1. Introduction
Solvency II was a major driver for European insurers to upgrade their quantitative risk assessment models both for the purposes of the assessment of the regulatory solvency position and internal risk management needs. Major European insurance groups have developed and implemented full or partial internal models, which value risks from the perspective of a company specific risk profile. However, as demonstrated in
Table 1, majority of the European insurers, predominantly small and medium sized firms, calculate the regulatory solvency capital requirement using the standard methods and stress scenarios prescribed by the legislation (Standard Formula). First, according to the Standard Formula, an insurer’s regulatory Solvency Capital Requirement (SCR) is estimated on individual risk module/sub-module level. Secondly, the individual risk assessments at risk module and sub-module level are aggregated to the total SCR by taking into account the diversification between the risks. For example, SCR for mortality risk sub-module is assessed by calculating the amount of loss of insurer’s available Solvency II regulatory capital (Basic Own Funds) resulting from an immediate and permanent
increase in mortality probabilities used for calculation of the Solvency II technical provisions. SCR for mortality risk is aggregated with SCR’s for other life underwriting risks such as lapse risk, longevity risk, expense risk and life CAT risk to derive SCR for the life underwriting risk module, which is used as an input for calculations of the overall SCR.
In practice, the use of the Standard Formula goes beyond the calculation of statutory solvency position. Insurers often treat the outcome of the Standard Formula risk assessments as the key risk indicators, which are embedded in their enterprise risk management systems. Insurers which are subject to Solvency II regulatory regime at least annually perform Own Risk and Solvency Assessment (ORSA), which includes qualitative and quantitative assessment of risks as well as analysis on how well the Standard Formula fits the company’s specific risk profile. Both insurers and regulators aim to ensure that such an assessment includes sufficient quantitative analysis of risks. Therefore, for Standard Formula users it is important to understand what is behind the calibration of Standard Formula standard stress scenarios and the key deviations of their risk profiles form the risk profile on which the Standard Formula calibration is based.
In its essence, the Standard Formula is designed to suit the risk profile of the “average” European insurer. However, insurers in the European Union (EU) are highly heterogeneous and the “average” insurer is difficult to define. For example, life insurers may be exposed to different levels of mortality risk due to the differences in products offered, distribution channels used, maturity of insurance portfolios, prevailing policy terms and conditions, volatility of mortality in a country where insurer operates and a number of other factors.
The topic of modelling solvency capital for the risk of variation of mortality rates in the literature was addressed mainly with the focus to longevity risk. Solvency II Directive requires that SCR is calibrated to the VaR of the basic own funds subject to a confidence level of
over a one-year period. However, as argued by
Richards et al. (
2013):
…some risk do not fit naturally into one year VaR framework and it would be excessively dogmatic to insist that longevity trend risk only be measured over a one year horizon.
It seems that this approach is shared by the European Insurance and Occupational Pensions Authority (EIOPA), who used run-off approach for the calibration of the uniform mortality shocks for mortality and longevity risks during the review of the Standard Formula (
EIOPA 2018).
Several models have been proposed to model mortality/longevity risk using one-year
approach, where the key challenge is how to model the risk of variation of technical provisions in one year’s time after the valuation date.
Börger et al. (
2014) and
Plat (
2011) developed models which explicitly model the mortality trend risk which is used as the proxy to capture the risk of variation of technical provisions.
Richards et al. (
2013) took into account the risk of changes in technical provisions by simulating one year’s portfolio mortality and subsequently refitting stochastic mortality model for each simulation scenario based on the results of the first year simulations. A similar approach was used by
Jarner and Møller (
2015) who proposed a model designed specifically for the Danish system of reserving for longevity risks.
Olivieri and Pitacco (
2009) developed a model, which included a Bayesian procedure for updating the parameters of projected distributions of deaths and formulated conditions for few alternative definitions of solvency capital rules, however, their model did not necessarily strictly follow a one-year
approach.
Calculation of mortality
usually requires the simulations from a stochastic mortality model as an input. A model proposed by
Lee and Carter (
1992) started a new generation of the extrapolative mortality projection methods, and in its original or modified form is widely used both in academic research and in practice. A number of improvements of Lee-Carter model have been proposed, both from the point of view of model specification and statistical estimation of parameters, for example, see
Lee and Miller (
2001),
Booth et al. (
2002);
Brouhns et al. (
2002);
Renshaw and Haberman (
2003). In parallel, several alternative extrapolative stochastic mortality models have been developed (see comparative study by
Cairns et al. (
2009), some of which explicitly model the cohort effect on mortality rates. The simulations of mortality rates may be performed using simple approaches based on randomly generated i.i.d. residuals or using more complex strategies with application of bootstrap or Bayesian methods. Different simulation approaches are discussed by
Renshaw and Haberman (
2008) and
Li (
2014).
The purpose of this paper is to analyse how closely
for mortality risk, calculated using Standard Formula, approximates the portfolio specific mortality
, and to identify factors which may affect the adequacy of this approximation. We performed the analysis for four selected European countries: Lithuania, Sweden, Poland and the Netherlands, which have substantially different mortality experience. In calculations we follow the approach similar to
EIOPA (
2018) with the following key modifications:
EIOPA follows run-off VaR approach and we examine the results using both run-off VaR and one-year VaR approaches.
EIOPA assumes random walk with drift (RWD) as the default model for forecasting of the time varying parameter, which is driving the projected mortality improvements. We perform formal statistical testing for the purpose of confirming the hypothesis that RWD does not contradict the historic data.
EIOPA fits the stochastic mortality model using the mortality data for ages 40–120 years (the same as for longevity risk). We fit the stochastic mortality model for ages 25–75 years. We assume, that for most of life assurance protection products the highest exposure to mortality risk is associated with mid-aged assured lives. Therefore, the model fitted using the experience from the target population range can provide the most relevant parametrisation for the forecast.
EIOPA calibrates VaR using temporary life expectancies, thus implicitly assuming that the benefit payable under life assurance policy decreases with time. Decreasing benefits are common in life assurance products linked to mortgages or other credit instruments. In addition, mortality sum at risk is decreasing with policy duration for some risk and savings products (e.g., traditional endowment insurance) where the total benefit payable on death is fixed and insurer is able to recoup part of the losses by reversing the accumulated savings amount. However, a significant part of life assurance products have fixed sums assured. In this paper we examine the effect on VaR of both benefit formulas: level (fixed) sum assured and sum assured which is decreasing linearly with time.
The rest of this paper is organized as follows:
Section 2 discusses overall approach to
calculations and provides the results.
Section 3 discusses the results.
Section 4 provides the details of the statistical fitting of Lee-Carter model.
Section 5 describes in detail our
calculation methodology.
2. Results
According to
McNeil et al. (
2005) (see page 38) given certain confidence level
can be defined as:
where
L is a random variable of a loss. Throughout the paper, consistently with the Solvency II legislation, we calculated
using
confidence level, that is, set
.
As we show in
Section 5, in the context of mortality risk in the Solvency II framework,
L is a loss/gain of the Solvency II capital (Basic Own Funds) due to variation of mortality rates. Thus,
defines extra capital needed to cover the unreserved mortality losses arising from the increase in the future mortality rates.
