1. Introduction
One of the most popular families of machine learning models are tree-based algorithms, which use the concept of many decision trees working together to create more generalized predictions (
Lundberg et al. 2020). Current implementations include random forests, gradient boosted forests, and others. These models are very good at learning relationships and have proven highly accurate in diverse areas. Currently, many aspects of life are affected by these algorithms as they have been implemented in business, technology, and more.
As these methods become more abundant, it is crucial that explanations of model output are easily available. Although there have been some advances in quantifying the uncertainty around black-box predictions as in
Ablad et al. (
2021), we search for more interpretable explanations that relate inputs to model outputs. The exact definition of “explanation” is a subject of debate, and
Lipton (
2018) argues that the word is often used in a very unscientific manner due to the confusion over its meaning. In this paper, we will regard an explainable system as what
Doran et al. (
2017) refer to as a comprehensible system, or one that “allow[s] the user to relate properties of the inputs to their output”.
Explainable models are important not only because some industries require them but also because understanding the why behind the output is essential to avoiding possible pitfalls. Understanding the reasoning behind model output allows for recognition of model bias, and increased security against the risk of harmful models being put into production. When implemented well, machine learning models can be more accurate than compared to traditional models. However, more accurate model families can be less explainable simply because of the nature of these algorithms. Generally, as predictive performance increases, model complexity also increases, decreasing the ability to understand the effects of inputs on the output (
Gunning 2017).
In this paper, we propose a methodology for explaining two-part models, which expands on the already prevalent TreeSHAP (Tree Model SHapley Additive exPlanations) algorithm (
Lundberg et al. 2020). This methodology, called mSHAP, will allow the output of two models to be multiplied together while maintaining explainability of the resulting prediction and deals with the issue of perturbation as described in (
Li et al. 2020). Although there have been significant advancements made in this area, current methods are unable to rapidly assign input contributions to outputs in two-part models. This lack of explainability is an issue in the insurance industry, and here we propose a method of explaining two-part models that works rapidly and effectively.
The remainder of the paper is outlined as follows. In
Section 2, we revisit existing SHAP-based methods and discuss where issues arise in the context of two-part models. In
Section 3, we discuss the math behind multiplying SHAP values and propose a context in which SHAP values for two existing models can be combined to explain a two-part model. Although this framework is robust, it does leave a part (which we call
) of the ultimate prediction that must be distributed back into the contributions of the variables. To this end, we run a simulation in
Section 4 across different methods of distributing
and score the methods in comparison to kernelSHAP, which is an existing method for estimating explanations of any type of model. Having scored these methods, we select the best one and apply the process of mSHAP on an auto insurance dataset in
Section 5. A conclusion and summary of our results is provided in
Section 6.
2. Motivation
The initial idea for this methodology came due to the problem of machine learning in auto insurance ratemaking (or pricing). Actuaries are tasked with taking historical data and using it to set current rates for insured consumers. Given the sensitive nature of the data and the potential impact it has to bias rates for different types of people, there are strict regulations on the models. The outputs of these models must be explainable so that regulators in the insurance industry can be sure that the rates are not unfairly discriminatory.
Many actuaries use a two-part model to set rates, where the first part predicts how many claims a policyholder will have (the claim frequency) and the second part predicts the average cost of an individual claim (
Frees and Sun 2010;
Heras et al. 2018;
Prabowo et al. 2019). Multiplying the two outputs of these models predicts the total cost of a given policyholder.
Two-part models are more difficult to explain than compared standard models, but the complexity increases when the two models themselves are not traditionally generalized linear models. Given this difficulty and the strict requirements of the regulators, machine learning models are not often used in actuarial ratemaking. Despite the lack of current industry use, machine learning models such as tree-based algorithms could improve the accuracy of ratemaking models (
Akinyemi and Leiser 2020). Since the data that actuaries work with is typically tabular, tree-based algorithms are a good fit for predicting on the data. In recent years, there have been many advances in explaining tree-based machine learning algorithms, which could result in greater adaptation in the field. One of the most important is the SHAP value.
2.1. SHAP Values and Current Implementations
SHAP values originate in the field of economics, where they are used to explain player contributions in cooperative game theory. Proposed by
Shapley (
1953), they predict what each player brings to a game. This idea was ported into the world of machine learning by
Lundberg and Lee (
2017). The basic algorithm calculates the contribution of a variable to the prediction for every possible ordering of variables, then it averages those contributions. This becomes computationally impractical very quickly, but
Lundberg and Lee (
2017) created a modified algorithm that approximates these SHAP values.
A couple of years later,
Lundberg et al. (
2020) published a new paper detailing a method called TreeSHAP. This method is a rapid method for computing exact SHAP values for any tree-based machine learning model. The fixed structure of trees in a tree-based model allows shortcuts to be taken in the computation of SHAP values, which greatly speeds up the process. With this improvement, it becomes feasible to explain millions of predictions from tree-based machine learning algorithms. These local explanations can then be combined to create an understanding of the entire model.
