
Robust Estimation of Value-at-Risk through Distribution-Free and Parametric Approaches Using the Joint Severity and Frequency Model: Applications in Financial, Actuarial, and Natural Calamities Domains

Abstract
:1. Introduction
- (a)
- We provide mathematical analyses for scenarios in which the assumption of the independence of frequency and severity does not hold, and show that the classical approach incurs large and systematic errors in the estimation of VaR, thus exposing a limitation in the approach.
- (b)
- We propose two methods that do not assume the independence of frequency and severity and subsequently provide robust estimates for VaR for diverse QRM applications. The first method, the data-driven partitioning of frequency and severity (DPFS), is non-parametric. It performs a clustering analysis to separate the loss data into clusters in which the independence assumption (approximately) holds. The second method, copula-based parametric modeling of frequency and severity (CPFS), parametrically models the relationship between loss frequency and loss severity using a statistical machinery known as a copula. We extend CPFS to the recently developed Gaussian mixture copula (Bilgrau et al. 2016; Wu et al. 2014; Bayestehtashk and Shafran 2015) along with the classical Gaussian and students-t copula in order to deal with instances of nonlinear, linear, and tail dependencies between loss frequency and loss severity.
- (c)
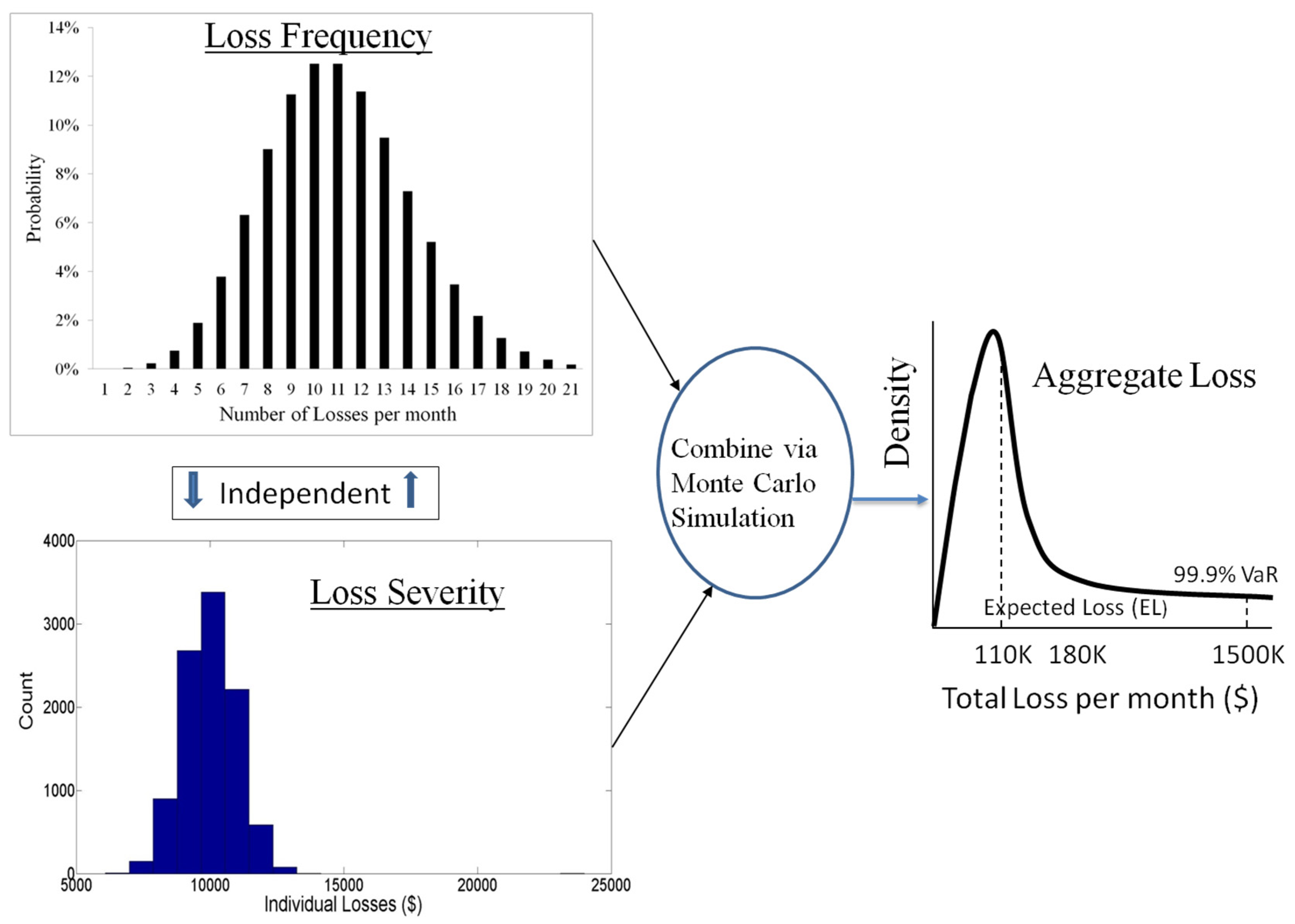
- We investigate the performance of the classical and DPFS and CPFS methodologies using both simulation experiments and publicly available real-world datasets from a diverse range of application domains; namely, financial market losses (Data available from Yahoo Finance 2017), chemical spills handled by the US Coast Guard (Data available at National Response Center 1990), automobile accidents (Charpentier 2014), and US hurricane losses (Charpentier 2014). The use of publicly available data sets this work distinctly apart from the majority of the empirical research into modern QRM which uses proprietary data (Aue and Kalkbrener 2006; OpRisk Advisory and Towers Perrin 2010; Gomes-Gonçalves and Gzyl 2014; Rachev et al. 2006; Embrechts et al. 2015; Li et al. 2014). Tests using simulations and real-world data demonstrate the merit of the two statistical approaches. A flowchart is provided for risk practitioners to select a methodology for VaR estimation depending on the loss data characteristics.
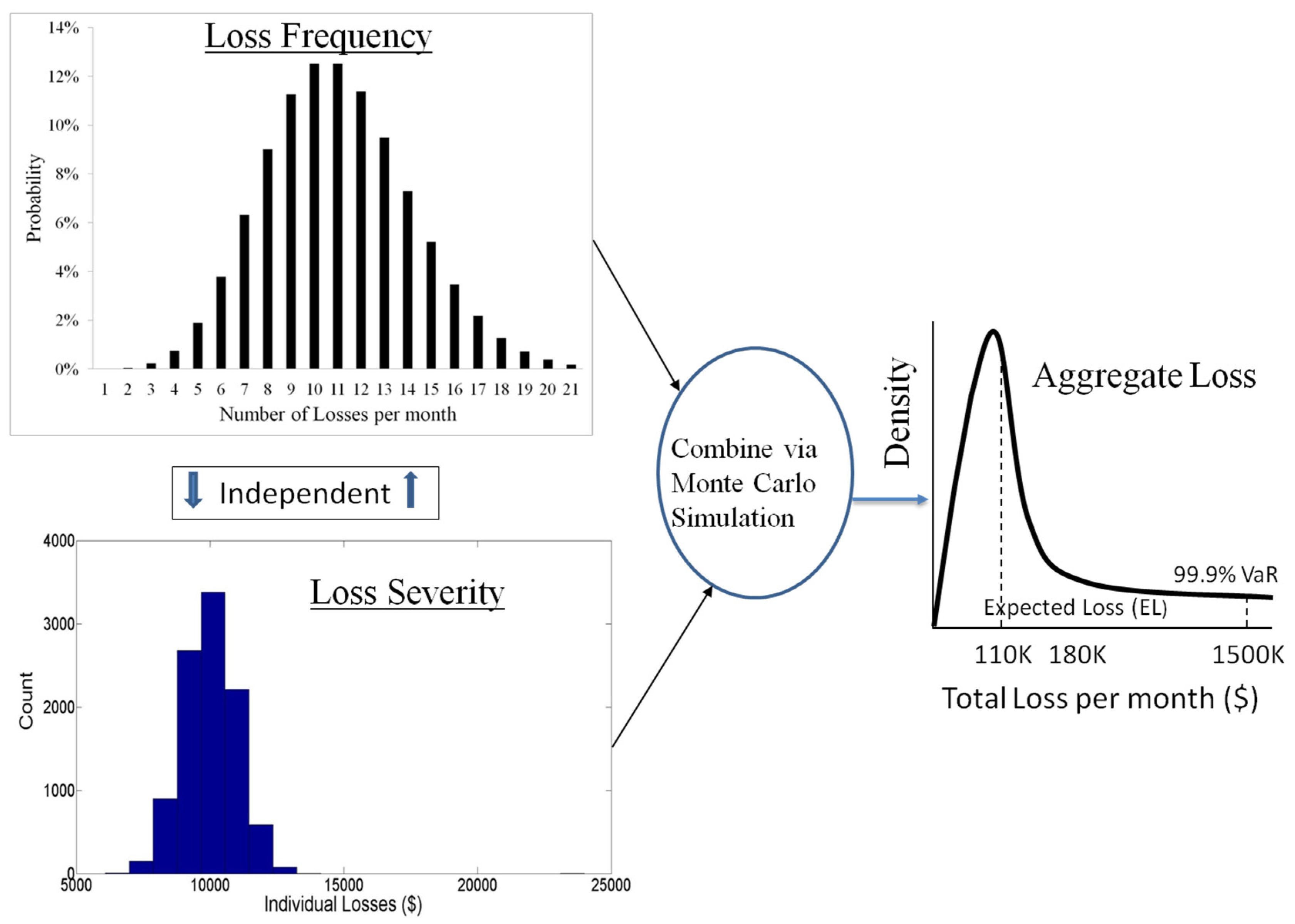
2. Background on Value-at-Risk
3. Methodology
3.1. VaR Estimation Bias using the Classical Method
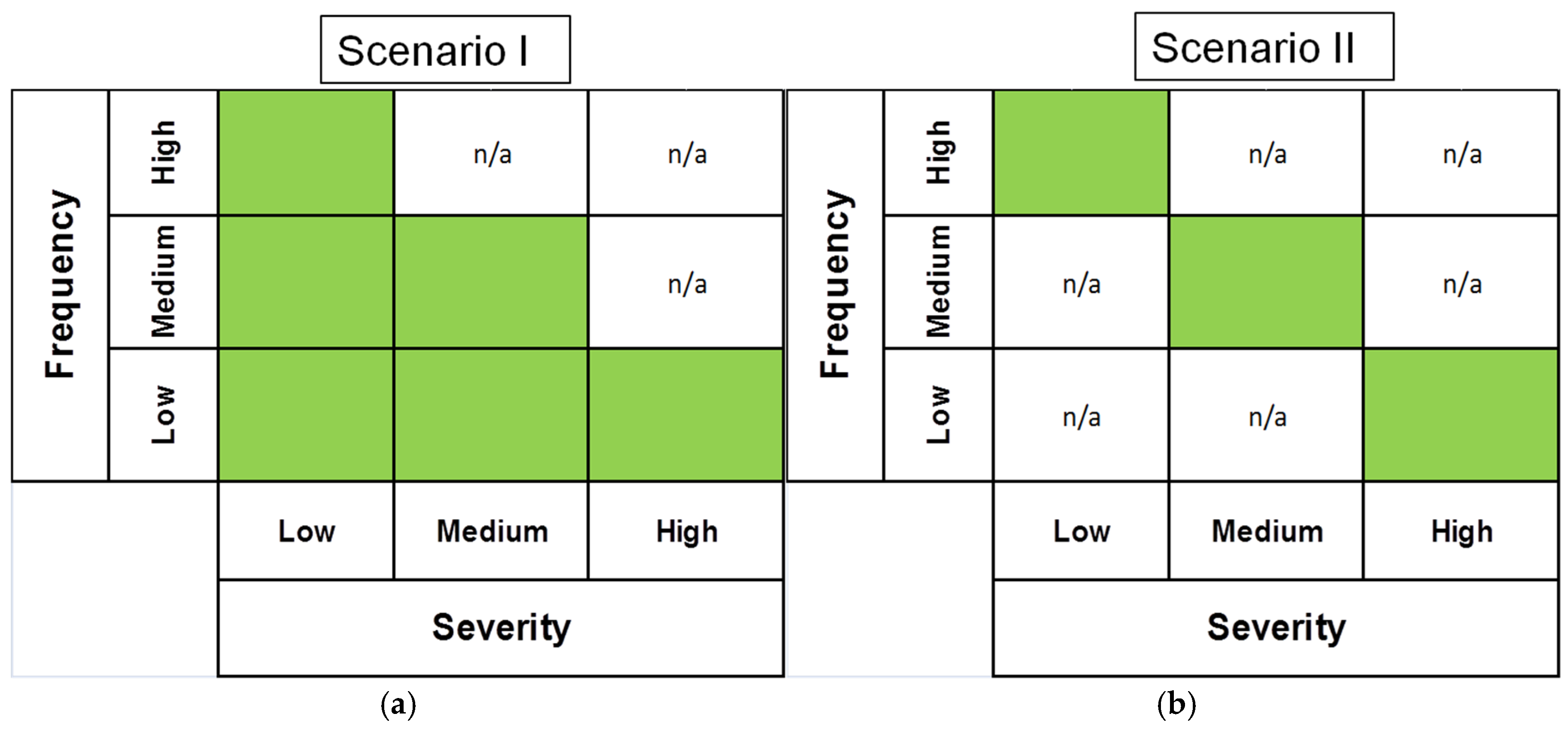
- Case (I): . This corresponds to a regime in which the mean severity dominates the frequency; i.e., a relatively small number of loss events but each loss is large (in magnitude).
