
Macro vs. Micro Methods in Non-Life Claims Reserving (an Econometric Perspective)



Abstract
:
1. Introduction
1.1. Macro and Micro Methods
- Those models neglect a lot of information that is available on a micro-level (per individual claim). Some additional covariates can be used, as well as exposure, etc. In most applications, not only is that information available, but usually, it has a valuable predictive power. To use that additional information, one cannot simply modify macro-level models, and it is necessary to change the general framework of the model. It becomes possible to emphasize large losses and to distinguish them from regular claims, to get more detailed information about future payments, etc.
- As discussed in this paper, macro-level models on aggregated data can be seen as models on clusters and not on individual observations, as we will do with micro-level models. In the context of macro-level models for loss reserving, [3] mention that prediction errors can be large, because of the small number of observations used in run-off triangles and the fact that clusters are usually not homogeneous. Quantifying uncertainty in claim reserving methods is not only important in actuarial practice and to assess accuracy of predictive models, it is also a regulatory issue. Finally, a small sample size can cause a lack of robustness and a risk of over-parametrization for macro-level models.
1.2. Agenda
2. Clustering in Generalized Linear Mixed Models
2.1. The Multiple Linear Regression Model
- (LRM1)
- no multicollinearity in the data matrix;
- (LRM2)
- exogeneity of the independent variables , , ; and
- (LRM3)
- homoscedasticity and nonautocorrelation of error terms with .
- (i)
- The ordinary least-squares estimator for - from Model (1)—is defined aswhich can also be writtenNow, observe thatwhere the first term is independent of (and can be removed from the optimization program), and the term with cross-elements sums to 0. Hence,where is the least square estimator of from Model (2), when weights are considered.
- (ii)
- (i)
- LetFor the equality of variances, we have
- (ii)
- LetThe proof of the equality of variances is similar.
2.2. The Quasi-Poisson Regression
- (i)
- Maximum likelihood estimator of is the solution ofor equivalentlyWith offsets , , maximum likelihood estimator of is the solution (as previously, we can remove ) ofHence, , as (unique) solutions of the same system of equations.
- (ii)
