1. Introduction
Let
be a collection of actuarial risks, that is let it contain random variables (r.v.’s)
defined on the probability space
and interpreted as the financial risks an insurer is exposed to. Often, for applications in insurance, actuaries would consider those
, whose distributions are supported on the non-negative real half-line, have positive skewness, and allow for a certain degree of heavy-tailness. One such distribution, which has been of prominent importance in insurance applications, is gamma. We refer to
Hürlimann (
2001),
Dornheim and Brazauskas (
2007),
Furman et al. (
2018), and
Zhou et al. (
2018) for applications in solvency assessment, loss reserving, and aggregate risk approximation, respectively.
Furthermore, let
and
denote, correspondingly, the shape and scale parameters, then the r.v.
X is said to be distributed gamma, succinctly
, if it has the probability density function (p.d.f.)
where
stands for the complete gamma function. The popularity of the r.v.’s distributed gamma in insurance applications is not surprising: the p.d.f.’s of the (aggregate) insurance losses have as a rule the same shape as p.d.f. (
1), i.e., they are positively skewed, unimodal and have positive supports; p.d.f. (
1) is log-convex for
and so has decreasing failure rate, thus allowing for moderate heavy-tailness (
Klugman et al. 2012); p.d.f. (
1) has been very well studied and has turned out remarkably tractable.
When it comes to multivariate extensions of p.d.f. (
1), there are an ample number of dependence structures with univariate margins distributed gamma to consider (e.g.,
Kotz et al. 2000;
Balakrishnan and Ristić 2016, for a recent development and a comprehensive reference, respectively). However, irrespective of whether the two-steps copula approach or the more ‘natural’ stochastic representation approach to formulate the desired multivariate gamma distribution is pursued, the tractability of the end-result is often an issue. For the former approach, the cumulative distribution function (c.d.f.) of (
1) cannot be written in a closed form, and consequently intensive numerical algorithms are often needed to implement copula-based multivariate gamma models (e.g.,
Cossette et al. 2018;
Bahraoui et al. 2015). For the latter approach, consider the following example. Let
for
and
be mutually independent r.v.’s, and set
. Then the distribution of the r.v.
is the multivariate gamma of
Mathai and Moschopoulos (
1991) (also, e.g.,
Avanzi et al. 2016;
Furman and Landsman 2005, for recent applications in insurance). Consequently, for the p.d.f. of the r.v.
, we have
for all
, which inconveniently takes distinct forms for each of the
orderings of
.
Remark 1. The r.v.’s and are often interpreted as, respectively, the specific and systematic risk factors. The systematic risk factor, , has also been referred to as the background risk (Gollier and Pratt 1996), and so the distribution of the r.v. can be associated with an Additive Background Risk Model with risk components distributed gamma (G-ABRM). Succinctly, for , we write , where serves as the dependence parameter. An alternative way to link the specific risk factors and the systematic (or background) risk factor is with the help of multiplication. Namely, in order to formulate a Multiplicative Background Risk Model with the risk components distributed gamma (G-MBRM), we must find a sequence of
independent r.v.’s
, say, such that
results in the coordinates of the r.v.
being distributed gamma. One solution of this exercise, which is of pivotal importance for this paper, can be found in
Feller (
1968) (also,
Albrecher et al. 2011;
Sarabia et al. 2018). We organize the rest of the paper as follows: in
Section 2, we explore the basic distributional properties of—what we call—the multiplicative multivariate gamma (MMG) distribution. Then, in
Section 3 and
Section 4, respectively, we discuss in detail and elucidate with examples of actuarial interest the aggregation and (tail) dependence properties of the MMG distribution.
Section 5 concludes the paper. All proofs are relegated to
Appendix A to facilitate the reading.
2. Definition and Basic Properties
Multivariate distributions lay the very foundation of the successful (insurance) risk measurement—and thus of the consequent risk management—processes. However, the toolbox of the available stochastic dependencies that can be used to link stand-alone risk components into risk portfolios is somewhat overwhelming. Indeed, there are infinitely many ways to formulate the joint distribution of two dependent risk r.v.’s, whereas there is a single way only to write this distribution under the assumption of independence. The case of the multivariate distributions with the margins distributed gamma is of course not an exception (e.g.,
Kotz et al. 2000).
