
A Novel Hybrid Deep Learning Method for Accurate Exchange Rate Prediction


Abstract
1. Introduction
2. Methodological Framework
2.1. Variational Mode Decomposition
- The Hilbert transform of each mode is calculated and then transformed into a respective uni-sided frequency spectrum;
- To estimate the center frequency of each mode , the mode is multiplied by the exponential tuned signal. This will modulate the mode spectra to the relevant baseband;
- The bandwidth of each mode is obtained by conducting the Gaussian smoothness on the demodulated signal.
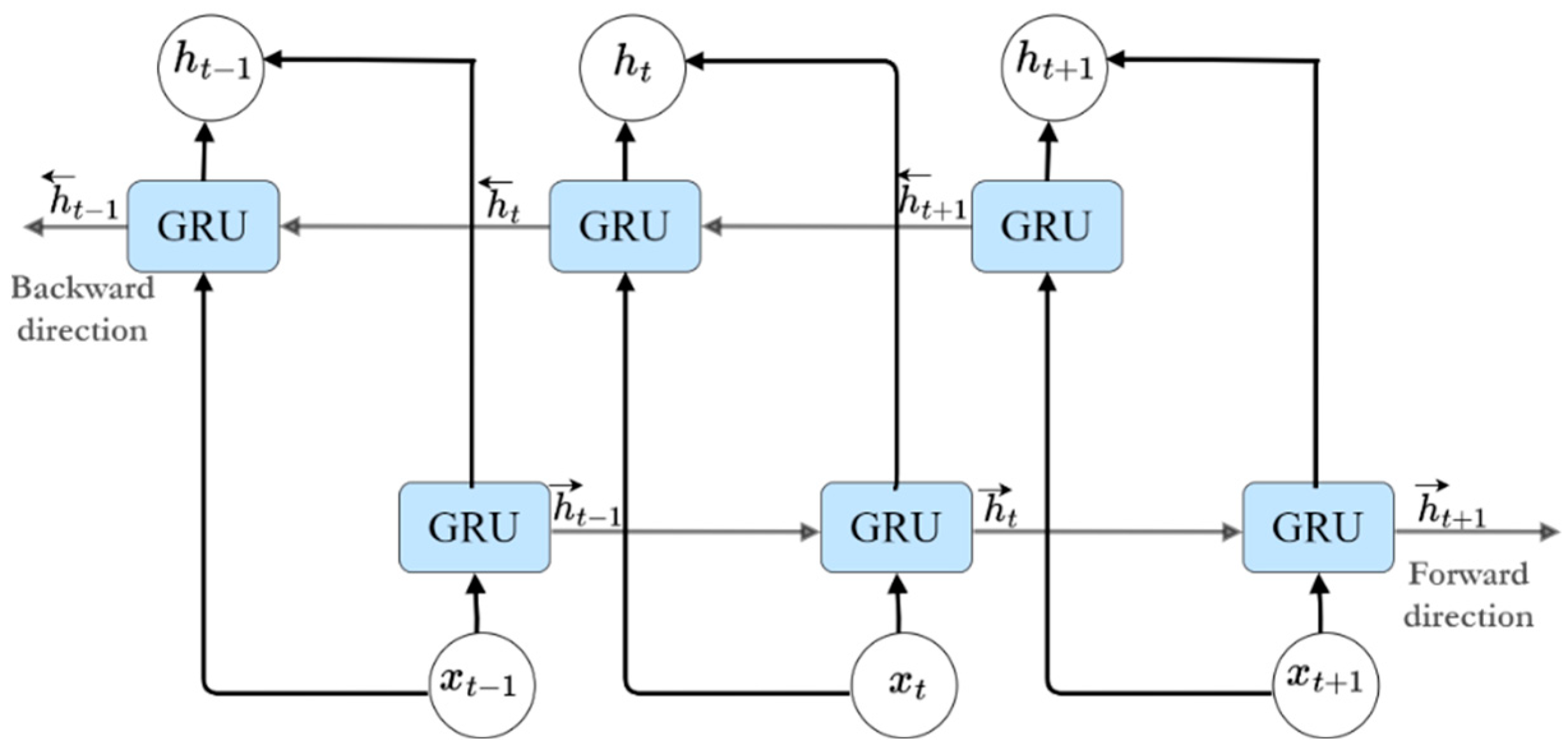
2.2. Bidirectional Gated Recurrent Unit Model
2.3. Data
2.4. Data Augmentation
2.5. The Proposed Model
2.6. Evaluation Measures
2.7. Benchmark Models and Parameter Values
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abedin, Mohammad Zoynul, Mahmudul Hassan Moon, Mohammad Kabir Hassan, and Petr Hajek. 2021. Deep learning-based exchange rate prediction during the COVID-19 pandemic. Annals of Operations Research 26: 1–52. [Google Scholar] [CrossRef]
- Adewale, Olumide Sunday, D. I. Aronu, and Adeniyi D. Adeniyi. 2021. Currency Exchange Forecasting Using Sample Mean Estimator and Multiple Linear Regression Machine Learning Models. FUOYE Journal of Engineering and Technology 6: 39–46. [Google Scholar] [CrossRef]
- Andonie, Razvan. 2019. Hyperparameter optimization in learning systems. Journal of Membrane Computing 1: 279–91. [Google Scholar] [CrossRef]
- Ayitey Junior, Micheal, Peter Appiahene, Obed Appiah, and Christopher Ninfaakang Bombie. 2023. Forex market forecasting using machine learning: Systematic Literature Review and meta-analysis. Journal of Big Data 10: 9. [Google Scholar] [CrossRef]
- Baek, Yujin, and Ha Young Kim. 2018. ModAugNet: A new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module. Expert Systems with Applications 113: 457–80. [Google Scholar] [CrossRef]
- Baillie, Richard T., and Patrick C. McMahon. 2000. The Foreign Exchange Market: Theory and Econometric Evidence, digital rep. ed. Cambridge: Cambridge University Press. [Google Scholar]
- Bao, Wei, Jun Yue, and Yulei Rao. 2017. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 12: e0180944. [Google Scholar] [CrossRef]
- Carvalho, Vinicius R., Marcio F. D. Moraes, Antonio De Padua Braga, and Eduardo M. A. M. Mendes. 2020. Evaluating five different adaptive decomposition methods for EEG signal seizure detection and classification. Biomedical Signal Processing and Control 62: 102073. [Google Scholar] [CrossRef]
- Chen, Jingxia X., Dongmei Jiang, and Yizhai Zhang. 2019. A Hierarchical Bidirectional GRU Model With Attention for EEG-Based Emotion Classification. IEEE Access 7: 118530–40. [Google Scholar] [CrossRef]
