
Knowledge-Based Intelligent Text Simplification for Biological Relation Extraction


Abstract
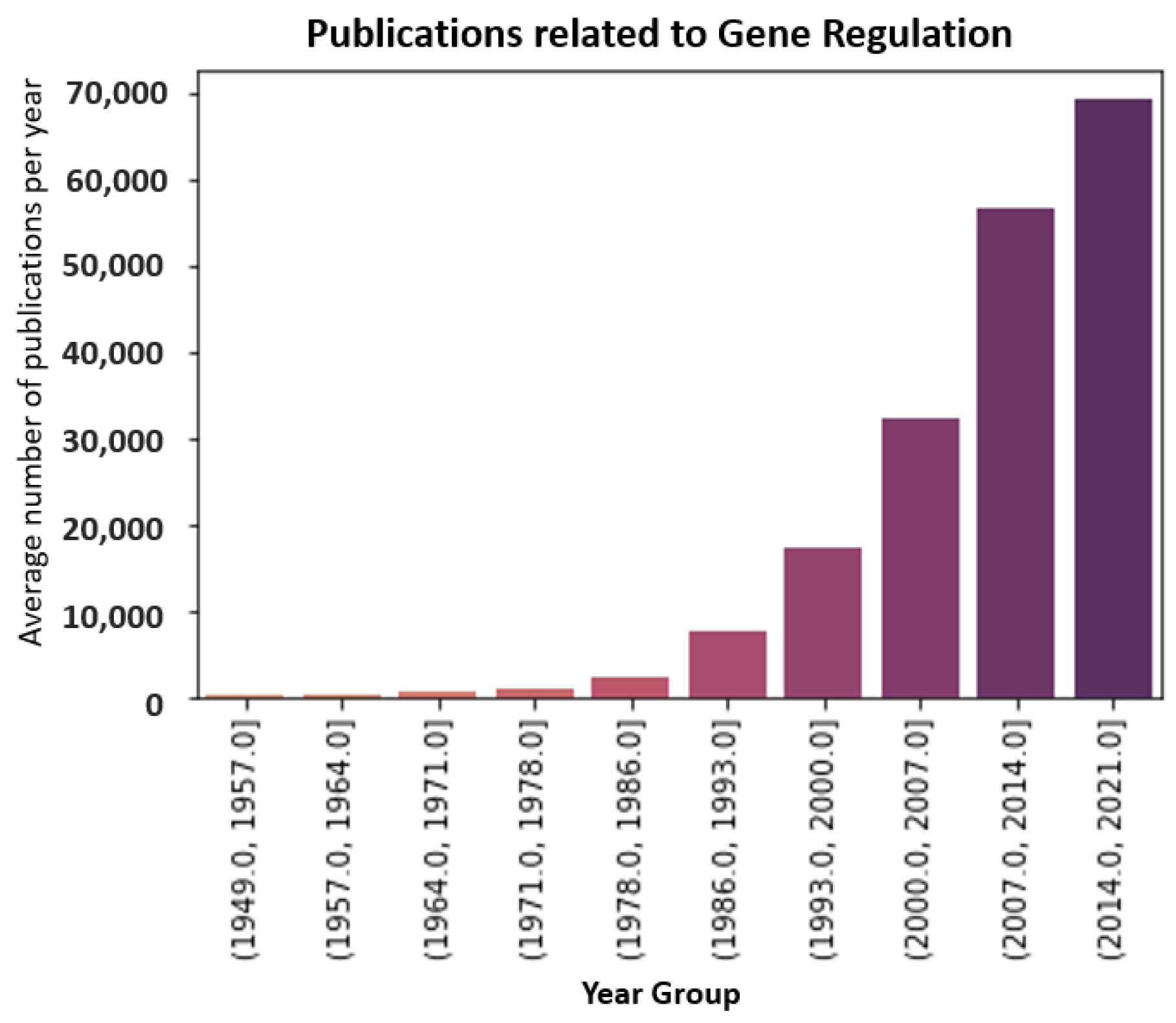
1. Introduction
2. Preliminaries
2.1. Relation Extraction
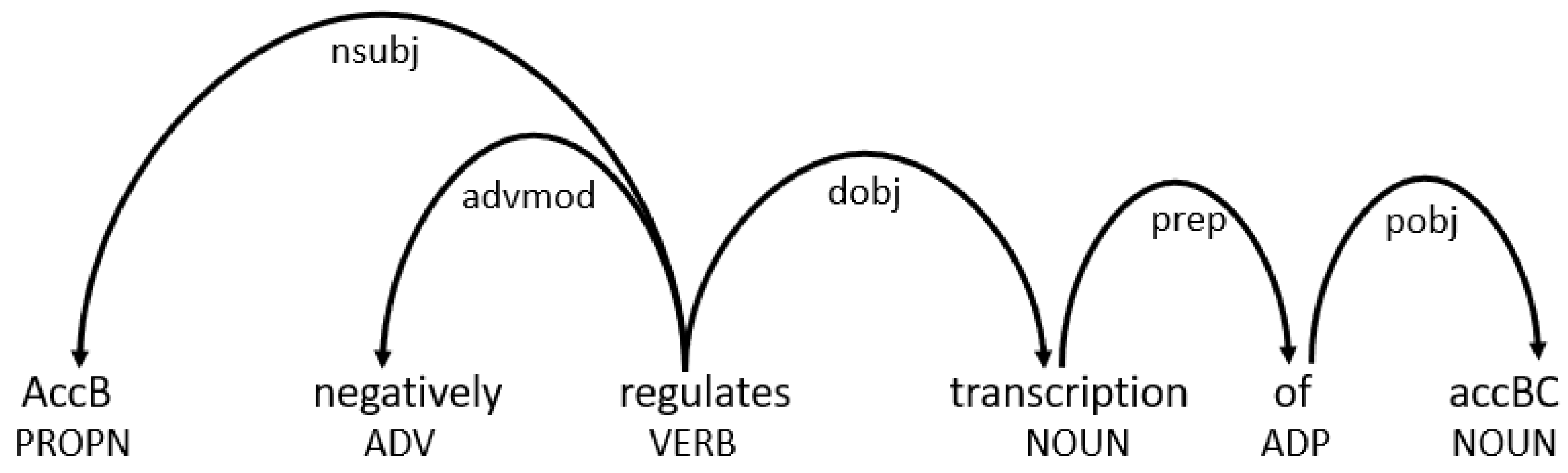
2.2. Dependency Parsing
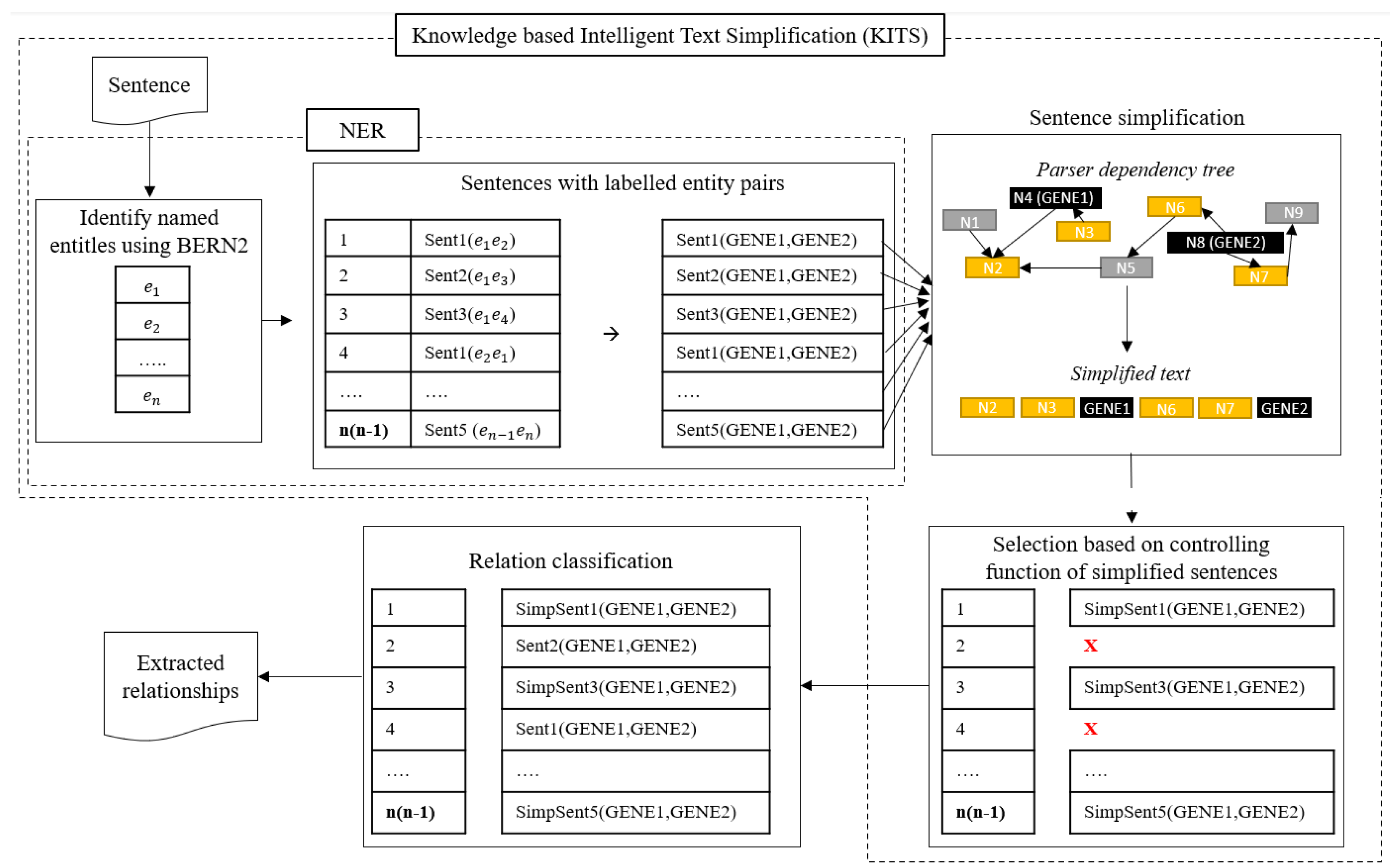
3. Materials and Methods
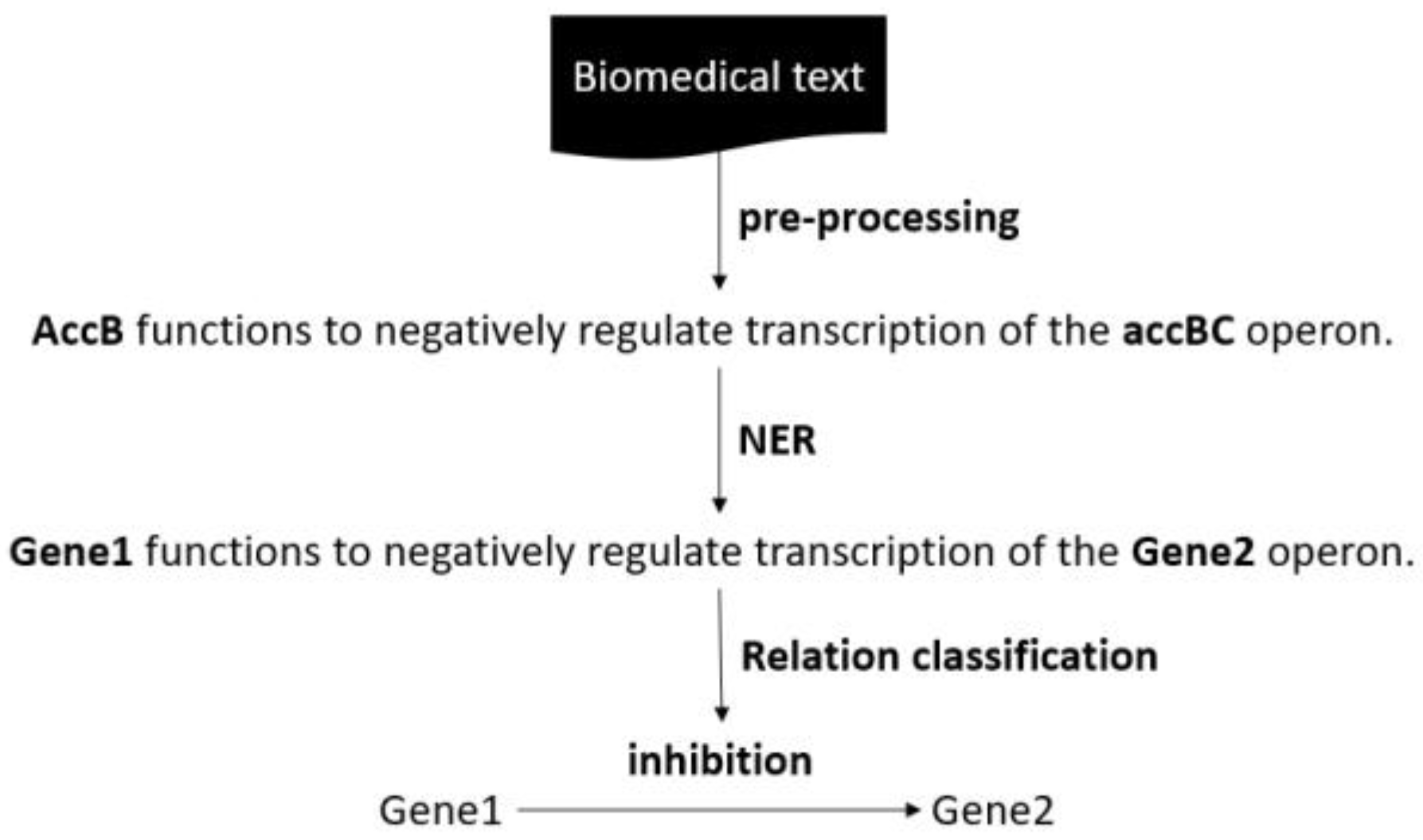
3.1. Named Entity Recognition (NER)
“A protein initially called Hst23 was identified as a product of the yvyD gene of Bacillus subtilis”
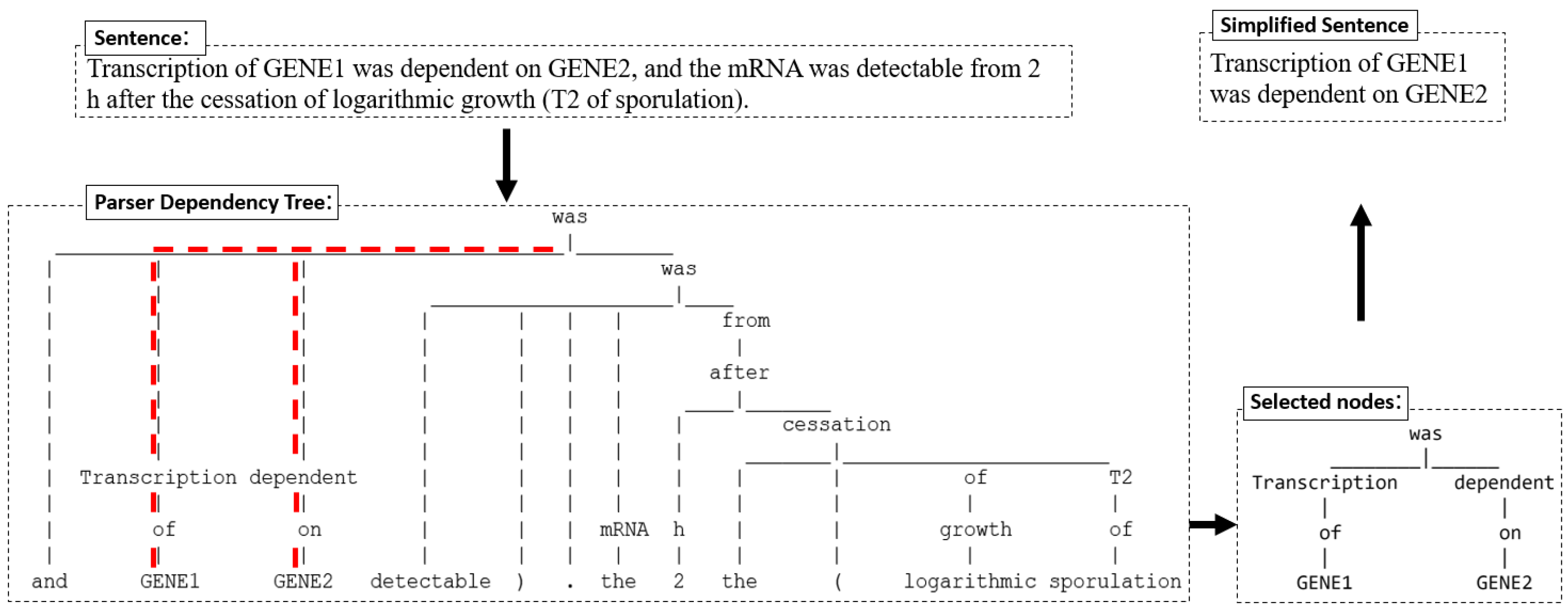
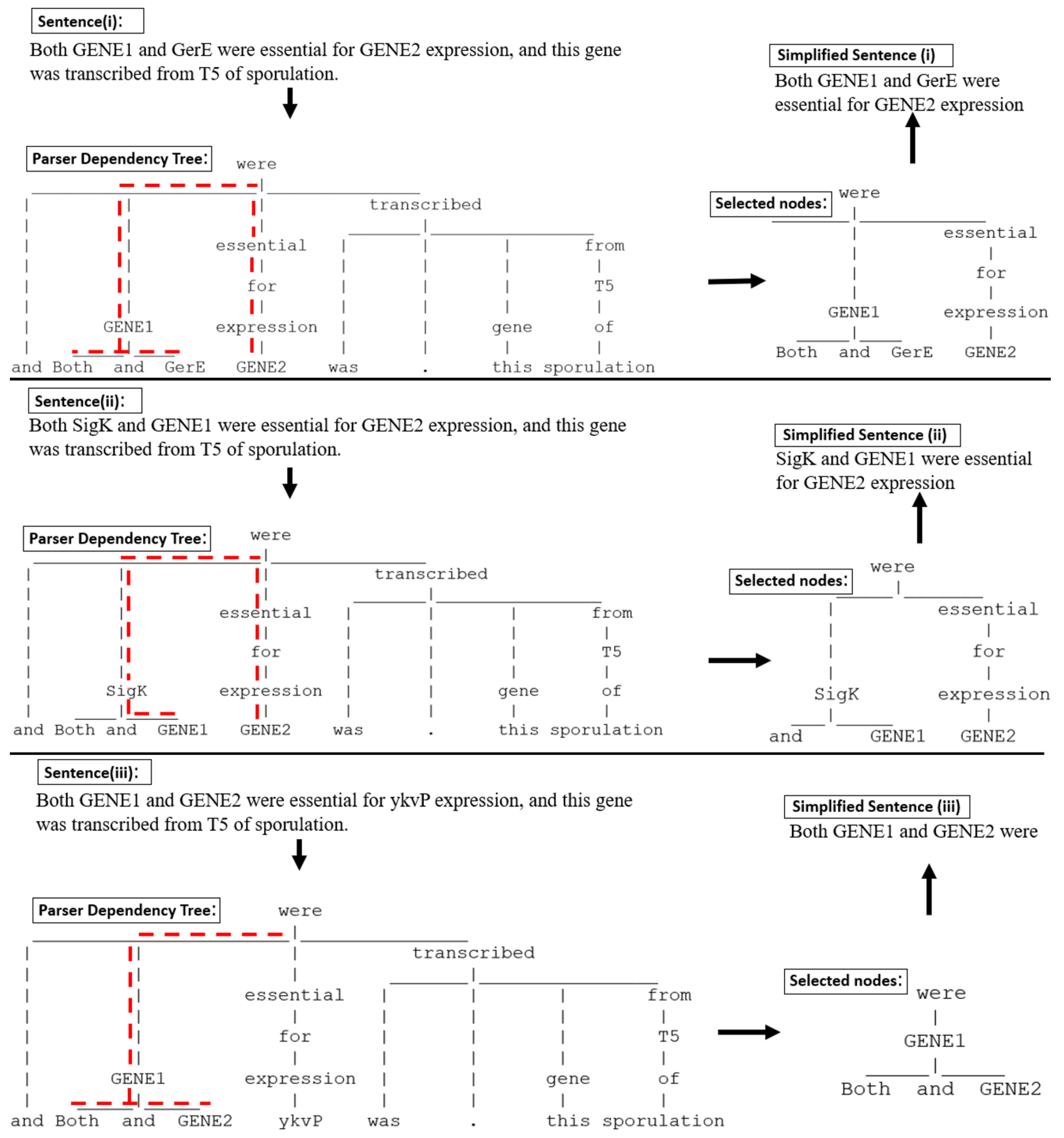
3.2. Text Simplification
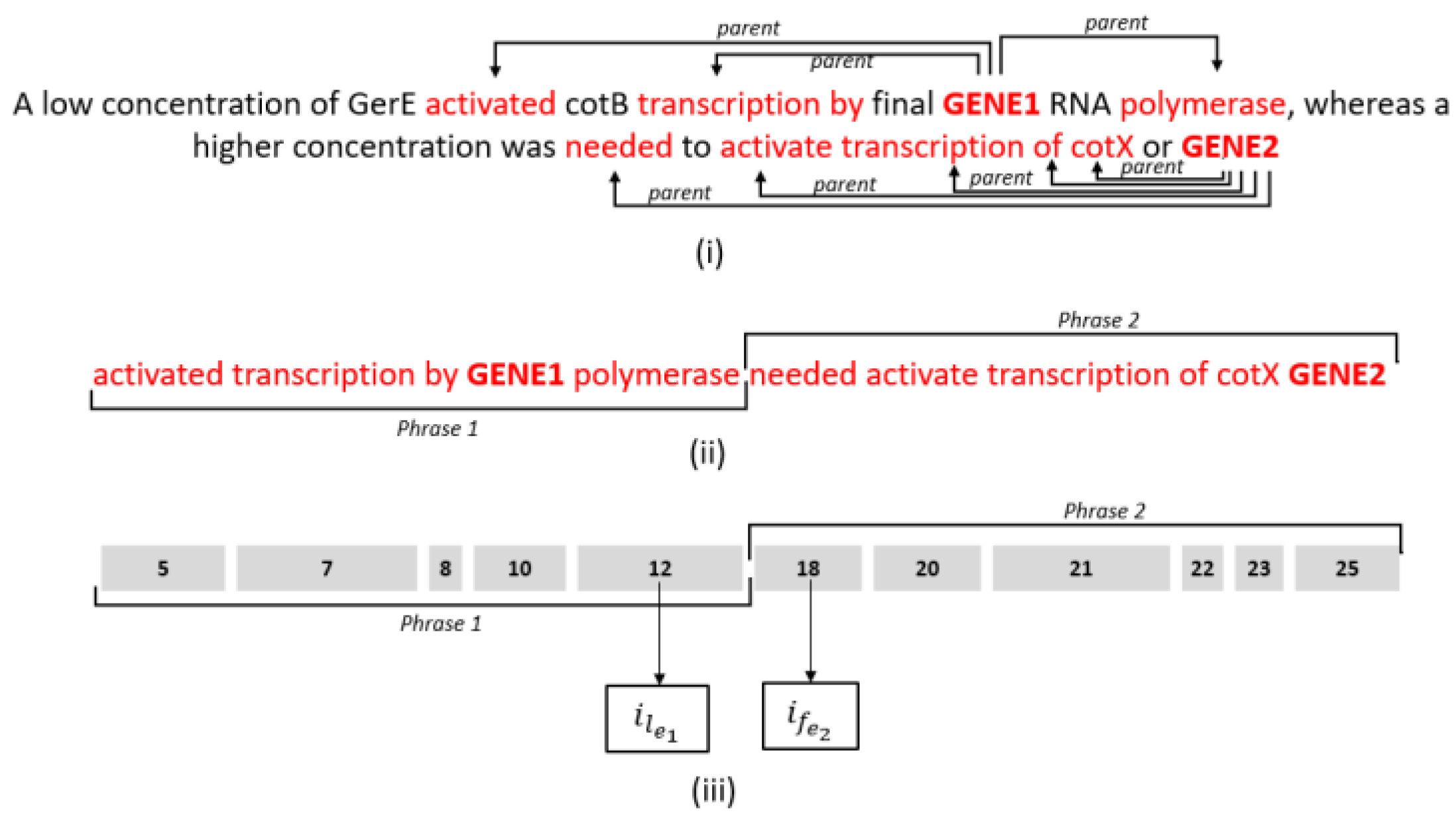
3.3. The Controlling Function for Simplified Sentences
4. Experiments and Results
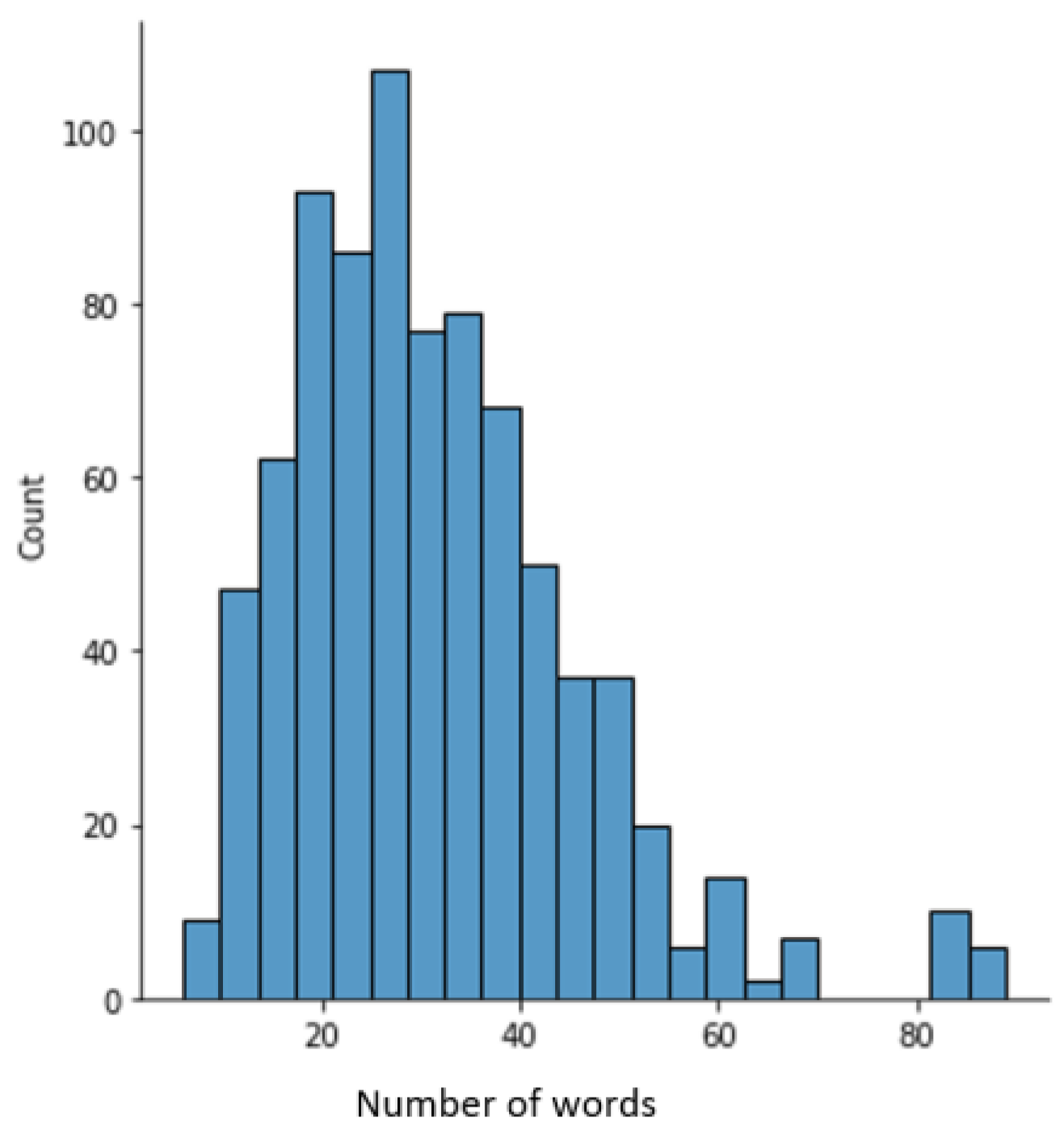
4.1. Datasets
4.2. Experimental Setup
4.3. The Experiment to Determine Threshold Value (
4.4. Results
4.5. Error Analysis
- Indirect relationships and the presence of negative terms such as ‘unable’ or ‘incapable’ make it more difficult for the model to accurately identify and extract positive relationships between entities. For instance, in the sentence “However, the mutant was unable to stimulate transcription by final GENE2-RNA polymerase from the GENE1-dependent spoIIG operon promoter”, the direct mention of the relationship between GENE1 and GENE2 is absent. Instead, the relationship between GENE1 and GENE2 is mediated through “the mutant” and “spollG”. Also, the presence of the negative term ‘unable’ poses challenges for the model to accurately classify this relationship as true.
- SpaCy’s ‘en_core_web_trf’ model may overlook the identification of all directly dependent nodes in certain cases. For example, the sentence “In this work, we show that GENE1 and GENE2 specifically interact with the Cdk1/CyclinB1 complex, but not with other Cdk/Cyclin complexes, in vitro and in vivo” was simplified to “show GENE1 and GENE2 interact”, resulting in the omission of important directly related nodes like “Cdk1/CyclinB1 complex”. This oversight could be attributed to entities being placed in a conjunctive form. To address this issue, an additional evaluation of conjunctive entity placement in sentences is necessary.
