Business Distress Prediction Using Bayesian Logistic Model for Indian Firms


Abstract
1. Introduction
2. Methodology
2.1. The Binomial Distribution
2.2. Logistic Regression Model
2.3. Bayesian Logistic Model
3. Data
3.1. Variables
- (a)
- Interest coverage ratio (<1): This ratio shows company’s ability to meet its interest obligations. A higher ratio is more desirable for safety and financial health of firm.
- (b)
- EBITDA (Earnings before interest tax depreciation and amortization) to expense ratio (<1): A value less than unity of this ratio signify operating profit to be insufficient buffer to compensate for expenses.
- (c)
- Networth to debt ratio (<1): A low ratio signifies aggressive leveraging practices that are often associated with high levels of risk. This may result in volatile earnings as a result of additional interest expenses.
- (d)
- Networth growth (negative for two consecutive years): The net worth growth for a firm is the measure of its performance. A negative growth reveals that the company is facing trouble in making profit.
3.2. Training and Testing Sample Selection
3.3. Covariates Selection Procedure
3.4. Exogenous Variables
4. Empirical Analysis and Results
4.1. Exploratory Analysis
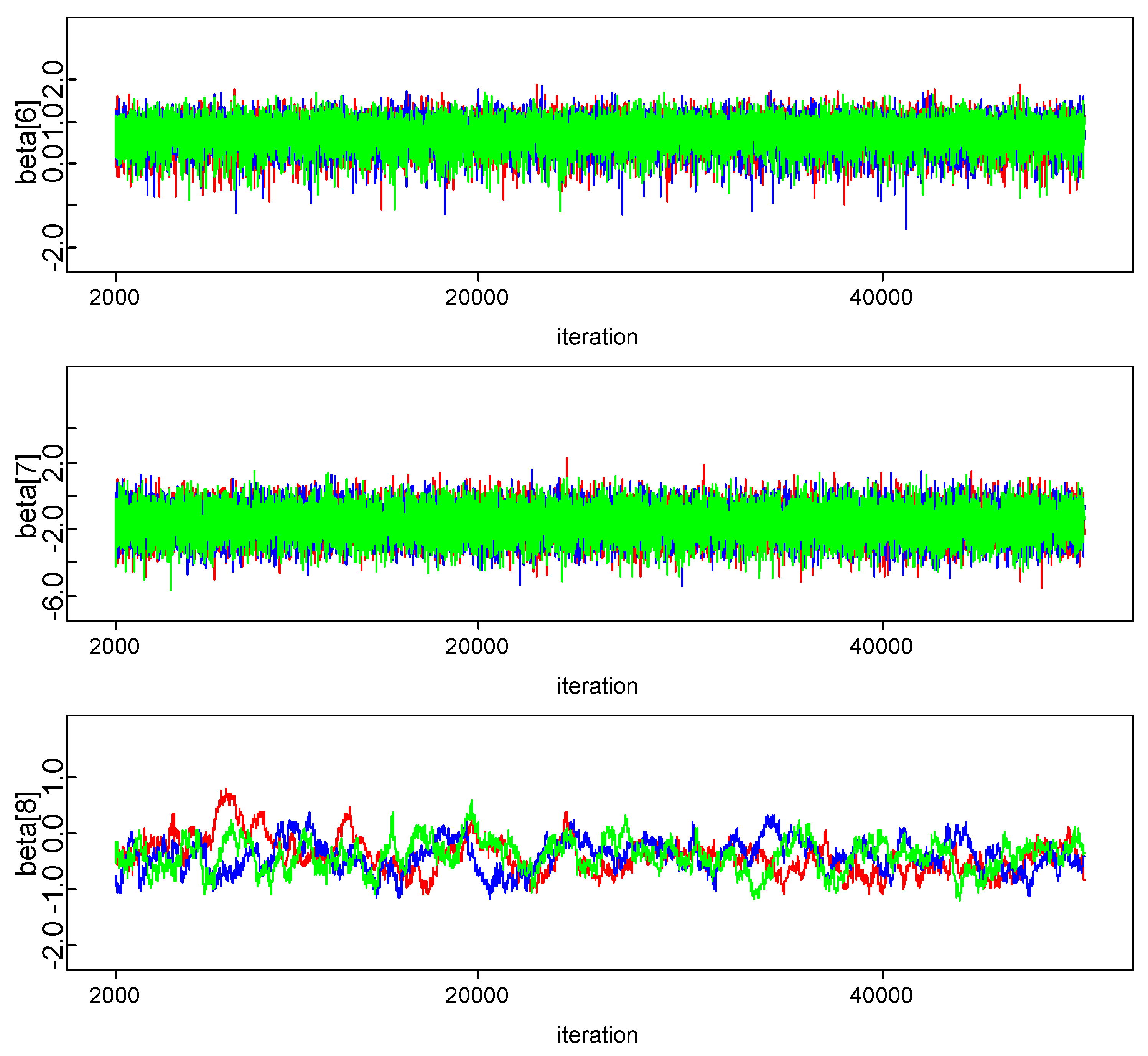
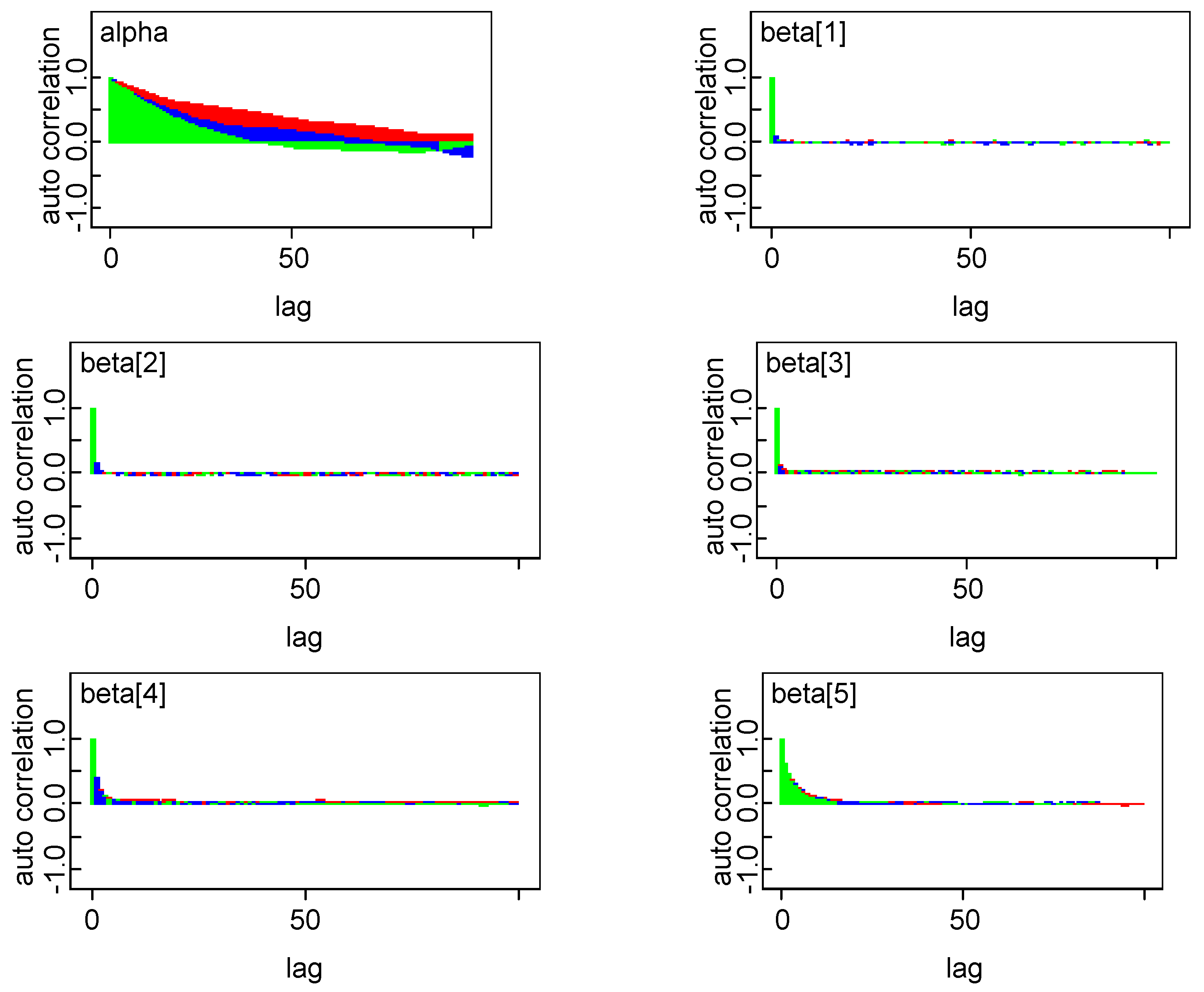
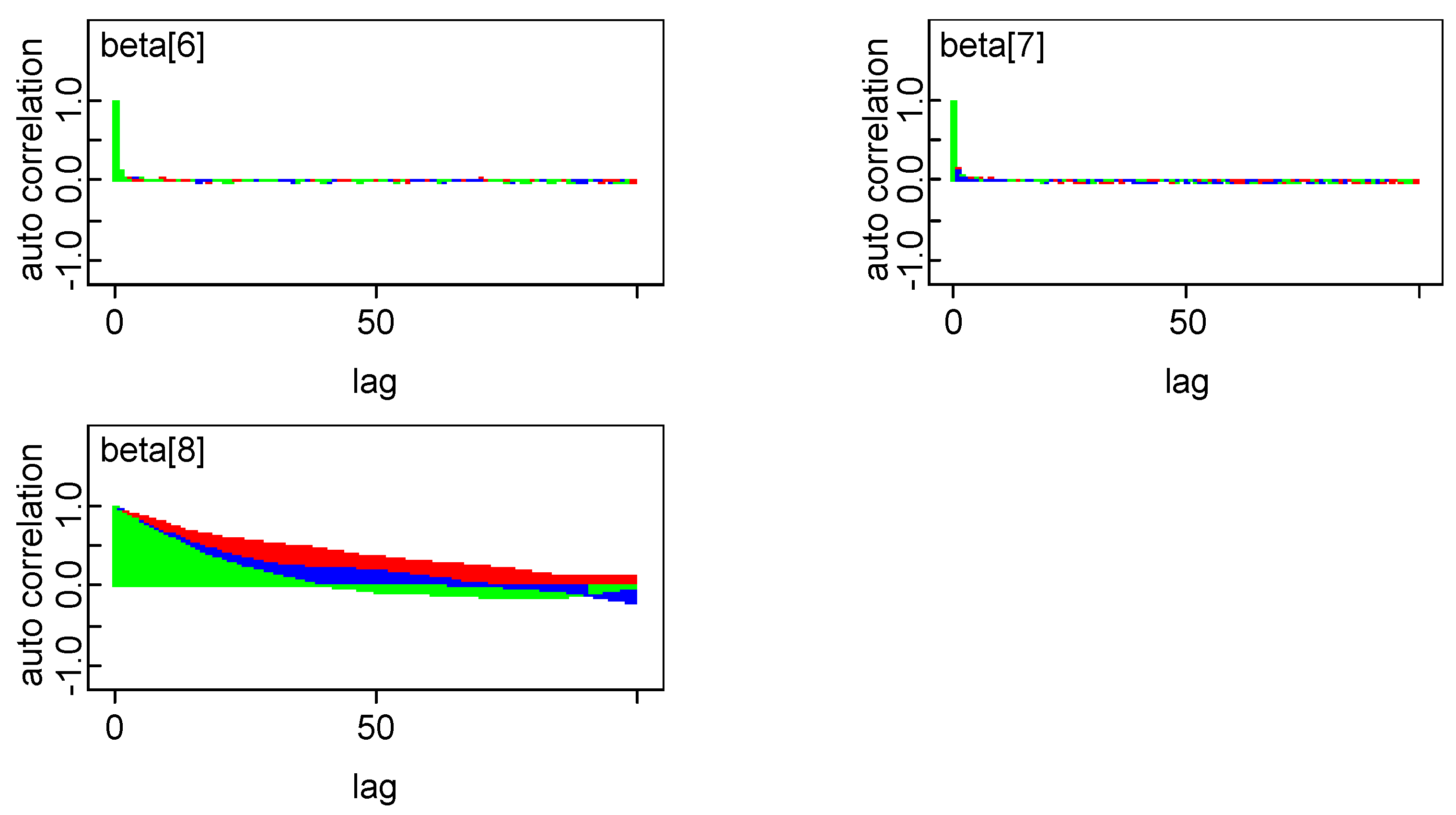
4.2. Model Comparison
4.3. Predictive Ability of Model
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A





References
