Machine Learning in Banking Risk Management: A Literature Review



Abstract
:1. Introduction
2. Theoretical Background
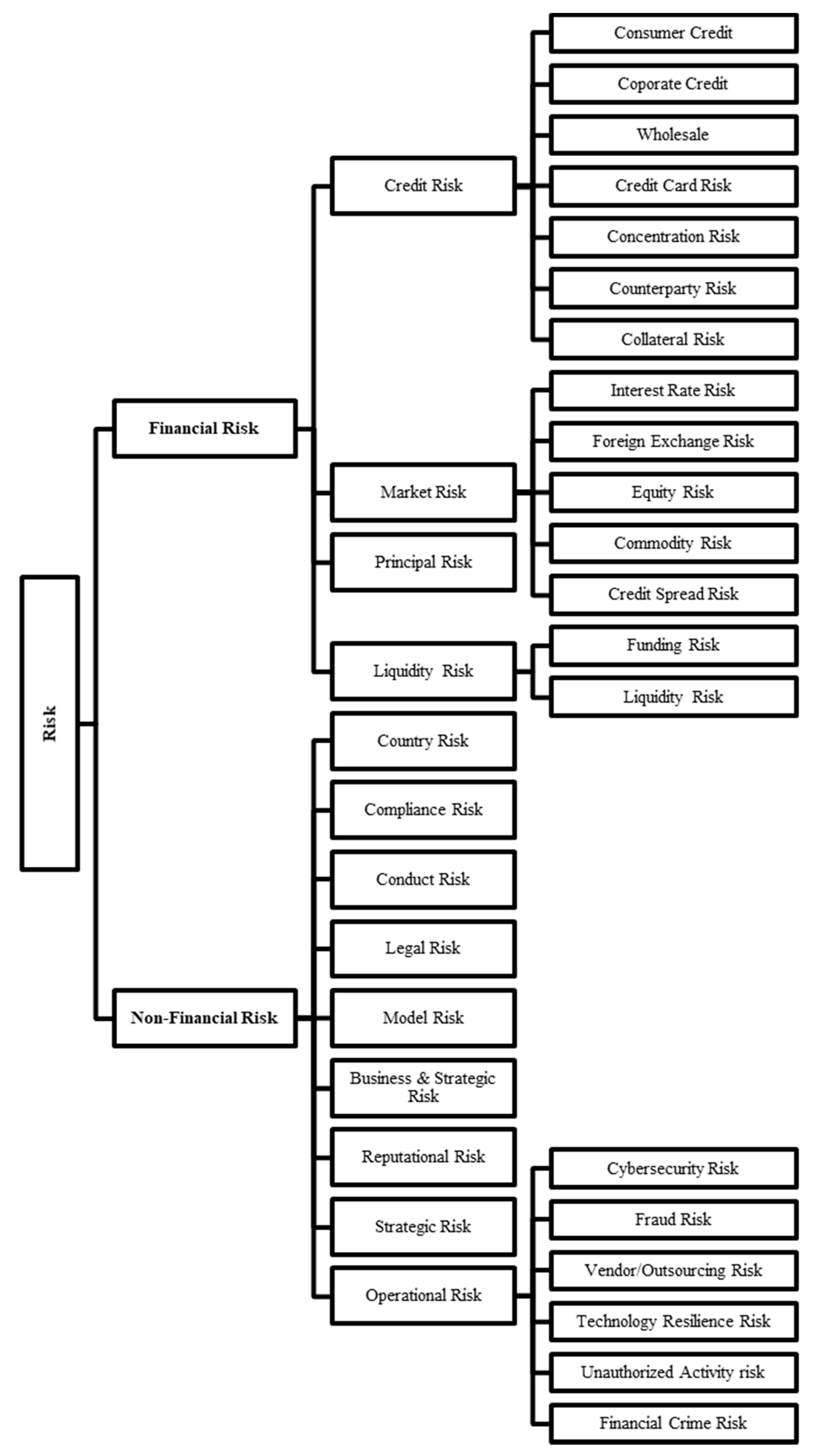
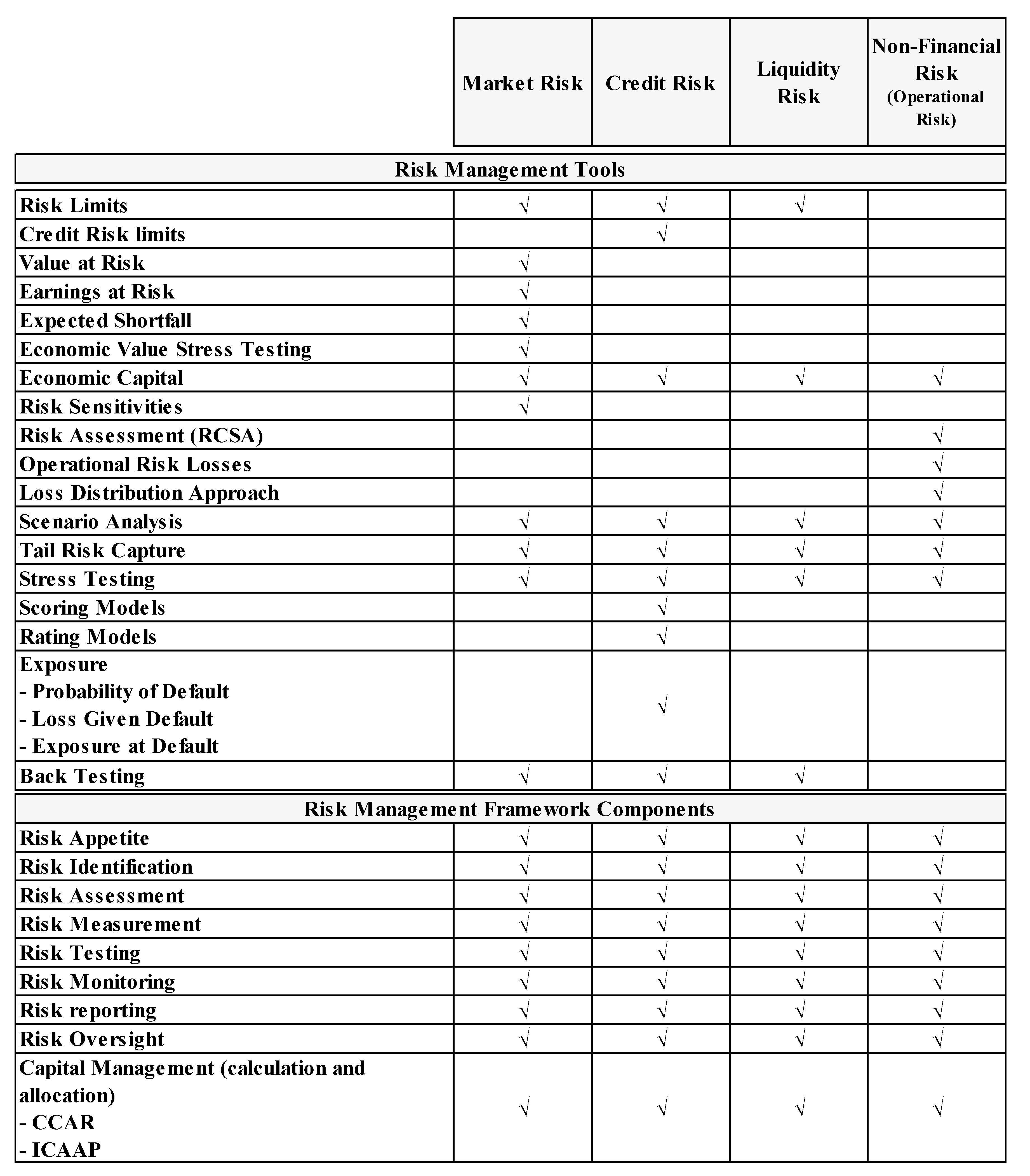
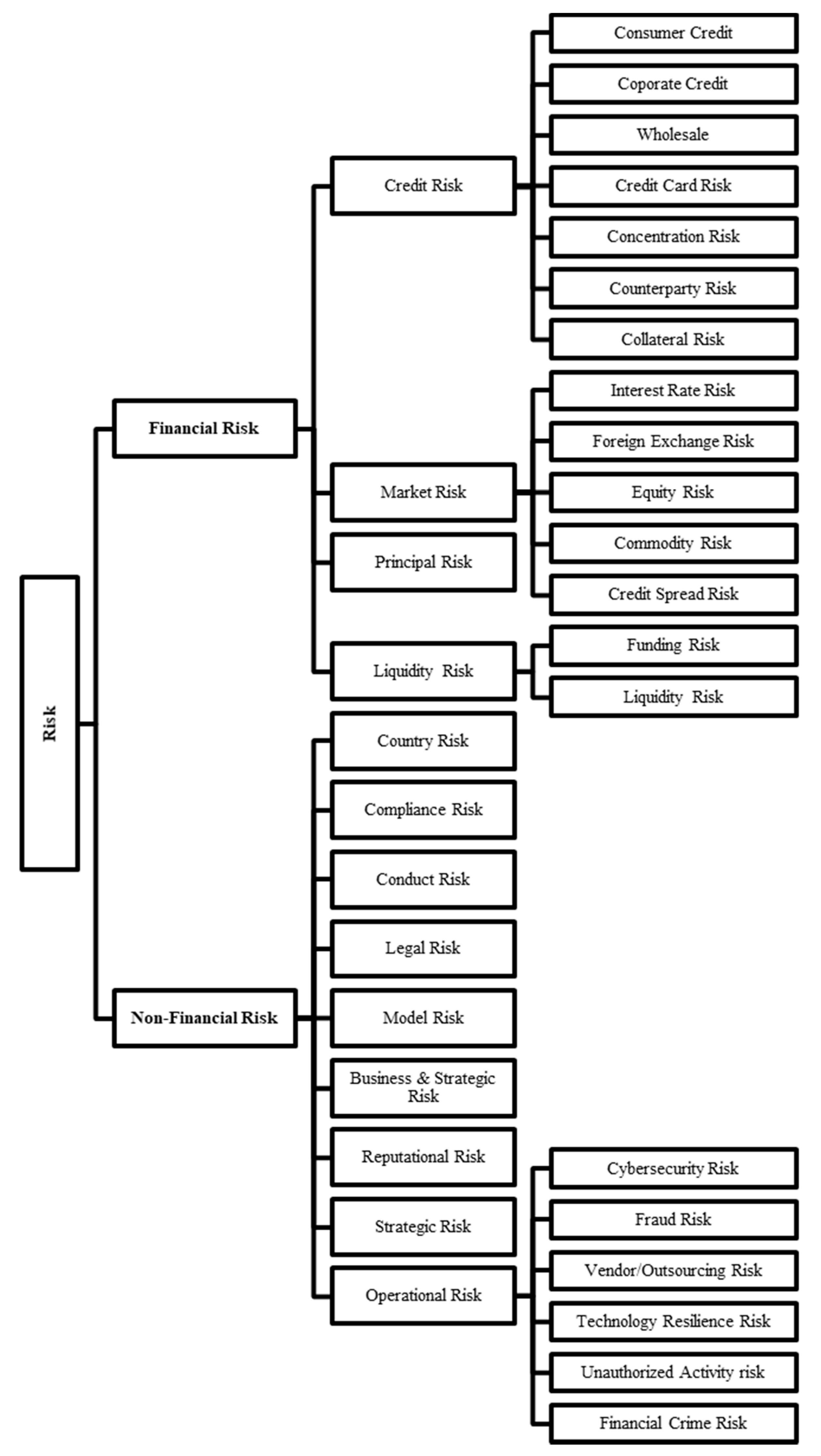
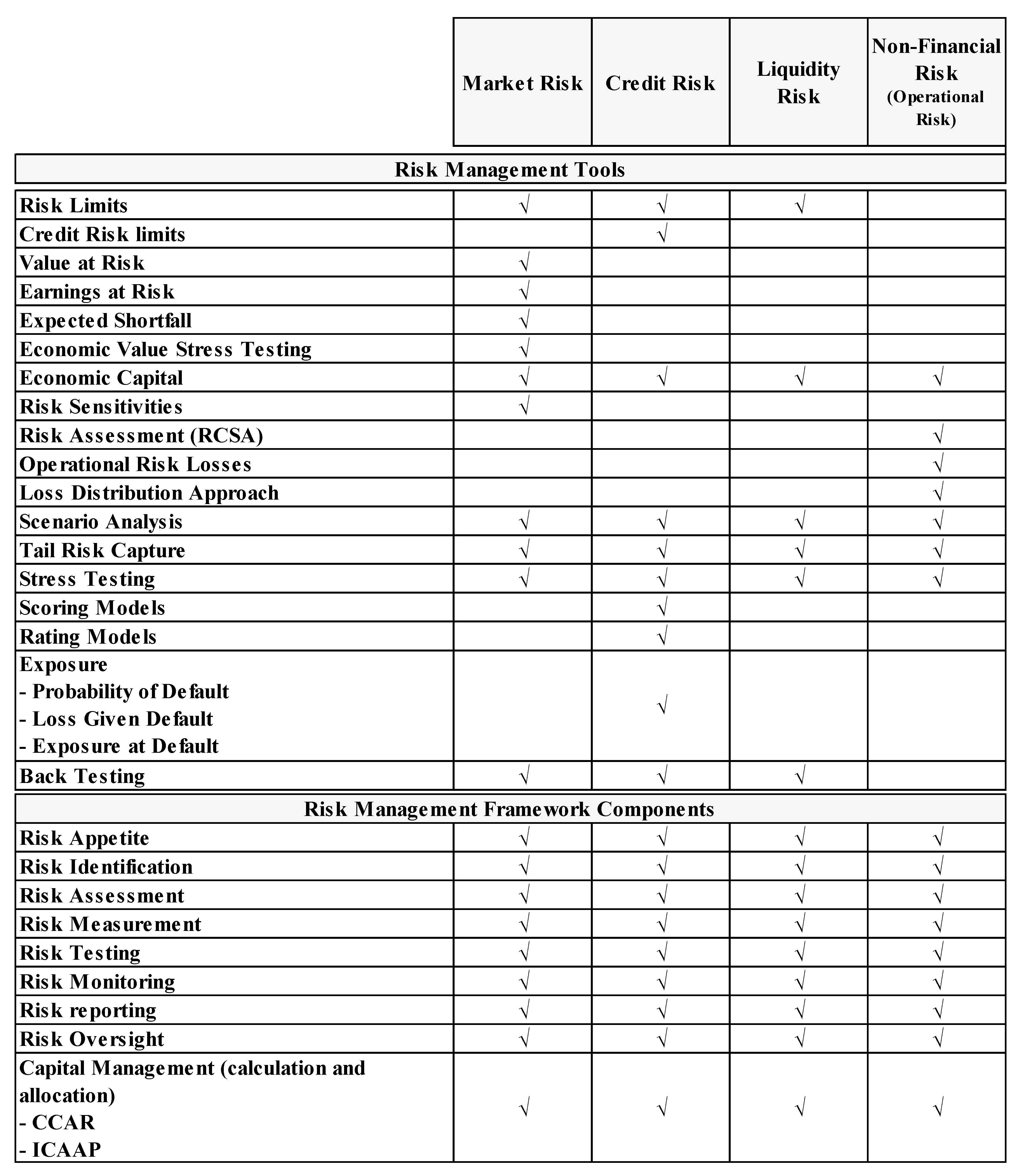
2.1. Risk Management at Banks
2.2. Machine Learning
3. Materials and Methods
3.1. Credit Risk
3.2. Market Risk
3.3. Liquidity Risk
3.4. Operational Risk
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| Risk Type | Risk Management Method/Tool | Reference | Algorithm |
|---|---|---|---|
| Compliance Risk Management | Risk Monitoring | Mainelli and Yeandle 2006 | SVM |
| Credit Risk Management—Concentration Risk | Stress Testing | Pavlenko and Chernyak 2009 | Bayesian Networks |
| Credit Risk Management—Consumer Credit | Exposure (PD, LGD, EAD) | Yeh and Lien 2009 | Bayesclassifier, Nearest neighbor, ANN, Classification trees |
| Credit Risk Management—Consumer Credit | Scoring Models | Bellotti and Crook 2009 | SVM |
| Credit Risk Management—Consumer Credit | Scoring Models | Galindo and Tamayo 2000 | CART, NN, KNN |
| Credit Risk Management—Consumer Credit | Scoring Models | Wang et al. 2015 | Lasso logistic regression |
| Credit Risk Management—Consumer Credit | Scoring Models | Hamori et al. 2018 | Bagging, Random Forest, Boosting |
| Credit Risk Management—Consumer Credit | Scoring Models | Harris 2013 | SVM |
| Credit Risk Management—Consumer Credit | Scoring Models | Huang et al. 2007 | SVM |
| Credit Risk Management—Consumer Credit | Scoring Models | Keramati and Yousefi 2011 | NN, Bayesian Classifier, DA, Logistic Regression, KNN, Decision tree, Survival Analysis, Fuzzy Rule based system, SVM, Hybrid mode |
| Credit Risk Management—Consumer Credit | Scoring Models | Khandani et al. 2010 | CART |
| Credit Risk Management—Consumer Credit | Scoring Models | Lai et al. 2006 | SVM |
| Credit Risk Management—Consumer Credit | Scoring Models | Lessmann et al. 2015 | Multiple algos assessed |
| Credit Risk Management—Consumer Credit | Scoring Models | Van-Sang and Nguyen 2016 | Deep Learning |
