1. Introduction
In the world ravaged by the pandemic, with a fragile macro-economic outlook, low interest rates, and record high leverage, any academic research on bankruptcy is welcome. As the authors of this paper, we are neither professionally prepared nor interested in the debate on the degree of macro fragility or the effectiveness of the unprecedented stimulus packages adopted worldwide. Mentioning the unparalleled global leverage positions or the global health crisis, we merely acknowledge the emergence of the almost unmatched global uncertainty. In contrast to more optimistic views, exemplified by the stock exchange post-COVID-19 valuations, we believe the uncertainty is the only certain thing around us these days. Understanding the process of going down (in these circumstances) seems to us more than critical. Throughout this paper, bankruptcy and default are used interchangeably.
Below are some universally available leverage statistics (
Altman 2020). Global non-financial corporate debt increased from the pre-Global Financial Crisis level of
$42 trillion to
$74 trillion in 2019. The government debt position more than doubled from
$33 trillion in 2007 to
$69 trillion in 2019. Even the financial sector increased its leverage from the record high pre-crisis level to
$62 trillion. Households increased their debt globally from
$34 trillion to
$48 trillion. With the exception of the financial sector, debt also grew in relation to global GDP. It increased to 93% for non-financials (up from 77%), to 88% for governments (up from 58%), and to 60% for households (up from 57%). Despite this, as
Altman (
2020) notes, the corporate high-yield bond default rate was surprisingly low at 2.9% in 2019, below a 3.3% historic average, the recovery rate of 43.5% was quite in line with the historic average of 46%, with the high-yield spreads lagging behind historic averages, too. Consequently, Altman believes that the pre-COVID-19 debt market, in contrast to the current state, was still at a benign cycle stage. However, the very levels of debt globally, coupled with the increased appeal of a very long end of the yield curve and a massive increase in the BBB issuance, makes the debt markets and the global economy quite vulnerable, even without the health crisis. The unconventional monetary policies and the low interest environment also lead to the proliferation of “zombie” firms. Regardless of the precise definition, these companies are kept alive rather artificially thanks to the availability of cheap debt.
Banerjee and Hofmann (
2018) estimate as much as 16% of US listed firms may have “zombie” status—eight times more than in 1990.
Acharya et al. (
2020) estimate that 8% of all loans may also be infected with the “zombie” virus. Needless to say, COVID-19 and the resultant generous governmental relief packages do not help mitigate the problem.
Bankruptcy research, in all its guises, has been truly impressive and has produced many insightful results for some decades now. Such results include the classical structural models of
Merton (
1974),
Fischer et al. (
1989), and
Leland (
1994), numerous reduced-form models ranging from the simple scoring methods of
Beaver (
1966,
1968) and
Altman (
1968), qualitative response models, such as the logit of
Ohlson (
1980) and probit of
Zmijewski (
1984), to the third generation of the reduced form, the duration-type models of, for e.g.,
Shumway (
2001),
Kavvathas (
2000),
Chava and Jarrow (
2004), and
Hillegeist et al. (
2004). They all propose various and divergent econometric methods and methodological approaches, with an impressive sectorial and geographic empirical coverage (see
Berent et al. 2017).
To discriminate healthy from unhealthy firms is one challenge; to predict the (multi-period) bankruptcy probabilities is another. One way to address the problem is to model default as a random counting process. A Poisson process is such an example. In the bankruptcy literature, it is the Poisson process with stochastic intensities that is frequently used. In the doubly stochastic setting, the stochastic intensity depends on some state variables which may be firm-specific or macroeconomic, also called “internal” or “external” in the works on the statistical analysis of the failure time data (
Lancaster 1990;
Kalbfleisch and Prentice 2002). We adopt the Duffie–Duan model, as described in
Duan et al. (
2012), who, with their forward intensity approach and the maximum pseudo-likelihood analysis, follow in the footsteps of
Duffie et al. (
2007). In 2007,
Duffie et al. (
2007) first formulated a doubly stochastic Poisson multi-period model with time-varying covariates and Gaussian vector autoregressions.
Duan et al. (
2012) resolve some specification and estimation challenges inherent in
Duffie et al. (
2007). With their forward intensity concept,
Duan et al. (
2012) no longer need a high-dimension state variable process to be assumed, but instead use the data known at the time of making predictions. Both
Duan et al. (
2012) and
Duffie et al. (
2007) are well grounded in the doubly stochastic hypothesis literature debated in, for e.g.,
Collin-Dufresne and Goldstein (
2001),
Giesecke (
2004),
Jarrow and Yu (
2001), and
Schoenbucher (
2003).
Duffie et al. (
2007) apply their model to US-listed industrial firms.
Duan et al. (
2012) use also US public companies traded on NYSE, AMEX, and Nasdaq. Other researchers use the Duffie–Duan model to assess the default risk of public firms and/or in the context of developed (e.g.,
Caporale et al. 2017), or emerging markets (
Duan et al. 2018). In this paper, we demonstrate that the Duffie–Duan model not only successfully describes a default process for public companies from developed countries with well-functioning capital markets, but is also equally successful in the context of privately owned equity markets with frequently patchy, low-quality data, operating in an emerging market characterized by lower transparency and governance standards (
Aluchna et al. 2019). Compared to
Duan et al. (
2012) and
Duffie et al. (
2007), we apply the model to a significantly larger dataset of over 15,000 firms. As it is the applicability of the model rather than the discrimination itself that is our priority, we are not optimizing any cut-off point to maximize the accuracy of discrimination (typically made within an in-sample estimation context), but we make use of the out-of-sample accuracy measure calculated across all cut-off points, as is done in the context of the ROC analysis.
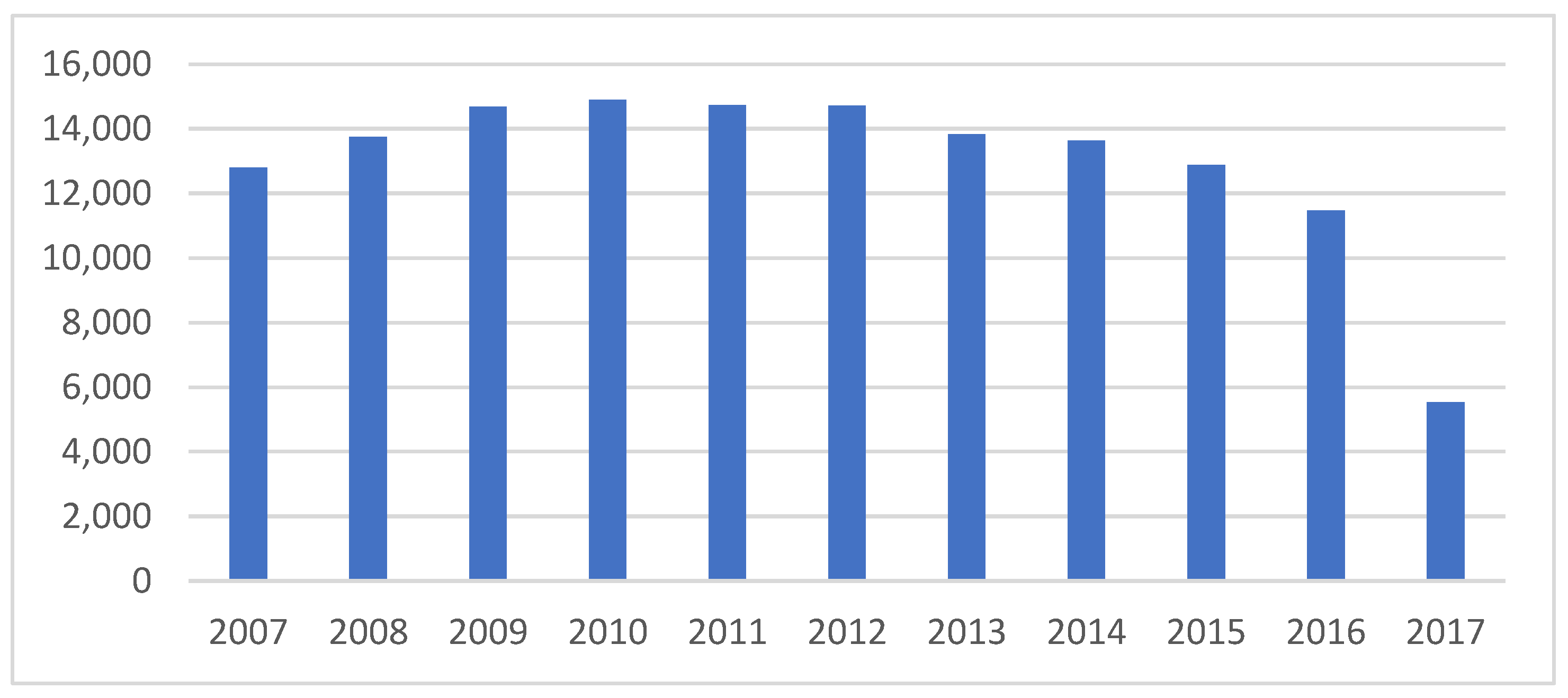
First, we collect a unique dataset for as many as 15,122 non-financial companies in Poland over the period 2007–2017. We make a huge effort to cross-check and cleanse the data so that the intricate estimation procedures could be run on this (initially) patchy input. Then, we document the performance differential (in the form of financial ratios) between the healthy and the (future) bankrupt firms one, two, and three years before default. In the next stage, company-specific variables (liquidity, profitability, leverage, rotation, and size) and macroeconomic variables (GDP growth, inflation, and interest rates) are used as state variables to estimate the default forward intensity employed in the doubly stochastic Poisson formulation. Partly due to the size of the dataset, we believe, we are able to exploit the differences between the attributes of the two groups. What we lose in the (data) quality, we seem to regain in (data) quantity. Our results surpassed our expectations. Not only are the estimated covariate parameters in line with the expectations and the literature, but the out-of-sample accuracy ratios produced—85% one year before default, 81% two years before default, and 76% three years before default—are at least as high, if not better, than those obtained for the high-quality public companies from developed countries. All our results are statistically significant and robust to the (state variable) model specification.
We hasten to repeat that this paper is not about searching for the determinants of default, neither is it about the maximization of the discrimination power between the two groups at any optimal cut-off point. In particular, we are not interested in artificially lifting up the in-sample fit. The main objective is to prove that the doubly stochastic Poisson model can be successfully used in the context of low-quality data for non-public companies from emerging markets. We believe this objective has been fully achieved. We are not aware of any similar effort in this area.
