1. Introduction
Black tea is one of the most widely consumed beverages globally, captivating the taste buds of two-thirds of the world’s population [
1,
2,
3]. The content of tea polyphenols is directly related to the quality of black tea. Tea polyphenols, mainly consisting of catechins, have various positive effects on the body, such as regulating gut microbiota, reducing obesity, and exhibiting antiviral and antibacterial properties [
4,
5,
6]. Due to these positive effects, there is an increasing consumer demand for tea products with a high catechin content, as they are associated with improved health outcomes. Consequently, the ability to accurately assess catechin content is crucial to ensure that tea products deliver the expected health benefits, making it essential for producers to meet market demands and maintain quality standards.
Traditional methods for evaluating tea quality primarily rely on professional tea evaluators who use sensory information to judge the quality of tea based on five aspects: appearance, liquor color, aroma, taste, and leaf residue [
7]. However, these sensory evaluations are subjective and prone to human error, leading to inconsistencies and potential biases in quality assessments. This subjectivity poses a significant challenge in standardizing tea quality evaluation across different evaluators and regions. The traditional method for detecting catechin content in tea usually involves a high-performance liquid chromatography (HPLC) [
8]. Although HPLC can effectively separate the various components of tea polyphenols and accurately detect their content, this method is often very time-consuming in practical testing [
9,
10]. Additionally, HPLC requires extensive sample preparation, complex procedures, and expensive equipment, making it less suitable for rapid, on-site analysis, limiting its widespread applicability for real-time quality control in the tea industry. Therefore, proposing an accurate and rapid detection method for catechin content is of great significance for evaluating the quality of black tea.
Near-infrared spectroscopy (NIRS) [
11] technology utilizes chemometric techniques to analyze the chemical information obtained from the near-infrared spectra of samples about the content or properties of the substances within them, thereby establishing quantitative or qualitative analysis models. These models enable the rapid prediction of the content or properties of specific substances. NIRS has been applied in areas such as tea origin tracing, quality grade identification, and the quantitative prediction of intrinsic components [
12]. Turgut et al. successfully predicted the sensory quality (appearance, shape, color, and overall quality) and other important component indicators (bulk density, cellulose, water extract, and moisture) of black tea samples by combining NIRS with partial least squares (PLS) regression [
13]. Dong et al. established an ELM discrimination model, achieving 100% accuracy in identifying black tea adulterated with exogenous sucrose [
14]. Chen et al. used NIRS to detect the caffeine, EGC, EGCG, EC, ECG, and total catechin content in fresh green tea leaves, developing effective quantitative prediction models with accuracies exceeding 0.9 [
15]. Liu et al. proposed the FICSS-ELM model to simultaneously predict the contents of EGC, EGCG, EC, and ECG in black tea. FICSS is used to extract the effective features of each catechin, while ELM is used for simultaneous prediction [
16]. Despite its advantages, chemometric modeling approaches in NIRS face challenges when handling complex, nonlinear relationships between spectral data and catechin content. These methods often require extensive preprocessing and feature selection to improve the model’s accuracy. Moreover, the presence of noise and irrelevant information in the spectral data can affect the reliability and robustness of the predictions.
In recent years, the rapid advancement of deep learning has opened new avenues for research in chemometric modeling. The integration of convolutional neural networks (CNNs) with NIRS analysis techniques has found extensive application in the domain of food quality control. Li et al. devised a one-dimensional convolutional neural network, optimized using a grid search algorithm, and fused it with NIRS to estimate the sugar content in Huangshan Maofeng tea leaves [
17]. Liu et al. developed an ensemble learning approach based on CNN estimation to identify two types of adulterants, hydrolyzed leather protein and melamine, in infant formulas [
18]. Yang et al. introduced a series of innovative NIR-based CNNs tailored for tea leaf data, namely TeaNet, TeaResnet, and TeaMobilenet, achieving a classification accuracy rate of 100% in tea-grade classification [
19]. Additionally, Luo et al. presented a tea polyphenol prediction model utilizing a CNN to extract spectral–spatial deep features, surpassing the limitations associated with traditional shallow features. This groundbreaking approach integrates deep learning methodologies into the realm of non-destructive tea leaf testing [
20].
Despite the notable advancements made by deep learning models in NIRS analysis, challenges persist due to the relatively small sample size and the vast number of wavelength variables present in tea NIRS data, particularly when aiming for the simultaneous evaluation of multiple active ingredient contents in tea leaves. These models can also suffer from overfitting and their performance can be limited by the lack of interpretability and the need for substantial computational resources. Previous studies have highlighted that the integration of attention mechanisms [
21] into deep learning models can significantly enhance their accuracy in quantitatively analyzing near-infrared spectroscopy data [
22,
23,
24]. However, there remains a paucity of research on the amalgamation of NIRS, CNNs, and attention mechanisms for the simultaneous prediction of multiple catechin contents in black tea.