Nevertheless, real applications impose significant constraints on the model choice. Namely, practitioners often opt for those multivariate distributions that: (i) admit meaningful and relevant interpretations; (ii) allow for an adequate fit to the modelled data, be it in the ‘tail’, in the ‘body’, and/or in the dependence; and (iii) can be readily implemented. We feel that the multivariate distribution with the univariate margins distributed gamma that we put forward next (also,
Albrecher et al. 2011;
Sarabia et al. 2018) is exactly such.
Formally, let
and
denote, respectively, an exponentially distributed r.v. with the rate parameter
and an arbitrarily distributed r.v. with the range
; assume that the r.v.’s
and
are independent. In addition, let ‘∗’ represent the mixture operator (e.g.,
Feller 1968;
Su and Furman 2017a), such that, for ‘
’ denoting equality in distribution, it holds that
. We note in passing that the just-mentioned mixture operator is referred to as ‘randomization’ in
Feller (
1968), and is closely related—via the Bernstein–Widder theorem—to the notion of the Laplace transform of the p.d.f. of
. More specifically, if
and
denote, correspondingly, the p.d.f. of
and its Laplace transform, which is
then (
3) establishes the decumulative distribution function (d.d.f.) of the r.v.
.
Recall that in this paper we are interested in formulating a multivariate distribution with the univariate margins distributed gamma and a dependence. To this end, we assume that the r.v.
is distributed as a special shifted inverse Beta, succinctly
, with the p.d.f.
where
is the shape parameter. In our context, the choice of p.d.f. (
4) is unique, which readily follows from the Bernstein–Widder theorem. The next few facts are used frequently later on in the paper, and are hence formulated as a lemma. In the following, the
k-th order derivative of the Laplace transform is denoted by
, also
.
Lemma 1. Let with p.d.f. (4), then: - (i)
The Laplace transform of (4) iswhere denotes the upper incomplete gamma function. - (ii)
The negative k-th order moment of the r.v. Λ is - (iii)
The alternating sign k-th order derivative of is
Let denote independent copies of , and let . In addition, let denote a vector of positive parameters.
Definition 1. Set , and then the r.v. has a multiplicative multivariate distribution with univariate margins distributed gamma, and we succinctly write , where and are parameters.
Remark 2. Let denote independent copies of a r.v. distributed exponentially with unit scale, then the joint distribution of the r.v. in Definition 1 admits the following multiplicative background risk model representation (see, Asimit et al. 2016; Frank et al. 2006, for the corresponding economic implication and application) Above, the r.v. Λ can be interpreted as the systematic risk factor that endangers every risk component of the portfolio in Equation (6). The Monte Carlo simulation of Equation (6) is immediate. Theorem 1. Let , and let be positive scale parameters, then the following assertions hold:
- (i)
The r.v. has the d.d.f.which is X is distributed gamma with the shape and scale parameters equal to and , respectively. - (ii)
The r.v. with the j-th coordinate , has the joint d.d.f.for all . - (iii)
The p.d.f. that corresponds to d.d.f. (7) is, for all ,
The following facts are immediate from Theorem 1: (i) the distribution of is marginally closed, namely, ; (ii) the mathematical expectation of the j-th coordinate is ; and (iii) the variance of the j-th coordinate is .
We further explore some less obvious properties of the MMG/G-MBRM and note with satisfaction that the risk portfolios with the joint distributions within this class are often more tractable than the portfolios having stochastically independent risk components distributed gamma. At the outset, we note in passing that the MMG distribution put forward in Definition 1 is a non-exchangeable generalization of the multivariate distributions having univariate margins distributed gamma that are discussed in
Albrecher et al. (
2011);
Sarabia et al. (
2018). As such, the MMG distribution requires a more delicate treatment when deriving the results below, which hinge crucially on the stochastic characteristics of the univariate margins of the r.v.
