

A Method for Analyzing Navigation Flows of Health Website Users Seeking Complex Health Information with Google Analytics


Abstract
:1. Background
2. Methods
2.1. Data Sources
2.2. Device and Traffic Types
2.3. Working with Paths of Web Pages
2.4. Deriving Navigation Flows
3. Results
3.1. Device and Traffic Types
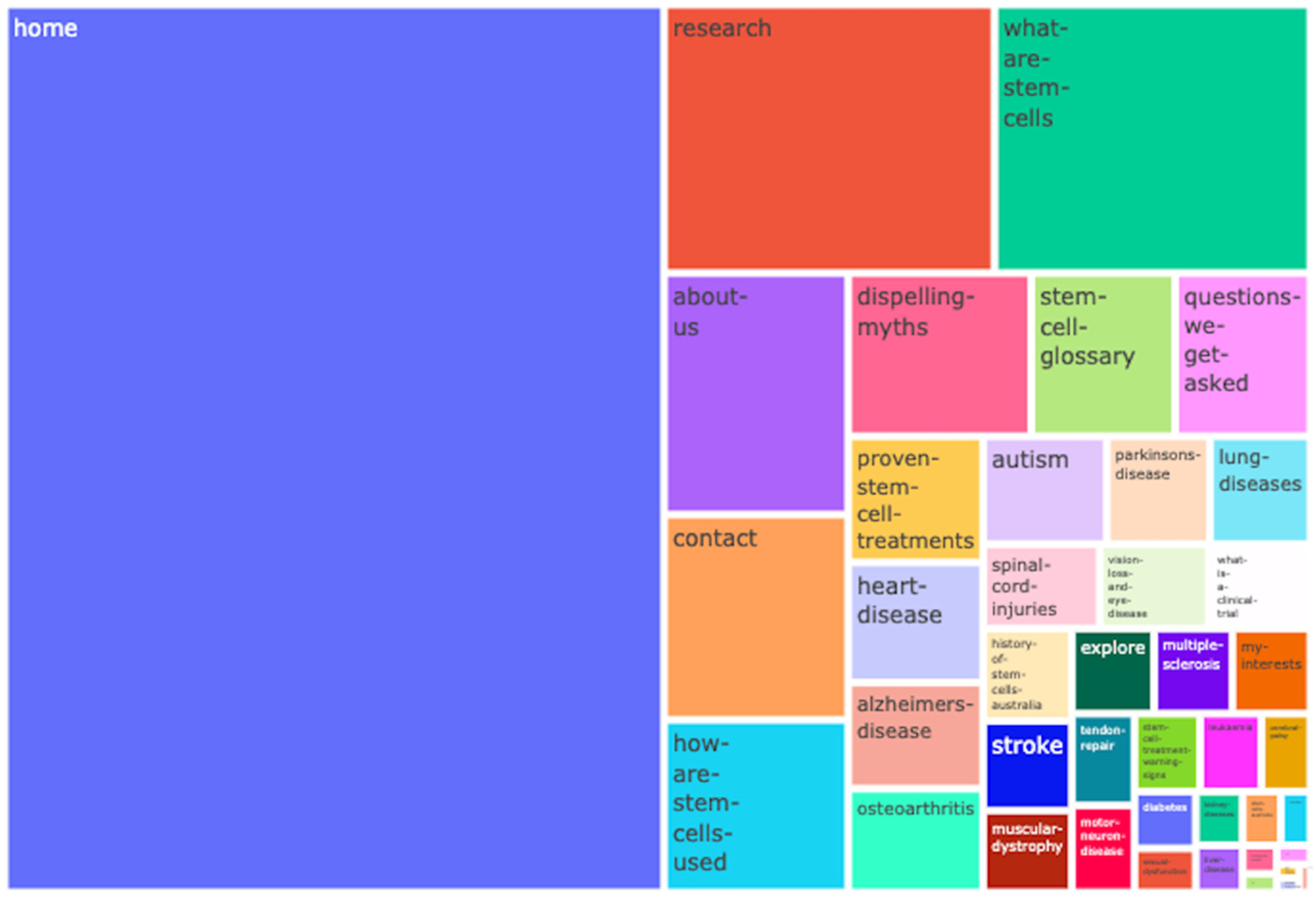
3.2. Path Analysis Results
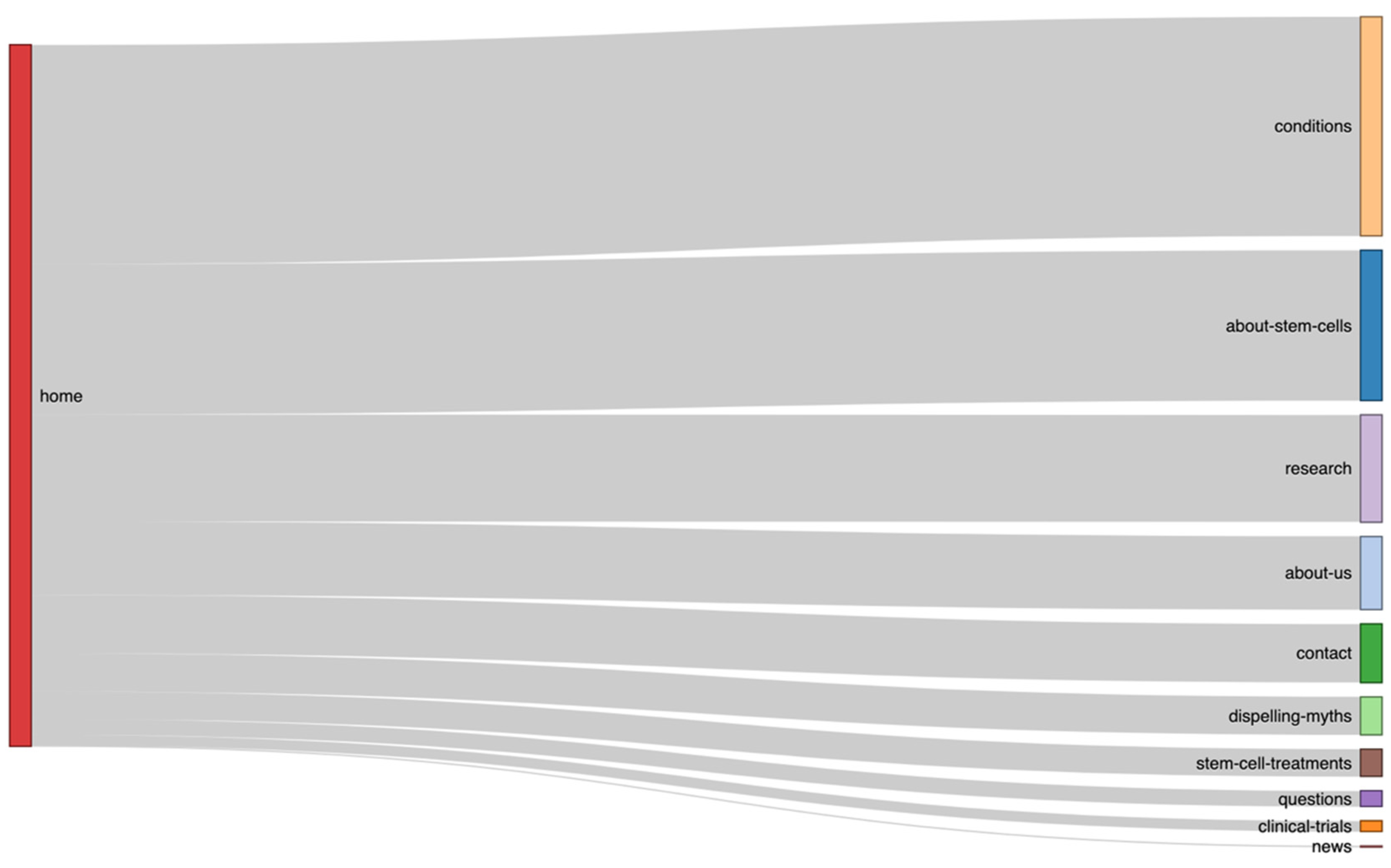
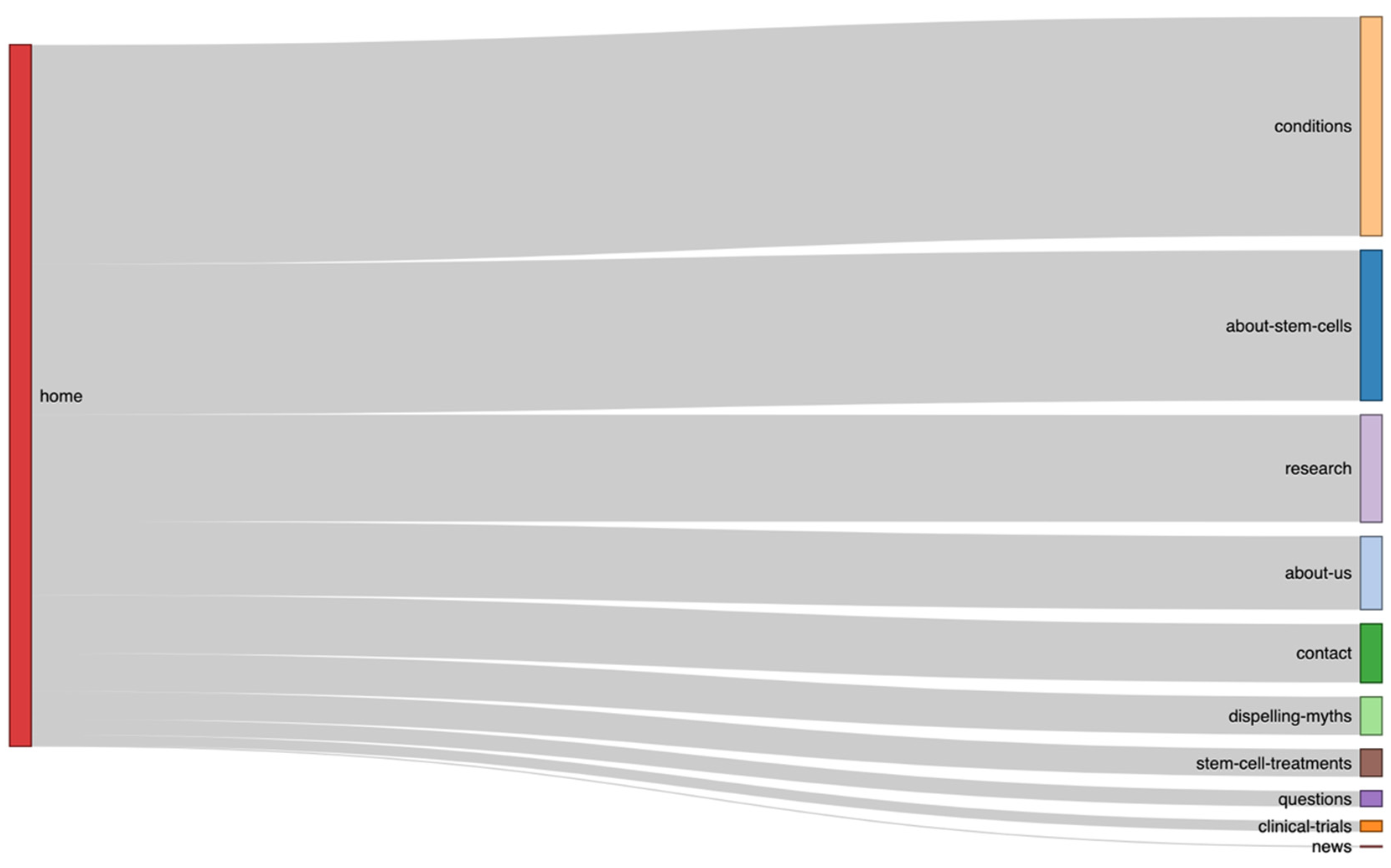
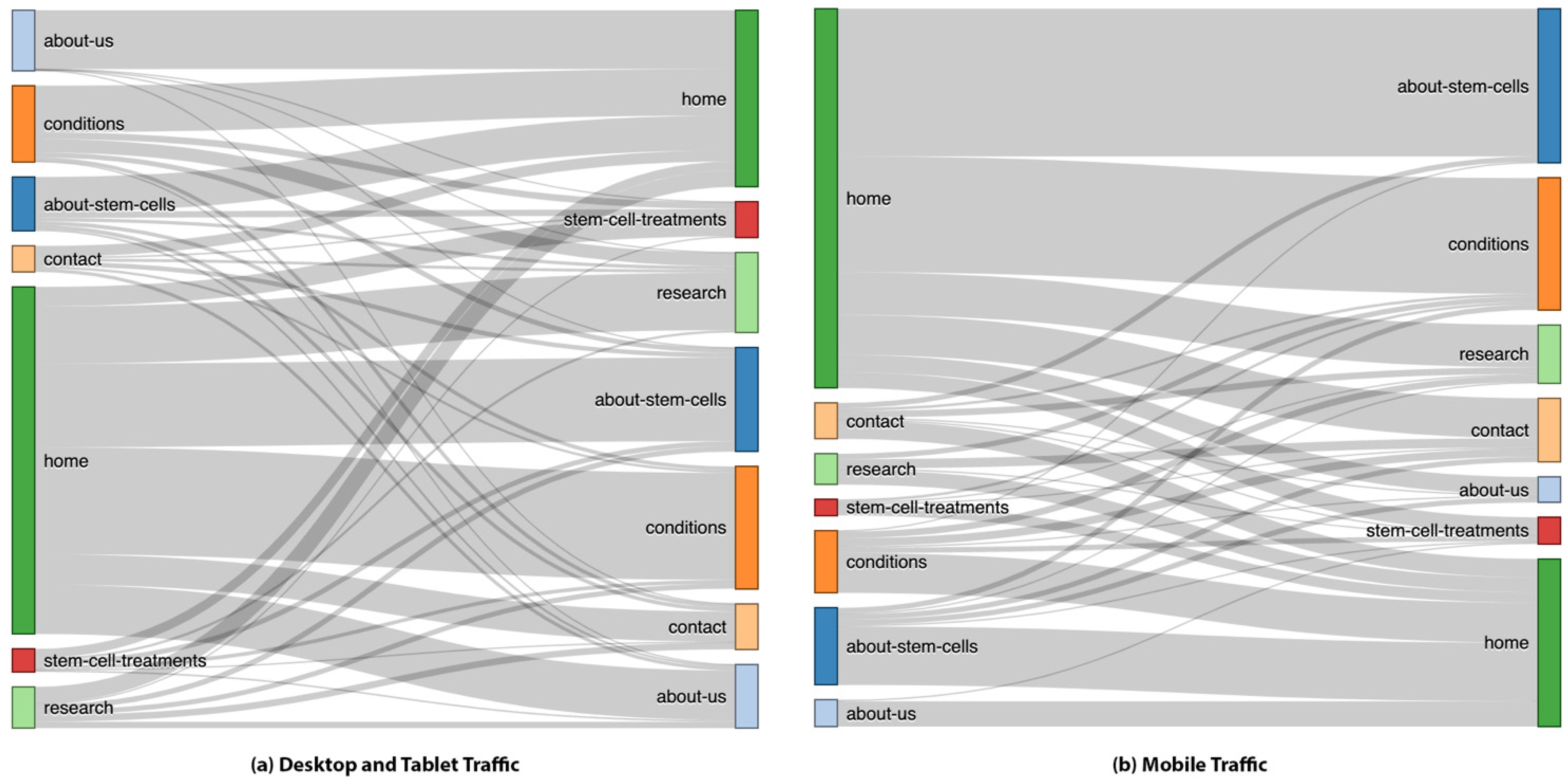
3.3. Results of Navigation Flow Analysis
4. Discussion
4.1. Principal Findings
4.2. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| GA | Google Analytics |
| SCA | Stem Cells Australia |
| URL | Uniform Resource Locator |
References
- Tao, D.; LeRouge, C.; Smith, K.J.; De Leo, G. Defining Information Quality Into Health Websites: A Conceptual Framework of Health Website Information Quality for Educated Young Adults. JMIR Hum. Factors 2017, 4, e25. [Google Scholar] [CrossRef] [PubMed]
- Gutierrez, N.; Kindratt, T.B.; Pagels, P.; Foster, B.; Gimpel, N.E. Health Literacy, Health Information Seeking Behaviors and Internet Use Among Patients Attending a Private and Public Clinic in the Same Geographic Area. J. Community Health 2014, 39, 83–89. [Google Scholar] [CrossRef]
- Zimmerman, M.S.; Shaw, G. Health Information Seeking Behaviour: A Concept Analysis. Health Inf. Libr. J. 2020, 37, 173–191. [Google Scholar] [CrossRef]
- Ahmed, H.; Jilani, T.A.; Haider, W.; Abbasi, M.A.; Nand, S.; Kamran, S. Establishing Standard Rules for Choosing Best KPIs for an E-Commerce Business Based on Google Analytics and Machine Learning Technique. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 5. [Google Scholar] [CrossRef]
