1. Introduction
Quantiles of probability distributions play a central role in the definition of risk measures (e.g., value-at-risk, conditional tail expectation) which in turn are used to capture the riskiness of the distribution tail. Estimates of risk measures are needed in many practical situations such as in pricing of extreme events, developing reserve estimates, designing risk transfer strategies, and allocating capital. When solving such problems, the first highly consequential task is to find point estimates of quantiles and to assess their variability. In this context, the empirical nonparametric approach is the simplest one to use (see
Jones and Zitikis 2003), but it lacks efficiency due to the scarcity of sample data in the tails. On the other hand, parametric estimators can significantly improve quantile estimators’ efficiency (see
Brazauskas and Kaiser 2004;
Kaiser and Brazauskas 2006). Moreover, the parametric approach can accommodate truncation and censoring that are common features of insurance loss data. Of course, the main drawback of parametric estimators is that they are sensitive to initial modeling assumptions, which creates model uncertainty
1.
There is a growing number of studies on various aspects of model risk in modeling, measuring and pricing risks.
Cairns (
2000) was the first author to systematically study model risk in insurance. He discussed different sources of model risk, including parameter uncertainty and model uncertainty, and presented methods to treat these uncertainties coherently.
Hartman et al. (
2017) focused on parameter uncertainty and analyzed its impact in different sectors of insurance practice, namely, life insurance, health insurance, and property/casualty insurance. They also gave a comprehensive review of the literature concerning parameter uncertainty. A recent article by
Hong et al. (
2018) shows typical claim predictions change when the model is uncertain. In particular, they illustrate such effects by using standard model selection tools such as Akaike Information Criterion to determine the “best” regression subset of covariates, and then apply the selected model for claim prediction.
Bignozzi et al. (
2015) and
Samanthi et al. (
2017) are two recent examples of theoretical and practical investigations, respectively, of the effects of the data dependence assumption on subsequent risk measuring. Also, an extensive simulation study involving estimation of upper quantiles of lognormal, log-logistic, and log-double exponential distributions under model and parameter uncertainty was conducted by
Modarres et al. (
2002). Their overall conclusion was that when modeling is done by assuming one of the three families and treating the other two as possible misspecification, the least severe effect on upper quantile estimates occurs when the lognormal distribution is assumed.
Further, there is even more interest in this topic in the financial risk management literature. Model uncertainty within the risk aggregation problems has been recently studied by
Embrechts et al. (
2015) and
Cambou and Filipović (
2017), and for value-at-risk estimation by
Alexander and Sarabia (
2012).
Cont et al. (
2010) and
Glasserman and Xu (
2014) linked financial risk measurement procedures, model risk, and robustness. The first paper suggests the use of the classical robust statistics techniques for managing model risk, while the second pursues model distance and entropy based techniques to derive the worst-case risk measurements (relative to measurements from a baseline model). Finally,
Aggarwal et al. (
2016) and
Black et al. (
2018) provide comprehensive accounts on model risk identification, measurement, and management in practice. These authors develop a model risk framework, identify distinct model cultures within an organization, review common methods and challenges for quantifying model risk, and discuss difficulties that arise in mapping model errors to actual financial impact.
The implied conclusion in many academic and practice oriented papers on model risk is that it can be reduced or mitigated by using all or a combination of the following: performing model validation, fitting multiple models, and applying various stress tests or sensitivity analysis. This idea was in part adopted in the case studies of
Brazauskas and Kleefeld (
2016), which were based on well-known (real) reinsurance data. What was discovered by these authors, however, is that fitting multiple models and using extensive model validation for each of them may not be sufficient if data are left-truncated. That is, they used quantile-quantile plots, Kolmogorov-Smirnov (KS) and Anderson-Darling (AD) tests, Akaike and Bayesian information criteria (AIC and BIC) and had concluded that six different models are acceptable for each of the 12 data sets analyzed. However, when all those models were used to estimate the 90% and 95% quantiles (value-at-risk measures) for ground-up loss, for some data sets they resulted in similar estimates, which would be expected, while for others they were far apart, which is counterintuitive. Moreover, using left-truncated operational risk data,
Yu and Brazauskas (
2017) have shown that even shifted parametric models (which might seem like a plausible option but nonetheless incorrectly account for data truncation) can pass those standard model validation tests. Next, due to the presence of deductibles and policy limits in insurance contracts, data truncation and censoring are unavoidable modifications of the loss severity variable. This suggests that quantile and, more generally, risk measure estimation requires careful thinking and analysis.
