4.1. Synthetic Data
The first set of numerical experiments compares the classification performance of SP-SVM, EEL-SVM, C-SVM,
-SVM and
-SVM for simulated data. We generated the data using a model with a classification decision known a priori. To achieve a fair comparison between the different SVM models, we conducted our experiments by adopting the experiment design used in the relevant literature; see
Huang et al. (
2014) and
Shen et al. (
2017). Note that we were not able to compare these five SVM classifiers with Ramp-KSVCR, since the publicly available code for it does not report the tuned separation hyper-plane parameters, though the classification performances of all six classifiers (including Ramp-KSVCR) are compared in
Section 4.2 in terms of accuracy and robustness resilience to contamination.
We do not assume DU in
Section 4.1.1, and data contamination is added in
Section 4.1.2. The non-contaminated data were simulated based on a Gaussian bivariate model, for which, the analytical/theoretical or ‘true’ linear classification boundary is known (referred to as
Bayes classifier from now on). Further, nested simulation was used to generate the labels via a Bernoulli random variable
B with probability of ‘success’
; therefore, we generated
random variates from this distribution, where
N is the total number of examples from the two classes. The features
were simulated according to
Note that we estimated in
Section 4.1.1 and
Section 4.1.2 the classifiers for these synthetic data, i.e.,
, and compared them with the Bayes classifier, i.e.,
, where
and
. SP-SVM training was performed by considering DU only with respect to the second feature that has a higher variance.
4.1.1. Synthetic Non-Contaminated Data
The data were simulated and we conducted a 10-fold cross-validation to tune the parameters of each classifier over the following parameter spaces:
SP-SVM: ;
EEL-SVM: ;
-SVM: ;
-SVM: , where and .
In the interest of fair comparisons, the parameter spaces had similar cardinality, except EEL-SVM, which has a smaller-sized parameter space, which does not create any advantage to EEL-SVM. We chose the same penalty value for all methods by setting (for C-SVM, SP-SVM, -SVM and -SVM) and (for EEL-SVM).
The five SVM classifiers were compared via 100 independent samples of size
N, for which,
was computed for all
. Each classifier was fairly compared against the Bayes classifier via the distance
where
and
are, respectively, the mean and standard deviation estimates of
based on the 100 point estimates. Our results are reported in
Table 1, where we observe no clear ranking among the methods under study for non-contaminated data, though
Section 4.1.2 shows a clear pattern when data contamination is introduced.
4.1.2. Synthetic Contaminated Data
We next investigated how robust the five SVM classifiers were. This was achieved by contaminating a percentage