- Altman, Edward I. 1968. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance 23: 589–609. [Google Scholar] [CrossRef]
- Altman, Edward I., Giancarlo Marco, and Franco Varetto. 1994. Corporate distress diagnosis: Comparisons using linear discriminant analysis and neural networks (the Italian experience). Journal of Banking & Finance 18: 505–29. [Google Scholar]
- Bapat, Varadraj, and Abhay Nagale. 2014. Comparison of Bankruptcy Prediction Models: Evidence from India. Accounting and Finance Research 3: 91. [Google Scholar] [CrossRef]
- Beaver, William H. 1966. Financial ratios as predictors of failure. Journal of Accounting Research 4: 71–111. [Google Scholar] [CrossRef]
- Campbell, John Y., Jens Hilscher, and Jan Szilagyi. 2008. In search of distress risk. The Journal of Finance 63: 2899–939. [Google Scholar] [CrossRef]
- Gepp, Adrian, and Kuldeep Kumar. 2015. Predicting financial distress: A comparison of survival analysis and decision tree techniques. Procedia Computer Science 54: 396–404. [Google Scholar] [CrossRef]
- Li, Zhiyong, Jonathan Crook, and Galina Andreeva. 2013. Chinese Companies Distress Prediction: An Application of Data Envelopment Analysis. Journal of the Operational Research Society. [Google Scholar] [CrossRef]
- Lin, S. M., Jake Ansell, and Galina Andreeva. 2012. Predicting default of a small business using different definitions of financial distress. Journal of the Operational Research Society 63: 539–48. [Google Scholar] [CrossRef]