.
We look into the minima and maxima r.v.’s first; both are of evident importance in insurance. To this end, denote by and by the minima and maxima r.v.’s. Then we have—unlike in the independent case—that the coordinates of the r.v. in Definition 1 are closed under minima.
Theorem 2. Let , then is distributed gamma. More specifically, we have , where is the positive scale parameter, and is the shape parameter. In addition, the d.d.f. of is a linear combination of the d.d.f.’s of the univariate r.v.’s distributed gamma, such thatwhere and with . Another r.v. of pivotal interest in insurance is the aggregate risk r.v. denoted by
; in addition, let
. It is well known that, if
are mutually independent and distributed gamma with arbitrary parameters, then
admits an infinite sum representation (
Moschopoulos 1985;
Provost 1989). We further show that for
and when all the scale parameters are distinct, then
is noticeably more elegant. The derivation of
in the general case—i.e., for arbitrary (possibly equal) scale parameters—is more cumbersome and is presented in
Section 3.
We often write omitting the vector of scale parameters for the simplicity of notation.
Proposition 1. Let and assume that all the scale parameters are distinct, which is for , then the d.d.f. of is The last result in this section provides an expression for the higher-order (product) moments of the r.v.
. We employ a special form of this expression later on in
Section 4 to derive the formula for the Pearson index of linear correlation.
Theorem 3. Let , then, for , we have We conclude the discussion in the present section by noticing that joint p.d.f. (
8) can be used to estimate the parameters of the MMG distribution via the (numerical) maximum likelihood approach, whereas expression (
11) is of interest if the moment-based estimation is being pursued.
4. Dependence Properties of the Multiplicative Multivariate Gamma Distribution
At first sight, the dependence structure that underlies the MMG distribution—that is d.d.f. (
7)— is not as versatile as the one behind the additive counterpart of
Mathai and Moschopoulos (
1991). This is because the Pearson correlation,
, for the former class of distributions does not attain every value in the interval
, whereas it does so in the context of the latter class of distributions (e.g.,
Das et al. 2007;
Su and Furman 2017a,
2017b, for a similar constraint in the context of default risk). More formally, we have the following proposition, the proof of which is a direct application of Theorem 3 and is thus omitted.
Proposition 4. Let , then the Pearson correlation between any pair of and , for iswhere . In addition, we have and it is a decreasing function of . In the rest of this section, we show that the just-mentioned seeming shortcoming should in fact be attributed to the Pearson index of correlation, , itself, rather than to the dependence structure of the MMG distribution. As hitherto, we divide our observations herein into two subsections.
4.1. Theoretical Considerations
At the outset, we observe that the dependence structure that underlies the MMG/G-MBRM is not linear in the—common—background r.v.
. Therefore, the machinery of copulas lands itself very naturally to exploring the relevant dependence properties. The next theorem states the copula function (e.g.,
Joe 1997) of
.
