, I.; Schlobach, S. Knowledge graphs as tools for explainable machine learning: A survey. Artif. Intell. 2022, 302, 103627. [Google Scholar] [CrossRef]
- Liu, S.; Zeng, Z.; Chen, L.; Ainihaer, A.; Ramasami, A.; Chen, S.; Xu, Y.; Wu, M.; Wang, J. TigerVector: Supporting Vector Search in Graph Databases for Advanced RAGs. arXiv 2025, arXiv:2501.11216. [Google Scholar] [CrossRef]
- He, X.; Tian, Y.; Sun, Y.; Chawla, N.; Laurent, T.; LeCun, Y.; Bresson, X.; Hooi, B. G-retriever: Retrieval-augmented generation for textual graph understanding and question answering. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2024, Vancouver, BC, Canada, 10–15 December 2024; NeurIPS Foundation: La Jolla, CA, USA, 2024; Volume 37, pp. 132876–132907. [Google Scholar]
- Shu, Y.; Yu, Z.; Li, Y.; Karlsson, B.F.; Ma, T.; Qu, Y.; Lin, C.Y. Tiara: Multi-grained retrieval for robust question answering over large knowledge bases. arXiv 2022, arXiv:2210.12925. [Google Scholar] [CrossRef]
- Lu, X. Automatic analysis of syntactic complexity in second language writing. Int. J. Corpus Linguist. 2010, 15, 474–496. [Google Scholar] [CrossRef]
- Yan, H.; Yang, J.; Wan, J. KnowIME: A system to construct a knowledge graph for intelligent manufacturing equipment. IEEE Access 2020, 8, 41805–41813. [Google Scholar] [CrossRef]
- Li, Y.; Liu, X.; Starly, B. Manufacturing service capability prediction with Graph Neural Networks. J. Manuf. Syst. 2024, 74, 291–301. [Google Scholar] [CrossRef]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar] [CrossRef]
- Es, S.; James, J.; Anke, L.E.; Schockaert, S. Ragas: Automated evaluation of retrieval augmented generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, St. Julian’s, Malta, 17–22 March 2024; pp. 150–158. [Google Scholar]
- Behmanesh, E.; Pannek, J. Modeling and random path-based direct encoding for a closed loop supply chain model with flexible delivery paths. IFAC-PapersOnLine 2016, 49, 78–83. [Google Scholar] [CrossRef]
- Zhang, J. Graph-toolformer: To empower llms with graph reasoning ability via prompt augmented by chatgpt. arXiv 2023, arXiv:2304.11116. [Google Scholar]
- Bast, H.; Haussmann, E. More accurate question answering on freebase. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1431–1440. [Google Scholar]
- Su, P.; Xiang, C.; Chen, D. Adopting Graph Neural Networks to Understand and Reason about Dynamic Driving Scenarios. IEEE Open J. Intell. Transp. Syst. 2025, 6, 579–589. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).