| Credit Risk Management—Consumer Credit | Scoring Models | Yu et al. 2016 | Deep belief network, Extreme Machine Learning |
| Credit Risk Management—Consumer Credit | Scoring Models | Y. Wang et al. 2005 | SVM, Fuzzy SVM |
| Credit Risk Management—Consumer Credit | Scoring Models | Zhou and Wang 2012 | Random Forest |
| Credit Risk Management—Coporate Credit | Exposure (PD, LGD, EAD) | Bastos 2014 | Bagging |
| Credit Risk Management—Coporate Credit | Exposure (PD, LGD, EAD) | Barboza et al. 2017 | Neural Network, SVM, Boosting, Bagging, Random Forest |
| Credit Risk Management—Coporate Credit | Exposure (PD, LGD, EAD) | Raei et al. 2016 | Neural Networks |
| Credit Risk Management—Coporate Credit | Exposure (PD, LGD, EAD) | Yang et al. 2011 | SVM |
| Credit Risk Management—Coporate Credit | Exposure (PD, LGD, EAD) | Yao et al. 2017 | SVR |
| Credit Risk Management—Coporate Credit | Scoring Models | Ala’raj and Abbod 2016b | Multiclassifer system (MCS)—Ensemble—neural networks (NN), support vector machines (SVM), random forests (RF), decision trees (DT) and naïve Bayes (NB). |
| Credit Risk Management—Coporate Credit | Scoring Models | Ala’raj and Abbod 2016a | GNG, MARS |
| Credit Risk Management—Coporate Credit | Scoring Models | Bacham and Zhao 2017 | ANN, Random Forest |
| Credit Risk Management—Coporate Credit | Scoring Models | Cao et al. 2013 | SVM |
| Credit Risk Management—Coporate Credit | Scoring Models | Van Gestel et al. 2003 | SVM |
| Credit Risk Management—Coporate Credit | Scoring Models | Guegan et al. 2018 | Elastic Net, random forest, Boosting, NN |
| Credit Risk Management—Coporate Credit | Scoring Models | Malhotra and Malhotra 2003 | NN |
| Credit Risk Management—Coporate Credit | Scoring Models | Wójcicka 2017 | Neural networks |
| Credit Risk Management—Coporate Credit | Scoring Models | W. Zhang 2017 | KNN, Random Forest |
| Credit Risk Management—Corporate Credit | Stress Testing | Blom 2015 | Lasso regression |
| Credit Risk Management—Corporate Credit | Stress Testing | Chan-Lau 2017 | Lasso regression |