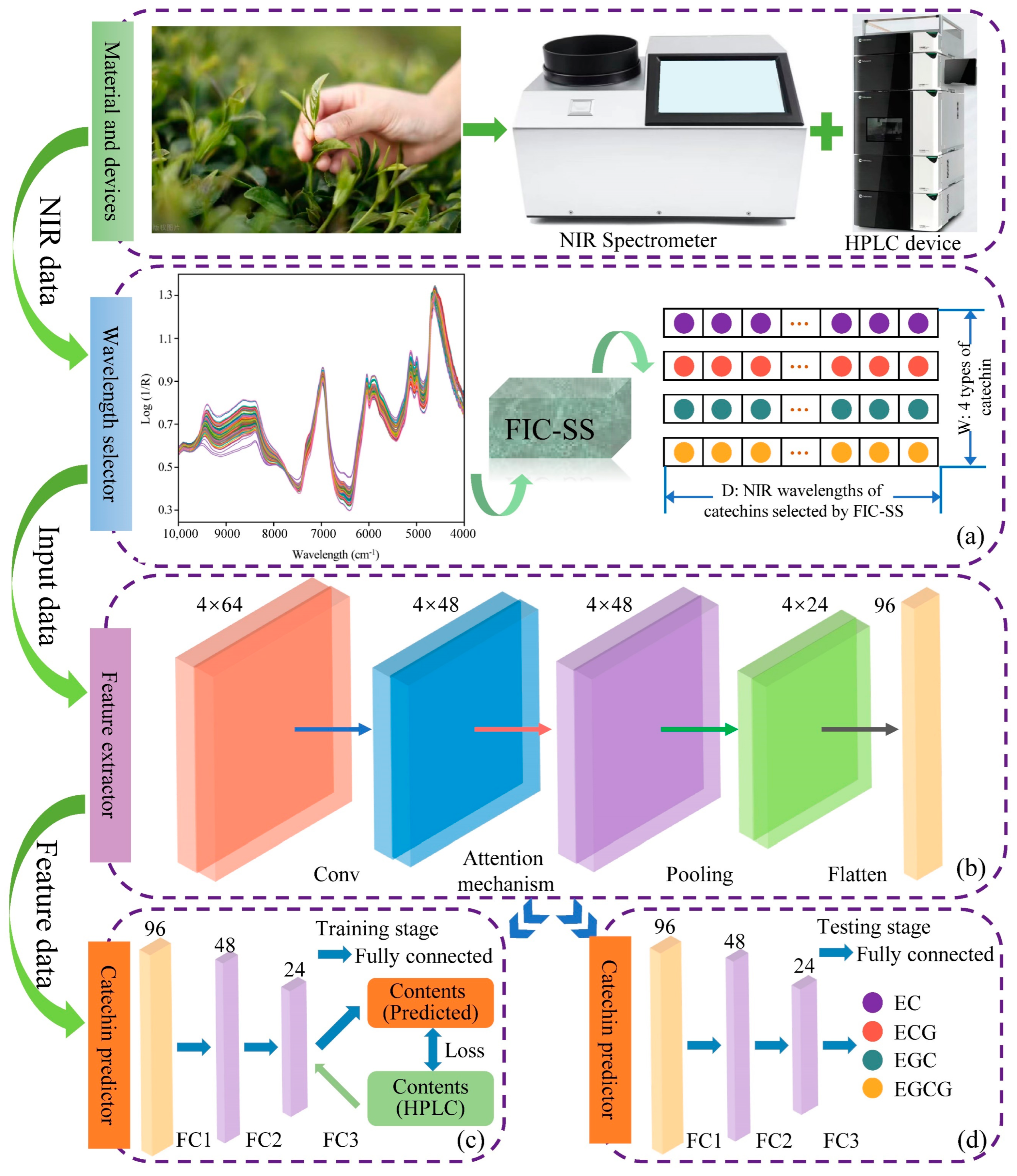
To tackle these challenges and enhance the accuracy of simultaneously predicting multiple catechin contents in black tea, a deep learning model named FICSS-CNN-CSAM is proposed, which integrates wavelength selection and attention mechanisms. This model comprises four key components: a wavelength selector, a feature extractor, attention mechanisms, and a catechin content predictor. Leveraging deep learning models equipped with wavelength selection and attention mechanisms enables adaptation to small-sample NIRS data learning, circumvents the need for intricate feature engineering, and facilitates the construction of a more precise mapping relationship between the content of different catechins and the unique NIRS spectra. The primary innovations are outlined as follows:
- (1)
A wavelength selection method named FICSS is introduced, which systematically screens wavelength variables through partitioning. FICSS eliminates overlapping intervals of various catechin spectra, selects the most representative wavelength variables for each type of catechin, reduces the prediction model’s complexity, and enhances the stability of the selection process.
