
Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach

Abstract
:1. Introduction
1.1. Motivation
1.2. Objective
1.3. Literature Review
1.3.1. Telematics Data
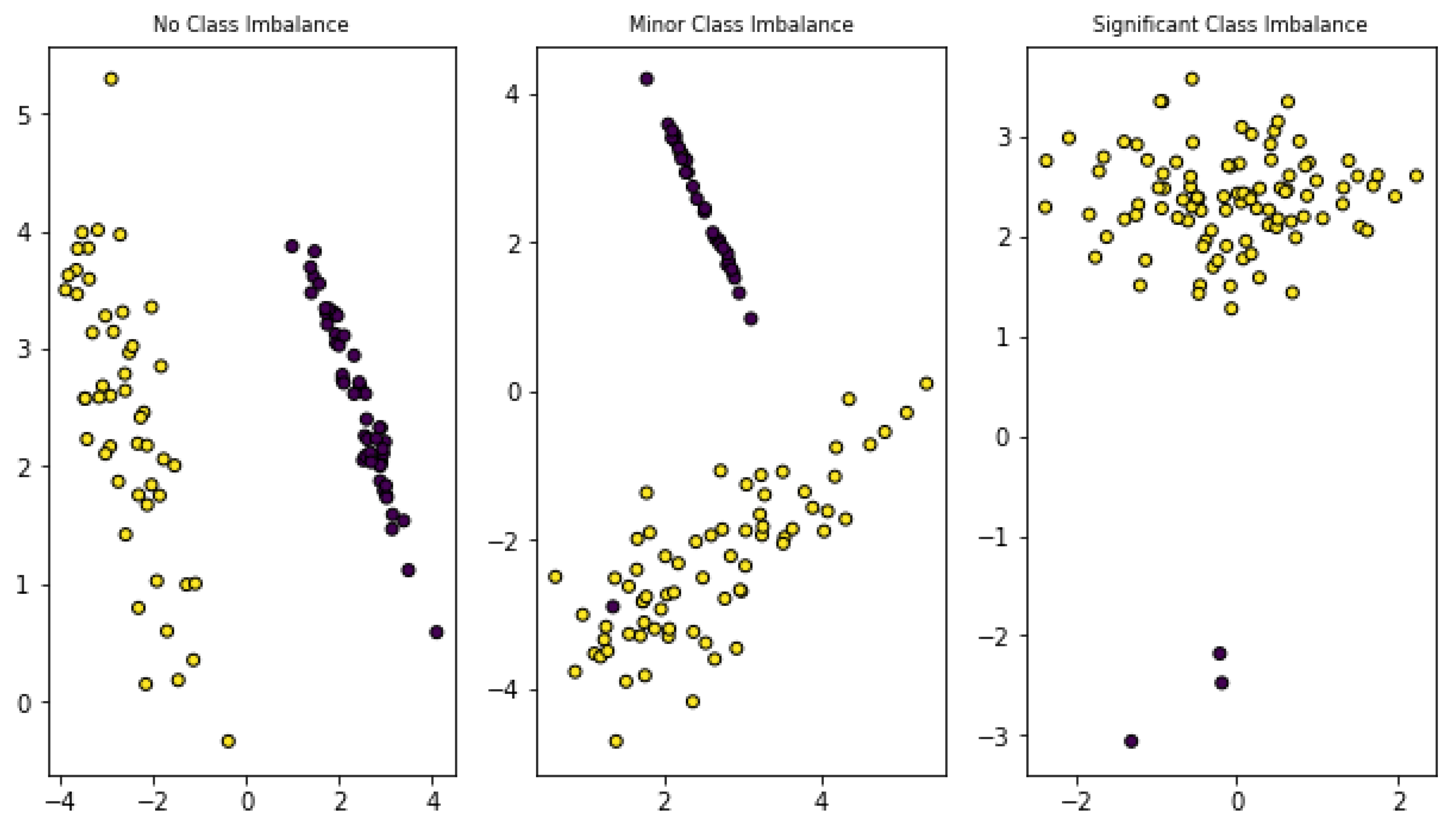
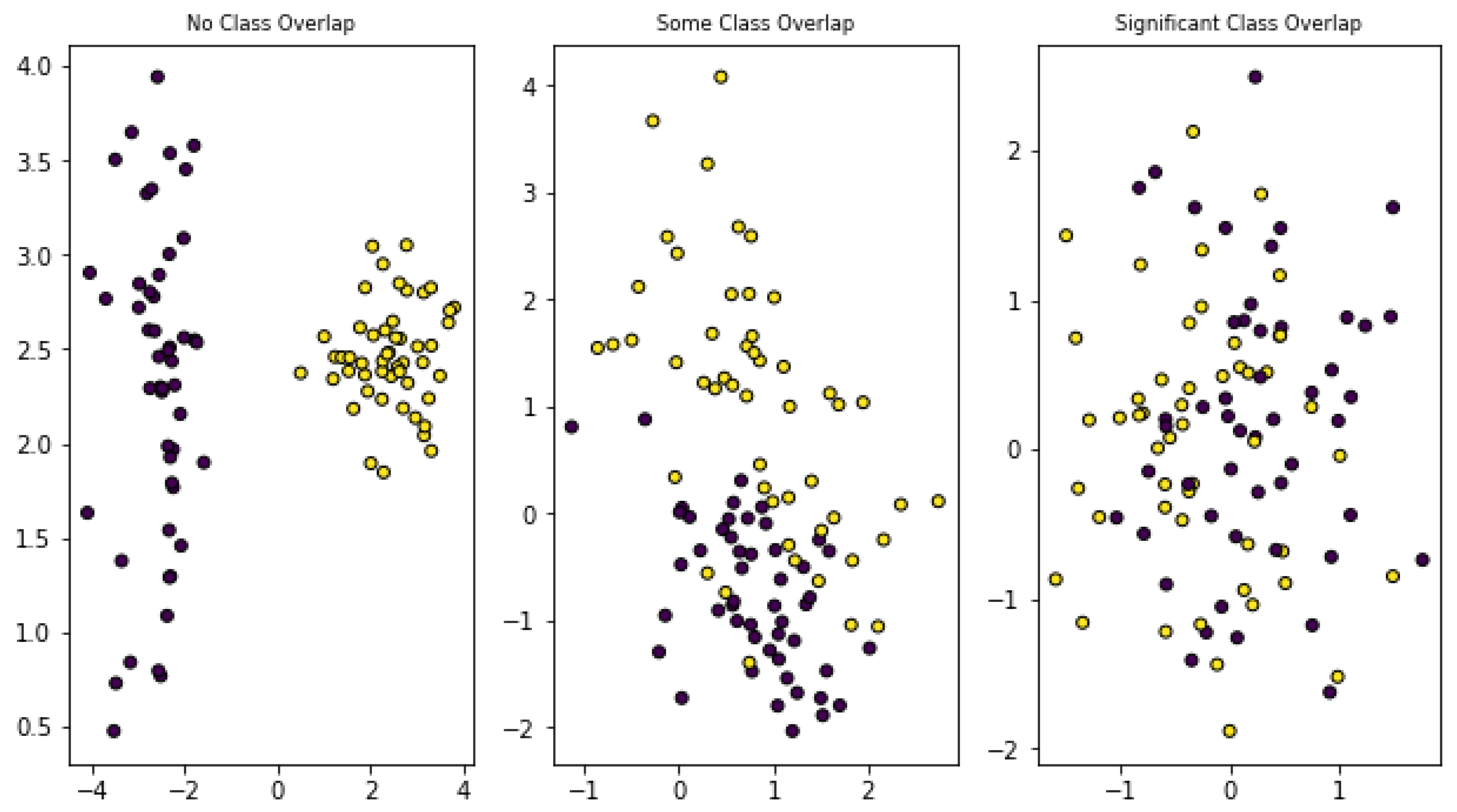
1.3.2. Imbalanced Data
2. Methods
2.1. Data
2.2. Outcome
2.3. Features
