1. Introduction
In a recent work, a modification in the bonus-malus systems was proposed
Gómez-Déniz (
2016), which are commonly applied in automobile insurance, that differentiated between two different types of claims by including a bivariate model based on the assumption of dependence. The aforementioned work studied the impact on the bonus-malus premium in a general setting without involving individual’s risk factors, such as gender, type of vehicle, area of circulation, etc.
It is well known that under the traditional bonus-malus system, the premium charged to each insured is based solely on the number of claims made. Therefore, an insured who has had an accident that causes a relatively small loss amount is penalised to the same extent as one who has experienced a more expensive accident. This event would seem to be unfair by the insureds. In the mentioned work a bivariate prior model, conjugated with respect to the likelihood, was also proposed, and as a result of this, simple credibility bonus-malus premiums that satisfy appropriate transition rules were obtained. These expressions were used to compute credibility bonus-malus premiums by considering two different types of claims: those ones above and below a threshold claim size, say .
Similar related works have been proposed in the actuarial literature. In this sense, the work in
Pinquet (
1998) computed bonus-malus rates in a multi-equation Poisson model with random effects. The work in
Ragulina (
2011) introduced a bonus-malus system with different claim types and varying deductibles. The work in
Walhin and Paris (
2001) showed how to set up a practical bonus-malus system with a finite number of classes using both the actual claim amount and claim frequency distribution. The work in
Bonsdorff (
2005) also incorporated the claim number and the severity in the bonus-malus system literature by using Markov chains. The work in
Bermúdez (
2009) examined, in automobile insurance claims, an a priori ratemaking procedure that included two different types of claim, i.e., with and without bodily injuries. See also
Bermúdez and Karlis (
2017).
The main objective of this work is to develop a reparametrization of the bivariate distribution proposed in the previous work with the purpose of incorporating individual information in the model to adjust the premiums charged to each policyholder. Additionally, some statistical properties of the proposed parametrization that were not addressed in the previous work will be shown. Furthermore, an extensive set of a priori classification variables such as age, gender, type and age of car, etc., will be used to incorporate, depending on the heterogeneity of the insured’s behaviour, prior distributions assigned to the parameters of the model to build up a posteriori credibility, bonus-malus premiums.
The rest of this paper is organised as follows. The main model and some of its properties are presented in
Section 2. In
Section 3, the regression model is introduced, and maximum likelihood estimation methods are illustrated. We will show that the estimation procedure is simply derived, and Fisher’s information matrix associated with this regression model is obtained in closed-form. Credibility premiums related to the regression models are provided in
Section 4. Numerical illustrations and results connected with the compound model are shown in
Section 5, and finally,
Section 6 concludes the work.
3. The Role of the Covariates
Clearly, the number of claims below and above
may be influenced by different characteristics and factors; likewise, explanatory variables may be useful to explain the individual premium to be charged. As (
1) satisfies that the marginal means are given by
and
, then covariates can be simply implemented in the model.
We now investigate the effect of including covariates to account for the total number of claims and the claims above the threshold
. Obviously, some factors are crucial when explaining the endogenous variables
. Two appropriate links are needed to connect the explanatory variables with the marginal means. A natural way to proceed is to assume that
for
follows the probability function (
1) and:
where
and
denote vectors of
m explanatory variables for the
observation, i.e., with components
and
,
, used to model
and
, respectively, and where
,
designates the corresponding vector of regression coefficients. The log-linear specification for
is widely used, while the link function for
was chosen in this way to ensure that the latter one would not be larger than
, and thus, it would be compatible with
.
These mean values may be influenced by several characteristics and variables, and the explanatory variables that are used to model each parameter
and
may not be the same in practice. In this respect, the work in
Cameron and Trivedi (
1998) provided good insight into standard count regression models.
