
A Finite Mixture Modelling Perspective for Combining Experts’ Opinions with an Application to Quantile-Based Risk Measures



Abstract
1. Introduction
2. Traditional Approaches for Combining Expert Judgements
2.1. Behavioural Approaches
2.2. Quantitative Approaches
2.3. Weights Determination
3. A Finite Mixture Modelling Viewpoint for Opinions Combination
3.1. Motivation Behind the Suggested Approach
3.2. Finite Mixture Models
3.2.1. Overview
3.2.2. Definition
3.2.3. Estimation via the Expectation Maximisation Algorithm
- The updated estimates are given by:
- The updated estimates are obtained using a weighted likelihood approach for each of the different component distributions with weights given by Equation (3). It is clear that ML estimation can be accomplished relatively easily when the M-Step is in closed form. On the contrary, when this is not the case, numerical optimization methods are required for maximizing the the weighted likelihood.
3.3. Opinions Combination Problem in a Finite Mixture Model Setting
4. Application to a Quantile-Based Financial Risk Measures Setting
4.1. Motivation Behind the Application
4.2. Risk Measures
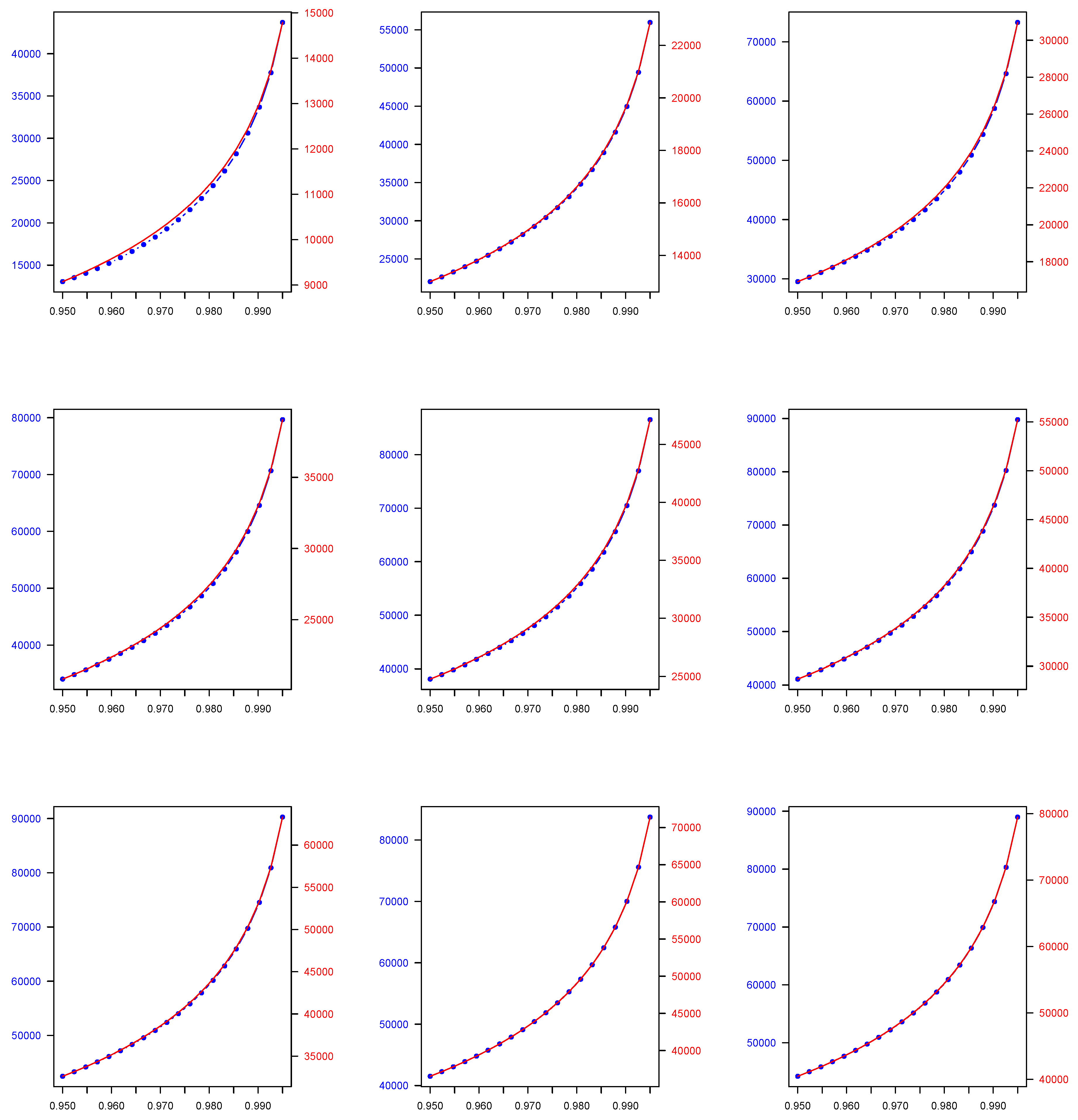
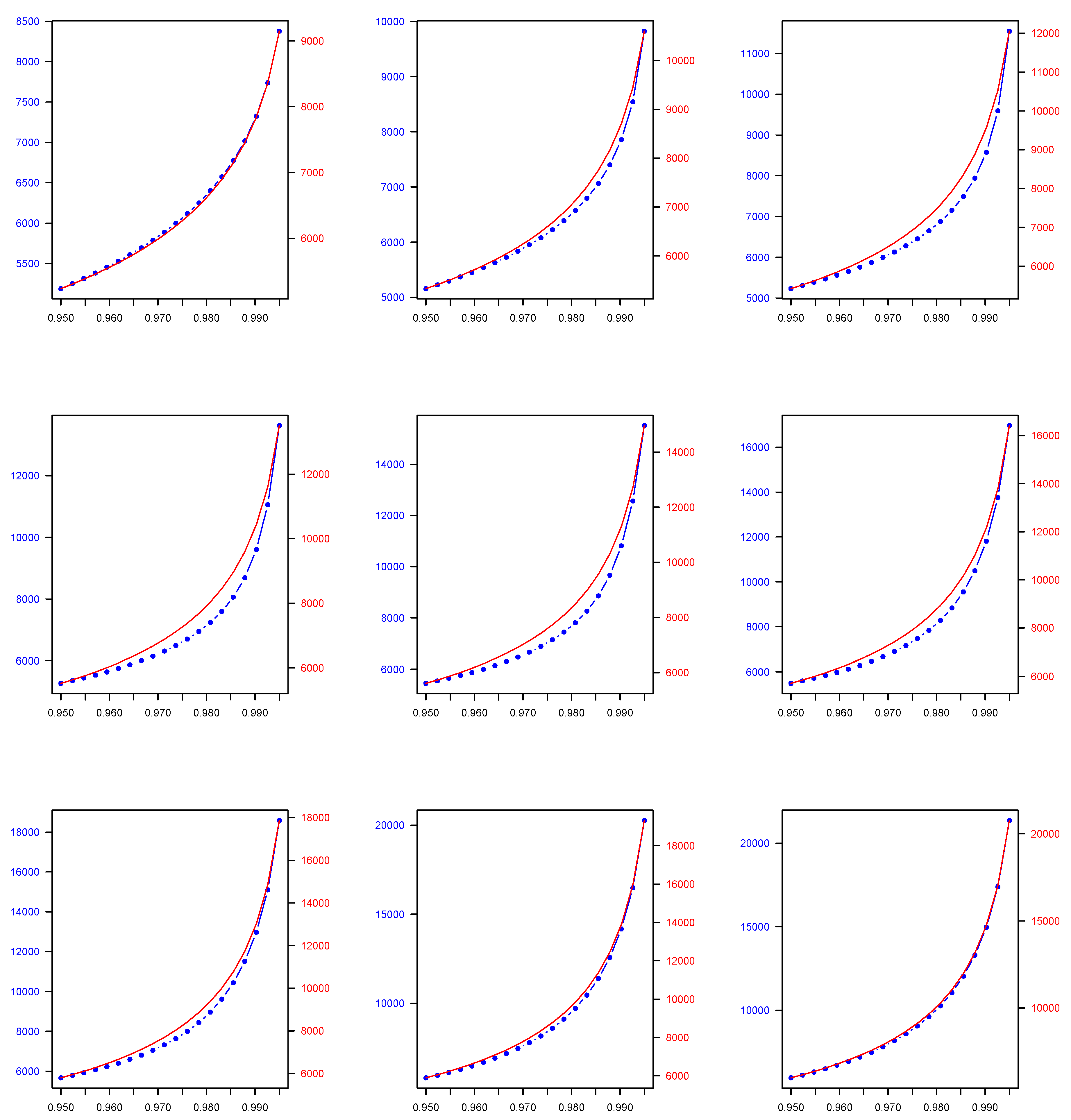
4.3. Computation of V@R Using Finite Mixtures Models
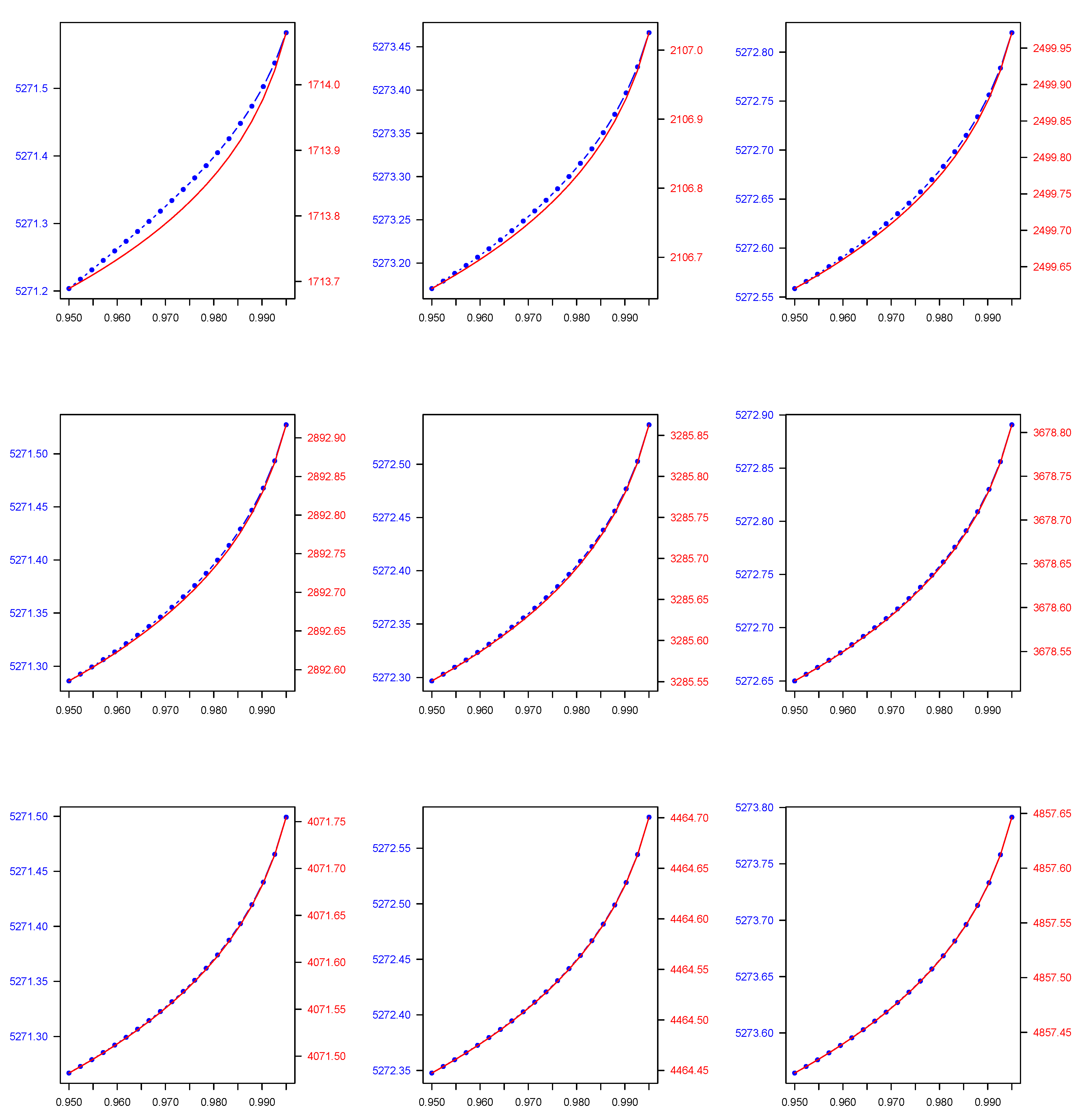
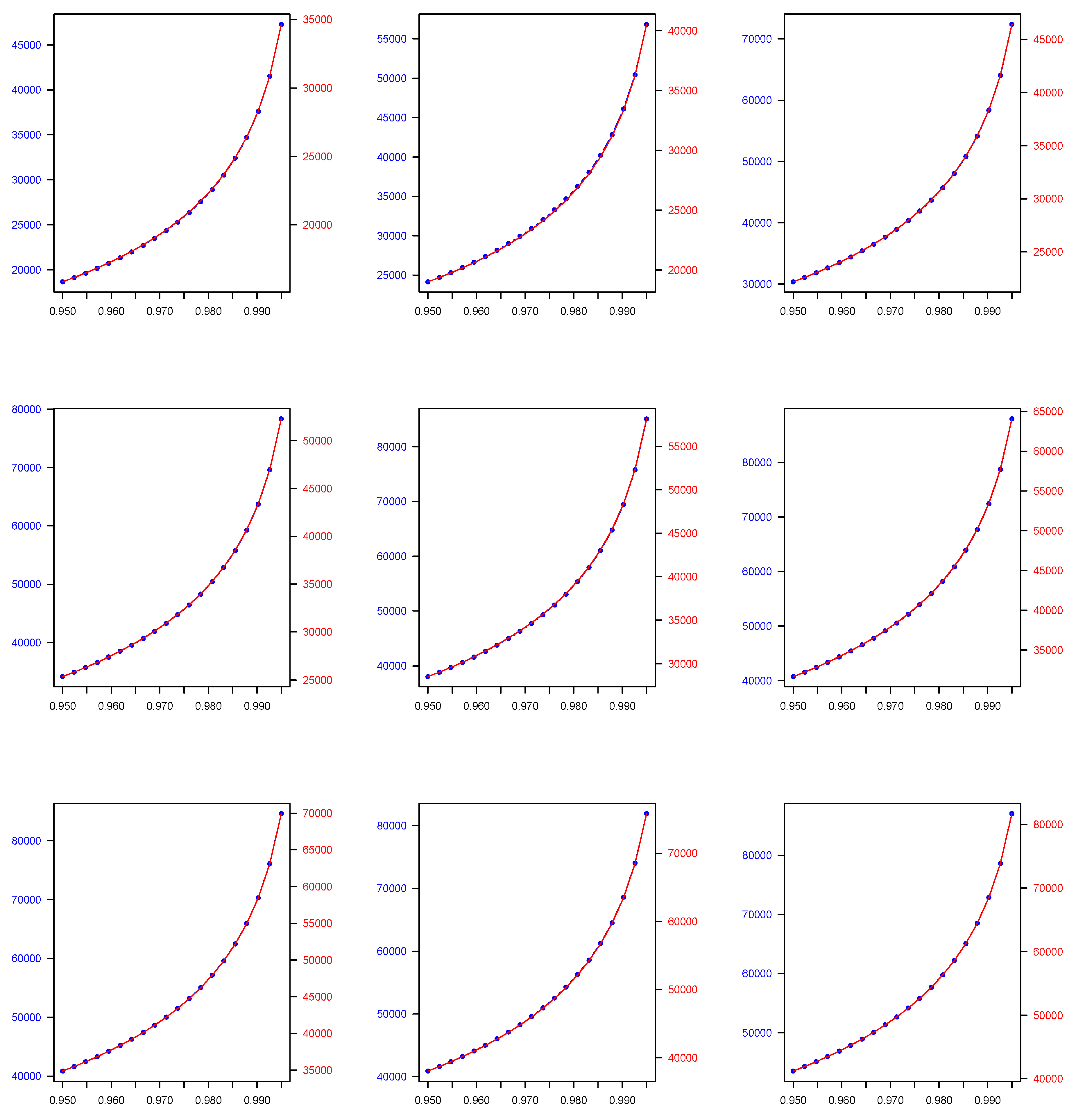
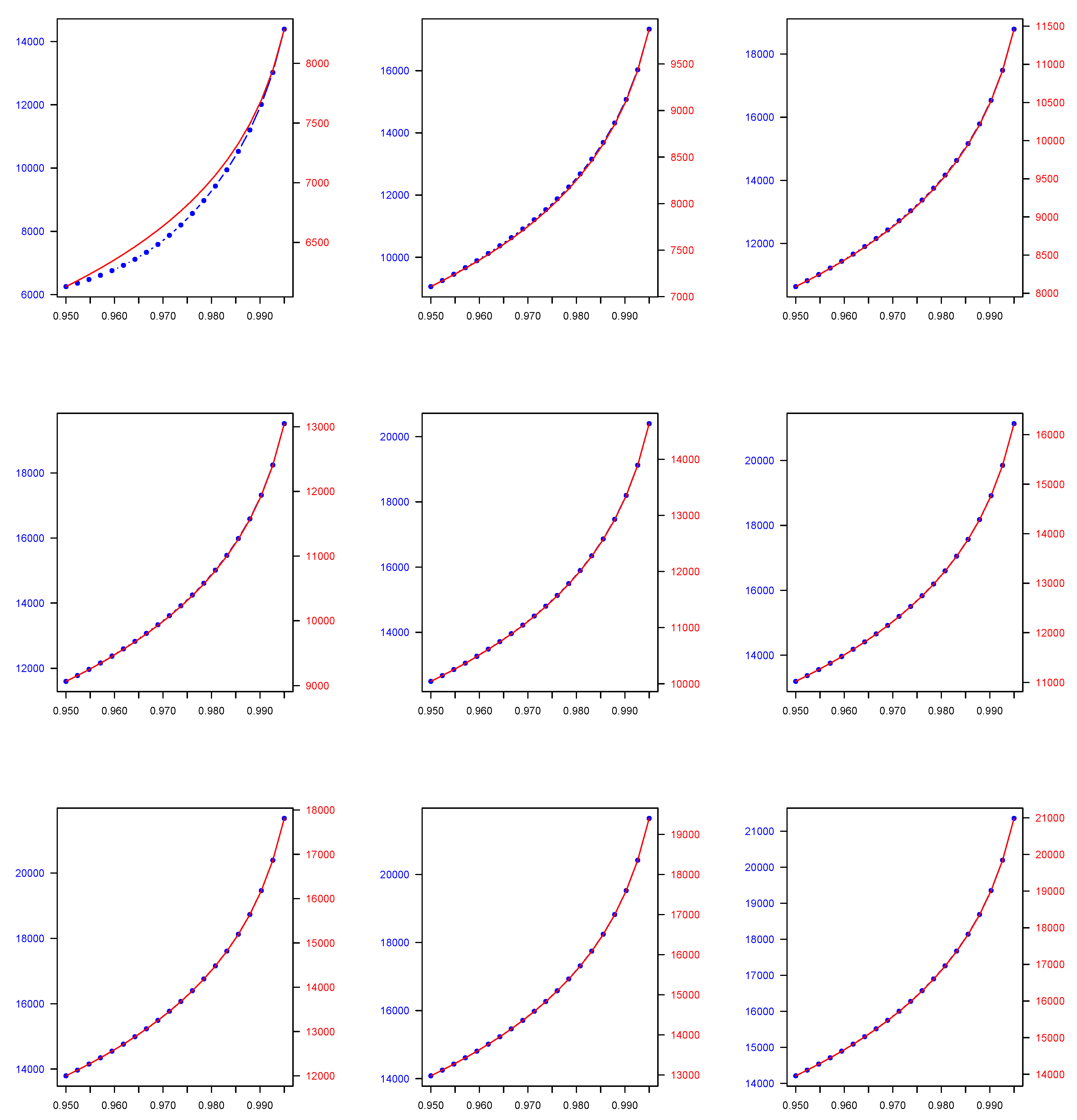
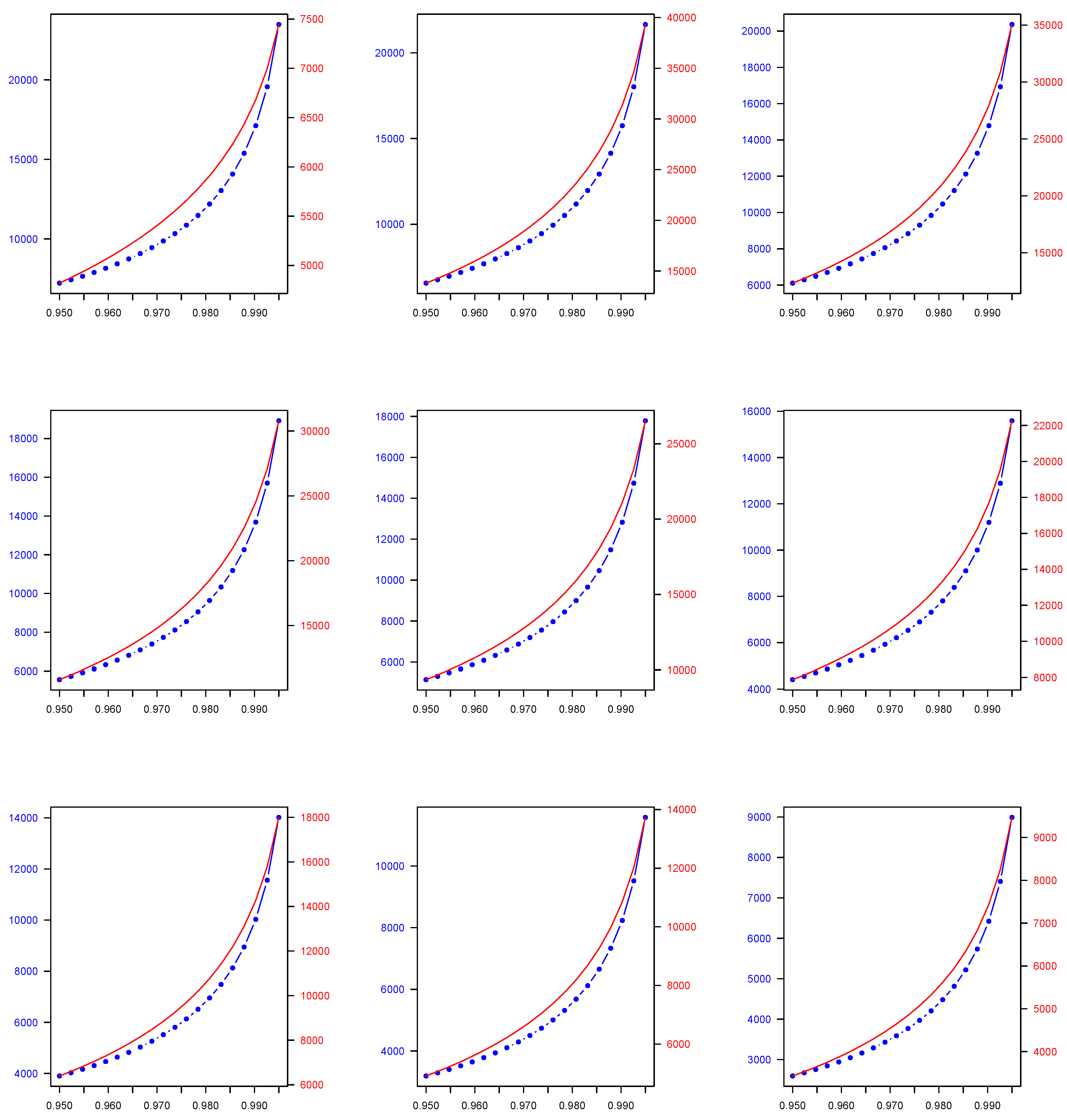
4.4. Numerical Application
- Normal distribution: the pdf of the Normal distribution is given by:for where and . The mean of is given by and the variance of X by . This parametric family is chosen for relatively symmetric insurance loss data, which take either positive or negative values.
- Lognormal distribution: the pdf of the Lognormal distribution is as follows:for where and . Here, and where .
- Gamma distribution: the density of the Gamma is given by:for , where and . This is a re-parameterisation, which was given in Equation (17.23) of Johnson et al. (1994) in p. 343, and it can be obtained by setting and . Moreover, and . The Gamma has a less heavier tail than the Lognormal one.
