
Optimization of Electronic Nose Sensor Array for Tea Aroma Detecting Based on Correlation Coefficient and Cluster Analysis



Abstract
:1. Introduction
2. Materials and Methods
2.1. Tea Samples Preparation
2.2. Preliminary Sensor Array
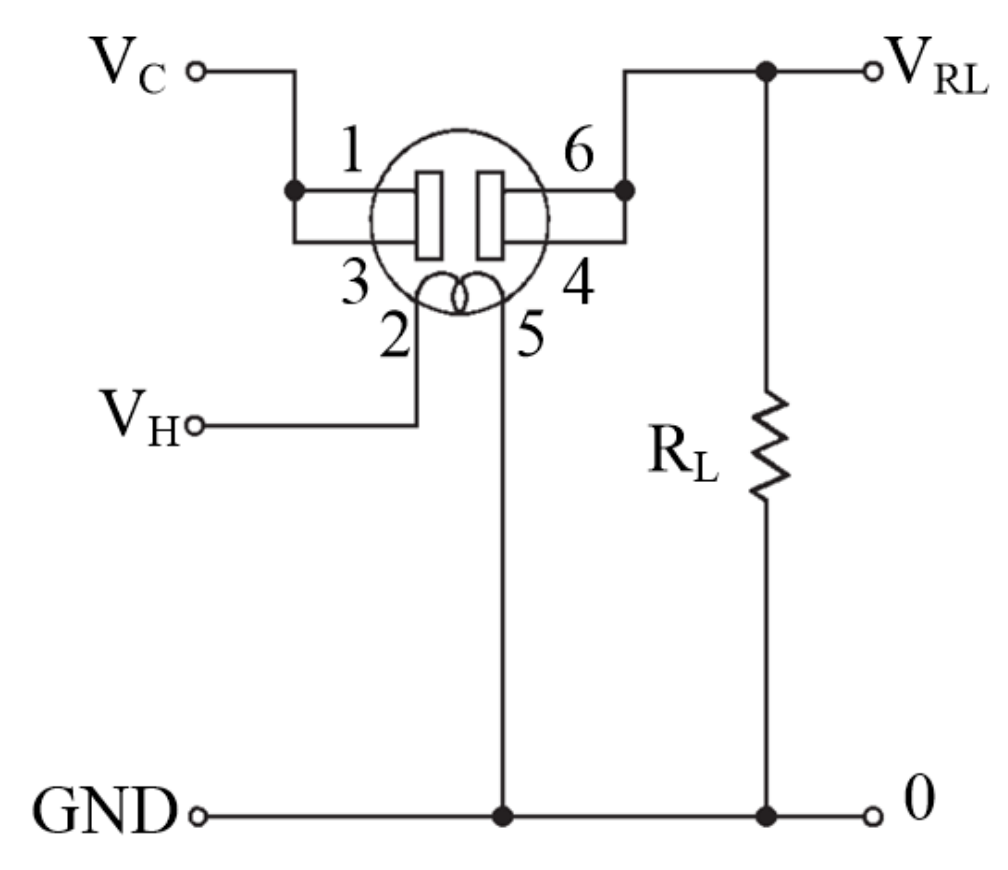
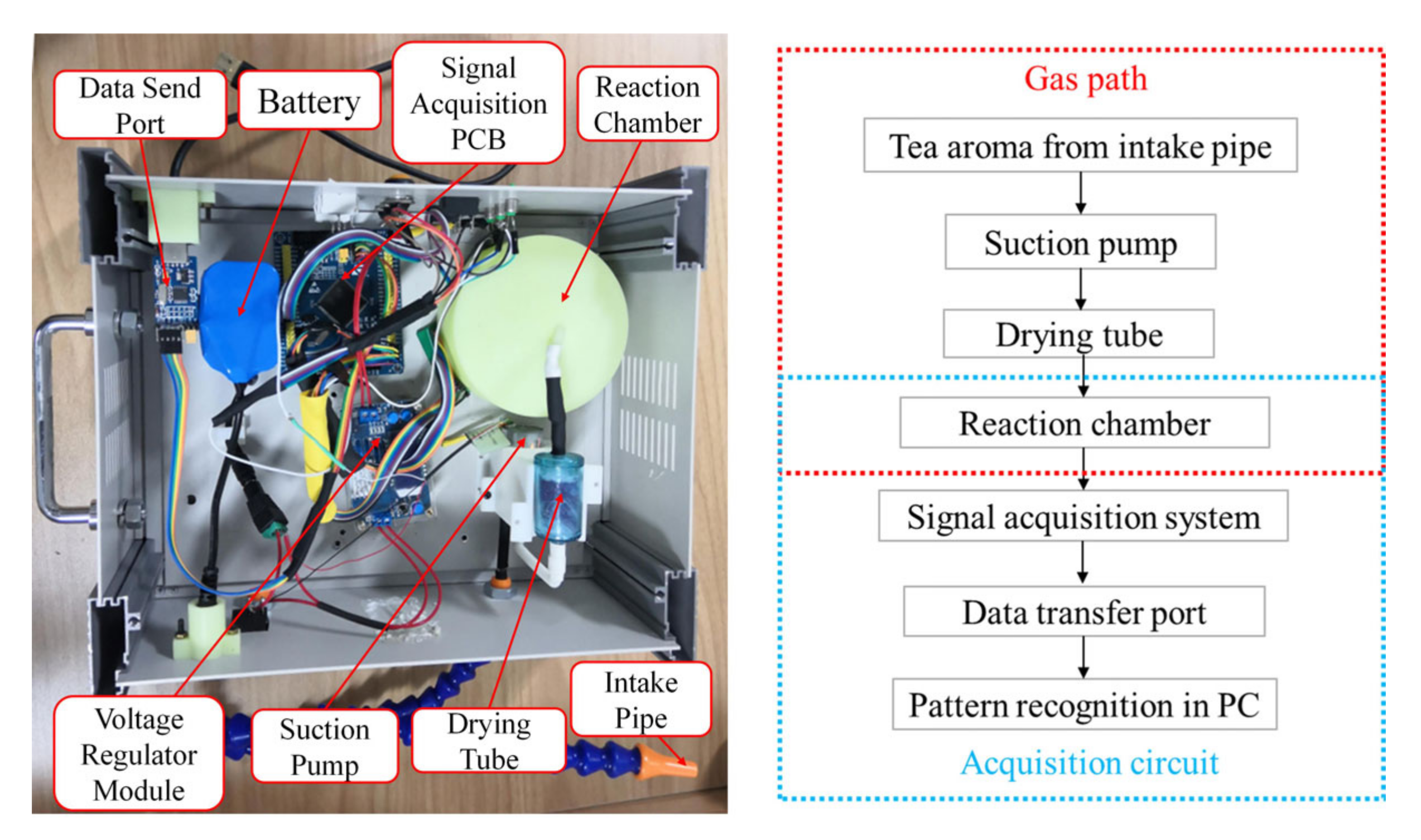
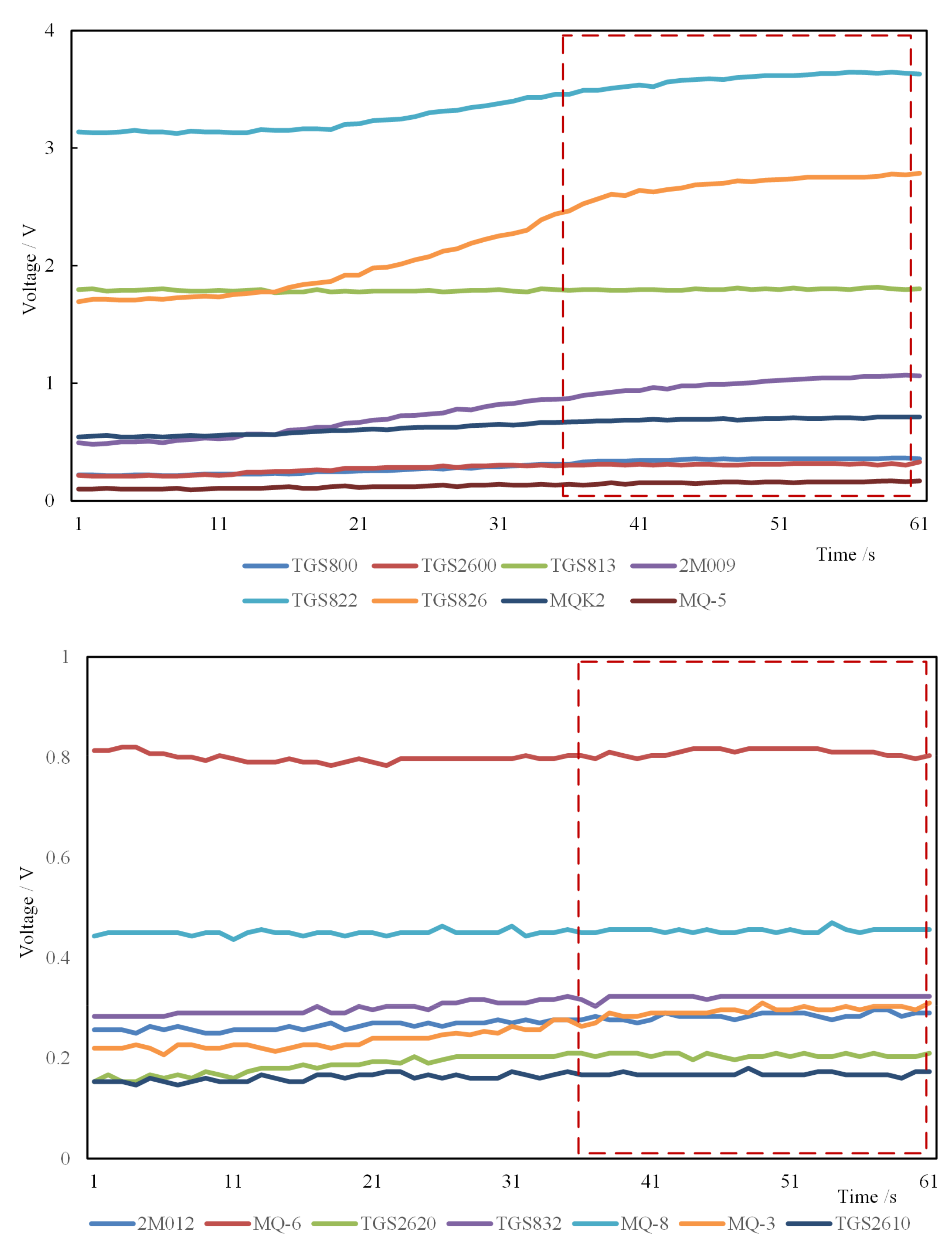
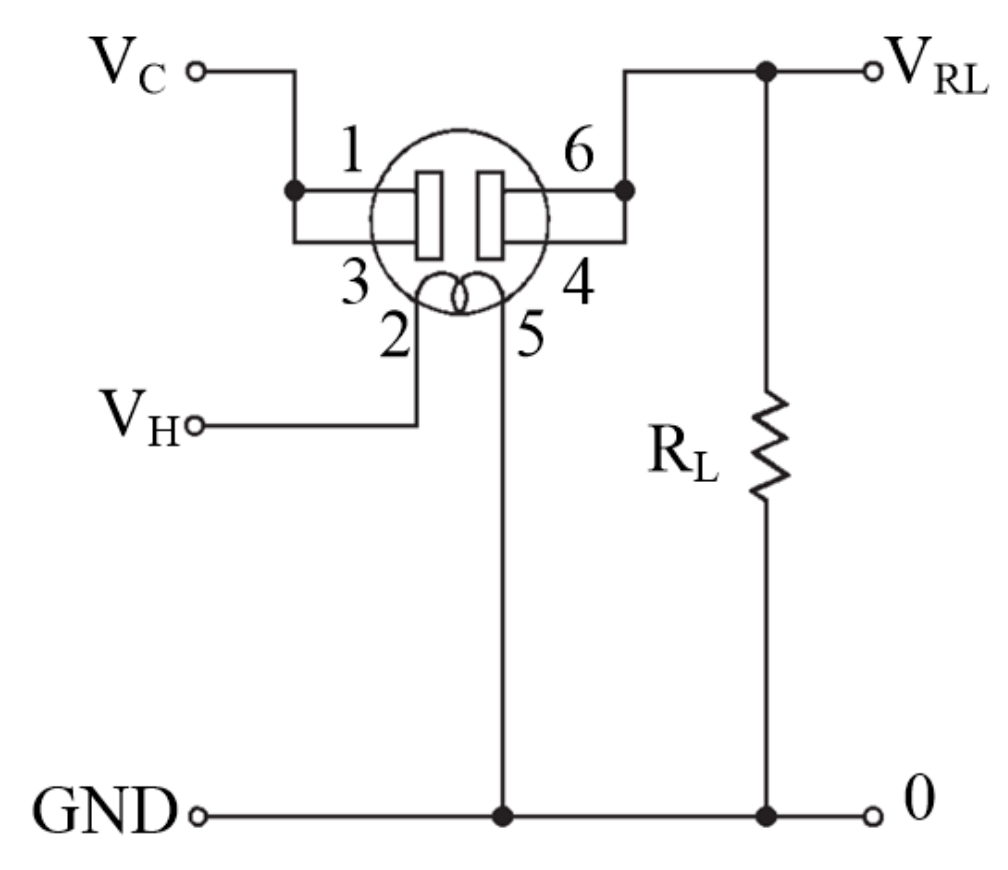
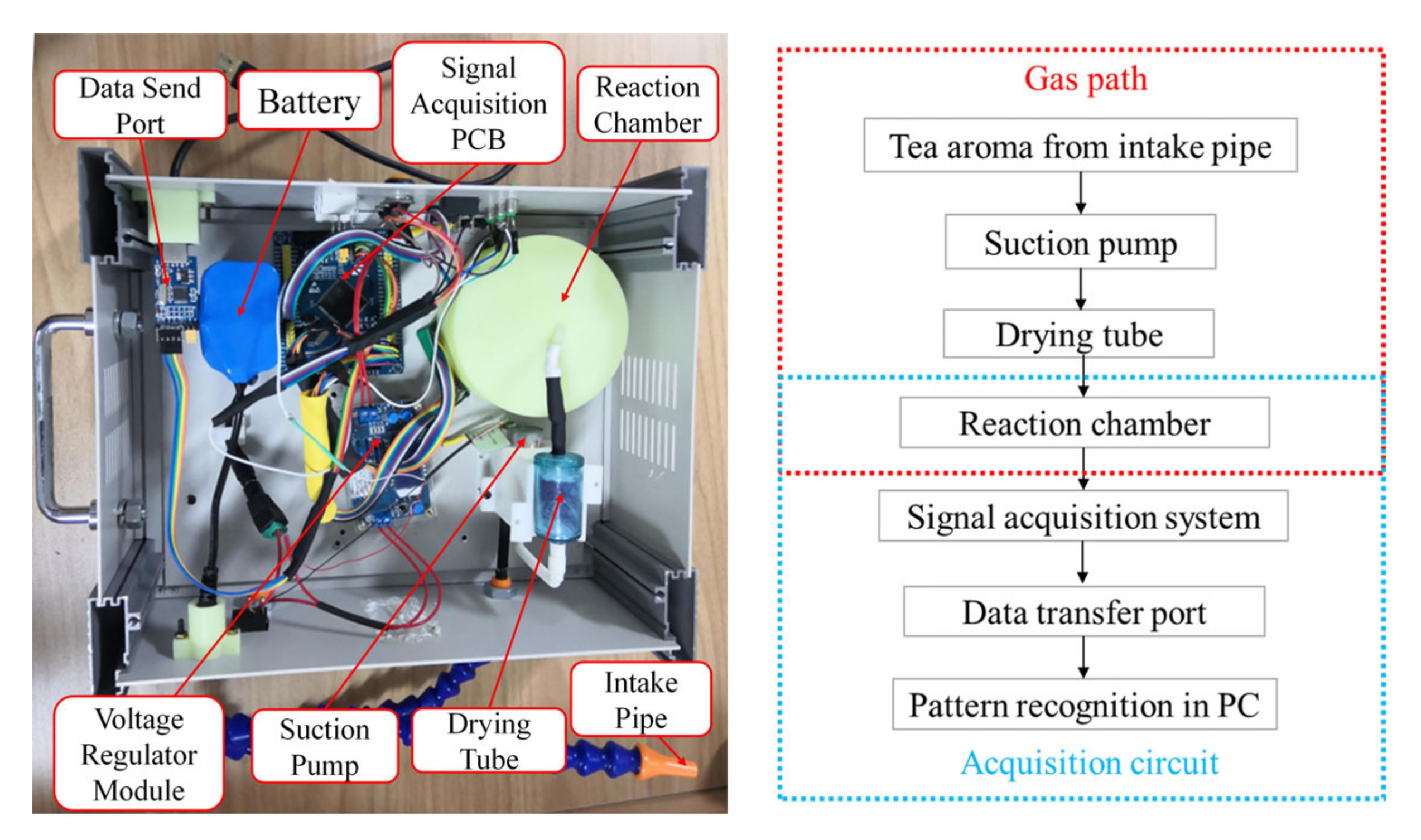
2.3. Electronic Nose System Set-Up
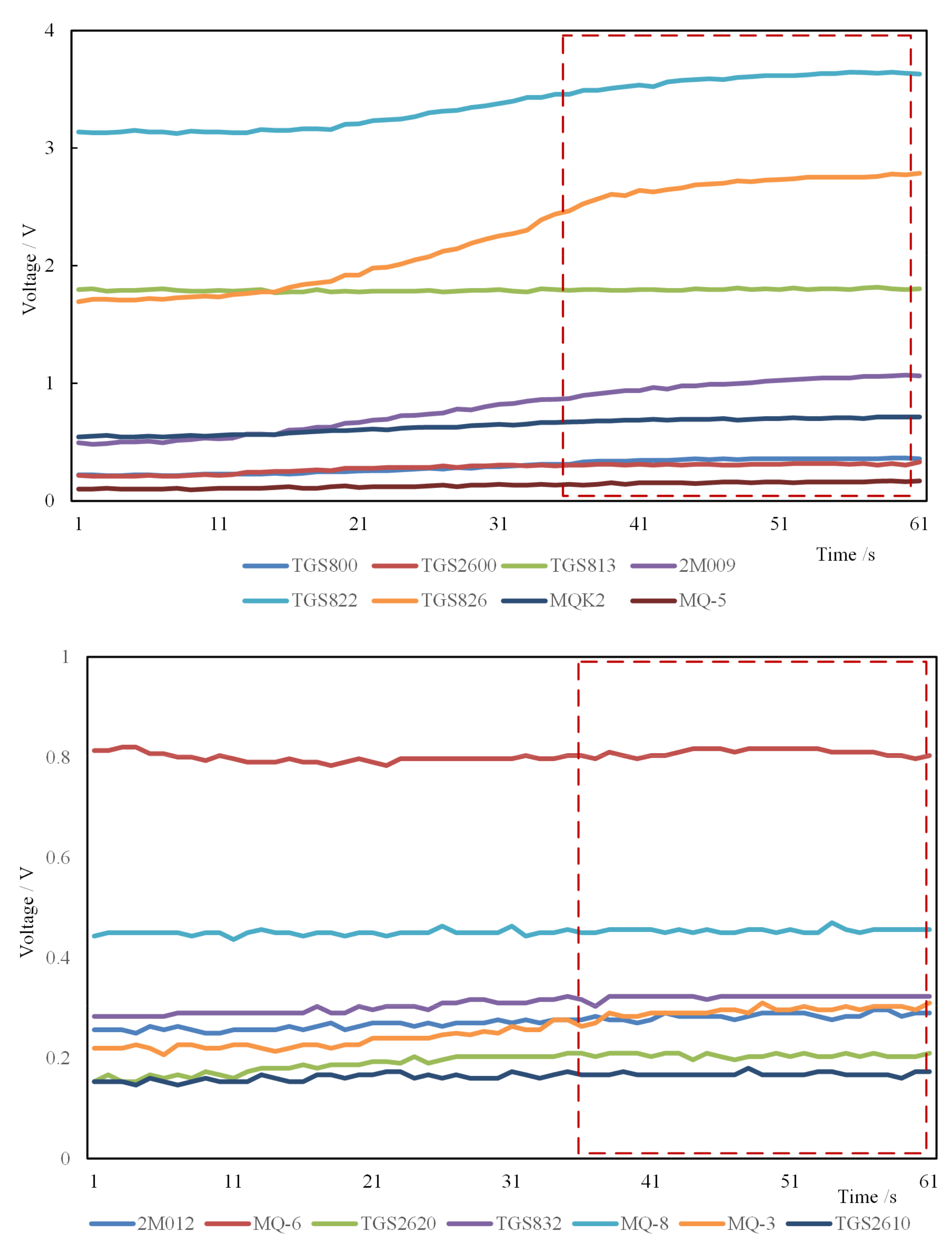
2.4. Data Analysis Methods
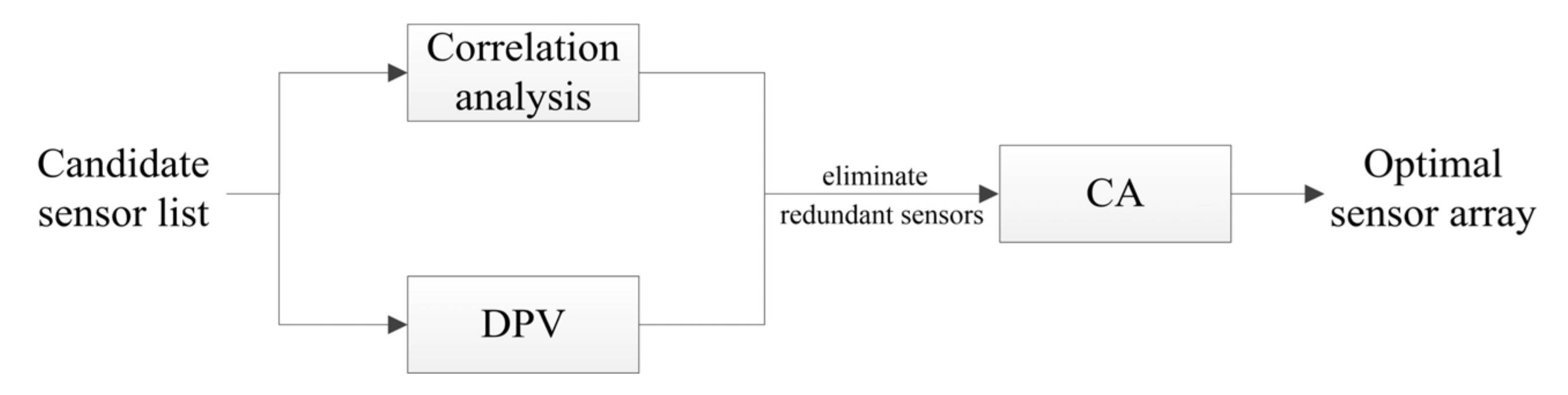
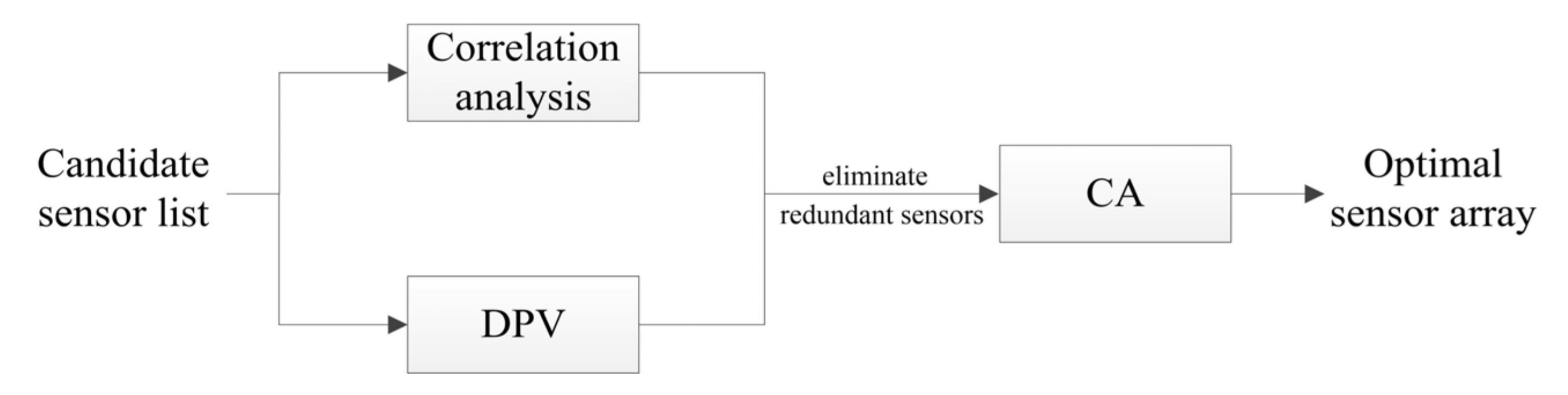
2.5. Sensor Array Optimization Methods
3. Results and Discussions
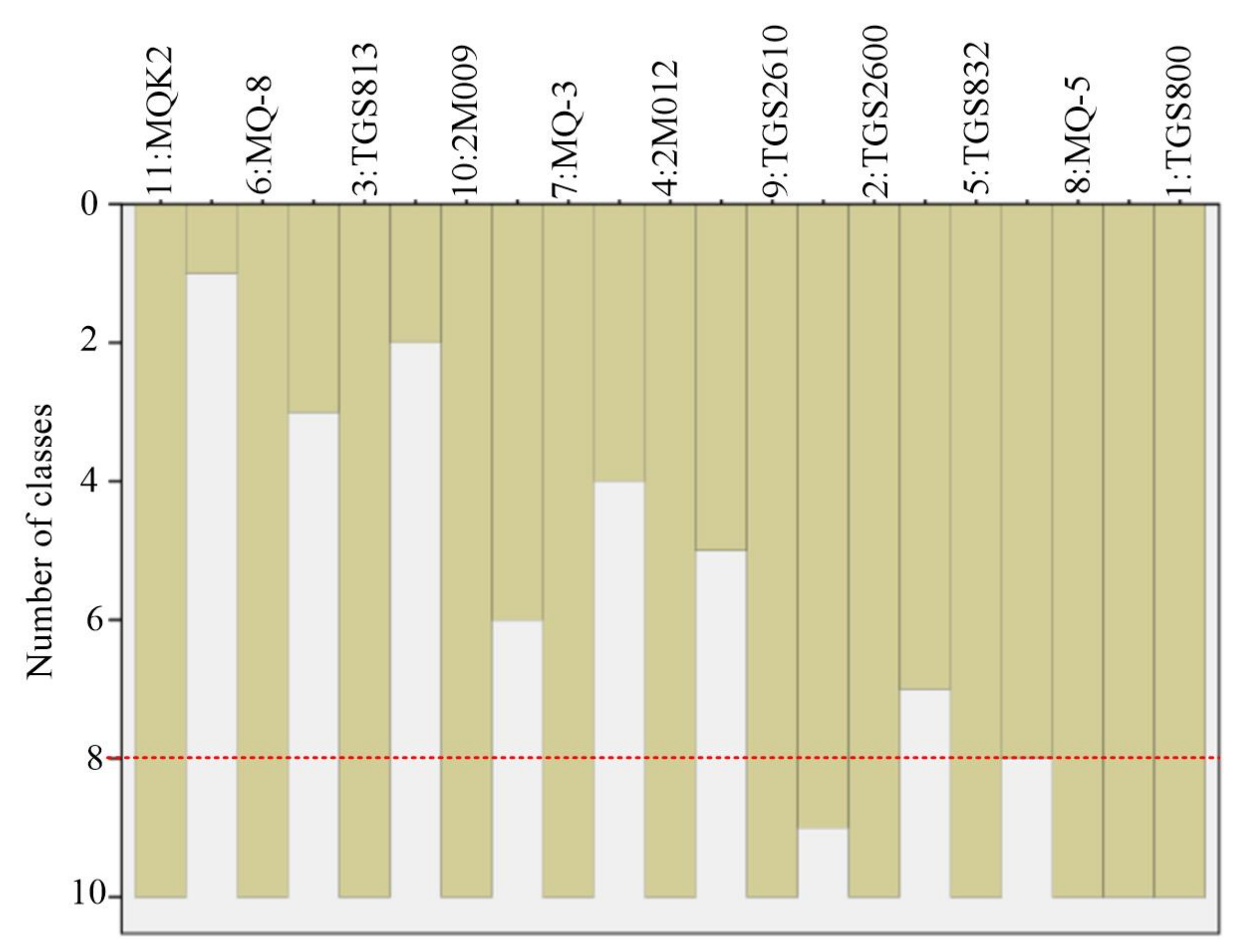
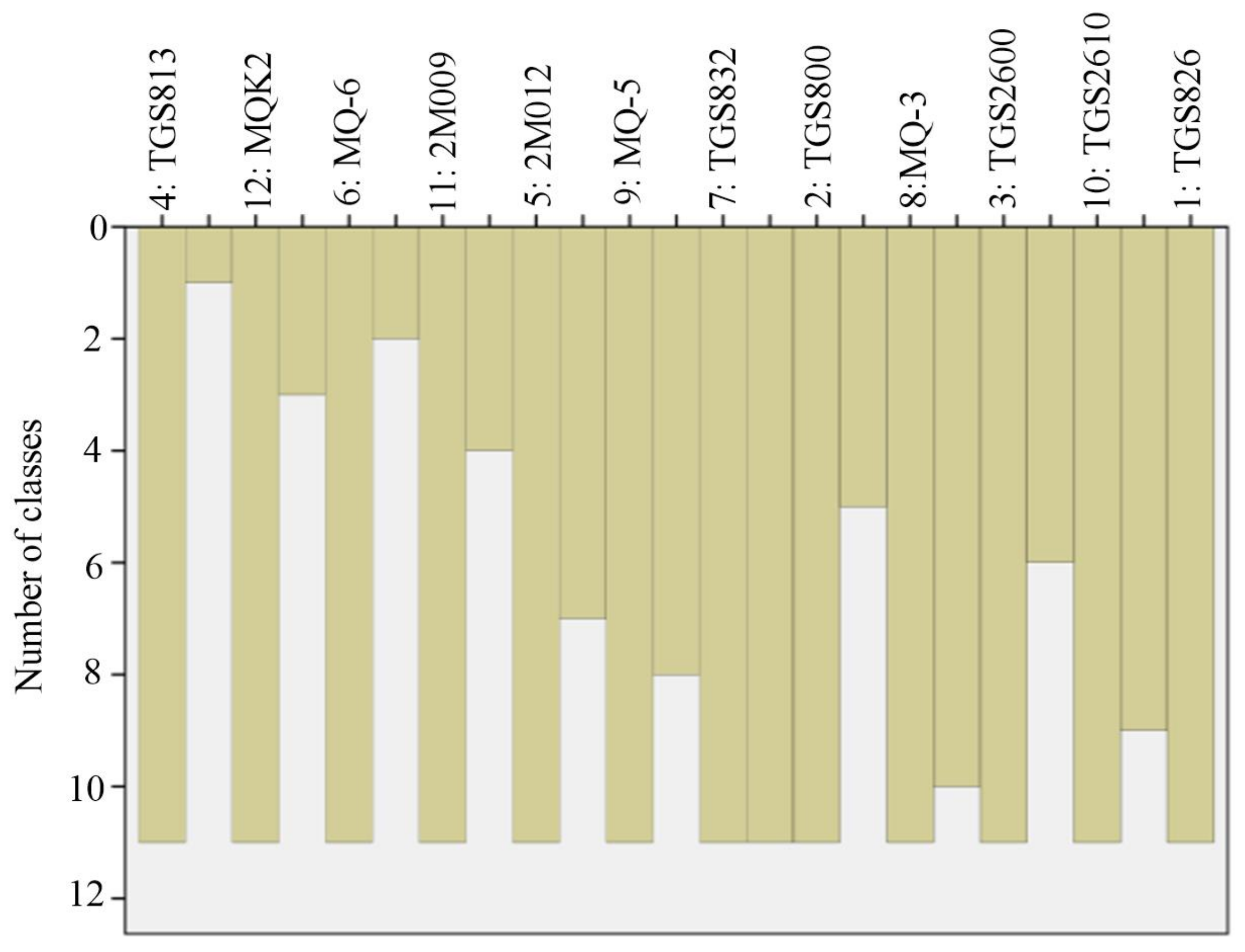
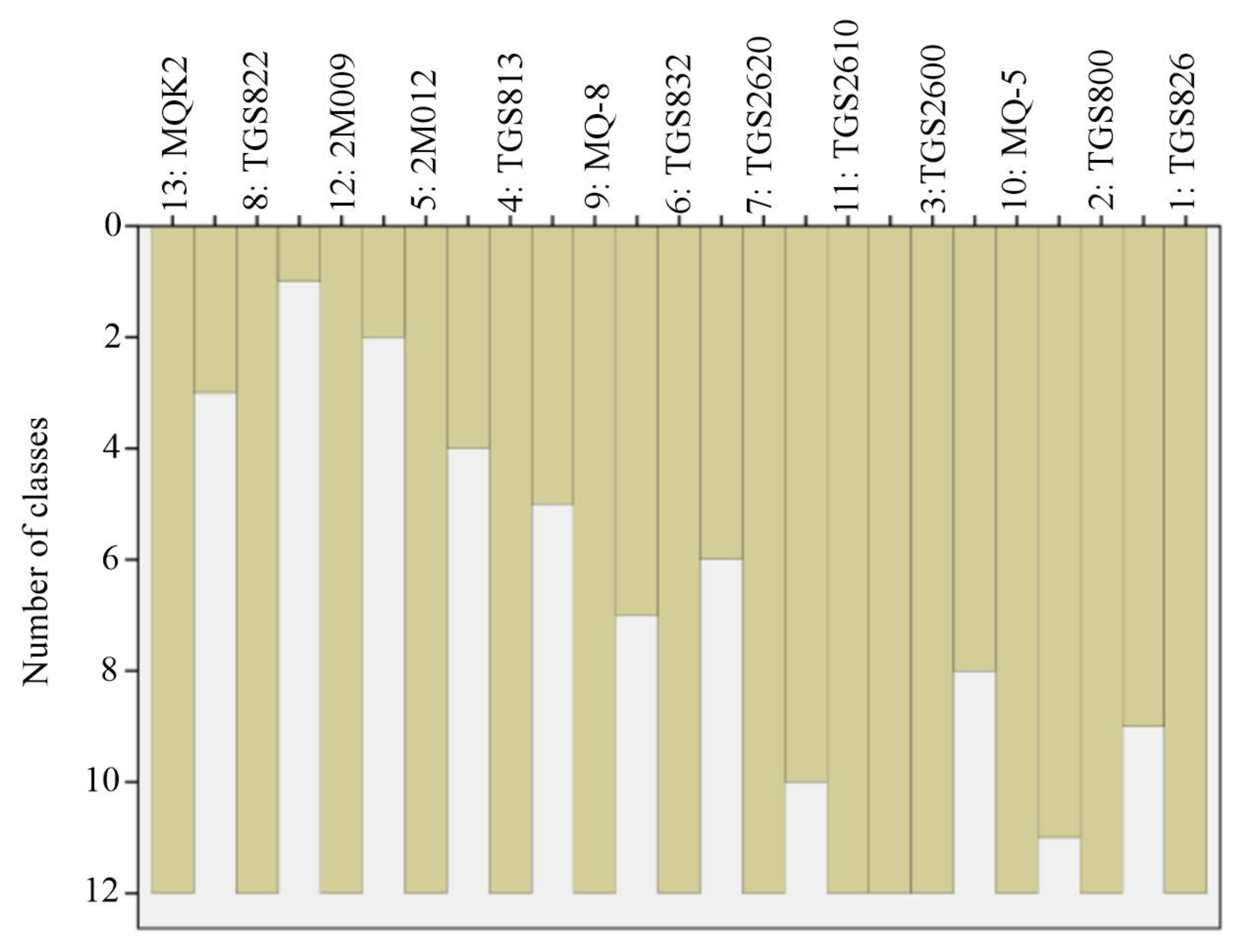
3.1. Sensor Array Optimization Results
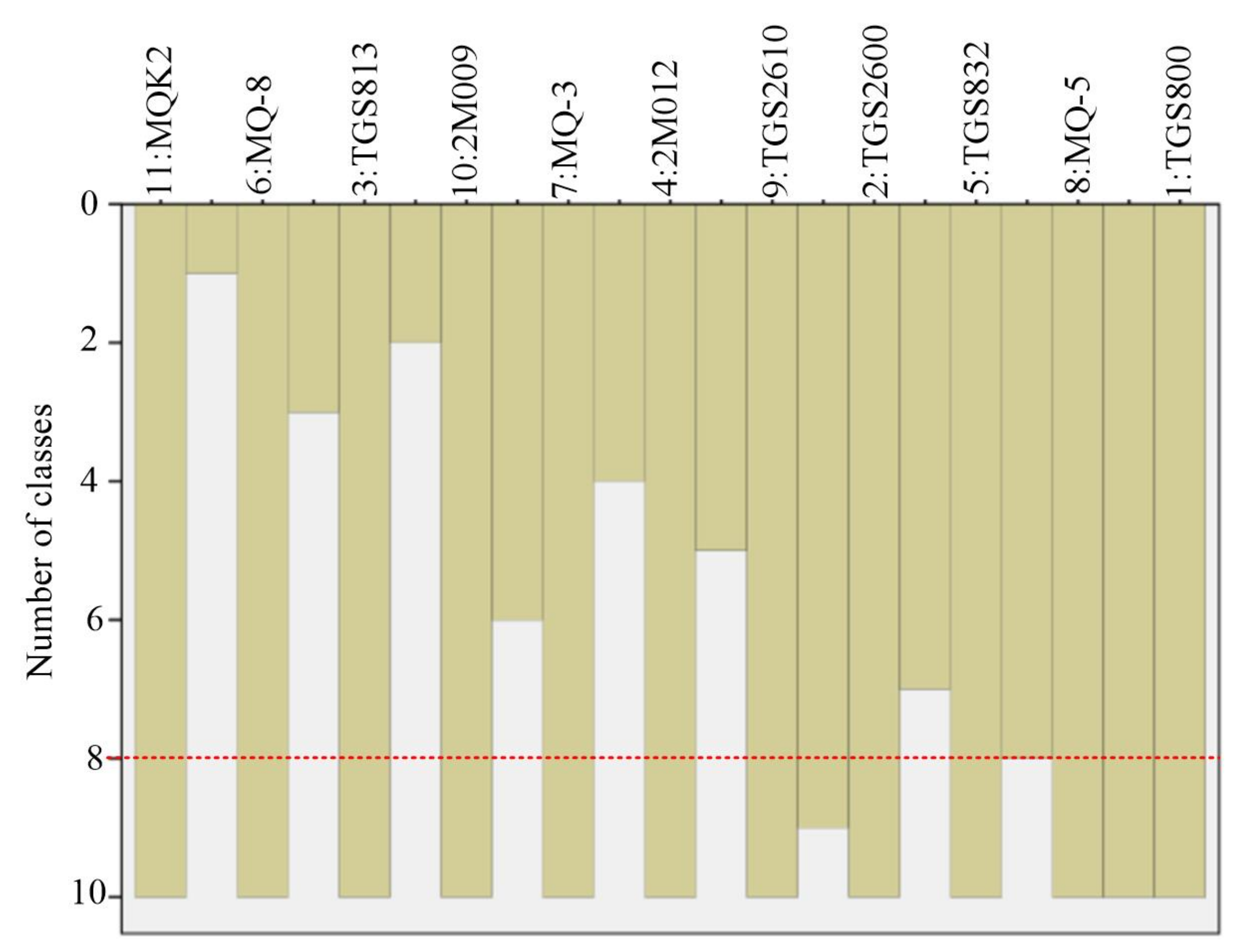
3.1.1. Optimization of Sensor Array LG for Green Tea
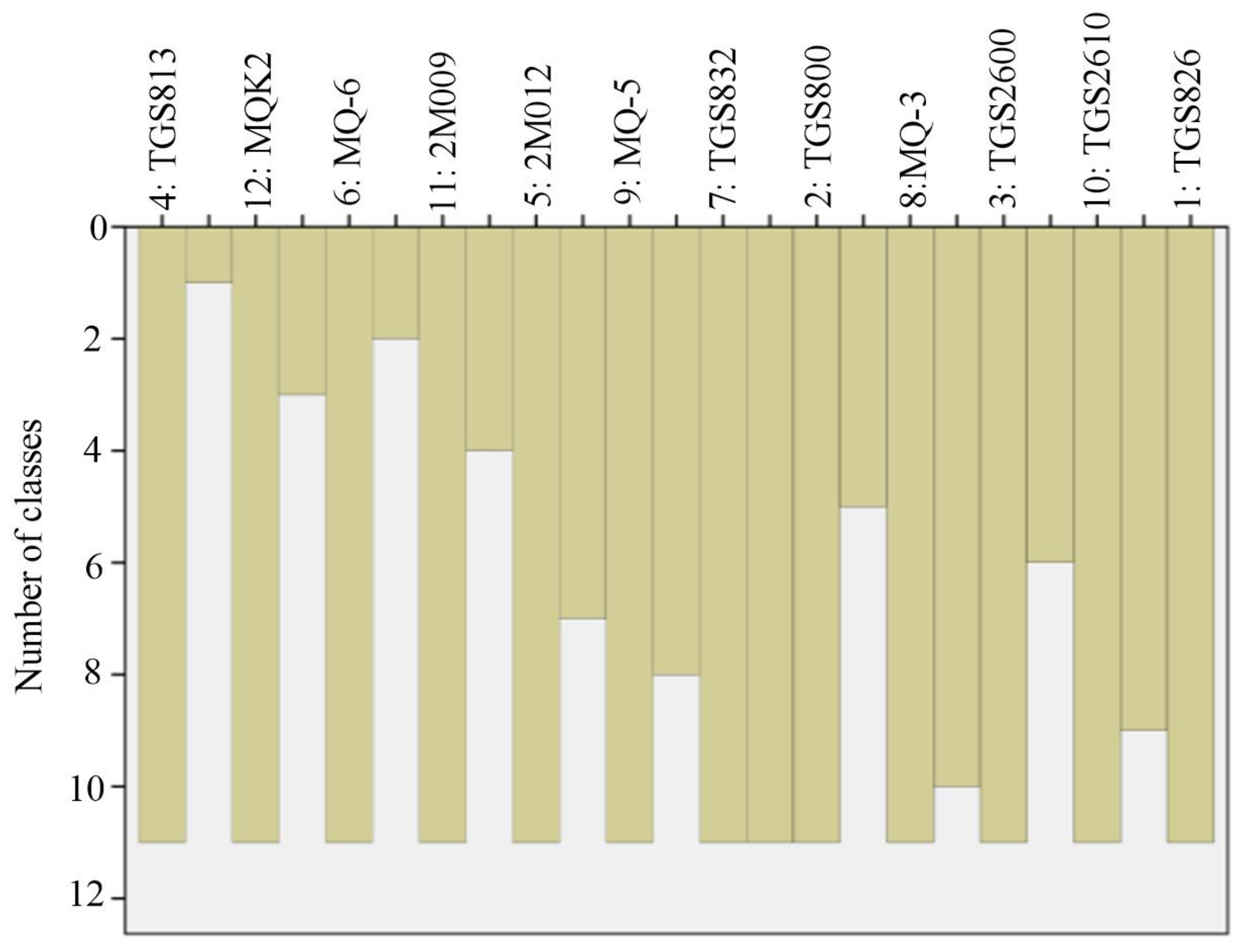
3.1.2. Optimization of Sensor Array LF for Fried Green Tea
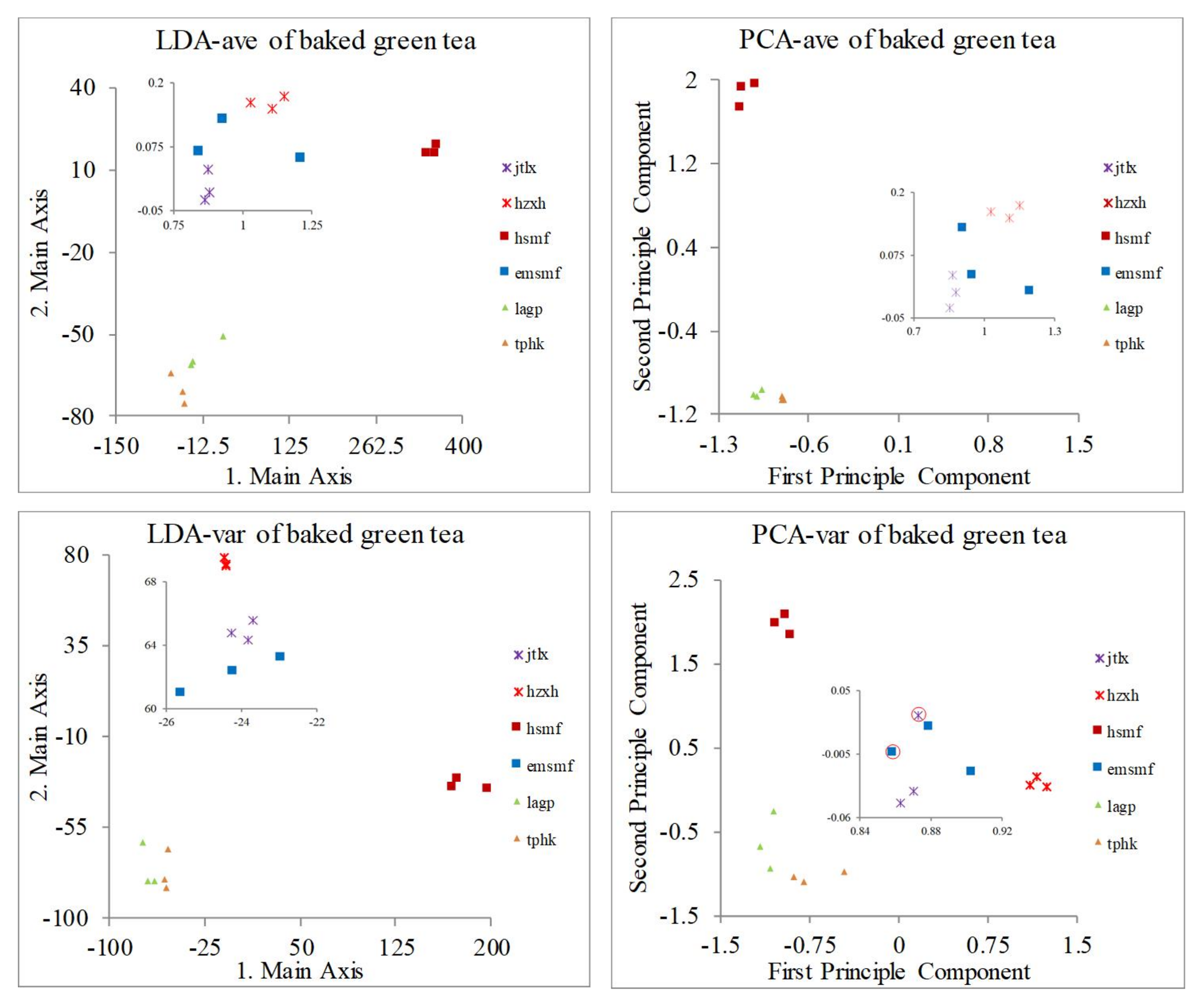
3.1.3. Optimization of Sensor Array LB for Baked Green Tea
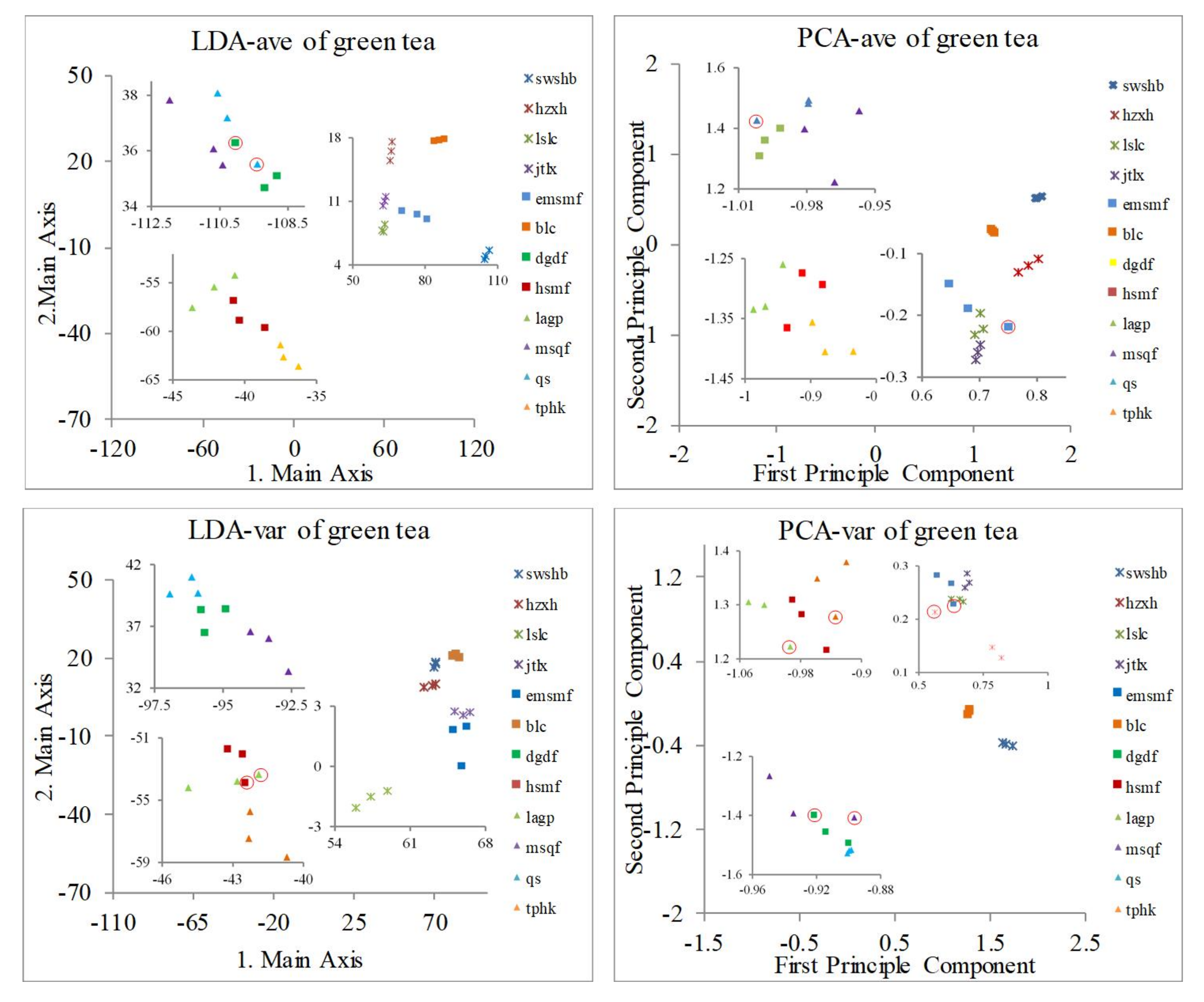
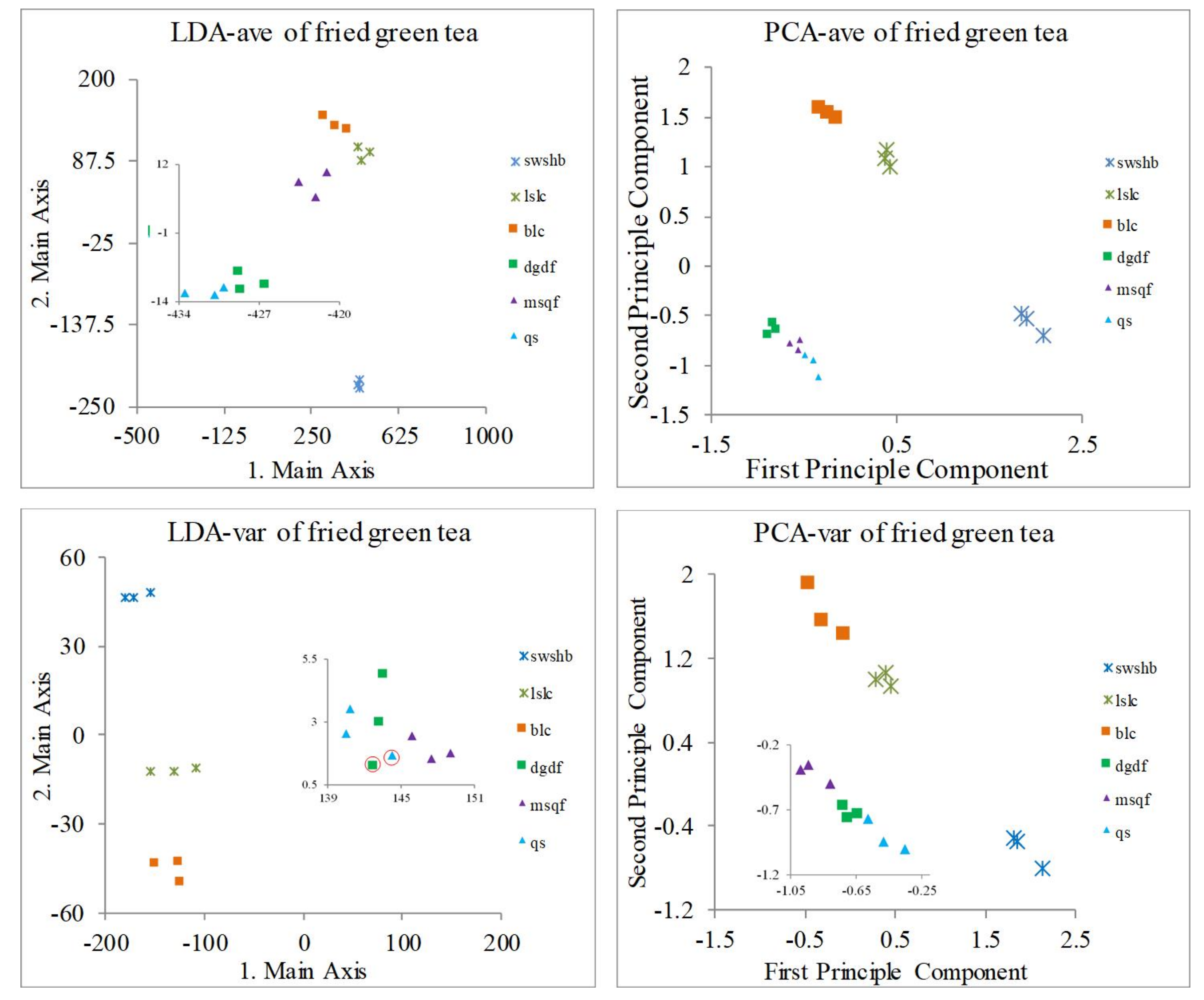
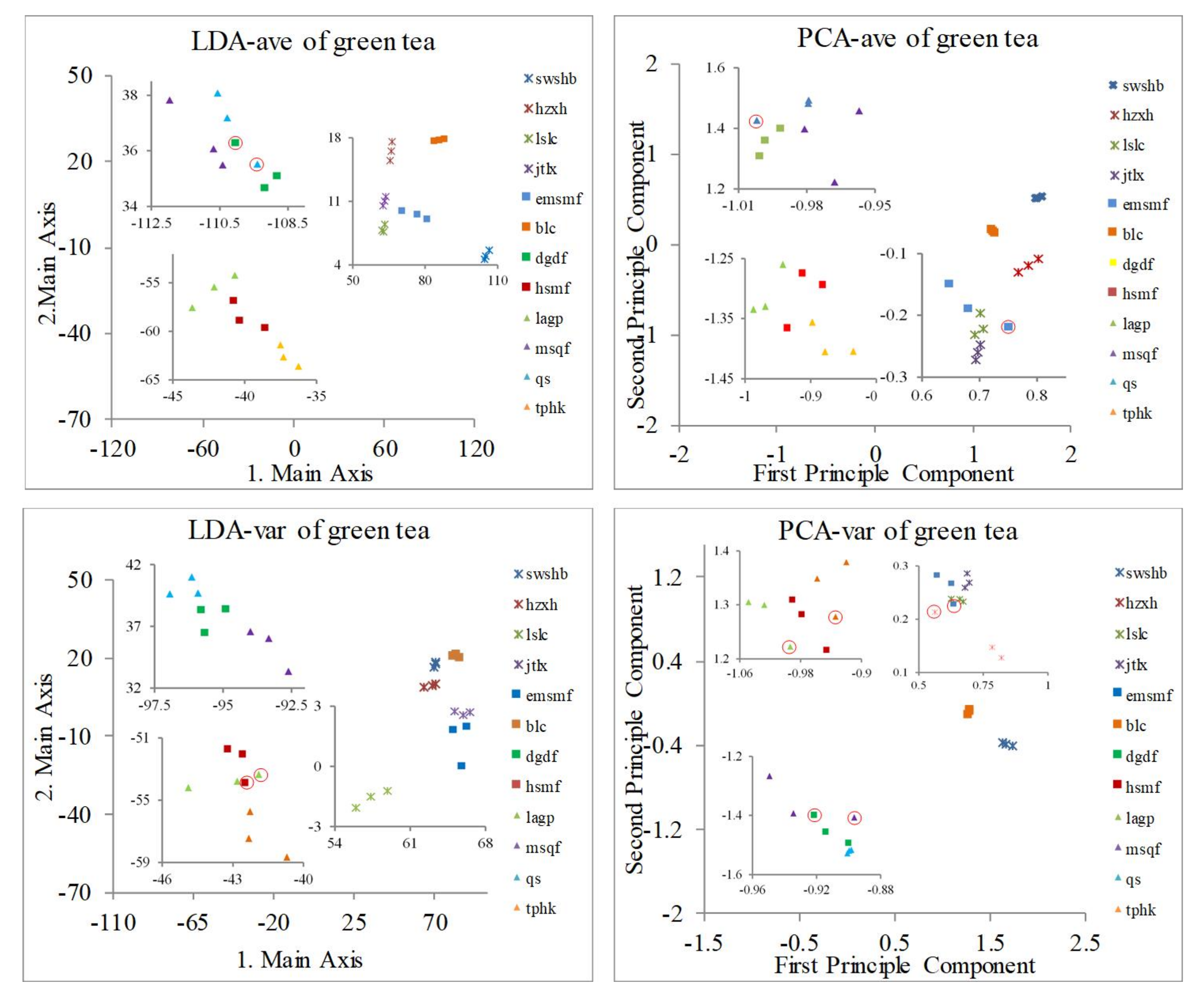
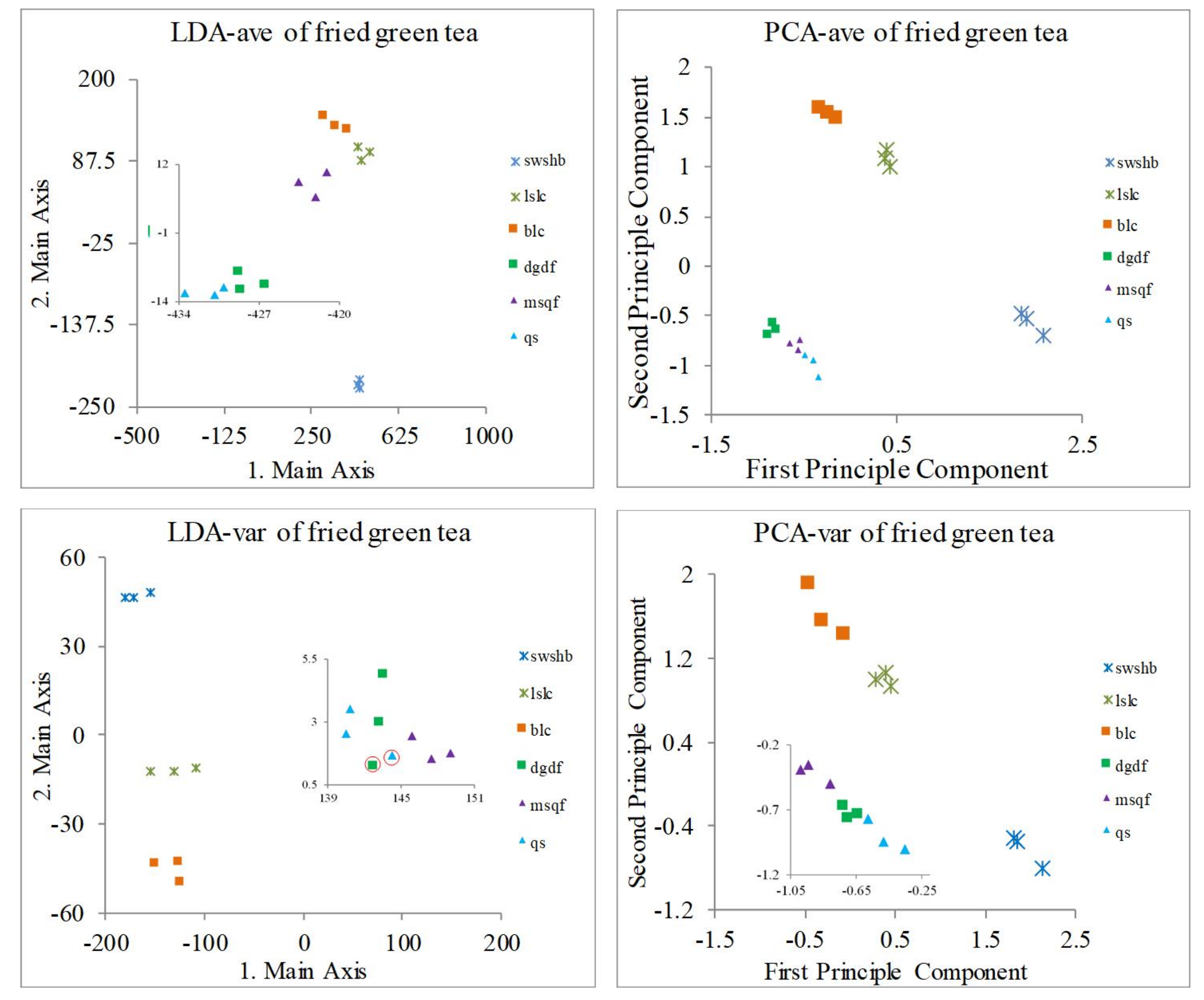
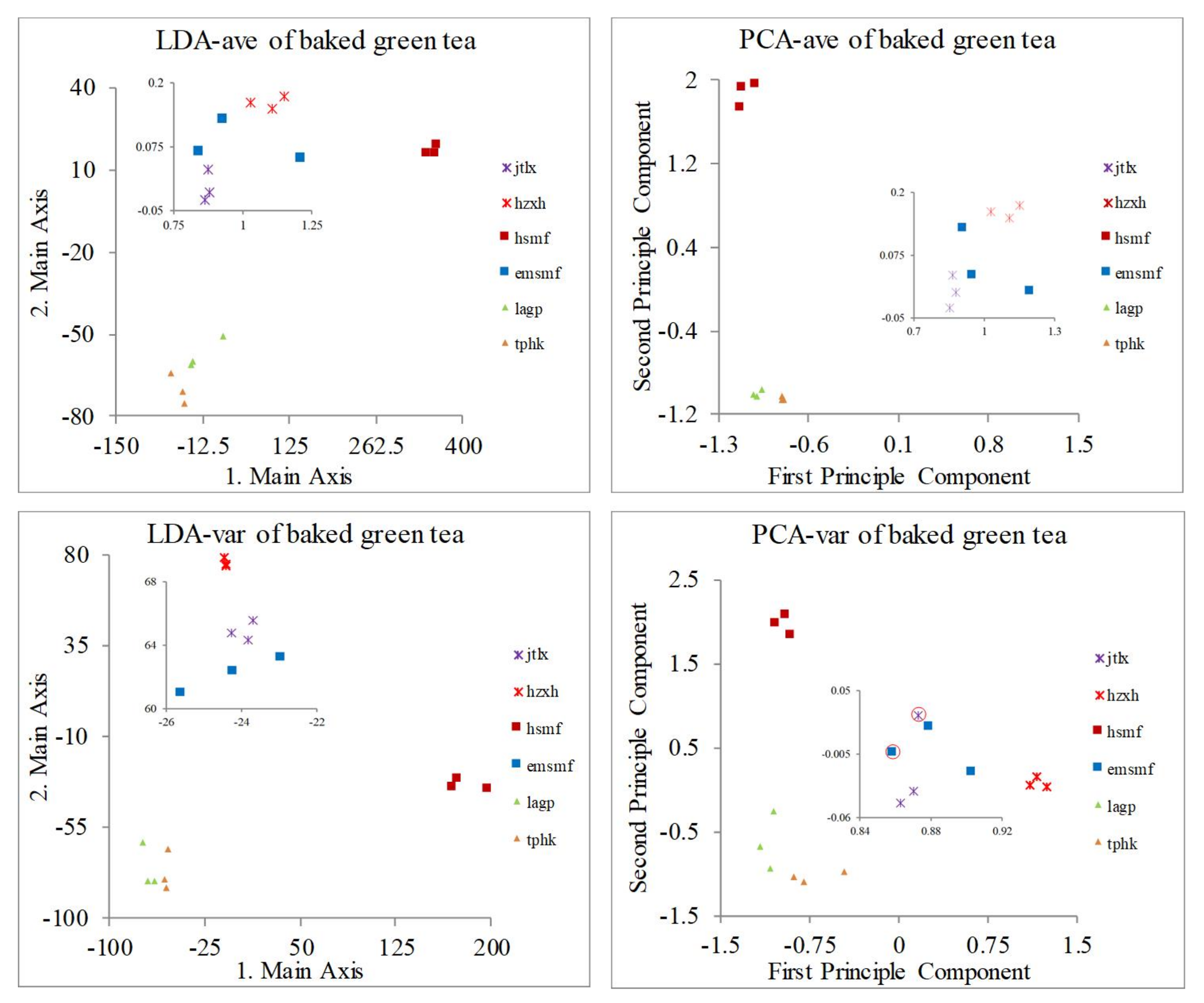
3.2. Classification of Green Tea Varieties
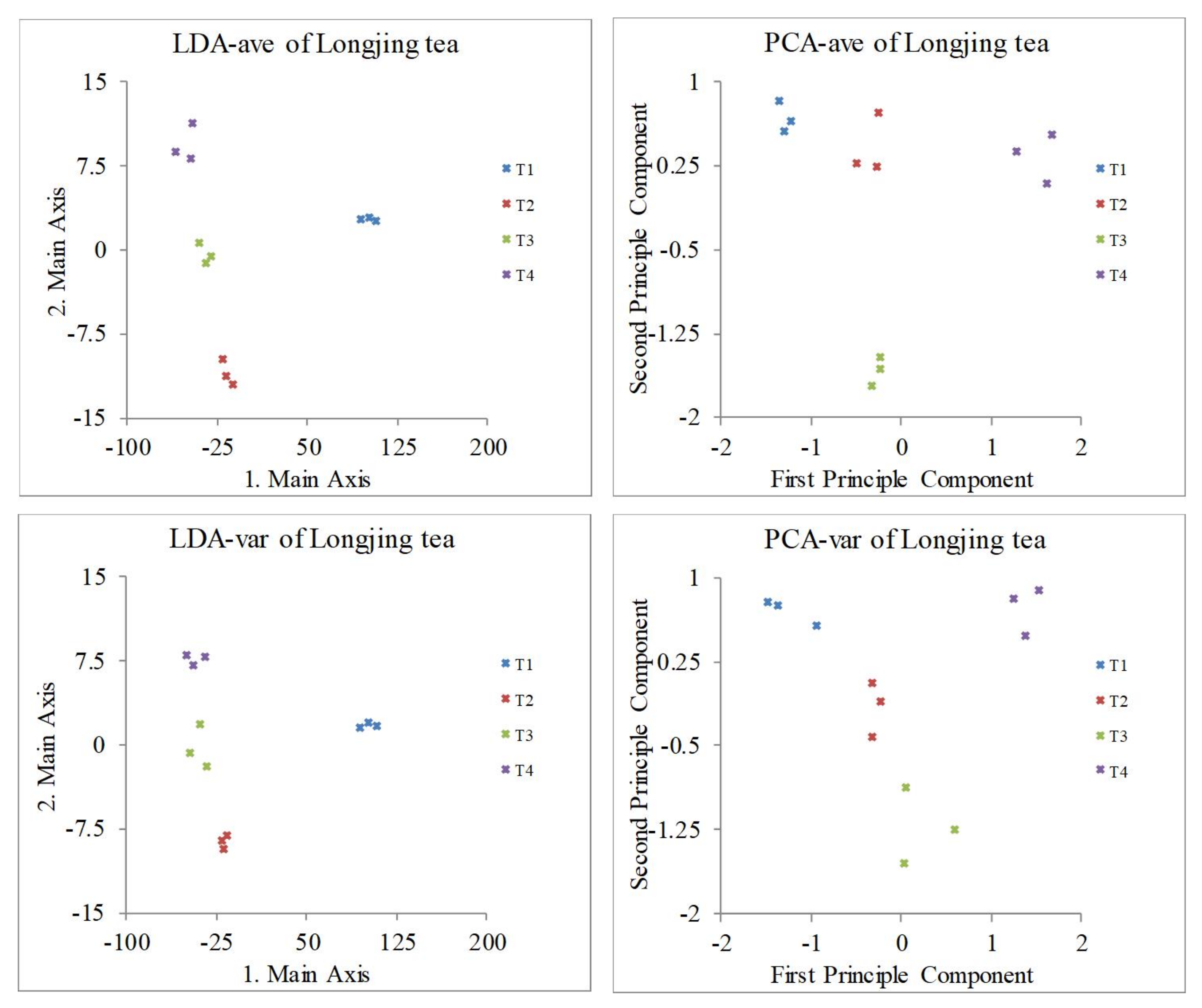
3.3. Classification of West Lake Longjing Tea Grade
3.4. Comparison of Correlation Analysis Methods and the Elimination of Sensors
3.5. Comparison of Screening Methods for Given Number of Sensors N
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ho, C.T.; Zheng, X.; Li, S. Tea aroma formation. Food Sci. Hum. Wellness 2015, 4, 9–27. [Google Scholar] [CrossRef] [Green Version]
- Xia, T.; Shi, S.; Wan, X. Impact of ultrasonic-assisted extraction on the chemical and sensory quality of tea infusion. J. Food Eng. 2006, 74, 557–560. [Google Scholar] [CrossRef]
- Qian, K.; Bao, Y.; Zhu, J.; Wang, J.; Wei, Z. Development of a portable electronic nose based on a hybrid filter-wrapper method for identifying the Chinese dry-cured ham of different grades. J. Food Eng. 2021, 290, 110250. [Google Scholar] [CrossRef]
- Bhattacharyya, N.; Bandyopadhyay, R.; Bhuyan, M.; Tudu, B.; Ghosh, D.; Jana, A. Electronic nose for black tea classification and correlation of measurements with “Tea Taster” marks. IEEE Trans. Instrum. Meas. 2008, 57, 1313–1321. [Google Scholar] [CrossRef]