The marginal effect reflects the variation of the conditional mean of
and
due to a one-unit change in the
covariate, and it is calculated as:
for
and
. Thus, the marginal effect indicates that a one-unit change in the
regressor increases or decreases the expectation of the total number of claims and the number of claims above the given threshold depending on the sign, positive or negative, of the regressor for each mean. For indicator variables such as
, which takes only the value zero or one, the marginal effect in terms of the odds-ratio is
for
and
for
. Therefore, for
, the conditional mean is
times larger if the indicator is one rather than zero. A similar conclusion is drawn for
. Certainly, if
and
share the same covariates, then (
5) does not correspond to the marginal effect of the
covariate since
may also change in response to the changes of this covariate.
3.1. Estimation
In this section, we derive estimators based on the maximum likelihood for the model with and without covariates, and we also provide closed-form expressions for Fisher’s information matrix.
3.1.1. Model without Covariates
Let
and a random sample consisting of
n observations
, taken from the probability function (
1). The log-likelihood is proportional to:
where
and
are the sample means of
and
, respectively. The normal equations to be solved are:
from which it is easy to obtain the solution to obtain the maximum likelihood estimators
and
which coincide with the moment estimators. The second partial derivatives are:
The expectation of the negative of the second partial derivative yields Fisher’s information matrix:
The asymptotic variance-covariance matrix of is obtained by inverting this information matrix.
3.1.2. Model with Covariates
When covariates are considered, the log-likelihood is proportional to:
where
.
Observe now that
and
, to emphasize that the first expression depends only on
and the second on both
and
. Thus,
for
and
.
Then, after some algebra, we obtain the normal equations,
where:
These equations provide the maximum likelihood estimates for the vector of parameters
and
. Similarly to the previous case, Fisher’s information matrix can be obtained in closed-form. See the details in
Appendix A.
The normal equations illustrated above can be used to estimate model parameters with and without covariates. The Newton–Raphson method provides solutions in a non-prohibitive time, obviously depending on the number of regressors used.
4. Credibility Regression Premiums
Briefly speaking, a bonus-malus system is an experience rating system that is based on the insured’s claim experience frequency rather than the claim size. Let us now assume some kind of heterogeneity between policyholders, by allowing that the parameters
,
follow some probability functions. For
, a gamma prior distribution will be assumed
with a shape hyperparameter
and a scale hyperparameter
, whereas a type beta prior distribution will be considered for
with the probability density function given by:
Here, , , and is the beta function given by where is the Euler gamma function.
The main benefit of selecting these prior distributions is that they are conjugate with respect to the likelihoods, and for that reason, they are common choices in Bayesian and actuarial statistics; see for instance
Heilmann (
1989);
Denuit et al. (
2009), and
Klugman et al. (
2008), among others.
Since
and
are dependent, we can choose the prior distribution given by:
which corresponds to the copula proposed by
Lee (
1996). Here,
,
, are bounded non-constant functions such that
, and
a real number, which satisfies that
,
. Now, given a sample
, where
t is the sample size, the posterior distribution of
given the sample information is computed according to Bayes’ theorem, and it is proportional to the product of the likelihood and the prior distribution. Thus, the posterior distribution is almost conjugated with respect to the likelihood and similar to the product of a gamma and a beta distribution and where the updated parameters are given by:
In practise, it is shown that is near zero, then in this case, , and the prior distribution reduces to , which is the case considered here.
Now, the unconditional means and cross moment are given by:
Finally, the unconditional bivariate distribution is:
For computational reasons, sometimes, it is more convenient to work with the parametrization and .
The maximum likelihood estimates for this mixture regression model can be simply obtained by means of the EM algorithm. This method is a powerful technique that provides an iterative procedure to compute maximum likelihood estimation when data contain missing information. Details on the derivation of the EM algorithm can be found in
Appendix B. The standard errors of the estimates
can be computed by using the method given by
Louis (
1982). Here, we use Fisher’s information matrix found in
Appendix A and replace the missing values by the corresponding pseudo-values calculated in the last iteration of the EM algorithm. Direct maximization of the likelihood surface is also possible to compute the maximum likelihood estimates of the mixture regression model.
