
Longitudinal Data to Enhance Dynamic Stroke Risk Prediction



Abstract
1. Introduction
2. Materials and Methods
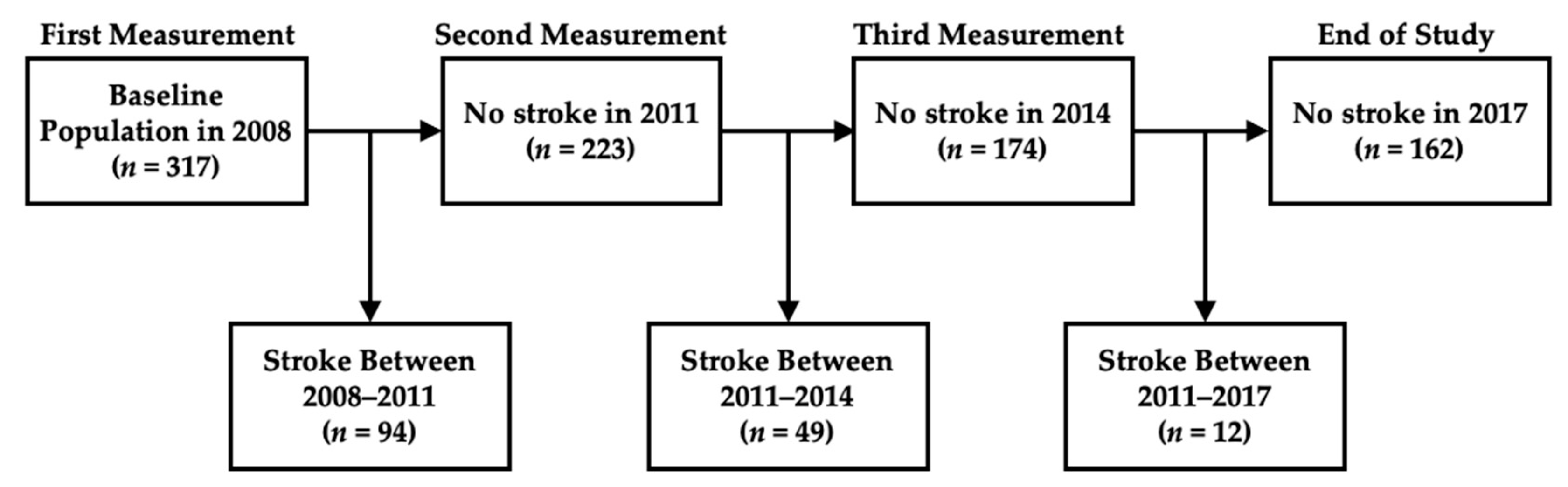
2.1. Dataset
2.2. Model Implementation
3. Results
3.1. Baseline Characteristics
3.2. Longitudinal Biomarker Equations and Relationships with Other Risk Factors
3.3. Model Performance
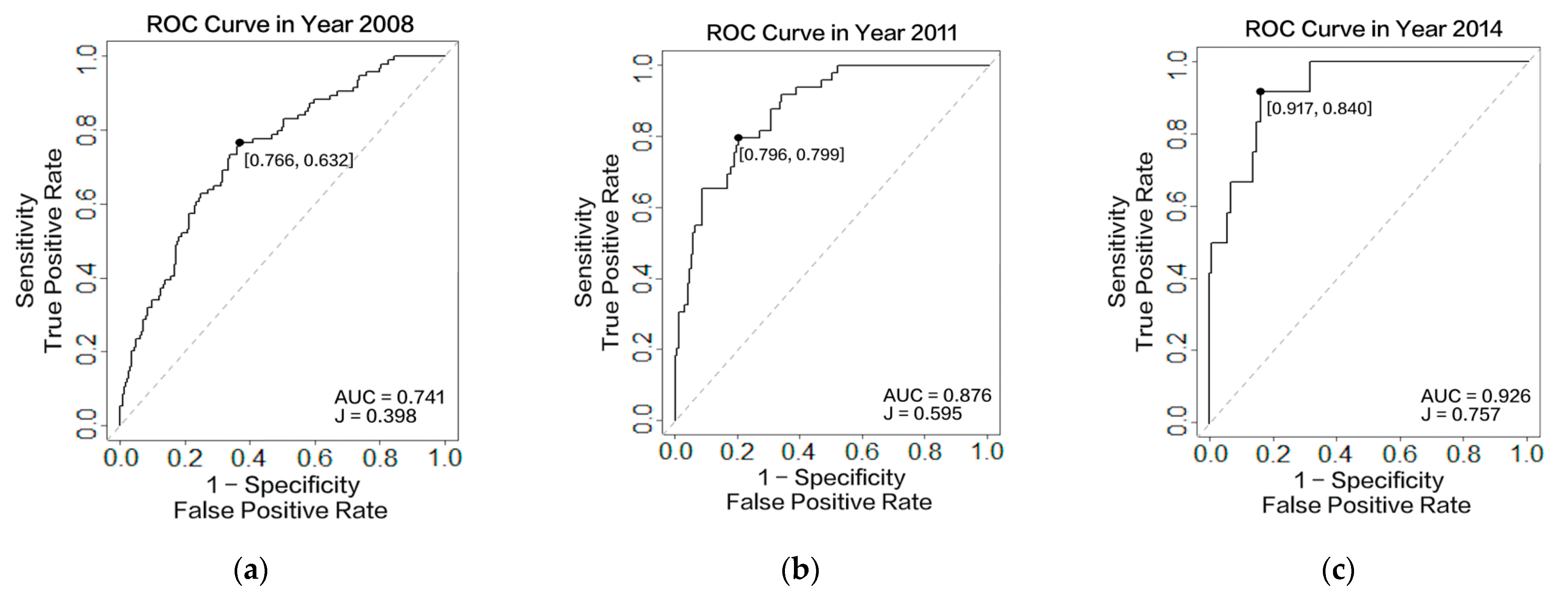
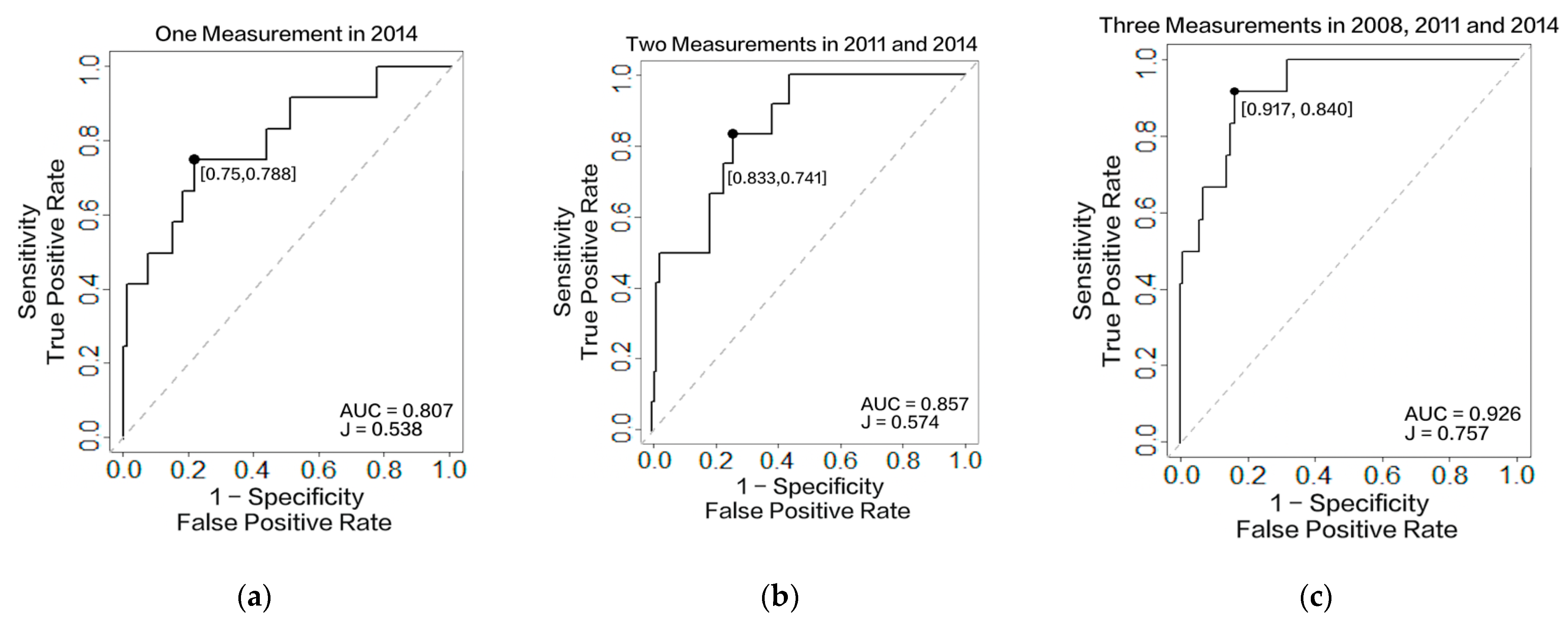
3.3.1. Accuracy Assessment
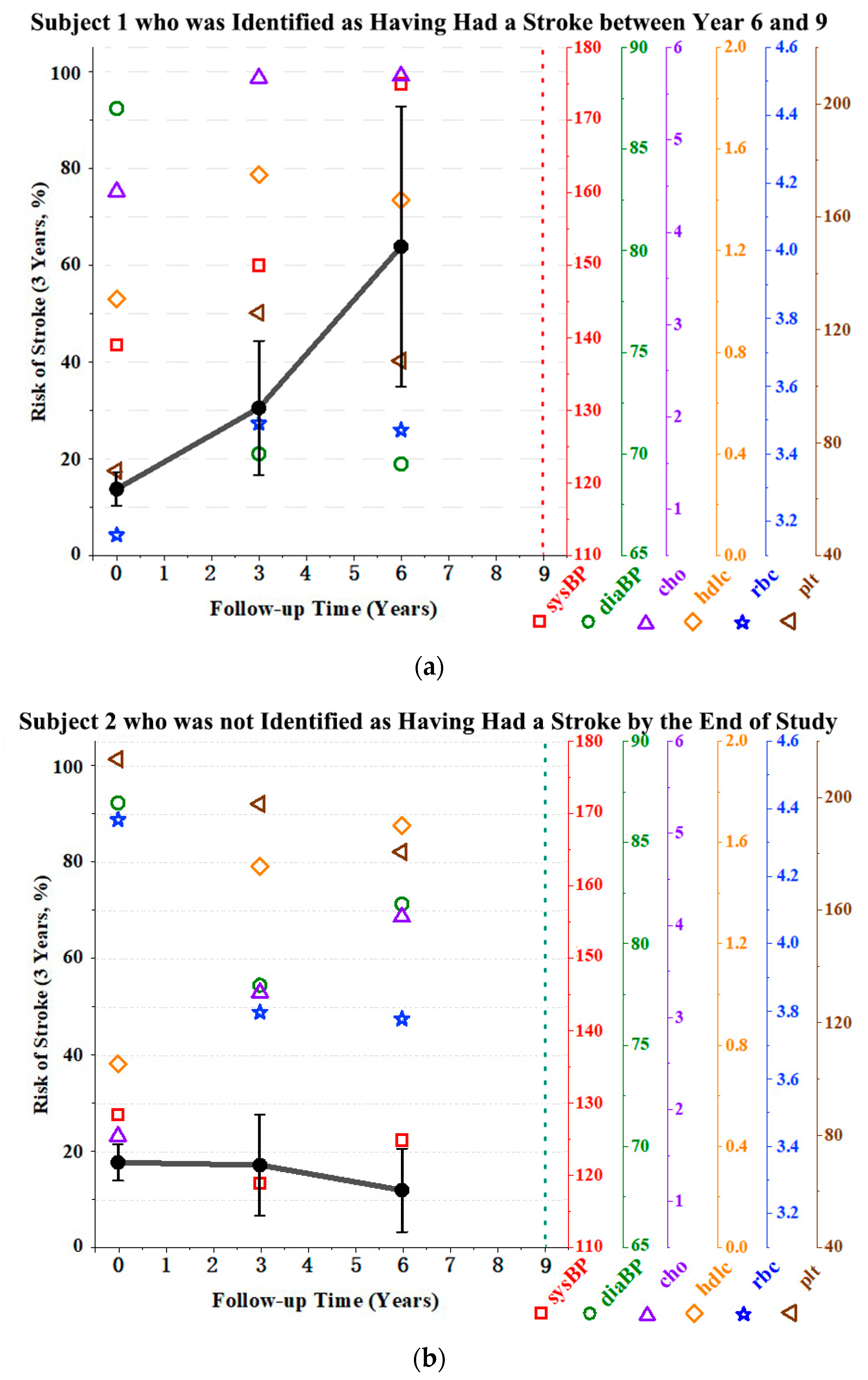
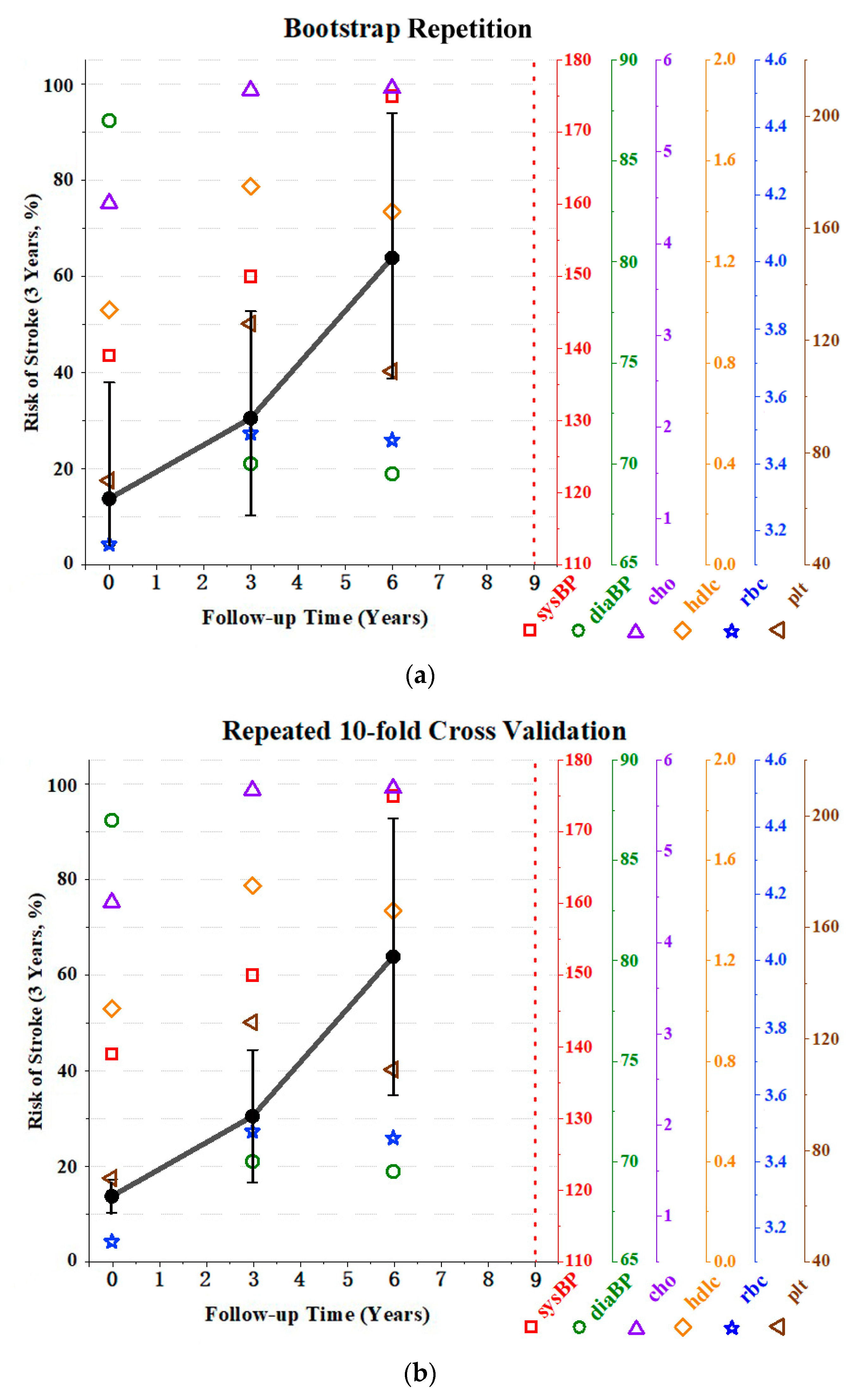
3.3.2. Dynamic Stroke Risk Prediction