| Credit Risk Management—Credit Card Risk | Exposure (PD, LGD, EAD) | Yao et al. 2017 | SVM |
| Credit Risk Management—Cross-risk | Stress Testing | Jacobs 2018 | MARS |
| Credit Risk Management—Wholesale | Stress Testing | Islam et al. 2013 | Cluster analysis |
| Liquidity Risk Management—Liquidity Risk | Risk Limits | Gotoh et al. 2014 | vSVM |
| Liquidity Risk Management—Liquidity Risk | Risk Monitoring | Sala 2011 | ANN |
| Liquidity Risk Management—Liquidity Risk | Scoring Models | Tavana et al. 2018 | ANN, Bayesian Networks |
| Management—Consumer Credit | Scoring Models | Brown and Mues 2012 | Gradient, Boosting, Random Forest, Least Squares—SVM |
| Market Risk Management—Equity Risk | Value at Risk | Zhang et al. 2017 | GELM |
| Market Risk Management—Equity Risk | Value at Risk | Mahdavi-Damghani and Roberts 2017 | Cluster analysis |
| Market Risk Management—Equity Risk | Value at Risk | Monfared and Enke 2014 | NN |
| Market Risk Management—Interest Rate Risk | Value at Risk | Kanevski and Timonin 2010 | SOM, Gaussian Mixtures, Cluster Analysis |
| Operational Risk Management—Cybersecurity | Risk Assessment (RCSA) | Peters et al. 2017 | Non-linear clustering method |
| Operational Risk Management—Fraud Risk | Operational Risk Losses | Pun and Lawryshyn 2012 | Neural Networks, k-Nearest Neighbor, Naïve Bayesian, Decision Tree |
| Operational Risk Management—Fraud Risk | Operational Risk Losses | Sharma and Choudhury 2016 | SOM |
| Operational Risk Management—Fraud Risk | Risk Monitoring | Ngai et al. 2011 | neural networks, Bayesian belief network, decision trees |
| Operational Risk Management—Fraud Risk | Risk Monitoring | Sudjianto et al. 2010 | SVM, Classification Trees, Ensemble Learning, CART, C4.5, Bayesian belief networks, HMM |
| Operational Risk Management—Money Laundering/Financial Crime | Risk Monitoring | Khrestina et al. 2017 | logistic regression |
References
- Ala’raj, Maher, and Maysam F. Abbod. 2016a. A New Hybrid Ensemble Credit Scoring Model Based on Classifiers Consensus System Approach. Expert Systems with Applications 64: 36–55. [Google Scholar] [CrossRef]