- The sum of predicted values is☐
- (i)
- (ii)
- By using a similar argument, we have when n goes to infinity☐
- (i)
- The property that variances are not equal is a direct consequence of classical results from the theory of generalized linear models (see [23]), since the covariance matrices of estimators are given byandwhen n goes to infinity. Thus, covariance matrices of estimators are asymptotically equal for the Poisson regression model but differ for the quasi-Poisson model because .
- (ii)
- Since the MLE and the QLE share the same asymptotic distribution (see [23]), the proof is similar to Corollary 4(ii).
2.3. Poisson Regression with Random Effect
3. Clustering and Loss Reserving Models
3.1. The Quasi-Poisson Model for Reserves
3.1.1. Construction
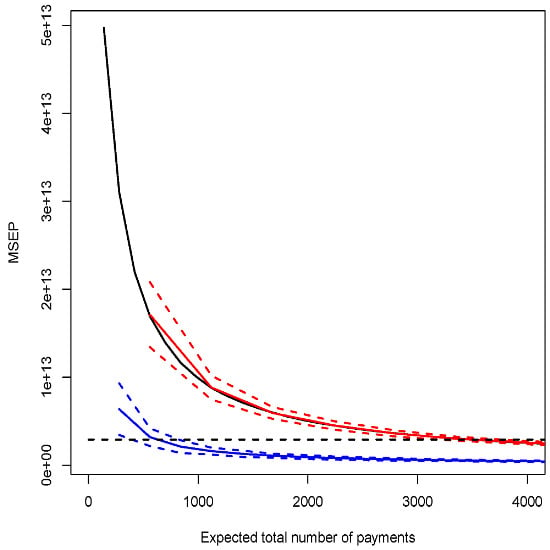
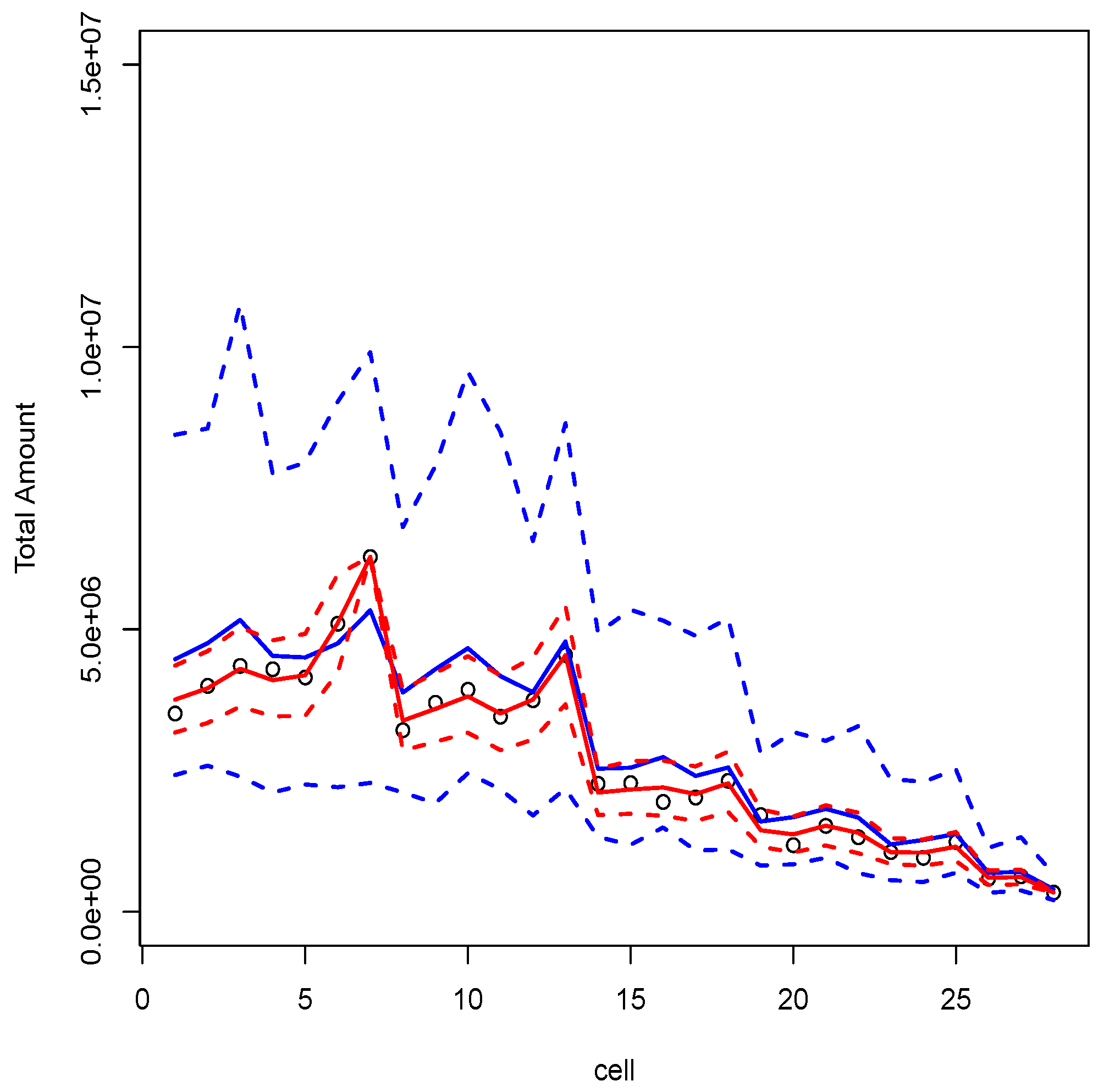
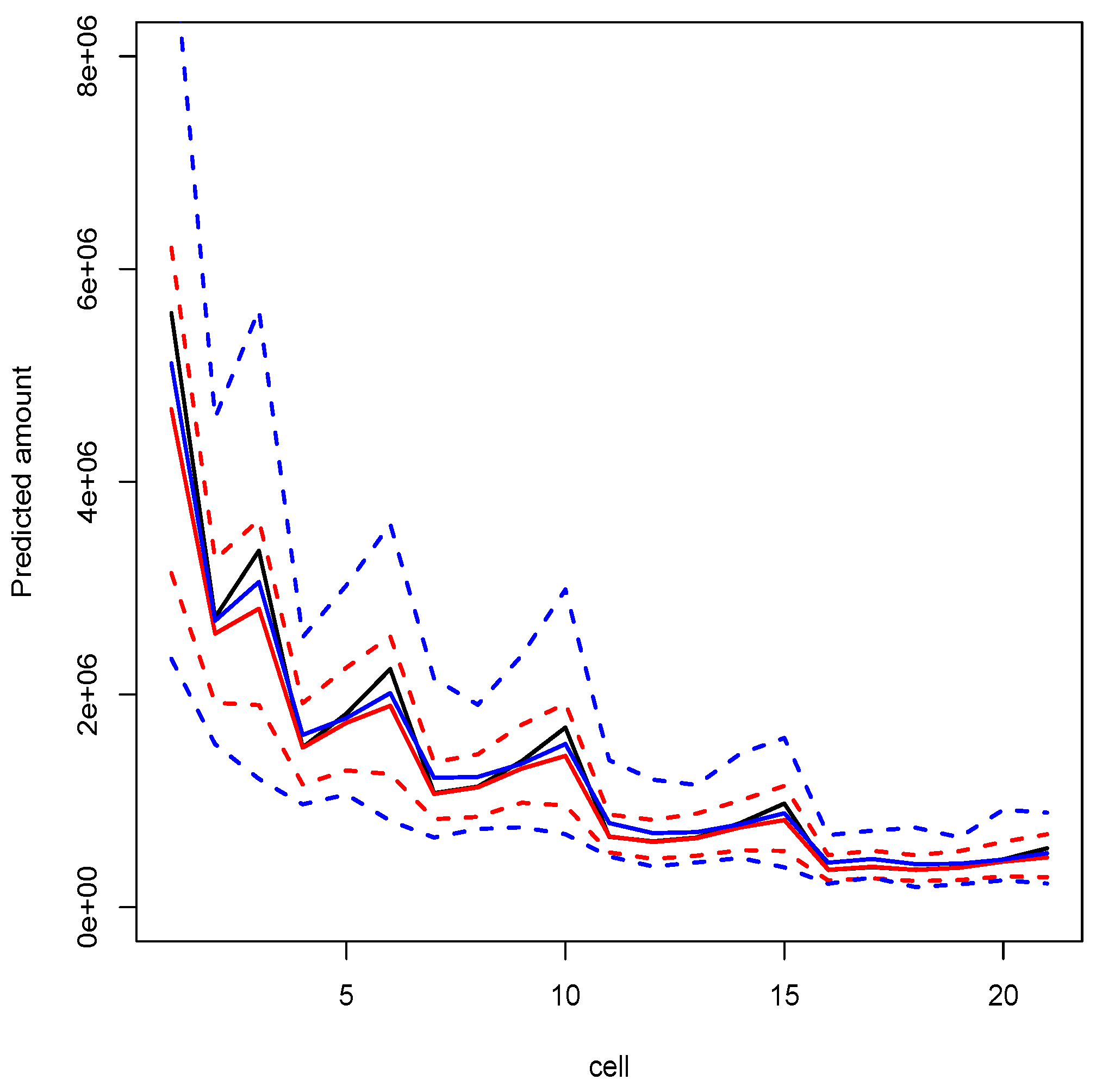
3.1.2. Illustration and Discussion
- simulate the number of payments for each cluster assuming , ;
- for each cluster, simulate a vector of proportions assuming , ;
- for each cluster, define
- adjust Model C and Model D; and
- calculate the best estimate and the MSEP of the reserve by using Proposition 6.
- (i)