- Case (II): . This corresponds to a regime in which frequency dominates severity; i.e., a large number of small (in magnitude) losses.
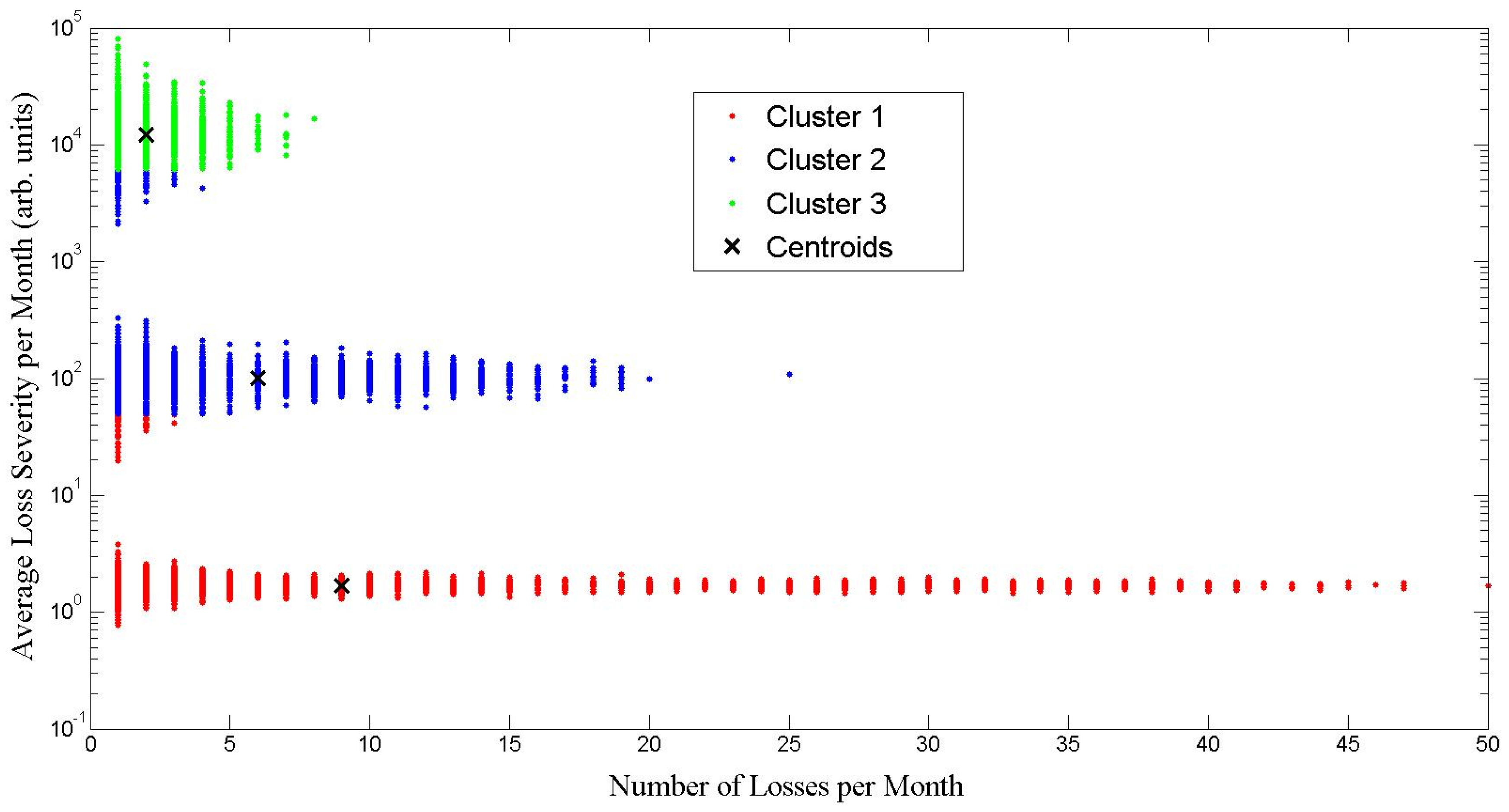
3.2. Non-Parametric DPFS Method for VaR Estimation
| Algorithm 1 Data-driving partitioning of frequency and severity (DPFS) (Methods I and II) VaR estimation |
|
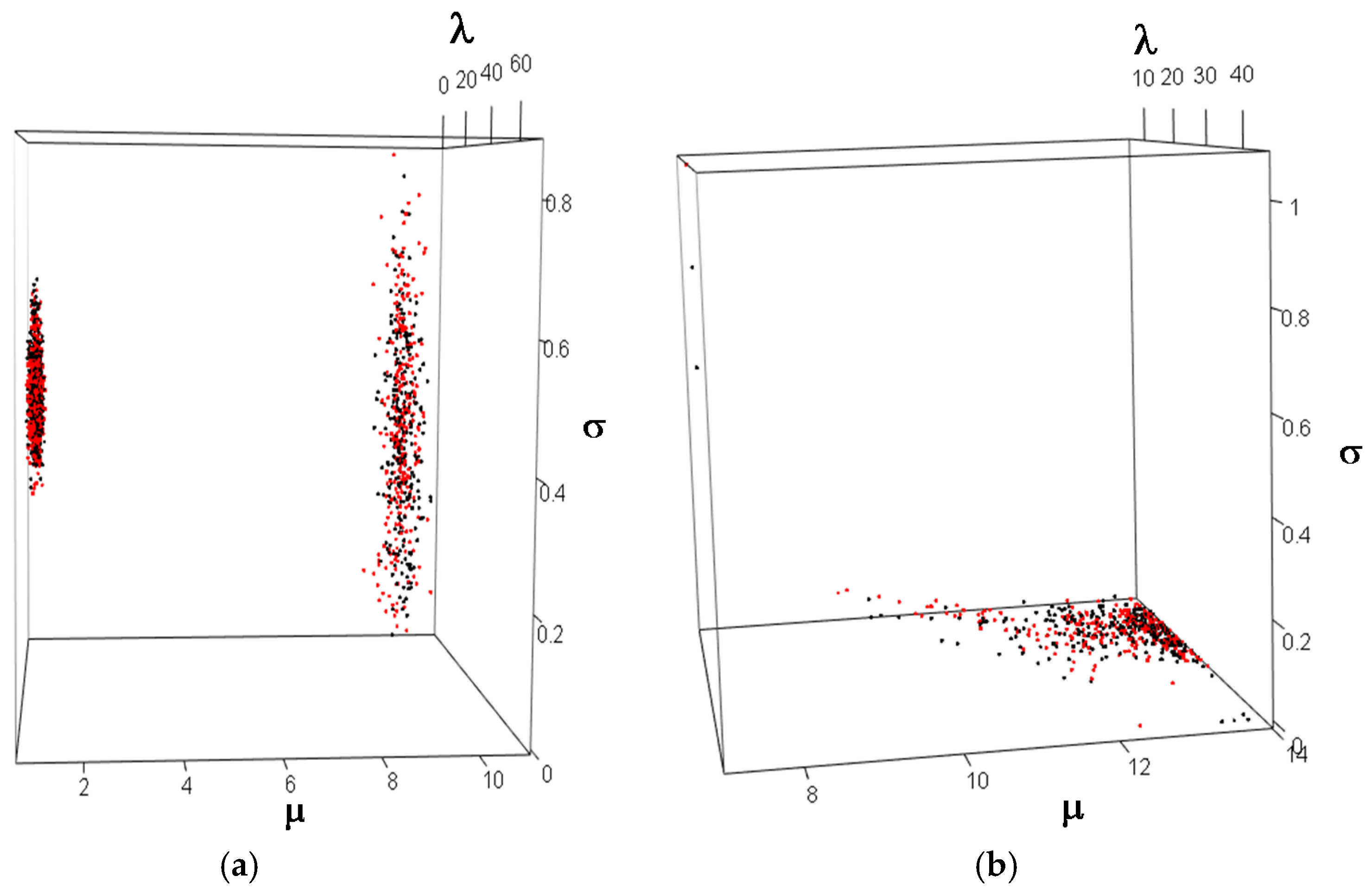
3.3. Parametric CPFS Method for VaR Estimation