- Ala’Raj, Maher, and Maysam F. Abbod. 2016b. Classifiers Consensus System Approach for Credit Scoring. Knowledge-Based Systems 104: 89–105. [Google Scholar] [CrossRef]
- Apostolik, Richard, Christopher Donohue, Peter Went, and Global Association of Risk Professionals. 2009. Foundations of Banking Risk: An Overview of Banking, Banking Risks, and Risk-Based Banking Regulation. New York: John Wiley. [Google Scholar]
- Arezzo, Maria, and Giuseppina Guagnano. 2018. Response-Based Sampling for Binary Choice Models with Sample Selection. Econometrics 6: 12. [Google Scholar] [CrossRef]
- Awad, Mariette, and Rahul Khanna. 2015. Machine Learning in Action: Examples. Efficient Learning Machines. [Google Scholar] [CrossRef]
- Aziz, Saqib, and Michael M. Dowling. 2018. AI and Machine Learning for Risk Management. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Bacham, Dinesh, and Janet Zhao. 2017. Machine Learning: Challenges and Opportunities in Credit Risk Modeling. Available online: https://www.moodysanalytics.com/risk-perspectives-magazine/managing-disruption/spotlight/machine-learning-challenges-lessons-and-opportunities-in-credit-risk-modeling (accessed on 2 April 2018).
- Barboza, Flavio, Herbert Kimura, and Edward Altman. 2017. Machine learning models and bankruptcy prediction. Expert Systems with Applications 83: 405–17. [Google Scholar] [CrossRef]
- Basel Committee on Banking Supervision. 2005a. Guidance on Paragraph 468 of the Framework Document. Basel: Bank for International Settlements. [Google Scholar]
- Basel Committee on Banking Supervision. 2005b. An Explanatory Note on the Basel II IRB Risk Weight Functions. Basel: Bank for International Settlements. [Google Scholar]
- Basel Committee on Banking Supervision. 2006. Minimum Capital Requirements for Market Risk. Basel: Bank for International Settlements. [Google Scholar]
- Basel Committee on Banking Supervision. 2008. Principles for Sound Liquidity Risk Management and Supervision. Basel: Bank for International Settlements. [Google Scholar]