- impossible to compute that average without individual data;
- (ii)
- discrete explanatory variables used in the micro-level model; and
- (iii)
- since claims reserve model have a predictive motivation, it is risky to project the value of an aggregated variable on future clusters.
3.2. The Mixed Poisson Model for Reserves
3.2.1. Construction
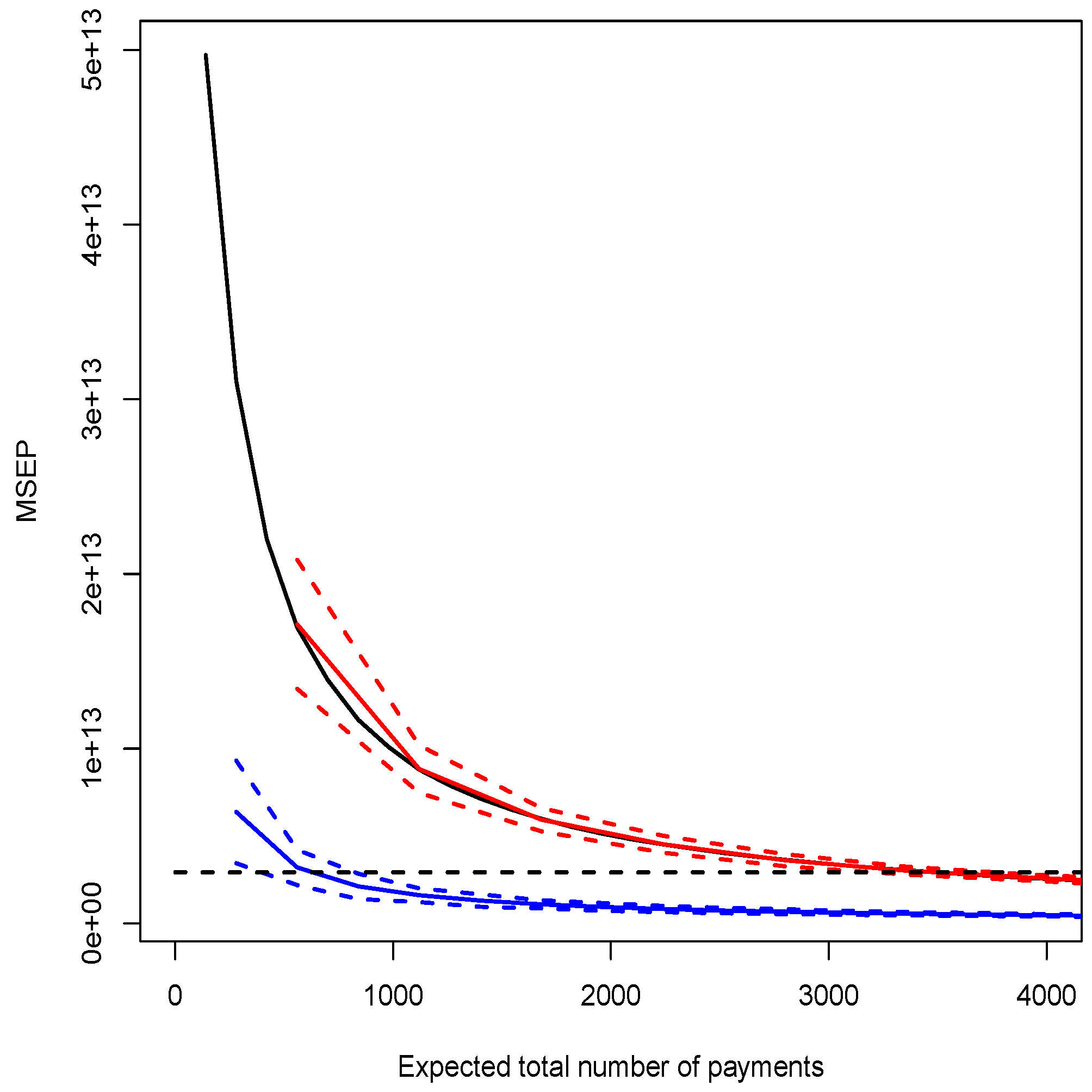
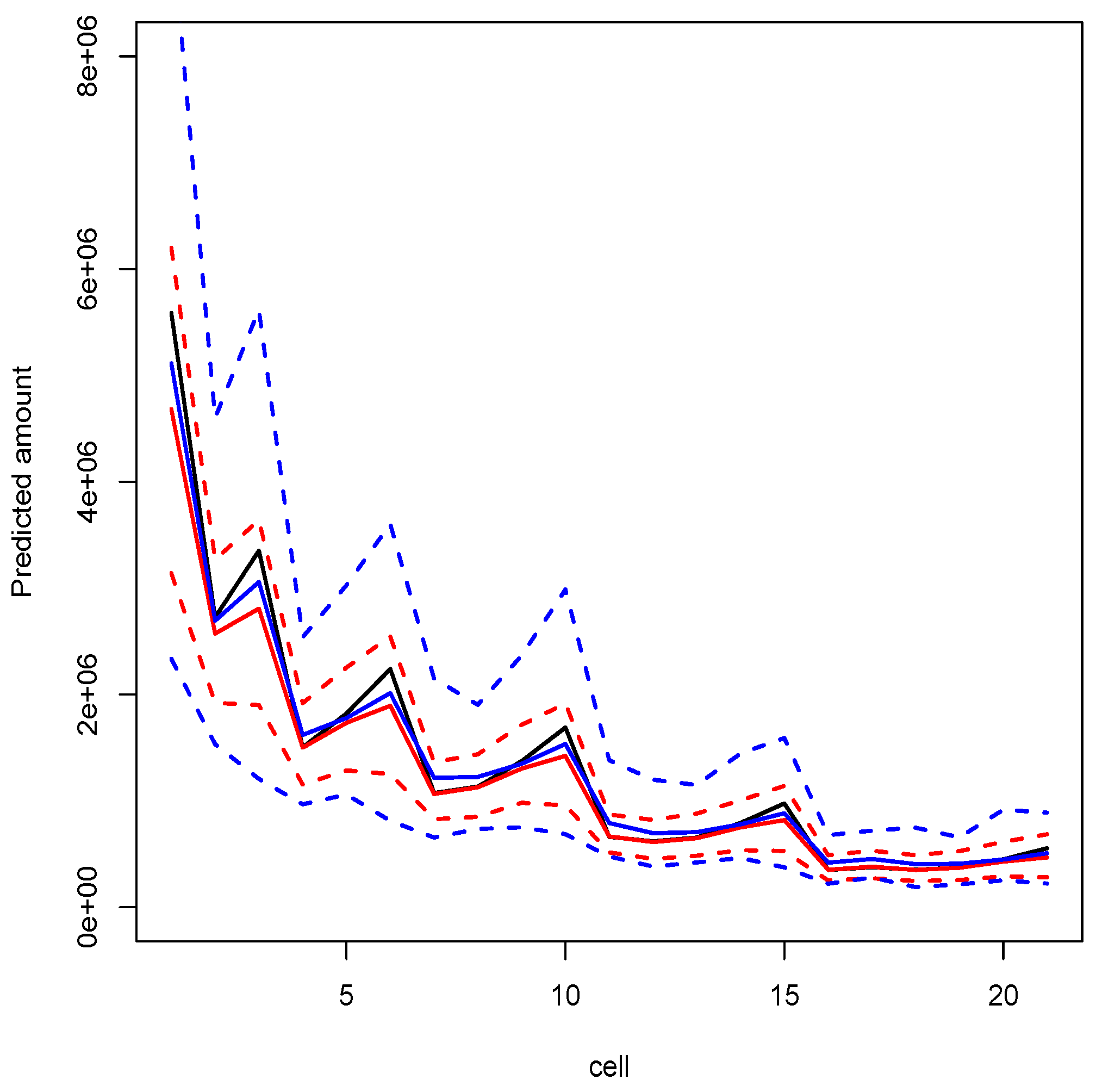
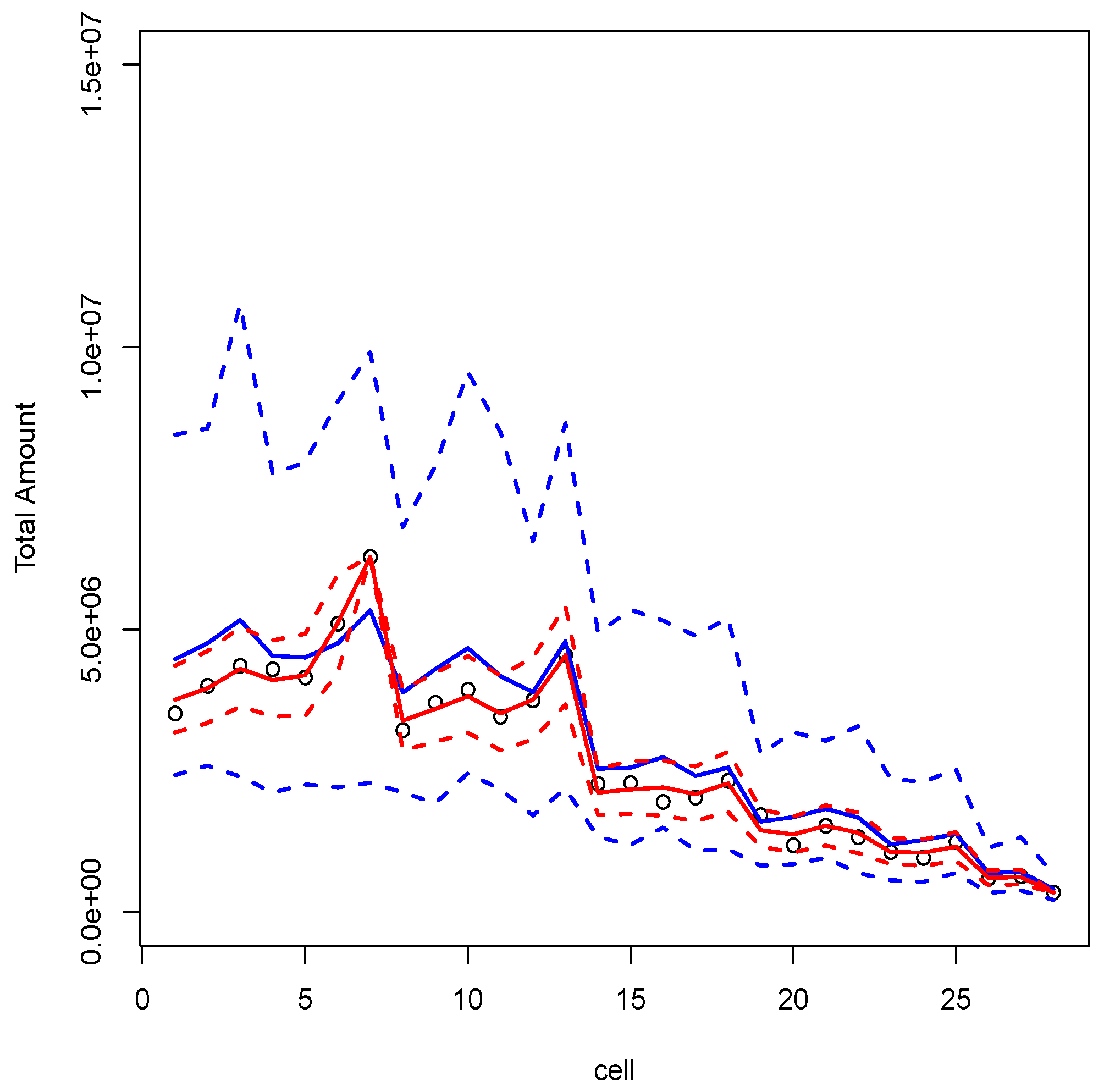
3.2.2. Illustration and Discussion
- 1-3.
- see previous section;
- 4.
- for each accident year, allocate randomly the source (t) of each payment;
- 5.
- fit model G; and
- 6.
- compute the best estimate and the MSEP of the reserve.
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- E. Astesan. Les réserves techniques des sociétés d’assurances contre les accidents automobiles. Paris, France: Librairie générale de droit et de jurisprudence, 1938. [Google Scholar]
- R. Mack. “Distribution-free calculation of the standard error of chain ladder reserve estimates.” ASTIN Bull. 23 (1993): 213–225. [Google Scholar] [CrossRef]
- P.D. England, and R.J. Verrall. “Stochastic claims reserving in general insurance.” Br. Actuar. J. 8 (2003): 443–518. [Google Scholar] [CrossRef]