| Algorithm 2 Copula-based parametric modeling of frequency and severity (CPFS) VaR estimation |
|
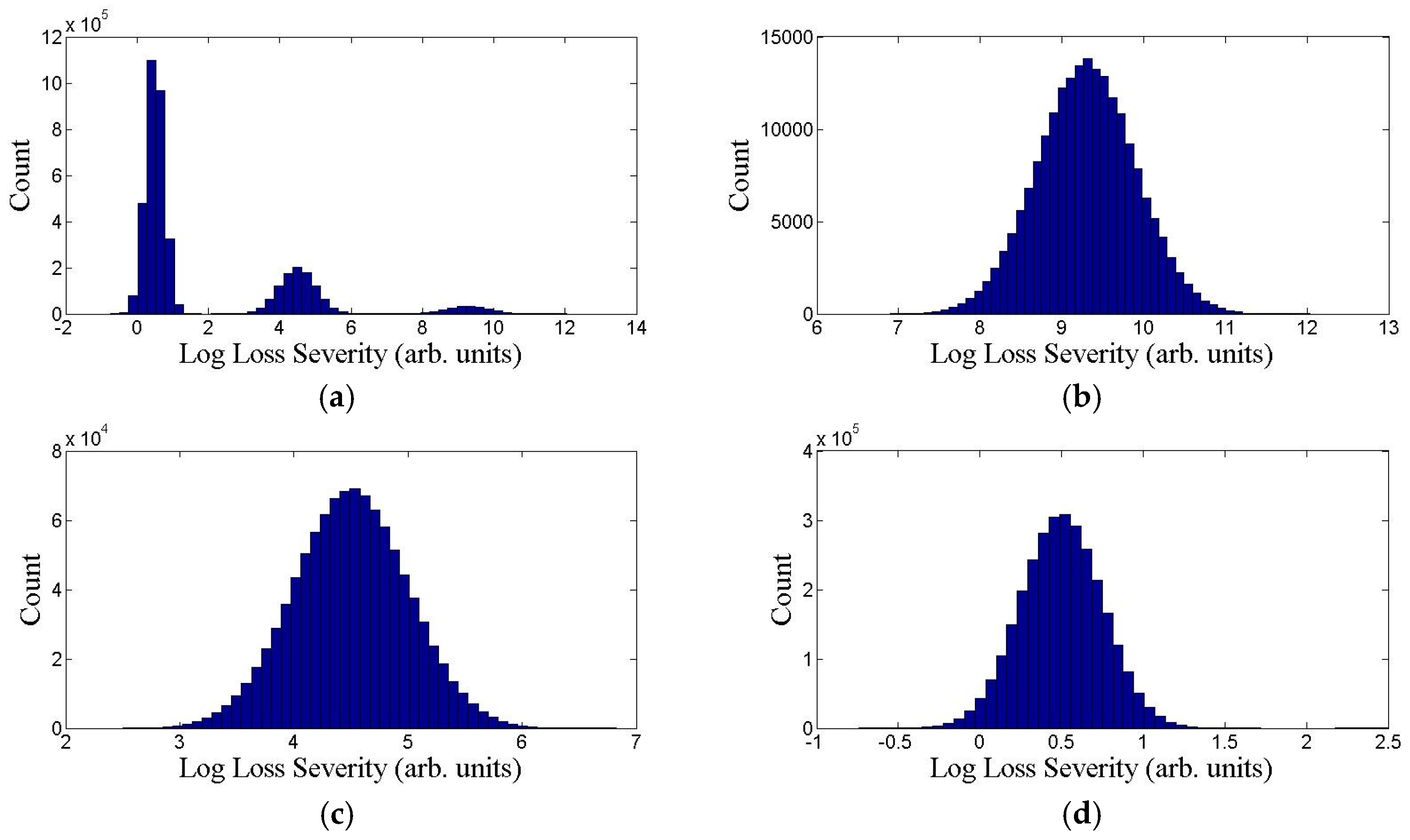
4. Simulated and Real-World Data
4.1. Simulated Data for Verification
4.2. Real-World Data for Validation
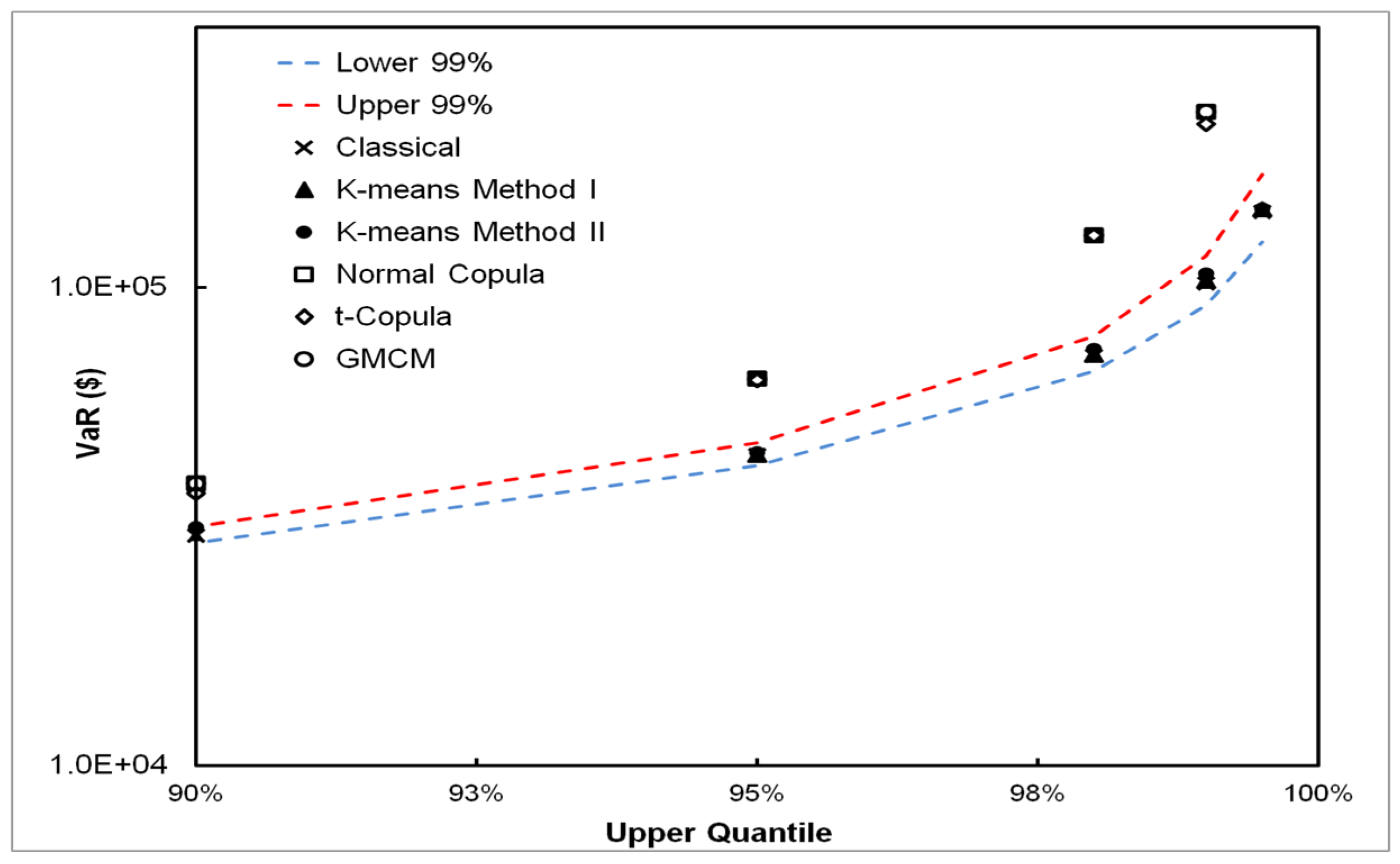
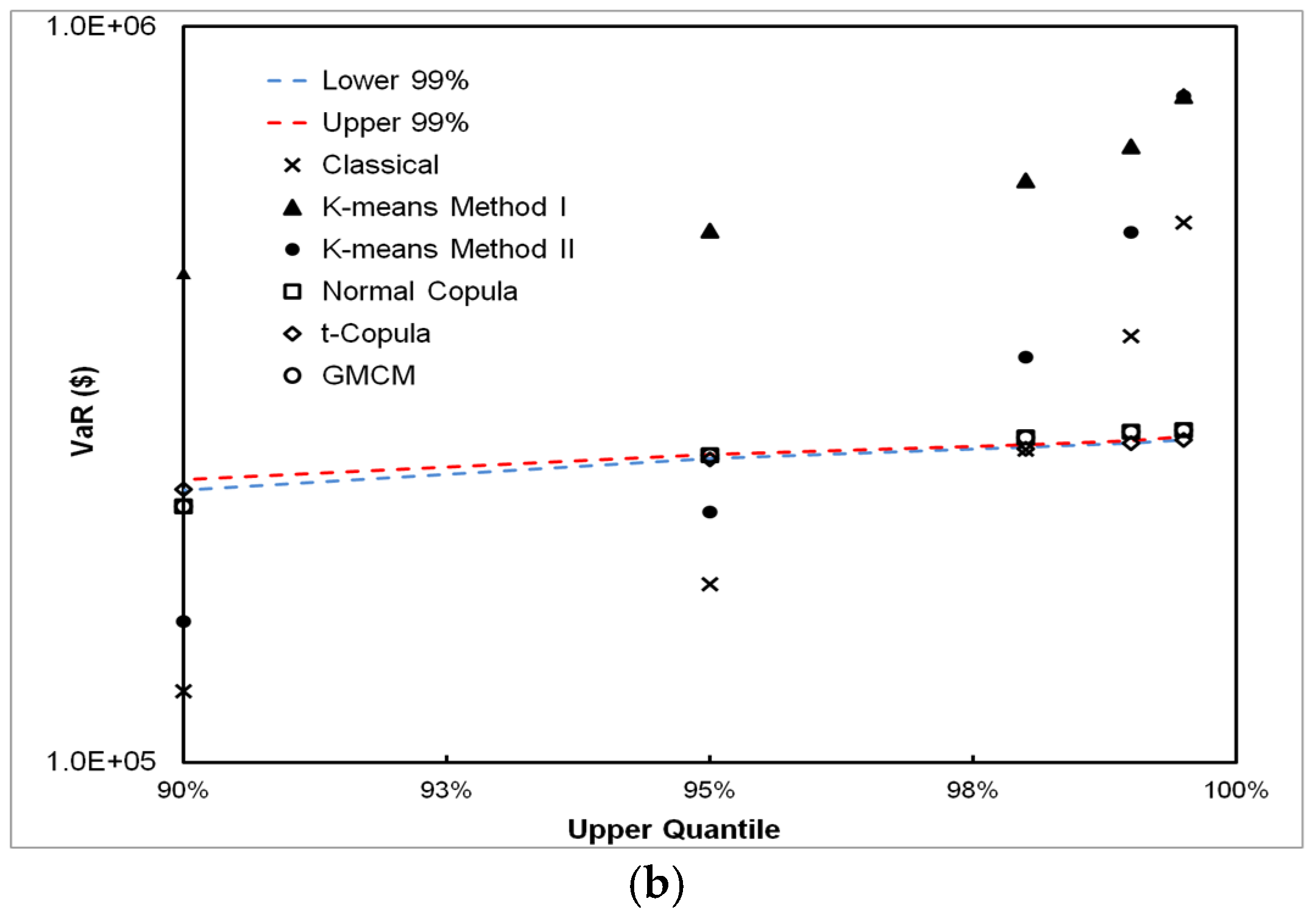
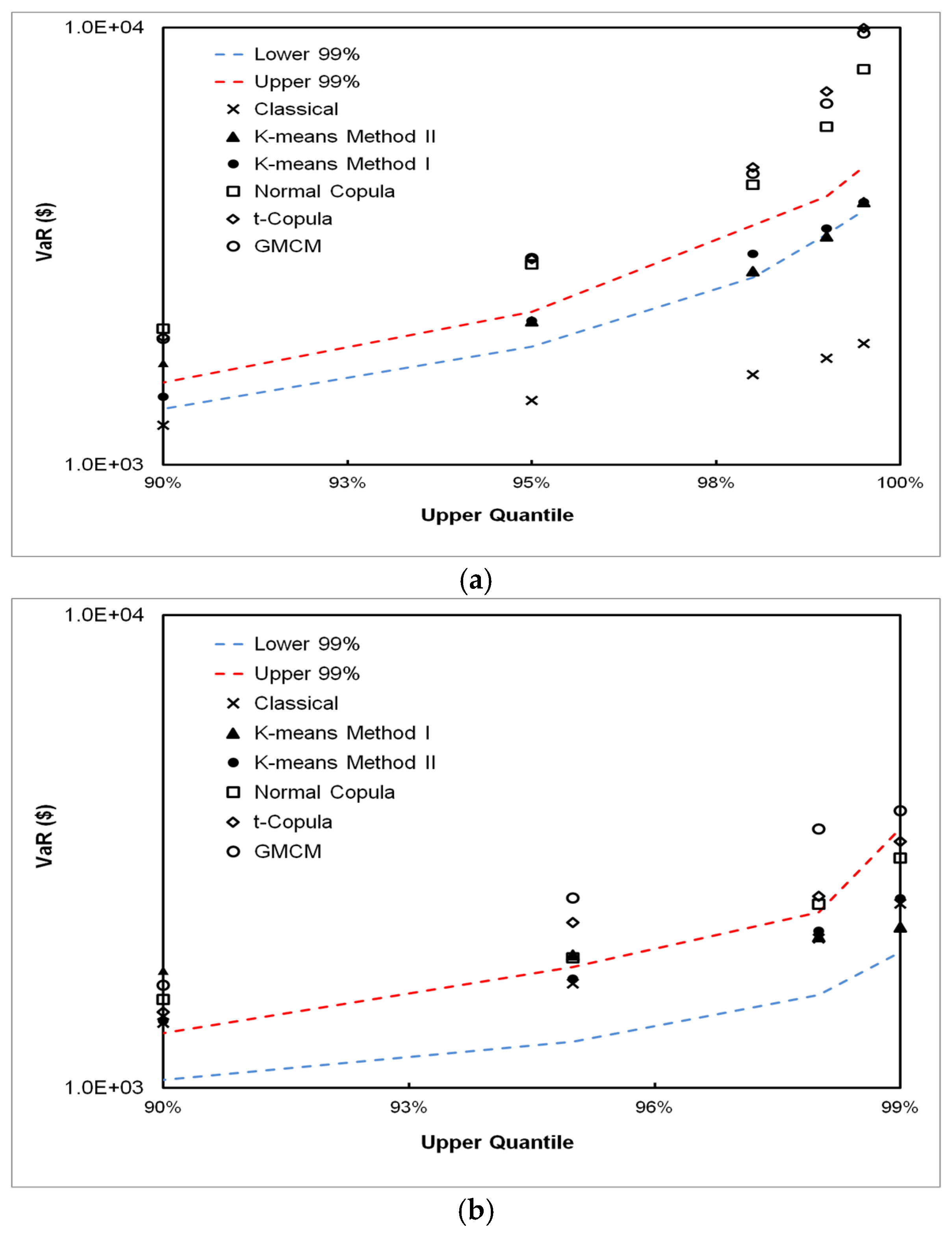
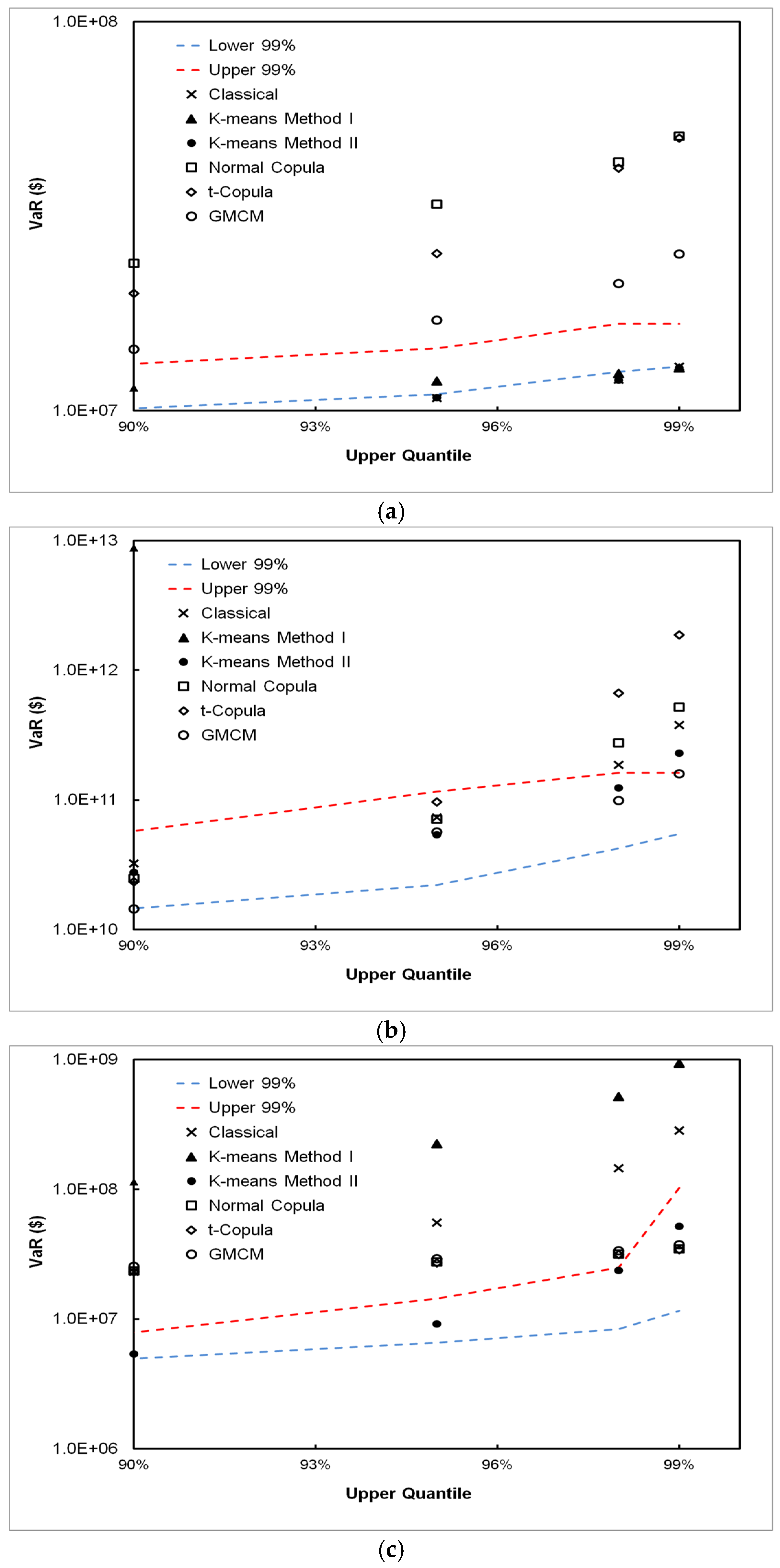
5. Results
5.1. DPFS Performance
5.2. CPFS Performance