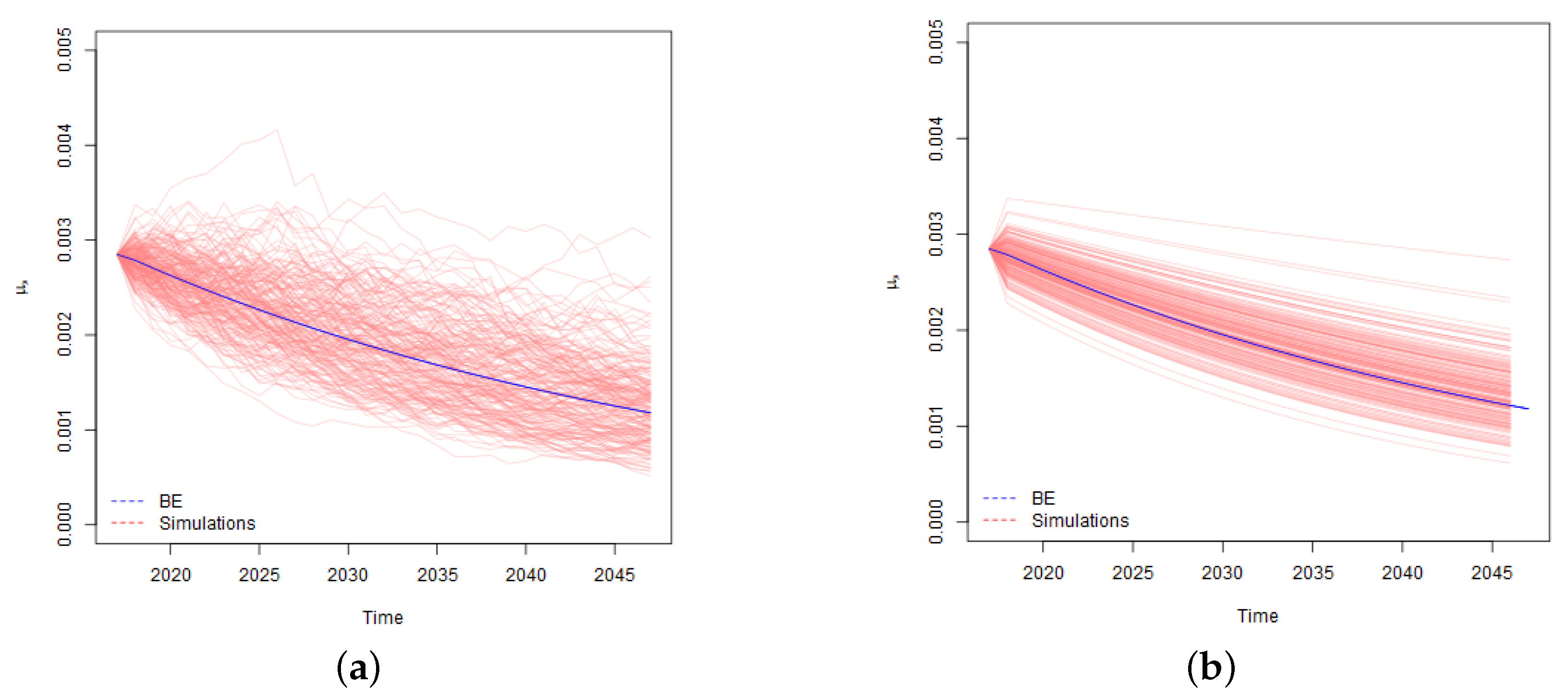
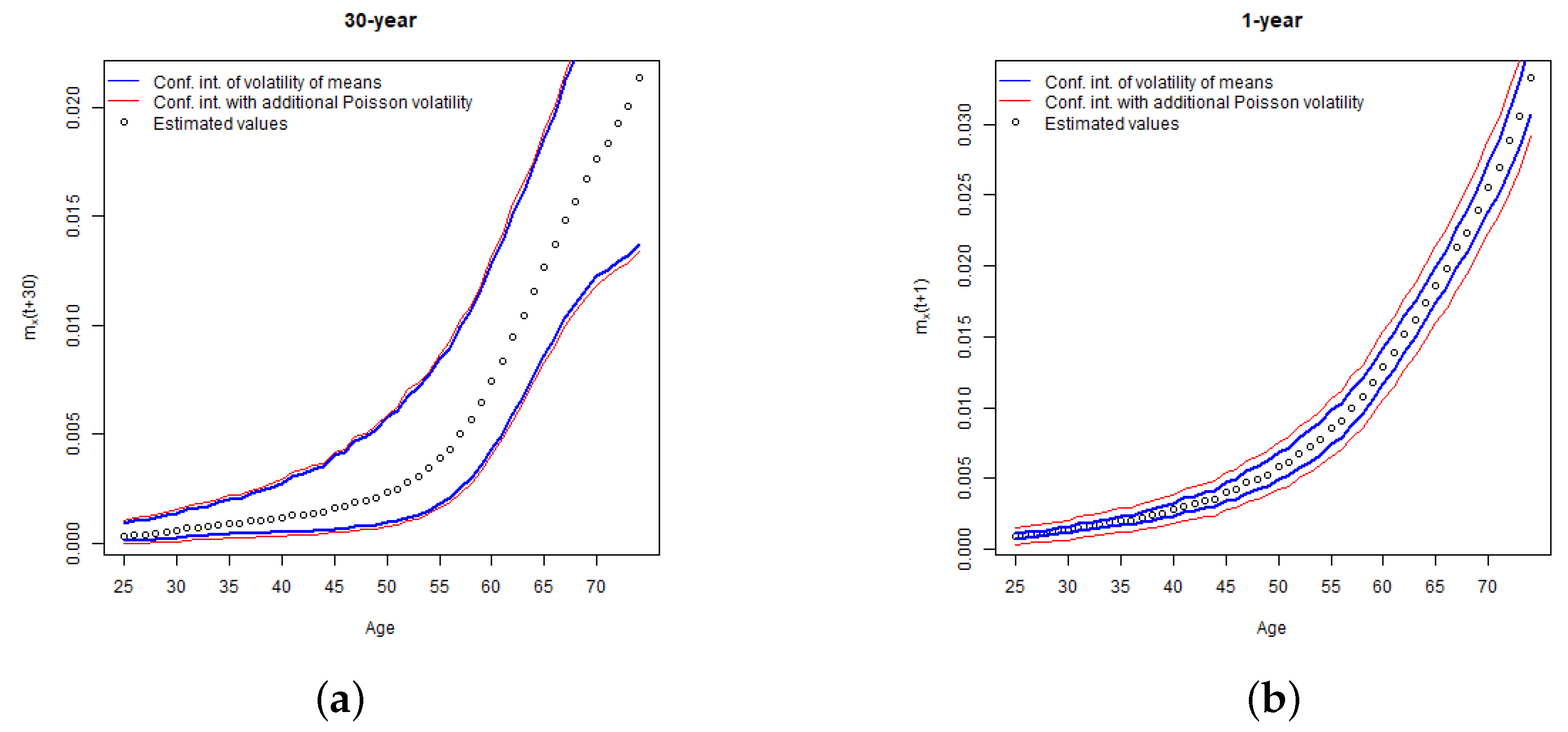
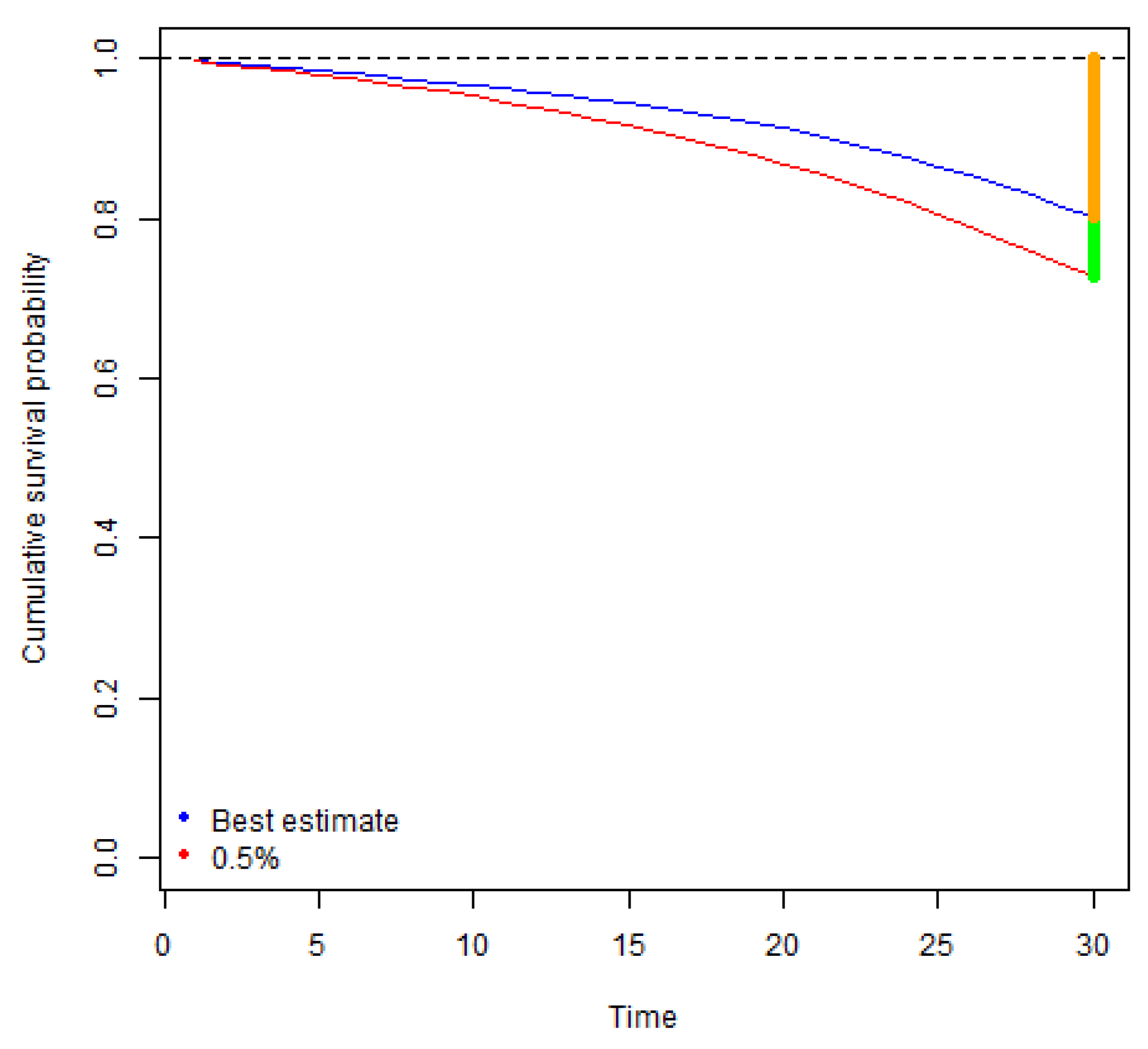
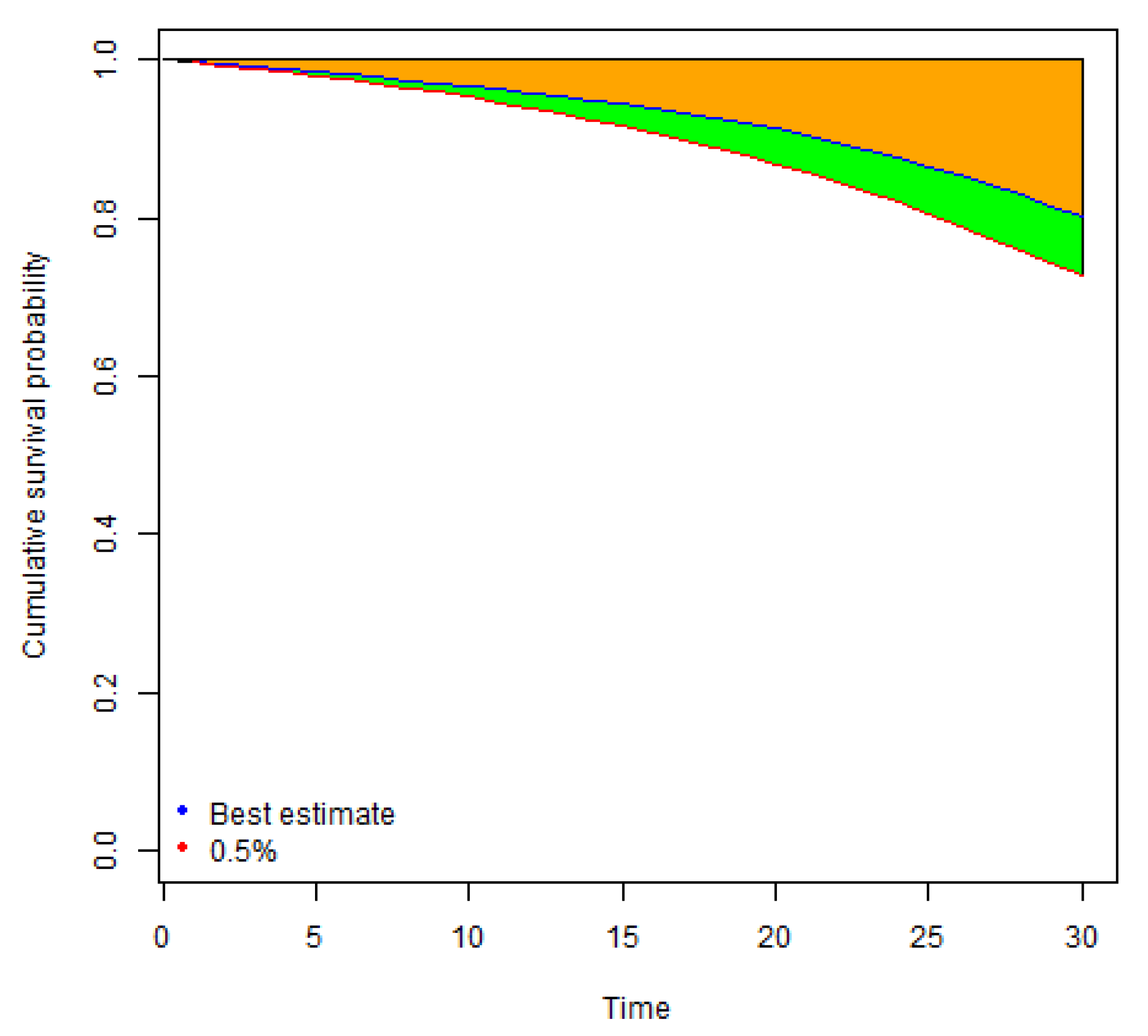
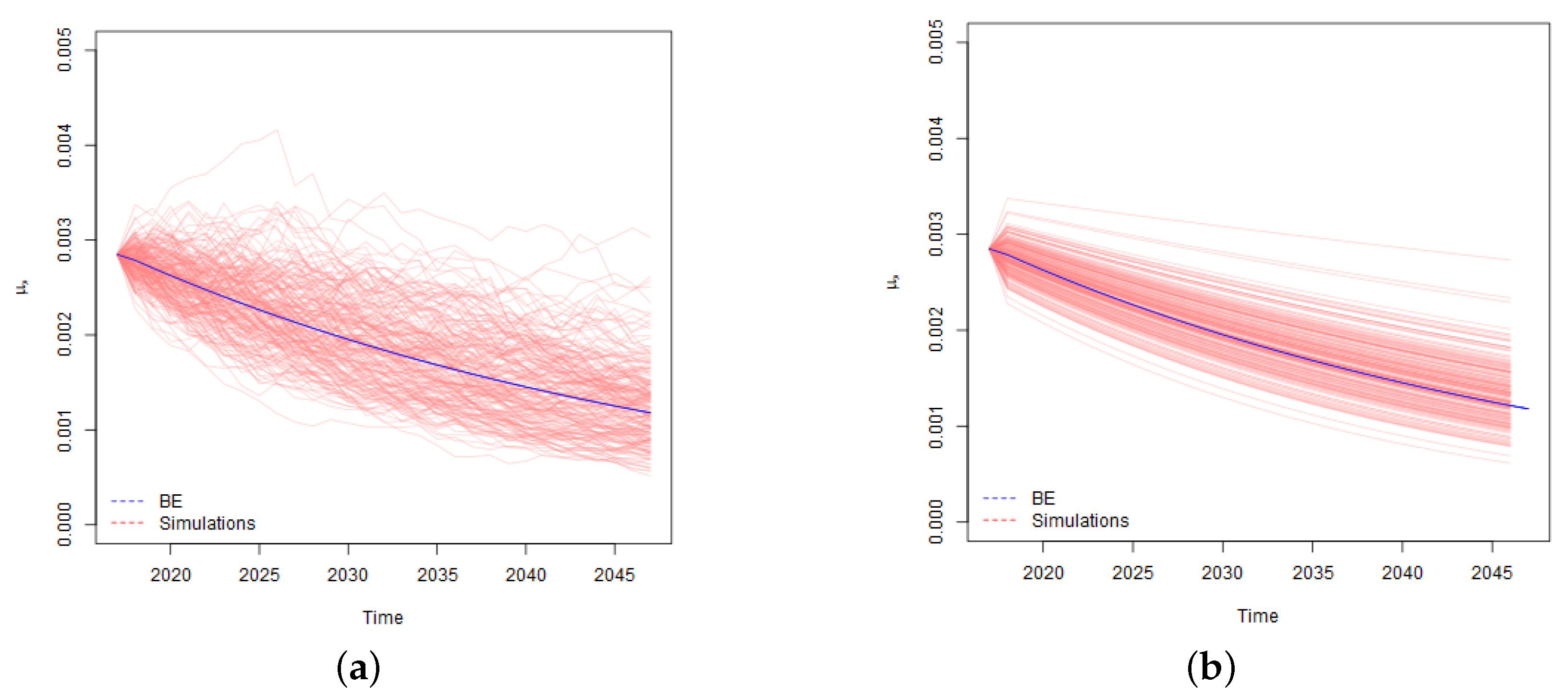
Taking the run-off approach, we consider the fluctuations in mortality rates until the maturity of a policy. In contrast, if we take a one-year view, the key drivers of risk become fluctuation of mortality rates in the first projection year and the risk of changes in reserving (Best Estimate) assumptions at the end of the first projection year. A graphical illustration of the contrast between run-off and one-year simulations of mortality rates is provided in
Figure 1.
As illustrated in the charts, in calculation of run-off VaR we apply simulated mortality rates which vary stochastically for the whole period of an insurance coverage. In contrast, in calculation of one-year , we use stochastically simulated mortality rates for modelling of death benefits in the first projection year, and for the remaining years we apply the curves of projected Best Estimate mortality rates, the level and trend of which depend on the outcome of the first year simulations. For example, if a certain simulation scenario stochastically results in a sharp increase of mortality rates in the first projection year, we assume that a curve of the projected Best Estimate mortality rates for that simulation scenario is shifted upwards as well. In addition, the results of the first year simulations, affect the trend of the Best Estimate mortality rates and the projected curves are not parallel. The bigger is the variation in the level and trend, the higher risk is associated with the changes in the Best Estimate technical provisions at the end of the first year, which results in the higher one-year .
Let’s consider what kind of practical reserving behaviour would be consistent with one-year model described above. Firstly, the model implies that actuaries in the reserving assumptions allow for the future mortality improvements (mortality reduction factors) which are projected with Lee-Carter model. In practice, actuaries often reserve life assurance products