
Anomaly Detection in Endemic Disease Surveillance Data Using Machine Learning Techniques


Abstract
1. Introduction
2. Methods
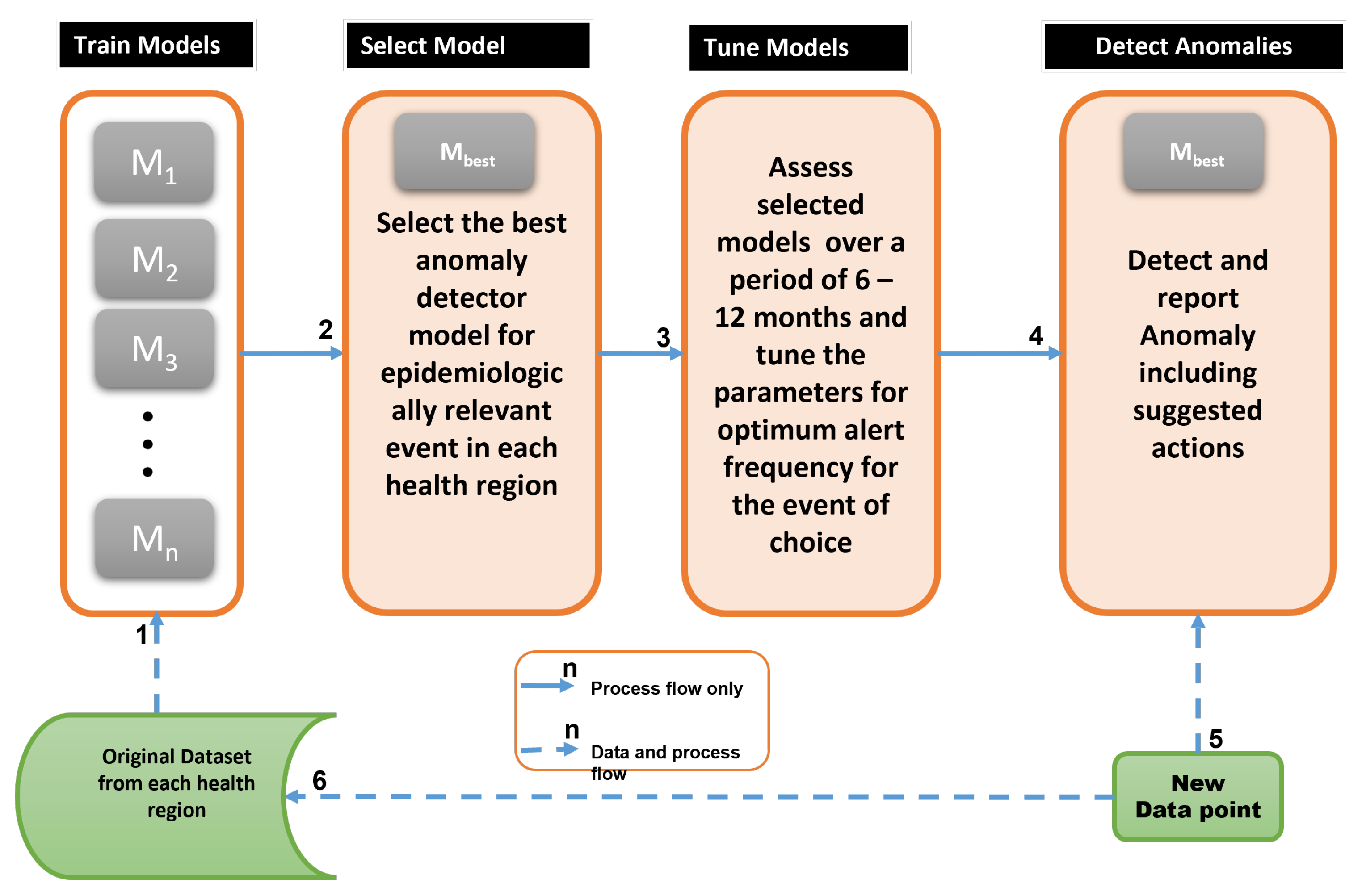
2.1. Anomaly Detection Framework
2.2. Epidemiological Feature Selection and Preprocessing
2.3. Selecting the Top-k Models for Maximum Coverage
3. Results
3.1. Anomalies by Contamination Rate
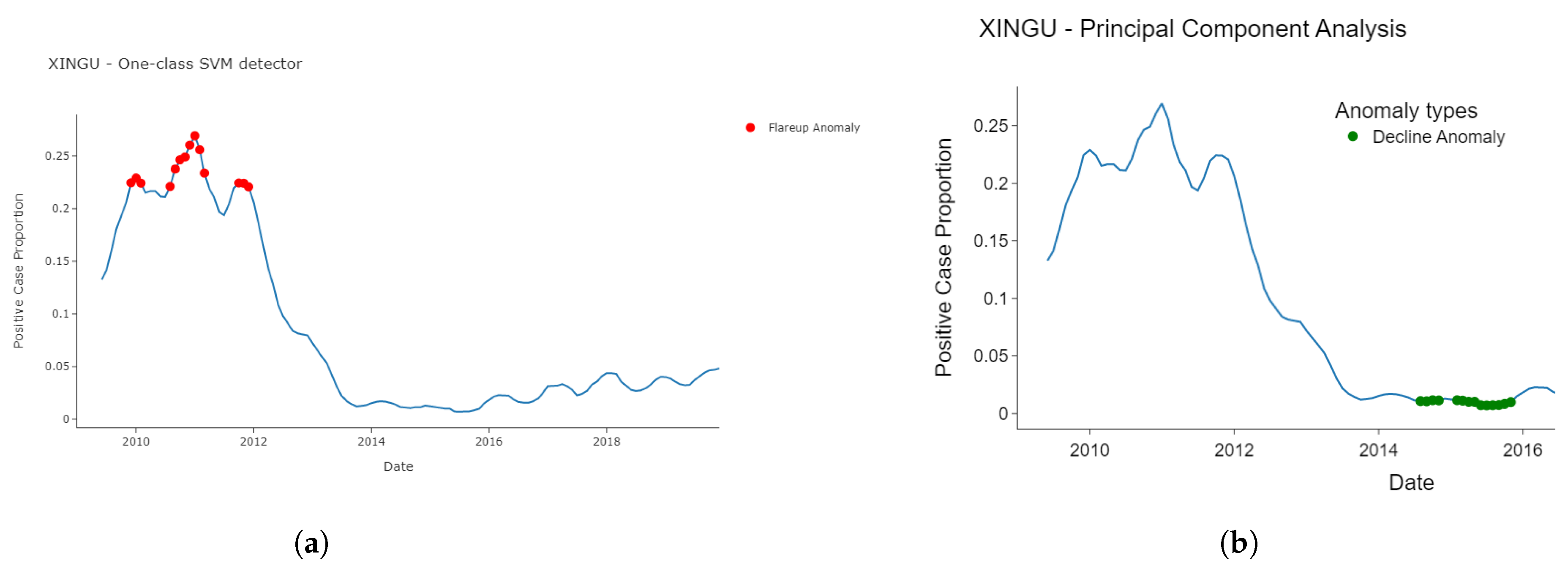
3.2. Detected Anomalies and Epidemiological Significance
3.3. Consistency and Variation in Anomalies Detected by Models
3.4. Temporal Location of Detected Anomalies
3.5. Model Selection for Inclusion in Endemic Disease Surveillance System
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| PCA | Principal Component Analysis |
| Probability Density Function | |
| SVM | Support Vector Machine |
References
- Health Australia. Surveillance Systems Reported in Communicable Diseases Intelligence. 2016. Available online: https://www.health.gov.au/topics/communicable-diseases/in-australia/surveillance (accessed on 16 June 2023).
- Dash, S.; Shakyawar, S.K.; Sharma, M. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- CDC. Principles of Epidemiology in Public Health Practice, Third Edition An Introduction to Applied Epidemiology and Biostatistics. Int. J. Syst. Evol. Microbiol. 2012, 1978, 5–6. [Google Scholar]
