1. Introduction
This article presents a computational formula for the stability of the survival function (s.f.) of the compound sum of independent and identically distributed (i.i.d.) random variables that are independent of their summation index. The compound sum typically represents the insurer total claim amount during a fixed period (e.g., a year): the i.i.d. random variables are the individual claim amounts and the number of claims within the period is a counting random variable or a counting stochastic process, if we let the period length vary. We define the stability of a sum as the standardized variation of the s.f. of the sum resulting from an infinitesimal perturbation at some point of the distribution of the summands.
More precisely, let
denote the Dirac distribution function (d.f.) over
with mass one at
x (thus jumping from level 0 to level 1 at point
x). If
F denotes the d.f. of the summands, then
is the
-perturbation of
F at
x, for any choice of
. The derivative of the s.f. of the sum under
with respect to (w.r.t.)
evaluated at
is the s.f. stability (s.f.s.) at the perturbation point
x.
This concept differs from the one of sensitivity of queueing theory or risk theory, which is defined as the derivative of the s.f. of the sum w.r.t. a parameter of
F (cf., e.g.,
Asmussen and Albrecher (
2010), sct. IV.9). From an abstract point of view, a parametric model spans only a low-dimensional or narrow subset of the space of probability distributions. Such a narrow subset is indeed beneficial to statistical data reduction, but often does not contain all realistic perturbations of the assumed model. In this sense, the sensitivity is a limited indicator of the model stability. Allowing for perturbations in all possible directions provides a more complete or realistic analysis of the model stability. In this sense, our concept of stability is preferable. This concept is in fact an important idea of robust statistics (e.g.,
Hampel et al. (
1986)). Mathematically, the quantity of interest of a stochastic model is regarded as a functional, and a functional derivative is computed. This approach is used, for example, in renewal theory by
Grübel (
1989), where the renewal function is a functional of the lifetime distribution, or by
Politis (
2006) for the probability of ruin of the risk process.
Practically, for a given actuarial aggregate loss model in the form of a compound sum, if a stability of low magnitude results from the perturbation in the form of a new large individual claim amount (viz. a large value of x), then the loss model is reliable under perturbations through extreme large claims. In the context of uncertainty (where for example catastrophic events are not incorporated in the model), this notion of stability appears practically relevant. The s.f.s. informs the risk manager about the variation of the upper tail probability of the aggregate loss when an uncertain large claim amount is considered. Still from the practical point of view, the sensitivity as described above has the alternative role of identifying important model parameters—the most significant ones have large sensitivity value. However, this interpretation holds only when the model is actually the correct one (which is often not simple to establish). Of course, both sensitivity and stability analyses can be carried out simultaneously.
Field and Ronchetti (
1985) considered this type of stability for the sample mean and called it a “tail area influence function”. Their applications concerned statistical testing. They computed the tail area influence function with the saddlepoint approximation of
Daniels (
1954). This article generalizes this approximation to the stability of the compound sum and suggests using this concept in risk management. The new formula is easy and fast to compute. Numerical illustrations for the total claim amount with gamma or Weibull individual claim amounts and Poisson or geometric number of claims are provided.
Most methods for computing sensitivities rely on Monte Carlo simulation (e.g.,
Asmussen and Rubinstein (
1999) and
Asmussen and Glynn (
2007), sct. VII). One exception is
Gatto and Peeters (
2015), who proposes evaluating the sensitivity of the s.f. of the random sum w.r.t. the parameter of the summation index distribution (which is either Poisson or geometric) with the saddlepoint approximation.
Gatto and Peeters (
2015) shows numerically that the sensitivities obtained by the saddlepoint approximation and by simulation with importance sampling are very close, even though importance sampling is computationally intensive. The high accuracy of the saddlepoint approximation is well illustrated in the literature of statistics and applied probability; refer, for example, to
Jensen (
1995) or to
Gatto and Mosimann (
2012) in the context of risk theory.
This article proceeds as follows.
Section 2 provides the approximations to s.f.s. based on the saddlepoint approximation.