2.3.1. Driver Risk Assessment
2.3.2. Journey Risk Assessment
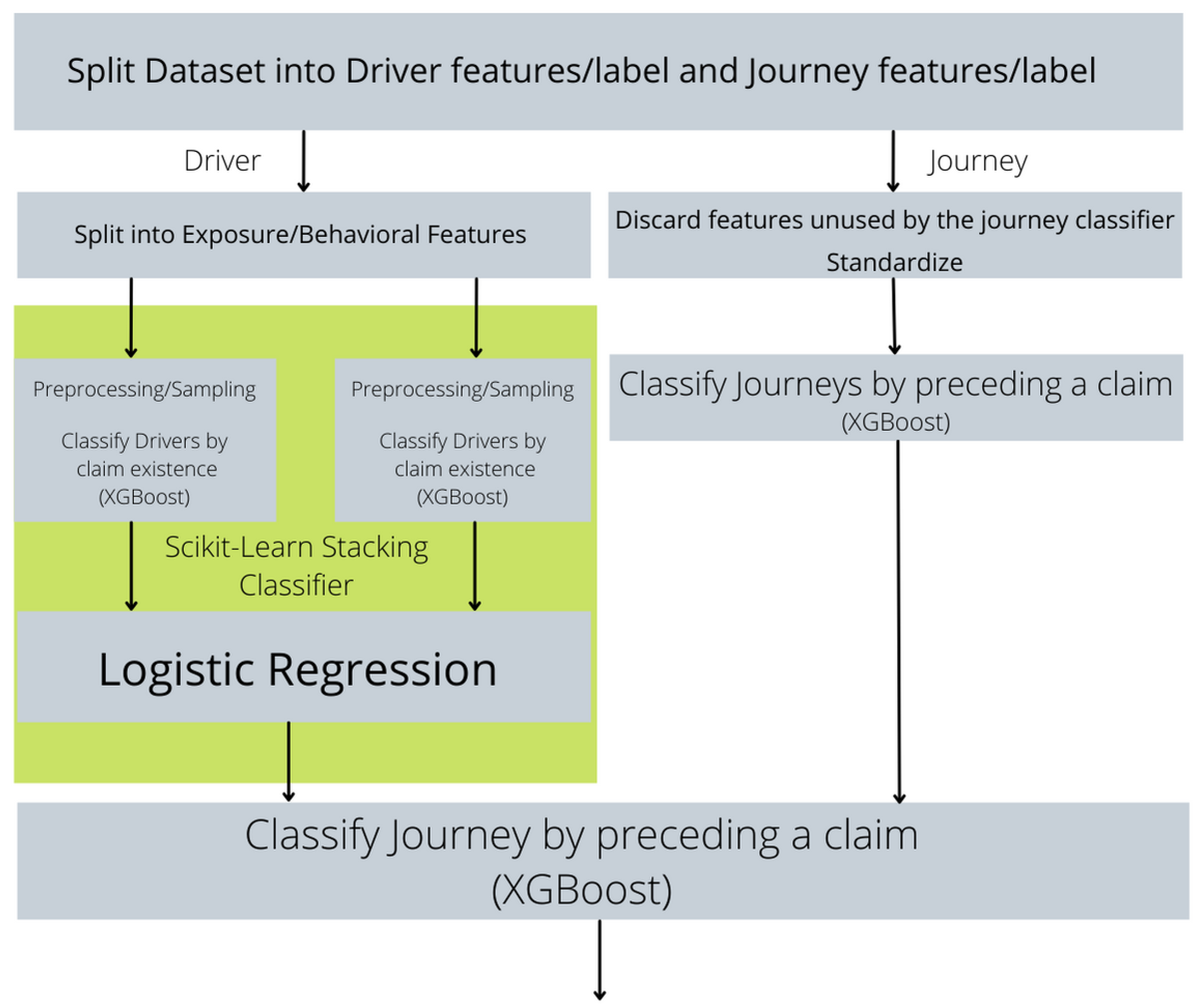
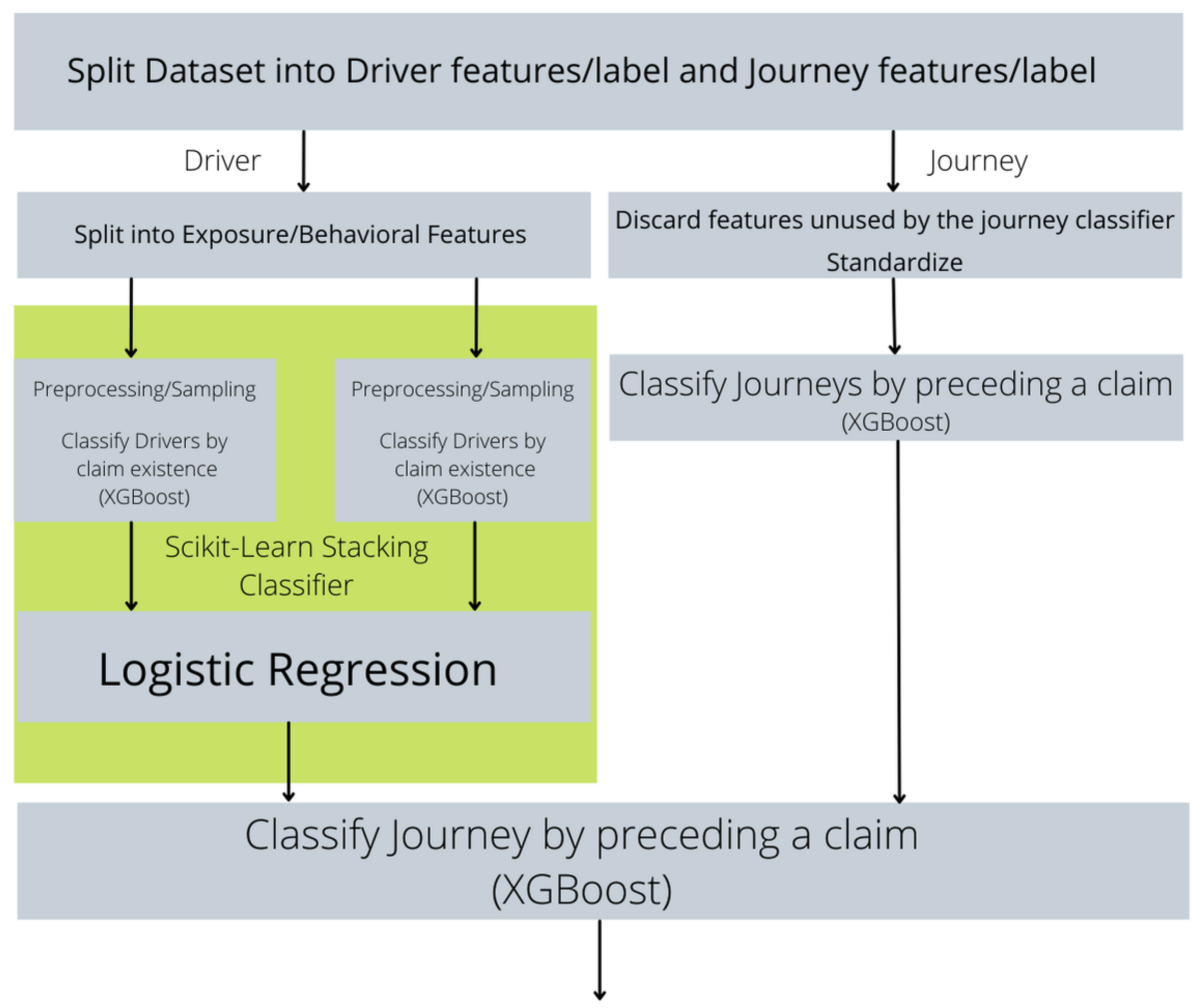
2.4. Model
2.5. Performance Metric and Validation Approach
| Algorithm 1 Group K-fold Cross Validation (scikit-learn). |
Input: ▹ Feature set, associated labels, and