without allowing for future mortality improvements, that is, some prudence is left in the Best Estimate, although strictly speaking this is not in line with the legislation. Overstatement of the Best Estimate means that the risk of its insufficiency due to fluctuation in mortality rates and consequently are lower. Thus, if the Best Estimate for life assurance products is calculated without allowance for future mortality improvements, the company specific one-year would be lower than one-year assessed by us.
Secondly, consistently with RWD model applied for modelling of Lee-Carter model time varying index, we assume that variation of the latest year mortality rates is fully translated to shifts in projected Best Estimate mortality curves. This implies, that actuaries base the Best Estimate mortality assumptions on the mortality level implied by the last year’s experience. In practice, actuaries often use various smoothing, averaging and similar methods, as a results of which the variation driven by the mortality level of the last observed year may be taken into account only partially. Application of such techniques may result in lower risk of changes in Best Estimate and lower .
Finally, even if the reserving methodology allows for mortality improvements, the sensitivity of the mortality reduction factors (trend risk) to the last year’s mortality experience may vary from insurer to insurer. In our calculations we use two levels of credibility factor
(
and
), which represents variation in reserve risk due to differences in actuarial methodologies applied. The credibility parameter may be interpreted as the proportion of evidence related to the last year’s experience accounted for in setting the assumed mortality reduction factors. Thus, in case of
mortality reduction factors are more sensitive to the last year’s experience than in case of
, and the modelled trend risk increases with the growth of
. See
Section 5.2 for more detailed discussion of the trend risk modelling.
Overall, the above considerations imply that our approach results in rather conservative estimate of one-year for two levels of selected trend risk parameters.