By following the same arguments as those ones provided in
Gómez-Déniz (
2016) and also based on the ideas in
Heilmann (
1989) (see also
Gerber 1979,
Rolski et al. 1999,
Bühlmann and Gisler 2005, and
Gómez-Déniz 2008; among others), a premium calculation principle assigns to each risk vector of parameters
a premium within the set
, the action space. Let
be the squared-error loss function sustained by a decision-maker who takes the action
P and is faced with the outcome
of a random experience. The premium must be determined in a way such that the expected loss is minimised. The unknown premium
, called the risk premium, can be obtained by minimising
, where
is an appropriate function of the number of claims with a claim size below
and above
, respectively. It seems reasonable to take
as:
where
are appropriate weights assigned to the number of claims for claim sizes above and below the critical value, respectively, with
. Now, simple algebra provides the risk premium given by,
where the expectation is taken on (
1). By taking
in (
14), this reduces to
, that is the risk premium depends only on the number of claims, irrespective of their size.
In the absence of experience, the actuary computes the collective premium,
Again, by inserting
into (
15), we obtain the collective premium computed under the traditional model,
. On the other hand, if experience is available, the actuary takes a sample
from the random variables
and uses this information to estimate the unknown risk premium
, through the Bayes premium
. Due to the fact that the posterior distribution is conjugated with the prior, the Bayes premium can be derived from (
15) by simply switching the parameters
and
with the updated parameters by using (
8)–(11). Furthermore, the Bayesian premium can be rewritten as a credibility expression, i.e., a linear function of the data and the collective premium.
Obviously, the Bayesian premium based on (
15) does not depend on the individual’s risk factors, and it is only based on the accumulated past claims. Individual’s risk factors can be incorporated into the premium by computing
, for
. This general pricing formula is a function of the number of accumulated claims and the individual’s significant characteristics in the regression component.
Finally, the Bayesian bonus-malus premium is computed as the ratio between the Bayesian premium and the collective premium. This bonus-malus premium is usually normalised by multiplying this ratio by 100.
5. Empirical Results
We will now analyse a dataset that includes information based on one-year vehicle insurance policies taken out in 2004 or 2005. This dataset is available on the website of the Faculty of Business and Economics, Macquarie University (Sydney, Australia) (see also
de Jong and Heller 2008). The total portfolio contained 67,856 policies, of which 4624 have at least one claim. With respect to the number of claims, the minimum and maximum were zero and four, respectively. The mean was 0.072, and standard deviation was 0.278. On the other hand, regarding the claim size, the minimum and maximum were zero and 55,922.10, respectively. The mean was 137.27, and the standard deviation was 1056.30. This value was very large for the severity of claims, which meant that a premium based only on the mean claim size was not adequate for computing the bonus-malus premiums. As this portfolio only included the aggregate value of the claims’ severity, we followed the approach provided in
Gómez-Déniz (
2016) to determine the exact value of all claims randomly. Since this portfolio only included the aggregate value of the claim amount for all of the claims in the portfolio, a simulation was performed to determine the exact amount corresponding to each claim. This simulation was carried out by using the Mathematica commands
Permute, RandomChoice, IntegerPartitions, IntegerPart and RandomPermutation, as shown in the Appendix provided in
Gómez-Déniz (
2016). It is convenient to note that the partition obtained only provided the integer part, and this did not seem very relevant in the analysis. Furthermore, due to the
RandomChoice command, the partition was different every time the program was run. The results obtained for the claim amounts via simulation are not shown in this work, but they are available from the authors upon request.