of the synthetic data generated in
Section 4.1.1. Data contamination was produced by generating random variates around a ‘central’ point from the ‘true’ separation hyper-plane; without loss of generality, the focal point was
. The contaminated data points were generated from three elliptical distributions centered at
, namely, a bivariate normal
and two bivariate Student’s
, with
degrees of freedom and a covariance matrix given by
The equal chance of labeling the response variable ensures even contamination on both sides of the linear separation line; moreover, the negative correlation of was chosen on purpose so that the DU became more pronounced.
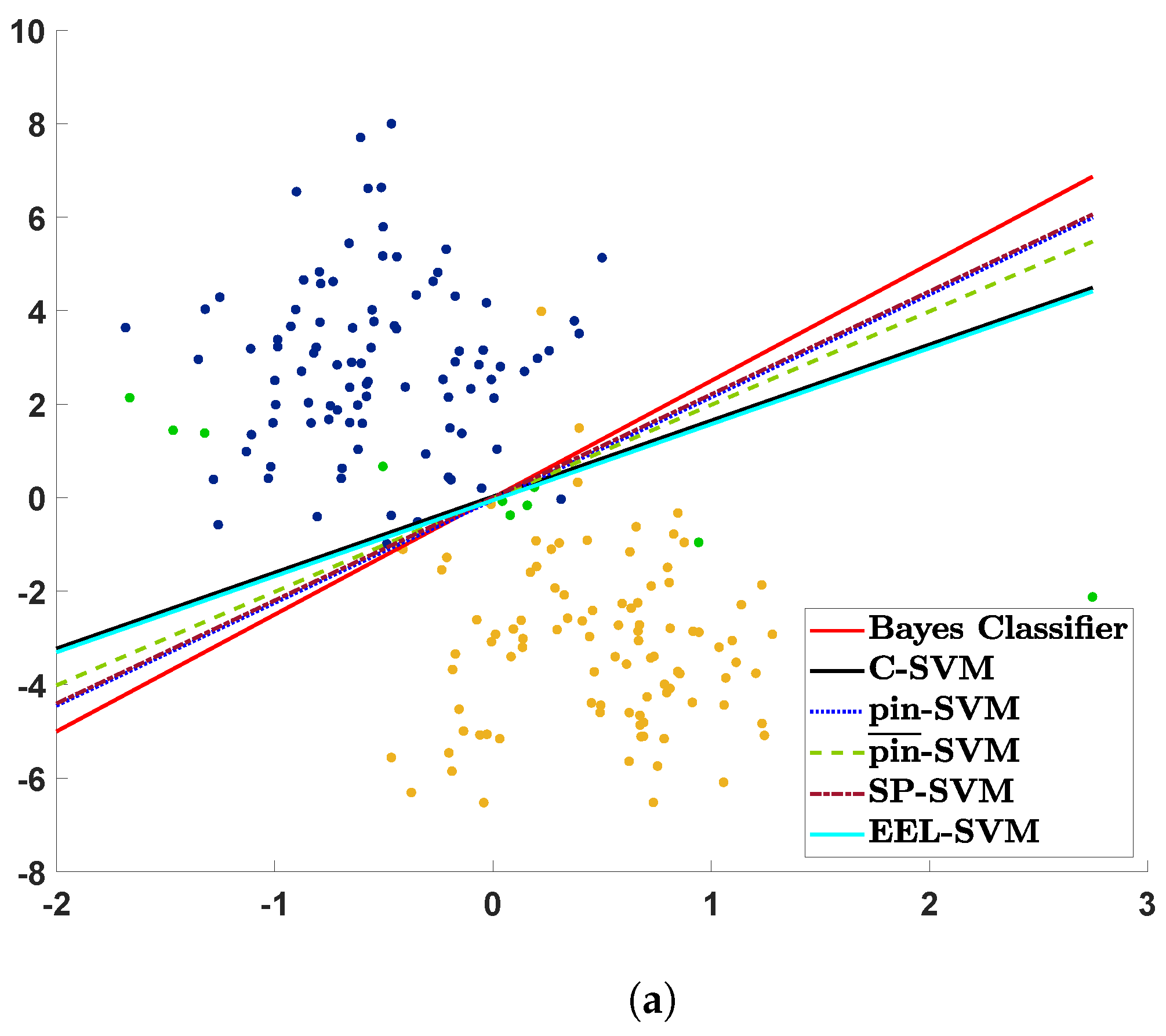
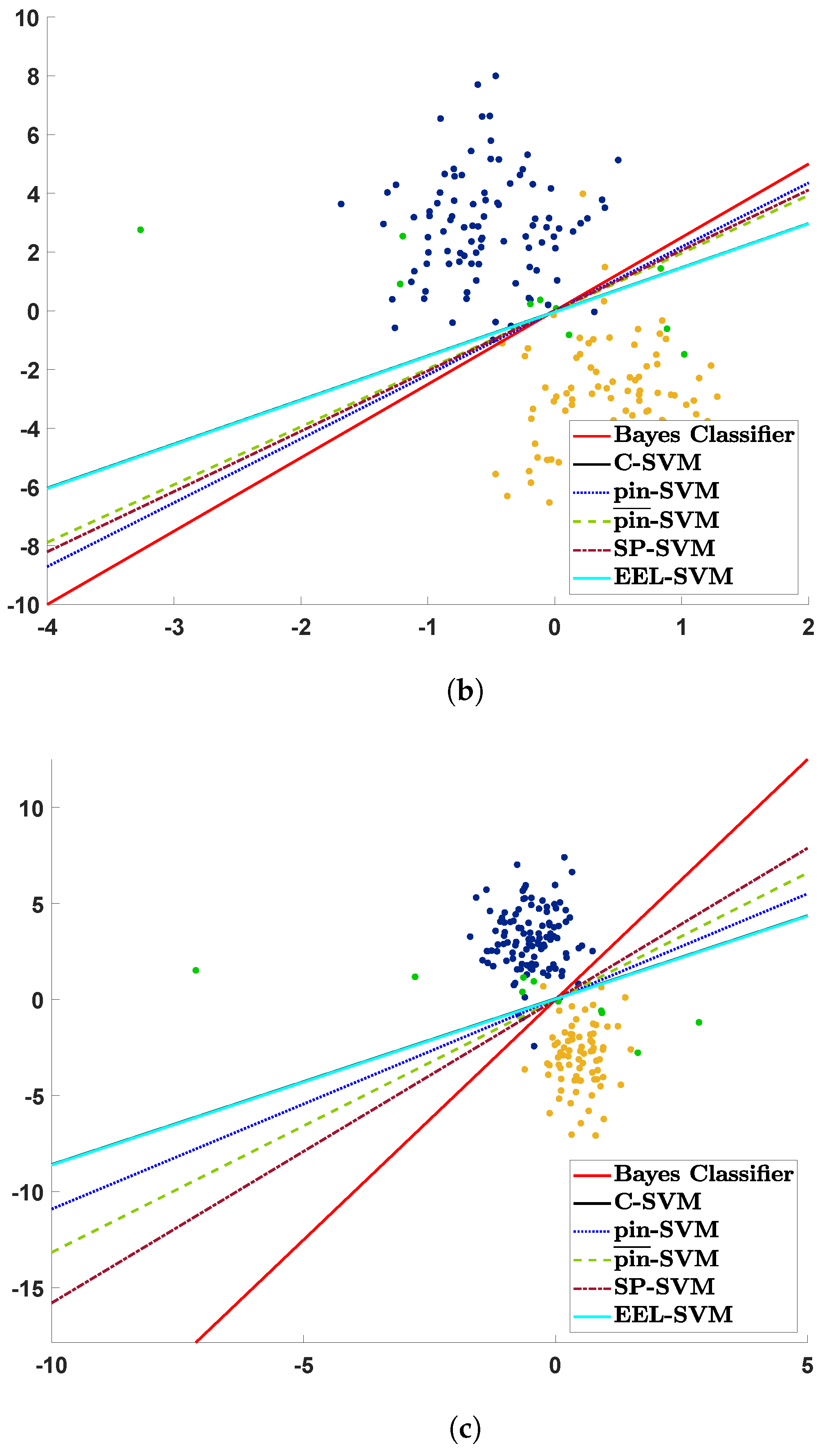
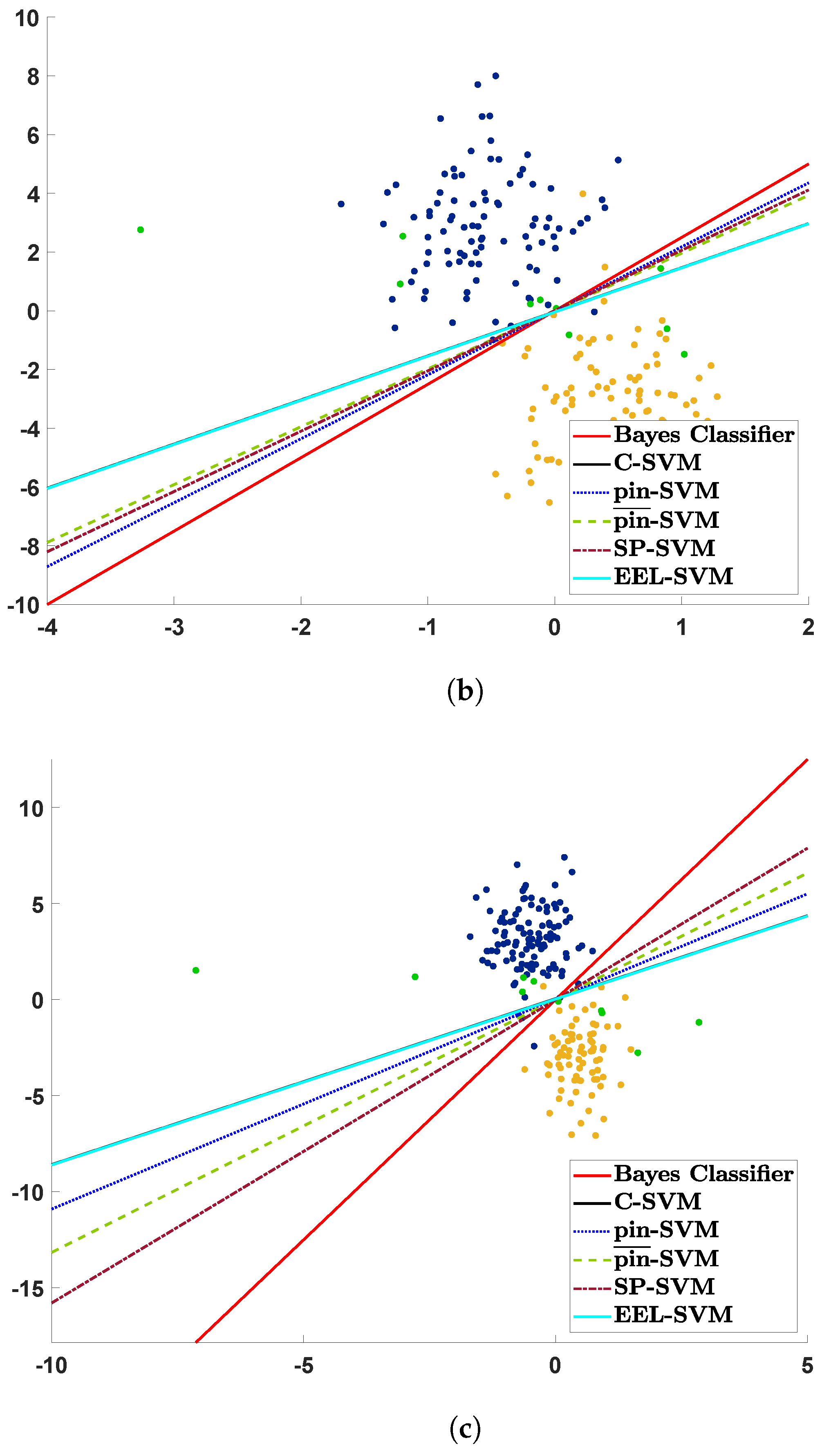
The contaminated data are plotted in
Figure 1 together with their estimated decision lines. The three scatter plots visualize the realization of a sample of size
that is contaminated with
, and the contaminated points appear in green. If a decision rule is close to the ‘true’ decision rule given by the red solid line, then we could say that its corresponding SVM classifier is more resilient to contamination, i.e., is more robust. Note that C-SVM and EEL-SVM overlap in
Figure 1 because the contaminated data points become outliers that are too extreme, even for EEL-SVM, and, thus, this finds the same decision rule as C-SVM.
