By drawing upon the principles of AI, ML, Intelligent Marketing, and One-to-One Marketing, we provide a proposal for a scalable MLaaS cloud platform that is tailored for marketing purposes and utilises MLaaS. This platform facilitates the seamless integration of relational marketing-oriented modules and encompassing various functionalities.
The One-2-One Product Recommendation, Churn Prediction, and Send Frequency Prediction features were built as separate modules.
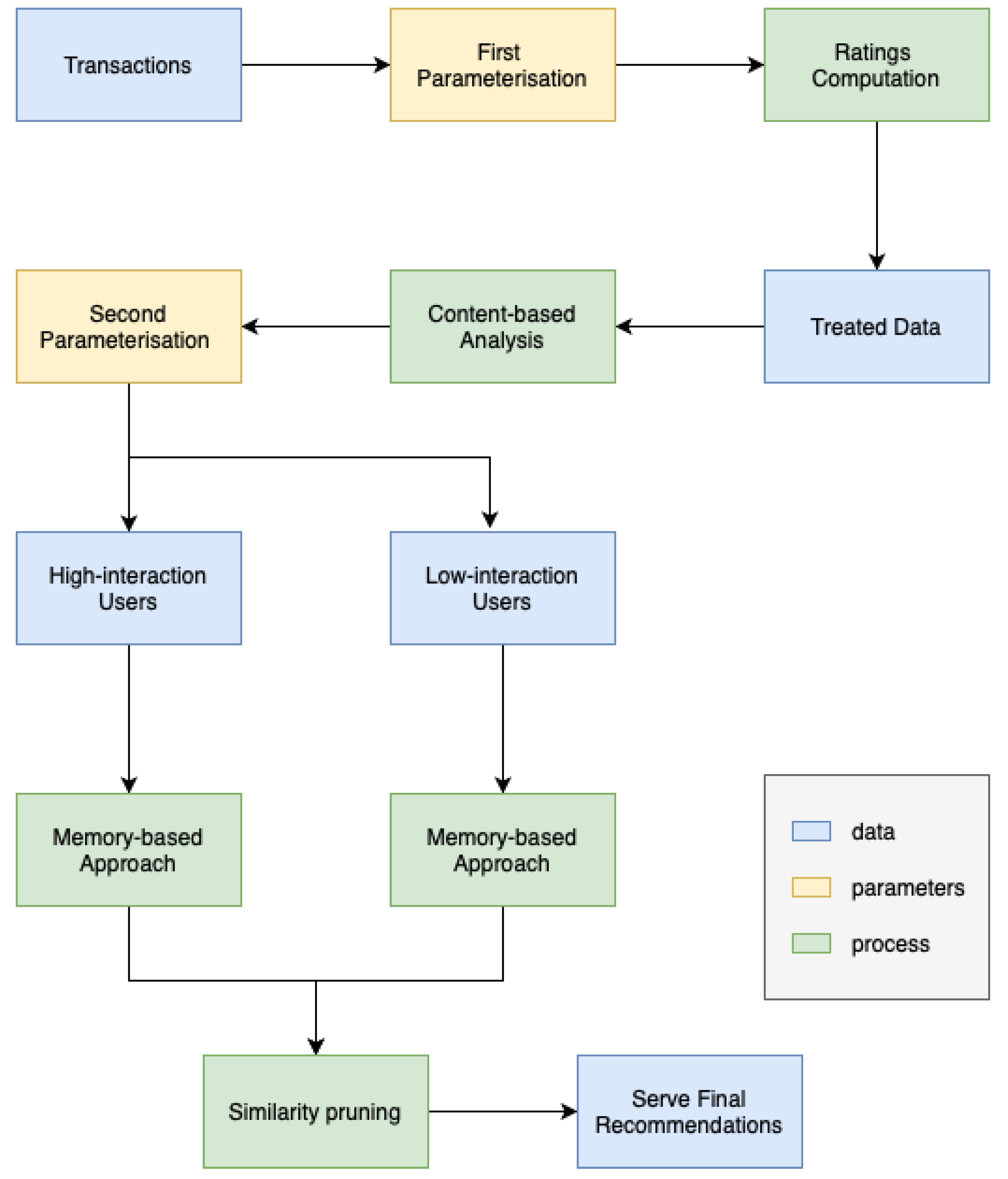
This section provides a comprehensive overview of the proposed architecture for MLaaS, along with a description of each module. The discussion encompasses aspects such as input data, Machine Learning algorithms, and output results.
3.1. MLaaS System Architecture
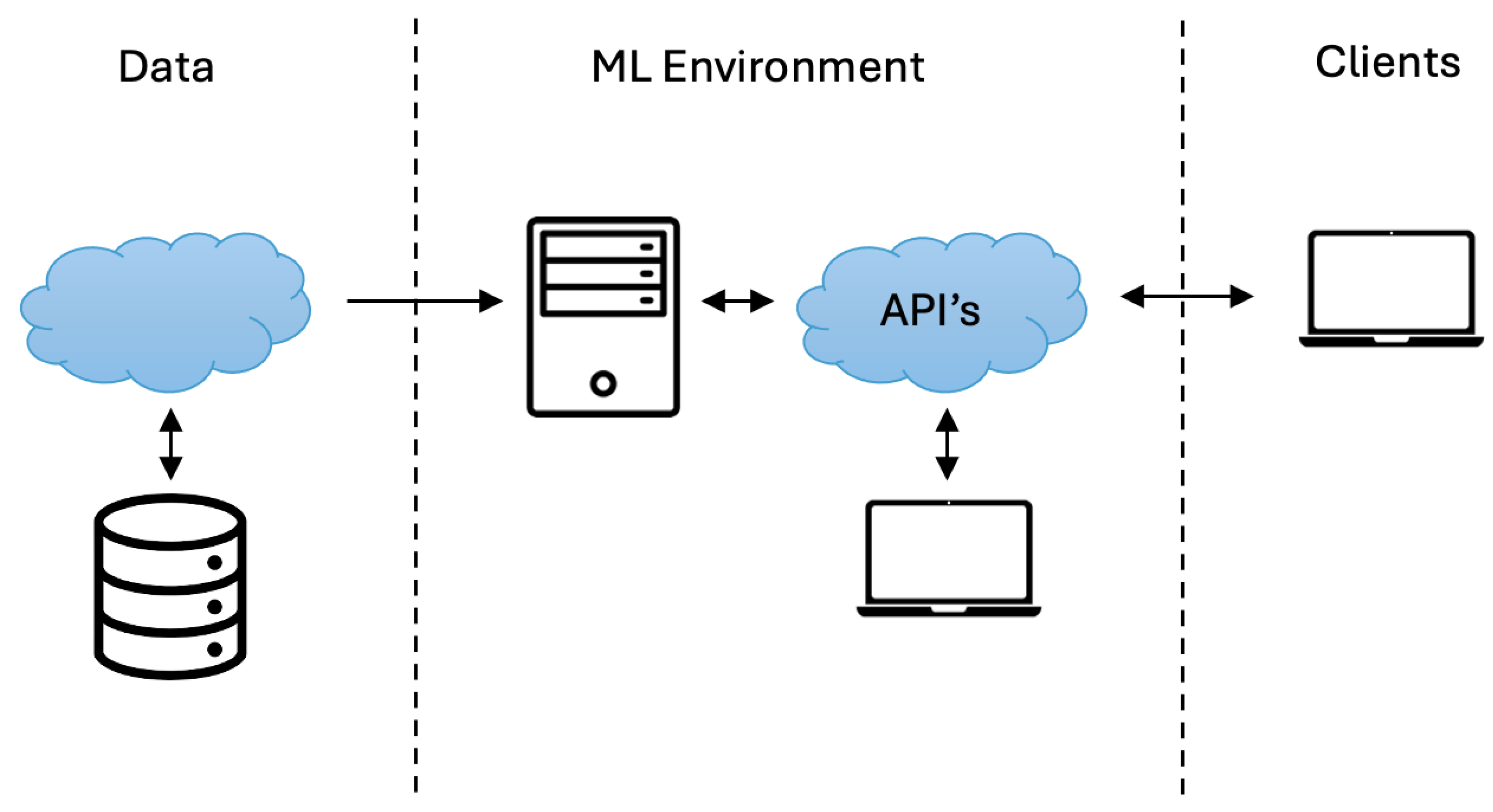
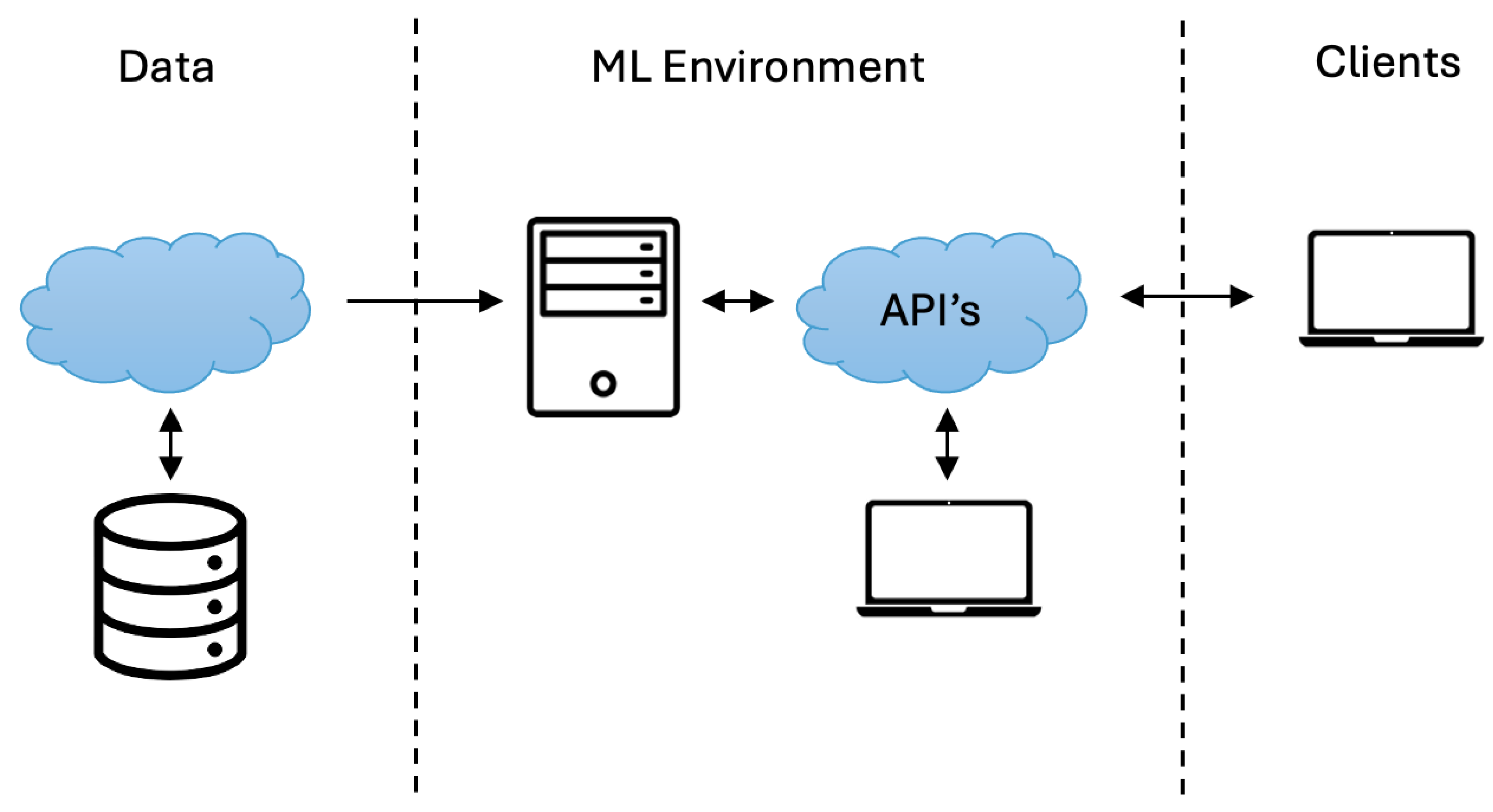
The design of the system’s general architecture encompasses the integration between the MLaaS cloud platform and the various modules. The optimisation of the interaction between the MLaaS platform and the modules was conducted to ensure effective functioning in a wide range of challenging scenarios, aiming to fulfill all functional needs and exceed all nonfunctional criteria.
To guarantee platform scalability, the overall architecture was delineated. The generation of containers for models is facilitated by each module, resulting in the creation of Docker images [
25]. Additionally, an external API has been built to serve as an intermediary between the user and the internal API operations. The construction and development strategy of the MLaaS cloud platform described in the application required modifications. It was determined that it was crucial to initiate preliminary developments of the different modules through pilot client proofs-of-concept.
Therefore, partnerships were established with pilot clients in the Retail and e-Commerce industries, and the necessary technological infrastructure was developed to facilitate the proof of concept being investigated. This infrastructure primarily focused on four key stages: data collection, data analysis, model development, and model deployment.
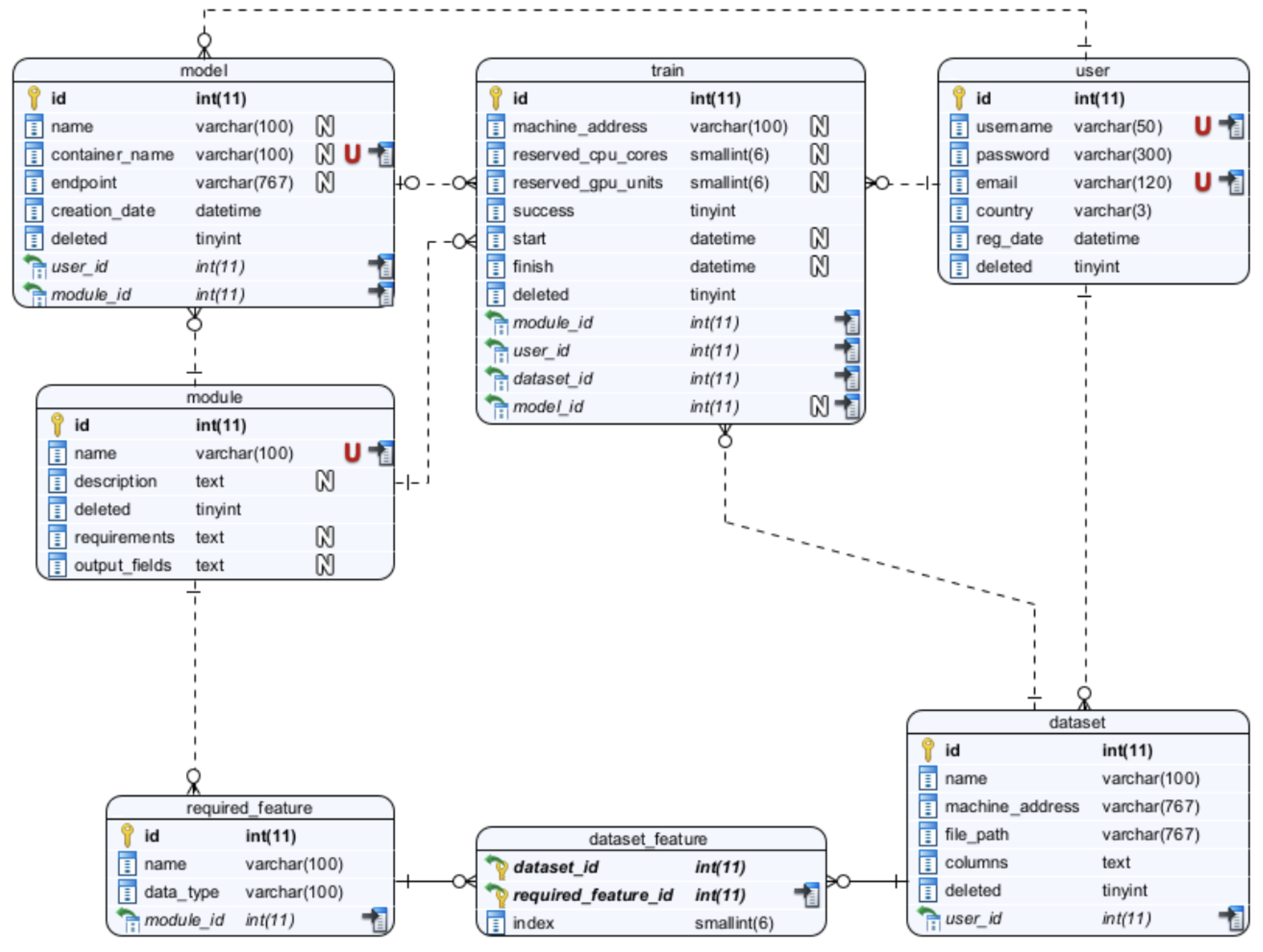
A framework was devised to facilitate the acquisition and analysis of data from a selected group of pilot clients. The framework encompassed a system of interlinked tables, methods for data adaption, and the incorporation of fundamental feature lists derived from the modules to be constructed. The Entity Diagram for the MLaaS cloud platform is depicted in
Figure 2. To delineate the MLaaS cloud platform, seven entities were considered. The attributes associated with the user entity encompass the username, password, email, country, date of registration, and a soft delete field. However, it is feasible to include additional information and extend support for hard deletes. The user is required to provide datasets with a minimum of two essential attributes: a name and a corresponding file location. The representation of functionalities enabled by the cloud platform is significantly influenced by the concept of modules. In the context of this study, the modules encompass Churn Prediction, One-2-One Product Recommendation, and Send Frequency Prediction. Nevertheless, it is important to note that the suggested platform exhibits adaptability and versatility. The primary significance of this entity diagram proposal stems from the essential characteristics mandated for each module. These qualities establish the connection between the datasets and the modules as well as the need for storing the training data and the resulting models formed by the modules. The acquisition of these models represents the final purpose of this proposal. To facilitate the training of the modules and the generation of models, it is important to retain certain information within the ‘train’ entity. The trained models are stored within containers and are associated with an endpoint that indicates the location at which the trained model may be accessed for consumption.
The research team obtained and analysed structured data from the pilot client(s). To enhance this procedure, the development of data reports with interactive visuals was undertaken. Remedial actions were undertaken to address any discrepancies observed at the structural level. The implementation of core data analysis techniques was contingent on the specific module being addressed, with the aim of facilitating expedient and optimal examination of data pertaining to newly acquired users. Additional analysis was deemed necessary depending on the specific domain of operation.
The model development process was inspired by the CRoss Industry Standard Process for Data Mining (CRISP-DM) [
26], which is a process model that serves as the base for a data science process. It has six sequential phases:
Business Context by acquiring a thorough comprehension of the organisation’s goals and defining the problem to be solved.
Data Exploration by examining and assessing the quality and relevance of available and required data.
Data Preparation by processing and organising data for modeling purposes.
Model Development by identifying and implementing suitable machine learning techniques or algorithms.
Model Evaluation by comparing and assessing the performance of various models to identify the one that most closely aligns with business objectives.
Model Deployment by ensuring that stakeholders are able to effectively access and utilise the insights generated by the selected model.