- Filvà, D.A.; Guerrero, M.J.C.; Forment, M.A. Google Analytics for Time Behavior Measurement in Moodle. In Proceedings of the 2014 9th Iberian Conference on Information Systems and Technologies (CISTI), Barcelona, Spain, 18–21 June 2014; pp. 1–6. [Google Scholar]
- Luo, H.; Rocco, S.; Schaad, C. Using Google Analytics to Understand Online Learning: A Case Study of a Graduate-Level Online Course. In Proceedings of the 2015 International Conference of Educational Innovation through Technology (EITT), Wuhan, China, 16–18 October 2015; pp. 264–268. [Google Scholar]
- Plaza, B. Monitoring Web Traffic Source Effectiveness with Google Analytics. Aslib Proc. 2009, 61, 474–482. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Harrop, M.; Verspoor, K.; Pearce, J.; Chang, S. What Are Health Website Visitors Doing: Insights from Visualisations towards Exploratory Search. In Proceedings of the 28th Australian Conference on Computer-Human Interaction; Association for Computing Machinery: New York, NY, USA, 2016; pp. 631–633. [Google Scholar]
- Fundingsland, E.L., Jr.; Fike, J.; Calvano, J.; Beach, J.; Lai, D.; He, S. Methodological Guidelines for Systematic Assessments of Health Care Websites Using Web Analytics: Tutorial. J. Med. Internet Res. 2022, 24, e28291. [Google Scholar] [CrossRef]
- Crutzen, R.; Roosjen, J.L.; Poelman, J. Using Google Analytics as a Process Evaluation Method for Internet-Delivered Interventions: An Example on Sexual Health. Health Promot. Int. 2013, 28, 36–42. [Google Scholar] [CrossRef]
- Song, M.J.; Ward, J.; Choi, F.; Nikoo, M.; Frank, A.; Shams, F.; Tabi, K.; Vigo, D.; Krausz, M. A Process Evaluation of a Web-Based Mental Health Portal (WalkAlong) Using Google Analytics. JMIR Ment. Health 2018, 5, e50. [Google Scholar] [CrossRef] [PubMed]