- Demir, N.; Ferraz, A.C.O.; Sargent, S.A.; Balaban, M.O. Classification of impacted blueberries during storage using an electronic nose. J. Sci. Food Agric. 2011, 91, 1722–1727. [Google Scholar] [CrossRef] [PubMed]
- Majchrzak, T.; Wojnowski, W.; Dymerski, T.; Gębicki, J.; Namieśnik, J. Electronic noses in classification and quality control of edible oils: A review. Food Chem. 2018, 246, 192–201. [Google Scholar] [CrossRef] [PubMed]
- Infante, R.; Farcuh, M.; Meneses, C. Monitoring the sensorial quality and aroma through an electronic nose in peaches during cold storage. J. Sci. Food Agric. 2008, 88, 2073–2078. [Google Scholar] [CrossRef]
- Chen, H.Z.; Zhang, M.; Bhandari, B.; Guo, Z. Evaluation of the freshness of fresh-cut green bell pepper (Capsicum annuum var. grossum) using electronic nose. LWT 2018, 87, 77–84. [Google Scholar] [CrossRef] [Green Version]
- Śliwińska, M.; Wiśniewska, P.; Dymerski, T.; Wardencki, W.; Namieśnik, J. Application of electronic nose based on fast GC for authenticity assessment of Polish homemade liqueurs called nalewka. Food Anal. Method 2016, 9, 2670–2681. [Google Scholar] [CrossRef] [Green Version]
- Chaparro-Torres, L.A.; Bueso, M.C.; Fernández-Trujillo, J.P. Aroma volatiles obtained at harvest by HS-SPME/GC-MS and INDEX/MS-E-nose fingerprint discriminate climacteric behaviour in melon fruit. J. Sci. Food Agric. 2016, 96, 2352–2365. [Google Scholar] [CrossRef]
- Liu, L.; Li, X.; Li, Z.; Shi, Y. Application of Electronic Nose in Detection of Fresh Vegetables Freezing Time Considering Odor Identification Technology. Chem. Eng. Trans. 2018, 68, 265–270. [Google Scholar] [CrossRef]
- Musatov, V.Y.; Sysoev, V.V.; Sommer, M.; Kiselev, I. Assessment of meat freshness with metal oxide sensor microarray electronic nose: A practical approach. Sens. Actuators B Chem. 2010, 144, 99–103. [Google Scholar] [CrossRef]
- Gamboa, J.C.R.; da Silva, A.J.; de Andrade Lima, L.L.; Ferreira, T.A. Wine quality rapid detection using a compact electronic nose system: Application focused on spoilage thresholds by acetic acid. LWT 2019, 108, 377–384. [Google Scholar] [CrossRef] [Green Version]
- Marek, G.; Dobrzański, B.; Oniszczuk, T.; Combrzyński, M.; Ćwikła, D.; Rusinek, R. Detection and differentiation of volatile compound profiles in roasted coffee arabica beans from different countries using an electronic nose and GC-MS. Sensors 2020, 20, 2124. [Google Scholar] [CrossRef]
- Gonzalez Viejo, C.; Tongson, E.; Fuentes, S. Integrating a Low-Cost Electronic Nose and Machine Learning Modelling to Assess Coffee Aroma Profile and Intensity. Sensors 2021, 21, 2016. [Google Scholar] [CrossRef]