In this paper, we present the empirical nonparametric, maximum likelihood, and percentile-matching estimators of ground-up loss distribution quantiles (at various levels). Asymptotic distributions of these estimators are derived when data are left-truncated and right-censored. Relative efficiency curves (REC) for all the estimators are then constructed, and plots of such curves are provided for exponential and single-parameter Pareto distributions. Then, we generate a sample of 50 observations from a left-truncated and right-censored Pareto I model and using that data set investigate how biased quantile estimates can be when one makes incorrect distributional assumptions or relies on a wrong modeling approach. The numerical analysis is also supplemented with standard model diagnostics and validation (e.g., quantile-quantile plots and KS and AD tests) and demonstrates how those methods can mislead the decision maker. In addition, we examine the information provided by RECs and conclude that such curves have strong potential for being developed into an effective diagnostic tool in this context.
The rest of the paper is organized as follows. In
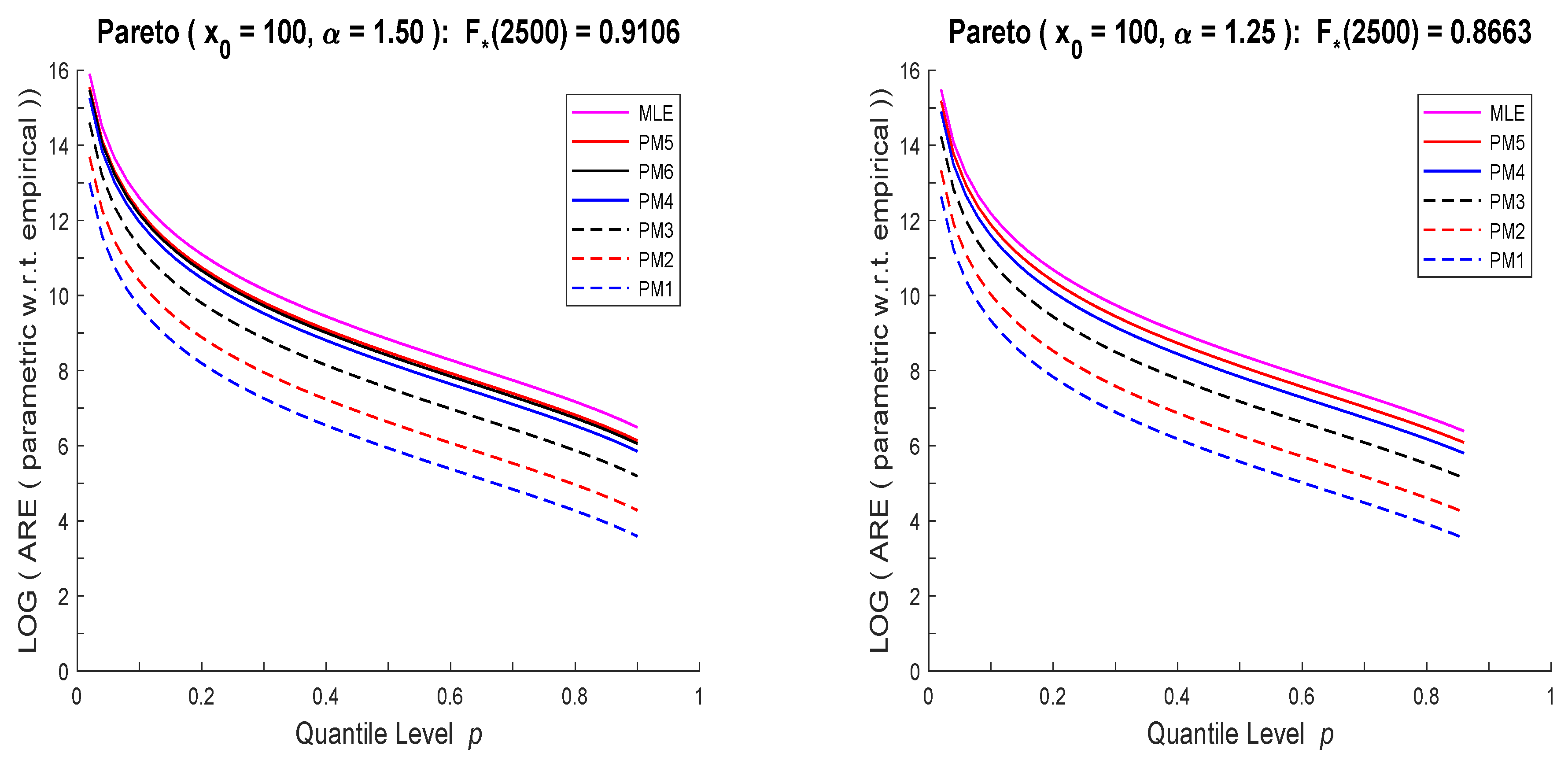
Section 2, nonparametric and parametric quantile estimators are defined and their asymptotic distributions are specified when the underlying random variable is left-truncated and right-censored. The next section presents two illustrative examples of RECs for exponential and single-parameter Pareto distributions. Specifically, RECs of maximum likelihood, percentile matching, and empirical estimators of quantiles of these distributions are plotted.