- Nam, Chae Woo, Tong Suk Kim, Nam Jung Park, and Hoe Kyung Lee. 2008. Bankruptcy prediction using a discrete-time duration model incorporating temporal and macroeconomic dependencies. Journal of Forecasting 27: 493–506. [Google Scholar] [CrossRef]
- Ohlson, James A. 1980. Financial ratios and the probabilistic prediction of bankruptcy. Journal of Accounting Research 18: 109–31. [Google Scholar] [CrossRef]
- Sheppard, Jerry Paul. 1994. Strategy and bankruptcy: An exploration in to organizational death. Journal of Management 20: 795–883. [Google Scholar]
- Shumway, Tyler. 2001. Forecasting bankruptcy more accurately: A simple hazard model. The Journal of Business 74: 101–24. [Google Scholar] [CrossRef]
- Yang, Zijiang, Wenjie You, and Guoli Ji. 2011. Using partial least squares and support vector machines for bankruptcy prediction. Expert Systems with Applications 38: 8336–42. [Google Scholar] [CrossRef]
- Zellner, Arnold, and Tomohiro Ando. 2010. Bayesian and non-Bayesian analysis of the seemingly unrelated regression model with Student-t errors, and its application for forecasting. International Journal of Forecasting 26: 413–34. [Google Scholar] [CrossRef]
- Zmijewski, Mark E. 1984. Methodological issues related to the estimation of financial distress prediction models. Journal of Accounting Research 22: 59–82. [Google Scholar] [CrossRef]