- (2)
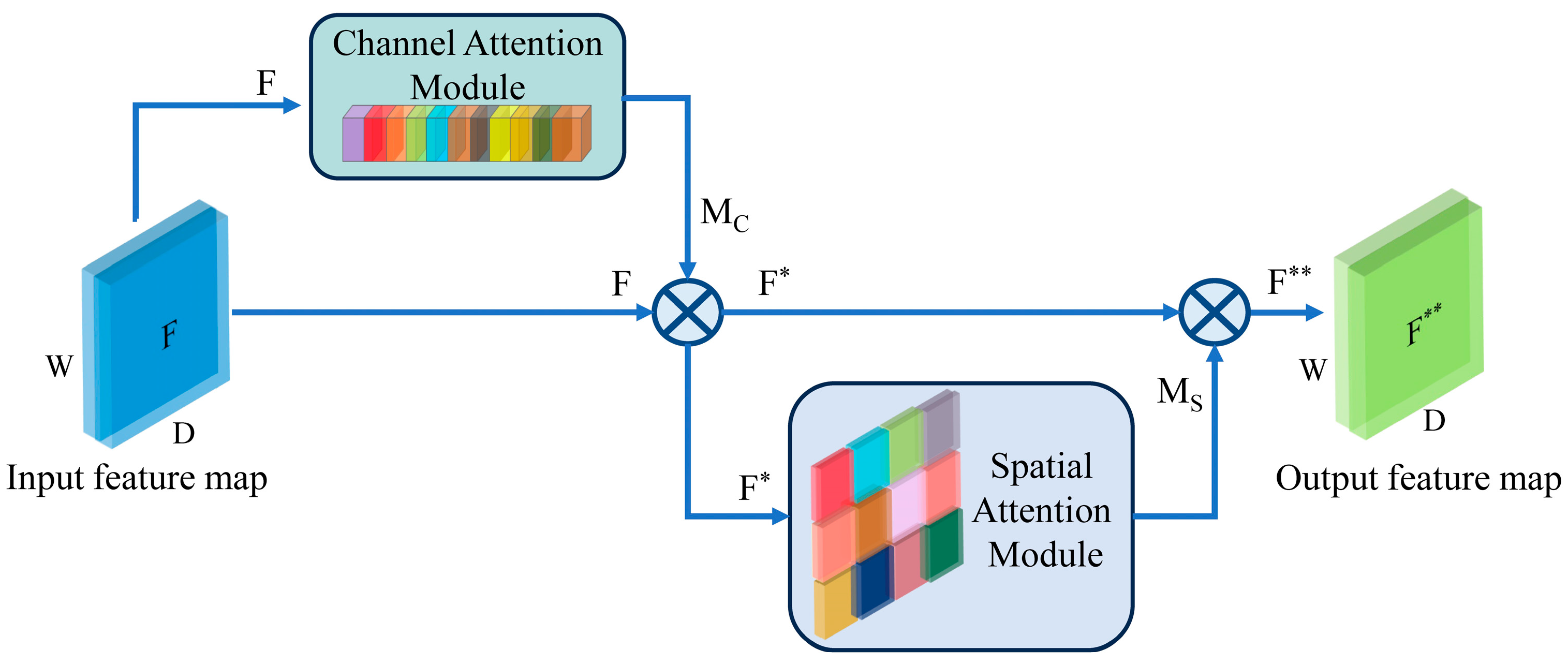
A novel deep learning model named CNN-CSAM is introduced to predict the content of four catechins in tea simultaneously. CNN-CSAM integrates a channel and spatial dimensions attention mechanism into its feature-extraction process. The CSAM selectively emphasizes the relevant features while diminishing the impact of the unimportant ones, thereby improving the accuracy of the catechin content prediction.
2. Materials
2.1. Black Tea Sample Preparation
In this study, we collected tea samples from Anshun City, Guizhou Province, including Jinjunmei, Maojian, Yunwu Tea, and others, totaling 105 experimental samples. The 105 tea samples were then randomly divided into two groups: a calibration set of 70 samples and a prediction set of 35 samples, with a ratio of 2:1.
2.2. NIR Spectra Acquisition
In this study, we collected tea samples from Anshun City, Guizhou Province, including varieties such as Jinjunmei, Maojian, and Yunwu Tea, totaling 105 experimental samples. We utilized an Antaris Fourier Transform Near-Infrared Spectrometer (Thermo Fisher Scientific Inc., Waltham, MA, USA) as our primary experimental equipment. Prior to the commencement of the experiment, the spectrometer was turned on and preheated for 30 min to achieve a stable operational state, ensuring the accuracy and reliability of the spectral measurements. The scanning wavenumber range was set to 4000–10,000 cm−1 with a resolution of 8 cm−1 and a scanning frequency of 64 scans per sample. Each tea sample was carefully weighed using a high-precision analytical balance (XPR226CDR/AC, Mettler Toledo, Columbus, OH, USA) to ensure an exact mass of 10 g and placed in a standardized culture dish to maintain uniformity across all measurements. The tea sample was compacted using a compactor to minimize air gaps and ensure a consistent packing density, which is critical for accurate spectral readings.
The NIR spectra acquisition was conducted in a controlled laboratory environment with a stable temperature of 25 °C and relative humidity of approximately 50%. These conditions were maintained to minimize the impact of environmental fluctuations on the spectral data quality. For each sample, three spectra were collected to account for any variability in the measurements, and the average of these three spectra was used as the representative spectral data. This detailed procedure was designed to maximize the reproducibility of our experiments, ensuring that future studies can replicate our methodology and validate our findings.
2.3. The Actual Value of Catechin Content Acquisition
The catechin content in tea samples was determined according to GB/T 8313-2008 [
25,
26]. The detection process involved using a LC-20A HPLC instrument (Shimadzu Corporation, Kyoto, Japan). For the analysis, a Waters C18 column (4.6 mm × 250 mm, 5 µm) was utilized. The mobile phases consisted of 2% acetic acid (phase A) and pure acetonitrile (phase B). The conditions set were an injection volume of 10 µL, a flow rate of 1 mL/min, a detection wavelength of 280 nm, and a column temperature of 35 °C.
The elution sequence was the following: mobile phase B increased from 6.5% to 15% over the first 16 min; from 16 to 25 min, it increased further to 25%; from 25 to 25.5 min, it decreased back to 6.5%; and from 25.5 to 30 min, phase B remained at 6.5%. The quantification of catechins was performed using the external standard method.
