Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions



Abstract
- 1. Introduction
- 2. Immunoglobulin (IG) or Antibody Molecular Genetics
- 2.1. Human Immunoglobulin (IG) or Antibody Structure and Dual Function
- 2.1.1. Immunoglobulin Fab and Fc Basic Structure
- 2.1.2. B Cell Differentiation
- 2.1.3. Membrane Immunoglobulins and B Cell Receptor
- 2.1.4. Secreted IG
- 2.2. Human IG Classes and Subclasses: Heavy and Light Chain Types
- 2.2.1. IG Heavy Chain Types
- 2.2.2. IG Light Chain Types
- 2.3. IG Chain Variable and Constant Domains
- 2.3.1. IG Variable Domains
- 2.3.2. IG Constant Domains
- 2.4. Synthesis and Expression of the Immunoglobulins (IG) or Antibodies
- 2.4.1. IG Molecular Synthesis Characteristics
- 2.4.2. Synthesis of the H-mu Chains: D-J and V-D-J Rearrangements in the IGH Locus
- 2.4.3. Synthesis of the L-kappa and L-lambda Chains: V-J Rearrangements in the IGK and IGL Loci
- 2.5. Origin of the Variable Domain Diversity of the Immunoglobulins
- 2.5.1. Overview
- 2.5.2. Combinatorial Diversity
- 2.5.3. Junctional Diversity
- 2.5.4. Somatic Hypermutations
- 2.6. Expression of the Heavy Chains and IG Classes
- 2.6.1. Coexpression of the Membrane H-mu and H-delta Chains
- 2.6.2. Expression of H-gamma, H-epsilon and H-alpha chains: Class Switch Recombination
- 2.6.3. Expression of H-delta Chains from IgM− IgD+ Cells
- 2.6.4. Expression of Membrane and Secreted Immunoglobulins
- 2.7. Regulation of the Rearrangements and Chain Expression
- 2.7.1. Allelic and Isotypic Exclusion. Rearrangement Chronology
- 2.7.2. Regulation of the IG Gene Expression: Enhancers
- 2.8. Structural and Biological Properties of the Secreted Immunoglobulins
- 2.8.1. IgM
- 2.8.2. IgD
- 2.8.3. IgG
- 2.8.4. IgA
- IgA1 and IgA2
- Secretory IgA
- IgA Effector Function
- 2.8.5. IgE
- 3. Immunoglobulin Genes: IMGT® Gene and Allele Nomenclature
- 3.1. IMGT® Standardized Genes and Alleles (CLASSIFICATION)
- 3.1.1. IG and TR Genes and Concepts of Classification: Birth of IMGT® and Immunoinformatics
- 3.1.2. Homo sapiens IG Genes and Concepts of Identification and Description
- 3.2. Homo sapiens IGH Locus and Genes
- 3.2.1. Organization of the Homo sapiens IGH Locus
- 3.2.2. IGHC Multigene Deletions and Gene Order, IGHC and IGHV Copy Number Variation (CNV) Haplotypes
- 3.2.3. IGH Orphons
- 3.2.4. Potential Homo sapiens IGH Genomic Repertoire
- 3.3. Homo sapiens IGK Locus and Genes
- 3.3.1. Organization of the Homo sapiens IGK Locus
- 3.3.2. IGK Orphons
- 3.3.3. Potential Homo sapiens IGK Genomic Repertoire
- 3.3.4. Homo sapiens IGKC Allotypes (Km Alleles)
- 3.4. Homo sapiens IGL Locus and Genes
- 3.4.1. Organization of the Homo sapiens IGL Locus
- 3.4.2. IGL Orphons
- 3.4.3. Potential Homo sapiens IGL Genomic Repertoire
- 3.4.4. Homo sapiens IGL Isotypes
- 4. Immunoglobulin Structures: IMGT Unique Numbering and IMGT® Collier de Perles
- 4.1. IMGT Unique Numbering and IMGT Colliers de Perles for V-DOMAIN (NUMEROTATION)
- 4.1.1. V Domain Definition and Main Characteristics
- 4.1.2. V-DOMAIN IMGT Colliers de Perles
- 4.1.3. V-DOMAIN Strands and Loops (FR-IMGT and CDR-IMGT)
- 4.1.4. V-DOMAIN Conserved Amino Acids
- 4.1.5. V-DOMAIN Delimitation
- 4.1.6. Protein Displays for the V-REGION and J-REGION
- 4.2. IMGT Unique Numbering and IMGT Colliers de Perles for C Domain (NUMEROTATION)
- 4.2.1. C Domain Definition and Main Characteristics
- 4.2.2. C Domain IMGT Colliers de Perles
- 4.2.3. C Domain Strands and loops
- 4.2.4. C Domain Conserved Amino Acids
- 4.2.5. C Domain Genomic Delimitation
- 4.2.6. C-REGION Protein Displays
- 5. IMGT® Databases and Tools for IG Sequences and Structures
- 5.1. IMGT®, the International ImMunoGeneTics Information System®
- 5.2. IMGT® Nucleotide Sequence and Repertoire Analysis
- 5.2.1. IMGT/V-QUEST for Nucleotide Sequence Analysis
- 5.2.2. IMGT/HighV-QUEST
- 5.3. IMGT® Amino Acid Sequence Analysis and Representation
- 5.3.1. IMGT/DomainGapAlign
- 5.3.2. IMGT/Collier-de-Perles Tool
- 5.4. IMGT® Structure and Amino Acid Databases
- 5.4.1. IMGT/3Dstructure-DB
- 5.4.2. IMGT/2Dstructure-DB
- 5.4.3. IMGT/mAb-DB
- 6. Using the IMGT Numbering for V and C-Domain for Antibody Description and Engineering
- 6.1. Antibody V-DOMAIN Humanization by IMGT-CDR Grafting
- 6.1.1. CDR-IMGT Delimitation for Grafting
- 6.1.2. Amino acid Interactions between FR-IMGT and CDR-IMGT
- 6.2. Only-Heavy-Chain Antibodies
- 6.2.1. Dromedary IgG2 and IgG3
- 6.2.2. Human Heavy Chain Diseases (HCD)
- 6.2.3. Nurse Shark IgN
- 6.3. Contact Analysis of TR-Mimic Antibodies and TR
- 6.4. Antibody C-Domain Post-Translational Modifications, Engineering and Allotypes
- 6.4.1. N-linked Glycosylation Sites CH2 N84.4
- 6.4.2. Knobs-into-Holes
- 6.4.3. Interface Ball-and-Socket-Like Joints
- 6.4.4. IGHG Alleles and Gm Allotypes
- 6.4.5. IGHG Engineered Variants and Effector Properties
- 7. Conclusions
1. Introduction
2. Immunoglobulin (IG) or Antibody Molecular Genetics
2.1. Human Immunoglobulin (IG) or Antibody Structure and Dual Function
2.1.1. Immunoglobulin Fab and Fc Basic Structure
2.1.2. B Cell Differentiation
2.1.3. Membrane Immunoglobulins and B Cell Receptor
2.1.4. Secreted IG
2.2. Human IG Classes and Subclasses: Heavy and Light Chain Types
2.2.1. IG Heavy Chain Types
2.2.2. IG Light Chain Types
2.3. IG Chain Variable and Constant Domains
2.3.1. IG Variable Domains
2.3.2. IG Constant Domains
2.4. Synthesis and Expression of the Immunoglobulins (IG) or Antibodies
2.4.1. IG Molecular Synthesis Characteristics
2.4.2. Synthesis of the H-Mu Chains: D-J and V-D-J Rearrangements in the IGH Locus
2.4.3. Synthesis of the L-Kappa and L-Lambda Chains: V-J Rearrangements in the IGK and IGL Loci
2.5. Origin of the Variable Domain Diversity of the Immunoglobulins
2.5.1. Overview
2.5.2. Combinatorial Diversity
2.5.3. Junctional Diversity
2.5.4. Somatic Hypermutations
2.6. Expression of the Heavy Chains and IG Classes
2.6.1. Coexpression of the Membrane H-Mu and H-Delta Chains
2.6.2. Expression of H-Gamma, H-Epsilon and H-Alpha Chains: Class Switch Recombination
2.6.3. Expression of H-Delta Chains from IgM− IgD+ Cells
2.6.4. Expression of Membrane and Secreted Immunoglobulins
2.7. Regulation of the Rearrangements and Chain Expression
2.7.1. Allelic and Isotypic Exclusion. Rearrangement Chronology
2.7.2. Regulation of the IG Gene Expression: Enhancers
2.8. Structural and Biological Properties of the Secreted Immunoglobulins
2.8.1. IgM
2.8.2. IgD
2.8.3. IgG
2.8.4. IgA
IgA1 and IgA2
Secretory IgA
IgA Effector Function
2.8.5. IgE
3. Immunoglobulin Genes: IMGT® Gene and Allele Nomenclature
3.1. IMGT® Standardized Genes and Alleles (Classification)
3.1.1. IG and TR Genes and Concepts of Classification: Birth of IMGT® and Immunoinformatics
3.1.2. Homo sapiens IG Genes and Concepts of Identification and Description
3.2. Homo sapiens IGH Locus and Genes
3.2.1. Organization of the Homo sapiens IGH Locus
3.2.2. IGHC Multigene Deletions and Gene Order, IGHC and IGHV Copy Number Variation (CNV) Haplotypes
3.2.3. IGH Orphons
3.2.4. Potential Homo sapiens IGH Genomic Repertoire
3.3. Homo sapiens IGK Locus and Genes
3.3.1. Organization of the Homo sapiens IGK Locus
3.3.2. IGK Orphons
3.3.3. Potential Homo sapiens IGK Genomic Repertoire
3.3.4. Homo sapiens IGKC Allotypes (Km Alleles)
3.4. Homo sapiens IGL Locus and Genes
3.4.1. Organization of the Homo sapiens IGL Locus
3.4.2. IGL Orphons
3.4.3. Potential Homo sapiens IGL Genomic Repertoire
3.4.4. Homo sapiens IGL Isotypes
4. Immunoglobulin Structures: IMGT Unique Numbering and IMGT® Collier de Perles
4.1. IMGT Unique Numbering and IMGT Colliers de Perles for V-DOMAIN (NUMEROTATION)
4.1.1. V Domain Definition and Main Characteristics
4.1.2. V-DOMAIN IMGT Colliers de Perles
4.1.3. V-DOMAIN Strands and Loops (FR-IMGT and CDR-IMGT)
4.1.4. V-DOMAIN Conserved Amino Acids
4.1.5. V-DOMAIN Delimitation
4.1.6. Protein Displays for the V-REGION and J-REGION
4.2. IMGT Unique Numbering and IMGT Colliers de Perles for C Domain (NUMEROTATION)
4.2.1. C Domain Definition and Main Characteristics
4.2.2. C Domain IMGT Colliers de Perles
4.2.3. C Domain Strands and Loops
4.2.4. C Domain Conserved Amino Acids
4.2.5. C Domain Genomic Delimitation
4.2.6. C-REGION Protein Displays
5. IMGT® Databases and Tools for IG Sequences and Structures
5.1. IMGT®, the International ImMunoGeneTics Information System®
5.2. IMGT® Nucleotide Sequence and Repertoire Analysis
5.2.1. IMGT/V-QUEST for Nucleotide Sequence Analysis
5.2.2. IMGT/HighV-QUEST
- a unique V-(D)-J-rearrangement (V and J genes and alleles) (nt)
- a unique CDR3-IMGT (AA)
- conserved anchors 104, 118 (C104, W118 or F118)
- (1).
- IMGT clonotypes (AA) per Nb
- (2).
- IMGT clonotypes (AA) per Nb with detailed clonotypes (nt)
- (3).
- IMGT clonotypes (AA) per V gene
- (4).
- IMGT clonotypes (AA) per V gene with detailed clonotypes (nt)
- (5).
- IMGT clonotypes (AA) per CDR3-IMGT length (AA)
- (6).
- IMGT clonotypes (AA) per CDR3-IMGT length (AA) with detailed clonotypes (nt)
- (7).
- IMGT clonotypes (AA) by CRD3-IMGT sequence (AA) alphabetical order with detailed clonotypes (nt)
- (8).
- IMGT clonotype (AA) diversity and expression histograms: per V, (D), J-GENE and per CDR3-IMGT length
- (9).
- IMGT clonotype (AA) diversity and expression tables: per V, (D), J-GENE and per CDR3-IMGT length
- (10).
- V gene and allele table: Rearrangements, Nb of sequences and Nb IMGT clonotypes (AA) per V-GENE and allele
5.3. IMGT® Amino Acid Sequence Analysis and Representation
5.3.1. IMGT/DomainGapAlign
- (1).
- (2).
- (3).
- (4).
- Description of AA changes (Figure 29C),
- (5).
5.3.2. IMGT/Collier-de-Perles Tool
5.4. IMGT® Structure and Amino Acid Databases
5.4.1. IMGT/3Dstructure-DB
- (1)
- (2)
- (3)
- (4)
- (5)
- (6)
5.4.2. IMGT/2Dstructure-DB
5.4.3. IMGT/mAb-DB
6. Using the IMGT Numbering for V and C-Domain for Antibody Description and Engineering
6.1. Antibody V-DOMAIN Humanization by IMGT-CDR Grafting
6.1.1. CDR-IMGT Delimitation for Grafting
6.1.2. Amino Acid Interactions between FR-IMGT and CDR-IMGT
6.2. Only-Heavy-Chain Antibodies
6.2.1. Dromedary IgG2 and IgG3
6.2.2. Human Heavy Chain Diseases (HCD)
6.2.3. Nurse Shark IgN
6.3. Contact Analysis of TR-Mimic Antibodies and TR
6.4. Antibody C-Domain Post-Translational Modifications, Engineering and Allotypes
6.4.1. N-Linked Glycosylation Sites CH2 N84.4
6.4.2. Knobs-into-Holes
6.4.3. Interface Ball-and-Socket-Like Joints
6.4.4. IGHG Alleles and Gm Allotypes
6.4.5. IGHG Engineered Variants and Effector Properties
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lefranc, M.-P. Immunoglobulin and T cell receptor genes: IMGT® and the birth and rise of immunoinformatics. Front. Immunol. 2014, 5, 22. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. The Immunoglobulin FactsBook; Academic Press: London, UK, 2001; pp. 1–457. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. The T Cell Receptor FactsBook; Academic Press: London, UK, 2001; pp. 1–397. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. A.1P.1–A.1P.37. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human T cell Receptor genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. A.1O.1–A.1O.23. [Google Scholar]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system. In Immunoinformatics: Bioinformatic Strategies for Better Understanding of Immune Function; Bock, G., Goode, J., Eds.; Novartis Foundation Symposium, John Wiley and Sons: Chichester, UK, 2003; Volume 254, pp. 126, discussion 136–142, 216–222, 250–252. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Chaume, D. IMGT, the international ImMunoGeneTics information system: The reference in immunoinformatics. Stud. Health Technol. Inform. 2003, 95, 74–79. [Google Scholar]
- Lefranc, M.-P. IMGT databases, web resources and tools for immunoglobulin and T cell receptor sequence analysis. Leukemia 2003, 17, 260–266. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT, the international ImMunoGenetics information system®. In Antibody Engineering Methods and Protocols, 2nd ed.; Lo, B.K.C., Ed.; Methods in Molecular Biology, Series of Humana Press: Totowa, NJ, USA, 2004; Volume 248, pp. 27–49. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Kaas, Q.; Duprat, E.; Jabado-Michaloud, J.; Scaviner, D.; Ginestoux, C.; Clément, O.; Chaume, D.; Lefranc, G. IMGT, the international ImMunoGeneTics information system. Nucleic Acids Res. 2009, 33, D593–D597. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system: A standardized approach for immunogenetics and immunoinformatics. Immunome Res. 2005, 20. [Google Scholar] [CrossRef][Green Version]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. In Immunoinformatics: Predicting Immunogenicity in Silico; Chapter 2; Flower, D.R., Ed.; Humana Press: Totowa, NJ, USA, 2007; Volume 409, pp. 19–42. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Regnier, L.; Duroux, P. IMGT®, a system and an ontology that bridge biological and computational spheres in bioinformatics. Brief. Bioinform. 2008, 9, 263–275. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. Mol. Biotechnol. 2008, 40, 101–111. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Jabado-Michaloud, J.; Folch, G.; Bellahcene, F.; Wu, Y.; Gemrot, E.; Brochet, X.; Lane, J.; et al. IMGT®, the international ImMunoGeneTics information system®. Nucleic Acids Res. 2009, 37, D1006–D1012. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT, the International ImMunoGeneTics Information System. Cold Spring Harb. Protoc. 2011, 6, 595–603. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Duroux, P.; Jabado-Michaloud, J.; Folch, G.; Aouinti, S.; Carillon, E.; Duvergey, H.; Houles, A.; Paysan-Lafosse, T.; et al. IMGT®, the international ImMunoGeneTics information system® 25 years on. Nucleic Acids Res. 2015, 43, D413–D422. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT® Information System. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; SpringerScience+Business Media, Springer: New York, NY, USA, 2013; pp. 959–964. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Immunoglobulin superfamily (IgSF). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. MH superfamily (MhSF). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. Ontology for immunogenetics: IMGT-ONTOLOGY. Bioinformatics 1999, 15, 1047–1054. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY: Gestion et découverte de connaissances au sein d’IMGT. In Extraction et Gestion des Connaissances (EGC’2003); Hacid, M.-S., Kodratoff, Y., Boulanger, D., Eds.; Actes des troisièmes journées Extraction et Gestion des Connaissances, Lyon, France, 22–24 janvier 2003; Revue des Sciences et Technologies de l’Information, RSTI, série Revue d’Intelligence Artificielle- Extraction des Connaissances et Apprentissage (RIA-ECA); Hermès Science Publications: Lavoisier, Cachan, Paris, 2003; Volume 17(1-2-3), pp. 13–23. ISBN 2-7462-0631-5. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Bosc, N.; Folch, G.; Guiraudou, D.; Jabado-Michaloud, J.; Magris, S.; Scaviner, D.; Thouvenin, V.; et al. IMGT-ONTOLOGY for immunogenetics and immunoinformatics. Silico Biol. 2004, 4, 17–29. [Google Scholar]
- Lefranc, M.-P. IMGT-ONTOLOGY and IMGT databases, tools and Web resources for immunogenetics and immunoinformatics. Mol. Immunol. 2004, 40, 647–660. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Clément, O.; Kaas, Q.; Duprat, E.; Chastellan, P.; Coelho, I.; Combres, K.; Ginestoux, C.; Giudicelli, V.; Chaume, D.; et al. IMGT-Choreography for Immunogenetics and Immunoinformatics. Silico Biol. 2005, 5, 45–60. [Google Scholar]
- Duroux, P.; Kaas, Q.; Brochet, X.; Lane, J.; Ginestoux, C.; Lefranc, M.-P.; Giudicelli, V. IMGT-Kaleidoscope, the formal IMGT-ONTOLOGY paradigm. Biochimie 2008, 90, 570–583. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, IMGT® databases, tools and Web resources for Immunoinformatics. In Immunoinformatics; Schoenbach, C., Ranganathan, S., Brusic, V., Eds.; Immunomics Reviews, Series of Springer Science and Business Media LLC; Springer: New York, NY, USA, 2008; Chapter 1; Volume 1, pp. 1–18. ISBN 978-0-387-72967-1. [Google Scholar]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY 2012. Frontiers in Bioinformatics and Computational Biology. Front. Genet. 2012, 3, 79. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013; pp. 964–972. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY IDENTIFICATION axiom to IMGT standardized keywords: For immunoglobulins (IG), T cell receptors (TR), and conventional genes. Cold Spring Harb. Protoc. 2011, 6, 604–613. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, IDENTIFICATION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Complementarity Determining Region (CDR-IMGT). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Framework Region (FR-IMGT). In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY DESCRIPTION axiom to IMGT standardized labels: For immunoglobulin (IG) and T cell receptor (TR) sequences and structures. Cold Spring Harb. Protoc. 2011, 6, 614–626. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, DESCRIPTION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin heavy (IGH) genes. Exp. Clin. Immunogenet. 2001, 18, 100–116. [Google Scholar] [CrossRef]
- Lefranc, M.-P. From IMGT-ONTOLOGY CLASSIFICATION axiom to IMGT standardized gene and allele nomenclature: For immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 627–632. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, CLASSIFICATION Axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Unique database numbering system for immunogenetic analysis. Immunol. Today 1997, 18, 509. [Google Scholar] [CrossRef]
- Lefranc, M.-P. The IMGT unique numbering for Immunoglobulins, T cell receptors and Ig-like domains. Immunologist 1999, 7, 132–136. [Google Scholar]
- Lefranc, M.-P.; Pommié, C.; Ruiz, M.; Giudicelli, V.; Foulquier, E.; Truong, L.; Thouvenin-Contet, V.; Lefranc, G. IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains. Dev. Comp. Immunol. 2003, 27, 55–77. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Pommié, C.; Kaas, Q.; Duprat, E.; Bosc, N.; Guiraudou, D.; Jean, C.; Ruiz, M.; Da Piedade, I.; Rouard, M.; et al. IMGT unique numbering for immunoglobulin and T cell receptor constant domains and Ig superfamily C-like domains. Dev. Comp. Immunol. 2005, 29, 185–203. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Duprat, E.; Kaas, Q.; Tranne, M.; Thiriot, A.; Lefranc, G. IMGT unique numbering for MHC groove G-DOMAIN and MHC superfamily (MhcSF) G-LIKE-DOMAIN. Dev. Comp. Immunol. 2005, 29, 917–938. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT unique numbering for the Variable (V), Constant (C), and Groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 633–642. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Immunoinformatics of the V, C, and G domains: IMGT® definitive system for IG, TR and IgSF, MH, and MhSF. In Immunoinformatics: From Biology to Informatics, 2nd ed.; De, R.K., Tomar, N., Eds.; Methods in Molecular Biology, Series of Humana Press; Springer: New York, NY, USA, 2014; Volume 1184, pp. 59–107. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT unique numbering. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013; pp. 952–959. [Google Scholar] [CrossRef]
- Ruiz, M.; Lefranc, M.-P. IMGT gene identification and Colliers de Perles of human immunoglobulins with known 3D structures. Immunogenetics 2002, 53, 857–883. [Google Scholar]
- Kaas, Q.; Lefranc, M.-P. IMGT Colliers de Perles: Standardized sequence-structure representations of the IgSF and MhcSF superfamily domains. Curr. Bioinform. 2007, 2, 21–30. [Google Scholar] [CrossRef]
- Kaas, Q.; Ehrenmann, F.; Lefranc, M.-P. IG, TR and IgSf, MHC and MhcSF: What do we learn from the IMGT Colliers de Perles? Brief. Funct. Genomic. Proteomic 2007, 6, 253–264. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT Collier de Perles for the Variable (V), Constant (C), and Groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 643–651. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. IMGT/Collier de Perles: IMGT Standardized representation of domains (IG, TR, and IgSF Variable and Constant domains, MH and MhSF Groove domains). Cold Spring Harb. Protoc. 2011, 6, 726–736. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT Collier de Perles. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013; pp. 944–952. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT-ONTOLOGY, NUMEROTATION axiom. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Giudicelli, V.; Busin, C.; Malik, A.; Mougenot, I.; Déhais, P.; Chaume, D. LIGM-DB/IMGT: An integrated database of Ig and TcR, part of the Immunogenetics database. Ann. N. Y. Acad. Sci. 1995, 764, 47–49. [Google Scholar] [CrossRef]
- Giudicelli, V.; Duroux, P.; Ginestoux, C.; Folch, G.; Jabado-Michaloud, J.; Chaume, D.; Lefranc, M.-P. IMGT/LIGM-DB, the IMGT® comprehensive database of immunoglobulin and T cell receptor nucleotide sequences. Nucleic Acids Res. 2006, 34, D781–D784. [Google Scholar] [CrossRef]
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/GENE-DB: A comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 2005, 33, D256–D261. [Google Scholar] [CrossRef]
- Kaas, Q.; Ruiz, M.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/StructuralQuery, a database and a tool for immunoglobulin, T cell receptor and MHC structural data. Nucleic Acids Res. 2004, 32, D208–D210. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Kaas, Q.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/DomainGapAlign: A database and a tool for immunoglobulins or antibodies, T cell receptors, MHC, IgSF and MhcSF. Nucleic Acids Res. 2010, 38, D301–D307. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/3Dstructure-DB: Querying the IMGT Database for 3D Structures in Immunology and Immunoinformatics (IG or Antibodies, TR, MH, RPI, and FPIA). Cold Spring Harb. Protoc. 2011, 6, 750–761. [Google Scholar] [CrossRef]
- Poiron, C.; Wu, Y.; Ginestoux, C.; Ehrenmann, F.; Duroux, P.; Lefranc, M.-P. IMGT/mAb-DB: The IMGT® database for therapeutic monoclonal antibodies. In Proceedings of the 11èmes Journées Ouvertes de Biologie. Informatique et Mathématiques (JOBIM), Montpellier, France, 7–9 September 2010. [Google Scholar]
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/V-QUEST, an integrated software for immunoglobulin and T cell receptor V-J and V-D-J rearrangement analysis. Nucleic Acids Res. 2004, 32, W435–W440. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. Interactive IMGT on-line tools for the analysis of immunoglobulin and T cell receptor repertoires. In New Research on Immunology; Veskler, B.A., Ed.; Nova Science Publishers Inc.: New York, NY, USA, 2005; pp. 77–105. [Google Scholar]
- Brochet, X.; Lefranc, M.-P.; Giudicelli, V. IMGT/V-QUEST: The highly customized and integrated system for IG and TR standardized V-J and V-D-J sequence analysis. Nucleic Acids Res. 2008, 36, W503–W508. [Google Scholar] [CrossRef]
- Giudicelli, V.; Lefranc, M.-P. IMGT® standardized analysis of immunoglobulin rearranged sequences. In Immunoglobulin Gene Analysis in Chronic Lymphocytic Leukemia; Ghia, P., Rosenquist, R., Davi, F., Eds.; Wolters Kluwer Health Italy Ltd.: Milan, Italy, 2008; Chapter 2; pp. 33–52. [Google Scholar]
- Giudicelli, V.; Brochet, X.; Lefranc, M.-P. IMGT/V-QUEST: IMGT standardized analysis of the immunoglobulin (IG) and T cell receptor (TR) nucleotide sequences. Cold Spring Harb. Protoc. 2011, 6, 695–715. [Google Scholar] [CrossRef]
- Alamyar, E.; Duroux, P.; Lefranc, M.-P.; Giudicelli, V. IMGT® tools for the nucleotide analysis of immunoglobulin (IG) and T cell receptor (TR) V-(D)-J repertoires, polymorphisms, and IG mutations: IMGT/V-QUEST and IMGT/HighV-QUEST for NGS. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2012; Chapter 32; Volume 882, pp. 569–604. [Google Scholar] [CrossRef]
- Yousfi Monod, M.; Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/JunctionAnalysis: The first tool for the analysis of the immunoglobulin and T cell receptor complex V-J and V-D-J JUNCTIONs. Bioinformatics 2004, 20, i379–i385. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT/JunctionAnalysis: IMGT standardized analysis of the V-J and V-D-J Junctions of the rearranged immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 716–725. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Protat, C.; Lefranc, M.-P. The IMGT strategy for the automatic annotation of IG and TR cDNA sequences: IMGT/Automat. In Proceedings of the European Conference on Computational Biology (ECCB 2003), Data and Knowledge Bases, Institut National de Recherche en Informatique et en Automatique, Paris, Poster DKB_31, ECCB 2003, Paris, France, 27–30 September 2003; pp. 103–104. [Google Scholar]
- Giudicelli, V.; Chaume, D.; Jabado-Michaloud, J.; Lefranc, M.-P. Immunogenetics sequence Annotation: The strategy of IMGT based on IMGT-ONTOLOGY. Stud. Health Technol. Inf. 2005, 116, 3–8. [Google Scholar]
- Alamyar, E.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. IMGT/HighV-QUEST: A high-throughput system and web portal for the analysis of rearranged nucleotide sequences of antigen receptors—High-throughput version of IMGT/V-QUEST. In Proceedings of the 11èmes Journées Ouvertes de Biologie, Informatique et Mathématiques (JOBIM), Montpellier, France, 7–9 September 2010. [Google Scholar]
- Alamyar, E.; Giudicelli, V.; Li, S.; Duroux, P.; Lefranc, M.-P. IMGT/HighV-QUEST: The IMGT® web portal for immunoglobulin (IG) or antibody and T cell receptor (TR) analysis from NGS high throughput and deep sequencing. Immunome Res. 2012, 8, 26. [Google Scholar]
- Li, S.; Lefranc, M.-P.; Miles, J.J.; Alamyar, E.; Giudicelli, V.; Duroux, P.; Freeman, J.D.; Corbin, V.; Scheerlinck, J.-P.; Frohman, M.A.; et al. IMGT/HighV-QUEST paradigm for T cell receptor IMGT clonotype diversity and next generation repertoire immunoprofiling. Nat. Commun. 2013, 4, 2333. [Google Scholar] [CrossRef]
- Giudicelli, V.; Duroux, P.; Lavoie, A.; Aouinti, S.; Lefranc, M.-P.; Kossida, S. From IMGT-ONTOLOGY to IMGT/HighV-QUEST for NGS immunoglobulin (IG) and T cell receptor (TR) repertoires in autoimmune and infectious diseases. Autoimmun. Infect. Dis. 2015, 1. [Google Scholar] [CrossRef]
- Giudicelli, V.; Duroux, P.; Kossida, S.; Lefranc, M.-P. IG and TR single chain Fragment variable (scFv) sequence analysis: A new advanced functionality of IMGT/V-QUEST and IMGT/HighV-QUEST. BMC Immunol. 2017, 18, 35. [Google Scholar] [CrossRef]
- Aouinti, S.; Malouche, D.; Giudicelli, V.; Kossida, S.; Lefranc, M.-P. IMGT/HighV-QUEST statistical significance of IMGT clonotype (AA) diversity per gene for standardized comparisons of next generation sequencing immunoprofiles of immunoglobulins and T cell receptors. PLoS ONE 2015, 10, e0142353, Correction in 2016, 11, e0146702. [Google Scholar] [CrossRef]
- Aouinti, S.; Giudicelli, V.; Duroux, P.; Malouche, D.; Kossida, S.; Lefranc, M.-P. IMGT/StatClonotype for pairwise evaluation and visualization of NGS IG and TR IMGT clonotype (AA) diversity or expression from IMGT/HighV-QUEST. Front. Immunol. 2016, 7, 339. [Google Scholar] [CrossRef]
- Lane, J.; Duroux, P.; Lefranc, M.-P. From IMGT-ONTOLOGY to IMGT/LIGMotif: The IMGT® standardized approach for immunoglobulin and T cell receptor gene identification and description in large genomic sequences. BMC Bioinform. 2010, 11, 223. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: IMGT standardized analysis of amino acid sequences of Variable, Constant, and Groove domains (IG, TR, MH, IgSF, MhSF). Cold Spring Harb. Protoc 2011, 6, 737–749. [Google Scholar] [CrossRef] [PubMed]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: The IMGT® tool for the analysis of IG, TR, MHC, IgSF and MhcSF domain amino acid polymorphism. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2012; Chapter 33; Volume 882, pp. 605–633. [Google Scholar] [CrossRef]
- Pommié, C.; Levadoux, S.; Sabatier, R.; Lefranc, G.; Lefranc, M.-P. IMGT standardized criteria for statistical analysis of immunoglobulin V-REGION amino acid properties. J. Mol. Recognit. 2004, 17, 17–32. [Google Scholar]
- Jefferis, R.; Lefranc, M.-P. Human immunoglobulin allotypes: Possible implications for immunogenicity. MAbs 2009, 1, 332–338. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Lefranc, G. Human Gm, Km and Am allotypes and their molecular characterization: A remarkable demonstration of polymorphism. In Immunogenetics; Christiansen, F., Tait, B., Eds.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2012; Chapter 34; Volume 882, pp. 635–680. [Google Scholar] [CrossRef]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for immunoglobulins and T cell receptors report. Immunogenetics 2007, 59, 899–902. [Google Scholar] [CrossRef]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for immunoglobulins and T cell receptors report August 2007, 13th International Congress of Immunology, Rio de Janeiro, Brazil. Dev. Comp. Immunol. 2008, 32, 461–463. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody nomenclature: From IMGT-ONTOLOGY to INN definition. MAbs 2011, 3, 1–2. [Google Scholar] [CrossRef]
- World Health Organization International Nonproprietary Names (INN) Programme. INN for Biological and Biotechnological Substances (A Review) - 2019. Available online: http://www.who.int/medicines/services/inn/publication/en/. (accessed on 29 August 2020).
- Lefranc, M.-P. Antibody databases and tools: The IMGT® experience. In Therapeutic Monoclonal Antibodies: From Bench to Clinic; Chapter 4; An, Z., Ed.; John Wiley and Sons: Hoboken, NJ, USA, 2009; pp. 91–114. [Google Scholar]
- Lefranc, M.-P. Antibody databases: IMGT®, a French platform of world-wide interest. Bases de données anticorps: IMGT®, une plate-forme française d’intérêt mondial. Médecine Sci. 2009, 25, 1020–1023. (In French) [Google Scholar] [CrossRef][Green Version]
- Ehrenmann, F.; Duroux, P.; Giudicelli, V.; Lefranc, M.-P. Standardized sequence and structure analysis of antibody using IMGT®. In Antibody Engineering; Kontermann, R., Dübel, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Chapter 2; Volume 2, pp. 11–31. [Google Scholar]
- Lefranc, M.-P.; Ehrenmann, F.; Ginestoux, C.; Duroux, P.; Giudicelli, V. Use of IMGT® databases and tools for antibody engineering and humanization. In Antibody Engineering; Chames, P., Ed.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2012; Chapter 1; Volume 907, pp. 3–37. [Google Scholar]
- Lefranc, M.-P. Immunoglobulins: 25 years of Immunoinformatics and IMGT-ONTOLOGY. Biomolecules 2014, 4, 1102–1139. [Google Scholar] [CrossRef]
- Lefranc, M.-P. IMGT® immunoglobulin repertoire analysis and antibody humanization. In Molecular Biology of B Cells, 2nd ed.; Alt, F.W., Honjo, T., Radbruch, A., Reth, M., Eds.; Academic Press, Elsevier Ltd.: London, UK, 2015; Chapter 26; pp. 481–514. ISBN 978-0-12-397933-9. [Google Scholar] [CrossRef]
- Lefranc, M.-P. How to use IMGT® for therapeutic antibody engineering. In Handbook of Therapeutic Antibodies, 2nd ed.; Dübel, S., Reichert, J., Eds.; Defining the Right Antibody Composition; Wiley-Blackwell: Hoboken, NJ, USA, 2014; Chapter 10; Volume 1, pp. 229–264. ISBN 978-3-527-68244-7. [Google Scholar]
- Alamyar, A.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. Antibody V and C domain sequence, structure and interaction analysis with special reference to IMGT®. In Monoclonal Antibodies: Methods and Protocols, 2nd ed.; Ossipow, V., Fischer, N., Eds.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2014; Volume 1131, pp. 337–381. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody informatics: IMGT®, the international ImMunoGeneTics information system®, the international ImMunoGeneTics information system®. Microbiol. Spectr. 2014, 2. [Google Scholar] [CrossRef]
- Shirai, H.; Prades, C.; Vita, R.; Marcatili, P.; Popovic, B.; Xu, J.; Overington, J.P.; Hirayama, K.; Soga, S.; Tsunoyama, K.; et al. Antibody informatics for drug discovery. Biochim. Biophys. Acta 2014, 1844, 2002–2015. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Antibody Informatics: IMGT, the International ImMunoGeneTics Information System. In Antibodies for Infectious Diseases; Crowe, J., Boraschi, D., Rappuoli, R., Eds.; ASM Press: Washington, DC, USA, 2015; pp. 363–379. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Ehrenmann, F.; Kossida, S.; Giudicelli, V.; Duroux, P. Use of IMGT® databases and tools for antibody engineering and humanization. In Antibody Engineering; Nevoltris, D., Chames, P., Eds.; Methods in Molecular Biology Series of Humana Press; Springer: New York, NY, USA, 2018; Volume 1827, pp. 35–69. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. IMGT® and 30 years of Immunoinformatics Insight in Antibody V and C domain structure and function. Antibodies 2019, 8, 29. [Google Scholar] [CrossRef]
- Porter, R.R. The hydrolysis of rabbit Y-globulin and antibodies with crystalline papain. Biochem. J. 1959, 73, 119–126. [Google Scholar] [CrossRef] [PubMed]
- Reth, M. Antigen receptor tail clue. Nature 1989, 338, 383–384. [Google Scholar] [CrossRef] [PubMed]
- Strosberg, D. Immunologie; Bach, J.F., Ed.; Flammarion Médecine-Sciences: Paris, France, 1986. [Google Scholar]
- Burton, D.R. Molecular Genetics of Immunoglobulin; Calabi, F., Neuberger, M.S., Eds.; Elsevier: Oxford, UK, 1987; pp. 1–50. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. Molecular genetics of immunoglobulin allotypes. In The Human IgG Subclasses: Molecular Analysis of Structure, Function and Regulation; Shakib, F., Ed.; Pergamon Press: Oxford, UK, 1990; pp. 43–78. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. Les immunoglobulines humaines. In l’Hématologie de Bernard Dreyfus; Breton-Gorius, J., Reyes, F., Rochant, H., Rosa, J., Vernant, J.P., Eds.; Flammarion Médecine-Sciences: Paris, France, 1992; pp. 197–254. [Google Scholar]
- Hamilton, R.G. Handbook of Human Immunology; Leffell, M.S., Donnenberg, A.D., Rose, N.R., Eds.; CRC Press: New York, NY, USA, 1997; pp. 65–109. [Google Scholar]
- Janeway, C.A.; Travers, P. Immunobiologie; De Boeck and Larder: Paris, France, 1997; pp. 111–151. [Google Scholar]
- Lefranc, G.; Loiselet, J.; Rivat, L.; Ropartz, C. Gm, Km and ISf allotypes in the Lebanese population. Acta Anthropog. 1976, 1, 34–45. [Google Scholar]
- Lefranc, G.; Rivat, L.; Serre, J.L.; Lalouel, J.M.; Pison, G.; Loiselet, J.; Ropartz, C.; De Lange, G.; Van Loghem, E. Common and uncommon immunoglobulin haplotypes among Lebanese communities. Hum. Genet. 1978, 41, 197–209. [Google Scholar] [CrossRef]
- Lefranc, G.; Rivat, L.; Rivat, C.; Loiselet, J.; Ropartz, C. Evidence for “deleted” or “silent” genes homozygous at the locus coding for the constant region of the gamma3 chain. Am. J. Hum. Genet. 1976, 28, 51–61. [Google Scholar]
- Geha, R.S.; Malakian, A.; Lefranc, G.; Chayban, D.; Serre, J.L. Immunologic reconstitution in severe combined immunodeficiency following transplantation with parental bone marrow. Pediatrics 1976, 58, 451–455. [Google Scholar]
- Lefranc, G.; Chaabani, H.; Van Loghem, E.; Lefranc, M.-P.; De Lange, G.; Helal, A.N. Simultaneous absence of the human IgG1, IgG2, IgG4 and IgA1 subclasses: Immunological and immunogenetical considerations. Eur. J. Immunol. 1983, 13, 240–244. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G.; Rabbitts, T.H. Inherited deletion of immunoglobulin heavy chain constant region genes in normal human individuals. Nature 1982, 300, 760–762. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G.; de Lange, G.; Out, T.A.; van den Broek, P.J.; van Nieuwkoop, J.; Radl, J.; Helal, A.N.; Chaabani, H.; van Loghem, E.; et al. Instability of the human immunoglobulin heavy chain constant region locus indicated by different inherited chromosomal deletions. Mol. Biol. Med. 1983, 1, 207–217. [Google Scholar]
- Wiebe, V.; Helal, A.; Lefranc, M.-P.; Lefranc, G. Molecular analysis of the T17 immunoglobulin CH multigene deletion (del A1-GP-G2-G4-E). Hum. Genet. 1994, 93, 520–528. [Google Scholar] [CrossRef]
- Osipova, L.P.; Posukh, O.L.; Wiebe, V.P.; Miyazaki, T.; Matsumoto, H.; Lefranc, G.; Lefranc, M.-P. BamHI-SacI RFLP and Gm analysis of the immunoglobulin IGHG genes in the Northern Selkups (West Siberia): New haplotypes with deletion, duplication and triplication. Hum. Genet. 1999, 105, 530–541. [Google Scholar] [CrossRef] [PubMed]
- Kabat, E.A.; Wu, T.T.; Reid-Miller, M.; Perry, H.; Gottesman, K. Sequences of Proteins of Immunological Interest, 4th ed.; U.S. Dept. of Health and Human Services, Public Health Service, National Institutes of Health: Washington, DC, USA, 1987; pp. 165–492.
