


Convolutional Neural Network Applications in Fire Debris Classification


Abstract
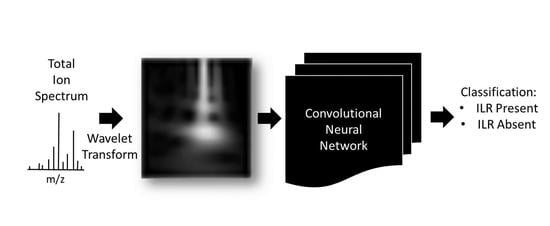
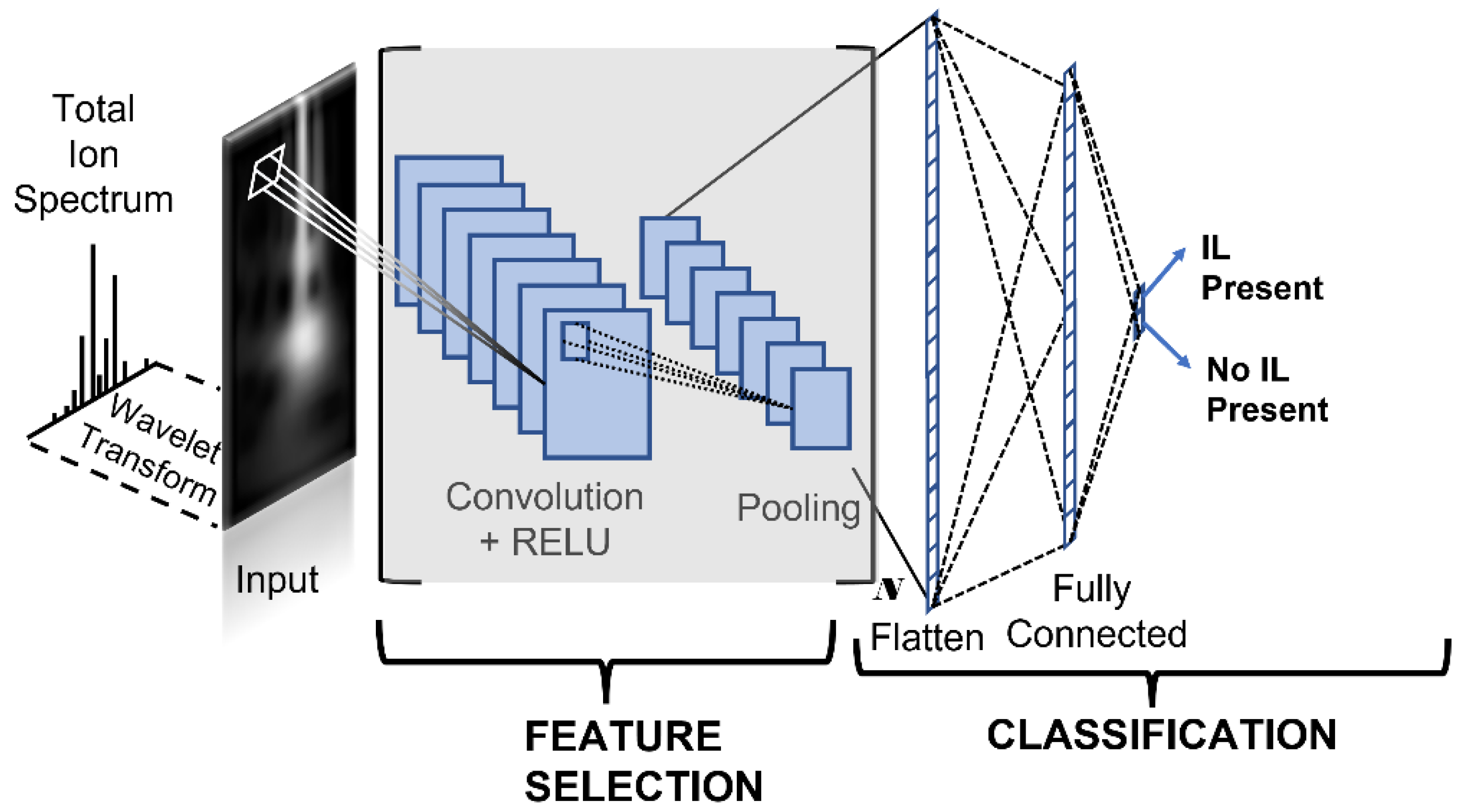
:
1. Introduction
2. Materials and Methods
3. Results
3.1. Generated Images for ILRC and Fire Debris Data
3.2. Likelihood Ratio Calculations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Keto, R.O.; Wineman, P.L. Detection of petroleum-based accelerants in fire debris by target compound gas chromatography/mass spectrometry. Anal. Chem. 1991, 63, 1964–1971. [Google Scholar] [CrossRef]
- Keto, R.O. GC/MS Data Interpretation for Petroleum Distillate Identification in Contaminated Arson Debris. J. Forensic Sci. 1995, 40, 412–423. [Google Scholar] [CrossRef]
- ASTM E 1618-01; Standard Test Method for Ignitable Liquid Residues in Extracts from Fire Debris Samples by Gas Chromatography—Mass Spectrometry. American Society for Testing and Materials: West Conshohocken, PA, USA, 2019.