vector of groups Output: A mapping of to the groups in the test set for fold i
|
2.5.1. Feature Selection
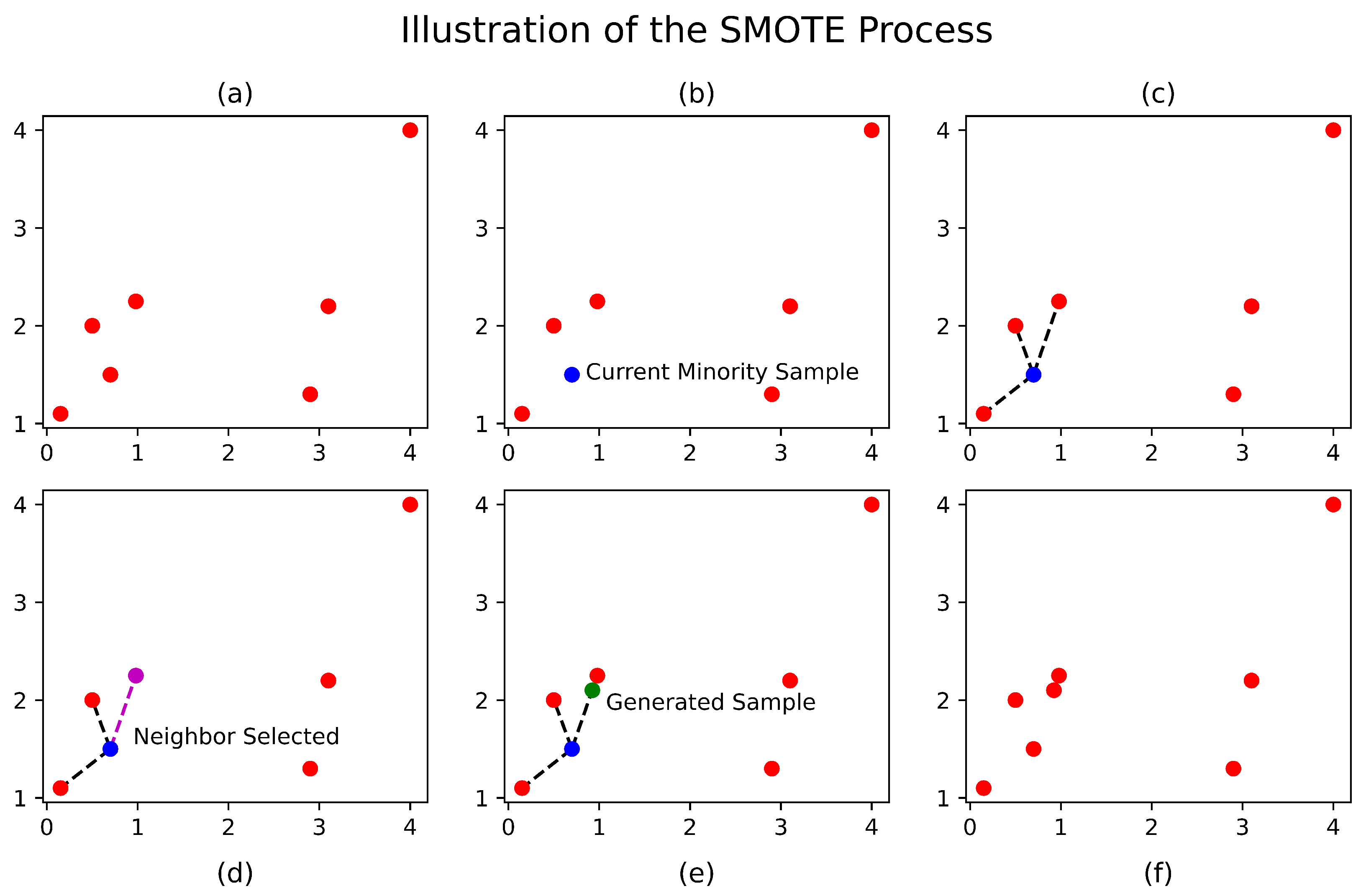
2.5.2. Addressing Class Imbalance
2.6. Combination of Journey-Driver Risk Assessment
3. Results
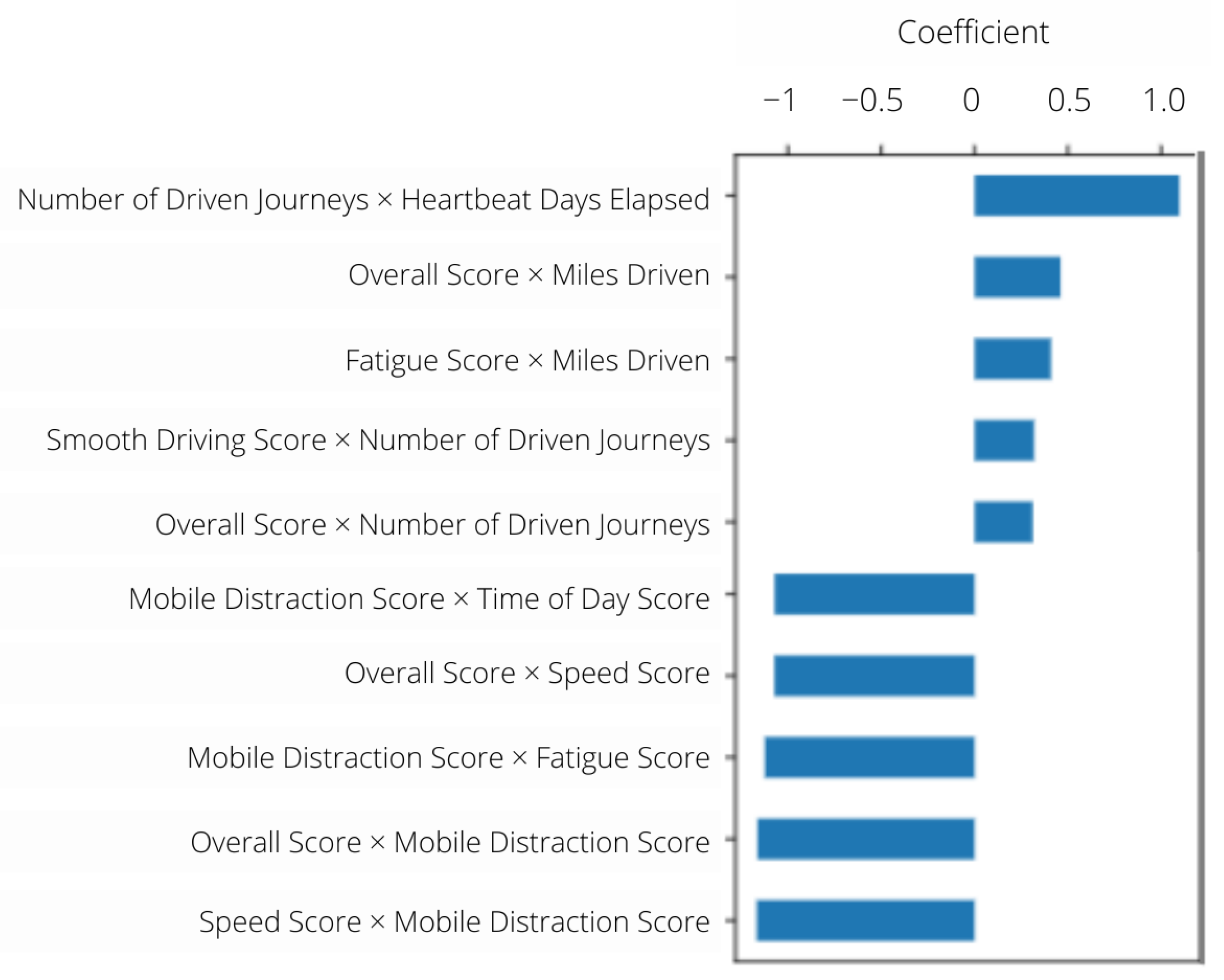
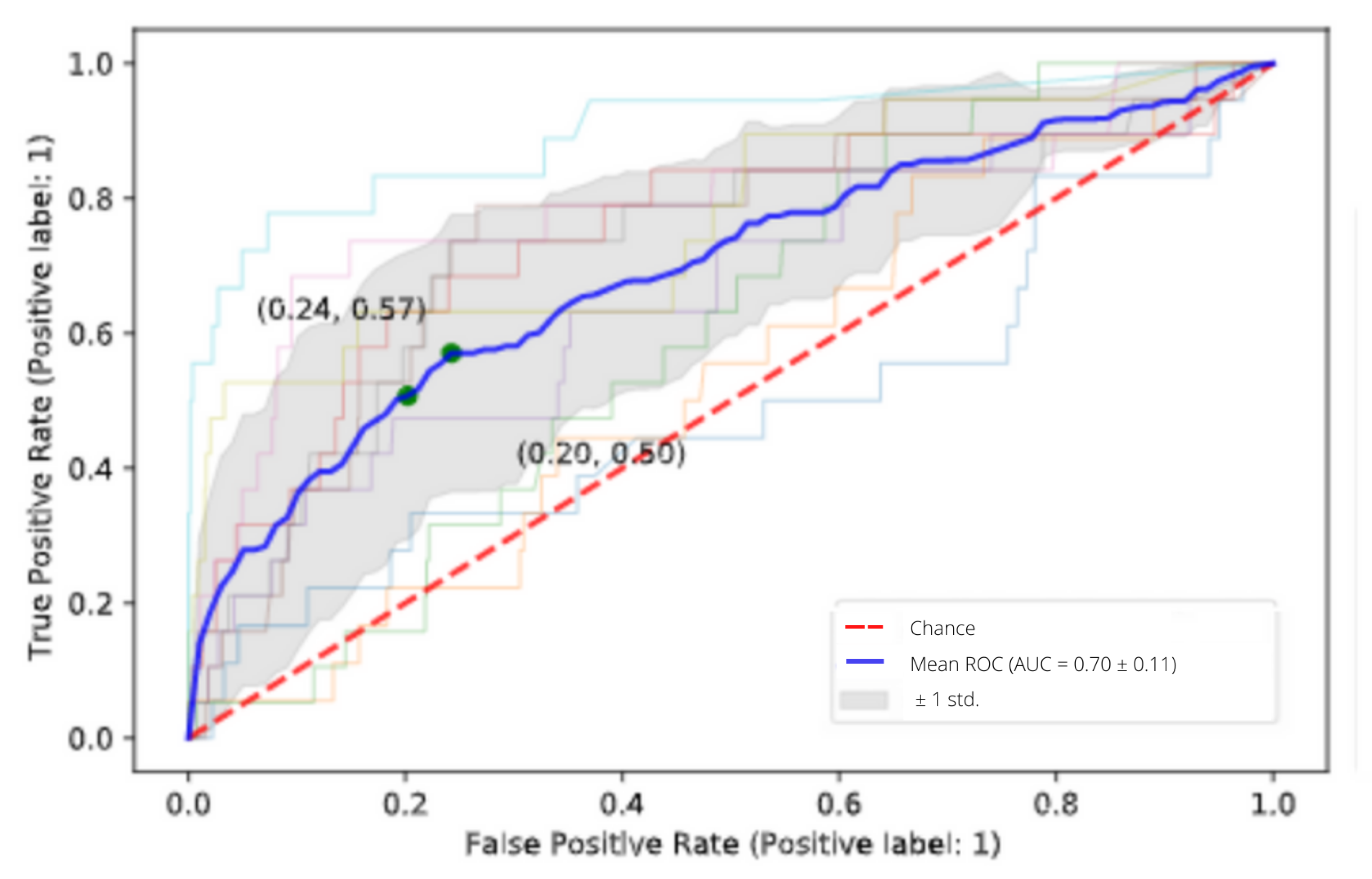