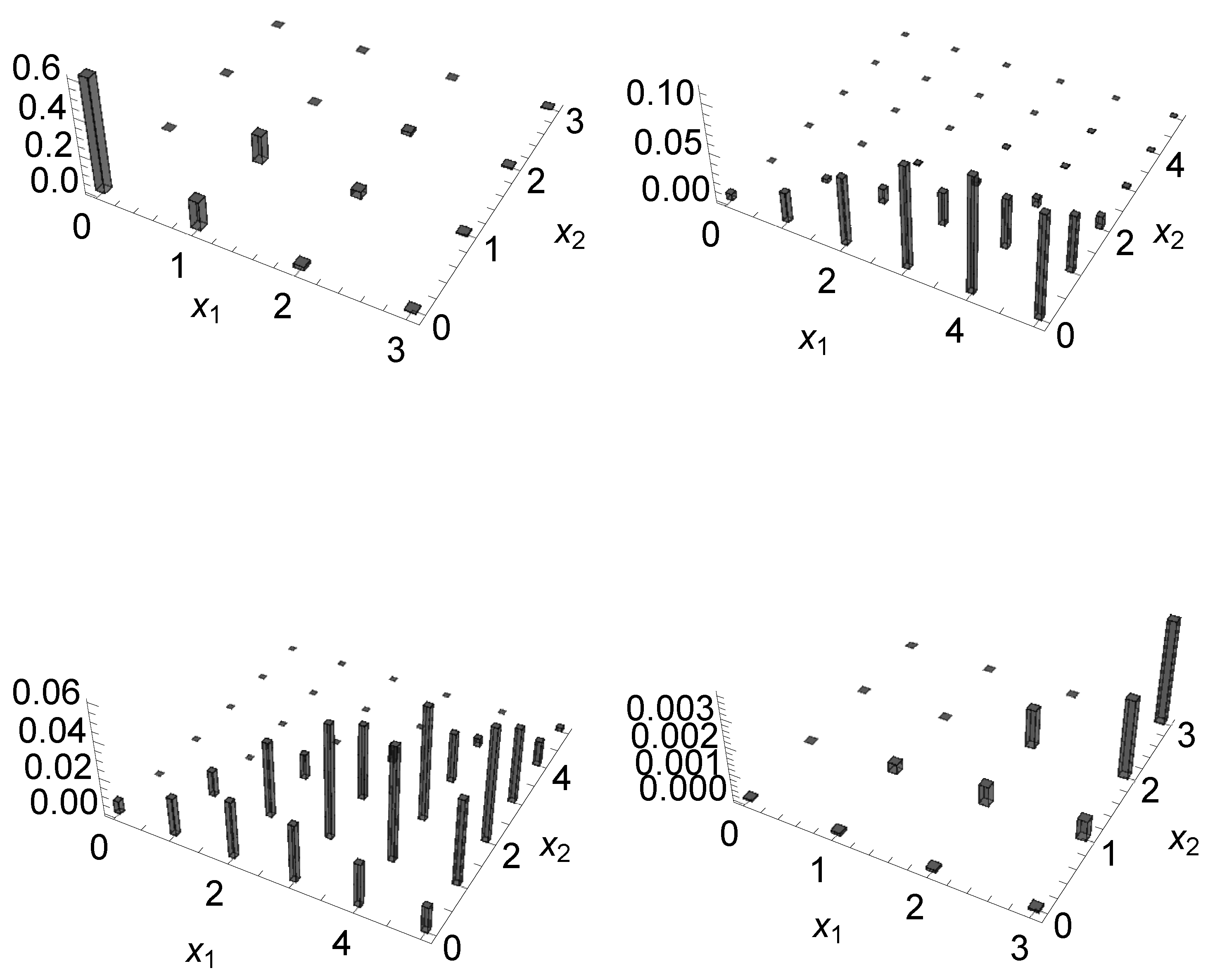
Below in
Table 1, the observed (in bold) and expected frequencies with the threshold value for the claims assumed to be
are shown. For each entry, observed frequencies (top row in bold), expected frequency under the basic model (given by using (
1) in the middle row), and mixture model (bottom row), obtained by using (
12), are illustrated. Furthermore, the marginal observed and expected frequencies are in the far right column and in the bottom row for
and
, respectively. The cells in this table are grouped to comply with the rule of five when applying the
test.