- Quigley-McBride, A.; Dror, I.E.; Roy, T.; Garrett, B.L.; Kukucka, J. A practical tool for information management in forensic decisions: Using Linear Sequential Unmasking-Expanded (LSU-E) in casework. Forensic Sci. Int. Synerg. 2022, 4, 100216. [Google Scholar] [CrossRef] [PubMed]
- Curley, L.J.; Munro, J.; Dror, I.E. Cognitive and human factors in legal layperson decision making: Sources of bias in juror decision making. Med. Sci. Law 2022, 62, 206–215. [Google Scholar] [CrossRef]
- Kukucka, J.; Dror, I. Human Factors in Forensic Science: Psychological Causes of Bias and Error; Oxford University Press: Oxford, UK, 2022. [Google Scholar]
- Whitehead, F.A.; Williams, M.R.; Sigman, M.E. Decision theory and linear sequential unmasking in forensic fire debris analysis: A proposed workflow. Forensic Chem. 2022, 29, 100426. [Google Scholar] [CrossRef]
- Waddell, E.E.; Song, E.T.; Rinke, C.N.; Williams, M.R.; Sigman, M. Progress Toward the Determination of Correct Classification Rates in Fire Debris Analysis. J. Forensic Sci. 2013, 58, 887–896. [Google Scholar] [CrossRef] [PubMed]
- Waddell, E.E.; Williams, M.R.; Sigman, M.E. Progress Toward the Determination of Correct Classification Rates in Fire Debris Analysis II: Utilizing Soft Independent Modeling of Class Analogy (SIMCA). J. Forensic Sci. 2014, 59, 927–935. [Google Scholar] [CrossRef] [PubMed]
- Sigman, M.E.; Williams, M.R. Assessing evidentiary value in fire debris analysis by chemometric and likelihood ratio approaches. Forensic Sci. Int. 2016, 264, 113–121. [Google Scholar] [CrossRef] [PubMed]
- Allen, A.; Williams, M.R.; Thurn, N.A.; Sigman, M.E. Model Distribution Effects on Likelihood Ratios in Fire Debris Analysis. Separations 2018, 5, 44. [Google Scholar] [CrossRef]
- Coulson, R.; Williams, M.R.; Allen, A.; Akmeemana, A.; Ni, L.; Sigman, M.E. Model-effects on likelihood ratios for fire debris analysis. Forensic Chem. 2018, 7, 38–46. [Google Scholar] [CrossRef]
- Thurn, N.A.; Wood, T.; Williams, M.R.; Sigman, M.E. Classification of ground-truth fire debris samples using artificial neural networks. Forensic Chem. 2021, 23, 100313. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Sahiner, B.; Pezeshk, A.; Hadjiiski, L.M.; Wang, X.; Drukker, K.; Cha, K.H.; Summers, R.M.; Giger, M.L. Deep learning in medical imaging and radiation therapy. Med. Phys. 2019, 46, e1–e36. [Google Scholar] [CrossRef] [PubMed]
- Suzuki, K. Overview of deep learning in medical imaging. Radiol. Phys. Technol. 2017, 10, 257–273. [Google Scholar] [CrossRef] [PubMed]
- Kim, M.; Yun, J.; Cho, Y.; Shin, K.; Jang, R.; Bae, H.-J.; Kim, N. Deep learning in medical imaging. Neurospine 2019, 16, 657. [Google Scholar] [CrossRef] [PubMed]
- Yue, T.; Wang, H. Deep learning for genomics: A concise overview. arXiv 2018, arXiv:1802.00810. [Google Scholar]
- Zou, J.; Huss, M.; Abid, A.; Mohammadi, P.; Torkamani, A.; Telenti, A. A primer on deep learning in genomics. Nat. Genet. 2019, 51, 12–18. [Google Scholar] [CrossRef]
