Fluctuation Theory for Upwards Skip-Free Lévy Chains


Abstract
:1. Introduction
2. Setting and Notation
- The nonnegative, nonpositive, positive and negative real numbers are denoted by , , and , respectively. Then , , and are the nonnegative, nonpositive, positive and negative integers, respectively.
- Similarly, for : , , and are the apposite elements of .
- The following introduces notation for the relevant half-planes of ; the arrow notation is meant to be suggestive of which half-plane is being considered: , , and . , , and are then the respective closures of these sets.
- and are the positive and nonnegative integers, respectively. () is the ceiling function. For : and .
- The Laplace transform of a measure on , concentrated on , is denoted by : (for all such that this integral is finite). To a nondecreasing right-continuous function , a measure may be associated in the Lebesgue-Stieltjes sense.
3. Fluctuation Theory
3.1. Laplace Exponent, the Reflected Process, Local Times and Excursions from the Supremum, Supremum Process and Long-Term Behaviour, Exponential Change of Measure
- The generator matrix of the Markov process on is given by (with ): , unless , in which case we have .
- For the reflected process Y, 0 is a holding point. The actual time spent at 0 by Y, which we shall denote L, is a local time at the maximum. Its right-continuous inverse , given by (for ; otherwise), is then a (possibly killed) compound Poisson subordinator with unit positive drift.
- Assuming that to avoid the trivial case, the expected length of an excursion away from the supremum is equal to ; whereas the probability of such an excursion being infinite is .
- Assume again to avoid the trivial case. Let N, taking values in , be the number of jumps the chain makes before returning to its running maximum, after it has first left it (it does so with probability 1). Then the law of is given by (for ):In particular, has a killing rate of , Lévy mass and its jumps have the probability law on given by the length of a generic excursion from the supremum, conditional on it being finite, i.e., that of an independent N-fold sum of independent -distributed random variables, conditional on N being finite. Moreover, one has, for , , where the coefficients satisfy the initial conditions:the recursions:and may be interpreted as the probability of X reaching level 0 starting from level for the first time on precisely the k-th jump ().
- The failure probability for the geometrically distributed is ().
- X drifts to , oscillates or drifts to according as to whether is positive, zero, or negative. In the latter case has a geometric distribution with failure probability .
- is a discrete-time increasing stochastic process, vanishing at 0 and having stationary independent increments up to the explosion time, which is an independent geometric random variable; it is a killed random walk.
- For every , .
- For every , the stopped process is identical in law under the measures and on the canonical space .
3.2. Wiener-Hopf Factorization
- The pairs and are independent and infinitely divisible, yielding the factorisation:where for ,Duality: is equal in distribution to . and are the Wiener-Hopf factors.
- The Wiener-Hopf factors may be identified as follows:andfor .
- Here, in terms of the law of X,andfor , and some constants .
- (Kyprianou 2006, pp. 157, 168) is also the Laplace exponent of the (possibly killed) bivariate descending ladder subordinator , where is a local time at the minimum, and the descending ladder heights process (on ; otherwise) is X sampled at its right-continuous inverse :
- As for the strict ascending ladder heights subordinator (on ; otherwise), being the right-continuous inverse of , and denoting the amount of time X has spent at a new maximum, we have, thanks to the skip-free property of X, as follows. Since , X stays at a newly achieved maximum each time for an -distributed amount of time, departing it to achieve a new maximum later on with probability , and departing it, never to achieve a new maximum thereafter, with probability . It follows that the Laplace exponent of is given by:(where ). In other words, is a killed Poisson process of intensity and with killing rate .
- For every and :and(the latter whenever ; for the unique such that , i.e., for , one has the right-hand side given by ).
- For some and then for every and :and(the latter whenever ; for the unique such that , i.e., for , one has the right-hand side given by ).
if and only if the following conditions are satisfied:There exists (in law) an upwards skip-free Lévy chain X with values in and with (i) γ being the killing rate of its strict ascending ladder heights process (see Remark 4-2), and (ii) , , being the Laplace exponent of its descending ladder heights process.