- Huck, S.; Fort, P.; Crawford, D.H.; Lefranc, M.-P.; Lefranc, G. Sequence of a human immunoglobulin gamma 3 heavy chain constant region gene: Comparison with the other human Cgamma genes. Nucleic Acids Res. 1986, 14, 1779–1789. [Google Scholar] [CrossRef] [PubMed]
- Huck, S.; Lefranc, G.; Lefranc, M.-P. A human immunoglobulin IGHG3 allele (Gmb0, b1, c3, c5, u) with an IGHG4 converted region and three hinge exons. Immunogenetics 1989, 30, 250–257. [Google Scholar] [CrossRef] [PubMed]
- Jefferis, R.; Lund, J.; Pound, J.D. IgG-Fc-mediated effector functions: Molecular definition of interaction sites for effector ligands and the role of glycosylation. Immunol. Rev. 1998, 163, 59–76. [Google Scholar] [CrossRef]
- Brack, C.; Hirama, M.; Lenhard-Schuller, R.; Tonegawa, S. A complete immunoglobulin gene is created by somatic recombination. Cell 1978, 15, 1–14. [Google Scholar] [CrossRef]
- Tonegawa, S. Somatic generation of antibody diversity. Nature 1983, 302, 575–581. [Google Scholar] [CrossRef]
- Weigert, M.; Perry, R.; Kelley, D.; Hunkapiller, T.; Schilling, J.; Hood, J.L. The joining of V and J gene segments creates antibody diversity. Nature 1980, 283, 497–499. [Google Scholar] [CrossRef]
- Sakano, H.; Hüppi, K.; Heinrich, G.; Tonegawa, S. Sequences at the somatic recombination sites of immunoglobulin light-chain genes. Nature 1979, 280, 288–294. [Google Scholar] [CrossRef]
- Schatz, D.G.; Oettinger, M.A.; Baltimore, D. The V(D)J recombination activating gene, RAG-1. Cell 1989, 59, 1035–1048. [Google Scholar] [CrossRef]
- Oettinger, M.A.; Schatz, D.G.; Gorka, C.; Baltimore, D. RAG-1 and RAG-2, adjacent genes that synergistically activate V(D)J recombination. Science 1990, 248, 1517–1523. [Google Scholar] [CrossRef] [PubMed]
- Early, P.; Huang, H.; Davis, M.; Calame, K.; Hood, L. An immunoglobulin heavy chain variable region gene is generated from three segments of DNA: VH, D and JH. Cell 1980, 19, 981–992. [Google Scholar] [CrossRef]
- Max, E.E.; Seidman, J.G.; Leder, P. Sequences of five potential recombination sites encoded close to an immunoglobulin kappa constant region gene. Proc. Natl. Acad. Sci. USA 1979, 76, 3450–3454. [Google Scholar] [CrossRef] [PubMed]
- Alt, F.W.; Baltimore, D. Joining of immunoglobulin heavy chain gene segments: Implications from a chromosome with evidence of three D-JH fusions. Proc. Natl. Acad. Sci. USA 1982, 79, 4118–4122. [Google Scholar] [CrossRef]
- Landau, N.R.; St John, T.P.; Weissman, I.L.; Wolf, S.C.; Silverstone, A.E.; Baltimore, D. Cloning of terminal transferase cDNA by antibody screening. Proc. Natl. Acad. Sci. USA 1984, 81, 5836–5840. [Google Scholar] [CrossRef]
- Lafaille, J.J.; DeCloux, A.; Bonneville, M.; Takagaki, Y.; Tonegawa, S. Junctional sequences of T cell receptor gamma delta genes: Implications for gamma delta T cell lineages and for a novel intermediate of V-(D)-J joining. Cell 1989, 59, 859–870. [Google Scholar] [CrossRef]
- Lewis, S.M. P nucleotide insertions and the resolution of hairpin DNA structures in mammalian cells. Proc. Natl. Acad. Sci. USA 1994, 91, 1332–1336. [Google Scholar] [CrossRef]
- Gearhart, P.J.; Johnson, N.D.; Douglas, R.; Hood, L. IgG antibodies to phosphorylcholine exhibit more diversity than their IgM counterparts. Nature 1981, 291, 29–34. [Google Scholar] [CrossRef]
- Petersen-Mahrt, S.K.; Harris, R.S.; Neuberger, M.S. AID mutates E. coli suggesting a DNA deamination mechanism for antibody diversification. Nature 2002, 418, 99–103. [Google Scholar] [CrossRef]
- Di Noia, J.; Neuberger, M.S. Altering the pathway of immunoglobulin hypermutation by inhibiting uracil-DNA glycosylase. Nature 2002, 419, 43–48. [Google Scholar] [CrossRef]
- Teng, G.; Papavasiliou, F.N. Immunoglobulin somatic hypermutation. Annu. Rev. Genet. 2007, 41, 107–120. [Google Scholar] [CrossRef]
- Di Noia, J.M.; Neuberger, M.S. Molecular mechanisms of antibody somatic hypermutation. Annu. Rev. Biochem. 2007, 76, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Peled, J.U.; Kuang, F.L.; Iglesias-Ussel, M.D.; Roa, S.; Kalis, S.L.; Goodman, M.F.; Scharff, M.D. The biochemistry of somatic hypermutation. Annu. Rev. Immunol. 2008, 26, 481–511. [Google Scholar] [CrossRef] [PubMed]
- Knapp, M.R.; Liu, C.P.; Newell, N.; Ward, R.B.; Tucker, P.W.; Strober, S.; Blattner, F. Simultaneous expression of immunoglobulin mu and delta heavy chains by a cloned B-cell lymphoma: A single copy of the VH gene is shared by two adjacent CH genes. Proc. Natl. Acad. Sci. USA 1982, 79, 2996–3000. [Google Scholar] [CrossRef] [PubMed]
- Maki, R.; Roeder, W.; Traunecker, A.; Sidman, C.; Wabl, M.; Raschke, W.; Tonegawa, S. The role of DNA rearrangement and alternative RNA processing in the expression of immunoglobulin delta genes. Cell 1981, 24, 353–365. [Google Scholar] [CrossRef]
- Kerr, W.G.; Hendershot, L.M.; Burrows, P.D. Regulation of IgM and IgD expression in human B-lineage cells. J. Immunol. 1991, 146, 3314–3321. [Google Scholar]
- Honjo, T.; Kataoka, T. Organization of immunoglobulin heavy chain genes and allelic deletion model. Proc. Natl. Acad. Sci. USA 1978, 75, 2140–2144. [Google Scholar] [CrossRef]
- Rabbitts, T.H.; Forster, A.; Dunnick, W.; Bentley, D.L. The role of gene deletion in the immunoglobulin heavy chain switch. Nature 1980, 283, 351–356. [Google Scholar] [CrossRef]
- Cory, S.; Adams, J.M. Deletions are associated with somatic rearrangement of immunoglobulin heavy chain genes. Cell 1980, 19, 37–51. [Google Scholar] [CrossRef]
- Iwasato, T.; Shimizu, A.; Honjo, T.; Yamagishi, H. Circular DNA is excised by immunoglobulin class switch recombination. Cell 1990, 62, 143–149. [Google Scholar] [CrossRef]
- Matsuoka, M.; Yoshida, K.; Maeda, T.; Usuda, S.; Sakano, H. Switch circular DNA formed in cytokine-treated mouse splenocytes: Evidence for intramolecular DNA deletion in immunoglobulin class switching. Cell 1990, 62, 135–142. [Google Scholar] [CrossRef]
- Chaudhuri, J.; Basu, U.; Zarrin, A.; Yan, C.; Franco, S.; Perlot, T.; Vuong, B.; Wang, J.; Phan, R.T.; Datta, A.; et al. Evolution of the immunoglobulin heavy chain class switch recombination mechanism. Adv. Immunol. 2007, 94, 157–214. [Google Scholar] [CrossRef] [PubMed]
- Stavnezer, J.; Guikema, J.E.J.; Schrader, C.E. Mechanism and regulation of class switch recombination. Annu. Rev. Immunol. 2008, 26, 261–292. [Google Scholar] [CrossRef] [PubMed]
- Kluin, P.M.; Kayano, H.; Zani, V.J.; Kluin-Nelemans, H.C.; Tucker, P.W.; Satterwhite, E.; Dyer, M.J. IgD class switching: Identification of a novel recombination site in neoplastic and normal B cells. Eur. J. Immunol. 1995, 25, 3504–3508. [Google Scholar] [CrossRef]
- Arpin, C.; de Bouteiller, O.; Razanajaona, D.; Fugier-Vivier, I.; Briere, F.; Banchereau, J.; Lebecque, S.; Liu, Y.J. The normal counterpart of IgD myeloma cells in germinal center displays extensively mutated IgVH gene, Cmu-Cdelta switch, and lambda light chain expression. J. Exp. Med. 1998, 187, 1169–1178. [Google Scholar] [CrossRef]
- Liu, Y.J.; de Bouteiller, O.; Arpin, C.; Briere, F.; Galibert, L.; Ho, S.; Martinez-Valdez, H.; Banchereau, J.; Lebecque, S. Normal human IgD+IgM- germinal center B cells can express up to 80 mutations in the variable region of their IgD transcripts. Immunity 1996, 4, 603–613. [Google Scholar] [CrossRef]
- Kehry, M.; Ewald, S.; Douglas, R.; Sibley, C.; Raschke, W.; Fambrough, D.; Hood, L. The immunoglobulin mu chains of membrane-bound and secreted IgM molecules differ in their C-terminal segments. Cell 1980, 21, 393–406. [Google Scholar] [CrossRef]
- Rabbitts, T.H.; Forster, A.; Milstein, C.P. Human immunoglobulin heavy chain genes: Evolutionary comparisons of C mu, C delta and C gamma genes and associated switch sequences. Nucleic Acids Res. 1981, 9, 4509–4524. [Google Scholar] [CrossRef][Green Version]
- Nelson, K.J.; Haimovich, J.; Perry, R.P. Characterization of productive and sterile transcripts from the immunoglobulin heavy-chain locus: Processing of muM and muS mRNA. Mol. Cell Biol. 1983, 3, 1317–1332. [Google Scholar] [CrossRef]
- Blattner, F.R.; Tucker, P.W. The molecular biology of immunoglobulin D. Nature 1984, 307, 417–422. [Google Scholar] [CrossRef]
- Hollis, G.F.; Evans, R.J.; Stafford-Hollis, J.M.; Korsmeyer, S.J.; McKearn, J.P. Immunoglobulin lambda light-chain-related genes 14.1 and 16.1 are expressed in pre-B cells and may encode the human immunoglobulin omega light-chain protein. Proc. Natl. Acad. Sci. USA 1989, 86, 5552–5556. [Google Scholar] [CrossRef] [PubMed]
- Schiff, C.; Bensmana, M.; Guglielmi, P.; Milili, M.; Lefranc, M.-P.; Fougereau, M. The immunoglobulin lambda-like gene cluster (14.1, 16.1 and F lambda 1) contains gene(s) selectively expressed in pre-B cells and is the human counterpart of the mouse lambda 5 gene. Int. Immunol. 1990, 2, 201–207. [Google Scholar] [CrossRef] [PubMed]
- Hieter, P.A.; Korsmeyer, S.J.; Waldmann, T.A.; Leder, P. Human immunoglobulin kappa light-chain genes are deleted or rearranged in lambda-producing B cells. Nature 1981, 290, 368–372. [Google Scholar] [CrossRef]
- Korsmeyer, S.J.; Hieter, P.A.; Ravetch, J.V.; Poplack, D.G.; Waldmann, T.A.; Leder, P. Developmental hierarchy of immunoglobulin gene rearrangements in human leukemic pre-B-cells. Proc. Natl. Acad. Sci. USA 1981, 78, 7096–7100. [Google Scholar] [CrossRef]
- Mather, E.L.; Perry, R.P. Transcriptional regulation of immunoglobulin V genes. Nucleic Acids Res. 1981, 9, 6855–6867. [Google Scholar] [CrossRef][Green Version]
- Bentley, D.L.; Farrell, P.J.; Rabbitts, T.H. Unrearranged immunoglobulin variable region genes have a functional promoter. Nucleic Acids Res. 1982, 10, 1841–1856. [Google Scholar] [CrossRef] [PubMed]
- Kemp, D.J.; Harris, A.W.; Cory, S.; Adams, J.M. Expression of the immunoglobulin C mu gene in mouse T and B lymphoid and myeloid cell lines. Proc. Natl. Acad. Sci. USA 1980, 77, 2876–2880. [Google Scholar] [CrossRef] [PubMed]
- Banerji, J.; Olson, L.; Schaffner, W. A lymphocyte-specific cellular enhancer is located downstream of the joining region in immunoglobulin heavy chain genes. Cell 1983, 33, 729–740. [Google Scholar] [CrossRef]
- Gillies, S.D.; Morrison, S.L.; Oi, V.T.; Tonegawa, S. A tissue-specific transcription enhancer element is located in the major intron of a rearranged immunoglobulin heavy chain gene. Cell 1983, 33, 717–728. [Google Scholar] [CrossRef]
- Mercola, M.; Wang, X.F.; Olsen, J.; Calame, K. Transcriptional enhancer elements in the mouse immunoglobulin heavy chain locus. Science 1983, 221, 663–665. [Google Scholar] [CrossRef]
- Neuberger, M.S. Expression and regulation of immunoglobulin heavy chain gene transfected into lymphoid cells. EMBO J. 1983, 2, 1373–1378. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, G.; Lefranc, M.-P. Regulation of the immunoglobulin gene transcription. Biochimie 1990, 72, 7–17. [Google Scholar] [CrossRef]
- Hayday, A.C.; Gillies, S.D.; Saito, H.; Wood, C.; Wiman, K.; Hayward, W.S.; Tonegawa, S. Activation of a translocated human c-myc gene by an enhancer in the immunoglobulin heavy-chain locus. Nature 1984, 307, 334–340. [Google Scholar] [CrossRef] [PubMed]
- Emorine, L.; Kuehl, M.; Weir, L.; Leder, P. A conserved sequence in the immunoglobulin J kappa-C kappa intron: Possible enhancer element. Nature 1983, 304, 447–449. [Google Scholar] [CrossRef] [PubMed]
- Gimble, J.M.; Max, E.E. Human immunoglobulin kappa gene enhancer: Chromatin structure analysis at high resolution. Mol. Cell Biol. 1987, 7, 15–25. [Google Scholar] [CrossRef]
- Judde, J.G.; Max, E.E. Characterization of the human immunoglobulin kappa gene 3′ enhancer: Functional importance of three motifs that demonstrate B-cell-specific in vivo footprints. Mol. Cell Biol. 1992, 12, 5206–5216. [Google Scholar] [CrossRef]
- Mills, F.C.; Harindranath, N.; Mitchell, M.; Max, E.E. Enhancer complexes located downstream of both human immunoglobulin Calpha genes. J. Exp. Med. 1997, 186, 845–858. [Google Scholar] [CrossRef]
- Flanagan, J.G.; Rabbitts, T.H. Arrangement of human immunoglobulin heavy chain constant region genes implies evolutionary duplication of a segment containing gamma, epsilon and alpha genes. Nature 1982, 300, 709–713. [Google Scholar] [CrossRef]
- Rabbitts, T.H.; Flanagan, J.G.; Lefranc, M.-P. Flexibility and change within the human immunoglobulin gene locus. In Genetic Rearrangement. Proceedings of the Fifth John Innes Symposium “Biological Consequences of DNA Structure and Genome Arrangement”; Chater, K.F., Cullis, C.A., Hopwood, D.A., Johnston, A.W.B., Woolhouse, H.W., Eds.; Croom Helm: London, UK, 1983; pp. 143–154. [Google Scholar]
- Keyeux, G.; Lefranc, G.; Lefranc, M.-P. A multigene deletion in the human IGH constant region locus involves highly homologous hot spots of recombination. Genomics 1989, 5, 431–441. [Google Scholar] [CrossRef]
- Blomberg, B.B.; Rudin, C.M.; Storb, U. Identification and localization of an enhancer for the human lambda L chain Ig gene complex. J. Immunol. 1991, 147, 2354–2358. [Google Scholar]
- Asenbauer, H.; Combriato, G.; Klobeck, H.G. The immunoglobulin lambda light chain enhancer consists of three modules which synergize in activation of transcription. Eur. J. Immunol. 1999, 29, 713–724. [Google Scholar] [CrossRef]
- Koshland, M.E. The coming of age of the immunoglobulin J chain. Annu. Rev. Immunol. 1985, 3, 425–453. [Google Scholar] [CrossRef] [PubMed]
- Perkins, S.J.; Nealis, A.S.; Sutton, B.J.; Feinstein, A. Solution structure of human Immunoglobulin, M. J. Mol. Biol. 1991, 221, 1345–1366. [Google Scholar] [CrossRef]
- Gessner, J.E.; Heiken, H.; Tamm, A.; Schmidt, R.E. The IgG Fc receptor family. Ann. Hematol. 1998, 76, 231–248. [Google Scholar] [CrossRef] [PubMed]
- Deisenhofer, J. Crystallographic refinement and atomic models of a human Fc fragment and its complex with fragment B of protein A from Staphylococcus aureus at 2.9- and 2.8-A resolution. Biochemistry 1981, 20, 2361–2370. [Google Scholar] [CrossRef]
- Sauer-Eriksson, A.E.; Kleywegt, G.J.; Uhlén, M.; Jones, T.A. Crystal structure of the C2 fragment of streptococcal protein G in complex with the Fc domain of human IgG. Structure 1995, 3, 265–278. [Google Scholar] [CrossRef]
- Burmeister, W.P.; Huber, A.H.; Bjorkman, P.J. Crystal structure of the complex of rat neonatal Fc receptor with Fc. Nature 1994, 372, 379–383. [Google Scholar] [CrossRef]
- Sondermann, P.; Huber, R.; Oosthuizen, V.; Jacob, U. The 3.2-A crystal structure of the human IgG1 Fc fragment-Fc gammaRIII complex. Nature 2000, 406, 267–273. [Google Scholar] [CrossRef]
- Halpern, M.S.; Koshland, M.E. Novel subunit in secretory IgA. Nature 1970, 228, 1276–1278. [Google Scholar] [CrossRef]
- Bennich, H.H.; Ishizaka, K.; Johansson, S.G.O.; Rowe, D.S.; Stanworth, D.R.; Terry, W.D. Immunoglobulin E, a new class of human immunoglobulin. World Health Organ. 1968, 38, 151–152. [Google Scholar] [CrossRef]
- Ishizaka, K.; Ishizaka, T.; Hornbrook, M.M. Physicochemical properties of reaginic antibody. V. Correlation of reaginic activity with E globulin antibody. J. Immunol. 1966, 97, 840–853. [Google Scholar] [PubMed]
- Platts-Mills, T.A.; Heymann, P.W.; Commins, S.P.; Woodfolk, J.A. The discovery of IgE 50 years later. Ann. Allergy Asthma Immunol. 2016, 116, 179–182. [Google Scholar] [CrossRef] [PubMed]
- Fitzsimmons, C.M.; Falcone, F.H.; Dunne, D.W. Helminth Allergens, Parasite-Specific IgE, and Its Protective Role in Human Immunity. Front. Immunol. 2014, 5, 61. [Google Scholar] [CrossRef] [PubMed]
- Sutton, B.J.; Davies, A.M.; Bax, H.J.; Karagiannis, S.N. IgE antibodies: From structure to function and clinical translation. Antibodies 2019, 8, 19. [Google Scholar] [CrossRef]
- Sutton, B.J.; Davies, A.M. Structure and dynamics of IgE-receptor interactions: Fc epsilonRI and CD23/Fc epsilonRII. Immunol. Rev. 2015, 268, 222–235. [Google Scholar] [CrossRef]
- Kraft, S.; Kinet, J.-P. New developments in Fc epsilonRI regulation, function and inhibition. Nat. Rev. Immunol. 2007, 7, 365–378. [Google Scholar] [CrossRef]
- Untersmayr, E.; Bises, G.; Starkl, P.; Bevins, C.L.; Scheiner, O.; Boltz-Nitulescu, G.; Wrba, F.; Jensen-Jarolim, E. The high affinity IgE receptor Fc epsilonRI is expressed by human intestinal epithelial cells. PLoS ONE 2010, 5, e9023. [Google Scholar] [CrossRef]
- Garman, S.C.; Wurzburg, B.A.; Tarchevskaya, S.S.; Kinet, J.P.; Jardetzky, T.S. Structure of the Fc fragment of human IgE bound to its high-affinity receptor Fc epsilonRI alpha. Nature 2000, 406, 259–666. [Google Scholar] [CrossRef]
- Wan, T.; Beavil, R.L.; Fabiane, S.M.; Beavil, A.J.; Sohi, M.K.; Keown, M.; Young, R.J.; Henry, A.J.; Owens, R.J.; Gould, H.J.; et al. The crystal structure of IgE Fc reveals an asymmetrically bent conformation. Nat. Immunol. 2002, 3, 681–686. [Google Scholar] [CrossRef]
- Davies, A.M.; Allan, E.G.; Keeble, A.H.; Delgado, J.; Cossins, B.P.; Mitropoulou, A.N.; Pang, M.O.Y.; Ceska, T.; Beavil, A.J.; Craggs, G.; et al. Allosteric mechanism of action of the therapeutic anti-IgE antibody omalizumab. J. Biol. Chem. 2017, 292, 9975–9987. [Google Scholar] [CrossRef]
- Drinkwater, N.; Cossins, B.P.; Keeble, A.H.; Wright, M.; Cain, K.; Hailu, H.; Oxbrow, A.; Delgado, J.; Shuttleworth, L.K.; Kao, M.W.; et al. Human immunoglobulin E flexes between acutely bent and extended conformations. Nat. Struct. Mol. Biol. 2014, 21, 397–404. [Google Scholar] [CrossRef]
- Chen, J.-B.; Ramadani, F.; Pang, M.O.Y.; Beavil, R.L.; Holdom, M.D.; Mitropoulou, A.N.; Beavil, A.J.; Gould, H.J.; Chang, T.-W.; Sutton, B.J.; et al. Structural basis for selective inhibition of immunoglobulin E-receptor interactions by an anti-IgE antibody. Sci. Rep. 2018, 8, 11548. [Google Scholar] [CrossRef] [PubMed]
- Yukawa, K.; Kikutani, H.; Owaki, H.; Yamasaki, K.; Yokota, A.; Nakamura, H.; Barsumian, E.L.; Hardy, R.R.; Suemura, M.; Kishimoto, T. A B cell-specific differentiation antigen, CD23, is a receptor for IgE (Fc epsilon R) on lymphocytes. J. Immunol. 1987, 138, 2576–2580. [Google Scholar] [PubMed]
- Bonnefoy, J.Y.; Aubry, J.P.; Peronne, C.; Wijdenes, J.; Banchereau, J. Production and characterization of a monoclonal antibody specific for the human lymphocyte low affinity receptor for IgE: CD 23 is a low affinity receptor for IgE. J. Immunol. 1987, 138, 2970–2978. [Google Scholar] [PubMed]
- Conrad, D.H.; Ford, J.W.; Sturgill, J.L.; Gibb, D.R. CD23: An overlooked regulator of allergic disease. Curr. Allergy Asthma Rep. 2007, 7, 331–337. [Google Scholar] [CrossRef]
- Palaniyandi, S.; Liu, X.; Periasamy, S.; Ma, A.; Tang, J.; Jenkins, M.; Tuo, W.; Song, W.; Keegan, A.D.; Conrad, D.H.; et al. Inhibition of CD23-mediated IgE transcytosis suppresses the initiation and development of allergic airway inflammation. Mucosal Immunol. 2015, 8, 1262–1274. [Google Scholar] [CrossRef]
- Cooper, A.M.; Hobson, P.S.; Jutton, M.R.; Kao, M.W.; Drung, B.; Schmidt, B.; Fear, D.J.; Beavil, A.J.; McDonnell, J.M.; Sutton, B.J.; et al. Soluble CD23 controls IgE synthesis and homeostasis in human B cells. J. Immunol. 2012, 188, 3199–3207. [Google Scholar] [CrossRef]
- Dhaliwal, B.; Yuan, D.; Pang, M.O.; Henry, A.J.; Cain, K.; Oxbrow, A.; Fabiane, S.M.; Beavil, A.J.; McDonnell, J.M.; Gould, H.J.; et al. Crystal structure of IgE bound to its B-cell receptor CD23 reveals a mechanism of reciprocal allosteric inhibition with high affinity receptor FcεRI. Proc. Natl. Acad. Sci. USA 2012, 109, 12686–12691. [Google Scholar] [CrossRef]
- Mitropoulou, A.N.; Bowen, H.; Dodev, T.; Davies, A.M.; Bax, H.; Beavil, R.L.; Beavil, A.J.; Gould, H.J.; James, L.K.; Sutton, B.J. Structure of a patient-derived antibody in complex with allergen reveals simultaneous conventional and superantigen-like recognition. Proc. Natl. Acad. Sci. USA 2018, 115, E8707–E8716. [Google Scholar] [CrossRef]
- Lefranc, M.-P. The Human T-cell rearranging gamma (TRG) genes and the gamma T-cell receptor. Biochimie 1988, 70, 901–908. [Google Scholar] [CrossRef]
- Lefranc, M.P.; Rabbitts, T.H. The human T-cell receptor gamma (TRG) genes. Trends Biochem. Sci. (TIBS) 1989, 14, 214–218. [Google Scholar] [CrossRef]
- Croce, C.M.; Shander, M.; Martinis, J.; Cicurel, L.; D’Ancona, G.G.; Dolby, T.W.; Koprowski, H. Chromosomal location of the genes for human immunoglobulin heavy chains. Proc. Natl. Acad. Sci. USA 1979, 76, 3416–3419. [Google Scholar] [CrossRef] [PubMed]
- Kirsch, I.R.; Morton, C.C.; Nakahara, K.; Leder, P. Human immunoglobulin heavy chain genes map to a region of translocations in malignant B lymphocytes. Science 1982, 216, 301–303. [Google Scholar] [CrossRef] [PubMed]
- McBride, O.W.; Battey, J.; Hollis, G.F.; Swan, D.C.; Siebenlist, U.; Leder, P. Localization of human variable and constant region immunoglobulin heavy chain genes on subtelomeric band q32 of chromosome 14. Nucleic Acids Res. 1982, 10, 8155–8170. [Google Scholar] [CrossRef] [PubMed]
- Shin, E.K.; Matsuda, F.; Nagaoka, H.; Fukita, Y.; Imai, T.; Yokoyama, K.; Soeda, E.; Honjo, T. Physical map of the 3′ region of the human immunoglobulin heavy chain locus: Clustering of autoantibody-related variable segments in one haplotype. EMBO J. 1991, 10, 3641–3645. [Google Scholar] [CrossRef]
- Matsuda, F.; Shin, E.K.; Nagaoka, H.; Matsumura, R.; Haino, M.; Fukita, Y.; Taka-ishi, S.; Imai, T.; Riley, J.H.; Anand, R.; et al. Structure and physical map of 64 variable segments in the 3′0.8-megabase region of the human immunoglobulin heavy-chain locus. Nat. Genet. 1993, 3, 88–94. [Google Scholar] [CrossRef]
- Cook, G.P.; Tomlinson, I.M.; Walter, G.; Riethman, H.; Carter, N.P.; Buluwela, L.; Winter, G.; Rabbitts, T.H. A map of the human immunoglobulin VH locus completed by analysis of the telomeric region of chromosome 14q. Nat. Genet. 1994, 7, 162–168. [Google Scholar] [CrossRef]
- Cook, G.P.; Tomlinson, I.M. The human immunoglobulin VH repertoire. Immunol. Today 1995, 16, 237–242. [Google Scholar] [CrossRef]
- Matsuda, F.; Ishii, K.; Bouvagnet, P.; Kuma Ki Hayashida, H.; Miyata, T.; Honjo, T. The complete nucleotide sequence of the human immunoglobulin heavy chain variable region locus. J. Exp. Med. 1998, 188, 2151–2162. [Google Scholar] [CrossRef]
- Matsuda, F.; Honjo, T. The human immunoglobulin VH locus. Immunologist 1999, 7, 171–176. [Google Scholar]
- Pallarès, N.; Lefebvre, S.; Contet, V.; Matsuda, F.; Lefranc, M.-P. The human immunoglobulin heavy variable genes. Exp. Clin. Immunogenet. 1999, 16, 36–60. [Google Scholar] [CrossRef] [PubMed]
- Siebenlist, U.; Ravetch, J.V.; Korsmeyer, S.; Waldmann, T.; Leder, P. Human immunoglobulin D segments encoded in tandem multigenic families. Nature 1981, 294, 631–635. [Google Scholar] [CrossRef] [PubMed]
- Buluwela, L.; Albertson, D.G.; Sherrington, P.; Rabbitts, P.H.; Spurr, N.; Rabbitts, T.H. The use of chromosomal translocations to study human immunoglobulin gene organization: Mapping DH segments within 35 kb of the C mu gene and identification of a new DH locus. EMBO J. 1988, 7, 2003–2010. [Google Scholar] [CrossRef] [PubMed]
- Ichihara, Y.; Matsuoka, H.; Kurosawa, Y. Organization of human immunoglobulin heavy chain diversity gene loci. EMBO J. 1988, 7, 4141–4150. [Google Scholar] [CrossRef]
- Corbett, S.J.; Tomlinson, I.M.; Sonnhammer, E.L.; Buck, D.; Winter, G. Sequence of the human immunoglobulin diversity (D) segment locus: A systematic analysis provides no evidence for the use of DIR segments, inverted D segments, “minor” D segments or D-D recombination. J. Mol. Biol. 1997, 270, 587–597. [Google Scholar] [CrossRef]
- Ruiz, M.; Pallarès, N.; Contet, V.; Barbié, V.; Lefranc, M.P. The human immunoglobulin heavy diversity (IGHD) and joining (IGHJ) segments. Exp. Clin. Immunogenet. 1999, 16, 173–184. [Google Scholar] [CrossRef]
- Ravetch, J.V.; Siebenlist, U.; Korsmeyer, S.; Waldmann, T.; Leder, P. Structure of the human immunoglobulin mu locus: Characterization of embryonic and rearranged J and D genes. Cell 1981, 27 Pt 2, 583–591. [Google Scholar] [CrossRef]
- Krawinkel, U.; Rabbitts, T.H. Comparison of the hinge-coding segments in human immunoglobulin gamma heavy chain genes and the linkage of the gamma 2 and gamma 4 subclass genes. EMBO J. 1982, 1, 403–407. [Google Scholar] [CrossRef] [PubMed]
- White, M.B.; Shen, A.L.; Word, C.J.; Tucker, P.W.; Blattner, F.R. Human Immunoglobulin D: Genomic Sequence of the Delta Heavy Chain. Science 1985, 228, 733–737. [Google Scholar] [CrossRef]
- Takahashi, N.; Ueda, S.; Obata, M.; Nikaido, T.; Nakai, S.; Honjo, T. Structure of human immunoglobulin gamma genes: Implications for evolution of a gene family. Cell 1982, 29, 671–679. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Rabbitts, T.H. Human immunoglobulin heavy chain A2 gene allotype determination by restriction fragment length polymorphism. Nucleic Acids Res. 1984, 12, 1303–1311. [Google Scholar] [CrossRef] [PubMed]
- Ellison, J.W.; Berson, B.J.; Hood, L.E. The nucleotide sequence of a human immunoglobulin C gamma1 gene. Nucleic Acids Res. 1982, 10, 4071–4079. [Google Scholar] [CrossRef] [PubMed]
- Max, E.E.; Battey, J.; Ney, R.; Kirsch, I.R.; Leder, P. Duplication and deletion in the human immunoglobulin epsilon genes. Cell 1982, 29, 691–699. [Google Scholar] [CrossRef]
- Bensmana, M.; Huck, S.; Lefranc, G.; Lefranc, M.-P. The human immunoglobulin pseudo-gamma IGHGP gene shows no major structural defect. Nucleic Acids Res. 1988, 16, 3108. [Google Scholar] [CrossRef][Green Version]
- Ellison, J.; Hood, L. Linkage and sequence homology of two human immunoglobulin gamma heavy chain constant region genes. Proc. Natl. Acad. Sci. USA 1982, 79, 1984–1988. [Google Scholar] [CrossRef]
- Ellison, J.; Buxbaum, J.; Hood, L. Nucleotide sequence of a human immunoglobulin C gamma 4 gene. DNA 1981, 1, 11–18. [Google Scholar] [CrossRef]
- Flanagan, J.G.; Rabbitts, T.H. The sequence of a human immunoglobulin epsilon heavy chain constant region gene, and evidence for three non-allelic genes. EMBO J. 1982, 1, 655–660. [Google Scholar] [CrossRef]
- Flanagan, J.G.; Lefranc, M.-P.; Rabbitts, T.H. Mechanisms of divergence and convergence of the human immunoglobulin alpha 1 and alpha 2 constant region gene sequences. Cell 1984, 36, 681–688. [Google Scholar] [CrossRef]
- Bensmana, M.; Chuchana, P.; Lefranc, G.; Lefranc, M.-P. Sequence of the CH1 and hinge-CH2 exons of the human immunoglobulin IGHA2 A2m(2) allele: Comparison with the nonallelic and allelic IGHA genes. Cytogenet. Cell Genet. 1991, 56, 128. [Google Scholar] [CrossRef]
- Scaviner, D.; Barbié, V.; Ruiz, M.; Lefranc, M.-P. Protein displays of the human immunoglobulin heavy, kappa and lambda variable and joining regions. Exp. Clin. Immunogenet. 1999, 16, 234–240. [Google Scholar] [CrossRef]
- Migone, N.; Oliviero, S.; de Lange, G.; Delacroix, D.L.; Boschis, D.; Altruda, F.; Silengo, L.; DeMarchi, M.; Carbonara, A.O. Multiple gene deletions within the human immunoglobulin heavy-chain cluster. Proc. Natl. Acad. Sci. USA 1984, 81, 5811–5815. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. Human immunoglobulin heavy-chain multigene deletions in healthy individuals. FEBS Lett. 1987, 213, 231–237. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Hammarström, L.; Smith, C.I.; Lefranc, G. Gene Deletions in the human immunoglobulin heavy chain constant region locus: Molecular and immunological analysis. Immunodefic. Rev. 1991, 2, 265–281. [Google Scholar] [PubMed]
- Lefranc, M.-P.; Lefranc, G. Consanguinity. In Encyclopedia of Genetics; Brenner, S., Miller, J.H., Eds.; Academic Press: London, UK, 2002; Volume 1, pp. 456–457. ISBN 978-0-1222-7080-2. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. Consanguinity. In Brenner’s Encyclopedia of Genetics, 2nd ed.; Maloy, S., Hughes, K., Eds.; Academic Press: San Diego, CA, USA, 2013; Volume 2, pp. 158–162. [Google Scholar]
- Bottaro, A.; Cariota, U.; DeMarchi, M.; Carbonara, A.O. Pulsed-field electrophoresis screening for immunoglobulin heavy-chain constant-region (IGHC) multigene deletions and duplications. Am. J. Hum. Genet. 1991, 48, 745–756. [Google Scholar] [PubMed]
- Bottaro, A.; Gallina, R.; Brusco, A.; Cariota, U.; Boccazzi, C.; Barilaro, M.R.; Plebani, A.; Ugazio, A.G.; van Leeuwen, A.M.; DeLange, G.G.; et al. Familial clustering of IGHC deletions and duplications: Functional and molecular analysis. Immunogenetics 1993, 37, 356–363. [Google Scholar] [CrossRef]
- Brusco, A.; Cariota, U.; Bottaro, A.; Boccazzi, C.; Delange, G.; Van Leewen, A.M.; Galanello, R.; Plebani, A.; Ugazio, A.U.; Guerra, M.G.; et al. Deletions, duplications and triplications of the IGHC region in different Italian populations. Immunodeficiency 1993, 4, 243–244. [Google Scholar]
- Brusco, A.; Cariota, U.; Bottaro, A.; Boccazzi, C.; Plebani, A.; Ugazio, A.G.; Galanello, R.; van Leeuwen, A.M.; DeLange, G.G.; Depelchin, S.; et al. Structural and immunologic analysis of gene triplications in the Ig heavy chain constant region locus. J. Immunol. 1994, 152, 129–135. [Google Scholar]
- Watson, C.T.; Steinberg, K.M.; Huddleston, J.; Warren, R.L.; Malig, M.; Schein, J.; Willsey, A.J.; Joy, J.B.; Scott, J.K.; Graves, T.A.; et al. Complete haplotype sequence of the human immunoglobulin heavy-chain variable, diversity, and joining genes and characterization of allelic and copy-number variation. Am. J. Hum. Genet. 2013, 92, 530–546. [Google Scholar] [CrossRef]
- Ghanem, N.; Lefranc, M.-P.; Lefranc, G. Definition of the RFLP alleles in the human immunoglobulin IGHG gene locus. Eur. J. Immunol. 1988, 18, 1059–1065. [Google Scholar] [CrossRef]
- Ghanem, N.; Bensmana, M.; Dugoujon, J.M.; Constans, J.; Lefranc, M.-P.; Lefranc, G. BamHI and SacI RFLPs of the human immunoglobulin IGHG genes with reference to the Gm polymorphism in African people: Evidence for a major polymorphism. Hum. Genet. 1989, 83, 37–44. [Google Scholar] [CrossRef]
- Ghanem, N.; Dugoujon, J.M.; Lefranc, M.-P.; Lefranc, G. BstEII restriction fragment alleles and haplotypes of the human IGHG genes with reference to the BamHI/SacI RFLPs and to the Gm polymorphism. Exp. Clin. Immunogenet. 1989, 6, 39–54. [Google Scholar] [PubMed]
- Hammarström, L.; Ghanem, N.; Smith, C.I.E.; Lefranc, G.; Lefranc, M.-P. RFLP of human immunoglobulin genes. Exp. Clin. Immunogenet. 1990, 7, 7–19. [Google Scholar] [PubMed]
- Battey, J.; Max, E.E.; McBride, W.O.; Swan, D.; Leder, P. A processed human immunoglobulin epsilon gene has moved to chromosome 9. Proc. Natl. Acad. Sci. USA 1982, 79, 5956–5960. [Google Scholar] [CrossRef] [PubMed]
- Malcolm, S.; Barton, P.; Murphy, C.; Ferguson-Smith, M.A.; Bentley, D.L.; Rabbitts, T.H. Localization of human immunoglobulin kappa light chain variable region genes to the short arm of chromosome 2 by in situ hybridization. Proc. Natl. Acad. Sci. USA 1982, 79, 4957–4961. [Google Scholar] [CrossRef]
- McBride, O.W.; Hieter, P.A.; Hollis, G.F.; Swan, D.; Otey, M.C.; Leder, P. Chromosomal location of human kappa and lambda immunoglobulin light chain constant region genes. J. Exp. Med. 1982, 155, 1480–1490. [Google Scholar] [CrossRef]
- Zachau, H.G. The immunoglobulin kappa locus-or-what has been learned from looking closely at one-tenth of a percent of the human genome. Gene 1993, 135, 167–173. [Google Scholar] [CrossRef]
- Zachau, H.G. The human immunoglobulin k genes. Immunologist 1996, 4, 49–54. [Google Scholar]
- Huber, C.; Schäble, K.F.; Huber, E.; Klein, R.; Meindl, A.; Thiebe, R.; Lamm, R.; Zachau, H.G. The V kappa genes of the L regions and the repertoire of V kappa gene sequences in the human germ line. Eur. J. Immunol. 1993, 23, 2868–2875. [Google Scholar] [CrossRef]
- Schäble, K.F.; Zachau, H.G. The variable genes of the human immunoglobulin kappa locus. Biol. Chem. Hoppe Seyler 1993, 374, 1001–1022. [Google Scholar]
- Cox, J.P.; Tomlinson, I.M.; Winter, G. A directory of human germ-line V kappa segments reveals a strong bias in their usage. Eur. J. Immunol. 1994, 24, 827–836. [Google Scholar] [CrossRef]