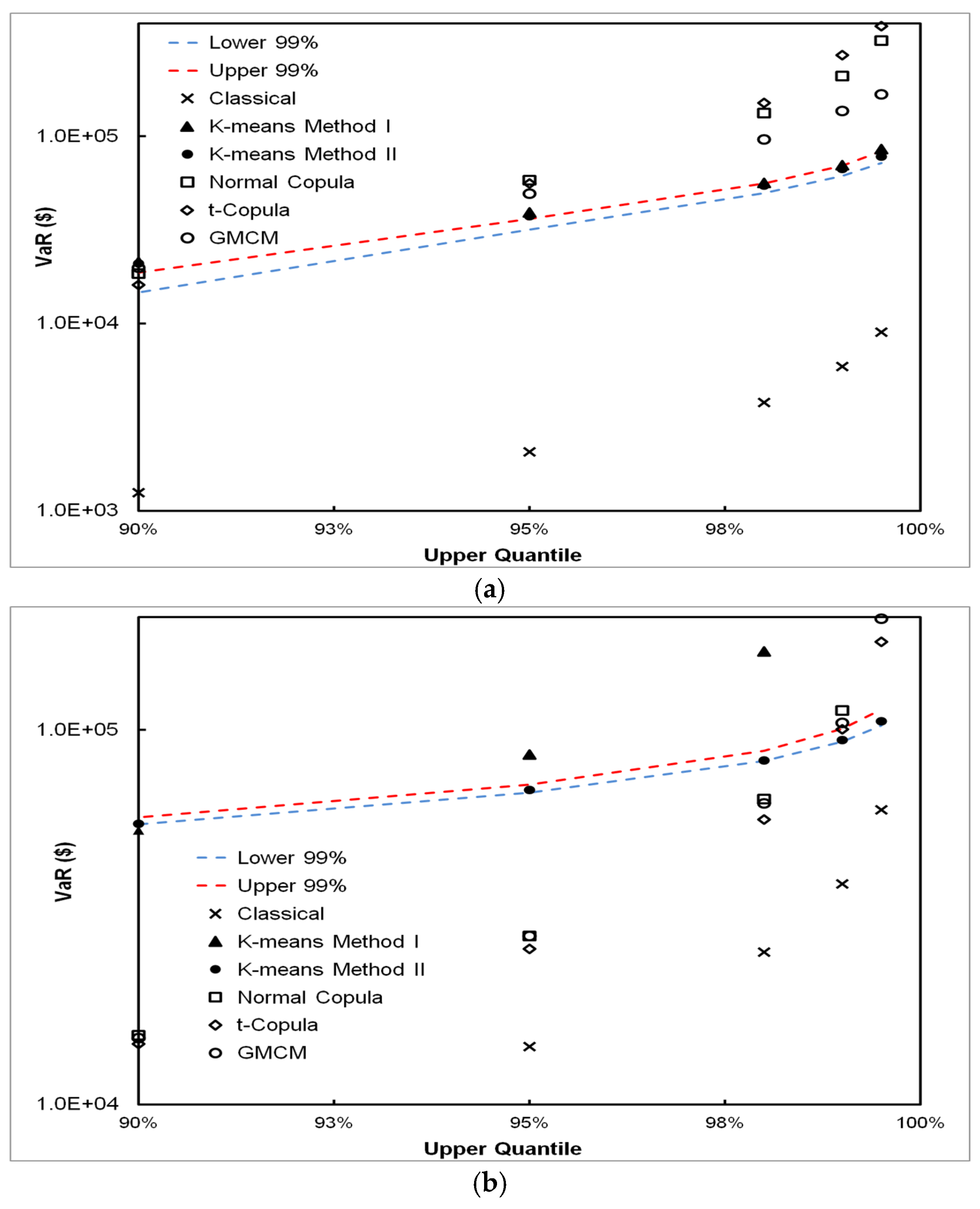
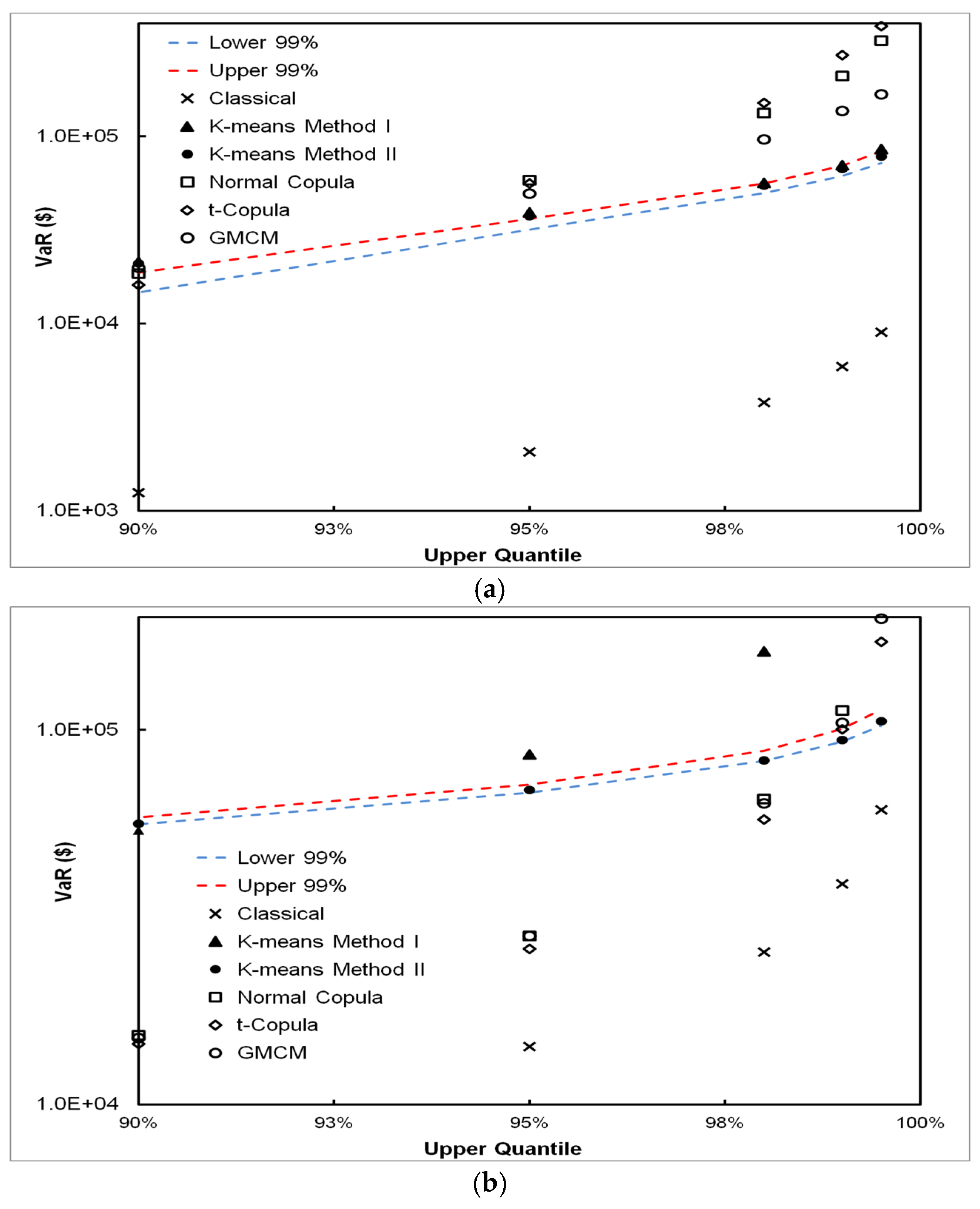
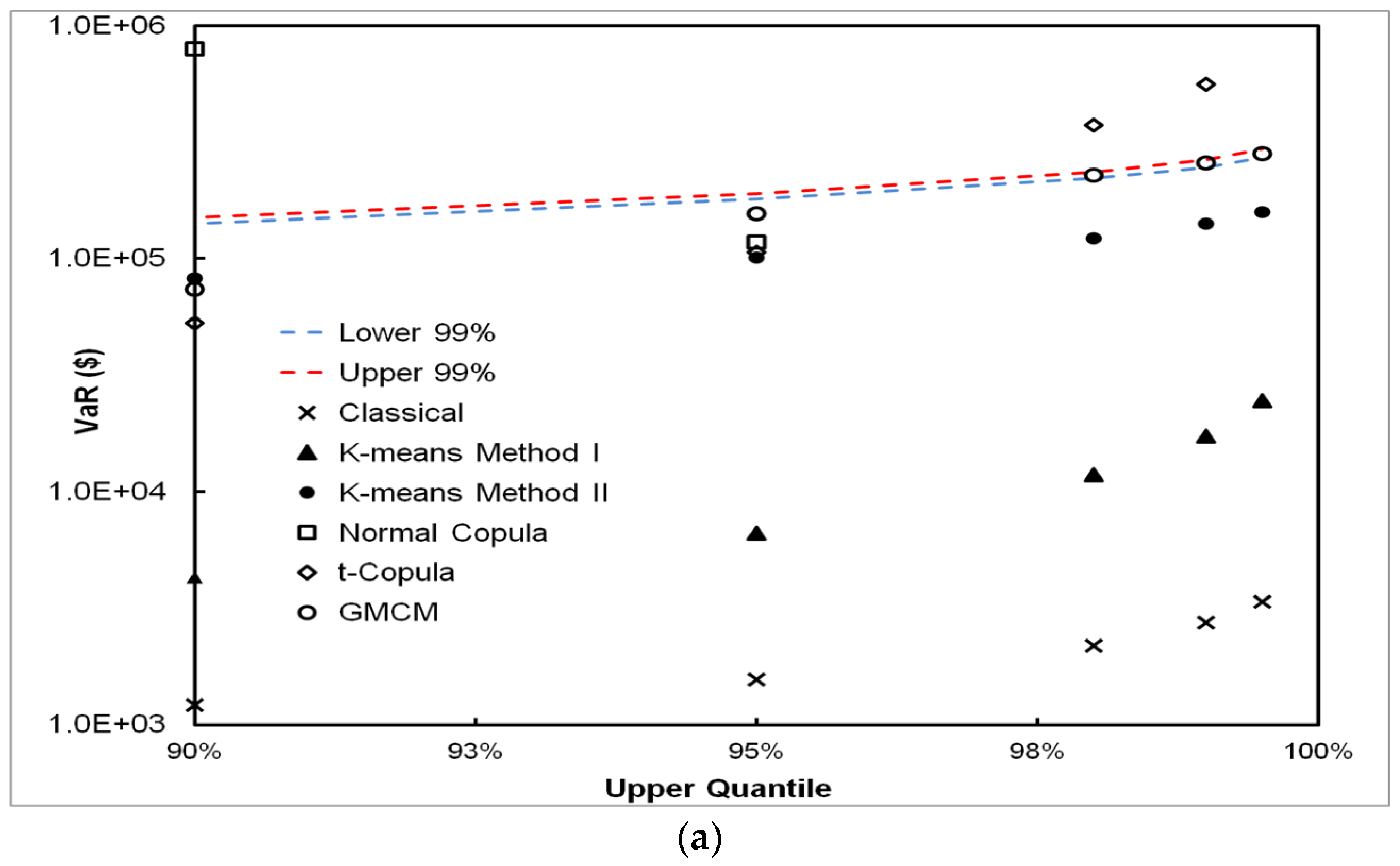
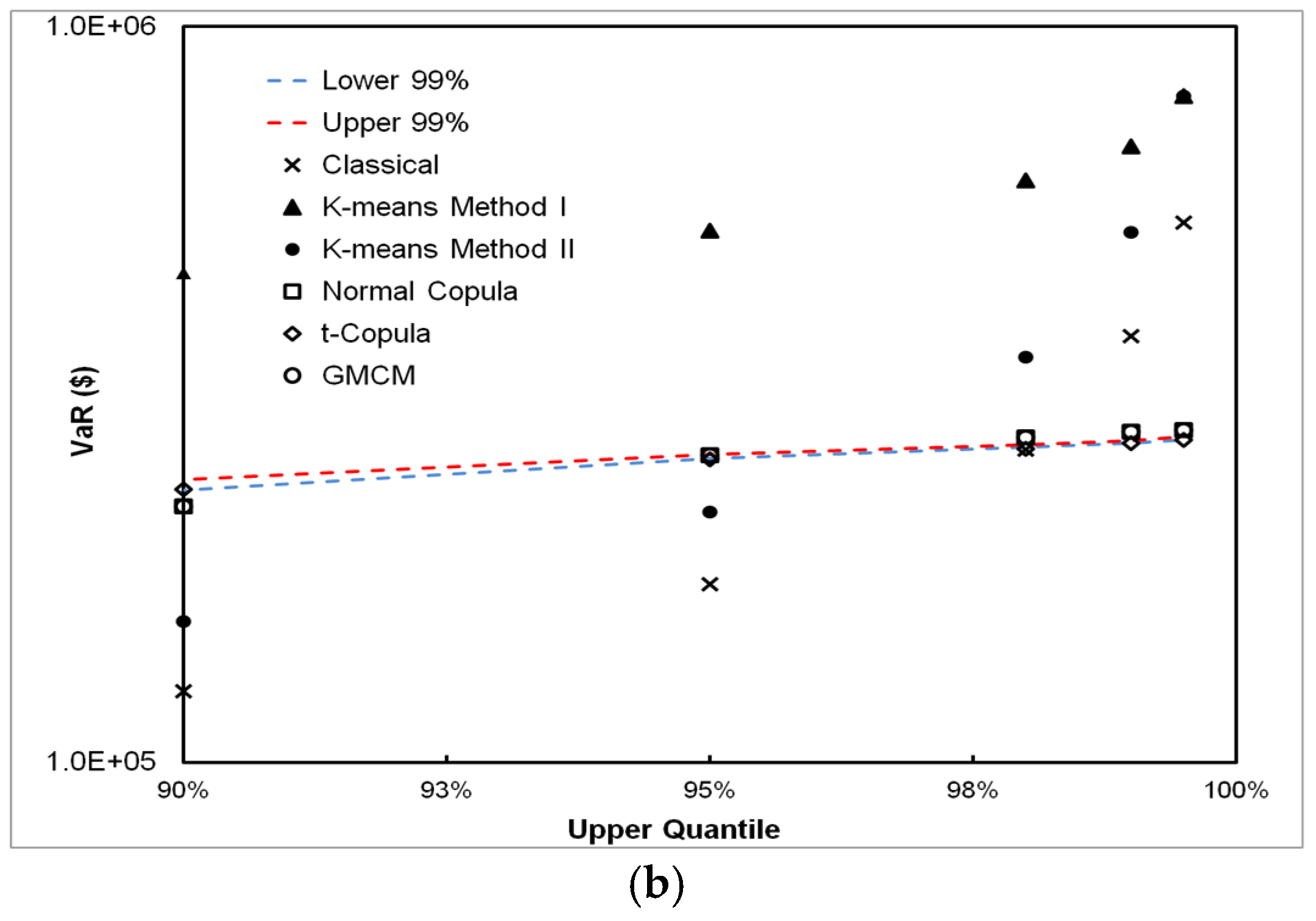
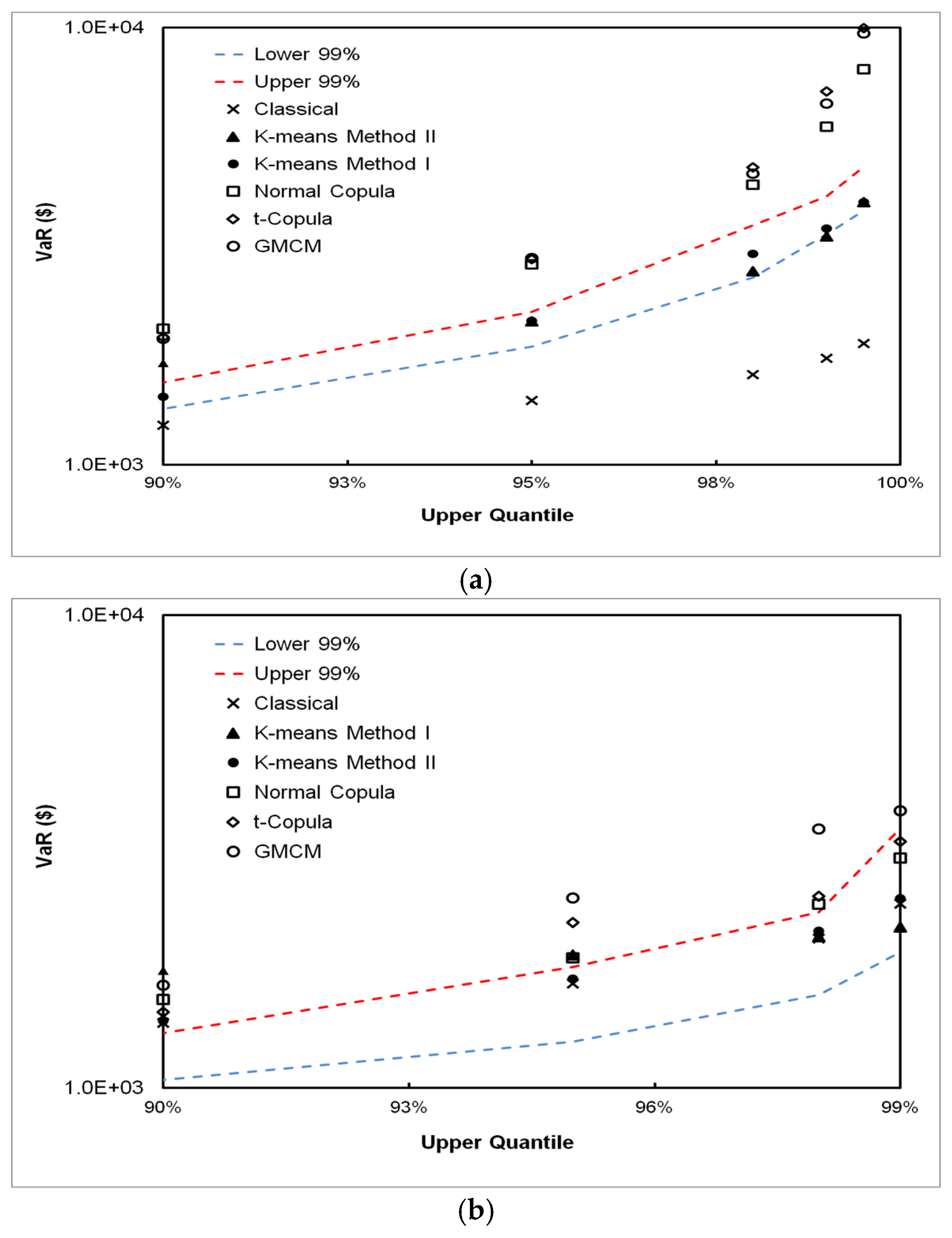
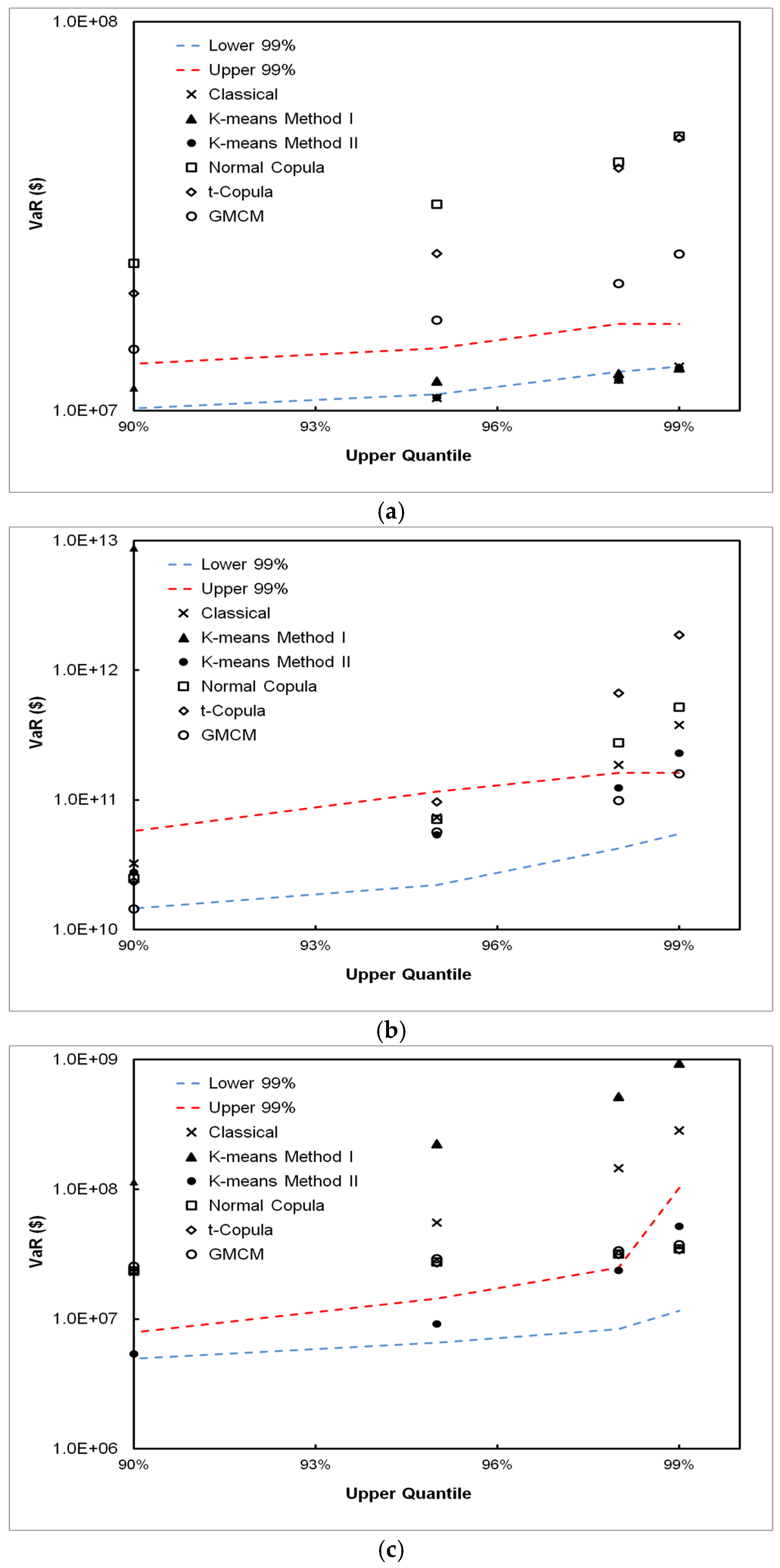
5.3. VaR Estimation Comparisons between Classical, CPFS and DPFS Approaches
6. Discussion
7. Conclusions
- (i)
- The classical approach works well if the independence assumption between frequency and severity approximately holds; however, it can grossly under or over-estimate VaR when this assumption does not hold. This is shown in both experiments on simulated and real-world data and through mathematical analysis, as described in the appendix.
- (ii)
- The DPFS method adapts to different frequency/severity relationships in which a finite partition can be found. In these situations, DPFS yields a robust VaR estimation.