- While most phrases split by semicolons in the three datasets were independent clauses, the incorrectly rejected eight relations for BioInfer were from sentences in which the purpose of the semicolon was to separate complex items in a list. This issue can be mitigated by verifying the type of the phrase before elimination.
- Some sentences contain incorrect annotations. For instance, in the sentence “Quantitation of the appearance of X22 banding in primary cultures of myotubes indicates that it precedes that of other myofibrillar proteins and that assembly takes place in the following order GENE2 myosin heavy chain GENE1”, the annotation depicts a positive relationship between GENE1 and GENE2. However, the sentence conveys a placement order of the entities without implying a causal relationship.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Algorithm A1: NamedEntityRecognition(S) | |
|
Input: S = Set of sentences Output: L = Refined NER Tagged Sentences | |
| 1 | L ← Initialise an empty List variable to contain refined tagged sentences of Si |
| 2 | For i = 1 to S Do |
| 3 | Ei ← Get all recognised gene/protein entity using BERN2 |
| 4 | Pi (Ai, Ti) ← Identify all possible pairs from Ei |
| 5 | Li ← Initialise an empty List variable to contain tagged variations of Si |
| 6 | For p = 1 to Pi Do |
| 7 | Sip ← Replace Ai with GENE1 and Bi with GENE2 in Si |
| 8 | If Sip contains a semicolon Do |
| 9 | Ssplit ← Split Sip by delimitator |
| 10 | Stemp = ”” ← Initialise an empty String variable |
| 11 | For ss = 1 to Ssplit Do |
| 12 | If GENE1 and GENE2 in Sss Do |
| 13 | Stemp = Sss ← Replace the tagged sentence with independent clause |
| 14 | |
| 15 | Break loop |
| 16 | End If |
| 17 | End For |
| 18 | If Stemp != ”” Do |
| 19 | Sip = Stemp |
| 20 | End If |
| 21 | End If |
| 22 | Append Sip to Li ← Add the refined tagged sentence to Li |
| 23 | End For |
| 24 | Append Li to L ← Add the refined tagged sentence for Si to L |
| 25 | End For |
| Algorithm A2: TextSimplification(S) | |
| Input: S = Sentence Output: Ssimp = Simplified sentence Psimp = Index position of words in simplified sentence | |