- .
- Setting x equal to 1, when , or to the unique solution of the equation:on the interval , otherwise2; and then defining , , ; it holds:
- .
- .
- , .
4. Theory of Scale Functions
4.1. The Scale Function W
4.2. The Scale Functions ,
- If or , then .
- If (hence ), then , but . Indeed, , if and , if .
4.3. The Functions ,
4.4. Calculating Scale Functions
- Skip-free chain. Let . Then , unless , in which case , .
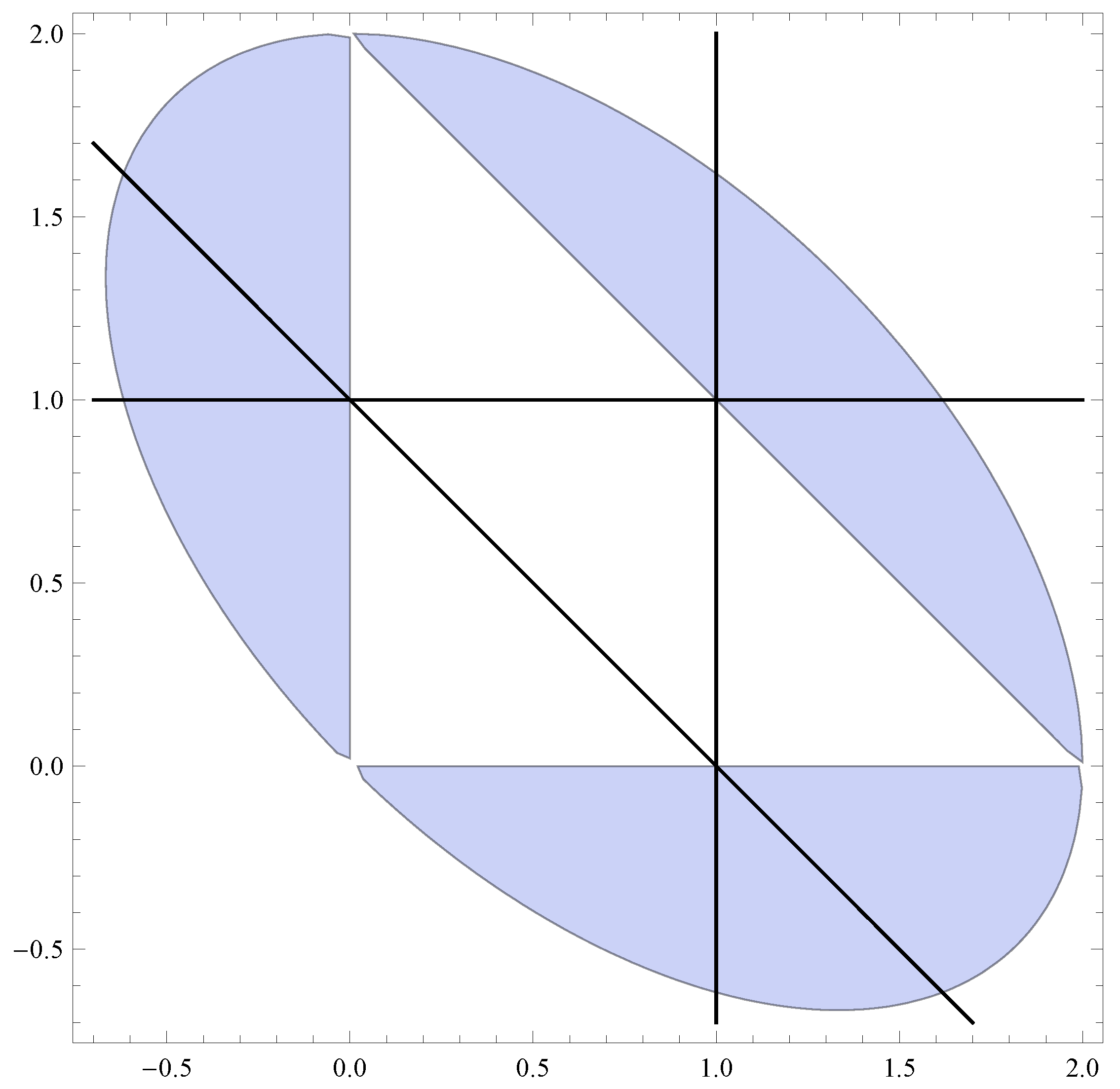
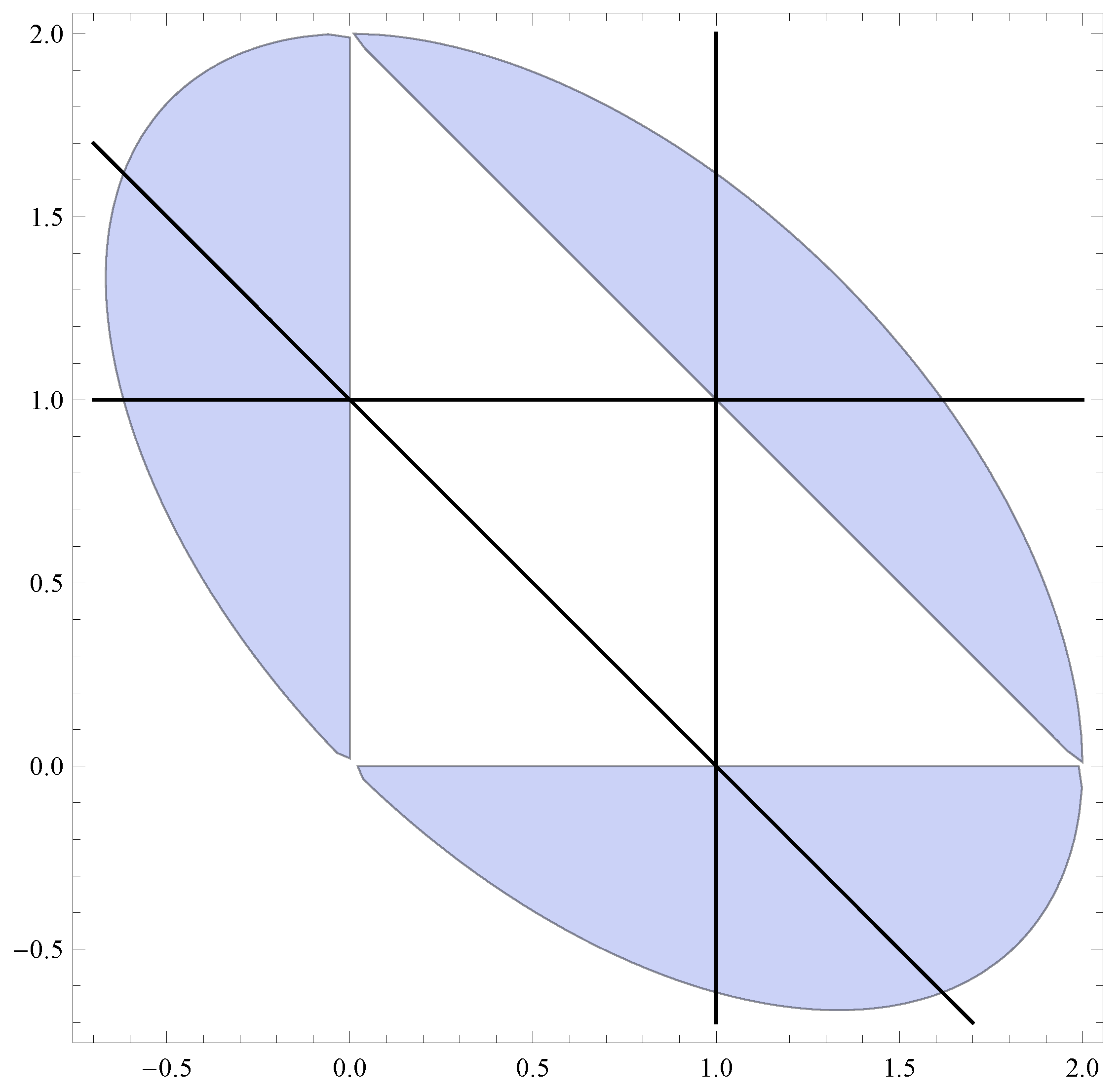
- “Reverse-engineered” chain. Let , and, with reference to (the caption of) Figure 1, , , . Then this corresponds (in the sense that has been made precise above) to an upwards skip-free Lévy chain with and with , for all , for some . Choosing (say) , we have from Proposition 4, ; and then from (20), , . This renders , , .