- Jeong, D.; Cheng, M.; St-Jean, M.; Jalali, A. Evaluation of eMentalHealth.ca, a Canadian Mental Health Website Portal: Mixed Methods Assessment. JMIR Ment. Health 2019, 6, e13639. [Google Scholar] [CrossRef]
- Kirk, M.; Morgan, R.; Tonkin, E.; McDonald, K.; Skirton, H. An Objective Approach to Evaluating an Internet-Delivered Genetics Education Resource Developed for Nurses: Using Google AnalyticsTM to Monitor Global Visitor Engagement. J. Res. Nurs. 2012, 17, 557–579. [Google Scholar] [CrossRef]
- Pakkala, H.; Presser, K.; Christensen, T. Using Google Analytics to Measure Visitor Statistics: The Case of Food Composition Websites. Int. J. Inf. Manag. 2012, 32, 504–512. [Google Scholar] [CrossRef]
- Burgess, K.; Atkinson, K.M.; Westeinde, J.; Crowcroft, N.; Deeks, S.L.; Wilson, K. Barriers and Facilitators to the Use of an Immunization Application: A Qualitative Study Supplemented with Google Analytics Data. J. Public Health 2017, 39, e118–e126. [Google Scholar] [CrossRef] [PubMed]
- Gordon, E.J.; Shand, J.; Black, A. Google Analytics of a Pilot Mass and Social Media Campaign Targeting Hispanics about Living Kidney Donation. Internet Interv. 2016, 6, 40–49. [Google Scholar] [CrossRef]
- Chong, C.; Smekal, M.; Hemmelgarn, B.; Elliott, M.; Allu, S.; Wick, J.; McBrien, K.; Jackson, W.; Bello, A.; Jindal, K.; et al. Use of Google Analytics to Explore Dissemination Activities for an Online CKD Clinical Pathway: A Retrospective Study. Can. J. Kidney Health Dis. 2022, 9, 20543581221097456. [Google Scholar] [CrossRef]