- Basel Committee on Banking Supervision. 2011. Principles for the Sound Management of Operational Risk. Basel: Bank for International Settlements, pp. 1–27. [Google Scholar]
- Bastos, João A. 2014. Ensemble Predictions of Recovery Rates. Journal of Financial Services Research 46: 177–93. [Google Scholar] [CrossRef]
- Bauguess, Scott W. 2015. The Hope and Limitations of Machine Learning in Market Risk Assessment. Washington, DC: U.S. Securities and Exchange Commission. [Google Scholar]
- Bellotti, Tony, and Jonathan Crook. 2009. Support Vector Machines for Credit Scoring and Discovery of Significant Features. Expert Systems with Applications. [Google Scholar] [CrossRef]
- Blom, Tineke. 2015. Top down Stress Testing: An Application of Adaptive Lasso to Forecasting Credit Loss Rates. Master’s Thesis, Faculty of Science, Hongkong, China. [Google Scholar]
- Brown, Iain, and Christophe Mues. 2012. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Systems with Applications 39: 3446–53. [Google Scholar] [CrossRef]
- Cao, Jie, Hongke Lu, Weiwei Wang, and Jian Wang. 2013. A Loan Default Discrimination Model Using Cost-Sensitive Support Vector Machine Improved by PSO. Information Technology and Management 14: 193–204. [Google Scholar] [CrossRef]
- Chan-Lau, Jorge. 2017. Lasso Regressions and Forecasting Models in Applied Stress Testing. IMF Working Papers 17: 1. [Google Scholar] [CrossRef]
- Chen, Ning, Bernardete Ribeiro, and An Chen. 2016. Financial Credit Risk Assessment: A Recent Review. Artificial Intelligence Review 45: 1–23. [Google Scholar] [CrossRef]
- Dal Pozzolo, Andrea. 2015. Adaptive Machine Learning for Credit Card Fraud Detection. Unpublished doctoral dissertation, Université libre de Bruxelles, Faculté des Sciences—Informatique, Bruxelles. [Google Scholar]
- Deloitte University Press. 2017. Global Risk Management Survey, 10th ed. Deloitte University Press: Available online: https://www2.deloitte.com/tr/en/pages/risk/articles/global-risk-management-survey-10th-ed.html (accessed on 4 October 2018).