| 1 | nlp ← load ‘en_core_web_sm’ from spaCy |
| 2 | Doc = nlp(S) ← Tokenise the sentences |
| 3 | Ssimp ← Initialise an empty list variable to save words of the simplified sentence |
| 4 | Psimp ← Initialise an empty list variable to save position of words of the simplified sentence |
| 5 | For token in Doc Do |
| 6 | Sc = Get the dependent nodes of token |
| 7 | Sh = Get the parent nodes of token |
| 8 | If “GENE1” in Sc or “GENE2” in Sc Do |
| 9 | Append token to Ssimp |
| 10 | Append Position(token) to Psimp |
| 11 | Else If “GENE1” in token or “GENE2” in token Do |
| 12 | Append Sh to Ssimp |
| 13 | Append Position(Sh) to Psimp |
| 14 | End If |
| 15 | End For |
| 16 | Ssimp ← Rearrange Ssimp as per their token position in Ssimp |
| Algorithm A3: ControllingFunctionEvaluation(Ssimp, Psimp, S) | |
| Input: Ssimp = Simplified sentence Psimp = Index position of words in simplified sentence S = Original sentence Output: Sf = Sentence used for relation classification | |
| 1 | Seqgene1 ← Identify phrase containing GENE1 |
| 2 | Seqgene1 ← Identify phrase containing GENE2 |
| 3 | If Seqgene1 not equal to Seqgene1 then |
| 4 | Seqgene1_last ← Get the position of last word in Seqgene1 |
| 5 | Seqgene2_first ← Get the position of first word in Seqgene2 |
| 6 | If abs(Seqgene2_first-Seqgene1_last) then |
| 7 | Sf = S |
| 8 | End If |
| 9 | Else |
| 10 | Sf = Ssimp |
| 11 | End If |
References
- Naseem, U.; Khushi, M.; Khan, S.K.; Shaukat, K.; Moni, M.A. A Comparative Analysis of Active Learning for Biomedical Text Mining. Appl. Syst. Innov. 2021, 4, 23. [Google Scholar] [CrossRef]
- Simon, C.; Davidsen, K.; Hansen, C.; Seymour, E.; Barnkob, M.B.; Olsen, L.R. BioReader: A text mining tool for performing classification of biomedical literature. BMC Bioinform. 2019, 19, 57. [Google Scholar] [CrossRef] [PubMed]
- Gamage, H.N.; Chetty, M.; Shatte, A.; Hallinan, J. Ensemble Regression Modelling for Genetic Network Inference. In Proceedings of the 2022 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), Ottawa, ON, Canada, 15–17 August 2022. [Google Scholar]
