1. Introduction
The concept of a trend has been fundamental in the field of technical analysis since Charles H. Dow introduced this term in the late 19th century. Following Rhea [
1], Dow said, e.g., concerning the characterization of
up-trends:
Successive rallies penetrating preceding high points, with ensuing declines terminating above preceding low points, offer a bullish indication.
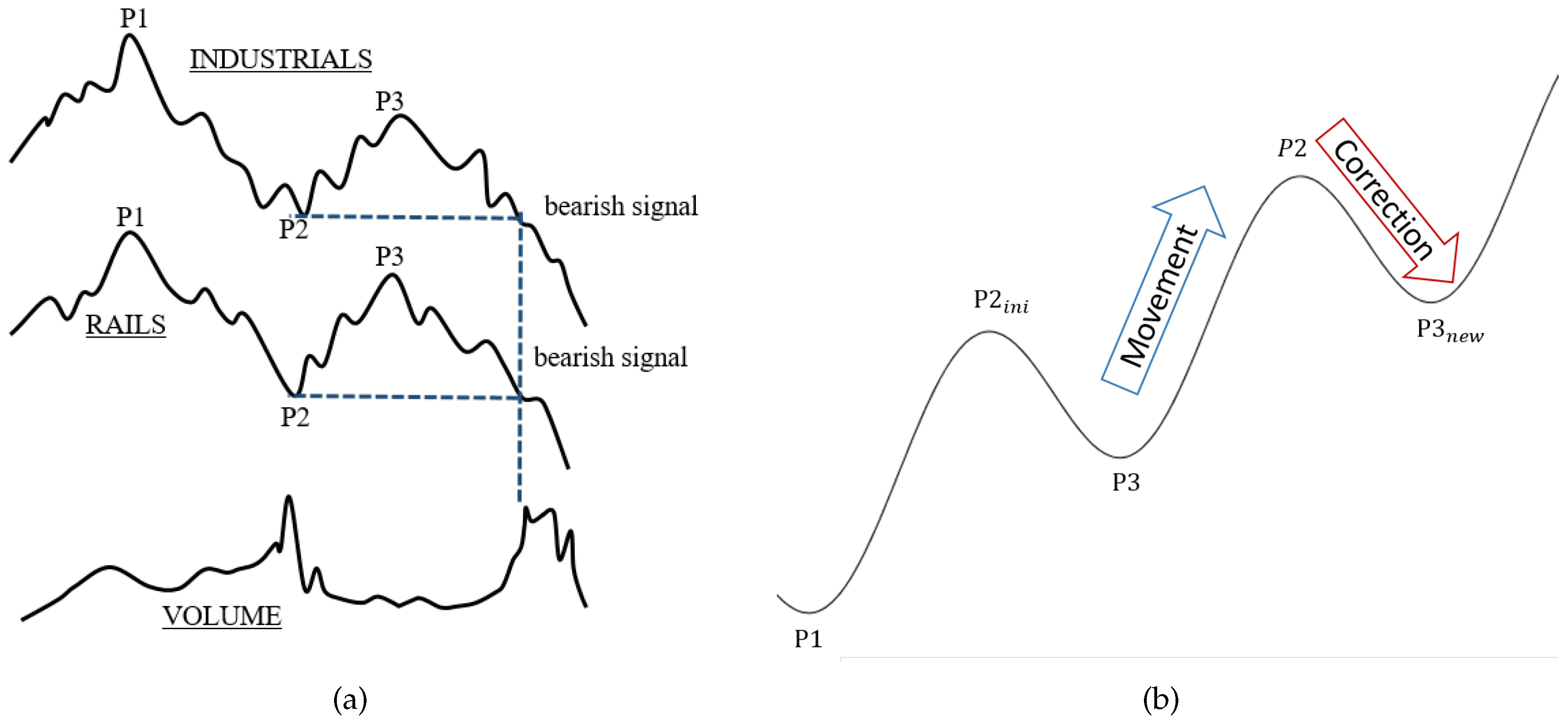
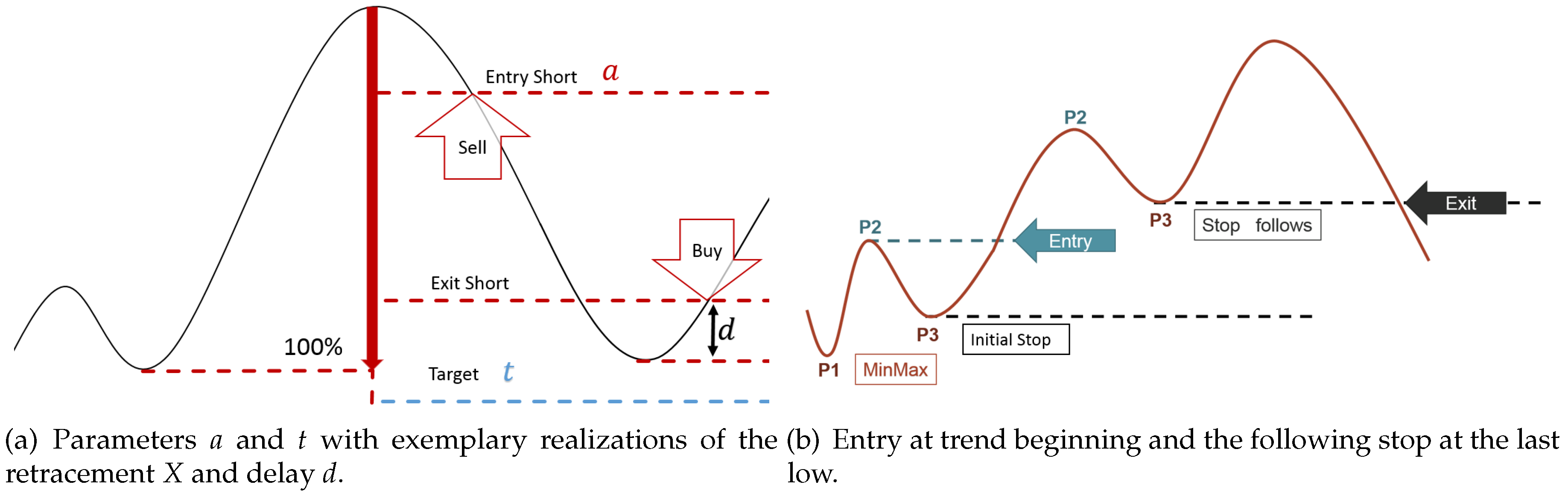
In
Figure 1a, an example of the inverse situation, a
down-trend, is given in a historical setup as Dow used it. Although this idea of a trend is so far “just” geometrical and clearly not precise at all, it is widely accepted among many market participants. Therefore, this geometric idea is fixed by the following market-technical definition of a Dow-trend, which is also employed in this article:
Definition 1 (market-technical trend or Dow-trend). A market is in an
up-/down-trend if and only if (at least) the two last relevant
lows (denoted by P1 and P3 in an up-trend) and
highs (denoted by P2 in an up-trend) are monotonically increasing/decreasing (see
Figure 1b). Otherwise, the market is temporarily
trendless. In the case of an up-trend, the phase between a low and the next high is called the
movement. In the same manner, the phase between a high and the following low is called the
correction. In case of a down-trend, movement and correction are defined in the exact opposite way.
It is to analyze these Dow-trends as they occur in real-world markets within a statistical framework. In order to do so, however, a mathematical exact method on how to determine relevant lows and highs of price data is necessary.
While the task to detect the extreme points in the theoretical
Figure 1b itself is trivial, it is not as easy when a real price chart is considered (see
Figure 3). This can be explained by the continuous price fluctuations, and hence, the extreme points
P1 −
P3 are hard to detect. The issue of detection is rooted in the subjectivity of the distinction between usual fluctuations and new extreme points. This is to say: the significance of an extreme point has to be evaluated in an algorithmic way to make automatic detection possible. Therefore, referring to Maier-Paape, the framework that is necessary for automatic trend-detection will be reviewed in
Section 2 [
2]. The trend-detection, in turn, is rooted in the automatic recognition of relevant minima and maxima in charts. With that at hand, empirical studies of trend data can be conducted as seen in [
3,
4]. On the one hand, in [
3], Hafizogullari, Maier-Paape and Platen collected several statistics on the performance of Dow-trends. On the other hand, in [
4], Maier-Paape and Platen constructed a geometrical method on how to detect lead and lag when two markets are directly compared, also based on the automatic detection of relevant highs and lows.
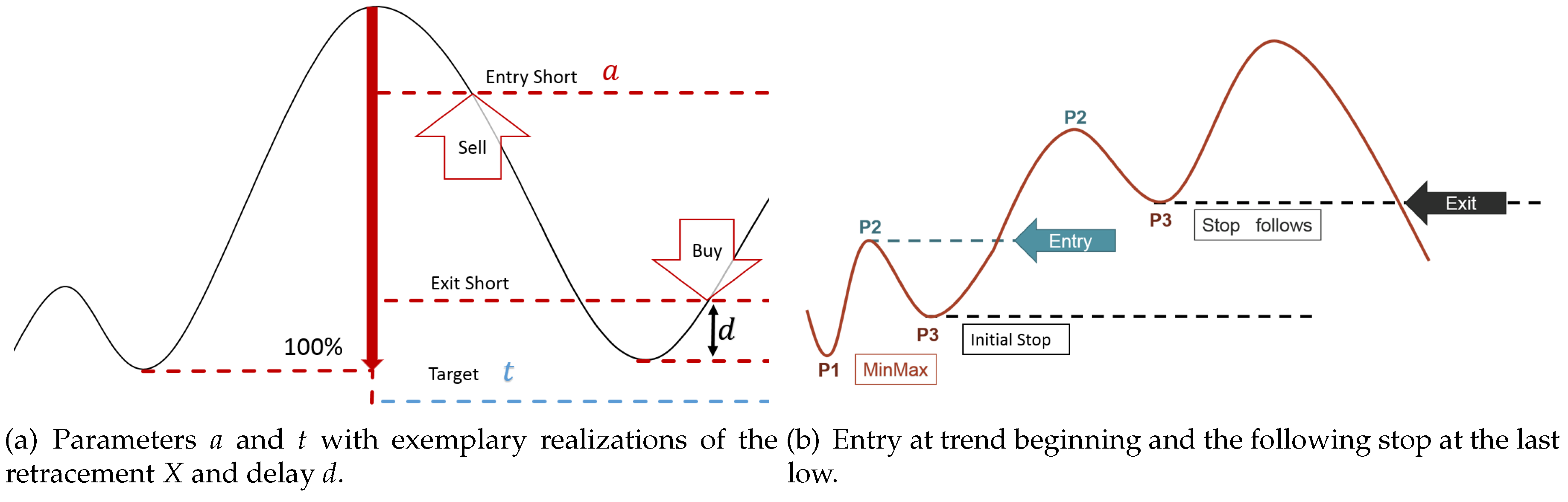
In this article, however, we want to pursue a different path. We are interested in several specific trend data, such as the retracement and the relative movement and correction. Since these trend data are fundamental for the whole paper, a precise definition is given here.