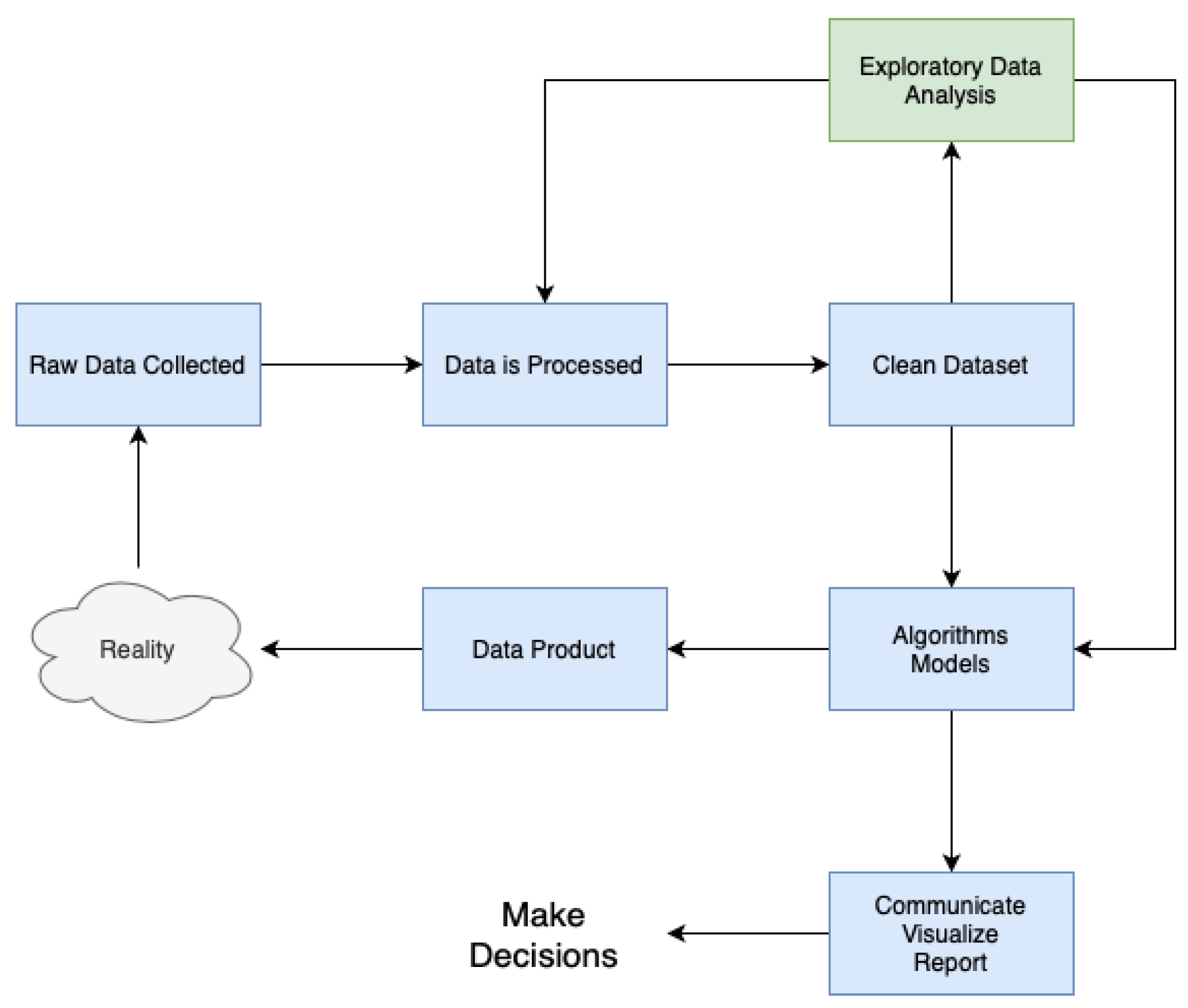
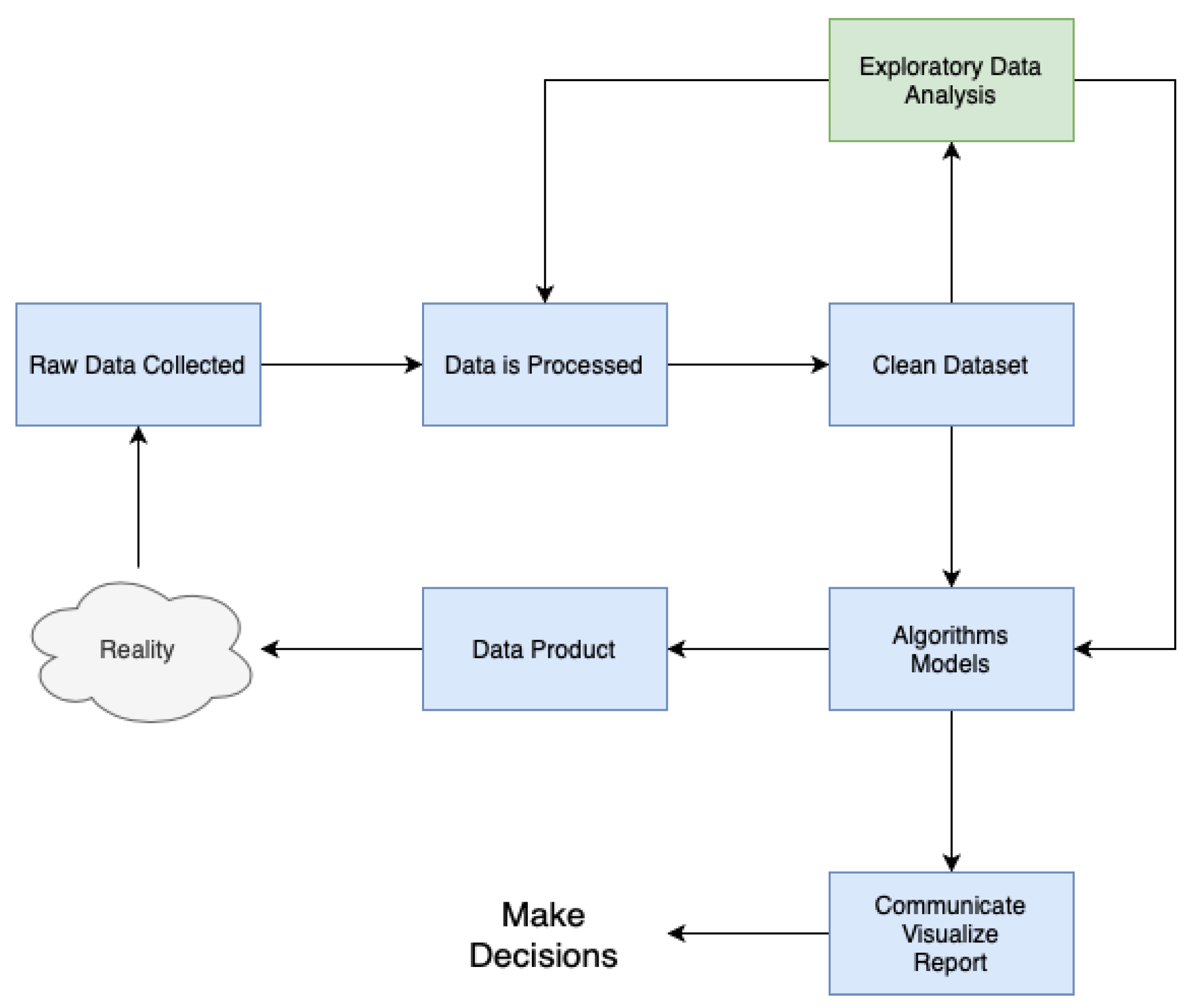
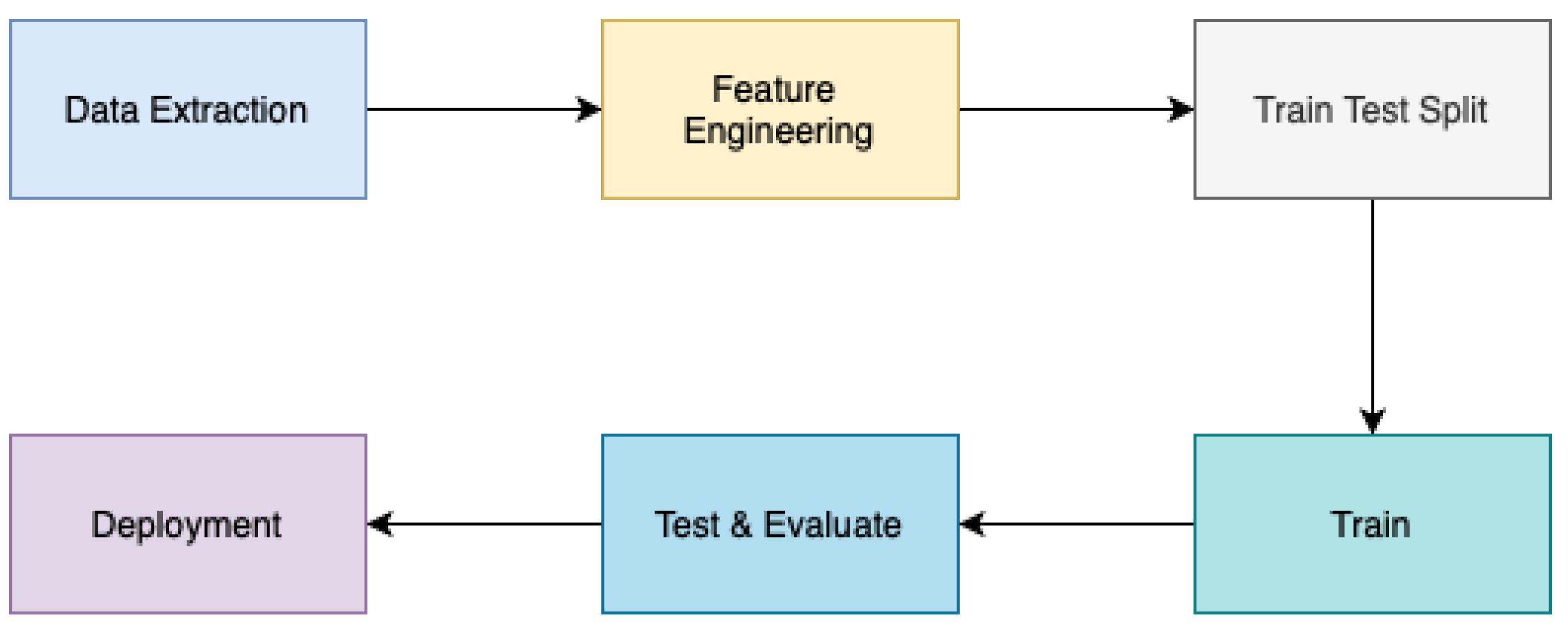
As depicted in
Figure 3, the implementation of all modules adhered to a methodology that closely resembled CRISP-DM. The approach commenced by obtaining unprocessed data from multiple sources, including a wide range of forms and architectures. Following this, the gathered data underwent meticulous processing and cleansing methods, with the objectives of correcting anomalies, addressing missing values, and standardising formats.
After the completion of data preprocessing, a comprehensive exploratory data analysis (EDA) phase was initiated, which played a crucial role in improving the dataset’s quality and integrity. Throughout this stage, a range of statistical methodologies, visualisation software, and data mining algorithms were utilised to reveal patterns, detect trends, and identify possible correlations within the dataset. The knowledge obtained from this initial step of exploration guided our future modelling endeavours while enhancing our overall comprehension of the fundamental data attributes.
The utilisation of advanced modelling approaches, which included a wide range of machine learning algorithms and statistical methods, is a key aspect of our methodology. The models are trained using the dataset and utilising the knowledge acquired during the exploratory analysis stage. Through continuous improvement and verification, these models develop to accurately represent the fundamental patterns and connections present in the data.
The final outcome of our methodology is the development of practical data products which function as concrete representations of the analytical insights obtained from the modelling process. These data products enhance the ability to communicate, visualise, and report findings in a smooth manner, enabling stakeholders to make educated decisions based on empirical evidence.
Our methodology encompasses a comprehensive approach to making decisions based on data. This strategy involves the smooth integration of several stages, including data collection, preprocessing, exploratory analysis, modelling, and deployment. The ultimate goal is to provide actionable insights.
APIs have been designed to enhance development and optimise performance through the implementation of prediction gathering routines, retraining mechanisms, role-based access restriction mechanisms, and active API documentation. The architecture employed to enhance service availability and efficiency is based on the Open API Specification (
https://spec.openapis.org/oas/v3.1.0 (accessed on 30 October 2023)).
The underlying architecture of the MLaaS cloud platform was intentionally built to be independent of any specific machine learning model. This facilitates the optimisation and efficacy of the system’s administration and improvement. Additionally, it facilitates the development of categorisation models that incorporate several hierarchical levels, enabling tailoring to specific business domains. In the context of recommendation systems, for instance, it is feasible to employ a conventional model known as collaborative filtering as well as more intricate models that offer enhanced capabilities for customisation and adaptation.
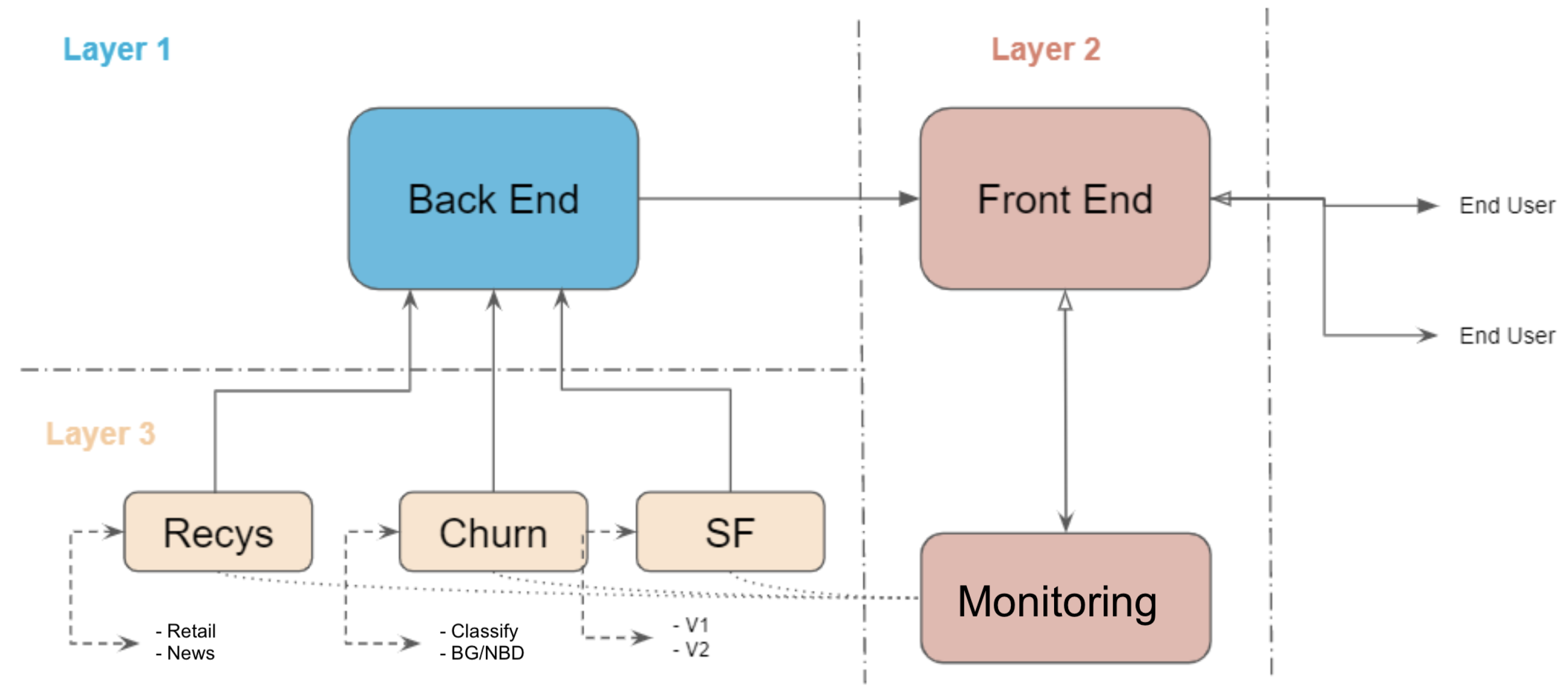
The proposed MLaaS platform prototype is structured into three separate layers, as illustrated in
Figure 4. Each layer plays a vital role in ensuring the smooth operation and scalability of the system.
Layer 1—Back-end: This layer forms the fundamental layer of the platform responsible for managing the complex message queuing systems that enable communication across various components of the system. The primary responsibilities of this layer are to effectively handle the management of connections to client databases, facilitate interaction with the specific machine learning models, and ensure smooth transmission of data and instructions across the platform’s entire system. The back-end plays a crucial role in ensuring the resilience and dependability of the fundamental architecture of the MLaaS platform by abstracting the difficulties associated with data management and model integration.
Layer 2—Front-end: The front-end layer is situated at the interface between the end-users and the underlying MLaaS functionality. It comprises a wide range of configurations and functionalities that are focused on the user. By utilising user-friendly interfaces and interactive dashboards, end-users are provided with exceptional access to the performance indicators of specific modules. This enables them to make informed decisions based on facts. Moreover, the front-end makes it easy for users to choose modules, allowing them to easily switch between different features such as recommendation systems or churn prediction modules. The front-end layer plays a crucial role in facilitating the realisation of the transformative capabilities of MLaaS for a wide range of stakeholders by placing emphasis on user experience and accessibility.
Layer 3—ML Modules: This layer contains the complex machinery of the machine learning models, and is specifically designed to meet various business needs and analytical problems. The purpose of this layer is to function as a storage and management system for a wide range of models that have been carefully designed to provide exceptional performance and precision. ML modules smoothly integrate into the broader MLaaS ecosystem following the communication requirements set by the back-end layer. This ensures interoperability and cohesiveness across different capabilities. Furthermore, the modular structure of Machine Learning modules allows for exceptional scalability and customizability, permitting organisations to adjust and develop their analytical capabilities in accordance with changing business requirements and technology trends.
The demarcation of these three strata highlights the architectural sophistication and versatility inherent in the proposed MLaaS platform, establishing the groundwork for revolutionary advancements and enduring expansion in the data-centric environment. By employing careful planning and precise implementation, every layer is seamlessly integrated to achieve the broader goal of making sophisticated analytics accessible to everyone and enabling organisations to fully utilise machine learning for a competitive edge.
Generating real-time outputs from a model, such as product recommendations poses challenges, and requires the presence of individual user databases. To mitigate the potential cost implications associated with acquiring data pertaining to the dataset to be predicted, a proposed solution involves training a model that generates predictions based on user-supplied data within the dataset. These predictions are subsequently stored in a centralised database until they are specifically requested by the relevant user. The reciprocal relationship between processing power and storage capacity contributes to the mitigation of this inherent system limitation.