- Chintakindi, Sanjay, Ali Alsamhan, Mustafa Haider Abidi, and Maduri Parveen Kumar. 2022. Annealing of Monel 400 Alloy Using Principal Component Analysis, Hyper-parameter Optimization, Machine Learning Techniques, and Multi-objective Particle Swarm Optimization. International Journal of Computational Intelligence Systems 15: 18. [Google Scholar] [CrossRef]
- Chung, Junyoung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv arXiv:1412.3555. [Google Scholar]
- Das, Pragyan, Paramita, Ranjeeta Bisoi, and Pradipta Kishore Dash. 2018. Data decomposition based fast reduced kernel extreme learning machine for currency exchange rate forecasting and trend analysis. Expert Systems with Applications 96: 427–49. [Google Scholar] [CrossRef]
- Dautel, Alexander Jakob, Wolfgang Karl Härdle, Stefan Lessmann, and Hsin-Vonn Seow. 2020. Forex exchange rate forecasting using deep recurrent neural networks. Digital Finance 2: 69–96. [Google Scholar] [CrossRef]
- Dragomiretskiy, Konstantin, and Dominique Zosso. 2014. Variational Mode Decomposition. IEEE Transactions on Signal Processing 62: 531–44. [Google Scholar] [CrossRef]
- Hansen, Peter Reinhard, and Asger Lunde. 2005. A forecast comparison of volatility models: Does anything beat a GARCH(1,1)? Journal of Applied Econometrics 20: 873–89. [Google Scholar] [CrossRef]
- Hansen, Peter Reinhard, Asger Lunde, and James M. Nason. 2011. The Model Confidence Set. Econometrica 79: 453–97. [Google Scholar] [CrossRef]
- Hassani, Hossein, and Emmanuel Sirimal Silva. 2015. Forecasting with Big Data: A Review. Annals of Data Science 2: 5–19. [Google Scholar] [CrossRef]
- Hestenes, Magnus Rudolph. 1969. Multiplier and gradient methods. Journal of Optimization Theory and Applications 4: 303–20. [Google Scholar] [CrossRef]
- Islam, Md. Saiful, and Emam Hossain. 2021. Foreign exchange currency rate prediction using a GRU-LSTM hybrid network. Soft Computing Letters 3: 100009. [Google Scholar] [CrossRef]
- Kausar, Rehan, Farhat Iqbal, Abdul Raziq, and Naveed Sheikh. 2023. A Hybrid Approach for Accurate Forecasting of Exchange Rate Prices Using Vmd-Ceemdan-Gru-Atcn Model. Sains Malaysiana 52: 3293–306. [Google Scholar] [CrossRef]
- Kelany, Omnia, Sherin Aly, and Mohamed Ismail. 2020. Deep Learning Model for Financial Time Series Prediction. Presented at the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, November 17–18; pp. 120–25. [Google Scholar] [CrossRef]
- Lee, Vincent Cheng-Siong, and Hsiao Tshung Wong. 2007. A multivariate neuro-fuzzy system for foreign currency risk management decision making. Neurocomputing, Advanced Neurocomputing Theory and Methodology 70: 942–51. [Google Scholar] [CrossRef]