- Felicity, T.C.; Matt, H. Seroepidemiology: An underused tool for designing and monitoring vaccination programmes in low- and middle-income countries. Trop. Med. Int. Health 2016, 21, 1086–1090. [Google Scholar] [CrossRef]
- Jayatilleke, K. Challenges in Implementing Surveillance Tools of High-Income Countries (HICs) in Low Middle Income Countries (LMICs). Curr. Treat. Options Infect. Dis. 2020, 12, 191–201. [Google Scholar] [CrossRef] [PubMed]
- Nekorchuk, D.M.; Gebrehiwot, T.; Awoke, W.; Mihretie, A.; Wimberly, M.C. Comparing malaria early detection methods in a declining transmission setting in northwestern Ethiopia. BMC Public Health 2021, 21, 788. [Google Scholar] [CrossRef] [PubMed]
- Charumilind, S.; Craven, M.; Lamb, M.; Lamb, J.; Singhal, S.; Wilson, M. Pandemic to Endemic: How the World Can Learn to Live with COVID-19; Mckinsey and Company: Melbourne, Australia, 2021; pp. 1–8. Available online: https://www.mckinsey.com/industries/healthcare-systems-and-services/our-insights/pandemic-to-endemic-how-the-world-can-learn-to-live-with-covid-19 (accessed on 21 March 2022).