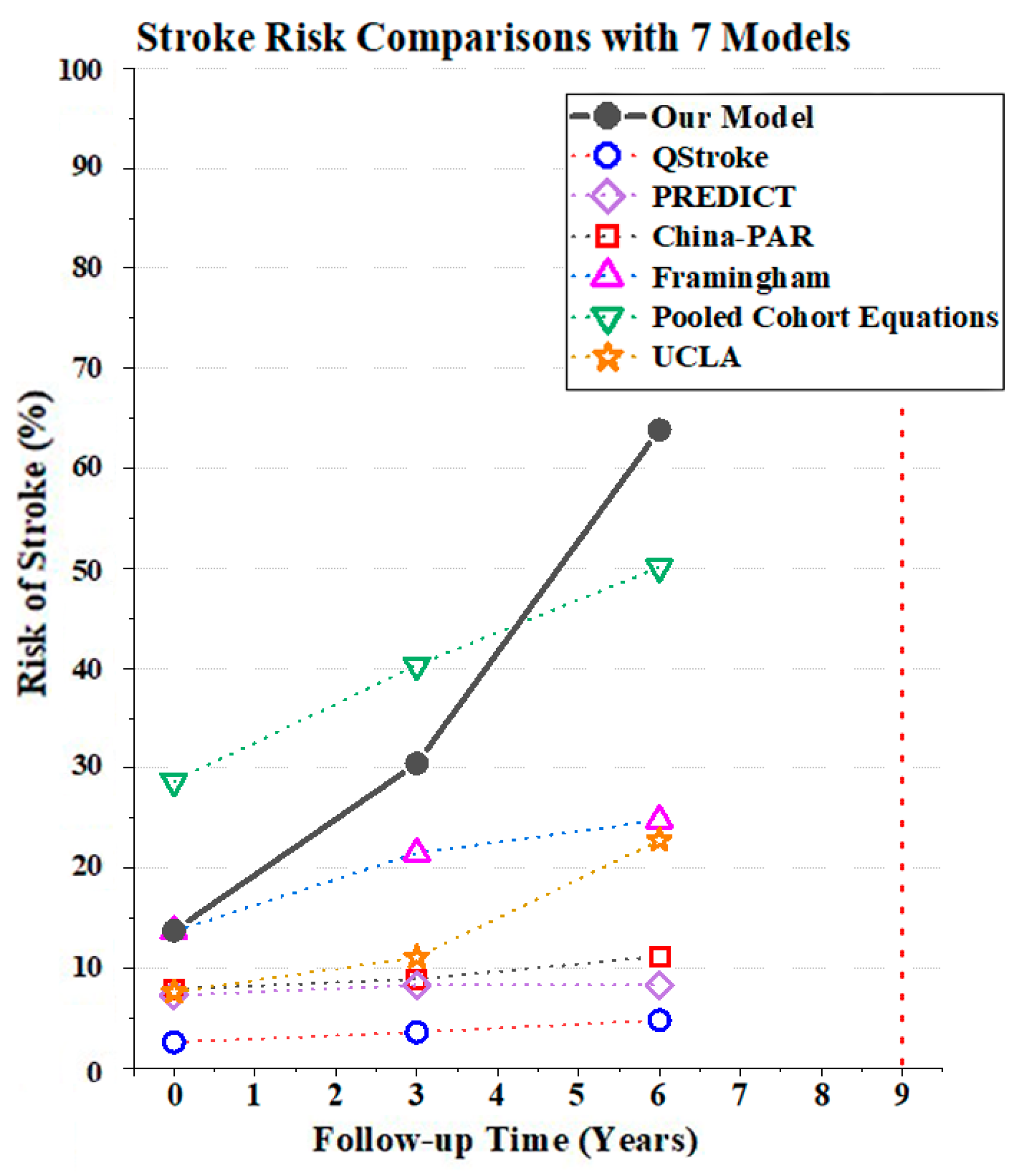
3.3.3. Model Comparisons
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, M.; Wang, H.; Zeng, X.; Yin, P.; Zhu, J.; Chen, W.; Li, X.; Wang, L.; Wang, L.; Liu, Y.; et al. Mortality, morbidity, and risk factors in China and its provinces, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet 2019, 394, 1145–1158. [Google Scholar] [CrossRef]
- Report on Stroke Prevention and Treatment in China Writing Group (2020). Brief report on stroke prevention and treatment in China, 2020. China J. Cerebrovasc. Dis. 2022, 19, 136–144. [Google Scholar]