Section 4 studies the effects of distribution choice and modeling approach on estimates of quantiles. Concluding remarks are offered in
Section 5. Finally, the appendix provides two asymptotic theorems of mathematical statistics and a detailed description of how to contruct RECs. These results are essential to analytic derivations in the paper, and we recommend the reader to review them first.
2. Quantile Estimation
Insurance contracts have coverage modifications that need to be taken into account when modeling the underlying loss severity variable. In this section, we specify the estimators of quantiles of the ground-up distribution and derive their asymptotic distributions when the loss variable is affected by left truncation (due to deductible) and right censoring (due to policy limit). We consider three types of estimators: empirical (
Section 2.1), aximum likelihood, MLE (
Section 2.2), and percentile matching, PM (
Section 2.3).
To present the estimators and their properties, let us start with notation and assumptions. Suppose we observe
n continuous independent identically distributed (i.i.d.) random variables
, where each
is equal to the ground-up variable
X, if
X exceeds threshold
t (
) but is capped at upper limit
u (
). That is,
is a mixed discrete-continuous random variable that satisfies the following conditional event relationship:
where
denotes “equal in distribution.” Also, let us denote the probability density function (pdf), cumulative distribution function (cdf), and quantile function (qf) of
X as
f,
F, and
, respectively. Then, the cdf
, pdf
, qf
of
are related to
F,
f,
and given by:
Note that we are interested in estimating the
pth quantile of
X (i.e.,
) based on the observed data
. Thus, Theorems A1 and A2 in
Appendix A.1 and the REC construction of
Appendix A.2 have to be applied to functions (
1)–(
3), not
F,
f,
.
2.1. Empirical Approach
As mentioned earlier, the empirical approach is restricted to the range of observed data. Indeed, based on
, the empirical estimator
. Thus, it cannot take full advantage of formulas (
1)–(
3), and yields a biased estimator that works within a limited range of quantile levels. In this case, the
estimator is
, and as follows from Theorem A1,
To see that this estimator is positively biased, i.e., any (estimable) quantile of the observable variable
is never below the corresponding quantile of the unobservable variable
X (which is what we want to estimate), notice that for the mean parameter in (
4), we have
with the inequality being strict unless
. The inequality holds because
is strictly increasing (loss severities are non-negative absolutely continuous random variables) and
.
2.2. MLE Approach
Parametric methods use the observed data
and fully recognize its distributional properties. The MLE approach is one of the most common estimation techniques. It takes into account (
1)–(
3) and finds parameter estimates by maximizing the following log-likelihood function:
where
denotes the indicator function.
Once parameter MLEs,
, are available, the
pth quantile estimate is found by plugging those MLE values into the parametric expression of
. Let us denote this estimator as
. Then, as follows from the MLE’s asymptotic distribution and the delta method,
where
, and the entries of
are given by (
A7) with
g replaced by (
2). Note that (
6) is defined for
, while (
4) for
.
2.3. PM Approach
A popular alternative to the MLE approach for estimation of loss distribution parameters is percentile matching (PM). To estimate
k unknown parameters with the PM method and using the ordered data
, one has to solve the following system of equations with respect to
:
where
and
. Once parameter PMs,
, are available, the
pth quantile estimate is found by plugging those PM values into
. Let us denote this estimator as
. Then, as follows from Theorem A2 and the delta method,
where
and
is specified in Theorem A2. The entries of
are given by (
A1) with
g and
replaced by expressions (
2) and (
3), respectively. Note that (
7) is defined for
, while (
4) for
.