- Pareto distribution: the pdf of the Pareto distribution is as follows:for , where and . Furthermore, , and exists only if . This is an alternative distributional class choice that may be preferred to model more heavily right-skewed insurance loss data than the previous two distribution choices.
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| EM | Expectation Maximization |
| ML | Maximum Likelihood |
| Value at Risk | |
| Tail Value at Risk | |
| 2C | Two component |
| Probability density function |
References
- Acciaio, Beatrice, and Irina Penner. 2011. Dynamic risk measures. In Advanced Mathematical Methods for Finance. Berlin/Heidelberg: Springer, pp. 1–34. [Google Scholar]
- Allison, David B., Gary L. Gadbury, Moonseong Heo, José R. Fernández, Cheol-Koo Lee, Tomas A. Prolla, and Richard Weindruch. 2002. A mixture model approach for the analysis of microarray gene expression data. Computational Statistics & Data Analysis 9: 1–20. [Google Scholar]
- Bamber, Jonathan L., Willy P. Aspinall, and Roger M. Cooke. 2016. A commentary on “how to interpret expert judgment assessments of twenty-first century sea-level rise” by Hylke de Vries and Roderik SW van de Wal. Climatic Change 137: 321–28. [Google Scholar] [CrossRef]
- Bansal, Saurabh, and Asa Palley. 2017. Is it better to elicit quantile or probability judgments? A comparison of direct and calibrated procedures for estimating a continuous distribution. In A Comparison of Direct and Calibrated Procedures for Estimating a Continuous Distribution (6 June 2017). Kelley School of Business Research Paper. Bloomington: Indiana University, pp. 17–44. [Google Scholar]
- Barrieu, Pauline, and Claudia Ravanelli. 2015. Robust capital requirements with model risk. Economic Notes: Review of Banking, Finance and Monetary Economics 44: 1–28. [Google Scholar] [CrossRef]
