Abstract
Intimate partner violence (IPV) remains a critical issue that requires data-driven solutions to improve victim profiling and intervention strategies. This study introduces Mujer Segura, an innovative web application designed to collect structured data on IPV cases and predict their severity using machine learning models. The methodology integrates Random Forest (RF) and Gradient Boosting Classifier (GBC) algorithms to classify IPV cases by leveraging historical data for predictive analysis. The RF model achieved an accuracy of 97%, with a precision of 1.00 for non-severe cases and 0.96 for severe cases, recall values of 0.93 and 1.00 respectively, and an ROC AUC of 0.9534. The GBC model demonstrated an accuracy of 89%, with a precision of 1.00 for non-severe cases and 0.98 for severe cases, recall values of 0.95 and 1.00 respectively, and an ROC AUC of 0.9891. The application also integrates geospatial visualization tools to identify high-risk areas in the State of Mexico, enabling real-time interventions. These findings confirm that machine learning can enhance the timely detection of IPV cases and support evidence-based decision-making for public safety agencies.
1. Introduction
Globally, both research and training on bystander intervention in cases of violence against women, as well as the adoption of technological tools, remain limited. Victims have reported that the response from authorities is often inconsistent [1]. In this context, the timely analysis of data through machine learning has proven to be an effective approach [2]. Violence against women is a major public health concern; one in three women worldwide has experienced physical or sexual violence, primarily perpetrated by an intimate partner [3]. Contributing factors include infidelity, jealousy, economic dependence, and intolerance [4].
The World Health Organization (WHO) defines intimate partner violence as acts committed by a partner or ex-partner that cause physical, sexual, or psychological harm. This includes physical aggression, sexual coercion, psychological abuse, and controlling behaviors. Countries such as India, the United States, and Mexico have conducted studies addressing this global health issue [5].
In Latin America, vulnerable groups have been identified, particularly Indigenous women, who comprise approximately 50 million individuals belonging to 500 different ethnic groups [6]. These populations often do not receive adequate attention regarding the root causes of intimate partner violence [7]. A study of 75 intimate partner homicide cases revealed that perpetrators often had criminal records, substance abuse problems, psychiatric disorders, and a history of repeated separations and reconciliation [8]. Furthermore, research has examined how motherhood influences women’s experiences of violence and the decision to flee with their children, noting that violence leads to isolation and increases the burden of protection and provision [9].
Violence is associated with significant costs, including medical expenses, shelter costs, legal fees, and work absenteeism. Women who have experienced intimate partner violence incur medical expenses that are 32% to 130% higher compared to those who have not suffered such violence [5].
In India, following the pandemic, technological solutions have been proposed to address domestic violence, including automatic voice recognition systems that assist individuals who cannot physically access official authorities [1].
Additionally, interactive maps have been developed to visualize violent incidents, utilizing models such as Q–R decomposition with column pivoting and projected clustering algorithms to identify significant crime patterns and locations. These tools facilitate the effective identification of high-crime areas in northern India [10].
In countries such as the United States, cognitive models have been implemented to predict conflict-related behaviors and to design technological interventions that support decision-making. These interventions aim to allocate resources to enhance the safety, autonomy, and resilience of victims during their recovery process [11].
Machine learning models such as artificial neural networks, k-nearest neighbors, Random Forests, decision trees, XGBoost, LightGBM, and CatBoost have been applied to predict women’s vulnerability to domestic violence. Analyses have shown that the LightGBM and Random Forest models achieved the highest accuracy, with rates of 81% and 82%, respectively [12]. Additionally, a large repository of articles on violence against women was created using web scraping techniques and various classifiers, including Support Vector Machines, Decision Trees, Bayesian Networks, XGBoost, Random Forest, and Artificial Neural Networks. Among these, the XGBoost classifier exhibited the best performance, followed by Random Forest [13].
In Mexico, ongoing studies focus on detecting linguistic patterns through supervised models. These efforts are based on the hypothesis that sentiment analysis can associate emotions with specific topics, facilitating the identification of potential cases of digital violence against women [14]. This article presents an innovative initiative in Mexico to analyze intimate partner violence through the development of a web application designed to collect high-quality data and accurately profile victims. The platform also aims to predict the likelihood of case escalation and prevent femicide. Beyond comprehensive data collection, the web application integrates machine learning models to analyze inputs, producing structured data sheets that support the classification of severe and non-severe cases.
The web application incorporates a geospatial component through the development of an interactive map that highlights incidents of violence by region. This functionality is essential for visualizing the geographic distribution of violence and identifying high-risk areas that require targeted interventions. By integrating data analysis with geospatial visualization, the platform offers a powerful tool for decision-makers, enabling more efficient and focused responses.