- Ogrodniczuk, J.S.; Beharry, J.; Oliffe, J.L. An Evaluation of 5-Year Web Analytics for HeadsUpGuys: A Men’s Depression E-Mental Health Resource. Am. J. Men’s Health 2021, 15, 15579883211063322. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Munsie, M.; Chang, S.; Tanner, C.; Walker, C. Participatory Design and Evaluation of “Stem Cell Australia” Website for Delivering Complex Health Knowledge: Mixed Methods Approach. J. Med. Internet Res. 2023, 25, e44733. [Google Scholar] [CrossRef]
- Komenda, M.; Víta, M.; Vaitsis, C.; Schwarz, D.; Pokorná, A.; Zary, N.; Dušek, L. Curriculum Mapping with Academic Analytics in Medical and Healthcare Education. PLoS ONE 2015, 10, e0143748. [Google Scholar] [CrossRef]
- Massanelli, J.; Sexton, K.W.; Lesher, C.T.; Jensen, H.K.; Kimbrough, M.K.; Privratsky, A.; Taylor, J.R.; Bhavaraju, A. Integration of Web Analytics Into Graduate Medical Education: Usability Study. JMIR Form. Res. 2021, 5, e29748. [Google Scholar] [CrossRef]
- Chen, S.-C.; Tsao, T.C.-Y.; Lue, K.-H.; Tsai, Y. Google Analytics of a Pilot Study to Characterize the Visitor Website Statistics and Implicate for Enrollment Strategies in Medical University. BMC Med. Educ. 2020, 20, 483. [Google Scholar] [CrossRef] [PubMed]
- Clark, D.J.; Nicholas, D.; Jamali, H.R. Evaluating Information Seeking and Use in the Changing Virtual World: The Emerging Role of Google Analytics. Learn. Publ. 2014, 27, 185–194. [Google Scholar] [CrossRef]
- Google Path Exploration. Available online: https://support.google.com/analytics/answer/9317498?hl=en (accessed on 1 July 2022).
- Google Glossary: Session. Available online: https://support.google.com/analytics/answer/6086069?hl=en (accessed on 1 July 2022).
- Tanner, C.; Petersen, A.; Munsie, M. ‘No One Here’s Helping Me, What Do You Do?’: Addressing Patient Need for Support and Advice about Stem Cell Treatments. Regen. Med. 2017, 12, 791–801. [Google Scholar] [CrossRef] [PubMed]