- Barrieu, Pauline, and Giacomo Scandolo. 2015. Assessing financial model risk. European Journal of Operational Research 242: 546–56. [Google Scholar] [CrossRef]
- Barrieu, Pauline, and Nicole El Karoui. 2005. Inf-convolution of risk measures and optimal risk transfer. Finance and Stochastics 9: 269–98. [Google Scholar] [CrossRef]
- Bermúdez, Lluís, Dimitris Karlis, and Isabel Morillo. 2020. Modelling unobserved heterogeneity in claim counts using finite mixture models. Risks 8: 10. [Google Scholar] [CrossRef]
- Blostein, Martin, and Tatjana Miljkovic. 2019. On modeling left-truncated loss data using mixtures of distributions. Insurance: Mathematics and Economics 85: 35–46. [Google Scholar] [CrossRef]
- Bogner, Konrad, Katharina Liechti, and Massimiliano Zappa. 2017. Combining quantile forecasts and predictive distributions of streamflows. Hydrology and Earth System Sciences 21: 5493–502. [Google Scholar] [CrossRef]
- Bolger, Donnacha, and Brett Houlding. 2016. Reliability updating in linear opinion pooling for multiple decision makers. Proceedings of the Institution of Mechanical Engineers, Part O: Journal of Risk and Reliability 230: 309–22. [Google Scholar] [CrossRef]
- Bouguila, Nizar. 2010. Count data modeling and classification using finite mixtures of distributions. IEEE Transactions on Neural Networks 22: 186–98. [Google Scholar] [CrossRef]
- Bühlmann, Hans, and Alois Gisler. 2006. A Course in Credibility Theory and Its Applications. Zurich: Springer Science & Business Media. [Google Scholar]
- Busetti, Fabio. 2017. Quantile aggregation of density forecasts. Oxford Bulletin of Economics and Statistics 79: 495–512. [Google Scholar] [CrossRef]
- Caravagna, Giulio, Timon Heide, Marc J. Williams, Luis Zapata, Daniel Nichol, Ketevan Chkhaidze, William Cross, George D. Cresswell, Benjamin Werner, Ahmet Acar, and et al. 2020. Subclonal reconstruction of tumors by using machine learning and population genetics. Nature Genetics 52: 898–907. [Google Scholar] [CrossRef]