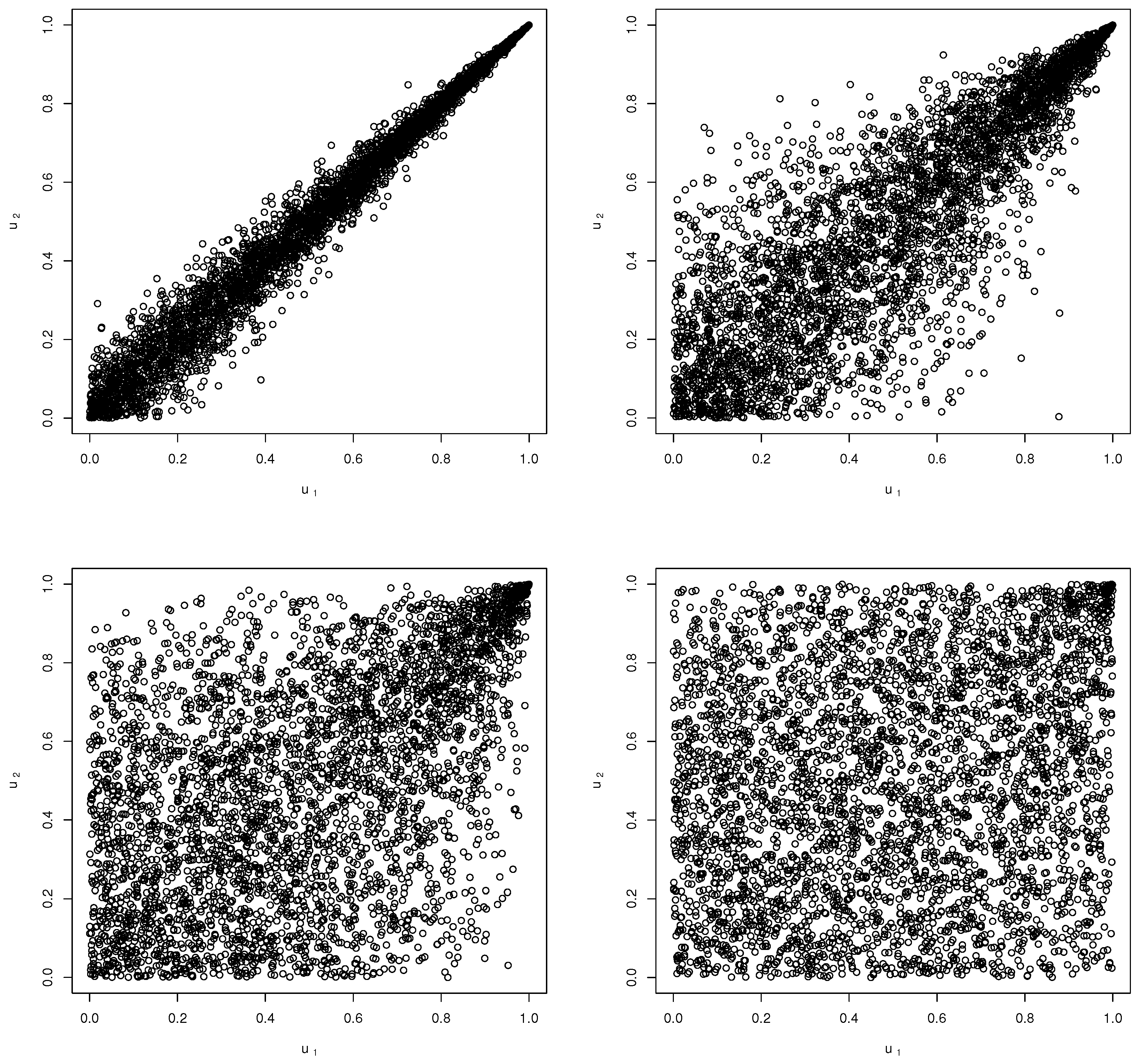
Theorem 5. Assume that , then the copula function underlying the d.d.f. of is given, for , bywhere and denotes the inverse incomplete gamma function evaluated at . Moreover, the p.d.f. associated with is given bywhere f denotes the p.d.f. of , and is obtained in Lemma 1. Figure 1 depicts the simulated scatter plots of the copula function
for varying values of the
parameter.
Remark 5. Copula function (19) is a member of the encompassing class of the Archimedean copulas. Specifically, setand observe that (19) admits the following form, for ,where is a legitimate completely monotonic function—known as the Archimedean generator—and is its inverse (e.g., McNeil and Nešlehová 2009). The MMG copula therefore enriches the encompassing toolbox of the distinct Archimedean copulas available to researchers and practitioners. We have already mentioned at the end of
Section 2 that the maximum likelihood approach can be used in order to numerically estimate the parameters of the MMG distribution. An alternative way to estimate the parameters is via the two-step copula approach. That is, we first fit the MMG copula to the pseudo uniform samples based on the empirical c.d.f.’s of
,
and estimate the
parameter (e.g.,
Embrechts and Hofert 2013;
Genest et al. 2011, and references therein), and we then estimate the
parameters based on the univariate marginal distributions assuming that the
parameter is known. Given the cumbersome form of p.d.f. (
8), the copula-based approach is computationally simpler.