- Rasekh, M.; Karami, H.; Wilson, A.D.; Gancarz, M. Performance Analysis of MAU-9 Electronic-Nose MOS Sensor Array Components and ANN Classification Methods for Discrimination of Herb and Fruit Essential Oils. Chemosensors 2021, 9, 243. [Google Scholar] [CrossRef]
- Xu, M.; Wang, J.; Gu, S. Rapid identification of tea quality by E-nose and computer vision combining with a synergetic data fusion strategy. J. Food Eng. 2019, 241, 10–17. [Google Scholar] [CrossRef]
- Lu, X.; Wang, J.; Lu, G.; Lin, B.; Chang, M.; He, W. Quality level identification of West Lake Longjing green tea using electronic nose. Sens. Actuators B Chem. 2019, 301, 127056. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Yao, C.; Zhang, H.; Yu, Y. Quality grade identification of green tea using E-nose by CA and ANN. LWT—Food Sci. Technol. 2008, 41, 1268–1273. [Google Scholar] [CrossRef]
- Zhu, J.; Chen, F.; Wang, L.; Niu, Y.; Xiao, Z. Evaluation of the synergism among volatile compounds in Oolong tea infusion by odour threshold with sensory analysis and E-nose. Food Chem. 2017, 221, 1484–1490. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J. Discrimination of LongJing green-tea grade by electronic nose. Sens. Actuators B Chem. 2007, 122, 134–140. [Google Scholar] [CrossRef]
- Yu, H.; Wang, J.; Xiao, H.; Liu, M. Quality grade identification of green tea using the eigenvalues of PCA based on the E-nose signals. Sens. Actuators B Chem. 2009, 140, 378–382. [Google Scholar] [CrossRef]
- Men, H.; Fu, S.; Yang, J.; Cheng, M.; Shi, Y.; Liu, J. Comparison of SVM, RF and ELM on an Electronic Nose for the Intelligent Evaluation of Paraffin Samples. Sensors 2018, 18, 285. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xu, L.; Yu, X.; Liu, L.; Zhang, R. A novel method for qualitative analysis of edible oil oxidation using an electronic nose. Food Chem. 2016, 202, 229–235. [Google Scholar] [CrossRef]
- Yin, Y.; Hao, Y.; Yu, H. Identification method for different moldy degrees of maize using electronic nose coupled with multi-features fusion. Trans. Chin. Soc. Agric. Eng. 2016, 32, 254–260. [Google Scholar]
- Yu, H.; Chu, B.; Yin, Y. Evaluation method of feature vector in vinegar identification by electronic nose. Trans. Chin. Soc. Agric. Eng. 2013, 29, 258–264. [Google Scholar]
- Zhi, R.; Zhao, L.; Zhang, D. A framework for the multi-level fusion of electronic nose and electronic tongue for tea quality assessment. Sensors 2017, 17, 1007. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Banerjee, M.B.; Roy, R.B.; Tudu, B.; Bandyopadhyay, R.; Bhattacharyya, N. Black tea classification employing feature fusion of E-Nose and E-Tongue responses. J. Food Eng. 2019, 244, 55–63. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F. Performance study of multilayer perceptrons in a low-cost electronic nose. IEEE Trans. Instrum. Meas. 2014, 63, 1670–1679. [Google Scholar] [CrossRef]