- Chai Fung, Tsz, Andrei L. Badescu, and X. Sheldon Lin. 2019. A class of mixture of experts models for general insurance: Application to correlated claim frequencies. ASTIN Bulletin 49: 647–88. [Google Scholar] [CrossRef]
- Clemen, Robert T. 1989. Combining forecasts: A review and annotated bibliography. International Journal of Forecasting 5: 559–83. [Google Scholar] [CrossRef]
- Clemen, Robert T. 2008. Comment on cooke’s classical method. Reliability Engineering & System Safety 93: 760–5. [Google Scholar]
- Clemen, Robert T., and Robert L. Winkler. 1999. Combining probability distributions from experts in risk analysis. Risk Analysis 19: 187–203. [Google Scholar] [CrossRef]
- Clemen, Robert T., and Robert L. Winkler. 2007. Aggregating Probability Distributions. Cambridge: Cambridge University Press, pp. 154–76. [Google Scholar] [CrossRef]
- Colson, Abigail R., and Roger M. Cooke. 2017. Cross validation for the classical model of structured expert judgment. Reliability Engineering & System Safety 163: 109–20. [Google Scholar]
- Cooke, Roger. 1991. Experts in Uncertainty: Opinion and Subjective Probability in Science. Oxford: Oxford University Press on Demand. [Google Scholar]
- Cooke, Roger M., and Louis L. H. J. Goossens. 2008. Tu delft expert judgment data base. Reliability Engineering & System Safety 93: 657–74. [Google Scholar]
- Couvreur, Christophe. 1997. The EM algorithm: A guided tour. In Computer Intensive Methods in Control and Signal Processing. Boston: Birkhäuser, pp. 209–22. [Google Scholar]
- Dalkey, Norman C. 1969. The Delphi Method: An Experimental Study of Group Opinion. Technical Report. Santa Monica: RAND Corporation. [Google Scholar]
- Danielsson, Jon, Paul Embrechts, Charles Goodhart, Con Keating, Felix Muennich, Olivier Renault, and Hyun Song Shin. 2001. An Academic Response to Basel II. Zurich: FMG. [Google Scholar]
- Delbecq, Andre L., Andrew H. Van de Ven, and David H. Gustafson. 1975. Group Techniques for Program Planning: A Guide to Nominal Group and Delphi Processes. Glenview: Scott Foresman. [Google Scholar]