Similarly,
Table 2 exhibits the observed and expected frequencies when the threshold amount was
. Again, the cells are combined to comply with the rule of five. As can be seen, the fitting values obtained by using the mixture model were much more flexible since it incorporated heterogeneity among policyholders via the prior distributions, and it also provided a better fit to the data than those ones computed under the basic model for both thresholds.
Maximum likelihood estimation was used in both cases. It is convenient to point out that in the case of the mixture model, it was proven that directly maximizing the logarithm of the log-likelihood function provided, as expected, the same results as using the EM algorithm shown in
Appendix B of this work. Mathematica and WinRaTs were the two packages used in this case.
Parameter estimates, standard errors (in brackets), the maximum of the log-likelihood function, figures of the chi-squared test statistics, degrees of freedom (d.f.), and the
p-value are exhibited in
Table 3 for the basic and mixture models. Results under the threshold value first
are shown in the second and third columns and
in the last two columns. Virtually, the same estimates were obtained for parameters
and
under the basic and mixture models. Similarly, no changes were discernible in the estimates between the estimates for the two thresholds with the exemption of the estimate of parameter
. In this case, it was observable that the estimate decreased when the threshold increased. By incrementing the threshold value, the fit to the data improved. The mixture model provided the best fit to the data in terms of the
test statistic and the negative of the maximum of the likelihood function
. Note that the mixture model was not rejected at the 5% significance level for the two thresholds previously considered. It is important to note that, although the gain in terms of maximum of the log-likelihood function did not seem significant, the mixture model was preferable in terms of the
test statistics since, unlike the basic one, it was not rejected at the 5% significance level (see the corresponding
p-values) in either of the two thresholds mentioned above.
We now implement explanatory variables in our analysis. The following covariates were considered: gender of driver, vehicle body, driver’s area of residence, age of vehicle, and driver’s age category. In addition, an intercept was also included in the study. Details about the codification of these variables can be found on the same website. Moreover, an offset variable (exposure, log of the time exposed to risk) was included in the linear predictor associated with the first variable.
Table 4 illustrates the estimates of the regressors for the mixture model associated with the random variables
and
again for a threshold of
and
. In the first case, the explanatory variables hardtop (HDTOP), motorized caravan (MCARA), driver’s area of residence C (AREAC), age of Vehicles 1 and 2 (VAGE1 and VAGE2), and driver’s Age Category 1 (AGE 1) were statistically significant at the 5% significance level for the random variable total number of claims given that the claim size exceeded
. Among these variables, only HDTOP, MCARA, VAGE1, VAGE2, and AGE1 were significant for both response variables. However, it is important to note that all these variables except for the regressors associated with AGE1 and AGE2, the sign of the estimates changed from positive to negative for claims above the threshold. Furthermore, the estimate of parameter
was statistically significant at the same nominal level. When the threshold value was increased up to
, the number of significative variables above the threshold considerably grew since now, the intercept (CONSTANT), gender of driver (GENDER), HDTOP, SEDAN, station wagon (STNWG), TRUCK, AREAA, AREAB, AREAC, AREAD, VAGE1, VAGE2, and AGE1, were relevant. However, only CONSTANT, HDTOP, STNWG, AREAD, VAGE1, VAGE2, and AGE1 were significant for both dependent variables at the same nominal level. The regressors associated with the explanatory variables CONSTANT, AREAD, and the AGE1 had the same sign for claims below and above
. The first two regressors were negatively correlated and the latter one positively correlated to the response variables, respectively. For the other regressors, once again, the sign of the estimates changed from positive to negative for claims above the threshold. Among the common statistically significant estimates for both threshold values, i.e., HDTOP, VAGE1, VAGE2, and AGE1, the same sign of the estimates in the variables
and
was observable. For the non-significant estimates, different signs were observed in the regressors. Furthermore, the estimates of parameters
and
were statistically significant at the same nominal level.