The first random variable describing trend data, which will be important in the following, is the
retracement denoted by
X. The retracement is defined as the size-ratio of the correction and the previous movement, i.e.,
Hence, in the case of an up-trend, this is given by:
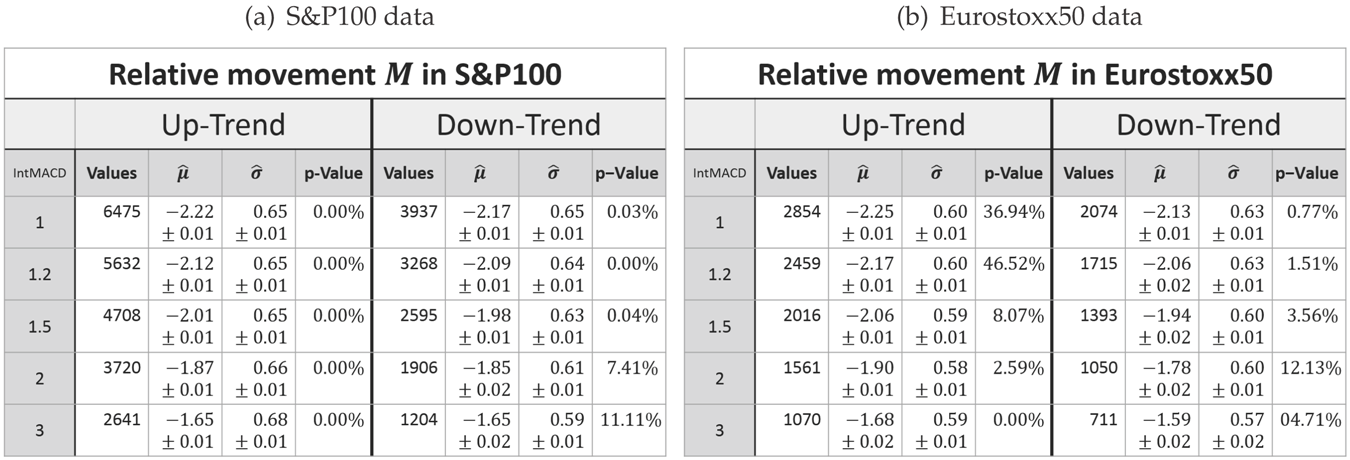
Another common random variable is the
relative movement, which for an up-trend is defined by the ratio of the movement and the last low, i.e.,
and the
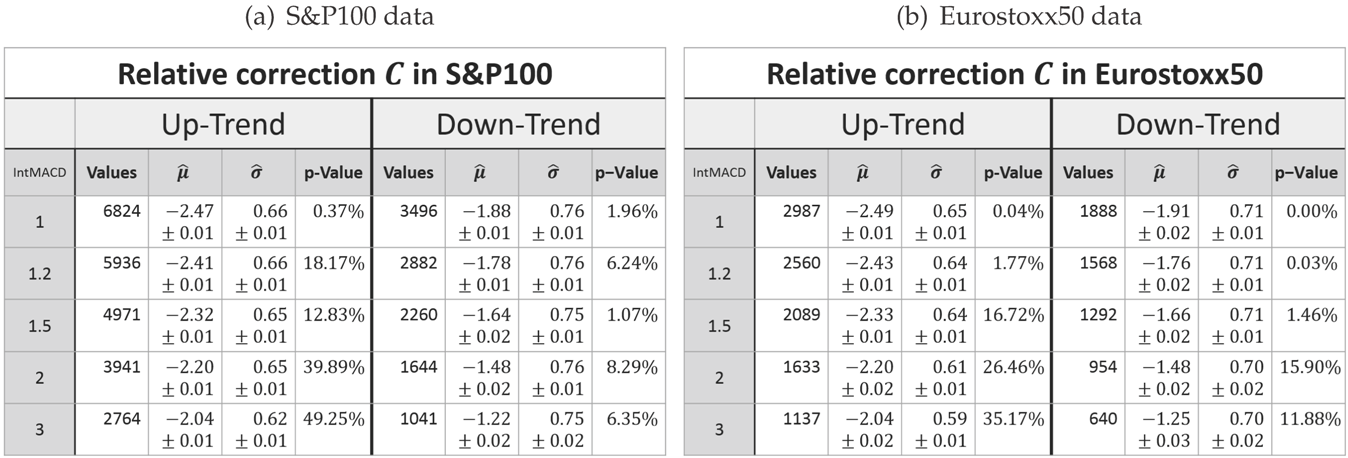
relative correction, which for an up-trend is defined as the ratio of the correction and the last high, i.e.,
In case of a down-trend, all situations are mirrored, such that:
The main scope of this survey is to collect and extend results on how the earlier defined trend variables (plus several other related ones) can be statistically modeled. By doing this, the log-normal distribution occurs frequently. Evidently, the log-normal distribution is very well known in the field of finance. We start off, in
Section 3, by giving a mathematical model of the retracement during Dow-trends and the delay of their recognition. Furthermore, the duration of the retracements and their joint distribution with the retracement will be evaluated. The results on relative movements and relative corrections during trends will be presented in
Section 4. In
Section 5, it will be demonstrated how the gained distributions of trend variables may be used to model trading systems mathematically.
It will be evident that the described trend data mostly fit very well to the log-normal distribution model, although there are significant aberrations for the duration of retracements (see
Subsection 3.2). In the past, there have been several attempts to match the log-normal distribution model to the evolution of stock prices. It already started in 1900 with Louis Bachelier’s PhD thesis [
6,
7] and the approach to use the geometric Brownian motion to describe the evolution of stock prices. This yields log-normally-distributed daily returns of stock prices. Nowadays, the geometric Brownian motion is widely used to model stock prices (see [
8]) especially as a part of the Black–Scholes model [
9]. Nevertheless, it has to be noted that empirical studies have shown that the log-normal distribution model does not fit perfectly to daily returns (e.g., see Fama [
10,
11], who refers to Mandelbrot [
12]).
Overall, we conclude that most of the trend data we describe fit better to the log-normal distribution model than daily returns of stock prices, although it is beyond the scope of this paper to do a formal comparison. In any case, the observed empirical facts of trend data contribute to a completely new understanding of financial markets. Furthermore, with the relatively easy calculations, which are based on the link of the log-normal distribution model to the normal distribution, complex market processes can now be discussed mathematically (e.g., with the truncated bivariate moments; see Lemma 1.21 in [
13]
1).
2. Detection of Dow-Trends
The issue of automatic trend-detection has been addressed by Maier-Paape [
2]. Clearly, the detection of relevant extreme points is a necessary step to detect Dow-trends. Fortunately, the algorithm introduced by Maier-Paape allows automatic detection of relevant extreme points in any market since it constructs, the so-called
MinMax-processes.
Definition 2 (MinMax-process, Definition 2.6 in [
2]). An alternating series of (relevant) highs and lows in a given chart is called a
MinMax-process.
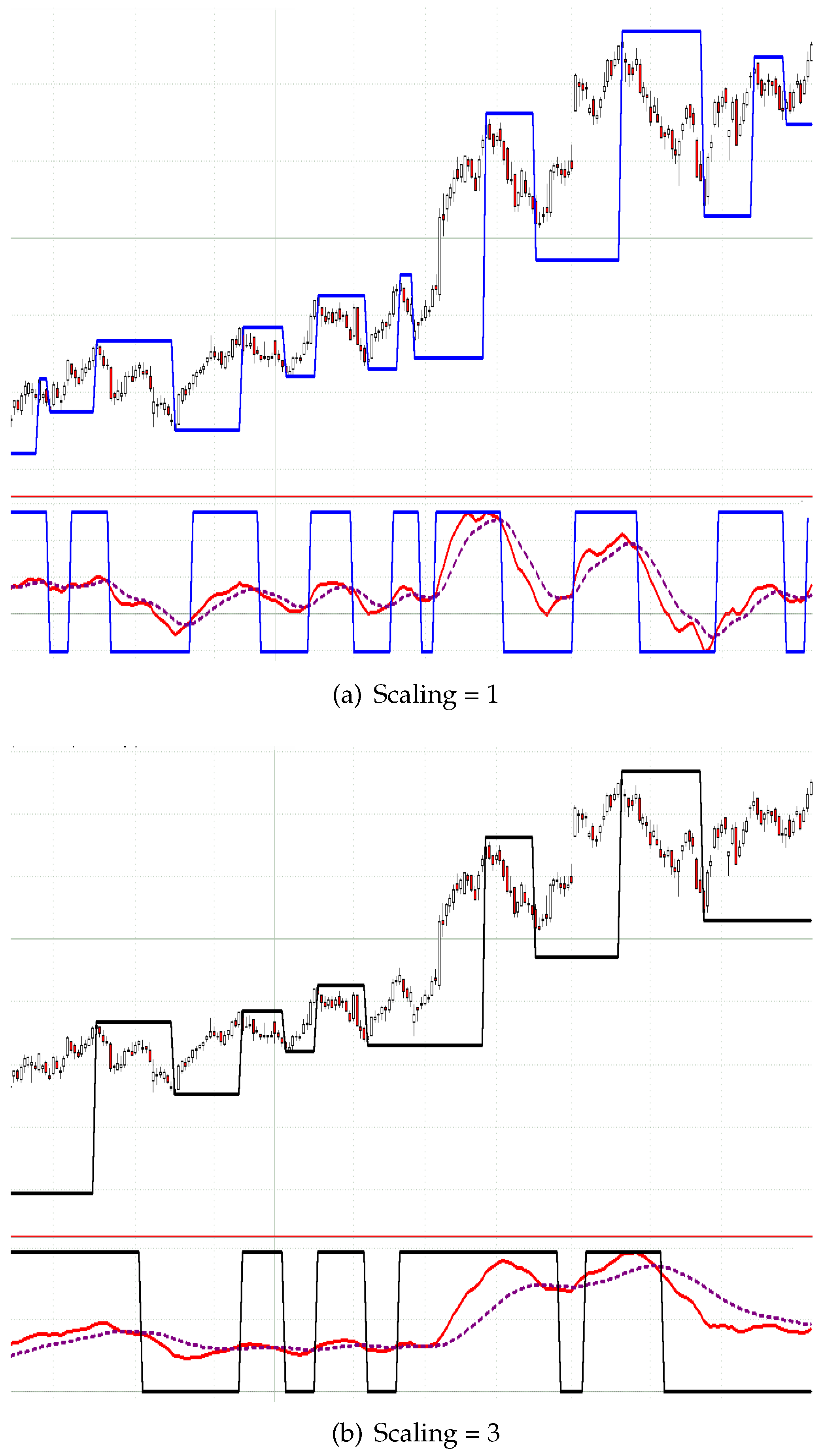
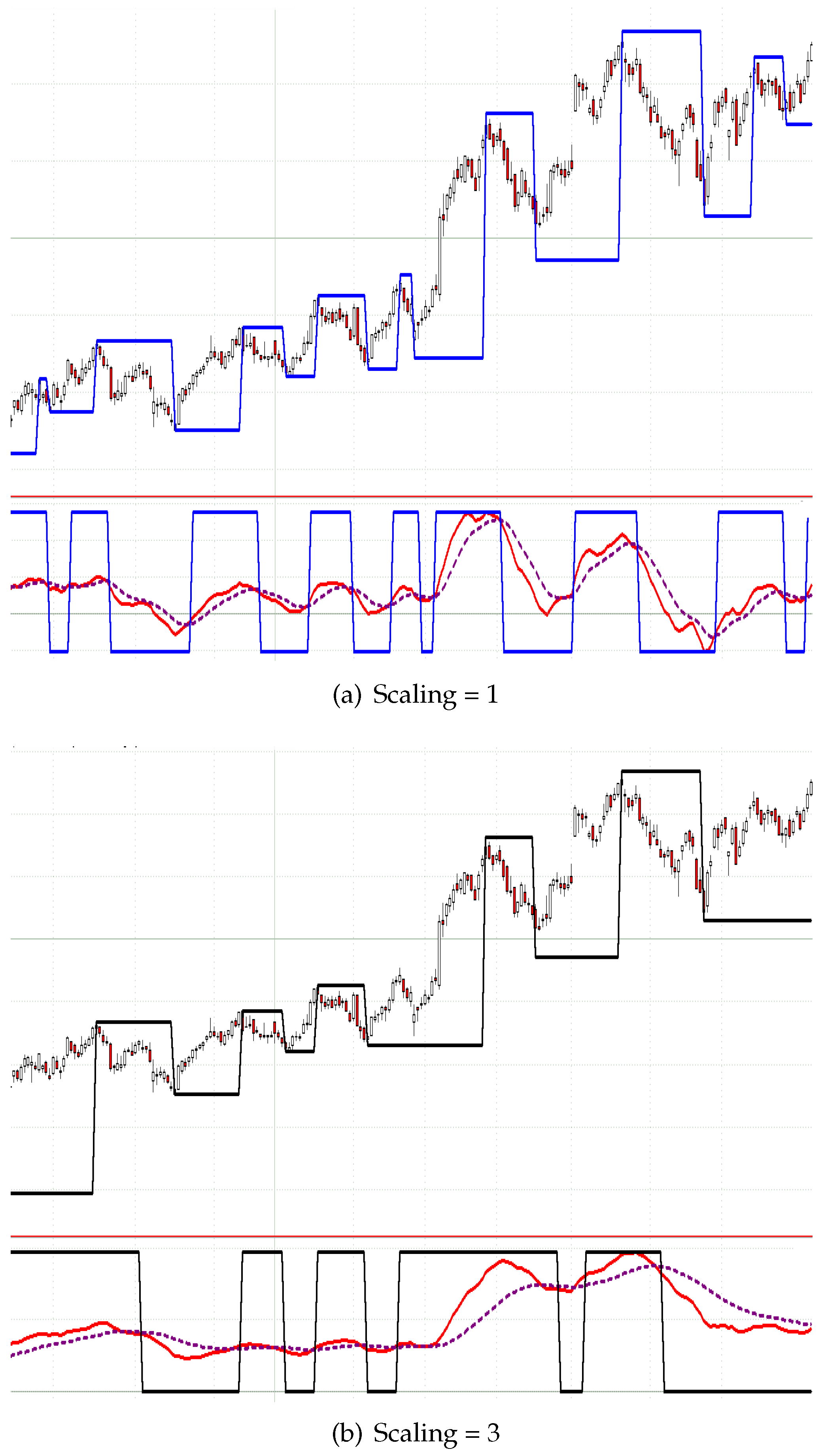
In
Figure 3, two automatically-constructed MinMax-processes are visualized by the corresponding indicator line. The construction is based on SAR-processes (
stop
and
reverseplease check the use of underlining throughout ).