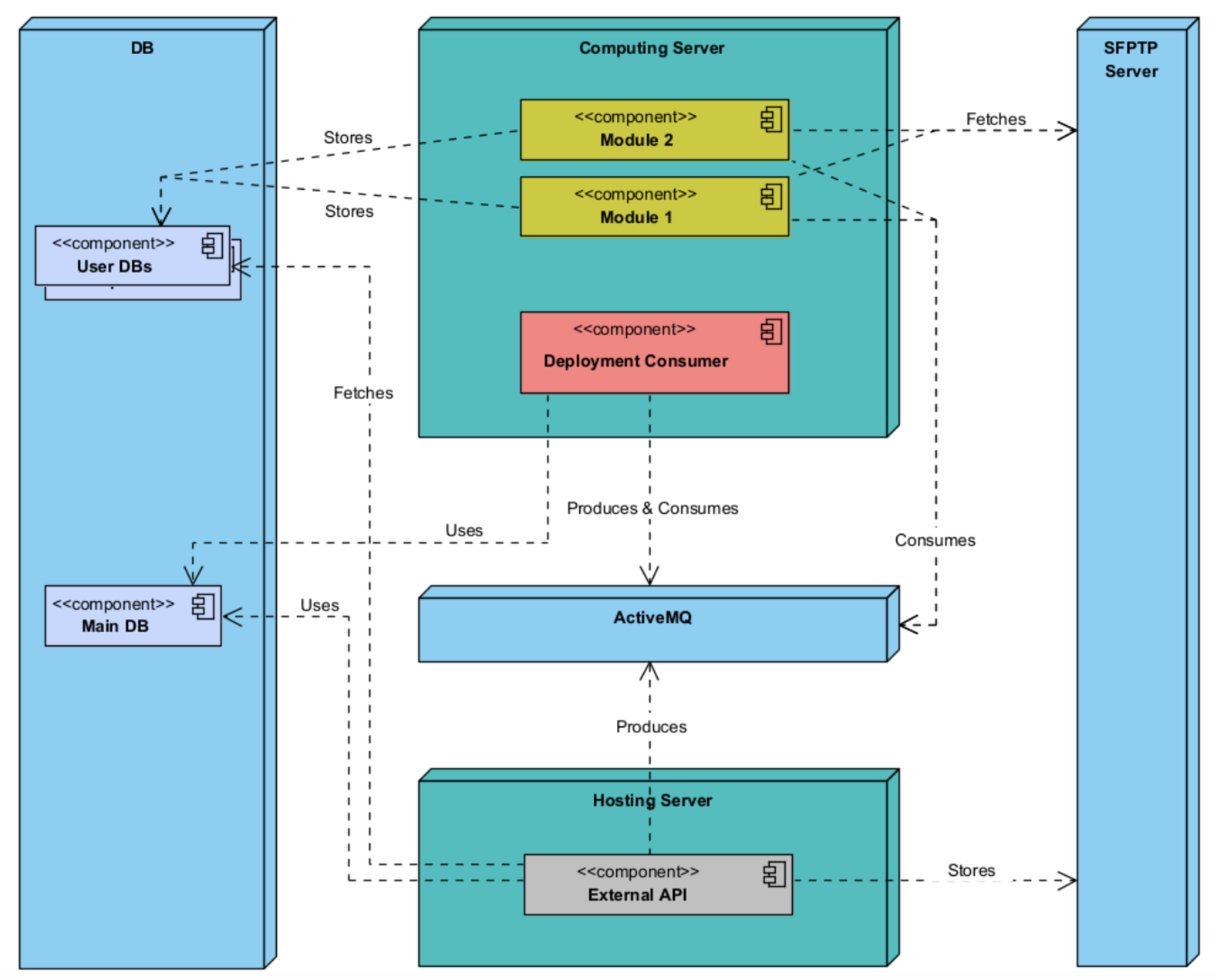
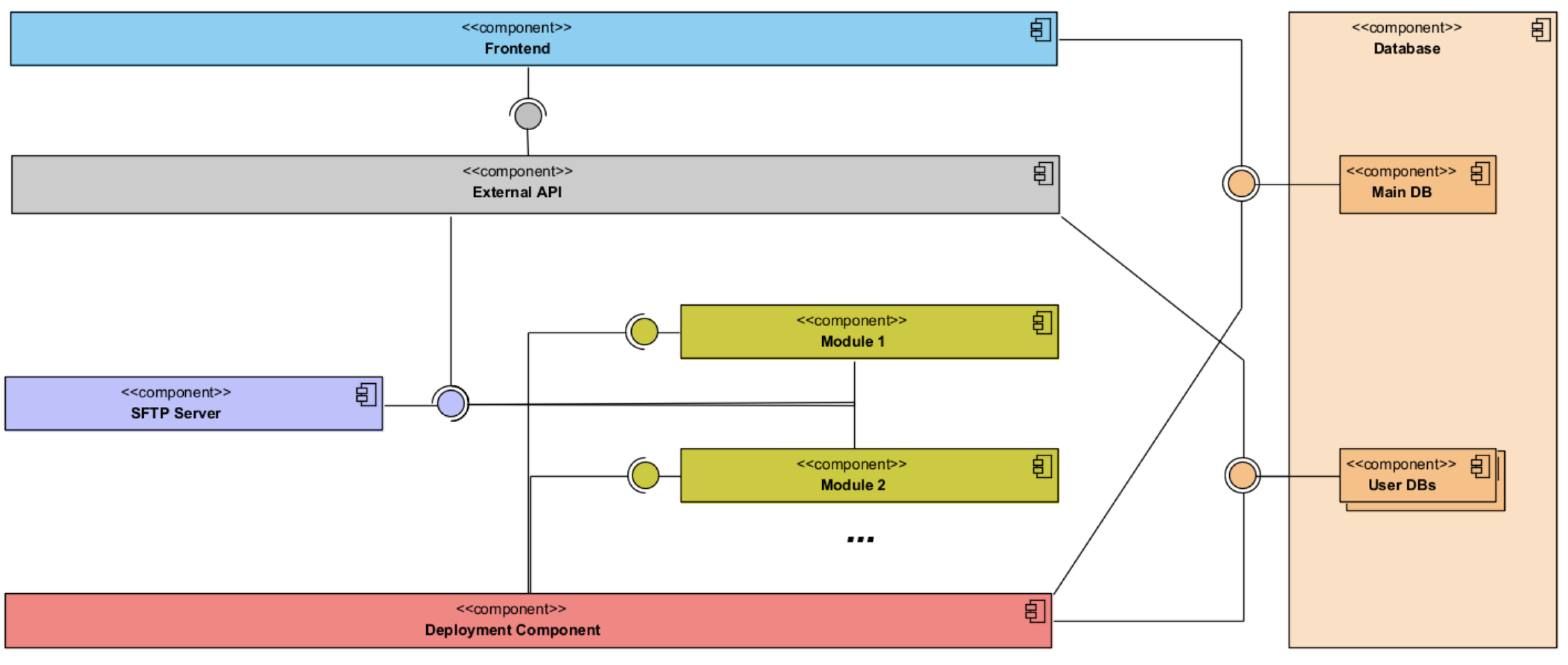
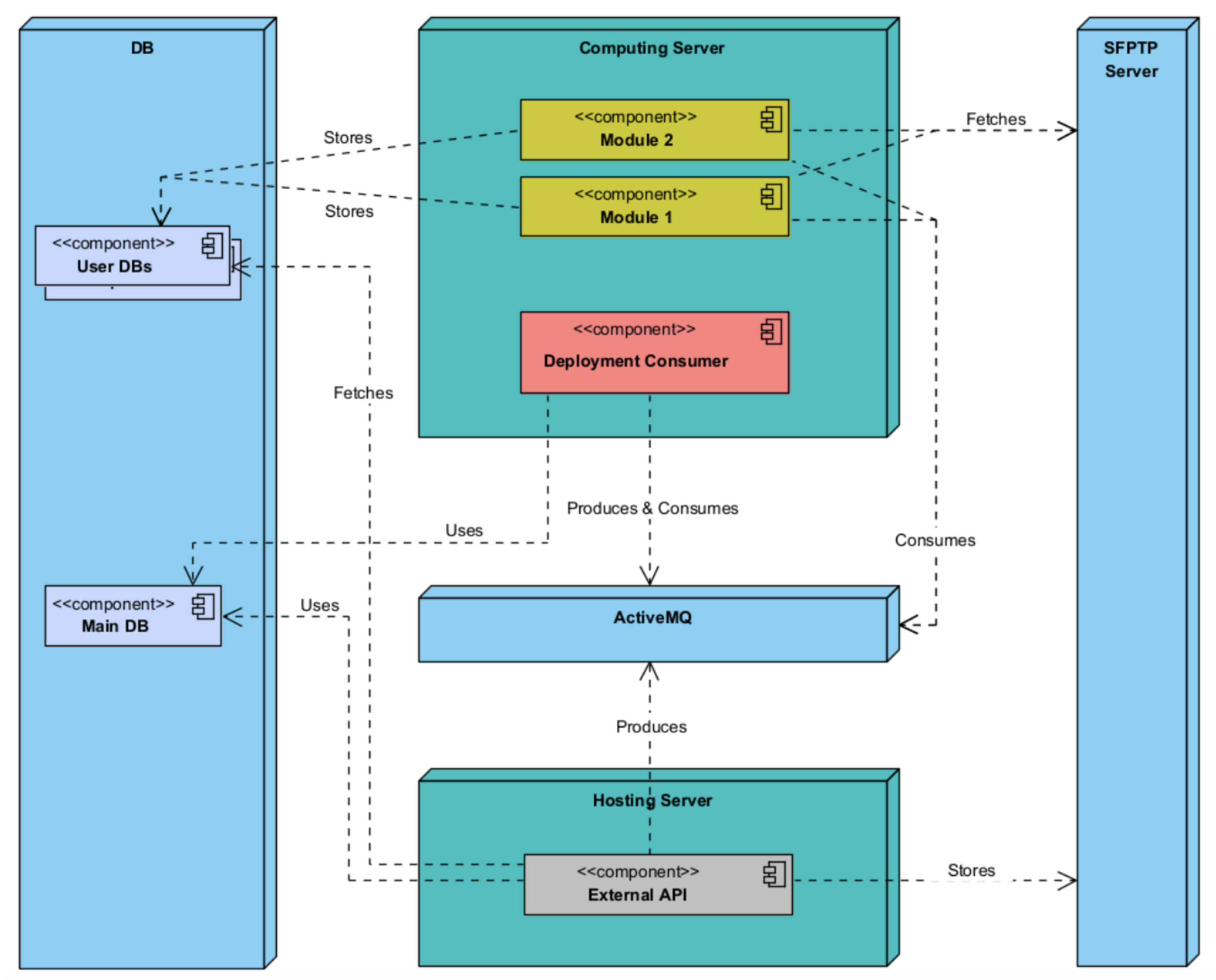
Figure 5 presents the components diagram, and
Figure 6 depicts the suggested deployment of the project’s various components in light of this consideration.
The External API component of the platform will be segregated on a separate server, establishing a security barrier between it and the other solution components. The training machine will then provide access to the modules and deployment/management component, as these components are heavily reliant on the server’s computing capacity. The optimal placement of the remaining components, including the DB, Secure File Transfer Protocol (SFTP) server, and ActiveMQ server, has not been specifically determined; however, it is recommended that the isolation of the External API on the hosting server be enhanced for maintenance and security purposes. Additionally, if feasible, deploying the DB on a separate server with dedicated disk access should be taken into account to further enhance security measures. The proposed system architecture exhibits modularity and decoupling, aligning with the software development concepts of Low Coupling and High Cohesion.
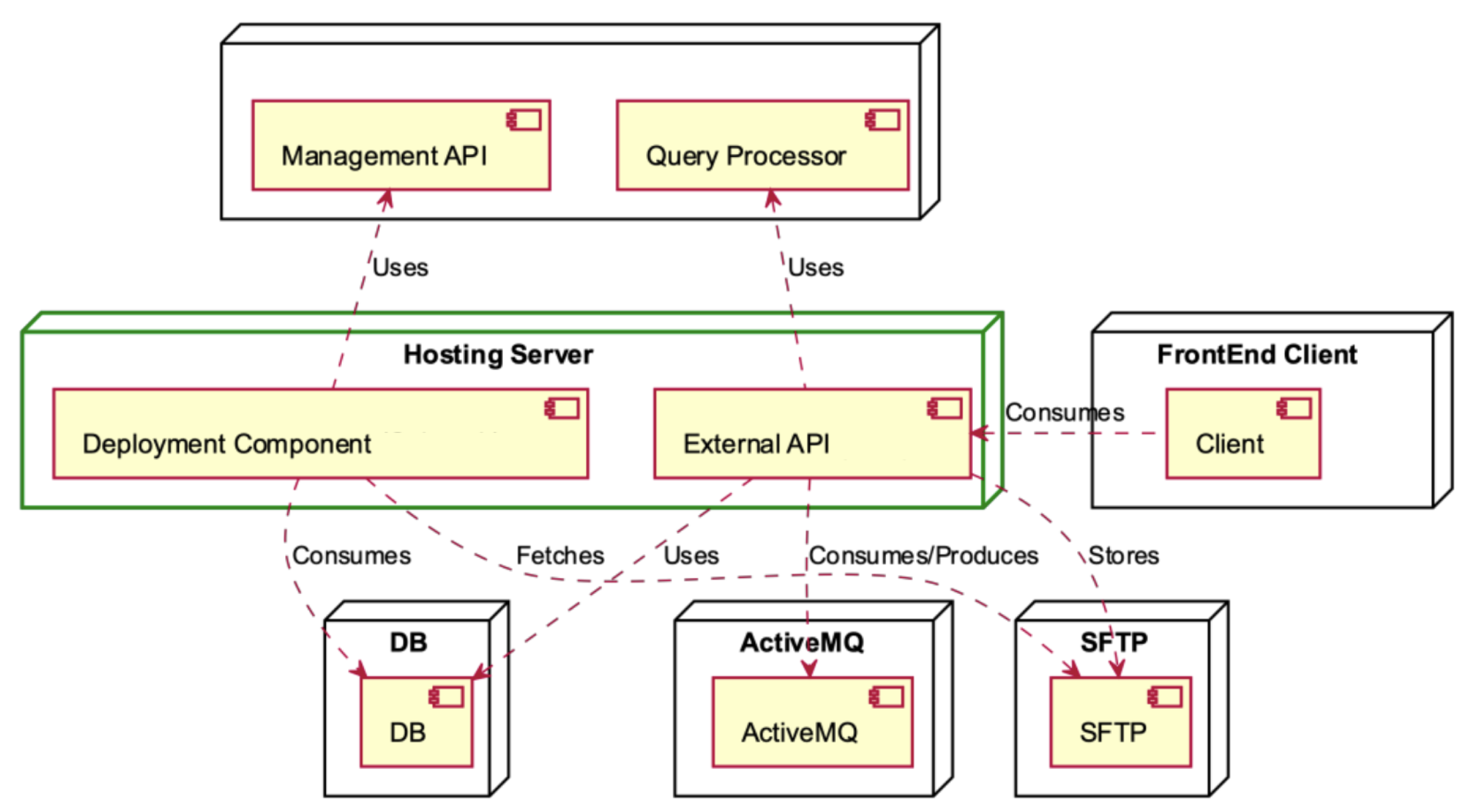
The Hosting Server is comprised of two main components, namely, the Deployment Component and the External API (see
Figure 7). In the initial setup, the Management API is employed to interface with the database and fetch data from the SFTP server. This integration streamlines data access operations, ensuring efficient retrieval processes within the system. The front-end client interacts with the External API, which relies on the Query Processor and the DB for data retrieval and storage. This interaction facilitates seamless communication between the front-end and the underlying data processing components, ensuring efficient handling of data within the system. Data are stored in the SFTP while being consumed and are produced through the utilisation of ActiveMQ, ensuring efficient data flow and management within the system.
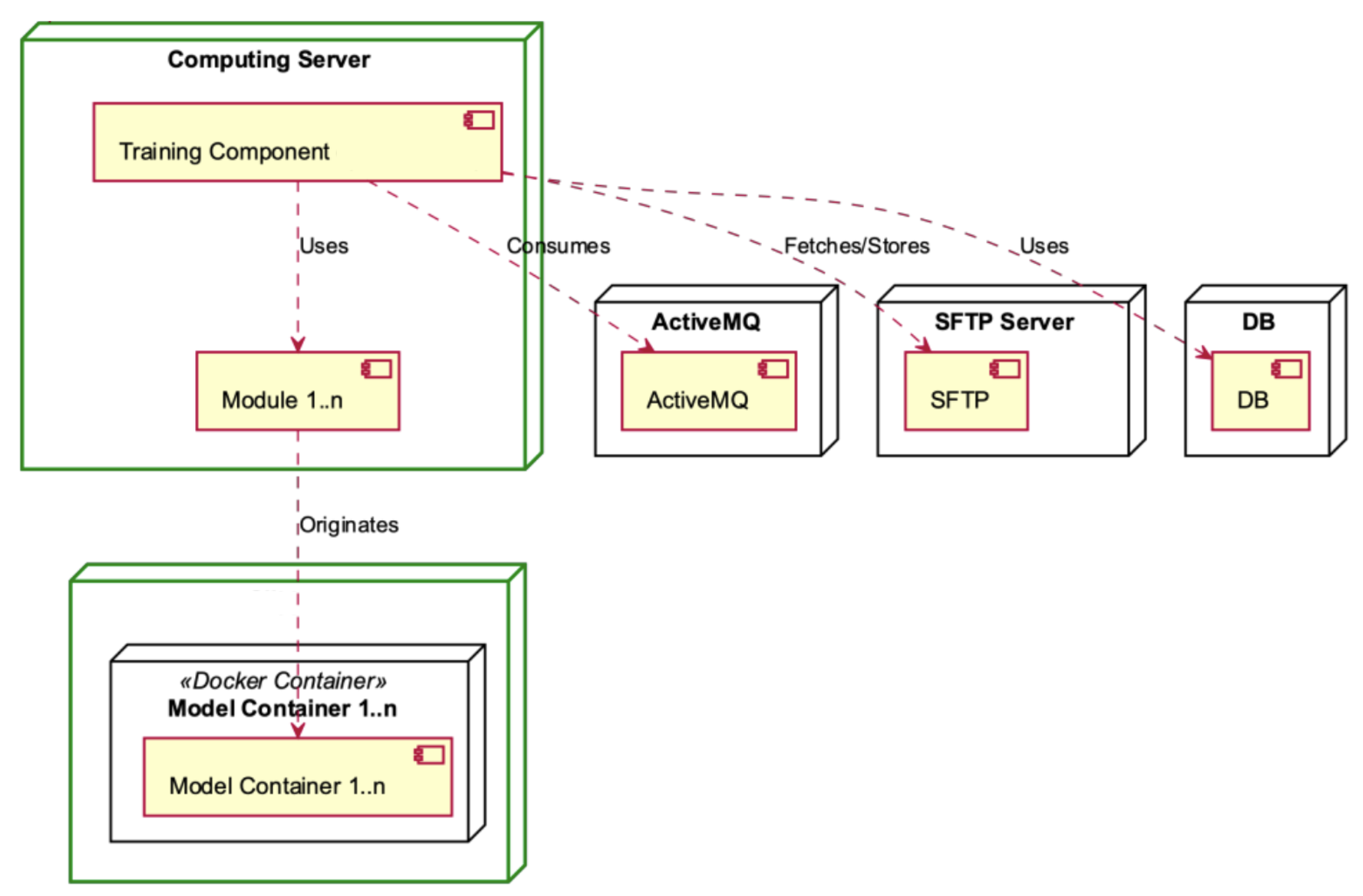
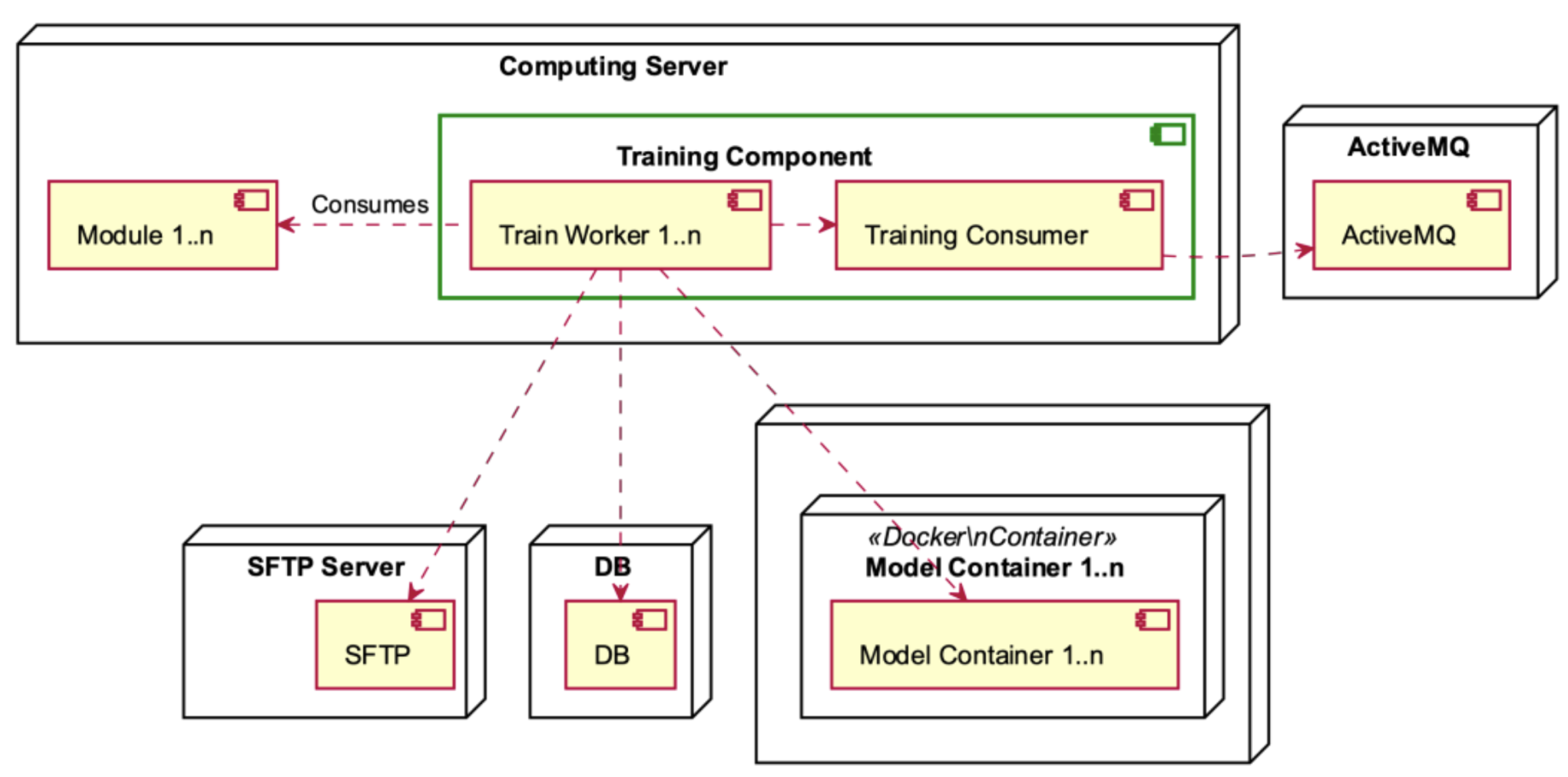
The Computing Server consists of the Training Component, which utilises many different modules (see
Figure 8). The Training Component assumes a crucial role by retrieving data from the ActiveMQ messaging system. Following this, it coordinates the transmission of this data to the SFTP Server for the purpose of secure storage, utilising the strong functionalities of a database for subsequent analysis. In the context of this framework, every module within the Training Component plays a role in producing one or more model containers. These containers include significant insights and predictive capabilities that are crucial for the system’s functionality and flexibility.
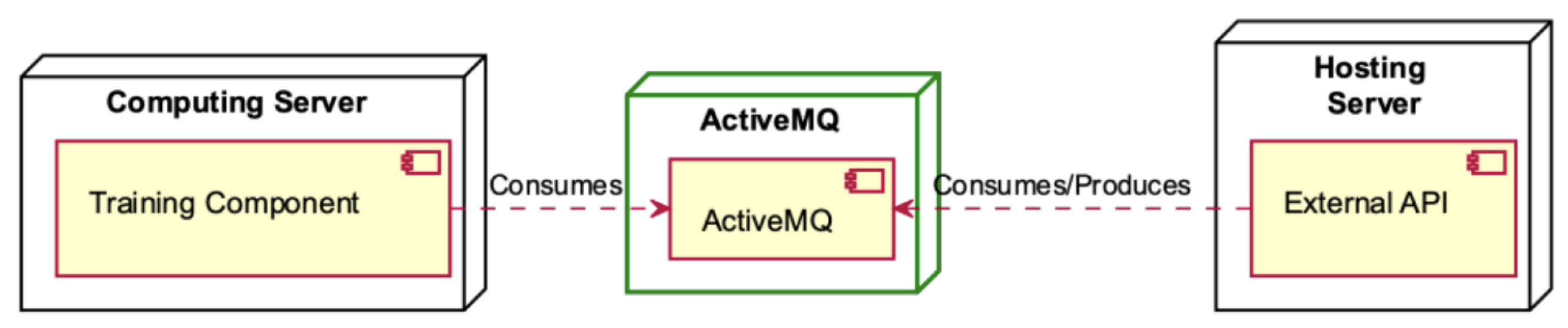
The Training Component, hosted within the Computing Server, interfaces with the ActiveMQ component for data consumption (refer to
Figure 9). Simultaneously, the External API within the Hosting Server serves a dual role, both consuming and producing data through the ActiveMQ component, facilitating seamless data exchange within the system architecture.