- Schäble, K.; Thiebe, R.; Flügel, A.; Meindl, A.; Zachau, H.G. The human immunoglobulin kappa locus: Pseudogenes, unique and repetitive sequences. Biol. Chem. Hoppe Seyler 1994, 375, 189–199. [Google Scholar] [CrossRef] [PubMed]
- Barbié, V.; Lefranc, M.-P. The human immunoglobulin kappa variable (IGKV) genes and joining (IGKJ) segments. Exp. Clin. Immunogenet. 1998, 15, 171–183. [Google Scholar] [CrossRef]
- Hieter, P.A.; Maizel, J.V., Jr.; Leder, P. Evolution of human immunoglobulin kappa J region genes. J. Biol. Chem. 1982, 257, 1516–1522. [Google Scholar] [PubMed]
- Hieter, P.A.; Max, E.E.; Seidman, J.G.; Maizel, J.V., Jr.; Leder, P. Cloned human and mouse kappa immunoglobulin constant and J region genes conserve homology in functional segments. Cell 1980, 22 Pt 1, 197–207. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin kappa (IGK) genes. Exp. Clin. Immunogenet. 2001, 18, 161–174. [Google Scholar] [CrossRef]
- Watson, C.T.; Steinberg, K.M.; Graves, T.A.; Warren, R.L.; Malig, M.; Schein, J.; Wilson, R.K.; Holt, R.A.; Eichler, E.E.; Breden, F. Version 2. Sequencing of the human IG light chain loci from a hydatidiform mole BAC library reveals locus-specific signatures of genetic diversity. Genes Immun. 2015, 16, 24–34. [Google Scholar] [CrossRef]
- Erikson, J.; Martinis, J.; Croce, C.M. Assignment of the genes for human lambda immunoglobulin chains to chromosome 22. Nature 1981, 294, 173–175. [Google Scholar] [CrossRef]
- Emanuel, B.S.; Cannizzaro, L.A.; Magrath, I.; Tsujimoto, Y.; Nowell, P.C.; Croce, C.M. Chromosomal orientation of the lambda light chain locus: V lambda is proximal to C lambda in 22q11. Nucleic Acids Res. 1985, 13, 381–387. [Google Scholar] [CrossRef] [PubMed]
- Dunham, I.; Shimizu, N.; Roe, B.A.; Chissoe, S.; Hunt, A.R.; Collins, J.E.; Bruskiewich, R.; Beare, D.M.; Clamp, M.; Smink, L.J.; et al. The DNA sequence of human chromosome 22. Nature 1999, 402, 489–495. [Google Scholar] [CrossRef] [PubMed]
- Frippiat, J.P.; Williams, S.C.; Tomlinson, I.M.; Cook, G.P.; Cherif, D.; Le Paslier, D.; Collins, J.E.; Dunham, I.; Winter, G.; Lefranc, M.-P. Organization of the human immunoglobulin lambda light-chain locus on chromosome 22q11.2. Hum. Mol. Genet. 1995, 4, 983–991. [Google Scholar] [CrossRef] [PubMed]
- Kawasaki, K.; Minoshima, S.; Schooler, K.; Kudoh, J.; Asakawa, S.; de Jong, P.J.; Shimizu, N. The organization of the human immunoglobulin lambda gene locus. Genome Res. 1995, 5, 125–135. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Williams, S.C.; Frippiat, J.P.; Tomlinson, I.M.; Ignatovich, O.; Lefranc, M.-P.; Winter, G. Sequence and evolution of the human germline V lambda repertoire. J. Mol. Biol. 1996, 264, 220–232. [Google Scholar] [CrossRef] [PubMed]
- Kawasaki, K.; Minoshima, S.; Nakato, E.; Shibuya, K.; Shintani, A.; Schmeits, J.L.; Wang, J.; Shimizu, N. One-megabase sequence analysis of the human immunoglobulin lambda gene locus. Genome Res. 1997, 7, 250–261. [Google Scholar] [CrossRef] [PubMed]
- Pallarès, N.; Frippiat, J.P.; Giudicelli, V.; Lefranc, M.-P. The human immunoglobulin lambda variable (IGLV) genes and joining (IGLJ) segments. Exp. Clin. Immunogenet. 1998, 15, 8–18. [Google Scholar] [CrossRef]
- Hieter, P.A.; Hollis, G.F.; Korsmeyer, S.J.; Waldmann, T.A.; Leder, P. Clustered arrangement of immunoglobulin lambda constant region genes in man. Nature 1981, 294, 536–540. [Google Scholar] [CrossRef] [PubMed]
- Taub, R.A.; Hollis, G.F.; Hieter, P.A.; Korsmeyer, S.; Waldmann, T.A.; Leder, P. Variable amplification of immunoglobulin lambda light-chain genes in human populations. Nature 1983, 304, 172–174. [Google Scholar] [CrossRef]
- Dariavach, P.; Lefranc, G.; Lefranc, M.-P. Human immunoglobulin C lambda 6 gene encodes the Kern+Oz-lambda chain and C lambda 4 and C lambda 5 are pseudogenes. Proc. Natl. Acad. Sci. USA. 1987, 84, 9074–9078. [Google Scholar] [CrossRef]
- Vasicek, T.J.; Leder, P. Structure and expression of the human immunoglobulin lambda genes. J. Exp. Med. 1990, 172, 609–620. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin lambda (IGL) genes. Exp. Clin. Immunogenet. 2001, 18, 242–254. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. Immunoglobulin lambda (IGL) genes of human and mouse. In Molecular Biology of B Cells; Honjo, T., Alt, F.W., Neuberger, M.S., Eds.; Academic Press, Elsevier Ltd.: Amsterdam, The Netherlands, 2004; pp. 37–59. ISBN 978-0-12-053641-2. [Google Scholar]
- Ghanem, N.; Dariavach, P.; Bensmana, M.; Chibani, J.; Lefranc, G.; Lefranc, M.-P. Polymorphism of immunoglobulin lambda constant region genes in populations from France, Lebanon and Tunisia. Exp. Clin. Immunogenet. 1988, 5, 186–195. [Google Scholar]
- Kay, P.H.; Moriuchi, J.; Ma, P.J.; Saueracker, E. An unusual allelic form of the immunoglobulin lambda constant region genes in the Japanese. Immunogenetics 1992, 35, 341–343. [Google Scholar] [CrossRef] [PubMed]
- Frippiat, J.P.; Dard, P.; Marsh, S.; Winter, G.; Lefranc, M.P. Immunoglobulin lambda light chain orphons on human chromosome 8q11.2. Eur. J. Immunol. 1997, 27, 1260–1265. [Google Scholar] [CrossRef] [PubMed]
- Hollis, G.F.; Hieter, P.A.; McBride, O.W.; Swan, D.; Leder, P. Processed genes: A dispersed human immunoglobulin gene bearing evidence of RNA-type processing. Nature 1982, 296, 321–325. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Pallarès, N.; Frippiat, J.P. Allelic polymorphisms and RFLP in the human immunoglobulin lambda light chain locus. Hum. Genet. 1999, 104, 361–369. [Google Scholar] [CrossRef]
- Passos Júnior, G.A.; Queiroz, R.G.; Brûlé, A. EcoRI restriction fragment-length polymorphism of the human immunoglobulin variable lambda 8 (IGLV8) subgroup reveals a gene family. Hum. Immunol. 1997, 55, 96–102. [Google Scholar] [CrossRef]
- da Silva, M.I.; Passos, G.A. The human immunoglobulin variable lambda locus IGLV9 gene is a monomorphic marker in the urban Brazilian population. Immunol. Lett. 1999, 69, 369–370. [Google Scholar] [CrossRef]
- Moraes Junta, C.; Passos, G.A. Genomic EcoRI polymorphism and cosmid sequencing reveal an insertion/deletion and a new IGLV5 allele in the human immunoglobulin lambda variable locus (22q11.2/IGLV). Immunogenetics 2003, 55, 10–15. [Google Scholar] [CrossRef]
- Chothia, C.; Lesk, A.M. Canonical structures for the hypervariable regions of immunoglobulins. J. Mol. Biol. 1987, 196, 901–917. [Google Scholar] [CrossRef]
- Chothia, C.; Lesk, A.M.; Tramontano, A.; Levitt, M.; Smith-Gill, S.J.; Air, G.; Sheriff, S.; Padlan, E.A.; Davies, D.; Tulip, W.R.; et al. Conformations of immunoglobulin hypervariable regions. Nature 1989, 342, 877–883. [Google Scholar] [CrossRef]
- Al-Lazikani, B.; Lesk, A.M.; Chothia, C. Standard conformations for the canonical structures of immunoglobulins. J. Mol. Biol. 1997, 273, 927–948. [Google Scholar] [CrossRef]
- Stamatopoulos, K.; Belessi, C.; Moreno, C.; Boudjograh, M.; Guida, G.; Smilevska, T.; Belhoul, L.; Stella, S.; Stavroyianni, N.; Crespo, M.; et al. Over 20% of patients with chronic lymphocytic leukemia carry stereotyped receptors: Pathogenetic implications and clinical correlations. Blood 2007, 109, 259–270. [Google Scholar] [CrossRef]
- Agathangelidis, A.; Darzentas, N.; Hadzidimitriou, A.; Brochet, X.; Murray, F.; Yan, X.J.; Davis, Z.; van Gastel-Mol, E.J.; Tresoldi, C.; Chu, C.C.; et al. Stereotyped B-cell receptors in one third of chronic lymphocytic leukemia: Towards a molecular classification with implications for targeted therapeutic interventions. Blood 2012, 119, 4467–4475. [Google Scholar] [CrossRef] [PubMed]
- Kostareli, E.; Gounari, M.; Janus, A.; Murray, F.; Brochet, X.; Giudicelli, V.; Pospisilova, S.; Oscier, D.; Foroni, L.; di Celle, P.F.; et al. Antigen receptor stereotypy across B-cell lymphoproliferations: The case of IGHV4-59/IGKV3-20 receptors with rheumatoid factor activity. Leukemia 2012, 26, 1127–1131. [Google Scholar] [CrossRef] [PubMed]
- Xochelli, A.; Bikos, V.; Polychronidou, E.; Galigalidou, C.; Agathangelidis, A.; Charlotte, F.; Moschonas, P.; Davis, Z.; Colombo, M.; Roumelioti, M.; et al. Disease-biased and shared characteristics of the immunoglobulin gene repertoires in marginal zone B cell lymphoproliferations. J. Pathol. 2019, 247, 416–421. [Google Scholar] [CrossRef] [PubMed]
- Hemadou, A.; Giudicelli, V.; Smith, M.L.; Lefranc, M.-P.; Duroux, P.; Kossida, S.; Heiner, C.; Hepler, N.L.; Kuijpers, J.; Groppi, A.; et al. Pacific Biosciences sequencing and IMGT/HighV-QUEST analysis of full-length single chain Fragment variable from an in vivo selected phage-display combinatorial library. Front. Immunol. 2017, 8, 1796. [Google Scholar] [CrossRef]
- Han, S.Y.; Antoine, A.; Howard, D.; Chang, B.; Chang, W.S.; Slein, M.; Deikus, G.; Kossida, S.; Duroux, P.; Lefranc, M.-P.; et al. Coupling of single molecule, long read sequencing with IMGT/HighV-QUEST analysis expedites identification of SIV gp140-specific antibodies from scFv phage display libraries. Front. Immunol. 2018, 9, 329. [Google Scholar] [CrossRef]
- Berman, H.M.; Westbrook, J.; Feng, Z.; Gilliland, G.; Bhat, T.N.; Weissig, H.; Shindyalov, I.N.; Bourne, P.E. The Protein Data Bank. Nucleic Acids Res. 2000, 28, 235–242. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Paratope. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Lefranc, M.-P. Epitope. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science+Business Media, Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Cho, H.S.; Mason, K.; Ramyar, K.X.; Stanley, A.M.; Gabelli, S.B.; Denney, D.W., Jr.; Leahy, D.J. Structure of the extracellular region of HER2 alone and in complex with the Herceptin Fab. Nature 2003, 421, 756–760. [Google Scholar] [CrossRef]
- Köhler, G.; Milstein, C. Continuous cultures of fused cells secreting antibody of predefined specificity. Nature 1975, 256, 495–497. [Google Scholar] [CrossRef]
- Riechmann, L.; Clark, M.; Waldmann, H.; Winter, G. Reshaping human antibodies for therapy. Nature 1988, 332, 323–327. [Google Scholar] [CrossRef]
- Marillet, S.; Lefranc, M.-P.; Boudinot, P.; Cazals, F. Novel structural parameters of Ig-Ag complexes yield a quantitative description of interaction specificity and binding affinity. Front. Immunol. 2017, 8, 34. [Google Scholar] [CrossRef] [PubMed]
- Hamers-Casterman, C.; Atarhouch, T.; Muyldermans, S.; Robinson, G.; Hamers, C.; Bajyana Songa, E.; Bendahman, N.; Hamers, R. Naturally occurring antibodies devoid of light chains. Nature 1993, 363, 446–448. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, V.K.; Hamers, R.; Wyns, L.; Muyldermans, S. Camel heavy-chain antibodies: Diverse germline VHH and specific mechanisms enlarge the antigen-binding repertoire. EMBO J. 2000, 19, 921–930. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, V.K.; Hamers, R.; Wyns, L.; Muyldermans, S. Loss of splice consensus signal is responsible for the removal of the entire CH1 domain of the functional camel IgG2a heavy chain antibodies. Mol. Immunol. 1999, 36, 515–524. [Google Scholar] [CrossRef]
- Beirnaert, E.; Desmyter, A.; Spinelli, S.; Lauwereys, M.; Aarden, L.; Dreier, T.; Loris, R.; Silence, K.; Pollet, C.; Cambillau, C.; et al. Bivalent llama single-domain antibody fragments against tumor necrosis factor have picomolar potencies due to intramolecular interactions. Front. Immunol. 2017, 8, 867. [Google Scholar] [CrossRef]
- Strokappe, N.M.; Hock, M.; Rutten, L.; Mccoy, L.E.; Back, J.W.; Caillat, C.; Haffke, M.; Weiss, R.A.; Weissenhorn, W.; Verrips, T. Super potent bispecific llama VHH antibodies neutralize HIV via a combination of gp41 and gp120 epitopes. Antibodies 2019, 8, 38. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. The constant region genes of the immunoglobulin heavy chains. Mol. Genet. (Life Sci. Adv.) 1988, 7, 39–45. [Google Scholar]
- Greenberg, A.S.; Avila, D.; Hughes, M.; Hughes, A.; McKinney, E.C.; Flajnik, M.F. A new antigen receptor gene family that undergoes rearrangement and extensive somatic diversification in sharks. Nature 1995, 374, 168–173. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. Antibody sequence and structure analyses using IMGT®: 30 years of immunoinformatics. In Computer Aided Antibody Design: Methods and Protocols; Tsumoto, K., Kuroda, D., Eds.; Methods in Molecular Biology Series; Springer Nature: London, UK, in press.
- Holland, C.J.; Crean, R.M.; Pentier, J.M.; de Wet, B.; Lloyd, A.; Srikannathasan, V.; Lissin, N.; Lloyd, K.A.; Blicher, T.H.; Conroy, P.J.; et al. Specificity of bispecific T cell receptors and antibodies targeting peptide-HLA. J. Clin. Investig. 2020, 130, 2673–2688. [Google Scholar] [CrossRef]
- Kaas, Q.; Chiche, L.; Lefranc, M.-P. IMGT unique numbering for standardized contact analysis of immunoglobulin/antigen and T cell receptor/peptide/MHC complexes. In BIOINFO 2005, Proceedings of the 2005 International Joint Conference of InCoB, AASBi and KSBI; Lee, D., Wong, L., Kim, D.-W., Kim, C., Tan, T.W., Lee, K.-H., Eds.; Kaist Press: Daejeon, Korea, 2005; pp. 209–214. ISBN 89-89453-12-7. [Google Scholar]
- Kaas, Q.; Lefranc, M.-P. T cell receptor/peptide/MHC molecular characterization and standardized pMHC contact sites in IMGT/3Dstructure-DB. Silico Biol. 2005, 5, 505–528. [Google Scholar]
- Kaas, Q.; Duprat, E.; Tourneur, G.; Lefranc, M.-P. IMGT standardization for molecular characterization of the T cell receptor/peptide/MHC complexes. In Immunoinformatics; Schoenbach, C., Ranganathan, S., Brusic, V., Eds.; Immunomics Reviews, Series of Springer Science and Business Media LL; Springer: New York, NY, USA, 2008; pp. 19–49. ISBN 978-0-387-72967-1. [Google Scholar]
- Ridgway, J.B.; Presta, L.G.; Carter, P. Knobs-into-holes’ engineering of antibody CH3 domains for heavy chain heterodimerization. Protein Eng. 1996, 9, 617–621. [Google Scholar] [CrossRef] [PubMed]
- Teplyakov, A.; Zhao, Y.; Malia, T.; Obmolova, G.; Gilliland, G.L. IgG2 Fc structure and the dynamic features of the IgG CH2-CH3 interface. Mol. Immunol. 2013, 56, 131–139. [Google Scholar] [CrossRef]
- Lesk, A.M.; Chothia, C. Elbow motion in the immunoglobulin involves a molecular ball-and-socket joint. Nature 1988, 335, 188–190. [Google Scholar] [CrossRef] [PubMed]
- Carter, P.; Presta, L.; Gorman, C.M.; Ridgway, J.B.; Henner, D.; Wong, W.L.; Rowland, A.M.; Kotts, C.; Carver, M.E.; Shepard, H.M. Humanization of an anti-p185HER2 antibody for human cancer therapy. Proc. Natl. Acad. Sci. USA 1992, 89, 4285–4289. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Mathieu, M.; Brezski, R.J. IgG Fc engineering to modulate antibody effector functions. Protein Cell 2018, 9, 63–73. [Google Scholar] [CrossRef]
- Strohl, W.R. Current progress in innovative engineered antibodies. Protein Cell 2018, 9, 86–120. [Google Scholar] [CrossRef]
- Elemento, O.; Gascuel, O.; Lefranc, M.-P. Reconstructing the duplication history of tandemly repeated genes. Mol. Biol. Evol. 2002, 19, 278–288. [Google Scholar] [CrossRef]
- Elemento, O.; Lefranc, M.-P. IMGT/PhyloGene: An online software package for phylogenetic analysis of immunoglobulin and T cell receptor genes. Dev. Comp. Immunol. 2003, 27, 763–779. [Google Scholar]
- Baum, P.; Pasqual, N.; Thuderoz, F.; Hierle, V.; Chaume, D.; Lefranc, M.-P.; Jouvin-Marche, E.; Marche, N.; Demongeot, J. IMGT/GeneInfo: Enhancing V(D)J recombination database accessibility. Nucleic Acids Res. 2004, 32, D51–D54. [Google Scholar] [CrossRef]
- Baum, T.P.; Hierle, V.; Pascal, N.; Bellahcene, F.; Chaume, D.; Lefranc, M.-P.; Jouvin-Marche, E.; Marche, P.N.; Demongeot, J. IMGT/GeneInfo: T cell receptor gamma TRG and delta TRD genes in database give access to all TR potential V(D)J recombinations. BMC Bioinform. 2006, 7, 224. [Google Scholar] [CrossRef]
- Bleakley, K.; Giudicelli, V.; Wu, Y.; Lefranc, M.-P.; Biau, G. IMGT standardization for statistical analyses of T cell receptor junctions: The TRAV-TRAJ example. Silico Biol. 2006, 6, 573–588. [Google Scholar]
- Bleakley, K.; Lefranc, M.-P.; Biau, G. Recovering probabilities for nucleotide trimming processes for T cell receptor TRA and TRG V-J junctions analyzed with IMGT tools. BMC Bioinform. 2008, 9, 408. [Google Scholar] [CrossRef] [PubMed]
- Artero, S.; Lefranc, M.-P. The Teleostei Immunoglobulin Light IGL1 and IGL2 V., J and C genes. Exp. Clin. Immunogenet. 2000, 17, 162–172. [Google Scholar] [CrossRef] [PubMed]
- Artero, S.; Lefranc, M.-P. The Teleostei Immunoglobulin Heavy IGH genes. Exp. Clin. Immunogenet. 2000, 17, 148–161. [Google Scholar] [CrossRef] [PubMed]
- Martinez-Jean, C.; Folch, G.; Lefranc, M.-P. Nomenclature and overview of the Mouse (Mus musculus and Mus sp.) Immunoglobulin Kappa (IGK) Genes. Exp. Clin. Immunogenet. 2001, 18, 255–279. [Google Scholar] [CrossRef]
- Bosc, N.; Lefranc, M.-P. IMGT Locus in Focus: The mouse (Mus musculus) T cell receptor alpha (TRA) and delta (TRD) variable genes. Dev. Comp. Immunol. 2003, 27, 465–497. [Google Scholar] [CrossRef]
- Schwartz, J.C.; Lefranc, M.-P.; Murtaugh, M.-P. Organization, complexity and allelic diversity of the porcine (Sus scrofa domestica) immunoglobulin lambda locus. Immunogenetics 2012, 64, 399–407. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Schwartz, J.C.; Lefranc, M.-P.; Murtaugh, M.P. Evolution of the porcine (Sus scrofa domestica) immunoglobulin kappa locus through germline gene conversion. Immunogenetics 2012, 64, 303–311. [Google Scholar] [CrossRef]
- Herzig, C.; Blumerman, S.; Lefranc, M.-P.; Baldwin, C. Bovine T cell receptor gamma variable and constant genes: Combinatorial usage by circulating γδ T cells. Immunogenetics 2006, 58, 138–151. [Google Scholar] [CrossRef]
- Conrad, M.L.; Mawer, M.A.; Lefranc, M.-P.; McKinneli, L.; Whitehead, J.; Davis, S.K.; Pettman, R.; Koop, B.F. The genomic sequence of the bovine T cell receptor gamma TRG loci and localization of the TRGC5 cassette. Vet. Immunol. Immunopathol. 2007, 115, 346–356. [Google Scholar] [CrossRef]
- Massari, S.; Bellahcene, F.; Vaccarelli, G.; Carelli, G.; Mineccia, M.; Lefranc, M.-P.; Antonacci, R.; Ciccarese, S. The deduced structure of the T cell receptor gamma locus in Canis lupus familiaris. Mol. Immunol. 2009, 46, 2728–2736. [Google Scholar] [CrossRef]
- Herzig, T.A.; Lefranc, M.-P.; Baldwin, C.L. Annotation and classification of the bovine T cell receptor delta genes. BMC Genom. 2010, 11, 100. [Google Scholar] [CrossRef]
- Antonacci, R.; Mineccia, M.; Lefranc, M.-P.; Ashmaoui, H.M.; Lanave, C.; Piccinni, B.; Pesole, G.; Hassanane, M.S.; Massari, S.; Ciccarese, S. Expression and genomic analyses of Camelus dromedarius T cell receptor delta (TRD) genes reveal a variable domain repertoire enlargement due to CDR3 diversification and somatic mutation. Mol. Immunol. 2011, 48, 1384–1396. [Google Scholar] [CrossRef] [PubMed]
- Buonocore, F.; Castro, R.; Randelli, E.; Lefranc, M.-P.; Six, A.; Kuhl, H.; Reinhardt, R.; Facchiano, A.; Boudinot, P.; Scapigliati, G. Diversity, molecular characterization and expression of T cell receptor gamma in a teleost fish, the sea bass (Dicentrarchus labrax, L). PLoS ONE 2012, 7, e47957. [Google Scholar] [CrossRef] [PubMed]
- Castro, R.; Jouneau, L.; Pham, H.P.; Bouchez, O.; Giudicelli, V.; Lefranc, M.-P.; Quillet, E.; Benmansour, A.; Cazals, F.; Six, A.; et al. Teleost fish mount complex clonal IgM and IgT responses in spleen upon systemic viral infection. PLoS Pathog. 2013, 9, e1003098. [Google Scholar] [CrossRef] [PubMed]
- Ciccarese, S.; Vaccarelli, G.; Lefranc, M.-P.; Tasco, G.; Consiglio, A.; Casadio, R.; Linguiti, G.; Antonacci, R. Characteristics of the somatic hypermutation in the Camelus dromedarius T cell receptor gamma (TRG) and delta (TRD) variable domains. Dev. Comp. Immunol. 2014, 46, 300–313. [Google Scholar] [CrossRef] [PubMed]
- Piccinni, B.; Massari, S.; Caputi Jambrenghi, A.; Giannico, F.; Lefranc, M.-P.; Ciccarese, S.; Antonacci, R. Sheep (Ovis aries) T cell receptor alpha (TRA) and delta (TRD) genes and genomic organization of the TRA/TRD locus. BMC Genom. 2015, 16, 709. [Google Scholar] [CrossRef] [PubMed]
- Linguiti, G.; Antonacci, R.; Tasco, G.; Grande, F.; Casadio, R.; Massari, S.; Castelli, V.; Consiglio, A.; Lefranc, M.-P.; Ciccarese, S. Genomic and expression analyses of Tursiops truncatus T cell receptor gamma (TRG) and alpha/delta (TRA/TRD) loci reveal a similar basic public γδ repertoire in dolphin and human. BMC Genom. 2016, 17, 634. [Google Scholar] [CrossRef]
- Yu, G.Y.; Mate, S.; Garcia, K.; Ward, M.D.; Brueggemann, E.; Hall, M.; Kenny, T.; Sanchez-Lockhart, M.; Lefranc, M.-P.; Palacios, G. Cynomolgus macaque (Macaca fascicularis) immunoglobulin heavy chain locus description. Immunogenetics 2016, 68, 417–428. [Google Scholar] [CrossRef] [PubMed]
- Deiss, T.C.; Vadnais, M.; Wang, F.; Chen, P.L.; Torkamani, A.; Mwangi, W.; Lefranc, M.-P.; Criscitiello, M.F.; Smider, V.V. Immunogenetic factors driving formation of ultralong VH CDR3 in Bos taurus antibodies. Cell Mol. Immunol. 2019, 16, 53–64. [Google Scholar] [CrossRef] [PubMed]
- Martin, J.; Ponstingl, H.; Lefranc, M.-P.; Archer, J.; Sargan, D.; Bradley, A. Comprehensive annotation and evolutionary insights into the canine (Canis lupus familiaris) antigen receptor loci. Immunogenetics 2018, 70, 223–236. [Google Scholar] [CrossRef]
- Magadan, S.; Krasnov, A.; Hadi Saljoqi, S.; Afanasyev, S.; Mondot, S.; Lallias, D.; Castro, R.; Salinas, I.; Sunyer, O.; Hansen, J.; et al. Standardized IMGT® nomenclature of Salmonidae IGH genes, the paradigm of Atlantic salmon and rainbow trout: From genomics to repertoires. Front. Immunol. 2019, 10, 2541. [Google Scholar] [CrossRef] [PubMed]
- Mondot, S.; Lantz, O.; Lefranc, M.-P.; Boudinot, P. The T cell receptor (TRA) locus in the rabbit (Oryctolagus cuniculus): Genomic features and consequences for invariant T cells. Eur. J. Immunol. 2019, 49, 2146–2158. [Google Scholar] [CrossRef] [PubMed]
- Pégorier, P.; Bertignac, M.; Chentli, I.; Nguefack Ngoune, V.; Folch, G.; Jabado-Michaloud, J.; Hadi-Saljoqi, S.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P.; et al. IMGT® biocuration and comparative study of the T cell receptor beta locus of veterinary species based on Homo sapiens TRB. Front. Immunol. 2020, 11, 821. [Google Scholar] [CrossRef] [PubMed]
- Radtanakatikanon, A.; Keller, S.M.; Darzentas, N.; Moore, P.F.; Folch, G.; Nguefack Ngoune, V.; Lefranc, M.-P.; Vernau, W. Topology and expressed repertoire of the Felis catus T cell receptor loci. BMC Genomics. 2020, 21, 20. [Google Scholar] [CrossRef] [PubMed]
- Antonacci, R.; Massari, S.; Linguiti, G.; Caputi Jambrenghi, A.; Giannico, F.; Lefranc, M.-P.; Ciccarese, S. Evolution of the T-cell Receptor (TR) loci in the adaptive immune response: The tale of the TRG locus in mammals. Genes 2020, 11, 624. [Google Scholar] [CrossRef]
- Buresi, C.; Ghanem, N.; Huck, S.; Lefranc, G.; Lefranc, M.-P. Exon duplication and triplication in the human T-cell receptor gamma constant region genes and RFLP in French, Lebanese, Tunisian, and Black African populations. Immunogenetics 1989, 29, 161–172. [Google Scholar] [CrossRef] [PubMed]
- Dard, P.; Lefranc, M.-P.; Osipova LSanchez-Mazas, A. DNA sequence variability of IGHG3 genes associated to the main G3m haplotypes in human populations. Eur. J. Hum. Genet. 2001, 9, 765–772. [Google Scholar] [CrossRef]
- Raux, G.; Gilbert, D.; Joly, P.; Martel, P.; Roujeau, J.-C.; Prost, C.; Lefranc, M.-P.; Tron, F. IGHV3 associated restriction fragment length polymorphisms confer susceptibility to bullous pemphigoid. Exp. Clin. Immunogenet. 2001, 18, 59–66. [Google Scholar] [CrossRef]
- Chardes, T.; Chapal, N.; Bresson, D.; Bes, C.; Giudicelli, V.; Lefranc, M.-P.; Peraldi-Roux, S. The human anti-thyroid peroxidase autoantibody repertoire in Graves’ and Hashimoto’s autoimmune thyroid diseases. Immunogenetics 2002, 54, 141–157. [Google Scholar] [CrossRef]
- Martinez, O.; Gangi, E.; Mordi, D.; Gupta, S.; Dorevitch, S.; Lefranc, M.-P.; Prabhakar, B.S. Diversity in the Complementarity Determining Region 3 (CDR3) of Antibodies from mice with evolving anti-TSHR antibody responses. Endocrinology 2007, 148, 752–761. [Google Scholar] [CrossRef][Green Version]
- Robert, R.; Lefranc, M.-P.; Ghochikyan, A.; Agadjanyan, M.G.; Cribbs, D.H.; Van Nostrand, W.E.; Wark, K.L.; Dolezal, O. Restricted V gene usage and VH/VL pairing of mouse humoral response against the N-terminal immunodominant epitope of the amyloid β peptide. Mol. Immunol. 2010, 48, 59–72. [Google Scholar] [CrossRef]
- Magdelaine-Beuzelin, C.; Kaas, Q.; Wehbi, V.; Ohresser, M.; Jefferis, R.; Lefranc, M.-P.; Watier, H. Structure-function relationships of the variable domains of monoclonal antibodies approved for cancer treatment. Crit. Rev. Oncol. Hematol. 2007, 64, 210–225. [Google Scholar] [CrossRef] [PubMed]
- Magdelaine-Beuzelin, C.; Vermeire, S.; Goodall, M.; Baert, F.; Noman, M.; Van Assche, G.; Ohresser, M.; Degenne, D.; Dugoujon, J.M.; Jefferis, R.; et al. IgG1 heavy chain-coding gene polymorphism (G1m allotypes) and development of antibodies-to-infliximab. Pharm. Genom. 2009, 19, 383–387. [Google Scholar] [CrossRef]
- Giest, S.; McWinnie, A.; Lefranc, M.-P.; Little, A.M.; Grace, S.; Mackinnon, S.; Madrigal, J.A.; Travers, P.J. CMV specific CD8+ T cells targeting different peptide / HLA combinations demonstrate varying T cell receptor diversity. Immunology 2012, 135, 27–39. [Google Scholar] [CrossRef] [PubMed]
- Ouled-Haddou, H.; Ghamlouch, H.; Regnier, A.; Trudel, S.; Herent, D.; Lefranc, M.-P.; Marolleau, J.; Gubler, B. Characterization of a new V gene replacement in the absence of activation-induced cytidine deaminase and its contribution to human BcR diversity. Immunology 2014, 141, 268–275. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wang, X.H.; Williams, C.; Volsky, B.; Steczko, O.; Seaman, M.S.; Luthra, K.; Nyambi, P.; Nadas, A.; Giudicelli, V.; et al. A broad range of mutations in HIV-1 neutralizing human monoclonal antibodies specific for V2, V3, and the CD4 binding site. Mol. Immunol. 2015, 66, 364–374. [Google Scholar] [CrossRef] [PubMed]
- Abed, R.E.; Khechine, A.E.; Omri, H.E.; Youssef, S.; Laatiri, A.; Lefranc, M.-P.; Khelif, A.; Soua, Z. Chemiluminescent detection of clonal immunoglobulin and T cell receptor gene rearrangements in Tunisian lymphoid malignancies, leukemias and lymphomas. Leuk. Lymphoma 2006, 47, 1129–1137. [Google Scholar] [CrossRef] [PubMed]
- Besbes, S.; Hamadou, W.S.; Boulland, M.L.; Lefranc, M.-P.; Ben Youssef, Y.; Achour, B.; Khelif, A.; Fest, T.; Soua, Z. Combined IKZF1 and IG markers as new tools for diagnosis and minimal residual disease assessment in Tunisian B-ALL. Bull. Cancer 2016, 103, 822–828. [Google Scholar] [CrossRef]
- Langerak, A.W.; Brüggemann, M.; Davi, F.; Darzentas, N.; van Dongen, J.J.M.; Gonzalez, D.; Cazzaniga, G.; Giudicelli, V.; Lefranc, M.-P.; Giraud, M.; et al. EuroClonality-NGS consortium. High-throughput immunogenetics for clinical and research applications in immunohematology: Potential and challenges. J. Immunol. 2017, 198, 3765–3774. [Google Scholar] [CrossRef]
- Rosenquist, R.; Ghia, P.; Hadzidimitriou, A.; Sutton, L.-A.; Agathangelidis, A.; Baliakas, P.; Darzentas, N.; Giudicelli, V.; Lefranc, M.-P.; Langerak, A.W.; et al. Immunoglobulin gene sequence analysis in chronic lymphocytic leukemia: Updated ERIC recommendations. Leukemia 2017, 31, 1477–1481. [Google Scholar] [CrossRef] [PubMed]
- Chassagne, S.; Laffly, E.; Drouet, E.; Herodin, F.; Lefranc, M.-P.; Thullier, P. A high affinity macaque antibody Fab with human-like framework regions obtained from a small phage display immune library. Mol. Immunol. 2004, 41, 539–546. [Google Scholar] [CrossRef] [PubMed]
- Laffly, E.; Danjou, L.; Condemine, F.; Vidal, D.; Drouet, E.; Lefranc, M.-P.; Bottex, C.; Thullier, P. Selection of a macaque Fab with human-like framework regions, high affinity, and that neutralizes the protective antigen (PA) of Bacillus anthracis. Antimicrob. Agents Chemother. 2005, 49, 3414–3420. [Google Scholar] [CrossRef]
- Pelat, T.; Hust, M.; Laffly, E.; Condemine, F.; Bottex, C.; Vidal, D.; Lefranc, M.-P.; Dubel, S.; Thullier, P. A high affinity, human-like antibody fragment (scFv) neutralising the lethal factor (LF) of Bacillus anthracis by inhibiting PA-LF complex formation. Antimicrob. Agents Chemother. 2007, 51, 2758–2764. [Google Scholar] [CrossRef] [PubMed]
- Pelat, T.; Bedouelle, H.; Rees, A.R.; Crennell, S.J.; Lefranc, M.-P.; Thullier, P. Germline humanization of a non-human Primate antibody that neutralizes the anthrax toxin, by in vitro and in silico engineering. J. Mol. Biol. 2008, 384, 1400–1407. [Google Scholar] [CrossRef] [PubMed]
- Pelat, T.; Hust, M.; Hale, M.; Lefranc, M.-P.; Dübel, S.; Thullier, P. Isolation of a human-like antibody fragment (scFv) that neutralizes ricin biological activity. BMC Biotechnol. 2009, 9, 60. [Google Scholar] [CrossRef] [PubMed]
- Duprat, E.; Kaas, Q.; Garelle, V.; Lefranc, G.; Lefranc, M.-P. IMGT standardization for alleles and mutations of the V-LIKE-DOMAINs and C-LIKE-DOMAINs of the immunoglobulin superfamily. Recent Res. Dev. Hum. Genet. 2004, 2, 111–136. [Google Scholar]
- Bertrand, G.; Duprat, E.; Lefranc, M.-P.; Marti, J.; Coste, J. Characterization of human FCGR3B*02 (HNA-1b, NA2) cDNAs and IMGT standardized description of FCGR3B alleles. Tissue Antigens Cover 2004, 64, 119–131. [Google Scholar] [CrossRef]
- Bernard, D.; Hansen, J.D.; du Pasquier, L.; Lefranc, M.-P.; Benmansour, A.; Boudinot, P. Costimulatory receptors in jawed vertebrates: Conserved CD28, odd CTLA4 and multiple BTLAs. Dev. Comp. Immunol. 2007, 31, 255–271. [Google Scholar] [CrossRef]
- Garapati, V.P.; Lefranc, M.-P. IMGT Colliers de Perles and IgSF domain standardization for T cell costimulatory activatory (CD28, ICOS) and inhibitory (CTLA4, PDCD1 and BTLA) receptors. Dev. Comp. Immunol. 2007, 31, 1050–1072. [Google Scholar] [CrossRef]
- Hansen, J.D.; Pasquier, L.D.; Lefranc, M.-P.; Lopez, V.; Benmansour, A.; Boudinot, P. The B7 family of immunoregulatory receptors: A comparative and evolutionary perspective. Mol. Immunol. 2009, 46, 457–472. [Google Scholar] [CrossRef] [PubMed]
- Duprat, E.; Lefranc, M.-P.; Gascuel, O. A simple method to predict protein binding from aligned sequences -application to MHC superfamily and beta2-microglobulin. Bioinformatics 2006, 22, 453–459. [Google Scholar] [CrossRef] [PubMed]
- Frigoul, A.; Lefranc, M.-P. MICA: Standardized IMGT allele nomenclature, polymorphisms and diseases. In Recent Research Developments in Human Genetics; Pandalai, S.G., Ed.; Research Signpost: Trivandrum, India, 2005; Volume 3, pp. 95–145. ISBN 81-7736-244-5. [Google Scholar]
- Boudinot, P.; Mondot, S.; Jouneau, L.; Teyton, L.; Lefranc, M.-P.; Lantz, O. Restricting nonclassical MHC genes coevolve with TRAV genes used by innate-like T cells in mammals. Proc. Natl. Acad. Sci. USA 2016, 113, E2983–E2992. [Google Scholar] [CrossRef] [PubMed]
- Dechavanne, C.; Guillonneau, F.; Chiappetta, G.; Sago, L.; Lévy, P.; Salnot, V.; Guitard, E.; Ehrenmann, F.; Broussard, C.; Chafey, P.; et al. Mass spectrometry detection of G3m and IGHG3 alleles and follow-up of differential mother and neonate IgG3. PLoS ONE 2012, 7, e46097. [Google Scholar] [CrossRef] [PubMed]
- Dambrun, M.; Dechavanne, C.; Emmanuel, A.; Aussenac, F.; Leduc, M.; Giangrande, C.; Vinh, J.; Dugoujon, J.M.; Lefranc, M.-P.; Guillonneau, F.; et al. Human immunoglobulin heavy gamma chain polymorphisms: Molecular confirmation of proteomic assessment. Mol. Cell Proteom. 2017, 16, 824–839. [Google Scholar] [CrossRef]
- Coelho, C.H.; Nadakal, S.T.; Hurtado, P.G.; Morrison, R.; Galson, J.D.; Neal, J.; Wu, Y.; King, C.R.; Price, V.; Miura, K.; et al. Antimalarial Antibody Repertoire Defined by Plasma IG Proteomics and Single B Cell IG Sequencing. Available online: http://videocast.nih.gov/watch=37965 (accessed on 29 August 2020).




















