| 1 | Recently, structural reforms have been undertaken in India for insolvency and resolution. The Insolvency and Bankruptcy Code, 2016 (IBC) has already been passed by the Indian Parliament on 28 May 2016. The provisions of the Act are in force since 5 August 2016. The code is a one stop solution for resolving insolvencies, which was earlier a long and cumbersome process for individuals, companies, and partnership firms. Additionally, Financial Resolution and Deposit Insurance Bill, 2017 has been introduced in Parliament. It provides for resolution plan of financial firms. |
| 2 | The results are available with authors on request. The results are not included to conserve space. |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Category | Mean | SD |
|---|---|---|---|
| EBIT_TAXPAID | 0 | 10.71 | 35.14 |
| 1 | −57.39 | 198.76 | |
| PROFIT_MARGIN | 0 | 0.15 | 0.12 |
| 1 | −0.16 | 0.29 | |
| REAT_EARNING_ASSET | 0 | 0.06 | 0.05 |
| 1 | −0.06 | 0.12 | |
| DEBT_ASSET | 0 | 0.13 | 0.13 |
| 1 | 0.20 | 0.19 | |
| RECEIVABLE_CURR_ASSET | 0 | 0.37 | 0.26 |
| 1 | 0.32 | 0.18 | |
| CASH_CURRENT_LIB | 0 | 0.26 | 0.59 |
| 1 | 0.13 | 0.35 | |
| WORKING_CAP_ASSET | 0 | 0.13 | 0.21 |
| 1 | 0.01 | 0.35 | |
| LOG_NETWORTH | 0 | 6.05 | 0.70 |
| 1 | 5.61 | 0.65 |
| Variable | Category | Mean | SD |
|---|---|---|---|
| EBIT_TAXPAID | 0 | 10.89 | 35.24 |
| 1 | −65.34 | 227.36 | |
| PROFIT_MARGIN | 0 | 0.15 | 0.11 |
| 1 | −0.16 | 0.29 | |
| REAT_EARNING_ASSET | 0 | 0.06 | 0.05 |
| 1 | −0.07 | 0.12 | |
| DEBT_ASST | 0 | 0.13 | 0.13 |
| 1 | 0.20 | 0.21 | |
| RECEIVABLE_CURR_ASST | 0 | 0.37 | 0.24 |
| 1 | 0.31 | 0.20 | |
| CASH_CURRENT_LIB | 0 | 0.25 | 0.53 |
| 1 | 0.11 | 0.31 | |