Definition 3 (SAR-process). An indicator is called a SAR-process if it can only take two values (e.g., −1 and one, which are considered to indicate a down and an up move of the market, respectively).
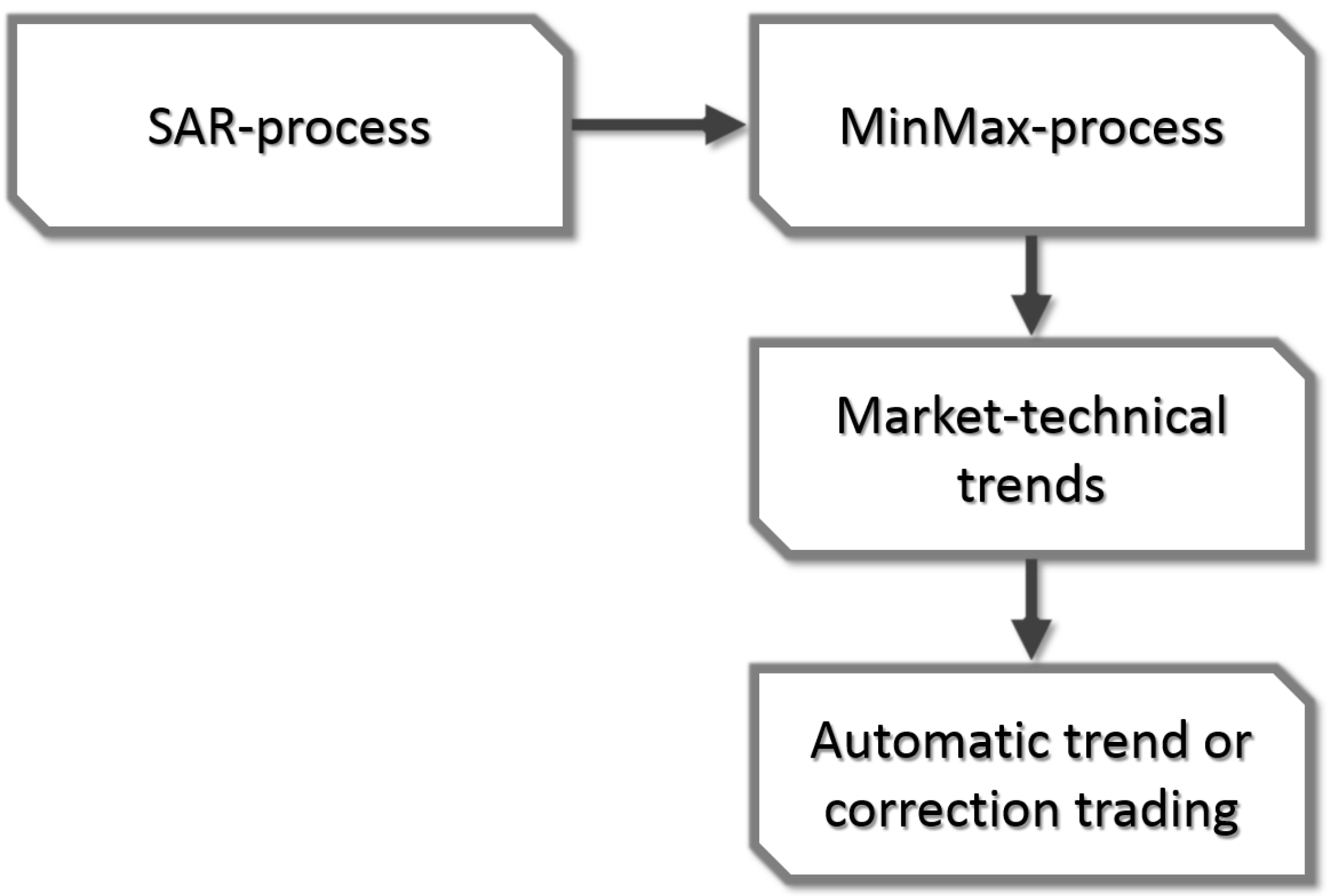
Generally speaking, Maier-Paape’s algorithm looks for relevant highs when the SAR-process indicates an up move and searches for relevant lows when the SAR-process indicates a down move. Thus, the relevant extrema are “fixed” when the SAR-process changes sign. By choosing a specific SAR-process, one can affect the sensitivity of the detection while the actual detection algorithm works objectively without the need for any further parameter. For more information, see [
2]. Maier-Paape also explains how to handle specific exceptional situations, for instance when a new significant low suddenly appears although the SAR-process is still indicating an up move.
It is shown by Theorem 2.13 in [
2] that for any combination of SAR-process and market, there exists such a MinMax-process, which can be calculated “in real time” by the algorithm of Maier-Paape. Based on any MinMax-process in turn, it is easy to detect market-technical trends as defined in Definition 1 and then to use this information for automatic trading systems as outlined in
Figure 2.
Calculating the MinMax-process “in real time” means that as time passes and the chart gets more and more candles, the extrema of the MinMax-process are constructed one by another. Besides the most recent extremum that is being searched for, all extrema found earlier are fixed from the moment of their detection, i.e., when the SAR-process changed sign.
Thus, applying the algorithm in real time also reveals some time
delay in detection. Obviously, the algorithm cannot predict the future progress of the chart to which it is applied. Consequently, some delay is needed to evaluate the significance of a possible new extreme value. This circumstance is crucial when considering automatic trading systems based on market-technical trends. Therefore, it also has to affect any mathematical model of such a trading system. An approach to this issue can be made by considering the delay as an inevitable slippage. This means, not the time aspect of the delay, but more likely, the effect it has on the entry or exit price in any market-technical trading system will be evaluated. In particular, the absolute value of the delay
dabs is given by:
with
P[0] indicating the last detected extreme value and
C[0] the close value of the current bar when this extreme value got detected.
For this article, the MinMax-process together with the
integral MACD SAR-process (
moving
average
convergence
divergence; see p. 166 in [
14]) was used. The integral MACD SAR (Definition 2.2 in [
2]) basically is a normal MACD SAR, which in turn indicates an up move if the so-called
MACD line is above the so-called
signal line. Otherwise, it indicates a down move. The MACD line is given by the difference of a fast and a slow (exponential) moving average. The signal line then is an (exponential) moving average of the MACD line.
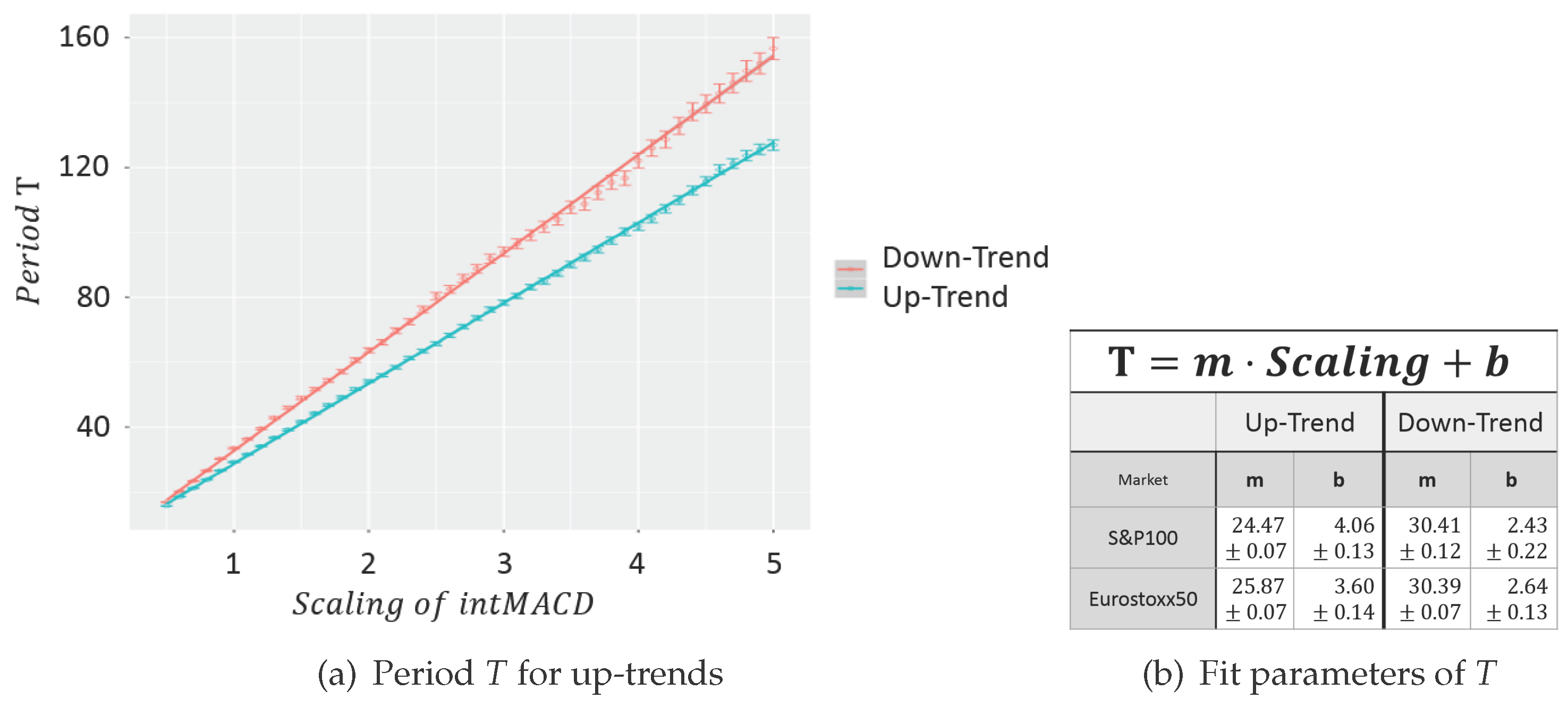
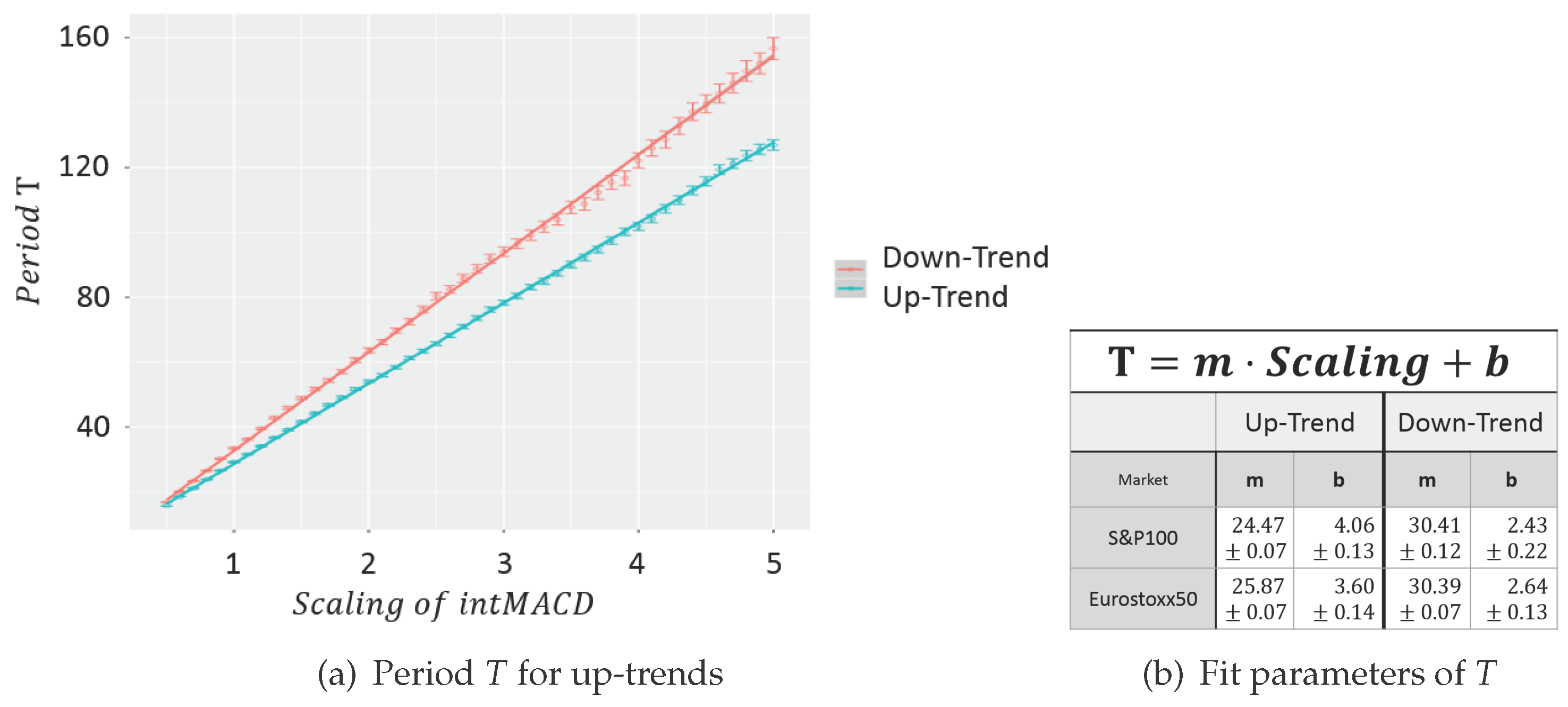
Consequently, the MACD usually takes three parameters for the fast, slow and signal line (standard values are: fast = 12, slow = 26, signal = 9). To reduce the number of needed parameters from three to one
scaling parameter only, the ratios of the standard parameters are fixed and consequently scaled by the scaling parameter. In particular, an MACD with scaling parameter two denotes a usual MACD with the parameters (24/52/18). Therefore, the sensitivity of the MinMax-process solely corresponds to one scaling parameter (see
Figure 3).