{kind=link}
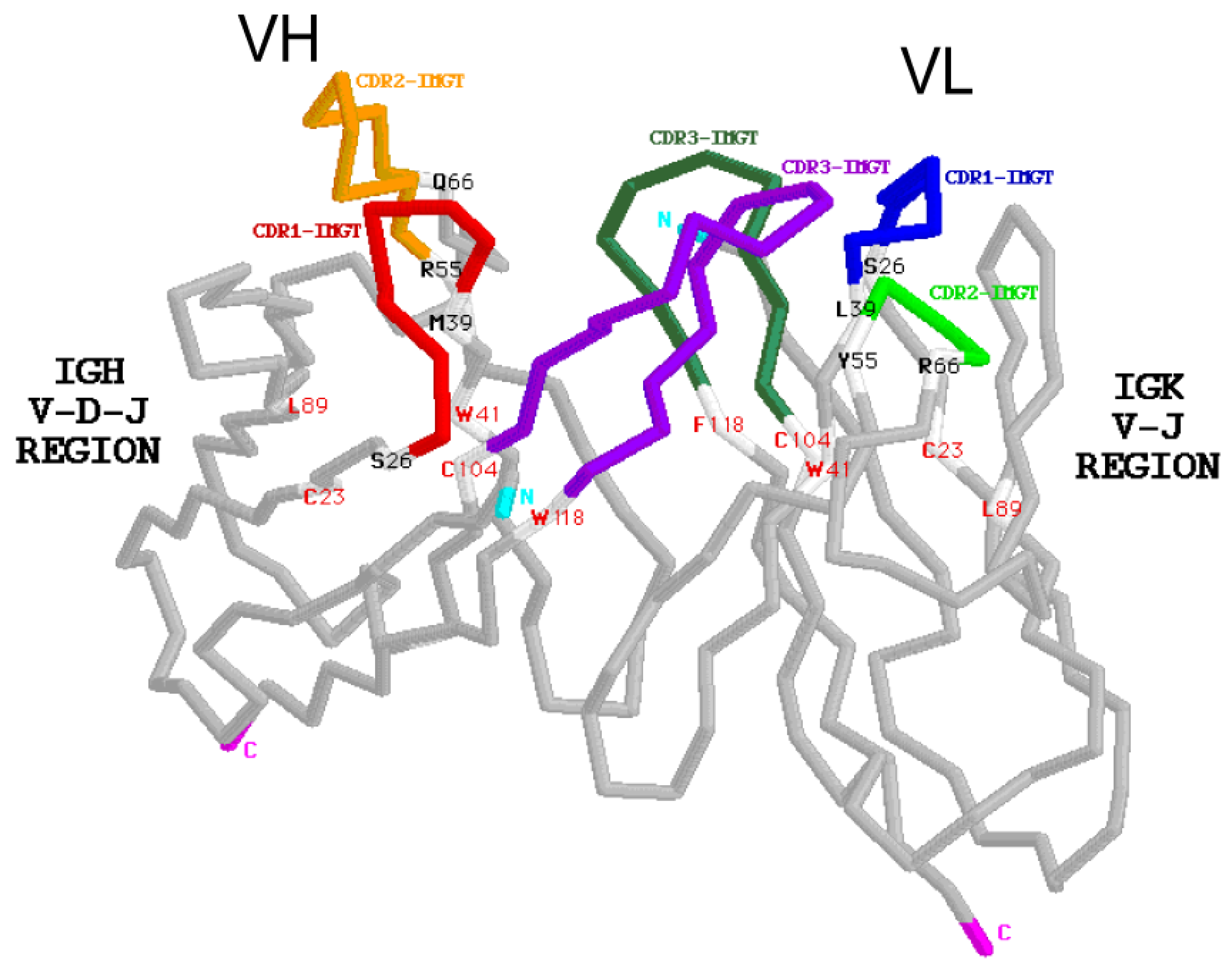{kind=link}
{kind=link}
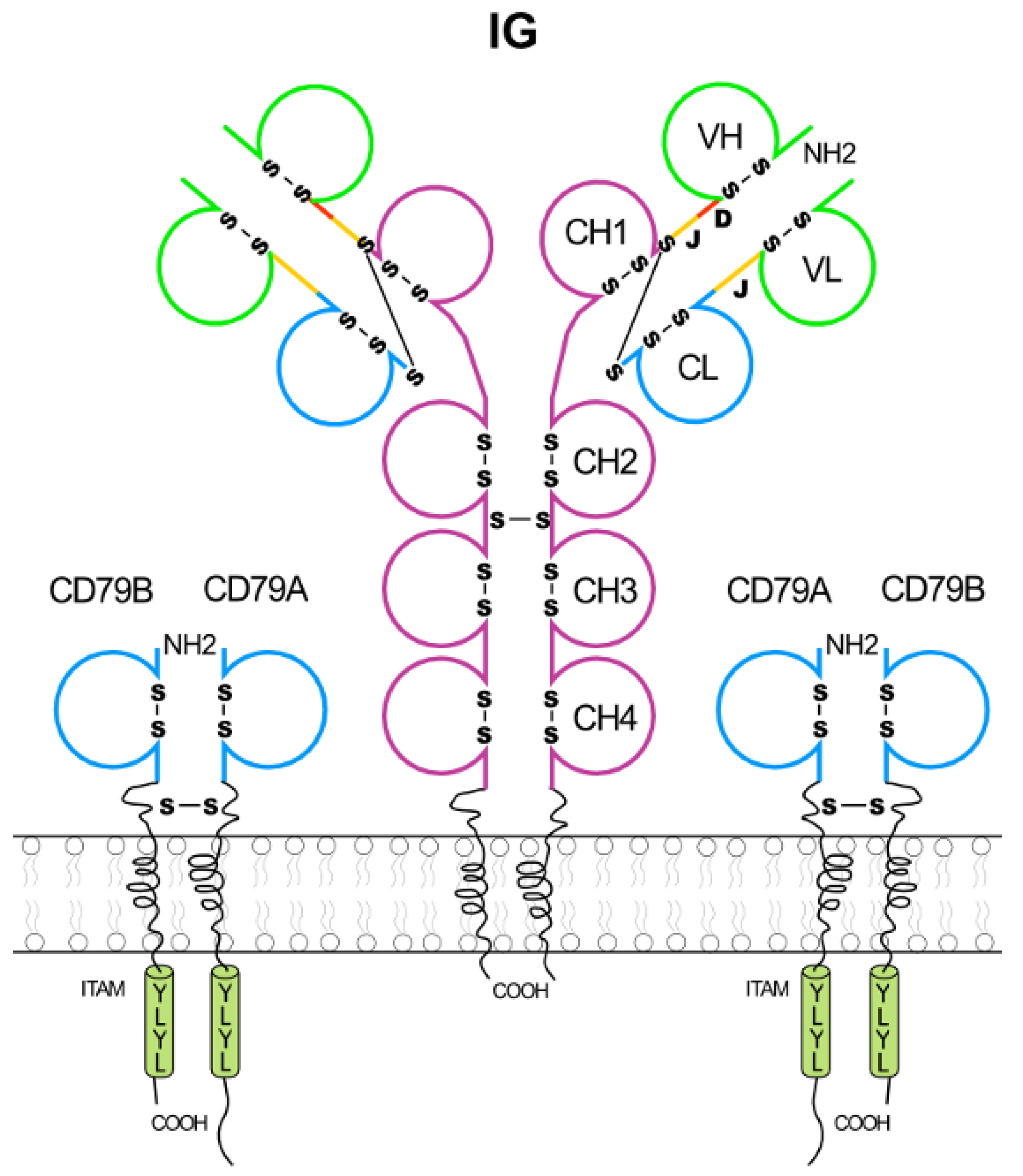{kind=link}
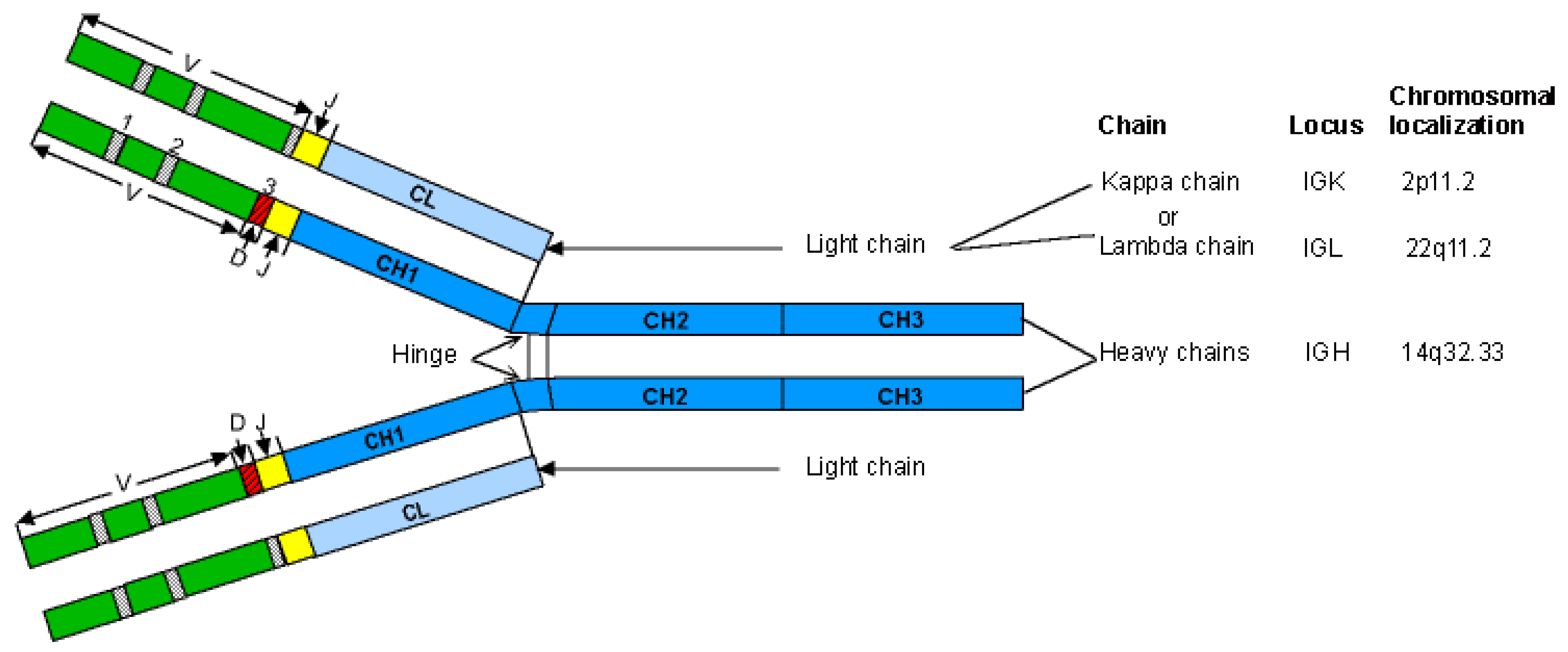{kind=link}
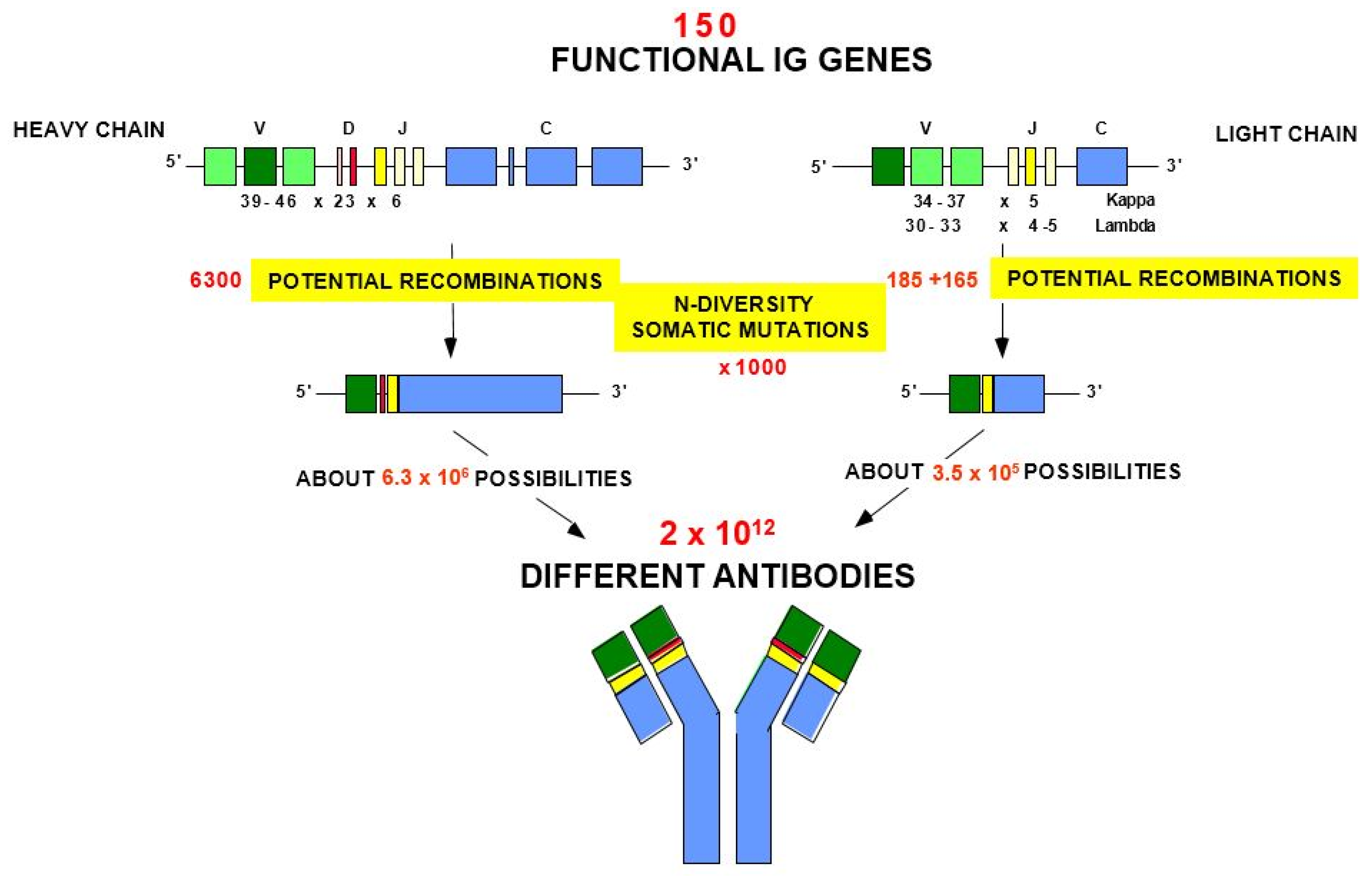{kind=link}
{kind=link}
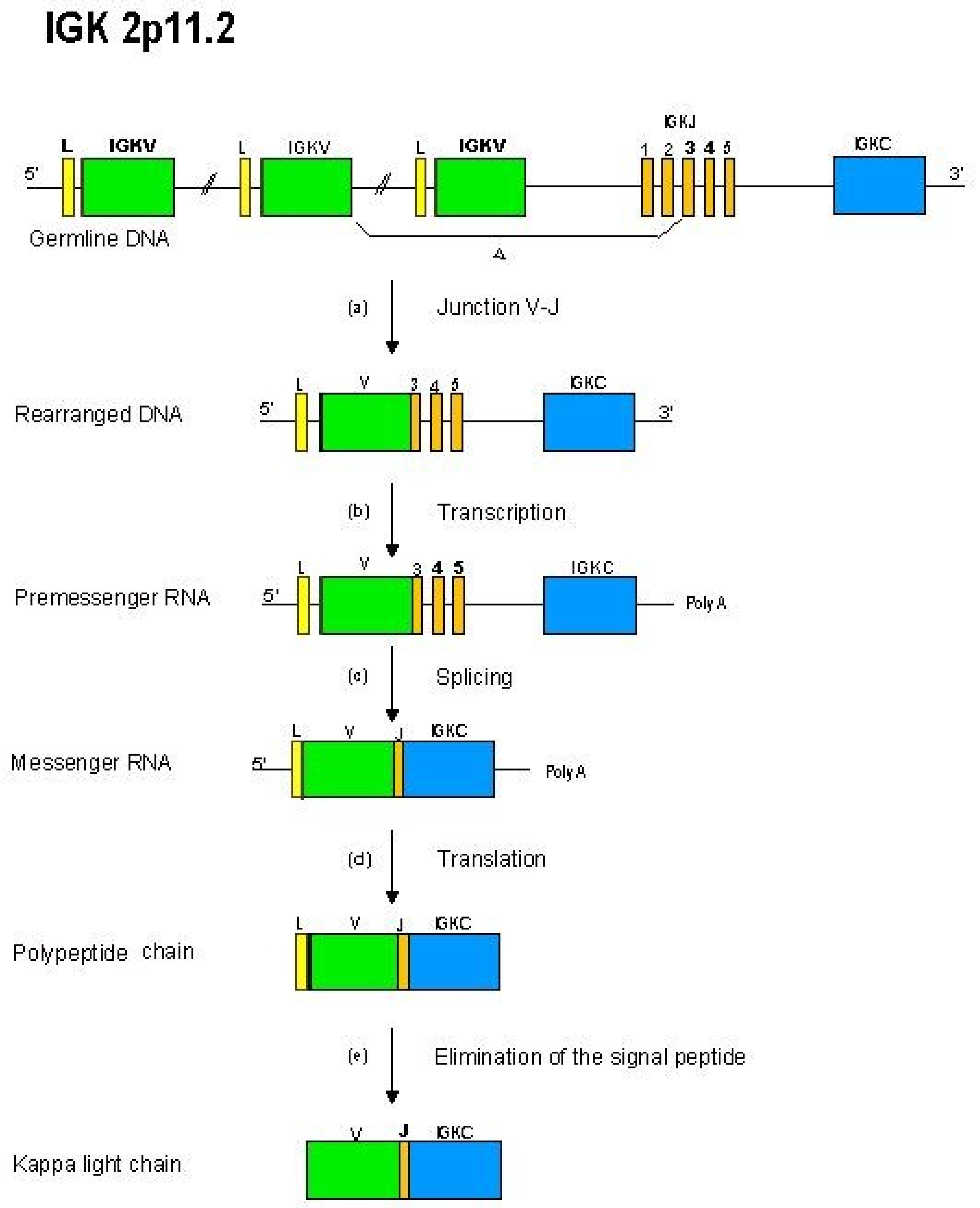{kind=link}
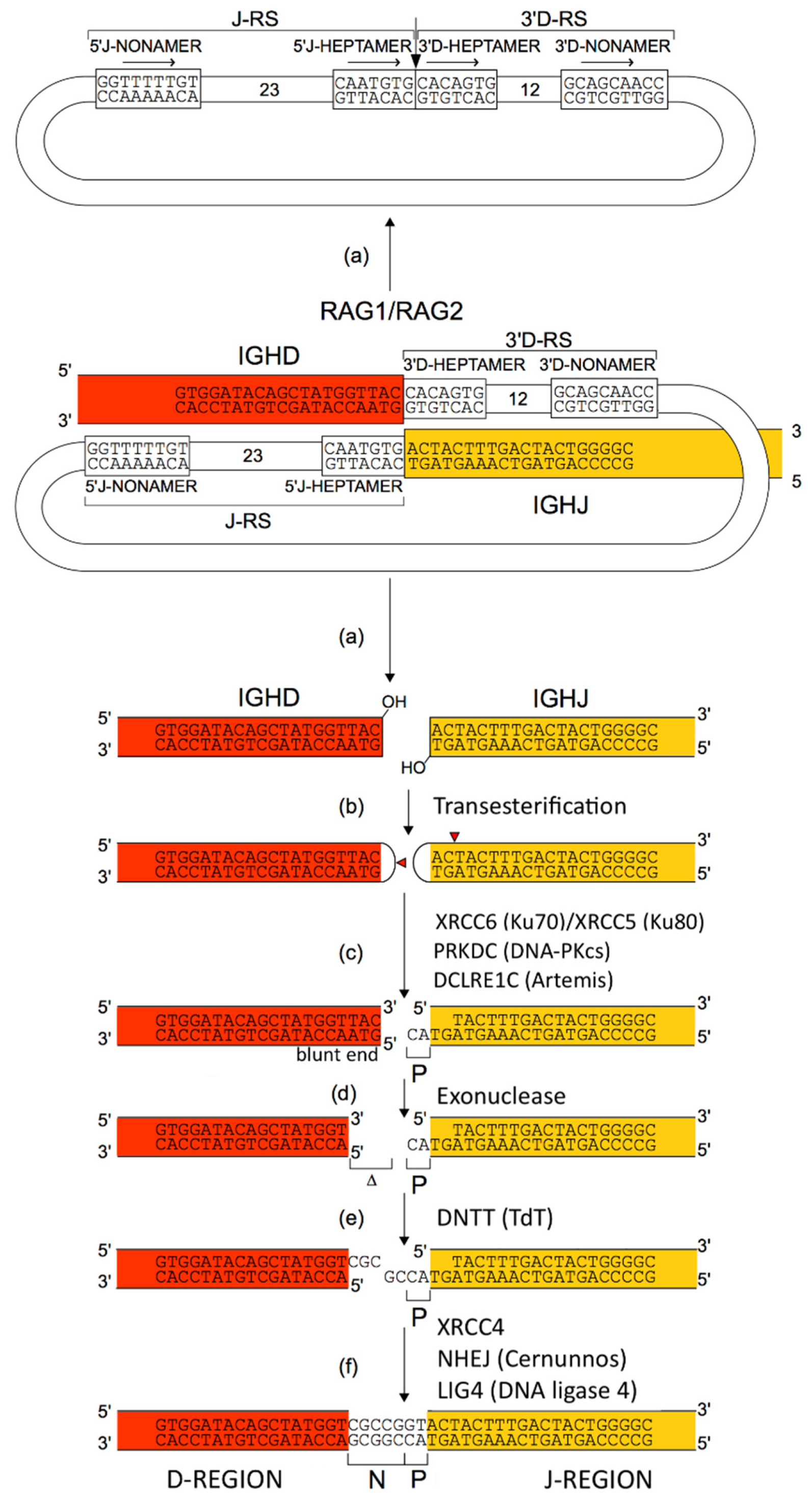{kind=link}
{kind=link}
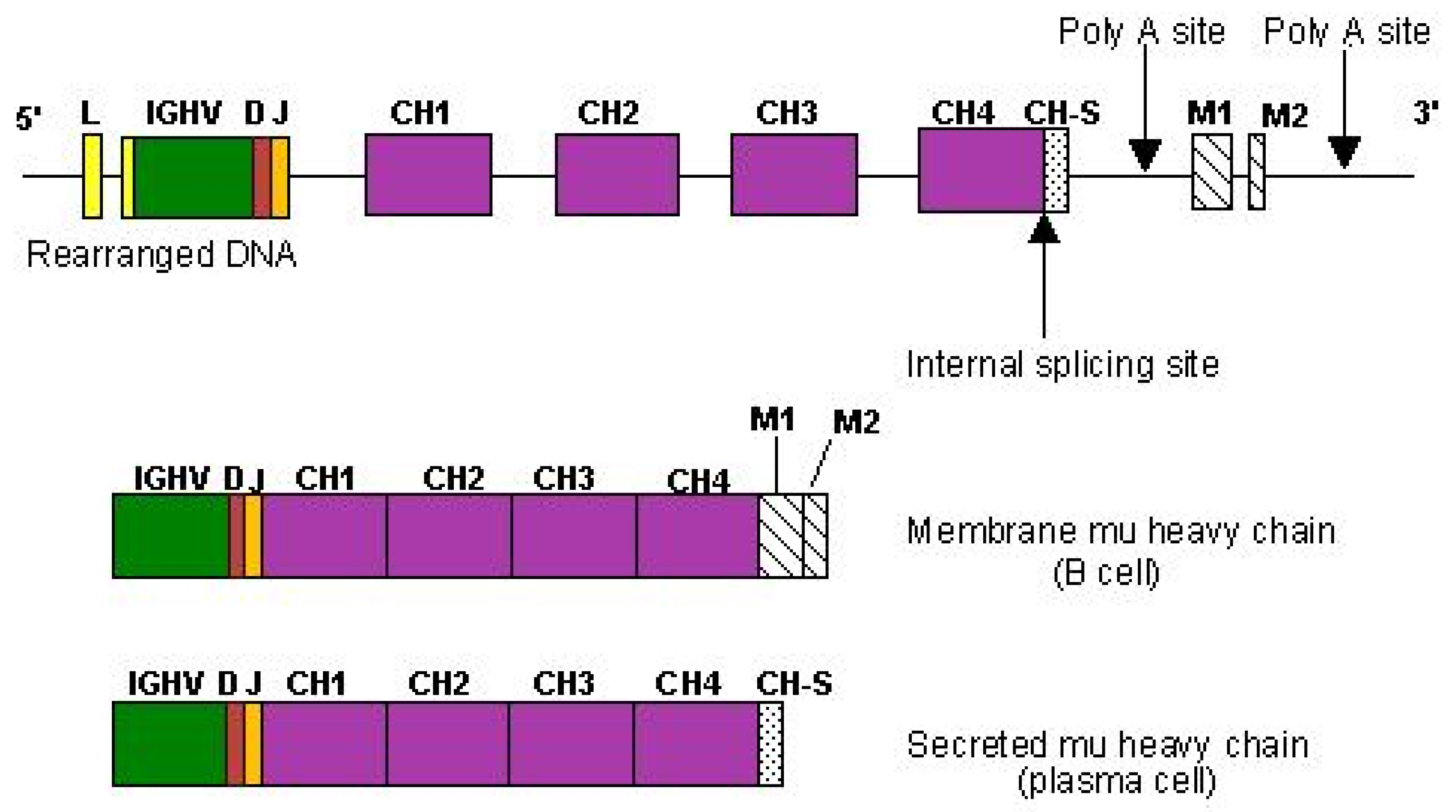{kind=link}
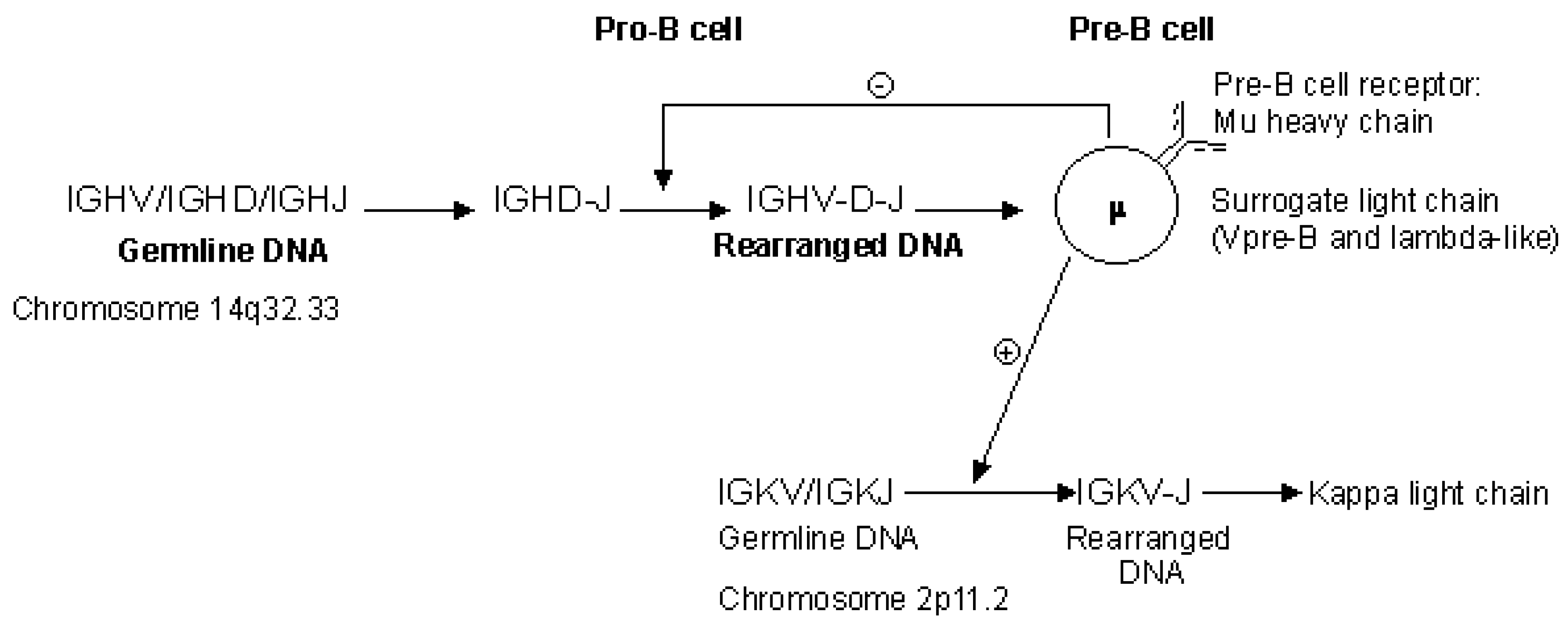{kind=link}
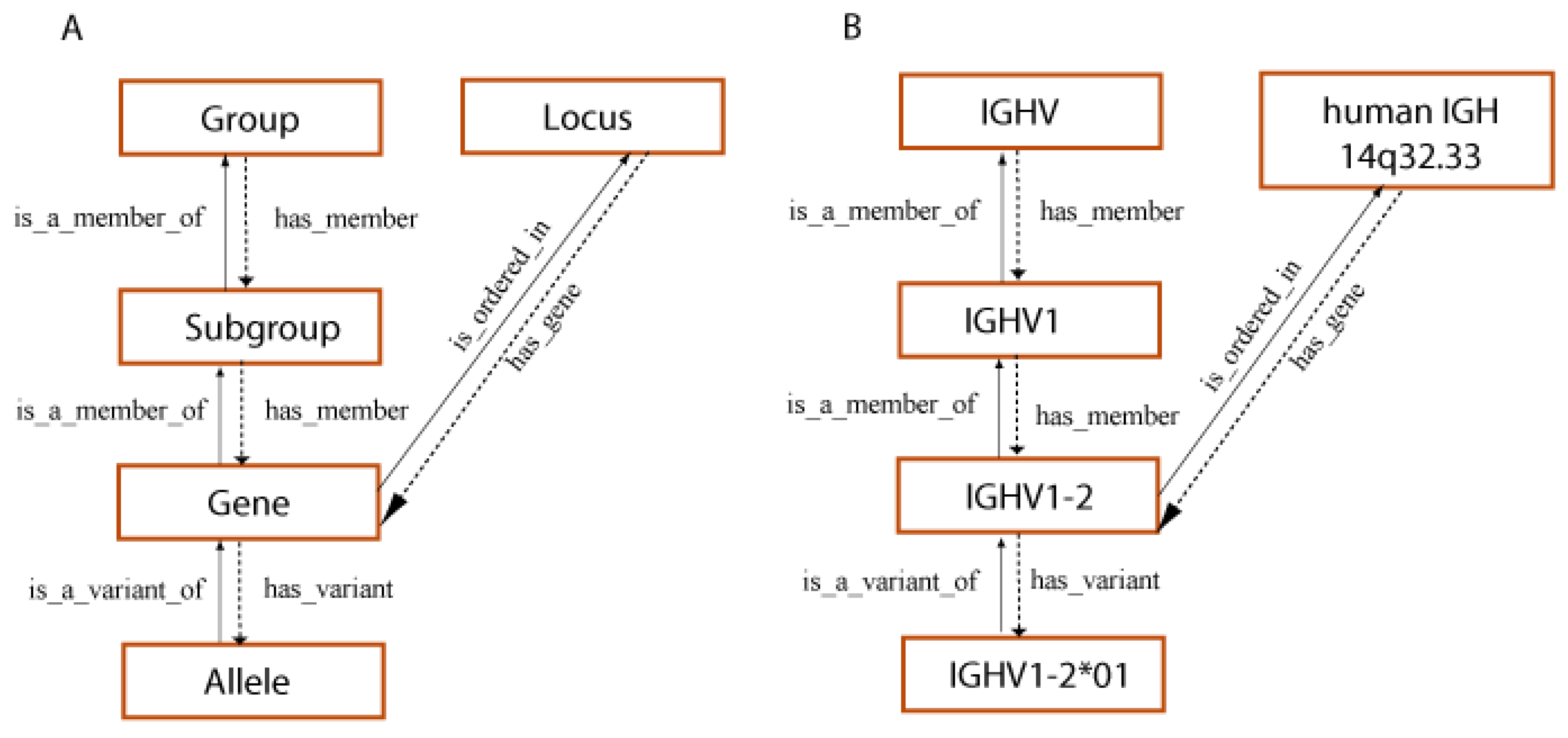{kind=link}
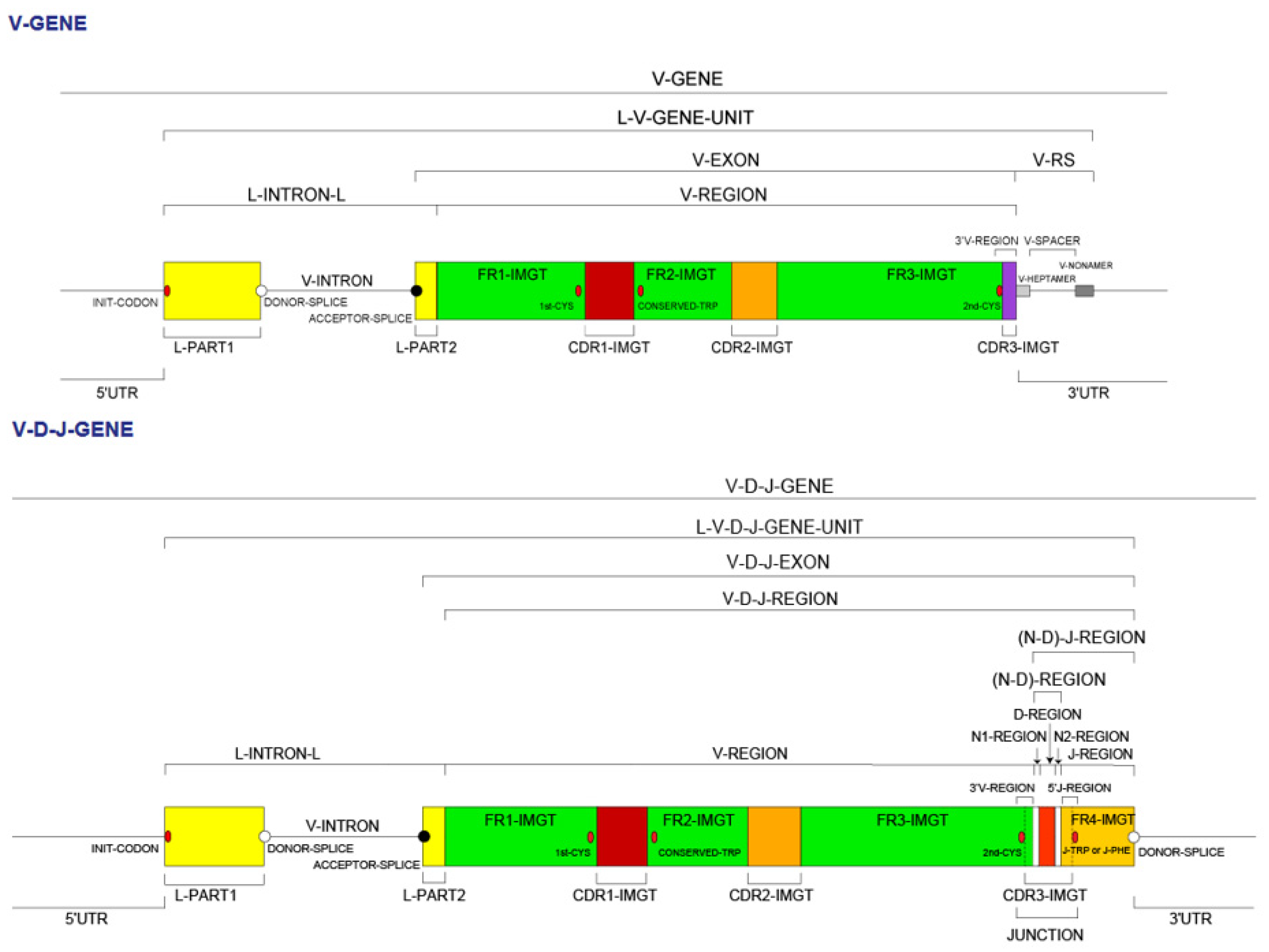{kind=link}
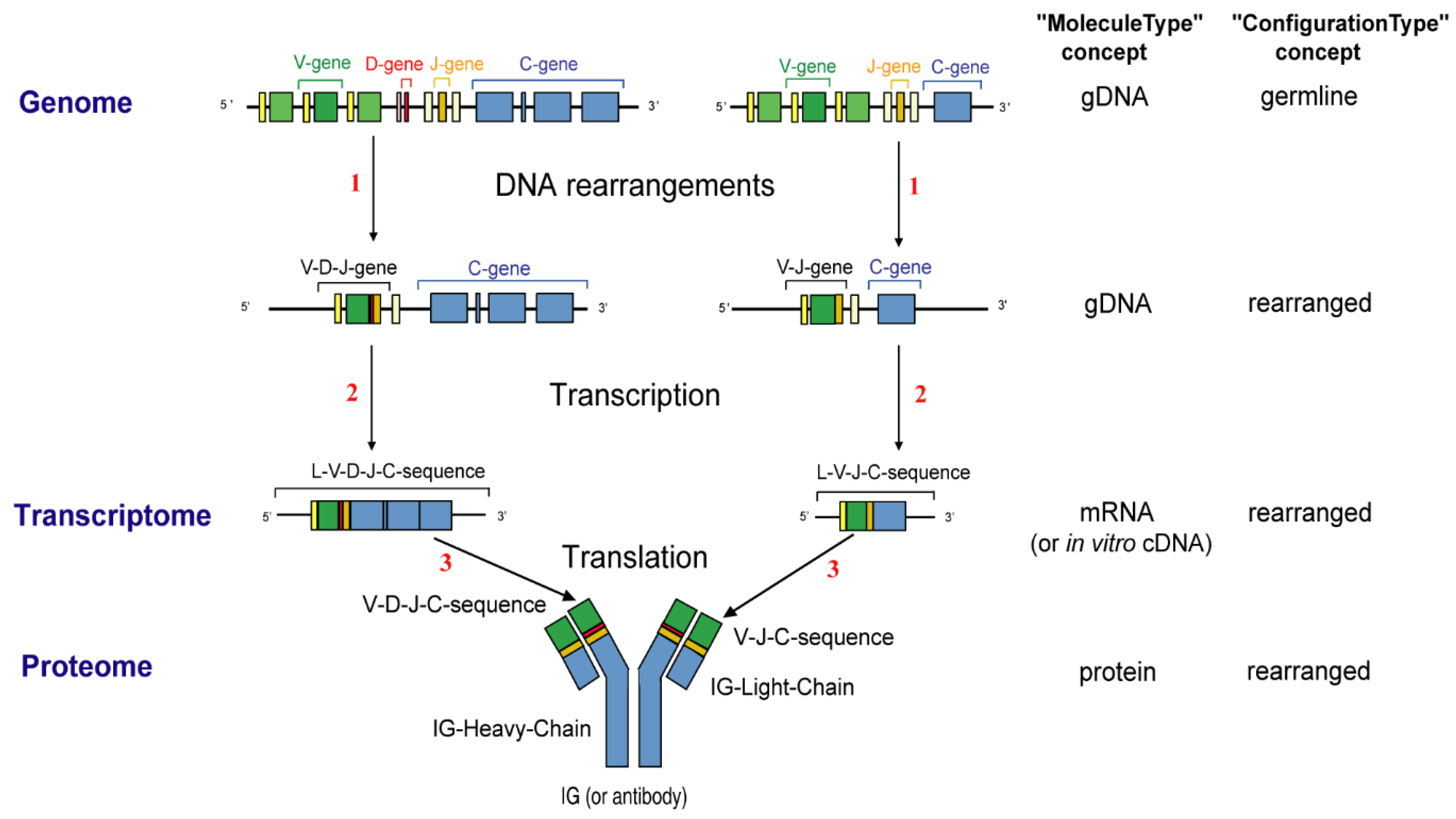{kind=link}
{kind=link}
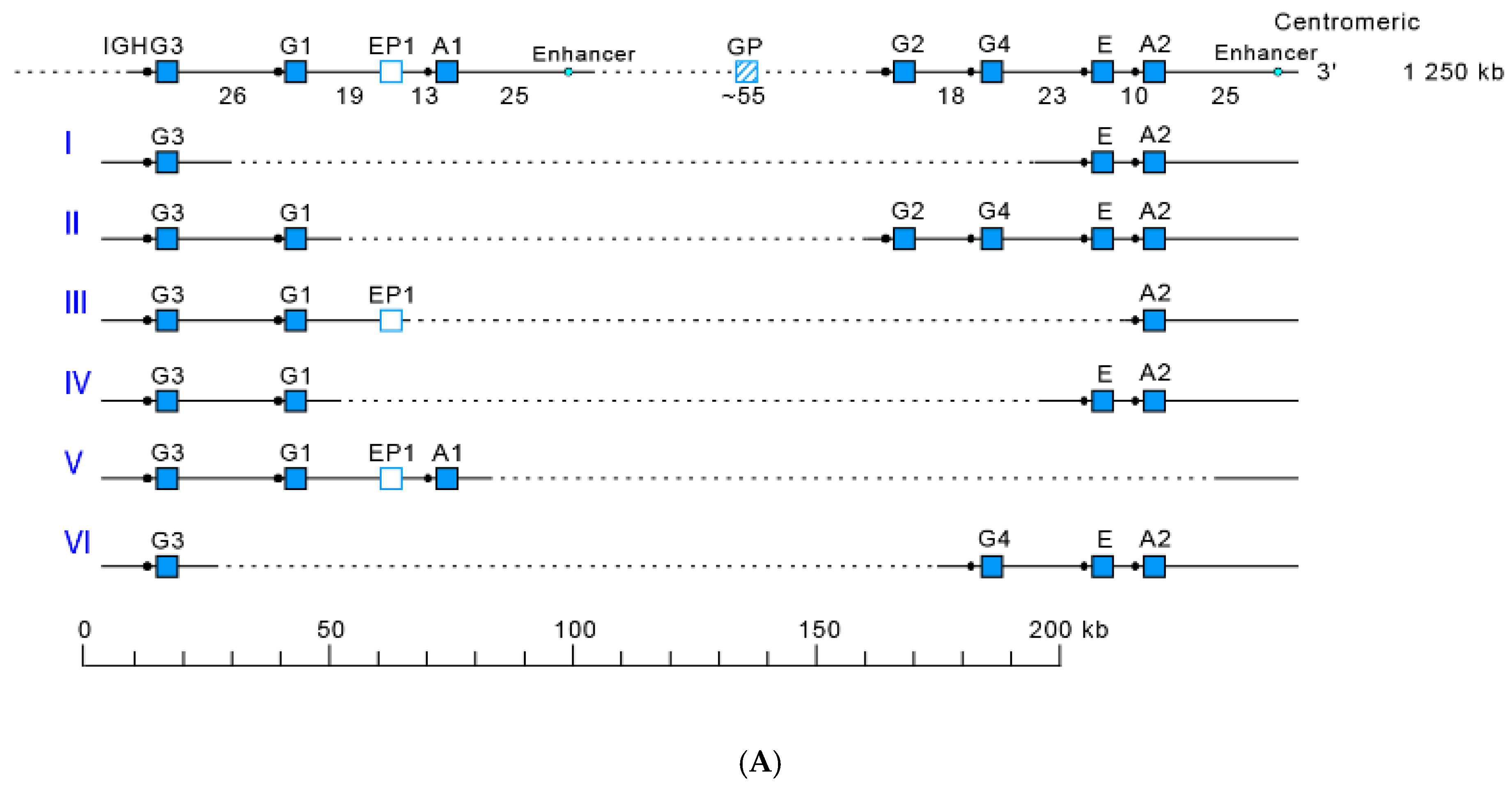{kind=link}
{kind=link}
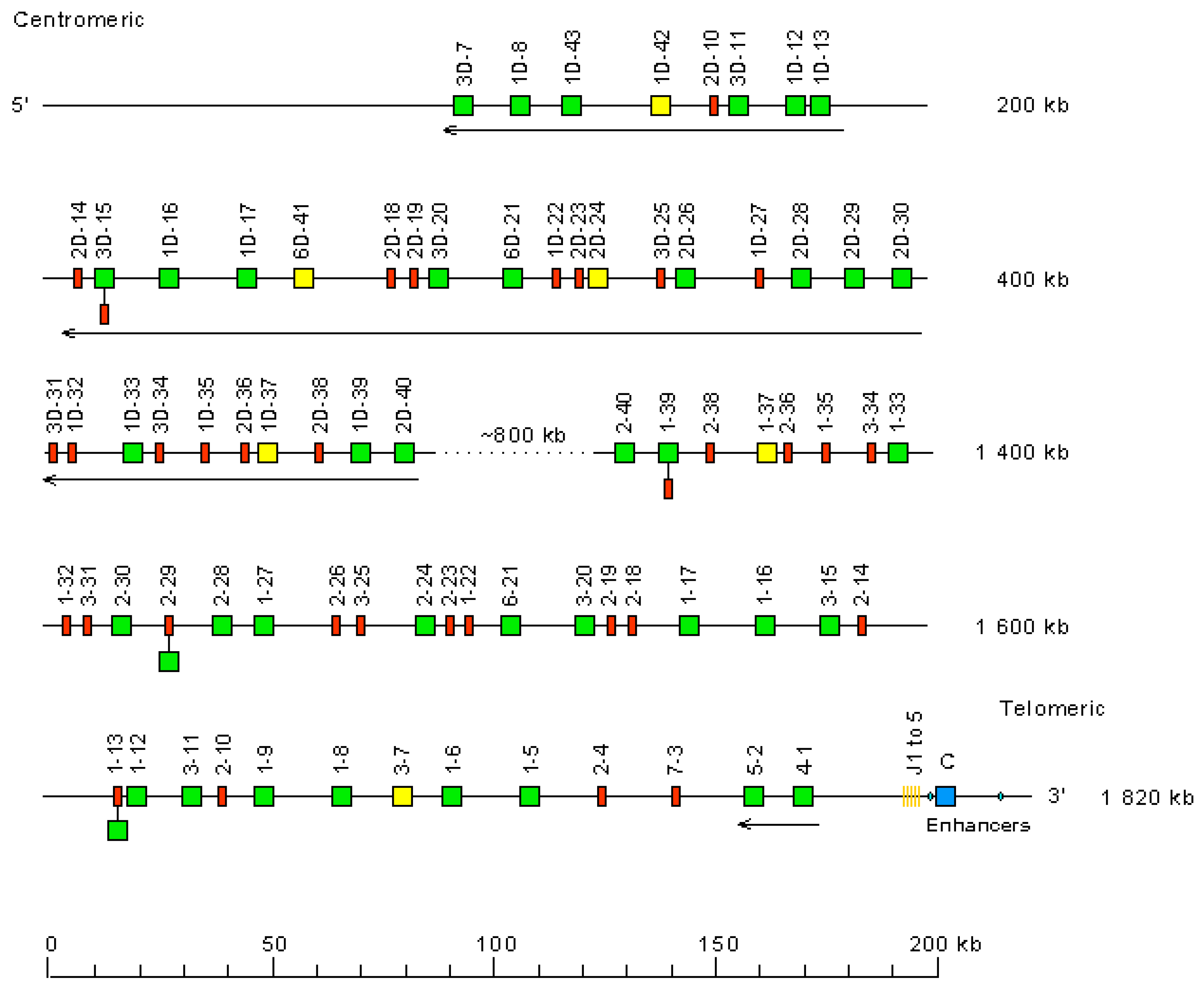{kind=link}
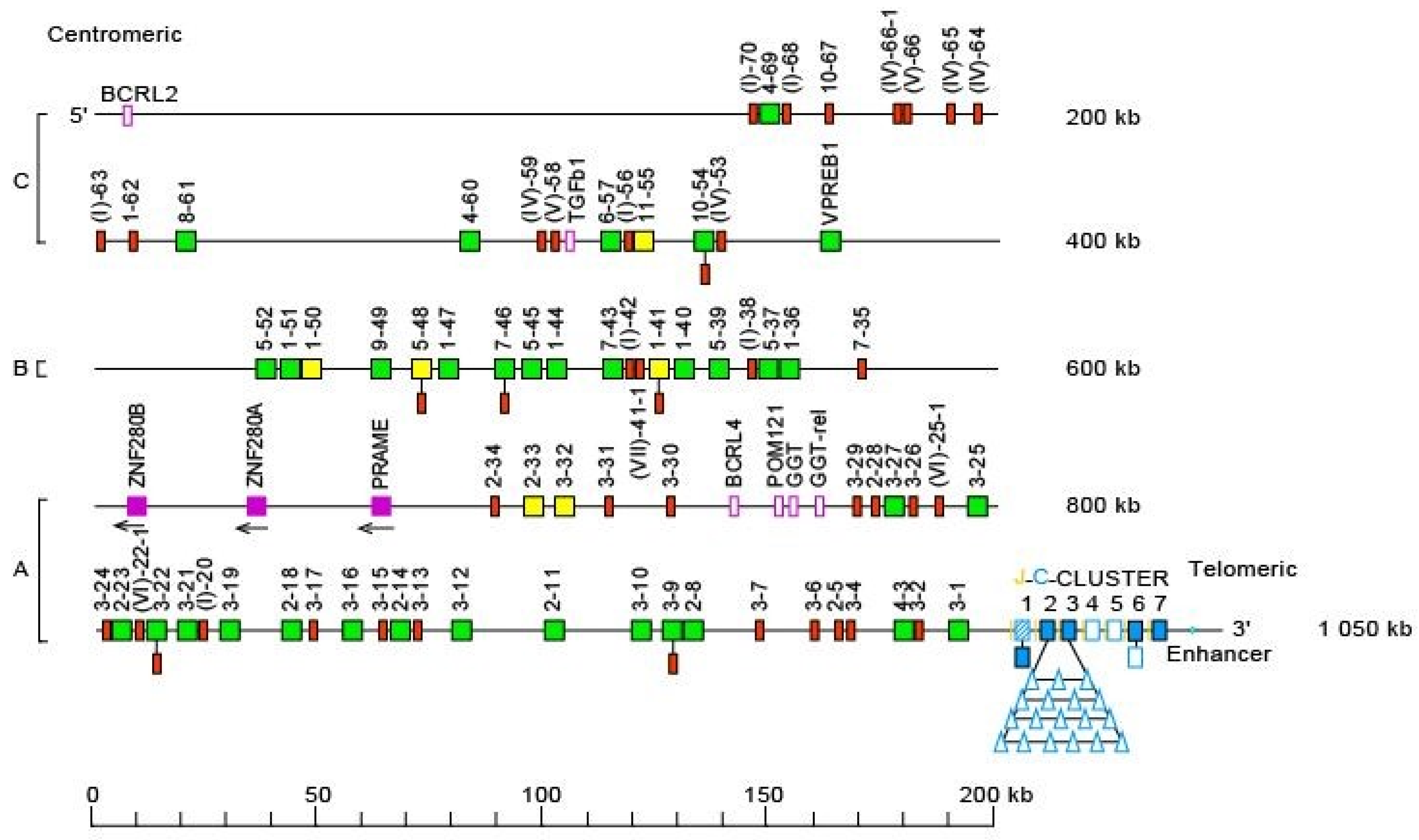{kind=link}
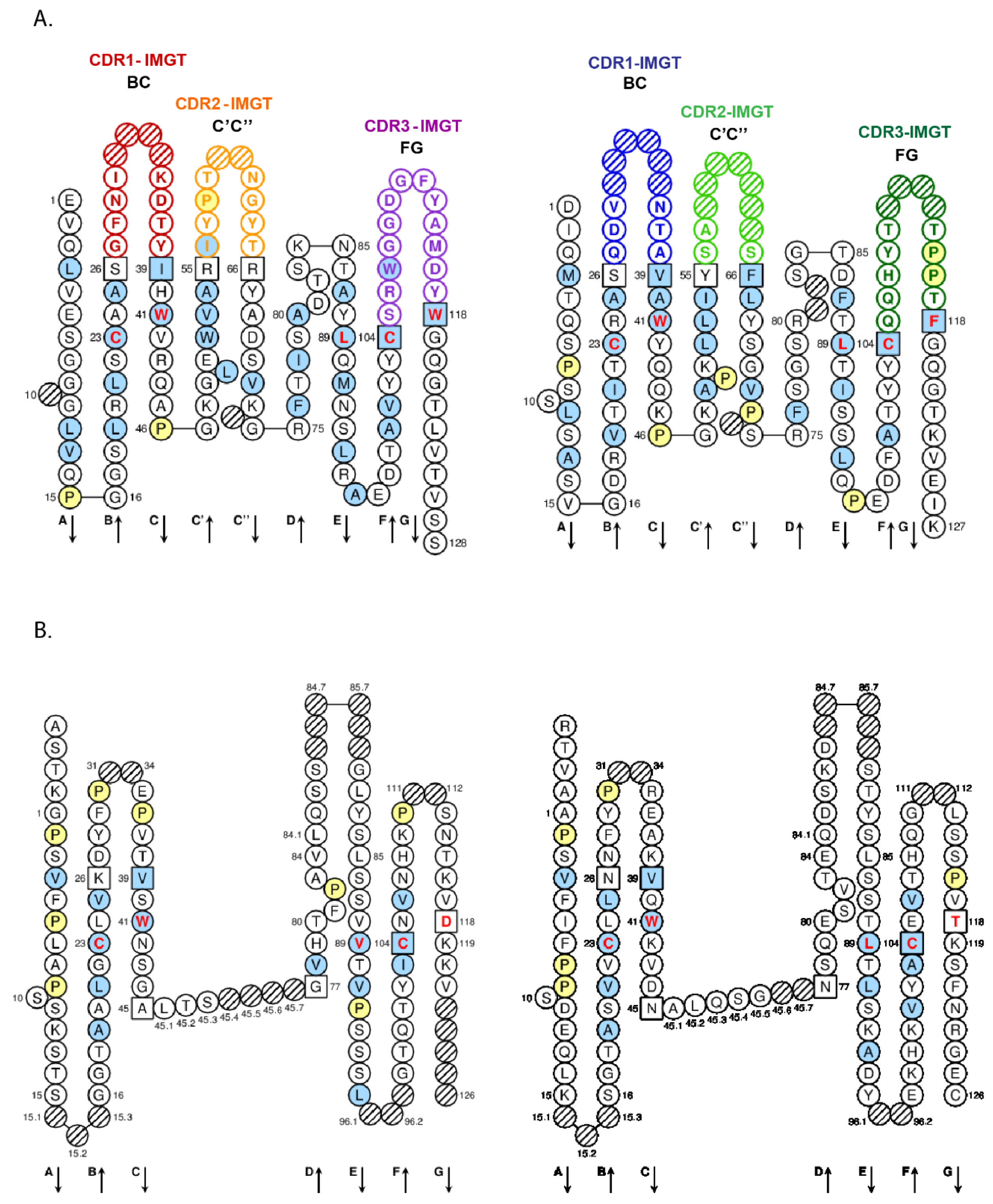{kind=link}
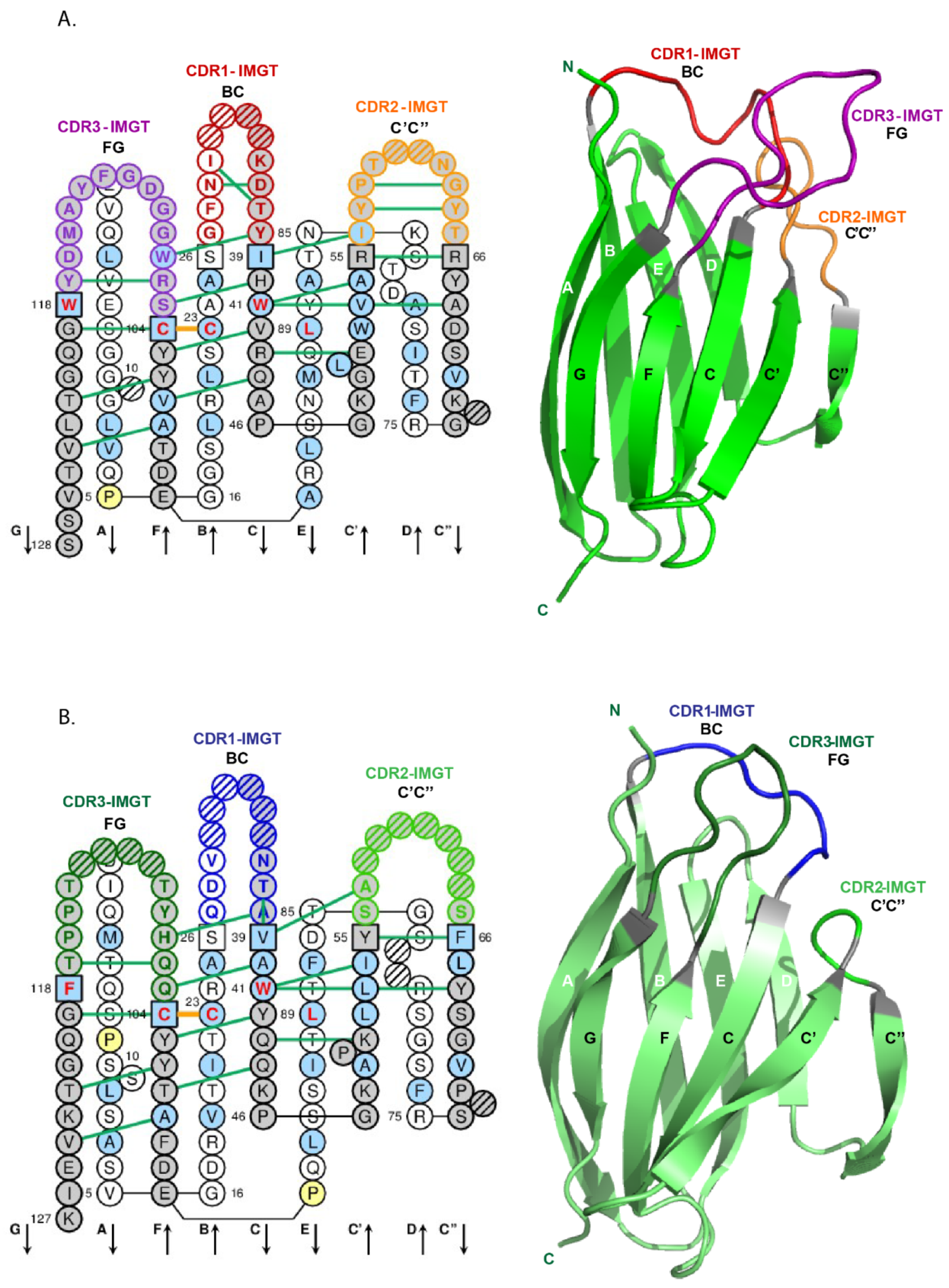{kind=link}
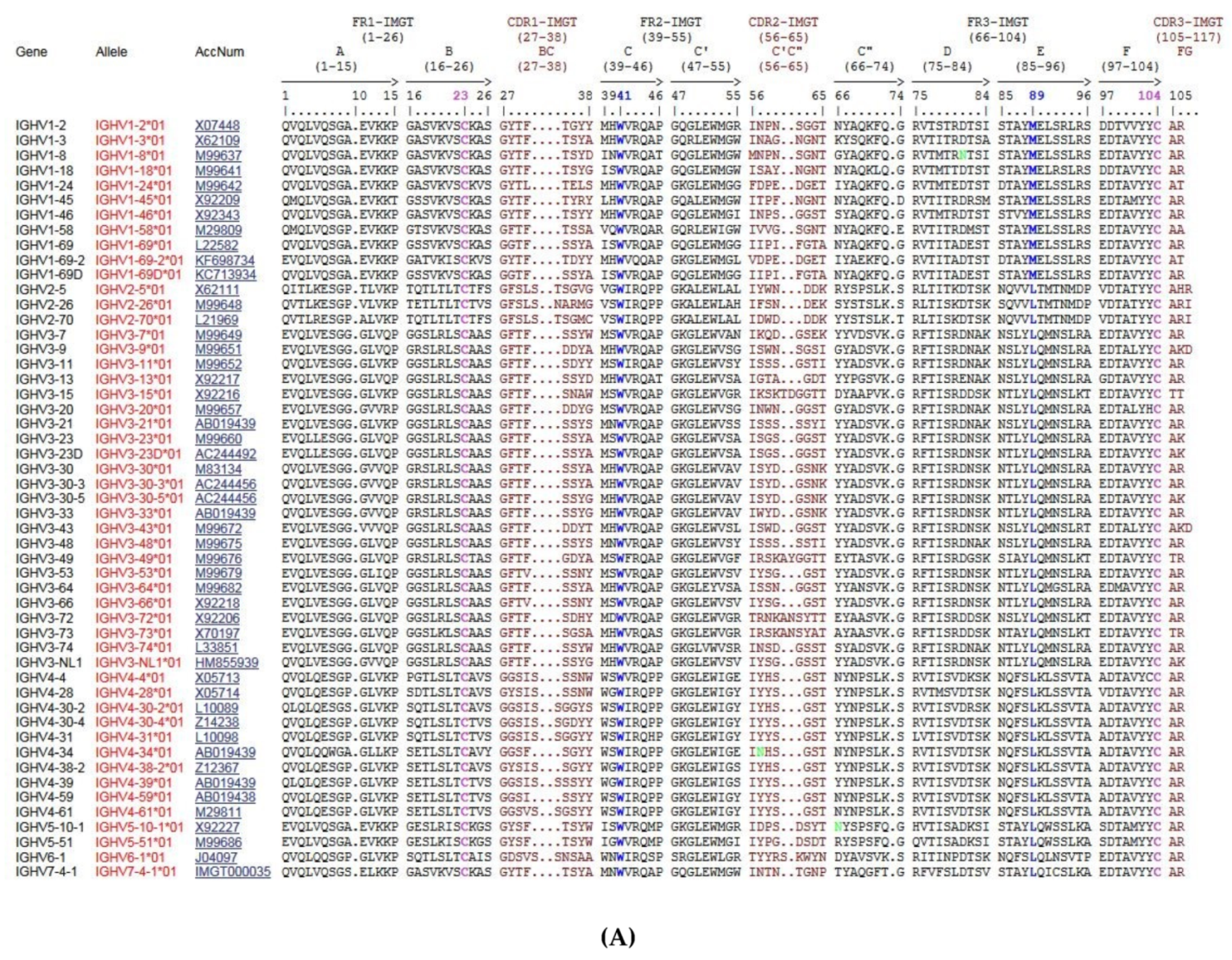{kind=link}
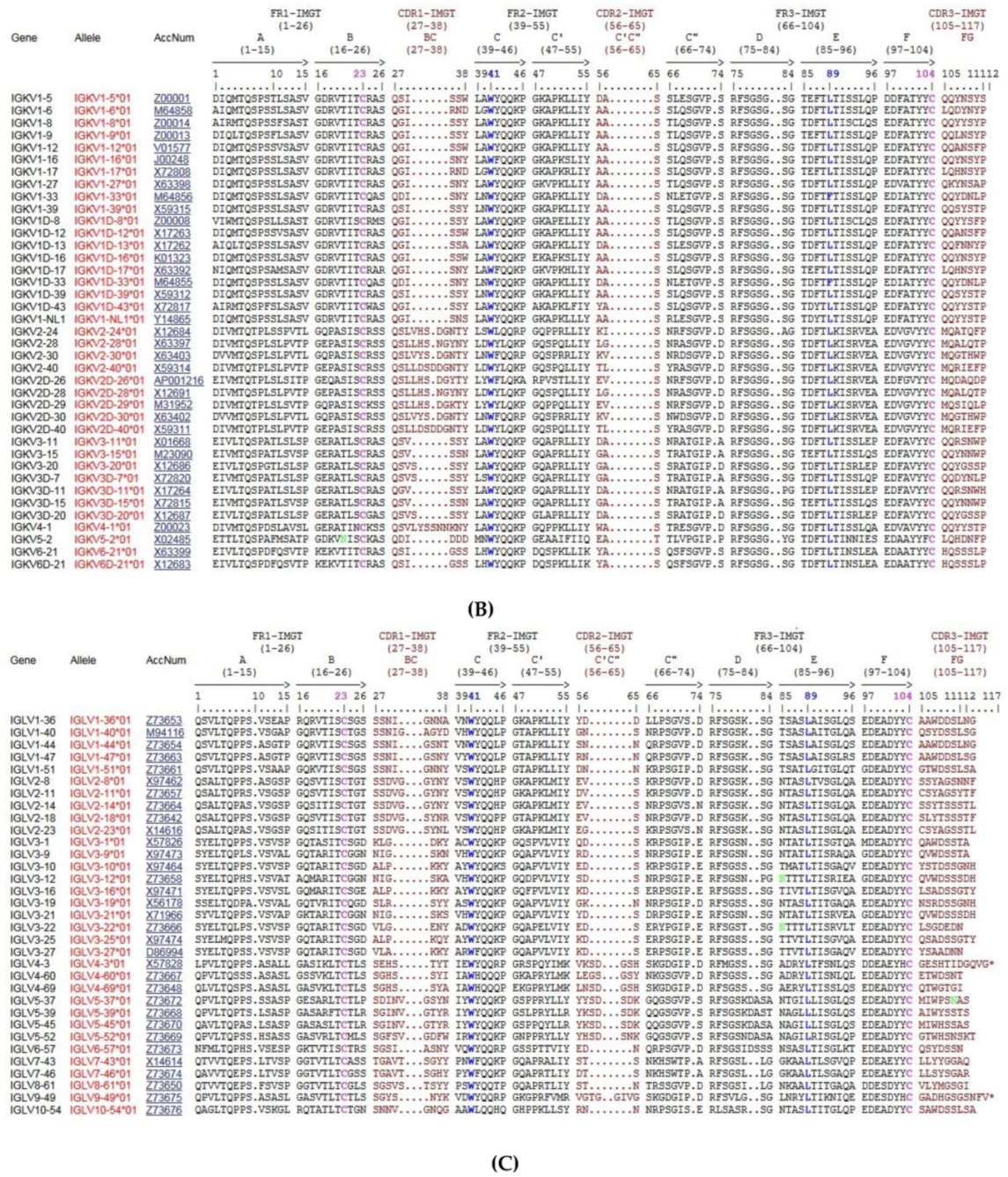{kind=link}
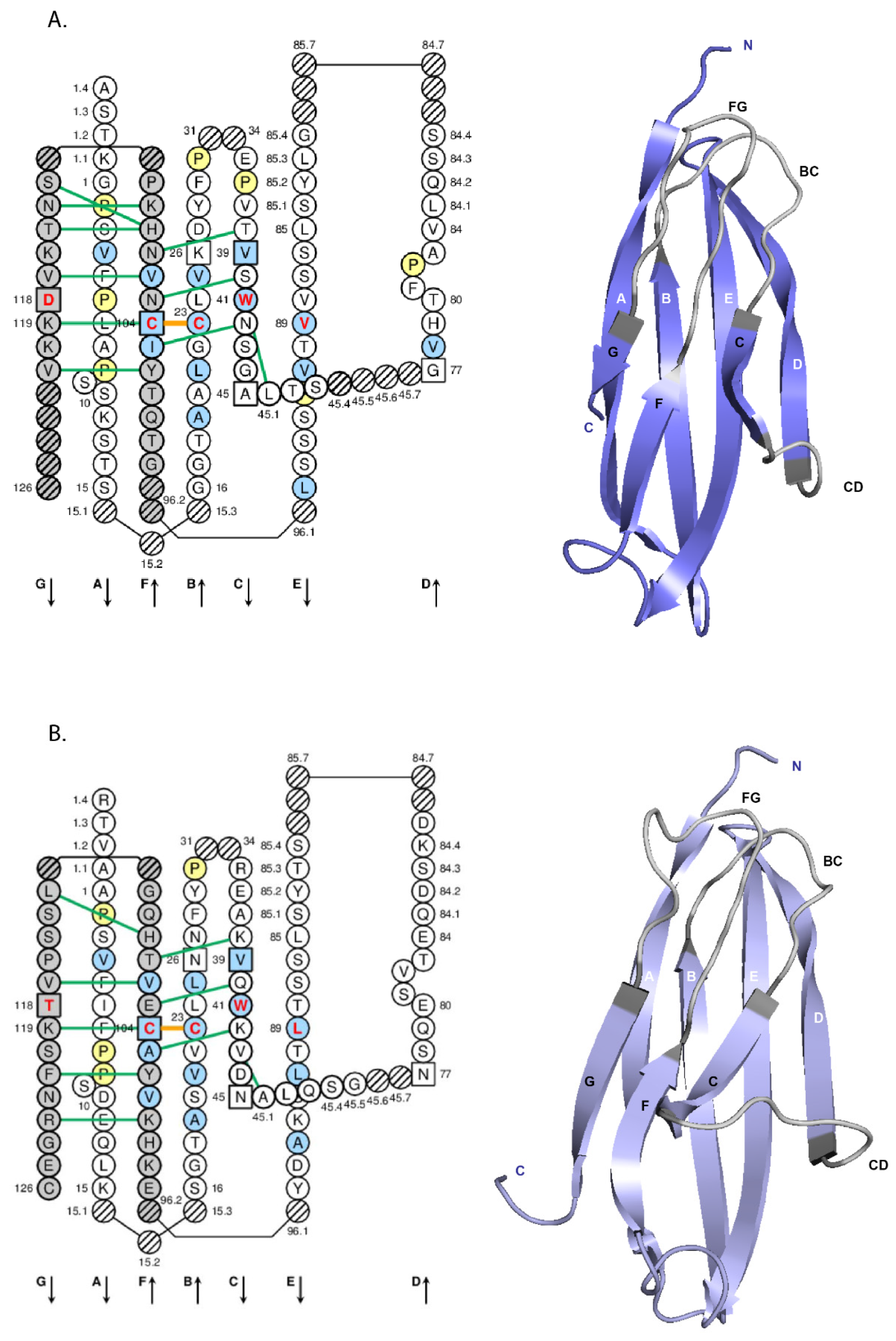{kind=link}
{kind=link}
{kind=link}
{kind=link}
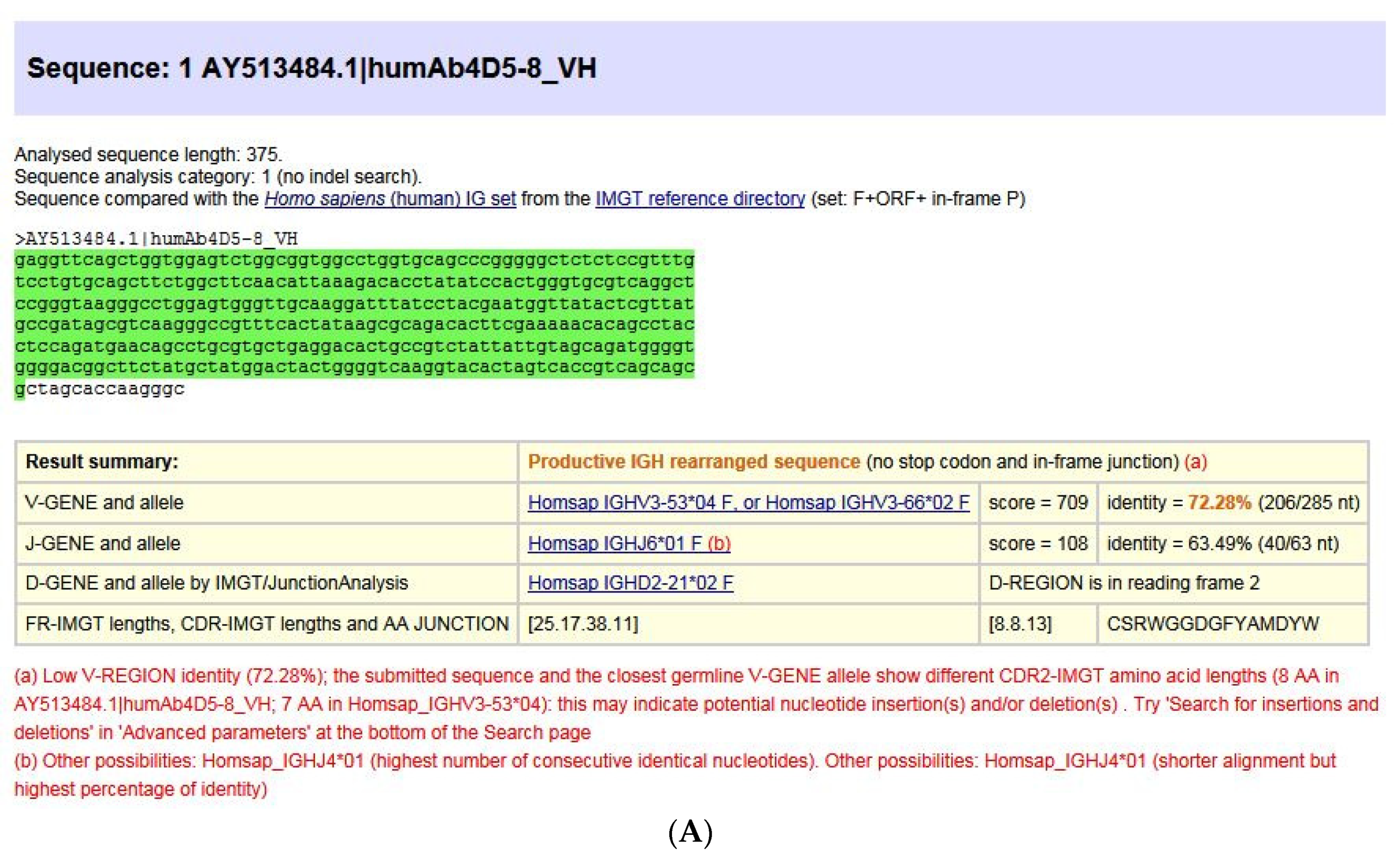{kind=link}
{kind=link}
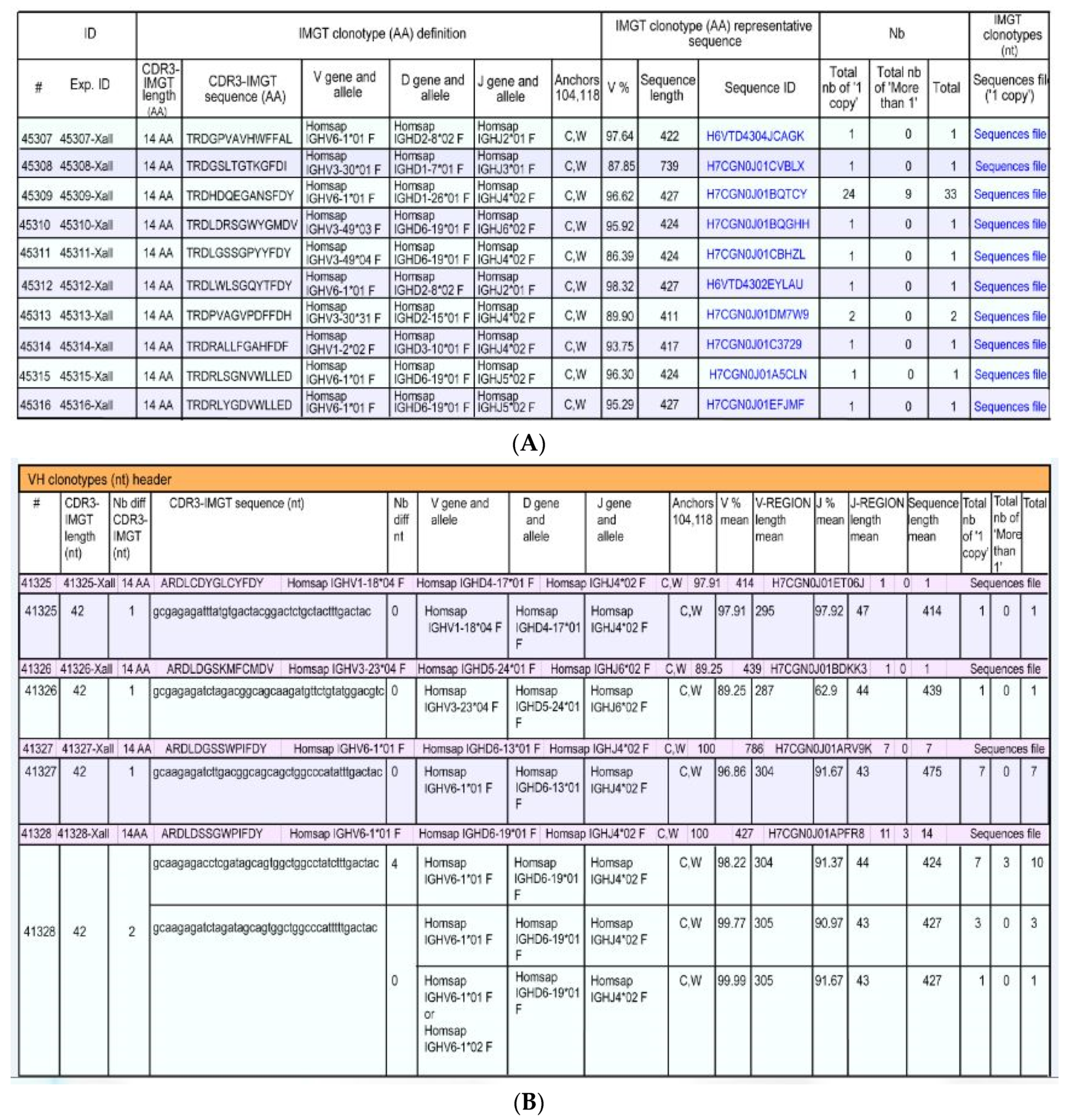{kind=link}
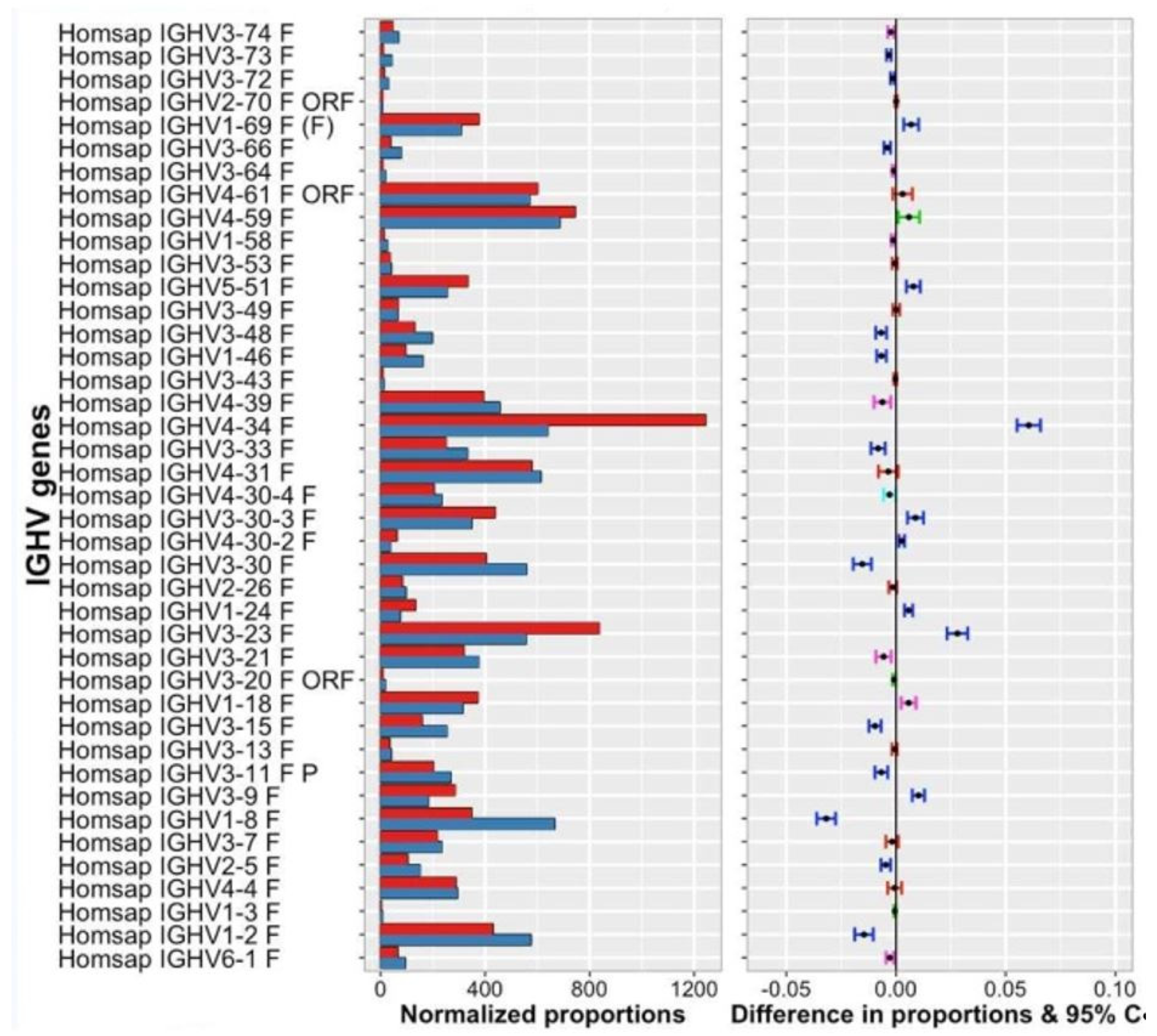{kind=link}
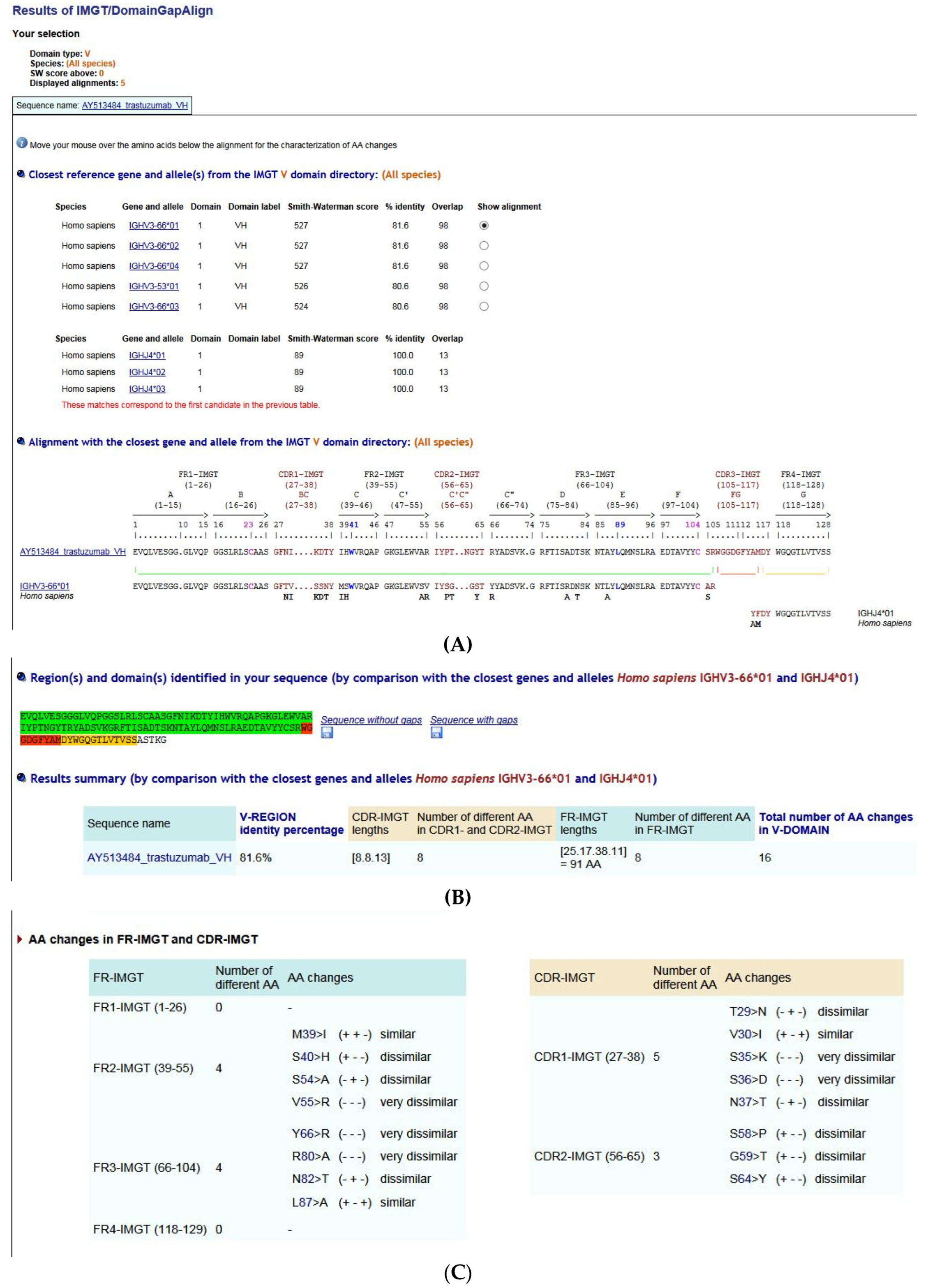{kind=link}
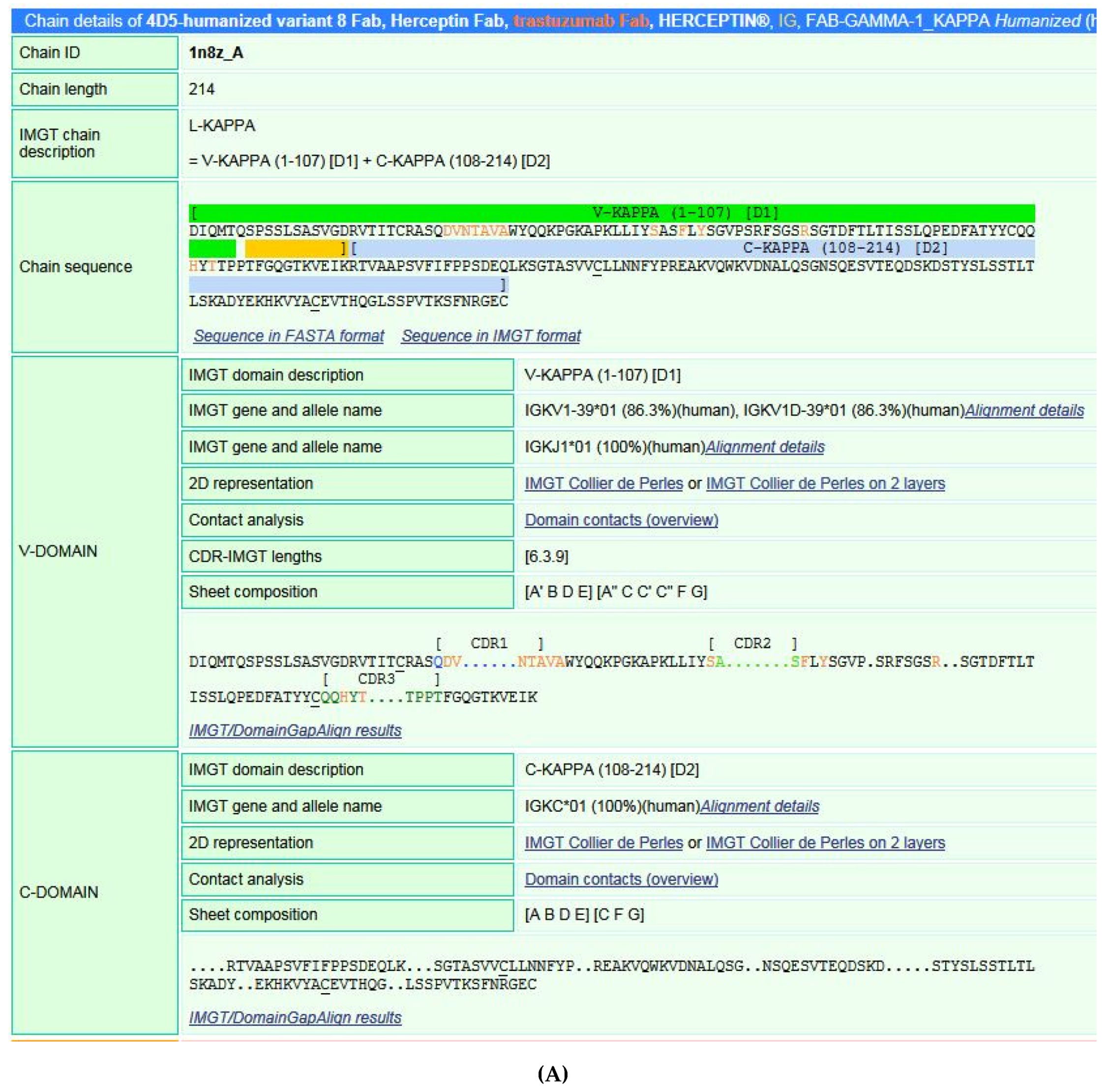{kind=link}
{kind=link}
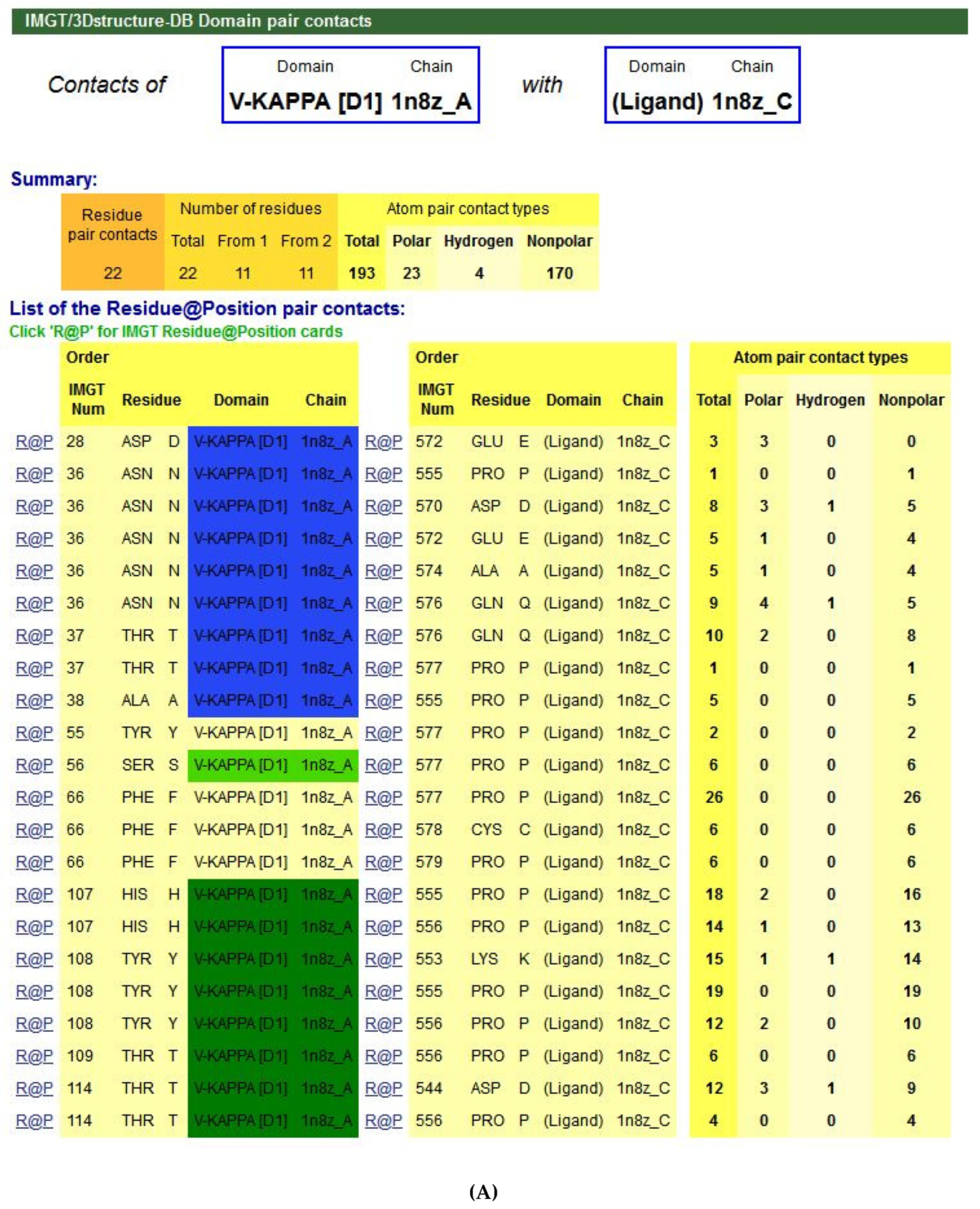{kind=link}
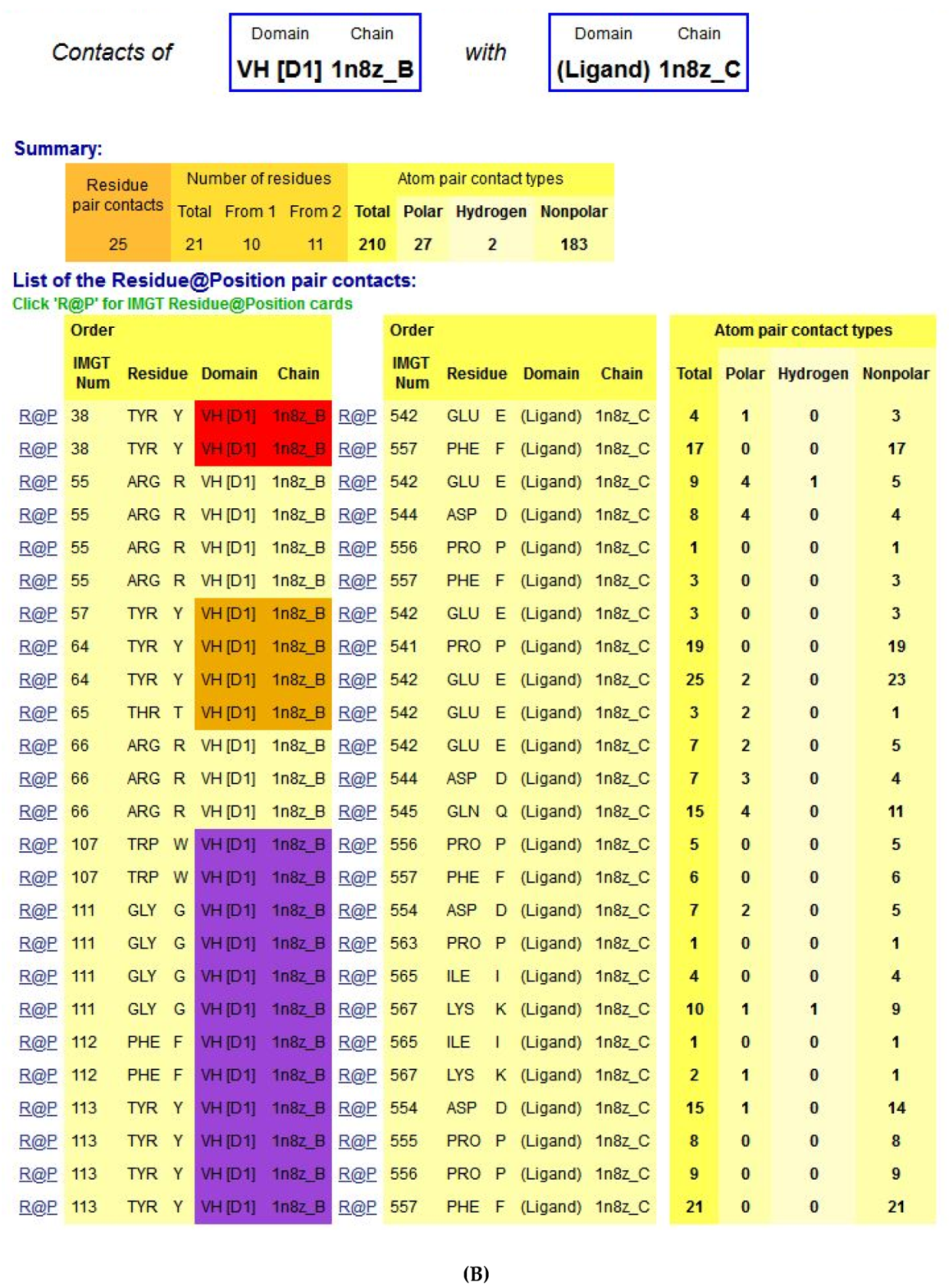{kind=link}
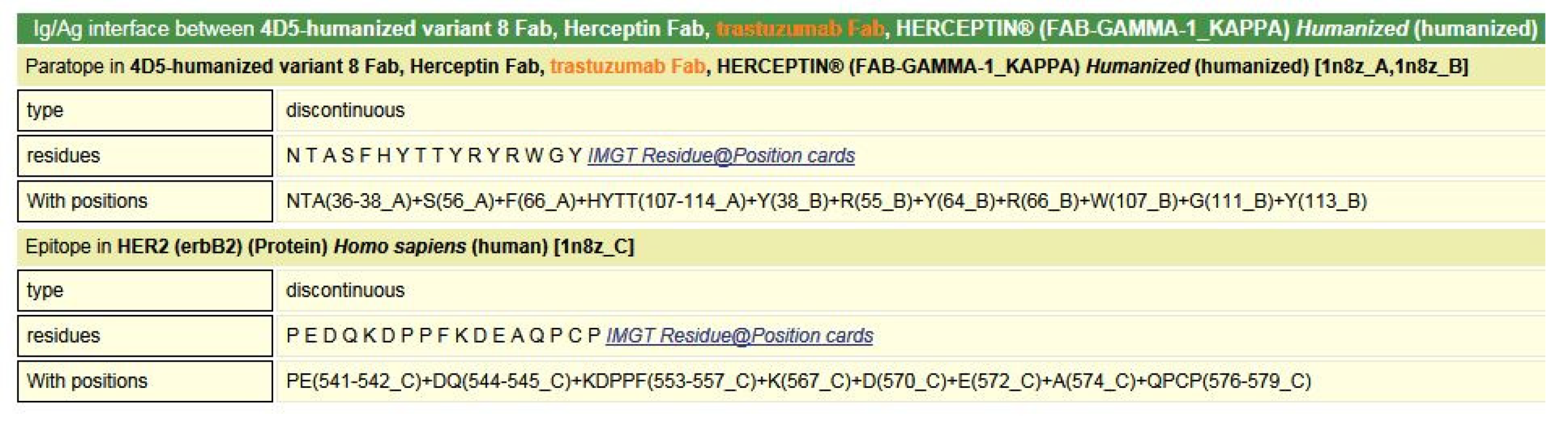{kind=link}
{kind=link}
{kind=link}
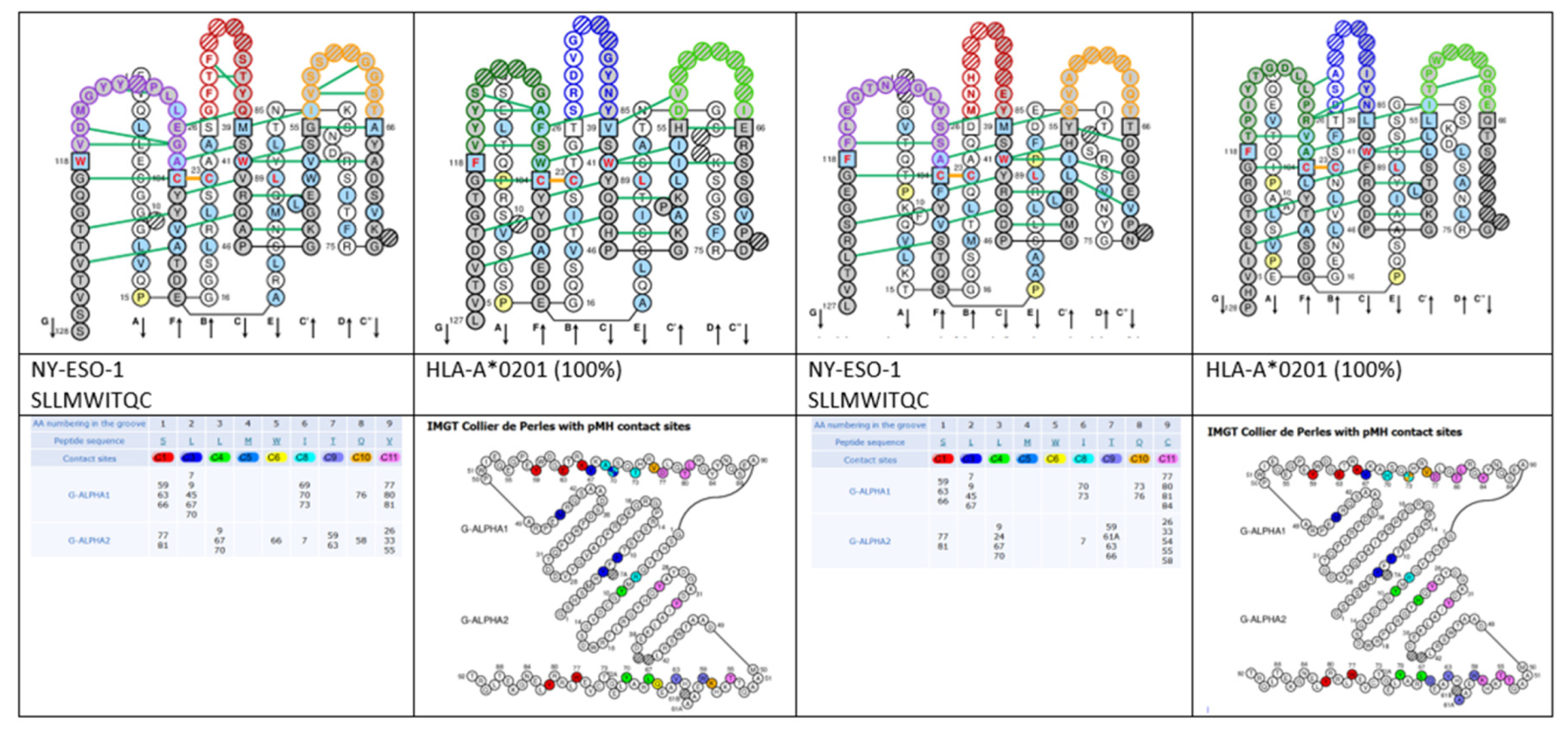{kind=link}
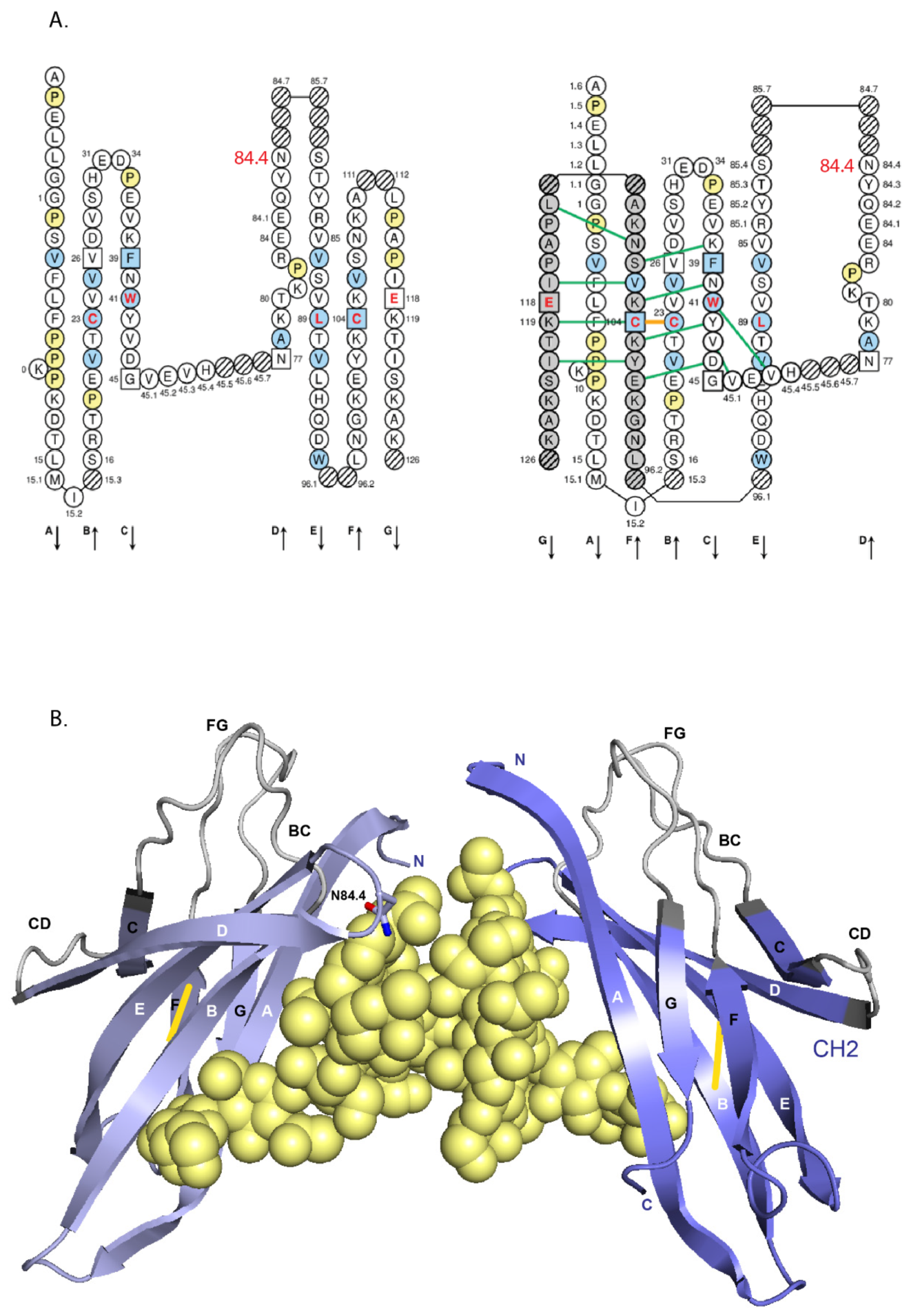{kind=link}
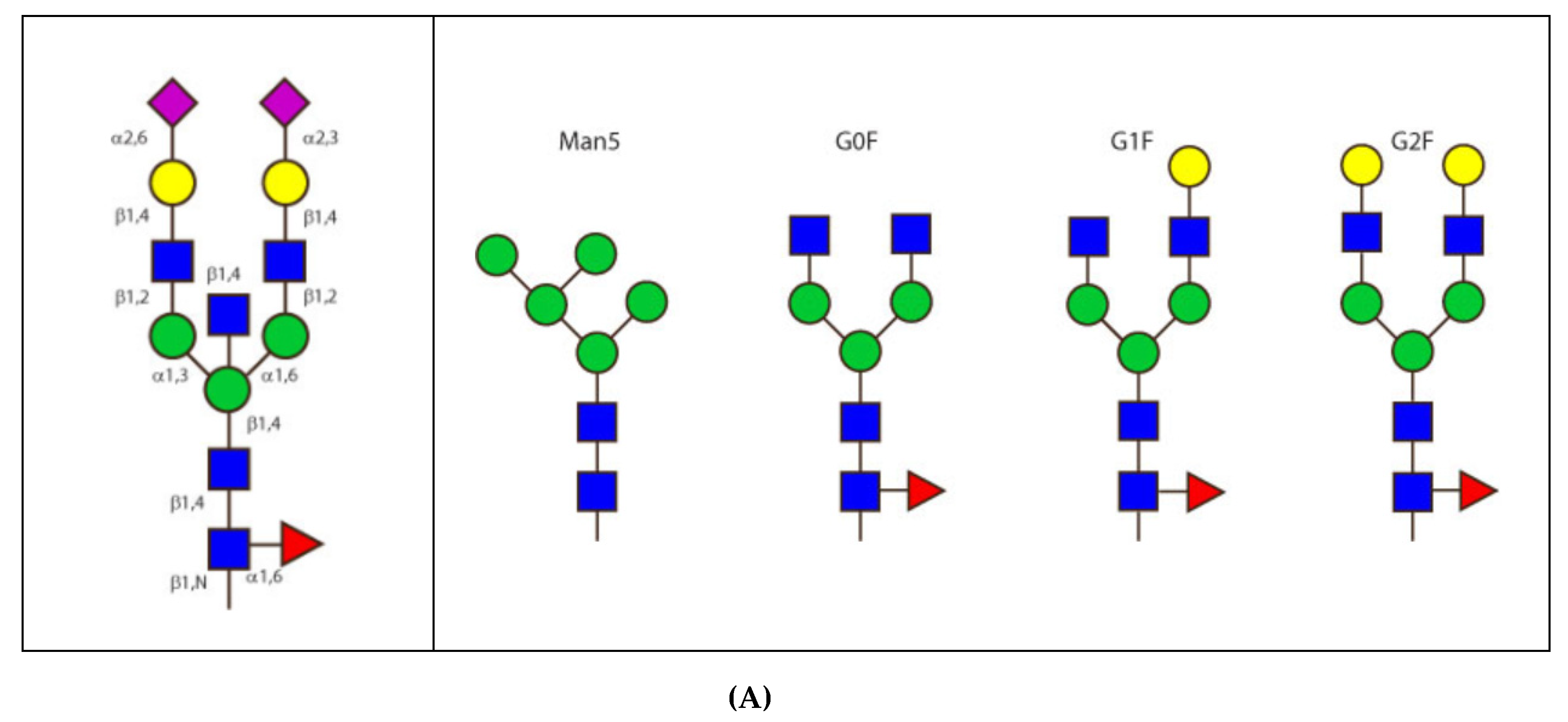{kind=link}
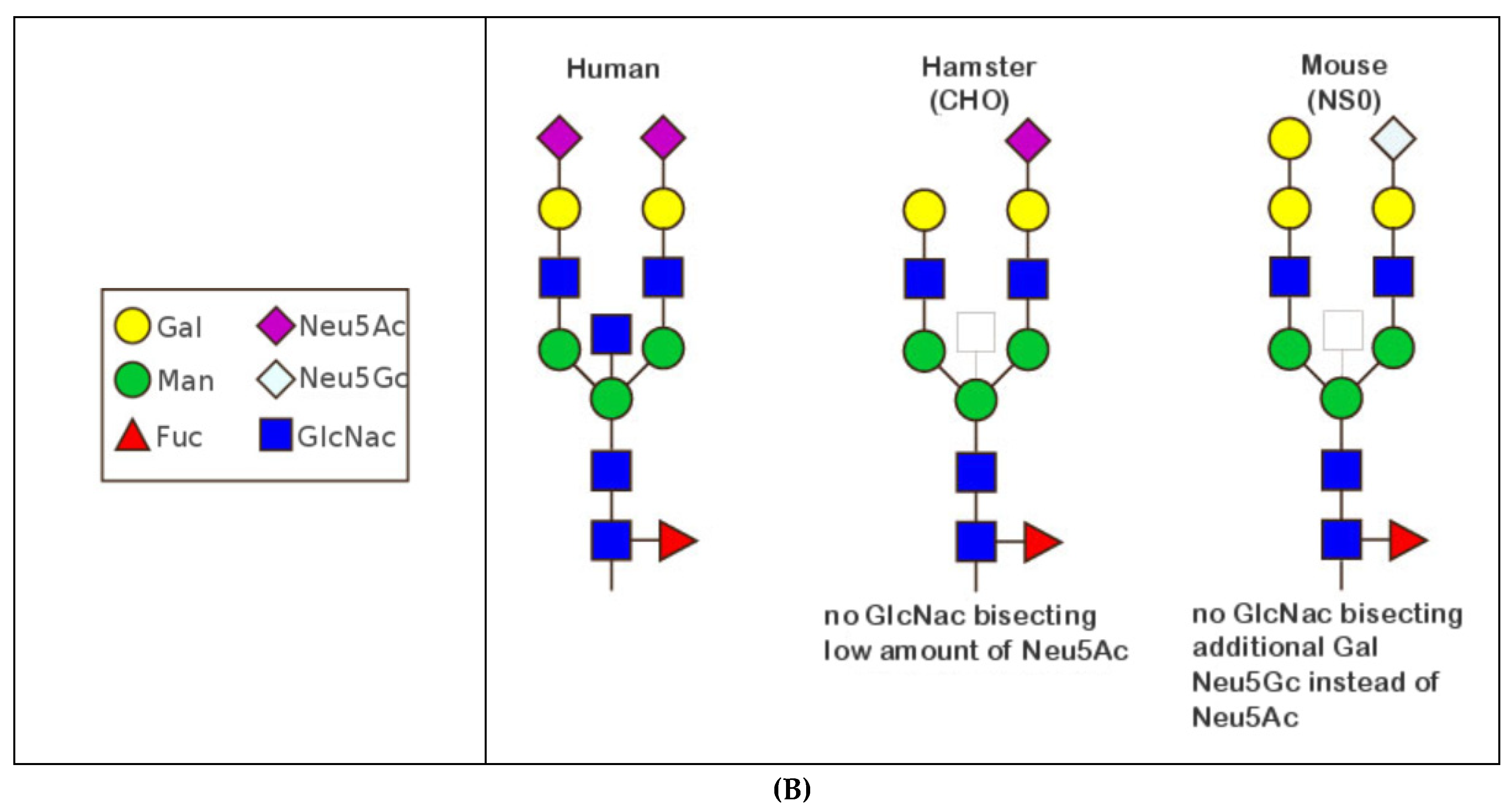{kind=link}
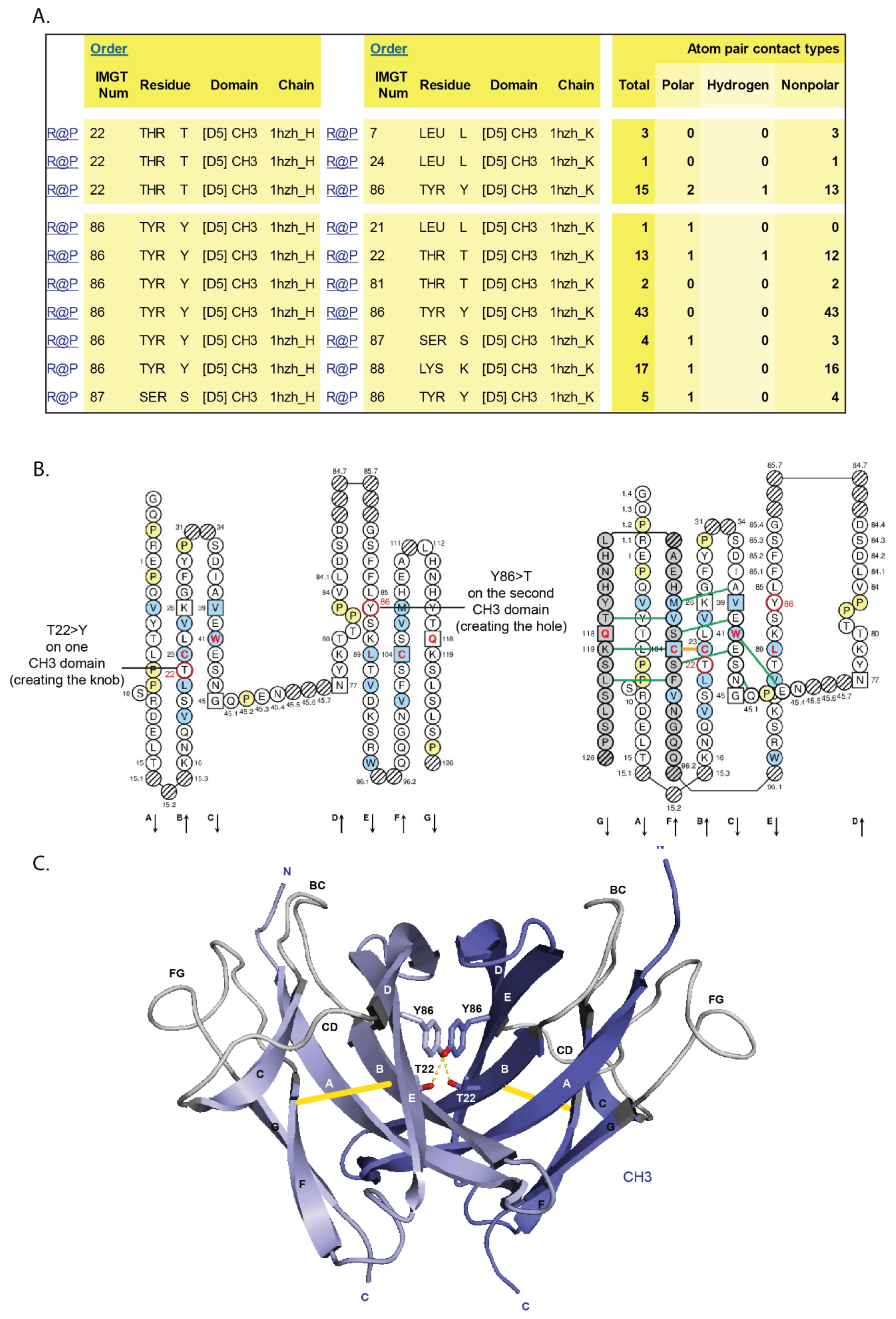{kind=link}
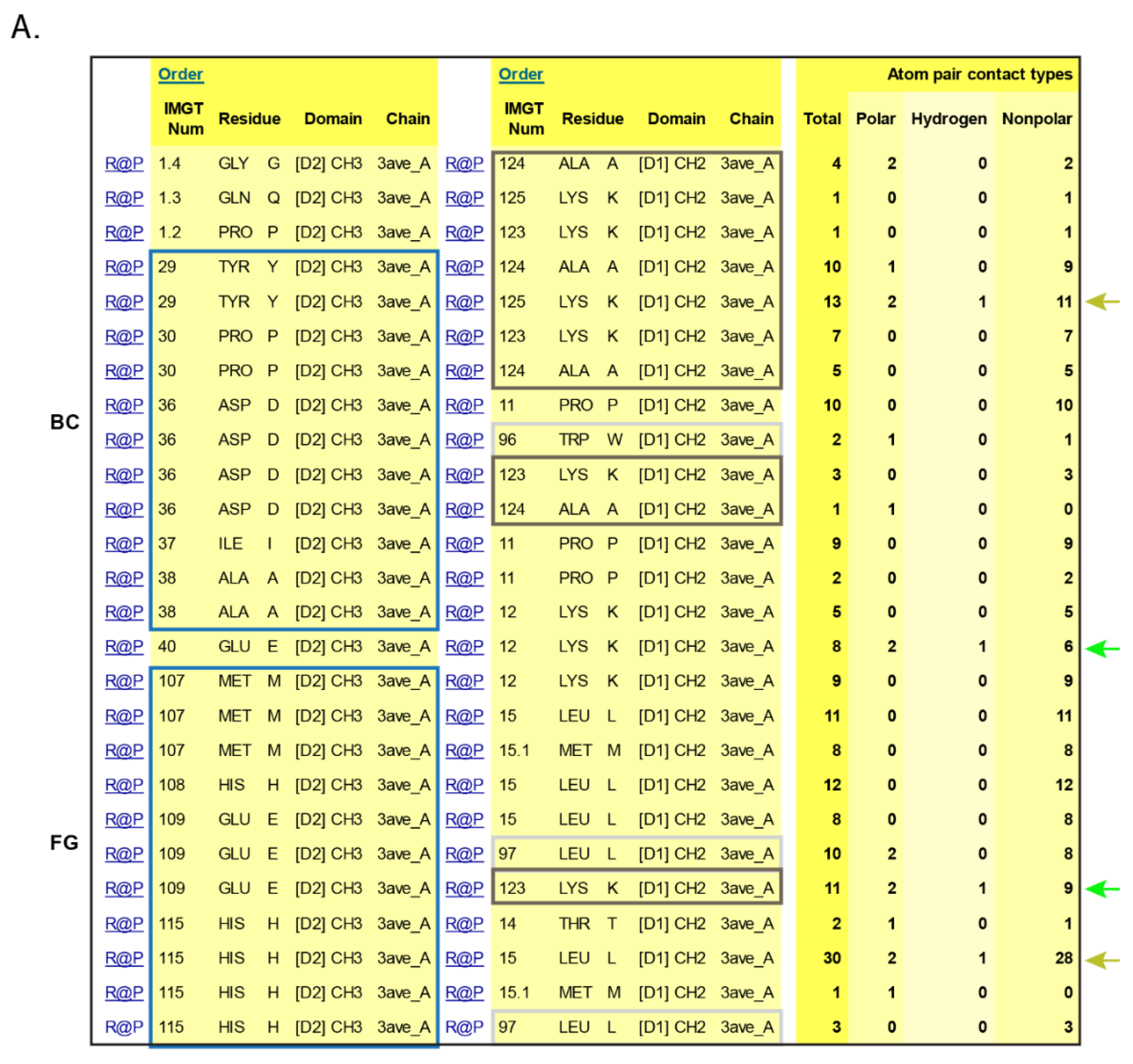{kind=link}
{kind=link}
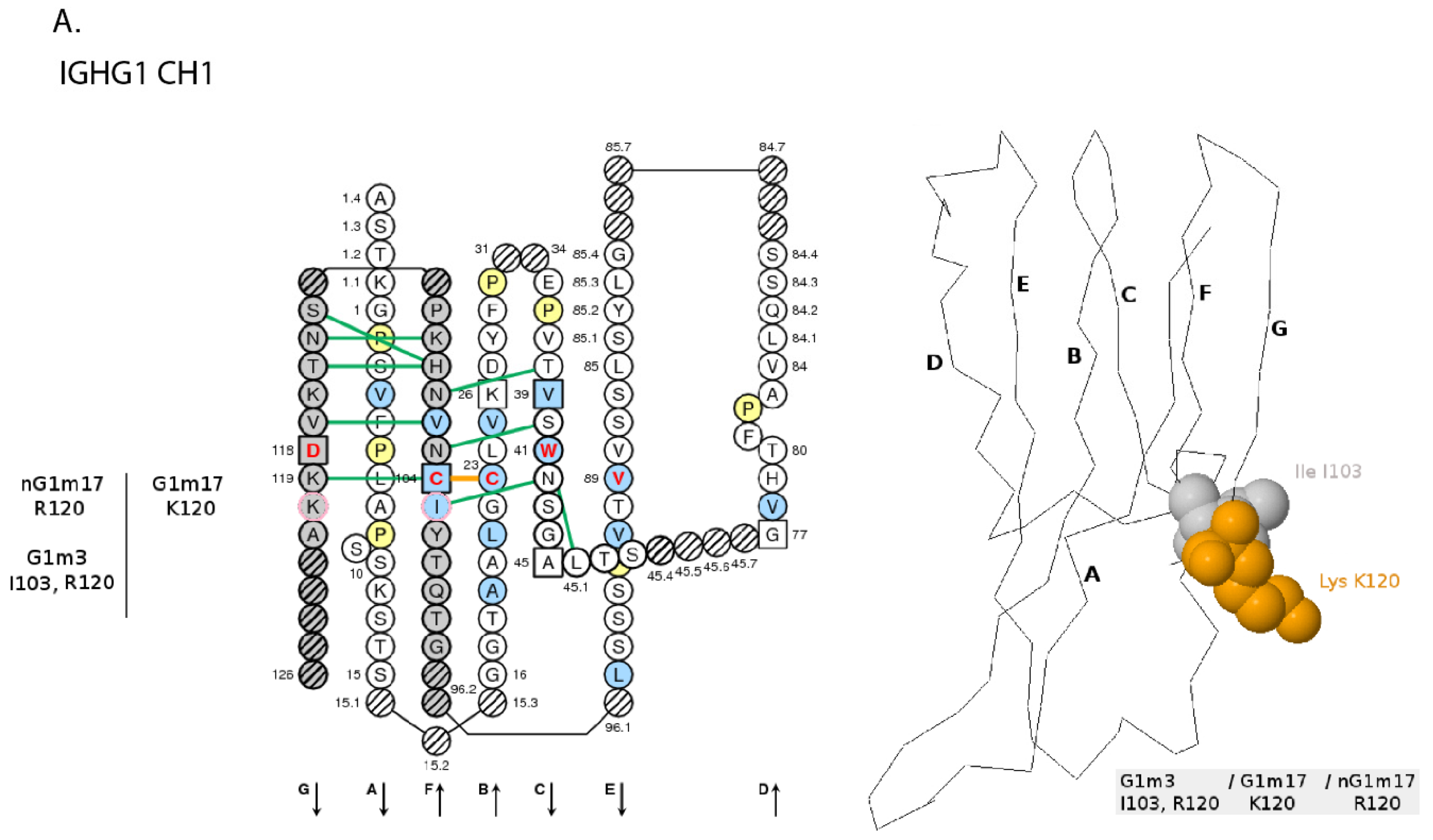{kind=link}
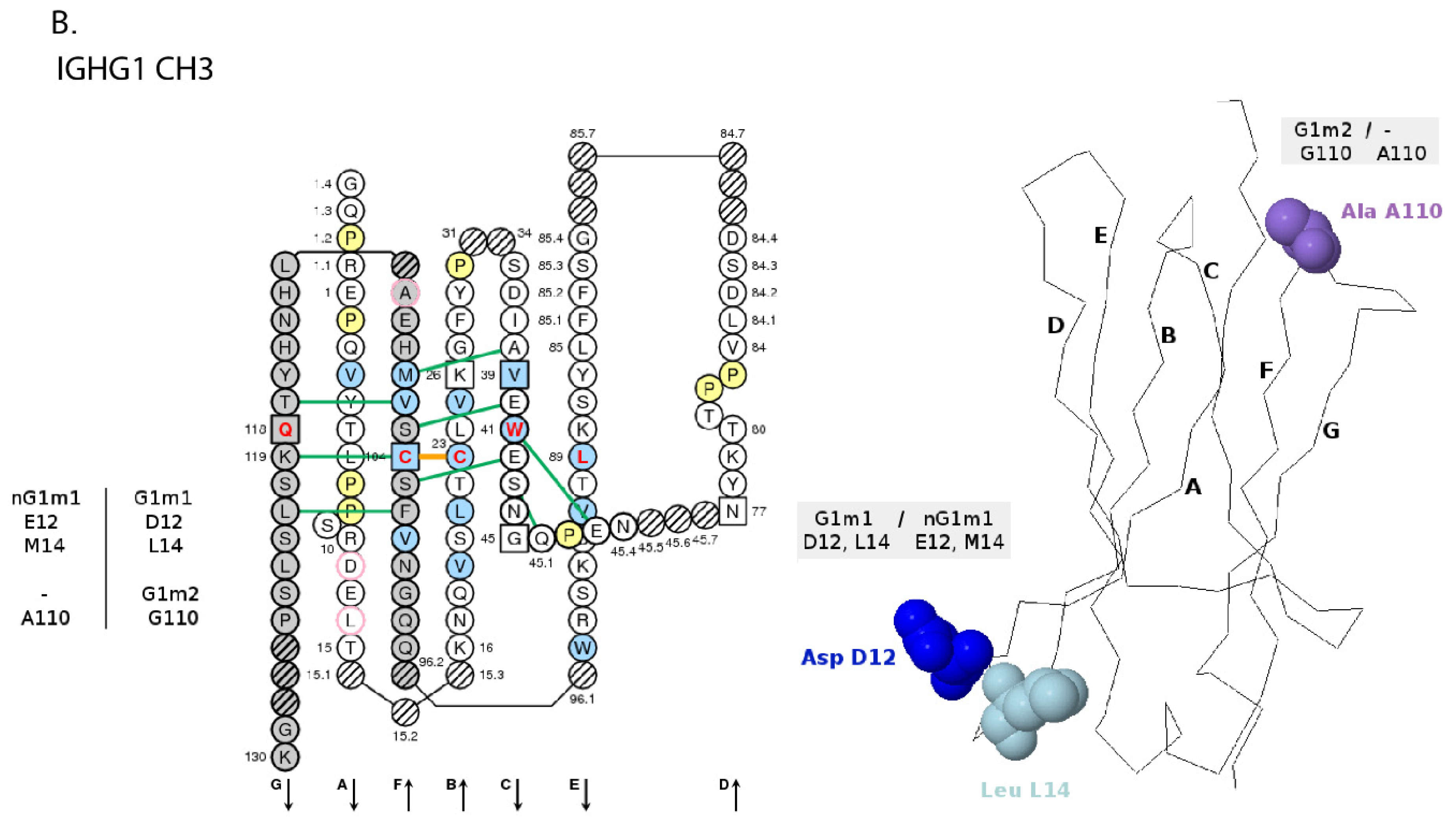{kind=link}
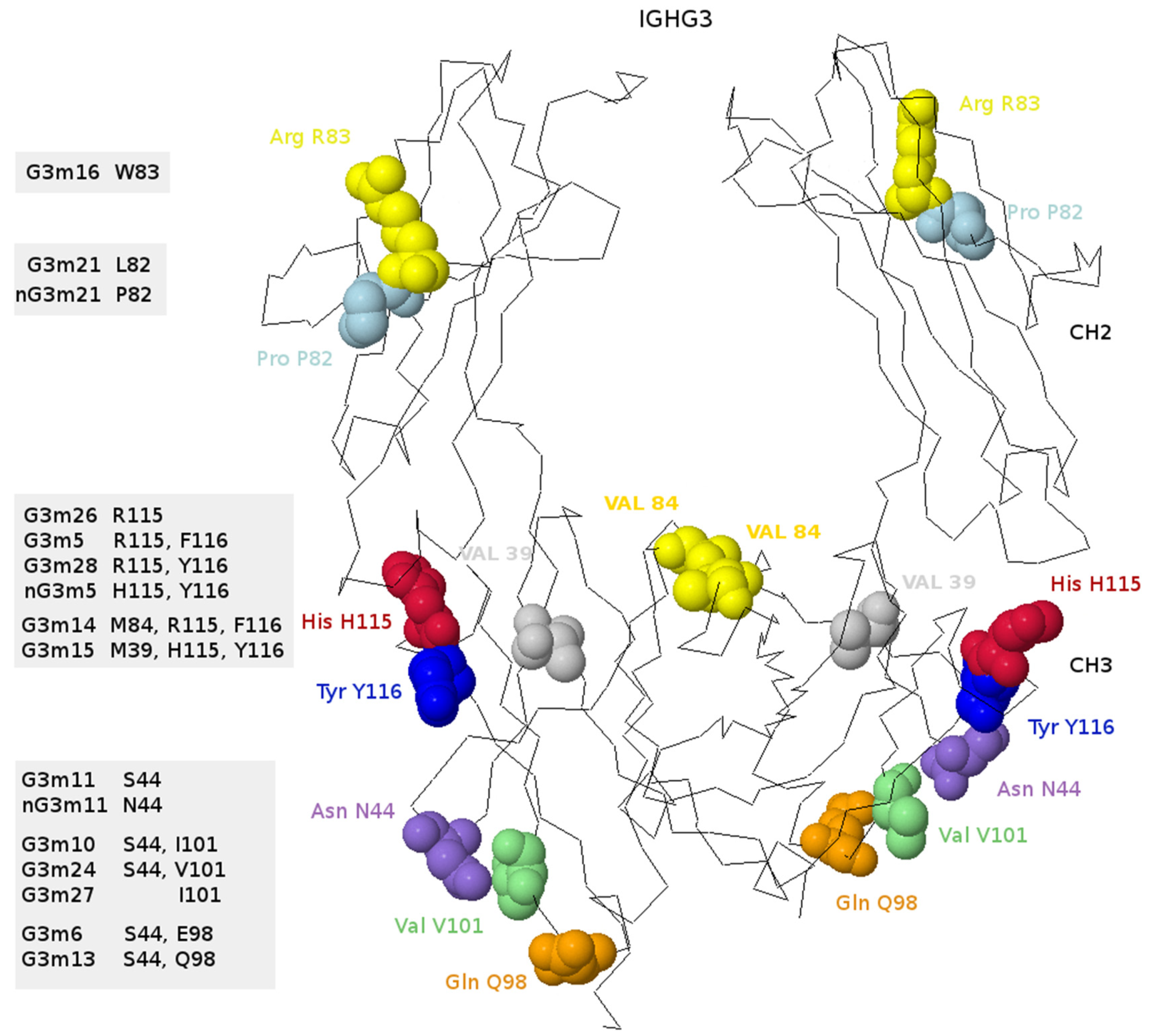{kind=link}
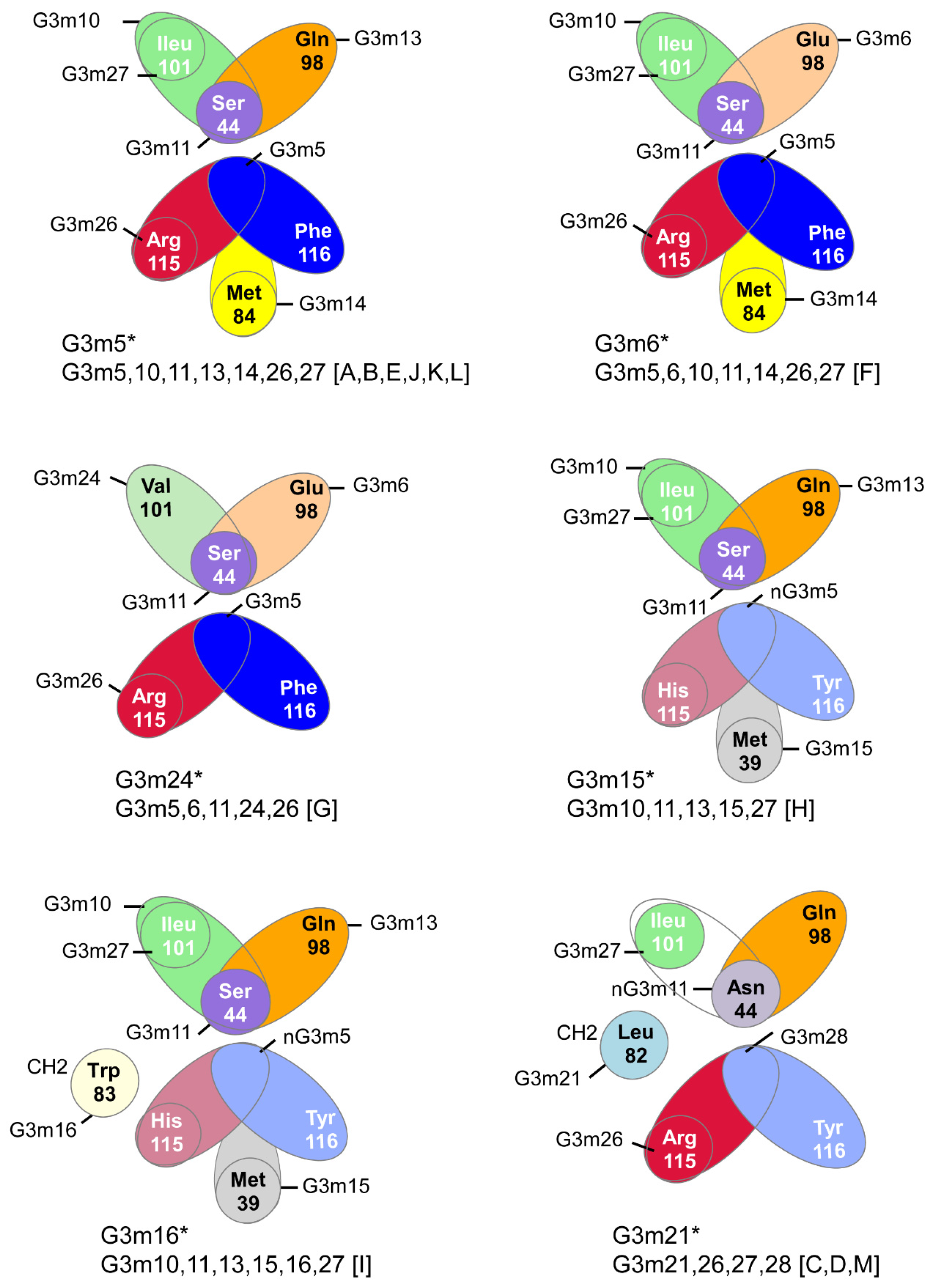{kind=link}
| A. | ||||
| IG Structure Labels (IMGT/3Dstructure-DB [57,58,59]) | Sequence Labels (IMGT/LIGM-DB [54,55]) | |||
| Receptor | Chain | Domain Type | Domain | Region 1 |
| IG-GAMMA-1_KAPPA | H-GAMMA-1 | V | VH | V-D-J-REGION |
| C | CH1 | C-REGION 2 | ||
| C | CH2 | |||
| C | CH3 | |||
| L-KAPPA | V | V-KAPPA | V-J-REGION | |
| C | C-KAPPA | C-REGION | ||
| B. | ||||
| IG Structure Labels (IMGT/3Dstructure-DB) [57,58,59] | Sequence Labels (IMGT/LIGM-DB) [54,55] | |||
| Receptor | Chain | Domain type | Domain | Region 1 |
| IG-MU_LAMBDA | H-MU | V | VH | V-D-J-REGION |
| C | CH1 | C-REGION 2 | ||
| C | CH2 | |||
| C | CH3 | |||
| C | CH4 3 | |||
| L-LAMBDA | V | V-LAMBDA | V-J-REGION | |
| C | C-LAMBDA-1 | C-REGION | ||
| Properties | Human IG Classes and Subclasses | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| IgM | IgD | IgG | IgA | IgE | |||||
| IgG1 | IgG2 | IgG3 | IgG4 | IgA1 | IgA2 | ||||
| Molecular weight of secreted form (kDa) 1 | 950 (p) | 170–180 | 150 | 150 | 155-165 | 150 | 160 (m) 300 (d) | 160 (m) 350 (d) | 190 |
| Chain composition (with number of H2L2 monomers, if more than one) | (μ2κ2)5 or (μ2λ2)5 | δ2κ2 or δ2λ2 | γ12κ2 or γ12λ2 | γ22κ2 or γ22λ2 | γ32κ2 or γ32λ2 | γ42κ2 or γ42λ2 | (α12κ2)1–2 or (α12λ2)1–2 | (α22κ2)1–2 or (α22λ2)1–2 | ε2κ2 or ε2λ2 |
| Functional valency (nb of antigen binding sites) | 5 or 10 | 2 | 2 | 2 or 4 | 2 | ||||
| Structure 2 | monomer (mb) pentamer (s) | monomer (mb, s) | monomer (mb, s) | monomer (mb, s) dimer (sec) | monomer (mb, s) | ||||
| Inter-heavy (H-H) disulfide bridges per monomer | 1 | 1 | 2 | 4 | 11 | 2 | 2 | 2 | 1 |
| Other chain | J chain(16 kDa) | − | − | J chain (16 kDa), secretory component (70 kDa) | − | ||||
| Sedimentation coefficient in Svedberg unit (S) | 18–20 | 7 | 6.5–7.0 | 7, 10, 13, 15, 17 | 7.9 | ||||
| Carbohydrate average (%) | 10–12 | 9–14 | 2–3 | 7–11 | 12–13 | ||||
| Adult level range (age 16-60) in serum (g/L) 3 | 0.25–3.1 | 0.03-0.4 | 5–12 | 2–6 | 0.5–1 | 0.2–1 | 1.4–4.2 | 0.2–0.5 | 0.0001–0.0002 |
| 8.0-16.8 | |||||||||
| Approximate % total IG in adult serum (% of the subclass in the class) | 10 | 0.2 | 45–53 (70–80) | 11–15 (18−23) | 3–6 (6−8) | 1–4 (2–6) | 11–14 (90) | 1–4 (10) | 0.004 |
| Synthetic rate (mg/kg weight/day) | 3.3 | 0.2 | 33 | 33 | 33 | 33 | 19–29 | 3.3–5.3 | 0.002 |
| Biological half-life (day) | 5–10 | 2–8 | 21–24 | 21–24 | 7–8 | 21–24 | 5–7 | 4–6 | 1–5 |
| Transplacental transfer | 0 | 0 | ++ | + | ++ | ++ | 0 | 0 | 0 |
| Complement activation classical pathway (C1q) | +++ | 0 | ++ | + | +++ | 0 | 0 | 0 | 0 |
| Complement activation alternative pathway | 0 | 0 | 0 | 0 | 0 | 0 | + | 0 | 0 |
| Binding macrophages and other phagocytic cells (FcγR or FCGR) 4 | 0 | + | +++ | +/– | +++ | +/– | 0 | 0 | 0 |
| Binding to mast cells and basophils (FcεR or FCER) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | +++ |
| Binding to epithelial poly-IG receptor | + | 0 | 0 | 0 | 0 | 0 | +++ | +++ | 0 |
| Reactivity with Staphyloccus protein A | 0 | 0 | ++ | ++ | (0) * | ++ | 0 | 0 | 0 |
| Chain Characteristics | Human IG Chain Types | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Heavy Chain (H) | Light Chain (L) | ||||||||||||
| μ | δ | γ1 | γ2 | γ3 | γ4 | α1 | α2 | ε | κ | λ | |||
| Molecular weight (kDa) | 70 | 60 | 50 | 50 | 53-57 | 50 | 55 | 55 | 70 | 25 | 25 | ||
| Number of variable (V) domains | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ||
| Number of constant (C) domains | 4 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 4 | 1 | 1 | ||
| Length (in number of amino acids) | Constant region | CH1 (for H) or CL (for L) | 104 | 101 | 97 | 97 | 98 | 97 | 104 | 102 | 103 | 107 | 104 or 106 |
| CH2 | 112 | 108 | 109 | 108 | 110 | 109 | 101 | 101 | 107 | − | − | ||
| CH3 | 112 | 108 | 106 | 106 | 105 | 106 | 112 | 111 | 108 | − | − | ||
| CH4 | 111 | − | − | − | − | − | − | − | 110 | − | − | ||
| Hinge region | 0 | 58 | 15 | 12 | 32, 47 or 62 | 12 | 19 | 6 | 0 | − | − | ||