For the purpose of comparability of our results with the Standard Formula mortality stress parameter we have converted the calculated ’s to equivalent rates. We define rate as g which satisfy the following condition
Here
L is random variable of a loss in basic own funds,
is the initial Best Estimate,
t is the valuation year,
n is projection term and
,
, are projected mortality benefits calculated according to the applicable benefit formula by applying the following
m year stressed mortality probabilities
where
x denotes age at time
t,
are the Best Estimates of one year mortality probabilities and
. In such a way, we search for rate
g, which makes the stressed Best Estimate equal to the initial Best Estimate plus
. The results of calculation of run-off VaR rates are presented in
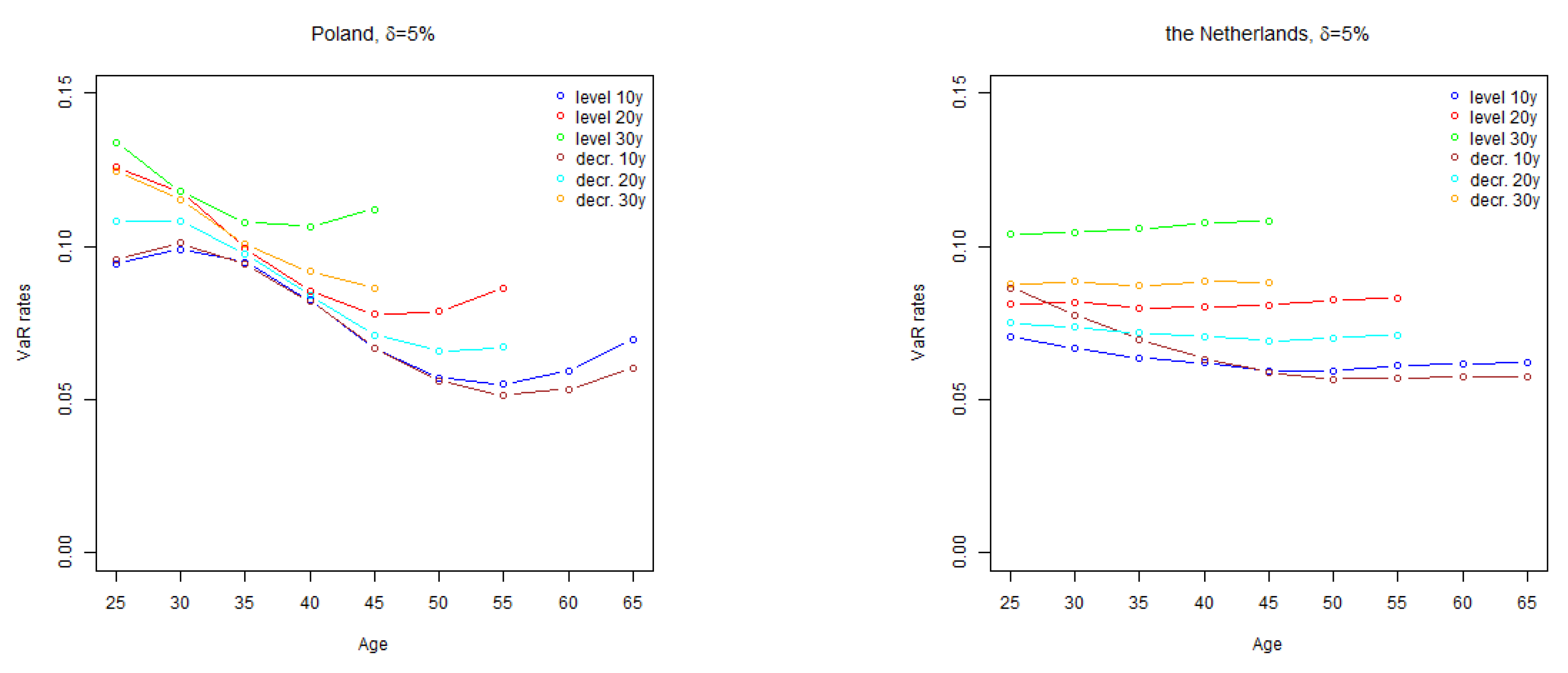
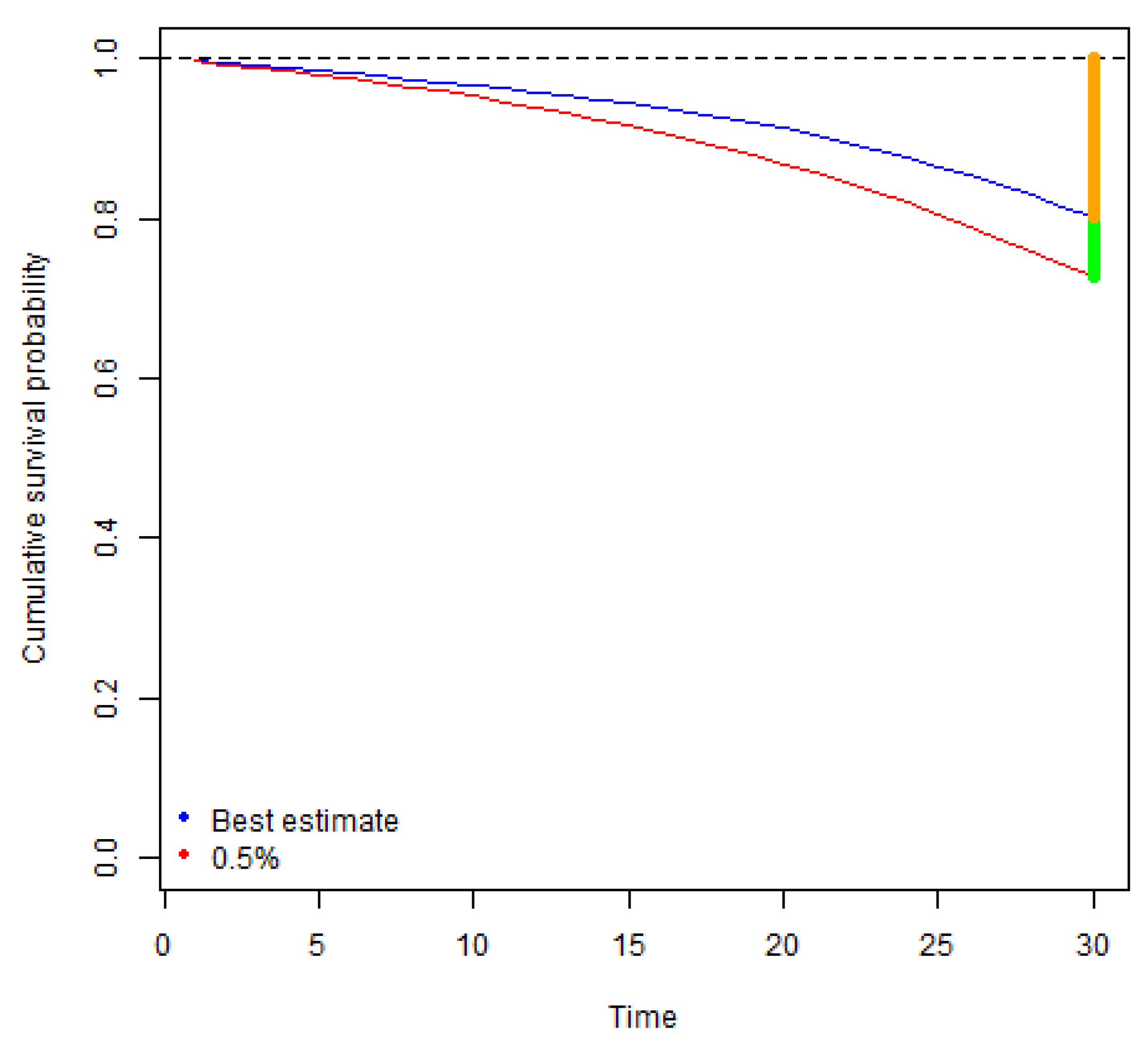
Figure 2.