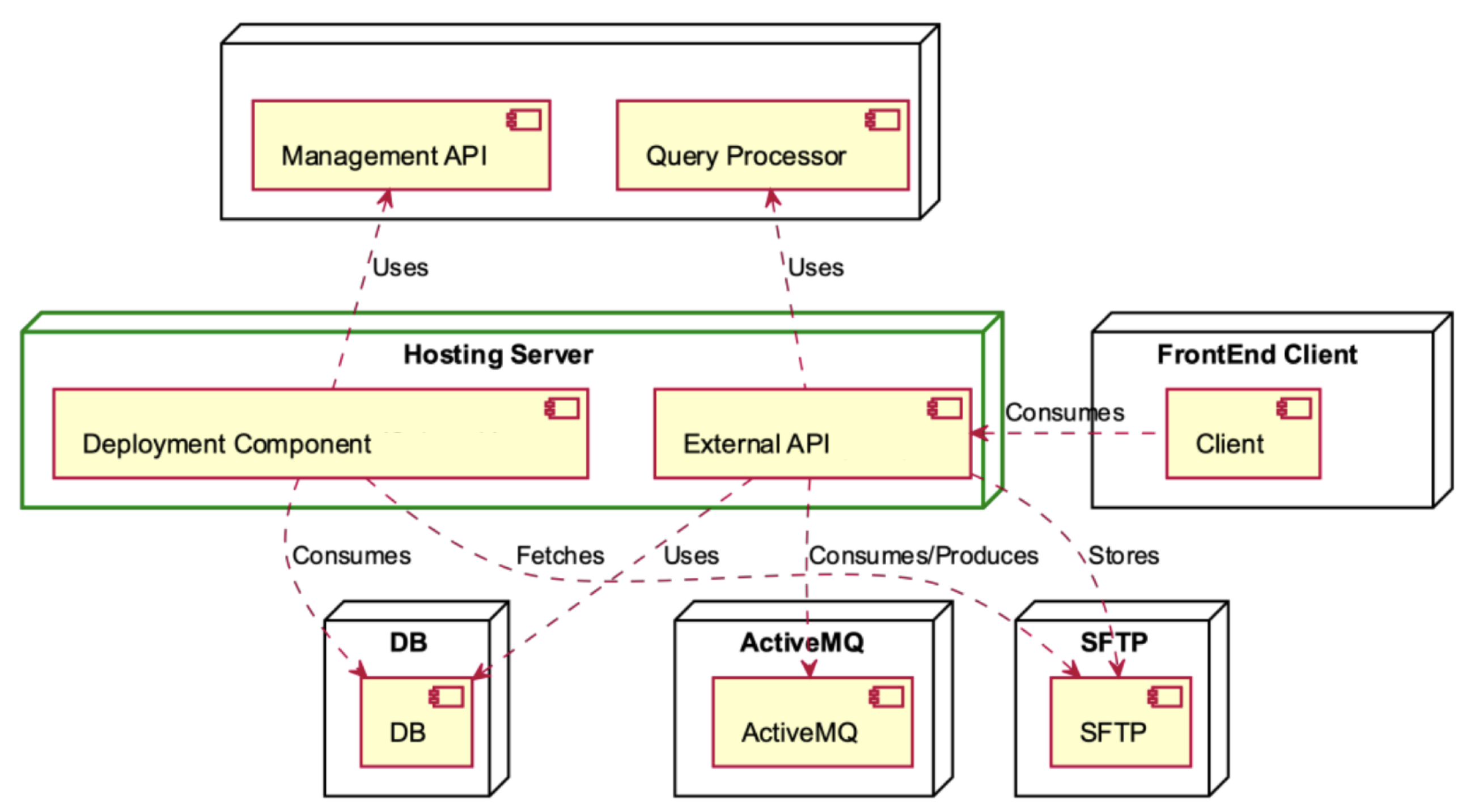
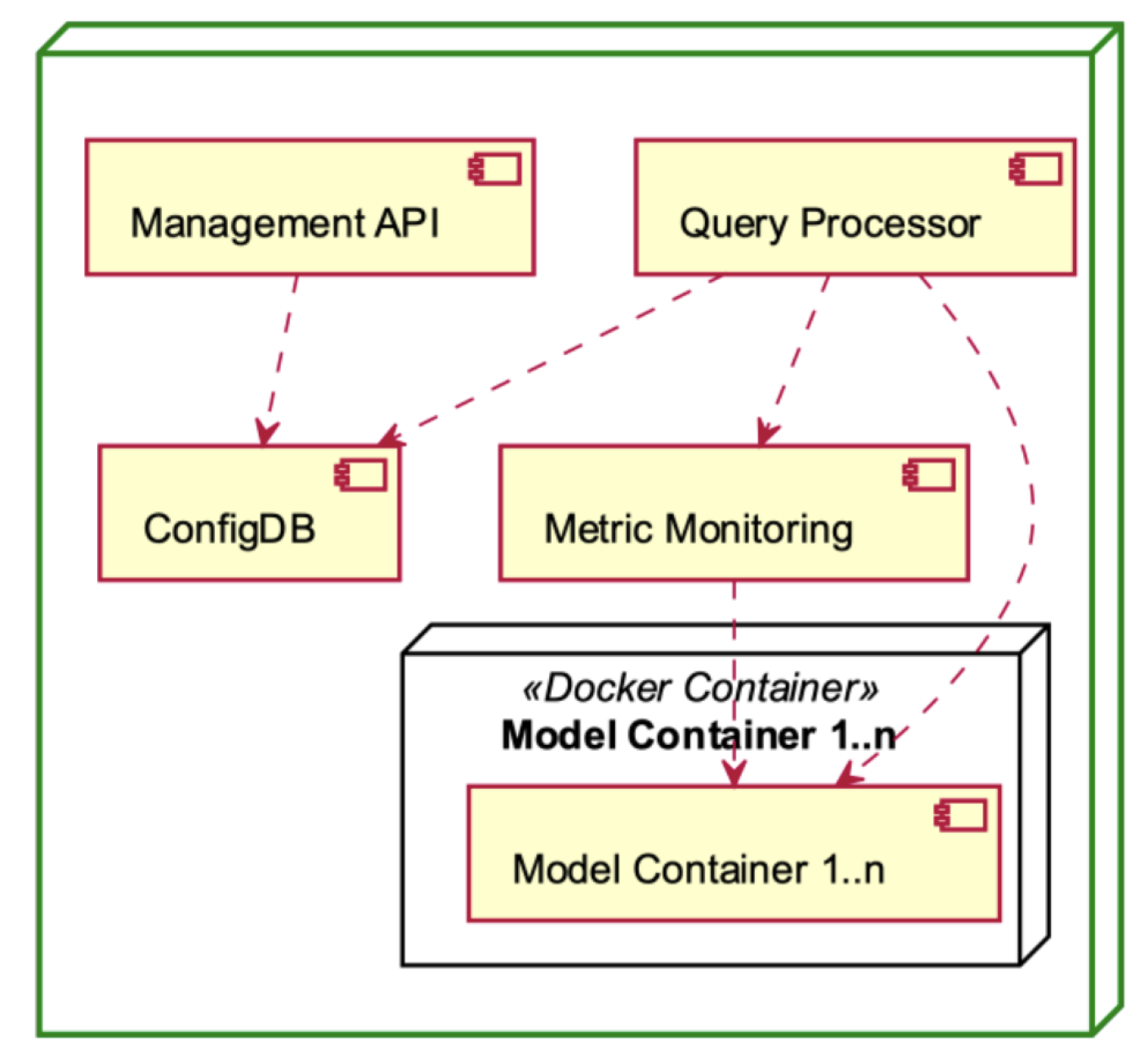
The Management Components, depicted in
Figure 10, serve as the operational backbone of the MLaaS platform. The Management API enables the delegation of external communication and control, while the Query Processor is responsible for executing data processing duties. Configuration settings are centralised in ConfigDB, while system performance is tracked in real time using Metric Monitoring. The Docker container encapsulates each model, providing both modularity and scalability. Collectively, these constituent elements facilitate effective functioning, resilient performance, and optimised resource allocation inside the MLaaS framework.
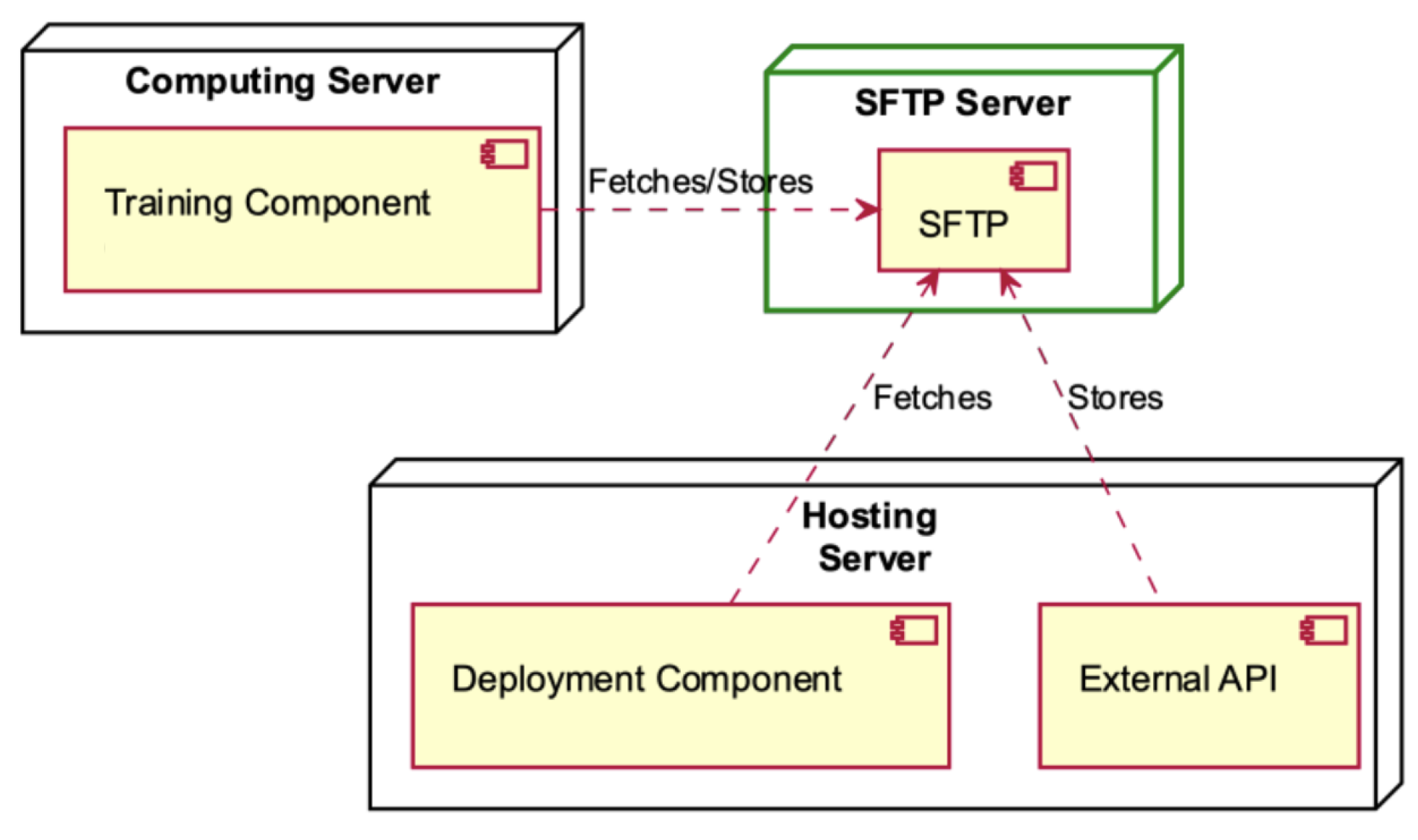
The SFTP Server establishes communication with the Computing and Hosting servers (see
Figure 11). The Training Component, which is hosted by the Computing Server, retrieves data and stores it in the SFTP Server. Within the context of the Hosting Server, the deployment component is responsible for retrieving data from the SFTP, while the external API is tasked with storing information in the SFTP server.
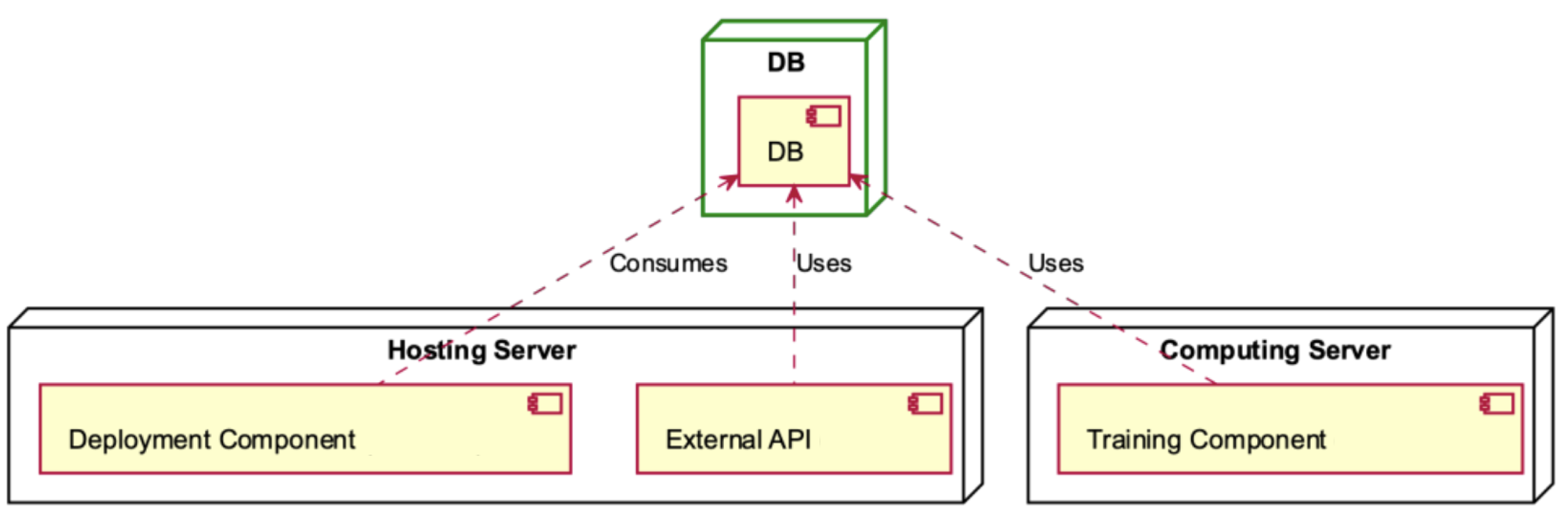
The Deployment Component of the Hosting Server utilises the DB component (
Figure 12), which is also used by the External API of the Hosting Server and the Training Component contained in the Computing Server.
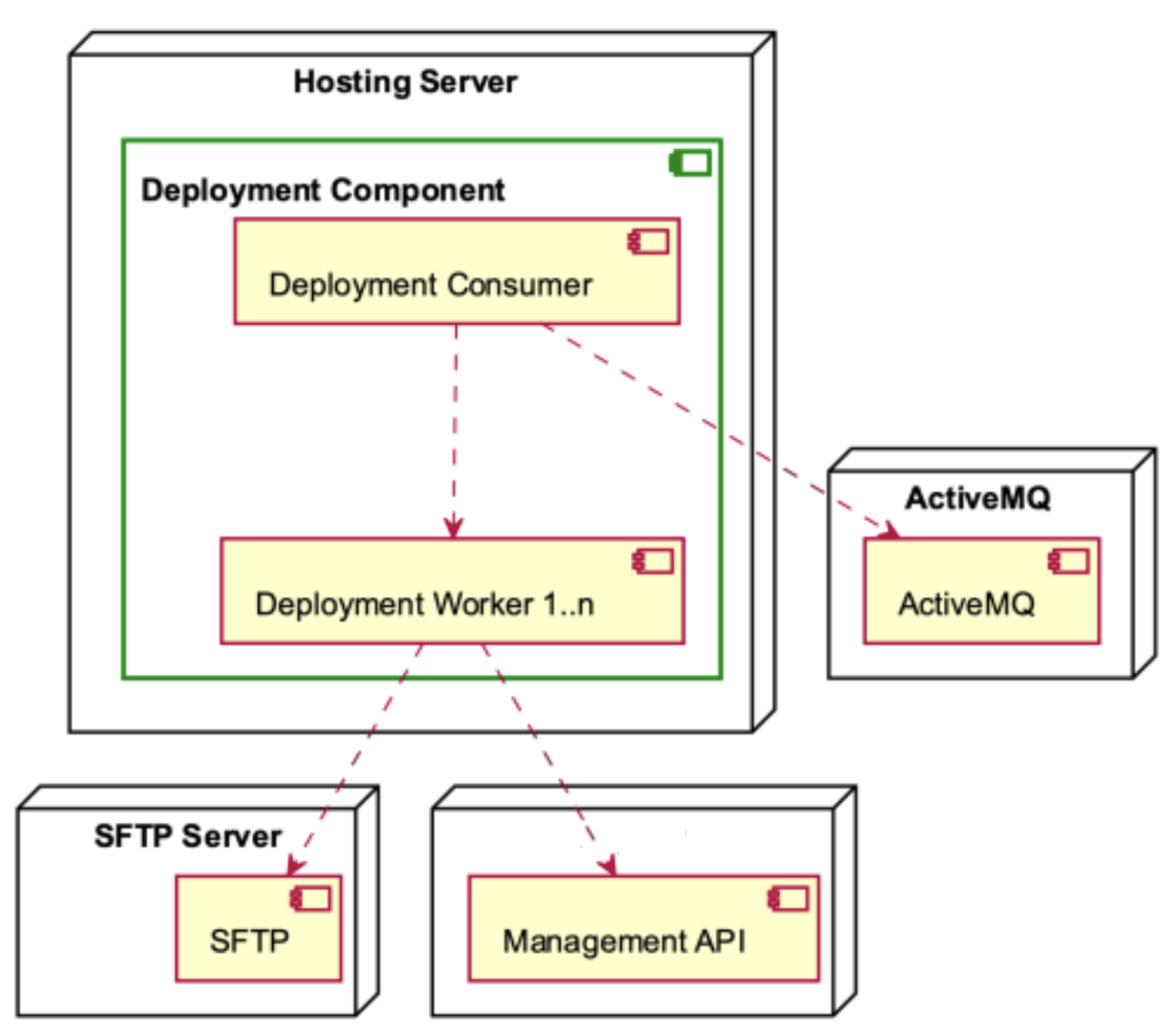
The Deployment Component, as depicted in
Figure 13, is hosted by the Hosting Server. It consists of the Deployment Consumer and many Deployment Workers. The Deployment Consumer engages in interactions with the ActiveMQ component and produces workers. The Deployment Workers engage in interactions with both the SFTP Server and the Management API.