| Membrane IG | Connecting region (CO) | 13 | 27 | 18 | 18 | 18 | 18 | 32 | 32 | 15 | − | − | |
| Transmembrane region (TM) | 27 | 27 | 27 | 27 | 27 | 27 | 27 | 27 | 27 | − | − | ||
| Cytoplamic region (CY) | 1 | 1 | 26 | 26 | 26 | 26 | 12 | 12 | 26 | − | − | ||
| Secreted IG | CHS 1 | 20 | 9 | 2 | 2 | 2 | 2 | 20 | 20 | 2 | − | − | |
| N-glycosylation sites 2 | 5 | 3 | 1 | 1 | 2 | 1 | 2 | 4 | 7 | 0 | 0 | ||
| O-glycosylation sites 3 | − | 7 | − | − | − | − | 8 | − | − | − | − | ||
| Allotypes [83] | − | − | G1m | G2m | G3m | G4m | − | A2m | Em | Km | − | ||
| Disulfide Bridges | Chain | Classes and Subclasses | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| IgM | IgD | IgG | IgA | IgE | |||||||
| IgG1 | IgG2 | IgG3 | IgG4 | IgA1 | IgA2 | ||||||
| Inter H-L | H | number | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Positions 1 | CH1 10 | CH1 11 | h 5 | CH1 10 | CH1 10 | CH1 10 | CH1 10 | CH1 123 | CH1 10, 11 | ||
| L | C-KAPPA | 126 (last amino acid) | |||||||||
| C-LAMBDA | 126 (penultimate amino acid) | ||||||||||
| Inter H-H | H | number | 1 | 1 | 2 | 4 | 11 | 2 | 2 | 2 | 1 |
| Positions 1 | CH2: 125 | CH2: 1.6 | h 11, h 14 | h 4, h 5, h 8, h 11 | h1 13, h1 16, h2 5, h2 11, h2 14, h3 5, h3 11, h3 14, h4 5, h4 11, h4 14 | h 8, h 11 | CH2: 1.1, 1.2 | CH2: 1.1, 1.2 | CH2: 1.6, 11, 124 | ||
| Locus | IGH | IGK | IGL | Total | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| IMGT Group | IGHV | IGHD | IGHJ | IGHC | Total IGH | IGKV | IGKJ | IGKC | Total IGK | IGLV | IGLJ | IGLC | Total IGL | ||
| Nb of genes | Major Locus | 159 | 27 | 9 | 11 | 206 | 77 | 5 | 1 | 83 | 78 | 11 1 | 11 1 | 100 | 389 |
| Orphon sets | 26 | 10 | 0 | 1 2 | 37 | 32 | 0 | 0 | 32 | 4 3 | 0 | 3 4 | 7 | 76 | |
| Locus total | 185 | 37 | 9 | 12 | 243 | 109 | 5 | 1 | 115 | 82 | 11 | 14 | 107 | 465 | |
| Nb of alleles | Major Locus | 494 | 34 | 19 | 91 | 638 | 114 | 9 | 5 | 128 | 144 | 10 | 21 | 175 | 941 |
| Orphon sets | 49 | 10 | 0 | 2 | 61 | 34 | 0 | 34 | 5 | 0 | 4 | 9 | 104 | ||
| Locus total | 543 | 44 | 19 | 93 | 699 | 148 | 9 | 5 | 162 | 149 | 14 | 25 | 186 | 1045 | |
| IDENTIFICATION (IMGT Standardized Keywords) [30] | DESCRIPTION (IMGT Standardized Labels) [34] | |||
|---|---|---|---|---|
| Molecular Entity Type | Configuration Type | Molecule Type | Functionality | Molecular Entity Prototype |
| V-gene | germline | gDNA | F, ORF, P | V-GENE |
| D-gene | germline | gDNA | F, ORF, P | D-GENE |
| J-gene | germline | gDNA | F, ORF, P | J-GENE |
| C-gene | undefined | gDNA | F, ORF, P | C-GENE |
| V-D-J-gene | rearranged | gDNA | productive, unproductive | V-D-J-GENE |
| V-J-gene | rearranged | gDNA | productive, unproductive | V-J-GENE |
| L-V-D-J-C-sequence | rearranged | cDNA | productive, unproductive | L-V-D-J-C-SEQUENCE |
| L-V-J-C-sequence | rearranged | cDNA | productive, unproductive | L-V-J-C-SEQUENCE |
| V-D-J-C-sequence or chain | rearranged | protein | productive, unproductive | H-MU, H-DELTA, H-GAMMA1, etc. |
| V-J-C-sequence or chain | rearranged | protein | productive, unproductive | L-KAPPA, L-LAMBDA1, etc. |
| A.Homo sapiens IGH V-CLUSTER. | |||||||
| IMGT IGHV Subgroup | IMGT Gene Name 1 | CDR-IMGT | Nb of Alleles F | Nb of Alleles ORF | Nb of Alleles P | Homo SapiensIGHV-CNV | Gene Order |
| IGHV1 | IGHV1-2 | [8.8.2] | 6 F | − | − | 159 | |
| IGHV1-3 | [8.8.2] | 3 F, 1 (F) | − | − | 157 | ||
| IGHV1-8 | [8.8.2] | 3 F | − | − | CNV5e1 | 147 | |
| IGHV1-18 | [8.8.2] | 4 F | − | − | 132 | ||
| IGHV1-24 | [8.8.2] | 1 F | − | − | 120 | ||
| IGHV1-45 | [8.8.2] | 3 F | − | − | 60 | ||
| IGHV1-46 | [8.8.2] | 4 F | − | − | 59 | ||
| IGHV1-58 | [8.8.2] | 2 F, 1 (F) | − | − | 41 | ||
| IGHV1-69 a | [8.8.2] | 17 F, 1 (F) | − | − | 21 | ||
| IGHV1-69D a | [8.8.2] | − | − | CNV1i | 17 | ||
| IGHV1-69-2 | [8.8.2] | 2 F | − | − | CNV1i | 18 | |
| IGHV2 | IGHV2-5 | [10.7.3] | 8 F (no *07) | − | − | 154 | |
| IGHV2-26 | [10.7.3] | 3 F | − | − | 117 | ||
| IGHV2-70 b | [10.7.3] | 19 F | 1 ORF | − | 16 | ||
| IGHV2-70D b | [10.7.3] | − | − | CNV1i | 20 | ||
| IGHV3 | IGHV3-7 | [8.8.2] | 3 F, 1 (F) | − | − | 150 | |
| IGHV3-9 | [8.8.3] | 3 F | − | − | CNV5e1 | 146 | |
| IGHV3-11 | [8.8.2] | 5 F | − | 1 P (0.1) | 144 | ||
| IGHV3-13 | [8.7.2] | 5 F | − | − | 141 | ||
| IGHV3-15 | [8.10.2] | 8 F | − | − | 138 | ||
| IGHV3-20 | [8.8.2] | 2 F | 2 ORF | − | 130 | ||
| IGHV3-21 | [8.8.2] | 4 F, 1 (F) | − | − | 128 | ||
| IGHV3-23 c | [8.8.2] | 5 F | − | − | 124 | ||
| IGHV3-23D c | [8.8.2] | − | − | CNV4i | 121 | ||
| IGHV3-30 d | [8.8.2] | 19 F | − | − | 109 | ||
| IGHV3-30-3 | [8.8.2] | 3 F | − | − | CNV3i | 102 | |
| IGHV3-30-5 d | [8.8.2] | − | − | CNV3i | 96 | ||
| IGHV3-33 | [8.8.2] | 7 F | − | − | 89 | ||
| IGHV3-43 e | [8.8.3] | 2 F | − | − | 65 | ||
| IGHV3-43D e | [8.8.3] | 2 F | − | − | CNV2i | 76 | |
| IGHV3-48 | [8.8.2] | 4 F | − | − | 55 | ||
| IGHV3-49 | [8.10.2] | 5 F | − | − | 54 | ||
| IGHV3-53 | [8.8.2] | 4 F, 1 (F) | − | − | 47 | ||
| IGHV3-62 | [8.8.2] | 1 F (* 04) 2 | − | 3 P (2.1) | 36 | ||
| IGHV3-64 f | [8.8.2] | 7 | − | − | 32 | ||
| IGHV3-64D f | [8.8.2] | − | − | CNV5e2 | 149 | ||
| IGHV3-66 | [8.7.2] | 4 F | − | − | 29 | ||
| IGHV3-72 | [8.10.2] | 2 F | − | − | 14 | ||
| IGHV3-73 | [8.10.2] | 2 F | − | − | 13 | ||
| IGHV3-74 | [8.8.2] | 3 F | − | − | 12 | ||
| IGHV3-NL1 | [8.8.2] | 1 F | − | − | 0 | ||
| IGHV4 | IGHV4-4 | [8.7.2] | 7 F, 2 (F) | − | − | 156 | |
| IGHV4-28 | [8.7.2] | 7 F | − | − | 113 | ||
| IGHV4-30-1 g | [10.7.2] | − | − | CNV3i | 106 | ||
| IGHV4-30-2 | [10.7.2] | 6 F | − | − | CNV3i | 105 | |
| IGHV4-30-4 | [10.7.2] | 7 F, 1 (F) | − | − | CNV3i | 99 | |
| IGHV4-31 g | [10.7.2] | 10 F, 1 (F) | − | − | CNV3d | 93 | |
| IGHV4-34 | [8.7.2] | 13 F | − | − | 86 | ||
| IGHV4-38-2 | [9.7.2] | 2 F | − | − | CNV2i | 79 | |
| IGHV4-39 | [10.7.2] | 7 F | − | − | 70 | ||
| IGHV4-59 | [8.7.2] | 12 F, 1 (F) | − | − | 40 | ||
| IGHV4-61 | [10.7.2] | 8 F, 1 (F) | 1 ORF | − | 37 | ||
| IGHV5 | IGHV5-10-1 | [8.8.2] | 4 F | − | − | CNV5e2 | 148 |
| IGHV5-51 | [8.8.2] | 6 F, 1 (F) | − | − | 51 | ||
| IGHV6 | IGHV6-1 | [10.9.2] | 2 F | − | 1 P (1.0) | 163 | |