Figure 1a shows that most of the classifiers, except C-SVM and EEL-SVM, are close to the ‘true’ classifier when a low level of DU is present due to the light-tailed Gaussian contamination; the same behavior is observed in
Figure 1b, where a medium level of DU is present due to Student’s
t with 5 degrees of freedom contamination. Recall that, the lower the number of degrees of freedom is, the more heavy-tailed Student’s
t distribution is; therefore,
Figure 1c illustrates the effect of a high level of DU, a case in which SP-SVM seems to be the most robust classifier.
The scatter plots in
Figure 1 explain the contamination mechanism, though these pictorial representations may be misleading due to the sampling error, since
Figure 1 relies on a single random sample. Therefore, we repeated the same exercise 100 times in order to properly compare the classifiers in
Table 2 and
Table 3. Moreover, for each sample, we conducted 10-fold cross-validation to tune the additional parameters, and we then computed the linear decision rule. The performance was measured via the distance (
13), and the summary of this analysis is provided in
Table 2 for samples of size
and a contamination ratio
. Note that the tuning parameters were calibrated as in
Section 4.1.1, except EEL-SVM, where the parameter space was enlarged (due to data contamination) as follows:
EEL-SVM requires a larger parameter space when DU is more pronounced, i.e., , but even in this extreme case, the cardinality of is not larger than the cardinality of any other parameter space. That is, we did not favor EEL-SVM in the implementation phase.
Table 2 shows that the performance of any classifier deteriorates when the level of DU increases; moreover, the distance from the Bayes classifier increases with the contamination ratio
r. The overall performances of SP-SVM and
-SVM are superior to all three other competitors, whereas
-SVM appears to be competitive in just a few cases and C-SVM and EEL-SVM have a similar low performance. SP-SVM is by far the most robust classifier when DU is more pronounced, which is observed in
Figure 1c but for a single sample.
We conclude our comparison by looking into the computational time ratios (with C-SVM as the baseline reference) that are reported in
Table 3. In particular, this provides the computational times after tuning each model, i.e., the training computational time, which is a standard and fair reporting when one would expect high computational times when tuning more model hyper-parameters. The reference computational time (in sec) of the C-SVM, for a machine with Inter(R) Core(TM) i7−1065G7 CPU @ 1.30GHz, is approximately 0.0019 for
, 0.004 for
and 0.0081 for
. EEL-SVM requires the lowest computational effort, though it is very close to SP-SVM, whereas
-SVM is consistently slower and
-SVM is by far the method with the largest computational time. These observations are not surprising because
-SVM relies on a non-convex (DCA) algorithm that has scalability issues; on the contrary,
-SVM, SP-SVM and EEL-SVM are solved via a convex LCQP of the same dimension, though EEL-SVM and
-SVM are, respectively, the most and least sparse.
4.2. Real Data Analysis
We now compare the classification accuracy for some real-life data and rank all six SVM classifiers, including Ramp-KSVCR. Ten well-known real-world datasets are chosen in this section, which can be retrieved from the UCI depository
1 and LIBSVM depository
2; a summary is given in
Table 4. It should be noted that all datasets had features rescaled to
. Moreover, the analysis was carried out over the original and contaminated data. DU was introduced via the MATLAB R2019a function
awgn with different
signal noise ratios (SNR); perturbations were separately introduced 10 times for each dataset before training; and the average classification accuracy was reported so that the sampling error was alleviated.
The data were randomly partitioned into the training and testing sets, as described in
Table 4. All SVM methods rely on the
radial basis function (RBF) kernel chosen to overcome the lack of linearity in the data. As before, SP-SVM methodology assumes that the feature with the largest standard deviation is the one mostly affected by DU. All hyper-parameters were tuned via a 10-fold cross-validation; the kernel parameter
and penalty parameter
C were tuned by allowing
for C-SVM, whereas
and
are allowed for all other classifiers. Note that C-SVM has fewer parameters than other classifiers, and, thus,
are allowed more values in the tuning process, so that all classifiers are treated as equally as possible. Note that Ramp-KSVCR has two penalty parameters
, an insensitivity parameter
and two additional model parameters
s and
t; the penalty parameters satisfy
, as in the original paper. The other parameters were tuned as follows:
SP-SVM: ;
EEL-SVM: ;
-SVM: ;
-SVM and ;
Ramp-KSVCR: .
A final note is that a computational budget of around 370 parameter combinations was imposed on all cases, except EEL-SVM, where 294 combinations were considered.
Table 5 summarizes the classification performance for all ten datasets for the original (non-contaminated) data and their contaminated variants with various SNR values, where a smaller SNR value means a higher degree of data contamination. EEL-SVM achieves the best performance in 14 out of 40 scenarios investigated, which is followed by Ramp-KSVCR, which performs best in 13 out of 40 scenarios; the other classifiers are ranked as follows: SP-SVM (11/40),
-SVM (10/40), C-SVM (7/40) and
-SVM (6/40). We also calculated the average ranks for each classifier by looking at each row of
Table 5 and ranking each entry from 1 to 6 from lowest to highest accuracy; SP-SVM and EEL-SVM yield the best average ranks among all classifiers and SP-SVM outperforms its competitors via this criterion.