Similarly to the case previously considered, the fit to the data improved when covariates were incorporated in the model and when the threshold value enlarged.
Table 5 exhibits the negative of the maximum of the likelihood function (
), Akaike’s information criterion (AIC), the Bayesian information criterion (BIC), and the consistent Akaike’s information criterion (CAIC) for the basic and mixture regression models. A lower value of these measures of model selection was desirable. It was observable that the latter model was preferable to the former one.
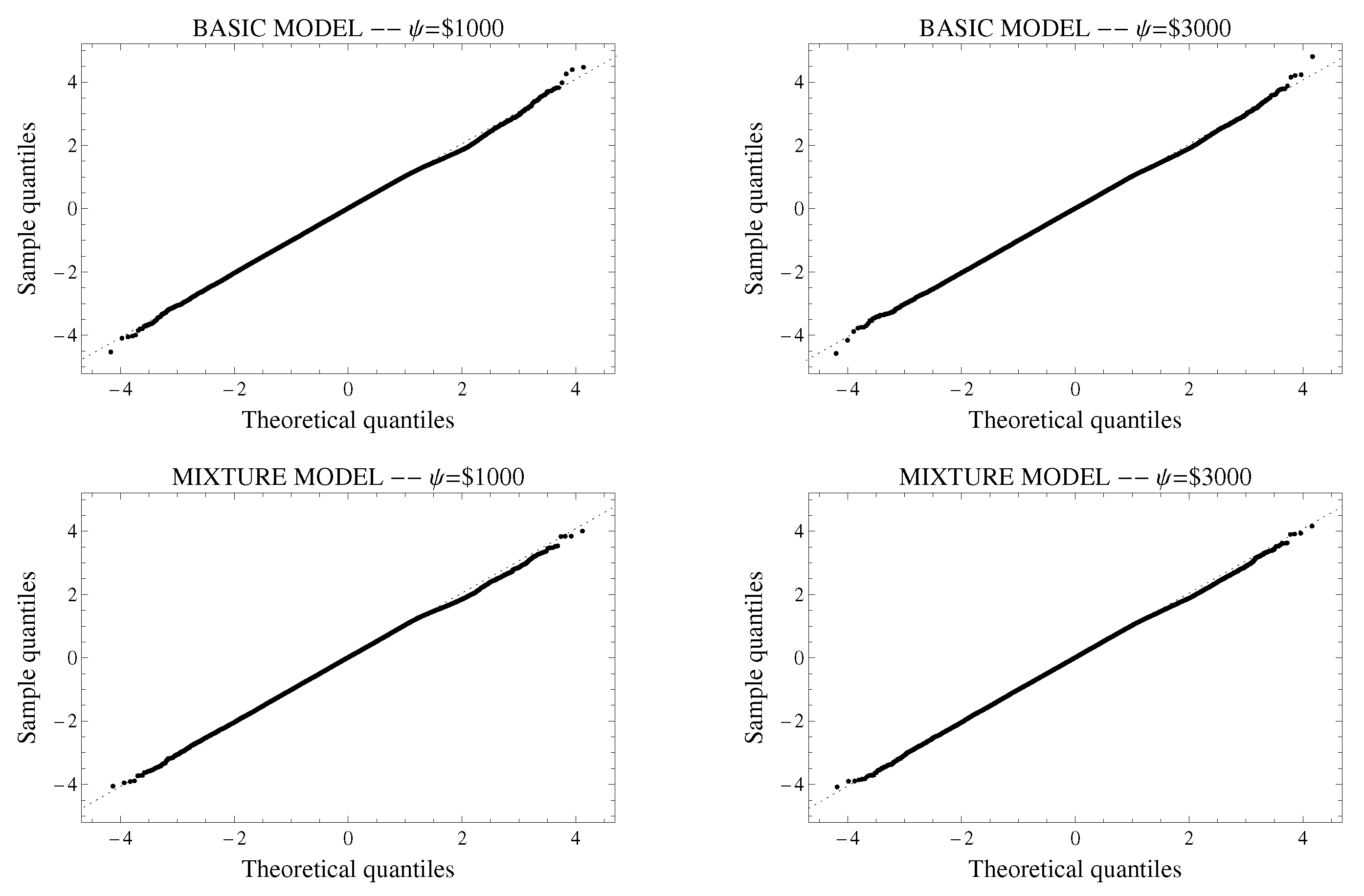
We plot the QQ-plots of the randomized quantile residuals to check for normality in
Figure 2. The residuals for the basic regression models are shown in the top row and for the mixture regression model in the bottom row. Furthermore, models that use
as the threshold value are exhibited in the left column and
in the right-hand column. A perfect alignment with the 45
line implies that the residuals are normally distributed. It was observable that the residuals for the larger threshold values adhered a little bit closer to the line, but these differences were not significant.
