
Trustworthy Breast Ultrasound Image Semantic Segmentation Based on Fuzzy Uncertainty Reduction



Abstract
1. Introduction
- The proposed spatial-wise fuzzy blocks (SFBs) are applied to measure and reduce the spatial uncertainties (spatial dimension) in convolutional feature maps, and the proposed channel-wise fuzzy blocks (CFBs) are proposed to handle the channel uncertainties (channel dimension) in convolutional feature maps.
- A novel membership function in deep learning is designed. Membership functions in fuzzy blocks are defined by convolutional operator with a Sigmoid activation function to increase the non-linearity of the membership function.
- A novel fuzzy logic uncertainty measurement method is proposed. Fuzzy entropy [29,30,31] calculated by the memberships of different categories are utilized to measure the uncertainties for pixels and channels. Uncertain pixels and channels are those with higher fuzzy entropies (details will be discussed in Section 3).
2. Related Works
2.1. BUS Image Segmentation
2.2. Attention Mechanisms
2.3. Fuzzy Logic in Deep Learning
3. Methods
3.1. Overview
3.2. Spatial-Wise Fuzzy Block
3.2.1. Fuzzification
3.2.2. Uncertainty Representation
3.2.3. Uncertainty Reduction
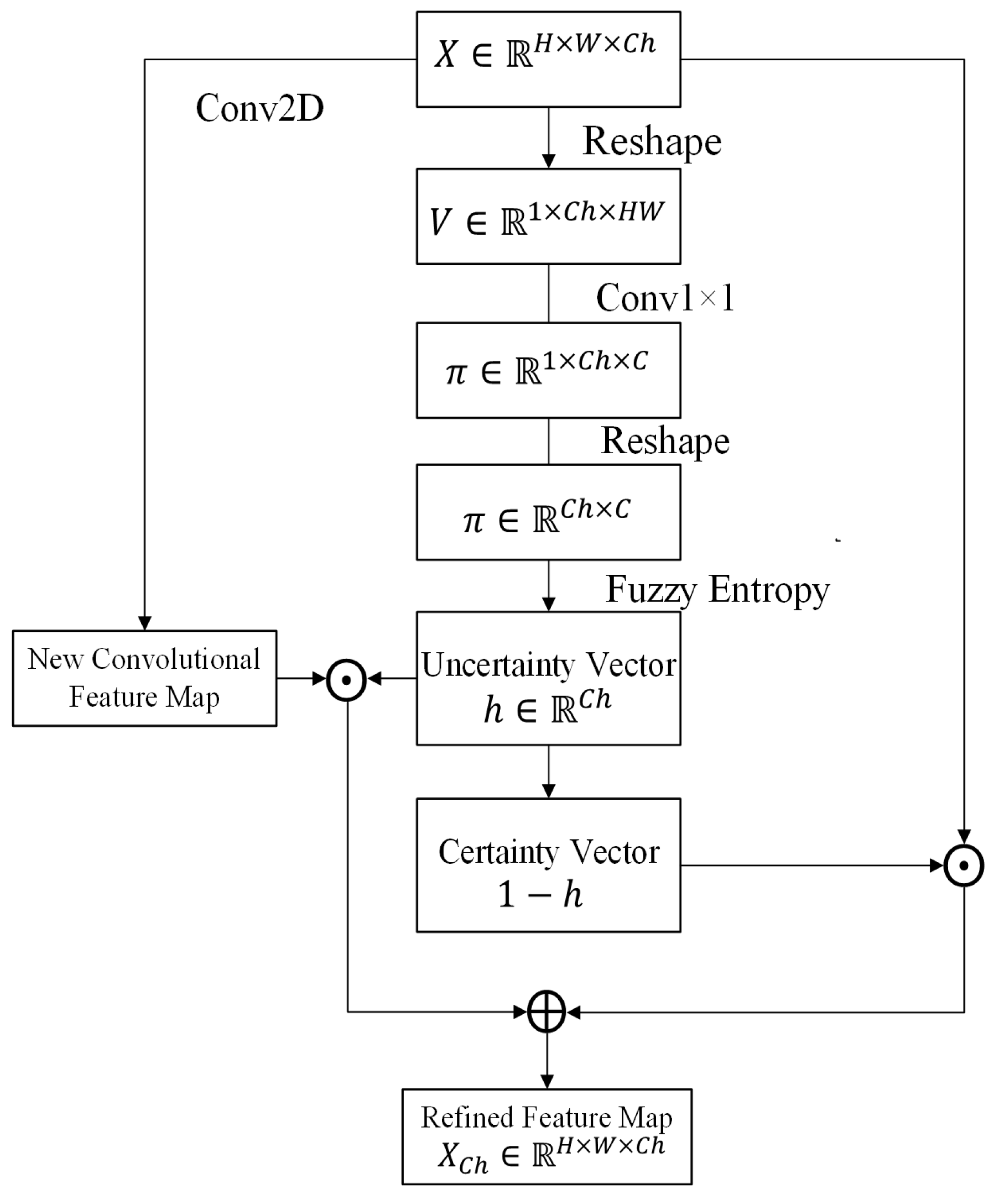
3.3. Channel-Wise Fuzzy Block
3.3.1. Fuzzification
3.3.2. Uncertainty Representation
3.3.3. Uncertainty Reduction
3.4. Loss Function
4. Experimental Results
4.1. Datasets
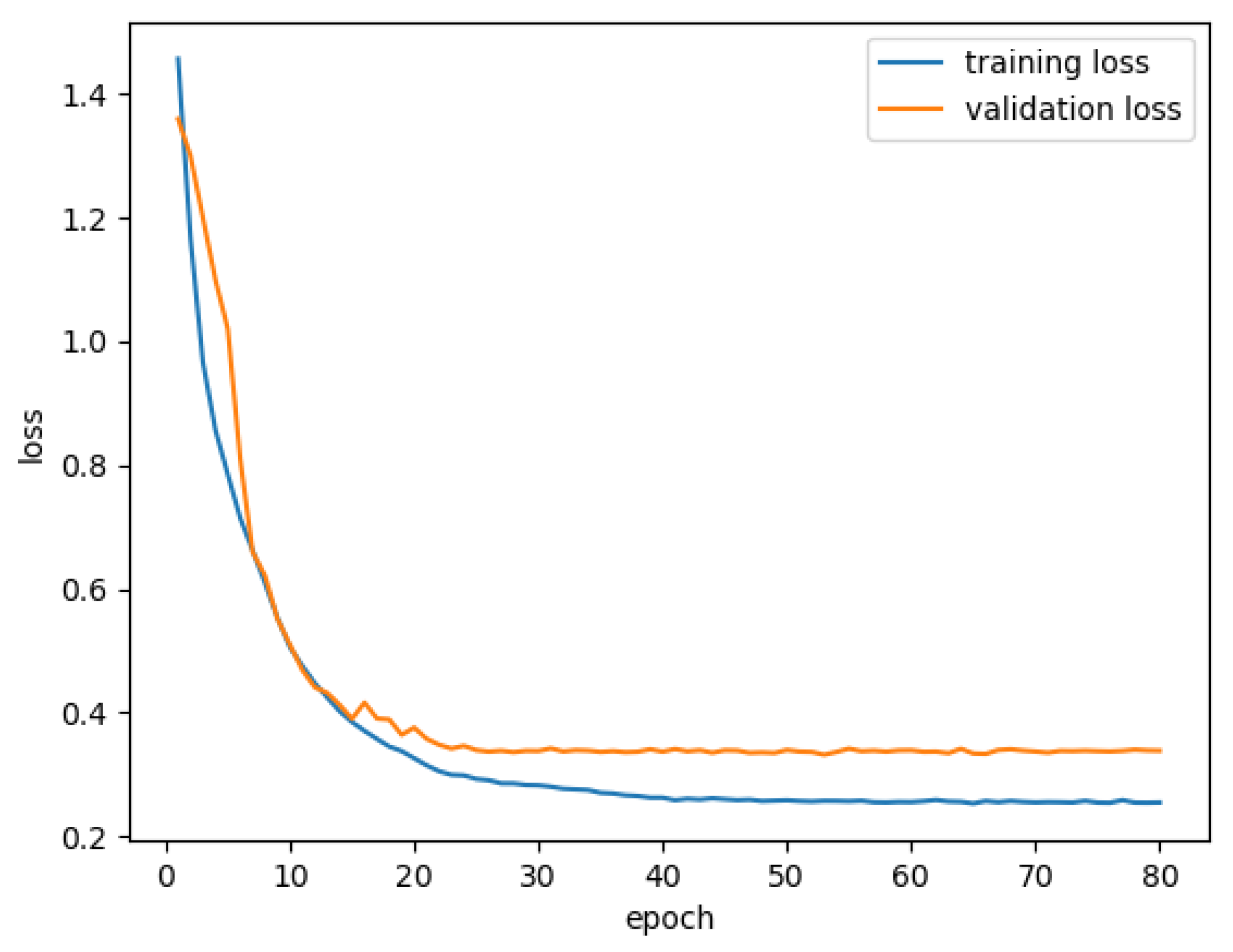
4.2. Experiment Details
4.2.1. Preprocessing and Augmentation
4.2.2. Experiment Environment
4.3. Metrics
4.4. Multi-Object Semantic Segmentation of BUS Images
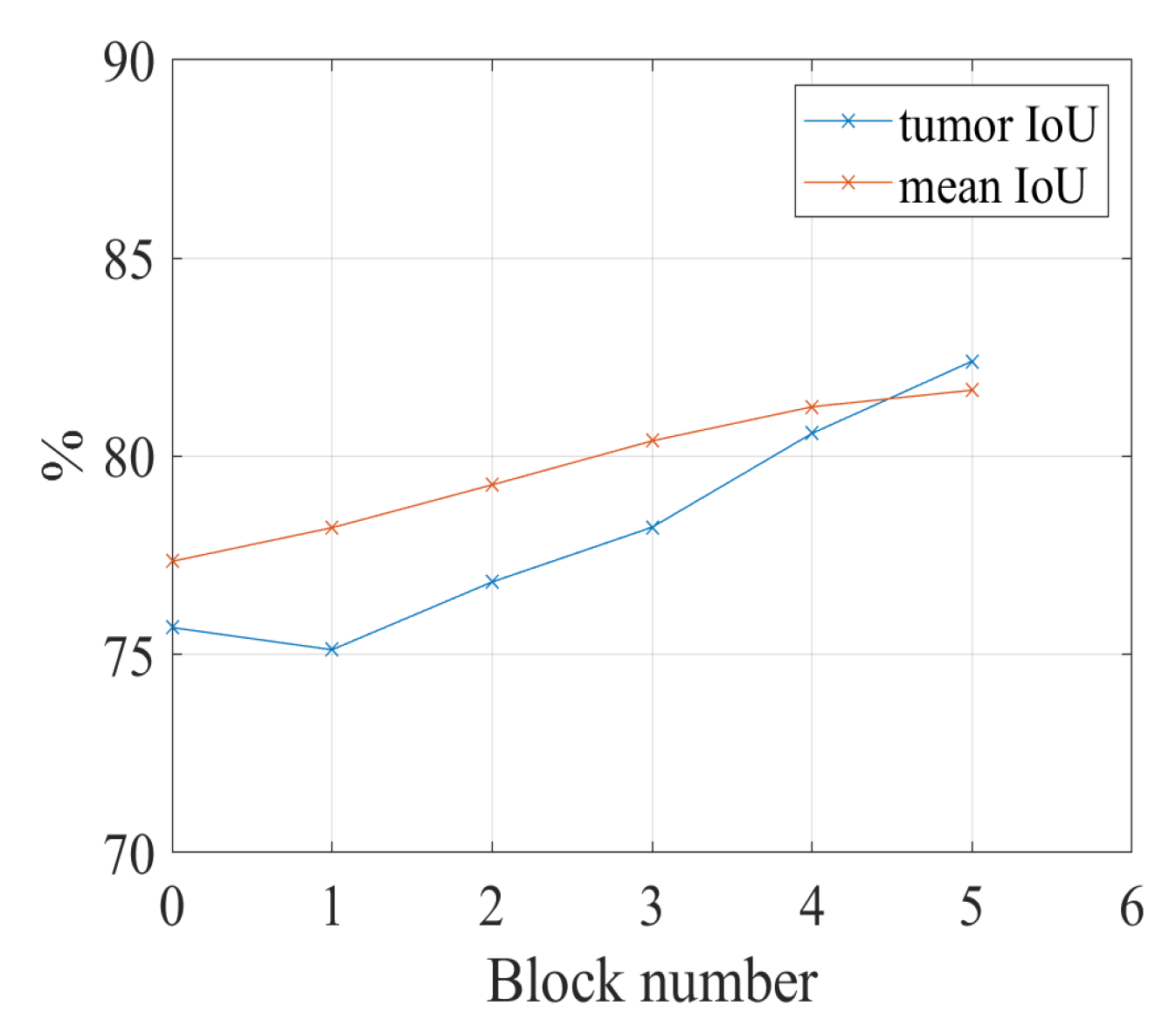
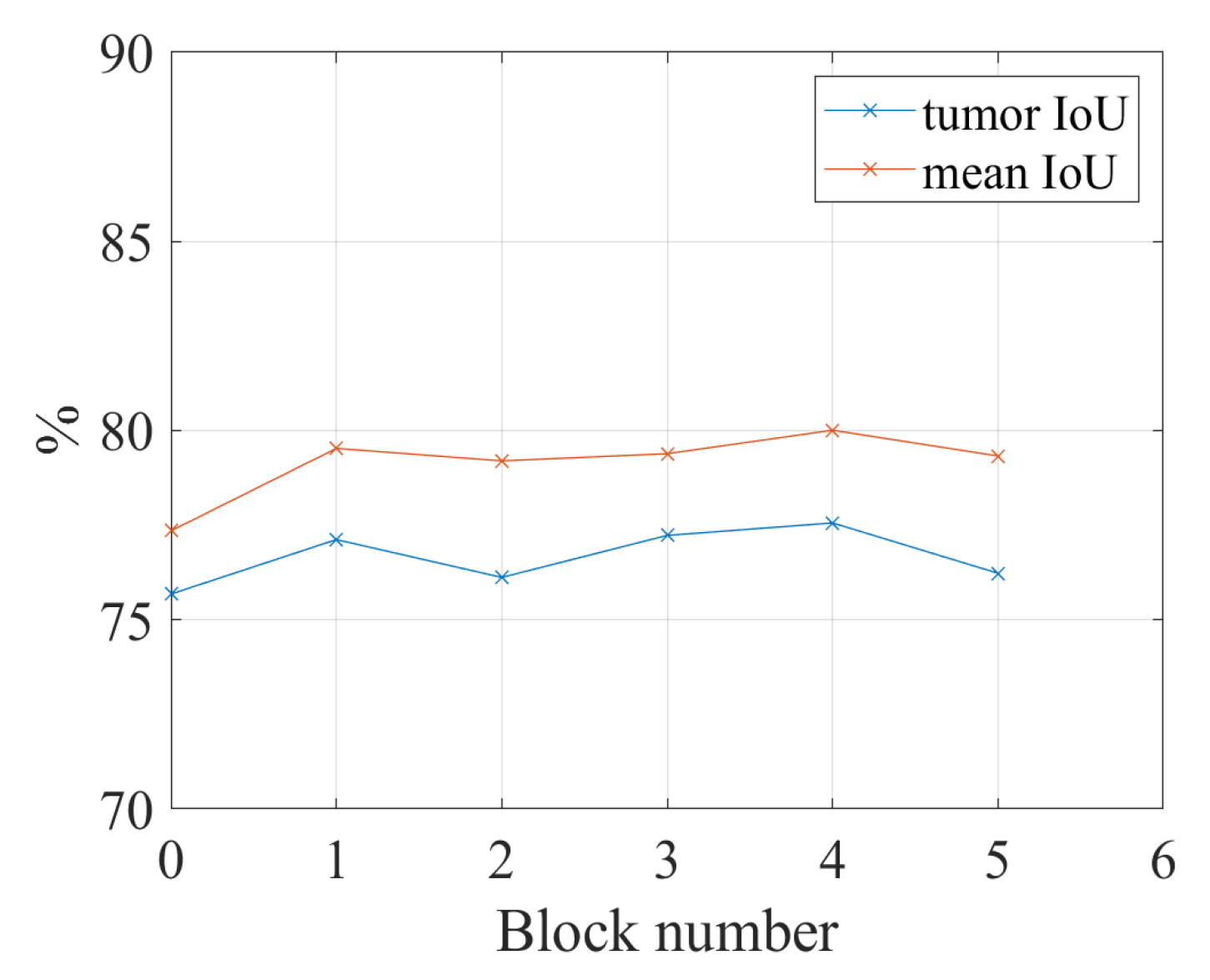
4.4.1. Segmentation Performance and the Number of Fuzzy Blocks
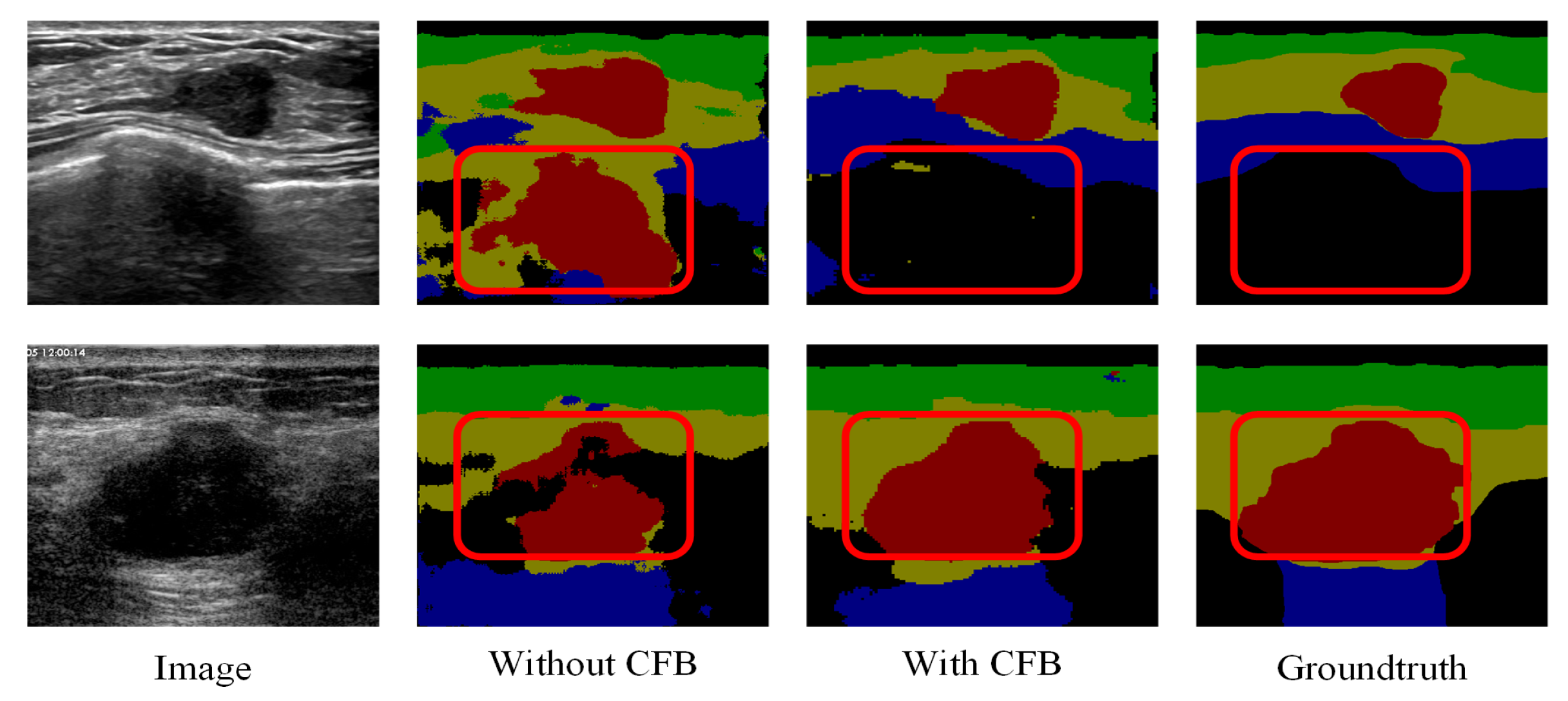
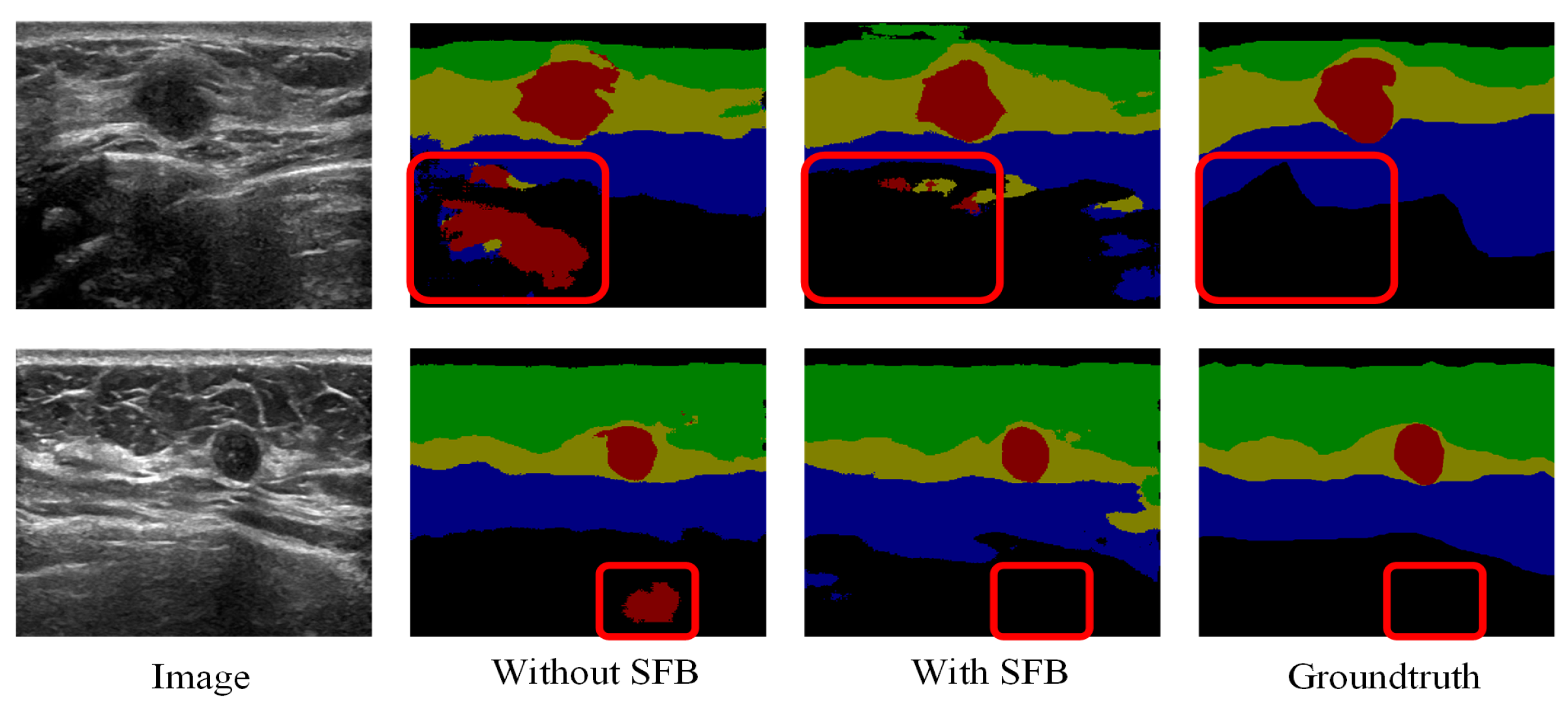
4.4.2. Ablation Study for Fuzzy Blocks
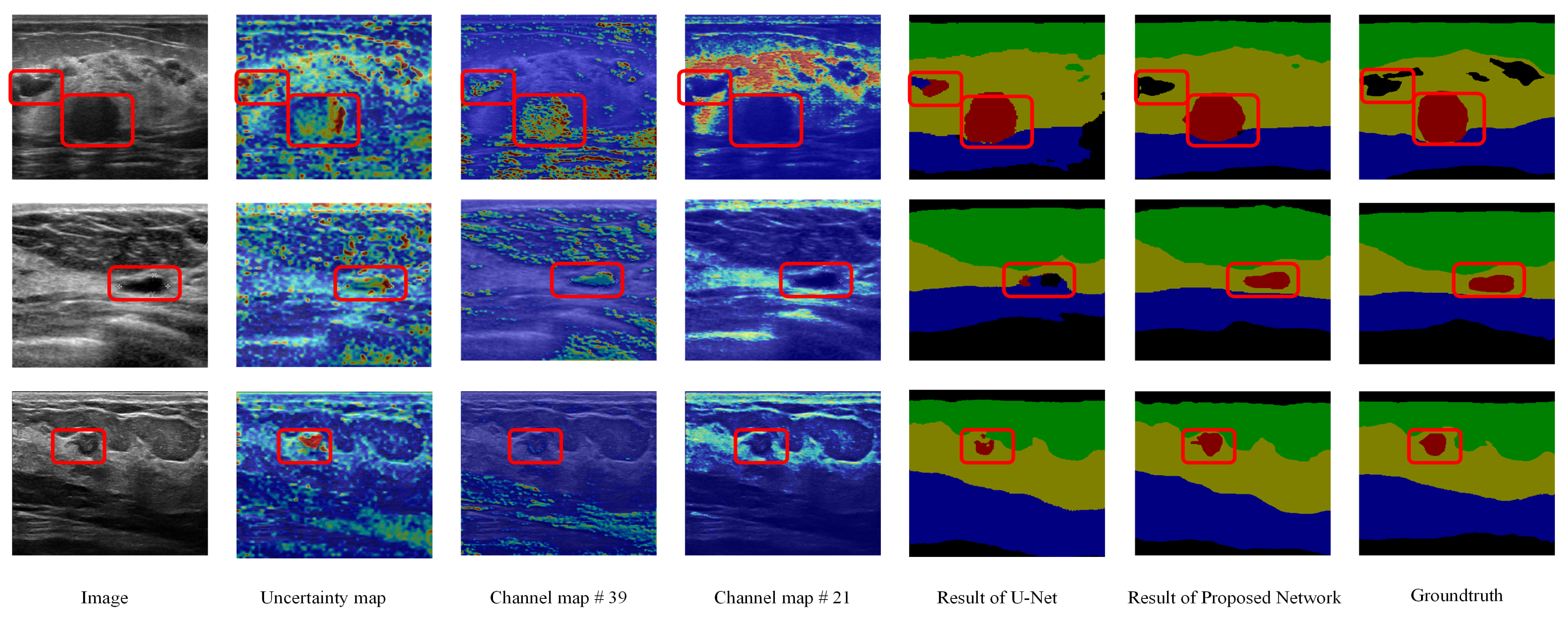
4.4.3. Visualization of Fuzzy Blocks
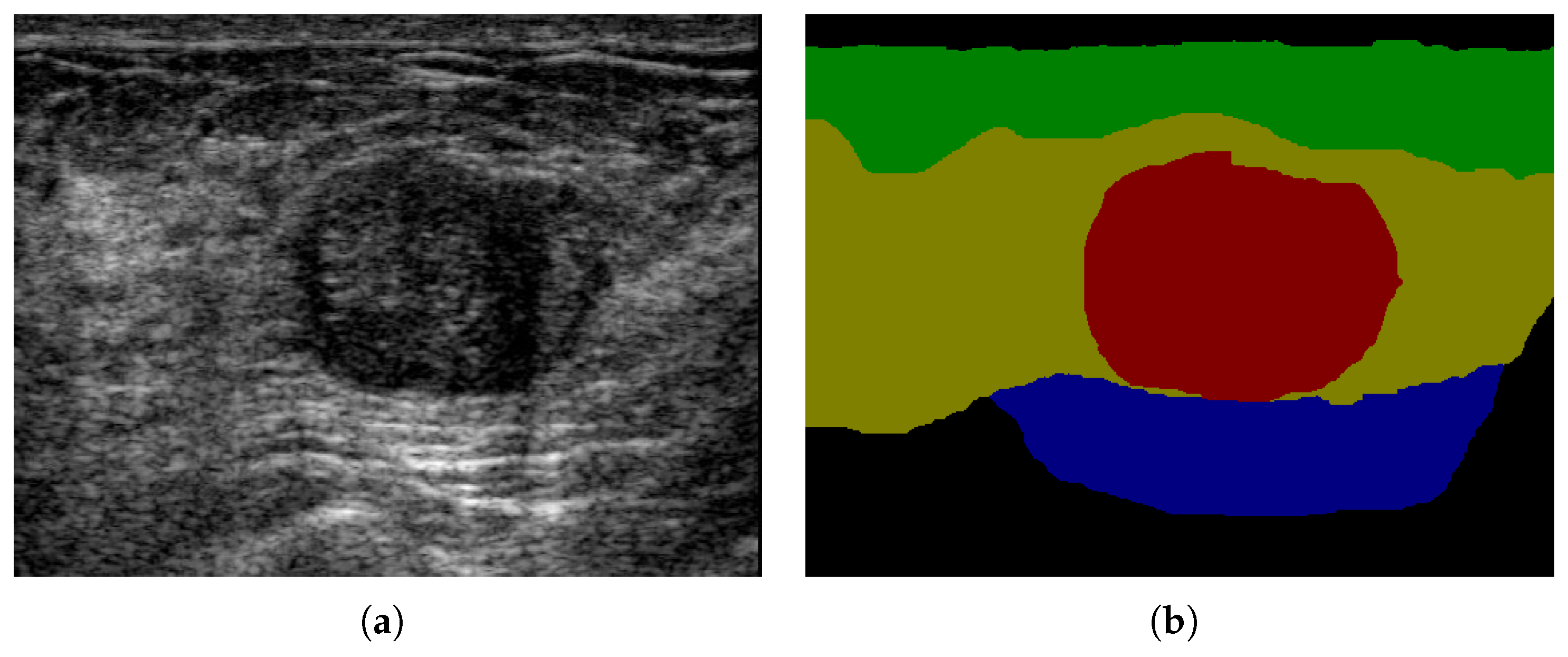
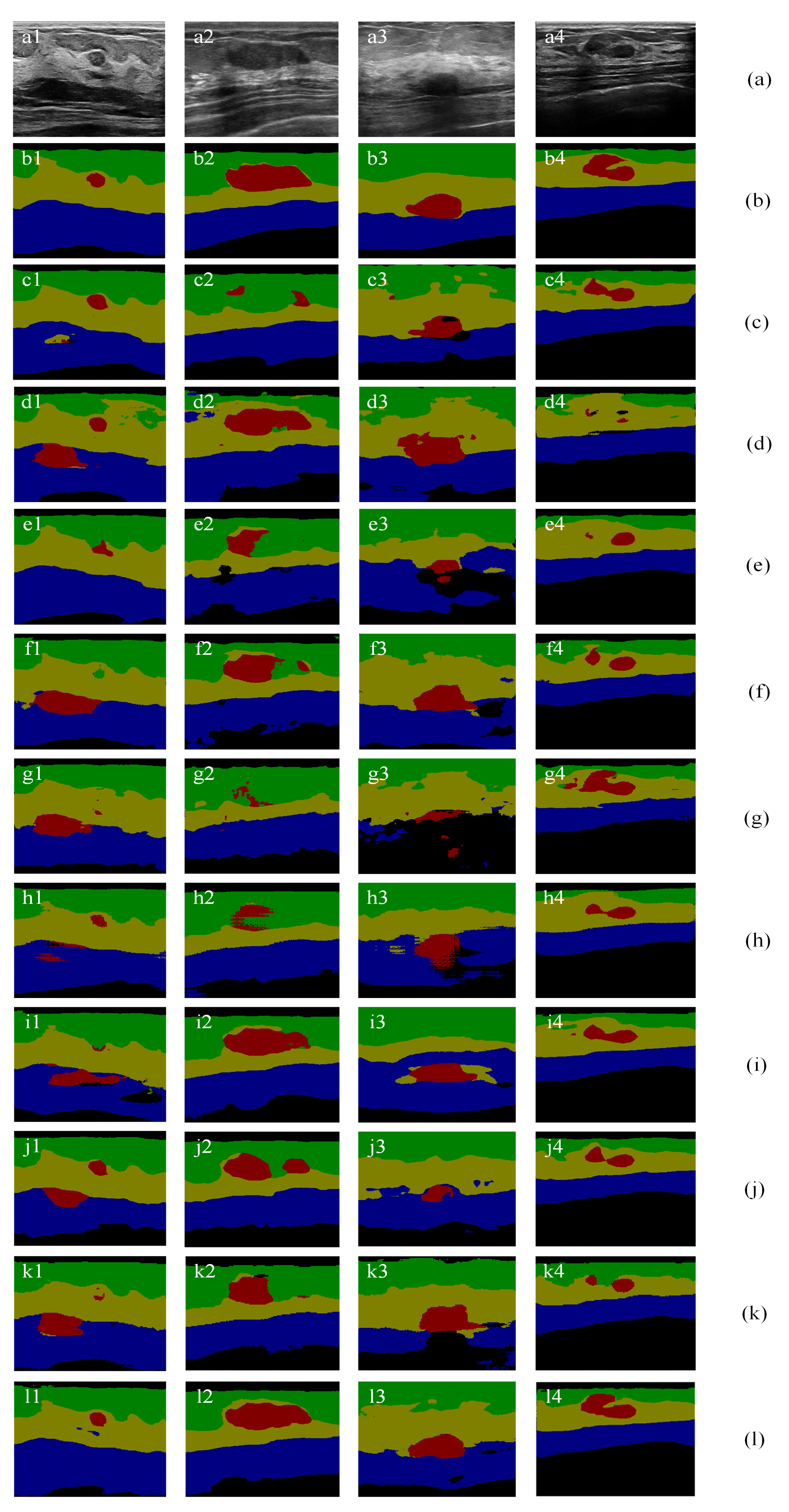
4.4.4. Semantic Segmentation Results
4.5. Semantic Segmentation on Three Public Two-Category Datasets
4.5.1. Overall Performance on Three Public Datasets
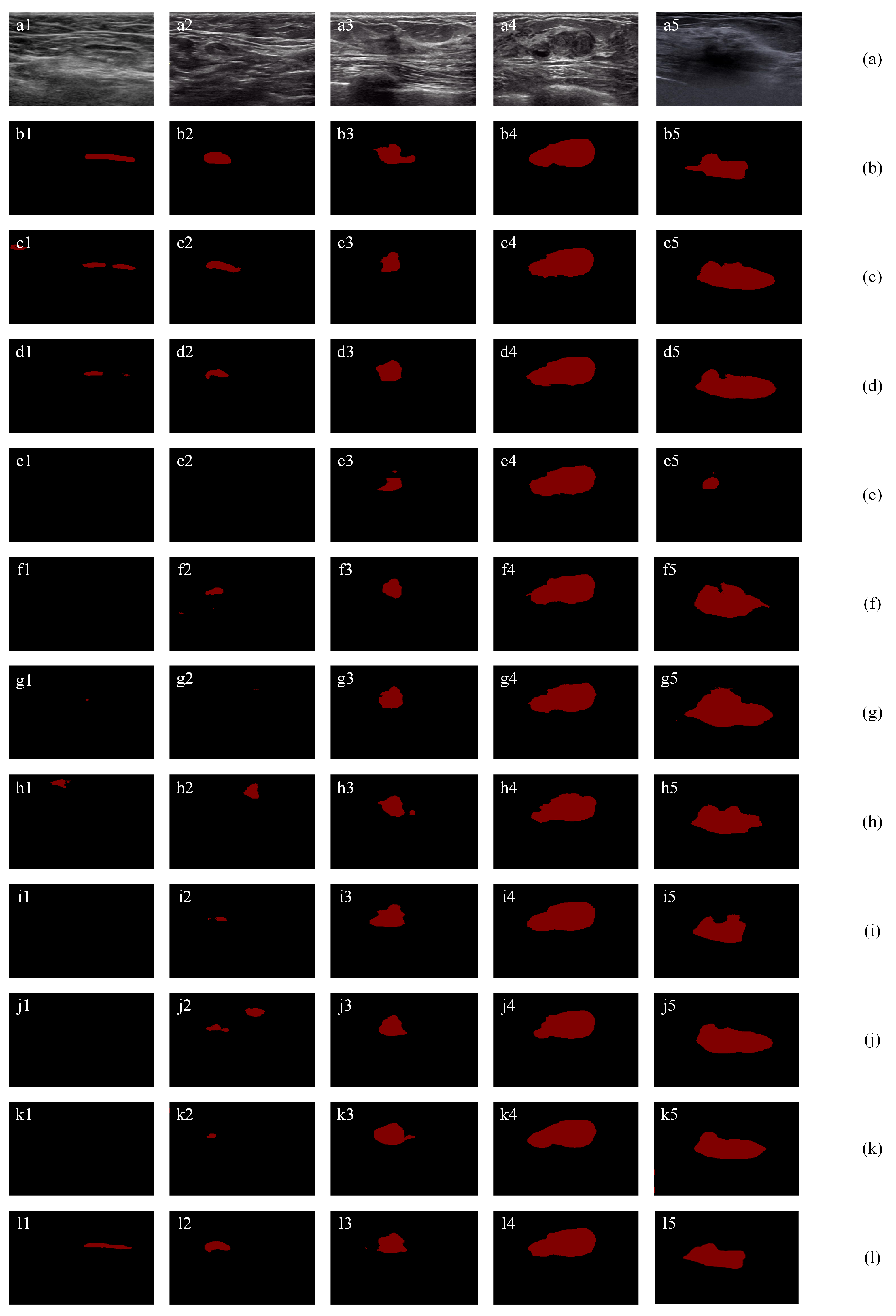
4.5.2. Small Tumor Segmentation
5. Discussion
5.1. Comparison with Previous Studies and Potential Usefulness
