
Comparison of Various Signal Processing Techniques and Spectral Regions for the Direct Determination of Syrup Adulterants in Honey Using Fourier Transform Infrared Spectroscopy and Chemometrics



Abstract
:1. Introduction
2. Materials and Methods
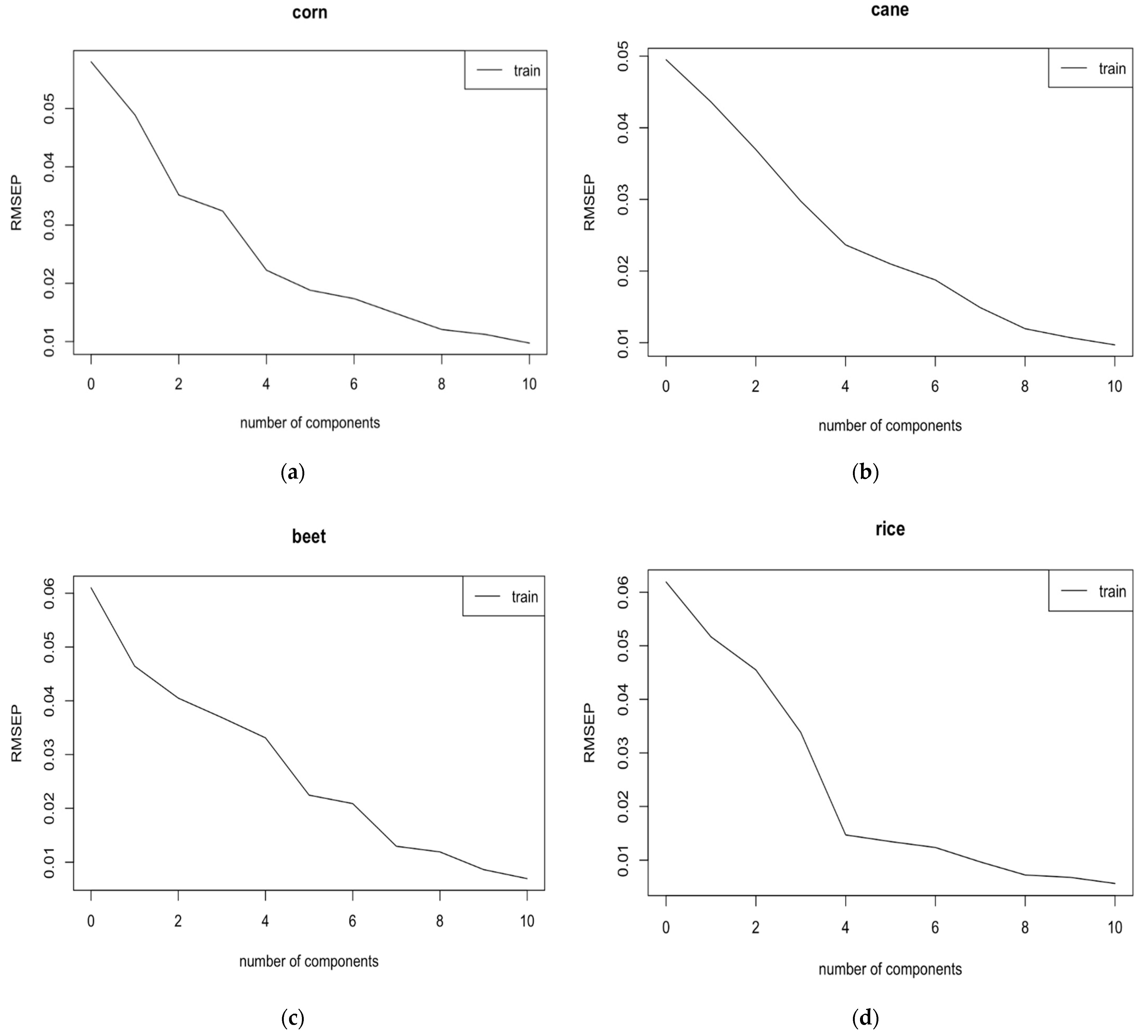
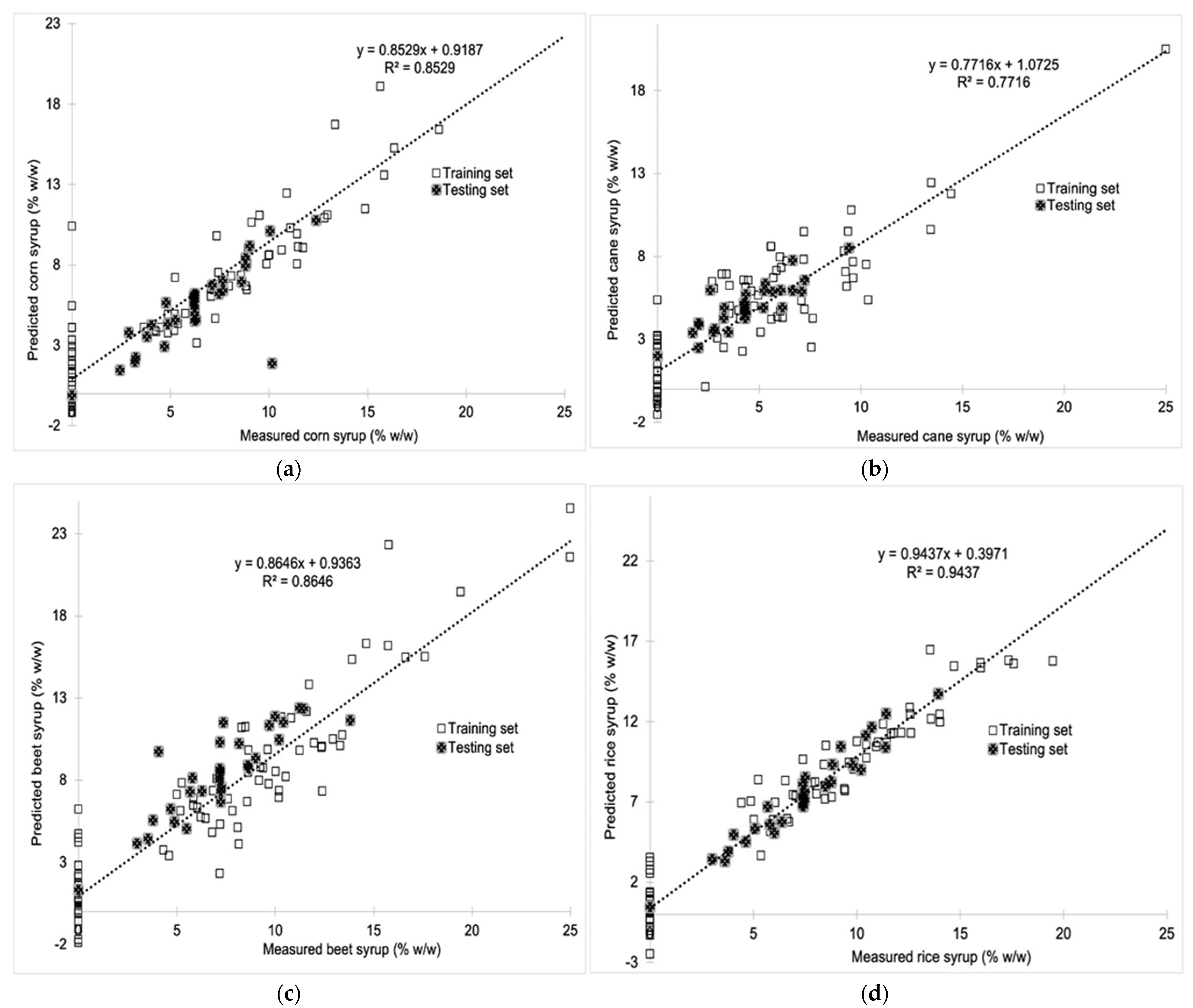
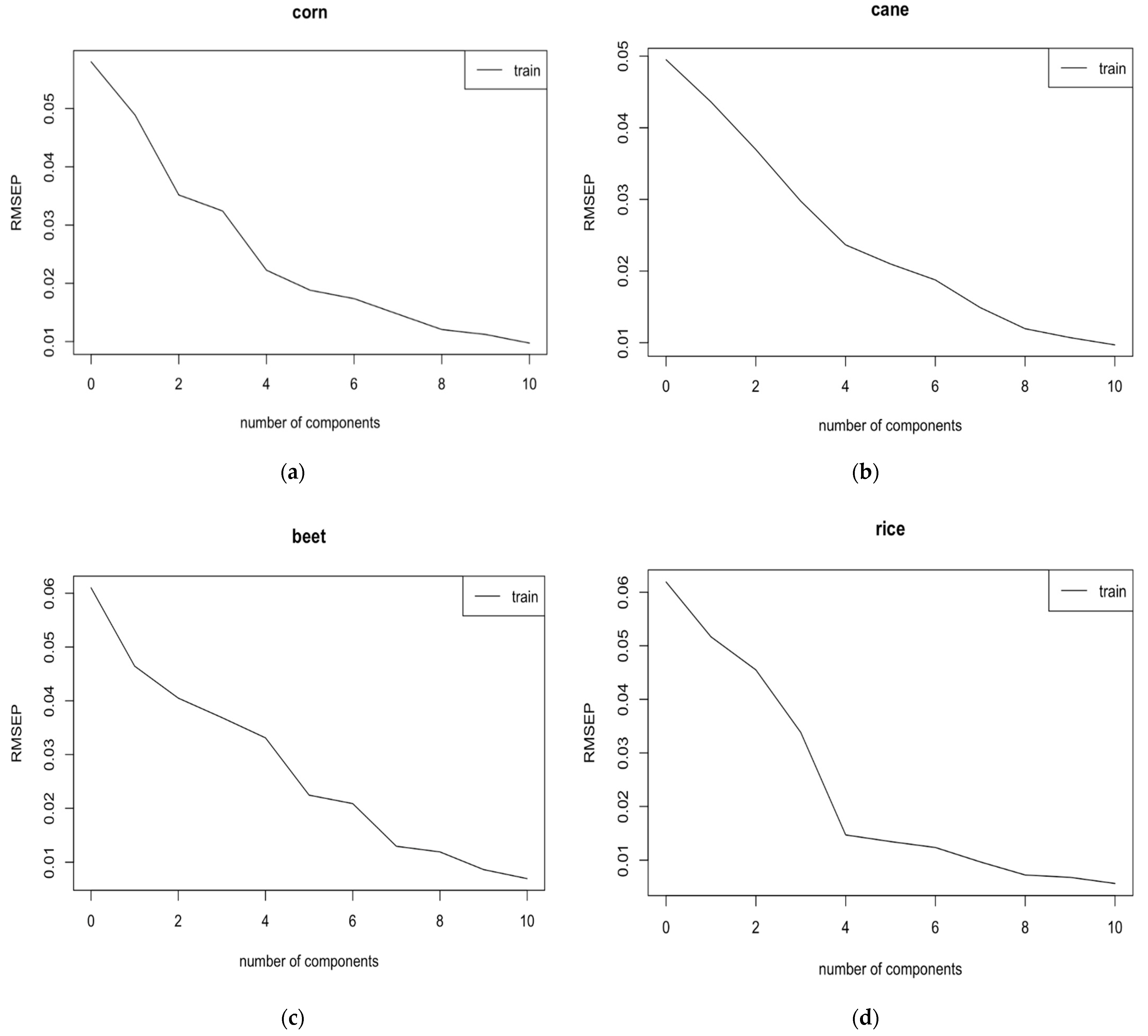
3. Results and Discussion
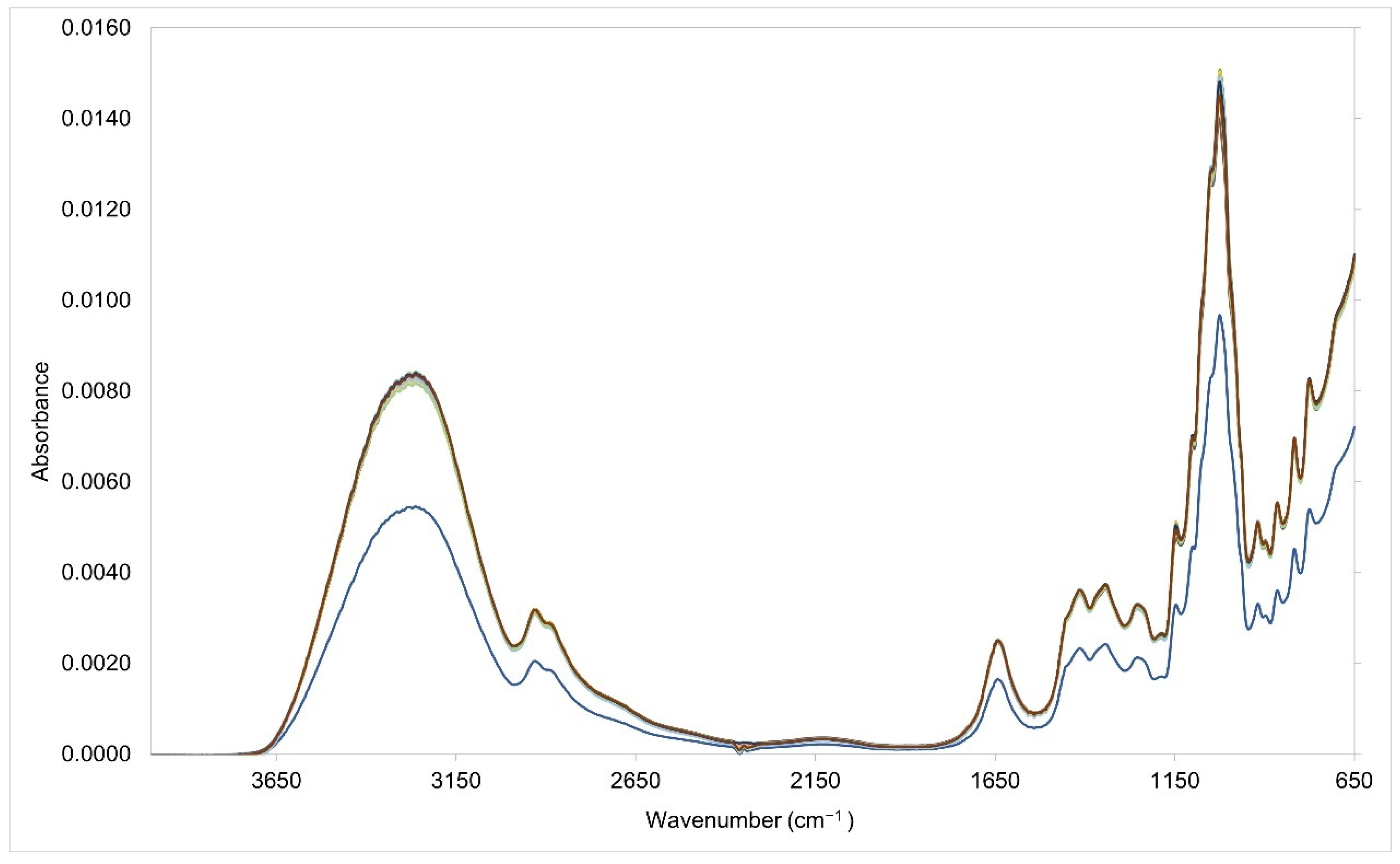
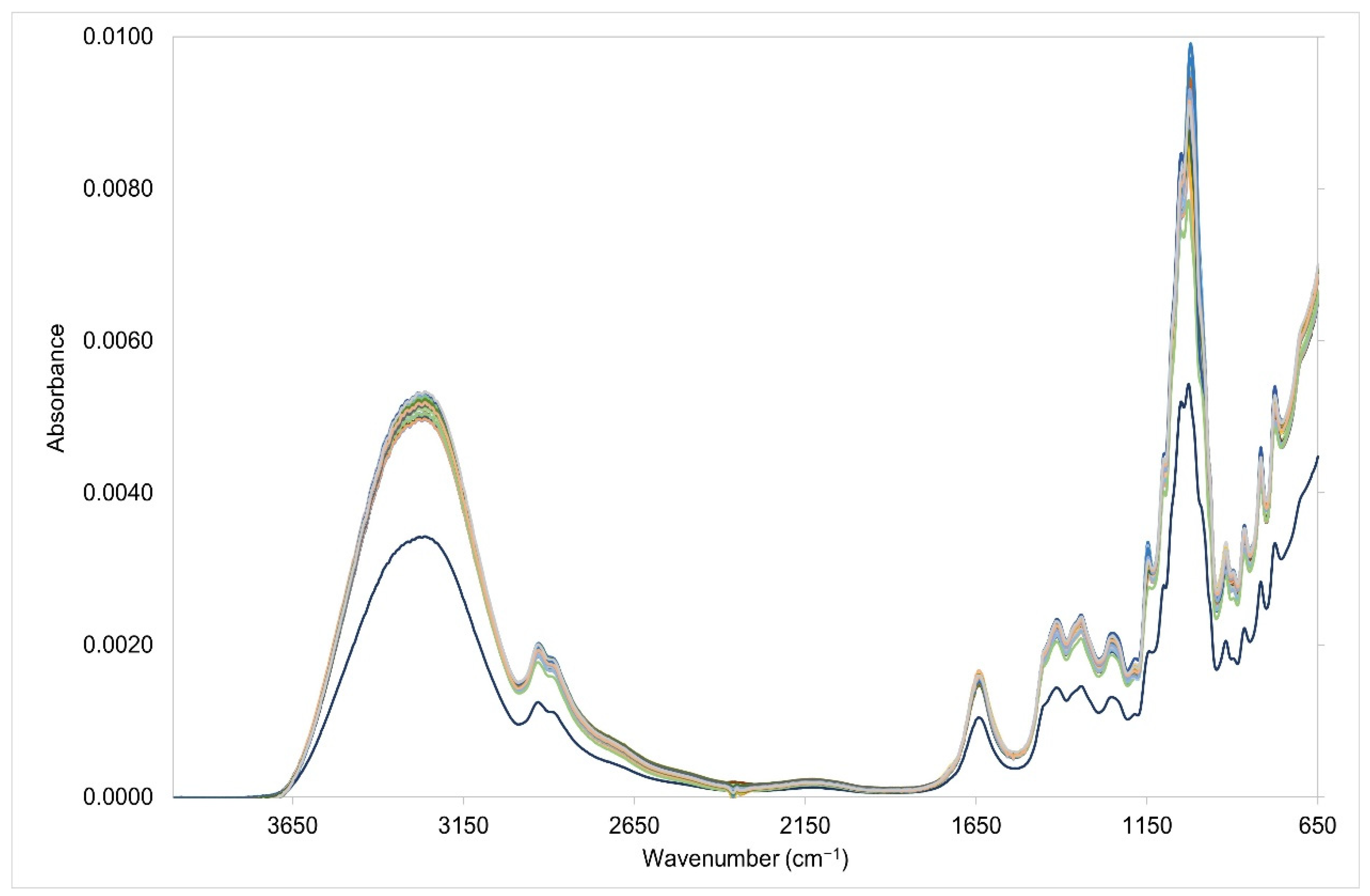
3.1. Analysis of the Entire Spectral Region (399–650 cm−1)
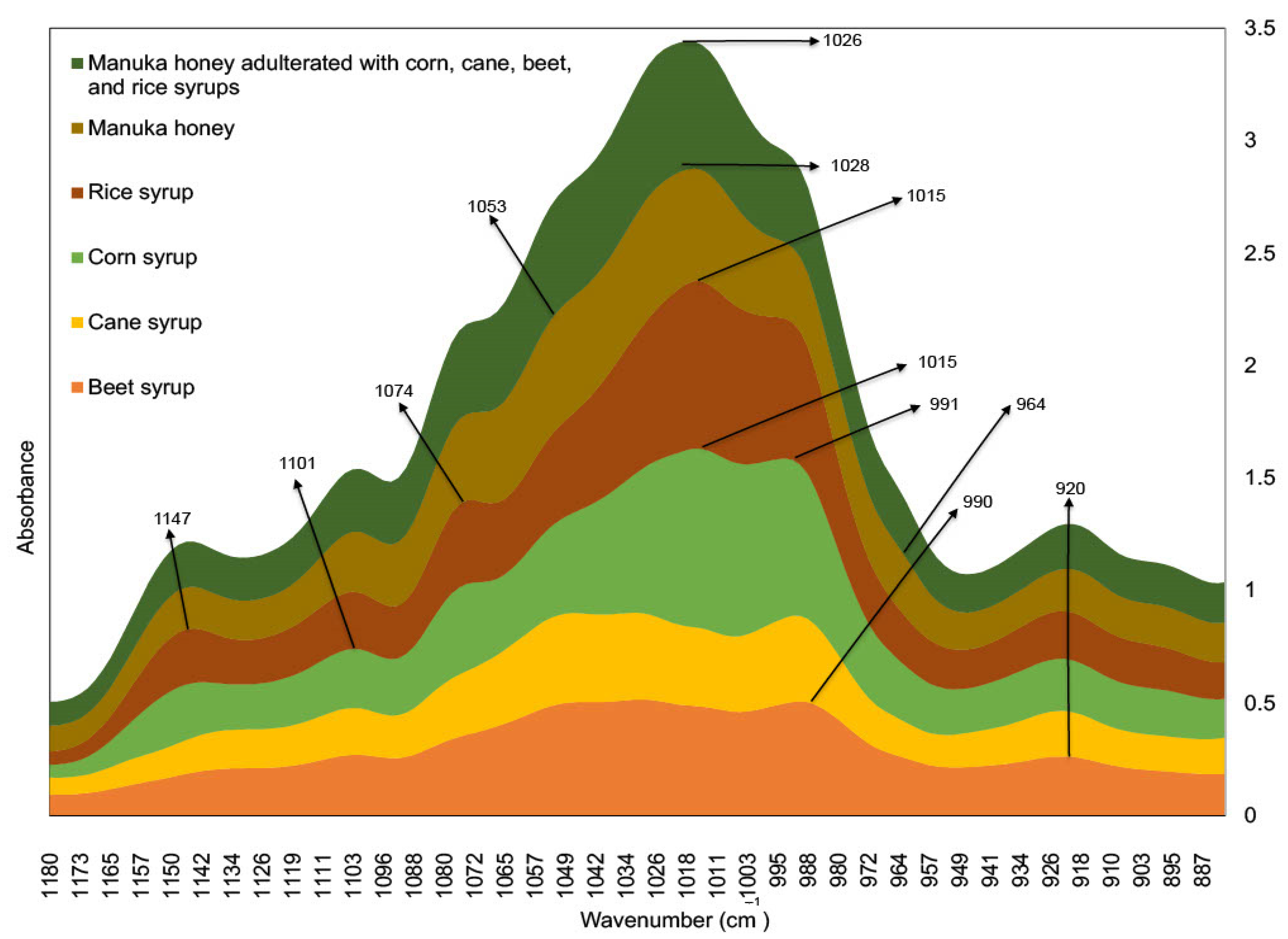
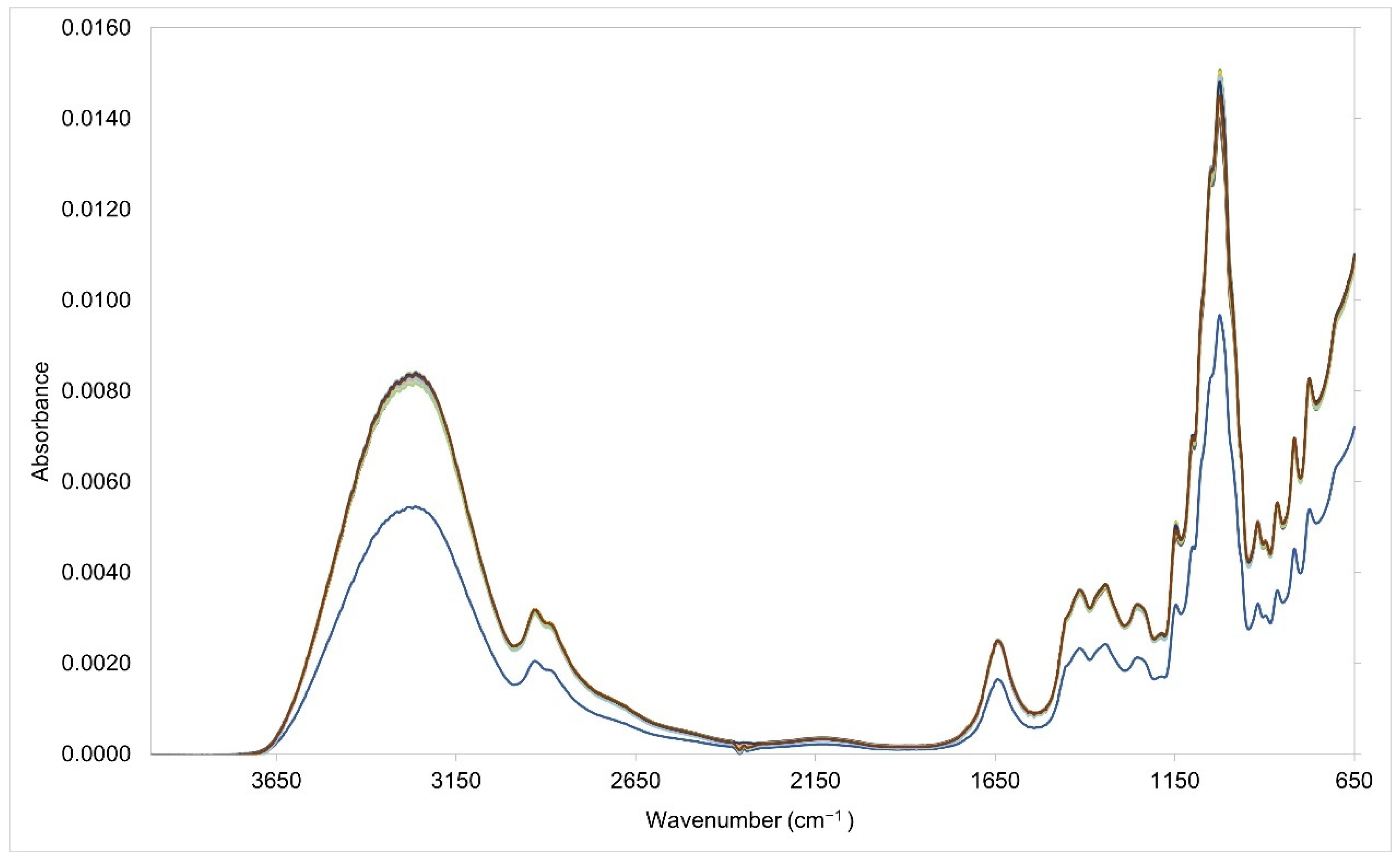
3.2. Analysis of the Specific Spectral Region (1501–799 cm−1)