4. Results and Discussion
To verify the predictive performance of the proposed method for catechin content, we conducted the following four experiments: catechin content prediction with different models of full-spectrum data; wavelength selection based on FICSS; the simultaneous prediction of catechin content with various deep learning models; and an attention mechanism ablation experiment. These four experiments comprehensively and objectively demonstrate the effectiveness of the FICSS algorithm in spectral feature extraction, the CSAM in enhancing the prediction accuracy of simultaneous predictions of four catechins, and the superior performance of the FICSS-CNN-CSAM model, compared to other chemometric and existing deep learning models for predicting catechin content.
4.1. Catechin Content Prediction with Different Models of Full-Spectrum Data
Due to the similar physical and chemical properties of different types of catechins in tea leaves, their respective near-infrared spectral features significantly overlap, greatly reducing the prediction accuracy of chemometric models. Fortunately, some studies have preliminarily addressed this issue by leveraging the powerful feature extraction capabilities of deep learning models and harnessing their inherent advantages in nonlinear mapping for multi-input and multi-output scenarios. This study conducted a comparative experiment on the simultaneous prediction performance of four catechins in black tea using the CNN (the structure is illustrated in
Figure 1c) and PLSR models.
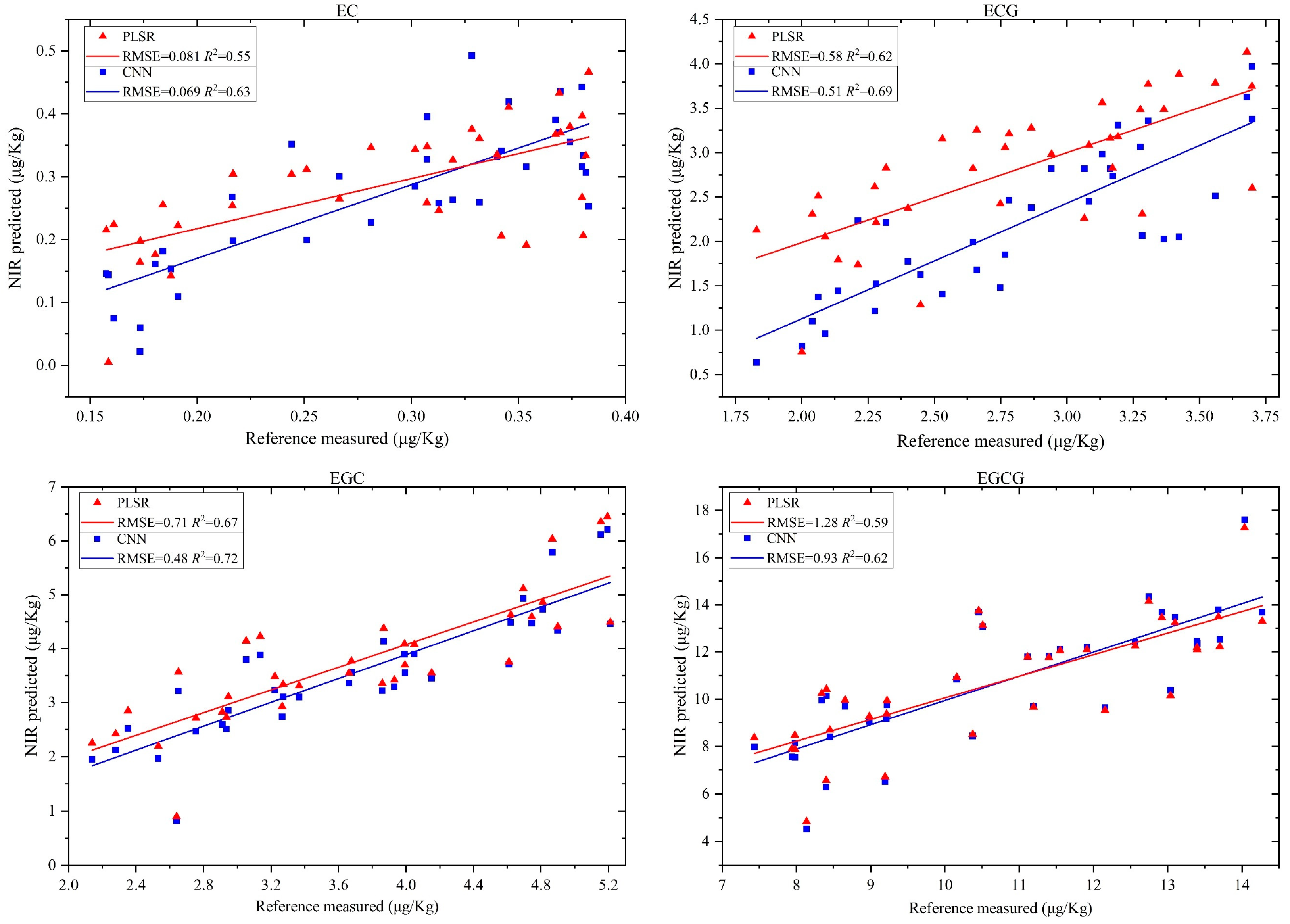
Figure 6 shows the prediction results of the content of four catechins in black tea using the PLSR and CNN models.