| WORKING_CAP_ASSET | 0 | 0.13 | 0.21 |
| 1 | −0.03 | 0.41 | |
| LOG_NETWORTH | 0 | 6.07 | 0.73 |
| 1 | 5.57 | 0.65 |
| Variable | Estimate | SE |
| Intercept | 1.748 | 1.636 |
| EBIT_TAXPAID | −0.033 ** | 0.016 |
| PROFIT_MARGIN | −44.665 *** | 4.839 |
| REAT_EARNING_ASSET | −6.367 * | 3.821 |
| DEBT_ASSET | 4.368 *** | 1.254 |
| RECEIVABLE_CURR_ASSET | −2.199 ** | 0.914 |
| CASH_CURRENT_LIB | 0.809 *** | 0.245 |
| WORKING_CAP_ASSET | −1.598 * | 0.861 |
| LOG_NETWORTH | −0.424 | 0.281 |
| Model Diagnostics | ||
| −2 Log likelihood | 247.167 | |
| Nagelkerke R square | 0.845 | |
| Iterations | 10 | |
| Variable | Mean | SD |
|---|---|---|
| Intercept | 1.636 | 0.296 |
| EBIT_TAXPAID | −0.038 ** | 1.719 |
| PROFIT_MARGIN | −45.59 *** | 0.016 |
| REAT_EARNING_ASSET | −7.114 * | 4.982 |
| DEBT_ASSET | 4.448 *** | 4.066 |
| RECEIVABLE_CURR_ASSET | −2.315 ** | 1.29 |
| CASH_CURRENT_LIB | 0.724 ** | 0.925 |
| WORKING_CAP_ASSET | −1.642 * | 0.32 |
| LOG_NETWORTH | −0.400 | 0.88 |
| Observed | Predicted | Percentage Correct | |
|---|---|---|---|
| Non-Distressed | Distressed | ||
| Non-Distressed | 2433 | 9 | 99.6 |
| Distressed | 27 | 150 | 84.7 |
| Overall Percentage | 98.6 | ||
| Observed | Predicted | Percentage Correct | |
|---|---|---|---|
| Non-Distressed | Distressed | ||
| Non-Distressed | 2435 | 7 | 99.7 |
| Distressed | 23 | 154 | 87.0 |
| Overall Percentage | 98.9 | ||
| Cut Value | Training Sample | Testing Sample | ||||||
|---|---|---|---|---|---|---|---|---|