The proposed methodology stands out for its comprehensive scope, encompassing all stages from data collection to analysis and visualization. This holistic approach not only enhances analytical accuracy but also facilitates the timely identification of victims, allowing for the implementation of effective intervention strategies.
Section 2 presents a detailed review of previous studies and current technologies used to address intimate partner violence. Section 3 identifies specific limitations in existing solutions and explains how the present proposal addresses these gaps. Section 4 describes the methodological framework in detail, including data collection, preprocessing, and modeling stages. Section 4.1 outlines the architecture and functionalities of the Mujer Segura platform. Furthermore, Section 4 describes the tools and techniques used in the study, ensuring replicability and scientific rigor. The experimental procedures and the conditions under which they were conducted are also described in detail. Section 5 and Section 6 provide a critical interpretation of the findings, comparing model performance. Finally, Section 7 summarizes the main conclusions and suggests potential directions for future research.
2. Literature Review
The application of machine learning models to the analysis of violence has been extensively studied, encompassing the identification of risk factors and the prediction of future incidents across various global contexts. These studies offer a strong foundation for understanding and mitigating different forms of violence.
2.1. Integration and Practical Application of Predictive Models
Machine learning techniques have been proposed to predict the risk of recidivism among gender violence offenders using data from the official Spanish system Gender Violence case tracking (VioGen), which contains more than 40,000 reports. Model performance was evaluated using two new quality measures: one focused on effective police protection and another on resource overload. The results indicate a 25% improvement over the existing risk assessment system. Additionally, a hybrid model combining statistical prediction and machine learning has been introduced to facilitate a smooth transition for authorities [15].
Biosocial factors contributing to domestic violence have also been investigated, revealing that the current understanding remains limited. In this context, machine learning techniques were applied to predict women’s vulnerability to domestic violence using data from the Liberia Demographic and Health Survey (2019–2020). Models such as Artificial Neural Networks (ANN), k-Nearest Neighbors (KNN), Random Forest (RF), Decision Tree (DT), Extreme Gradient Boosting (XGBoost), Light Gradient Boosting Machine (LightGBM), and Categorical Boosting (CatBoost) were employed. Among these, the LightGBM and RF models achieved the highest accuracy, with rates of 81% and 82%, respectively. A key finding was that the number of individuals who experienced emotional violence emerged as a significant predictive feature. These results offer valuable insights into the risk factors associated with domestic violence against women in Liberia [12].
Various algorithmic approaches have been compared to predict and detect the drivers of homicides, with XGBoost demonstrating the highest accuracy. SHAP (SHapley Additive exPlanations) was employed to interpret the patterns, highlighting features such as the circumstances of the homicide, the type of weapons used, the sex and race of the victims, and the number of perpetrators and victims. Explainable machine learning proved valuable in enhancing the understanding of these patterns [16].
Additionally, machine learning techniques have been applied to analyze natural language on platforms such as Twitter, emphasizing the importance of developing public policies to protect women from cyber harassment. This analysis identified patterns of violent behavior and contributed to raising awareness about the issue by promoting behavior modification [17].
2.2. Identification of Risk Factors and Prediction of Incidents
Risk factors for requesting protection orders against spousal violence in Singapore have been analyzed using data from administrative records. Key variables identified include education level, type of housing, marital status, early parenthood, and history of violence. The application of machine learning and network-based approaches facilitated timely interventions aimed at minimizing the effects of spousal violence [18].
In Namibia, Africa, Support Vector Machine (SVM) has been implemented to predict the incidence of gender-based violence and to develop early prevention strategies. This approach is particularly valuable given that government programs in the region primarily focus on punishing perpetrators rather than preventing violence [19].
2.3. Understanding Victims’ Experiences
A study conducted in Central Java, Indonesia, examined the perspectives of victims and proposed effective solutions to address violence against women. Questionnaires were administered to 960 women and girls, exploring variables such as age, education level, occupation, and financial situation. Among the respondents, 91% reported having experienced physical violence, with 71% of the cases perpetrated by individuals emotionally connected to the victims. The most significant risk factors included being under 50 years of age, having a low education level, unemployment, and low income, highlighting the importance of addressing these underlying causes to effectively combat violence [20].
The increasing pattern of violence has been associated with femicides, suggesting that prevention is possible through proper risk assessment of victims. The Long Short-Term Memory (LSTM) technique was employed to identify behavioral patterns in Brazilian police reports, achieving an accuracy of 66% [21].
2.4. Development of Intervention Strategies and Public Policies
In the area of prevention, web scraping techniques have been developed to collect news articles related to violence against women. These data were then analyzed using text mining and exploratory analysis. Topic modeling was employed to identify thematic patterns, and various classification models were implemented to determine the specific type of violence. The methodology also incorporated the use of specialized dictionaries for types of violence, as well as the identification of both predominant and associated forms of violence. Among the models tested, XGBoost demonstrated the best performance, followed by Random Forest [22].