- Australian Research Council Stem Cells Australia Highlights ARC-Funded Research. Available online: https://www.arc.gov.au/news-publications/media/research-highlights/stem-cells-australia-highlights-arc-funded-research (accessed on 1 August 2022).
- Kennedy, A.B.W.; Sankey, H.R. The Thermal Efficiency of Steam Engines. Minutes Proc. Inst. Civ. Eng. 1898, 134, 278–312. [Google Scholar] [CrossRef]
- Lee, K.; Hoti, K.; Hughes, J.D.; Emmerton, L. Dr Google and the Consumer: A Qualitative Study Exploring the Navigational Needs and Online Health Information-Seeking Behaviors of Consumers with Chronic Health Conditions. J. Med. Internet Res. 2014, 16, e262. [Google Scholar] [CrossRef]
- Marchionini, G. Exploratory Search: From Finding to Understanding. Commun. ACM 2006, 49, 41–46. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Verspoor, K.; Chang, S.; Pearce, J. Conceptualising Health Information Seeking Behaviours and Exploratory Search: Result of a Qualitative Study. Health Technol. 2015, 5, 45–55. [Google Scholar] [CrossRef]
- Petersen, A.; Tanner, C.; Munsie, M. Navigating the Cartographies of Trust: How Patients and Carers Establish the Credibility of Online Treatment Claims. Sociol. Health Illn. 2019, 41, 50–64. [Google Scholar] [CrossRef]
- Pang, P.C.-I.; Temple-Smith, M.; Bellhouse, C.; Trieu, V.-H.; Kiropoulos, L.; Williams, H.; Coomarasamy, A.; Brewin, J.; Bowles, A.; Bilardi, J. Online Health Seeking Behaviours: What Information Is Sought by Women Experiencing Miscarriage? Stud. Health Technol. Inform. 2018, 252, 118–125. [Google Scholar]