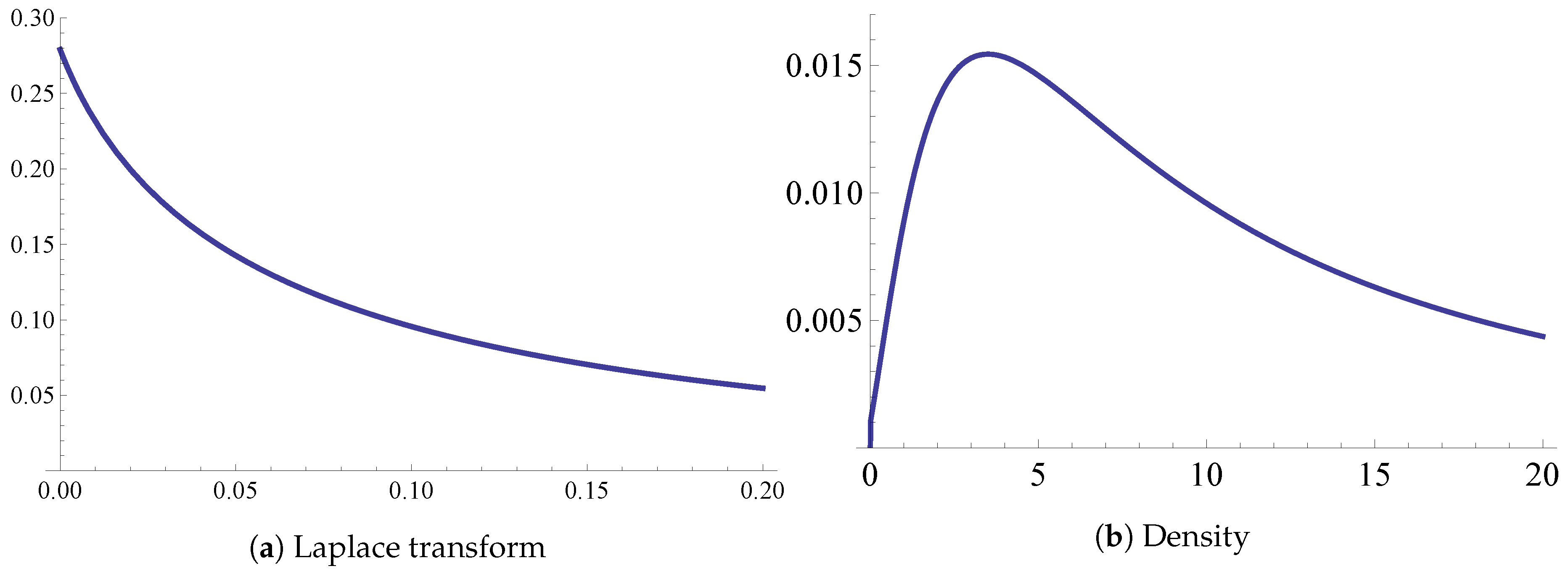
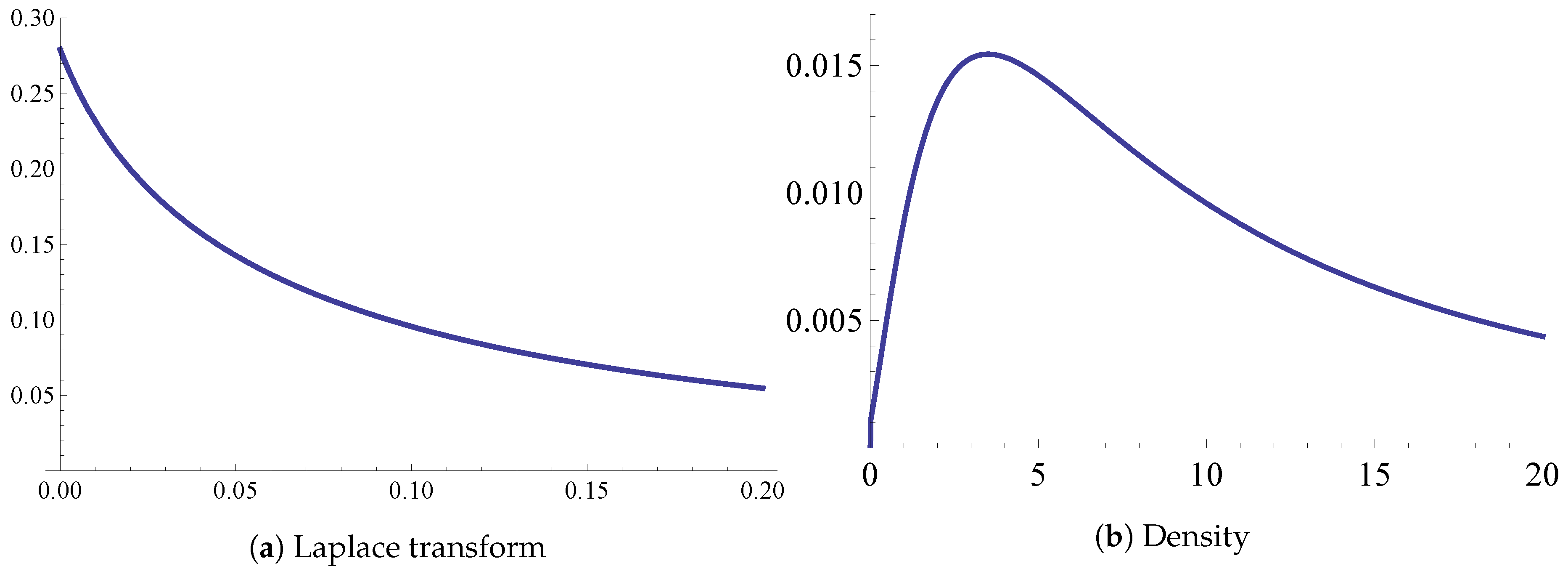
- “Geometric” chain. Assume , take an , and let for . Then (20) implies for that , i.e., for the relation , a homogeneous second order linear difference equation with constant coefficients. Specialize now to and take . Solving the difference equation with the initial conditions that are got from the known values of and leads to , . This example is further developed in Section 5, in the context of the modeling of the capital surplus process of an insurance company.