We also performed a statistical test to verify whether the performances produced by one method are significantly better than the others on these datasets. In particular, the right-tailed paired sample
t-test was considered. Under the null hypothesis, the difference between the paired population means is equal to 0. Conversely, the alternative hypothesis states that this difference is greater than 0. The tests were conducted considering all of the results reported in
Table 5, and the corresponding
p-values are shown in
Table 6. Each table cell reports the
p-value obtained by testing the performances of the row against the column models as indicated. We set the significance level equal to 5% and reported
p-values below this in bold. Interestingly, we observed that
-SVM,
-SVM and SP-SVM perform significantly better than Ramp-KSVCR. Furthermore, we observed that the
p-values associated with SP-SVM are generally lower than the other methods. Indeed, SP-SVM is the only method that also outperforms C-SVM, making it preferable to other strong competitors.
In summary, despite the EEL-SVM performing very well on the real-world data, we conclude that SP-SVM exhibits a competitive advantage over competitors.
4.3. Interpretable Classifiers
The performance of SVM classifiers for real-life data has been analyzed in
Section 4.2 without interpreting the decision rules so that the presence of DU is better understood and the fairness of the decision is assessed. We achieved that now by providing a granular analysis for the classification of the following two sources of data:
US mortgage lending data that are downloaded from the
Home Mortgage Disclosure Act (HMDA) website
3; specifically, we collected the 2020 data for two states, namely,
Maine (ME) and
Vermont (VT), with a focus on
subordinated lien mortgages;
Insurance fraud data named
car insurance (CI) that are available on Kaggle website
4.
The US mortgage lending data refer to subordinate-lien (‘piggyback’) loans that are taken out at the same time as first-lien mortgages on the same property by borrowers, mainly to avoid paying mortgage insurance on the first-lien mortgage (due to the extra down payment).
Eriksen et al. (
2013) find evidence that borrowers with subordinate loans have an increased-by-62.7% chance to default each month on their primary loan. Such borrowers may sequentially default on each loan since subordinate lenders will not pursue foreclosure if the borrowers have insufficient equity until at least housing markets start to recover. Subordinate-lien loans are high-risk mortgages and we aimed to classify the instances as ‘loan originated’ (
) or ‘application denied’ (
) using the available features. The HMDA data have numerous features and the following representative ones were chosen: (F1) loan amount, (F2) loan-to-value ratio (F1 divided by the ‘property_value’), (F3) percentage of minority population to total population for tract, (F4) percentage of tract median family income compared to MSA (metropolitan statistical area) median family income. Two categorical features were also considered, namely, (F5) derived sex and (F6) age.
The insurance fraud detection data refer to motor insurance claims, and the aim was to identify if a claim is fraudulent () or not (). The CI dataset is quite balanced since of the claims are recorded as fraudulent. Several features were available, and a preliminary round of features engineering was performed. We considered the following numerical features: (G1) the age of the policyholder, (G2) the percentage of the ‘injury_claim’ on the total claim amount, (G3) the percentage of the ‘vehicle_claim’ on the total claim amount, (G4) the total claim amount and (G5) the age of the vehicle at the time of the incident. The last one was computed as the period between the ‘auto_year’ (the year of registration of the vehicle) and the ‘incident_date’. In addition, we included the categorical features related to the policy, namely, (G6) the state and (G7) the deductible; related to the insured, namely, (G8) the gender, (G9) educational level and (G10) relationship; and, related to the incident, that is, (G11) type, G12) severity and (G13) state.
All categorical features (of the two sources of data) were pre-processed via standard one-hot encoding procedure and all features were rescaled to
before training. Random sampling was performed to extract the training and testing sets, so that the training set was twice as large as the testing set. The hyper-parameter tuning of the three methods (C-SVM, SP-SVM, EEL-SVM) was performed via 10-fold cross-validation using the hyper-parameter spaces in
Section 4.2. SP-SVM identifies F1 (loan amount) and G4 (claim amount) as the features affected by DU that have the largest standard deviation at the same time. This is not surprising since both features have a massive impact on the target variable and they are heavily influenced by all other features.
Table 7 reports the details of the training–testing splitting and the out-of-sample accuracy of the three SVM methods.
We observed that EEL-SVM obtains the best result for the CI data, whereas SP-SVM performs best in terms of accuracy, with C-SVM and EEL-SVM relatively close. The next step was to interpret the classification rule and explain the DU effect, but also to evaluate the effect of an automatized mortgage lending decision. The latter was measured by looking into unfavorable decisions where the loan is denied, i.e., .
The Equal Credit Opportunity Act (ECOA) prohibits a creditor from discriminating against any borrower on the basis of age, marital status, race, religion or sex, known as protected characteristics; such a regulatory requirement is imposed not only in the US, but also similar ones are in place in the EU, UK and elsewhere. Under ECOA, regulatory agencies assess the lending decision fairness of lending institutions by comparing the unfavorable decision () across different groups with given protected characteristics. Our next analysis focuses on checking whether an automatized lending decision could lead to unintentional discrimination, known as disparate impact. First, we looked at the entry data and provided evidence on whether or not the loan amount is massively different across the applicants’ gender at birth, income and racial structure in their postal code, which would explain if DU is present or not. Second, we evaluated the fairness of the lending decision obtained via SVM classification and argued which SVM-based decision is more compliant with such non-discrimination regulation (with respect to the sex attribute).