For a given MinMax-process, it is obvious to decide the starting and ending candle of a market-technical trend. The computation of several trend variables, such as the retracement, is therefore obvious.
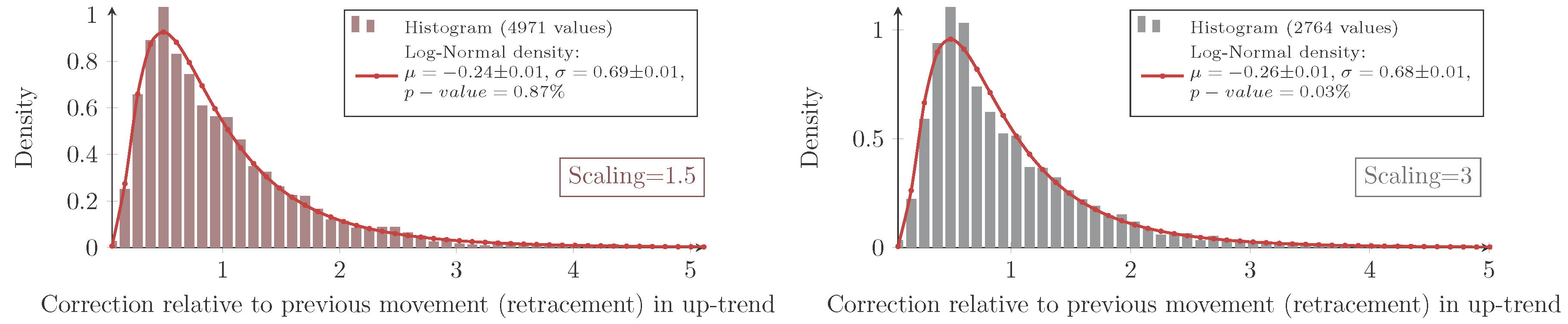
The automatic detection of Dow-trends and in particular the possibility to deduce a MinMax-process out of any market given by candle data enables one to create a large dataset of empirical trend variables. The model will be based on empirical data acquired by the MinMax-process based on the integral MACD with scaling variables 1, 1.2, 1.5, 2 and 3 applied on all stocks of the current S&P100 and Eurostoxx50 in the period from January 1989 until January 2016.
3. Retracements
3.1. Distribution of the Retracement
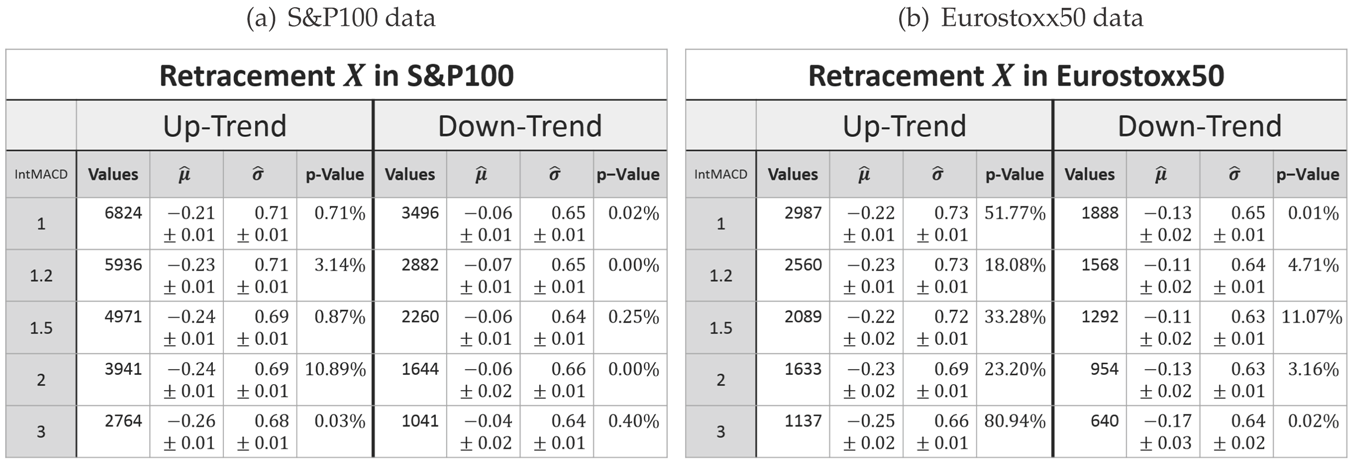
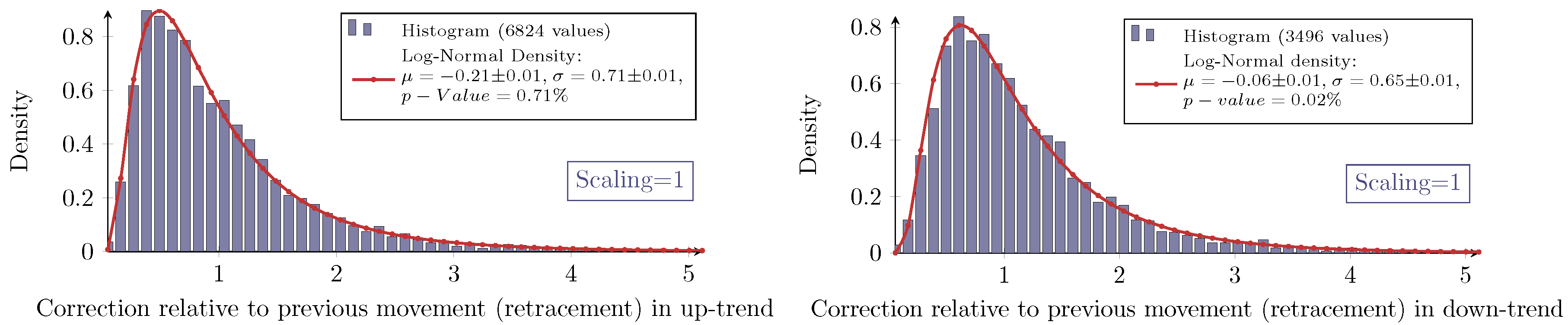
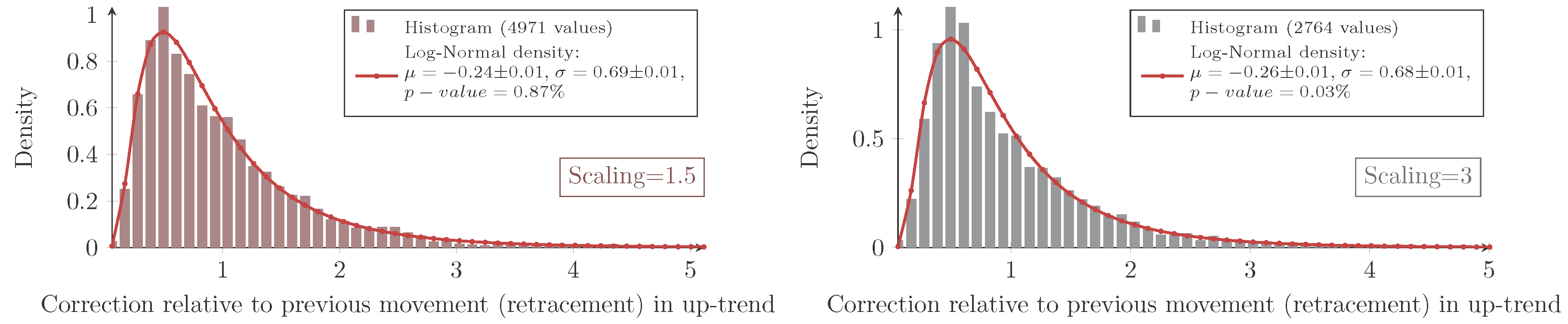
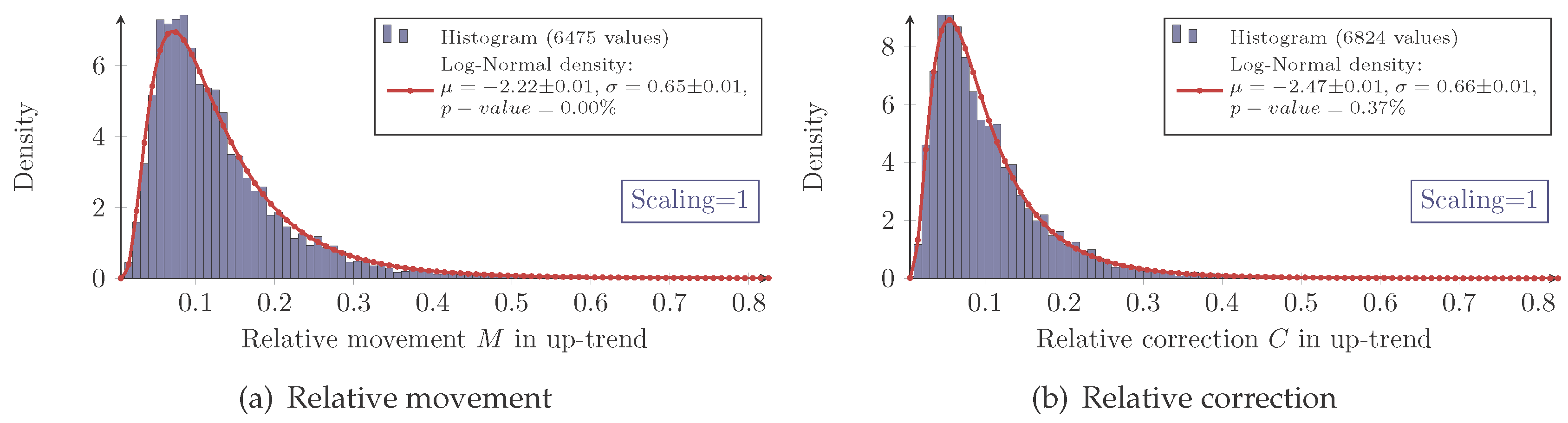
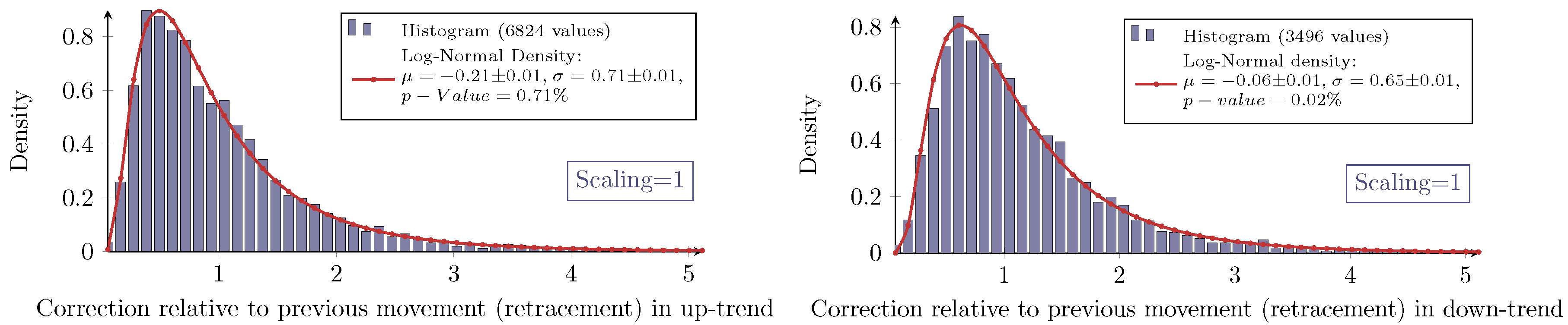
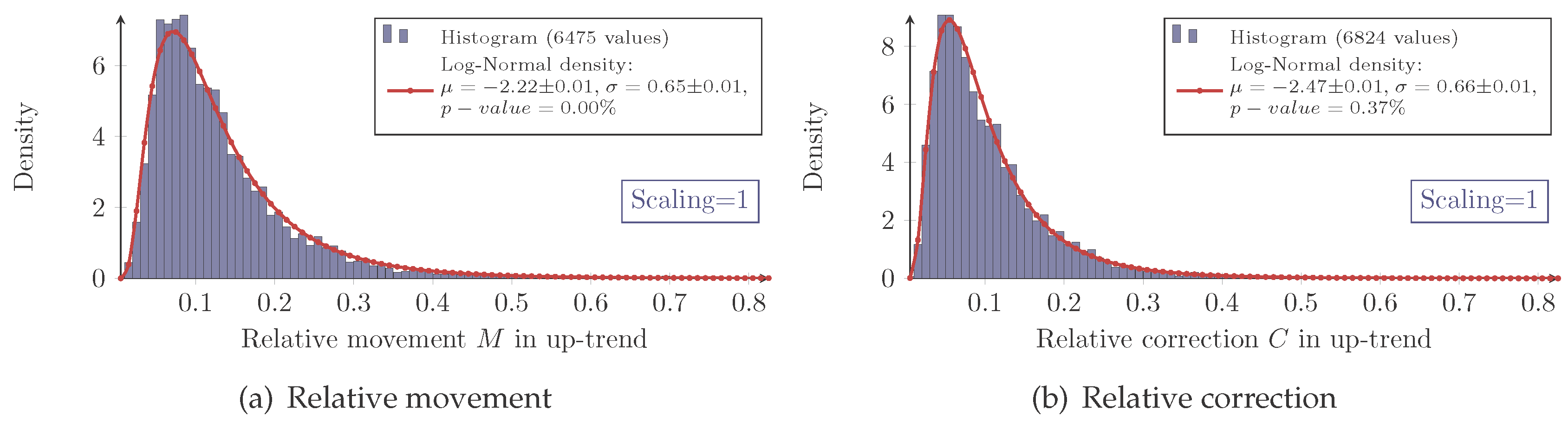
For all combinations of the regarded scalings and markets, the measured retracement data show the same characteristic distribution as seen in
Figure 4 and
Figure 5. Indeed, they show the typical asymmetric characteristic of a log-normal distribution, the density of which is given by:
for the retracement
X and with the (true) parameters μ and σ. It is well known how to calculate moments of log-normally-distributed random variables. In this particular context, the median of the distribution
X equals
eμ, and the mean is given by:
To evaluate this distribution assumption, the maximum-likelihood-estimators (MLE) denoted by
for the log-normal distribution are computed:
with
xi denoting the
n measured retracements. Furthermore, the
p-value calculated with the Anderson–Darling test (recommended test by Stephens in [
15], Chapter “Test based on EDF statistics”) being applied to the logarithmic transformed data is checked. The so-obtained values are summarized in
Table 1.
The inconsistency of the