- Makimori, G.Y.F.; Bona, E. Commercial instant coffee classification using an electronic nose in tandem with the ComDim-LDA approach. Food Anal. Methods 2019, 12, 1067–1076. [Google Scholar] [CrossRef]
- Yin, Y.; Zhao, Y. A feature selection strategy of E-nose data based on PCA coupled with Wilks Λ-statistic for discrimination of vinegar samples. J. Food Meas. Charact. 2019, 13, 2406–2416. [Google Scholar] [CrossRef]
- Pardo, M.; Sberveglieri, G. Classification of electronic nose data with support vector machines. Sens. Actuators B Chem. 2005, 107, 730–737. [Google Scholar] [CrossRef]
- Tan, J.; Kerr, W.L. Determining degree of roasting in cocoa beans by artificial neural network (ANN)-based electronic nose system and gas chromatography/mass spectrometry (GC/MS). J. Sci. Food Agric. 2018, 98, 3851–3859. [Google Scholar] [CrossRef]
- Wijaya, D.R.; Afianti, F. Stability assessment of feature selection algorithms on homogeneous datasets: A study for sensor array optimization problem. IEEE Access 2020, 8, 33944–33953. [Google Scholar] [CrossRef]
- Chen, R.R.; Luo, D.H.; Sun, Y.; Sun, Y.L.; Gholam Hossini, H. A Sensor Array Optimization Method Based on Variance Difference for Machine Olfaction. In Applied Mechanics and Materials; Trans Tech Publications Ltd.: Freinbach, Switzerland, 2014; Volume 618, pp. 523–527. [Google Scholar] [CrossRef]
- Zhou, H.T.; Yin, Y.; Yu, H.C. Optimization method of gas sensor array for identification of Jing Wine based on electronic nose. Chin. J. Sens. Actuators 2009, 22, 175–178, (In Chinese with English abstract). [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Processing Technology | Fried Green Tea | Baked Green Tea | ||||
|---|---|---|---|---|---|---|
| Tea samples for training | msqf | dgdf | qs | lagp | hsmf | tphk |
| Place | Changzhou | Huangshan | Hefei | Huangshan | Huangshan | Huangshan |
| Date | 03/2018 | 03/2018 | 04/2018 | 03/2018 | 03/2018 | 04/2018 |
| Tea samples for validation | swshb | lslc | blc | jtlx | hzxh | emsmf |
| Place | Shengzhou | Qingdao | Suzhou | Xuancheng | Xi’an | Chengdu |
| Date | 04/2020 | 04/2020 | 04/2020 | 04/2020 | 04/2020 | 04/2020 |
| Scheme | Sensitivity to Gases | Heating Resistance/Ω |
|---|---|---|
| TGS813 | Isobutane, propane, ethanol, methane, etc. | 30.0 ± 3.0 |
| TGS822 | Acetone, ethanol, benzene, ethane, etc. | 38.0 ± 3.0 |
