1. Introduction
In the early 1990s, the international economic and financial consultancy G30 published the report “derivatives practices and principles” based on the research on financial derivatives, and then proposed Value at Risk (VaR) model to measure the market risk. JP Morgan Bank then launched the VaR risk measurement and control model. Since VaR is accurate and comprehensive to the application of risk measurement and makes up the deficiency of Markowitz mean-variance model, it is generally welcomed by the international financial community, including regulatory authorities, and has become a standard to manage and control financial risk. Furthermore, VaR is widely used to measure credit risks and trading risks.
The biggest benefit of VaR is the ability to critically analyze risk through systematic analysis. The organization can control the front end and back end of the business by calculating VaR to understand the financial risks it faces and establish an independent risk management mechanism.
However, VaR also has its own limitations.
Mausser and Rosen (
1999) put forward the most obvious limitations of VaR: it does not provide absolute maximum loss value, which can only be expected in a certain confidence level. Another drawback of VaR is that when the calculation is based on historical data, the future situation of any event should be duplicated or fitted by historical data. However, the reality is that we cannot guarantee the future case of an event is just as old as. In addition, some researchers such as
Artzner et al. (
1999) criticized the VaR model because it does not meet sub-additivity.
The obvious limitation existing in VaR is that it is only used to illustrate the maximum possible loss for the given conditions and is only a single index to characterize the risk, which provides less information to users about other information such as income. In practice, what people usually care about is how much profit they can get while taking risks.
Based on the above considerations, we hope to follow the definition of VaR and Markowitz’s portfolio theory, and then construct a double-VaR, that is, we will extend one-dimensional single-risk monitoring indicator-VaR to two-dimensional revenue-risk monitoring indicators-VaR (or double-VaR for short).
There is abundant literature about VaR. Here, the main research literature involved in this paper is described briefly as follows.
Duffie and Pan (
1997) made a detailed background description of VaR, characteristics, applications, and the entire VaR-system.
Beder (
1995) used eight different models to calculate VaR values and compare them. Some foreign scholars studied mainly the calculation of VaR, such as
Jorion (
1996);
Linsmeier and Pearson (
1996);
Duffie and Pan (
1997);
Engle and Manganelli (
1999). Based on different situations, they arrived at many calculation skills such as the variance-covariance matrix method, historical simulation, and Monte Carlo simulation method, and the related characteristics of VaR, etc.
After 1999, there are an increasing number of new VaR models in the financial, industrial, and other different applied areas.
Potters and Bouchaud (
1999) proposed how to use the normality of asset volatilities to calculate the VaR of nonlinear combination. Some other scholars studying the nature of VaR and other risk measurement methods, such as
Artzner et al. (
1999), proposed VaR does not meet sub-additivity;
Wang (
1999) studied the characteristics of dynamic risk measures;
Mausser and Rosen (
1999) proposed that if a small-probability event happened in the case of loss exceeding the VaR, then VaR models cannot measure the size of potential losses;
Chen et al. (
2014) studied future cash arbitrage with VaR-portfolio problems;
Tang et al. (
2018) investigated the no-arbitrage problem with VaR-like arguments;
Cong and Zhao (
2018;
2019) posed a non-cash risk measure and a generalized non-cash risk measure, respectively, which improved in some sense VaR under the distribution of any random variable that is uncertain. In addition, some scholars extended the classical Markowitz mean-variance model to the mean-VaR model; for instance,
Pearson (
2002) and
Jorion (
2007) used these models with constraints to manage the risk-profit for a fund company.
In addition, many scholars have proposed a series of improved calculation methods based on different markets and different assumptions.
Berkowitz (
1999) proposed a new method for evaluation of VaR.
Taylor et al. (
2000) proposed to use the t distribution to fit the income sequence;
Hu (
2012) based their research on the mixed Copula model to study the evaluation value of VaR;
Ze-To (
2013) used the Heath-Jarrow-Morton model to measure the value of VaR, and pointed out that the model can capture the non-normal income distribution well and can accurately provide the value of VaR;
Li et al. (
2017) confirmed that using the Bootstrap method to calculate VaR and CVaR can effectively improve the estimation accuracy.
Meanwhile, many foreign scholars have also attached great importance to the empirical applications of VaR.
Jackson et al. (
1997) studied how to apply VaR into bank reserves.
Berkowitz and O’Brien (
2002) proposed how to evaluate the transaction risk of commercial banks through the prediction accuracy of the VaR model.
Basak and Shapiro (
2001) analyzed the optimal dynamic portfolio risks with VaR model.
In the present paper, we will extend one-dimensional single-risk monitoring indicator—VaR—to two-dimensional benefit-risk monitoring indicators—double-VaR.