This review of the literature illustrates how machine learning serves as a powerful tool to address violence against women from multiple perspectives, enabling both predictive and preventive strategies.
3. Opportunity Niche
The implementation of machine learning (ML) to address violence against women has proven to be an effective tool for understanding and combating this social issue. In this case study, the RF and Gradient Boosting Classifier (GBC) models are employed, as they have demonstrated superior performance in the literature [22].
These models enable a deeper understanding of the factors and motivations underlying violence against women, while also supporting the classification of cases that require immediate attention. The ability to predict and analyze the behavior of victims is essential for developing effective prevention strategies and enhancing the responsiveness of authorities and public services.
Studies indicate that government platforms for reporting violence against women in Mexico face several limitations that hinder comprehensive data analysis. These include incomplete records, limited platform availability, and technological incompatibilities [23]. ML+ models, with their capacity to process large volumes of data and produce accurate predictions, support rapid and efficient intervention—an essential component in the fight against intimate partner violence. The precision offered by these models is critical for safeguarding victims and preventing future incidents.
Moreover, ML models can identify risk factors and behavioral patterns that may not be readily observable using traditional methods. This enables a more profound understanding of the root causes of violence and supports the design of more effective policies and intervention strategies. The adaptability of ML models also makes them suitable for use in diverse geographic and cultural contexts—an important advantage when addressing a global issue like intimate partner violence, where solutions must be both contextually relevant and culturally sensitive.
To tackle these challenges, the Mujer Segura web application was developed, incorporating a machine learning module. It is important to emphasize that data quality directly impacts the reliability and effectiveness of the predictive models [24]. Web applications like Mujer Segura, which utilize normalized databases, help ensure the integrity and consistency of the collected data, thereby significantly improving its quality. This enhanced data quality, in turn, increases confidence in the analysis outcomes and in the predictions generated by ML models [25].
4. Methodology
To obtain reliable results and achieve the desired objectives, it is essential to implement a structured methodology such as CRISP-DM (Cross-Industry Standard Process for Data Mining) [26]. This methodology comprises the following phases: data selection, data preprocessing, feature selection, model training, model evaluation, and result interpretation (see Figure 1).
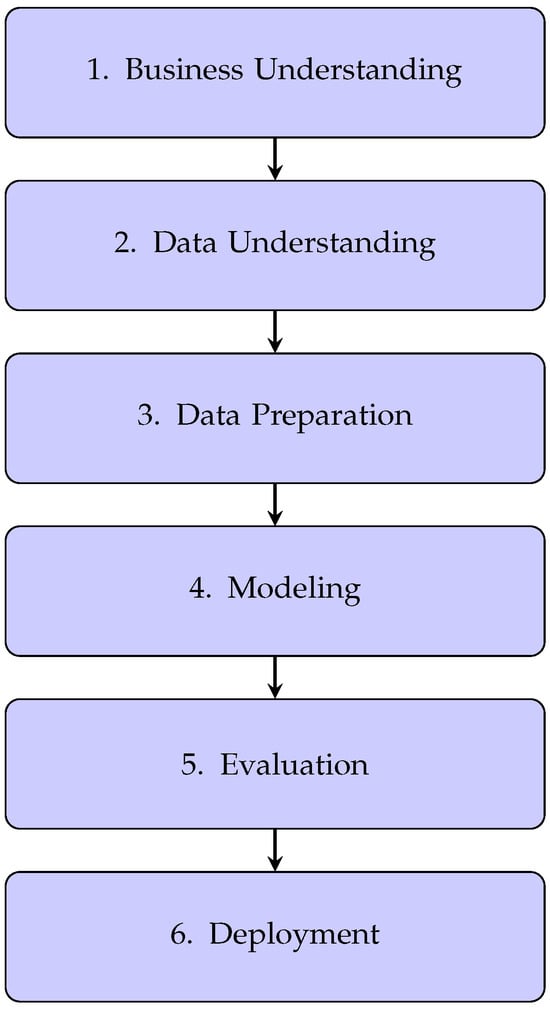
Figure 1.
CRISP-DM process flow: the six-phase standard methodology for data mining projects. Figure adapted from the CRISP-DM model [27].
The implementation of the RF and GBC models in the web application for intimate partner violence analysis followed a structured process, beginning with the collection and validation of detailed incident data. Statistical and machine learning models were applied to process and analyze these data, identifying patterns and risk factors associated with different types of violence.
The effectiveness of the models was evaluated using specific metrics such as accuracy, sensitivity, and specificity, ensuring that they are not only precise but also effective for predicting and mitigating future incidents. Additionally, an interactive map was integrated to geographically visualize areas with higher incidence rates, thereby facilitating rapid and targeted interventions. Continuous validation of the models through performance testing and user feedback ensures ongoing adaptation and improvement of the system.