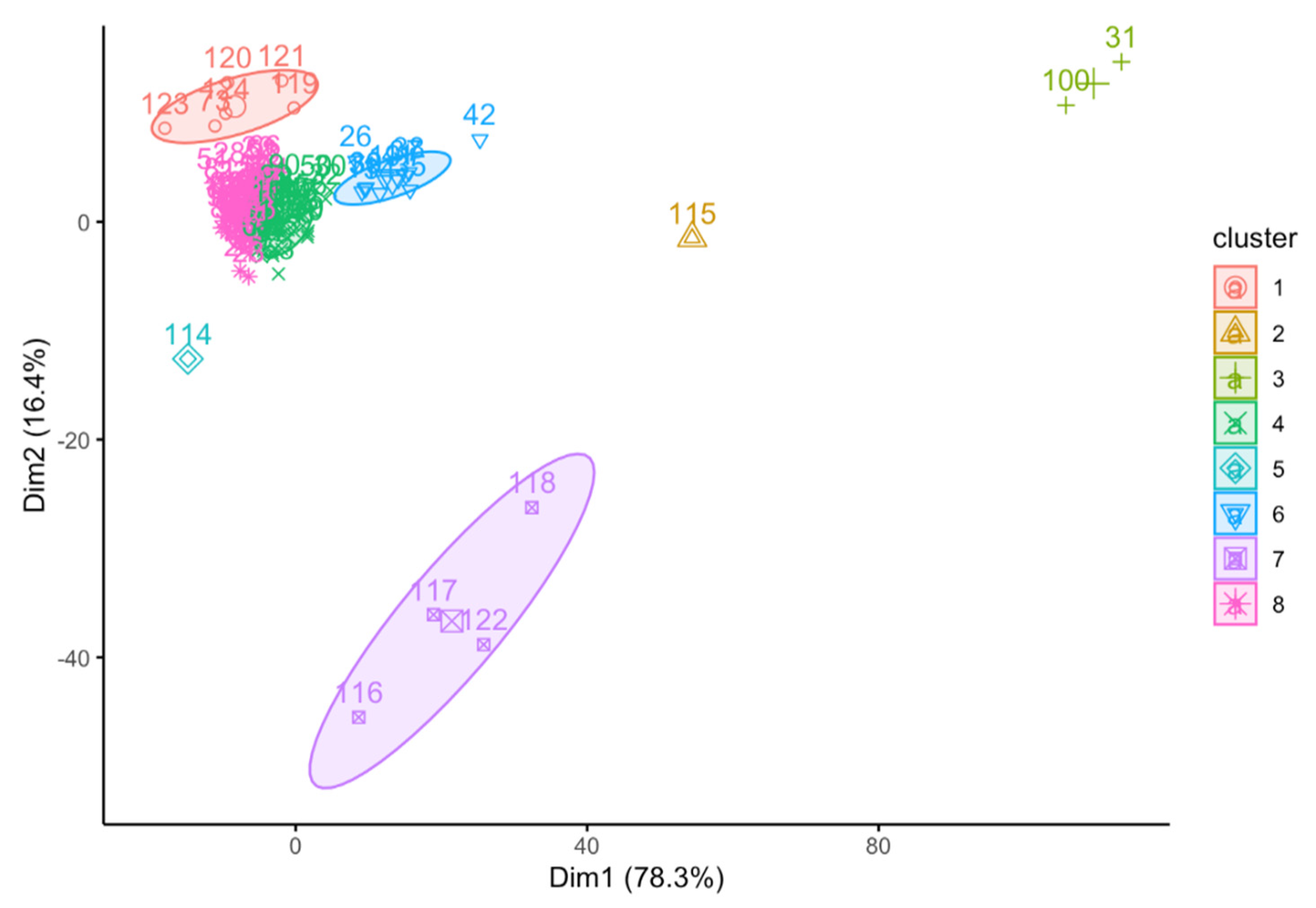
3.3. Exploratory Analysis of Syrup Adulterants and Honey Samples
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Fakhlaei, R.; Selamat, J.; Khatib, A.; Razis, A.F.A.; Sukor, R.; Ahmad, S.; Babadi, A.A. The Toxic Impact of Honey Adulteration: A Review. Foods 2020, 9, 1538. [Google Scholar] [CrossRef] [PubMed]
- Ciursă, P.; Pauliuc, D.; Dranca, F.; Ropciuc, S.; Oroian, M. Detection of Honey Adulterated with Agave, Corn, Inverted Sugar, Maple and Rice Syrups Using FTIR Analysis. Food Control 2021, 130, 108266. [Google Scholar] [CrossRef]