5.2. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shojaii, R.; Alirezaie, J.; Babyn, P. Automatic lung segmentation in CT images using watershed transform. In Proceedings of the IEEE International Conference on Image Processing 2005, Genoa, Italy, 11–14 September 2005; Volune 2, p. II–1270. [Google Scholar] [CrossRef]
- Gu, Z.; Cheng, J.; Fu, H.; Zhou, K.; Hao, H.; Zhao, Y.; Liu, J. CE-Net: Context encoder network for 2D medical image segmentation. IEEE Trans. Med. Imaging 2019, 38, 2281–2292. [Google Scholar] [CrossRef] [PubMed]
- Yu, Q.; Huang, K.; Zhu, Y.; Chen, X.; Meng, W. Preliminary results of computer-aided diagnosis for magnetic resonance imaging of solid breast lesions. Breast Cancer Res. Treat. 2019, 177, 419–426. [Google Scholar] [CrossRef] [PubMed]
- Gilles, B.; Magnenat-Thalmann, N. Musculoskeletal MRI segmentation using multi-resolution simplex meshes with medial representations. Med. Image Anal. 2010, 14, 291–302. [Google Scholar] [CrossRef]
- Saad, M.N.; Muda, Z.; Ashaari, N.S.; Hamid, H.A. Image segmentation for lung region in chest X-ray images using edge detection and morphology. In Proceedings of the 2014 IEEE International Conference on Control System, Computing and Engineering (ICCSCE 2014), Penang, Malaysia, 28–30 November 2014; pp. 46–51. [Google Scholar] [CrossRef]
- Son, L.H.; Tuan, T.M. A cooperative semi-supervised fuzzy clustering framework for dental X-ray image segmentation. Expert Syst. Appl. 2016, 46, 380–393. [Google Scholar] [CrossRef]
- Huang, Q.; Luo, Y.; Zhang, Q. Breast ultrasound image segmentation: A survey. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 493–507. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Yang, F.; Liu, L.; Li, X. Automatic segmentation of breast lesions for interaction in ultrasonic computer-aided diagnosis. Inf. Sci. 2015, 314, 293–310. [Google Scholar] [CrossRef]
- Moon, W.K.; Lo, C.M.; Chen, R.T.; Shen, Y.W.; Chang, J.M.; Huang, C.S.; Chen, J.H.; Hsu, W.-W.; Chang, R.F. Tumor detection in automated breast ultrasound images using quantitative tissue clustering. Med. Phys. 2014, 41, 042901. [Google Scholar] [CrossRef]
- Liu, B.; Cheng, H.D.; Huang, J.; Tian, J.; Tang, X.; Liu, J. Probability density difference-based active contour for ultrasound image segmentation. Pattern Recognit. 2010, 43, 2028–2042. [Google Scholar] [CrossRef]