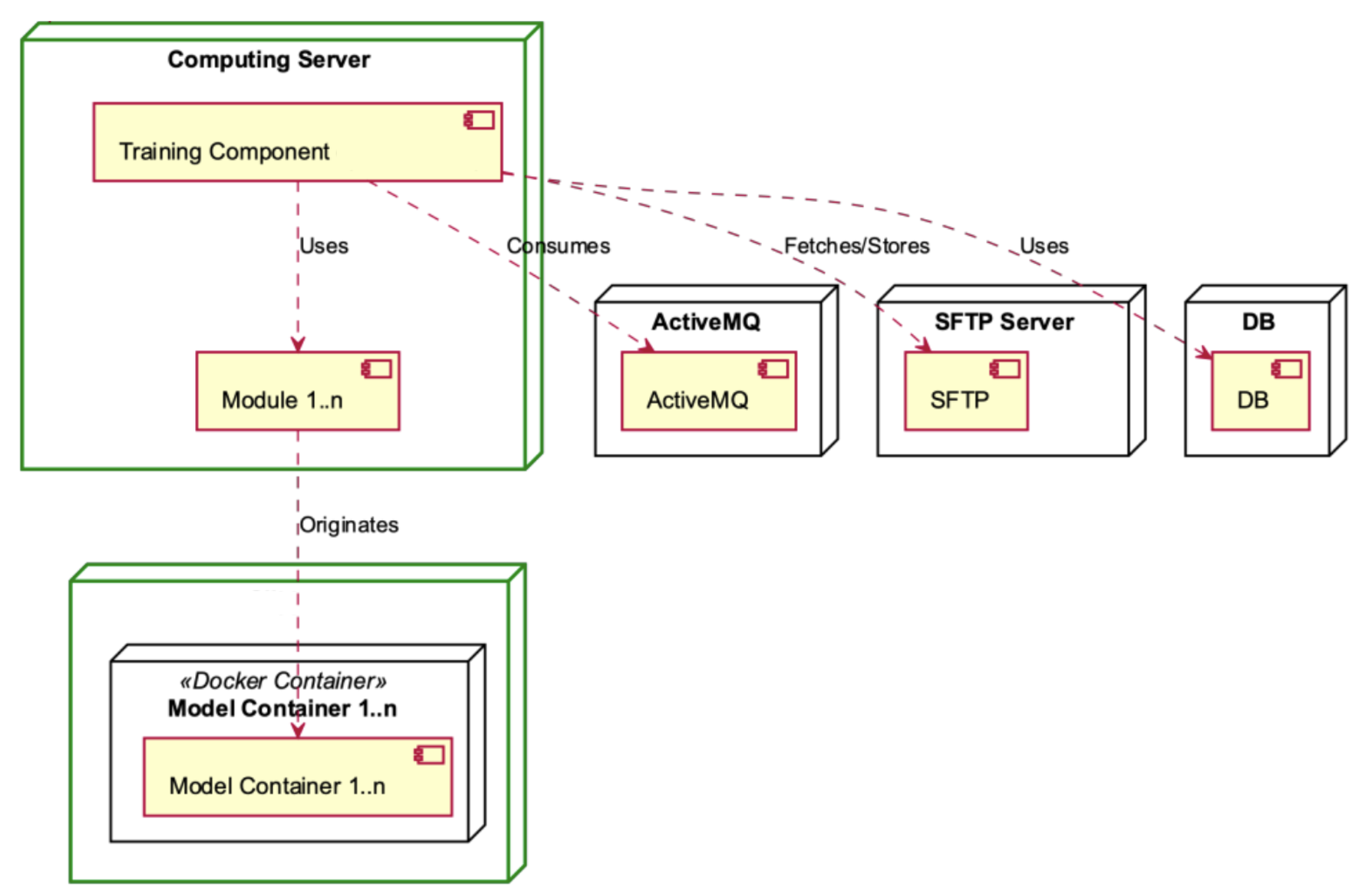
The Training Component, depicted in
Figure 14, is contained within the Computing Server. It consists of Training Workers and the Training Consumer who consumes the ActiveMQ. The Training Workers engage in the consumption of modules and interact with the SFTP server, the database, and the model containers.
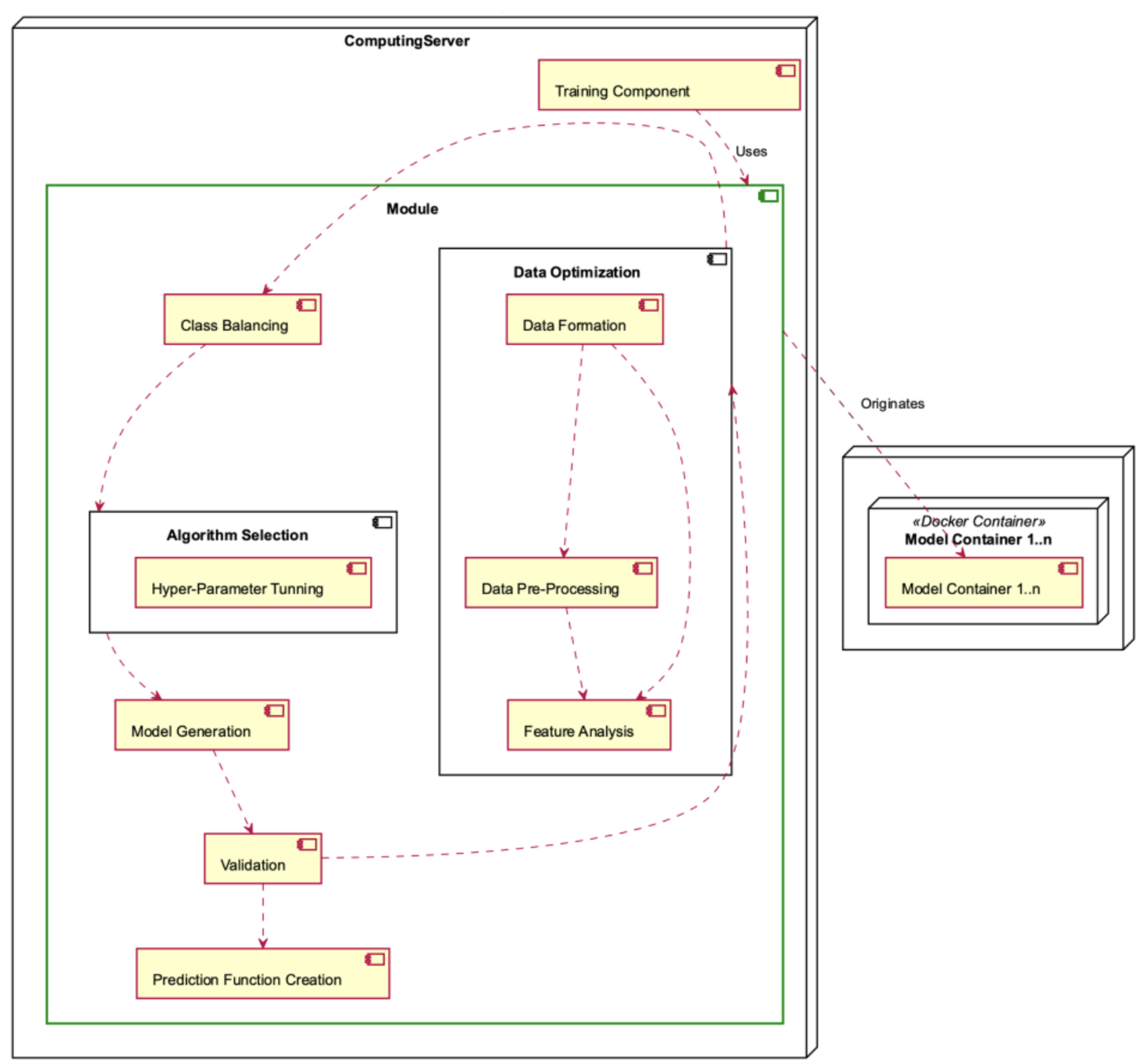
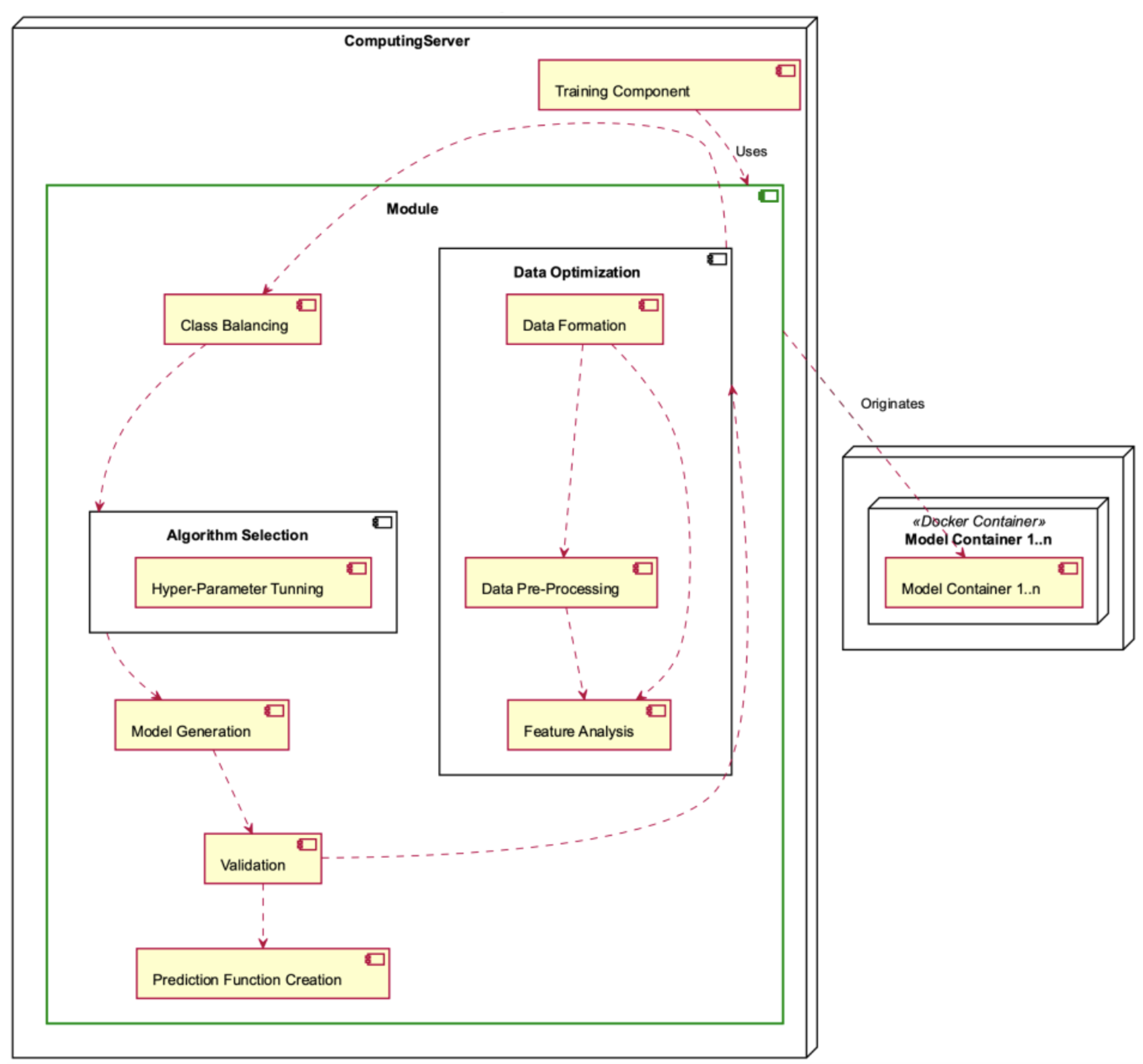
The Module Deployment Component, depicted in
Figure 15, is situated within the Computing Server and is characterised by its intricate nature, as it encompasses multiple operations. The Module consists of the Data Optimisation sub-module, which encompasses the responsibilities of Data Formation, Data Preprocessing, and Feature Analysis. The Module also includes class balancing, algorithm selection (including hyperparameter tuning), model generation, validation, and construction of the prediction function. Each module generates one or more model containers.
When evaluating the scalability of a microservices solution, it is crucial to take into account the trade-offs associated with transmitting requests and responses among different services, the expenses related to upgrading the infrastructure’s hardware, and the potential for parallelising processes to leverage hardware enhancements.
When designing prototypes for performance evaluation, it is customary to employ the following dimensions to assess the most favourable balance. Performance refers to the duration needed to finish a solitary transaction, while Throughput pertains to the quantity of transactions that a system can handle within a specified time frame. Capacity, on the other hand, represents the highest level of throughput that a system can maintain under a given workload while ensuring an acceptable response time for each individual request.
There are two options for making a system accessible: locally, sometimes known as on-premises, or remotely through the use of remote hosting services. When implementing a remote solution, it is imperative to take into account the geographical location of the data. Additionally, the choice of hosting architecture may vary based on the service provider. In a local solution, the responsibility for the physical architecture lies with the organisation, which can be comparable to certain resilient remote hosting options.
The logical accessibility of a system can be achieved through two means, namely, Plugins and Services. Plugins offer advantages such as the ability to decrease the size of the request payload; however, they present certain disadvantages as well, such as challenges associated with managing the different versions of plugins and the need to update several plugins simultaneously. One of the benefits associated with services is the streamlined administration of versions and updates. However, it is important to note that there are drawbacks, such as the increased payload of requests and responses. It is imperative to ascertain whether the solution employing recommendation services is hosted on the same platform as the recommendation system, as this can potentially result in latency issues during the data transfer process between the two systems. The most appropriate strategies may involve the implementation of a shared database between the two systems and the utilisation of APIs to facilitate the seamless transfer of information from the solution to the recommendation system.
3.2. Churn Prediction Module
The Churn Prediction module utilises customer behaviour data to forecast the likelihood of each customer discontinuing their engagement with the brand and ceasing interactions. The aim of this study is to forecast client attrition in a business or activity. There are two distinct forms of churn: explicit churn, which arises when a user chooses not to renew a contractual agreement within the specified timeframe, and implicit churn, which transpires when a consumer engages with a platform or service without being obligated by any contractual obligations.
In the context of implicit churn, the sole indicator of customer turnover is the absence of any engagement or activity on the respective platform or service. There are limited approaches that possess the capability to effectively handle the comprehensive nature of the implicit churn issue. This phenomenon can be attributed in part to the autonomy of each service in defining its own metrics and measures to establish a distinct perspective on consumer behaviour. Furthermore, certain services may lack comprehensive activity tracking systems for individual customers, relying solely on purchase data.
As a result of this concern and the subsequent need for the module to be applicable in a general context (i.e., for use with multiple clients), we decided to use a methodology focused on analysing the frequency of customer activities. In [
27], the researchers employed the Beta-Geometric/Negative Binomial Distribution (BG/NBD) model for this aim. The BG/NBD model is a probabilistic model employed for the purpose of forecasting client behaviour, particularly with regard to future purchasing patterns. The model utilises a customer’s historical purchase data to make predictions on the quantity of transactions they are likely to engage in over a specified period. The present model is founded upon the Pareto distribution, although it exhibits notable enhancements in terms of both training and application speed compared to conventional Pareto models while maintaining a comparable level of performance.
The Churn Prediction module is centered on the dynamic examination of the frequency of a specific activity for an individual user or customer. The customer’s likelihood of discontinuing their use of the company’s products is deduced from their prior contacts and activities, which are indicated by a collection of predictors. To counteract the rise in costs and tackle the issue of insufficient supply in this area, the module facilitates the production of abandonment forecasts with a significant level of detail for each individual customer in real time.
Our investigation into churn prediction commenced with an initial exploratory examination. The initial methodology employed in a simulated setting involved an endeavor to expand the classification technique to a dataset associated with an implicit scenario that corresponds to a daily step. Emphasis was placed on identifying traits that might effectively distinguish between active consumers and those who had churned. Nevertheless, the results of all conducted experiments failed to demonstrate a satisfactory level of performance. The primary factor contributing to the subpar performance of the previously proposed approach was the consumption profile of individual users.
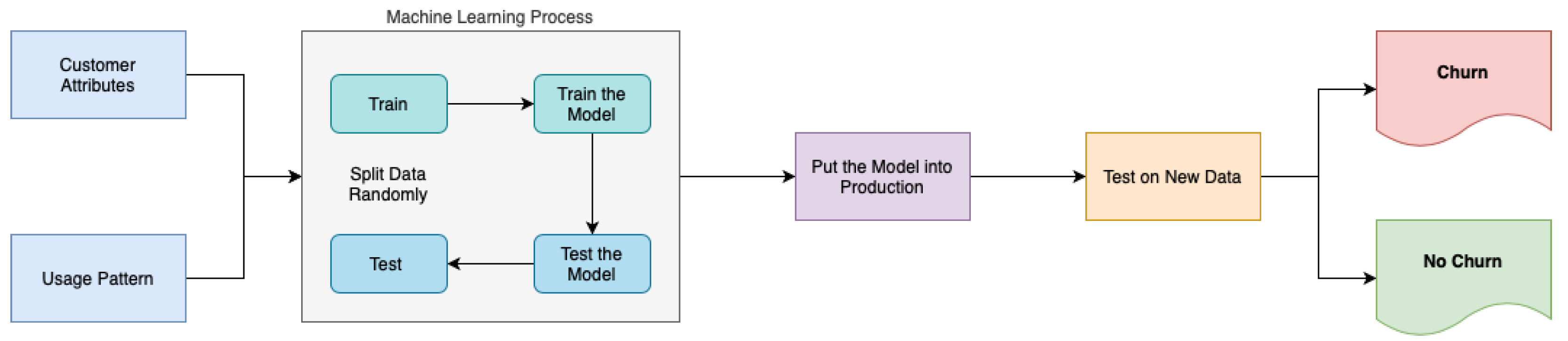
The machine learning methodology employed for churn prediction, as delineated in
Figure 16, follows a structured process flow. Initially, consumer attributes and usage patterns are collected and partitioned into training and testing datasets. Subsequently, a model generation phase ensues in which machine learning algorithms are trained on the training data to develop predictive models.
After the completion of the training process, the model is subsequently deployed to a production environment, where it is then utilised for real-time churn prediction jobs. The deployed model undergoes testing using new data specifically sourced from production datasets in order to verify its effectiveness and performance. The purpose of this thorough testing phase is to evaluate the model’s precision and dependability in detecting possible instances of customer churn. This evaluation can provide valuable insights for making strategic decisions to improve customer retention.
An implicit churn problem approach was chosen for the module, as the intention was to maintain a high level of abstraction in the module’s context. As stated earlier, the selected model was BG/NBD, which utilises Pareto methodologies and has notable computational efficiency compared to conventional Pareto models. The primary emphasis of this approach lies in performing a dynamic analysis of the frequency at which a particular action occurs for a specific user or customer. Furthermore, this methodology may be generalised to accommodate various use cases and encompass several representative qualities of the activity.
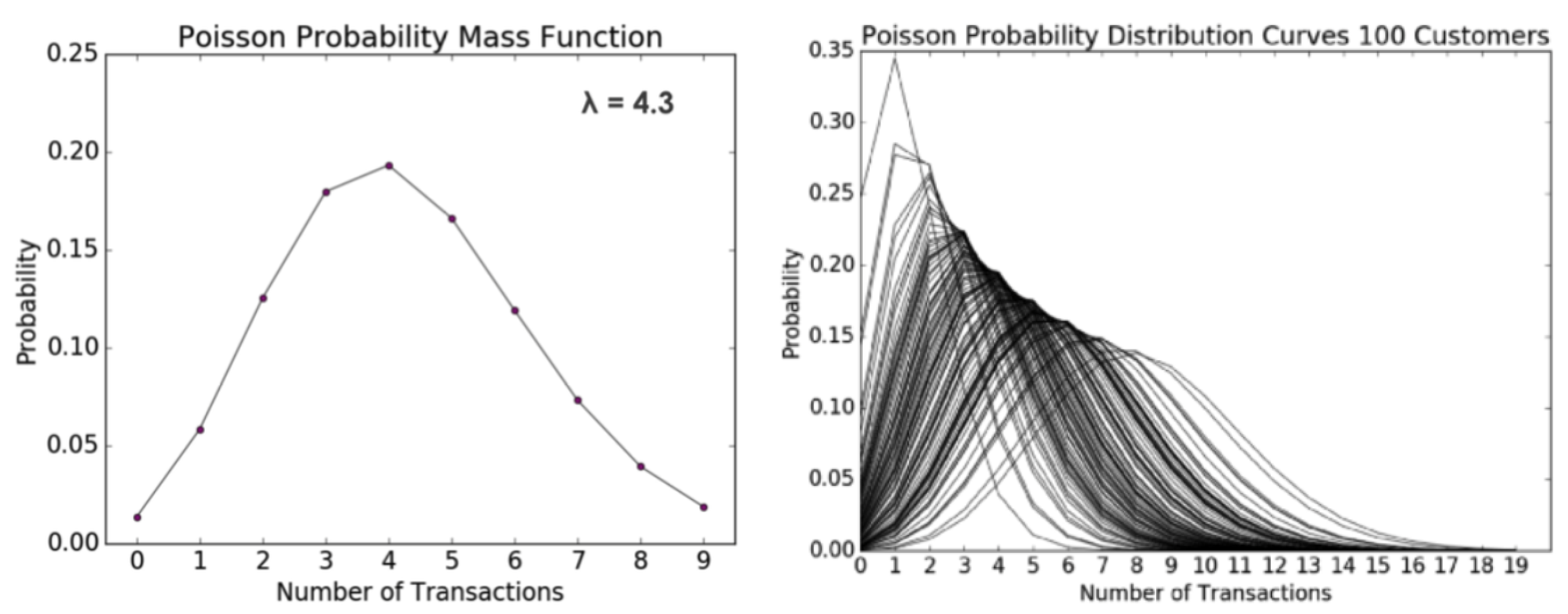
The BG/NBD probabilistic model is employed to assess the anticipated quantity of forthcoming activities and their likelihood of being active. The approach considers the customer’s activity behaviour as a stochastic process, resembling a coin toss; two coins are employed to determine the likelihood of the customer engaging in an action and the likelihood of the customer discontinuing any further actions. The underlying assumptions of the model are as follows: first, it is assumed that the number of activities performed by the customer adheres to a Poisson process, as seen in
Figure 17; second, the activity rate, which represents the expected number of activities within a specific time frame, is also considered; lastly, the model assumes that there is heterogeneity in the activity rate among customers, which is assumed to follow a Gamma distribution.