Table 8 reports the
Kolmogorov–Smirnov distances for loan amount samples of applicants based on gender characteristics. There is overwhelming evidence that joint loan applications and female applicants have very different loan amount distributions in both training and testing data, though VT data exhibit the largest distance when comparing male and female applicants with a favorable mortgage lending decision. This could be explained by socio-economic disparities between males and females, though DU plays a major role in this instance. Gender information in the HMDA data is expected to have a self-selection bias, since applicants at risk are quite unlikely to report gender information as they believe that the lending decision would be influenced by that. Consequently, we removed a significant portion of the data, i.e., examples for which the gender information is unknown, which is clear evidence of self-selection bias in our entry data.
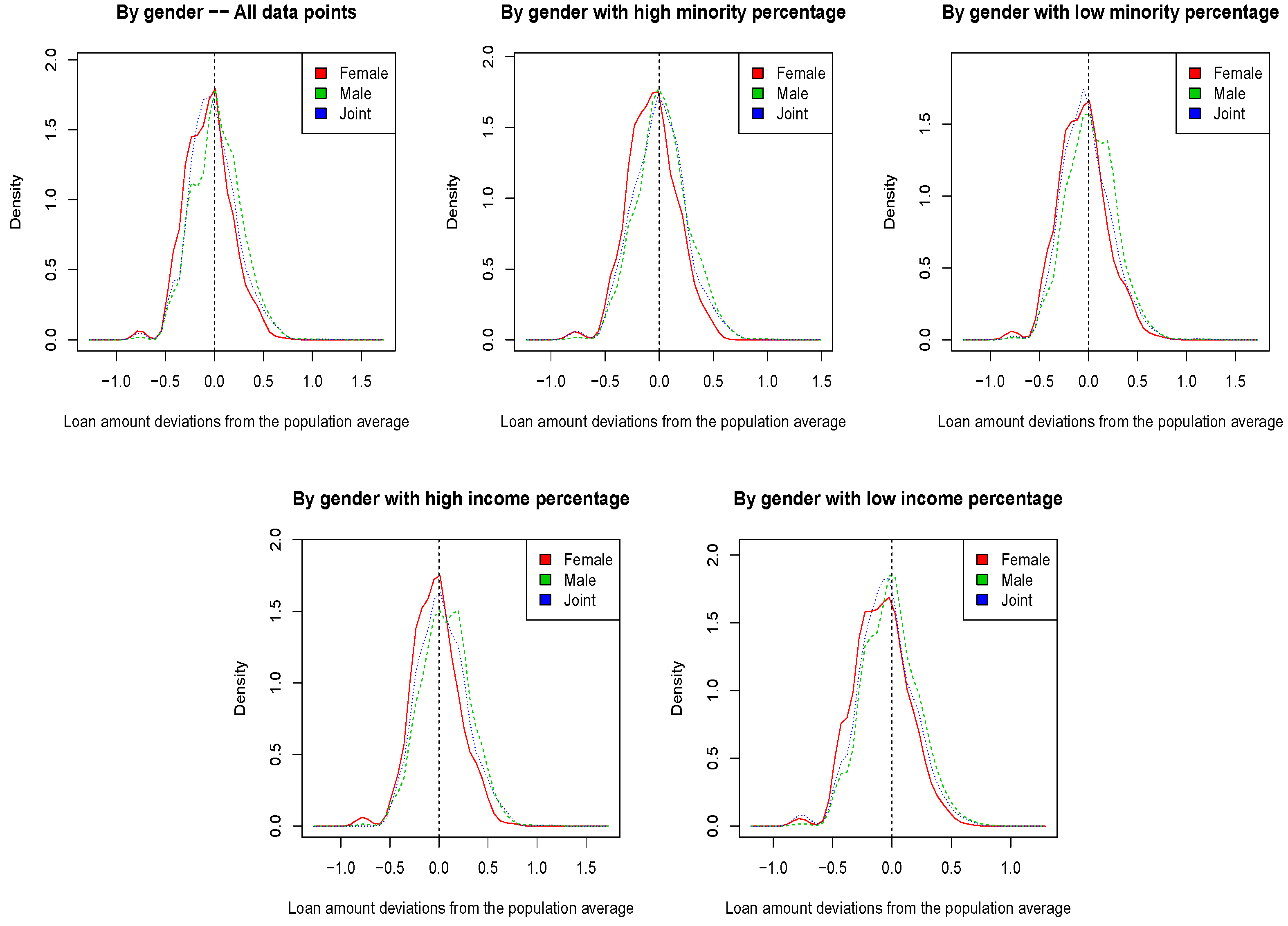
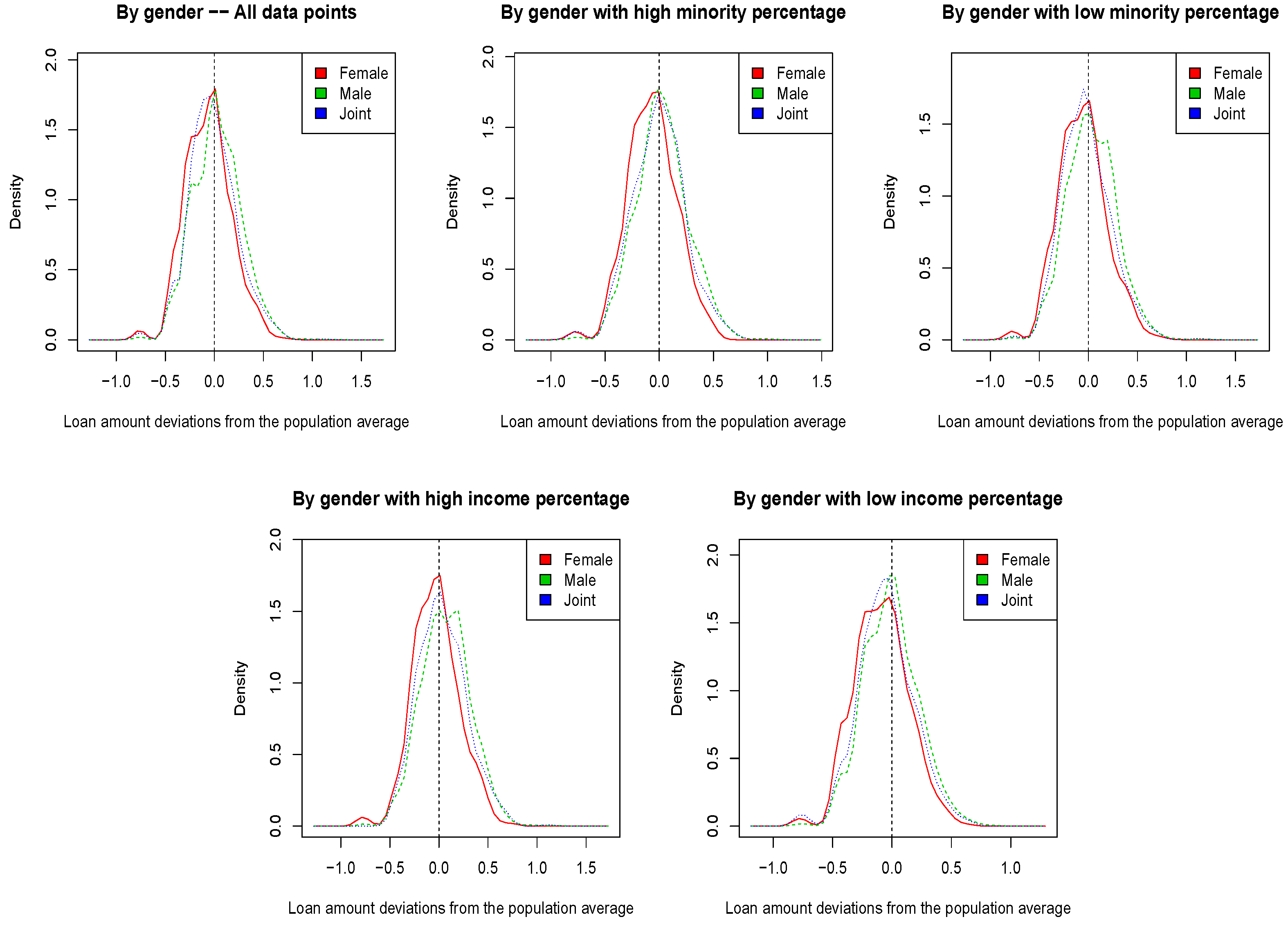
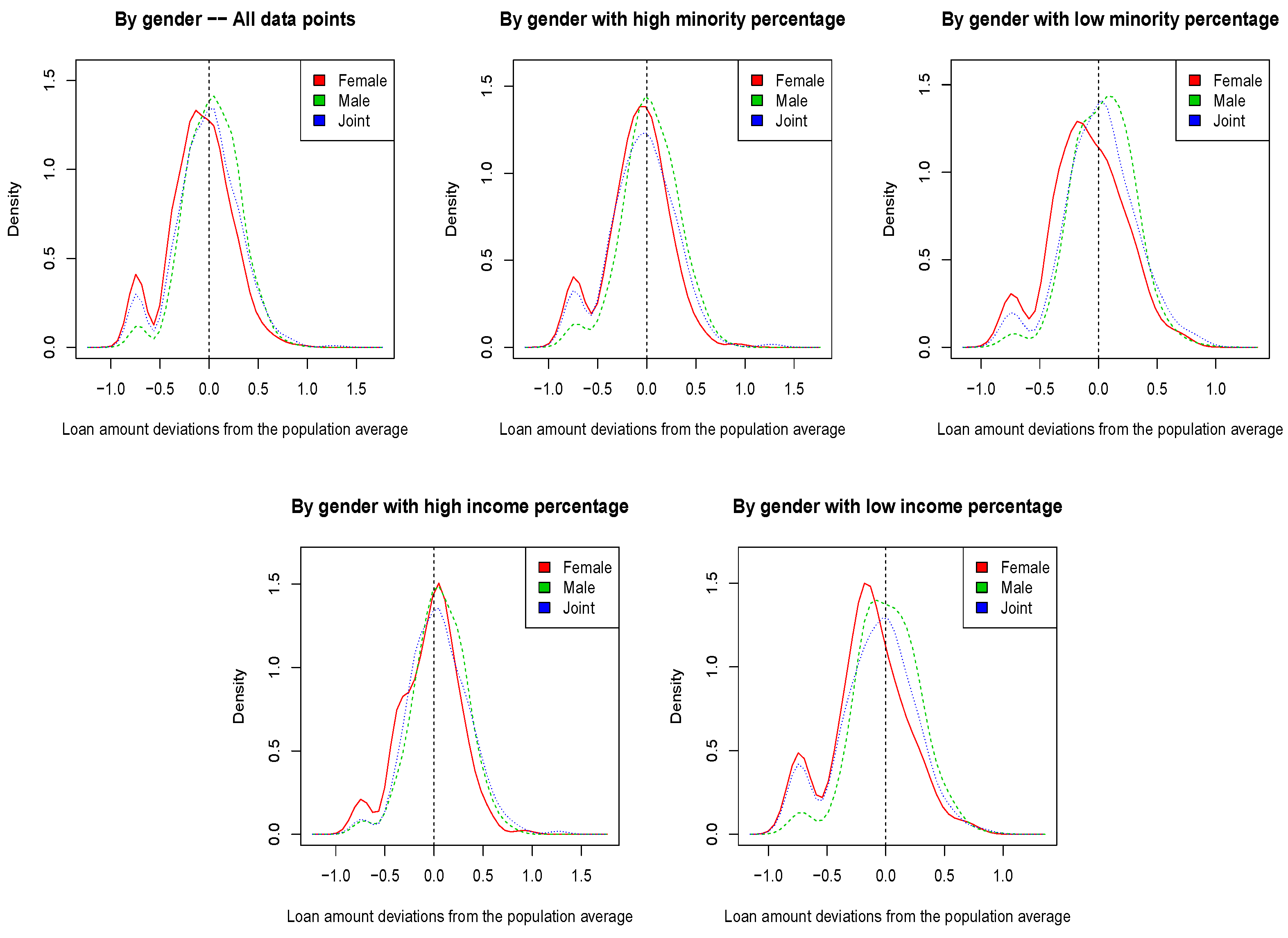
Figure 2 and
Figure 3 show the kernel densities of the deviation in the log-transformed loan amount from the population mean. In particular, we plotted such deviations for the entire dataset, but also for sub-populations with a low/high minority and income percentage. A low/high minority percentage means that the mortgage