From
Figure 6, it is evident that, compared to the PLSR, the CNN achieved the highest prediction accuracy for the contents of EC, ECG, EGC, and EGCG, respectively. Compared to the PLSR, for the EC catechin, the CNN improved
R2 and the RMSE by 12.70% and 14.81%, respectively; for the ECG catechin, the CNN’s
R2 and RMSE improved by 10.14% and 12.06%; for the EGC catechin, the improvements in
R2 and the RMSE were 6.94% and 32.39%; for the EGCG catechin, the CNN’s
R2 and RMSE improved by 4.84% and 27.34%. This improvement is primarily attributed to the CNN model’s ability to capture complex nonlinear relationships in the spectral data, which are often missed by linear models, like the PLSR. Additionally, we can observe that the average
R2 values predicted by the PLSR and the CNN for four types of catechins simultaneously are 0.61 and 0.67, respectively, which only increased by 8.96% and is not a satisfactory result. This is because the sample size and input data dimensions have a much greater impact on the prediction performance of the CNN model compared to the PLSR. In this experiment, the full-spectrum data of black tea leaves were used, with 1500 wavelength variables, while the training sample size was only 65. Even under such unfavorable conditions, the CNN model still demonstrated a significant advantage compared to the PLSR model. Additionally, this indicates that wavelength selection is crucial for further improving the performance of the CNN.
4.2. Wavelength Selection Based on the FICSS Algorithm
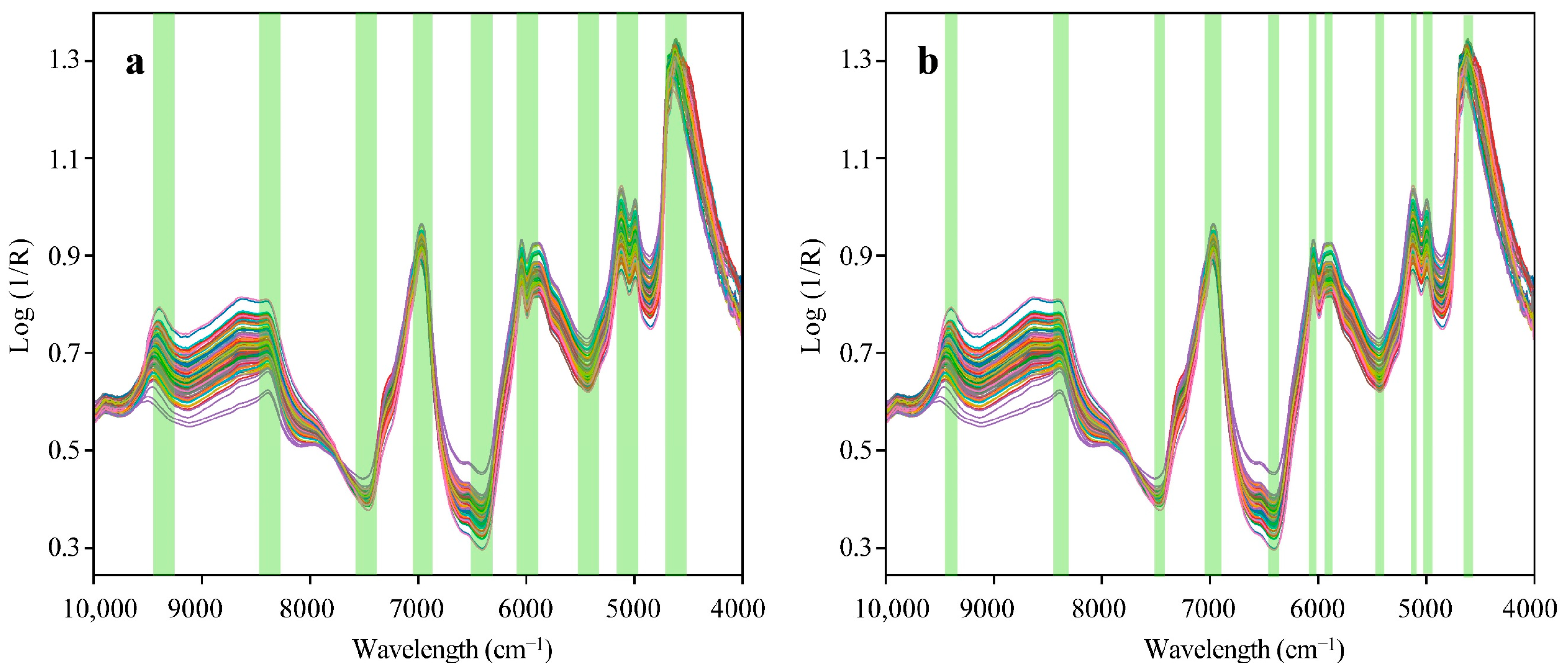
Wavelength selection not only enhances the stability of the model but also makes the model more parsimonious. The wavelength selector proposed in this study is based on the FICSS algorithm, and the selection process consists of two steps. The first step is feature interval combination (FIC), and the second step is sensitivity factor segmentation (SS). FICSS is used to select wavelength variables from the full-spectrum data that are the most independently expressive of the four black tea catechins (EC, ECG, EGC, EGCG). This provides stable and high-quality input data for the subsequent deep learning models. Following the steps in
Figure 2, the full-spectrum data is evenly divided into 20 sub-intervals, and a PLSR model is established and predicted for each sub-interval. The RMSE values for each interval are obtained, and the average RMSE value for each interval is used as the threshold for feature interval combination. Sub-intervals with RMSE values greater than the threshold are eliminated and the remaining sub-intervals are combined to the optimal interval combination.