- Xian, M.; Huang, J.; Zhang, Y.; Tang, X. Multiple-domain knowledge based MRF model for tumor segmentation in breast ultrasound images. In Proceedings of the 2012 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 2021–2024. [Google Scholar] [CrossRef]
- Cheng, H.D.; Shan, J.; Ju, W.; Guo, Y.; Zhang, L. Automated breast cancer detection and classification using ultrasound images: A survey. Pattern Recognit. 2010, 43, 299–317. [Google Scholar] [CrossRef]
- Xian, M.; Zhang, Y.; Cheng, H.D.; Xu, F.; Zhang, B.; Ding, J. Automatic breast ultrasound image segmentation: A survey. Pattern Recognit. 2018, 79, 340–355. [Google Scholar] [CrossRef]
- Bian, C.; Lee, R.; Chou, Y.H.; Cheng, J.Z. Boundary regularized convolutional neural network for layer parsing of breast anatomy in automated whole breast ultrasound. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Quebec City, QC, Canada, 10–14 September 2017; pp. 259–266. [Google Scholar] [CrossRef]
- Vourtsis, A.; Berg, W.A. Breast density implications and supplemental screening. Eur. Radiol. 2019, 29, 1762–1777. [Google Scholar] [CrossRef] [PubMed]
- Huang, K.; Cheng, H.D.; Zhang, Y.; Zhang, B.; Xing, P.; Ning, C. Medical Knowledge Constrained Semantic Breast Ultrasound Image Segmentation. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1193–1198. [Google Scholar] [CrossRef]
- Lei, B.; Huang, S.; Li, R.; Bian, C.; Li, H.; Chou, Y.H.; Cheng, J.Z. Segmentation of breast anatomy for automated whole breast ultrasound images with boundary regularized convolutional encoder–decoder network. Neurocomputing 2018, 321, 178–186. [Google Scholar] [CrossRef]
- Lei, B.; Huang, S.; Li, H.; Li, R.; Bian, C.; Chou, Y.H.; Qin, J.; Zhou, P.; Gong, X.; Cheng, J.Z. Self-co-attention neural network for anatomy segmentation in whole breast ultrasound. Med. Image Anal. 2020, 64, 101753. [Google Scholar] [CrossRef] [PubMed]
- Shen, X.; Wang, L.; Zhao, Y.; Liu, R.; Qian, W.; Ma, H. Dilated transformer: Residual axial attention for breast ultrasound image segmentation. Quant. Imaging Med. Surg. 2022, 12, 4512–4528. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Vakanski, A.; Xian, M.; Ding, J.; Ning, C. EMT-NET: Efficient multitask network for computer-aided diagnosis of breast cancer. In Proceedings of the 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI), Kolkata, India, 28–31 March 2022; pp. 1–5. [Google Scholar]