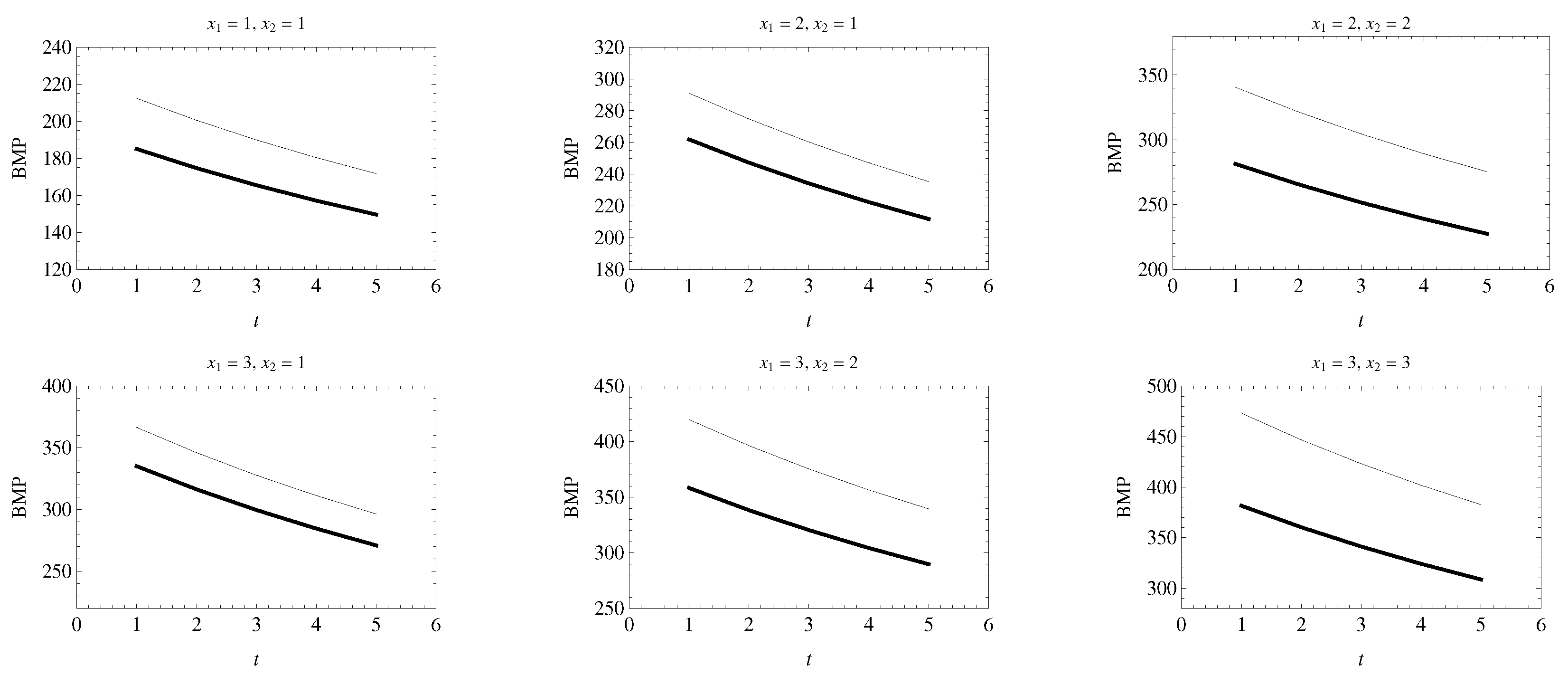
Figure 3 exhibits the bonus-malus premiums (BMP) for the mixture model without covariates. Here,
is the total number of claims when
claims out of
have a size larger than
. In each chart, the thick line represents
, and the thin line denotes
. It was noticeable that the BMP decreased with the time period when the observed pair
and
was fixed for the two thresholds considered. The BMP was consistently lower when the threshold
decreased. Although for both values of
, the premium charged increased when
and
grew, the premium paid also increased with
when
was fixed.