- Kopp, W.; Monti, R.; Tamburrini, A.; Ohler, U.; Akalin, A. Deep learning for genomics using Janggu. Nat. Commun. 2020, 11, 3488. [Google Scholar] [CrossRef]
- Hwang, J.-J.; Jung, Y.-H.; Cho, B.-H.; Heo, M.-S. An overview of deep learning in the field of dentistry. Imaging Sci. Dent. 2019, 49, 1–7. [Google Scholar] [CrossRef]
- Rodrigues, J.A.; Krois, J.; Schwendicke, F. Demystifying artificial intelligence and deep learning in dentistry. Braz. Oral Res. 2021, 35. [Google Scholar] [CrossRef]
- Corbella, S.; Srinivas, S.; Cabitza, F. Applications of deep learning in dentistry. Oral Surg. Oral Med. Oral Pathol. Oral Radiol. 2021, 132, 225–238. [Google Scholar] [CrossRef]
- Zeng, J.; Zeng, J.; Qiu, X. Deep learning based forensic face verification in videos. In Proceedings of the 2017 International Conference on Progress in Informatics and Computing (Pic), Nanjing, China, 27–29 October 2017; IEEE: Nanjing, China, 2017; pp. 77–80. [Google Scholar]
- Liang, Y.; Han, W.; Qiu, L.; Wu, C.; Shao, Y.; Wang, K.; He, L. Exploring Forensic Dental Identification with Deep Learning. Adv. Neural Inf. Process. Syst. 2021, 34, 3244–3258. [Google Scholar]
- Karie, N.M.; Kebande, V.R.; Venter, H. Diverging deep learning cognitive computing techniques into cyber forensics. Forensic Sci. Int. Synerg. 2019, 1, 61–67. [Google Scholar] [CrossRef] [PubMed]
- Allaire, J.J.; Chollet, F. keras: R Interface to ‘Keras’, R Package Version 2.9.0. 2021. Available online: https://cran.r-project.org/web/packages/keras/index.html (accessed on 20 September 2022).
- Allaire, J.J.; Tang, Y. Tensorflow: R Interface to ‘TensorFlow’, R Package Version 2.9.0. 2021. Available online: https://cran.r-project.org/web/packages/tensorflow/index.html (accessed on 20 September 2022).
- Ke, Q.; Liu, J.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. Chapter 5—Computer Vision for Human–Machine Interaction. In Computer Vision for Assistive Healthcare; Leo, M., Farinella, G.M., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 127–145. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Wu, J. Introduction to Convolutional Neural Networks; National Key Lab for Novel Software Technology, Nanjing University: Nanjing, China, 2017; Volume 5, p. 495. [Google Scholar]
- Wood, T. What Is the Softmax Function? Available online: https://deepai.org/machine-learning-glossary-and-terms/softmax-layer (accessed on 3 April 2022).
- Ignitable Liquid Reference Collection. National Center for Forensic Science. Available online: https://ilrc.ucf.edu/ (accessed on 3 May 2022).
- Substrate Database. National Center for Forensic Science. Available online: https://ilrc.ucf.edu/substrate/index.php (accessed on 5 May 2022).
- Torrence, C.; Compo, G.P. A practical guide to wavelet analysis. Bull. Am. Meteorol. Soc. 1998, 79, 61–78. [Google Scholar] [CrossRef]
- Vicente, J.B.; Rafael, B. wavScalogram: Wavelet Scalogram Tools for Time Series Analysis. R Package Version 1.1.1. 2021. Available online: https://CRAN.R-project.org/package=wavScalogram (accessed on 20 September 2022).