- Pandian, J.D.; Gall, S.L.; Kate, M.P.; Silva, G.S.; Akinyemi, R.O.; Ovbiagele, B.I.; Lavados, P.M.; Gandhi, D.B.; Thrift, A.G. Prevention of stroke: A global perspective. Lancet 2018, 392, 1269–1278. [Google Scholar] [CrossRef]
- Hankey, G. Preventable stroke and stroke prevention. J. Thromb. Haemost. 2005, 3, 1638–1645. [Google Scholar] [CrossRef]
- Hippisley-Cox, J.; Coupland, C.; Brindle, P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: Prospective cohort study. BMJ 2017, 357, j2099. [Google Scholar] [CrossRef]
- Fauchier, L.; Bodin, A.; Bisson, A.; Herbert, J.; Spiesser, P.; Clementy, N.; Babuty, D.; Chao, T.-F.; Lip, G.Y.H. Incident Comorbidities, Aging and the Risk of Stroke in 608,108 Patients with Atrial Fibrillation: A Nationwide Analysis. J. Clin. Med. 2020, 9, 1234. [Google Scholar] [CrossRef] [PubMed]
- Fitzmaurice, G.M.; Laird, N.M.; Ware, J.H. Applied Longitudinal Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Poudel, G.R.; Stout, J.C.; Domínguez D, J.F.; Gray, M.A.; Salmon, L.; Churchyard, A.; Chua, P.; Borowsky, B.; Egan, G.F.; Georgiou-Karistianis, N. Functional changes during working