5. Application to the Modeling of an Insurance Company’s Risk Process
Funding
Acknowledgments
Conflicts of Interest
References
- Asmussen, Søren, and Hansjörg Albrecher. 2010. Ruin Probabilities. Advanced series on statistical science and applied probability; Singapore: World Scientific. [Google Scholar]
- Avram, Florin, Andreas E. Kyprianou, and Martijn R. Pistorius. 2004. Exit Problems for Spectrally Negative Lévy Processes and Applications to (Canadized) Russian Options. The Annals of Applied Probability 14: 215–38. [Google Scholar]
- Avram, Florin, Zbigniew Palmowski, and Martijn R. Pistorius. 2007. On the optimal dividend problem for a spectrally negative Lévy process. The Annals of Applied Probability 17: 156–80. [Google Scholar] [CrossRef]
- Avram, Florin, and Matija Vidmar. 2017. First passage problems for upwards skip-free random walks via the Φ, W, Z paradigm. arXiv, arXiv:1708.0608. [Google Scholar]
- Bao, Zhenhua, and He Liu. 2012. The compound binomial risk model with delayed claims and random income. Mathematical and Computer Modelling 55: 1315–23. [Google Scholar] [CrossRef]
- Bertoin, Jean. 1996. Lévy Processes. Cambridge Tracts in Mathematics. Cambridge: Cambridge University Press. [Google Scholar]
- Bhattacharya, Rabindra Nath, and Edward C. Waymire. 2007. A Basic Course in Probability Theory. New York: Springer. [Google Scholar]
- Biffis, Enrico, and Andreas E. Kyprianou. 2010. A note on scale functions and the time value of ruin for Lévy insurance risk processes. Insurance: Mathematics and Economics 46: 85–91. [Google Scholar]
- Bingham, Nicholas Hugh, Charles M. Goldie, and Jozef L. Teugels. 1987. Regular Variation. Encyclopedia of Mathematics and its Applications. Cambridge: Cambridge University Press. [Google Scholar]
- Brown, Mark, Erol A. Peköz, and Sheldon M. Ross. 2010. Some results for skip-free random walk. Probability in the Engineering and Informational Sciences 24: 491–507. [Google Scholar] [CrossRef]
- Bühlmann, Hans. 1970. Mathematical Methods in Risk Theory. Grundlehren der mathematischen Wissenschaft: A series of comprehensive studies in mathematics; Berlin/ Heidelberg: Springer. [Google Scholar]
- Chiu, Sung Nok, and Chuancun Yin. 2005. Passage times for a spectrally negative Lévy process with applications to risk theory. Bernoulli 11: 511–22. [Google Scholar] [CrossRef]
- De Vylder, Florian, and Marc J. Goovaerts. 1988. Recursive calculation of finite-time ruin probabilities. Insurance: Mathematics and Economics 7: 1–7. [Google Scholar] [CrossRef]
- Dickson, David C. M., and Howard R. Waters. 1991. Recursive calculation of survival probabilities. ASTIN Bulletin 21: 199–221. [Google Scholar] [CrossRef]
- Doney, Ronald A. 2007. Fluctuation Theory for Lévy Processes: Ecole d’Eté de Probabilités de Saint-Flour XXXV-2005. Edited by Jean Picard. Number 1897 in Ecole d’Eté de Probabilités de Saint-Flour. Berlin/Heidelberg: Springer. [Google Scholar]
- Engelberg, Shlomo. 2005. A Mathematical Introduction to Control Theory. Series in Electrical and Computer Engineering; London: Imperial College Press, vol. 2. [Google Scholar]
- Hubalek, Friedrich, and Andreas E. Kyprianou. 2011. Old and New Examples of Scale Functions for Spectrally Negative Lévy Processes. In Seminar on Stochastic Analysis, Random Fields and Applications VI. Edited by Robert Dalang, Marco Dozzi and Francesco Russo. Basel: Springer, pp. 119–45. [Google Scholar]
- Kallenberg, Olav. 1997. Foundations of Modern Probability. Probability and Its Applications. New York and Berlin/Heidelberg: Springer. [Google Scholar]
- Karatzas, Ioannis, and Steven E. Shreve. 1988. Brownian Motion and Stochastic Calculus. Graduate Texts in Mathematics. New York: Springer. [Google Scholar]