- Clark, J.; Liu, Z.; Japkowicz, N. Adaptive Threshold for Outlier Detection on Data Streams. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 41–49. [Google Scholar] [CrossRef]
- Zhao, M.; Chen, J.; Li, Y. A Review of Anomaly Detection Techniques Based on Nearest Neighbor. In Proceedings of the 2018 International Conference on Computer Modeling, Simulation and Algorithm (CMSA 2018), Beijing, China, 22–23 April 2018; Volume 151, pp. 290–292. [Google Scholar]
- Hagemann, T.; Katsarou, K. A Systematic Review on Anomaly Detection for Cloud Computing Environments. In Proceedings of the 2020 ACM 3rd Artificial Intelligence and Cloud Computing Conference, Kyoto, Japan, 18–20 December 2020; pp. 83–96. [Google Scholar] [CrossRef]
- Baroni, L.; Pedroso, M.; Barcellos, C.; Salles, R.; Salles, S.; Paixão, B.; Chrispino, A.; Guedes, G. An integrated dataset of malaria notifications in the Legal Amazon. BMC Res. Notes 2020, 13, 274. [Google Scholar] [CrossRef] [PubMed]
- Baena-garcia, M.; Campo-avila, J.D.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams, Philadelphia, PA, USA, 20 August 2006; pp. 1–10. [Google Scholar]
- Weaveworks. Building Continuous Delivery Pipelines Deliver Better Features, Faster; Weaveworks Inc. 2018; pp. 1–26. Available online: https://www.weave.works/assets/images/blta8084030436bce24/CICD_eBook_Web.pdf (accessed on 16 July 2022).
- Shereen, M.A.; Khan, S.; Kazmi, A.; Bashir, N.; Siddique, R. COVID-19 infection: Origin, transmission, and characteristics of human coronaviruses. J. Adv. Res. 2020, 24, 91–98. [Google Scholar] [CrossRef] [PubMed]
- Ali, M. PyCaret: An Open Source, Low-Code Machine Learning Library in Python, PyCaret Version 1.0.0. 2020. Available online: https://www.pycaret.org (accessed on 22 June 2023).
- Schubert, E.; Wojdanowski, R.; Kriegel, H.P. On Evaluation of Outlier Rankings and Outlier Scores. In Proceedings of the 2012 SIAM International Conference on Data Mining, Anaheim, CA, USA, 26–28 April 2012; pp. 1047–1058. [Google Scholar] [CrossRef]
- Tang, J.; Chen, Z.; Fu, A.W.; Cheung, D.W. Enhancing Effectiveness of Outlier Detections for Low Density Patterns. In Advances in Knowledge Discovery and Data Mining; Chen, M.S., Yu, P.S., Liu, B., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2336, pp. 535–548. [Google Scholar] [CrossRef]
- Akshara. Anomaly detection using Isolation Forest—A Complete Guide. Anal. Vidya 2021, 2336. Available online: https://www.analyticsvidhya.com/blog/2021/07/anomaly-detection-using-isolation-forest-a-complete-guide/ (accessed on 29 June 2022).
- Goldstein, M.; Dengel, A. Histogram-based Outlier Score (HBOS): A fast Unsupervised Anomaly Detection Algorithm. Conf. Pap. 2012, 1–6. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.401.5686&rep=rep1&type=pdf (accessed on 29 January 2023).
- Gu, X.; Akogluand, L.; Fu, A.W.; Rinaldo, A. Statistical Analysis of Nearest Neighbor Methods for Anomaly Detection. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 1–11. Available online: https://proceedings.neurips.cc/paper/2019/file/805163a0f0f128e473726ccda5f91bac-Paper.pdf (accessed on 17 April 2023).
- Tax, D.M.J.; Duin, R.P.W. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. Available online: https://link.springer.com/content/pdf/10.1023/B:MACH.0000008084.60811.49.pdf (accessed on 17 April 2023). [CrossRef]
- McCaffrey, J. Anomaly Detection Using Principal Component Analysis (PCA). Vis. Studio Mag. 2021, 582–588. Available online: https://visualstudiomagazine.com/articles/2021/10/20/anomaly-detection-pca.aspx (accessed on 17 April 2023).
- Fauconnier, C.; Haesbroeck, G. Outliers detection with the minimum covariance determinant estimator in practice. Stat. Methodol. 2009, 6, 363–379. [Google Scholar] [CrossRef]
- Janssens, J.H.M. Outlier Selection and One-Class Classification. Ph.D. Thesis, Tilburg University, Tilburg, The Netherlands, 2013; pp. 59–95. Available online: https://github.com/jeroenjanssens/phd-thesis/blob/master/jeroenjanssens-thesis.pdf (accessed on 17 April 2023).