| TGS2600 | Hydrogen sulfide gas | ≈83.0 |
| TGS2620 | Organic solvents | ≈83.0 |
| MQ-6 | Olefins, 2 to 4 carbon alkanes | 26.0 ± 3.0 |
| MQ-5 | Combustible gas | 31.0 ± 3.0 |
| TGS832 | Halogenated hydrocarbons, alcohols | 30.0 ± 3.0 |
| TGS826 | Ammonia | 30.0 ± 3.0 |
| TGS2610 | Hydrogen sulfide gas | ≈59.0 |
| 2M009 | Toluene and benzene gas | 33.0 ± 3.0 |
| MQ-8 | Diethyl ether | 31.0 ± 3.0 |
| MQK2 | Methanol, ethanol gas | 31.0 ± 3.0 |
| 2M012 | Hydrogen | 33.0 ± 3.0 |
| MQ-3 | Ethanol vapor | 29.0 ± 3.0 |
| TGS800 | Methane, isobutane, hydrogen, etc. | 38.0 ± 3.0 |
| msqf | dgdf | qs | |||
|---|---|---|---|---|---|
| Sensor model | Sensor model | Sensor model | |||
| TGS826/TGS822 | 0.96 | TGS832/TGS2620 | 0.98 | MQK2/TGS822 | 0.95 |
| MQK2/TGS822 | 0.97 | TGS822/TGS813 | 0.96 | TGS822/MQ-8 | 0.92 |
| TGS2620/TGS822 | 0.95 | MQ-8/TGS822 | 0.93 | MQ-6/MQK2 | 0.91 |
| TGS822/2M009 | 0.96 | TGS813/MQ-8 | 0.90 | MQ-6/TGS822 | 0.91 |
| TGS2620/MQK2 | 0.95 | TGS826/TGS813 | 0.93 | MQ-8/MQK2 | 0.93 |
| lagp | hsmf | tphk | |||
| Sensor model | Sensor model | Sensor model | |||
| MQ-6/2M012 | 0.88 | MQ-6/TGS822 | 0.96 | MQ-3/TGS832 | 0.92 |
| MQ-3/2M012 | 0.88 | MQ-6/MQ-5 | 0.90 | MQ-6/TGS832 | 0.86 |
| MQ-3/MQ-6 | 0.88 | TGS822/MQ-5 | 0.87 | MQ-6/MQ-3 | 0.86 |
| Sensors | DPVs for 6 General Green Teas | Ranking | DPVs for 3 Fried Green Teas | Ranking | DPVs for 3 Baked Green Teas | Ranking |
|---|---|---|---|---|---|---|
| TGS826 | 4.59 | 9 | 0.32 | 9 | 0.25 | 9 |
| TGS800 | 0.17 | 15 | 0.15 | 14 | 0.16 | 12 |
| TGS2600 | 3.89 | 11 | 0.27 | 10 | 0.12 | 13 |
| TGS813 | 65.21 | 6 | 0.5965 | 6 | 0.67 | 6 |
| 2M012 | 218.39 | 4 | 22.37 | 2 | 0.186 | 11 |
| MQ-6 | 189.95 | 5 | 40.51 | 1 | 1.21 | 5 |
| TGS832 | 6.56 | 8 | 0.26 | 11 | 5.87 | 2 |
| TGS2620 | 1.64 | 13 | 0.14 | 15 | 0.65 | 7 |
| TGS822 | 13.74 | 7 | 0.1896 | 12 | 1.94 | 4 |
| MQ-8 | 1279.00 | 1 | 0.58 | 8 | 12.73 | 1 |
| MQ-3 | 401.99 | 3 | 2.16 | 3 | 0.30 | 8 |
| MQ-5 | 2.06 | 12 | 0.82 | 5 | 0.05 | 14 |
| TGS2610 | 1.28 | 14 | 0.5964 | 7 | 0.195 | 10 |
| 2M009 | 4.32 | 10 | 0.1891 | 13 | 0.01 | 15 |
| MQK2 | 1278.08 | 2 | 1.16 | 4 | 3.56 | 3 |
| Tea Varieties | Sensors Retained in the Array | Sensors Eliminated |
|---|---|---|
| msqf | TGS813, TGS832, MQ-6, MQ-8, MQ-5, MQ-3, 2M012, TGS2600, TGS2610, MQK2, TGS800 | TGS826, TGS822, TGS2620, 2M009 |
| dgdf | 2M009, TGS832, MQ-6, MQ-8, MQ-5, MQ-3, 2M012, TGS2600, TGS2610, MQK2, TGS800 | TGS826, TGS2620, TGS813, TGS822 |
| qs | 2M009, TGS813, TGS832, MQ-8, MQ-5, MQ-3, 2M012, TGS2620, TGS2600, TGS2610, TGS826, TGS800 | TGS822, MQ-6, MQK2 |