Besides the just-mentioned statistical inference, a useful contribution of copulas to the vast literature of multivariate modelling is that they have given rise to a number of indices of dependence that circumvent the known fallacies of the Pearson . Such indices of dependence are, e.g., the Kendall and Spearman measures of rank correlation, and we derive these two in the next subsection in the context of the MMG copula function .
In the rest of this subsection, we build up the theoretical groundwork necessary for exploring the tail dependence of . As tail dependence represents the co-movement of extreme risks, it is of particular importance in the era following the financial crisis of 2007–2009. We note in passing that, since the majority of the existing methods for quantifying tail dependence mainly aim at random pairs, we specialize the discussion in this part of the present report to the bivariate case only.
Let
denote the survival copula that corresponds to
C, that is
, for
. Then the first order lower and upper tail dependence parameters (e.g.,
Joe 1997) are given by
whereas the second order tail dependence parameters (
Coles et al. 1999) are given by
Recently, an argument has been put forward that tail dependence measures (
21) and (
22) may underestimate the extent of the tail dependence inherent in a copula. More specifically,
Furman et al. (
2015) claim and elucidate with numerous examples that as measures (
21) and (
22) are computed along the main diagonal
, their values are not necessarily maximal when alternative paths in
are considered. This motivated the following definitions of the admissible paths and the paths of maximal dependence in ibid.
Definition 2. A function is called admissible if it satisfies the following conditions:
- (C1)
for every ; and
- (C2)
and converge to 0 when .
Then the path is admissible whenever the function φ is admissible. In addition, we denote by the set of all admissible functions φ.
Definition 3. The path(s) in are called paths of maximal dependence if they maximize the probabilityor, equivalently, the distance functionwhere is the independence copula, i.e., for all . Obviously, the function
is admissible and yields the representation of the diagonal path that serves as a building block for classical indices (
21) and (
22). For the Archimedean class of copulas, the following property of the maximal dependence path holds. The verification of the condition stated in Lemma 3 below is not trivial, and is carried out for the MMG copula
in Theorem 6.
Lemma 3 (
Furman et al. 2015)
. For an Archimedean copula with generator ϕ, if is increasing on then the path of maximal dependence coincides with the main diagonal. The next lemma on a L’Hospital type rule for monotonicity, plays an importantly auxiliary role when deriving the maximal dependence path for .
Lemma 4 (
Pinelis 2002)
. Let , also and be differentiable functions over the interval . Assume that for , and and . Then, is increasing on if is increasing. Our last result in this subsection implies that measures of tail dependence (
21) and (
22) are in fact maximal in the context of the MMG copula
.
Theorem 6. The maximal dependence path of the copula function in (19) is diagonal. 4.2. Applications
The next assertion reports the Kendall tau and Spearman rho rank correlations, implied by the MMG copula (
19). The hypergeometric function plays a pivotal role in deriving the Spearman rho correlation in the following proposition, and it is given in
Gradshteyn and Ryzhik (
2014)
For all positive, and these are the cases of interest in the present report. The radius of convergence of the series is the open disk . On the boundary , the series converges absolutely if , and it converges except at if .