- Wang, K.; Liang, S.; Zhong, S.; Feng, Q.; Ning, Z.; Zhang, Y. Breast ultrasound image segmentation: A coarse-to-fine fusion convolutional neural network. Med. Phys. 2021, 48, 4262–4278. [Google Scholar] [CrossRef] [PubMed]
- Tang, F.; Wang, L.; Ning, C.; Xian, M.; Ding, J. CMU-Net: A Strong ConvMixer-based Medical Ultrasound Image Segmentation Network. arXiv 2022, arXiv:2210.13012. [Google Scholar]
- Baumgartner, C.F.; Tezcan, K.C.; Chaitanya, K.; Hötker, A.M.; Muehlematter, U.J.; Schawkat, K.; Becker, A.S.; Donati, O.; Konukoglu, E. PHiSeg: Capturing Uncertainty in Medical Image Segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019, Shenzhen, China, 13–17 October 2019; pp. 119–127. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T. Aleatoric uncertainty estimation with test-time augmentation for medical image segmentation with convolutional neural networks. Neurocomputing 2019, 338, 34–45. [Google Scholar] [CrossRef]
- Gao, C.; Ye, H.; Cao, F.; Wen, C.; Zhang, Q.; Zhang, F. Multiscale fused network with additive channel–spatial attention for image segmentation. Knowl.-Based Syst. 2021, 214, 106754. [Google Scholar] [CrossRef]
- Punn, N.S.; Agarwal, S. RCA-IUnet: A residual cross-spatial attention-guided inception U-Net model for tumor segmentation in breast ultrasound imaging. Mach. Vis. Appl. 2022, 33, 27. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Chen, N.; Chen, S.; Liu, J. Novel fuzzy clustering algorithm with variable multi-pixel fitting spatial information for image segmentation. Pattern Recognit. 2022, 121, 108201. [Google Scholar] [CrossRef]
- Alomoush, W.; Khashan, O.A.; Alrosan, A.; Houssein, E.H.; Attar, H.; Alweshah, M.; Alhosban, F. Fuzzy Clustering Algorithm Based on Improved Global Best-Guided Artificial Bee Colony with New Search Probability Model for Image Segmentation. Sensors 2022, 22, 8956. [Google Scholar] [CrossRef] [PubMed]
- Kittaneh, O.A.; Khan, M.A.U.; Akbar, M.; Bayoud, H.A. Average Entropy: A New Uncertainty Measure with Application to Image Segmentation. Am. Stat. 2016, 70, 18–24. [Google Scholar] [CrossRef]
- Maassen, H.; Uffink, J.B. Generalized entropic uncertainty relations. Phys. Rev. Lett. 1988, 60, 1103. [Google Scholar] [CrossRef]
- Wehner, S.; Winter, A. Entropic uncertainty relations—A survey. New J. Phys. 2010, 12, 025009. [Google Scholar] [CrossRef]