- J. Van Eeghen. “Loss reserving methods.” In Surveys of Actuarial Studies 1. The Hague, The Netherlands: Nationale-Nederlanden, 1981. [Google Scholar]
- G.C. Taylor. Claims Reserving in Non-Life Insurance. Amsterdam, The Netherlands: North-Holland, 1986. [Google Scholar]
- J.E. Karlsson. “The expected value of IBNR claims.” Scand. Actuar. J. 1976 (1976): 108–110. [Google Scholar] [CrossRef]
- E. Arjas. “The claims reserving problem in nonlife insurance—Some structural ideas.” ASTIN Bull. 19 (1989): 139–152. [Google Scholar] [CrossRef]
- W.S. Jewell. “Predicting IBNYR events and delays I. Continuous time.” ASTIN Bull. 19 (1989): 25–55. [Google Scholar] [CrossRef]
- R. Norberg. “Prediction of outstanding liabilities in non-life insurance.” ASTIN Bull. 23 (1993): 95–115. [Google Scholar] [CrossRef]
- O. Hesselager. “A Markov model for loss reserving.” ASTIN Bull. 24 (1994): 183–193. [Google Scholar] [CrossRef]
- R. Norberg. “Prediction of outstanding liabilities II: Model variations and extensions.” ASTIN Bull. 29 (1999): 5–25. [Google Scholar] [CrossRef]
- O. Hesselager, and R.J. Verrall. “Reserving in Non-Life Insurance.” Available online: http://onlinelibrary.wiley.com (accesssed on 29 February 2016).