2.2. Properties of SHAP Values
There are three essential properties of SHAP values: local accuracy/efficiency, consistency/monotonicity, and missingness (
Lundberg and Lee 2017). These three properties are satisfied by the equation used to calculate SHAP values, as implemented by
Lundberg and Lee (
2017). While we focus on the local accuracy property for the rest of this section, we note that since mSHAP is built on top of treeSHAP, it automatically incorporates consistency/monotonicity and missingness properties.
2.2.1. Local Accuracy in Implementation
The most important of the above mentioned properties in the context of mSHAP is the property of local accuracy/efficiency. In the context of machine learning, this property says that the contributions of the variables should add up to the difference between the prediction and the average prediction of the model. The average prediction can be thought of as the model bias term, which is what the model will predict, on average, across all inputs (assuming representative training data). For a more mathematical definition of local accuracy, see
Appendix A. In the TreeSHAP algorithm, the average prediction of the model is computed as the mean of all predictions for the training data set. The SHAP values are then computed to explain deviance from the average prediction.
Thus, given an arbitrary model Y with prediction based on two predictors, and , we can represent the mean prediction with and the SHAP values for the two covariates as and . Based on the property of local accuracy, we know that .
This principle applies to models with any number of predictors and is very desireable in explainable machine learning (
Arrieta et al. 2020).
2.2.2. The Problem of Local Accuracy
Since it is so important that the SHAP values add up to the model output, any attempt at explaining two-part model output from the SHAP values of the individual parts must maintain this property. However, multiplying the output of two models blends the contributions from different variables, making it unclear what contributions should be given to what variables. The idea of combining models and using SHAP values of the individual models to obtain the SHAP values for the combined model has been implemented before. In a related github issue, Scott Lundberg assures that averaging model output is compatible with averaging SHAP values, as long as the SHAP values (and model output) are in their untransformed state (
Slundberg 2020). Even though averaging SHAP values for each variable works when averaging model outputs, the same principle does not apply when multiplying model outputs.
When considered, this is apparent. In the most simple of cases, we observe that if we have two models that both predict some outcomes based on two covariates
and
, we can average their results and likely obtain a better prediction. We will call these models
A and
B, respectively. For a given observation, model
A predicts
and model
B predicts
. When run through a SHAP explainer, we can break down these predictions even further. Since SHAP values are additive, we know that
and
. It follows the following is obtained.
Equation (1) means that we can find the contribution to the overall model from by averaging and , and likewise for the contribution to the overall model from .
However, if we for some reason wished to stack our models such that the two outputs (
and
) are multiplied, we run into a problem. This occurs because, despite the longings of all algebra students, the following is the case.
Instead, we end up with the following.
Even in this simple case, it is difficult to assign a single contribution to our two different variables when presented with the SHAP values of the two original models. This problem grows even more difficult with the addition of other explanatory features. mSHAP is the methodology developed to solve this problem.
3. The Math behind Multiplying SHAP Values
In a two-part model, the output of one model is multiplied by the output of a second model to obtain the response. The principal driver behind mSHAP is the explanation of these sorts of models, and it requires that the SHAP values be multiplied together in some manner to obtain a final SHAP value for the output. The mathematics behind mSHAP are explained here in the general case for any given number of predictors with a training set of arbitrary size. Although an exact solution for the SHAP values of a two-part model is still out of reach, this method proves very accurate in its results.
3.1. Definitions
Consider three different predictive models, and h and a single input (training) matrix A. We will let the number of columns and rows in A be arbitrary. In other words, let A be an matrix where each column is a covariate and each row is an observation. Moreover, let denote the ith observation (row) of A. Furthermore, define h to be the product of f and g; thus, .
Recall that the sum of the SHAP values for each covariate and the average model output must add up to the model prediction. For simplicity in presentation, we will define , , and and the contribution of the jth predictor to as . With these considerations in place, we can define the output space of our three models on the training data set, as shown in Equations (3) to (5).
For model
f, we have the following.
For model
g, we have the following.
Moreover, for model
h, we have the following.
Furthermore, given our training data
A, we can extract the values of
and
. As explained above, these are the average values of the model predictions on the training set.
In practice, it is necessary to be able to pull
out of
. When implemented, it is important to note that
. Since every expansion of SHAP values from
contains
, we substitute
, where
is essential and
becomes a term that we label
and distribute among all the SHAP values. A more formalized definition of
is provide in
Appendix B.
3.2. Obtaining ’s SHAP Values
We now derive the individual SHAP values for each variable as it pertains to the prediction of model
h. Again, we will allow this output be an arbitrary
. Recall the following.
Using a tabular form for visual simplicity, we obtain the following expansion of Equation (9).
We break these terms into the SHAP values for each variable, one through
p, for
. Our approach breaks
into two parts, which we call
and
. By using the method of obtaining
, which can take on several forms,
is always as follows (where
j refers to the
jth covariate).
In other words and with the aid of the table above, Equation (10) can be described as the sum of the
jth row and
jth column, where every term is divided by two except the terms with
and
. When applied to each variable, this can be written as follows:
and by applying the breakdown we derived in Equation (10), while simplifying Equation (11) as well, we arrive at the following.