- Karthik, R.; Menaka, R.; Kathiresan, G.; Anirudh, M.; Nagharjun, M. Gaussian Dropout Based Stacked Ensemble CNN for Classification of Breast Tumor in Ultrasound Images. IRBM 2021, 43, 715–733. [Google Scholar] [CrossRef]
- Khanna, P.; Sahu, M.; Singh, B.K. Improving the classification performance of breast ultrasound image using deep learning and optimization algorithm. In Proceedings of the 2021 IEEE International Conference on Technology, Research, and Innovation for Betterment of Society (TRIBES), Raipur, India, 17–19 December 2021; pp. 1–6. [Google Scholar]
- Samundeeswari, E.S.; Saranya, P.K.; Manavalan, R. Segmentation of Breast Ultrasound image using Regularized K-Means (ReKM) clustering. In Proceedings of the 2016 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 23–25 March 2016; pp. 1379–1383. [Google Scholar] [CrossRef]
- Yap, M.H.; Pons, G.; Marti, J.; Ganau, S.; Sentis, M.; Zwiggelaar, R.; Davison, A.K.; Marti, R.; Yap, M.H.; Pons, G.; et al. Automated Breast Ultrasound Lesions Detection Using Convolutional Neural Networks. IEEE J. Biomed. Health Inform. 2018, 22, 1218–1226. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; NeurIPS: Long Beach, CA, USA, 2017; pp. 1097–1105. [Google Scholar]
- Cheng, J.Z.; Ni, D.; Chou, Y.H.; Qin, J.; Tiu, C.M.; Chang, Y.C.; Huang, C.S.; Shen, D.; Chen, C.M. Computer-aided diagnosis with deep learning architecture: Applications to breast lesions in US images and pulmonary nodules in CT scans. Sci. Rep. 2016, 6, 1–13. [Google Scholar] [CrossRef]
- Shareef, B.; Xian, M.; Vakanski, A. Stan: Small tumor-aware network for breast ultrasound image segmentation. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Bach, F., Blei, D., Eds.; PMLR: Lille, France, 2015; Volume 37, pp. 2048–2057. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Rueckert, D. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Gao, J.; Wang, Q.; Yuan, Y. SCAR: Spatial-/channel-wise attention regression networks for crowd counting. Neurocomputing 2019, 363, 1–8. [Google Scholar] [CrossRef]
- Chuang, K.S.; Tzeng, H.L.; Chen, S.; Wu, J.; Chen, T.J. Fuzzy c-means clustering with spatial information for image segmentation. Comput. Med. Imaging Graph. 2006, 30, 9–15. [Google Scholar] [CrossRef]
- Cheng, H.D.; Xu, H. A novel fuzzy logic approach to contrast enhancement. Pattern Recognit. 2000, 33, 809–819. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Han, B.; Zhang, Y.; Zhang, X.; Su, Y. Fully automatic Breast ultrasound image segmentation based on fuzzy cellular automata framework. Biomed. Signal Process. Control 2018, 40, 433–442. [Google Scholar] [CrossRef]