- Li, Audeliano, and Guilherme Sousa Bastos. 2020. Stock Market Forecasting Using Deep Learning and Technical Analysis: A Systematic Review. IEEE Access 8: 185232–42. [Google Scholar] [CrossRef]
- Li, Jinchao, Shaowen Zhu, and Qianqian Wu. 2019. Monthly crude oil spot price forecasting using variational mode decomposition. Energy Economics 83: 240–53. [Google Scholar] [CrossRef]
- Lin, Hualing, Qiubi Sun, and Sheng-Qun Chen. 2020. Reducing Exchange Rate Risks in International Trade: A Hybrid Forecasting Approach of CEEMDAN and Multilayer LSTM. Sustainability 12: 2451. [Google Scholar] [CrossRef]
- Liu, Yang. 2019. Novel volatility forecasting using deep learning—Long Short Term Memory Recurrent Neural Networks. Expert Systems with Applications 132: 99–109. [Google Scholar] [CrossRef]
- Liu, Yapei, Jianhong Ma, Yongcai Tao, Lei Shi, Lin Wei, and Linna Li. 2020. Hybrid Neural Network Text Classification Combining TCN and GRU. Presented at the 2020 IEEE 23rd International Conference on Computational Science and Engineering (CSE), Guangzhou, China, December 20–January 1; pp. 30–35. [Google Scholar] [CrossRef]
- Mou, Lichao, Pedram Ghamisi, and Xiao Xiang Zhu. 2017. Deep Recurrent Neural Networks for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing 55: 3639–55. [Google Scholar] [CrossRef]
- Pesaran, Mohammad Hashem, and Allan Timmermann. 1992. A Simple Nonparametric Test of Predictive Performance. Journal of Business & Economic Statistics 10: 461–65. [Google Scholar] [CrossRef]
- Rodrigues, Paulo Canas, Olushina Olawale Awe, Jonatha Sousa Pimentel, and Rahim Mahmoudvand. 2020. Modelling the Behaviour of Currency Exchange Rates with Singular Spectrum Analysis and Artificial Neural Networks. Stats 3: 12. [Google Scholar] [CrossRef]
- Rossi, Barbara. 2013. Exchange Rate Predictability. Journal of Economic Literature 51: 1063–119. [Google Scholar] [CrossRef]
- Sarangi, Kumar Pradeepa, Muskaan Chawla, Pinaki Ghosh, Sunny Singh, and Pramod Kumar Singh. 2022. FOREX trend analysis using machine learning techniques: INR vs. USD currency exchange rate using ANN-GA hybrid approach. Materials Today: Proceedings, National Conference on Functional Materials: Emerging Technologies and Applications in Materials Science 49: 3170–76. [Google Scholar] [CrossRef]
- Sezer, Omer Berat, Mehmet Ugur Gudelek, and Ahmet Murat Ozbayoglu. 2020. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Applied Soft Computing 90: 106181. [Google Scholar] [CrossRef]
- Shen, Hua, and Xun Liang. 2016. A Time Series Forecasting Model Based on Deep Learning Integrated Algorithm with Stacked Autoencoders and SVR for FX Prediction. In Artificial Neural Networks and Machine Learning—ICANN 2016. Edited by Alessandro E. P. Villa, Paolo Masulli and Antonio Javier Pons Rivero. Cham: Springer International Publishing, pp. 326–35. [Google Scholar] [CrossRef]