- X.B. Zhao, X. Zhou, and J.L. Wang. “Semiparametric model for prediction of individual claim loss reserving.” Insur. Math. Econ. 45 (2009): 1–8. [Google Scholar] [CrossRef]
- X. Zhao, and X. Zhou. “Applying copula models to individual claim loss reserving methods.” Insur. Math. Econ. 46 (2010): 290–299. [Google Scholar] [CrossRef]
- M. Pigeon, K. Antonio, and M. Denuit. “Individual loss reserving using paid-incurred data.” Insur. Math. Econ. 58 (2014): 121–131. [Google Scholar] [CrossRef]
- K. Antonio, and R. Plat. “Micro-level stochastic loss reserving for general insurance.” Scand. Actuar. J. 2014 (2014): 649–669. [Google Scholar] [CrossRef]
- X. Jin, and E.W. Frees. “Comparing Micro- and Macro-Level Loss Reserving Models.” Madison, WI, USA: Presentation at ARIA, 2015. [Google Scholar]
- A. Johansson. “Claims Reserving on Macro- and Micro-Level.” Master’s Thesis, Royal Institute of Technology, Stockholm, Sweden, 2015. [Google Scholar]
- J. Friedland. Estimating Unpaid Claims Using Basic Techniques. Arlington, VA, USA: Casualty Actuarial Society, 2010. [Google Scholar]
- G.J. Van den Berga, and B. van der Klaauw. “Combining micro and macro unemployment duration data.” J. Econom. 102 (2001): 271–309. [Google Scholar] [CrossRef]
- F. Altissimo, B. Mojon, and P. Zaffaroni. Fast Micro and Slow Macro: Can Aggregation Explain the Persistence of Inflation? European Central Bank Working Papers; 2007, Volume 0729. [Google Scholar]
- W.H. Greene. Econometric Analysis, 5th ed. Upper Saddle River, NJ, USA: Prentice Hall, 2003. [Google Scholar]
- P. McCullagh, and J.A. Nelder. Generalized Linear Models. London, UK: Chapman & Hall, 1989. [Google Scholar]