- Dempster, Arthur P., Nan M. Laird, and Donald B. Rubin. 1977. Maximum likelihood from incomplete data via the em algorithm. Journal of the Royal Statistical Society: Series B (Methodological) 39: 1–22. [Google Scholar]
- Efron, Bradley. 2008. Microarrays, empirical bayes and the two-groups model. Statistical Science 23: 1–22. [Google Scholar]
- Eggstaff, Justin W., Thomas A. Mazzuchi, and Shahram Sarkani. 2014a. The development of progress plans using a performance-based expert judgment model to assess technical performance and risk. Systems Engineering 17: 375–91. [Google Scholar] [CrossRef]
- Eggstaff, Justin W., Thomas A. Mazzuchi, and Shahram Sarkani. 2014b. The effect of the number of seed variables on the performance of cooke’s classical model. Reliability Engineering & System Safety 121: 72–82. [Google Scholar]
- Elguebaly, Tarek, and Nizar Bouguila. 2014. Background subtraction using finite mixtures of asymmetric gaussian distributions and shadow detection. Machine Vision and Applications 25: 1145–62. [Google Scholar] [CrossRef]
- Embrechts, Paul, Giovanni Puccetti, Ludger Rüschendorf, Ruodu Wang, and Antonela Beleraj. 2014. An academic response to basel 3.5. Risks 2: 25–48. [Google Scholar] [CrossRef]
- Everitt, Brian S., and David J. Hand. 1981. Finite mixture distributions. In Monographs on Applied Probability and Statistics. London and New York: Chapman and Hall. [Google Scholar]
- Flandoli, Franco, Enrico Giorgi, William P. Aspinall, and Augusto Neri. 2011. Comparison of a new expert elicitation model with the classical model, equal weights and single experts, using a cross-validation technique. Reliability Engineering & System Safety 96: 1292–310. [Google Scholar]
- Föllmer, Hans, and Alexander Schied. 2010. Convex and Coherent Risk Measures. Journal of Quantitative Finance. 12. Available online: https://www.researchgate.net/publication/268261458_Convex_and_coherent_risk_measures (accessed on 8 June 2021).