- Kelly, J.F.D.; Downey, G.; Fouratier, V. Initial Study of Honey Adulteration by Sugar Solutions Using Midinfrared (MIR) Spectroscopy and Chemometrics. J. Agric. Food Chem. 2004, 52, 33–39. [Google Scholar] [CrossRef] [PubMed]
- Sivakesava, S.; Irudayaraj, J. A Rapid Spectroscopic Technique for Determining Honey Adulteration with Corn Syrup. J. Food Sci. 2001, 66, 787–791. [Google Scholar] [CrossRef]
- Siddiqui, A.J.; Musharraf, S.G.; Choudhary, M.I.; Rahman, A.-U. Application of Analytical Methods in Authentication and Adulteration of Honey. Food Chem. 2017, 217, 687–698. [Google Scholar] [CrossRef]
- Ribeiro, R.D.O.R.; Mársico, E.T.; da Silva Carneiro, C.; Monteiro, M.L.G.; Júnior, C.C.; de Jesus, E.F.O. Detection of Honey Adulteration of High Fructose Corn Syrup by Low Field Nuclear Magnetic Resonance (LF 1H NMR). J. Food Eng. 2014, 135, 39–43. [Google Scholar] [CrossRef]
- Ruiz-Matute, A.I.; Soria, A.C.; Martínez-Castro, I.; Sanz, M.L. A New Methodology Based on GC−MS To Detect Honey Adulteration with Commercial Syrups. J. Agric. Food Chem. 2007, 55, 7264–7269. [Google Scholar] [CrossRef]
- Başar, B.; Özdemir, D. Determination of Honey Adulteration with Beet Sugar and Corn Syrup Using Infrared Spectroscopy and Genetic-Algorithm-Based Multivariate Calibration. J. Sci. Food Agric. 2018, 98, 5616–5624. [Google Scholar] [CrossRef]