- Zarzeczny, A.; Tanner, C.; Barfoot, J.; Blackburn, C.; Couturier, A.; Munsie, M. Contact Us for More Information: An Analysis of Public Enquiries about Stem Cells. Regen. Med. 2020, 14, 1137–1150. [Google Scholar] [CrossRef]


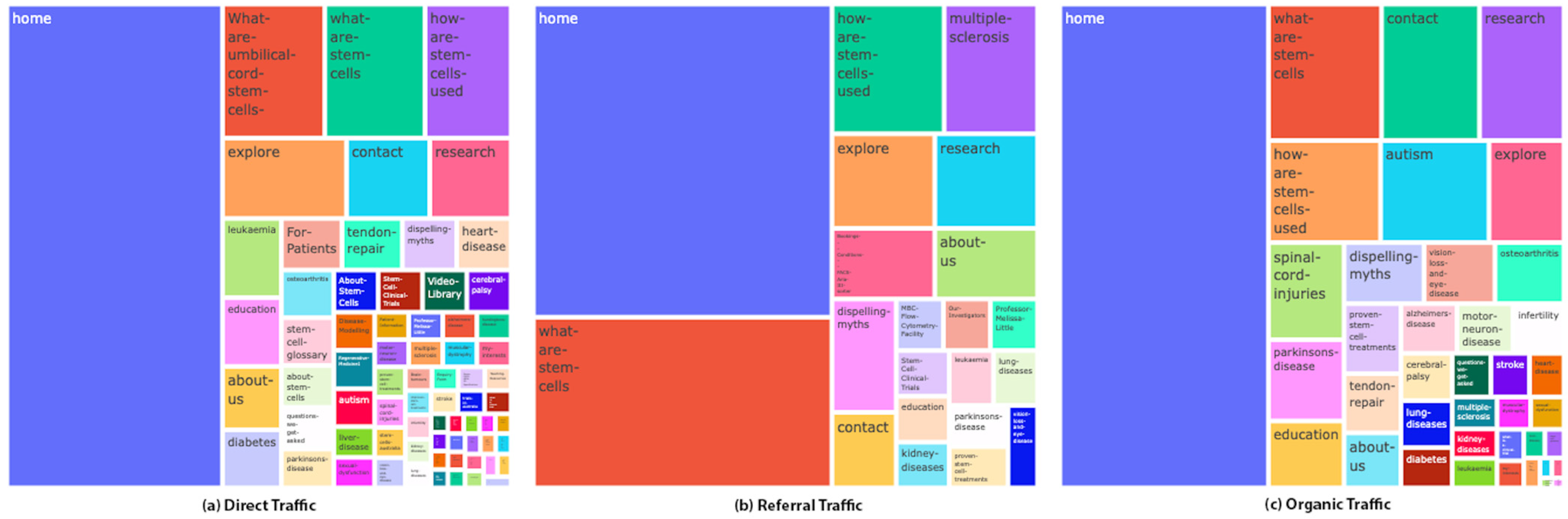


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Research That Used the Variable |
|---|---|---|
| New and Returning Users | The numbers of users that are new to a website or revisiting a website | [4,13,16] |
| Session Count and Length | A session refers to a period of time that a user is active on a website. These variables count the number of sessions and their durations | [16,17,18,20,21] |
| Bounce Rate | Bounce rate is the ratio of users that visit a website exiting without going to the second page. It usually means that users do not achieve their goals through interacting with a website | [6,7,10,13,16,17,18,20,21] |
| Time on Site | The duration of time users spent on a website | [6,10,13,16,17,18,20,21,22] |
| Page Views | The total number of web pages viewed in a session on a website | [7,10,11,13,16,17,18,20,21,22] |
| Path (Collected from GA) | Top Category (Derived) | Sub-Category (Derived) | Number of Views |
|---|---|---|---|
| /about/about-stem-cells/how-are-stem-cells-used/ | about | about-stem-cells | 140 |
| /conditions/explore/spinal-cord-injuries/ | conditions | explore | 74 |
| /conditions/explore/osteoarthritis/ | conditions | explore | 68 |
| /contact/ | contact | (N/A) | 12 |
| /Research/ | research | (N/A) | 12 |
| Path | Previous Page Path | Number of Views |
|---|---|---|
| /about-stem-cells/for-patients.aspx | /(denotes the home page) | 274 |
| /contact/ | /research/ | 12 |
| /News-Events/What-s-On-.aspx | /News-Events.aspx | 6 |