The rest of the paper is organized as follows. Below, still within the introduction section, we briefly introduce Poland’s bankruptcy law, an important ingredient, given the recent overhaul of the legislation framework. In the Materials and Methods section, we describe our unique dataset, introduce the model and the micro and macro covariates, and then we define the accuracy ratio, our preferred goodness-of-fit measure, the ROC curves, and the statistical tests applied. In the Results section, we first produce and comment on the descriptive statistics, separately for survivors and defaulters, one, two, and three years prior to bankruptcy. We then analyze the estimated covariate parameters and accuracy ratios, in- and out-of-sample. The critical discussion of our results, in the context of the literature, follows in the Discussion section. We conclude with some proposals for future research in the Conclusions section.
Poland’s Bankruptcy Law
With regard to Poland’s bankruptcy law, it was not until 2003, nearly one and a half decades after the end of communism in Poland, that the new legislation came into force. The new Bankruptcy and Rehabilitation Act replaced the pre-war ordinance of the President of the Republic of Poland, dated as far back as 1934. The new law was universally praised for bringing together, under one umbrella, two separate bankruptcy and restructuring (composition) proceedings, hitherto governed by the two separate legal acts. It is paradoxical that the essence of the latest changes in Poland’s bankruptcy law consisted in the carving out of the rehabilitation part into once again a separate Restructuring Act, which came into force in 2016. Apart from some substantial changes to the proceedings (e.g., the extension of both the time as well as the list of persons entitled/obliged to file for bankruptcy), the new law gave a debtor the option to choose, depending on the severity of insolvency, between four distinct ways to reach an agreement with the creditors. Given the discontinuity/alteration of the default definition brought upon the changes in the legal frameworks, care must be taken while conducting research in the bankruptcy field in Poland.
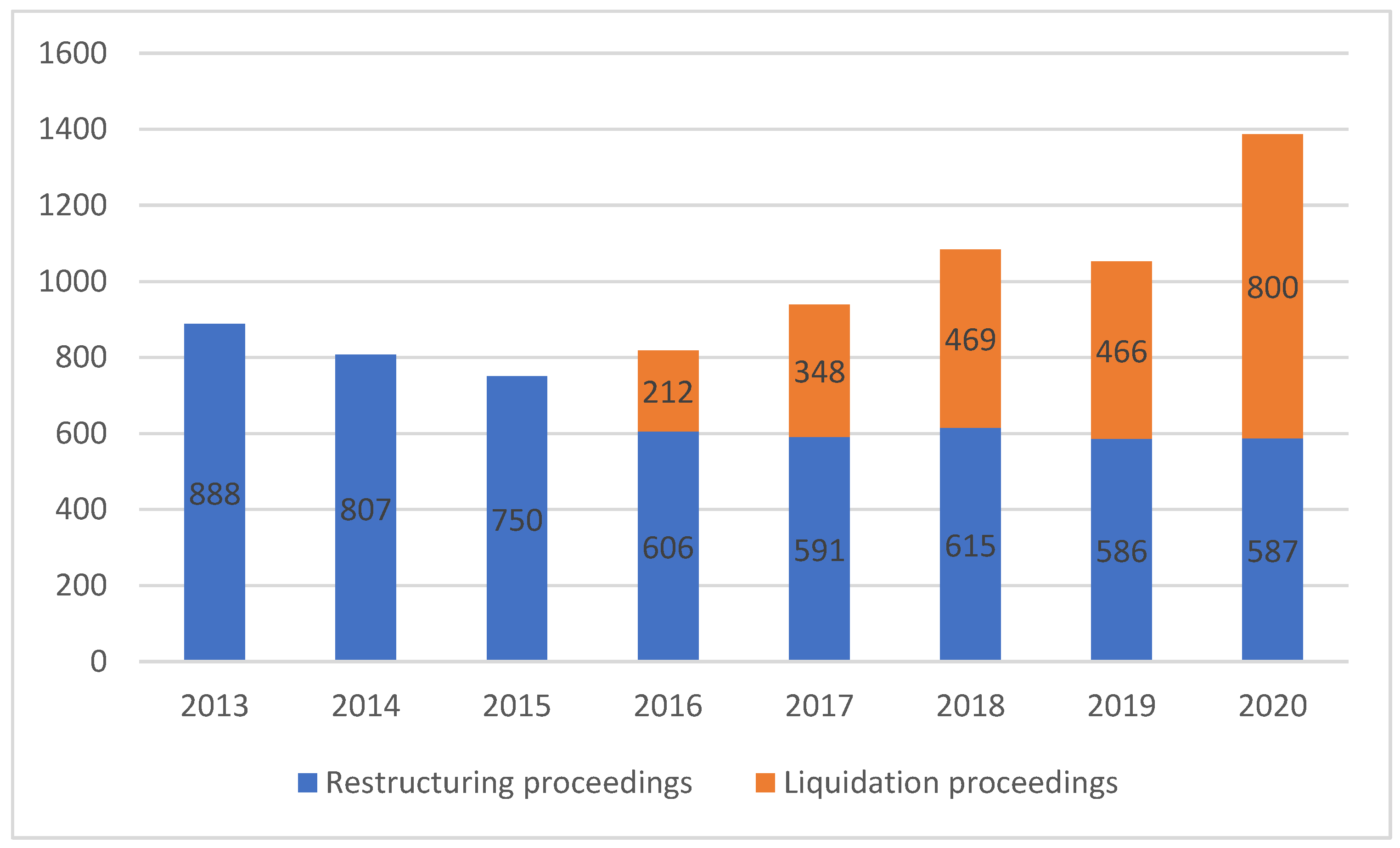
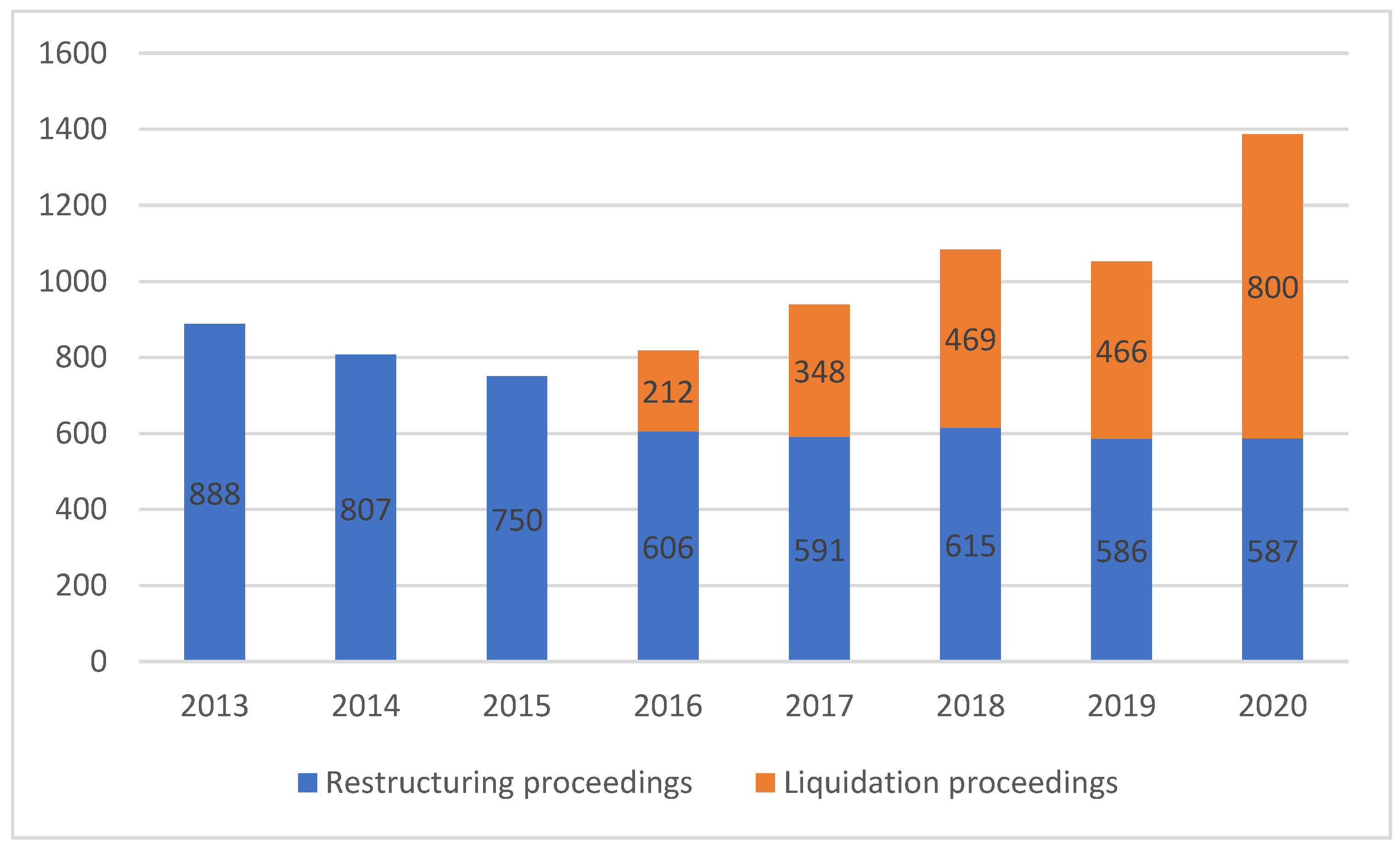
The motivation for the new 2016 law was clear, as the number of liquidation proceedings dwarfed the restructurings by the ratio of 5:1. As
Figure 1 illustrates, the effort was worth making, as the number of restructuring proceedings has significantly improved ever since. In 2020, restructuring proceedings outnumbered liquidations, partly due to COVID-19-driven regulations. The trend is generally assumed to remain even after the pandemic.
4. Discussion
The structural models (
Merton 1974;
Fischer et al. 1989;
Leland 1994) make use of the distance to default to predict the moment when the firm’s liabilities exceed its equity. This is clearly an approach determined endogenously. Other research (
Beaver 1966,
1968;
Altman 1968;
Ohlson 1980;
Zmijewski 1984;
Kavvathas 2000;
Shumway 2001;
Chava and Jarrow 2004;
Hillegeist et al. 2004) applies various statistical tools to optimize the discrimination between (future) defaulters and healthy companies using reduced-form formulations. Our model, instead, assumes that at each point in time, default occurs at random, with the probability of default, following
Duffie et al. (
2007) and
Duan et al. (
2012), depending on some company-specific and/or macroeconomic explanatory variables. Swapping the model of
Duffie et al. (
2007), which requires the knowledge of the exact level for the future state random variables, for the model of
Duan et al. (
2012), we can fully rely on the information available to us at the moment of making a prediction. If the model for the dynamics of the covariates proposed by
Duffie et al. (
2007) is mis-specified, then the predictions are contestable. The model of
Duan et al. (
2012), with its maximum pseudo-likelihood estimation procedure, is void of these problems. We should therefore agree with
Duan et al. (
2012) that apart from the computational efficiency, their approach is more robust, especially for long-term predictions. We use the model proposed by
Duan et al. (
2012), but throughout the paper refer to it as the Duffie–Duan model.