- Nair, A.; Chetty, M.; Wangikar, P.P. Improving gene regulatory network inference using network topology information. Mol. BioSystems 2015, 11, 2449–2463. [Google Scholar] [CrossRef] [PubMed]
- Morshed, N.; Chetty, M.; Vinh, N.X. Simultaneous learning of instantaneous and time-delayed genetic interactions using novel information theoretic scoring technique. BMC Syst. Biol. 2012, 6, 62. [Google Scholar] [CrossRef]
- Kononova, O.; He, T.; Huo, H.; Trewartha, A.; Olivetti, E.A.; Ceder, G. Opportunities and challenges of text mining in materials research. iScience 2021, 24, 102155. [Google Scholar] [CrossRef] [PubMed]
- Corlan, A.D. Medline Trend: Automated Yearly Statistics of PubMed Results for Any Query. Available online: http://dan.corlan.net/medline-trend.html (accessed on 14 February 2023).
- Mercatellia, D.; Scalambra, L.; Triboli, L.; Ray, F.; Giorgi, F.M. Gene regulatory network inference resources: A practical overview. Biochim. Et Biophys. Acta (BBA)-Gene Regul. Mech. 2020, 1863, 194430. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, H.; Yang, Z.; Wang, J.; Sun, Y.; Xu, B.; Zhao, Z. Neural network-based approaches for biomedical relation classification: A review. J. Biomed. Inform. 2019, 99, 103294. [Google Scholar] [CrossRef]
- BioCreative. BioCreative VI Challenge and Workshop. Available online: https://biocreative.bioinformatics.udel.edu/events/biocreative-vi/biocreative-vi-challenge/ (accessed on 12 November 2023).
- Peng, Y.; Rios, A.; Kavuluru, R.; Lu, Z. Extracting chemical–protein relations with ensembles of SVM and deep learning models. Database J. Biol. Databases Curation 2018, 2018, bay073. [Google Scholar] [CrossRef]
- Wang, H.; Qin, K.; Zakari, R.Y.; Lu, G.; Yin, J. Deep neural network-based relation extraction: An overview. Neural Comput. Appl. 2022, 34, 4781–4801. [Google Scholar] [CrossRef]
- Zhao, S.; Lu, C.S.Z.; Wang, F. Recent advances in biomedical literature mining. Brief. Bioinform. 2021, 22, bbaa057. [Google Scholar] [CrossRef]
- Kilicoglu, H. Biomedical text mining for research rigor and integrity: Tasks, challenges, directions. Brief. Bioinform. 2018, 19, 1400–1414. [Google Scholar] [CrossRef]