- Kyprianou, Andreas E. 2006. Introductory Lectures on Fluctuations of Lévy Processes with Applications. Berlin/ Heidelberg: Springer. [Google Scholar]
- Marchal, Philippe. 2001. A Combinatorial Approach to the Two-Sided Exit Problem for Left-Continuous Random Walks. Combinatorics, Probability and Computing 10: 251–66. [Google Scholar] [CrossRef]
- Mijatović, Aleksandar, Matija Vidmar, and Saul Jacka. 2014. Markov chain approximations for transition densities of Lévy processes. Electronic Journal of Probability 19: 1–37. [Google Scholar] [CrossRef]
- Mijatović, Aleksandar, Matija Vidmar, and Saul Jacka. 2015. Markov chain approximations to scale functions of Lévy processes. Stochastic Processes and their Applications 125: 3932–57. [Google Scholar] [CrossRef]
- Norris, James R. 1997. Markov Chains. Cambridge series in statistical and probabilistic mathematics; Cambridge: Cambridge University Press. [Google Scholar]
- Parthasarathy, Kalyanapuram Rangachari. 1967. Probability Measures on Metric Spaces. New York and London: Academic Press. [Google Scholar]
- Quine, Malcolm P. 2004. On the escape probability for a left or right continuous random walk. Annals of Combinatorics 8: 221–23. [Google Scholar] [CrossRef]
- Revuz, Daniel, and Marc Yor. 1999. Continuous Martingales and Brownian Motion. Berlin/Heidelberg: Springer. [Google Scholar]
- Rudin, Walter. 1970. Real and Complex Analysis. International student edition. Maidenhead: McGraw-Hill. [Google Scholar]
- Sato, Ken-iti. 1999. Lévy Processes and Infinitely Divisible Distributions. Cambridge studies in advanced mathematics. Cambridge: Cambridge University Press. [Google Scholar]
- Spitzer, Frank. 2001. Principles of Random Walk. Graduate texts in mathematics. New York: Springer. [Google Scholar]
- Vidmar, Matija. 2015. Non-random overshoots of Lévy processes. Markov Processes and Related Fields 21: 39–56. [Google Scholar]
- Wat, Kam Pui, Kam Chuen Yuen, Wai Keung Li, and Xueyuan Wu. 2018. On the compound binomial risk model with delayed claims and randomized dividends. Risks 6: 6. [Google Scholar] [CrossRef]
- Xiao, Yuntao, and Junyi Guo. 2007. The compound binomial risk model with time-correlated claims. Insurance: Mathematics and Economics 41: 124–33. [Google Scholar] [CrossRef]
- Yang, Hailiang, and Lianzeng Zhang. 2001. Spectrally negative Lévy processes with applications in risk theory. Advances in Applied Probability 33: 281–91. [Google Scholar] [CrossRef]
| 1. | However, such a treatment did eventually become available (several years after this manuscript was essentially completed, but before it was published), in the preprint Avram and Vidmar (2017). |
| 2. | It is part of the condition, that such an x should exist (automatically, given the preceding assumptions, there is at most one). |

{kind=link}
{kind=link}
| Long-Term Behaviour | Excursion Length | |||
|---|---|---|---|---|
| 0 | drifts to | finite expectation | ||
| 0 | 0 | oscillates | a.s. finite with infinite expectation | |
| drifts to | infinite with a positive probability |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vidmar, M. Fluctuation Theory for Upwards Skip-Free Lévy Chains. Risks 2018, 6, 102. https://doi.org/10.3390/risks6030102
Vidmar M. Fluctuation Theory for Upwards Skip-Free Lévy Chains. Risks. 2018; 6(3):102. https://doi.org/10.3390/risks6030102
Chicago/Turabian StyleVidmar, Matija. 2018. "Fluctuation Theory for Upwards Skip-Free Lévy Chains" Risks 6, no. 3: 102. https://doi.org/10.3390/risks6030102
APA StyleVidmar, M. (2018). Fluctuation Theory for Upwards Skip-Free Lévy Chains. Risks, 6(3), 102. https://doi.org/10.3390/risks6030102