For a proof that this formula and the subsequent distribution of
maintains the local accuracy property of SHAP values, refer to
Appendix B.1.
3.3. Methods for Distributing
We now arrive at the aforementioned point of deciding how to distribute
into each
. There are four methods that we tested for distributing
: the first being simple uniform distribution and the others being variations of weighting based on the value of
. All four of these methods maintain the local accuracy property of SHAP values, and a detailed proof of the absolute value case can be found in
Appendix B.1. We acknowledge that there is no easy interpretation of
and our choices for distributing/weighting it were arbitrary methods of dividing a whole into parts. In Equation (13), we evenly distributed
over the contributions from all covariates, while in Equation (15), we weighted each part by its corresponding contribution to the model. Both Equations (16) and (17) are variations on weighting the parts, but they use different methods to ensure that all the weights are positive. Different methods for distributing
may be a topic for further research.
3.3.1. Uniformly Distributed
The simplest method of distributing
between all the
’s is to divide it evenly. In this case, our resulting equation for each variable’s SHAP value would be the following.
This method could prove a strong baseline.
3.3.2. Raw Weights
The computation of this method is made easier by recalling from Equation (11) that the following is the case:
which allows us to use
as the whole upon which we base our weighting. When applied, this method defines each SHAP value as follows.
3.3.3. Absolute Weights
This method differs from that of the raw weights in that instead of summing the
’s, we sum their absolute values. The weight for each SHAP value is calculated with the following.
3.3.4. Squared Weights
Finally, instead of working with the absolute values, we could work with squares. Similarly to the equation above, the SHAP values under this method are computed by the following.
4. Simulation Study for Distributing
To test the differences between these methods of distributing , we simulated various multiplicative models based on known equations and compared the results of our multiplicative method with the output from kernelSHAP. KernelSHAP is an existing generalized method for estimating the contributions based on any prediction function. However, it is extremely computationally expensive when compared with TreeSHAP. When training on millions of rows with many variables, it becomes unrealistic to use kernelSHAP for computing the SHAP values.
4.1. Scoring the Methods
Several factors were considered in scoring, including the mean absolute error of the SHAP values, the directions of the SHAP values, and the rank (in magnitude) of the SHAP values for each variable. The score needed to be a singular method to asses how close the method approaches the kernelSHAP estimates. Even though kernelSHAP is an estimate and not necessarily the truth, we used it as a benchmark in the different parts of our score. This allowed us to compare new variations of the mSHAP method to existing methods for the computation of SHAP values.
For ease of notation, if we define the SHAP value, we are estimating it as ; then, we can define its counterpart as computed by kernelSHAP, as .
4.1.1. General Equation for Scoring
In the end, an equation was formed to create a raw “score” based on the direction of the SHAP value, the relative value of the SHAP value, and the rank (importance) of the SHAP value in comparison to kernelSHAP. The score ranges from 0 to 3 (with 3 being the best possible score), and is defined by the following:
where the following is the case:
and imp
is the importance of that SHAP value relative to the other contributions in the observation (where importance is determined by the magnitude of the absolute value).
In this function (and as will be described in the following section), is the contribution from the signs of the SHAP values, is the contribution from the relative value of the SHAP values, and is the contribution from the relative ranking (importance) of the SHAP values.
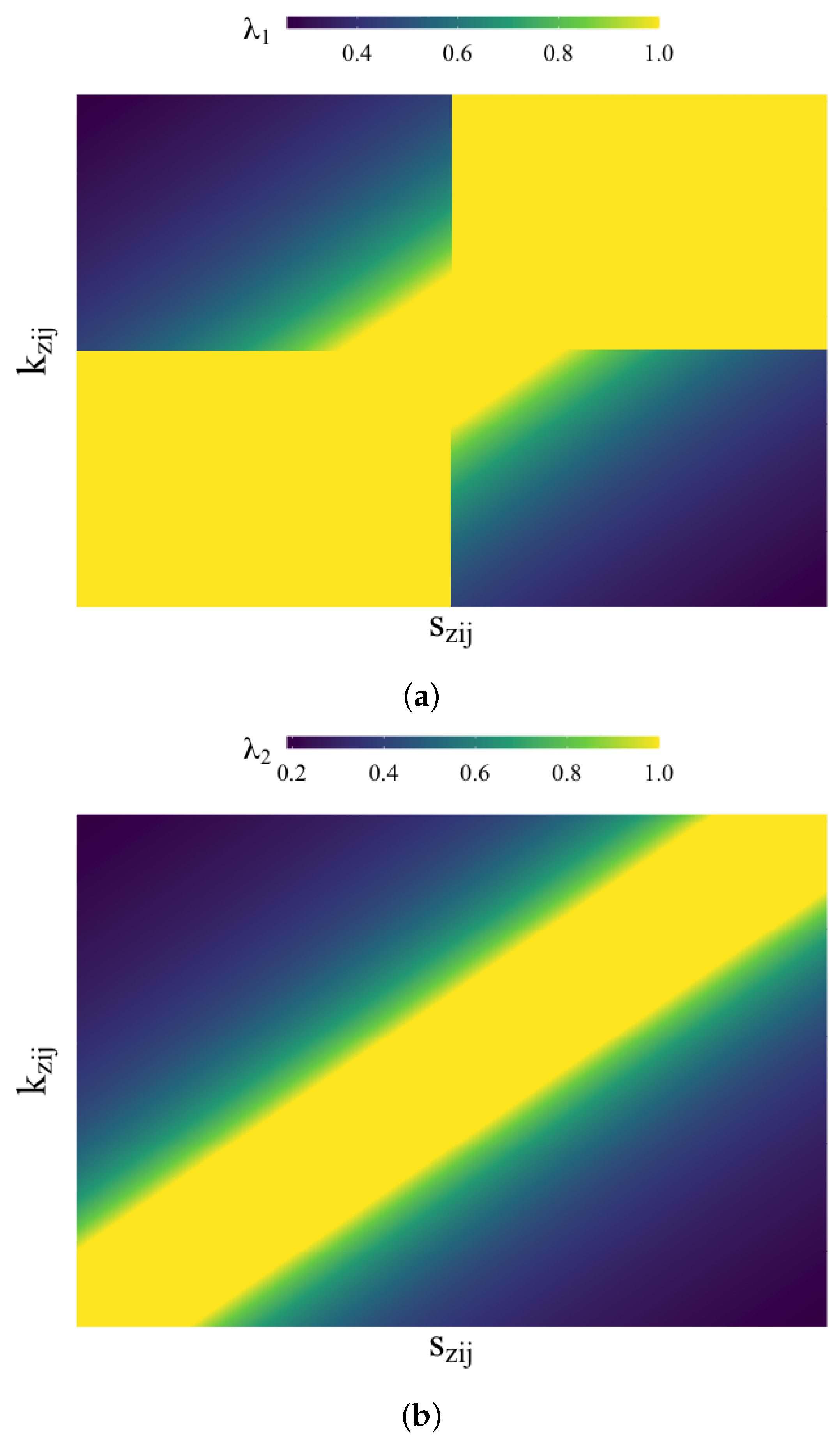
4.1.2. Lambda Functions
In order to gain some intuition about the
functions (Equations (19)–(21)) and the impact of
and
, we depict them in
Figure 1.
For , which measures whether the two SHAP values are the same sign, any values in the first and third quadrants return a perfect score of 1, since the two values have the same sign. It also allows for some wiggle room with by allowing anything within the lines and to be 1. Beyond those boundaries, the scores gradually decrease.
The function , which compares the values, also creates boundary lines for the perfect score of 1 at and . In other words, as long as the difference between and is less than , the function will return 1. Beyond that, the value begins to decrease.
Out of the three , the rank measure is the easiest to understand. In a given observation, each SHAP value is given a rank (between 1 and p, inclusive) based on its absolute value. These ranks are then compared, and the closer they are together, the higher the score, with a perfect score of 1 being obtained if the two rankings are the same.
4.2. Simulation Study
As mentioned above, we simulated various multiplicative models based on known equations and compared the results of our multiplicative method with the output from kernelSHAP in order to test the model. The type of simulation used here is a Monte Carlo simulation that is commonly used in actuarial literature, as in
Appendix C Romaniuk (
2017).
Specifically, we used three variables, , and in a variety of response equations and to create models for and and then multiply their outputs together. Using the multiplied output and the covariates, we were able to use kernelSHAP to compute an estimate of the SHAP values. We could then compared this estimate to the result from our multiplicative method, as described above, with different methods of distributing applied.
More details on the simulation can be found in
Appendix C.
For testing, we used 100 samples in each iteration for faster computation, which allowed us to simulate over 2500 scenarios. Specifically, we worked with all possible combinations of the following values (see
Table 1).
For each combination of values in the above table, we distributed
in each of the four methods mentioned in
Section 3.3. The resulting table, therefore, had results for each model and each method of distributing
. In general, we averaged across all rows of the same method to obtain the scores that were compared to each other.
In our examples, our covariates were distributed as follows.
4.3. Results of the Simulation
In general, the multiplicative SHAP method performed very well when compared to the kernelSHAP output. Since kernelSHAP is an estimation as well, it is hard to determine exactly how well the multiplicative SHAP method does, but we will summarize some statistics here.
4.3.1. Distributing
After trying the aforementioned four methods for distributing
into the SHAP values, we came to the conclusion that the weighted by absolute value method was the best. This came by way of the score as well as other metrics. Details can be observed in the
Table 2 (all values are averaged across all 2520 simulations).