- Fleuren, W.W.; Alkema, W. Application of text mining in the biomedical domain. Methods 2015, 75, 97–106. [Google Scholar] [CrossRef] [PubMed]
- Nédellec, C. Learning language in logic—Genic interaction extraction challenge. In Proceedings of the Learning Language in Logic Workshop (LLL05), Bonn, Germany, 1 April 2005. [Google Scholar]
- Huang, C.-C.; Lu, Z. Community challenges in biomedical text mining over 10 years: Success, failure and the future. Brief. Bioinform. 2016, 17, 132–144. [Google Scholar] [CrossRef] [PubMed]
- Singhal, A.; Leaman, R.; Catlett, N.; Lemberger, T.; McEntyre, J.; Polson, S.; Xenarios, I.; Arighi, C.; Lu, Z. Pressing needs of biomedical text mining in biocuration and beyond: Opportunities and challenges. Database 2016, 2016, baw161. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Torii, M.; Wu, C.H.; Vijay-Shanker, K. A generalizable NLP framework for fast development of pattern-based biomedical relation extraction systems. BMC Bioinform. 2014, 15, 285. [Google Scholar] [CrossRef]
- Jonnalagadda, S.; Tari, L.; Hakenberg, J.; Baral, C.; Gonzalez, G. Towards Effective Sentence Simplification for Automatic Processing of Biomedical Text. arXiv 2010, arXiv:1001.4277. [Google Scholar]
- Bach, N.; Gao, Q.; Vogel, S.; Waibel, A. TriS: A Statistical Sentence Simplifier with Log-linear Models and Margin-based Discriminative Training. In Proceedings of the 5th International Joint Conference on Natural Language Processing, Chiang Mai, Thailand, 2 June 2011. [Google Scholar]
- Hakenberg, J.; Leaman, R.; Vo, N.H.; Jonnalagadda, S.; Sullivan, R.; Miller, C.; Tari, L.; Baral, C.; Gonzalez, G. Efficient extraction of protein-protein interactions from Full-Text Articles. IEEE/ACM Trans. Comput. Biol. Bioinform. 2010, 7, 481–494. [Google Scholar] [CrossRef]
- Miao, Q.; Zhang, S.; Zhang, B.; Yu, H. Extracting and Visualizing Semantic Relationships from Chinese Biomedical Text. In Proceedings of the 26th Pacific Asia Conference on Language, Information, and Computation, Bali, Indonesia, 7–10 November 2012. [Google Scholar]
- Ondov, B.; Attal, K.; Demner-Fushman, D. A survey of automated methods for biomedical text simplification. J. Am. Med. Inform. Assoc. 2022, 29, 976–1988. [Google Scholar] [CrossRef]