- (iii)
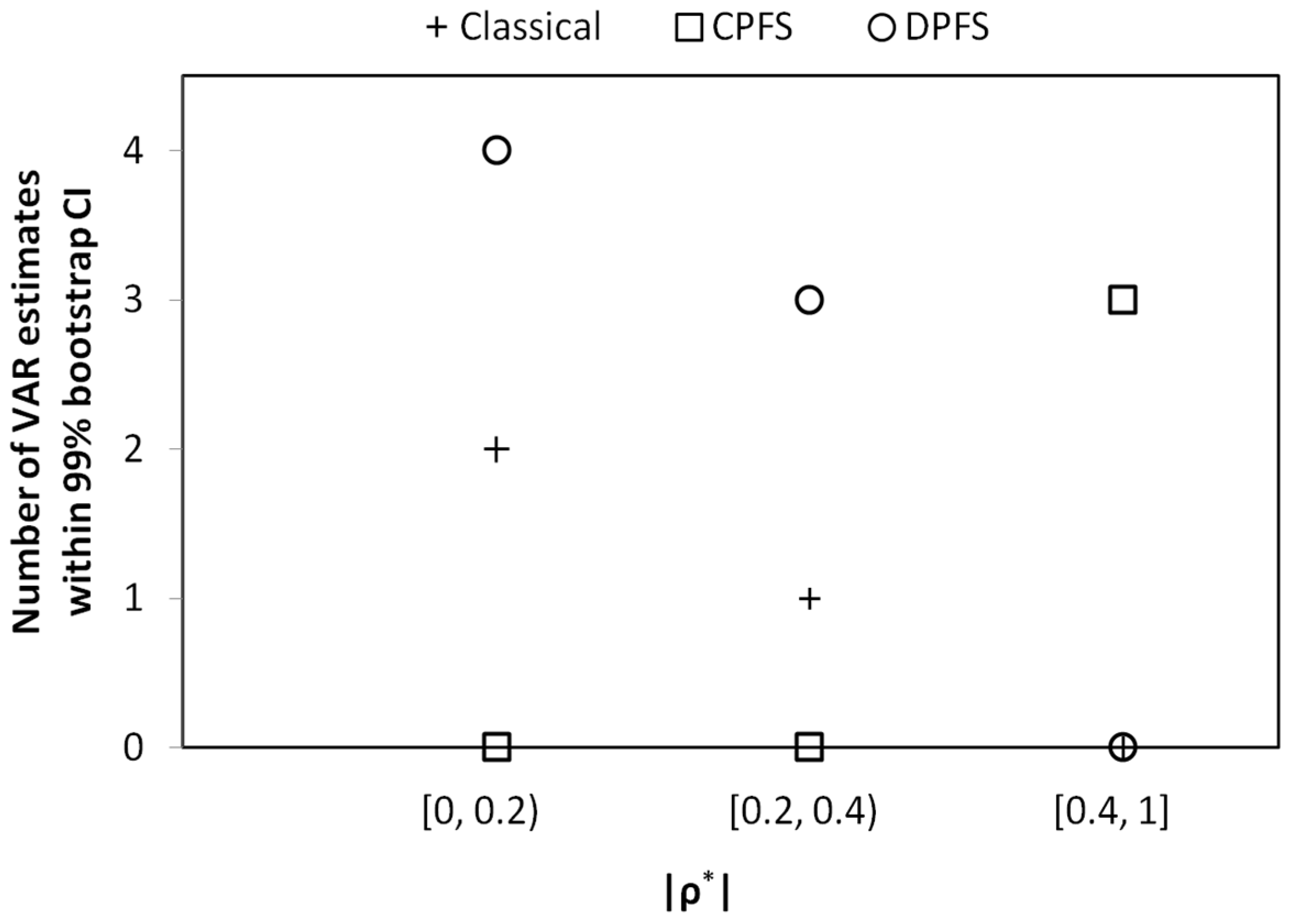
- The CPFS method works best where a reasonable positive/negative correlation, e.g., || 0.4, between loss frequency and loss severity exists.
- (iv)
- We have found that, for all simulated and real-world datasets, either the CPFS or the DPFS methodology provides the best VaR estimate. We have not found a single case where either CPFS or DPFS performs worse than the classical method in estimating VaR. Therefore, even in instances of loss datasets where independence between loss frequency and loss severity is observed, the classical methodology is not necessarily needed for robust VaR estimation.
- (v)
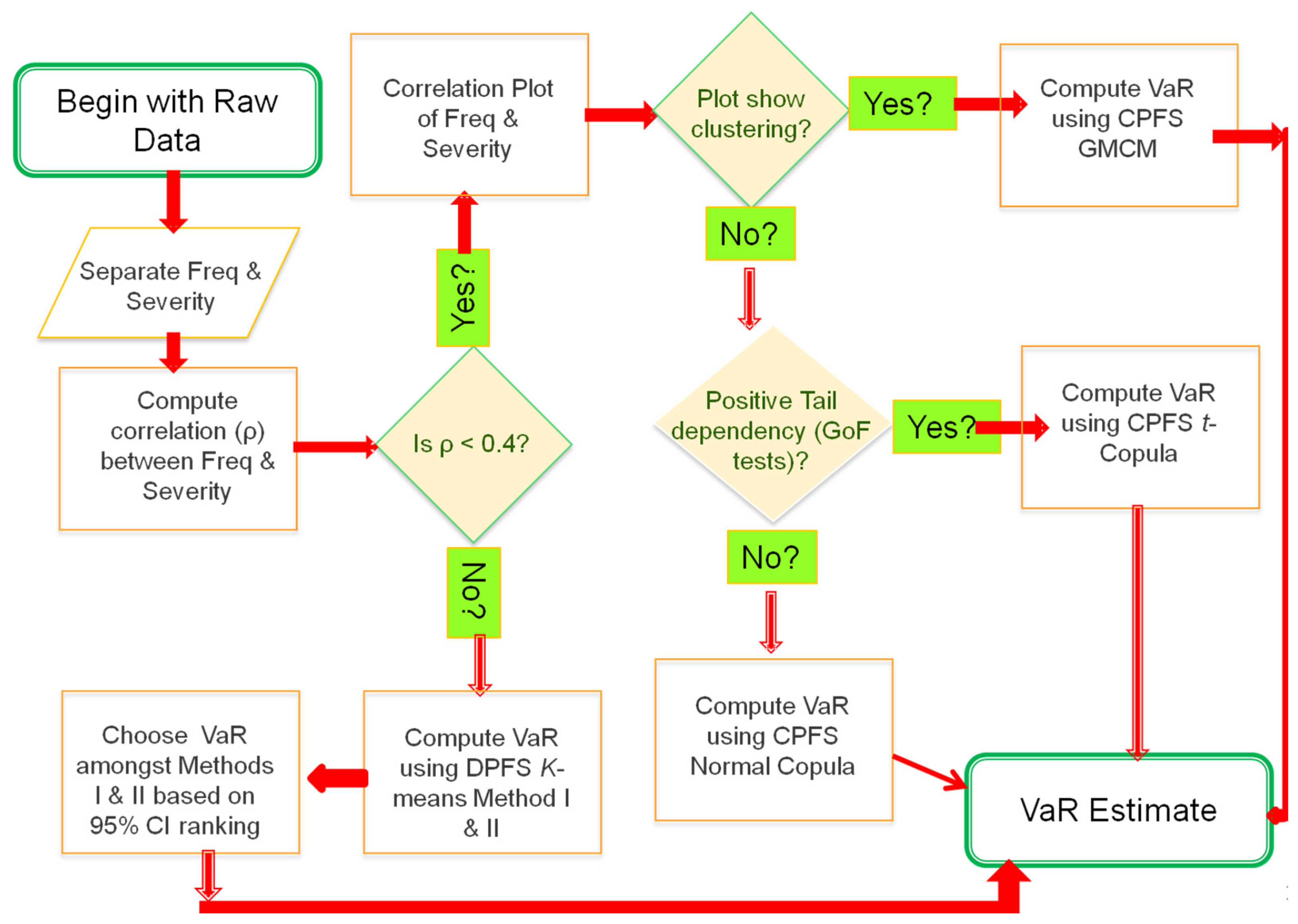
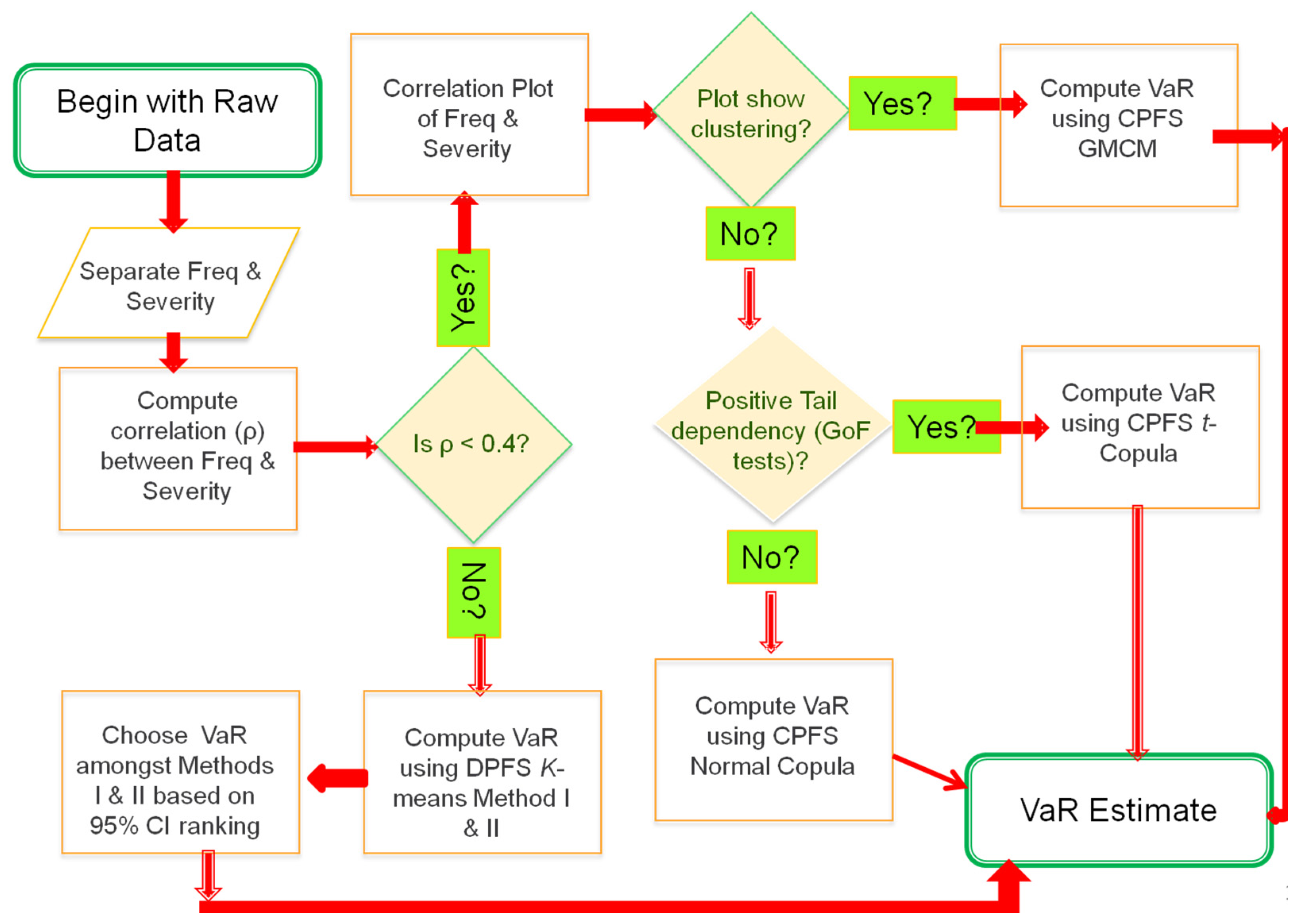
- We provide a flowchart that can help risk practitioners in selecting the appropriate VaR estimation methodology.