4. Evaluation of Model Uncertainty
In this section, using simulated data we demonstrate how model uncertainty can emerge in a surprising way and examine how wrong quantile estimates can be when one makes incorrect modeling assumptions. In particular, we generate
observations from the exponential distribution of
Section 3.1 (with
,
,
,
), fit the exponential model using MLE and PM (
) estimators to it, and perform standard model diagnostics (e.g., quantile-quantile plots) and validation (e.g., Kolmogorov-Smirnov and Anderson-Darling tests). As expected, the exponential distribution is not rejected by any of the tests. Then, using the same data we repeat the exercise by assuming a Pareto distribution, and find that it also passes all the tests. In both cases, we additionally compute AIC and BIC values, which under the
incorrect Pareto assumption are better than the ones under the
correct exponential assumption. Next, to make sure that this conclusion was not random, we simulate
observations from the Pareto distribution of
Section 3.2 (with
,
,
,
), fit and validate both models, and find yet again that both distributional assumptions are acceptable. This exercise shows that standard model diagnostic methods can mislead the decision maker, which would be not a major issue if quantile estimates based on incorrect modeling assumptions were close to the true values of quantiles, however, that’s not the case. For completeness, we include the empirical estimates of quantiles although it is known they are incorrect. Below we provide the details of the described exercises so the interested reader can reproduce the results.
The data sets were simulated using
R with a seed of 200 (it is used to initialize the random number generator). They are presented in
Table 1, where censored observations are
italicized.
In
Figure 3, the quantile-quantile plots (QQ-plots) are provided. The plots are parameter free. That is, since the exponential and Pareto distributions are location-scale and log-location-scale families, respectively, their QQ-plots can be constructed without first estimating model parameters. Note also that only actual data can be used in these plots (i.e., no observations
). As is evident from
Figure 3, the points in all graphs form a (roughly) straight line; thus both distributions are acceptable for both data sets.
To formally evaluate the appropriateness of the fitted model to data, we perform KS and AD goodness-of-fit tests. The models are fitted using two parameter estimation methods, MLE and PM (
), to check the sensitivity of overall conclusions to model fitting procedures. The values of the test statistics along with the corresponding
p-values are reported in
Table 2. (The
p-values are computed using parametric bootstrap with 1000 simulation runs. For a brief description of the parametric bootstrap procedure, see, for example, Section 20.4.5 of
Klugman et al. (
2012)). We can see that except for one isolated case (Pareto data, Pareto model, PM estimation) the
p-values are above 0.10 for both distributions, all parameter estimation methods, and both tests. Thus, the fitted exponential and Pareto models are acceptable for both data sets. In addition, the table contains AIC and BIC values, which can be used as model selection tools. Based on these metrics (smaller values are better), the Pareto model would be chosen for both data sets. Of course, the decision to accept Pareto when data came from an exponential distribution is incorrect.
Next, to see whether it really matters which model we select at this stage of the analysis, we have to examine the true probability models that generated data and check how much off target our upper quantile estimates are. For the data sets of
Table 1, the underlying distributions are exponential (
) and Pareto (
), with the quantile functions given by:
Thus, the true values of the 90%, 95% and 99% quantiles (estimation targets) are:
The quantile estimation results are summarized in
Table 3. There, we clearly see that the parametric estimates of the quantiles based on the correctly identified model are fairly close to their targets, but those based on the incorrect model are significantly off their targets. Also, the empirical estimates are way off target (
for the exponential data set is a lucky coincidence, not a rule).