- Devaraj, A.; Marshall, I.J.; Wallace, B.C.; Li, J.J. Paragraph-level Simplification of Medical Texts. In Proceedings of the 2021 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Online, 6–11 June 2021. [Google Scholar]
- Wang, T.; Chen, P.; Rochford, J.; Qiang, J. Text Simplification Using Neural Machine Translation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Siddharthan, A. Text Simplification using Typed Dependencies: A Comparison of the robustness of different generation strategies. In Proceedings of the 13th European Workshop on Natural Language Generation, Nancy, France, 28–31 September 2011. [Google Scholar]
- Siddharthan, A. Hybrid text simplification using synchronous dependency grammars with hand-written and automatically harvested rules. In Proceedings of the 13th European Workshop on Natural Language Generation, Nancy, France, 28–31 September 2011. [Google Scholar]
- Chatterjee, N.; Agarwal, R. DEPSYM: A Lightweight Syntactic Text Simplification Approach using Dependency Trees. In Proceedings of the CTTS@ SEPLN, Málaga, Spain, 21–24 September 2021. [Google Scholar]
- Percha, B.; Altman, R.B. A global network of biomedical relationships derived from text. Bioinformatics 2018, 34, 2614–2624. [Google Scholar] [CrossRef]
- Fundel, K.; Küffner, R.; Zimmer, R. RelEx—Relation extraction using dependency parse trees. Bioinformatics 2007, 23, 365–371. [Google Scholar] [CrossRef]
- Zhou, D.; Zhong, D.; He, Y.I.S. Biomedical Relation Extraction: From Binary to Complex. Comput. Math. Methods Med. 2014, 2014, 298473. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Yu, Z.; Guo, Y.; Bian, J.; Wu, Y. Clinical Relation Extraction Using Transformer-based Models. arXiv 2021, arXiv:2107.08957. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Goyal, A.; Gupta, V.; Kumar, M. Recent Named Entity Recognition and Classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Habibi, M.; Weber, L.; Neves, M.; Wiegandt, D.L.; Leser, U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 2017, 33, i37–i48. [Google Scholar] [CrossRef]