p-values reveals that the log-normal model does not fit perfectly to the measured retracement data. In fact, all histograms show a slightly sharper density for the measured data with different intensities. Hence, for higher retracement values, the log-normal model predicts slightly fewer values than actually observed. Besides these small systematical aberrations, the log-normal model maps the measurement very well; especially for the Eurostoxx50. In addition, the log-normal model obviously fits much better to the retracement distribution than to for instance daily returns of stock prices (see Fama [
10]).
To conclude the evaluation of the retracement alone, a fundamental observation about the retracement can be made (based on the log-normal assumption and the fit values derived from the data).
Observation 4 (Log-normal model for the retracement). The parameters μ and σ of the log-normal distribution are more or less scale invariant for the retracement. In the case of an up-trend, the parameters are also market invariant.
Furthermore, the parameter μ is affected by the trend direction. It is larger for down-trends, i.e., the retracements in down-trends are overall more likely to be larger than in up-trends. In spite of that, the parameter σ is more or less invariant for the trend direction.
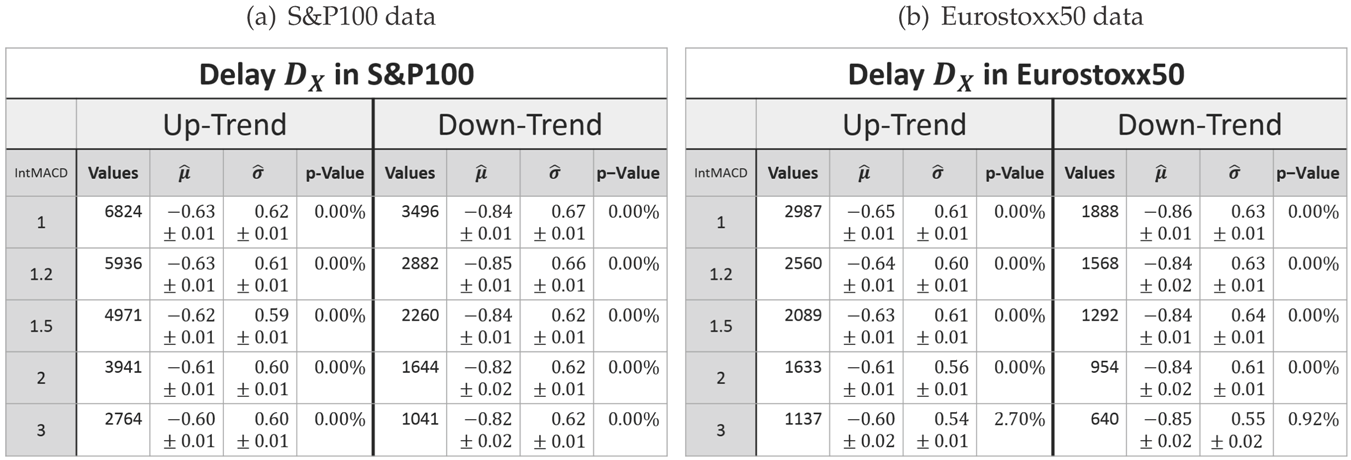
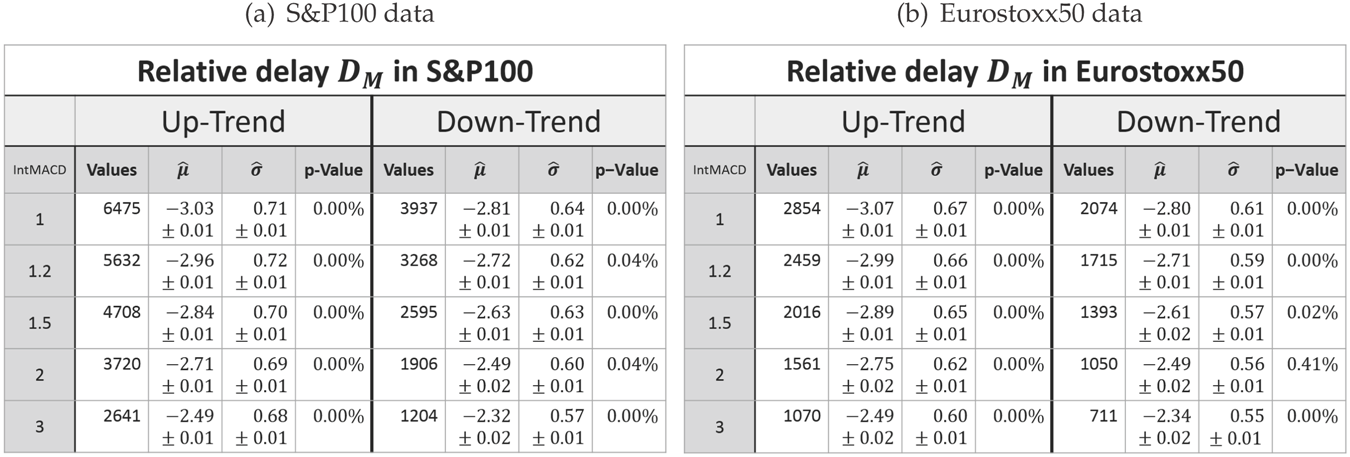
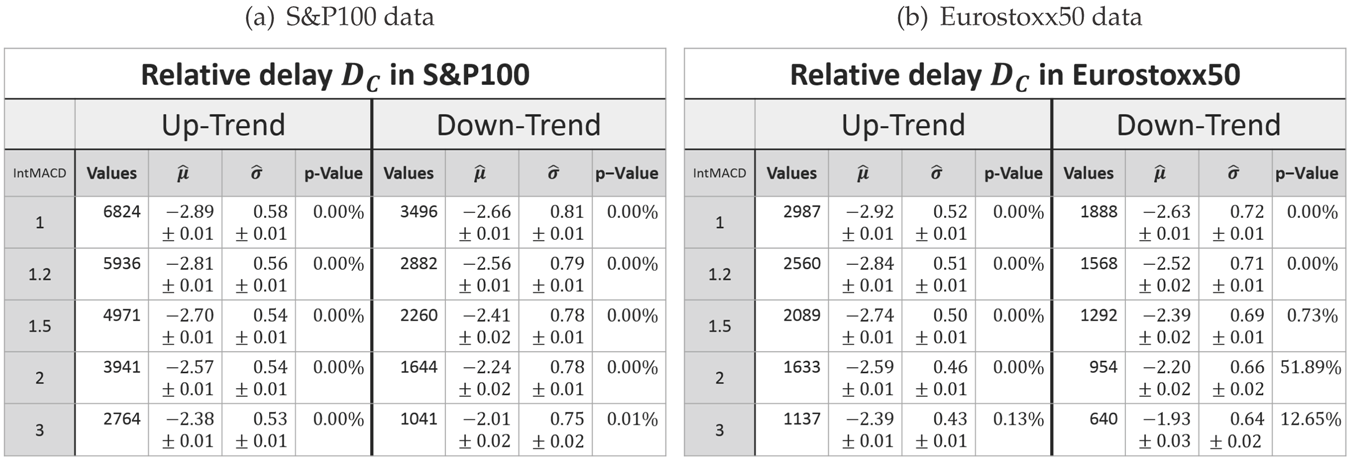
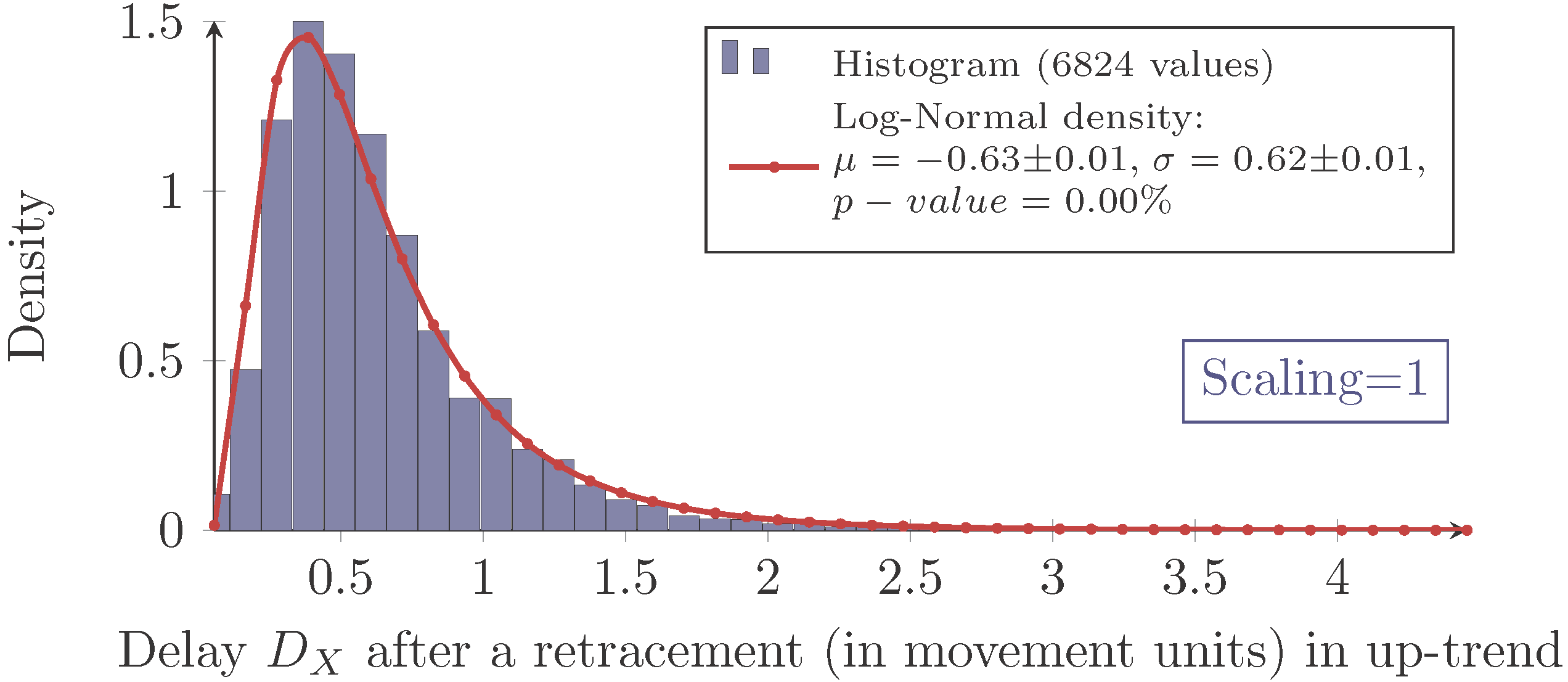
3.2. Delay after a Retracement
As already mentioned, the delay of the MinMax-process is inevitable. Therefore, it will be evaluated in the same way as the retracement. In order to be able to compare the delay
dabs after a retracement is recognized (as defined in (4)) with the retracement
X itself, both must have the same unit. Therefore, the delay will also be considered in units of the last movement. It will be denoted as random variable
DX:
It should be noted that (at this point), there is no statement made on whether or not
DX may somehow depend on the preceding retracement
X. The notation with subscript
X is only used to denote the delay after a retracement and to distinguish it from other delays to come.