The likelihood of a client transitioning into an inactive state following an activity is allocated among the activities in accordance with a geometric distribution. Following the completion of each activity, every consumer discards a second coin, symbolising their decision to abstain from participating in the activity again. The likelihood of being in a state of “being alive” is equivalent to the complement of the likelihood of being in a state of inactivity ().
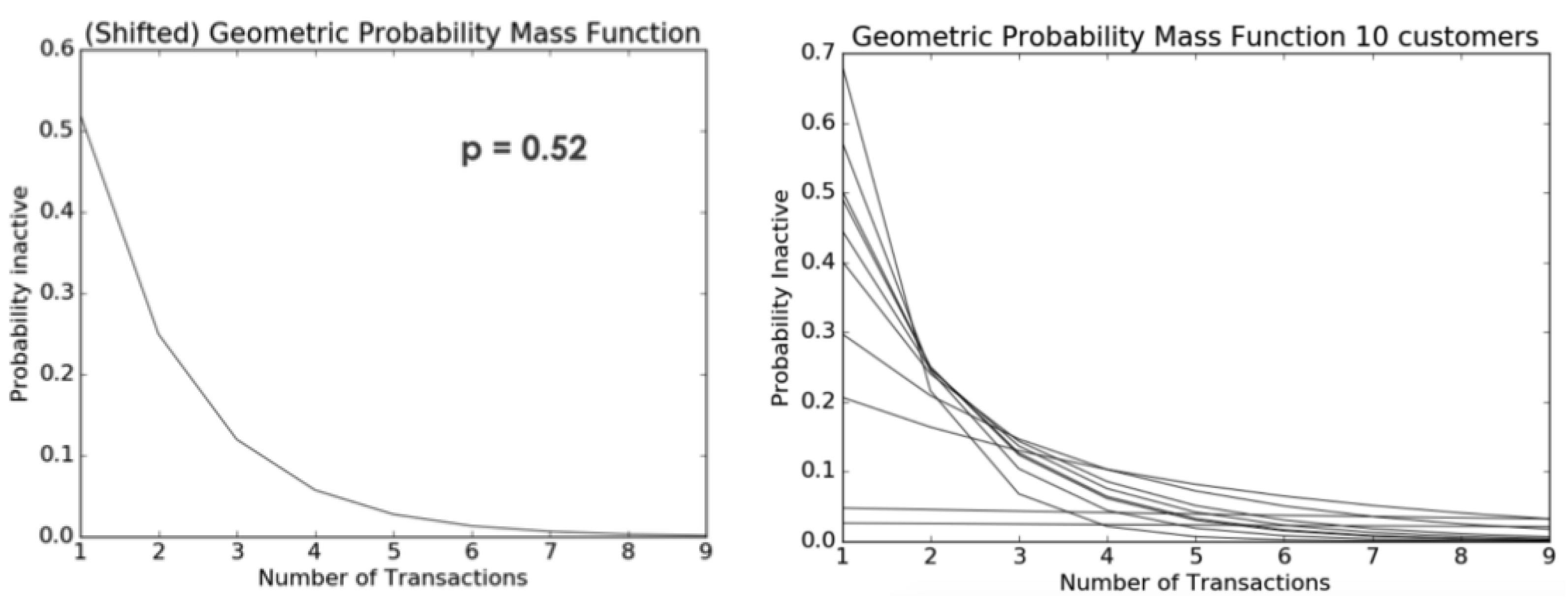
As an illustration, if we consider a scenario where a customer has a 52% probability of becoming inactive (as shown in
Figure 18), the likelihood of the client becoming inactive after the second activity is 25%, and the likelihood of their becoming inactive after the third activity is 12%. The heterogeneity in the variable
p can be modeled using a Beta distribution. Each client possesses an individual currency, representing the probability of not engaging in a certain activity again. This currency is determined by the customer’s likelihood of being “alive” after a specific number of actions. As depicted in
Figure 18, a simulation was conducted with a sample of ten clients. The probability parameter
p in this simulation was modeled using a Beta distribution with alpha = 2 and beta = 3.
Upon utilisation of the aforementioned probability distributions to analyse the historical customer data, a full range of results becomes apparent for each individual customer. These outcomes comprise three crucial elements:
Initially, the quantification of the probability of detecting various activities within a defined time interval is established. This analysis offers valuable insights into the probability of customers engaging in different behaviours over a period of time, enabling businesses to proactively predict and strategise for varying levels of customer activity.
Furthermore, it becomes possible to determine the anticipated number of activities that are scheduled to take place during a specific period of time. Through the utilisation of distribution models, organisations have the ability to make estimations regarding the magnitude of client activities. This in turn facilitates the allocation of resources, management of inventories, and planning of operational operations.
Finally, the distribution models additionally enable computation of the likelihood of customers migrating to an inactive state at a particular moment in time. This intelligence is highly important in the identification of possible churn clients, facilitating the implementation of proactive retention measures aimed at re-engaging consumers and mitigating attrition.
The utilisation of these probability distributions in analysing past client data provides firms with a comprehensive comprehension of the dynamics of customer behaviour. The utilisation of data-driven decision-making helps organisations to make informed choices, thereby optimising resource allocation and improving tactics for managing client relationships.
3.3. One-2-One Product Recommendation Module
The One-2-One Product Recommendation module is responsible for producing personalised recommendations to consumers based on their unique consumption profiles. To assure the proper functioning of the system, an evaluation was conducted to determine the key elements that influence the design of a product recommendation system. The most effective methodology employed in this study was collaborative filtering [
28] with Alternating Least Squares as the optimisation technique [
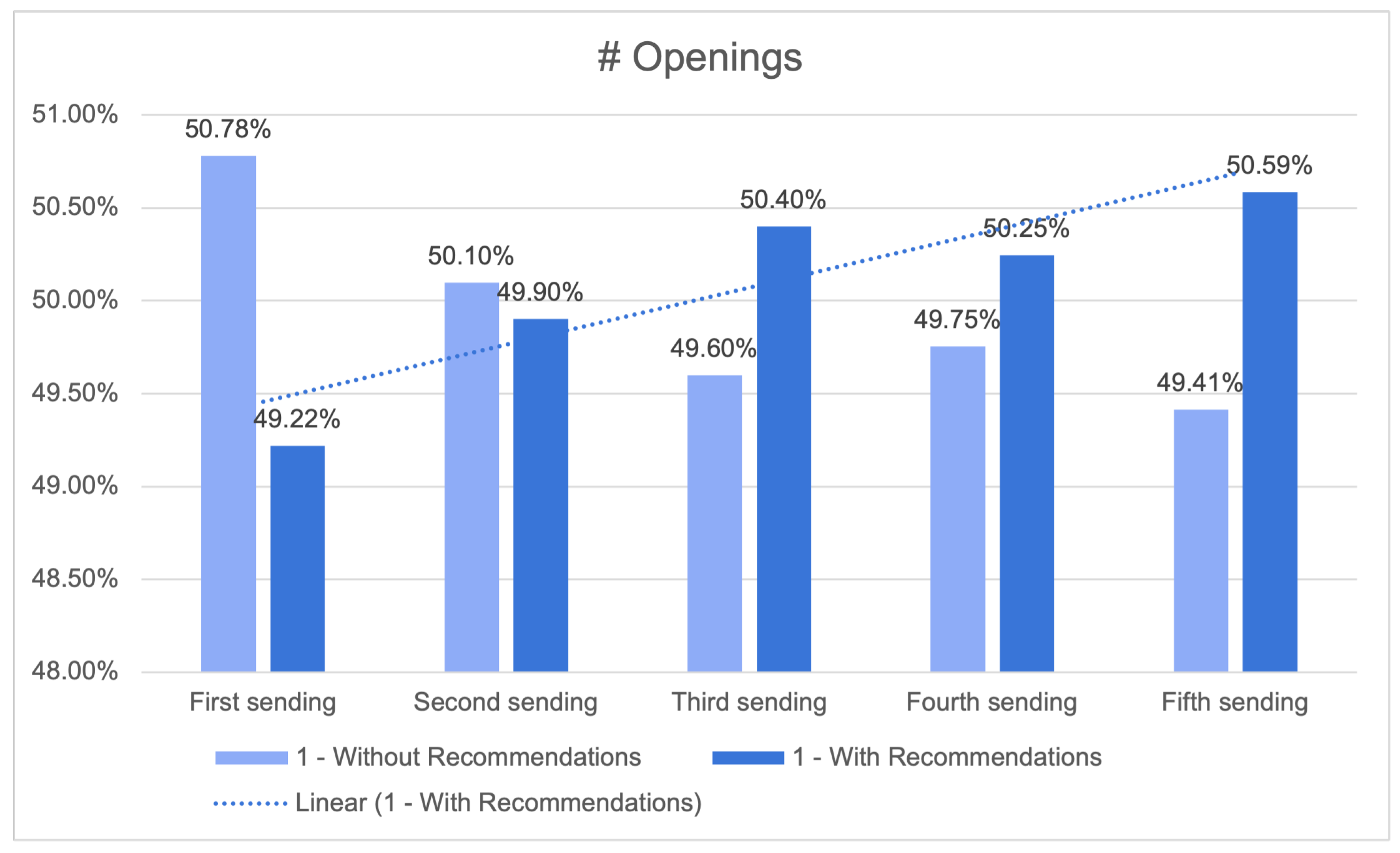
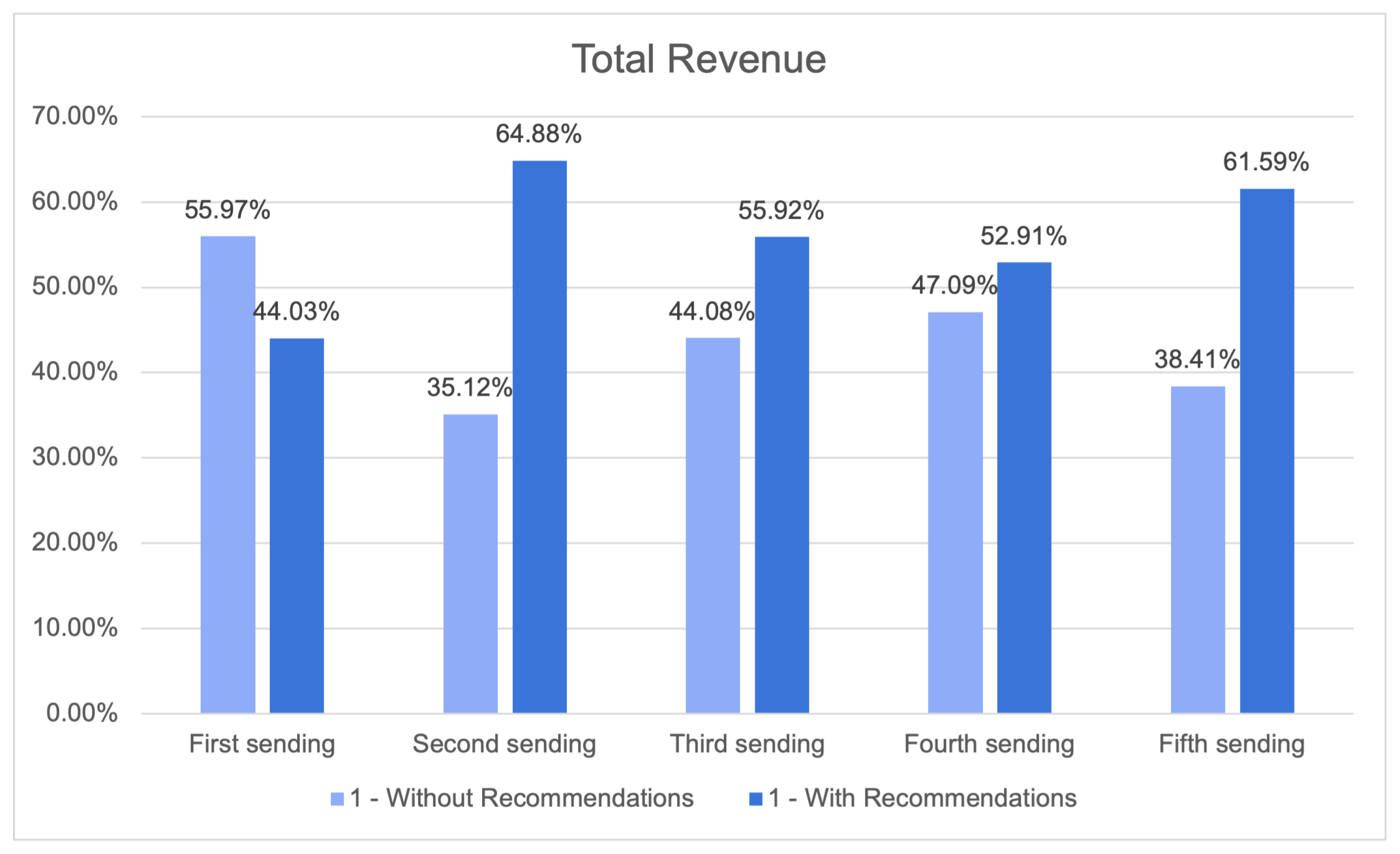
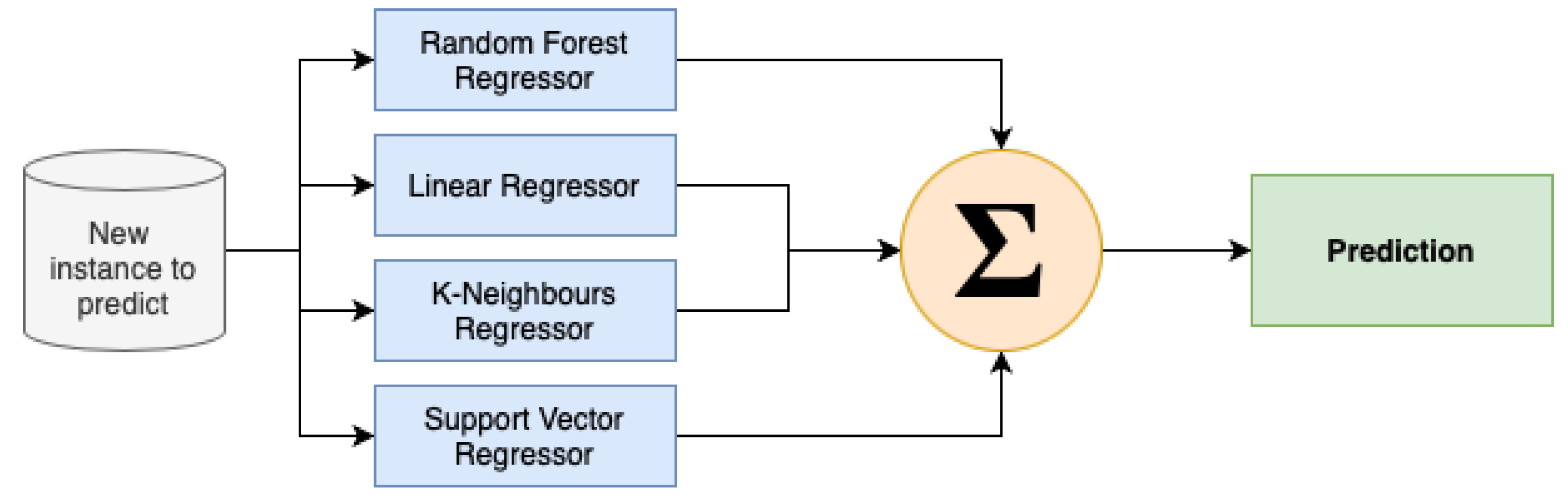
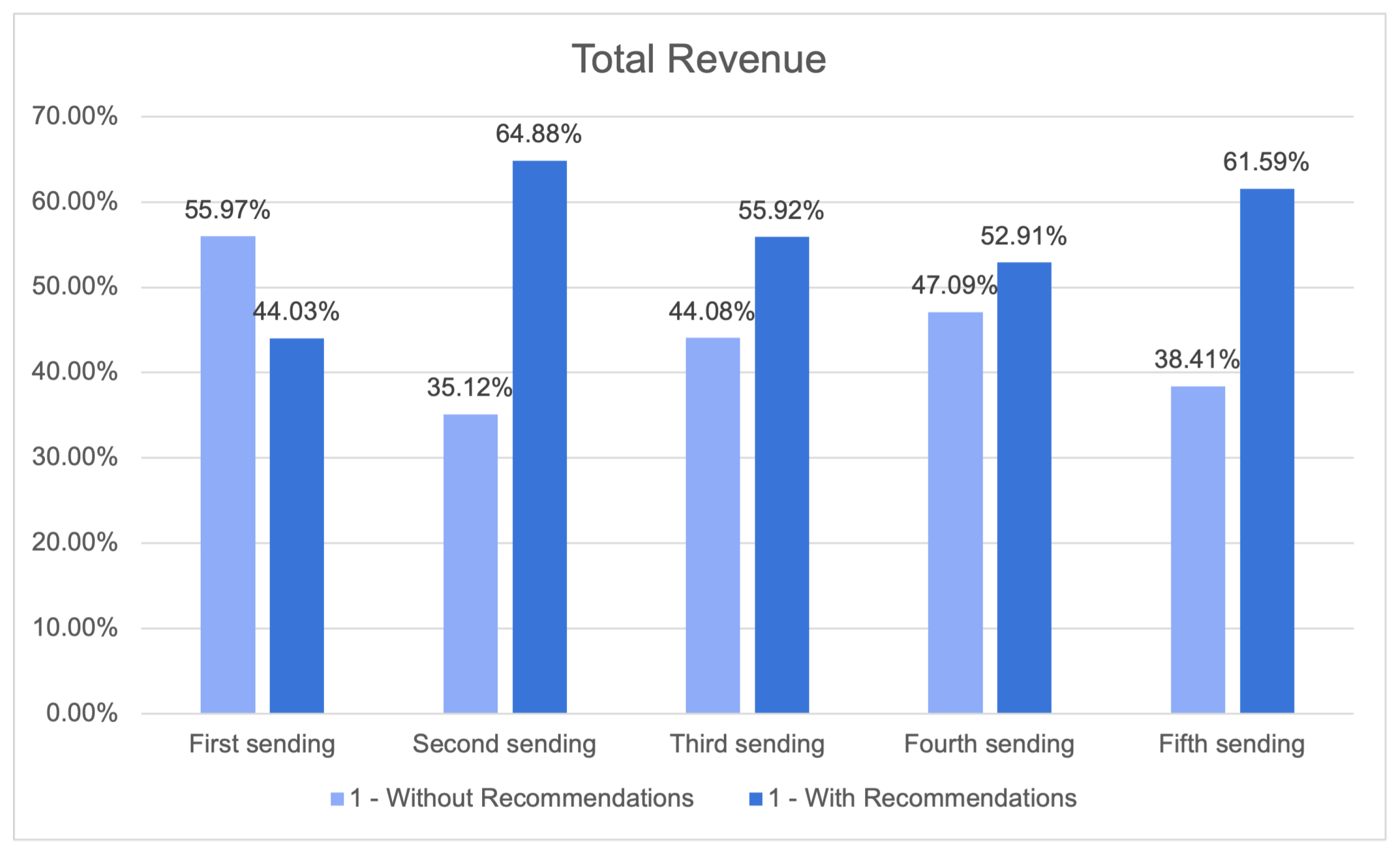
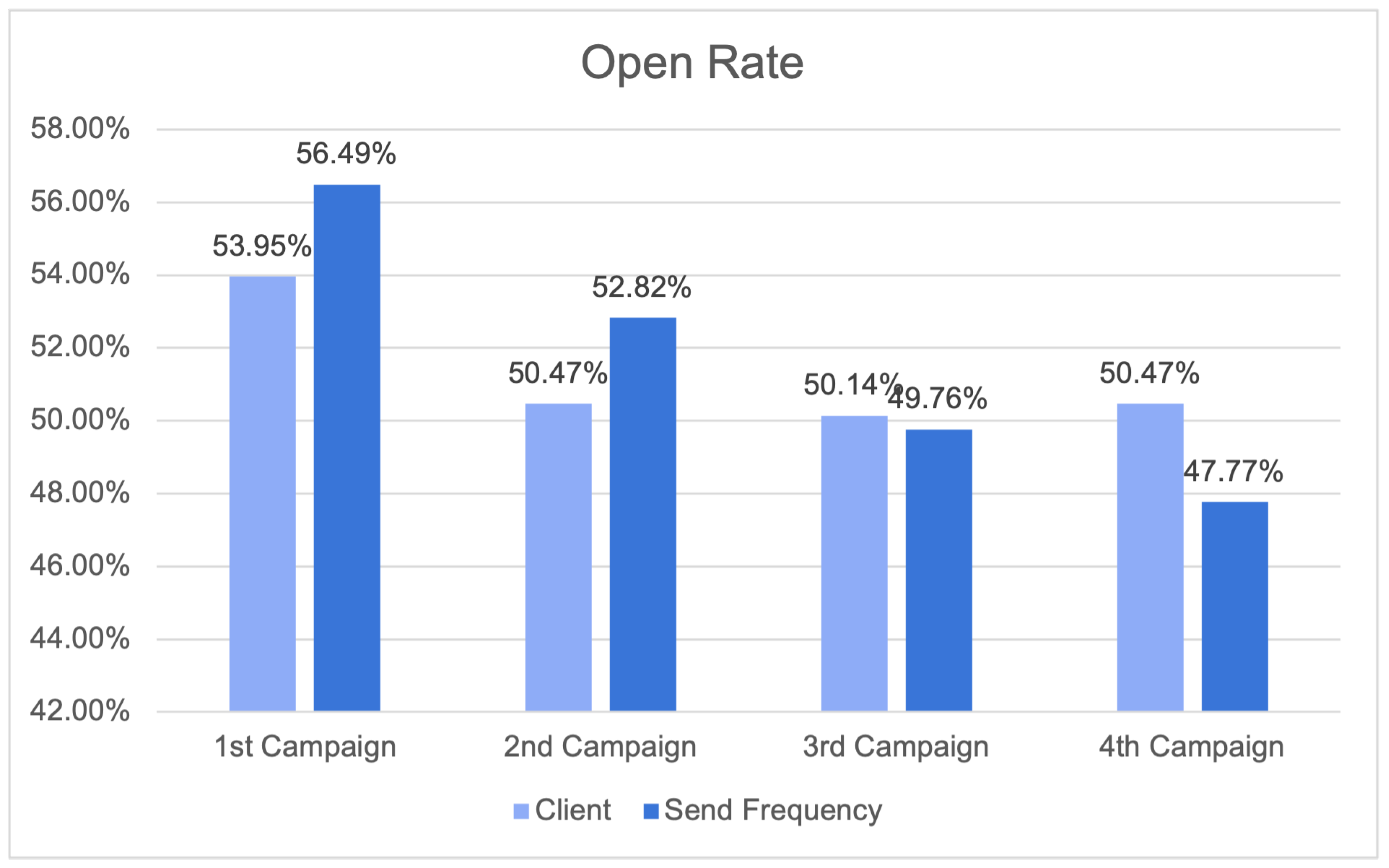
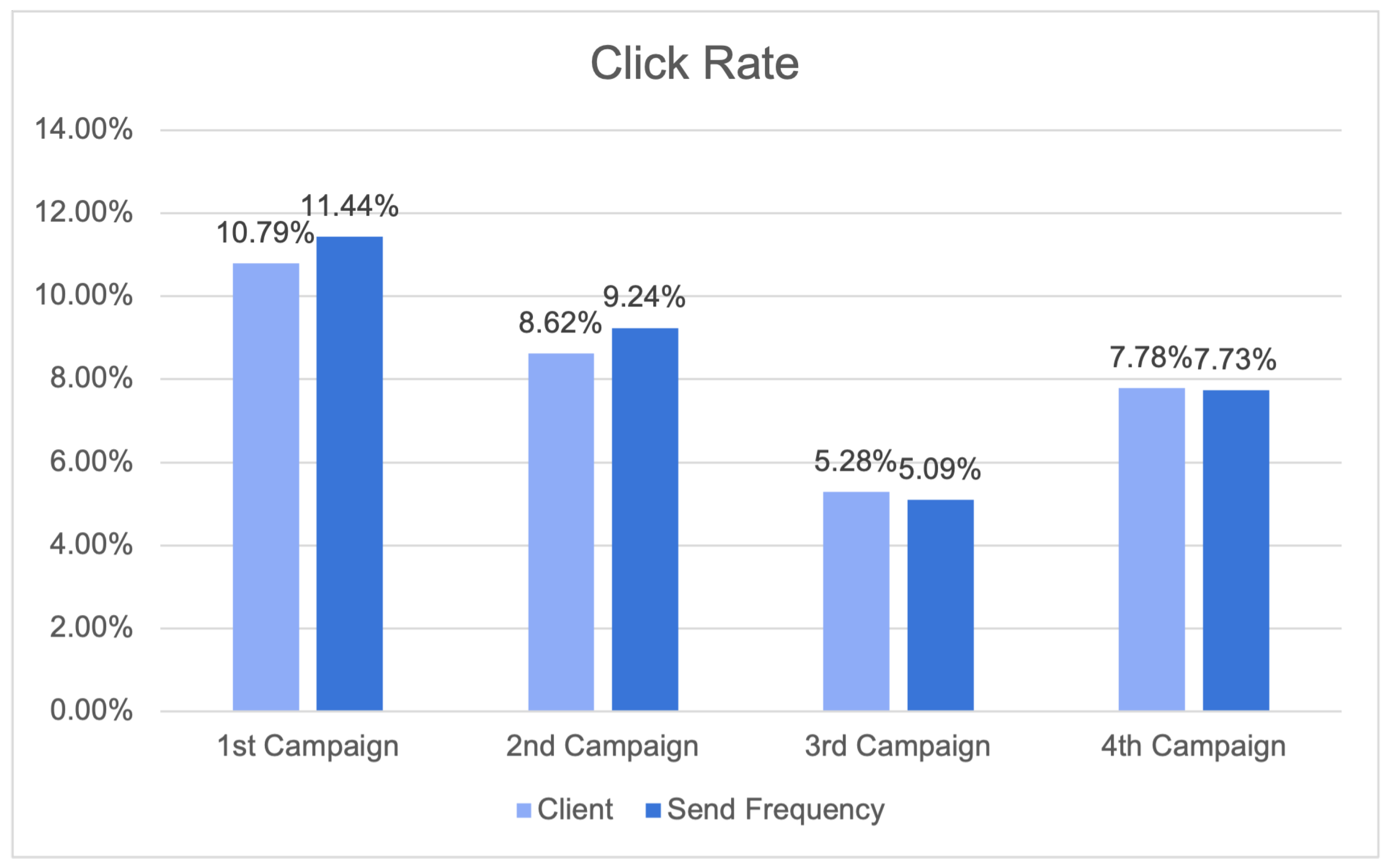
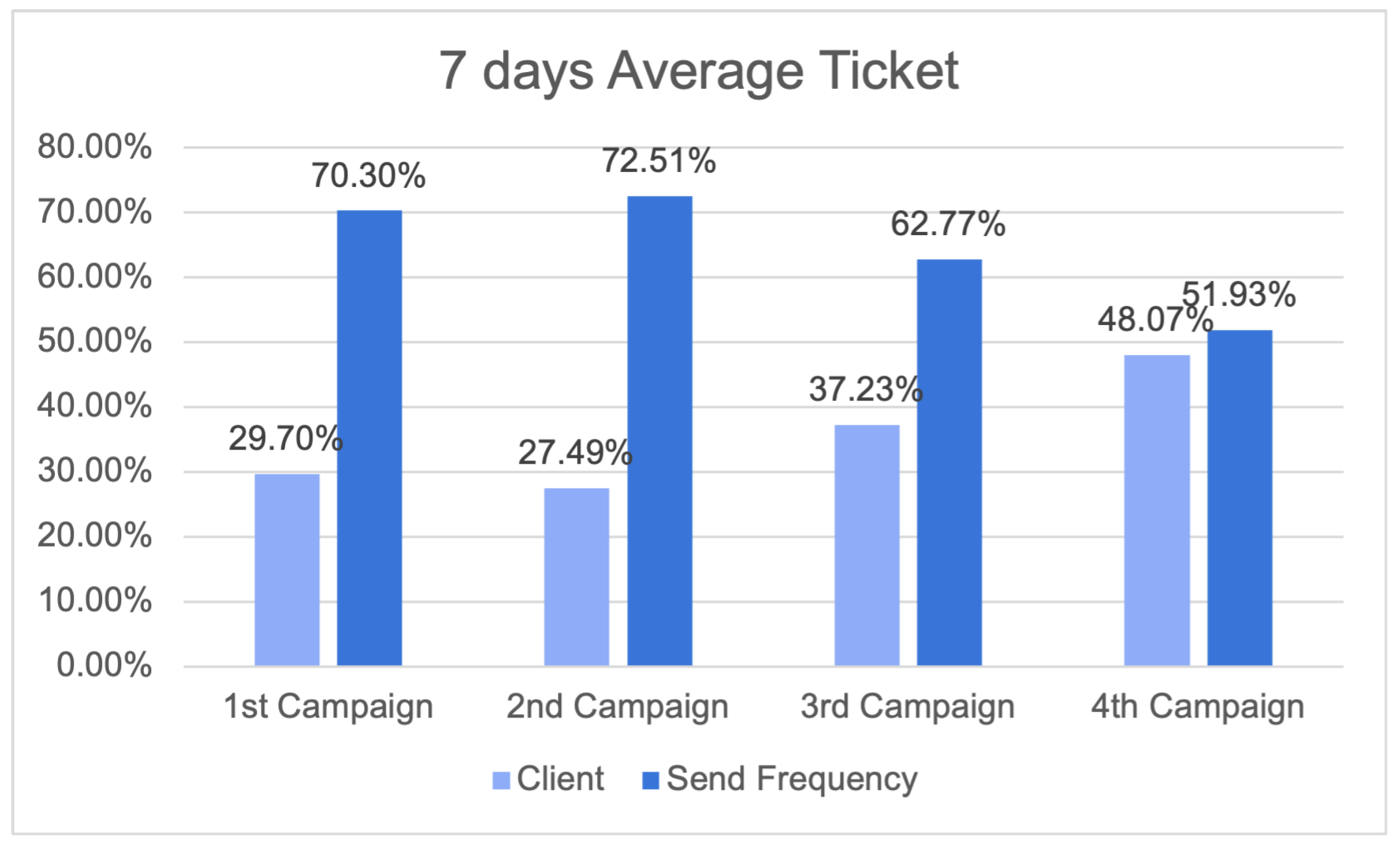
29]. The construction of precise consumer profiles and the development of tailored content for newsletters or other dissemination tools were achieved through the utilisation of historical data and algorithms possessing self-learning capabilities. The utilisation of offline measurements instilled a greater level of certainty in the capacity to attain accuracy while maintaining a balance in terms of the ability to make recommendations across the entirety of the customer’s catalog. Furthermore, this approach resulted in a higher median price per recommendation compared to basic baseline methods.