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proof of Proposition 1
Appendix B. Description of the Process for Generating Simulated Scenarios (I)–(V)
| Algorithm A1 Procedure for generating synthetic data corresponding to Scenario (I) |
| 1. For i = 1 to n months/years do (a) Generate a uniform random number, u ~ U[0, 1]. (I) If (u ≤ 1/2) then (I.1) Generate a random realization of λLow ~ Pois(2) (I.2) Generate discrete uniform (DU) random number m {1,2,3} (I.3) If (m = 1) then Generate losses ~ LN(0.5, 0.25) Elseif (m = 2) then Generate losses ~ LN(4.5, 0.5) Else Generate losses ~ LN(9.3, 0.6) End if (II) If (1/2 < u ≤ 5/6) then (II.1) Generate a random realization of λMedium ~ Pois(10) (II.2) Generate discrete uniform random number m {1,2} (II.3) If (m = 1) then Generate losses ~ LN(0.5, 0.25) Else Generate losses ~ LN(4.5, 0.5) End if (III) Else (III.1) Generate a random realization of λHigh ~ Pois(30) (III.2) Generate losses ~ LN(9.3, 0.6) End if (b) Return loss frequency (λLow/λMedium/λHigh) (c) Return loss severities for month/year i |
| 2. End for loop |
| Algorithm A2 Procedure for generating synthetic data corresponding to Scenario (II) |
| 1. For i = 1 to n months/years do (a) Generate a random realization of λLow ~ Pois(2) (I) Generate losses ~ LN(9.3, 0.6) (b) Generate a random realization of λMedium ~ Pois(10) (I) Generate losses ~ LN(4.5, 0.5) (c) Generate a random realization of λHigh ~ Pois(30) (I) Generate losses ~ LN(0.5, 0.25) (d) Compute frequency for month/year i = λLow + λMedium + λHigh (e) Return loss frequency (λLow + λMedium + λHigh) (f) Return loss severities for month/year i |
| 2. End for loop |
| Algorithm A3 Procedure for generating synthetic data corresponding to Scenario (III) |
| 1. For i = 1 to n months/years do (a) Generate a random realization of λunique ~ Pois(14) (I) Generate losses ~ LN(5, 2) (b)Return loss frequency (λunique) (c) Return loss severities for month/year i |
| 2. End for loop |
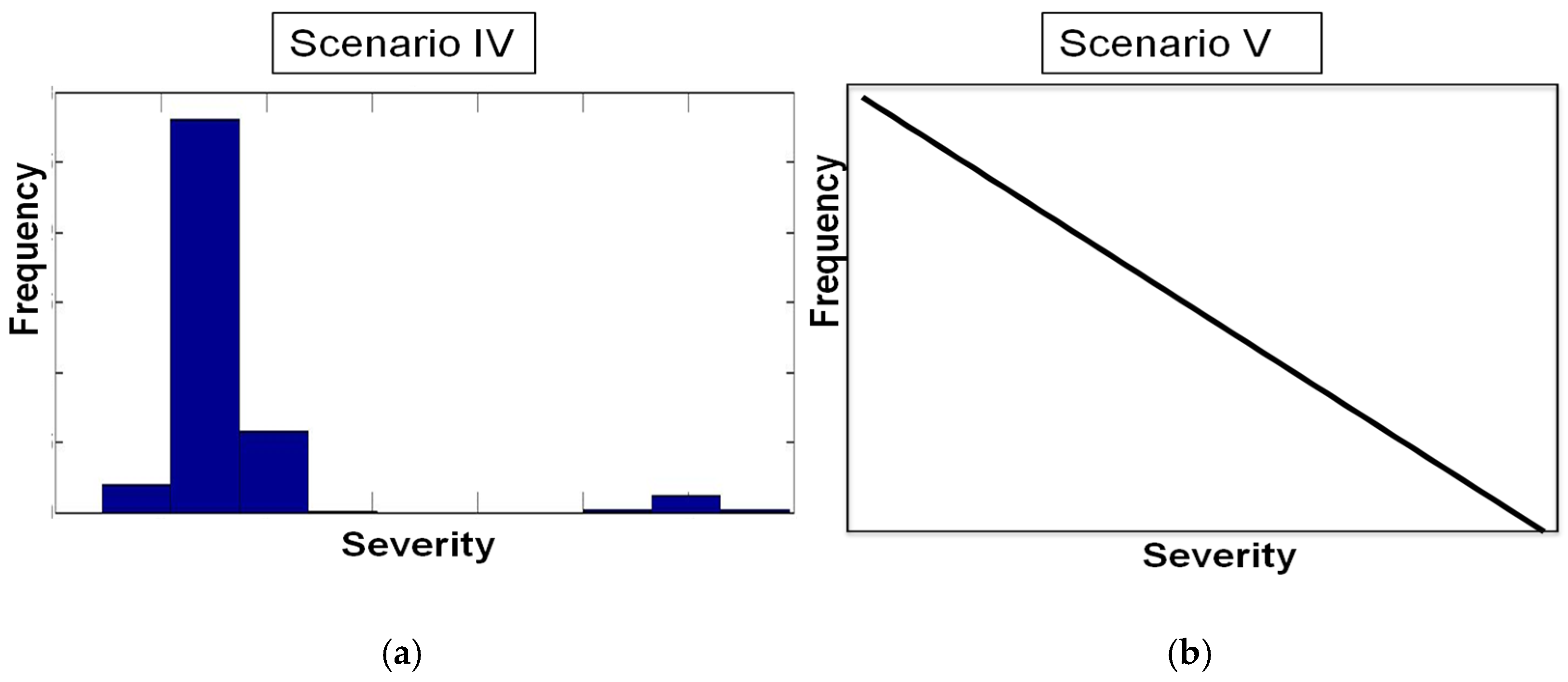
| Algorithm A4 Procedure for generating synthetic data corresponding to Scenario (IV) |
| 1. For i = 1 to n months/years do (a) Generate a uniform random number, u ~ U [0, 1]. (I) If (u ≤ 3/10) then (I.1) Generate a random realization of λLow ~ Pois(5) (I.2) Generate losses ~ LN(10, 0.5) Else (I.3) Generate a random realization of λLow ~ Pois(5) (I.4) Generate losses ~ LN(1, 0.5) End if (b) Return loss frequency (λLow/λHigh) (c) Return loss severities for month/year i |
| 2. End for loop |
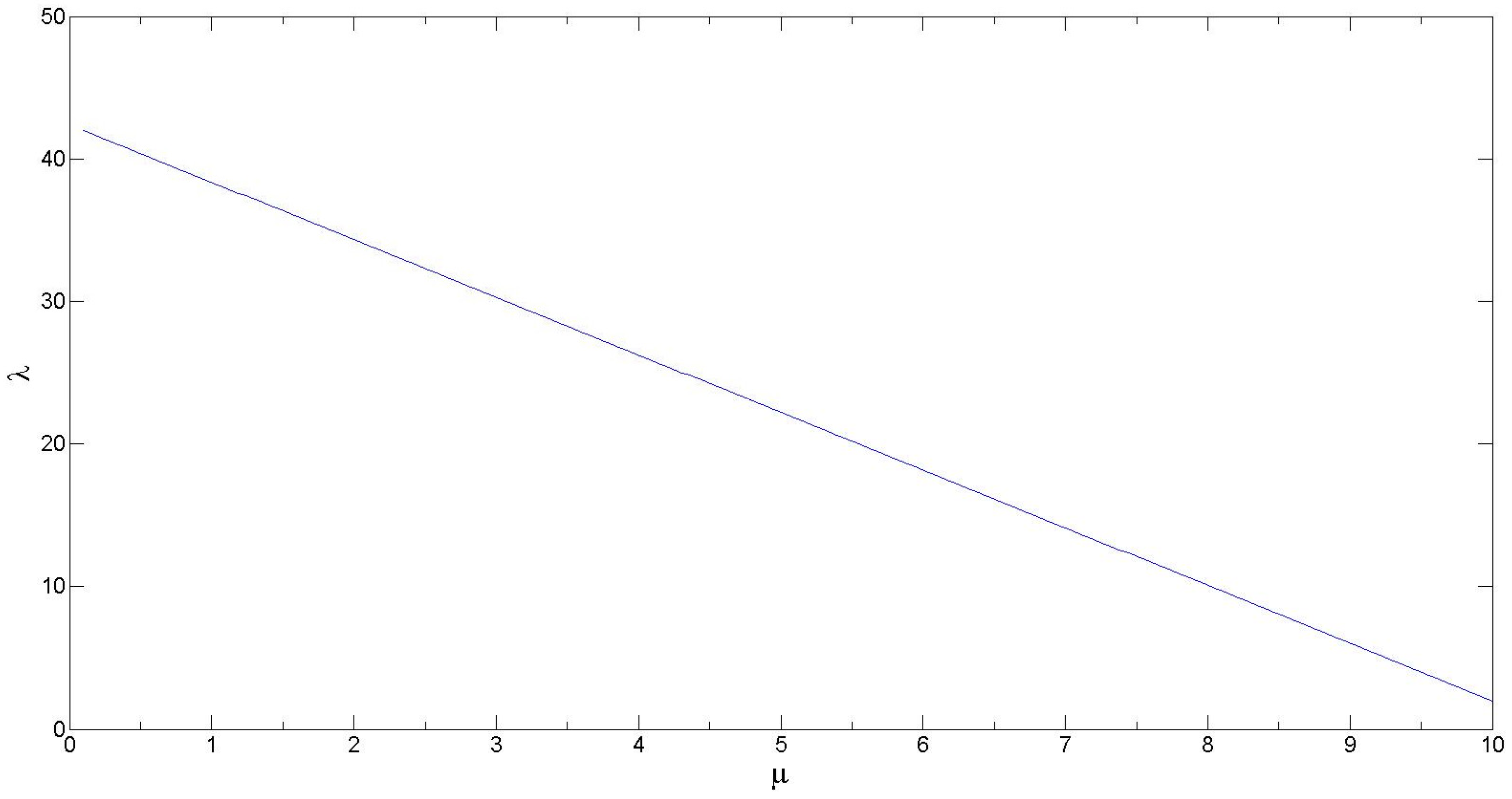
| Algorithm A5 Procedure for generating synthetic data corresponding to Scenario (V) |
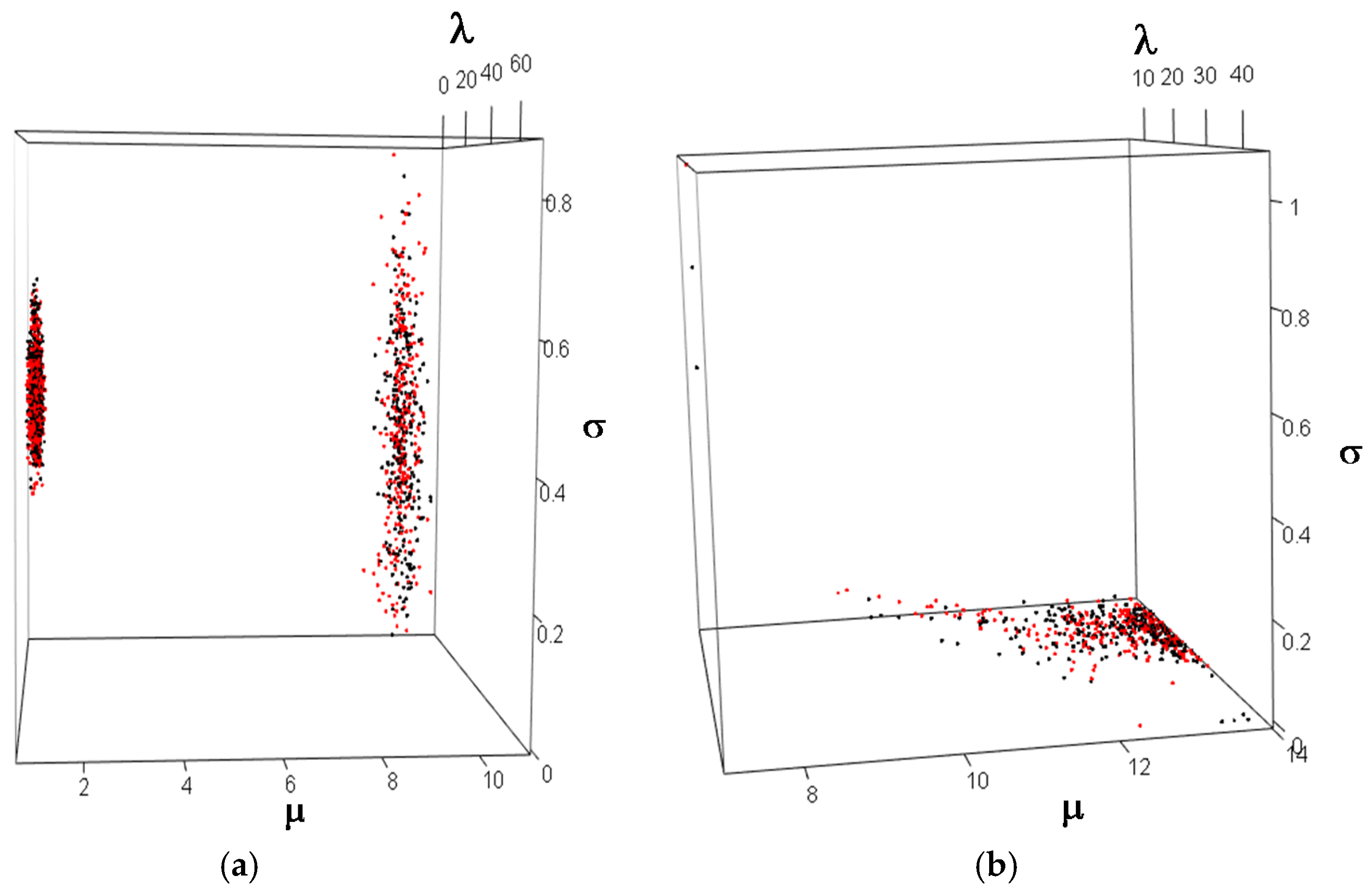
| 1. For i = 1 to n months/years do (a) Generate a discrete uniform random number, λFixed ~ DU[10, 210]. (b) Given a λFixed, calculate the corresponding μi from the Figure A1. (c) Generate losses ~ LN(μi, 0.1) (d) Return loss frequency (λFixed) for month/year i (e) Return loss severities for month/year i |
| 2. End for loop |
References
- OpRisk Advisory, and Towers Perrin. 2010. A New Approach for Managing Operational Risk: Addressing the Issues Underlying the 2008 Global Financial Crisis. Sponsored by Joint Risk Management, Section Society of Actuaries, Canadian Institute of Actuaries & Casualty Actuarial Society. Available online: https://www.soa.org/research-reports/2009/research-new-approach/ (accessed on 25 July 2017).