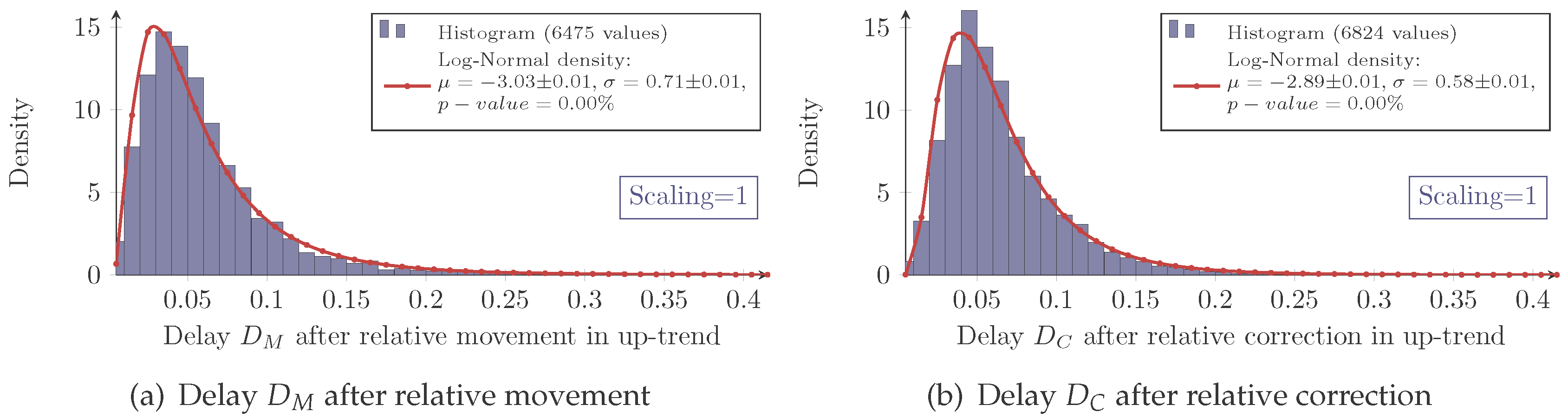
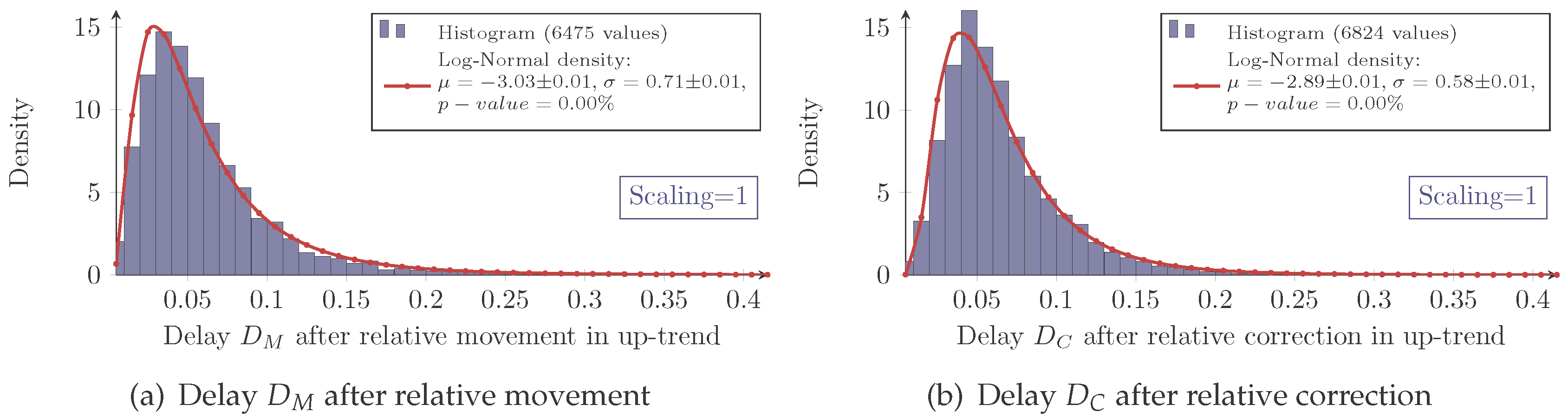
Again, the measured delay data show the characteristic of a log-normal distribution for each combination of scaling and market as exemplarily shown in
Figure 6.
However, as expressed by the significant
p-values in
Table 2, the log-normal assumption lags verification.
The histograms show a systematical deviation in regard to skewness. The measured delays have a less positive skewness than predicted by the model.
Besides this systematical aberration, the log-normal model maps the characteristics precisely enough. Hence, it will be used for the following analysis.
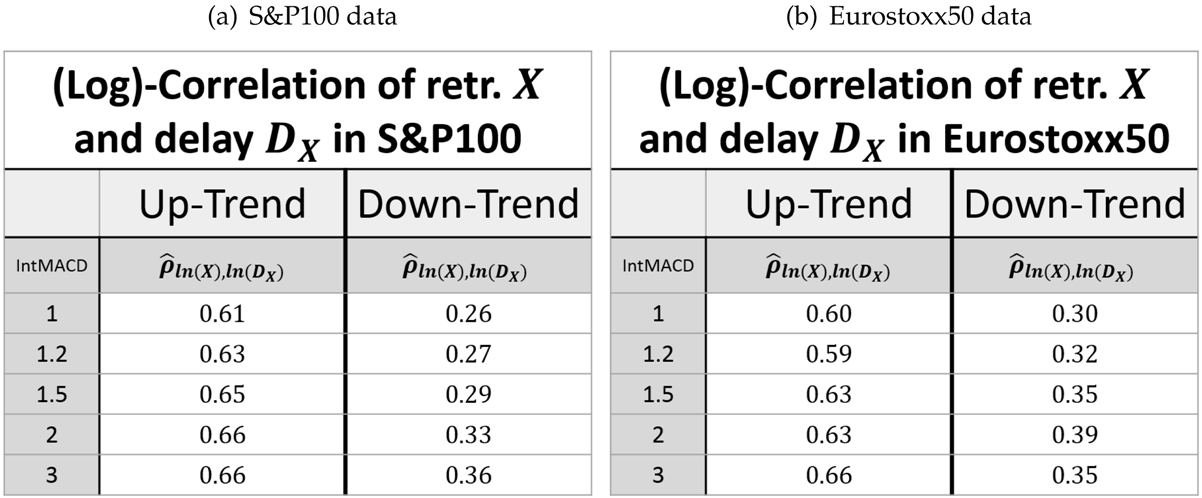
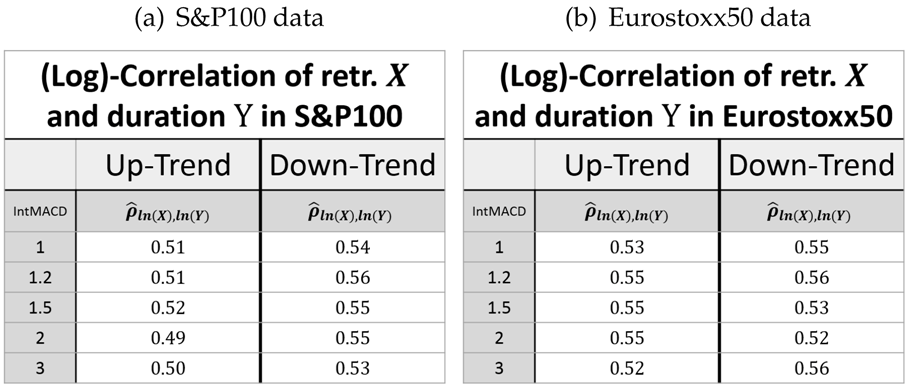
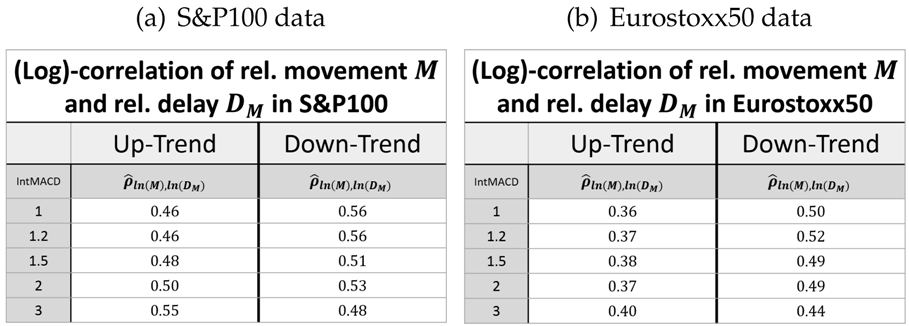
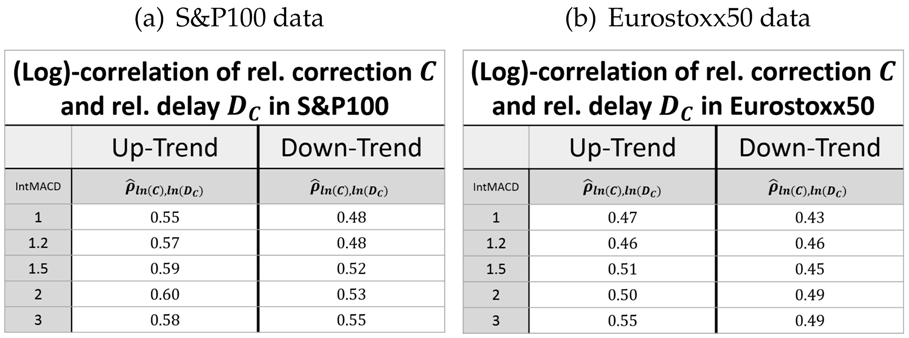
The retracement and the delay can be considered as one sequence. We therefore look for a combined log-normal distribution of retracement and delay. In this context, it is important to evaluate the estimator of the correlation
ρ between the logarithm of the two variables, i.e.,
for measured values
. The estimated values of
are given in
Table 3.
This shows that the retracement and the following delay are indeed positively correlated (regarded in the same units). This way, it is possible to give a joint bivariate log-normal distribution for the retracement
X and the delay
D (both in units of the preceding movement) by virtue of its density function.