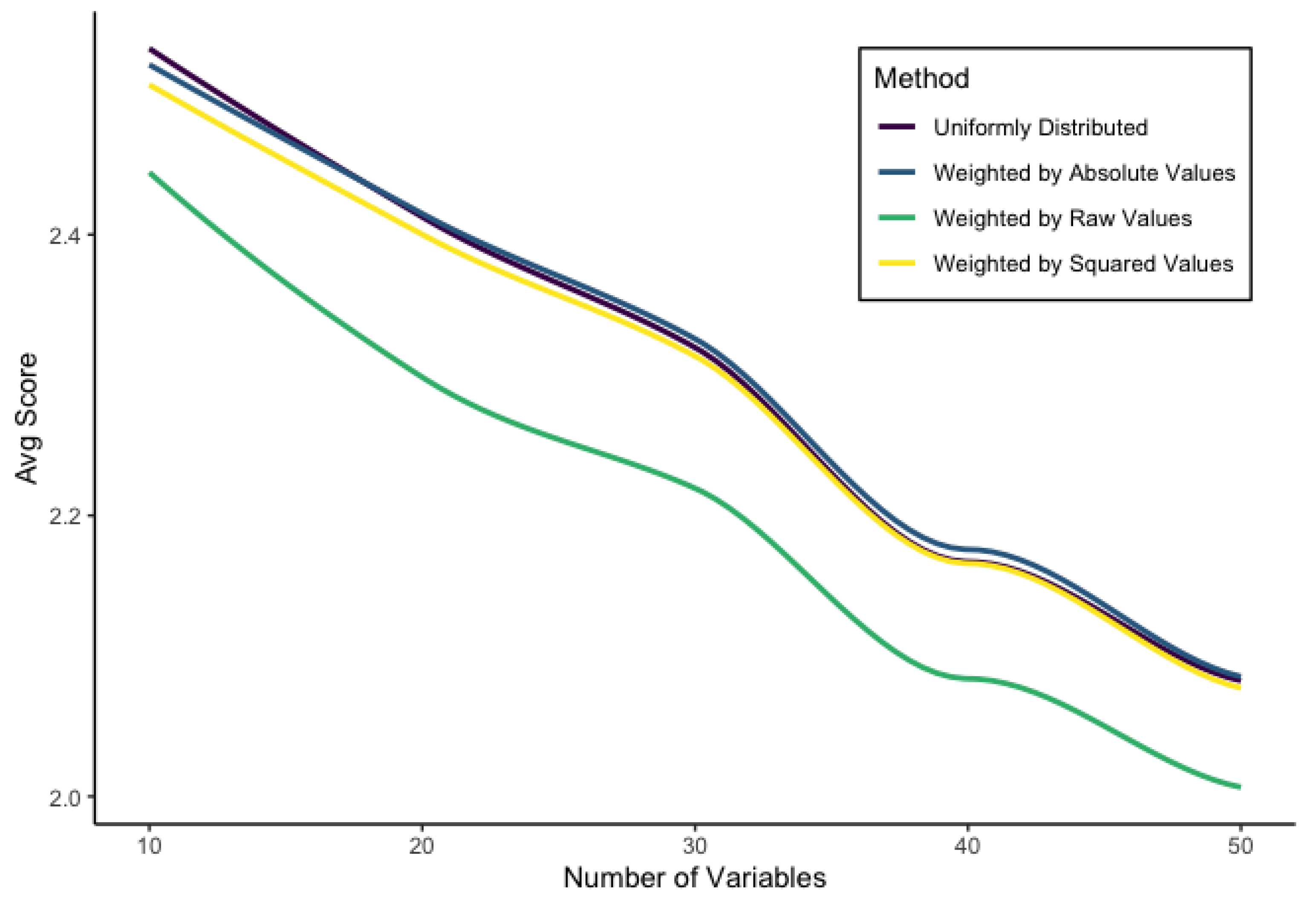
4.3.2. Impact of and
We plotted the effects of the different values for and on the overall score based on type of method of distribution.
As observed, in
Figure 2 and
Figure 3, changing the value of these two parameters has a similar impact across all scoring methods.