- Provost, F.; Fawcett, T. Robust Classification for Imprecise Environments. Mach. Learn. 2001, 42, 203–231. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Class Population and Fractional Contribution: In Silico | Class Population and Fractional Contribution: GTFD | Class Population and Fractional Contribution: ILSUB | |||
|---|---|---|---|---|---|---|
| SUB | 25,000 | 0.5 | 345 | 0.376 | 553 | 0.345 |
| ISO | 3125 | 0.0625 | 62 | 0.068 | 84 | 0.052 |
| OXY | 3125 | 0.0625 | 55 | 0.060 | 171 | 0.107 |
| MISC | 3125 | 0.0625 | 68 | 0.074 | 194 | 0.121 |
| AL | 3125 | 0.0625 | 60 | 0.065 | 60 | 0.037 |
| GAS | 3125 | 0.0625 | 65 | 0.071 | 83 | 0.052 |
| PD | 3125 | 0.0625 | 146 | 0.159 | 329 | 0.205 |
| AR | 3125 | 0.0625 | 59 | 0.064 | 72 | 0.045 |
| NP | 3125 | 0.0625 | 58 | 0.063 | 57 | 0.036 |
| Total | 50,000 | 918 | 1603 | |||
| Testing Accuracy | |||
|---|---|---|---|
| Model | Training Accuracy | ILSUB | FDIL |
| 1 | 0.943 | 0.986 | 0.775 |
| 2 | 0.940 | 0.986 | 0.798 |
| 3 | 0.942 | 0.990 | 0.797 |
| 4 | 0.932 | 0.984 | 0.776 |
| 5 | 0.939 | 0.989 | 0.786 |
| 6 | 0.941 | 0.986 | 0.783 |
| 7 | 0.938 | 0.988 | 0.775 |
| 8 | 0.941 | 0.988 | 0.790 |
| 9 | 0.938 | 0.989 | 0.800 |
| 10 | 0.940 | 0.991 | 0.801 |
| LLR = 0.78 | Predicted class | |
| Correct class | IL | SUB |
| IL | TP = 258 (45%) | FN = 315 |
| SUB | FP = 9 (3%) | TN = 336 |
| LLR = 0.22 | Predicted class | |
| Correct class | IL | SUB |
| IL | TP = 404 (71%) | FN = 169 |
| SUB | FP = 38 (11%) | TN = 307 |
| IL Class | LLR = 0.78 (Slope = 10 and 5) | LLR = 0.22 (Slope = 2.5) |
|---|---|---|
| TPR (%) (GTFD) | TPR (%) (GTFD) | |
| AR | 55.9 | 74.6 |
| GAS | 41.5 | 64.6 |
| ISO | 61.3 | 82.3 |
| MISC | 32.4 | 75 |
| NAL | 46.7 | 68.3 |
| NP | 56.9 | 74.1 |
| OXY | 21.8 | 45.5 |
| PD | 44.5 | 73.3 |
| IL Class | LLR = −0.33 (Slope = 10, 5 and 2.5) |
|---|---|
| TPR (%) (ILSUB) | |
| AR | 100 |
| GAS | 100 |
| ISO | 100 |
| MISC | 94.3 |
| NAL | 100 |
| NP | 100 |
| OXY | 93 |
| PD | 99 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akmeemana, A.; Williams, M.R.; Sigman, M.E. Convolutional Neural Network Applications in Fire Debris Classification. Chemosensors 2022, 10, 377. https://doi.org/10.3390/chemosensors10100377
Akmeemana A, Williams MR, Sigman ME. Convolutional Neural Network Applications in Fire Debris Classification. Chemosensors. 2022; 10(10):377. https://doi.org/10.3390/chemosensors10100377
Chicago/Turabian StyleAkmeemana, Anuradha, Mary R. Williams, and Michael E. Sigman. 2022. "Convolutional Neural Network Applications in Fire Debris Classification" Chemosensors 10, no. 10: 377. https://doi.org/10.3390/chemosensors10100377
APA StyleAkmeemana, A., Williams, M. R., & Sigman, M. E. (2022). Convolutional Neural Network Applications in Fire Debris Classification. Chemosensors, 10(10), 377. https://doi.org/10.3390/chemosensors10100377