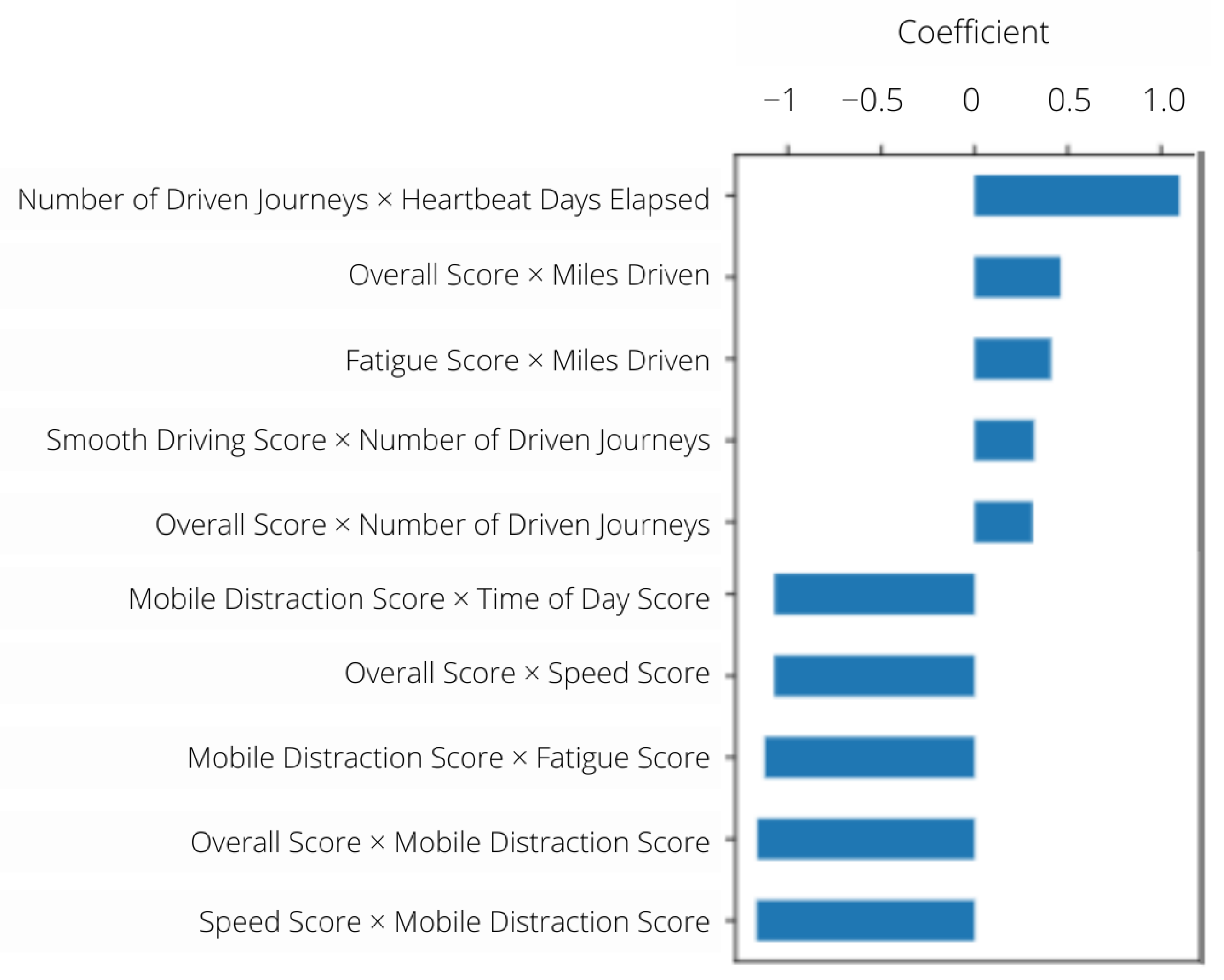
3.1. Driver Classification Results
3.2. Journey Classification Results
Combination of Journey-Driver Risk Assessment Results
4. Discussion
4.1. Significance
4.2. Limitations
- does influencing a driver away from patterns associated with claims at the population level decrease the claims propensity of that driver?
- how can we best combine insights from population level studies and and personalized advice derived from a drivers own data only?
4.3. Future Directions
- After identifying that a driver is at increased risk, what is the best method of intervention?
- Does the timing of the intervention influence its effectiveness in reducing a driver’s risk?
- Can we identify the reason why the driver was considered to be at risk, and personalize the intervention to that individual? (e.g, are there signatures in the data indicative of anger, alcohol consumption or extreme stress?)