Figure 4 illustrates the bonus-malus premiums (BMP) to be charged to the subgroup of policyholders with SEDAN and AREAA. In this case, we used the mixture regression model including the rest of the explanatory variables and the exposure. Similar conclusions could be drawn from this set of graphs. Again, the BMP was persistently lower when the threshold
decreased. The premium charged increased when
and
grew for either value of
; moreover, the premium paid rose with
when
was held fixed. As compared to the premiums obtained under this regression model were way higher than those ones derived before, this could be surely explained by the small sample size used to estimate regressors and also for the incorporation of the offset variable that without any doubt affected the individual average number of claims and the probability of making a claim higher than the threshold. Other different subgroups of policyholders could also be used for tarification purposes; however, for some of these classes, non-reliable estimates were obtained due to the very low sample size.
Computations in the Compound Model
Although it is customary to calculate the bonus-malus premium based on the variable number of claims (it is usually considered that once a loss has occurred, the company does not have the ability to model the amount corresponding to the loss), some attempts have been made to implement the severity in the calculation of the premium. Some works related to this topic are
Frangos and Vrontos (
2001);
Pinquet (
1998), and
Gómez-Déniz et al. (
2014), among others. As the practitioner wishes to calculate the premium using both variables, it is useful to rely on the composite collective model. Similarly to the univariate case, the bivariate compound distributions for the aggregate claim size random variable can be simply derived as follows:
and this is the the joint probability density function of
, where
,
are the aggregate severities,
and
being mutually independent and also independent of
with probability functions (discrete or continuous)
, respectively, with
and
-fold convolutions
and
, respectively. General expressions for
,
and
, where
, were provided in
Partrat (
1994).
Recursion for bivariate count distributions and their compound distributions given in the form (
16) have been previously considered in the actuarial literature; see Theorem 2.1. in
Hesselager (
1996). Other similar recursions can be found in
Vernic (
1997);
Walhin and Paris (
2000);
Walhin and Paris (
2001);
Sundt (
2002), and
Sundt and Vernic (
2009), among others. Moreover, bivariate recursions are useful in prediction problems involving the conditional
of
Y, given
; see Hesselager (1996) for more details.
Let us now assume that the random variables and represent two kinds of claims, for instance bodily injury and material damage, or as in our study, claims below and above a threshold .
The fact that the probability generating function of (
1) is analytically obtained helps us to derive the probability generating function of the joint random variable
for
, which can be deduced in type
claim amounts. Here,
is the random variable corresponding to the yearly frequency of type
i claims exceeding
. The work in
Partrat (
1994) then showed that the probability generating function of the random variable
is given by:
where
and
are the cumulative distribution functions of the random variables
and
, respectively; while the probability generating function of the random variable
, with
, is given by:







{kind=link}
{kind=link}
{kind=link}
{kind=link}