- G.M. Cordeiro, and P. McCullagh. “Bias correction in generalized linear models.” J. R. Stat. Soc. B 53 (1991): 629–643. [Google Scholar]
- M. Wüthrich, and M. Merz. Stochastic Claims Reserving Methods. Hoboken, NJ, USA: Wiley Interscience, 2008. [Google Scholar]
- M. Ruoyan. “Estimation of Dispersion Parameters in GLMs with and without Random Effects.” Stockholm University, 2004. Available online: http://www2.math.su.se/matstat/reports/serieb/2004/rep5/report.pdf (accessed on 29 February 2016).
- T.A.B. Snijders, and R.J. Bosker. Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling. Thousand Oaks, CA, USA: Sage Publishing, 2012. [Google Scholar]
- S.G. Self, and K.Y. Liang. “Asymptotic properties of maximum likelihood estimators and likelihood ratio tests under nonstandard conditions.” J. Am. Stat. Assoc. 82 (1987): 605–610. [Google Scholar] [CrossRef]
- D. Dunson. Random Effect and Latent Variable Model Selection. Lecture Notes in Statistics; New York, NY, USA: Springer-Verlag, 2008, Volume 192. [Google Scholar]
- S. Christofides. “Regression models based on log-incremental payments.” Claims Reserv. Man. 2 (1997): D5.1–D5.53. [Google Scholar]
- T. Mack, and G. Venter. “A comparison of stochastic models that reproduce chain ladder reserve estimates.” Insur. Math. Econ. 26 (2000): 101–107. [Google Scholar] [CrossRef]
- A. Skrondal, and S. Rabe-Hesketh. “Prediction in multilevel generalized linear models.” J. R. Stat. Soc. A 172 (2009): 659–687. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Components | Macro | Micro |
|---|---|---|
| Exp. value | ||
| Inv. link func. | ||
| with | with | |
| Variance | ||
| Pred. value | ||
| Known values |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|