- Raul Garreta, G.M.T.H.G.H. Scikit-Learn: Machine Learning Simplified: Implement Scikit-Learn into Every Step of the Data Science Pipeline; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J.W.J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Sung, M.; Jeong, M.; Choi, Y.; Kim, D.; Lee, J.; Kang, J. BERN2: An advanced neural biomedical named entity recognition and normalization tool. Bioinformatics 2022, 38, 4837–4839. [Google Scholar] [CrossRef]
- Vacariu, A.V. A High-Throughput Dependency Parser. 2017. Available online: https://summit.sfu.ca/item/17739 (accessed on 4 September 2023).
- Siddharthan, A. A survey of research on text simplification. ITL-Int. J. Appl. Linguist. 2014, 165, 259–298. [Google Scholar] [CrossRef]
- Millstein, F. NLTK, Natural Language Processing with Python: Natural Language Processing Using. 2020. Available online: https://scholar.google.com.hk/scholar?hl=zh-TW&as_sdt=0%2C5&q=NLTK%2C+Natural+Language+Processing+with+Python%3A+Natural+Language+Processing+Using&btnG=#d=gs_cit&t=1702266004906&u=%2Fscholar%3Fq%3Dinfo%3ARrd7HVVyN8IJ%3Ascholar.google.com%2F%26output%3Dcite%26scirp%3D0%26hl%3Dzh-TW (accessed on 4 September 2023).
- Nazaruka, E.; Osis, J.; Griberman, V. Using Stanford CoreNLP Capabilities for Semantic Information Extraction from Textual Descriptions. In Proceedings of the International Conference on Evaluation of Novel Approaches to Software Engineering, Heraklion, Greece, 4–5 May 2019. [Google Scholar]
- Okhapkin, V.P.; Okhapkina, E.P.; Iskhakova, A.O.; Iskhakov, A.Y. Constructing of Semantically Dependent Patterns Based on SpaCy and StanfordNLP Libraries. In Proceedings of the Futuristic Trends in Network and Communication Technologies: Third International Conference, FTNCT 2020, Taganrog, Russia, 14–16 October 2020. [Google Scholar]
- Vasiliev, Y. Natural Language Processing with Python and spaCy: A Practical Introduction; No Starch Press: San Francisco, CA, USA, 2020. [Google Scholar]
- Honnibal, M.; Montani, I.; Landeghem, S.V.; Boyd, A. spaCy: Industrial-strength Natural Language Processing in Python. 2020. Available online: https://github.com/explosion/spaCy (accessed on 4 September 2023).