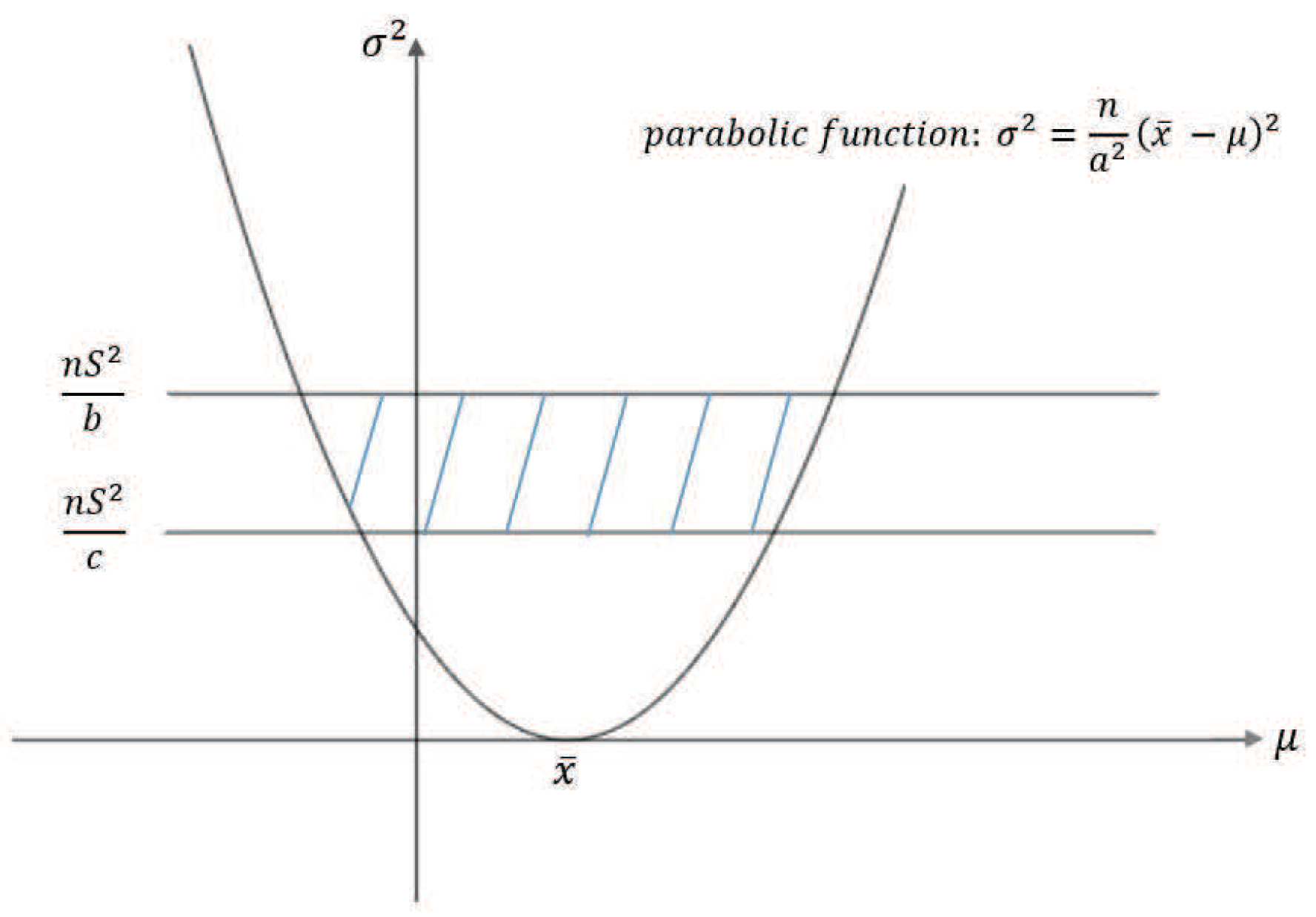
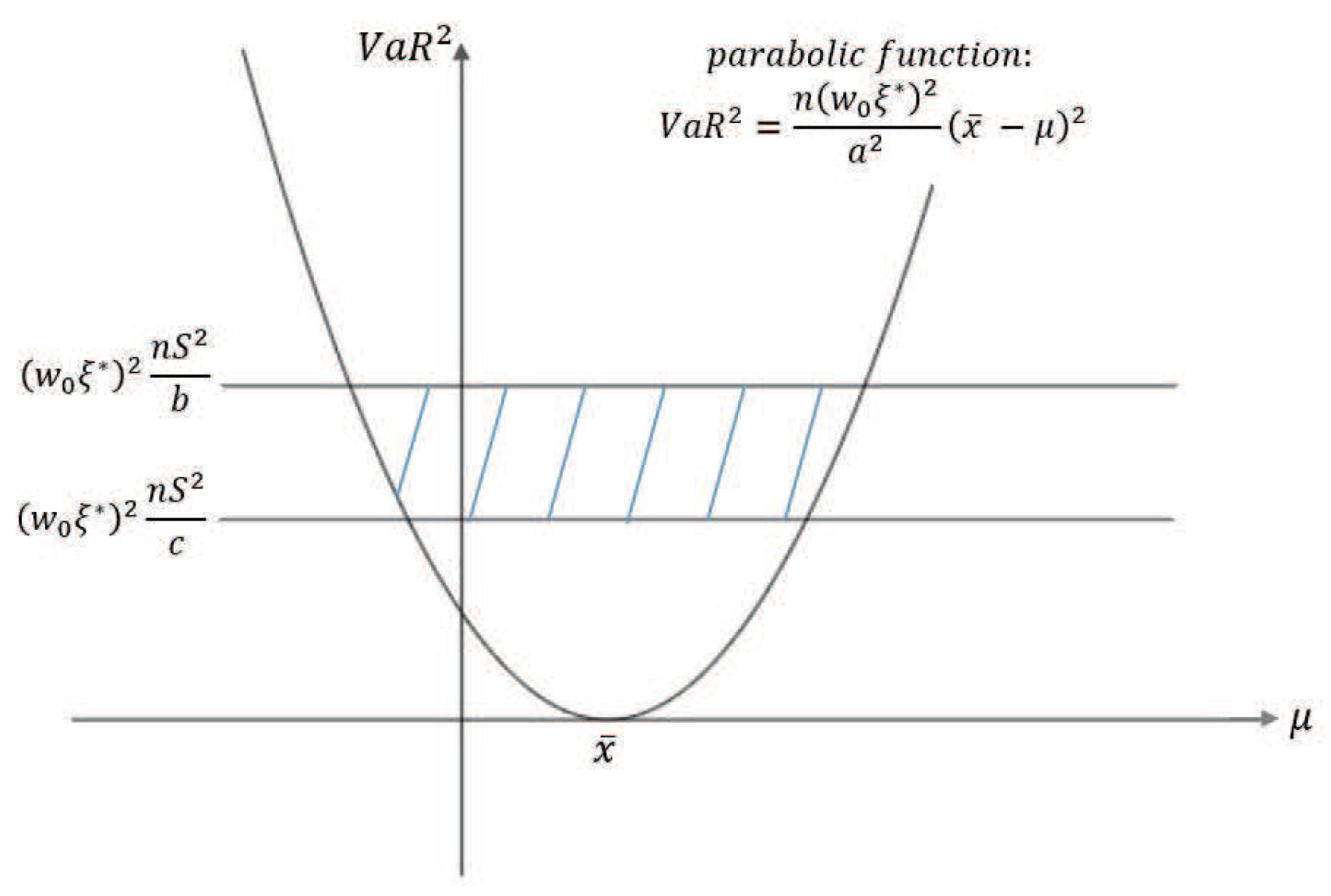
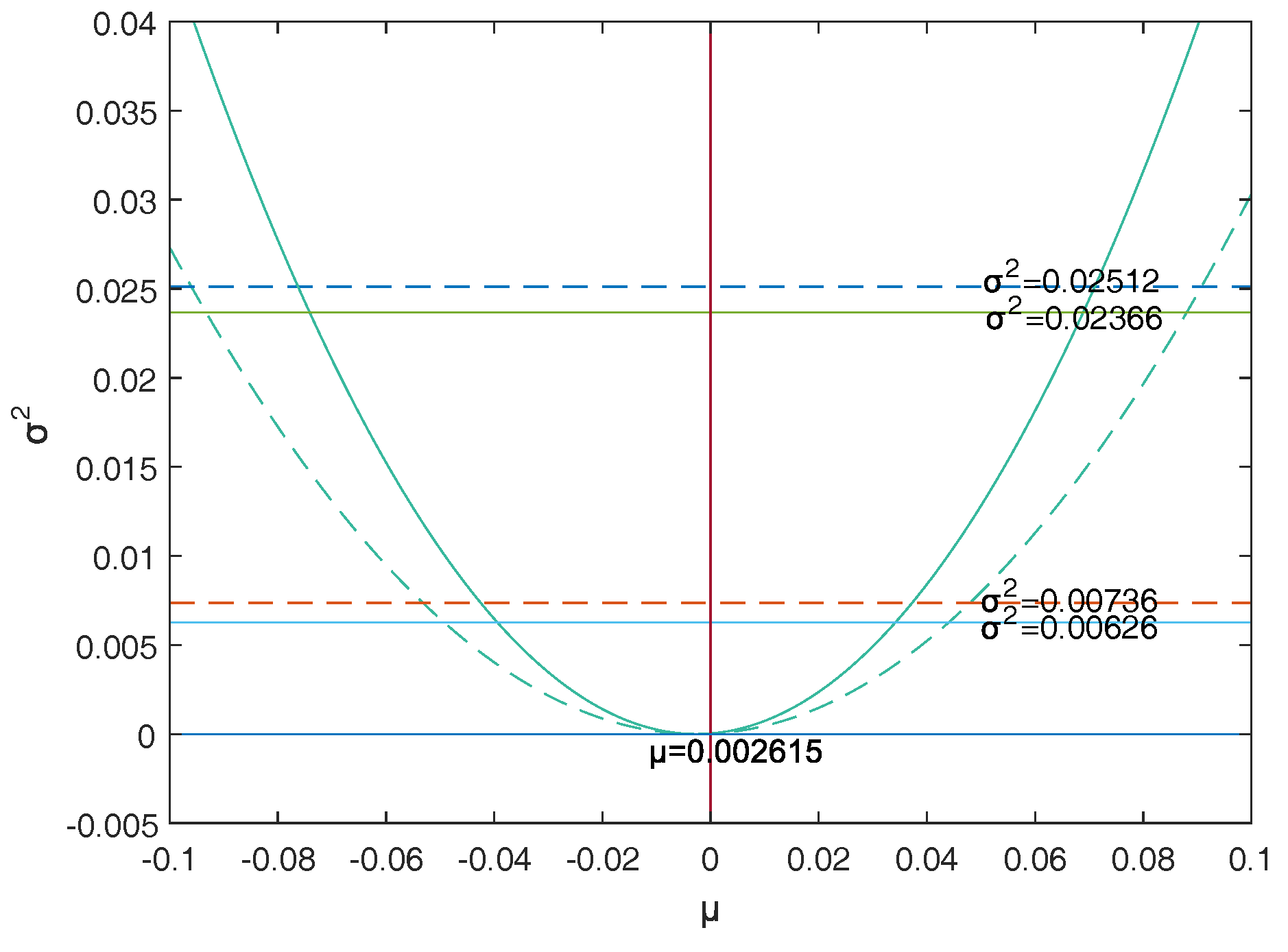
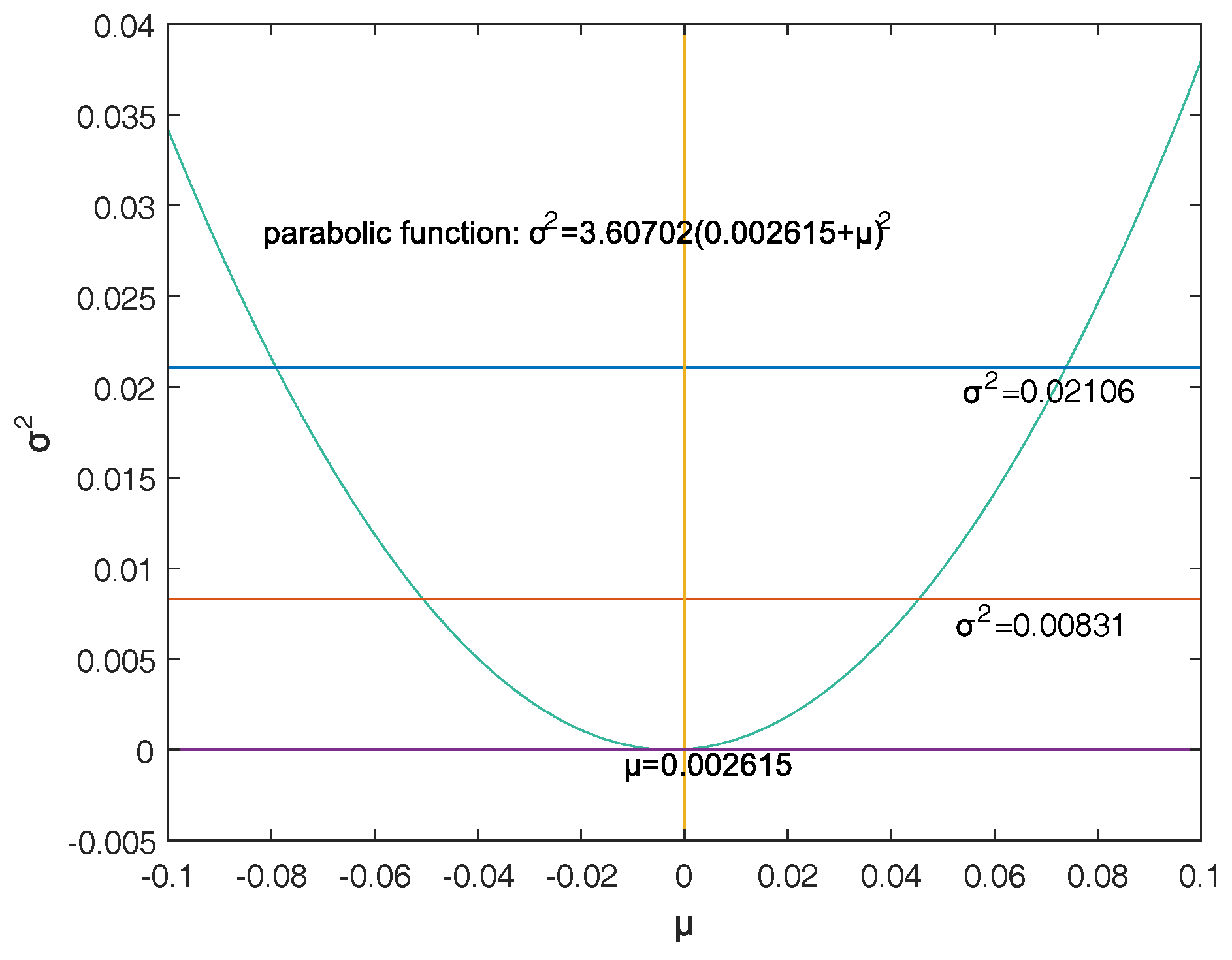
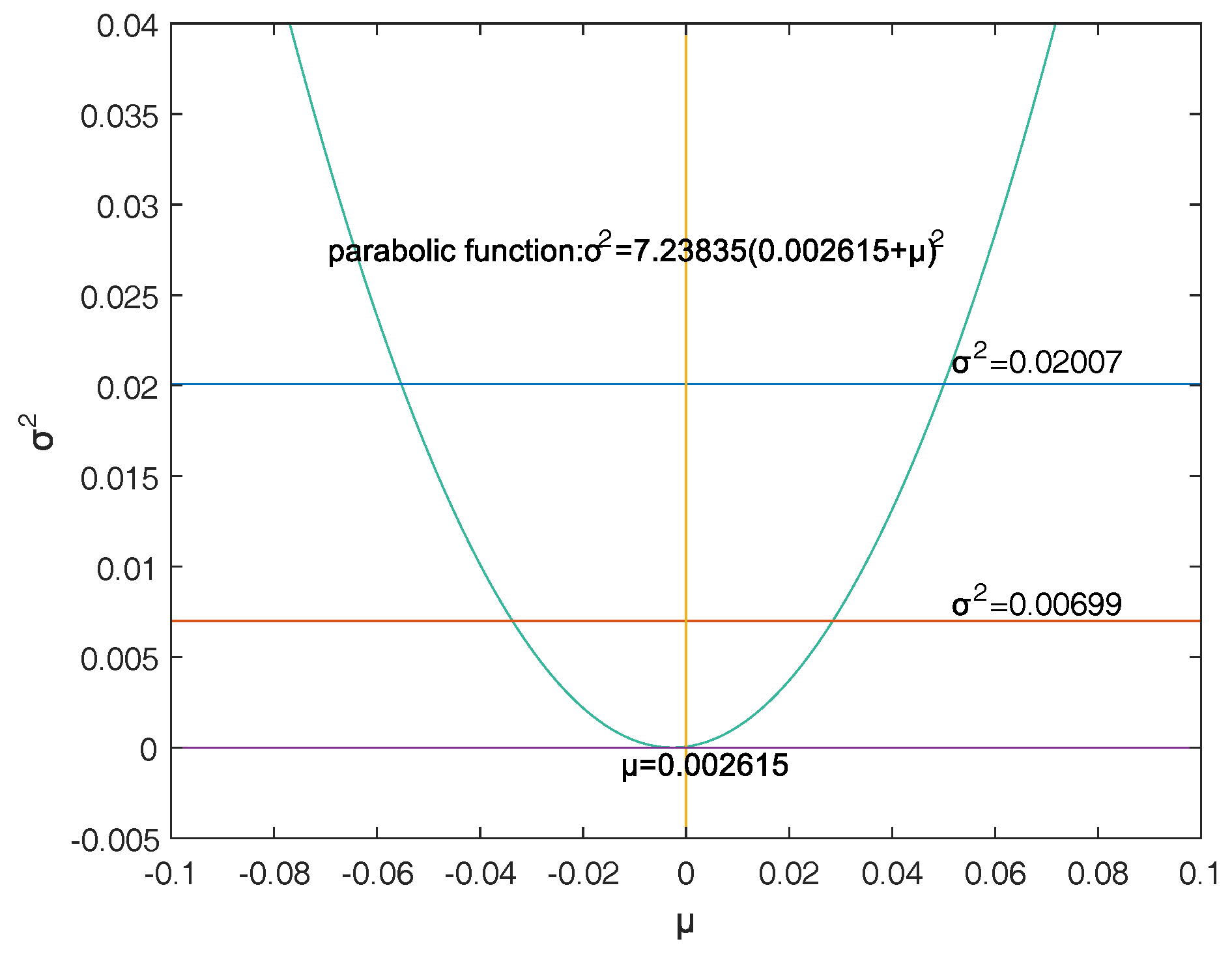
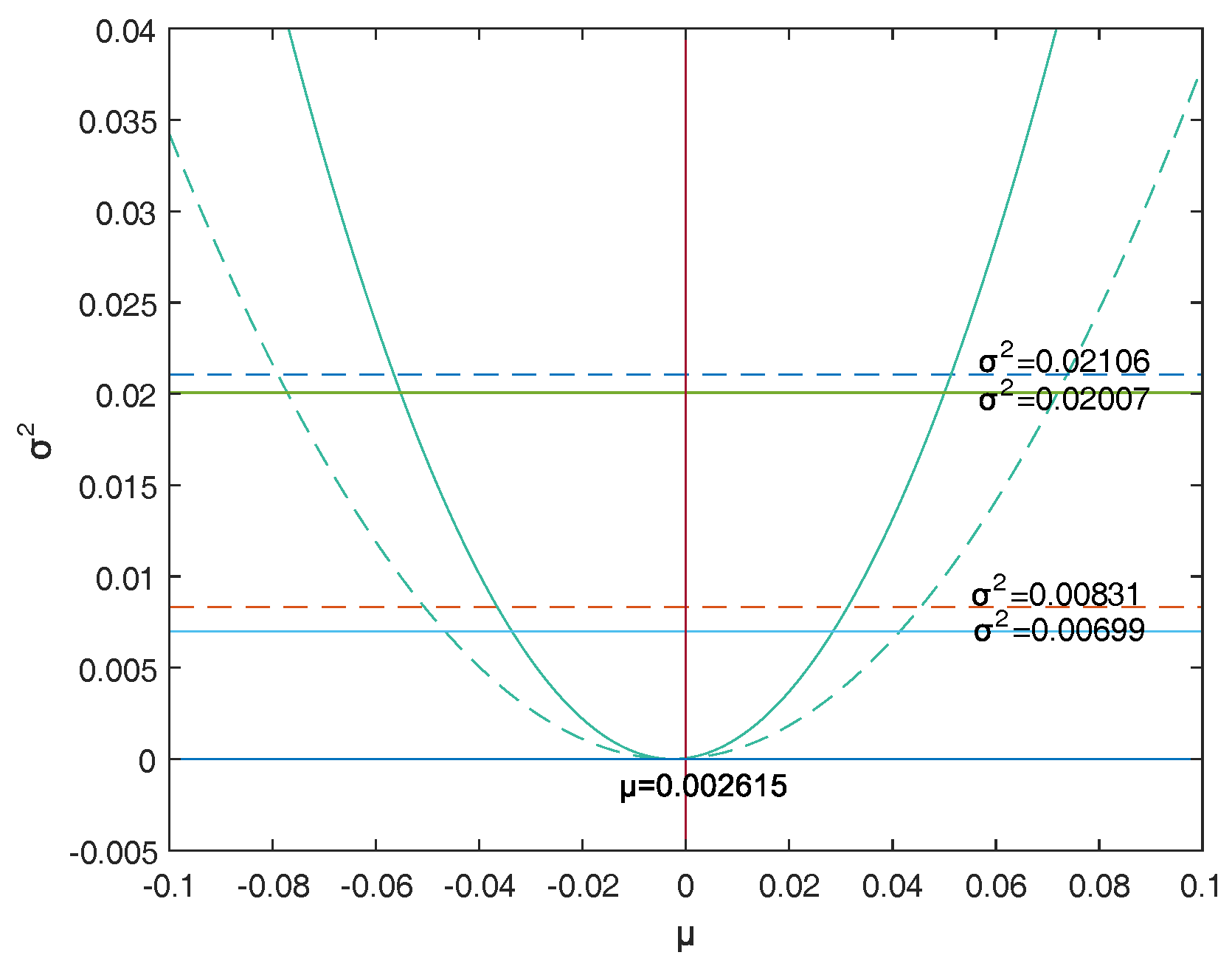
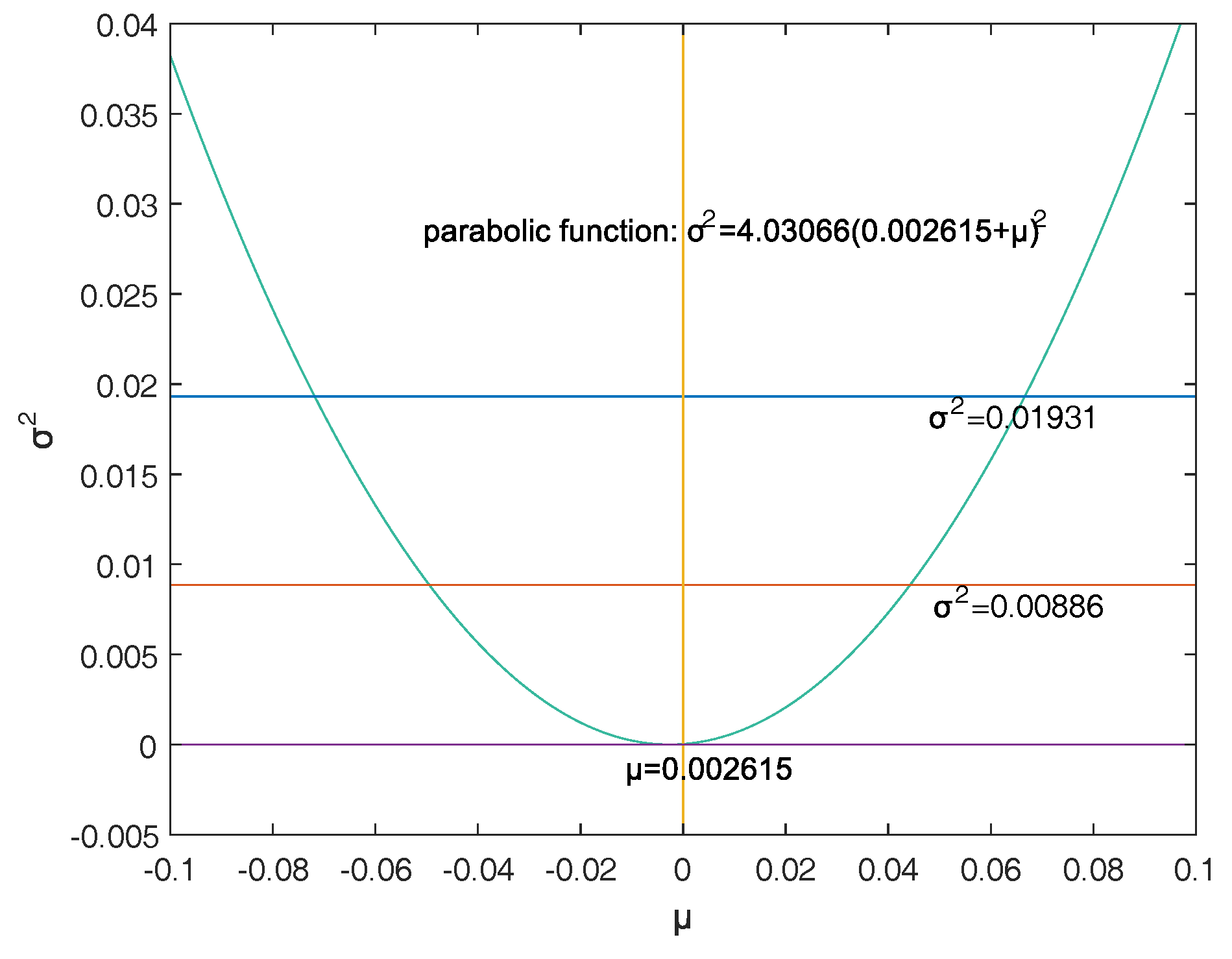
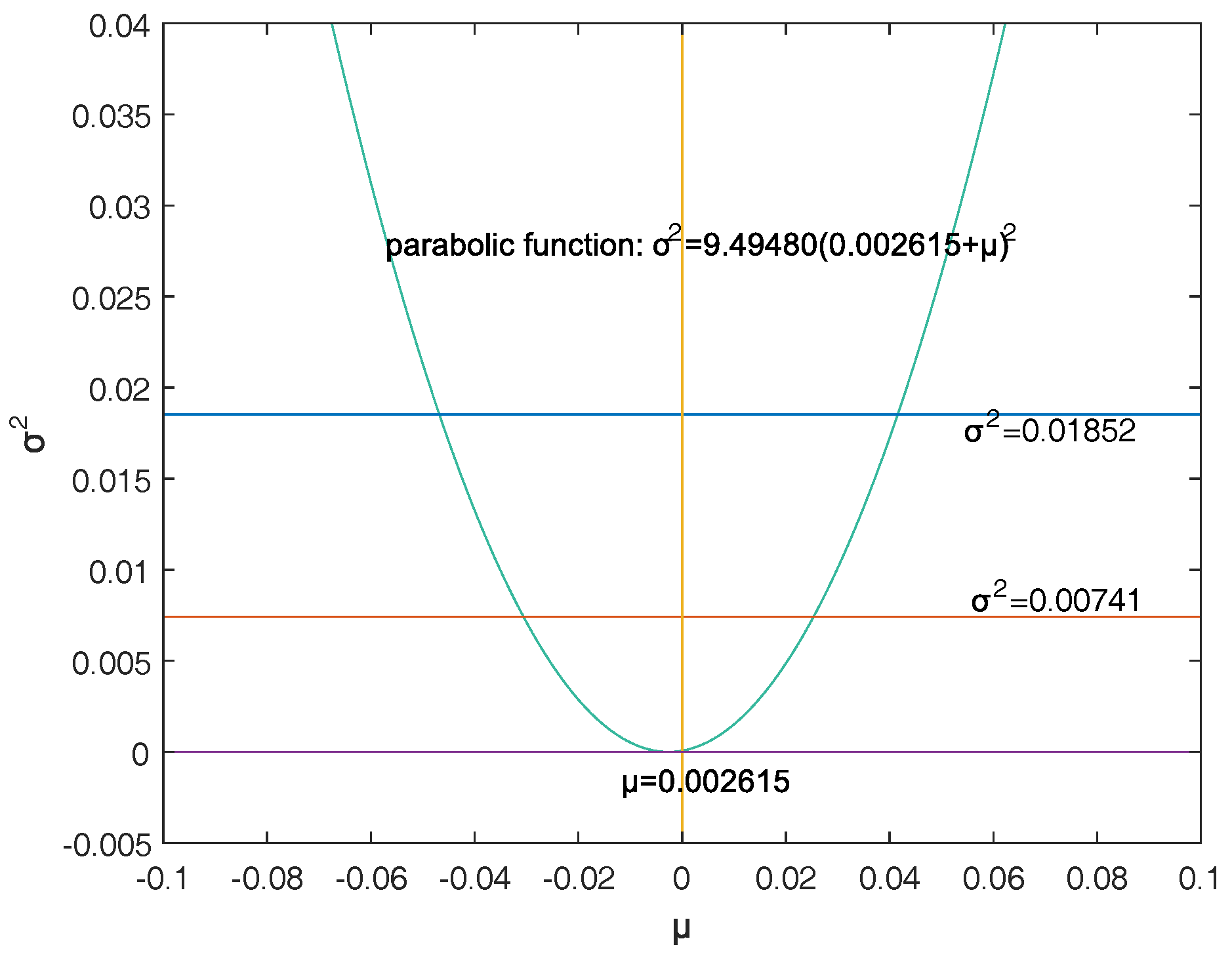
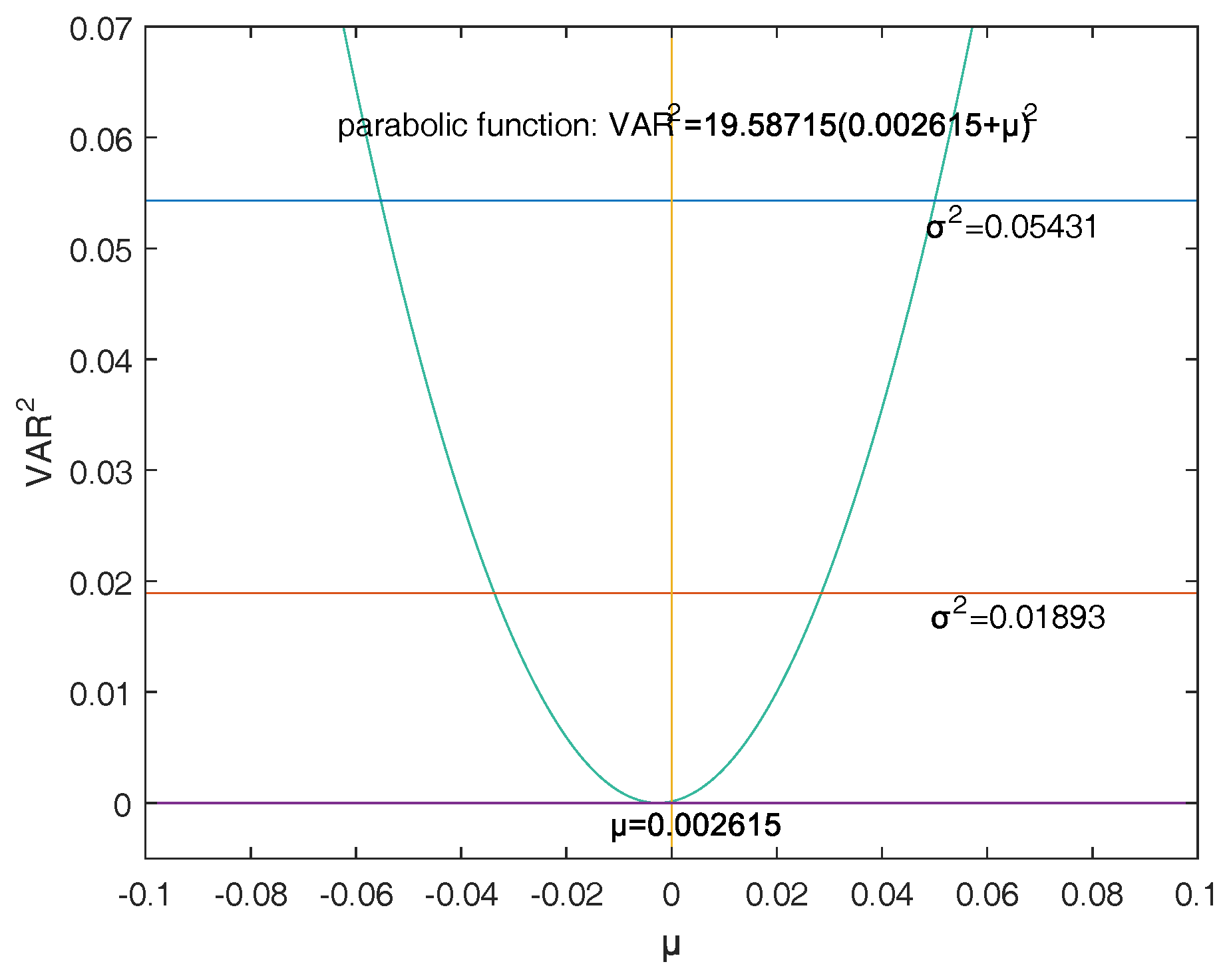
Firstly, a reasonable definition of two-dimensional VaR (double-VaR) is given. For a better understanding of double-VaR