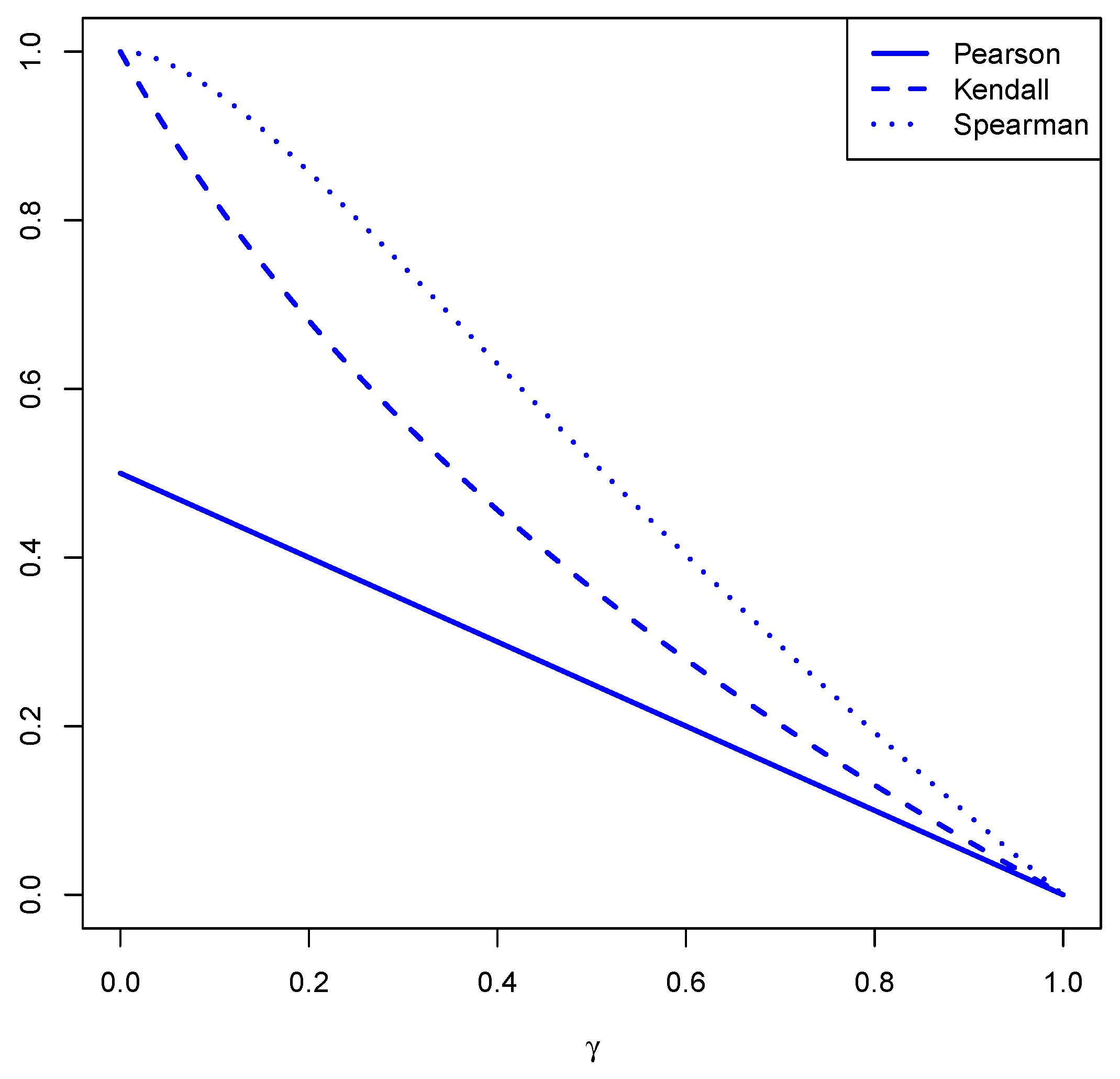
Proposition 5. For the copula , the Kendall τ rank correlation is given byand the Spearman rank correlation is given by Figure 2 depicts the values for the Pearson
, Kendall
and Spearman
indices of correlation with varying
. The figure confirms that, while the Pearson
does not attain all values in
for the MMG/G-MBRM distribution, the other two indices are able to achieve this goal.
Proposition 6. Assume that has copula , the lower maximal tail dependence of is The upper maximal tail dependence of is Proposition 6 readily implies—recall to this end that the copula is in fact a survival copula (by construction)—that the coordinates of are asymptotically dependent in the lower tail, but independent in the upper tail. Speaking bluntly, this means that is more likely to take smaller values simultaneously, but less likely to form a cluster of large values. This conforms to the already made intuitive observation that the copula can serve as a reflected variant of the well-studied Clayton copula.


{kind=link}
{kind=link}