For calculations based on this distribution, the (true) parameters and must be replaced by their estimators.
Finally, the concluding observation regarding the retracement can be expanded by the delay part.
Observation 5 (Log-normal model for the retracement and delay). The parameters μ and σ of the log-normal distribution are more or less scale invariant for the retracement and the delay. In the case of an up-trend, the parameters are also market invariant.
Furthermore, the parameter μ is affected by the trend direction. In the case of the retracement, it is larger for down-trends, whereas it is smaller for down-trends in the case of the delay. In spite of that, the parameter σ is more or less invariant of the trend direction.
Finally, the correlation between the logarithms of the retracement and the delay is close to scale and market invariant, while the correlation in up-trends is significantly larger than in down-trends.
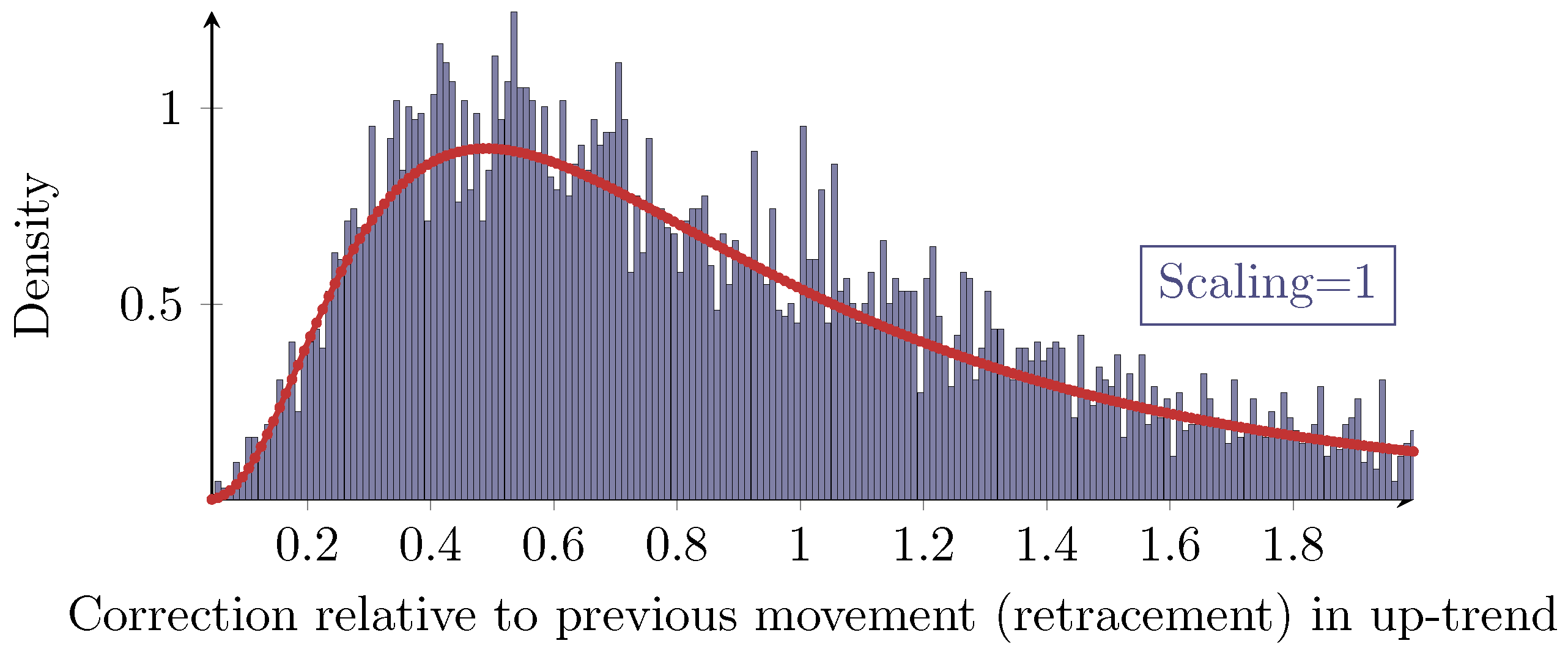
3.3. Fibonacci Retracements
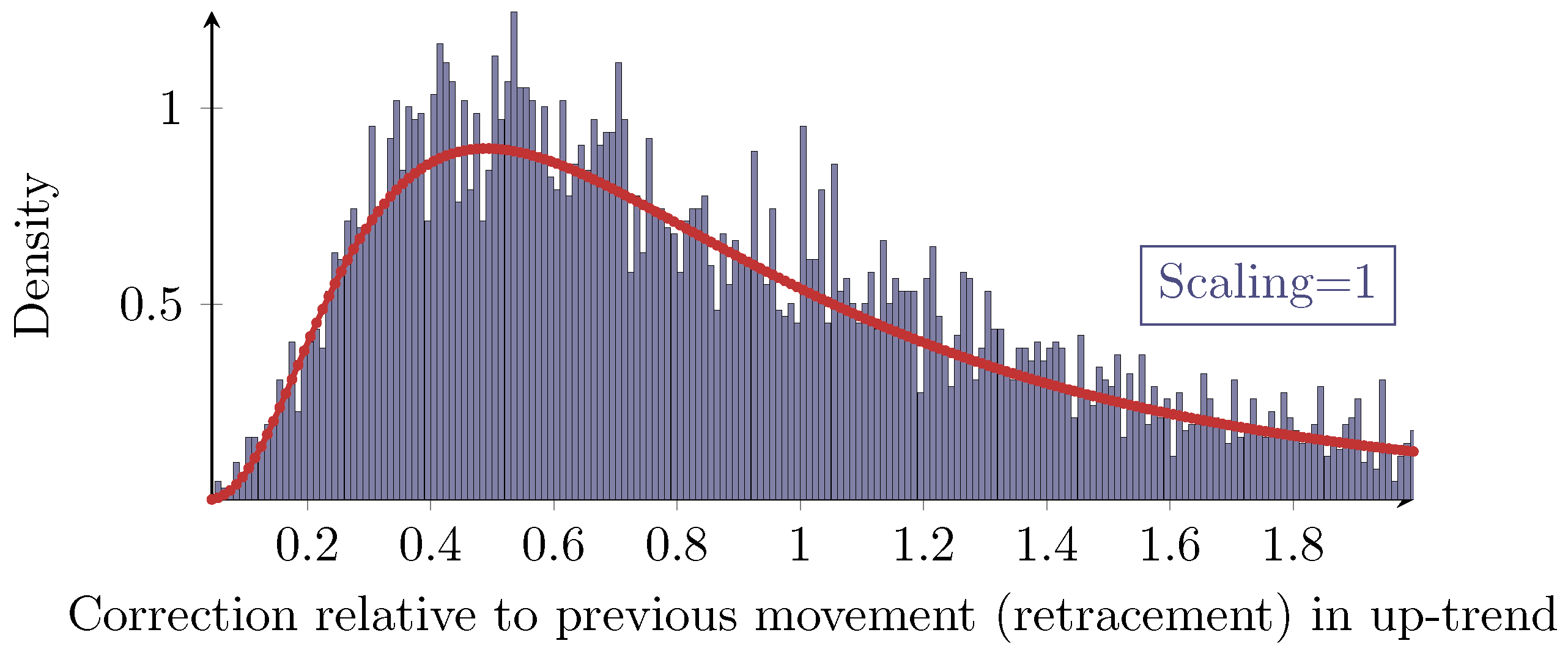
A propagated idea in the field of technical analysis for dealing with retracements is the concept of so-called
Fibonacci retracements. Based on specific retracement levels derived from several powers of the inverse of the golden ratio, a priori predictions for future retracements shall be made. Obviously, this assumes that there are such significant retracement values. However, the evaluation of the retracement above reveals that there are no levels with a great statistical significance, but the retracements follow a continuous distribution overall. Even a finer histogram as shown in
Figure 7 does not reveal any significant retracements.
On the assumption that there are specific values with statistical significance in some regard, then the 100%-level would be most significant. For a closer look on significant retracement levels, see [
16]
2.
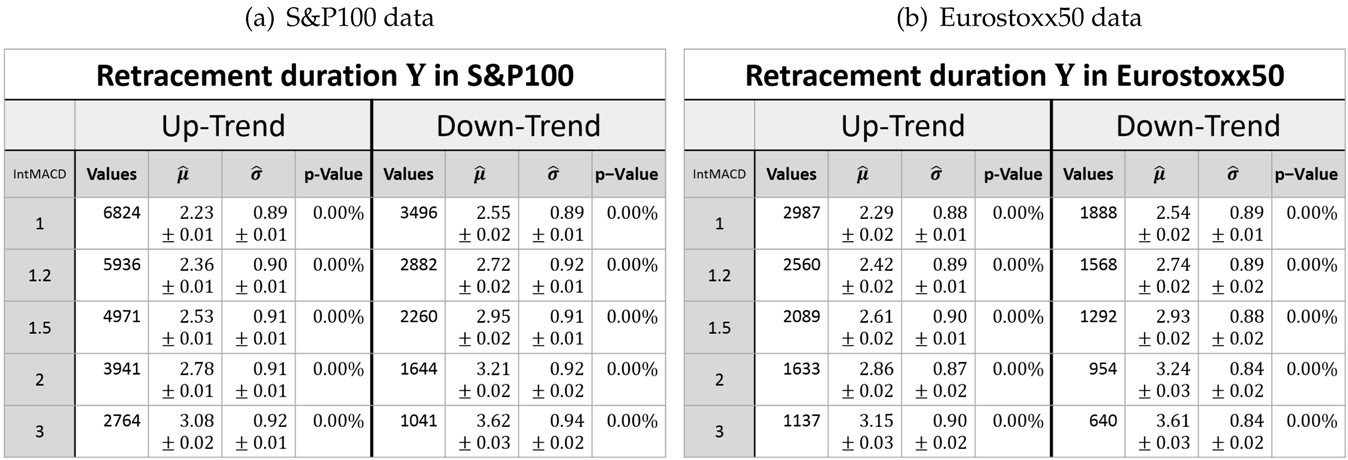
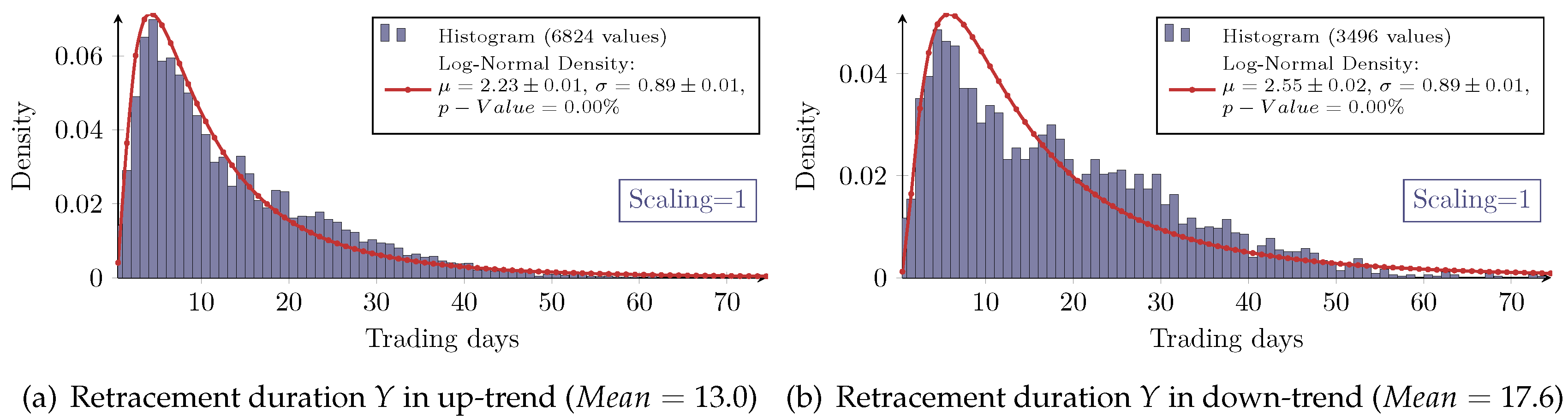
3.4. Duration of the Retracement
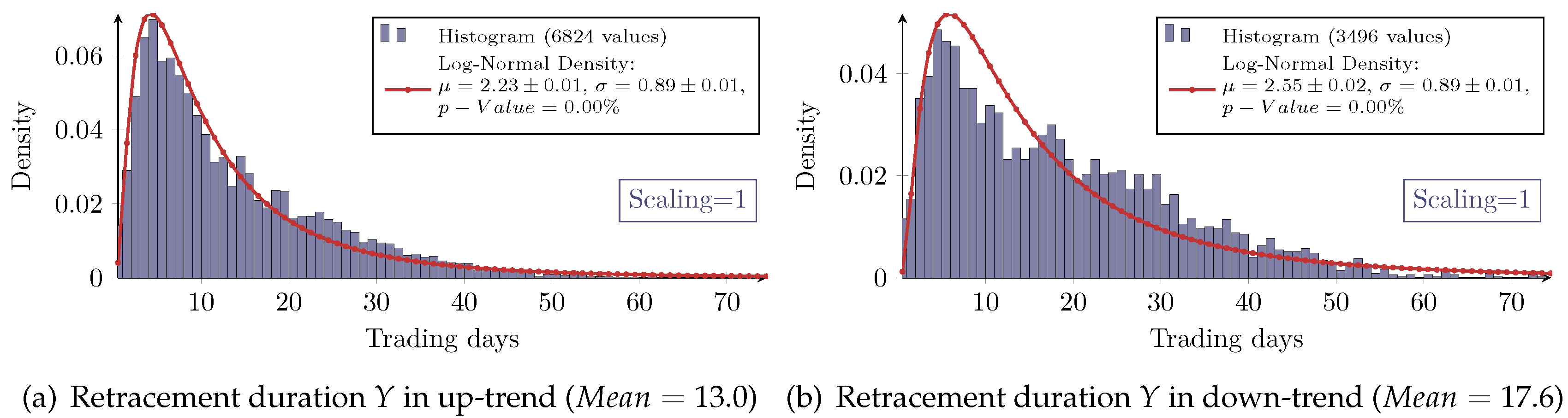
Beside the retracement, the
duration of a trend correction denoted by
Y is also of interest. It is given by the difference in trading days between the last
P2 and the new
P3 (see
Figure 1b). The distributions of the retracement duration overall show the asymmetric log-normal-like behavior, as exemplarily shown in
Figure 8. However, the goodness of the log-normal assumption is obviously worse as in the case of the retracement itself. In particular, the measured densities of the retracement duration in a down-trend all show significant aberrations from the log-normal model.