4.1. Description of the Safe Woman Platform
The Mujer Segura platform is a web application designed to enable agencies responsible for managing reports of violence against women to efficiently and systematically record relevant information. This application guides users through step-by-step forms, helping to prevent information overload while ensuring the comprehensive capture of all necessary data to accurately characterize and monitor each instance of intimate partner violence. The platform incorporates a normalized relational database to guarantee the integrity and quality of the collected information [28].
The required data fields were predefined by a team of specialists from the Women’s Coordination Office, which includes experts in psychology, law, and indigenous languages. Based on an extensive state-of-the-art review, a highly available and user-friendly platform was developed to meet users’ needs and enhance the efficiency of managing incidents of intimate partner violence.
4.2. Description of the Data Set
The State of Mexico is one of the 32 federal entities of Mexico, located in the central region of the country. It is the most populous state in the nation and the second smallest in terms of land area, covering approximately 22,499 square kilometers. It shares borders with Querétaro and Hidalgo to the north, Tlaxcala and Puebla to the east, Morelos and Mexico City to the south, and Michoacán and Mexico City to the west [29].
Intimate partner violence in the State of Mexico remains a critical issue that demands a comprehensive and coordinated response. Despite the efforts implemented to date, considerable challenges persist in terms of prevention, victim protection, and access to justice. Meaningful progress requires sustained collaboration between governmental authorities, civil society organizations, and local communities. Table 1 shows the general statistics of the average data of women who have been victims of violence in the State of Mexico, highlighting that the percentages are alarming (see Table 1).

Table 1.
Statistics of women victimized by violence in the state of Mexico (ENDIREH 2021) [30].
Valle de Bravo, located in the State of Mexico, had a total population of 61,590 inhabitants in 2020, of which 51.2% were women and 48.8% were men [29]. The data used in this study were obtained from the Mujer Segura platform, which gathers detailed information through a normalized relational database. This database stores comprehensive records of each reported incident of violence against women registered on the platform. The variables analyzed were drawn from a predefined selection established by experts from the Women’s Coordination and are listed in Table 2.
Table 2.
Description of variables and data types.
Data collection is carried out by the personnel of the Women’s Coordination, and the information is systematically stored in the platform’s database. Real-time analysis of the data enables the identification of active cases, facilitating timely and effective responses to situations of violence against women (see Table 2).
Before processing, the data fragment was extracted from the Mujer Segura platform (see Table 3).
Table 3.
Original data sheet (Fragment).
These data were collected at the Women’s Coordination office in Valle de Bravo. However, during the requirements-gathering phase, an opportunity arose to visit communities surrounding the municipality. One such location was Donato Guerra, where, according to information obtained through personal interviews, a significant number of intimate partner violence cases go unreported due to a prevailing lack of reporting culture among victims. This situation highlighted the need for a mobile application that enables access to the web platform from remote communities.
Structured Query Language (SQL) was used for information extraction. This language facilitates the efficient access and manipulation of large volumes of structured data. Its capacity to handle relational data in a precise and scalable manner makes it a valuable tool for analyzing relevant information in studies on intimate partner violence [31]. A data extraction routine was developed to gather the necessary information for training the models. These data are stored in a view that aggregates information from multiple tables, optimizing the querying process and supporting comprehensive analysis [31]. Both historical and real-time data stored within the web application were utilized in this process.
4.3. Feature Analysis
To enhance model performance and mitigate overfitting, a combination of feature selection techniques was employed. The process involved three key stages: (1) an initial assessment using a machine learning–based importance measure, (2) statistical tests to evaluate feature relevance, and (3) L1 regularization to eliminate non-contributory variables.
First, the Random Forest (RF) model was used to estimate feature importance based on the decrease in impurity. Specifically, the Gini index was computed at each node, and the reduction in impurity was aggregated across all trees to determine each feature’s overall contribution. Features ranking below the fifth percentile in importance were considered weak predictors and flagged for further evaluation.
Next, statistical tests were applied to validate the relevance of each feature:
- The Chi-square test assessed the independence between categorical variables and the target variable. The test statistic was computed as [32]where O represents the observed frequency and E the expected frequency. Features with a p-value greater than 0.05 were considered statistically insignificant.
- Analysis of Variance (ANOVA) evaluated whether the mean of numerical features differed significantly between classes [33]. The F-statistic was computed as follows:Features with a p-value greater than 0.05 were deemed non-discriminative.
Finally, L1 regularization was applied through LASSO regression to refine the feature set further. LASSO introduces an L1 penalty to the regression model, which forces the coefficients of less important variables to shrink to zero, effectively performing feature selection. The optimization function used in LASSO regression is given by [34]:
where is the regularization parameter that controls the degree of shrinkage. Features with coefficients equal to zero were removed from the final model.