Finally, in
Table 4 we present estimated RECs, given by (
11) and (
17), at selected quantile levels. The curves are estimated using the MLE values from
Table 2 and show how many times the parametric approach is more efficient than the empirical one in estimating a quantile. Note that as was seen in
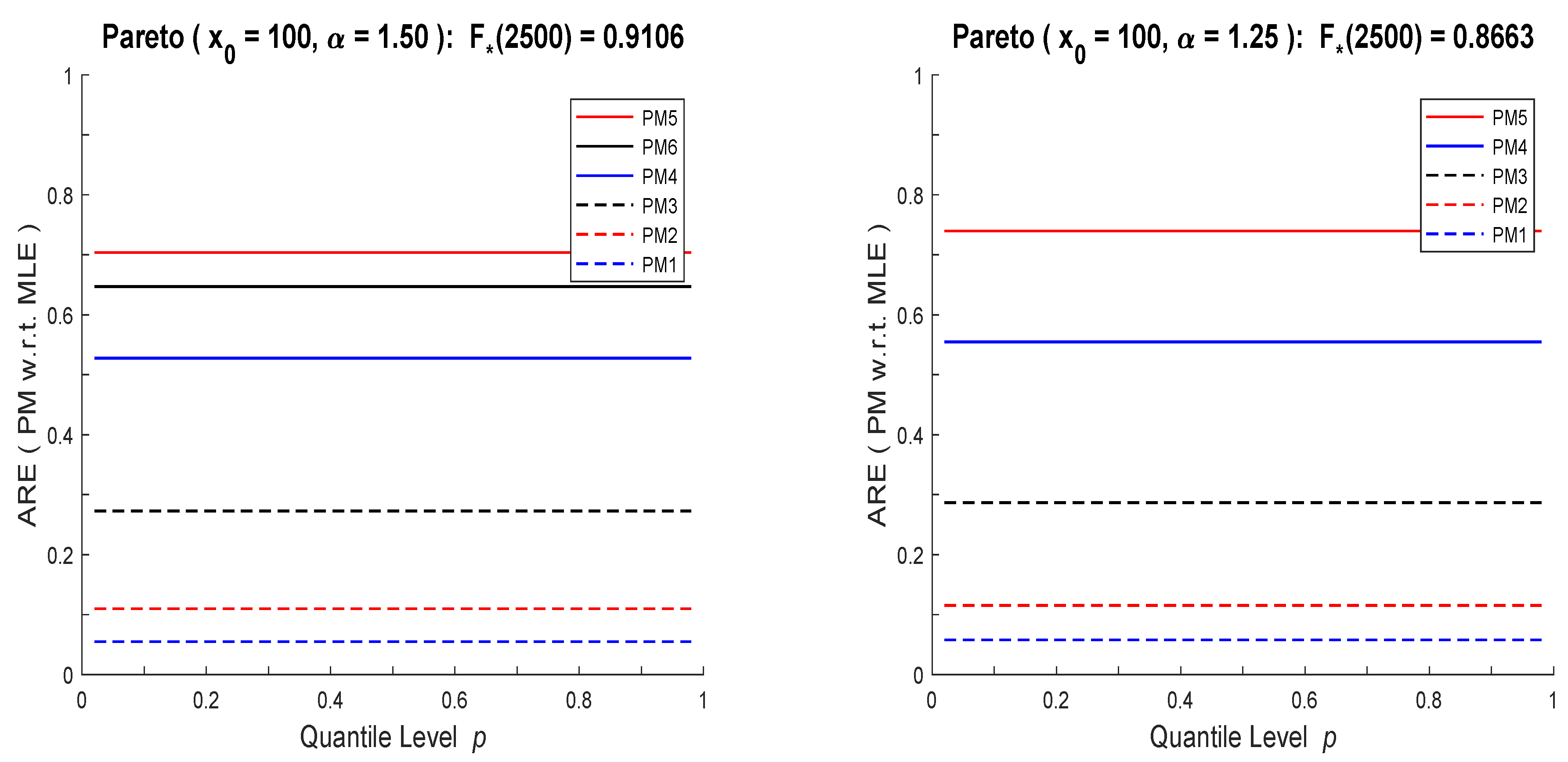
Figure 1 and
Figure 2, RECs based on PM estimators have the same shapes as those of MLE, just rescaled by a constant (smaller than one). Thus PM based conclusions would not change from those of MLE and one method of analysis will be sufficient. What stands out from these computations is the vast differences between the corresponding exponential and Pareto RECs, when they are estimated using the same data set (especially for small
p). We conjecture that with some additional work one can develop an effective diagnostic tool to differentiate between the models.
5. Concluding Remarks
The relative efficiency curves, REC, were introduced as a practical tool for comparison of two competing statistical procedures, when data are complete. In this paper, we have redesigned and extended such curves to the left-truncated and right-censored data scenarios that are common in insurance analytics. Our illustrations have focused on the parametric (MLE and PM) and empirical nonparametric approaches for estimation of quantiles that are key inputs for further risk analysis (e.g., contract pricing, risk measurement, capital allocation). Further, we have developed specific examples of RECs for exponential and single-parameter Pareto distributions under a few data truncation and censoring scenarios. Then, using simulated exponential and Pareto data we have examined how wrong quantile estimates can be when incorrect modeling assumptions are made. The numerical analysis involved application of standard model diagnostics and validation (e.g., QQ-plots, KS and AD tests, AIC and BIC criteria) and has demonstrated how those methods can mislead the decision maker. Finally, the newly developed RECs have been applied to study the discrepancies between the quality of quantile estimates of the fitted exponential and Pareto distributions. Our conclusion is that RECs have strong potential for being developed into an effective diagnostic tool in this context.






{kind=link}
{kind=link}
{kind=link}
{kind=link}