Section 2.1 considers the the deterministic sum and
Section 2.2 the compound sum, viz. the insurer aggregate claim amount.
Section 3 provides numerical illustrations.
Section 3.1 considers the aggregate claim amount with Poisson-distributed number of claims and gamma-distributed individual claim amounts. In
Section 3.2, the number of claims follows the geometric distribution and the individual claim amounts follow the Weibull distribution. Some related long derivatives are provided in the
Appendix A.
3. Numerical Illustrations
This section provides numerical illustrations of the results of
Section 2.2 for two important aggregate loss models: the Poisson number of occurrences with gamma individual claim amounts, in
Section 3.1, and the geometric number of occurrences with Weibull individual claim amounts, in
Section 3.2.
This numerical study was performed with
Matlab (R2017b, The MathWorks, Natick, MA, USA), and the function
fminsearch was used for computing the saddlepoint.
Matlab’s programs used for these computations are available at
http://www.stat.unibe.ch.
3.1. Poisson-Gamma Total Claim Amount
Assume that the total number of claims of an insurance company that occur during a fixed time horizon, denoted by
N, is Poisson-distributed with parameter
; viz.
, for
. Let
. The m.g.f. of
N and its derivatives are given by
Assume that the individual claim amounts or losses
are gamma-distributed, with density
,
, for some parameters
. Let
. The c.g.f. of
and its derivatives are given by
The m.g.f. of the aggregate loss
is given by
and so the c.g.f. of
, viz.
Z given
, is given by
With these formulae we can obtain the values of
s,
r, and
required in Theorem 2. So, we can compute the s.f.s.
given in (
24).
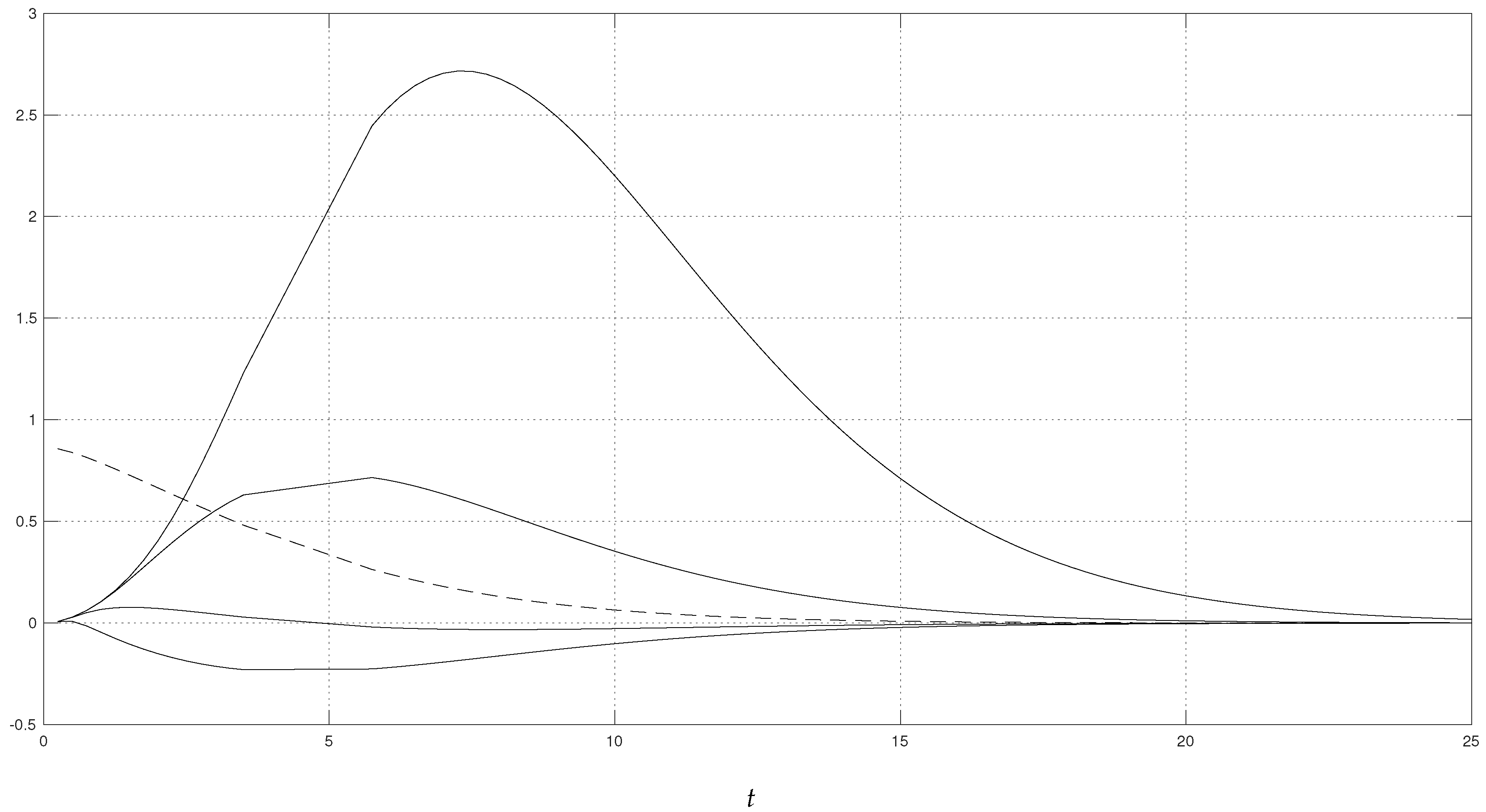
For the numerical illustration, we fixed
,
, and
. The results are shown in
Figure 1. The dashed curve shows the saddlepoint approximation
to the s.f. (see (
22)) for all relevant values of
t. The four solid curves of