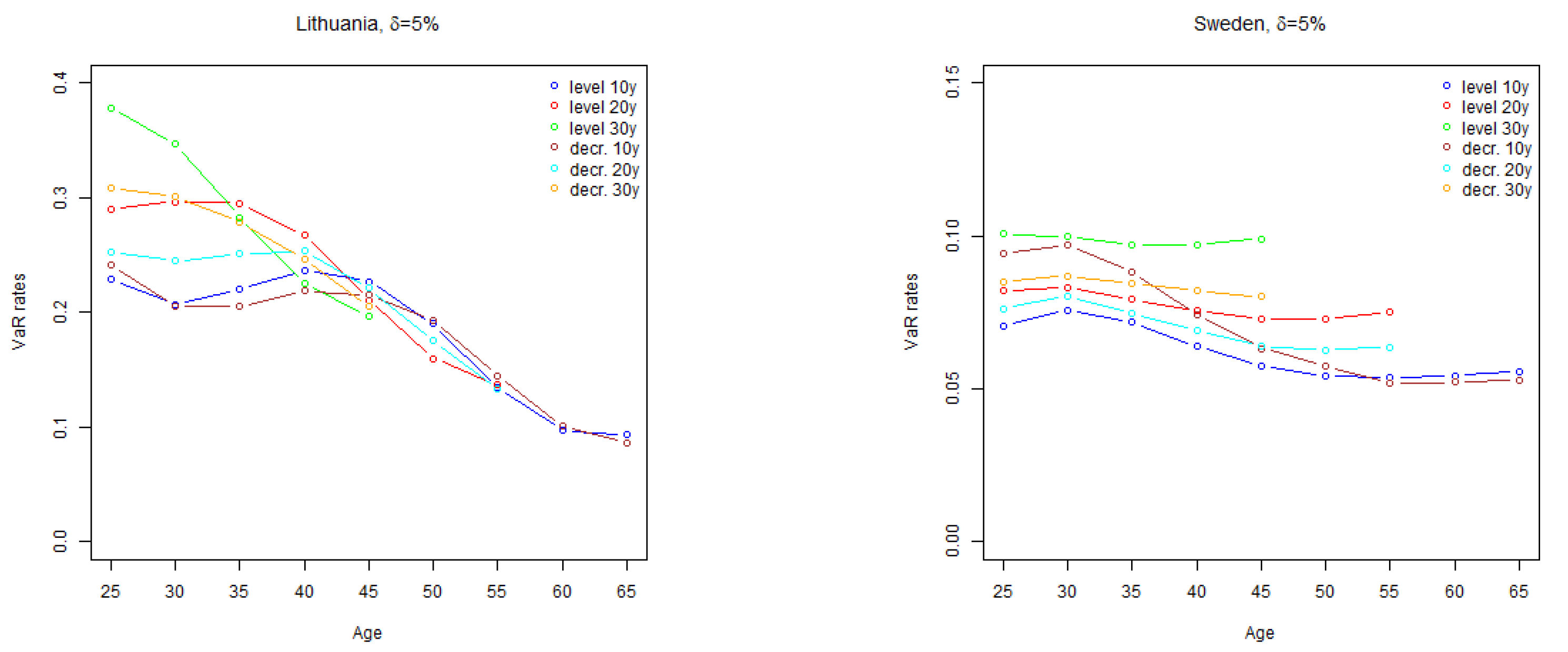
The results obtained indicate that run-off rates tend to increase with policy term. Uncertainty about the future mortality rates grows with time, which leads to wider confidence intervals of mortality rates for long term projections.
Similarly, for the policies with decreasing sum assured, higher sums assured are paid in early policy years when the mortality uncertainty is lower than in later policy years, which implies that run-off rates are generally lower for policies with decreasing sum assured than for equivalent policies with fixed sum assured.
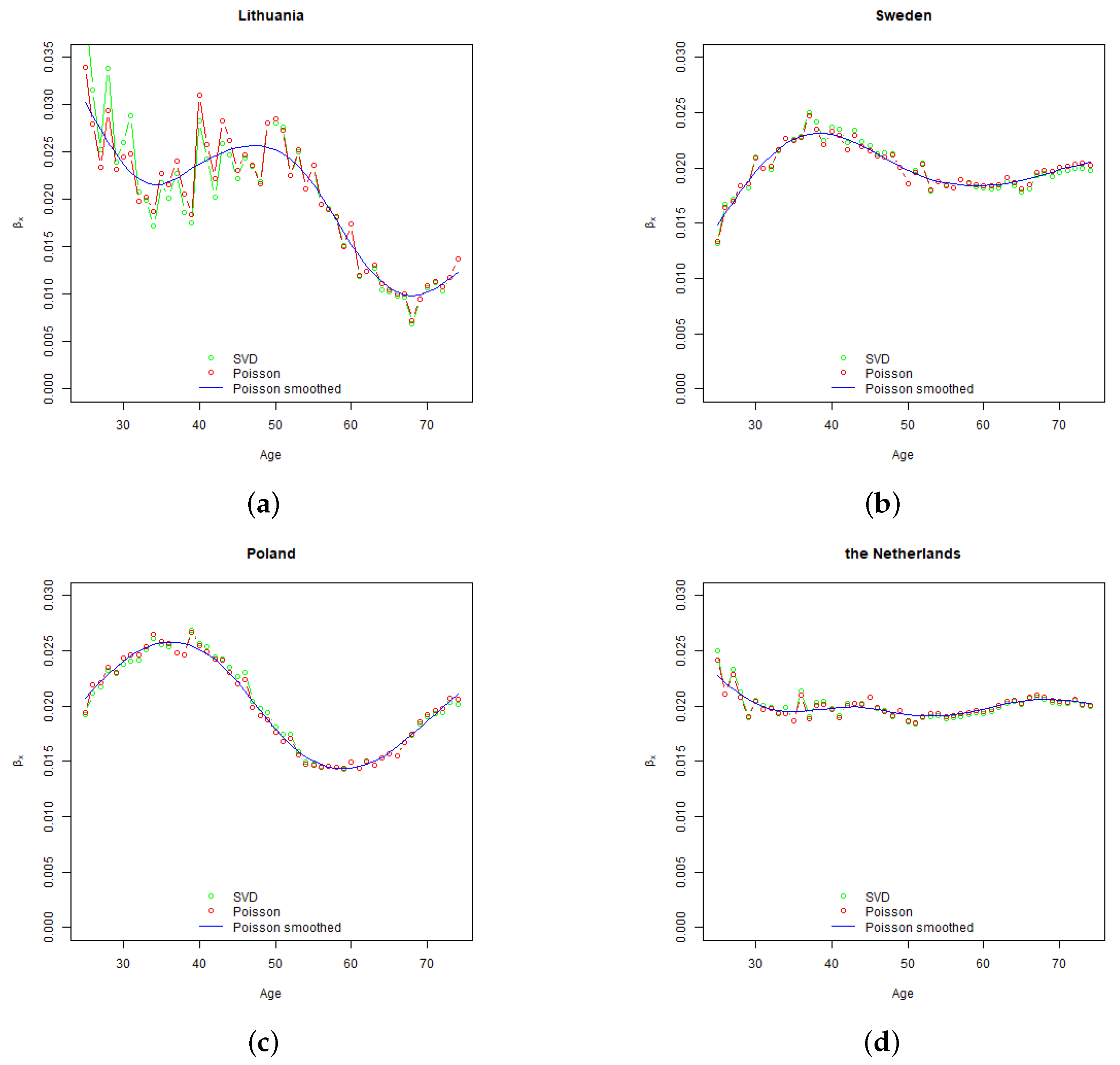
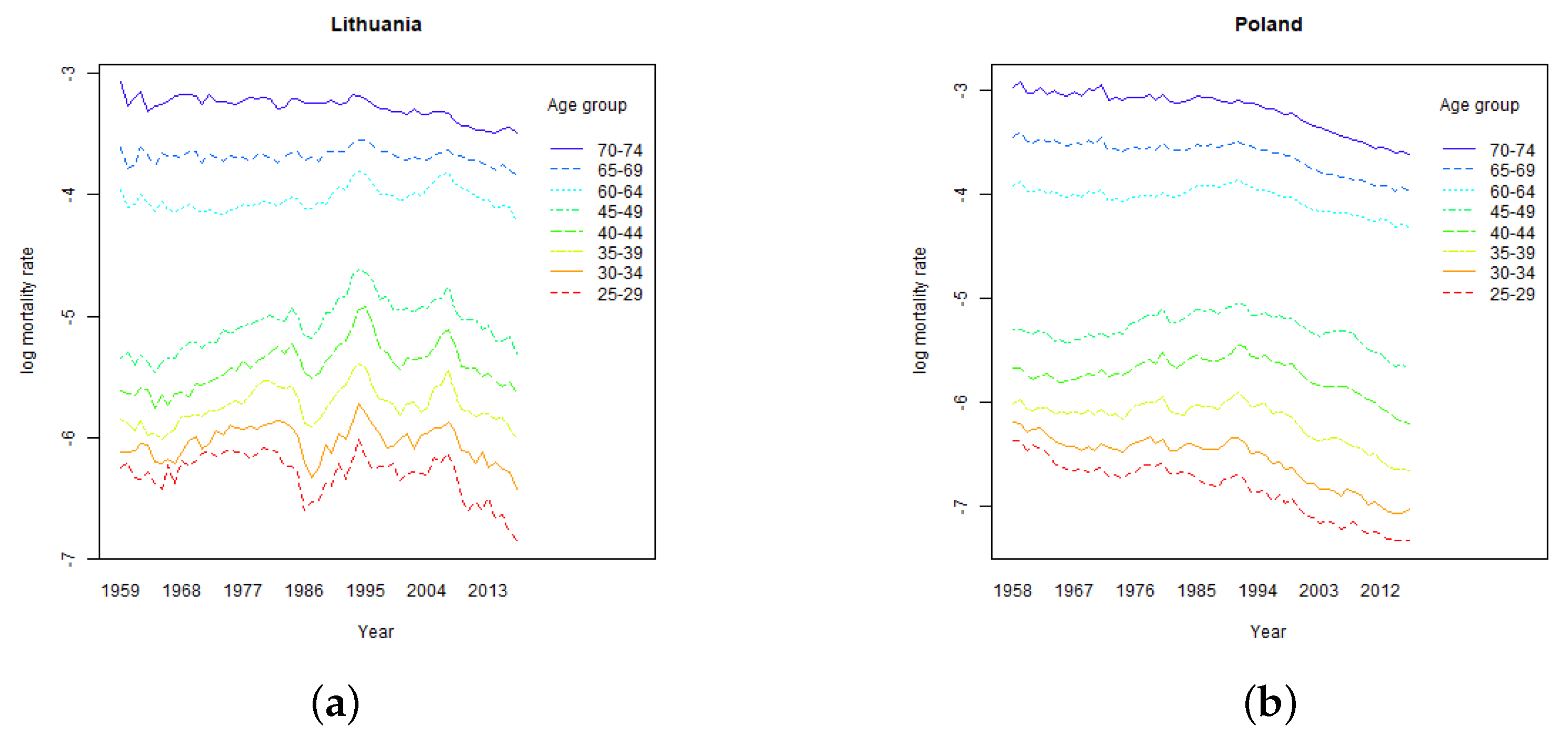
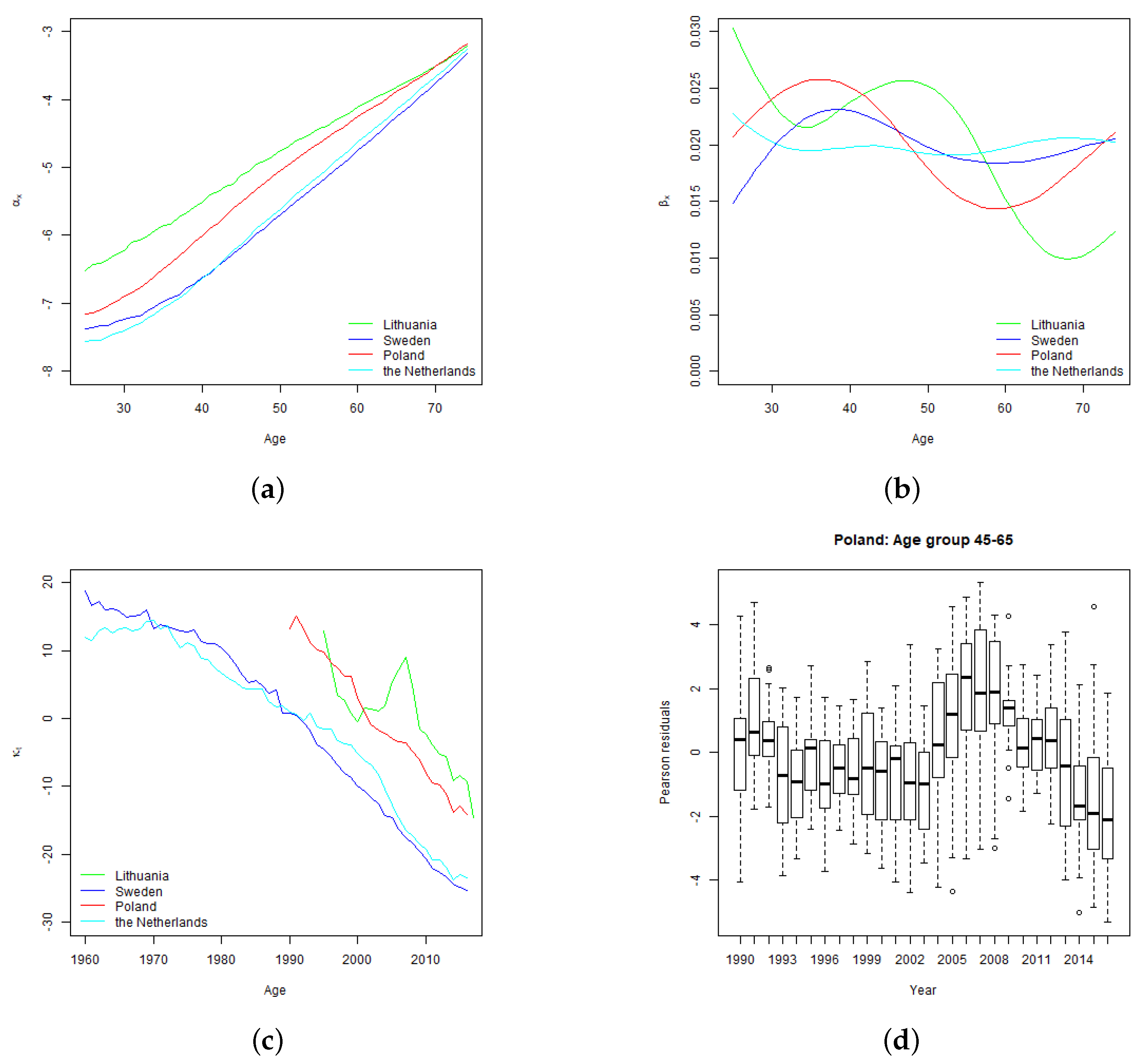
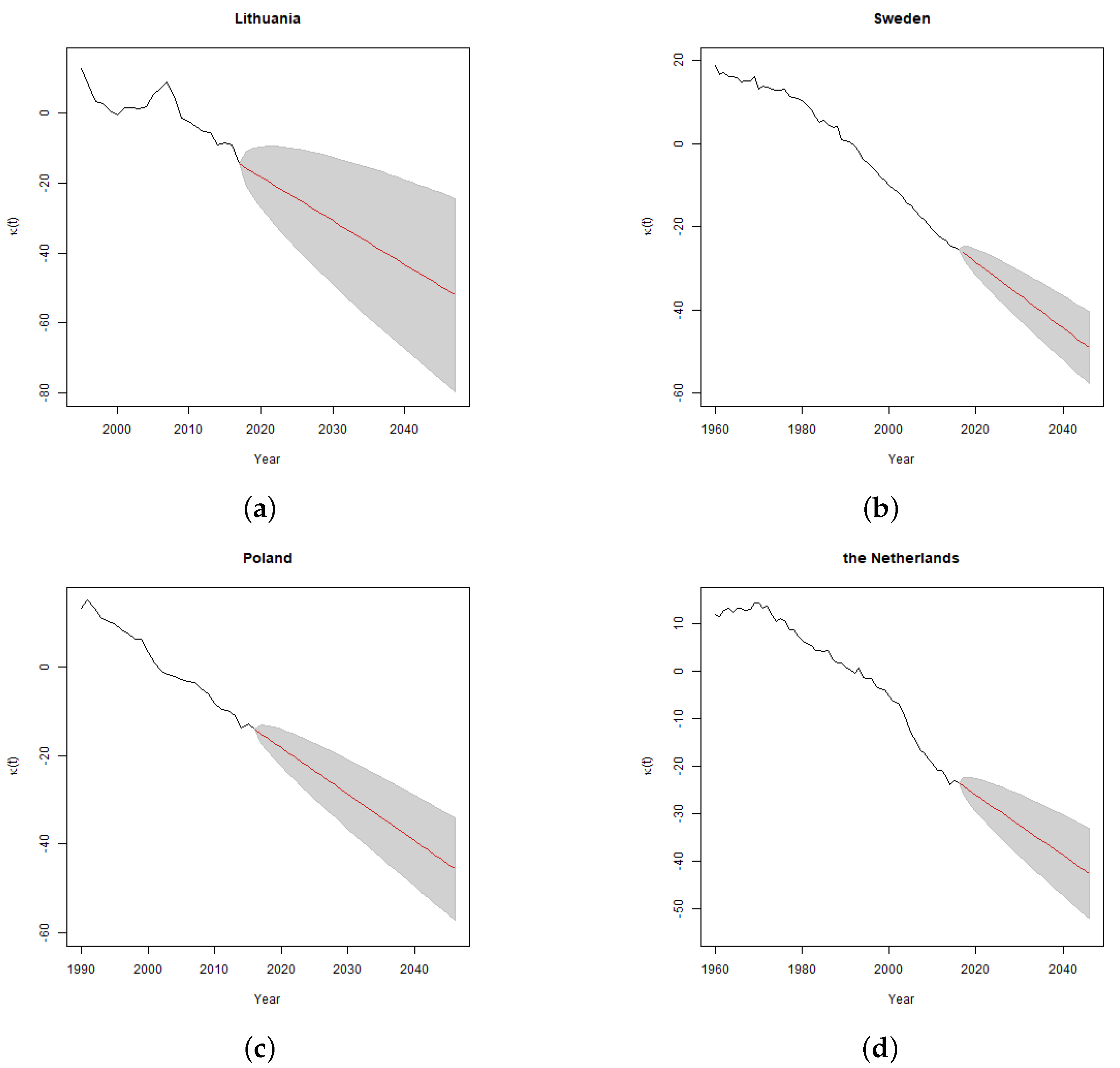
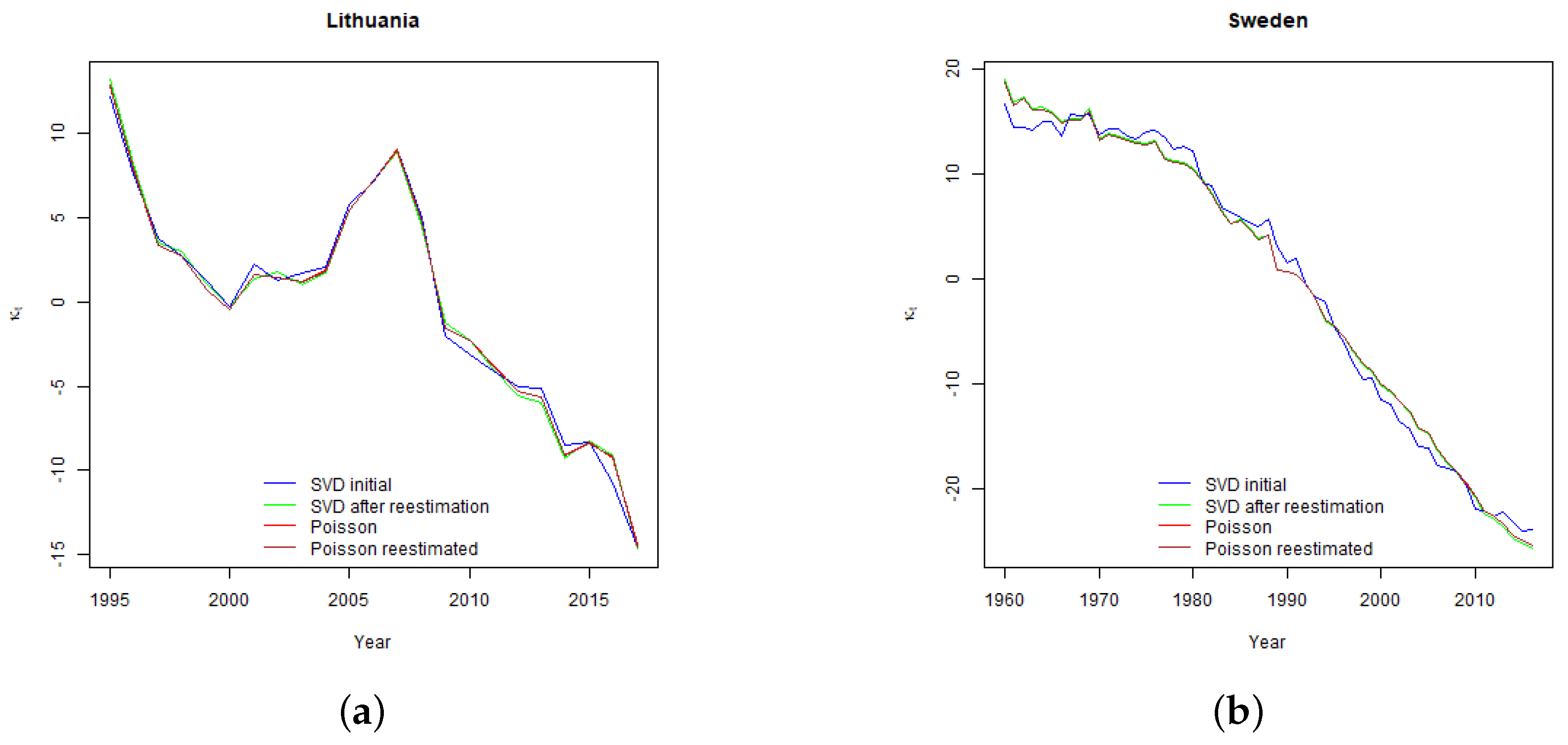
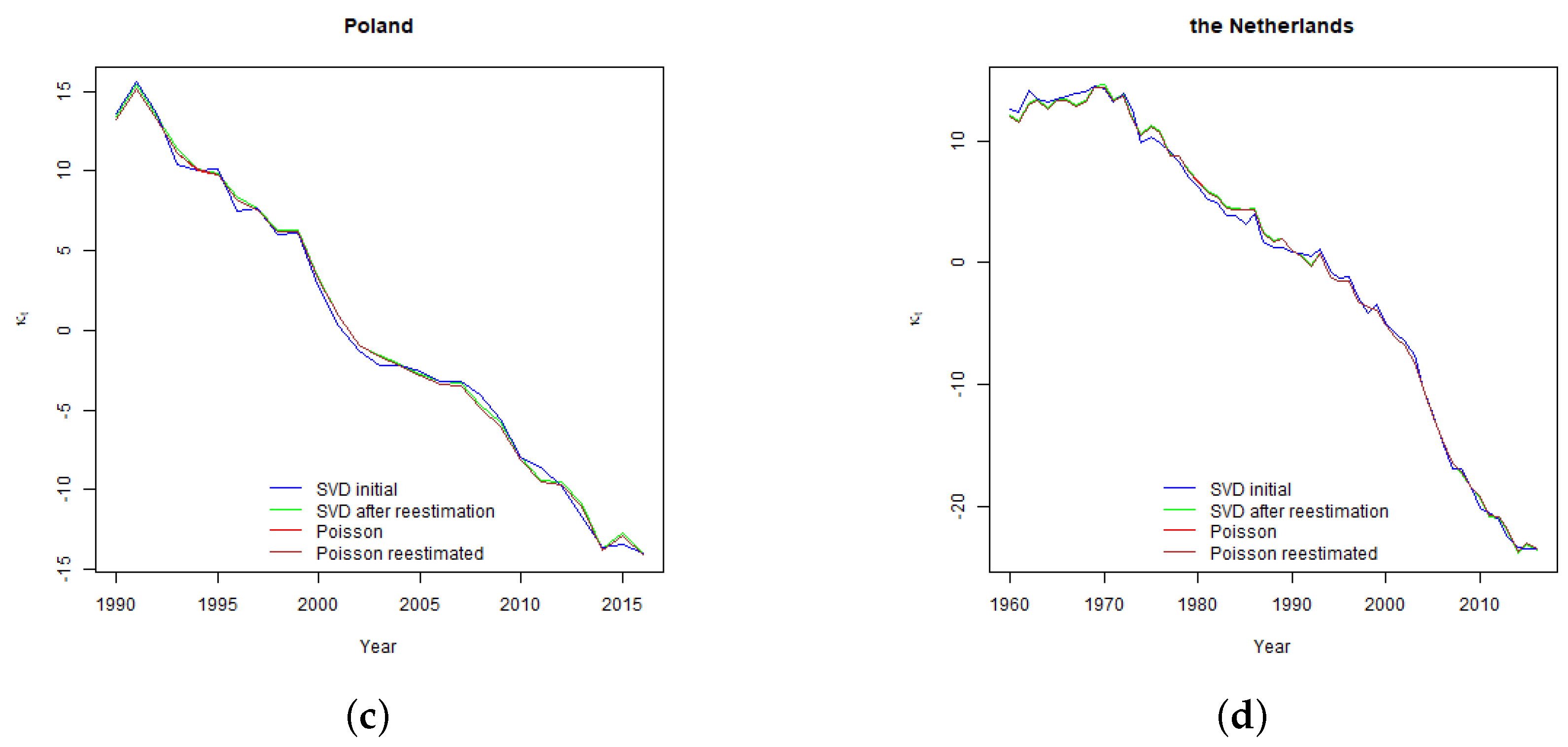
The shape of
rate by age curves is related to the shape of Lee-Carter parameter
(see
Section 4) which determines the sensitivity of projected age specific mortality rates to the changes in the time varying parameter, and drives the relative level of age specific projected volatility of mortality rates. As demonstrated in
Section 4, Sweden and the Netherlands have relatively stable parameter
over the modelled ages. Consequently, for those countries run-off
rate curves are flat as well. For Lithuania and Poland, higher volatility of mortality rates at younger ages increase the run-off
rates for policies issued to younger policyholders.
Comparing the results with the standard Solvency II stress level of
, the calculated
rates are significantly higher for Lithuania, however, for other countries the results are close to the value of the standard parameter. As discussed in
Section 4, Lithuanian mortality improvement trend is not so settled as in other countries, which resulted in high standard error of time varying index and wide confidence intervals of projected mortality rates.
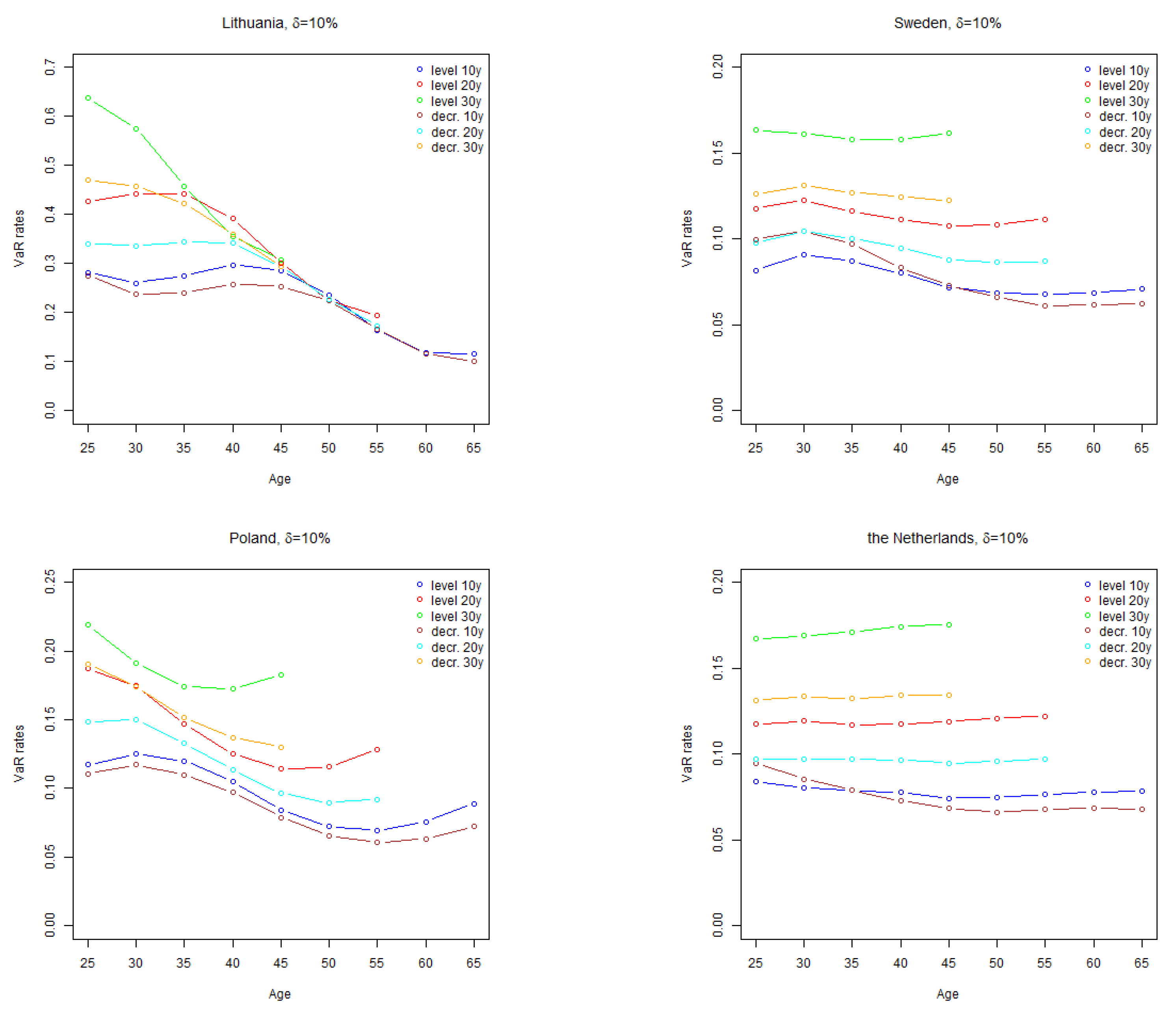
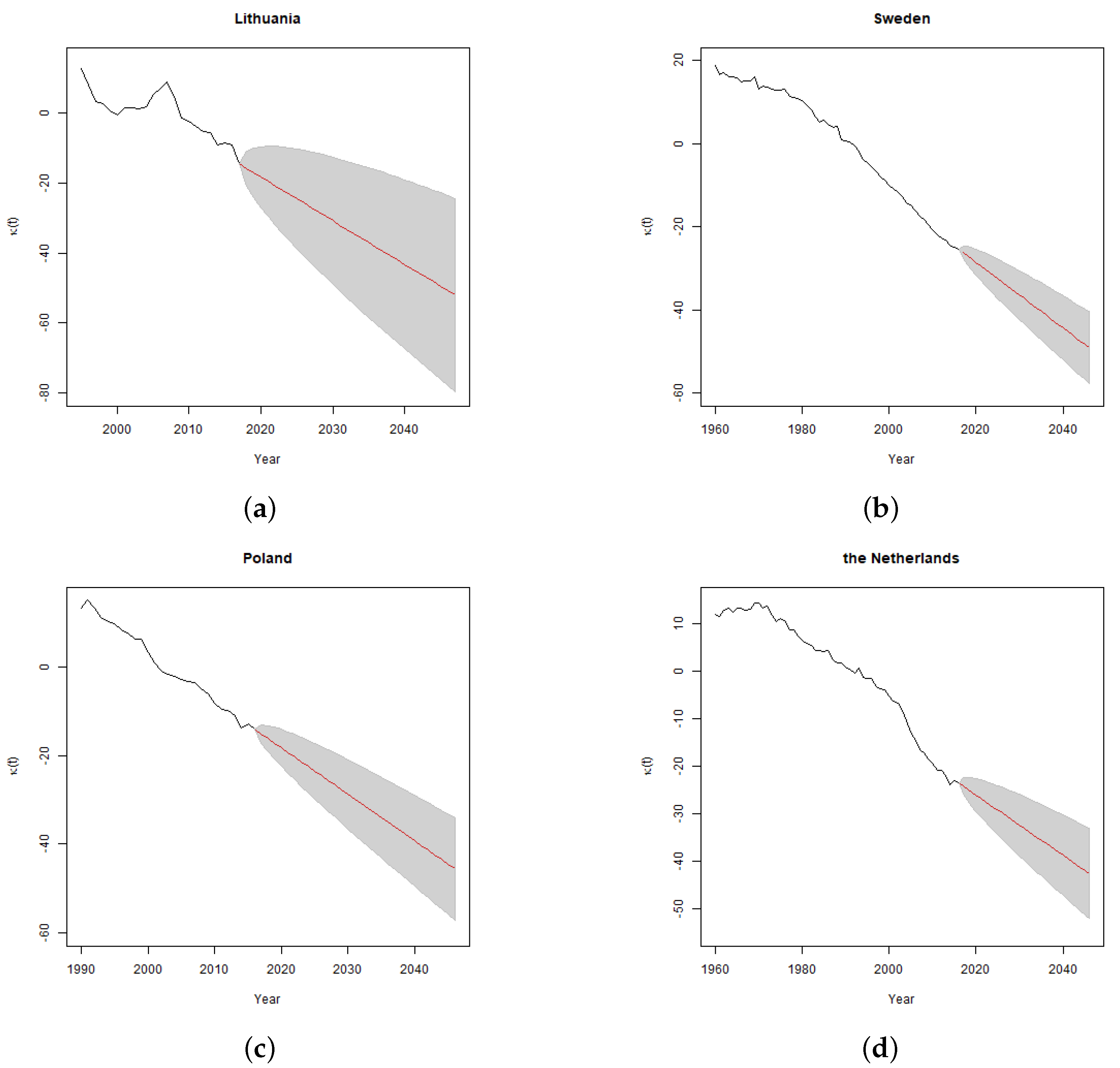
The results of calculation of one-year
for two levels of trend risk parameter
, are presented in
Figure 3 and
Figure 4.