| IGHV7 | IGHV7-4-1 | [8.8.2] | 5 F | − | - | CNV6i | 155 |
| IGHV8 | IGHV8-51-1 | [8.8.2] | 0 F | 1 ORF | 2 P (2.0) | ||
| B.Homo sapiens IGH D-J-C-CLUSTER. | |||||||
| D-J-C-CLUSTER | IMGT gene names | Nb of alleles F | Nb of alleles ORF and P | Gene order | |||
| IGHD | IGHD1-1 | 1 F | − | 165 | |||
| IGHD2-2 | 3 F | − | 166 | ||||
| IGHD3-3 | 1 F | − | 167 | ||||
| IGHD4-4 | 1 F | − | 168 | ||||
| IGHD5-5 | 1 F | − | 169 | ||||
| IGHD6-6 | 1 F | − | 170 | ||||
| IGHD1-7 | 1 F | − | 171 | ||||
| IGHD2-8 | 2 F | − | 172 | ||||
| IGHD3-9 | 1 F | − | 173 | ||||
| IGHD3-10 | 2 F | − | 174 | ||||
| IGHD4-11 | - | 1 ORF | 175 | ||||
| IGHD5-12 | 1 F | − | 176 | ||||
| IGHD6-13 | 1 F | − | 177 | ||||
| IGHD1-14 | - | 1 ORF | 178 | ||||
| IGHD2-15 | 1 F | − | 179 | ||||
| IGHD3-16 | 2 F | − | 180 | ||||
| IGHD4-17 | 1 F | − | 181 | ||||
| IGHD5-18 | 1 F | − | 182 | ||||
| IGHD6-19 | 1 F | − | 183 | ||||
| IGHD1-20 | 1 F | − | 184 | ||||
| IGHD2-21 | 2 F | − | 185 | ||||
| IGHD3-22 | 1 F | − | 186 | ||||
| IGHD4-23 | − | 1 ORF | 187 | ||||
| IGHD5-24 | − | 1 ORF | 188 | ||||
| IGHD6-25 | 1 F | − | 189 | ||||
| IGHD1-26 | 1 F | − | 190 | ||||
| IGHD7-27 | 1 F | − | 192 | ||||
| IGHJ | IGHJ1 | 1 F | − | 193 | |||
| IGHJ2 | 1 F | − | 194 | ||||
| IGHJ3 | 2 F | − | 196 | ||||
| IGHJ4 | 3 F | − | 197 | ||||
| IGHJ5 | 2 F | − | 198 | ||||
| IGHJ6 | 4 F | − | 200 | ||||
| IGHC | IGHM | 4 F | − | 201 | |||
| IGHD | 2 F | − | 202 | ||||
| IGHG3 | 29 F | − | 203 | ||||
| IGHG1 | 12 F, 2 (F) | − | 204 | ||||
| IGHEP1 | - | 4 P | 205 | ||||
| IGHA1 | 3 F | − | 206 | ||||
| IGHGP | - | 2 ORF, 1P | 207 | ||||
| IGHG2 | 17 F | − | 208 | ||||
| IGHG4 | 8 F | − | 209 | ||||
| IGHE | 4 F | − | 210 | ||||
| IGHA2 | 3 F | − | 211 | ||||
| A. | ||||||||||
| IMGT IGKV Subgroup | IMGT Gene Name | CDR-IMGT | Nb of Alleles F | Nb of Alleles ORF | Nb of Alleles P | Cluster | Gene Order | |||
| IGKV1 | IGKV1-5 | [6.3.7] | 3 F | - | - | proximal | 72 | |||
| IGKV1-6 | [6.3.7] | 2F | - | - | proximal | 71 | ||||
| IGKV1-8 | [6.3.7] | 1 F | - | - | proximal | 69 | ||||
| IGKV1-9 | [6.3.7] | 1 F | - | - | proximal | 68 | ||||
| IGKV1-12 | [6.3.7] | 2 F | - | - | proximal | 65 | ||||
| IGKV1-13 | [6.3.7] | 1 F | - | 1 P (1.0) | proximal | 64 | ||||
| IGKV1-16 | [6.3.7] | 1 F, 1 [F] | - | - | proximal | 61 | ||||
| IGKV1-17 | [6.3.7] | 3 F | - | - | proximal | 60 | ||||
| IGKV1-27 | [6.3.7] | 1 F | - | - | proximal | 50 | ||||
| IGKV1-33 | [6.3.7] | 1 F | - | - | proximal | 44 | ||||
| IGKV1-39 | [6.3.7] | 1 F | - | 1 P (1.0) | proximal | 38 | ||||
| IGKV1D-8 | [6.3.7] | 3 F | - | - | distal | 2 | ||||
| IGKV1D-12 | [6.3.7] | 2 F | - | - | distal | 7 | ||||
| IGKV1D-13 | [6.3.7] | 2 F | - | - | distal | 8 | ||||
| IGKV1D-16 | [6.3.7] | 2 F | - | - | distal | 11 | ||||
| IGKV1D-17 | [6.3.7] | 1F | - | - | distal | 12 | ||||
| IGKV1D-33 | [6.3.7] | 1 F | - | - | distal | 29 | ||||
| IGKV1D-39 | [6.3.7] | 1 F | - | - | distal | 35 | ||||
| IGKV1D-43 | [6.3.7] | 1 F | - | - | distal | 3 | ||||
| IGKV1-NL1 | [6.3.7] | 1 F | - | - | 0 | |||||
| IGKV2 | IGKV2-24 | [11.3.7] | 1 F | - | - | proximal | 53 | |||
| IGKV2-28 | [11.3.7] | 1 F | - | - | proximal | 49 | ||||
| IGKV2-29 | [11.3.7] | 2 F | - | 1 P (1.0) | proximal | 48 | ||||
| IGKV2-30 | [11.3.7] | 1 F, 1 [F] | - | - | proximal | 47 | ||||
| IGKV2-40 | [12.3.7] | 2 F | - | - | proximal | 37 | ||||
| IGKV2D-26 | [11.3.7] | 3 F | - | - | distal | 22 | ||||
| IGKV2D-28 | [11.3.7] | 1 F | - | - | distal | 24 | ||||
| IGKV2D-29 | [11.3.7] | 2 F | - | - | distal | 25 | ||||
| IGKV2D-30 | [11.3.7] | 1 F | - | - | distal | 26 | ||||
| IGKV2D-40 | [12.3.7] | 1 F | - | - | distal | 36 | ||||
| IGKV3 | IGKV3-11 | [6.3.7] | 2 F | - | - | proximal | 66 | |||
| IGKV3-15 | [6.3.7] | 1 F | - | - | proximal | 62 | ||||
| IGKV3-20 | [7.3.7] | 2 F | - | - | proximal | 57 | ||||
| IGKV3D-7 | [7.3.7] | 1 F | - | - | distal | 1 | ||||
| IGKV3D-11 | [6.3.7] | 3 F | - | - | distal | 6 | ||||
| IGKV3D-15 | [6.3.7] | 2 F | - | 1 P (1.0) | distal | 10 | ||||
| IGKV3D-20 | [7.3.7] | 1 F | 1 ORF | - | distal | 16 | ||||
| IGKV4 | IGKV4-1 | [12.3.7] | 1 F | - | - | proximal | 76 | |||
| IGKV5 | IGKV5-2 | [6.3.7] | 1 F | - | - | proximal | 75 | |||
| IGKV6 | IGKV6-21 | [6.3.7] | 2 F | - | - | proximal | 56 | |||
| IGKV6D-21 | [6.3.7] | 2 F | - | - | distal | 17 | ||||
| B. | ||||||||||
| J-C-CLUSTER | IMGT Gene Names | Nb of Alleles F | Nb of Alleles ORF, P | Gene Order | ||||||
| IGKJ | IGKJ1 | 1 F | - | 77 | ||||||
| IGKJ2 | 1 F, 3 (F) | - | 78 | |||||||
| IGKJ3 | 1 F | - | 79 | |||||||
| IGKJ4 | 1F, 1 (F) | - | 80 | |||||||
| IGKJ5 | 1 F | - | 81 | |||||||
| IGKC | IGKC | 4 F, 1 (F) | - | 82 | ||||||
| A. | |||||||
| IMGT IGLV Subgroup | IMGT Gene Name | CDR-IMGT | Nb of Alleles F | Nb of Alleles ORF | Nb of Alleles P | Cluster | Gene Order |
| IGLV1 | IGLV1-36 | [8.3.9] | 1 F | − | − | B | 40 |
| IGLV1-40 | [9.3.9] | 3 F | − | − | B | 36 | |
| IGLV1-44 | [8.3.9] | 1 F | − | − | B | 31 | |
| IGLV1-47 | [8.3.9] | 2 F | − | − | B | 28 | |
| IGLV1-51 | [8.3.9] | 2 F | − | − | B | 24 | |
| IGLV2 | IGLV2-8 | [9.3.9] | 3 F | − | − | A | 77 |
| IGLV2-11 | [9.3.9] | 3 F | − | − | A | 74 | |
| IGLV2-14 | [9.3.9] | 4 F | − | − | A | 71 | |
| IGLV2-18 | [9.3.9] | 4 F | − | − | A | 67 | |
| IGLV2-23 | [9.3.9] | 3 F | − | − | A | 61 | |
| IGLV3 | IGLV3-1 | [6.3.7] | 1 F | − | − | A | 84 |
| IGLV3-9 | [6.3.7] | 2 F | − | 1 P (0.1) | A | 76 | |
| IGLV3-10 | [6.3.9] | 2 F | − | − | A | 75 | |
| IGLV3-12 | [6.3.9] | 2 F | − | − | A | 73 | |
| IGLV3-16 | [6.3.9] | 1 F | − | − | A | 69 | |
| IGLV3-19 | [6.3.9] | 1 F | − | − | A | 66 | |
| IGLV3-21 | [6.3.9] | 3 F | − | − | A | 64 | |
| IGLV3-22 | [6.3.7] | 1 F | − | 1 P (0.1) | A | 63 | |
| IGLV3-25 | [6.3.9] | 3 F | − | − | A | 59 | |
| IGLV3-27 | [6.3.7] | 1 F | − | − | A | 56 | |
| IGLV4 | IGLV4-3 | [7.7.12] | 1 F | − | − | A | 82 |
| IGLV4-60 | [7.7.7] | 3 F | − | − | C | 13 | |
| IGLV4-69 | [7.7.7] | 2 F | − | − | C | 3 | |
| IGLV5 | IGLV5-37 | [9.7.8] | 1 F | − | − | B | 39 |
| IGLV5-39 | [9.7.8] | 2 F | − | − | B | 37 | |