As for the choice of covariates, the approaches vary widely, not only in the context of broadly conceived default debate, but also within the doubly stochastic Poisson literature. For example,
Duffie et al. (
2007) choose two firm-specific (the share price performance and the distance-to-default) and two macro factors (the three-month Treasury bill rate and the trailing one-year return on the S&P index).
Duan et al. (
2012) choose the same two macro factors and complement them with as many as six company-specific variables. In contrast to
Duffie et al. (
2007),
Duan et al. (
2012) opt for more traditional factors measuring a company’s liquidity, profitability, and size. In addition, they add the idiosyncratic volatility and P/BV ratio.
Caporale et al. (
2017), applying the Duffie–Duan model to general insurance firms in the UK, are even more “lavish” in the use of state variables: they go for no less than twelve micro and six macro factors. Apart from the insurance-specific variables, all other standard company-specific candidates are represented: liquidity, profitability, leverage, size, growth, etc. Macro conditions are proxied by interest rates, inflation, and GDP growth, but also by exchange rate and FDI indices.
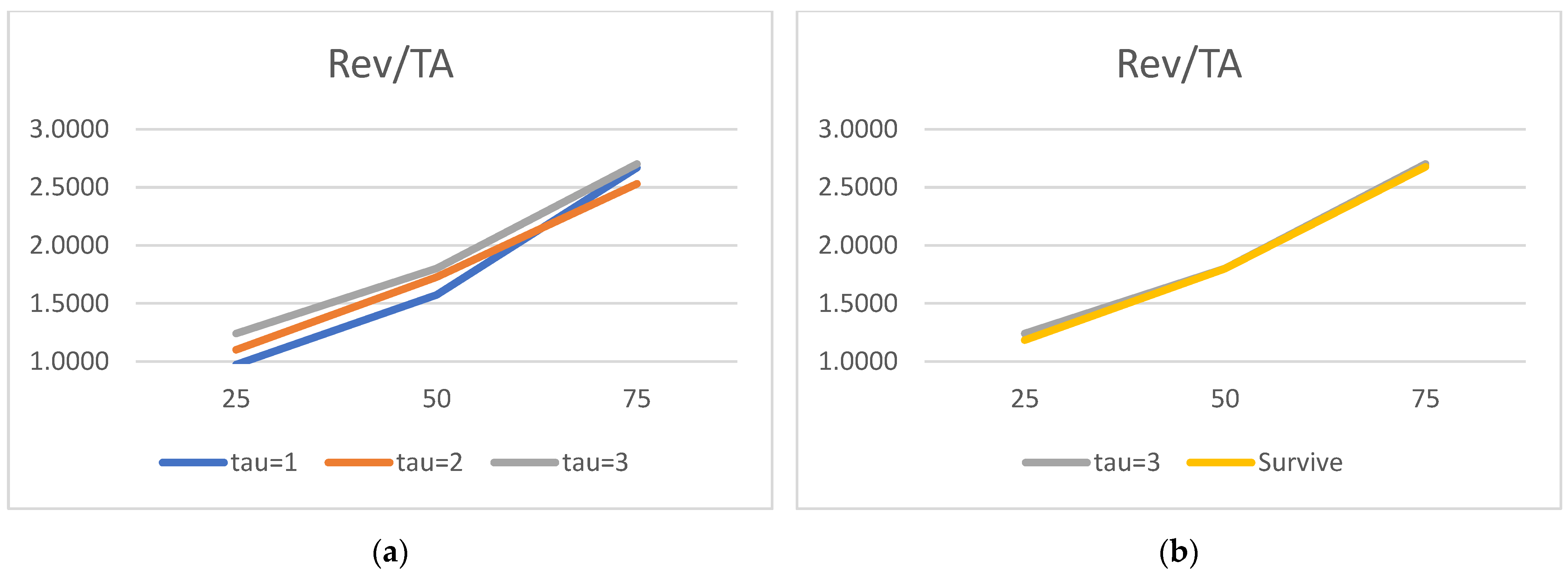