The feature selection process was conducted in a hierarchical manner, where each method refined the variable set step by step. A feature was removed from the model if it met at least two of the following three conditions: (1) ranked below the fifth percentile in the RF importance ranking, (2) had a p-value > 0.05 in both the Chi-square test and ANOVA, or (3) had a coefficient of zero in LASSO regression.
The results of L1 regularization were used in combination with RF rankings, where variables eliminated by LASSO were cross-checked with RF rankings to determine whether their contribution was negligible. This integration allowed us to refine the feature set while ensuring that relevant features were preserved.
Following this procedure, the features no_cases, address, entity_followup, and date were removed, leaving a final subset of Y features for model training. Table 4 presents the relative importance of the selected features.
Table 4.
Features ranked by importance.
4.4. Models Description
In this study, two machine learning models were implemented to classify the severity of intimate partner violence (IPV) cases. These models were selected based on their effectiveness in handling structured data and their capability to identify complex patterns associated with violence-related risk factors. The selection was guided by prior research on machine learning applications in the social sciences, particularly those focusing on outcome prediction in sensitive domains such as violence prevention [35].
The first model employed was Random Forest (RF), an ensemble learning technique that constructs multiple decision trees and aggregates their predictions to improve classification performance. RF was chosen for its high interpretability, robustness against overfitting, and ability to handle a mix of categorical and numerical features. This model has been widely applied in predictive analytics and has demonstrated strong performance in classifying social and behavioral data [36].
The second model was Gradient Boosting Classifier (GBC), a boosting-based method that sequentially refines weak learners to enhance predictive accuracy. GBC is known for its superior performance in classification tasks, especially when dealing with complex datasets featuring intricate feature interactions. Although more computationally intensive than RF, GBC was included to evaluate whether the potential performance improvements justified the increased complexity. Both models were implemented using the Scikit-learn library, and their hyperparameters were optimized using a combination of Random Search and Grid Search techniques to ensure optimal performance. Evaluation metrics included accuracy, precision, recall, F1-score, and ROC-AUC to provide a comprehensive assessment of model effectiveness.
5. Results and Analysis
The performance of the classification models was evaluated using several metrics, including precision, recall, F1-score, and the area under the receiver operating characteristic curve (ROC AUC). These metrics were used to assess the effectiveness of each model in identifying and classifying cases of intimate partner violence. This section presents the evaluation results for both the Random Forest (RF) and Gradient Boosting Classifier (GBC) models, highlighting their predictive capabilities and comparative performance.
Performance Evaluation
Both models were trained using an 80/20 data split, with 146 instances allocated for training and 37 for testing. Hyperparameter tuning was performed using Grid Search with 5-fold cross-validation. Given the models’ differing sensitivities to hyperparameter configurations, a total of 216 parameter combinations were tested for RF, while 243 combinations were evaluated for GBC, ensuring that each model was optimally configured.
For the RF model, the following hyperparameters were optimized:
- Number of trees (n_estimators): 50, 100, 200
- Maximum tree depth (max_depth): None, 10, 20, 30
- Minimum samples to split a node (min_samples_split): 2, 5, 10
- Minimum samples per leaf (min_samples_leaf): 1, 2, 4
- Bootstrap sampling (bootstrap): True, False
The best RF model was selected based on the highest ROC AUC score, resulting in the following final configuration:
- n_estimators: 100
- max_depth: None
- min_samples_split: 5
- min_samples_leaf: 2
- bootstrap: True
For the Gradient Boosting Classifier model, the following hyperparameters were optimized:
- Number of boosting stages (n_estimators): 50, 100, 200
- Learning rate (learning_rate): 0.01, 0.1, 0.2
- Maximum depth of trees (max_depth): 3, 5, 7
- Minimum samples to split a node (min_samples_split): 2, 5, 10
- Minimum samples per leaf (min_samples_leaf): 1, 2, 4
The best Gradient Boosting Classifier model was also selected based on the ROC AUC score, leading to the following final configuration:
- n_estimators: 100
- learning_rate: 0.1
- max_depth: 5
- min_samples_split: 5
- min_samples_leaf: 2
Since Gradient Boosting Classifier (GBC) models tend to be more sensitive to hyperparameter selection, a slightly larger number of combinations (243) were tested compared to Random Forest (RF), for which 216 combinations were evaluated. This approach ensured that each model was fine-tuned appropriately, accounting for the greater complexity and flexibility of boosting algorithms in contrast to ensemble methods like RF.
The classification results for both models are summarized in Table 5.
Table 5.
Performance metrics of the Gradient Boosting Classifier and RF models.