memory in Huntington’s disease: 30-month longitudinal data from the IMAGE-HD study. Brain Struct. Funct. 2015, 220, 501–512. [Google Scholar] [CrossRef]
- Shen, F.; Li, L. Backward joint model and dynamic prediction of survival with multivariate longitudinal data. Stat. Med. 2021, 40, 4395–4409. [Google Scholar] [CrossRef]
- Zhao, J.; Feng, Q.; Wu, P.; Lupu, R.A.; Wilke, R.A.; Wells, Q.S.; Denny, J.C.; Wei, W.-Q. Learning from longitudinal data in electronic health record and genetic data to improve cardiovascular event prediction. Sci. Rep. 2019, 9, 717. [Google Scholar] [CrossRef]
- Center for Healthy Aging and Development Studies. The Chinese Longitudinal Healthy Longevity Survey (CLHLS)-Longitudinal Data (1998–2018). 2020. Available online: https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi:10.18170/DVN/WBO7LK (accessed on 22 November 2021).
- Center for Healthy Aging and Development Studies. Chinese Longitudinal Healthy Longevity Survey (CLHLS) Biomarkers Dataset (2009, 2012, 2014). 2017. Available online: https://opendata.pku.edu.cn/dataset.xhtml?persistentId=doi:10.18170/DVN/FWVGN5 (accessed on 22 November 2021).