Subsequently, sensitivity factors are introduced based on these combined feature intervals, and the average sensitivity factor for the optimal combination interval is computed as the segmentation value. The wavelength variables with sensitivity factors below the threshold are segmented and adjusted. The process of selecting the wavelength variables for black tea NIRS using the FICSS algorithm is illustrated in
Figure 7. When comparing the wavelength selection results in
Figure 7a,b, it was observed that sensitivity segmentation effectively eliminated the wavelengths mistakenly selected in the FIC method due to uniform partitioning.
As shown in
Figure 7, the FICSS selected a total of 64 wavelength variables, while the FIC selected 115 variables. The FICSS reduced the number of wavelength variables by 44.35%, significantly reducing the model’s computational complexity and information redundancy. Additionally, compared to the wavelength variables selected by the FIC, the PLSR model, established based on the wavelength variables chosen by FICSS, achieved an average
R2 value of 0.73 for the prediction of the four catechins, representing an 8.22% improvement. Moreover, according to the RMSE values, the FICSS consistently outperformed the FIC method in terms of prediction performance.
The FICSS algorithm optimizes this process by retaining the most informative spectral features. This results in a more parsimonious and stable model, as the reduction in the wavelength variables decreases the model’s computational complexity and reduces the risk of overfitting. The targeted selection of wavelengths leads to higher-quality input data, which improves the model’s predictive accuracy for catechin content, with an 8.22% improvement in the R2 values compared to the FIC method. Additionally, FICSS effectively eliminates any irrelevant wavelengths, reducing noise and increasing the signal–to–noise ratio, thus enhancing the model’s robustness. By providing high-quality data, FICSS supports efficient learning and generalization in the overall model, further boosting overall performance.
4.3. The Simultaneous Prediction of Catechin Content with Various Deep Learning Models
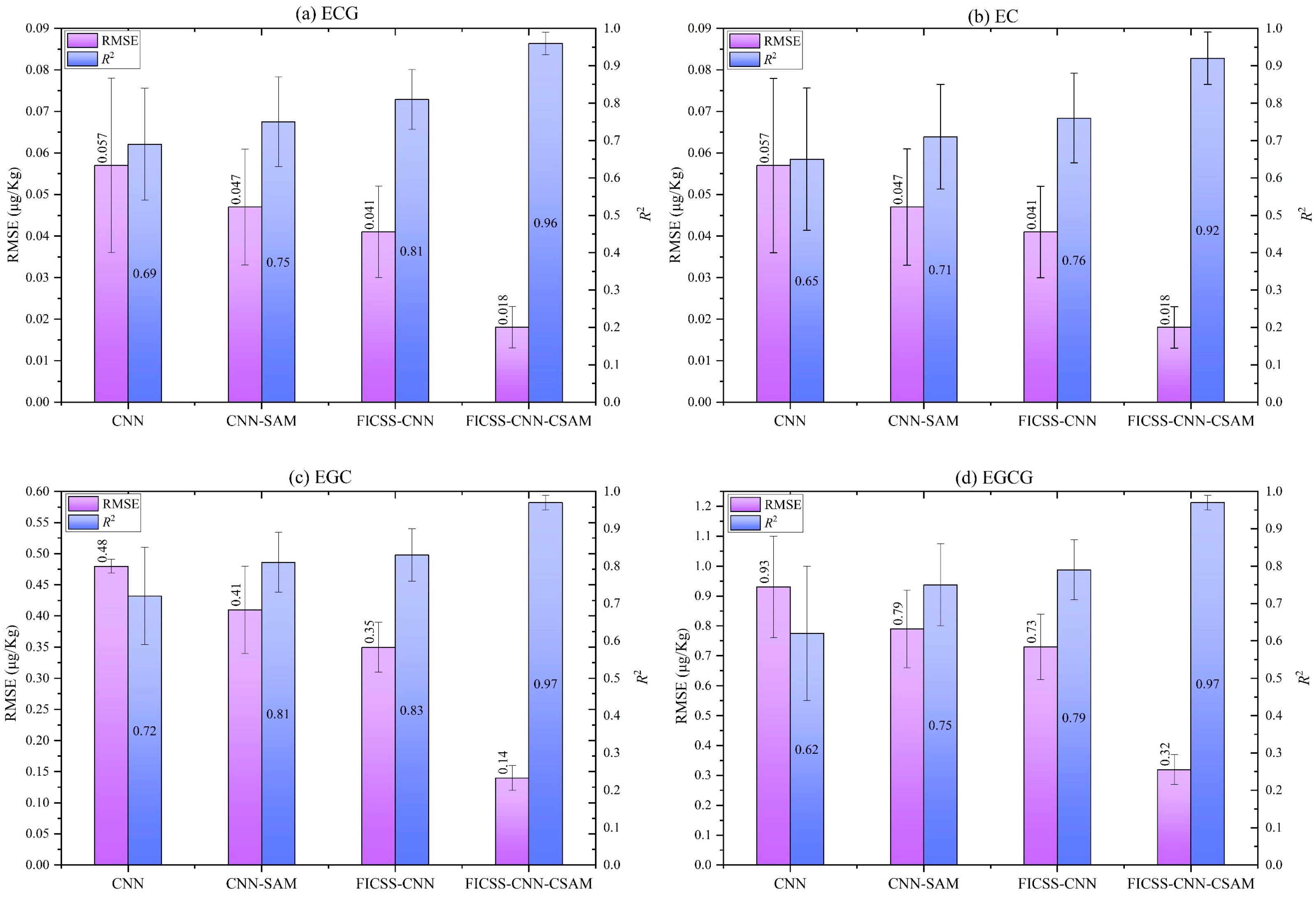
To validate the higher accuracy of the FICSS-CNN-CSAM model to simultaneously predict the various catechin contents in tea, we compared it with the CNN model, the CNN-CSAM model, and the FICSS-CNN model. All models in this study followed the same training strategy, with consistent structure and parameters for the CNN, as shown in
Table 2. To mitigate the impact of random initialization in deep learning models, we used 10-fold cross-validation. The prediction results of the above four deep learning models for the contents of four catechins in tea are shown in
Figure 8 and
Table 3. Compared to the other three models, the FICSS-CNN-CSAM model demonstrate a significant advantage in simultaneously predicting the contents of the four catechins, as evidenced by the RMSE and
R2 metrics.