- Föllmer, Hans, and Alexander Schied. 2016. Stochastic Finance: An Introduction in Discrete Time. Berlin: De Gruyter. [Google Scholar]
- Forgy, Edward W. 1965. Cluster analysis of multivariate data: Efficiency versus interpretability of classifications. Biometrics 21: 768–69. [Google Scholar]
- French, Simon. 1983. Group Consensus Probability Distributions: A Critical Survey. Manchester: University of Manchester. [Google Scholar]
- Fung, Tsz Chai, George Tzougas, and Mario Wuthrich. 2021. Mixture composite regression models with multi-type feature selection. arXiv arXiv:2103.07200. [Google Scholar]
- Gambacciani, Marco, and Marc S. Paolella. 2017. Robust normal mixtures for financial portfolio allocation. Econometrics and Statistics 3: 91–111. [Google Scholar] [CrossRef]
- Genest, Christian. 1992. Vincentization revisited. The Annals of Statistics 20: 1137–42. [Google Scholar] [CrossRef]
- Genest, Christian, and Kevin J. McConway. 1990. Allocating the weights in the linear opinion pool. Journal of Forecasting 9: 53–73. [Google Scholar] [CrossRef]
- Genest, Christian, Samaradasa Weerahandi, and James V. Zidek. 1984. Aggregating opinions through logarithmic pooling. Theory and Decision 17: 61–70. [Google Scholar] [CrossRef]
- Gneiting, Tilmann, and Adrian E. Raftery. 2007. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association 102: 359–78. [Google Scholar] [CrossRef]
- Government Office for Science. 2020. Transparency Data List of Participants of Sage and Related Sub-Groups. London: Government Office for Science. [Google Scholar]
- Grün, Bettina, and Friedrich Leisch. 2008. Finite mixtures of generalized linear regression models. In Recent Advances in Linear Models and Related Areas. Heidelberg: Physica-Verlag, pp. 205–30. [Google Scholar]
- Henry, Marc, Yuichi Kitamura, and Bernard Salanié. 2014. Partial identification of finite mixtures in econometric models. Quantitative Economics 5: 123–44. [Google Scholar] [CrossRef]
- Hogarth, Robert M. 1977. Methods for aggregating opinions. In Decision Making and Change in Human Affairs. Dordrecht: Springer, pp. 231–55. [Google Scholar]
- Hora, Stephen C., Benjamin R. Fransen, Natasha Hawkins, and Irving Susel. 2013. Median aggregation of distribution functions. Decision Analysis 10: 279–91. [Google Scholar] [CrossRef]
- Johnson, Norman L., Samuel Kotz, and Narayanaswamy Balakrishnan. 1994. Continuous Univariate Distributions. Models and Applications, 2nd ed. New York: John Wiley & Sons. [Google Scholar]
- Jose, Victor Richmond R., Yael Grushka-Cockayne, and Kenneth C. Lichtendahl, Jr. 2013. Trimmed opinion pools and the crowd’s calibration problem. Management Science 60: 463–75. [Google Scholar] [CrossRef]
- Kaplan, Stan. 1992. ‘expert information’versus ‘expert opinions’. another approach to the problem of eliciting/combining/using expert knowledge in pra. Reliability Engineering & System Safety 35: 61–72. [Google Scholar]
- Karlis, Dimitris, and Evdokia Xekalaki. 1999. Improving the em algorithm for mixtures. Statistics and Computing 9: 303–7. [Google Scholar] [CrossRef]
- Karlis, Dimitris, and Evdokia Xekalaki. 2005. Mixed poisson distributions. International Statistical Review/Revue Internationale de Statistique 73: 35–58. [Google Scholar] [CrossRef]
- Koksalmis, Emrah, and Özgür Kabak. 2019. Deriving decision makers’ weights in group decision making: An overview of objective methods. Information Fusion 49: 146–60. [Google Scholar] [CrossRef]
- Lambrigger, Dominik D., Pavel V. Shevchenko, and Mario V. Wüthrich. 2009. The quantification of operational risk using internal data, relevant external data and expert opinions. arXiv arXiv:0904.1361. [Google Scholar] [CrossRef]
- Lichtendahl, Kenneth C., Yael Grushka-Cockayne, and Robert L. Winkler. 2013. Is it better to average probabilities or quantiles? Management Science 59: 1594–611. [Google Scholar] [CrossRef]
- Linstone, Harold A., and Murray Turoff. 1975. The Delphi Method. Reading: Addison-Wesley Reading. [Google Scholar]
- MacQueen, James. 1967. Some methods for classification and analysis of multivariate observations. Paper presented at the fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, January 1, vol. 1, pp. 281–97. [Google Scholar]
- Maitra, Ranjan. 2009. Initializing partition-optimization algorithms. IEEE/ACM Transactions on Computational Biology and Bioinformatics 6: 144–57. [Google Scholar] [CrossRef] [PubMed]
- McLachlan, Geoffrey J., and David Peel. 2000a. Finite Mixture Models. New York: John Wiley & Sons. [Google Scholar]
- McLachlan, Geoffrey J., and David Peel. 2000b. Finite Mixture Models. New York: Wiley Series in Probability and Statistics. [Google Scholar]
- McLachlan, Geoffrey J., and Kaye E. Basford. 1988. Mixture Models: Inference and Applications to Clustering. New York: M. Dekker, vol. 38. [Google Scholar]
- McLachlan, Geoffrey J., Kim-Anh Do, and Christophe Ambroise. 2005. Analyzing Microarray Gene Expression Data. Hoboken: John Wiley & Sons, vol. 422. [Google Scholar]
- McLachlan, Geoffrey J., Sharon X. Lee, and Suren I. Rathnayake. 2019. Finite mixture models. Annual Review of Statistics and Its Application 6: 355–78. [Google Scholar] [CrossRef]
- McNichols, Maureen. 1988. A comparison of the skewness of stock return distributions at earnings and non-earnings announcement dates. Journal of Accounting and Economics 10: 239–73. [Google Scholar] [CrossRef]
- Mengersen, Kerrie L., Christian Robert, and Mike Titterington. 2011. Mixtures: Estimation and Applications. Chichester: John Wiley & Sons, vol. 896. [Google Scholar]
- Miljkovic, Tatjana, and Bettina Grün. 2016. Modeling loss data using mixtures of distributions. Insurance: Mathematics and Economics 70: 387–96. [Google Scholar] [CrossRef]
- Newcomb, Simon. 1886. A generalized theory of the combination of observations so as to obtain the best result. American Journal of Mathematics 8: 343–66. [Google Scholar] [CrossRef]