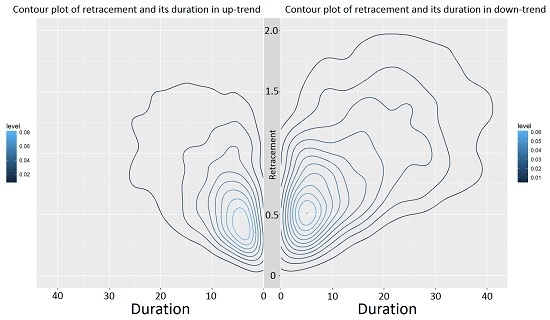
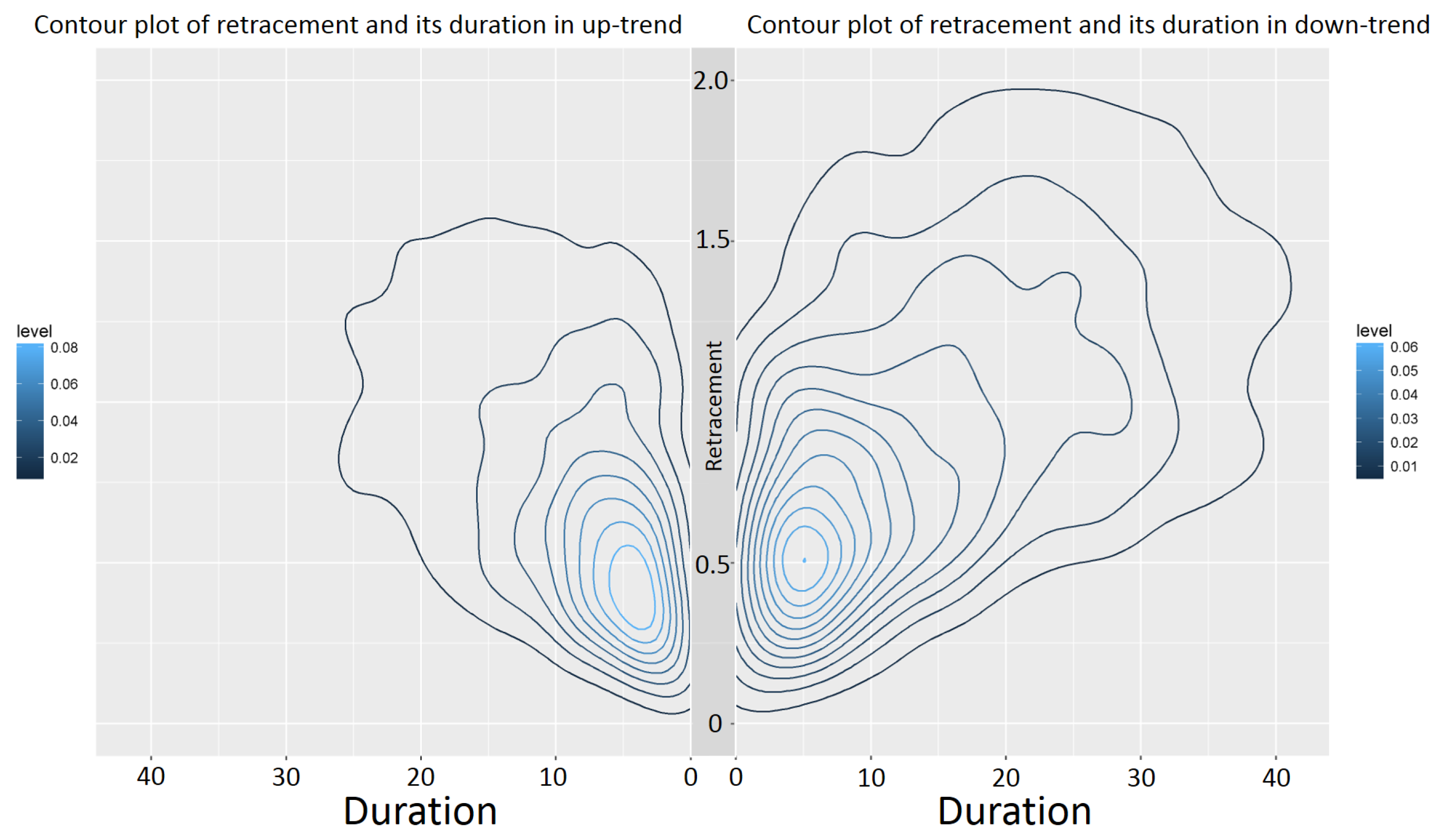
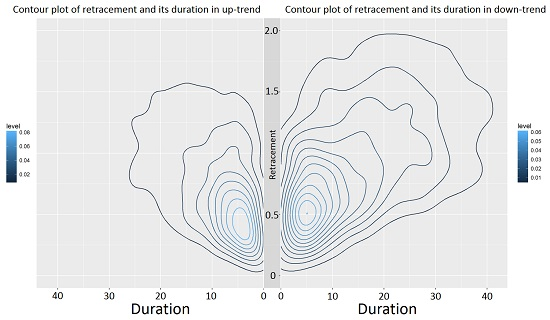
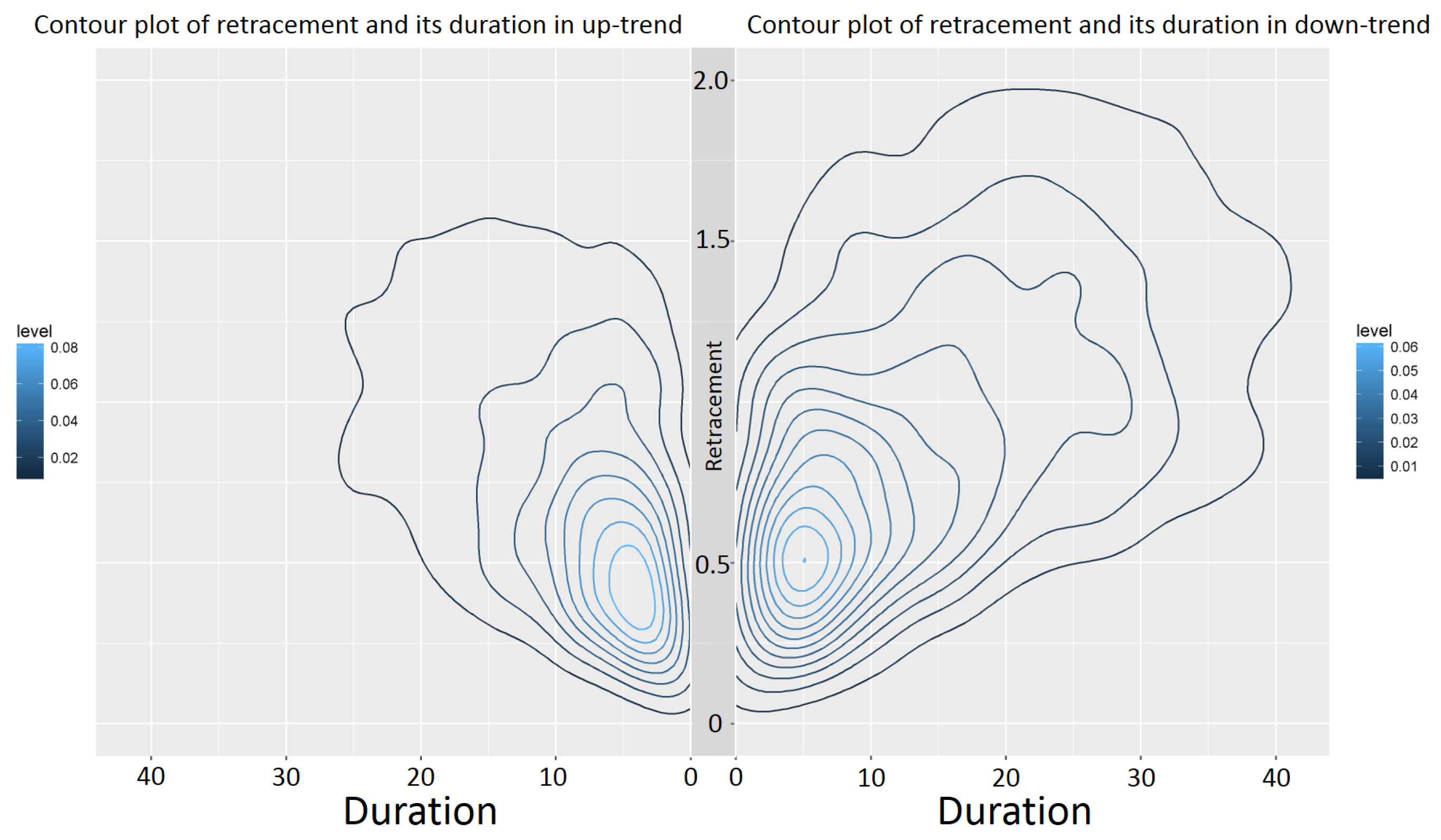
Since every retracement value is associated with a duration, the joint distribution of the retracement and its duration can be examined (see
Table 4 and
Table 5).
Figure 9 exemplarily shows that the retracement in down-trends has higher values than in up-trends. This was already seen in
Table 1 and Observation 4. However,
Figure 9 exemplarily also depicts that the retracement in down-trends has larger durations compared to the retracement in up-trends.
6. Conclusions and Outlook
In this survey, the applications of the log-normal distribution model on market-technical trend data is introduced. On the one hand, it is remarkable that the log-normal model fits better to the trend data presented than to daily returns of stock prices. In contrast to the approach on the latter, however, there has not been found any explanation for this observation yet. In particular, it has not yet been clarified whether the log-normal distribution is a result of a limit process or can be explained with the log-normal model for the daily returns of stock prices. As far as applications in the direction of modeling of trading systems are concerned, we introduced a simple model for an anti-cyclic trading setup based on log-normally distributed data.
On the other hand, trend following, i.e., pro-cyclic trading systems, are more widely used than anti-cyclic ones. In fact, empirical backtests have already shown the profitability of such trading systems. Consequently, there is a need for a mathematical model. Unfortunately, pro-cyclic trading usually implies holding a position over several iterations of movement and correction as outlined in
Figure 13b.
This makes the problem far more complicated in mathematical terms since the joint distribution of a random number of relative movements and corrections, with possible correlations, has to be considered. Nevertheless, the log-normal model for the trend data represents a promising approach to this issue, as well.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}