The RF model achieved an overall accuracy of 97.0%, with an F1-score of 0.98 for severe cases and a ROC AUC of 0.9534. The model demonstrated strong performance with high precision (1.00 for non-severe cases and 0.96 for severe cases) and a recall of 0.93 for non-severe cases and 1.00 for severe cases. It made only one misclassification in the test dataset, confirming its stability and strong generalization capacity.
The Gradient Boosting Classifier (GBC) also demonstrated competitive performance, achieving an F1-score of 0.98 for severe cases and a higher ROC AUC (0.9891), indicating greater discriminatory power. However, GBC exhibited a lower overall accuracy (89.0%), suggesting that although it effectively distinguishes between classes, it is more susceptible to classification errors. Specifically, GBC misclassified more instances in the test set compared to the Random Forest (RF) model.
Given the small size of the test set (37 instances), variations in AUC and F1-score estimates should be interpreted with caution. Although both models showed strong classification performance, the most meaningful indicator in this context is the error rate, as minor fluctuations in precision, recall, and AUC may be influenced by data variability.
These findings suggest that RF offers more stable performance with fewer misclassifications, making it a more reliable option for generalization. In contrast, GBC provides stronger discrimination capability but is more sensitive to small variations in the dataset, which may affect its robustness in real-world applications.
6. Discussion
From the results obtained, both the RF and GBC models demonstrated strong performance in analyzing intimate partner violence. However, the inclusion of temporal features in the GBC model resulted in slightly higher accuracy and enhanced discriminatory power, as reflected in the ROC AUC scores. This indicates that GBC may be more effective at capturing temporal patterns that are critical for predicting the severity of violence cases.
Given the context of the Mujer Segura web application, where accurate and timely identification of severe cases is essential, the model incorporating temporal features appears to be the most appropriate choice. Temporal variables improve the model’s ability to capture the dynamics and timing of violent incidents, thereby enabling more precise real-time predictions. This enhancement supports faster and more effective interventions, ultimately strengthening the platform’s capacity to inform decision-making in violence prevention efforts.
7. Conclusions and Future Work
In conclusion, both evaluated models—the GBC with temporal features and the RF—demonstrated strong capabilities in classifying the severity of violence cases. However, the model incorporating temporal features stood out due to its superior ability to capture critical temporal patterns, as reflected in its higher ROC AUC. This added capability makes the GBC model more suitable for implementation within the Mujer Segura web platform, where accurate identification of severe violence cases is essential. The use of temporal features not only enhances class discrimination but also improves responsiveness to the evolving nature of violent events, facilitating faster and more accurate interventions.
The Mujer Segura platform ensures data quality by optimizing model inputs and delivering preprocessed data for analysis.
Regarding potential extensions of this work, the integration of additional data sources to expand the current dataset is deemed essential. This includes incorporating historical records, socioeconomic indicators, and other relevant risk factors to enable a more accurate and contextualized characterization of violence victims. Such an approach would support deeper and more nuanced analyses.
Another important direction is the development of an early warning system, to be embedded in the Mujer Segura platform. This system would leverage temporal feature-based models to notify authorities and potential victims of imminent risks. The deployment of such a system could significantly improve emergency response capabilities.
Additionally, external validation studies should be conducted using data from different regions and contexts to ensure the robustness and generalizability of the proposed model. These validations are critical for confirming the model’s effectiveness in diverse scenarios.
Finally, personalized recommendations for enhancing the platform’s user interface are envisioned. The interface should be intuitive and accessible, enabling seamless interaction with the classification system. Enhancing usability will not only improve user experience but also increase system adoption and overall effectiveness.
Author Contributions
Conceptualization, M.C.C.-M. and R.A.M.-A.; methodology, J.C.-R. and J.M.-B.; software, M.C.C.-M. and R.A.M.-A.; validation, J.C.-R. and J.M.-B.; writing—original draft preparation, M.C.C.-M. and R.A.M.-A.; writing—review and editing, J.C.-R. and J.M.-B.; supervision, R.A.M.-A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data are available on the request to the corresponding author.