The One-2-One Product Recommendation module is structured around two primary meta-processes: the training of the model using client data, and the generation of results. The training step is comprised of three distinct sub-processes, namely, the acquisition of the client dataset, the creation of artifacts, and their subsequent upload. The initial stage involves computing the significance of each customer–product contact, taking into account factors such as price, quantity, and date. The hyperparameter optimisation for matrix factorisation is performed automatically for each individual application. Following the completion of training, many artifacts are produced to facilitate the prediction phase. These artifacts encompass the matrix of customer–product interactions, models, dictionaries, and a database containing historical purchases organised by customer. The process of generating results will consider both the customer ID and the model ID, then load the corresponding created artifacts and proceed to calculate the recommendations.
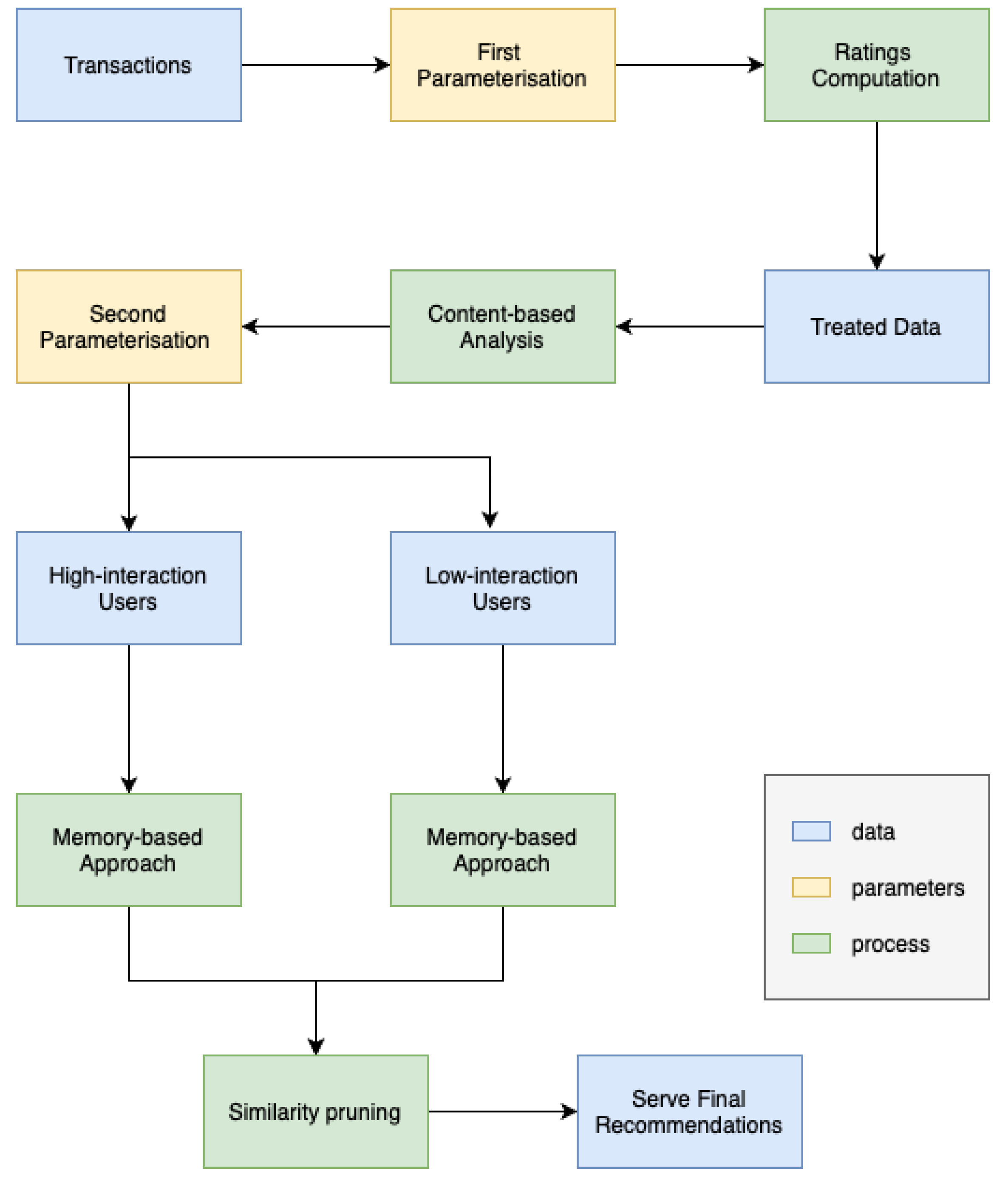
The approach we employ integrates model-based, memory-based, and content-based techniques inside a system that falls under the category of cascade–hybrid recommender systems. The name “cascade” is derived from the observation that each subsequent approach in a series progressively improves upon the predictions provided by the previous one. Our primary objective was to design an algorithm that possesses user-friendly features, adaptability, robustness, and ease of auditability, while minimising any potential performance drawbacks. The method is depicted in
Figure 19, and further elaboration may be found in the work by [
30].
An essential element of this cascade approach which sets it apart is its utilisation of the “similarity pruning” methodology to refine precomputed recommendations from other approaches. This proves to be beneficial, not necessarily in reducing the inaccuracy, but in providing recommendations that are more contextually relevant and accurate.
The recommendations generated by the precomputed latent-model are refined using the content-based technique outlined in Algorithm 1. By employing precomputing with the latent-model, the quantity of products required in the final result is doubled or tripled. This approach provides sufficient diversity and serendipity in the recommendations. Additionally, the use of “similarity pruning” ensures that suboptimal suggestions, such as mixing recommendations for both girls and boys, were not included for clients who have only purchased boys’ clothes in the past.
Similar to the model-based method used to recommend for high interaction users, the precomputed Item-KNN recommendations for low-interaction users were likewise filtered using the content-based technique outlined in Algorithm 1. The technique employed in this situation was similar to the one used previously, which involves suggesting a quantity of products that is two or three times greater than what is actually needed and then narrowing down the selection based on similarity of content. This ensures that suboptimal proposals are eliminated while taking the business context into account.
| Algorithm 1 Get most similar items (adapted from [30]) |
- 1:
procedure
algorithm - 2:
- 3:
for all user id do - 4:
- 5:
] - 6:
- 7:
- 8:
] - 9:
- 10:
indeces from (most similar to the history) - 11:
- 12:
return product ids
|
To ensure a weekly repetition of suggestions, it is imperative to have a file that contains the updated history. This file must be guaranteed prior to each shipment; alternatively, automatic database access must be made available.
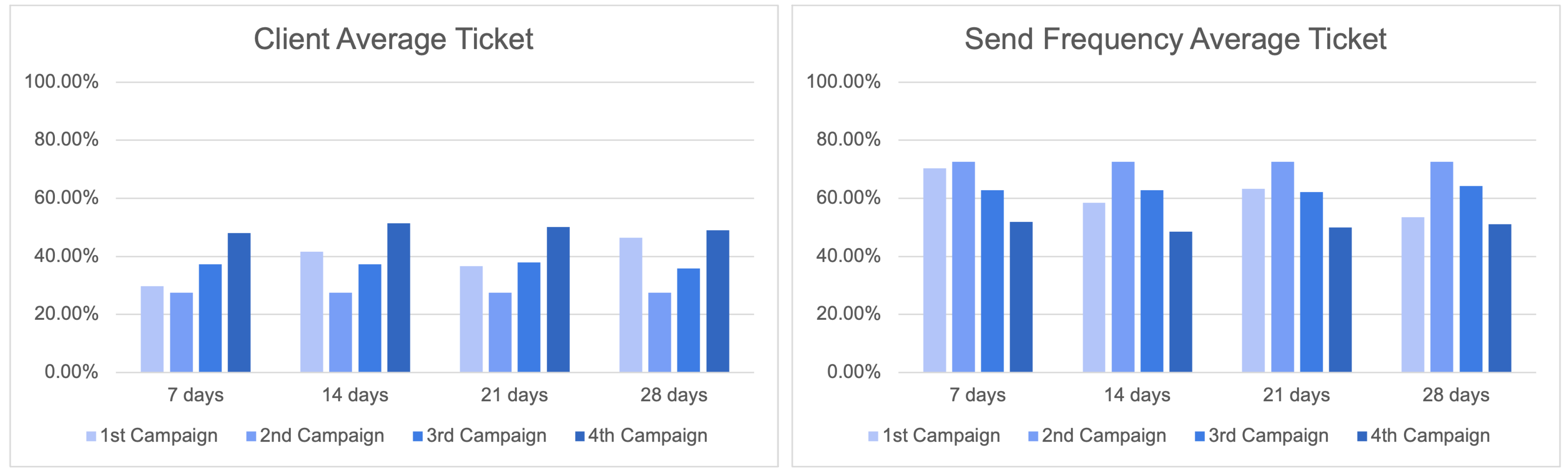
The system initiates its operations by autonomously computing the significance (evaluations) of previous transactions while taking into account meta-factors such as the date of purchase, quantity, and price. Subsequently, the system endeavours to ascertain the accurate significance of the items by leveraging the purchasing history. A clear differentiation exists between users, who are characterised by high and low levels of involvement. Users with low interaction tend to contribute less information, resulting in predictions that are accompanied by a significant degree of uncertainty. The current system is deemed incompatible with the existing business model, necessitating a requirement for customers to have engaged in a minimum of four purchases involving distinct products throughout the preceding six-month period.