| lagp | 2M009, TGS813, TGS822, TGS832, MQ-8, MQ-5, MQ-3, TGS2620, TGS2600, TGS2610, TGS826, MQK2, TGS800 | MQ-6, 2M012 |
| hsmf | 2M009, TGS813, TGS832, MQ-6, MQ-8, MQ-3, 2M012, TGS2620, TGS2600, TGS2610, TGS826, MQK2, TGS800 | TGS822, MQ-5 |
| tphk | 2M009, TGS813, TGS822, MQ-8, MQ-5, MQ-3, 2M012, TGS2620, TGS2600, TGS2610, TGS826, MQK2, TGS800 | MQ-6, TGS832 |
| Ranking | Sensor Group | Value | |
|---|---|---|---|
| 1 | TGS800 | MQ-5 | 0.002 |
| 2 | TGS2600 | TGS2610 | 0.006 |
| 3 | TGS800 | TGS832 | 0.047 |
| 4 | TGS800 | TGS2600 | 0.080 |
| 5 | MQ-3 | 2M009 | 0.381 |
| 6 | TGS800 | 2M012 | 0.490 |
| 7 | TGS800 | MQ-3 | 2.296 |
| 8 | TGS813 | MQ-8 | 2.911 |
| 9 | TGS800 | TGS813 | 22.894 |
| 10 | TGS800 | MQK2 | 28.746 |
| Clusters Number | CA Results | Optimized Sensor Arrays with Different Number N by CA and DPVs |
|---|---|---|
| 2 | MQK2, (MQ-8/TGS813/2M009/MQ-3/ 2M012/TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8 |
| 3 | MQK2, (MQ-8/TGS813), (2M009/MQ-3/ 2M012/TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8, MQ-3 |
| 4 | MQK2, MQ-8, TGS813, (2M009/MQ-3/ 2M012/TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8, TGS813, MQ-3 |
| 5 | MQK2, MQ-8, TGS813, (2M009/MQ-3), (2M012/TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8, TGS813, MQ-3, 2M012 |
| 6 | MQK2, MQ-8, TGS813, (2M009/MQ-3),2M012, (TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8, TGS813, MQ-3, 2M012, TGS832 |
| 7 | MQK2, MQ-8, TGS813, 2M009,MQ-3, 2M012, (TGS2610/TGS2600/TGS832/MQ-5/TGS800) | MQK2, MQ-8,TGS813, 2M009, MQ-3, 2M012, TGS832 |
| 8 | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, (TGS2610/TGS2600), (TGS832/MQ-5/TGS800) | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2600, TGS832 |
| 9 | MQK2, MQ-8, TGS813, 2M009,MQ-3, 2M012, (TGS2610/TGS2600), TGS832, (MQ-5/TGS800) | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2600, TGS832, MQ-5 |
| 10 | MQK2, MQ-8, TGS813, 2M009,MQ-3, 2M012, TGS2610, TGS2600, TGS832, (MQ-5/TGS800) | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2610, TGS2600, TGS832, MQ-5 |
| Number of Sensors (N) | Sensor Arrays Optimized by CA and DPV | Discrimination Accuracy by RFML [18] |
|---|---|---|
| 2 | MQK2, MQ-8 | 93.84% |
| 3 | MQK2, MQ-8, MQ-3 | 94.35% |
| 4 | MQK2, MQ-8, TGS813, MQ-3 | 96.09% |
| 5 | MQK2, MQ-8, TGS813, MQ-3, 2M012 | 97.07% |
| 6 | MQK2, MQ-8, TGS813, MQ-3, 2M012, TGS832 | 98.42% |
| 7 | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS832 | 98.88% |
| 8 | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2600, TGS832 | 98.90% |
| 9 | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2600, TGS832, MQ-5 | 98.80% |