With our standard five micro and three macro factors, we are located somewhere in-between. As for the company-specific set (liquidity, profitability, leverage, rotation, and size), we attempt to link our research to the seminal papers of
Altman (
1968). We include the assets rotation for its Dupont analysis appeal. As for the firm size, large firms are thought to have more financial flexibility than small firms, hence size should be crucial. Yet, as
Duffie et al. (
2007) demonstrate, the size insignificance results from the wide representation of other variables in the model (see also
Shumway 2001). In terms of the macro set (inflation, interest rates, and GDP growth), we could hardly be more conservative. We admit that in choosing more variables, we have also been encouraged by
Caporale et al. (
2017), who show that all of their chosen factors (18 in total) proved statistically significant.
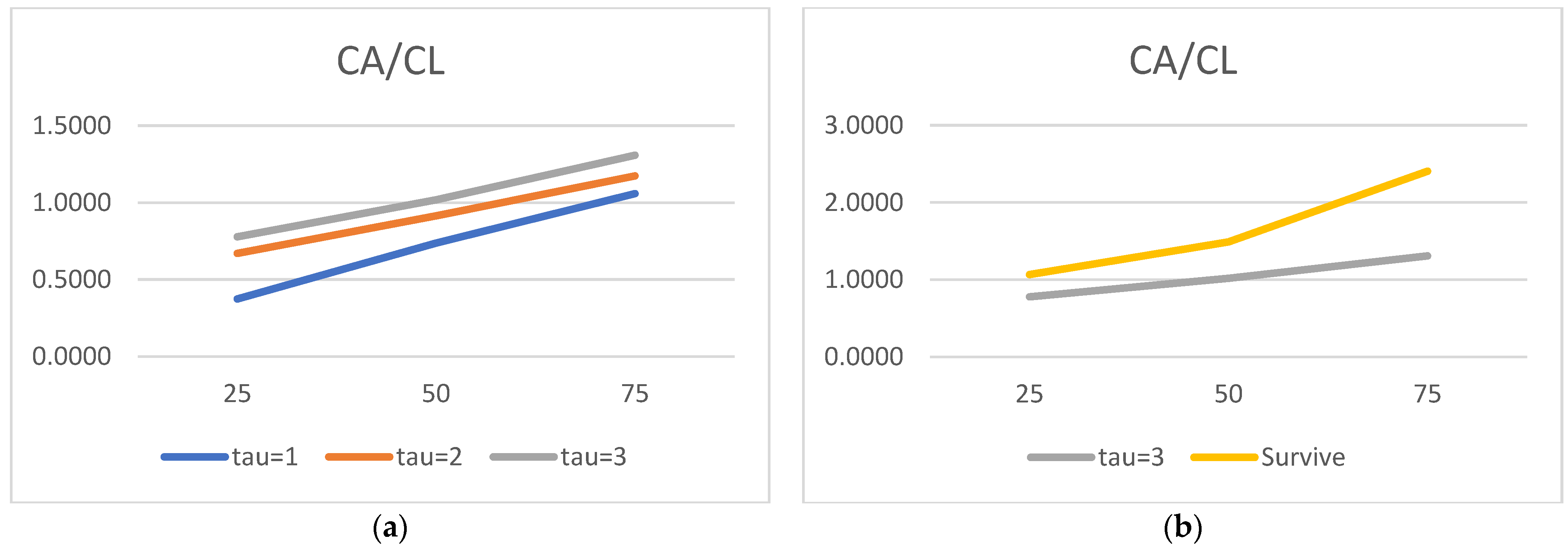
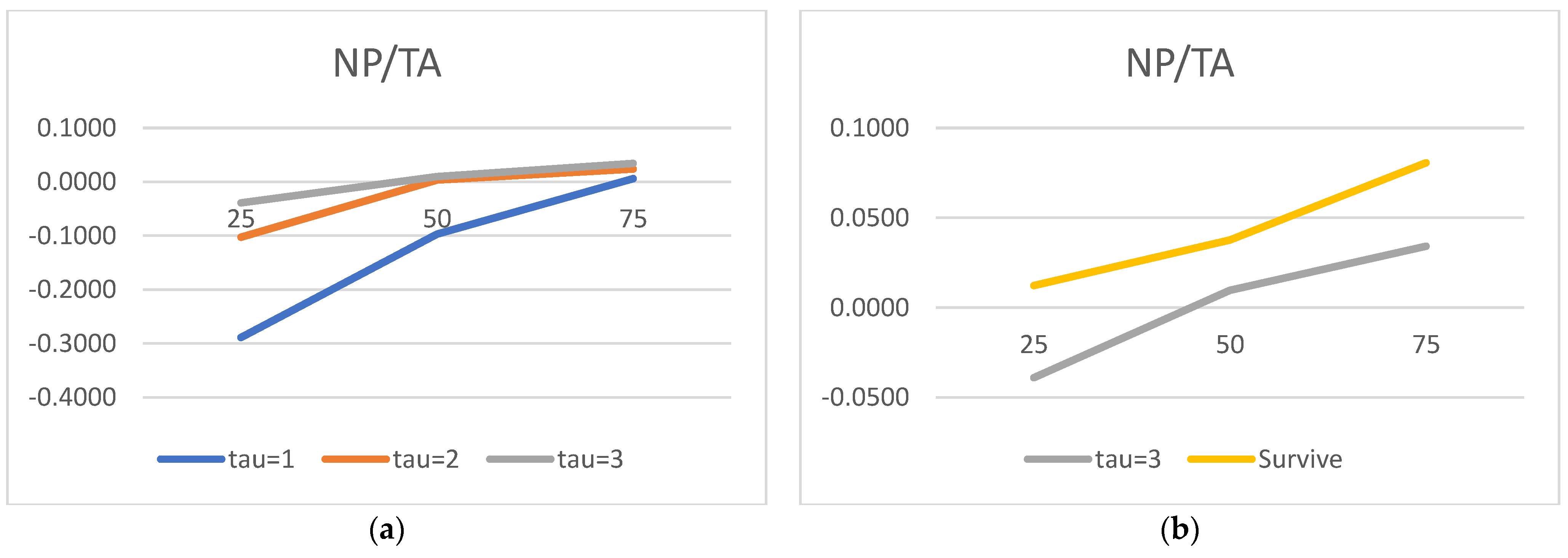
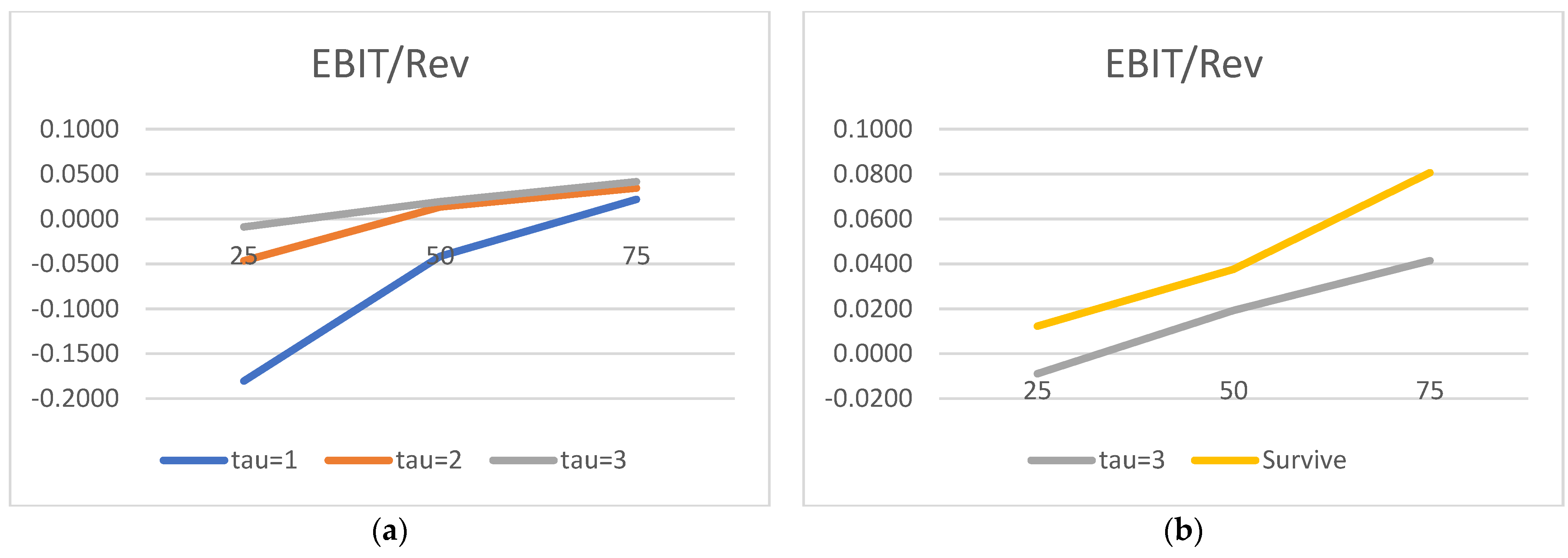
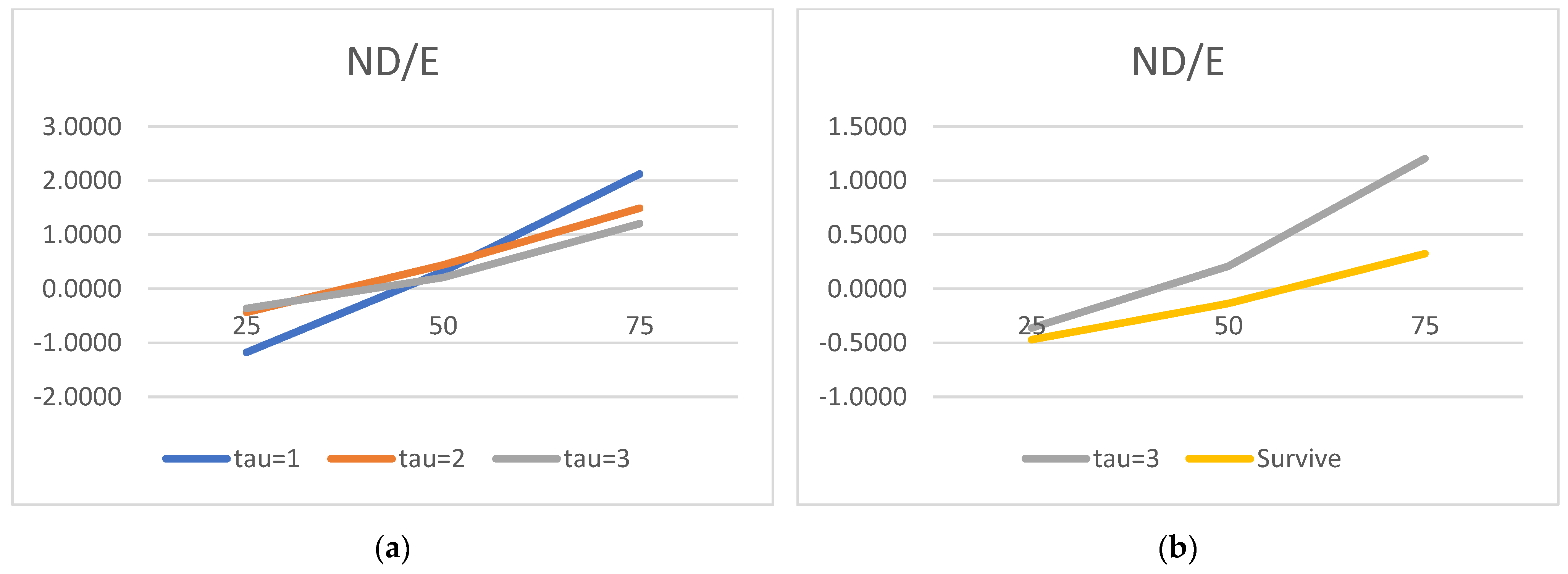
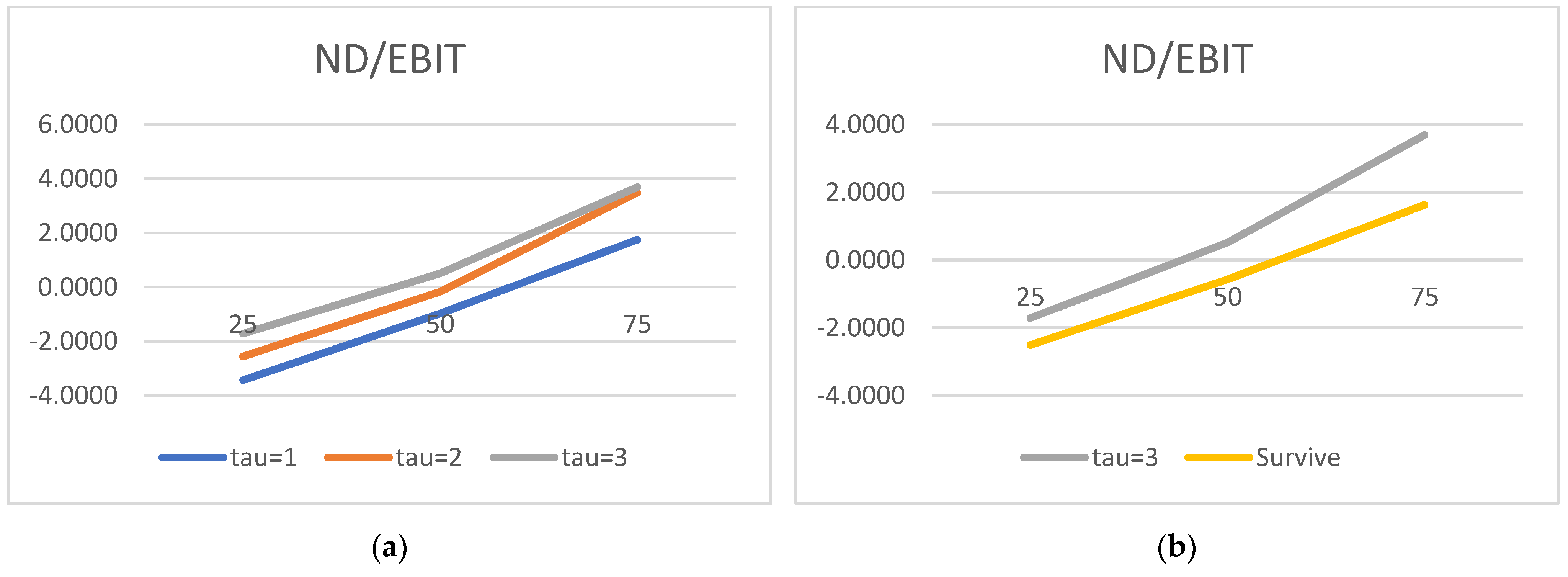
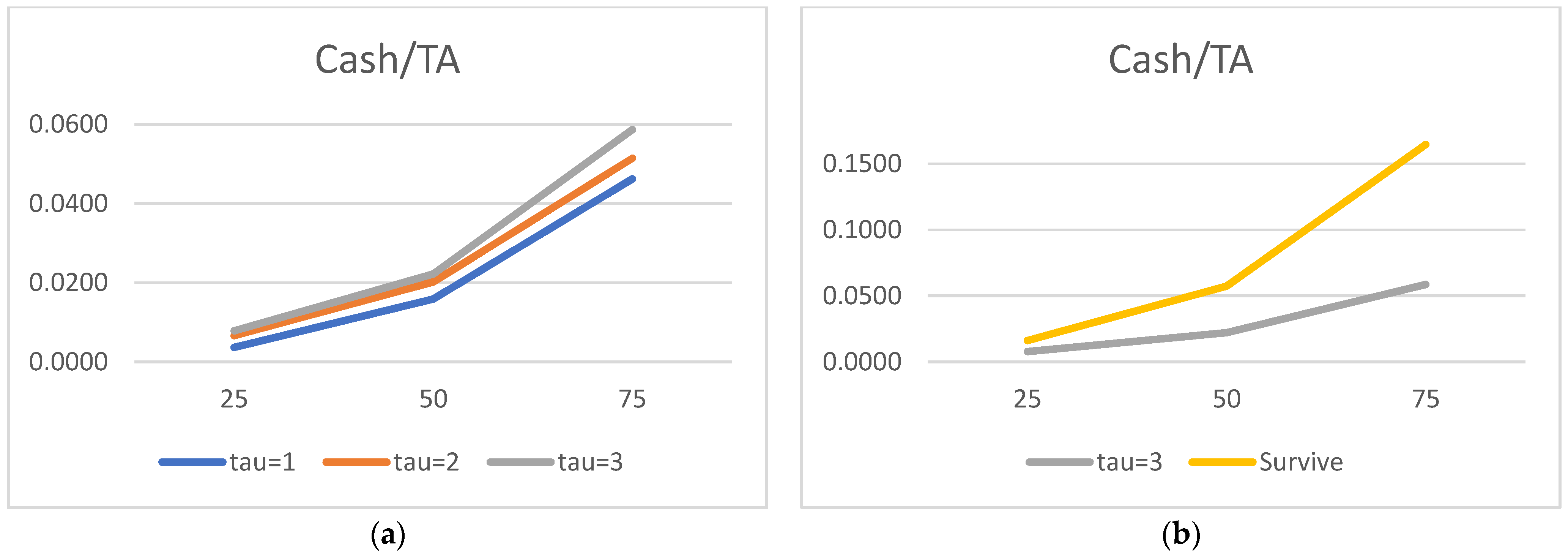
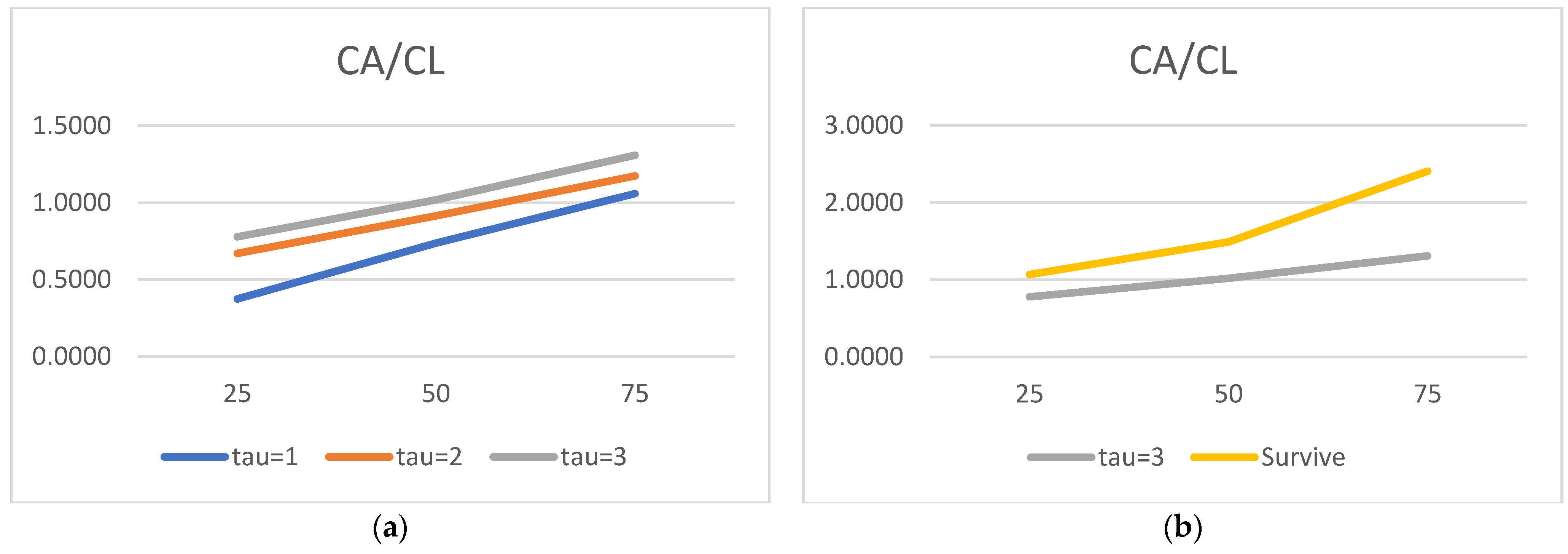
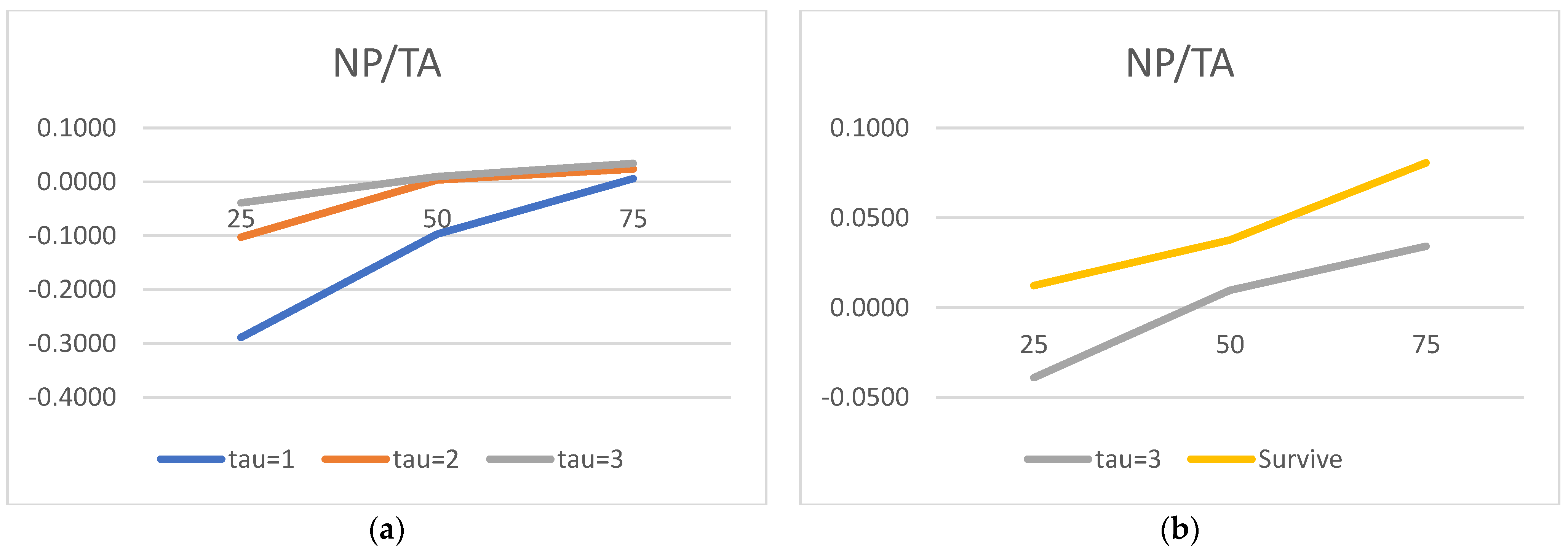
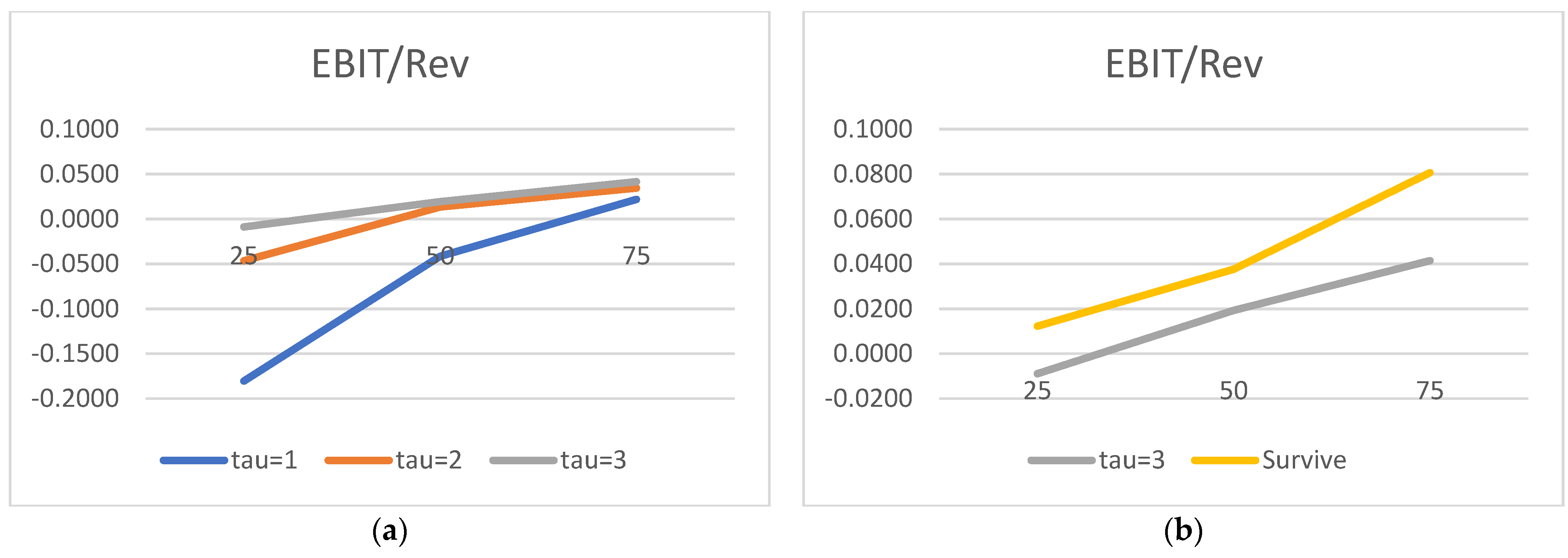
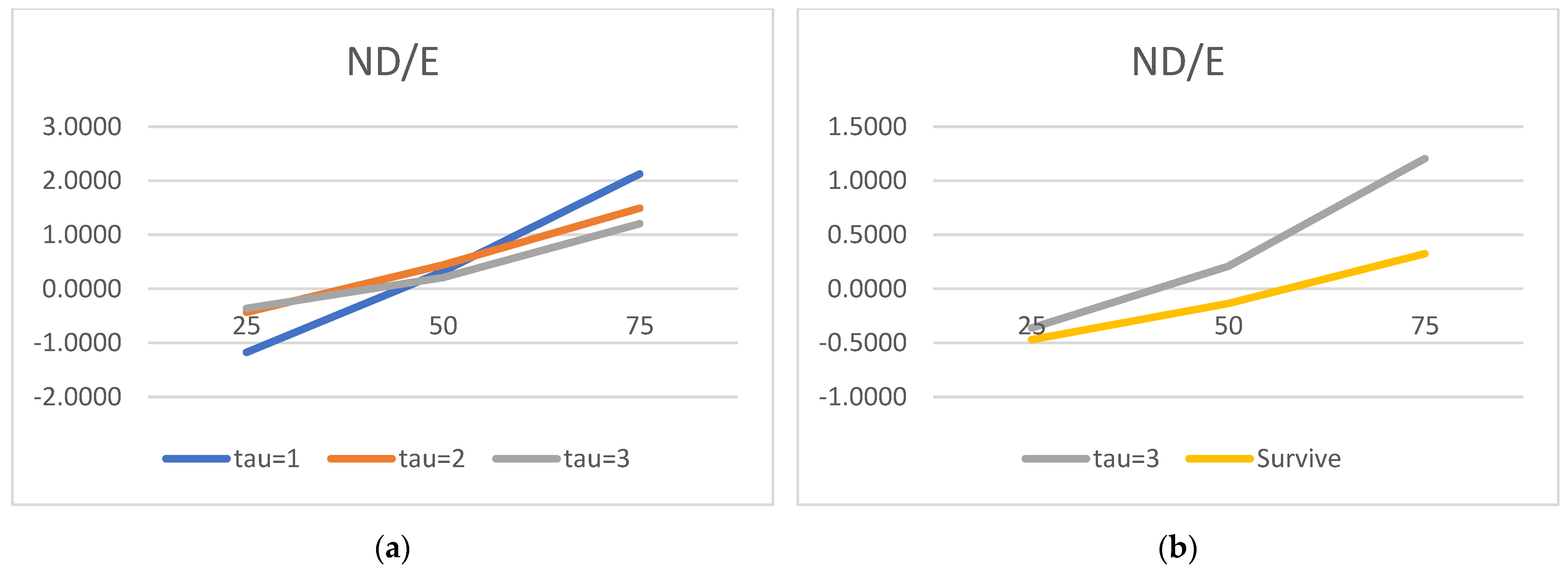
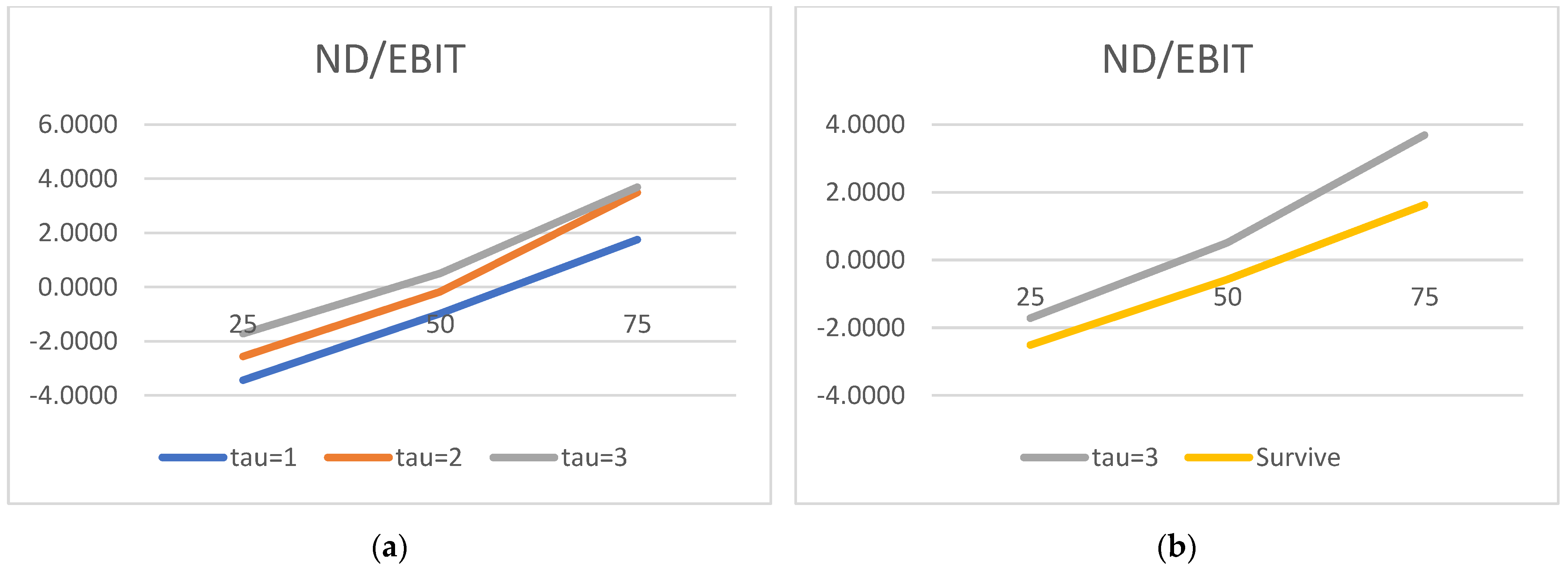
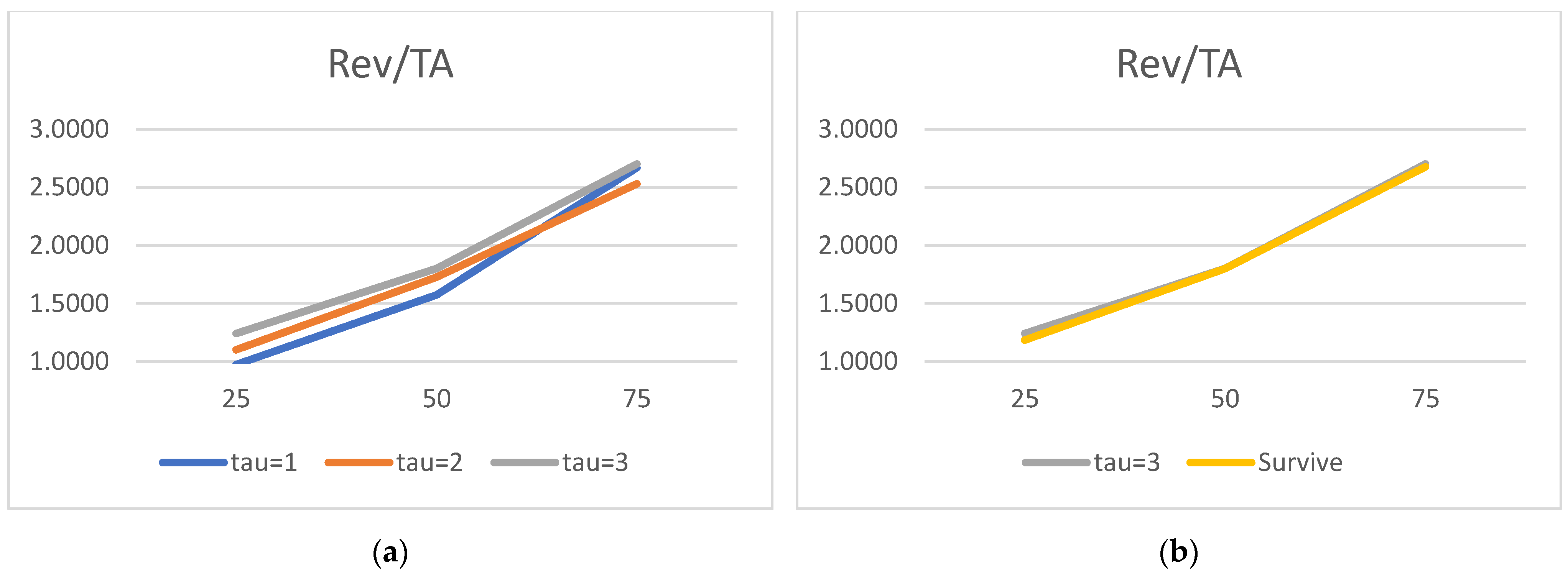