Figure 1 show the approximation to the stability
, for the perturbation points
, and for relevant values of
t. The highest curves correspond to the largest values of
x. This is what we would have expected. A large perturbation point
x yields a large increase of the upper tail probability, and thus a large value of the stability. A vanishing perturbation point
x yields either a small increase or a decrease of the upper tail probability, and thus a small value of the stability. We should note that the numerical computation of these curves is very fast. Thus, the proposed approximation to the s.f.s. inherits the well-known computational efficiency of the saddlepoint approximation. Any purely numerical technique (e.g., Monte Carlo simulation) would be computationally intensive and thus slower.
For a practical illustration, consider the following values from the setting of
Figure 1:
and
. If the insurance believes that additional claim amounts of
with small frequency
‰ have to be considered, then the tail probability of the non-perturbed model would rise by
, because
.
3.2. Geometric-Weibull Total Claim Amount
The suggested approximation was tested with a different aggregate loss model. Assume that the total number of claims
N follows the geometric distribution with parameter
, precisely
, for
. The m.g.f. of
N and its derivatives at
are given by
Assume the individual losses
follow the Weibull distribution with density
,
, for some
. We can easily compute its moments
, for
. The m.g.f. of the Weibull distribution
exists for all
v over a neighborhood of zero iff
. Thus, the Weibull distribution is light-tailed in this sense iff
. Therefore, the power series representation
holds for any
v within a neighborhood of zero. Moreover, for
v in this neighborhood,
with
. With this, the m.g.f. of the aggregate loss can be expressed as
is given by
and the c.g.f. of
can be written as
These formulae allow us to compute
s,
r, and
of Theorem 2, and thus we can compute the s.f.s.
given in (
24).