- Deng, Y.; Ren, Z.; Kong, Y.; Bao, F.; Dai, Q. A Hierarchical Fused Fuzzy Deep Neural Network for Data Classification. IEEE Trans. Fuzzy Syst. 2017, 25, 1006–1012. [Google Scholar] [CrossRef]
- Huang, K.; Zhang, Y.; Cheng, H.; Xing, P.; Zhang, B. Semantic segmentation of breast ultrasound image with fuzzy deep learning network and breast anatomy constraints. Neurocomputing 2021, 450, 319–335. [Google Scholar] [CrossRef]
- Al-Sharhan, S.; Karray, F.; Gueaieb, W.; Basir, O. Fuzzy entropy: A brief survey. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems (Cat. No. 01CH37297), Melbourne, Australia, 2–5 December 2001; Volume 3, pp. 1135–1139. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar] [CrossRef]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Lille, France, 2019; Volume 97, pp. 7354–7363. [Google Scholar]
- Zhang, Y.; Xian, M.; Cheng, H.D.; Shareef, B.; Ding, J.; Xu, F.; Huang, K.; Zhang, B.; Ning, C.; Wang, Y. BUSIS: A Benchmark for Breast Ultrasound Image Segmentation. Healthcare 2022, 10, 729. [Google Scholar] [CrossRef]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Fahmy, A. Dataset of breast ultrasound images. Data Brief 2020, 28, 104863. [Google Scholar] [CrossRef]
- Xian, M.; Zhang, Y.; Cheng, H.D. Fully automatic segmentation of breast ultrasound images based on breast characteristics in space and frequency domains. Pattern Recognit. 2015, 48, 485–497. [Google Scholar] [CrossRef]
- Shan, J.; Cheng, H.D.; Wang, Y. Completely automated segmentation approach for breast ultrasound images using multiple-domain features. Ultrasound Med. Biol. 2012, 38, 262–275. [Google Scholar] [CrossRef] [PubMed]
- Shao, H.; Zhang, Y.; Xian, M.; Cheng, H.D.; Xu, F.; Ding, J. A saliency model for automated tumor detection in breast ultrasound images. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 1424–1428. [Google Scholar] [CrossRef]
- Liu, Y.; Cheng, H.D.; Huang, J.; Zhang, Y.; Tang, X. An effective approach of lesion segmentation within the breast ultrasound image based on the cellular automata principle. J. Digit. Imaging 2012, 25, 580–590. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Müller, K.R. Efficient backprop. In Neural Networks: Tricks of the Trade; Springer: New York, NY, USA, 2012; pp. 9–48. [Google Scholar] [CrossRef]