- Financial Stability Board. 2017. Artificial Intelligence and Machine Learning in Financial Services. Market Developments and Financial Stability Implications. Financial Stability Board. November 1. Available online: http://www.fsb.org/2017/11/artificial-intelligence-and-machine-learning-in-financial-service/ (accessed on 2 July 2018).
- Galindo, Jorge, and Pablo Tamayo. 2000. Credit Risk Assessment Using Statistical and Machine Learning: Basic Methodology and Risk Modeling Applications. Computational Economics 15: 107–43. [Google Scholar] [CrossRef]
- Gotoh, Jun-ya, Akiko Takeda, and Rei Yamamoto. 2014. Interaction between financial risk measures and machine learning methods. Computational Management Science 11: 365–402. [Google Scholar] [CrossRef]
- Greene, William H. 1992. A Statistical Model for Credit Scoring. NYU Working Paper No. EC-92-29. Available online: https://ssrn.com/abstract=1867088 (accessed on 8 April 1992).
- Guegan, Dominique, Peter Addo, and Bertrand Hassani. 2018. Credit risk analysis using machine and deep learning models. Risks 6: 38. [Google Scholar]
- Hamori, Shigeyuki, Minami Kawai, Takahiro Kume, Yuji Murakami, and Chikara Watanabe. 2018. Ensemble Learning or Deep Learning? Application to Default Risk Analysis. Journal of Risk and Financial Management 11: 12. [Google Scholar] [CrossRef]
- Hand, David J., and William E. Henley. 1997. Statistical Classification Methods in Consumer Credit Scoring: A Review. Journal of the Royal Statistical Society Series A: Statistics in Society. [Google Scholar] [CrossRef]
- Harris, Terry. 2013. Quantitative credit risk assessment using support vector machines: Broad versus Narrow default definitions. Expert Systems with Applications 40: 4404–13. [Google Scholar] [CrossRef]
- Helbekkmo, Hans, Alok Kshirsagar, Andreas Schlosser, Francesco Selandari, Uwe Stegemann, and Joyce Vorholt. 2013. Enterprise Risk Management—Shaping the Risk Revolution. New York: McKinsey & Co., Available online: www.rmahq.org (accessed on 18 June 2018).
- Huang, Cheng Lung, Mu Chen Chen, and Chieh Jen Wang. 2007. Credit Scoring with a Data Mining Approach Based on Support Vector Machines. Expert Systems with Applications 33: 847–56. [Google Scholar] [CrossRef]
- Hull, John. 2012. Risk Management and Financial Institutions. New York: John Wiley and Sons, vol. 733. [Google Scholar]
- Islam, Tushith, Christos Vasilopoulos, and Erik Pruyt. 2013. Stress—Testing Banks under Deep Uncertainty. Paper presented at the 31st International Conference of the System Dynamics Society, Cambridge, MA, USA, July 21–25; Available online: http://repository.tudelft.nl/islandora/object/uuid:c162de43-4235-4d29-8eed-3246df87e119?collection=education (accessed on 17 July 2018).
- Jacobs, Michael, Jr. 2018. The validation of machine-learning models for the stress testing of credit risk. Journal of Risk Management in Financial Institutions 11: 218–43. [Google Scholar]
- Jorion, Philippe. 2007. Value at Risk: The New Benchmark for Managing Financial Risk. New York: McGraw-Hill. [Google Scholar]
- Kanevski, Mikhail F., and Vadim Timonin. 2010. Machine learning analysis and modeling of interest rate curves. Paper presented at the 18th European Symposium on Artificial Neural Networks ESANN, Bruges, Belgium, April 28–30; Available online: https://www.elen.ucl.ac.be/Proceedings/esann/esannpdf/es2010-17.pdf (accessed on 18 June 2018).