we choose mean and variance as the parameters to build the first double-VaR model. Thus, for a given confidence level , one can not only know the scope of asset risks but also can know their income range. Such indicators are better able to make trade-offs to the risk-return of assets.
Secondly, to solve the first model—double-VaR with respect to —we extend the one-dimensional likelihood ratio method to two-dimensional likelihood ratio method, and derive the joint confidence region containing the unknown parameters. Then, we can solve a specific joint confidence region with ideal point method and area minimization method as well as to compare the results of these two methods.
Finally, according to the accuracy theory of VaR we study the double-VaR based on so that for a given confidence interval we cannot only know the biggest value of possible asset loss but we can also get the gain range. In this situation a better trade-off of the asset is possible.
The organization of the paper is as follows.
Section 2 introduces some necessary conditions and terminologies.
Section 3 is devoted to constructing double-VaR models with
and
.
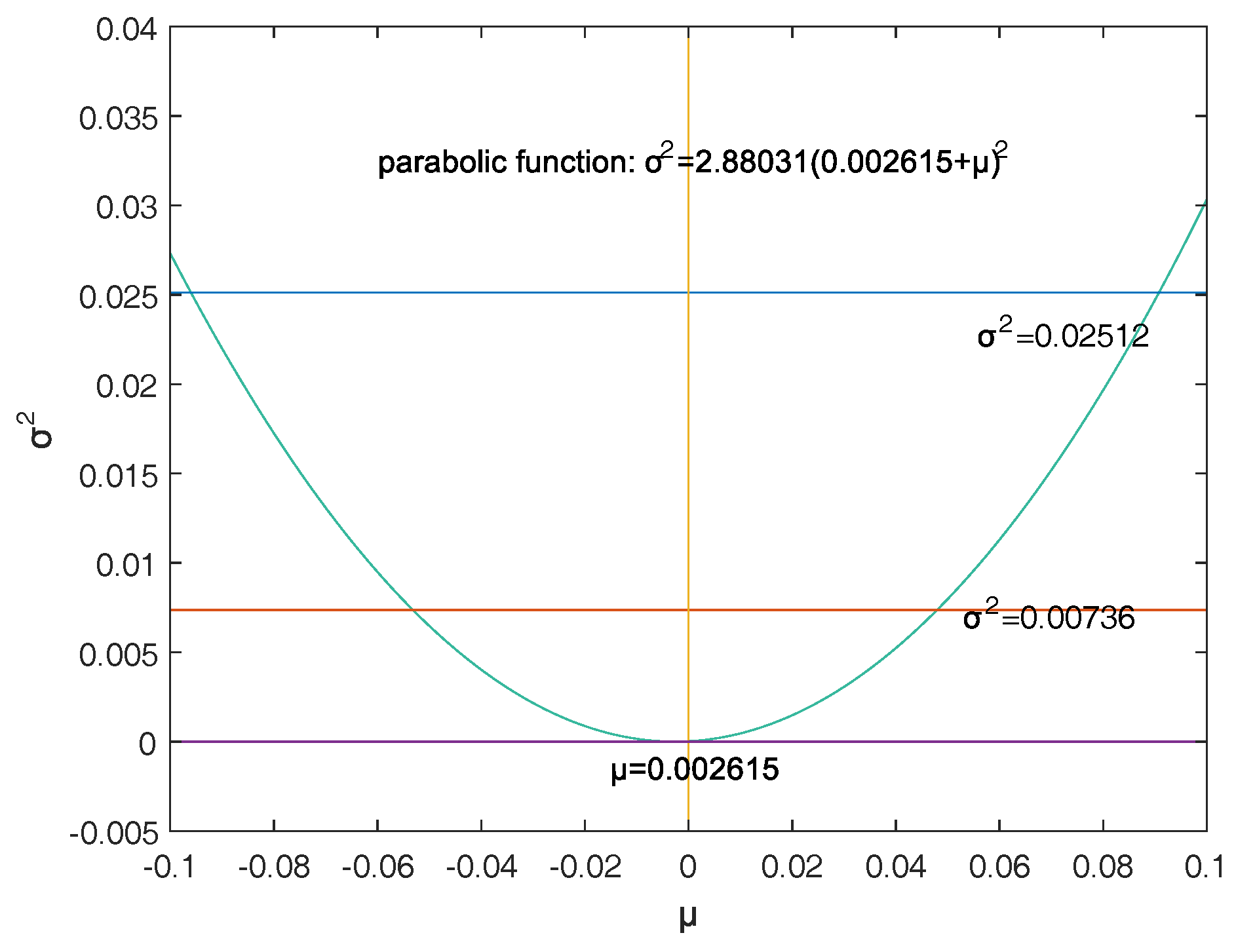
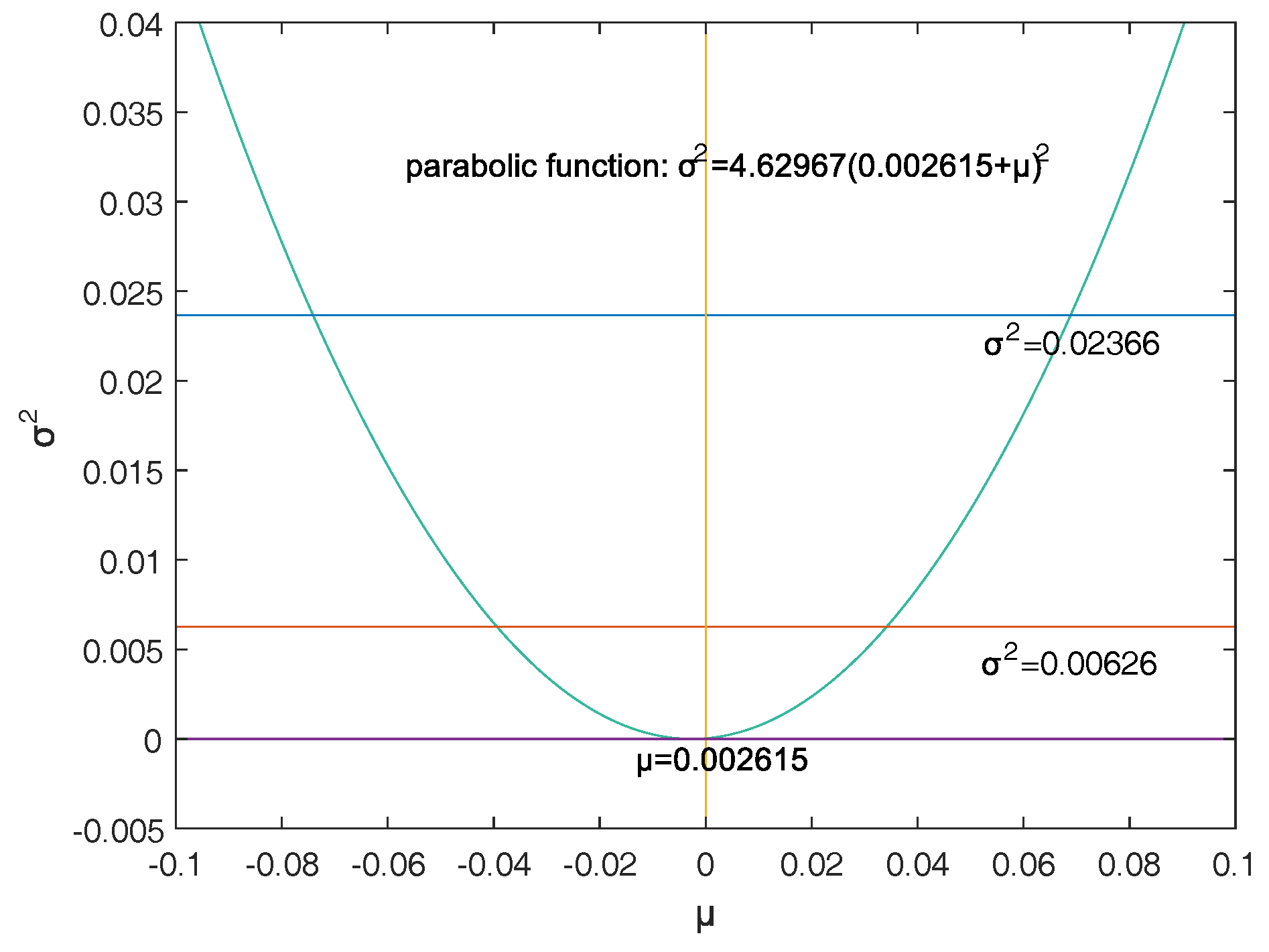
Section 4 confirms that the double-VaR models are effective via some examples.
5. Conclusions
VaR is just a single indicator value to characterize risk, providing less information to the user, and the risk warning function is too thin. In practice, people often need to know both the benefits they may receive and the risks they are involved with. Therefore, this paper studies and constructs the double VaR according to the definition and research methods of VaR, expanding the one-dimensional single-risk monitoring indicator-VaR into a two-dimensional revenue-risk monitoring indicator.
This paper selects and as the models of the double-VaR. It shows the risk/maximum loss of an asset at a given time in the future and the area in which the revenue is located. Such indicators can better weigh the risk–return of assets, and deduce the joint confidence region of (or ) by virtue of the two-dimensional likelihood ratio method. Then, the ideal joint method and the area minimization method are used to solve the specific joint confidence domain, and the solution effect of the two methods is compared. The obtained area minimization method is more accurate and better. After the VaR is double-expanded, users can know more information and better evaluate assets and avoid certain financial risks.
In this paper, only the normal distribution is considered in terms of its own knowledge structure and time. In fact, the author has great interest in risk management in the case of market with fat tails and the probability of extreme events, which will have important practical significance. We will discuss this in the next article on VaR.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}