- Gamper, J.; Koohbanani, N.A.; Benet, K.; Khuram, A.; Rajpoot, N. PanNuke: An open pan-cancer histology dataset for nuclei instance segmentation and classification. In Proceedings of the European Congress on Digital Pathology, Warwick, UK, 10–13 April 2019; Springer: New York, NY, USA, 2019; pp. 11–19. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Number | Ground Truths | |
|---|---|---|
| Dataset 1 [35] | 163 | Tumor/Background |
| Dataset 2 [60] | 780 | Tumor/Background |
| Dataset 3 [59] | 562 | Tumor/Background |
| Multi-layer Dataset | 325 | Fat/Mammary/Muscle/Tumor/Background |
| Encoder | SFB | CFB | Tumor IoU | Mean IoU |
|---|---|---|---|---|
| VGG-16 | 74.66% | 75.13% | ||
| VGG-16 | ✓ | 76.60% | 77.54% | |
| VGG-16 | ✓ | 75.63% | 78.81% | |
| VGG-16 | ✓ | ✓ | 78.34% | 79.36% |
| ResNet-101 | 75.68% | 77.35% | ||
| ResNet-101 | ✓ | 79.12% | 78.67% | |
| ResNet-101 | ✓ | 80.43% | 80.12% | |
| ResNet-101 | ✓ | ✓ | 82.40% | 81.67% |
| Fat | Mammary | Muscle | Background | Tumor | Mean | |
|---|---|---|---|---|---|---|
| ResNet-50 | 82.58 | 73.98 | 73.08 | 77.23 | 76.34 | 76.64 |
| ResNet-101 | 82.50 | 74.41 | 75.69 | 77.47 | 75.68 | 77.35 |
| FCN-8s | 82.57 | 75.47 | 75.53 | 78.59 | 74.42 | 77.32 |
| PSPNet | 82.07 | 74.40 | 74.49 | 77.36 | 74.75 | 76.61 |
| Deeplab | 78.91 | 68.71 | 67.33 | 73.94 | 69.04 | 71.58 |
| Attention U-Net | 83.99 | 77.61 | 75.69 | 77.99 | 76.26 | 78.31 |
| SE-Net | 80.91 | 75.21 | 71.23 | 76.57 | 75.90 | 75.96 |
| Self-attention | 82.53 | 76.23 | 75.91 | 80.29 | 78.81 | 78.75 |
| [16] | 84.05 | 75.92 | 74.89 | 78.35 | 74.88 | 77.62 |
| Proposed | 84.72 | 79.84 | 77.39 | 83.98 | 82.40 | 81.67 |
| TPR | FPR | JI | DSC | AER | |
|---|---|---|---|---|---|
| Semi-Automatic Methods | |||||
| [10] | 0.82 | 0.13 | 0.73 | 0.84 | 0.31 |
| [64] | 0.84 | 0.07 | 0.79 | 0.88 | 0.23 |
| Fully-Automatic Methods | |||||
| [61] | 0.81 | 0.16 | 0.72 | 0.83 | 0.36 |
| [62] | 0.81 | 1.06 | 0.60 | 0.70 | 1.25 |
| [63] | 0.67 | 0.18 | 0.61 | 0.71 | 0.51 |
| Deeplab | 0.89 | 0.11 | 0.82 | 0.89 | 0.22 |
| ResNet50 | 0.92 | 0.08 | 0.86 | 0.92 | 0.16 |
| ResNet101 | 0.92 | 0.10 | 0.85 | 0.91 | 0.18 |
| FCN8s | 0.94 | 0.10 | 0.86 | 0.92 | 0.16 |
| PSPNet | 0.93 | 0.09 | 0.86 | 0.92 | 0.16 |
| Attention U-Net | 0.92 | 0.09 | 0.85 | 0.91 | 0.17 |
| SE-Net | 0.92 | 0.10 | 0.85 | 0.91 | 0.18 |