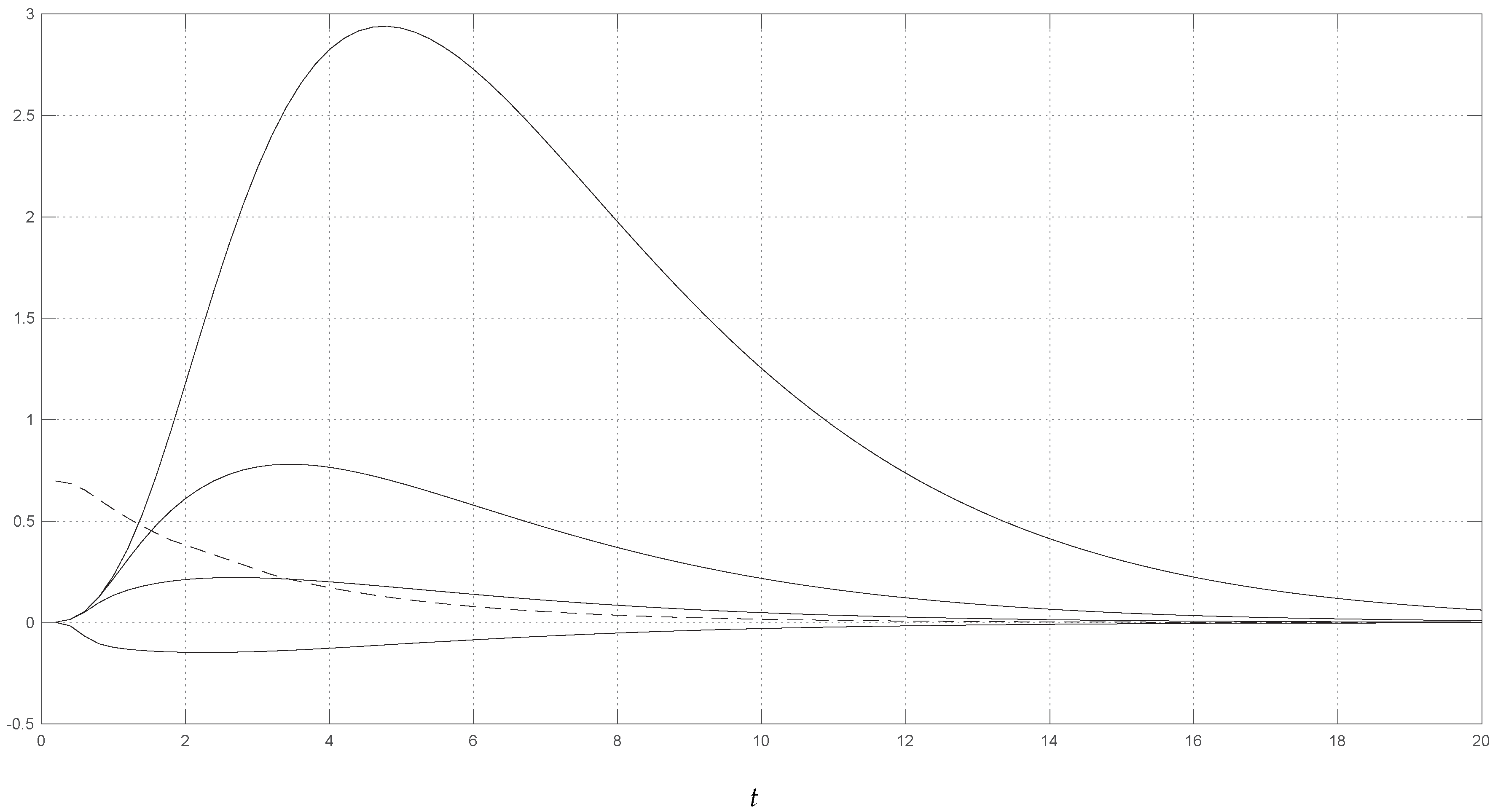
For the numerical example, we considered
and
.
Figure 2 shows the numerical results. The dashed curve indicates the saddlepoint approximation
to the s.f., cf. (
22), for all relevant values of
t. The four solid curves of
Figure 2 show the approximation to the s.f.s.
, for the perturbation points
, and for relevant values of
t. The highest curves correspond to the largest values of
x. The numerical evaluation of the above series representations of m.g.f. and c.g.f. does not give any particular problem: after only a few summands, numerical convergence is obtained. We note that the numerical results are similar to the ones of the Poisson-gamma aggregate loss of
Section 3.1. Additionally, as with the Poisson-gamma model, the approximate s.f.s. can be computed very quickly. Thus, it can be conveniently applied to practical problems and it provides an additional indicator of the reliability of the model under uncertainty.


{kind=link}
{kind=link}