- Se, K.W.; Wahab, R.A.; Syed Yaacob, S.N.; Ghoshal, S.K. Detection Techniques for Adulterants in Honey: Challenges and Recent Trends. J. Food Compos. Anal. 2019, 80, 16–32. [Google Scholar] [CrossRef]
- Mendes, E.; Duarte, N. Mid-Infrared Spectroscopy as a Valuable Tool to Tackle Food Analysis: A Literature Review on Coffee, Dairies, Honey, Olive Oil and Wine. Foods 2021, 10, 477. [Google Scholar] [CrossRef]
- Cozzolino, D.; Corbella, E.; Smyth, H.E. Quality Control of Honey Using Infrared Spectroscopy: A Review. Appl. Spectrosc. Rev. 2011, 46, 523–538. [Google Scholar] [CrossRef]
- Brereton, R.G. Introduction to Multivariate Calibration in Analytical Chemistry. Analyst 2000, 125, 2125–2154. [Google Scholar] [CrossRef]
- Næs, T.; Isaksson, T.; Fearn, T.; Davies, T. A User-Friendly Guide to Multivariate Calibration and Classification; NIR Publications: Chichester, UK, 2002. [Google Scholar]
- Groemping, U.; Amarov, B.; Xu, H. DoE.Base: Full Factorials, Orthogonal Arrays and Base Utilities for DoE Packages, R Package Version 1.2; 2021. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- Lenth, R. Rsm: Response-Surface Analysis, R Package Version 2.10.3; 2021. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- RStudio. Available online: https://rstudio.com/ (accessed on 20 September 2021).