- Andersson, Frederick, Helmut Mausser, Dan Rosen, and Stanislav Uryasev. 2001. Credit risk optimization with conditional value-at-risk criterion. Mathematical Programming 89: 273–91. [Google Scholar] [CrossRef]
- Aue, Falko, and Michael Kalkbrener. 2006. LDA at work: Deutsche Bank’s approach to quantifying operational risk. Journal of Operational Risk 1: 49–93. [Google Scholar] [CrossRef]
- Balthazar, Laurent. 2006. From Basel 1 to Basel 3. In From Basel 1 to Basel 3: The Integration of State-of-the-Art Risk Modeling in Banking Regulation. London: Palgrave Macmillan, pp. 209–13. [Google Scholar]
- Bayestehtashk, Alireza, and Izhak Shafran. 2015. Efficient and accurate multivariate class conditional densities using copula. Paper presented at the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, QLD, Australia, April 19–24. [Google Scholar]
- Bilgrau, Anders E., Poul S. Eriksen, Jakob G. Rasmussen, Hans E. Johnsen, Karen Dybkær, and Martin Bøgsted. 2016. GMCM: Unsupervised clustering and meta-analysis using Gaussian mixture copula models. Journal of Statistical Software 70: 1–23. [Google Scholar] [CrossRef]
- Böcker, Klaus, and Claudia Klüppelberg. 2005. Operational VaR: A closed-form approximation. Risk-London-Risk Magazine Limited 18: 90. [Google Scholar]
- Böcker, Klaus, and Jacob Sprittulla. 2006. Operational VAR: Meaningful means. Risk 19: 96–98. [Google Scholar]
- Bose, Indranil, and Xi Chen. 2015. Detecting the migration of mobile service customers using fuzzy clustering. Information & Management 52: 227–38. [Google Scholar]
- Byeon, Yeong-Hyeon, and Kuen-Chang Kwak. 2015. Knowledge discovery and modeling based on Conditional Fuzzy Clustering with Interval Type-2 fuzzy. Paper presented at the 2015 7th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management (IC3K), Lisbon, Portugal, 12–14 November; vol. 1, pp. 440–44. [Google Scholar]
- Campbell, Sean D. 2006. A review of backtesting and backtesting procedures. The Journal of Risk 9: 1. [Google Scholar] [CrossRef]
- Charpentier, Arthur, ed. 2014. Computational Actuarial Science with R. Boca Raton: CRC Press. [Google Scholar]
- Chavez-Demoulin, Valérie, Paul Embrechts, and Marius Hofert. 2016. An extreme value approach for modeling operational risk losses depending on covariates. Journal of Risk and Insurance 83: 735–76. [Google Scholar] [CrossRef]
- Chen, Yen-Liang, and Hui-Ling Hu. 2006. An overlapping cluster algorithm to provide non-exhaustive clustering. European Journal of Operational Research 173: 762–80. [Google Scholar]
- Cossin, Didier, Henry Schellhorn, Nan Song, and Satjaporn Tungsong. 2010. A Theoretical Argument Why the t-Copula Explains Credit Risk Contagion Better than the Gaussian Copula. Advances in Decision Sciences 2010: 1–29, Article ID 546547. [Google Scholar] [CrossRef]
- Data available at National Response Center. Available online: http://nrc.uscg.mil/ (accessed on 1 January 2016).
- Data available from Yahoo Finance. 2017. Available online: https://finance.yahoo.com/quote/%5EDJI/history?p=%5EDJI(DJIA); https://finance.yahoo.com/quote/%5EGSPC/history?p=%5EGSPC (S & P 500) (accessed on 1 January 2016).
- Dias, Alexandra. 2013. Market capitalization and Value-at-Risk. Journal of Banking & Finance 37: 5248–60. [Google Scholar]
- Embrechts, Paul, and Marius Hofert. 2014. Statistics and quantitative risk management for banking and insurance. Annual Review of Statistics and Its Application 1: 493–514. [Google Scholar] [CrossRef]
- Embrechts, Paul, Bin Wang, and Ruodu Wang. 2015. Aggregation-robustness and model uncertainty of regulatory risk measures. Finance and Stochastics 19: 763–90. [Google Scholar] [CrossRef]
- Giles, Mike. 2011. Approximating the erfinv function. GPU Computing Gems 2: 109–16. [Google Scholar]
- Gomes-Gonçalves, Erika, and Henryk Gzyl. 2014. Disentangling frequency models. Journal of Operational Risk 9: 3–21. [Google Scholar] [CrossRef]
- Guharay, Sabyasachi. 2016. Methodological and Empirical Investigations in Quantification of Modern Operational Risk Management. Ph.D. Dissertation, George Mason University, Fairfax, VA, USA, August. [Google Scholar]
- Guharay, Sabyasachi, and KC Chang. 2015. An application of data fusion techniques in quantitative operational risk management. Paper presented at the 2015 18th International Conference on In Information Fusion (Fusion), Washington, DC, USA, 6–9 July; pp. 1914–21. [Google Scholar]
- Guharay, Sabyasachi, KC Chang, and Jie Xu. 2016. Robust Estimation of Value-at-Risk through Correlated Frequency and Severity Model. Paper presented at the 2016 19th International Conference on Information Fusion (Fusion), Heidelberg, Germany, 5–8 July; pp. 995–1002. [Google Scholar]
- Hirschinger, Micha, Alexander Spickermann, Evi Hartmann, Heiko Gracht, and Inga-Lena Darkow. 2015. The Future of Logistics in Emerging Markets—Fuzzy Clustering Scenarios Grounded in Institutional and Factor-Market Rivalry Theory. Journal of Supply Chain Management 51: 73–93. [Google Scholar] [CrossRef]
- Hull, John C. 2015. Risk Management and Financial Institutions, 4th Edition ed. Hoboken: John Wiley & Sons. [Google Scholar]
- Kaufman, Leonard, and Peter J. Rousseeuw. 2009. Finding Groups in Data: an Introduction to Cluster Analysis. Hoboken: John Wiley & Sons, vol. 344. [Google Scholar]
- Kojadinovic, Ivan, and Jun Yan. 2010. Modeling multivariate distributions with continuous margins using the copula R package. Journal of Statistical Software 34: 1–20. [Google Scholar] [CrossRef]
- Kojadinovic, Ivan, and Jun Yan. 2011. A goodness-of-fit test for multivariate multiparameter copulas based on multiplier central limit theorems. Statistics and Computing 21: 17–30. [Google Scholar] [CrossRef]
- Kole, Erik, Kees Koedijk, and Marno Verbeek. 2007. Selecting copulas for risk management. Journal of Banking & Finance 31: 2405–23. [Google Scholar]
- Li, Jianping, Xiaoqian Zhu, Yongjia Xie, Jianming Chen, Lijun Gao, Jichuang Feng, and Wujiang Shi. 2014. The mutual-information-based variance-covariance approach: An application to operational risk aggregation in Chinese banking. The Journal of Operational Risk 9: 3–19. [Google Scholar] [CrossRef]
- MacKay, David J.C. 2003. Information Theory, Inference and Learning Algorithms. Cambridge: Cambridge University Press. [Google Scholar]
- Mancini, Loriano, and Fabio Trojani. 2011. Robust value at risk prediction. Journal of financial econometrics 9: 281–313. [Google Scholar] [CrossRef]
- Martinez, Wendy L., and Angel R. Martinez. 2007. Computational Statistics Handbook with MATLAB. Boca Raton: CRC Press, vol. 22. [Google Scholar]
- Mehta, Neelesh B., Jingxian Wu, Andreas F. Molisch, and Jin Zhang. 2007. Approximating a sum of random variables with a lognormal. IEEE Transactions on Wireless Communications 6: 2690–99. [Google Scholar] [CrossRef]
- Nelsen, Roger B. 2007. An Introduction to Copulas. Berlin and Heidelberg: Springer Science & Business Media. [Google Scholar]
- Panchenko, Valentyn. 2005. Goodness-of-fit test for copulas. Physica A: Statistical Mechanics and its Applications 355: 176–82. [Google Scholar] [CrossRef]
- Panjer, Harry. 2006. Operational Risk: Modeling Analytics. Hoboken: John Wiley & Sons, vol. 620. [Google Scholar]
- Rachev, Svetlozar T., Anna Chernobai, and Christian Menn. 2006. Empirical examination of operational loss distributions. Perspectives on Operations Research DUV: 379–401. [Google Scholar]
- Sklar, Abe. 1959. Fonctions de Répartition À N Dimensions Et Leurs Marges. Paris: Publications de l’Institut de Statistique de l’Université de Paris, pp. 229–31. [Google Scholar]
- Tewari, Ashutosh, Michael J. Giering, and Arvind Raghunathan. 2011. Parametric characterization of multimodal distributions with non-Gaussian modes. Paper presented at the 2011 IEEE 11th International Conference on Data Mining Workshops, Vancouver, BC, Canada, 11 December; pp. 286–92. [Google Scholar]
- Wang, Wenzhou, Limeng Shi, and Xiaoqian Zhu. 2016. Operational Risk Aggregation Based on Business Line Dependence: A Mutual Information Approach. Discrete Dynamics in Nature and Society 2016: 1–7. [Google Scholar] [CrossRef]
- Wipplinger, Evert. 2007. Philippe Jorion: Value at Risk—The New Benchmark for Managing Financial Risk. Financial Markets and Portfolio Management 21: 397–98. [Google Scholar] [CrossRef]
- Wu, Juan, Xue Wang, and Stephen G. Walker. Bayesian nonparametric inference for a multivariate copula function. Methodology and Computing in Applied Probability 16: 747–63.
- Xu, Rui, and Donald C. Wunsch. 2009. Clustering. Hoboken: Wiley-IEEE Press. [Google Scholar]
- Xu, Rui, Jie Xu, and Donald C. Wunsch. 2010. Clustering with differential evolution particle swarm optimization. Paper presented at the 2010 IEEE Congress on Evolutionary Computation (CEC), Barcelona, Spain, 18–23 July; pp. 1–8. [Google Scholar]
- Xu, Rui, Jie Xu, and Donald C. Wunsch. 2012. A comparison study of validity indices on swarm intelligence-based clustering. IEEE Transactions on Systems Man and Cybernetics Part B 42: 1243–56. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | VaR Estimation Methodology | |||
|---|---|---|---|---|
| DPFS | CPFS | Classical | ||
| Simulated Scenarios Data | Scenario I: Hi/Med/Low Severity → Hi/Med/Low Frequency (One-to-Many) | X | ||
| Scenario II: Hi/Med/Low Severity → Hi/Med/Low Frequency (1-to-1) | X | |||
| Scenario III: Frequency Independent Severity | Δ | |||
| Scenario IV: Hi/Low Severity Mixture → Hi/Low Frequency | X | |||
| Scenario V: Perfect Correlation between Frequency & Severity | X | |||
| Real-World Data | S&P 500 | X | ||
| DJIA | Δ | |||
| Chemical Spills | X | |||
| Automobile Accidents | Δ | Δ | ||
| US Hurricanes | X | |||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guharay, S.; Chang, K.; Xu, J. Robust Estimation of Value-at-Risk through Distribution-Free and Parametric Approaches Using the Joint Severity and Frequency Model: Applications in Financial, Actuarial, and Natural Calamities Domains. Risks 2017, 5, 41. https://doi.org/10.3390/risks5030041
Guharay S, Chang K, Xu J. Robust Estimation of Value-at-Risk through Distribution-Free and Parametric Approaches Using the Joint Severity and Frequency Model: Applications in Financial, Actuarial, and Natural Calamities Domains. Risks. 2017; 5(3):41. https://doi.org/10.3390/risks5030041
Chicago/Turabian StyleGuharay, Sabyasachi, KC Chang, and Jie Xu. 2017. "Robust Estimation of Value-at-Risk through Distribution-Free and Parametric Approaches Using the Joint Severity and Frequency Model: Applications in Financial, Actuarial, and Natural Calamities Domains" Risks 5, no. 3: 41. https://doi.org/10.3390/risks5030041
APA StyleGuharay, S., Chang, K., & Xu, J. (2017). Robust Estimation of Value-at-Risk through Distribution-Free and Parametric Approaches Using the Joint Severity and Frequency Model: Applications in Financial, Actuarial, and Natural Calamities Domains. Risks, 5(3), 41. https://doi.org/10.3390/risks5030041