- Song, X.; Mitnitski, A.; Cox, J.; Rockwood, K. Comparison of machine learning techniques with classical statistical models in predicting health outcomes. Stud. Health Technol. Inf. 2004, 107, 736–740. [Google Scholar]
- SCORE2-OP Working Group; ESC Cardiovascular Risk Collaboration. SCORE2-OP risk prediction algorithms: Estimating incident cardiovascular event risk in older persons in four geographical risk regions. Eur. Heart J. 2021, 42, 2455–2467. [Google Scholar] [CrossRef] [PubMed]
- Singh, M.S.; Choudhary, P. Stroke prediction using artificial intelligence. In Proceedings of the 2017 8th Annual Industrial Automation and Electromechanical Engineering Conference (IEMECON), Bangkok, Thailand, 16–18 August 2017; pp. 158–161. [Google Scholar]
- Abedi, V.; Avula, V.; Chaudhary, D.; Shahjouei, S.; Khan, A.; Griessenauer, C.J.; Li, J.; Zand, R. Prediction of Long-Term Stroke Recurrence Using Machine Learning Models. J. Clin. Med. 2021, 10, 1286. [Google Scholar] [CrossRef] [PubMed]
- Park, D.; Jeong, E.; Kim, H.; Pyun, H.W.; Kim, H.; Choi, Y.-J.; Kim, Y.; Jin, S.; Hong, D.; Lee, D.W.; et al. Machine Learning-Based Three-Month Outcome Prediction in Acute Ischemic Stroke: A Single Cerebrovascular-Specialty Hospital Study in South Korea. Diagnostics 2021, 11, 1909. [Google Scholar] [CrossRef]
- MacKenzie, G.; Gould, L.; Ireland, S.; LeBlanc, K.; Sahlas, D. Detecting cognitive impairment in clients with mild stroke or transient ischemic attack attending a stroke prevention clinic. Can. J. Neurosci. Nurs. 2011, 33, 47–50. [Google Scholar]
- Finch, W.H. Imputation methods for missing categorical questionnaire data: A comparison of approaches. J. Data Sci. 2010, 8, 361–378. [Google Scholar] [CrossRef]
- Engels, J.M.; Diehr, P. Imputation of missing longitudinal data: A comparison of methods. J. Clin. Epidemiol. 2003, 56, 968–976. [Google Scholar] [CrossRef]
- Scheffer, J. Dealing with missing data. Res. Lett. Inf. Math. Sci. 2002, 3, 153–160. [Google Scholar]
- Voyle, N.; Keohane, A.; Newhouse, S.; Lunnon, K.; Johnston, C.; Soininen, H.; Kloszewska, I.; Mecocci, P.; Tsolaki, M.; Vellas, B. A pathway based classification method for analyzing gene expression for Alzheimer’s disease diagnosis. J. Alzheimer’s Dis. 2016, 49, 659–669. [Google Scholar] [CrossRef]
- Li, L.; Wu, C.-H.; Ning, J.; Huang, X.; Shih, Y.-C.T.; Shen, Y. Semiparametric estimation of longitudinal medical cost trajectory. J. Am. Stat. Assoc. 2018, 113, 582–592. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the International Joint Conferences on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; pp. 1137–1145. [Google Scholar]
- Goff, D.C.; Lloyd-Jones, D.M.; Bennett, G.; Coady, S.; D’Agostino, R.B.; Gibbons, R.; Greenland, P.; Lackland, D.T.; Levy, D.; O’Donnell, C.J.; et al. 2013 ACC/AHA Guideline on the Assessment of Cardiovascular Risk. Circulation 2014, 129, S49–S73. [Google Scholar] [CrossRef]
- Yang, X.; Li, J.; Hu, D.; Chen, J.; Li, Y.; Huang, J.; Liu, X.; Liu, F.; Cao, J.; Shen, C. Predicting the 10-year risks of atherosclerotic cardiovascular disease in Chinese population: The China-PAR Project (Prediction for ASCVD Risk in China). Circulation 2016, 134, 1430–1440. [Google Scholar] [CrossRef] [PubMed]
- Welch, B.L. The generalization of ‘STUDENT’S’problem when several different population varlances are involved. Biometrika 1947, 34, 28–35. [Google Scholar] [CrossRef]
- Lewis, S.L.; Bucher, L.; Heitkemper, M.M.; Harding, M.M.; Kwong, J.; Roberts, D. Medical-Surgical Nursing-E-Book: Assessment and Management of Clinical Problems, Single Volume; Elsevier Health Sciences: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Hematocrit: MedlinePlus Medical Encyclopedia. Available online: https://web.archive.org/web/20200928153118/https://medlineplus.gov/ency/article/003646.htm (accessed on 4 August 2022).