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
| 1 | https://www.iii.org/fact-statistic/facts-statistics-auto-insurance#Auto%20claims (accessed on 20 May 2022). |
References
- Abdelhadi, Shady, Khaled Elbahnasy, and Mohamed Abdelsalam. 2020. A proposed model to predict auto insurance claims using machine learning techniques. Journal of Theoretical and Applied Information Technology 98: 3428–37. [Google Scholar]
- Abulkhair, Maysoon F., Hesham A. Salman, and Lamiaa F. Ibrahim. 2015. Using mobile platform to detect and alerts driver fatigue. International Journal of Computer Applications 123: 27–35. [Google Scholar]
- Alamir, Endalew, Teklu Urgessa, Ashebir Hunegnaw, and Tiruveedula Gopikrishna. 2021. Motor insurance claim status prediction using machine learning techniques. International Journal of Advanced Computer Science and Applications 12: 457–63. [Google Scholar] [CrossRef]
- Arumugam, Subramanian, and R. Bhargavi. 2019. A survey on driving behavior analysis in usage based insurance using big data. Journal of Big Data 6: 1–21. [Google Scholar] [CrossRef] [Green Version]
- Bahiraie, Alireza, Farbod Khanizadeh, and Farzan Khamesian. 2022. Insurance claim classification: A new genetic programming approach. Advances in Mathematical Finance and Applications 7: 437–46. [Google Scholar]
- Boucher, Jean-Philippe, and Roxane Turcotte. 2020. A longitudinal analysis of the impact of distance driven on the probability of car accidents. Risks 8: 91. [Google Scholar] [CrossRef]
- Boucher, Jean-Philippe, Steven Côté, and Montserrat Guillen. 2017. Exposure as duration and distance in telematics motor insurance using generalized additive models. Risks 5: 54. [Google Scholar] [CrossRef] [Green Version]
- Carfora, Maria Francesca, Fabio Martinelli, Francesco Mercaldo, Vittoria Nardone, Albina Orlando, Antonella Santone, and Gigliola Vaglini. 2019. A “pay-how-you-drive” car insurance approach through cluster analysis. Soft Computing 23: 2863–75. [Google Scholar] [CrossRef]
- Chawla, Nitesh V., Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. 2002. Smote: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research 16: 321–57. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A scalable tree boosting system. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’16), ACM, New York, NY, USA, August 13–17; pp. 785–94. [Google Scholar] [CrossRef] [Green Version]
- Denil, Misha, and Thomas Trappenberg. 2010. Overlap versus imbalance. In Canadian Conference on Artificial Intelligence. Berlin/Heidelberg: Springer, pp. 220–31. [Google Scholar]
- Freund, Yoav, and Robert E. Schapire. 1997. A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences 55: 119–39. [Google Scholar] [CrossRef] [Green Version]
- Guillen, Montserrat, Jens Perch Nielsen, Mercedes Ayuso, and Ana M. Pérez-Marín. 2019. The use of telematics devices to improve automobile insurance rates. Risk Analysis 39: 662–72. [Google Scholar] [CrossRef]
- Guo, Haixiang, Yijing Li, Jennifer Shang, Mingyun Gu, Yuanyue Huang, and Bing Gong. 2017. Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications 73: 220–39. [Google Scholar]
- Hanafy, Mohamed, and Ruixing Ming. 2021. Machine learning approaches for auto insurance big data. Risks 9: 42. [Google Scholar] [CrossRef]
- Hastie, Trevor, Robert Tibshirani, Jerome H. Friedman, and Jerome H. Friedman. 2009. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Berlin/Heidelberg: Springer, vol. 2. [Google Scholar]
- Jinnette, Rachael, Ai Narita, Byron Manning, Sarah A. McNaughton, John C. Mathers, and Katherine M. Livingstone. 2021. Does personalized nutrition advice improve dietary intake in healthy adults? a systematic review of randomized controlled trials. Advances in Nutrition 12: 657–69. [Google Scholar] [CrossRef]
- Kotsiantis, Sotiris, Dimitris Kanellopoulos, and Panayiotis Pintelas. 2006. Handling imbalanced datasets: A review. GESTS International Transactions on Computer Science and Engineering 30: 25–36. [Google Scholar]
- Kovács, György. 2019. Smote-variants: A python implementation of 85 minority oversampling techniques. Neurocomputing 366: 352–54. [Google Scholar] [CrossRef]
- Lemaître, Guillaume, Fernando Nogueira, and Christos K. Aridas. 2017. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. Journal of Machine Learning Research 18: 1–5. [Google Scholar]
- Litman, Todd. 2004. Pay-as-You-Drive Pricing for Insurance Affordability. Victoria Transport Policy Institute. Available online: http://www.vtpi.org/payd_aff.pdf (accessed on 1 January 2022).
- López, Victoria, Alberto Fernández, Salvador García, Vasile Palade, and Francisco Herrera. 2013. An insight into classification with imbalanced data: Empirical results and current trends on using data intrinsic characteristics. Information Sciences 250: 113–41. [Google Scholar] [CrossRef]
- Ma, Yu-Luen, Xiaoyu Zhu, Xianbiao Hu, and Yi-Chang Chiu. 2018. The use of context-sensitive insurance telematics data in auto insurance rate making. Transportation Research Part A: Policy and Practice 113: 243–58. [Google Scholar] [CrossRef]