Acknowledgments
The authors thank SECIHTI for the support provided to carry out this research through the scholarship 2021-000018-02NACF-14204.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Pokhriyal, D.; Bahuguna, R.; Memoria, M.; Kumar, R. Artificial Intelligence Based Legal Application For Combating Domestic Violence. In Proceedings of the 2023 International Conference on Advancement in Computation & Computer Technologies (InCACCT), Gharuan, India, 5–6 May 2023; pp. 81–86. [Google Scholar] [CrossRef]
- Rubio Rodríguez, G.A.; Alejandra, T.; Ospina, M.; Guillermo, J.; Cardozo, A.; Wilfredo Méndez González, D.; Milena, E.; Soza, V.; Rodríguez, R.; González, M. The Facts Associated with Violence Against Women by a Spouse; Technical Report; Revista Conrado: Cienfuegos, Cuba, 2021. [Google Scholar]
- Women, U.N. Facts and Figures: Ending Violence Against Women and Girls; UN Women: New York, NY, USA, 2023. [Google Scholar]
- Chen, Y.; Mendes, K.; Gosse, C.; Hodson, J.; Veletsianos, G. Canadian Gender-Based Violence Prevention Programs: Gaps and Opportunities. Violence Against Women 2024, 10778012241259727. [Google Scholar] [CrossRef] [PubMed]
- William, J.; Loong, B.; Hanna, D.; Parkinson, B.; Loxton, D. Lifetime health costs of intimate partner violence: A prospective longitudinal cohort study with linked data for out-of-hospital and pharmaceutical costs. Econ. Model. 2022, 116, 106013. [Google Scholar] [CrossRef]
- United Nations Economic Commission for Latin America and the Caribbean. Violence Against Indigenous Women in Latin America; United Nations Economic Commission for Latin America and the Caribbean: Santiago, Chile, 2024. [Google Scholar]
- Wands, Z.E.; Mirzoev, T. Intimate Partner Violence Against Indigenous Women in Sololá, Guatemala: Qualitative Insights Into Perspectives of Service Providers. Violence Against Women 2022, 28, 150–168. [Google Scholar] [CrossRef] [PubMed]
- Matias, A.; Gonçalves, M.; Soeiro, C.; Matos, M. Intimate Partner Homicide in Portugal: What Are the (As)Symmetries Between Men and Women? Eur. J. Crim. Policy Res. 2021, 27, 471–494. [Google Scholar] [CrossRef]
- López Ricoy, A.; Andrews, A.; Medina, A. Exit as Care: How Motherhood Mediates Women’s Exodus From Violence in Mexico and Central America. Violence Against Women 2022, 28, 211–231. [Google Scholar] [CrossRef] [PubMed]
- Harikumar, S.; Mannam, V.; Mahanta, C.; Smitha, M.; Zaman, S. Interactive Map Using Data Visualization and Machine Learning. In Proceedings of the 2020 6th IEEE Congress on Information Science and Technology (CiSt), Essaouira, Morocco, 5–12 June 2021; pp. 104–109. [Google Scholar] [CrossRef]
- Talwalkar, S.; Crooks, C.L. Designing User-Centered Artificial Intelligence to Assist in Recovery from Domestic Abuse. In Proceedings of the 2023 Congress in Computer Science, Computer Engineering, & Applied Computing (CSCE), Las Vegas, NV, USA, 24–27 July 2023; pp. 375–377. [Google Scholar] [CrossRef]
- Rahman, R.; Khan, M.N.A.; Sara, S.S.; Rahman, M.A.; Khan, Z.I. A comparative study of machine learning algorithms for predicting domestic violence vulnerability in Liberian women. BMC Women’s Health 2023, 23, 542. [Google Scholar] [CrossRef] [PubMed]
- Stephanie, E.M.A.; Ruiz, L.G.B.; Vila, M.A.; Pegalajar, M.C. Study of violence against women and its characteristics through the application of text mining techniques. Int. J. Data Sci. Anal. 2024, 18, 35–48. [Google Scholar] [CrossRef]
- González, G.A.R.; Cantu-Ortiz, F.J. A Sentiment Analysis and Unsupervised Learning Approach to Digital Violence Against Women: Monterrey Case. In Proceedings of the 2021 4th International Conference on Information and Computer Technologies (ICICT), Kahului, HI, USA, 11–14 March 2021; pp. 18–26. [Google Scholar] [CrossRef]
- González-Prieto, A.; Brú, A.; Nuño, J.C.; González-Álvarez, J.L. Hybrid machine learning methods for risk assessment in gender-based crime. Knowl.-Based Syst. 2023, 260, 110130. [Google Scholar] [CrossRef]
- Campedelli, G.M. Explainable machine learning for predicting homicide clearance in the United States. J. Crim. Justice 2022, 79, 101898. [Google Scholar] [CrossRef]
- González, G.A.R.; Gabarrot, M.; Cantu-Ortiz, F.J. Understanding Violence Against Women in Digital Space from a Data Science Perspective: Full/Regular Research Papers-CSCI-ISNA. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 263–269. [Google Scholar] [CrossRef]
- Xu, X.; Ong, H.L.; Lai, P.; Ting, M.H.; Wong, W.M.; Chu, C.M. Understanding the Risk Factors of Spousal Violence Victimization Using Machine Learning and Network Approaches. J. Fam. Violence 2024, 39, 1581–1592. [Google Scholar] [CrossRef]
- Shifidi, P.P.; Stanley, C.; Azeta, A.A. Machine Learning-Based Analytical Process for Predicting the Occurrence of Gender-Based Violence. In Proceedings of the 2023 International Conference on Emerging Trends in Networks and Computer Communications (ETNCC), Windhoek, Namibia, 16–18 August 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, W. Ethnical Issues ofWomen’s Protection: Ending the Violent Crime Against Women in Indonesia. In Proceedings of the 2020 International Conference on Public Health and Data Science (ICPHDS), Guangzhou, China, 20–22 November 2020; pp. 60–63. [Google Scholar] [CrossRef]
- Lima, V.; de Oliveira, J.A. Identifying Risk Patterns in Brazilian Police Reports Preceding Femicides: A Long Short Term Memory (LSTM) Based Analysis. In Proceedings of the 2023 IEEE Global Humanitarian Technology Conference (GHTC), Radnor, PA, USA, 12–15 October 2023; pp. 144–150. [Google Scholar] [CrossRef]
- Forciniti, A.; Zavarrone, E. Data Quality and Violence Against Women: The Causes and Actors of Femicide. Soc. Indic. Res. 2024, 175, 1073–1097. [Google Scholar] [CrossRef]
- Rubén, D.; Uribe, R.; Sofía, M.; Huerta, M.; Patrocinio, I.E.; Burgos, C. 20 Informe Trimestral de Seguimiento a las Medidas de la AVG en Veracruz, Noviembre 2019–Junio 2020. Available online: https://www.gob.mx/cms/uploads/attachment/file/747590/20._Informe_AVGM_V.F._Nov_2019-Junio2020.pdf (accessed on 15 March 2024).