- Kannan, Somasundaram, and K. Somasundaram. 2017. Autoregressive-Based Outlier Algorithm to Detect Money Laundering Activities. Journal of Money Laundering Control 20: 190–202. [Google Scholar] [CrossRef]
- Keramati, Abbas, and Niloofar Yousefi. 2011. A proposed classification of data mining techniques in credit scoring. Paper presented at the 2011 International Conference of Industrial Engineering and Operations Management, Kuala Lumpur, Malaysia, January 22–24. [Google Scholar]
- Khandani, Amir E., Adlar J. Kim, and Andrew W. Lo. 2010. Consumer credit-risk models via machine-learning algorithms. Journal of Banking & Finance 34: 2767–87. [Google Scholar]
- Khrestina, Marina Pavlovna, Dmitry Ivanovich Dorofeev, Polina Andreevna Kachurina, Timur Rinatovich Usubaliev, and Aleksey Sergeevich Dobrotvorskiy. 2017. Development of Algorithms for Searching, Analyzing and Detecting Fraudulent Activities in the Financial Sphere. European Research Studies Journal 20: 484–98. [Google Scholar]
- Lai, Kin Keung, Lean Yu, Ligang Zhou, and Shouyang Wang. 2006. Credit risk evaluation with least square support vector machine. In International Conference on Rough Sets and Knowledge Technology. Berlin/Heidelberg: Springer, pp. 490–95. [Google Scholar]
- Lessmann, Stefan, Bart Baesens, Hsin Vonn Seow, and Lyn C. Thomas. 2015. Benchmarking State-of-the-Art Classification Algorithms for Credit Scoring: An Update of Research. European Journal of Operational Research 247: 124–36. [Google Scholar] [CrossRef]
- Mahdavi-Damghani, Babak, and Stephen Roberts. 2017. A Proposed Risk Modeling Shift from the Approach of Stochastic Differential Equation towards Machine Learning Clustering: Illustration with the Concepts of Anticipative and Responsible VaR. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Mainelli, Michael, and Mark Yeandle. 2006. Best execution compliance: New techniques for managing compliance risk. The Journal of Risk Finance 7: 301–12. [Google Scholar] [CrossRef]
- Malhotra, Rashmi, and D. K. Malhotra. 2003. Evaluating Consumer Loans Using Neural Networks. Omega 31: 83–96. [Google Scholar] [CrossRef]
- MetricStream. 2018. The Chief Risk Officer’s Role in 2018 and Beyond Managing the Challenges and Opportunities of a Digital Era New Roles of the CRO. Available online: https://www.metricstream.com/insights/chief-risk-officer-role-2018.htm (accessed on 23 June 2018).
- Monfared, Soheil Almasi, and David Enke. 2014. Volatility Forecasting Using a Hybrid GJR-GARCH Neural Network Model. Procedia Computer Science 36: 246–53. [Google Scholar] [CrossRef]
- Ngai, Eric W. T., Yong Hu, Yiu Hing Wong, Yijun Chen, and Xin Sun. 2011. The Application of Data Mining Techniques in Financial Fraud Detection: A Classification Framework and an Academic Review of Literature. Decision Support Systems 50: 569. [Google Scholar] [CrossRef]
- Oliver Wyman. 2017. Next Generation Risk Management. Available online: https://www.oliverwyman.com/content/dam/oliver-wyman/v2/publications/2017/aug/Next_Generation_Risk_Management_Targeting_A-Technology_Dividend.pdf (accessed on 1 May 2018).
- Pavlenko, Tatjana, and Oleksandr Chernyak. 2009. Bayesian Networks for Modeling and Assessment of Credit Concentration Risks. International Statistical Conference Prague. Available online: http://www.czso.cz/conference2009/proceedings/data/methods/pavlenko_paper.pdf (accessed on 21 July 2018).
- Peters, Gareth, Pavel V. Shevchenko, Ruben Cohen, and Diane Maurice. 2017. Statistical Machine Learning Analysis of Cyber Risk Data: Event Case Studies. Available online: https://ssrn.com/abstract=3073704 (accessed on 18 June 2018).
- Proofpoint. 2010. MLX Whitepaper “Machine Learning to Beat Spam Today and Tomorrow”. Available online: https://www.excelmicro.com/datasheets/Proofpoint-White-Paper-MLX-Technology.pdf (accessed on 2 May 2018).
- Pun, Joseph, and Yuri Lawryshyn. 2012. Improving credit card fraud detection using a meta-classification strategy. International Journal of Computer Applications 56: 41–46. [Google Scholar] [CrossRef]
- Raei, Reza, Mahdi Saeidi Kousha, Saeid Fallahpour, and Mohammad Fadaeinejad. 2016. A Hybrid Model for Estimating the Probability of Default of Corporate Customers. Iranian Journal of Management Studies 9: 651–73. [Google Scholar]
- Ray, Sunil. 2015. Understanding Support Vector Machine Algorithm from Examples (along with Code). Available online: https://www.analyticsvidhya.com/blog/2017/09/understaing-support-vector-machine-example-code/ (accessed on 16 August 2018).
- Sala, Jordi Petchamé. 2011. Liquidity Risk Modeling Using Artificial Neural Network. Master’s thesis, Universitat Politècnica de Catalunya, Barcelona, Spain. [Google Scholar]
- Saunders, Anthony, Marcia Millon Cornett, and Patricia Anne McGraw. 2006. Financial Institutions Management: A Risk Management Approach. New York: McGraw-Hill. [Google Scholar]
- Shalev-Shwartz, Shai, and Shai Ben-David. 2014. Understanding Machine Learning: From Theory to Algorithms. Cambridge: Cambridge University Press. [Google Scholar] [CrossRef]
- Sharma, Shashank, and Arjun Roy Choudhury. 2016. Fraud Analytics: A Survey on Bank Fraud Prediction Using Unsupervised Learning Based Approach. International Journal of Innovation in Engineering Research and Technology 3: 1–9. [Google Scholar]
- Sudjianto, Agus, Sheela Nair, Ming Yuan, Aijun Zhang, Daniel Kern, and Fernando Cela-Díaz. 2010. Statistical Methods for Fighting Financial Crimes. Technometrics 52: 5–19. [Google Scholar] [CrossRef]
- Tavana, Madjid, Amir Reza Abtahi, Debora Di Caprio, and Maryam Poortarigh. 2018. An Artificial Neural Network and Bayesian Network Model for Liquidity Risk Assessment in Banking. Neurocomputing 275: 2525–54. [Google Scholar] [CrossRef]
- Vaidya, Avanti H., and Sudhir W. Mohod. 2014. Internet Banking Fraud Detection using HMM and BLAST-SSAHA Hybridization. International Journal of Science and Research (IJSR) 3: 574–9. [Google Scholar]
- Van Gestel, Ir Tony, Bart Baesens, Ir Joao Garcia, and Peter Van Dijcke. 2003. A support vector machine approach to credit scoring. In Forum Financier—Revue Bancaire Et Financiaire Bank En Financiewezen. Bruxelles: Larcier, pp. 73–82. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.93.6492&rep=rep1&type=pdf (accessed on 7 July 2018).