| 10 | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012, TGS2610, TGS2600, TGS832, MQ-5 | 98.87% |
| No. Tea Varieties | Sensor Array | LDA-ave | PCA-ave | LDA-var | PCA-var |
|---|---|---|---|---|---|
| 12 kinds of green tea | LG | 2 tea areas overlap (qs and dgdf) | 2 tea areas overlap (lslc and emsmf) | 2 tea areas overlap (lagp and hsmf) | 4 tea areas overlap (msqf and dgdf, lslc and emsmf) |
| 6 kinds of fried green tea | LF | 100% | 100% | 2 tea areas overlap (dgdf and qs) | 100% |
| 6 kinds of baked green tea | LB | 100% | 100% | 100% | 2 tea areas overlap (emsmf and jtlx) |
| No. Tea Varieties | Sensor Array | LDA-ave +NNC | PCA-ave +NNC | LDA-var +NNC | PCA-var +NNC |
| 12 kinds of green tea | LG | 94.44% | 94.44% | 94.44% | 83.33% |
| 6 kinds of fried green tea | LF | 100% | 100% | 88.89% | 100% |
| 6 kinds of baked green tea | LB | 100% | 94.44% | 100% | 88.89% |
| Methods | LDA-ave (+NNC) | PCA-ave (+NNC) | LDA-var (+NNC) | PCA-var (+NNC) |
|---|---|---|---|---|
| LF | 100% | 100% | 100% | 100% |
| Method | Principle | Characteristics |
|---|---|---|
| Correlation analysis | The correlation calculation formula is identical to Formula (1) in this paper. | Calculate the sum of each sensor’s correlation coefficients and eliminate the sensor with the largest sum. Optimizes the correlation between sensors, but does not judge the discriminating ability of the sensor. |
| COV | Where is the i-th test value of the gas sensor, is the average value of the gas sensor at different times, and is the total number of tests. | The larger the coefficient of variation, the greater the intra-class dispersion of the sensor to detect the same class of tea. Therefore, sensors with large coefficients of variation were eliminated. This method does not judge the dispersion between classes and does not optimize the correlation between sensors. |
| DPV | The calculation formula for DPV is introduced in Equation (2) of this paper. | The DPV considers the inter- and intra-class dispersion of sensors. Optimizes sensors’ discriminating performances but does not optimize the correlation between sensors. |
| Sensor Screening Method | Selected Sensor Array | Discrimination Accuracy | ||||
|---|---|---|---|---|---|---|
| RFML [18] | LDA-ave | PCA-ave | LDA-var | PCA-var | ||
| Random selection 1 | TGS826, TGS899, TGS2600, TGS813, 2M012, MQ6, TGS2620, TGS822, MQ3, 2M009, MQK2 | 97.81% | 100.00% | 72.22% | 88.89% | 66.67% |
| Random selection 2 | TGS826, TGS899, TGS2600, TGS813, 2M012, MQ6, TGS2620, TGS822, MQ3, TGS2610, MQK2 | 98.15% | 100.00% | 72.22% | 94.44% | 66.67% |