We would now like to turn to the state variable estimated parameters and acknowledge the truly surprising consistency of the covariate signs. As many as 27 out of 30 alphas are consistent with the theory. We show evidence that the lower the liquidity, profitability, asset rotation, and size, the higher the probability of default. Conversely, the lower the leverage, the higher the chance of the survival. Moreover, this result is surprisingly robust. The covariates’ parameters barely move with the change of a state variable vector. We have verified it with as many as 100 different versions of the model. The accuracy ratios do go down when the number of state variables is drastically reduced, but the parameter signs (and frequently their magnitude) are broadly unchanged.
Regarding the time sequence towards default, just like in
Duan et al. (
2012), we report ever higher (in absolute terms) negative coefficients for both versions of the liquidity ratios. The closer to the default moment, the more painful the drop in liquidity. We also report a similar time trend for the return on assets: the closer to default, the lower the profitability, resulting in a higher probability of failure. As for rotation, it is also observed for total assets turnover.
In contrast to the micro variables, some of our results on the macro factors are less intuitive. We hasten to add it is a regularly received outcome in the default literature using doubly stochastic formulations. For example,
Duffie et al. (
2007), just like us, report a negative relationship between short-term interest rates and default intensities; i.e., the higher the interest rates (the higher the costs of debt), the lower the chance of going bust. They argue that this counter-intuitive result may be explained by the fact that “short rates are often increased by the US Federal Reserve in order to ‘cool down’ business expansions” (p. 650). Similarly, to find a positive relation between the S&P index and default intensity is to say that when the equity market performs well, firms are more likely to default. This clearly counter-intuitive result is produced by both
Duan et al. (
2012) and
Duffie et al. (
2007). The correlation between the S&P 500 index return and other firm-specific attributes are quoted to be responsible for this outcome—i.e., in the boom years, financial ratios tend to overstate the true financial health. We must admit that we find these explanations somewhat arbitrary. What we take from this debate, however, is simple: adding the macro dimension is beneficial to the power of the model (see also
Beaver et al. 2005;
Shumway 2001; or
Berent et al. 2017). This is precisely what we aim at in our paper. It is less important for us to measure the strength or to rank the importance of various macro (and micro) constituents. It is the performance of the whole model that is at stake here.