| Distress Prediction | Non-Distress Prediction | Type I Error | Type II Error | Distress Prediction | Non-Distress Prediction | Type I Error | Type II Error | |
| 0.1 | 93.8 | 96.9 | 6.2 | 3.1 | 92.5 | 97.2 | 7.5 | 2.8 |
| 0.2 | 91.5 | 98.4 | 8.5 | 1.6 | 89.6 | 98.5 | 10.4 | 1.5 |
| 0.3 | 88.1 | 98.9 | 11.9 | 1.1 | 86.6 | 98.8 | 13.4 | 1.2 |
| 0.4 | 87.6 | 99.5 | 12.4 | 0.5 | 83.6 | 99.1 | 16.4 | 0.9 |
| 0.5 | 84.7 | 99.6 | 15.3 | 0.4 | 82.1 | 99.2 | 17.9 | 0.8 |
| 0.6 | 80.8 | 99.8 | 19.2 | 0.2 | 80.6 | 99.3 | 19.4 | 0.7 |
| 0.7 | 77.4 | 99.9 | 22.6 | 0.1 | 76.1 | 99.5 | 23.9 | 0.5 |
| 0.8 | 74.6 | 100 | 25.4 | 0.0 | 73.1 | 99.5 | 26.9 | 0.5 |
| 0.9 | 68.4 | 100 | 31.6 | 0.0 | 67.2 | 99.5 | 32.8 | 0.5 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shrivastava, A.; Kumar, K.; Kumar, N. Business Distress Prediction Using Bayesian Logistic Model for Indian Firms. Risks 2018, 6, 113. https://doi.org/10.3390/risks6040113
Shrivastava A, Kumar K, Kumar N. Business Distress Prediction Using Bayesian Logistic Model for Indian Firms. Risks. 2018; 6(4):113. https://doi.org/10.3390/risks6040113
Chicago/Turabian StyleShrivastava, Arvind, Kuldeep Kumar, and Nitin Kumar. 2018. "Business Distress Prediction Using Bayesian Logistic Model for Indian Firms" Risks 6, no. 4: 113. https://doi.org/10.3390/risks6040113
APA StyleShrivastava, A., Kumar, K., & Kumar, N. (2018). Business Distress Prediction Using Bayesian Logistic Model for Indian Firms. Risks, 6(4), 113. https://doi.org/10.3390/risks6040113