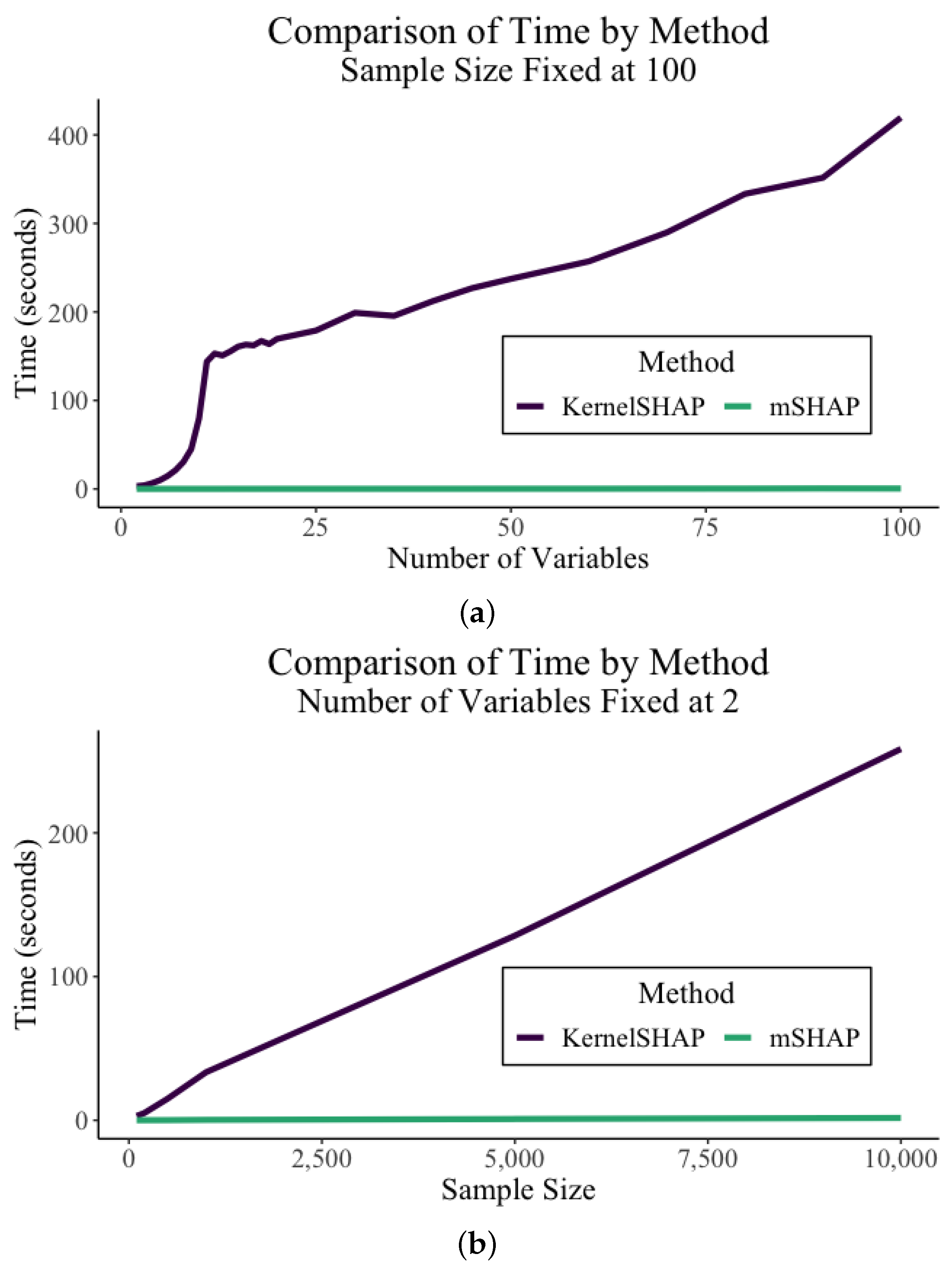
4.3.3. Computational Time
The most dramatic benefit of mSHAP over kernelSHAP is the computational efficiency of mSHAP. The times shown in this section were obtained using a personal MacBook Air laptop computer with a 1.8 GHz Dual-Core Intel Core i5 processor.
In
Figure 4, we are able to observe the comparison in run time between the kernelSHAP and mSHAP methods (including the individual treeSHAP value calculations). Both an increase in the number of variables and the number of samples causes the time of kernelSHAP to grow greatly, while the multiplicative method remains fairly constant. In these trials, the number of background samples was fixed at 100 for kernelSHAP.
A case study can show the importance of this. In the auto insurance dataset, there are 5,000,000 rows in the test set, with 46 variables. For the sake of simplicity, let us assume that we use 45 of those variables and that 100 background samples are enough to compute accurate SHAP values. In reality, it would need many more background samples, but that only accentuates the point, as a large quantity of background samples slows kernelSHAP drastically. KernelSHAP computes SHAP values for 45 variables at a rate of about 2.268 s per observation on a personal laptop. In order to compute the SHAP values for the entire test set, one would need about 131 days of continuous compute time.
In contrast, our multiplicative method, using treeSHAP on two tree-based models, computes SHAP values at a rate of about 0.00175 s per observation for a model with 45 variables. To compute the SHAP values for the entire test set using this method, it would take a little less than three hours of continuous computation time.
4.4. Final Equation for mSHAP
Based on the results of the simulation, we determine that the best method of distributing
is the method of weighting by absolute values (as described above). Recall from Equation (16) that in this method, we have the following:
and that
refers to an initial mSHAP value, before the correction introduced by
as in Equation (10). It is calculated as follows.
Thus, the final equation for the mSHAP value of the
jth predictor on the
ith observation can be written as follows.
For a complete proof that local accuracy holds with this equation, see
Appendix B.1.
5. Case Study
In order to prove the efficacy of mSHAP, it is necessary to put it into practice. We obtained an insurance dataset including over 20 million auto insurance policies for a large insurance provider in the United States. Using these data, we created a two-part model that predicts the expected property damage cost of each policy. Both parts of this model consist of tree-based methods, specifically random forests. After creating this model, we used the shap python library to explain the predictions of each individual part on a sample of 50,000 observations from our test set. We then applied the final mSHAP method, as described above, to obtain explanations for the overall model and used the mshap R package to visualize some of the results. Although there has been recent studies on models that span multiple types of claims on one policy as in
Gómez-Déniz and Calderín-Ojeda (
2021), the data were such that we could only focus on one specific type of claim for each model.