- Liland, K.H.; Mevik, B.-H.; Wehrens, R.; Hiemstra, P. Pls: Partial Least Squares and Principal Component Regression, R Package Version 2.8-0; 2021. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- Arroz, E.; Jordan, M.; Dumancas, G.G. Development of a Direct Spectrophotometric and Chemometric Method for Determining Food Dye Concentrations. Appl. Spectrosc. 2017, 71, 1633–1639. [Google Scholar] [CrossRef] [PubMed]
- Adams, L.J.; Bello, G.; Dumancas, G.G. Development and Application of a Genetic Algorithm for Variable Optimization and Predictive Modeling of Five-Year Mortality Using Questionnaire Data. Bioinforma. Biol. Insights 2015, 9s3, BBI.S29469. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- G Dumancas, G.; Bello, G.; Hughes, J.; Diss, M. Comparison of Chemometric Algorithms for Multicomponent Analyses and Signal Processing: An Example from 4-(2-Pyridylazo) Resorcinol-Metal Colored Complexes. Recent Pat. Signal Process. Discontin. 2014, 4, 106–115. [Google Scholar] [CrossRef]
- Dumancas, G.G.; Ramasahayam, S.; Bello, G.; Hughes, J.; Kramer, R. Chemometric Regression Techniques as Emerging, Powerful Tools in Genetic Association Studies. TrAC Trends Anal. Chem. 2015, 74, 79–88. [Google Scholar] [CrossRef]
- Otto, M. Chemometrics: Statistics and Computer Application in Analytical Chemistry; John Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Brereton, R.G. Chemometrics: Data Driven Extraction for Science; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Stevens, A.; Ramirez-Lopez, L. Prospectr: Miscellaneous Functions for Processing and Sample Selection of Vis-NIR Diffuse Reflectance Data, R Package Version 0.1.3; 2014. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- Zimmermann, B.; Kohler, A. Optimizing Savitzky–Golay Parameters for Improving Spectral Resolution and Quantification in Infrared Spectroscopy. Appl. Spectrosc. 2013, 67, 892–902. [Google Scholar] [CrossRef] [Green Version]
- Stevens, A.; Ramirez-Lopez, L.; Hans, G. Prospectr: Miscellaneous Functions for Processing and Sample Selection of Spectroscopic Data, R Package Version 0.2.2; 2021. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- Savitzky, A.; Golay, M.J. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Use R! Springer: New York, NY, USA, 2009; ISBN 978-0-387-98141-3. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining, Southeast Asia Edition: Concepts and Techniques; Morgan Kaufmann: Burlington, MA, USA, 2006. [Google Scholar]
- Chakrabarti, S.; Cox, E.; Frank, E.; Güting, R.H.; Han, J.; Jiang, X.; Kamber, M.; Lightstone, S.S.; Nadeau, T.P.; Neapolitan, R.E.; et al. Data Mining: Know It All; Morgan Kaufmann: Burlington, MA, USA, 2008; ISBN 978-0-08-087788-4. [Google Scholar]
- Faber, N.K.M. Estimating the Uncertainty in Estimates of Root Mean Square Error of Prediction: Application to Determining the Size of an Adequate Test Set in Multivariate Calibration. Chemom. Intell. Lab. Syst. 1999, 49, 79–89. [Google Scholar] [CrossRef]
- Kassambara, A.; Mundt, F. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses, R Package Version 1.0.5; 2017. Available online: https://www.r-project.org/ (accessed on 23 December 2022).
- Timm, N.H. Applied Multivariate Analysis: Springer Texts in Statistics; Springer: New York, NY, USA, 2002. [Google Scholar]
- Ferreiro-González, M.; Espada-Bellido, E.; Guillén-Cueto, L.; Palma, M.; Barroso, C.G.; Barbero, G.F. Rapid Quantification of Honey Adulteration by Visible-near Infrared Spectroscopy Combined with Chemometrics. Talanta 2018, 188, 288–292. [Google Scholar] [CrossRef]
- Callao, M.P.; Ruisánchez, I. An Overview of Multivariate Qualitative Methods for Food Fraud Detection. Food Control 2018, 86, 283–293. [Google Scholar] [CrossRef]
- Spink, J.; Moyer, D.C.; Speier-Pero, C. Introducing the Food Fraud Initial Screening Model (FFIS). Food Control 2016, 69, 306–314. [Google Scholar] [CrossRef]
- Head, J.; Kinyanjui, J.; Talbott, M. FTIR-ATR Characterization of Commercial Honey Samples and Their Adulteration with Sugar Syrups Using Chemometric Analysis. Pittcon 2015, 2220–2221. [Google Scholar]
- Lang, J.; McNitt, L. The Use of FT-IR Spectroscopy as a Technique for Verifying Maple Syrup Authenticity; PerkinElmer, Inc.: Shelton, CT, USA, 2014. [Google Scholar]
- Tul’chinsky, V.M.; Zurabyan, S.E.; Asankozhoev, K.A.; Kogan, G.A.; Khorlin, A.Y. Study of the Infrared Spectra of Oligosaccharides in the Region 1,000-40 Cm−1. Carbohydr. Res. 1976, 51, 1–8. [Google Scholar] [CrossRef]
- Hineno, M. Infrared Spectra and Normal Vibration of β-d-Glucopyranose. Carbohydr. Res. 1977, 56, 219–227. [Google Scholar] [CrossRef]
- Smith, B.C. Alcohols—The Rest of the Story. Spectroscopy 2017, 32, 19–23. [Google Scholar]