| /conditions/explore/parkinsons-disease/ | /conditions/explore/autism/ | 5 |
| /Our-Research/Previous-Research-Programs.aspx | /about/AboutUs.aspx | 10 |
| Origin | Destination | Number of Views |
|---|---|---|
| home | about-stem-cells | 274 |
| research | contact | 12 |
| news-events | news-events | 6 |
| conditions | conditions | 5 |
| our-research | about | 10 |
| Desktop and Tablet Traffic | Mobile Traffic | t Statistic | p-Value | |
|---|---|---|---|---|
| Users | 2485 | 1046 | --- | --- |
| New Users | 2074 | 967 | --- | --- |
| Sessions | 2684 | 1113 | --- | --- |
| Bounce Rate | 0.69 (SD = 0.059) | 0.72 (SD = 0.080) | 12.348 | p < 0.0001 * |
| Pages Per Session | 1.95 (SD = 0.309) | 1.65 (SD = 0.264) | −28.378 | p < 0.0001 * |
| Average Session Duration (Seconds) | 100.06 (SD = 41.180) | 53.68 (SD = 35.744) | −32.798 | p < 0.0001 * |
| Direct Traffic | Referral Traffic | Organic Traffic | F Statistic | p-Value | |
|---|---|---|---|---|---|
| Users | 516 | 82 | 2944 | --- | --- |
| New Users | 449 | 76 | 2516 | --- | --- |
| Sessions | 62 | 84 | 3151 | --- | --- |
| Bounce Rate | 0.76 (SD = 0.118) | 0.77 (SD = 0.310) | 0.69 (SD = 0.049) | 1.650 | p = 0.1978 |
| Pages Per Session | 1.93 (SD = 1.404) | 1.43 (SD = 1.200) | 1.87 (SD = 0.239) | 1.990 | p = 0.1426 |
| Average Session Duration (Seconds) | 105.93 (SD = 142.799) | 95.86 (SD = 130.272) | 85.10 (SD = 29.224) | 2.813 | p = 0.0653 |
| Web Page Name | Number of Views |
|---|---|
| home | 3686 |
| about-us | 280 |
| how-are-stem-cells-used | 200 |
| research | 558 |
| what-are-stem-cells | 534 |
| Origin | Destination | Count |
|---|---|---|
| home | about-stem-cells | 229 |
| home | about-us | 112 |
| home | clinical-trials | 16 |