- Gong, Y.; Liu, G.; Xue, Y.; Li, R.; Meng, L. A survey on dataset quality in machine learning. Inf. Softw. Technol. 2023, 162, 107268. [Google Scholar] [CrossRef]
- Srivastava, S.; Shah, R.N.; Teodoriu, C.; Sharma, A. Impact of data quality on supervised machine learning: Case study on drilling vibrations. J. Pet. Sci. Eng. 2022, 219, 111058. [Google Scholar] [CrossRef]
- Schröer, C.; Kruse, F.; Gómez, J.M. A Systematic Literature Review on Applying CRISP-DM Process Model. Procedia Comput. Sci. 2021, 181, 526–534. [Google Scholar] [CrossRef]
- Lundén, N.; Bekar, E.T.; Skoogh, A.; Bokrantz, J. Domain Knowledge in CRISP-DM: An Application Case in Manufacturing. IFAC-PapersOnLine 2023, 56, 7603–7608. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, G.; Xu, Y.; Huang, L.; Zhang, C.; Xiao, S. FedDQA: A novel regularization-based deep learning method for data quality assessment in federated learning. Decis. Support Syst. 2024, 180, 114183. [Google Scholar] [CrossRef]
- INEGI. Subsistema de Información Demográfica y Social; INEGI: Aguascalientes, Mexico, 2024.
- Comisión Nacional para Prevenir y Erradicar la Violencia Contra las Mujeres. Centros de Justicia para las Mujeres|Comisión Nacional para Prevenir y Erradicar la Violencia Contra las Mujeres|Gobierno|gob.mx, 2021. Available online: https://www.gob.mx/conavim/acciones-y-programas/centros-de-justicia-para-las-mujeres (accessed on 13 May 2023).
- Choi, H.; Lee, S. Forensic analysis of SQL server transaction log in unallocated area of file system. Forensic Sci. Int. Digit. Investig. 2023, 46, 301605. [Google Scholar] [CrossRef]
- Dey, S.K.; Uddin, K.M.M.; Babu, H.M.H.; Rahman, M.M.; Howlader, A.; Uddin, K.A. Chi2-MI: A hybrid feature selection based machine learning approach in diagnosis of chronic kidney disease. Intell. Syst. Appl. 2022, 16, 200144. [Google Scholar] [CrossRef]
- Pinder, J.P. Chapter 9—Simulation fit and significance: Chi-square and ANOVA. In Introduction to Business Analytics Using Simulation, 2nd ed.; Pinder, J.P., Ed.; Academic Press: Cambridge, MA, USA, 2022; pp. 273–325. [Google Scholar] [CrossRef]
- Tugnait, J.K. Sparse-Group Lasso for Graph Learning From Multi-Attribute Data. IEEE Trans. Signal Process. 2021, 69, 1771–1786. [Google Scholar] [CrossRef]
- Chen, Z.; Ma, W.; Li, Y.; Guo, W.; Wang, S.; Zhang, W.; Chen, Y. Using machine learning to estimate the incidence rate of intimate partner violence. Sci. Rep. 2023, 13, 5533. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Chang, L.; Liu, T. Predicting Student Performance in Online Learning Using a Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 12th IFIP TC 12 International Conference, IIP 2022, Qingdao, China, 27–30 May 2022; Shi, Z., Zucker, J.D., An, B., Eds.; Springer: Cham, Switzerland, 2022; pp. 508–521. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).