- Sipper, Moshe. 2022. High Per Parameter: A Large-Scale Study of Hyperparameter Tuning for Machine Learning Algorithms. Algorithms 15: 315. [Google Scholar] [CrossRef]
- Wang, Yudong, Zhiyuan Pan, Li Liu, and Chongfeng Wu. 2019. Oil price increases and the predictability of equity premium. Journal of Banking & Finance 102: 43–58. [Google Scholar] [CrossRef]
- Yang, Li, and Abdallah Shami. 2020. On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice. Neurocomputing 415: 295–316. [Google Scholar] [CrossRef]
- Yasar, Harun, and Zeynep Hilal Kilimci. 2020. US Dollar/Turkish Lira Exchange Rate Forecasting Model Based on Deep Learning Methodologies and Time Series Analysis. Symmetry 12: 1553. [Google Scholar] [CrossRef]
- Yasir, Muhammad, Mehr Yahya Durrani, Sitara Afzal, Muazzam Maqsood, Farhan Aadil, Irfan Mehmood, and Seungmin Rho. 2019. An Intelligent Event-Sentiment-Based Daily Foreign Exchange Rate Forecasting System. Applied Sciences 9: 2980. [Google Scholar] [CrossRef]
- Yilmaz, Firat Melih, and Ozer Arabaci. 2021. Should Deep Learning Models be in High Demand, or Should They Simply be a Very Hot Topic? A Comprehensive Study for Exchange Rate Forecasting. Computational Economics 57: 217–45. [Google Scholar] [CrossRef]
- Yu, Lean, Shouyang Wang, and Kin Keung Lai. 2008. Forecasting crude oil price with an EMD-based neural network ensemble learning paradigm. Energy Economics 30: 2623–35. [Google Scholar] [CrossRef]
- Zhang, Chu, Jianzhong Zhou, Chaoshun Li, Wenlong Fu, and Tian Peng. 2017. A compound structure of ELM based on feature selection and parameter optimization using hybrid backtracking search algorithm for wind speed forecasting. Energy Conversion and Management 143: 360–76. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| EUR/SAR Exchange Rate | EUR/CNY Exchange Rate | |
|---|---|---|
| Mean | 4.480 | 8.465 |
| Std. Dev. | 0.597 | 1.167 |
| Minimum | 3.173 | 6.652 |
| Maximum | 5.916 | 11.222 |
| Skewness | −0.058 | 0.642 |
| Kurtosis | 2.624 | 2.155 |
| Jarque–Bera | 1.859 | 28.348 *** |
| Models | Training | Testing | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | DA (%) | MSE | MAE | MAPE | DA (%) | |||
| Ridge | 0.0179 | 0.0993 | 0.0218 | 0.9551 | 51.77 | 0.0072 | 0.0704 | 0.0170 | 0.8377 | 45.61 |
| MLP | 0.0436 | 0.1634 | 0.0366 | 0.8907 | 56.63 | 0.0295 | 0.1533 | 0.0371 | 0.3319 | 43.86 |
| LightGBM | 0.0089 | 0.0633 | 0.0139 | 0.9777 | 79.65 | 0.0112 | 0.0860 | 0.0210 | 0.7464 | 57.90 |
| ANN | 0.0174 | 0.0981 | 0.0214 | 0.9565 | 53.98 | 0.0074 | 0.0720 | 0.0173 | 0.8333 | 45.61 |