The shape of one-year rate by age curves is similar to the shapes of run-off rate curves of the corresponding countries. The overall level of the curves to a large extend depends on the value of trend risk parameter , especially for longer term policies. For countries other than Lithuania, the overall level of one-year rates, given the analysed values of parameter , tend to be lower than the standard Solvency II mortality stress parameter of .
3. Discussion
When comparing the estimated rates to the Solvency II Standard Formula mortality stress, on average, EIOPA’s calibration looks adequate. Lithuania, which experienced high volatility of mortality of mid-aged population, can be considered as an exception. It is possible, that the mortality trend will stabilize and the width of the confidence bands of the projected mortality rates will become more similar to other EU countries. Meanwhile, actuaries should take into account the risk extra volatility of mortality rates related to Lithuanian exposures.
Overall, the general level of our estimates is comparable with
EIOPA (
2018). The curved shape of development of EIOPA’s calculated
rates with age is likely to be caused by the shape of Lee-Carter parameter
(see
Section 4). Our estimates of parameter
are likely to be different from EIOPA’s due to different range of ages and populations used for model fitting. Nevertheless, actuaries should take into account that mortality
of their insurance portfolios might be higher than the Standard Formula estimate. In particular, in cases of very long term policies with fixed benefits actuaries should consider the need to perform portfolio specific mortality risk assessments.
It should be noted also that some components of mortality risk have been omitted from our assessment. In particular, parameter risk, model risk and basis risk (the risk that the estimates based on the general population data differ from the estimates based on the insured population data) might be significant. In addition, for small portfolios, the risk of random mortality fluctuations might increase the volatility (process risk) substantially.
Olivieri and Pitacco (