For the EC, compared to the baseline models, the FICSS-CNN-CSAM model achieves reductions in the RMSE value by 68.42%, 61.70%, and 56.09%, respectively. For the ECG, compared to the baseline models, the FICSS-CNN-CSAM model achieves reductions in the RMSE value by 78.43%, 73.81%, and 69.44%. For the EGC, compared to the baseline models, the FICSS-CNN-CSAM model achieves reductions in the RMSE value by 70.83%, 65.85%, and 60.00%. For the EGCG, compared to the baseline models, the FICSS-CNN-CSAM model achieves reductions in the RMSE value by 65.59%, 59.49%, and 56.16%.
Additionally, as shown in
Figure 8, the FICSS-CNN-CSAM model exhibits a lower standard deviation and a more stable performance compared to other models in terms of prediction stability. These results indicate that the CNN models with attention mechanisms outperform the pure CNN models in the simultaneous prediction of catechin content. Moreover, the CNN models with attention mechanisms following wavelength selection by the FICSS algorithm outperform those without wavelength selection but with attention mechanisms.
4.4. The Attention Mechanism Ablation Experiment
In the previous experimental analysis, it has been demonstrated that the proposed FICSS-CNN-CSAM model can accurately predict various catechin contents in tea. To objectively compare the impacts of different attention mechanisms on the model’s predictive performance, we conducted an ablation experiment. This experiment compared the predictive performance of four models, nonattention (FICSS-CNN), CAM only (FICSS-CNN-CAM), SAM only (FICSS-CNN-SAM), and CAM placed after SAM (FICSS-CNN-SCAM), against our proposed model.
Table 3 compares the predictions of tea catechin content made by the five models. Compared to other models, the FICSS-CNN-CSAM model achieved the highest prediction accuracy. Based on the average
R2 value predicted by these models for four types of catechin simultaneously, the FICSS-CNN-CSAM model outperformed the FICSS-CNN-CAM model by 7.05%, the FICSS-CNN-SAM model by 10.46%, the FICSS-CNN-SCAM model by 7.61%, and the FICSS-CNN model by 16.50%. Additionally, based on the RMSE, the FICSS-CNN-CSAM model’s predictive performance consistently surpassed that of the other four models.
In contrast to the experimental findings, our observations indicate that in CSAMs, the CAM plays a more crucial role than the SAM in the simultaneous and effective extraction of NIRS features from multiple catechins. When spatial attention is used alone, capturing the information interactions between specific channels becomes challenging. Therefore, the input features must be processed by the CAM before being passed to the SAM. This arrangement of CSAMs helps recognize the feature channels containing key information, reduces unnecessary interference, and improves the effectiveness of spatial attention.
5. Conclusions
In this study, we introduce a deep learning model, named FICSS-CNN-CSAM, aimed at enhancing the simultaneous estimation accuracy of multiple catechins using near-infrared spectroscopy. The FICSS-based wavelength selector effectively identifies the wavelength variables that distinctly represent the four catechins, thereby reducing spectral redundancy and facilitating the deconvolution of overlapping spectra. Additionally, the integration of channel and spatial attention mechanisms enables the efficient extraction of the deep features most pertinent to each catechin while mitigating unnecessary interference. Subsequently, this feature information is inputted into a CNN-based catechin content predictor, facilitating the simultaneous estimation of EC, ECG, EGC, and EGCG in black tea.
The findings from our experiments reveal that the FICSS-CNN-CSAM model achieves the highest precision when predicting EC, ECG, EGC, and EGCG content simultaneously, with R2 values of 0.92, 0.96, 0.97, and 0.97. Meanwhile, the corresponding RMSE values are 0.018, 0.11, 0.14, and 0.32. In comparison to baseline models and traditional chemometric models, the FICSS-CNN-CSAM model exhibits enhanced stability and predictive precision. High stability ensures a consistent performance across different datasets and conditions, making the model reliable for various production environments. Precision when predicting catechin content allows for more accurate quality control, enabling producers to optimize the grading and pricing of tea products. However, since the experimental samples only include naturally grown black tea, the model may perform differently across various types of tea, particularly those with unique chemical compositions or processing methods not represented in our sample set. Additionally, extreme variations in moisture content or particle size distribution could degrade the model’s predictive accuracy. Therefore, future research could expand the dataset to include a wider range of tea types, including those with distinct processing methods, to help improve the generalizability of the model.