- Pedregosa, Fabian, Gael Varoquaux, Alexandre Gramfort, Alexandre Michel, Alexandre Thirion, Alexandre Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Pesantez-Narvaez, Jessica, Montserrat Guillen, and Manuela Alcañiz. 2019. Predicting motor insurance claims using telematics data—Xgboost versus logistic regression. Risks 7: 70. [Google Scholar] [CrossRef] [Green Version]
- Rohit, Fnu, Vinod Kulathumani, Rahul Kavi, Ibrahim Elwarfalli, Vlad Kecojevic, and Ashish Nimbarte. 2017. Real-time drowsiness detection using wearable, lightweight brain sensing headbands. IET Intelligent Transport Systems 11: 255–63. [Google Scholar] [CrossRef]
- Shalev-Shwartz, Shai, and Shai Ben-David. 2014. Understanding Machine Learning: From Theory to Algorithms. Cambridge: Cambridge University Press. [Google Scholar]
- So, Banghee, Jean-Philippe Boucher, and Emiliano A. Valdez. 2021a. Cost-sensitive multi-class adaboost for understanding driving behavior based on telematics. ASTIN Bulletin: The Journal of the IAA 51: 719–51. [Google Scholar] [CrossRef]
- So, Banghee, Jean-Philippe Boucher, and Emiliano A. Valdez. 2021b. Synthetic dataset generation of driver telematics. Risks 9: 58. [Google Scholar] [CrossRef]
- Tselentis, Dimitrios I., George Yannis, and Eleni I. Vlahogianni. 2016. Innovative insurance schemes: Pay as/how you drive. Transportation Research Procedia 14: 362–71. [Google Scholar] [CrossRef] [Green Version]
- Valiant, Leslie G. 1984. A theory of the learnable. Communications of the ACM 27: 1134–42. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall | Smooth Driving | Mobile Distraction | Time of Day | Fatigue | Speed | Driven Journeys | Kilometers Driven | |
|---|---|---|---|---|---|---|---|---|
| All Drivers (N = 5647) | ||||||||
| Mean | 80.61 | 71.30 | 86.33 | 75.53 | 83.59 | 79.90 | 418.15 | 6425.50 |
| Stdev | 5.28 | 8.54 | 9.14 | 3.41 | 9.17 | 5.18 | 435.79 | 8246.59 |
| Max | 100.00 | 100.00 | 100.00 | 93.28 | 100.00 | 100.00 | 5076 | 156,937.85 |
| Min | 28.89 | 12.07 | 36.38 | 38.81 | 42.86 | 51.13 | 1 | 0.80 |
| Claims Group (N = 181) | ||||||||
| Mean | 79.58 | 69.61 | 85.03 | 75.09 | 84.84 | 78.72 | 658.17 | 9130.041 |
| Stdev | 4.74 | 7.45 | 9.18 | 3.38 | 7.19 | 4.93 | 506.12 | 8077.00 |
| Max | 92.83 | 86.45 | 100.00 | 91.27 | 97.81 | 92.83 | 2786 | 56,436.50 |
| Min | 61.05 | 40.35 | 52.73 | 61.05 | 63.04 | 63.70 | 1 | 4.18 |
| No Claims Group (N = 5466) | ||||||||
| Mean | 80.64 | 71.36 | 86.38 | 75.55 | 83.54 | 79.94 | 410.21 | 6335.94 |
| Stdev | 5.29 | 8.56 | 9.13 | 3.41 | 9.23 | 5.18 | 431.04 | 8237.69 |
| Max | 100.00 | 100.00 | 100.00 | 93.28 | 100.00 | 100.00 | 5076 | 156,937.85 |
| Min | 28.89 | 12.07 | 36.38 | 38.81 | 42.86 | 51.13 | 1 | 0.80 |
| Journey | Smooth Driving | Mobile Distraction | Time of Day | Fatigue | Speed | Duration (min) | Kilometers | |
|---|---|---|---|---|---|---|---|---|
| All Drivers (N = 3,446,522) | ||||||||
| Mean | 80.04 | 68.92 | 86.53 | 76.22 | 93.81 | 81.78 | 17.88 | 15.42 |
| Stdev | 9.19 | 12.85 | 14.99 | 6.72 | 6.66 | 10.05 | 25.00 | 30.89 |
| Max | 100.00 | 100.00 | 100.00 | 93.28 | 100.00 | 100.00 | 1876.6 | 1353.94 |
| Min | 13.90 | 6.98 | 21.88 | 21.85 | 42.86 | 37.50 | 0.0 | 0.0 |
| Claims Group (N = 189,246) | ||||||||
| Mean | 79.65 | 68.34 | 86.05 | 75.86 | 94.21 | 81.71 | 17.03 | 13.81 |
| Stdev | 9.07 | 12.71 | 15.40 | 7.27 | 5.85 | 10.01 | 25.75 | 25.74 |
| Max | 100.00 | 100.00 | 100.00 | 93.28 | 100.00 | 100.00 | 1440.87 | 683.97 |
| Min | 17.27 | 6.98 | 21.88 | 21.85 | 42.86 | 37.50 | 0.43 | 0.00 |
| No Claims Group (N = 3,257,276) | ||||||||
| Mean | 80.09 | 69.01 | 86.38 | 76.28 | 93.84 | 81.71 | 17.93 | 15.52 |
| Stdev | 9.12 | 12.72 | 9.13 | 6.66 | 6.61 | 10.07 | 24.95 | 31.165 |
| Max | 100.00 | 100.00 | 100.00 | 93.28 | 100.00 | 100.00 | 1876.60 | 1353.94 |
| Min | 13.90 | 6.98 | 36.37 | 21.85 | 42.86 | 37.50 | 0.05 | 0.00 |
| Model | Target | Mean AUROC |
|---|---|---|
| Logistic Regression | Driver Claims | 0.69 |
| XGBoost (Exposure features) | Driver Claims | 0.70 |
| Stacking Classifier | Driver Claims | 0.70 |
| XGBoost | Journey Risk | 0.59 |
| Combined Classifier | Journey Risk | 0.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Williams, A.R.; Jin, Y.; Duer, A.; Alhani, T.; Ghassemi, M. Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach. Risks 2022, 10, 118. https://doi.org/10.3390/risks10060118
Williams AR, Jin Y, Duer A, Alhani T, Ghassemi M. Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach. Risks. 2022; 10(6):118. https://doi.org/10.3390/risks10060118
Chicago/Turabian StyleWilliams, Allen R., Yoolim Jin, Anthony Duer, Tuka Alhani, and Mohammad Ghassemi. 2022. "Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach" Risks 10, no. 6: 118. https://doi.org/10.3390/risks10060118
APA StyleWilliams, A. R., Jin, Y., Duer, A., Alhani, T., & Ghassemi, M. (2022). Nightly Automobile Claims Prediction from Telematics-Derived Features: A Multilevel Approach. Risks, 10(6), 118. https://doi.org/10.3390/risks10060118