| 1 | 3511 | 3215 | 2266 | 1712 | 1059 | 587 | 340 |
| 2 | 4001 | 3702 | 2278 | 1180 | 956 | 629 | – |
| 3 | 4355 | 3932 | 1946 | 1522 | 1238 | – | – |
| 4 | 4295 | 3455 | 2023 | 1320 | – | – | – |
| 5 | 4150 | 3747 | 2320 | – | – | – | – |
| 6 | 5102 | 4548 | – | – | – | – | – |
| 7 | 6283 | – | – | – | – | – | – |
| Method | ||
|---|---|---|
| Mack’s model | 28655773 | 1417267 |
| Poisson reg. | ||
| Model A | 28655773 | 11622 |
| Model C | 28655773 | 11622 |
| quasi-Poisson reg. | ||
| Model B | 28655773 | 1708196 |
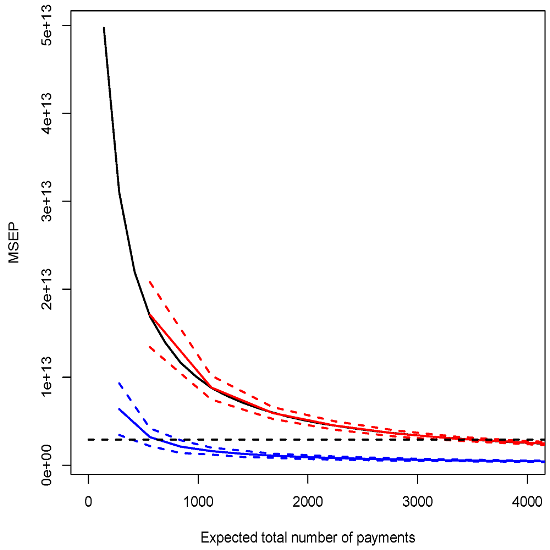
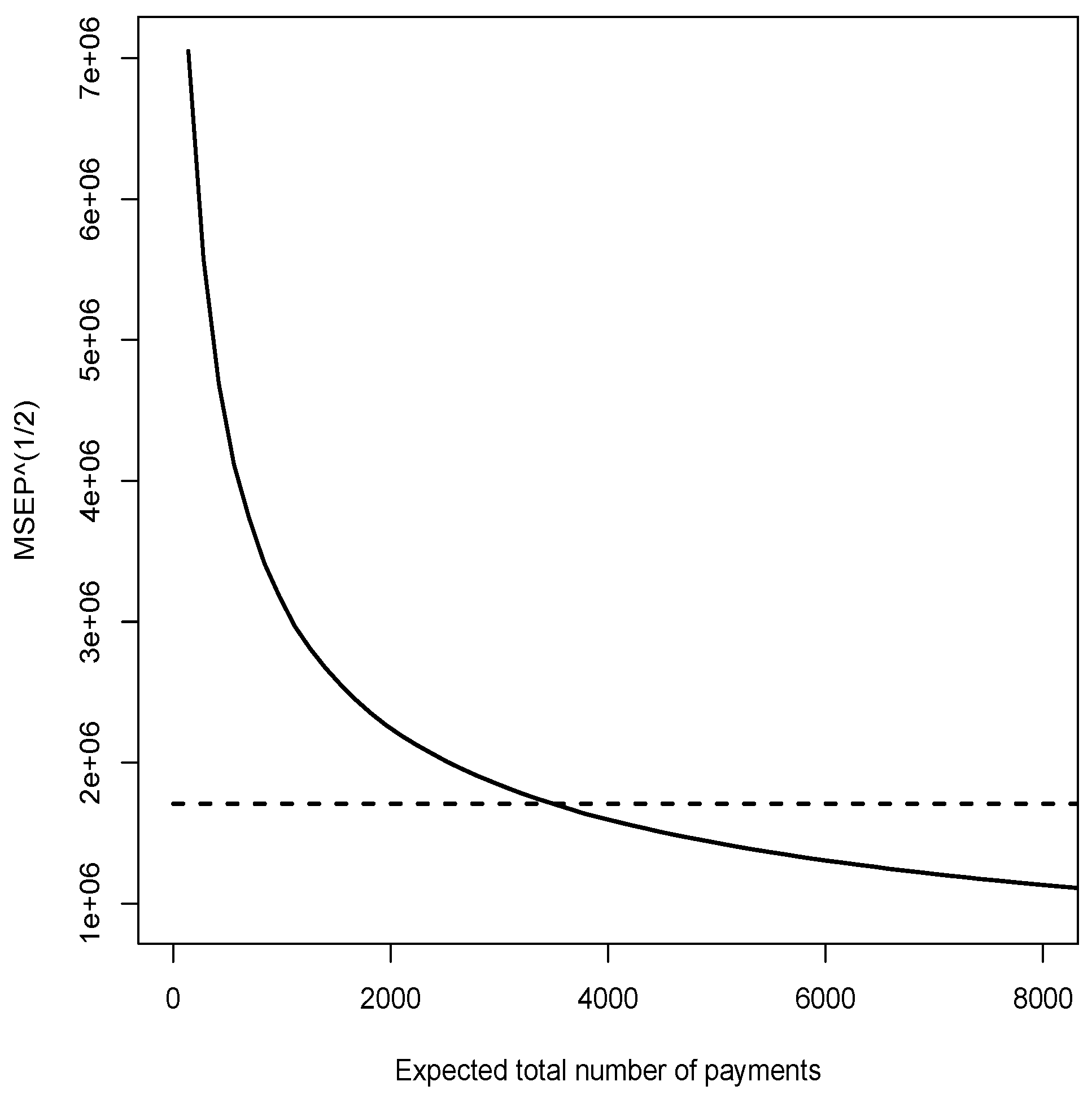
| Model D | 28655773 | see Figure 1 |
| quasi-Poisson reg. | ||
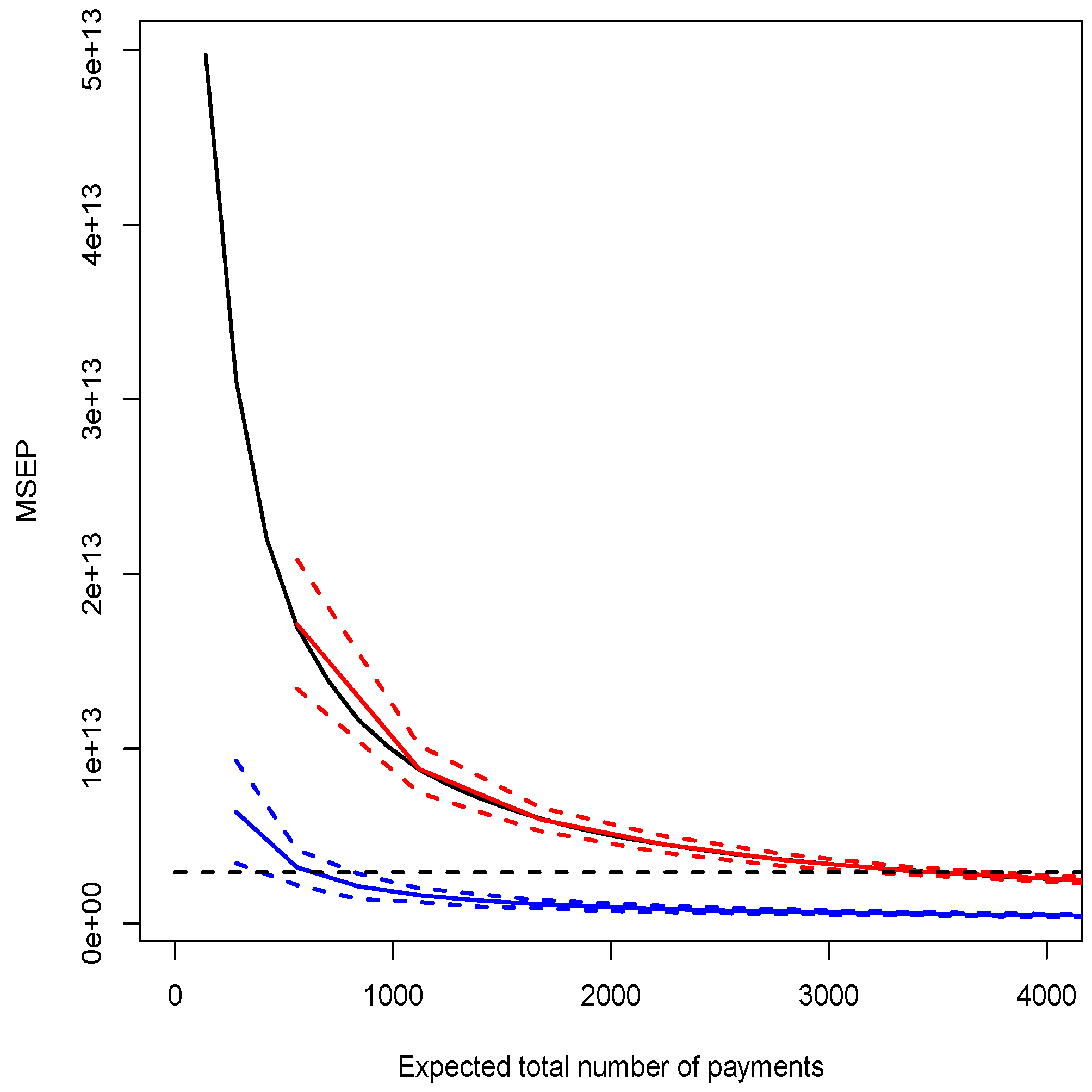
| Model E () | 28657364 | see Figure 2 |
| Model F () | 20514566 | see Figure 2 |
| Modèle | ||
|---|---|---|
| coll. quasi-Pois. | 28656423 | 1708216 |
| mixed Poisson non-cond. | 27930624 | 3297401 |
| mixed Poisson cond. | 25972947 | 2280902 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Charpentier, A.; Pigeon, M. Macro vs. Micro Methods in Non-Life Claims Reserving (an Econometric Perspective). Risks 2016, 4, 12. https://doi.org/10.3390/risks4020012
Charpentier A, Pigeon M. Macro vs. Micro Methods in Non-Life Claims Reserving (an Econometric Perspective). Risks. 2016; 4(2):12. https://doi.org/10.3390/risks4020012
Chicago/Turabian StyleCharpentier, Arthur, and Mathieu Pigeon. 2016. "Macro vs. Micro Methods in Non-Life Claims Reserving (an Econometric Perspective)" Risks 4, no. 2: 12. https://doi.org/10.3390/risks4020012
APA StyleCharpentier, A., & Pigeon, M. (2016). Macro vs. Micro Methods in Non-Life Claims Reserving (an Econometric Perspective). Risks, 4(2), 12. https://doi.org/10.3390/risks4020012