- Oboh, Bromensele Samuel, and Nizar Bouguila. 2017. Unsupervised learning of finite mixtures using scaled dirichlet distribution and its application to software modules categorization. Paper presented at the 2017 IEEE International Conference on Industrial Technology (ICIT), Toronto, ON, Canada, March 22–25; pp. 1085–90. [Google Scholar]
- O’Hagan, Anthony, Caitlin E. Buck, Alireza Daneshkhah, J. Richard Eiser, Paul H. Garthwaite, David J. Jenkinson, Jeremy E. Oakley, and Tim Rakow. 2006. Uncertain Judgements: Eliciting Experts’ Probabilities. Chichester: John Wiley & Sons. [Google Scholar]
- Parenté, Frederik J., and Janet K. Anderson-Parenté. 1987. Delphi inquiry systems. Judgmental Forecasting, 129–56. [Google Scholar]
- Pearson, Karl. 1894. Contributions to the mathematical theory of evolution. Philosophical Transactions of the Royal Society of London. A 185: 71–110. [Google Scholar]
- Peiro, Amado. 1999. Skewness in financial returns. Journal of Banking & Finance 23: 847–62. [Google Scholar]
- Plous, Scott. 1993. The Psychology of Judgment and Decision Making. New York: Mcgraw-Hill Book Company. [Google Scholar]
- Punzo, Antonio, Angelo Mazza, and Antonello Maruotti. 2018. Fitting insurance and economic data with outliers: A flexible approach based on finite mixtures of contaminated gamma distributions. Journal of Applied Statistics 45: 2563–84. [Google Scholar] [CrossRef]
- Rufo, M. J., C. J. Pérez, and Jacinto Martín. 2010. Merging experts’ opinions: A bayesian hierarchical model with mixture of prior distributions. European Journal of Operational Research 207: 284–89. [Google Scholar] [CrossRef]
- Samadani, Ramin. 1995. A finite mixtures algorithm for finding proportions in sar images. IEEE Transactions on Image Processing 4: 1182–86. [Google Scholar] [CrossRef] [PubMed]
- Schlattmann, Peter. 2009. Medical Applications of Finite Mixture Models. Berlin/Heidelberg: Springer. [Google Scholar]
- Shevchenko, Pavel V., and Mario V. Wüthrich. 2006. The structural modelling of operational risk via bayesian inference: Combining loss data with expert opinions. The Journal of Operational Risk 1: 3–26. [Google Scholar] [CrossRef]
- Stone, Mervyn. 1961. The linear opinion pool. The Annals of Mathematical Statistics 32: 1339–42. [Google Scholar] [CrossRef]
- Titterington, D. M. 1990. Some recent research in the analysis of mixture distributions. Statistics 21: 619–41. [Google Scholar] [CrossRef]
- Titterington, D. Michael, Adrian F. M. Smith, and Udi E. Makov. 1985. Statistical Analysis of Finite Mixture Distributions. Chichester: Wiley. [Google Scholar]
- Tzougas, George, Spyridon Vrontos, and Nicholas Frangos. 2014. Optimal bonus-malus systems using finite mixture models. Astin Bulletin 44: 417–44. [Google Scholar] [CrossRef]
- Tzougas, George, Spyridon Vrontos, and Nicholas Frangos. 2018. Bonus-malus systems with two-component mixture models arising from different parametric families. North American Actuarial Journal 22: 55–91. [Google Scholar] [CrossRef]
- Vincent, Stella Burnham. 1912. The functions of the Vibrissae in the Behavior of the White Rat. Chicago: University of Chicago, vol. 1. [Google Scholar]
- Wallach, Michael A., Nathan Kogan, and Daryl J. Bem. 1962. Group influence on individual risk taking. The Journal of Abnormal and Social Psychology 65: 75. [Google Scholar] [CrossRef]
- Wedel, Michel, and Wayne S. DeSarbo. 1994. A review of recent developments in latent class regression models. In Advanced Methods of Marketing Research. Edited by Richard Bagozzi. Oxford: Blackwell Publishing Ltd., pp. 352–88. [Google Scholar]
- Winkler, Robert L. 1968. The consensus of subjective probability distributions. Management Science 15: B-61. [Google Scholar] [CrossRef]
- Winkler, Robert L., Javier Munoz, José L. Cervera, José M. Bernardo, Gail Blattenberger, Joseph B. Kadane, Dennis V. Lindley, Allan H. Murphy, Robert M. Oliver, and David Ríos-Insua. 1996. Scoring rules and the evaluation of probabilities. Test 5: 1–60. [Google Scholar] [CrossRef]
- Yung, Yiu-Fai. 1997. Finite mixtures in confirmatory factor-analysis models. Psychometrika 62: 297–330. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parametric Family | ||||||
| 0.098 | 0.902 | 5271.210 | 1333.022 | 0.228 | 0.442 | |
| 0.203 | 0.797 | 5273.012 | 1342.762 | 0.231 | 0.448 | |
| 0.300 | 0.700 | 5272.341 | 1341.234 | 0.225 | 0.448 | |
| 0.400 | 0.600 | 5271.032 | 1340.012 | 0.221 | 0.446 | |
| 2C Normal | 0.500 | 0.500 | 5272.002 | 1342.569 | 0.230 | 0.447 |
| 0.600 | 0.400 | 5272.321 | 1343.812 | 0.238 | 0.449 | |
| 0.700 | 0.300 | 5270.921 | 1341.989 | 0.236 | 0.444 | |
| 0.800 | 0.200 | 5271.981 | 1345.091 | 0.239 | 0.449 | |
| 0.901 | 0.099 | 5273.182 | 1343.991 | 0.240 | 0.447 | |
| 0.090 | 0.910 | 9.538 | 8.042 | 0.723 | 0.884 | |
| 0.200 | 0.800 | 9.521 | 8.025 | 0.717 | 0.879 | |
| 0.299 | 0.701 | 9.539 | 8.042 | 0.772 | 0.883 | |
| 0.398 | 0.602 | 9.537 | 8.041 | 0.771 | 0.881 | |
| 2C Lognormal | 0.498 | 0.502 | 9.538 | 8.064 | 0.778 | 0.899 |
| 0.600 | 0.400 | 9.548 | 8.053 | 0.766 | 0.896 | |
| 0.700 | 0.300 | 9.528 | 8.035 | 0.741 | 0.873 | |
| 0.802 | 0.198 | 9.508 | 0.722 | 8.016 | 0.858 | |
| 0.901 | 0.099 | 9.511 | 0.733 | 8.023 | 0.867 | |
| 0.086 | 0.914 | 6786.348 | 3162.126 | 0.625 | 0.352 | |
| 0.207 | 0.793 | 6737.558 | 3127.165 | 0.629 | 0.340 | |
| 0.307 | 0.693 | 6738.557 | 3124.408 | 0.635 | 0.342 | |
| 0.400 | 0.600 | 6739.659 | 3127.512 | 0.629 | 0.344 | |
| 2C Gamma | 0.499 | 0.501 | 6784.309 | 3171.627 | 0.630 | 0.357 |
| 0.601 | 0.399 | 6754.742 | 3123.512 | 0.638 | 0.341 | |
| 0.700 | 0.300 | 6783.127 | 3170.006 | 0.636 | 0.346 | |
| 0.799 | 0.201 | 6783.021 | 3172.871 | 0.621 | 0.341 | |
| 0.902 | 0.098 | 6786.735 | 3172.513 | 0.599 | 0.343 | |