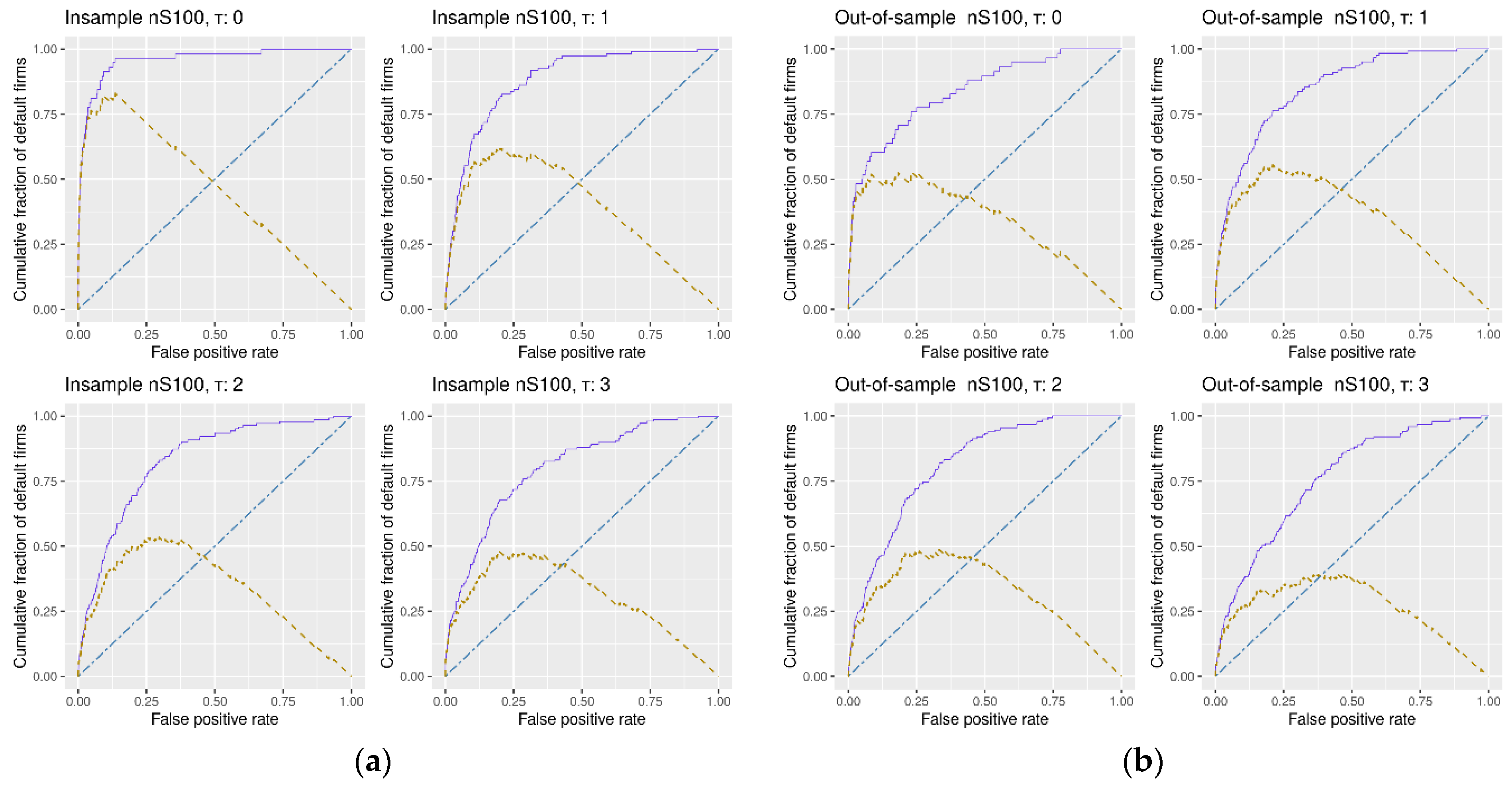
We turn now to the measures of the model’s goodness-of-fit—the pivotal part of this research. As already mentioned, our accuracy ratios are very high by all standards. This is further documented by
Table 17. Compared to
Duffie et al. (
2007) and
Duan et al. (
2012), two seminal papers in this area, our results (in- and out-of-sample) tend to be quite good: better than those of
Duan et al. (
2012) and similar to the (out-of-sample) results of
Duffie et al. (
2007). The latter do not publish in-sample statistics, with only one and five year ahead out-of-sample accuracy ratios released.
To put our results into perspective, we quote
Duffie et al. (
2007), who in turn place their results in the context of other research. They note that their out-of-sample accuracy ratio of 88% favorably compares to the 65% produced by Moody’s credit ratings, 69% based on ratings adjustments on Watchlist and Outlook, and 74% based on bond yield spreads, all reported by
Hamilton and Cantor (
2004).
Duffie et al. (
2007) also quote
Bharath and Shumway (
2008) who, using KMV estimated default frequencies, place approximately 69% of the defaulting firms in the lowest decile. The model of
Beaver et al. (
2005), based on accounting ratios, places 80% of the year-ahead defaulters in the lowest two deciles, out of sample, for the period 1994–2002. Against all these measures, the accuracy ratios of
Duffie et al. (
2007) compare more than favorably. We reiterate that our (out-of-sample) accuracy ratios are very close to those of
Duffie et al. (
2007).
We are particularly (positively) surprised by the level of our out-of-sample fit. Having no prior evidence from any other research on the accuracy of the doubly stochastic Poisson formulation in modelling default within the context of non-public emerging market companies, we could not have expected the levels of accuracy compared to the models using high-quality data from developed markets. What we lost in the quality of the data, we hoped to recoup in the sample size and the power of the tests. Indeed, we believe our results may have benefited from the size of the sample, as our over 15,000 population of firms modelled significantly outnumber the sample size of either
Duan et al. (
2012), who use 12,268 firms, and of
Duffie et al. (
2007), with 2770 firms. Others using the Duffie–Duan model apply it to even smaller samples, as evidenced by, for e.g., the 366 (one sector) companies used in
Caporale et al. (
2017).
It is also possible that our results are so strong because the defaulters representing non-public companies are so weak financially, compared to the public companies from the developed markets used elsewhere, that the discrimination between the positives and the negatives in our sample is simply easier, no matter what model is used. This said, we have not seen many examples of emerging market data outperforming the results originating from the developed markets default literature.
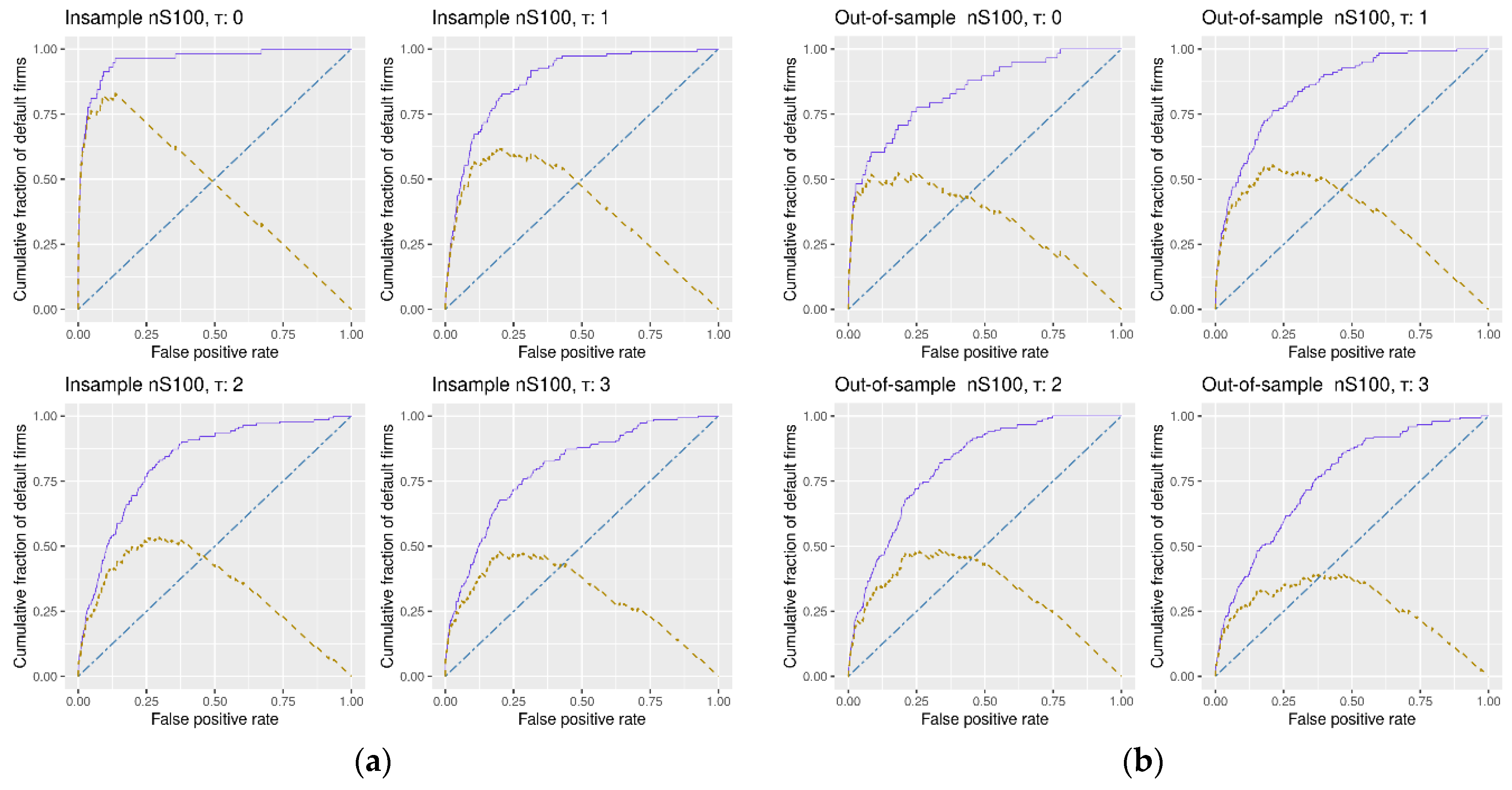
Our accuracy ratio is not the same as the area under curve, or AUC, also used in the literature. The latter amounts to 0.5 for a random classifier, an equivalent of the accuracy ratio of zero (see
Table 3). Hence, the accuracy ratios of 0.8475, 0.8114, or 0.7590, that we record out-of-sample for tau = 1, tau = 2, and tau = 3, respectively, imply an AUC of 0.9238, 0.9057, and 0.8795, respectively. The difference between 0.7590 and 0.8795 in reported statistics is worth noting. The awareness of what measure is used to gauge the goodness-of-fit is important in any research. In the default literature, it is critical.
We also note the relatively low drop in the out-of-sample accuracy of 2–4 p.p., compared to the in-sample statistics. The finding is broadly in line with
Duan et al. (
2012). As illustrated by
Table 17, the drop reported in
Duan et al. (
2012) is even smaller and amounts to merely one percentage point. As for the statistical inference, neither
Duffie et al. (
2007) nor
Duan et al. (
2012) deliver any statistical tests for the accuracy ratios. In contrast, our results are fully documented to be statistically significant at the 1% level using two different statistical tests.
In summary, we would like to reiterate the coherence and the robustness of the results obtained. Firstly, we note again that the signs of covariates, including those for critically important variables, are almost perfectly in line with the theoretical expectations. This is particularly rewarding, as we decided to represent every and each micro factor with two closely related ratios. We have verified this result by running an additional 100 different model specifications, e.g., with and without macro input, with micro variables represented by one or two ratios each, with or without the size control variable, etc. The signs stayed broadly unaffected. Secondly, the coefficient magnitudes confirm the time-dependent relationships. The closer to default, the greater the drop in liquidity and profitability, for example, resulting in ever higher default forward intensities. Thirdly, both in- and out-of-sample accuracy ratios are large and comparable in size with those generated for developed markets and public companies. Fourthly, the accuracy ratios monotonically change with time—the further away from default, the lower the power of the model discrimination. This is precisely what we expect. Fifthly, the accuracy of the model changes in line with the addition (or subtraction) of additional variables to the model. For example, scrapping the double representation of company-specific ratios results in the loss of accuracy ratios of around 3–4 percentage points. Aborting the macro factors cuts AR by another 4–5 percentage points. Finally, all of our replications result in both in- and out-of-sample results that are statistically significant at the 1% level, using two different tests. This all proves the model is far more resilient than traditionally used linear regression specifications to different model specification changes.