| home | conditions | 334 |
| home | contact | 89 |
| home | dispelling-myths | 58 |
| home | news | 2 |
| Desktop and Tablet Traffic | Mobile Traffic | |||||
|---|---|---|---|---|---|---|
| Origin | Count of Outgoing Traffic | Count Returning Home | Percentage | Count of Outgoing Traffic | Count Returning Home | Percentage |
| about-stem-cells | 129 | 83 | 64.3% | 58 | 44 | 75.9% |
| about-us | 144 | 140 | 97.2% | 20 | 19 | 95.0% |
| conditions | 182 | 111 | 61.0% | 47 | 30 | 63.8% |
| contact | 62 | 26 | 41.9% | 27 | 14 | 51.9% |
| research | 98 | 39 | 39.8% | 23 | 11 | 47.8% |
| stem-cell-treatments | 55 | 22 | 40.0% | 12 | 8 | 66.7% |
| total | 670 | 421 | 62.8% | 187 | 126 | 67.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, P.C.-I.; Munsie, M.; Chang, S. A Method for Analyzing Navigation Flows of Health Website Users Seeking Complex Health Information with Google Analytics. Informatics 2023, 10, 80. https://doi.org/10.3390/informatics10040080
Pang PC-I, Munsie M, Chang S. A Method for Analyzing Navigation Flows of Health Website Users Seeking Complex Health Information with Google Analytics. Informatics. 2023; 10(4):80. https://doi.org/10.3390/informatics10040080
Chicago/Turabian StylePang, Patrick Cheong-Iao, Megan Munsie, and Shanton Chang. 2023. "A Method for Analyzing Navigation Flows of Health Website Users Seeking Complex Health Information with Google Analytics" Informatics 10, no. 4: 80. https://doi.org/10.3390/informatics10040080
APA StylePang, P. C.-I., Munsie, M., & Chang, S. (2023). A Method for Analyzing Navigation Flows of Health Website Users Seeking Complex Health Information with Google Analytics. Informatics, 10(4), 80. https://doi.org/10.3390/informatics10040080