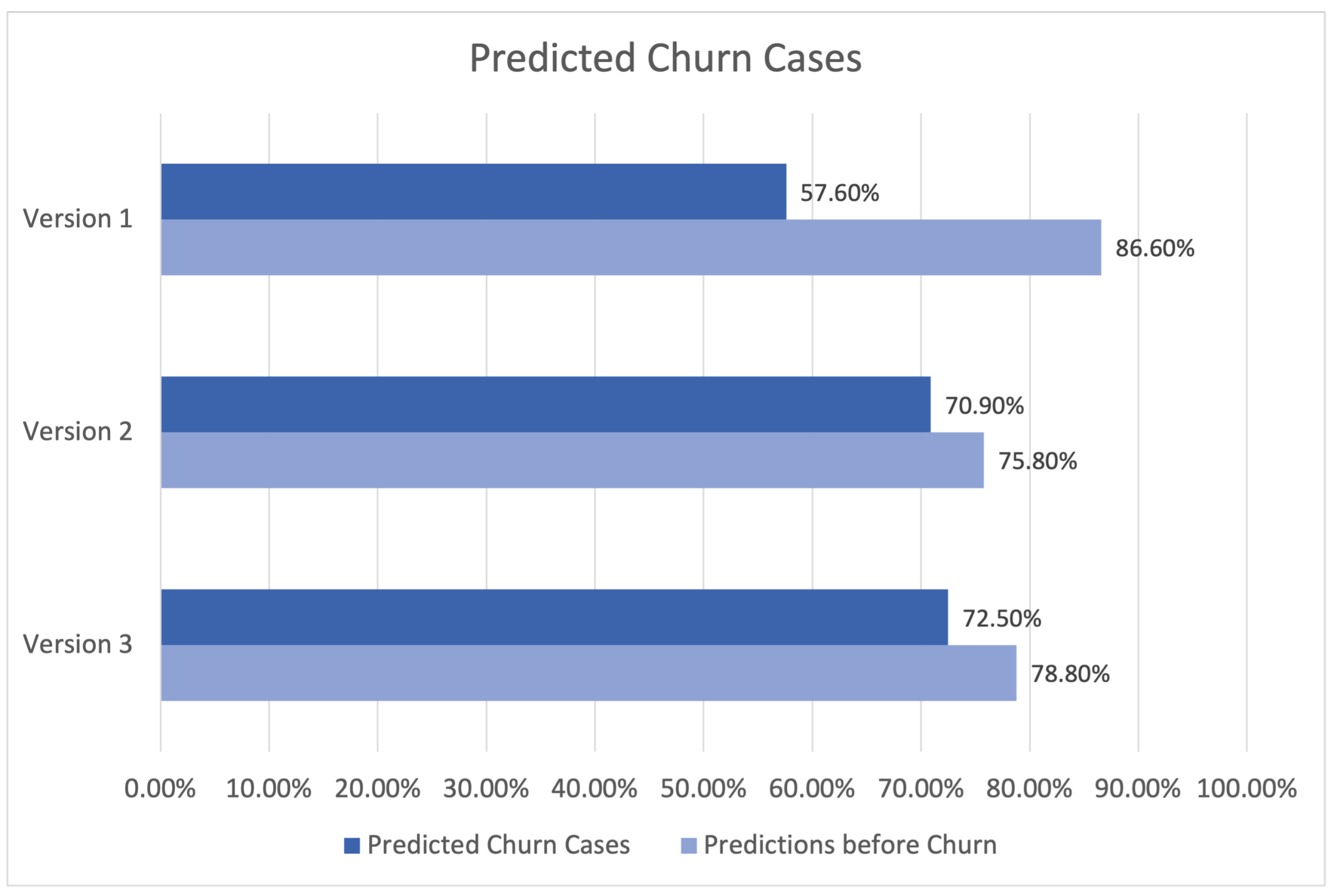
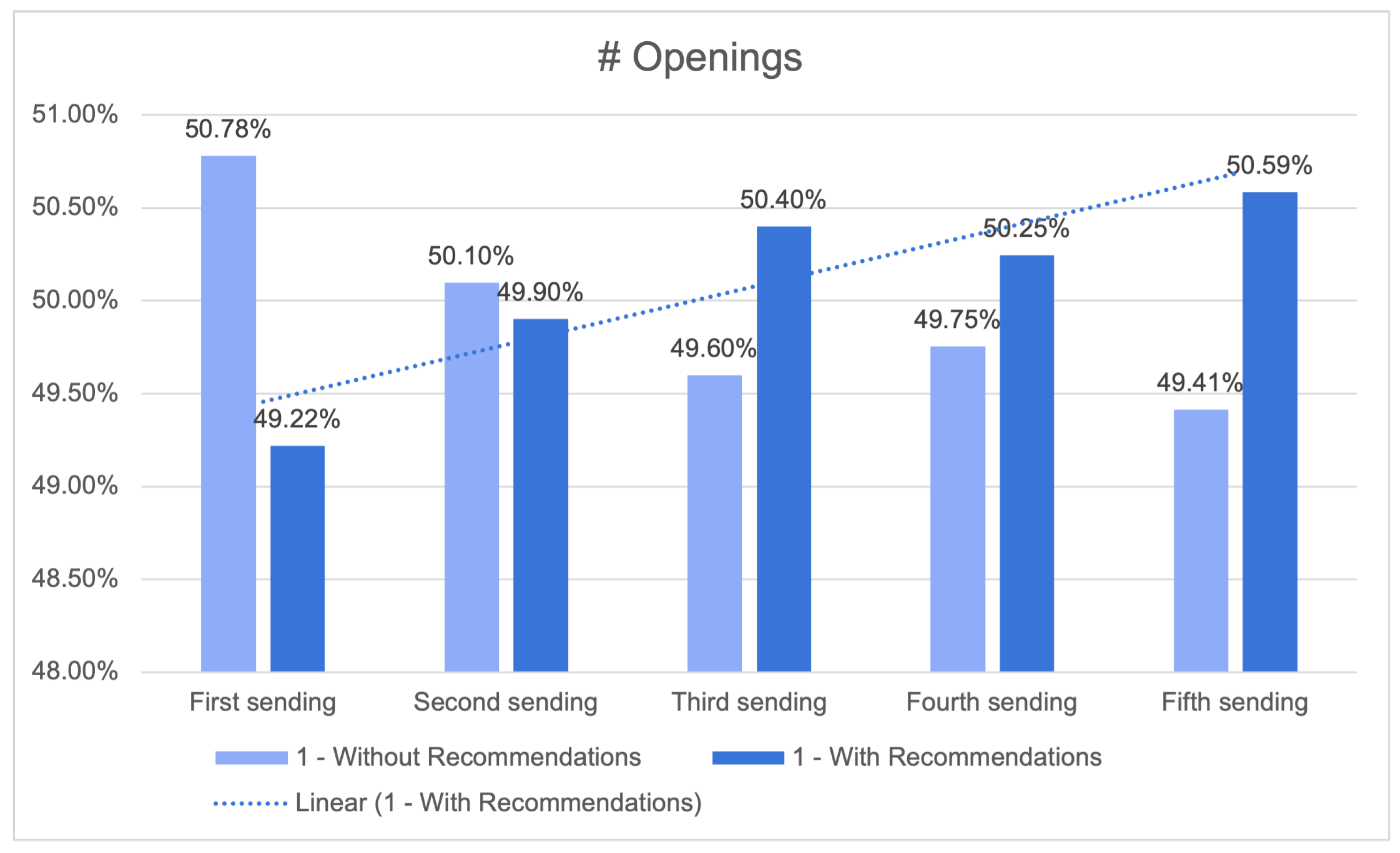
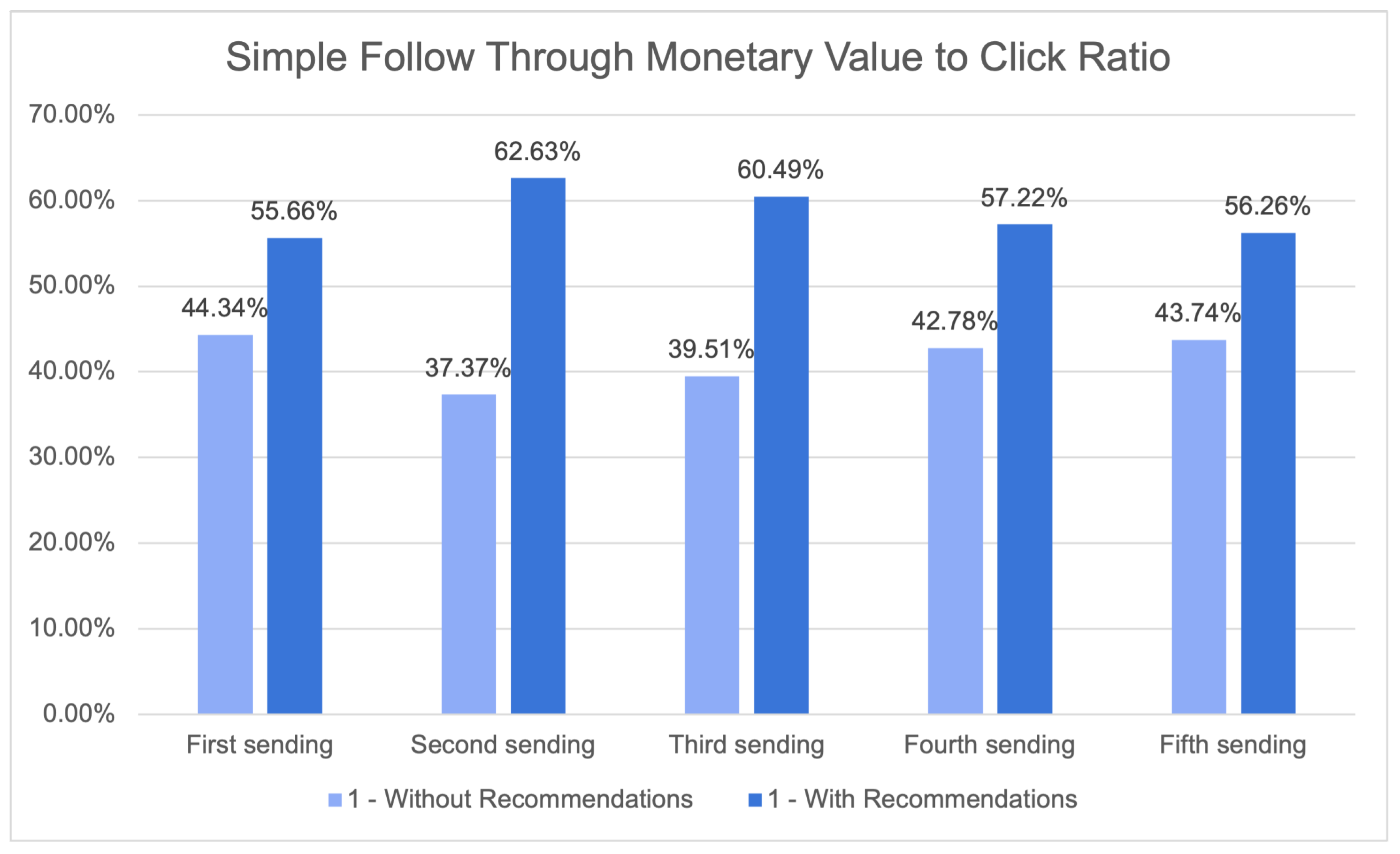
Despite the inherent limitations associated with accurately evaluating these systems, significant endeavours have been undertaken to establish formal offline evaluation criteria. These metrics play a crucial role in enabling a more objective review of the internal performance of our model before its implementation. To assess the model’s performance, three measures were formally defined: novelty score, catalogue coverage, and median recommendation price. The formalisation of catalogue coverage, a vital component of recommendation systems, involves quantifying the percentage of goods that are recommended to at least one client.
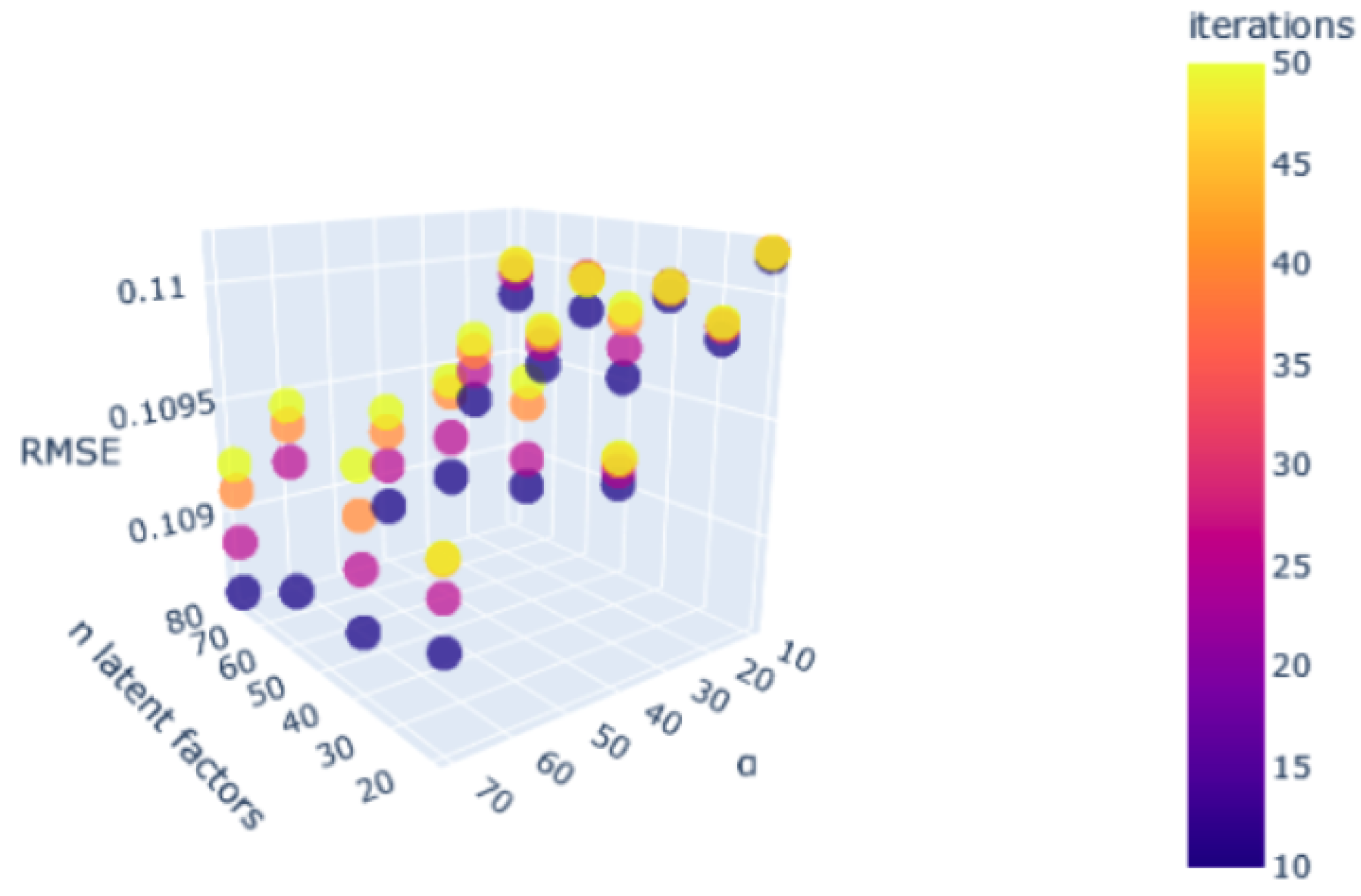
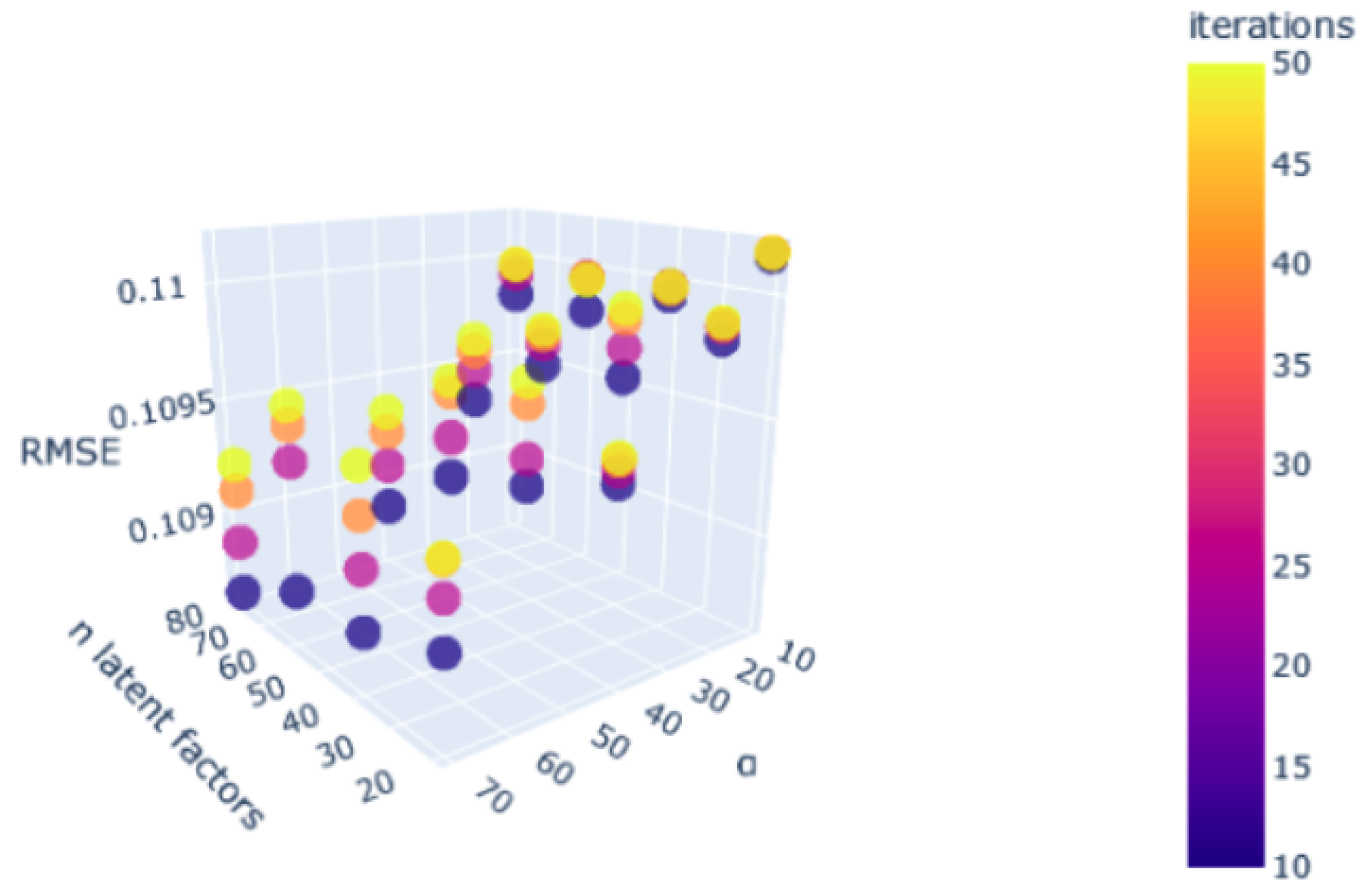
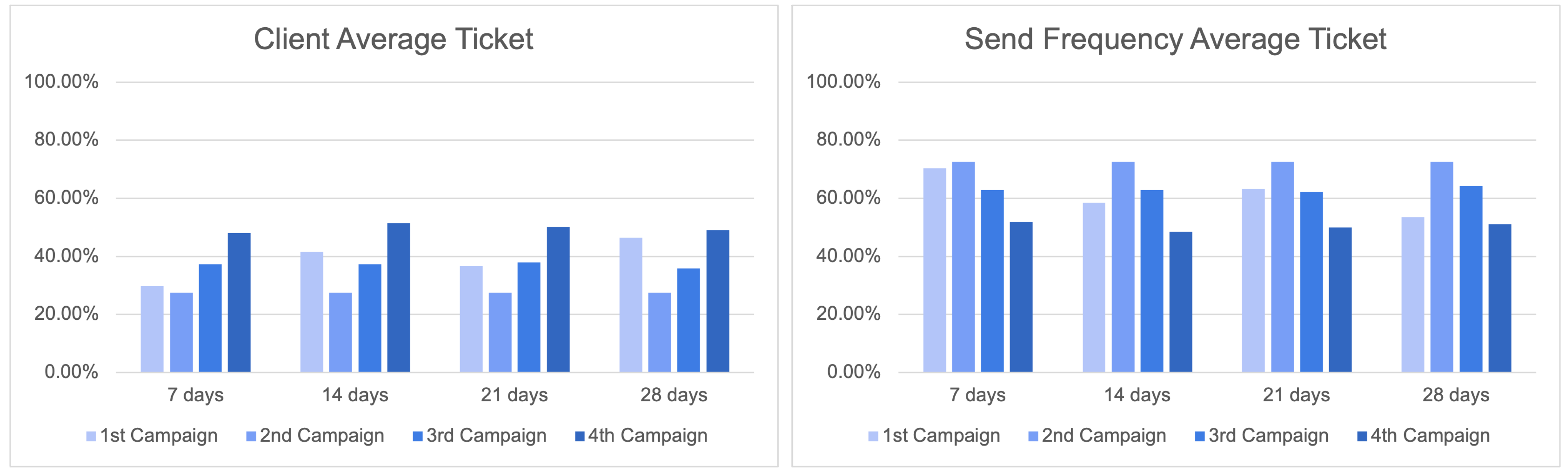
A notable enhancement was observed in the performance of the procedure for optimising the ideal hyperparameter space, as depicted in
Figure 20. The repetition of this essential step is necessary for accurate modelling of the problem across different cases.
The determination of the significance of previous purchases (ratings) by considering meta-factors such as the date, number, and price of the items acquired is an essential component of the problem at hand. This augments the matrix with supplementary data, enabling its use beyond binary data. The relative significance of different product categories can be influenced by various factors, including the date. Initially, a factor was incorporated into the model to represent the annual cycle and account for the seasonal nature of purchases. This adjustment allows for a small emphasis on interactions occurring during periods of high activity. Next, a weighting factor was calculated, representing a concave function that reaches its highest point at 0 (indicating the same month) and its lowest points at −6 and +6 (representing different months). This mechanism aims to adjust the annual cycle based on the specific month being recommended, prioritising purchases made during months that are closer in proximity to the recommended month as opposed to those that are further away. For instance, if the calculation is conducted during the summer season, it will give preference to interactions that occurred during the previous summer, taking into account the seasonal patterns observed in various product categories. The rating is computed using (
1), where
is the weight of the interaction,
is the weight assigned to the quantity purchased, and
is the weight assigned to the unit price.
More details about the One-2-One Product Recommendation module can be found in [
30].


 ,
, 






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}