| 0.088 | 0.912 | 1364.138 | 3148.568 | 3.354 | 2.439 | |
| 0.204 | 0.796 | 1329.177 | 3099.778 | 3.342 | 2.442 | |
| 0.295 | 0.705 | 1326.426 | 3100.769 | 3.344 | 2.448 | |
| 0.405 | 0.595 | 1329.524 | 3101.871 | 3.346 | 2.443 | |
| 2C Pareto | 0.494 | 0.506 | 1373.639 | 3146.521 | 3.359 | 2.444 |
| 0.605 | 0.395 | 1325.524 | 3116.954 | 3.343 | 2.452 | |
| 0.694 | 0.306 | 1372.018 | 3145.339 | 3.348 | 2.450 | |
| 0.805 | 0.195 | 1374.883 | 3145.233 | 3.343 | 2.434 | |
| 0.896 | 0.104 | 1374.525 | 3148.947 | 3.345 | 2.422 | |
| 0.088 | 0.912 | 1902.904 | 2393.673 | 2.085 | 0.604 | |
| 0.204 | 0.796 | 1867.943 | 2344.883 | 2.073 | 0.608 | |
| 0.295 | 0.705 | 1865.186 | 2345.882 | 2.075 | 0.614 | |
| 0.404 | 0.596 | 1868.129 | 2346.984 | 2.077 | 0.608 | |
| 2C Lognormal-Gamma | 0.494 | 0.506 | 1912.405 | 2391.634 | 2.079 | 0.609 |
| 0.605 | 0.395 | 1864.289 | 2362.067 | 2.074 | 0.617 | |
| 0.694 | 0.306 | 1910.784 | 2390.452 | 2.079 | 0.615 | |
| 0.805 | 0.195 | 1913.649 | 2394.123 | 2.074 | 0.602 | |
| 0.896 | 0.104 | 1912.018 | 2396.106 | 2.076 | 0.599 | |
| 0.088 | 0.912 | 9.538 | 3175.526 | 0.725 | 0.737 | |
| 0.197 | 0.803 | 9.522 | 3140.588 | 0.722 | 0.741 | |
| 0.297 | 0.703 | 9.543 | 3139.065 | 0.781 | 0.747 | |
| 0.396 | 0.604 | 9.547 | 3142.169 | 0.777 | 0.742 | |
| 2C Pareto-Gamma | 0.496 | 0.504 | 9.547 | 3186.286 | 0.784 | 0.743 |
| 0.598 | 0.402 | 9.558 | 3138.171 | 0.772 | 0.751 | |
| 0.698 | 0.302 | 9.537 | 3184.665 | 0.765 | 0.749 | |
| 0.800 | 0.200 | 9.517 | 3187.353 | 0.728 | 0.734 | |
| 0.899 | 0.101 | 9.520 | 3189.272 | 0.739 | 0.729 |
| Finite Mixture Model-Based Quantile | ||||||
|---|---|---|---|---|---|---|
| 2C Normal | 2C Lognormal | 2C Gamma | 2C Pareto | 2C Lognormal-Gamma | 2C Pareto-Gamma | |
| 0.950 | 5271.204 | 18,674.230 | 6254.920 | 7221.820 | 13,053.610 | 5189.413 |
| 0.990 | 5271.499 | 37,254.660 | 11,911.220 | 16,895.230 | 33,302.150 | 7286.269 |
| 0.950 | 5273.171 | 24,144.120 | 9057.693 | 6569.990 | 22,039.780 | 5157.749 |
| 0.990 | 5273.394 | 45,694.640 | 14,982.950 | 15,542.580 | 44,546.370 | 7797.691 |
| 0.950 | 5272.559 | 30,361.480 | 10,637.600 | 6108.752 | 29,534.510 | 5231.247 |
| 0.990 | 5272.754 | 57,847.270 | 16,443.240 | 14,589.80 | 58,206.920 | 8493.526 |
| 0.950 | 5271.286 | 34,225.830 | 11,600.840 | 5564.221 | 34,066.590 | 5273.603 |
| 0.990 | 5271.465 | 63,167.590 | 17,229.970 | 13,503.800 | 63,994.280 | 9481.466 |
| 0.950 | 5272.297 | 38,063.000 | 12,505.360 | 5147.291 | 38,106.660 | 5449.650 |
| 0.990 | 5272.474 | 68,905.430 | 18,108.690 | 12,655.920 | 69,880.110 | 10,662.670 |
| 0.950 | 5272.650 | 40,758.710 | 13,203.380 | 4409.509 | 41,120.820 | 5487.197 |
| 0.990 | 5272.827 | 71,836.230 | 18,826.360 | 11,044.520 | 73,116.860 | 11,643.710 |
| 0.950 | 5271.267 | 40,870.610 | 13,793.70 | 3904.314 | 42,478.650 | 5662.312 |
| 0.990 | 5271.438 | 69,767.140 | 19,373.060 | 9889.721 | 73,938.670 | 12,784.550 |
| 0.950 | 5272.348 | 40,907.890 | 14,083.190 | 3191.665 | 41,516.230 | 5810.997 |
| 0.990 | 5272.517 | 68,097.500 | 19,440.430 | 8118.793 | 69,476.320 | 13,964.470 |
| 0.950 | 5273.564 | 43,519.640 | 14,211.730 | 2596.741 | 44,222.170 | 5958.190 |
| 0.990 | 5273.731 | 72,328.780 | 19,271.110 | 6335.289 | 73,824.540 | 14,757.320 |
| Weighted average-based quantile | ||||||
| 2C Normal | 2C Lognormal | 2C Gamma | 2C Pareto | 2C Lognormal-Gamma | 2C Pareto-Gamma | |
| 0.950 | 1713.689 | 15,847.350 | 6130.278 | 6974.334 | 9075.481 | 5234.196 |
| 0.990 | 1713.975 | 28,081.790 | 7666.813 | 16,133.486 | 12,933.270 | 7791.443 |
| 0.950 | 2106.655 | 19,018.620 | 7108.780 | 6415.912 | 12,999.186 | 5328.475 |
| 0.990 | 2106.926 | 33,072.860 | 9074.596 | 14,783.290 | 19,607.500 | 8635.935 |
| 0.950 | 2499.620 | 22,189.900 | 8087.282 | 5857.489 | 16,922.892 | 5422.755 |
| 0.990 | 2499.877 | 38,063.930 | 10,482.379 | 13,433.094 | 32,955.980 | 9480.427 |
| 0.950 | 2892.586 | 25,361.170 | 9065.785 | 5299.066 | 20,846.597 | 5517.035 |
| 0.990 | 2892.828 | 43,054.990 | 11,890.162 | 12,082.899 | 26,281.740 | 10,324.919 |
| 0.950 | 3285.551 | 28,532.450 | 10,044.287 | 4740.644 | 24,770.303 | 5611.315 |
| 0.990 | 3285.779 | 48,046.060 | 13,297.946 | 10,732.703 | 39,630.220 | 11,169.410 |
| 0.950 | 3678.516 | 31,703.730 | 11,022.790 | 4182.221 | 28,694.008 | 5705.594 |
| 0.990 | 3678.730 | 53,037.130 | 14,705.729 | 9382.508 | 46,304.450 | 12,013.902 |
| 0.950 | 4071.482 | 34,875.000 | 12,001.292 | 3623.798 | 32,617.714 | 5799.874 |
| 0.990 | 4071.682 | 58,028.200 | 16,113.512 | 8032.312 | 52,978.690 | 12,858.394 |
| 0.950 | 4464.447 | 38,046.280 | 12,979.794 | 3065.376 | 36,541.419 | 5894.154 |
| 0.990 | 4464.633 | 63,019.270 | 17,521.295 | 6682.116 | 59,652.930 | 13,702.886 |
| 0.950 | 4857.413 | 41,217.550 | 13,958.297 | 2506.953 | 40,465.125 | 5988.433 |
| 0.990 | 4857.584 | 68,010.340 | 18,929.078 | 5331.921 | 66,327.170 | 14,547.377 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Makariou, D.; Barrieu, P.; Tzougas, G. A Finite Mixture Modelling Perspective for Combining Experts’ Opinions with an Application to Quantile-Based Risk Measures. Risks 2021, 9, 115. https://doi.org/10.3390/risks9060115
Makariou D, Barrieu P, Tzougas G. A Finite Mixture Modelling Perspective for Combining Experts’ Opinions with an Application to Quantile-Based Risk Measures. Risks. 2021; 9(6):115. https://doi.org/10.3390/risks9060115
Chicago/Turabian StyleMakariou, Despoina, Pauline Barrieu, and George Tzougas. 2021. "A Finite Mixture Modelling Perspective for Combining Experts’ Opinions with an Application to Quantile-Based Risk Measures" Risks 9, no. 6: 115. https://doi.org/10.3390/risks9060115
APA StyleMakariou, D., Barrieu, P., & Tzougas, G. (2021). A Finite Mixture Modelling Perspective for Combining Experts’ Opinions with an Application to Quantile-Based Risk Measures. Risks, 9(6), 115. https://doi.org/10.3390/risks9060115