Last but not least, we reiterate that the doubly stochastic Poisson model used in this paper is still dependent, by definition, on the doubly stochastic assumption under which firms’ default times are correlated only in the way implied by the correlation of factors determining their default intensities. Notwithstanding our highly satisfactory and robust results, these results should be viewed with caution, as no doubt the model implies unrealistically low estimates of default correlations compared to the sample correlations. This has been reported by, for e.g.,
Das et al. (
2007) and
Duffie et al. (
2000). It should also be remembered that the overlapped pseudo-likelihood function proposed by
Duan et al. (
2012) used in this paper does violate the standard assumptions, and the implications of this are not immediately clear. Still, the potential biases introduced affect the results of both
Duffie et al. (
2007) and/or
Duan et al. (
2012) as much they affect our findings.


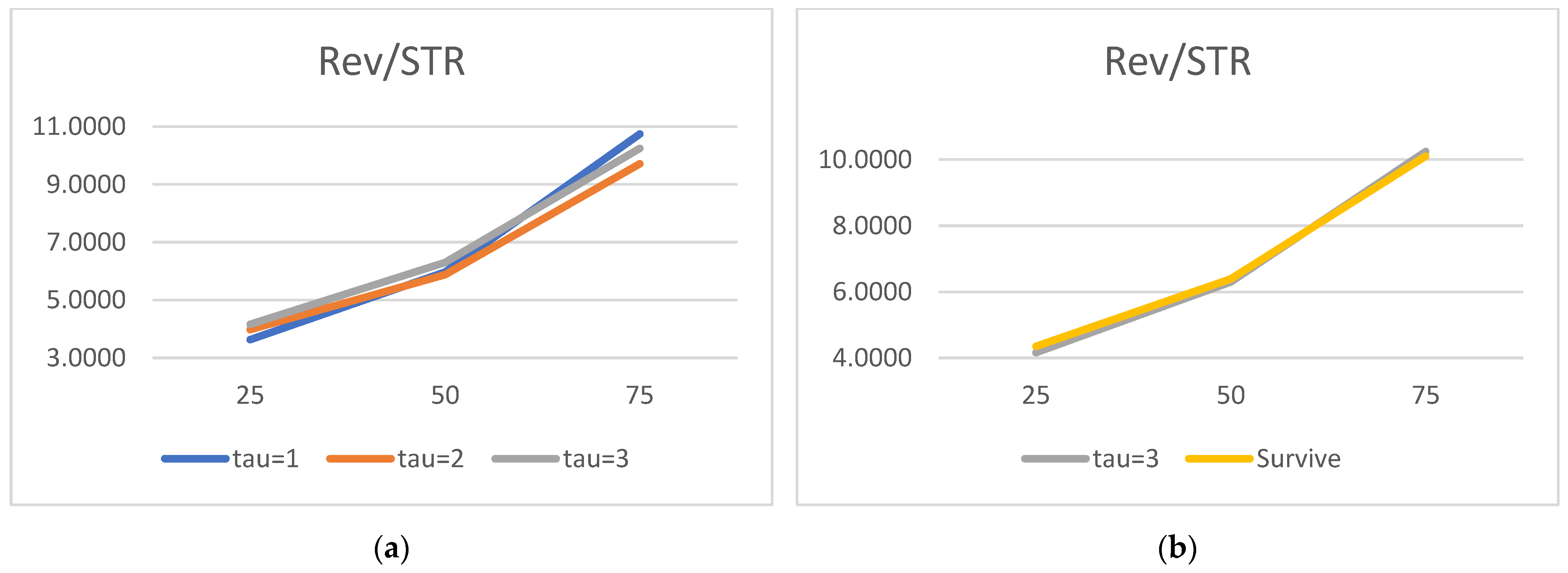
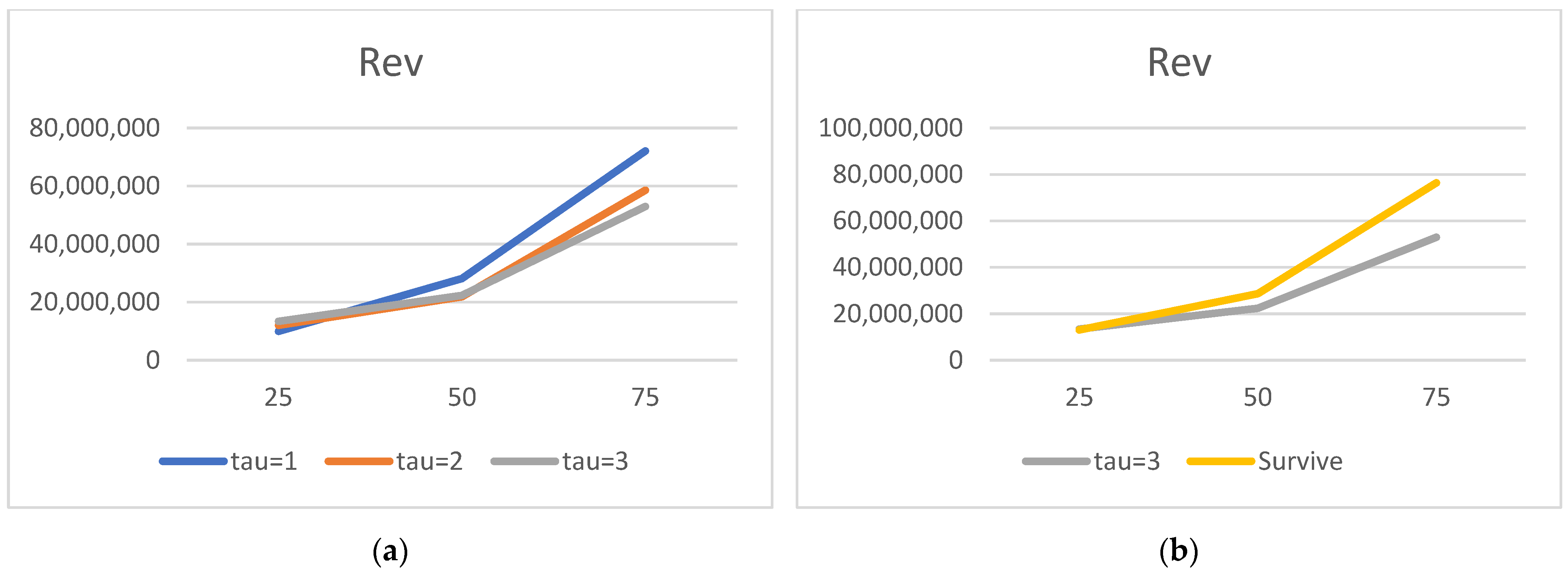

{kind=link}
{kind=link}
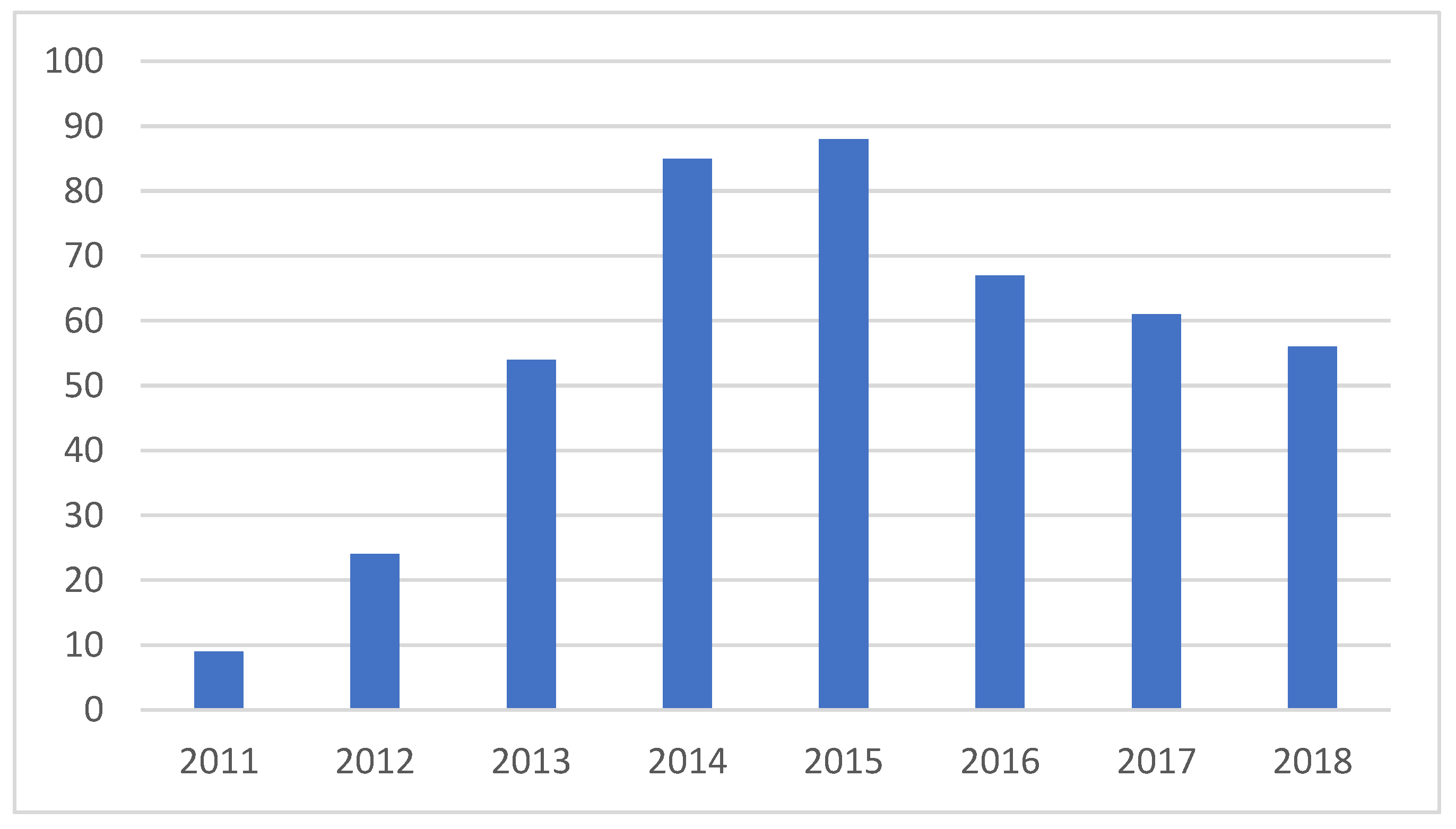{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}