| V-ANN | 0.0037 | 0.0476 | 0.0105 | 0.9907 | 81.86 | 0.0025 | 0.0396 | 0.0097 | 0.9442 | 82.46 |
| MV-ANN | 0.0194 | 0.1078 | 0.0233 | 0.9514 | 54.87 | 0.0075 | 0.0663 | 0.0159 | 0.8312 | 63.16 |
| RNN | 0.0179 | 0.1009 | 0.0224 | 0.9552 | 57.52 | 0.0115 | 0.0861 | 0.0209 | 0.7401 | 49.12 |
| V-RNN | 0.0036 | 0.0481 | 0.0108 | 0.9909 | 81.86 | 0.0018 | 0.0341 | 0.0082 | 0.9597 | 89.47 |
| MV-RNN | 0.0345 | 0.1429 | 0.0318 | 0.9136 | 61.50 | 0.0484 | 0.1866 | 0.0458 | 0.8368 | 57.37 |
| BiLSTM | 0.0176 | 0.0987 | 0.0216 | 0.9559 | 54.42 | 0.0075 | 0.0727 | 0.0175 | 0.8302 | 45.61 |
| V-BiLSTM | 0.0036 | 0.0481 | 0.0108 | 0.9909 | 82.31 | 0.0020 | 0.0350 | 0.0085 | 0.9554 | 85.97 |
| MVO-BiLSTM | 0.0025 | 0.0399 | 0.0088 | 0.9938 | 82.32 | 0.0011 | 0.0262 | 0.0063 | 0.9744 | 89.49 |
| BiGRU | 0.0175 | 0.0986 | 0.0216 | 0.9561 | 53.54 | 0.0077 | 0.0737 | 0.0178 | 0.8264 | 45.61 |
| V-BiGRU | 0.0041 | 0.0516 | 0.0118 | 0.9897 | 81.86 | 0.0029 | 0.0446 | 0.0109 | 0.9336 | 82.46 |
| MVO-BiGRU | 0.0015 | 0.0303 | 0.0066 | 0.9963 | 89.38 | 0.0007 | 0.0208 | 0.0050 | 0.9846 | 94.77 |
| Models | Training | Testing | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | DA (%) | MSE | MAE | MAPE | DA (%) | |||
| Ridge | 0.0610 | 0.1830 | 0.0211 | 0.9578 | 53.09 | 0.0153 | 0.0988 | 0.0130 | 0.8524 | 54.39 |
| MLP | 0.1060 | 0.2465 | 0.0286 | 0.9267 | 54.42 | 0.0345 | 0.1570 | 0.0209 | 0.6683 | 56.14 |
| LightGBM | 0.0200 | 0.1015 | 0.0117 | 0.9862 | 80.09 | 0.0301 | 0.1372 | 0.0179 | 0.7105 | 50.88 |
| ANN | 0.0583 | 0.1791 | 0.0207 | 0.9597 | 54.87 | 0.0157 | 0.0995 | 0.0131 | 0.8486 | 50.88 |
| V-ANN | 0.0134 | 0.0946 | 0.0109 | 0.9907 | 80.53 | 0.0111 | 0.0832 | 0.0108 | 0.8930 | 75.43 |
| MV-ANN | 0.0693 | 0.1971 | 0.0229 | 0.952 | 63.72 | 0.0190 | 0.1101 | 0.0146 | 0.8177 | 56.14 |
| RNN | 0.0605 | 0.1881 | 0.0218 | 0.9582 | 53.54 | 0.0230 | 0.1192 | 0.0155 | 0.7790 | 52.63 |
| V-RNN | 0.0129 | 0.0925 | 0.0107 | 0.9911 | 80.53 | 0.0626 | 0.1860 | 0.0254 | 0.3979 | 70.18 |
| MV-RNN | 0.1163 | 0.2571 | 0.0296 | 0.9196 | 55.75 | 0.0325 | 0.1467 | 0.0193 | 0.6871 | 56.14 |
| BiLSTM | 0.0562 | 0.177 | 0.0204 | 0.9611 | 56.64 | 0.0163 | 0.1038 | 0.0136 | 0.8435 | 45.61 |
| V-BiLSTM | 0.0129 | 0.0924 | 0.0106 | 0.9911 | 80.53 | 0.0109 | 0.0810 | 0.0106 | 0.8955 | 75.44 |
| MVO-BiLSTM | 0.0049 | 0.0528 | 0.0061 | 0.9966 | 88.05 | 0.0063 | 0.0587 | 0.0076 | 0.9392 | 78.95 |
| BiGRU | 0.0560 | 0.1773 | 0.0205 | 0.9613 | 53.98 | 0.0166 | 0.1056 | 0.0139 | 0.8405 | 45.61 |
| V-BiGRU | 0.0128 | 0.0918 | 0.0106 | 0.9911 | 80.97 | 0.0147 | 0.0959 | 0.0124 | 0.8586 | 70.18 |
| MVO-BiGRU | 0.0010 | 0.0249 | 0.0029 | 0.9993 | 91.15 | 0.0039 | 0.051 | 0.0067 | 0.9624 | 85.96 |