- Ramesh, S.; Tiwari, A.; Choubey, P.; Kashyap, S.; Khose, S.; Lakara, K.; Singh, N.; Verma, U. BERT based Transformers lead the way in Extraction of Health Information from Social Media. In Proceedings of the Sixth Social Media Mining for Health Workshop, Mexico City, Mexico, 10 June 2021. [Google Scholar]
- Algamdi, S.; Albanyan, A.; Shah, S.K.; Tariq, Z. Twitter Accounts Suggestion: Pipeline Technique SpaCy Entity Recognition. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022. [Google Scholar]
- Kandji, A.K.; Ndiaye, S. Design and realization of an NLP application for the massive processing of large volumes of resumes. In Proceedings of the IEEE Multi-conference on Natural and Engineering Sciences for Sahel’s Sustainable Development (MNE3SD), Bobo-Dioulasso, Burkina Faso, 23–25 February 2023. [Google Scholar]
- Pyysalo, S.; Ginter, F.; Heimonen, J.; Björne, J.; Boberg, J.; Järvinen, J.; Salakoski, T. BioInfer: A corpus for information extraction in the biomedical domain. BMC Bioinform. 2007, 8, 50. [Google Scholar] [CrossRef]
- Panyam, K.V.N.C.; Cohn, T.; Ramamohanarao, K. Exploiting graph kernels for high performance biomedical relation extraction. J. Biomed. Semant. 2018, 9, 7. [Google Scholar] [CrossRef]
- Chang, Y.-C.; Chu, C.-H.; Su, Y.-C.; Chen, C.C.; Hsu, W.-L. PIPE: A protein-protein interaction passage extraction module for BioCreative challenge. Database J. Biol. Databases Curation 2016, 2016, 101. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Guan, R.; Zhou, F.; Liang, Y.; Zhan, Z.-H.; Huang, L.; Feng, X. A protein-protein interaction extraction approach based on deep neural network. IEEE Access 2019, 7, 89354–89365. [Google Scholar] [CrossRef]
- Zhang, Y.; Lin, H.; Yang, Z.; Wang, J.; Zhang, S.; Sun, Y.; Yang, L. A hybrid model based on neural networks for biomedical relation. J. Biomed. Inform. 2018, 81, 83–92. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.; Islam, J.; Samee, M.R.; Mercer, R.E. Identifying Protein-Protein Interaction using Tree LSTM and Structured Attention. In Proceedings of the 2019 IEEE 13th international conference on semantic computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019. [Google Scholar]
- Park, G.; McCorkle, S.; Soto, C.; Blaby, I.; Yoo, S. Extracting Protein-Protein Interactions (PPIs) from Biomedical Literature using Attention-based Relational Context Infor-mation. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 2052–2061. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Positive | Negative | Unique Sentences |
|---|---|---|---|
| BioInfer | 2534 | 7132 | 1100 |
| HPRD50 | 163 | 270 | 145 |
| LLL | 164 | 166 | 77 |
| Dataset | LLL | HPRD50 | BioInfer | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model | DTC | BioBERT | DTC | BioBERT | DTC | BioBERT | ||||||
| Threshold | P | F | P | F | P | F | P | F | P | F | P | F |
| = 2 | 68.23 | 61.35 | 79.34 | 78.88 | - | - | - | - | - | - | - | - |
| = 3 | 75.57 | 76.23 | 81.23 | 82.43 | - | - | - | - | - | - | - | - |
| = 4 | 79.89 | 72.45 | 84.56 | 83.24 | 57.27 | 54.51 | 72.41 | 72.35 | 74.23 | 61.32 | 78.76 | 65.78 |
| = 5 | 82.96 | 79.87 | 86.37 | 87.67 | 64.76 | 68.11 | 86.28 | 88.02 | 76.10 | 65.98 | 77.65 | 73.16 |
| = 6 | 81.21 | 76.45 | 85.67 | 86.21 | 64.76 | 68.11 | 84.54 | 87.21 | 78.23 | 63.04 | 71.54 | 72.42 |
| = 7 | 72.34 | 68.11 | 79.96 | 81.31 | - | - | - | - | - | - | - | - |
| = 8 | 67.45 | 64.98 | 75.43 | 74.56 | - | - | - | - | - | - | - | - |
| Dataset | BioInfer | HPRD50 | LLL | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | P | F | P | F | P | F | |||
| ASM | 67.20 | 22.60 | 33.80 | 66.00 | 58.30 | 61.90 | 79.3 | 28.00 | 41.4 |
| APG | 68.60 | 28.60 | 40.40 | 62.30 | 69.90 | 65.90 | 84.70 | 57.30 | 68.30 |
| PIPE | 57.60 | 59.90 | 58.70 | 62.50 | 83.30 | 71.40 | 73.20 | 89.60 | 80.60 |
| DTC (w/o KITS) | 66.20 | 62.01 | 64.25 | 50.77 | 64.24 | 59.35 | 62.01 | 66.76 | 64.30 |
| DTC (w KITS) | 76.10 | 64.96 | 65.98 | 64.76 | 78.13 | 68.11 | 82.96 | 76.74 | 79.87 |
| Dataset | BioInfer | HPRD50 | LLL | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Method | P | F | P | F | P | F | |||
| PIPE | 57.60 | 59.90 | 58.70 | 62.50 | 83.30 | 71.40 | 73.20 | 89.60 | 80.60 |
| DNN | 53.90 | 72.90 | 61.60 | 58.70 | 92.40 | 71.30 | 76.00 | 91.00 | 81.40 |
| RNN + CNN | 56.70 | 67.30 | 61.30 | 69.60 | 82.70 | 75.10 | 72.50 | 87.20 | 76.50 |
| iLSTM + tAttn | 61.80 | 54.20 | 57.60 | 78.60 | 78.70 | 78.50 | 84.80 | 84.30 | 84.20 |
| BioBERT (w/o KITS) | 70.14 | 79.25 | 74.31 | 76.45 | 80.36 | 75.24 | 70.80 | 84.23 | 83.81 |
| BioBERT (w KITS) | 73.16 | 85.66 | 77.65 | 86.28 | 81.43 | 88.02 | 86.37 | 91.16 | 87.67 |
| Dataset | Number of Sentences Successfully Simplified |
|---|---|
| LLL | 84 |
| HPRD50 | 185 |
| BioInfer | 3566 |
| Dataset | BioInfer | HPRD50 | LLL | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | P | Sf | F | P | Sf | F | P | Sf | F | |||
| DTC (w/o KITS) | 53.37 | 46.01 | 68.25 | 50.74 | 53.75 | 66.71 | 72.82 | 50.47 | 72.02 | 71.76 | 47.23 | 70.23 |
| DTC (w KITS) | 75.30 | 65.38 | 82.47 | 68.49 | 69.49 | 68.71 | 87.16 | 59.46 | 86.96 | 82.47 | 91.18 | 85.67 |
| BioBERT (w/o KITS) | 73.67 | 71.76 | 78.43 | 77.84 | 79.24 | 74.85 | 83.75 | 76.78 | 79.21 | 83.54 | 78.91 | 80.45 |
| BioBERT (w KITS) | 86.31 | 89.67 | 91.57 | 84.76 | 84.32 | 89.81 | 94.69 | 87.34 | 91.92 | 94.69 | 97.23 | 93.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gill, J.; Chetty, M.; Lim, S.; Hallinan, J. Knowledge-Based Intelligent Text Simplification for Biological Relation Extraction. Informatics 2023, 10, 89. https://doi.org/10.3390/informatics10040089
Gill J, Chetty M, Lim S, Hallinan J. Knowledge-Based Intelligent Text Simplification for Biological Relation Extraction. Informatics. 2023; 10(4):89. https://doi.org/10.3390/informatics10040089
Chicago/Turabian StyleGill, Jaskaran, Madhu Chetty, Suryani Lim, and Jennifer Hallinan. 2023. "Knowledge-Based Intelligent Text Simplification for Biological Relation Extraction" Informatics 10, no. 4: 89. https://doi.org/10.3390/informatics10040089
APA StyleGill, J., Chetty, M., Lim, S., & Hallinan, J. (2023). Knowledge-Based Intelligent Text Simplification for Biological Relation Extraction. Informatics, 10(4), 89. https://doi.org/10.3390/informatics10040089