- Van Liebergen, Bart. 2017. Machine Learning: A Revolution in Risk Management and Compliance? Journal of Financial Transformation 45: 60–67. [Google Scholar]
- Van-Sang, Ha, and Ha-Nam Nguyen. 2016. Credit Scoring with a Feature Selection Approach Based Deep Learning. In MATEC Web of Conferences. Les Ulis: EDP Sciences, volume 54, p. 05004. Available online: https://www.matec-conferences.org/articles/matecconf/abs/2016/17/matecconf_mimt2016_05004/matecconf_mimt2016_05004.html (accessed on 19 July 2018).
- Villalobos, Miguel Agustín, and Eliud Silva. 2017. A Statistical and Machine Learning Model to Detect Money Laundering: An Application. Available online: http://hddavii.eventos.cimat.mx/sites/hddavii/files/Miguel_Villalobos.pdf (accessed on 21 June 2018).
- Wang, Yongqiao, Shouyang Wang, and Kin Keung Lai. 2005. A New Fuzzy Support Vector Machine to Evaluate Credit Risk. IEEE Transactions on Fuzzy Systems 13: 820–31. [Google Scholar] [CrossRef]
- Wang, Hong, Qingsong Xu, and Lifeng Zhou. 2015. Large Unbalanced Credit Scoring Using Lasso-Logistic Regression Ensemble. PLoS ONE 10: e0117844. [Google Scholar] [CrossRef] [PubMed]
- Wójcicka, Aleksandra. 2017. Neural Networks vs. Discriminant Analysis in the Assessment of Default. Electronic Economy, 339–49. [Google Scholar] [CrossRef]
- Yang, Zijiang, Wenjie You, and Guoli Ji. 2011. Using partial least squares and support vector machines for bankruptcy prediction. Expert Systems with Applications 38: 8336–42. [Google Scholar] [CrossRef]
- Yao, Xiao, Jonathan Crook, and Galina Andreeva. 2015. Support vector regression for loss given default modelling. European Journal of Operational Research 240: 528–38. [Google Scholar] [CrossRef]
- Yao, Xiao, Jonathan Crook, and Galina Andreeva. 2017. Enhancing two-stage modelling methodology for loss given default with support vector machines. European Journal of Operational Research 263: 679–89. [Google Scholar] [CrossRef]
- Yeh, I. Cheng, and Chehui Lien. 2009. The Comparisons of Data Mining Techniques for the Predictive Accuracy of Probability of Default of Credit Card Clients. Expert Systems with Applications. [Google Scholar] [CrossRef]
- Yu, Lean, Zebin Yang, and Ling Tang. 2016. A Novel Multistage Deep Belief Network Based Extreme Learning Machine Ensemble Learning Paradigm for Credit Risk Assessment. Flexible Services and Manufacturing Journal 28: 576–92. [Google Scholar] [CrossRef]
- Zareapoor, Masoumeh, and Pourya Shamsolmoali. 2015. Application of Credit Card Fraud Detection: Based on Bagging Ensemble Classifier. Procedia Computer Science 48: 679–86. [Google Scholar] [CrossRef]
- Zhang, Wenhao. 2017. Machine Learning Approaches to Predicting Company Bankruptcy. Journal of Financial Risk Management 6: 364–74. [Google Scholar] [CrossRef]
- Zhang, Heng Guo, Chi Wei Su, Yan Song, Shuqi Qiu, Ran Xiao, and Fei Su. 2017. Calculating Value-at-Risk for High-Dimensional Time Series Using a Nonlinear Random Mapping Model. Economic Modelling 67: 355–67. [Google Scholar] [CrossRef]
- Zhou, Lifeng, and Hong Wang. 2012. Loan Default Prediction on Large Imbalanced Data Using Random Forests. TELKOMNIKA Indonesian Journal of Electrical Engineering. [Google Scholar] [CrossRef]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leo, M.; Sharma, S.; Maddulety, K. Machine Learning in Banking Risk Management: A Literature Review. Risks 2019, 7, 29. https://doi.org/10.3390/risks7010029
Leo M, Sharma S, Maddulety K. Machine Learning in Banking Risk Management: A Literature Review. Risks. 2019; 7(1):29. https://doi.org/10.3390/risks7010029
Chicago/Turabian StyleLeo, Martin, Suneel Sharma, and K. Maddulety. 2019. "Machine Learning in Banking Risk Management: A Literature Review" Risks 7, no. 1: 29. https://doi.org/10.3390/risks7010029
APA StyleLeo, M., Sharma, S., & Maddulety, K. (2019). Machine Learning in Banking Risk Management: A Literature Review. Risks, 7(1), 29. https://doi.org/10.3390/risks7010029