| Self-attention | 0.91 | 0.07 | 0.86 | 0.92 | 0.15 |
| [16] | 0.92 | 0.09 | 0.86 | 0.92 | 0.16 |
| Proposed | 0.94 | 0.06 | 0.88 | 0.93 | 0.14 |
| TPR | FPR | JI | DSC | AER | ||
|---|---|---|---|---|---|---|
| Dataset [35] | Deeplab | 63.68% | 36.06% | 52.93% | 61.91% | 72.38% |
| ResNet50 | 81.29% | 36.58% | 68.70% | 76.94% | 55.29% | |
| ResNet101 | 83.58% | 34.40% | 71.43% | 79.45% | 50.82% | |
| FCN8s | 82.72% | 41.14% | 67.50% | 76.87% | 58.42% | |
| PSPNet | 81.08% | 40.42% | 69.77% | 78.24% | 59.34% | |
| Attention-UNet | 83.58% | 34.40% | 71.43% | 79.45% | 50.82% | |
| Self-attention | 82.58% | 26.39% | 73.83% | 81.37% | 33.81% | |
| SE-Net | 79.23% | 36.75% | 70.90% | 79.10% | 35.12% | |
| [16] | 81.19% | 31.63% | 71.48% | 80.21% | 48.44% | |
| Proposed | 84.70% | 44.69% | 73.27% | 81.08% | 59.99% | |
| Dataset [60] | Deeplab | 59.88% | 39.39% | 49.65% | 59.39% | 79.52% |
| ResNet50 | 78.45% | 49.39% | 67.09% | 76.36% | 68.94% | |
| ResNet101 | 79.40% | 46.02% | 69.26% | 77.90% | 66.62% | |
| FCN8s | 74.23% | 46.69% | 63.16% | 73.03% | 72.63% | |
| PSPNet | 77.11% | 46.65% | 65.21% | 74.75% | 69.54% | |
| Attention-UNet | 77.52% | 38.67% | 67.81% | 76.77% | 60.92% | |
| Self-attention | 79.02% | 29.30% | 71.49% | 78.46% | 55.50% | |
| SE-Net | 78.40% | 38.95% | 68.30% | 77.24% | 60.55% | |
| [16] | 78.07% | 42.37% | 68.43% | 76.96% | 64.30% | |
| Proposed | 79.86% | 22.01% | 72.14% | 80.51% | 42.15% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, K.; Zhang, Y.; Cheng, H.-D.; Xing, P. Trustworthy Breast Ultrasound Image Semantic Segmentation Based on Fuzzy Uncertainty Reduction. Healthcare 2022, 10, 2480. https://doi.org/10.3390/healthcare10122480
Huang K, Zhang Y, Cheng H-D, Xing P. Trustworthy Breast Ultrasound Image Semantic Segmentation Based on Fuzzy Uncertainty Reduction. Healthcare. 2022; 10(12):2480. https://doi.org/10.3390/healthcare10122480
Chicago/Turabian StyleHuang, Kuan, Yingtao Zhang, Heng-Da Cheng, and Ping Xing. 2022. "Trustworthy Breast Ultrasound Image Semantic Segmentation Based on Fuzzy Uncertainty Reduction" Healthcare 10, no. 12: 2480. https://doi.org/10.3390/healthcare10122480
APA StyleHuang, K., Zhang, Y., Cheng, H.-D., & Xing, P. (2022). Trustworthy Breast Ultrasound Image Semantic Segmentation Based on Fuzzy Uncertainty Reduction. Healthcare, 10(12), 2480. https://doi.org/10.3390/healthcare10122480