2009) discussed the process risk and showed that it reduces for large portfolios.
In our VaR model we tried not to depart too far from Solvency II interpretation of the mortality risk used by regulators and the market. Consistently with the Solvency II legislation we have not taken into account the risk of catastrophic events (e.g., pandemics) which are allowed for in a separate Standard Formula submodule. By using Lee-Carter model as a basis for the calibration of the stochastic mortality model we have implicitly assumed that the trend observed in the period used for calibration of the model will continue in the future. Considering that the calibration is based on the periods of favorable social, economic and political development, implicitly we assume that there will be no major disturbances (such as wars, long term economic depressions, changes in the political systems, etc.) during our projection period. Modelling of such events would be inevitably subjective and would make our results less comparable with
EIOPA (
2018).
Basis risk can have a material impact on the results of VaR calculation. Changes in level, trend or volatility of mortality can differ for insured population and the general population, for example, due to differences in the level of income, socio-economic status, regional differences and other factors. However, the effect of the basis risk is difficult to estimate, mainly due to lack of high quality, consistent and sufficient statistical data on mortality of insured lives for an extended time period, which for many countries is not available.
Taking the above into account the results of our calculations should not be interpreted as a comprehensive insurer’s economic capital sufficient to cover mortality risk from all sources of risk with probability. Actuaries and risk managers should take this into account when performing realistic mortality risk assessments of their portfolios.
We note that the results of one-year