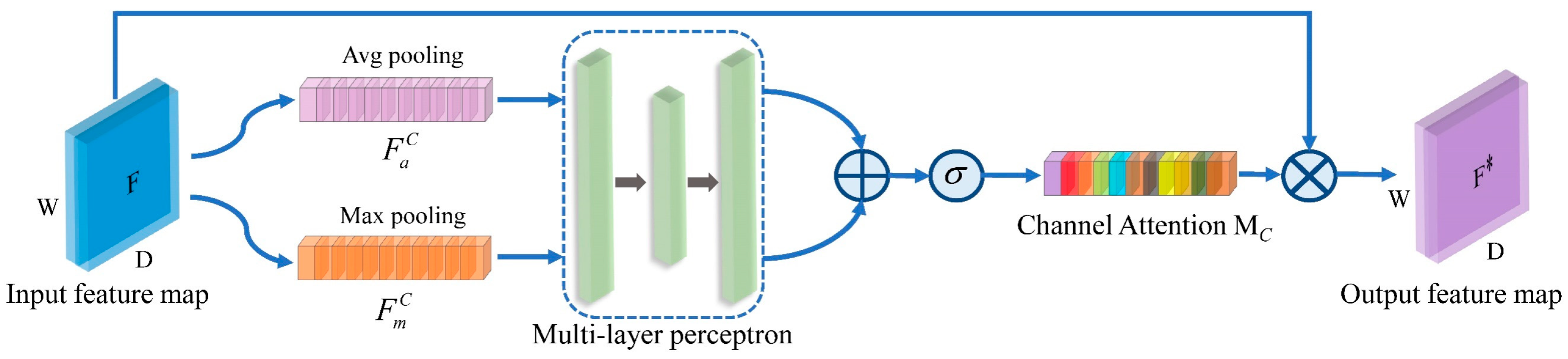
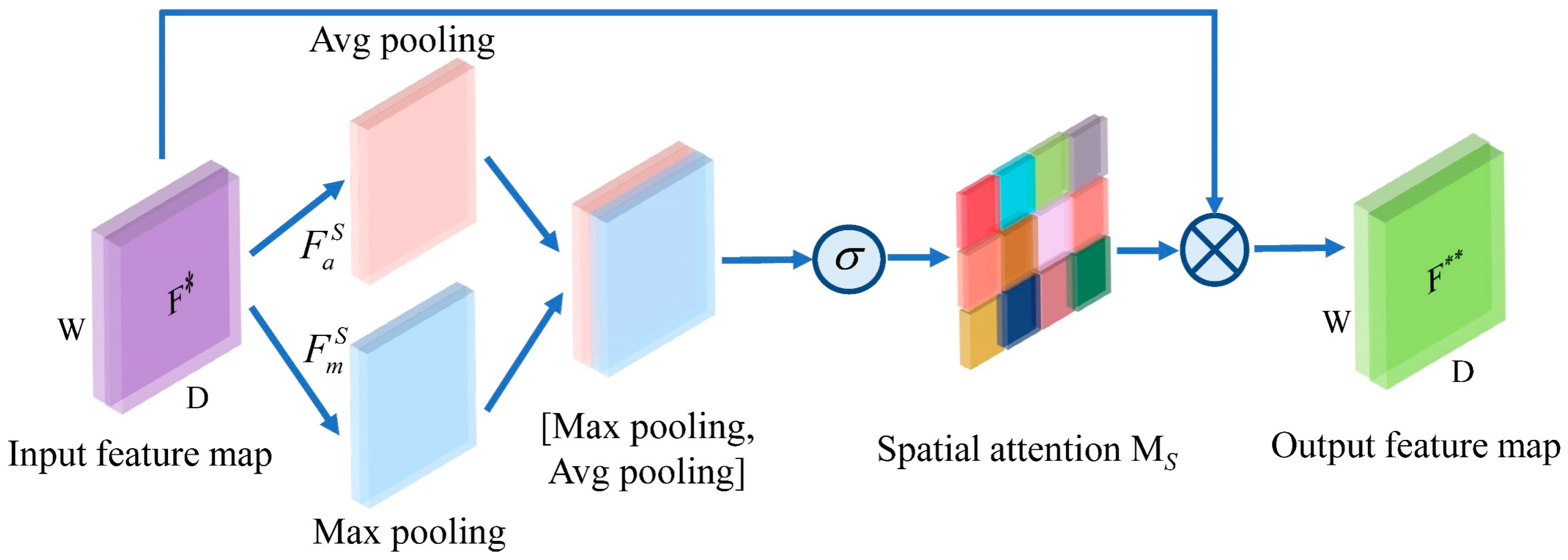
Moreover, the CAM helps the model focus on the most informative spectral features by assigning higher importance to specific channels that are more relevant to predicting catechin content. By dynamically adjusting the attention weights, the CAM enables the model to adapt to variations in the spectral data, further enhancing stability. The SAM contributes to the model’s effectiveness by emphasizing spatially important features in the spectral data. It allows the model to capture local interactions and dependencies between the different spectral regions, which improves the model’s ability to generalize across different tea samples and conditions. The application of deep learning will further drive the development of new technologies in the field of non-destructive tea detection.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}