| Random selection 3 | TGS822, MQ5, TGS826, MQ6, 2M012, TGS2600, TGS2610, TGS800, 2M009, TGS2620, MQ3 | 96.05% | 88.89% | 61.11% | 83.33% | 77.78% |
| Preliminary sensors | TGS2600, TGS813, 2M012, MQ-6, TGS832, GS2620, MQ-8, MQ-3, MQ-5, TGS2610, 2M009, MQK2, TGS822, TGS826, TGS800 | 99.85% | 100.00% | 72.22% | 100.00% | 66.67% |
| Correlation analysis and COV | TGS2600, TGS813, 2M012, MQ-8, MQ-3, MQ5, TGS2610, 2M009, MQK2, TGS800, TGS826 | 98.33% | 100.00% | 66.67% | 83.33% | 72.22% |
| Correlation analysis and DPV | TGS800, TGS2600, TGS813, 2M012, TGS832, MQ-8, MQ-3, MQ-5, TGS2610, 2M009, MQK2 | 98.90% | 100% | 83.33% | 94.44% | 88.89% |
| Sensor Screening Method | Selected Sensor Array | Discrimination Accuracy | ||||
|---|---|---|---|---|---|---|
| RFML [15] | LDA-ave | PCA-ave | LDA-var | PCA-var | ||
| Random selection-1 | TGS832, MQ-8, MQ-3, MQ-5, TGS2610, 2M009,TGS2600, TGS813 | 96.60% | 88.89% | 83.33% | 100% | 88.89% |
| Random selection-2 | MQ-8, MQ-3, MQ-5, TGS2610, 2M009, MQK2, TGS832, TGS813 | 97.26% | 83.33% | 83.33% | 94.44% | 77.78% |
| Random selection-3 | MQ-8, MQ-3, MQ-5, TGS2610, 2M009, MQK2, TGS813, 2M012 | 97.64% | 94.44% | 77.78% | 88.89% | 66.67% |
| Random selection-4 | TGS813, TGS2600, 2M012, MQ-3, 2M009, TGS800, MQ-5, TGS2610 | 83.08% | 88.89% | 77.78% | 94.44% | 83.33% |
| CA and DPV | MQK2, MQ-8, TGS813, 2M009, MQ-3, 2M012 TGS2600, TGS832 | 98.84% | 88.89% | 88.89% | 100% | 94.44% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Zhang, C.; Chang, M.; He, W.; Lu, X.; Fei, S.; Lu, G. Optimization of Electronic Nose Sensor Array for Tea Aroma Detecting Based on Correlation Coefficient and Cluster Analysis. Chemosensors 2021, 9, 266. https://doi.org/10.3390/chemosensors9090266
Wang J, Zhang C, Chang M, He W, Lu X, Fei S, Lu G. Optimization of Electronic Nose Sensor Array for Tea Aroma Detecting Based on Correlation Coefficient and Cluster Analysis. Chemosensors. 2021; 9(9):266. https://doi.org/10.3390/chemosensors9090266
Chicago/Turabian StyleWang, Jin, Cheng Zhang, Meizhuo Chang, Wei He, Xiaohui Lu, Shaomei Fei, and Guodong Lu. 2021. "Optimization of Electronic Nose Sensor Array for Tea Aroma Detecting Based on Correlation Coefficient and Cluster Analysis" Chemosensors 9, no. 9: 266. https://doi.org/10.3390/chemosensors9090266
APA StyleWang, J., Zhang, C., Chang, M., He, W., Lu, X., Fei, S., & Lu, G. (2021). Optimization of Electronic Nose Sensor Array for Tea Aroma Detecting Based on Correlation Coefficient and Cluster Analysis. Chemosensors, 9(9), 266. https://doi.org/10.3390/chemosensors9090266