calculations depend on insurer’s internal reserving procedures and methodologies. It might be the case that the sensitivity of changes of reserving assumptions with experience depends on severity of changes in actual rates: in case of extreme changes in the actual mortality major revision in assumptions is more likely than in case of the minor deviations. Overall, unless there is an established procedure on how the Best Estimate assumptions are updated with the latest experience, the mortality one-year
model and its assumptions will result in substantial simplification in comparison with the real world. However, there are examples of the objective link between experience and Best Estimate assumptions, see
Jarner and Møller (
2015) for an example of the case where the procedure of updating mortality assumptions is set on the national level. The topic of modelling of the process of updating actuarial assumptions with experience may be an interesting subject for further research. Evidence from such research could help to provide additional justification of one-year
model assumptions and could foster insurers to use such approach more widely in the risk management area.
In addition, analysis of drivers of the mortality improvement and their impact on VaR for mortality risk would be an interesting area for further research. For example, insights from the examination of the effect of changes in smoking habits, obesity, pollution, medical advances and other factors on trend and volatility of mortality could provide valuable input to models and assumptions of VaR for mortality risk. On the other hand, the credibility of such analysis is often compromised by the lack of credible data and complex interdependencies between the mortality data and the underlying drivers of mortality improvement.
In conclusion, based on the analysis performed for the selected countries, we found the overall calibration of the Standard Formula for mortality risk adequate, given the current definition and interpretation of the mortality risk in Solvency II. However, there are insurance portfolio or country specific differences which can result in portfolio specific VaR higher or lower than the capital requirement produced by the Standard Formula.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}