- Sajesh, T.; Srinivasan, M. Outlier detection for high dimensional data using the comedian approach. J. Stat. Comput. Simul. 2012, 82, 745–757. [Google Scholar] [CrossRef]
- Cabana, E.; Lillo, R.E.; Laniado, H. Multivariate outlier detection based on a robust Mahalanobis distance with shrinkage estimators. Stat. Pap. 2012, 62, 1583–1609. [Google Scholar] [CrossRef]
- Chandu, D.P. Big Step Greedy Heuristic for Maximum Coverage Problem. Int. J. Comput. Appl. 2015, 125, 19–24. Available online: https://arxiv.org/pdf/1506.06163 (accessed on 13 October 2022).
- Farrington, C.P.; Andrews, N.J.; Beale, A.J.; Catchpole, D. A statistical algorithm for the early detection of outbreaks of infectious disease. J. R. Stat. Soc. Ser. 1996, 159, 547–563. [Google Scholar] [CrossRef]
- Noufaily, A.; Enki, D.G.; Farrington, P.; Garthwaite, P.; Andrews, N.; Charlett, A. An improved algorithm for outbreak detection in multiple surveillance systems. Stat. Med. 2012, 32, 1206–1222. [Google Scholar] [CrossRef] [PubMed]
- Abdiansah, A.; Wardoyo, R. Time Complexity Analysis of Support Vector Machines (SVM) in LibSVM. Int. J. Comput. Appl. 2018, 128, 28–34. [Google Scholar] [CrossRef]
- Jaramillo-Valbuena, S.; Londono-Pelaz, J.O.; Cardona, S.A. Performance evaluation of concept drift detection techniques in the presence of noise. Revista 2017, 38, 16. Available online: https://www.revistaespacios.com/a17v38n39/a17v38n39p16.pdf (accessed on 17 April 2023).
- Geyshis, D. 8 Concept Drift Detection Methods. Aporia 2021, 1–5. Available online: https://www.aporia.com/blog/concept-drift-detection-methods/ (accessed on 17 April 2022).
- Shweta, B.; Gerardo, C.; Lone, S.; Alessandro, V.; Cécile, V.; Lake, M. Big Data for Infectious Disease Surveillance and Modeling. J. Infect. Dis. 2016, 214, s375–s379. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step No. | Major Activities |
|---|---|
| 1 | Train candidate anomaly detectors per health region using train set |
| 2 | Based on local epidemic demands, select best anomaly detector, |
| 3 | Tune model parameters after using for 6–12 months to evaluate performance |
| 4 | As new data arrives, use the best detector, to detect and interpret anomaly |
| 5 | New data for evaluation and model re-training |
| 6 | Update the models with the new data and repeat from Step 1 |
| No. | Model ID. | Model Name | Core Distance Measure |
|---|---|---|---|
| 1 | cluster | Clustering-Based Local Outlier [16] | Local outlier factor |
| 2 | cof | Connectivity-Based Local Outlier [17] | average chaining distance |
| 3 | iforest | Isolation Forest [18] | Depth of leaf branch |
| 4 | histogram | Histogram-based Outlier Detection [19] | HBOS |
| 5 | knn | K-Nearest Neighbors Detector [20] | Distance Proximity |
| 6 | lof | Local Outlier Factor [16] | Reacheability distance |
| 7 | svm | One-class SVM detector [21] | hyper-sphere volume |
| 8 | pca | Principal Component Analysis [22] | Magnitude of reconstruction error |
| 9 | mcd | Minimum Covariance Determinant [23] | Robust distance from MCD |
| 10 | sos | Stochastic Outlier Selection [24] | Affinity probability density |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Eze, P.U.; Geard, N.; Mueller, I.; Chades, I. Anomaly Detection in Endemic Disease Surveillance Data Using Machine Learning Techniques. Healthcare 2023, 11, 1896. https://doi.org/10.3390/healthcare11131896
Eze PU, Geard N, Mueller I, Chades I. Anomaly Detection in Endemic Disease Surveillance Data Using Machine Learning Techniques. Healthcare. 2023; 11(13):1896. https://doi.org/10.3390/healthcare11131896
Chicago/Turabian StyleEze, Peter U., Nicholas Geard, Ivo Mueller, and Iadine Chades. 2023. "Anomaly Detection in Endemic Disease Surveillance Data Using Machine Learning Techniques" Healthcare 11, no. 13: 1896. https://doi.org/10.3390/healthcare11131896
APA StyleEze, P. U., Geard, N., Mueller, I., & Chades, I. (2023). Anomaly Detection in Endemic Disease Surveillance Data Using Machine Learning Techniques. Healthcare, 11(13), 1896. https://doi.org/10.3390/healthcare11131896