applicant is in an area of lower/higher minority than the population median. Moreover, a low/high income percentage means that the mortgage applicant household income is lower/higher than the household income in her/his MSA. ME data from
Figure 2 do not show any evidence of DU with respect to the loan amount, which explains the results in
Table 7, where SP-SVM and EEL-SVM did not improve the non-robust counterpart. VT data show a very different scenario in
Figure 3, where the loan amount deviations have a bimodal distribution. In addition, within the low minority sub-population, female applicants exhibit significantly lower loan amounts than all other applicants; the same pattern is observed in the low income sub-population. Therefore, the DU in the VT data is evident, and confirms the findings in
Table 8, but also those in
Table 7, where SP-SVM and EEL-SVM did improve the non-robust C-SVM.
We have concluded the first part of our qualitative analysis, where we have explained the DU, and we now evaluate how compliant the automatized mortgage lending process would be for the VT data; we do not report the ME results due to a lack of DU. Fairness compliance requires the lending decision—especially the unfavorable decisions (
)—to be independent of the applicant’s gender at birth information, i.e.,
Table 9 tells us that the desirable lack of disparity in (
14) is achieved best by EEL-SVM. In addition, EEL-SVM estimates the unfavorable decisions very similarly to the ‘true’ decisions, and this can be seen by inspecting the probabilities that appear in bold.
One popular fairness metric is the
conditional demographic disparity (CDD), which is discussed in
Wachter et al. (
2021), where the data are assumed to be part of multiple strata. The CDD formulation for our data (with three strata, i.e., female, male and joint) is defined as
where
is the
demographic disparity within the
stratum, i.e.,
CDD could capture and explain peculiar data behavior similar to Simpson’s paradox, where the same trend is observed in each stratum, but the opposite trend is observed in the whole dataset. Amazon SageMaker, a cloud machine-learning platform developed by Amazon, has included CDD in their practice to enhance model explainability and bias detection; for details, see the Amazon SageMaker Developer Guide.
Table 9 shows that EEL-SVM has a superior performance to C-SVM and SP-SVM when looking at the overall CDD fairness performance. In fact, EEL-SVM exhibits fairer post-training decisions than the pre-training fairness measured on the ‘true’ mortgage lending decisions observed in the testing data. In summary, the unanimous conclusion is that EEL-SVM shows the fairest and most robust mortgage-lending automatized decision.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}