| IGLV5-45 | [9.7.8] | 4 F | − | − | B | 30 | |
| IGLV5-52 | [9.7.9] | 1 F | − | − | B | 23 | |
| IGLV6 | IGLV6-57 | [8.3.7] | 2 F | − | − | C | 17 |
| IGLV7 | IGLV7-43 | [9.3.8] | 1 F | − | − | B | 32 |
| IGLV7-46 | [9.3.8] | 2 F | 1 P (0.1) | B | 29 | ||
| IGLV8 | IGLV8-61 | [9.3.8] | 3 F | − | C | 12 | |
| IGLV9 | IGLV9-49 | [7.8.12] | 3 F | − | B | 26 | |
| IGLV10 | IGLV10-54 | [8.3.9] | 2 F | 1 P (1.0) | C | 20 | |
| B. | |||||||
| J-C-CASSETTE | IMGT Gene Name | Nb of Alleles F | Nb of Alleles ORF, P | Gene Order | |||
| 1 | IGLJ1 | 1 F | − | 85 | |||
| IGLC1 | 1 F | 1 ORF | 86 | ||||
| 2 | IGLJ2 | 1 F | − | 87 | |||
| IGLC2 | 3 F | − | 88 | ||||
| 3 | IGLJ3 | 2 F | − | 89 | |||
| IGLC3 | 4 F | − | 90 | ||||
| 4 | IGLJ4 | − | 1 ORF | 91 | |||
| IGLC4 | − | 2 P | 92 | ||||
| 5 | IGLJ5 | − | 2 ORF | 93 | |||
| IGLC5 | − | 2 P | 94 | ||||
| 6 | IGLJ6 | 1 F | − | 95 | |||
| IGLC6 | 1 F | 4 P | 96 | ||||
| 7 | IGLJ7 | 2F | − | 97 | |||
| IGLC7 | 5 F | − | 98 | ||||
| V Domain Strands and Loops 1 | IMGT Positions 2 | Lengths 3 | Characteristic IMGT Residue@Position 4 | V-DOMAIN FR-IMGT and CDR-IMGT |
|---|---|---|---|---|
| A-STRAND | 1–15 | 15 (14 if gap at 10) | FR1-IMGT | |
| B-STRAND | 16–26 | 11 | 1st-CYS 23 | |
| BC-LOOP | 27–38 | 12 (or less) | CDR1-IMGT | |
| C-STRAND | 39–46 | 8 | CONSERVED-TRP 41 | FR2-IMGT |
| C′-STRAND | 47–55 | 9 | ||
| C′C″-LOOP | 56–65 | 10 (or less) | CDR2-IMGT | |
| C″-STRAND | 66–74 | 9 (or 8 if gap at 73) | FR3-IMGT | |
| D-STRAND | 75–84 | 10 (or 8 if gaps at 81, 82) | ||
| E-STRAND | 85–96 | 12 | hydrophobic 89 | |
| F-STRAND | 97–104 | 8 | 2nd-CYS 104 | |
| FG-LOOP | 105–117 | 13 (or less, or more) | CDR3-IMGT | |
| G-STRAND | 118–128 | 11 (or 10) | V-DOMAIN J-PHE 118 or J-TRP 118 5 | FR4-IMGT |
| CDR3-IMGT Lengths | IMGT Additional Positions for CDR3-IMGT Length > 13 AA 1 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| --- | ||||||||||
| 21 | 111 | 111.1 | 111.2 | 111.3 | 111.4 | 112.4 | 112.3 | 112.2 | 112.1 | 112 |
| 20 | 111 | 111.1 | 111.2 | 111.3 | − | 112.4 | 112.3 | 112.2 | 112.1 | 112 |
| 19 | 111 | 111.1 | 111.2 | 111.3 | − | − | 112.3 | 112.2 | 112.1 | 112 |
| 18 | 111 | 111.1 | 111.2 | − | − | − | 112.3 | 112.2 | 112.1 | 112 |
| 17 | 111 | 111.1 | 111.2 | − | − | − | − | 112.2 | 112.1 | 112 |
| 16 | 111 | 111.1 | − | − | − | − | − | 112.2 | 112.1 | 112 |
| 15 | 111 | 111.1 | − | − | − | − | − | − | 112.1 | 112 |
| 14 | 111 | − | − | − | − | − | − | − | 112.1 | 112 |
| C Domain Strands, Turns and Loops 1 | IMGT Positions 2 | Lengths 3 | Characteristic IMGT Residue@Position 4 |
|---|---|---|---|
| A-STRAND | 1–15 | 15 (14 if gap at 10) | |
| AB-TURN | 15.1–15.3 | 0–3 | |
| B-STRAND | 16–26 | 11 | 1st-CYS 23 |
| BC-LOOP | 27–31 34–38 | 10 (or less) | |
| C-STRAND | 39–45 | 7 | CONSERVED-TRP 41 |
| CD-STRAND | 45.1–45.9 | 0–9 | |
| D-STRAND | 77–84 | 8 (or 7 if gap at 82) | |
| DE-TURN | 84.1–84.7 85.1–85.7 | 0–14 | |
| E-STRAND | 85–96 | 12 | hydrophobic 89 |
| EF-TURN | 96.1–96.2 | 0–2 | |
| F-STRAND | 97–104 | 8 | 2nd-CYS 104 |
| FG-LOOP | 105–117 | 13 (or less, or more) | |
| G-STRAND | 118–128 | 11 (or less) |
| File Number 1 | File Name | Number of Columns | Results Content 2 |
|---|---|---|---|
| #1 | Summary | 25–29 | Identity percentage with the closest V, D and J genes and alleles, FR-IMGT and CDR-IMGT lengths, Amino acid (AA) JUNCTION, Description of insertions and deletions if any. |
| #2 | IMGT-gapped-nt-sequences | 18 | Nucleotide (nt) sequences gapped according to the IMGT unique numbering for the labels V-D-J-REGION, V-J-REGION, V-REGION, FR1-IMGT, CDR1-IMGT, FR2-IMGT, CDR2-IMGT, FR3-IMGT, nt sequences of CDR3-IMGT, JUNCTION, J-REGION and FR4-IMGT. |
| #3 | Nt-sequences | 63–78 | nt sequences of all labels that can been automatically annotated by IMGT/Automat. |
| #4 | IMGT-gapped-AA-sequences | 18 | AA sequences gapped according to the IMGT unique numbering for the labels V-D-J-REGION, V-J-REGION, V-REGION, FR1-IMGT, CDR1-IMGT, FR2-IMGT, CDR2-IMGT, FR3-IMGT, AA sequences of CDR3-IMGT, JUNCTION, J-REGION and FR4-IMGT. |
| #5 | AA-sequences | 18 | Same columns as ‘IMGT-gapped-AA-sequences’ (#4), but sequences of labels are without IMGT gaps. |
| #6 | Junction | 33, 46, 66 or 77 | Results of IMGT/JunctionAnalysis (JUNCTION, CDR3, N regions, trimmed V (D)J nucleotides, P regions, D regions and D-REGION reading frame (for IGH, TRB and TRD sequences), molecular mass, pI. |
| #7 | V-REGION-mutation-and-AA-change table | 11 | List of mutations (nt mutations, AA changes, AA class identity (+) or change (−)) for V-REGION, FR1-IMGT, CDR1-IMGT, FR2-IMGT, CDR2-IMGT, FR3-IMGT and germline CDR3-IMGT. |
| #8 | V-REGION-nt-mutation-statistics | 130 | Number (nb) of nt positions including IMGT gaps, nb of nt, nb of identical nt, total nb of mutations, nb of silent mutations, nb of nonsilent mutations, nb of transitions (a > g, g > a, c > t, t > c) and nb of transversions (a > c, c > a, a > t, t > a, g > c, c > g, g > t, t > g) for V-REGION, FR1-IMGT, CDR1-IMGT, FR2-IMGT, CDR2-IMGT, FR3-IMGT and germline CDR3-IMGT. |
| #9 | V-REGION-AA-change-statistics | 189 | nb of AA positions including IMGT gaps, nb of AA, nb of identical AA, total nb of AA changes, nb of AA changes according to AAclassChangeType (+++, ++−, +−+, +−−, −+−, −−+, −−−), and nb of AA class changes according to AAclassSimilarityDegree (nb of Very similar, nb of Similar, nb of Dissimilar, nb of Very dissimilar) for V-REGION, FR1-IMGT, CDR1-IMGT, FR2-IMGT, CDR2-IMGT, FR3-IMGT and germline CDR3-IMGT. |
| #10 | V-REGION-mutation-hotspots | 8 | Hot spots motifs ((a/t) a, t (a/t), (a/g) g (c/t) (a/t), (a/t) (a/g) c (c/t) detected in the closest germline V-REGION with positions in FR-IMGT and CDR-IMGT. |
| #11 | Parameters | Date of the analysis, IMGT/V-QUEST programme version, IMGT/V-QUEST reference directory release, Parameters used for the analysis: species, receptor type or locus, IMGT reference directory set and Advanced parameters. |
| IGHG1 Alleles | G1m Alleles 1 | IMGT Amino Acid Positions 2 | Populations [83] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Allotypes | Isoallotype 3 | CH1 | CH3 | ||||||||