| Models | EUR/SAR | EUR/CNY | ||||
|---|---|---|---|---|---|---|
| MSE | MAE | MAPE | MSE | MAE | MAPE | |
| Ridge | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| MLP | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| LightGBM | 0.002 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| ANN | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| V-ANN | 0.006 | 0.000 | 0.000 | 0.003 | 0.000 | 0.000 |
| MV-ANN | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| RNN | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| V-RNN | 0.000 | 0.000 | 0.000 | 0.075 | 0.046 | 0.050 |
| MV-RNN | 0.005 | 0.000 | 0.000 | 0.001 | 0.000 | 0.000 |
| BiLSTM | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| V-BiLSTM | 0.002 | 0.000 | 0.000 | 0.003 | 0.000 | 0.000 |
| MVO-BiLSTM | 0.046 | 0.036 | 0.043 | 0.327 | 0.517 | 0.546 |
| BiGRU | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| V-BiGRU | 0.002 | 0.000 | 0.000 | 0.003 | 0.000 | 0.000 |
| MVO-BiGRU | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Models | EUR/SAR | EUR/CNY | ||
|---|---|---|---|---|
| DA (%) | p-Value | DA (%) | p-Value | |
| Ridge | 45.61 | 0.316 | 54.39 | 0.869 |
| MLP | 43.86 | 0.316 | 56.14 | 0.963 |
| LightGBM | 57.90 | 0.513 | 50.88 | 0.977 |
| ANN | 45.61 | 0.479 | 50.88 | 0.796 |
| V-ANN | 82.46 *** | 0.000 | 75.43 *** | 0.000 |
| MV-ANN | 63.16 | 0.233 | 56.14 | 0.963 |
| RNN | 49.12 | 0.423 | 52.63 | 0.844 |
| V-RNN | 89.47 *** | 0.000 | 70.18 *** | 0.000 |
| MV-RNN | 57.37 | 0.034 | 56.14 | 0.156 |
| BiLSTM | 45.61 | 0.316 | 45.61 | 0.703 |
| V-BiLSTM | 85.97 *** | 0.000 | 75.44 *** | 0.000 |
| MVO-BiLSTM | 89.49 *** | 0.000 | 78.95 *** | 0.000 |
| BiGRU | 45.61 | 0.409 | 45.61 | 0.703 |
| V-BiGRU | 82.46 *** | 0.000 | 70.18 *** | 0.000 |
| MVO-BiGRU | 94.77 *** | 0.000 | 85.96 *** | 0.000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iqbal, F.; Koutmos, D.; Ahmed, E.A.; Al-Essa, L.M. A Novel Hybrid Deep Learning Method for Accurate Exchange Rate Prediction. Risks 2024, 12, 139. https://doi.org/10.3390/risks12090139
Iqbal F, Koutmos D, Ahmed EA, Al-Essa LM. A Novel Hybrid Deep Learning Method for Accurate Exchange Rate Prediction. Risks. 2024; 12(9):139. https://doi.org/10.3390/risks12090139
Chicago/Turabian StyleIqbal, Farhat, Dimitrios Koutmos, Eman A. Ahmed, and Lulwah M. Al-Essa. 2024. "A Novel Hybrid Deep Learning Method for Accurate Exchange Rate Prediction" Risks 12, no. 9: 139. https://doi.org/10.3390/risks12090139
APA StyleIqbal, F., Koutmos, D., Ahmed, E. A., & Al-Essa, L. M. (2024). A Novel Hybrid Deep Learning Method for Accurate Exchange Rate Prediction. Risks, 12(9), 139. https://doi.org/10.3390/risks12090139