- Li, Q.; Zeng, J.; Lin, L.; Zhang, J.; Zhu, J.; Yao, L.; Wang, S.; Yao, Z.; Wu, Z. Low Risk of Category Misdiagnosis of Rice Syrup Adulteration in Three Botanical Origin Honey by ATR-FTIR and General Model. Food Chem. 2020, 332, 127356. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Techniques Performed | Signal Processing | Corn | Cane | Beet | Rice | Average |
|---|---|---|---|---|---|---|
| Signal processing and PLS analysis of entire spectral region (3996–650 cm−1) | No Pre-processing | 0.030 | 0.015 | 0.019 | 0.031 | 0.024 |
| First Derivative | 0.022 | 0.02 | 0.02 | 0.017 | 0.020 | |
| Second Derivative | 0.014 | 0.012 | 0.02 | 0.014 | 0.015 | |
| Moving Average | 0.030 | 0.015 | 0.019 | 0.031 | 0.024 | |
| Binning | 0.031 | 0.015 | 0.019 | 0.031 | 0.024 | |
| Savitzky-Golay | 0.042 | 0.018 | 0.016 | 0.035 | 0.028 | |
| Standard Normal Variate | 0.038 | 0.025 | 0.016 | 0.030 | 0.027 | |
| Signal processing and PLS analysis of specific spectral region (1501–799 cm−1) | No Pre-Processing | 0.028 | 0.013 | 0.018 | 0.019 | 0.020 |
| First Derivative | 0.022 | 0.024 | 0.023 | 0.015 | 0.021 | |
| Second Derivative | 0.016 | 0.021 | 0.030 | 0.018 | 0.021 | |
| Moving Average | 0.028 | 0.013 | 0.018 | 0.019 | 0.020 | |
| Binning | 0.029 | 0.014 | 0.018 | 0.02 | 0.020 | |
| Savitzky-Golay | 0.033 | 0.023 | 0.019 | 0.028 | 0.026 | |
| Standard Normal Variate | 0.029 | 0.018 | 0.025 | 0.021 | 0.023 |
| Techniques Performed | Signal Processing | Corn | Cane | Beet | Rice | Average |
|---|---|---|---|---|---|---|
| Signal processing and PLS analysis of entire spectral region (3996–650 cm−1) | No Pre-processing | 0.724 | 0.913 | 0.903 | 0.757 | 0.824 |
| First Derivative | 0.858 | 0.845 | 0.891 | 0.925 | 0.880 | |
| Second Derivative | 0.943 | 0.938 | 0.897 | 0.948 | 0.932 | |
| Moving Average | 0.724 | 0.913 | 0.903 | 0.757 | 0.824 | |
| Binning | 0.722 | 0.912 | 0.902 | 0.756 | 0.823 | |
| Savitzky-Golay | 0.458 | 0.86 | 0.927 | 0.681 | 0.732 | |
| Standard Normal Variate | 0.579 | 0.741 | 0.931 | 0.763 | 0.754 | |
| Signal processing and PLS analysis of specific spectral region (1501–799 cm−1) | No Pre-Processing | 0.759 | 0.926 | 0.914 | 0.903 | 0.876 |
| First Derivative | 0.853 | 0.772 | 0.865 | 0.944 | 0.859 | |
| Second Derivative | 0.925 | 0.824 | 0.755 | 0.913 | 0.854 | |
| Moving Average | 0.759 | 0.926 | 0.914 | 0.903 | 0.876 | |
| Binning | 0.756 | 0.925 | 0.913 | 0.901 | 0.874 | |
| Savitzky-Golay | 0.679 | 0.777 | 0.906 | 0.798 | 0.790 | |
| Standard Normal Variate | 0.75 | 0.872 | 0.834 | 0.881 | 0.834 |
| Techniques Performed | Signal Processing | Corn | Cane | Beet | Rice | Average |
|---|---|---|---|---|---|---|
| Signal processing and PLS analysis of entire spectral region (3996–650 cm−1) | No Pre-processing | 0.022 | 0.027 | 0.019 | 0.034 | 0.026 |
| First Derivative | 0.018 | 0.012 | 0.018 | 0.018 | 0.017 | |
| Second Derivative | 0.020 | 0.017 | 0.024 | 0.025 | 0.022 | |
| Moving Average | 0.022 | 0.027 | 0.011 | 0.034 | 0.024 | |
| Binning | 0.022 | 0.027 | 0.011 | 0.034 | 0.024 | |
| Savitzky-Golay | 0.022 | 0.015 | 0.012 | 0.024 | 0.018 | |
| Standard Normal Variate | 0.021 | 0.016 | 0.021 | 0.018 | 0.019 | |
| Signal processing and PLS analysis of specific spectral region (1501–799 cm−1) | No Pre-Processing | 0.021 | 0.015 | 0.024 | 0.019 | 0.020 |
| First Derivative | 0.017 | 0.012 | 0.018 | 0.007 | 0.014 | |
| Second Derivative | 0.011 | 0.02 | 0.022 | 0.015 | 0.017 | |
| Moving Average | 0.021 | 0.015 | 0.024 | 0.019 | 0.020 | |
| Binning | 0.02 | 0.015 | 0.024 | 0.019 | 0.020 | |
| Savitzky-Golay | 0.013 | 0.008 | 0.015 | 0.006 | 0.011 | |
| Standard Normal Variate | 0.018 | 0.016 | 0.011 | 0.017 | 0.016 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dumancas, G.; Ellis, H.; Neumann, J.; Smith, K. Comparison of Various Signal Processing Techniques and Spectral Regions for the Direct Determination of Syrup Adulterants in Honey Using Fourier Transform Infrared Spectroscopy and Chemometrics. Chemosensors 2022, 10, 51. https://doi.org/10.3390/chemosensors10020051
Dumancas G, Ellis H, Neumann J, Smith K. Comparison of Various Signal Processing Techniques and Spectral Regions for the Direct Determination of Syrup Adulterants in Honey Using Fourier Transform Infrared Spectroscopy and Chemometrics. Chemosensors. 2022; 10(2):51. https://doi.org/10.3390/chemosensors10020051
Chicago/Turabian StyleDumancas, Gerard, Helena Ellis, Jossie Neumann, and Khalil Smith. 2022. "Comparison of Various Signal Processing Techniques and Spectral Regions for the Direct Determination of Syrup Adulterants in Honey Using Fourier Transform Infrared Spectroscopy and Chemometrics" Chemosensors 10, no. 2: 51. https://doi.org/10.3390/chemosensors10020051
APA StyleDumancas, G., Ellis, H., Neumann, J., & Smith, K. (2022). Comparison of Various Signal Processing Techniques and Spectral Regions for the Direct Determination of Syrup Adulterants in Honey Using Fourier Transform Infrared Spectroscopy and Chemometrics. Chemosensors, 10(2), 51. https://doi.org/10.3390/chemosensors10020051