| 103 | 120 | 12 | 14 | 101 | 110 | 115 | 116 | ||||
| G1m17/ nG1m17 | G1m1/ nG1m1 | /G1m27 | /G1m2 | /G1m28 - | |||||||
| G1m3 4 | |||||||||||
| IGHG1*01 5, IGHG1*02 5, IGHG1*05 5 | G1m17,1 | I | K | D | L | V | A | H | Y | Caucasoid Negroid Mongoloid | |
| IGHG1*03 | G1m3 | nG1m1, nG1m17 | I | R | E | M | V | A | H | Y | Caucasoid |
| IGHG1*04 | G1m17,1,27 | I | K | D | L | I | A | H | Y | Negroid | |
| IGHG1*05p 6 | G1m17,1,28 | I | K | D | L | V | A | R | Y | Negroid | |
| IGHG1*06p 6 | G1m,17,1,27,28 | I | K | D | L | I | A | R | Y | Negroid | |
| IGHG1*07p 6 | G1m17,1,2 | I | K | D | L | V | G | H | Y | Caucasoid Mongoloid | |
| IGHG1*08p 6 | G1m3,1 | nG1m17 | I | R | D | L | V | A | H | Y | Mongoloid |
| Species and IMGT Gene Name | IMGT Engineered Variant Nomenclature | IGHG Gene Variant Description | Property Modifications | |||||
|---|---|---|---|---|---|---|---|---|
| CH2 | AA and IMGT Position in CH2 of IGHG Gene Variant | CH3 | AA and IMGT Position in CH3 of IGHG Gene Variant | ADCC Enhancement or Reduction, ADCP Enhancement, B Cell Inhibition | CDC Enhancement or Reduction | Half-IG Exchange Reduction, Half-Life Increase, Knobs-into-Holes | ||
| CDC enhnHomo sapiens IGHG1 | IGHG1v1 | CH2 | P1.4 (233) | ADCC reduction | ||||
| IGHG1v2 | CH2 | V1.3 (234) | ADCC reduction | |||||
| IGHG1v3 | CH2 | A1.2 (235) | ADCC reduction | |||||
| IGHG1v4 | CH2 | A114 (329) | ADCC reduction | CDC reduction | ||||
| IGHG1v5 | CH2 | W109 (326) | ADCC reduction | CDC enhancement | ||||
| IGHG1v6 | CH2 | A85.4 (298), A118 (333), A119 (334) | ADCC enhancement | |||||
| IGHG1v7 | CH2 | D3 (239), E117 (332) | ADCC enhancement | |||||
| IGHG1v8 | CH2 | D3 (239), L115 (330), E117 (332) | ADCC enhancement | CDC reduction | ||||
| IGHG1v9 | CH2 | L7 (243), P83 (292), L85.2 (300), I88 (305) | CH3 | L83 (396) | ADCC enhancement | |||
| IGHG1v10 | CH2 | Y1.3 (234), Q1.2 (235), W1.1 (236), M3 (239), D30 (268), E34 (270), A85.4 (298) | ADCC enhancement | |||||
| IGHG1v11 | CH2 | E34 (270), D109 (326), M115 (330), E119 (334) | ADCC enhancement | |||||
| IGHG1v12 | CH2 | A1.1 (236), D3 (239), L115 (330), E117 (332) | ADCC enhancement | |||||
| IGHG1v13 | CH2 | A1.1 (236), D3 (239), E117 (332) | ADCP enhancement | |||||
| IGHG1v14 | CH2 | A1.3 (234), A1.2 (235) | ADCC reduction | CDC reduction | ||||
| IGHG1v15 | CH2 | S118 (333) | CDC enhancement | |||||
| IGHG1v16 | CH2 | W109 (326), S118 (333) | CDC enhancement | |||||
| IGHG1v17 | CH2 | E29 (267), F30 (268), T107 (324) | CDC enhancement | |||||
| IGHG1v18 | CH3 | R1 (345), G109 (430), Y120 (440) | CDC enhancement | Favors hexamerisation | ||||
| IGHG1v19 | CH2 | A34 (270) | CDC reduction | |||||
| IGHG1v20 | CH2 | A105 (322) | CDC reduction | |||||
| IGHG1v21 | CH2 | Y15.1 (252), T16 (254), E18 (256) | Half-life increase | |||||
| IGHG1v22 | CH2 | Y15.1 (252), T16 (254), E18 (256) | CH3 | K113 (433), F114 (434), H116 (436) | Half-life increase | |||
| IGHG1v23 | CH2 | E1.2 (235) | ADCC reduction | CDC reduction | ||||
| IGHG1v24 | CH3 | L107 (428), S114 (434) | Half-life increase | |||||
| IGHG1v25 | CH2 | E29 (267), F113 (328) | B cell inhibition | |||||
| IGHG1v26 | CH3 | Y22 (366), | Knob in knobs-into-holes interaction | |||||
| IGHG1v27 | CH2 | C3 (239) | Site-specific drug attachment | |||||
| IGHG1v28 | CH2 | insC3A (239^240) | Site-specific drug attachment | |||||
| IGHG1v29 | CH2 | A84.4 (297) | No N-glycosylation site | |||||
| IGHG1v30 | CH2 | G84.4 (297) | No N-glycosylation site | |||||
| IGHG1v31 | CH3 | T86 (407) | Hole in knobs-into-holes interaction | |||||
| IGHG1v32 | CH3 | W22 (366) | Knob in knobs-into-holes interaction | |||||
| IGHG1v33 | CH3 | S22 (366), A24 (368), V86 (407) | Hole in knobs-into-holes interaction | |||||
| IGHG1v34 | CH3 | G109 (430) | Favors hexamerisation | |||||
| IGHG1v35 | CH2 | E29 (267) | CDC enhancement | |||||
| IGHG1v36 | CH2 | Q84.4 (297) | No N-glycosylation site | |||||
| IGHG1v37 | h | S5 (220) | No disulfide bridge inter H-L | |||||
| IGHG1v38 | CH2 | S108 (325), F113 (328) | Abrogation of FcyRIII binding | Abrogation of C1q bnding | ||||
| Homo sapiens IGHG2 | IGHG2v1 | CH2 | L1.3 (234), L1.2 (235), G1.1 (236), G1 (237) | ADCC enhancement | ||||
| IGHG2v2 | CH2 | Q30 (268), L92 (309), S115 (330), S116 (S331) | ADCC reduction | CDC reduction | ||||
| IGHG2v3 | CH2 | A1.2 (235), A1 (237), S2 (238), A30 (268), L92 (309), S115 (330), S116 (331) | ADCC reduction | CDC reduction | ||||
| IGHG2v4 | CH2 | Q14 (250) | Half-life increase | |||||
| IGHG2v5 | CH3 | L107 (428) | Half-life increase | |||||
| IGHG2v6 | CH2 | Q14 (250) | CH3 | L107 (428) | Half-life increase | |||
| Homo sapiens IGHG3 | IGHG3v1 | CH3 | H115 (435) | Half-life increase | ||||
| Homo sapiens IGHG4 | IGHG4v1 | CH2 | L1.3 (234) | ADCC enhancement | ||||
| IGHG4v2 | CH2 | P116 (331) | CDC enhancement | |||||
| IGHG4v3 | CH2 | E1.2 (235) | ADCC reduction | CDC reduction | ||||
| IGHG4v4 | CH2 | A1.3 (234), A1.2 (235) | ADCC reduction | CDC reduction | ||||
| IGHG4v5 | h | P10 (228) | Half-IG exchange reduction | |||||
| IGHG4v6 | CH3 | K88 (409) | Half-IG exchange reduction | |||||
| IGHG4v21 | CH2 | Y15.1 (252), T16 (254), E18 (256) | Half-life increase | |||||
| IGHG4v36 | CH2 | Q84.4 (297) | No N-glycosylation site | |||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lefranc, M.-P.; Lefranc, G. Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions. Biomedicines 2020, 8, 319. https://doi.org/10.3390/biomedicines8090319
Lefranc M-P, Lefranc G. Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions. Biomedicines. 2020; 8(9):319. https://doi.org/10.3390/biomedicines8090319
Chicago/Turabian StyleLefranc, Marie-Paule, and Gérard Lefranc. 2020. "Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions" Biomedicines 8, no. 9: 319. https://doi.org/10.3390/biomedicines8090319
APA StyleLefranc, M.-P., & Lefranc, G. (2020). Immunoglobulins or Antibodies: IMGT® Bridging Genes, Structures and Functions. Biomedicines, 8(9), 319. https://doi.org/10.3390/biomedicines8090319