5.1. Model Creation
As mentioned above, the model is a two-part model for predicting the expected cost of the policy. The first part of the model predicts the frequency of the claims. It is a random forest that predicts the probability of each of four possible outcomes (a multinomial model). In our dataset, there existed policies with up to seven claims, but we chose the classes of zero, one, two, and three and bundled everything over three into the third class. The data were heavily imbalanced; thus, we used a combination of upsampling the minority classes (one, two, and three claims) and downsampling the majority class (0 claims) to obtain a more balanced training data set. This allowed the model to use the information to predict meaningful probabilities instead of always assigning a very high probability to zero claims.
The second part is a random forest which predicts the severity component of the two-part model or the expected cost per claim.
Once these models were created, we could calculate the expected value (or in this case, the expected cost) of a policy in the following manner. If we let
denote the predicted probability of the for the
ith policy of the
ath class and
be the predicted severity of the policy, then we have the following.
The final two-part model was used to predict the expected cost of 50,000 policies from the test dataset. For more specific details about the model and how it was tuned, see
Appendix E.
5.2. Model Explanation
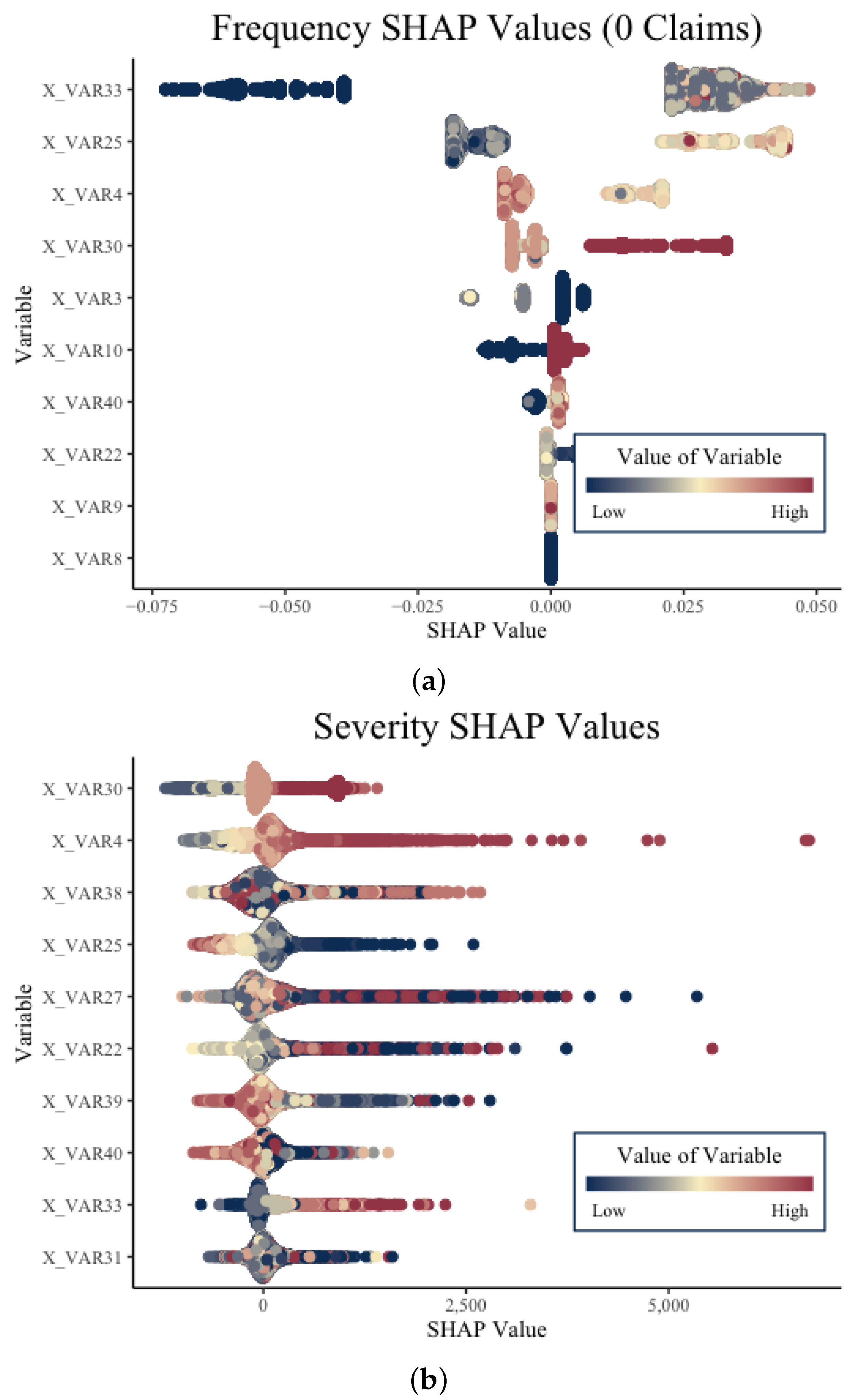
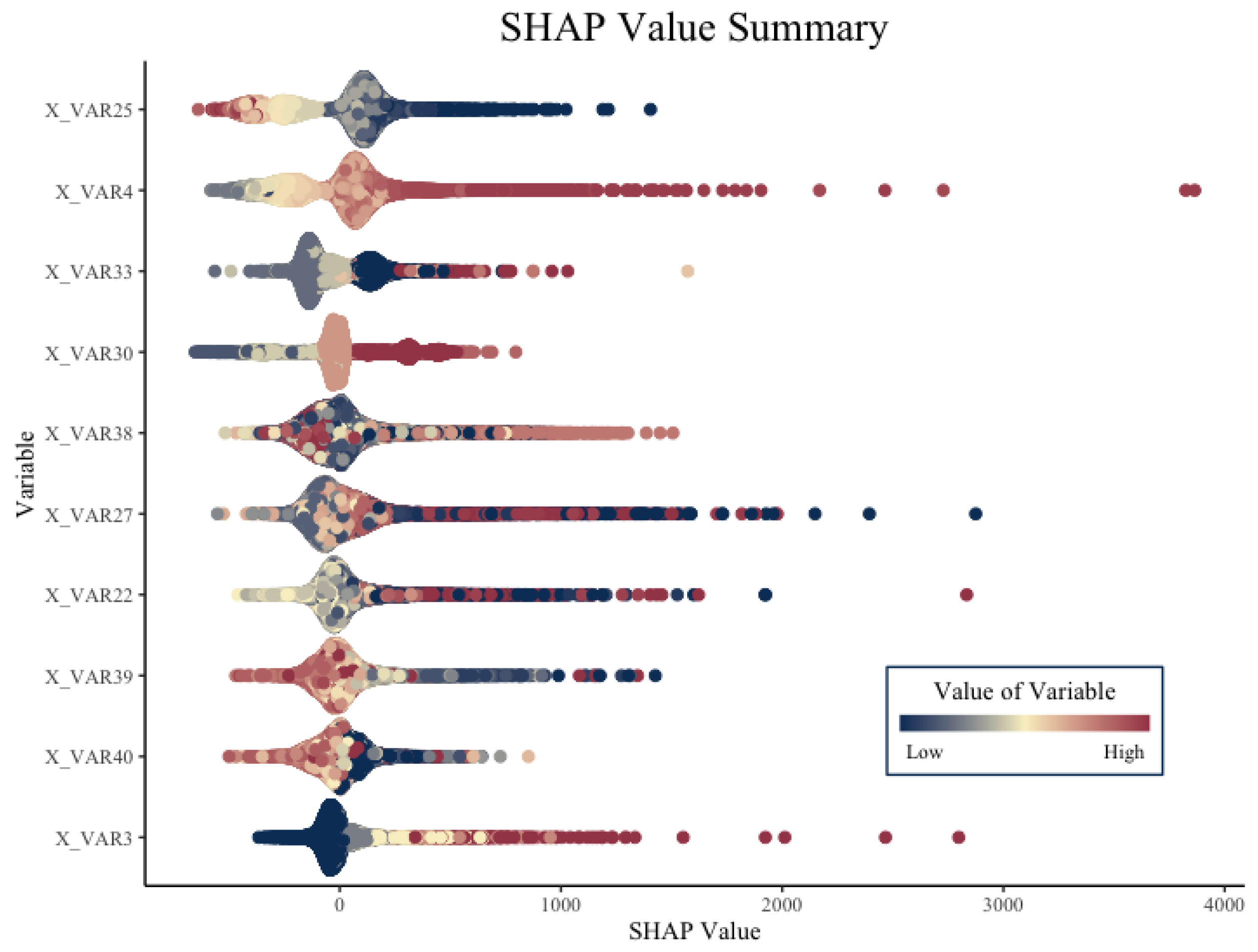
After creating the two-part model and obtaining final predictions for the expected cost of the claims, we were able to apply mSHAP to explain final model predictions. Before performing this, we computed SHAP values on the individual models so that we have the necessary data to apply the mSHAP method for explaining two-part models. Summary plots for the five different sets of SHAP values (one for severity, and one for each class of the frequency model) can be created. In
Figure 5, we depict the SHAP values for one of the frequency classes from the frequency model and the SHAP values for the severity model.
After computing these SHAP values, we applied the mSHAP method detailed in this paper. When applying mSHAP, the expected value formula above is simply a linear combination, and we are able to perform that same linear combination on the SHAP values before (or after) applying mSHAP. This process left us with a single mSHAP value for each variable in every row of our test set and an overall expected value across the training set. The summary plot of those final mSHAP values can be oberved in
Figure 6, and an example of an observation plot is shown in
Figure 7.
The beauty of the mSHAP method is that it allows for a two-part model to be explained in the same manner that tree-based models can be easily explained with SHAP values. As observed in the plots, general trends across variables can be established, as well as specific policies dissected to observe individual motivators behind each prediction. The ability of mSHAP to explain these types of models opens the door to using two-part models that are both powerful and explainable.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}