- Huang, Z.-X.; Lin, X.-L.; Lu, H.-K.; Liang, X.-Y.; Fan, L.-J.; Liu, X.-T. Lifestyles correlate with stroke recurrence in Chinese inpatients with first-ever acute ischemic stroke. J. Neurol. 2019, 266, 1194–1202. [Google Scholar] [CrossRef] [PubMed]
- Delorme, M.; Vergotte, G.; Perrey, S.; Froger, J.; Laffont, I. Time course of sensorimotor cortex reorganization during upper extremity task accompanying motor recovery early after stroke: An fNIRS study. Restor. Neurol. Neurosci. 2019, 37, 207–218. [Google Scholar] [CrossRef] [PubMed]
- Carrington, A.M.; Fieguth, P.W.; Qazi, H.; Holzinger, A.; Chen, H.H.; Mayr, F.; Manuel, D.G. A new concordant partial AUC and partial c statistic for imbalanced data in the evaluation of machine learning algorithms. BMC Med. Inform. Decis. Mak. 2020, 20, 4. [Google Scholar] [CrossRef]
- Youden, W.J. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Wang, L. The blood pressure of the elderly aged 80 and above in China should be controlled at 110~150/70~90 mmHg. Chin. Med. Inf. Her. 2021, 36, 17. [Google Scholar] [CrossRef]
- Goodman, D.S.; Hulley, S.B.; Clark, L.T.; Davis, C.; Fuster, V.; LaRosa, J.C.; Oberman, A.; Schaefer, E.J.; Steinberg, D.; Brown, W.V. Report of the National Cholesterol Education Program Expert Panel on detection, evaluation, and treatment of high blood cholesterol in adults. Arch. Intern. Med. 1988, 148, 36–69. [Google Scholar] [CrossRef]
- Salhadar, A. The Interactive Case Study Companion to Robbins Pathologic Basis of Disease (CD-ROM). Arch. Pathol. Lab. Med. 2000, 124, 1566. [Google Scholar] [CrossRef]
- Ross, D.W.; Ayscue, L.H.; Watson, J.; Bentley, S.A. Stability of hematologic parameters in healthy subjects: Intraindividual versus interindividual variation. Am. J. Clin. Pathol. 1988, 90, 262–267. [Google Scholar] [CrossRef]
- Hippisley-Cox, J.; Coupland, C.; Brindle, P. Derivation and validation of QStroke score for predicting risk of ischaemic stroke in primary care and comparison with other risk scores: A prospective open cohort study. BMJ 2013, 346, f2573. [Google Scholar] [CrossRef] [PubMed]
- Pylypchuk, R.; Wells, S.; Kerr, A.; Poppe, K.; Riddell, T.; Harwood, M.; Exeter, D.; Mehta, S.; Grey, C.; Wu, B.P. Cardiovascular disease risk prediction equations in 400 000 primary care patients in New Zealand: A derivation and validation study. Lancet 2018, 391, 1897–1907. [Google Scholar] [CrossRef]
- D’Agostino, R.B., Sr.; Vasan, R.S.; Pencina, M.J.; Wolf, P.A.; Cobain, M.; Massaro, J.M.; Kannel, W.B. General cardiovascular risk profile for use in primary care: The Framingham Heart Study. Circulation 2008, 117, 743–753. [Google Scholar] [CrossRef] [PubMed]
- Stroke Risk Calculator. Available online: https://www.uclahealth.org/stroke/stroke-risk-calculator (accessed on 6 April 2022).
- Liu, M.; Wu, B.; Wang, W.-Z.; Lee, L.-M.; Zhang, S.-H.; Kong, L.-Z. Stroke in China: Epidemiology, prevention, and management strategies. Lancet Neurol. 2007, 6, 456–464. [Google Scholar] [CrossRef]
- Wu, Y.; Fang, Y. Stroke prediction with machine learning methods among older Chinese. Int. J. Environ. Res. Public Health 2020, 17, 1828. [Google Scholar] [CrossRef]
- Kang, K.; Pan, D.; Song, X. A joint model for multivariate longitudinal and survival data to discover the conversion to Alzheimer’s disease. Stat. Med. 2022, 41, 356–373. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, H.; Zhu, Y.; Guo, Y.; Gan, Y.; Tian, Q.; Lou, Y.; Cao, S.; Lu, Z. Association of the Time to First Cigarette and the Prevalence of Chronic Respiratory Diseases in Chinese Elderly Population. J. Epidemiol. 2022, 32, 415–422. [Google Scholar] [CrossRef]
- Deng, Q.; Liu, W. Physical exercise, social interaction, access to care, and community service: Mediators in the relationship between socioeconomic status and health among older patients with diabetes. Front. Public Health 2020, 8, 589742. [Google Scholar] [CrossRef]
- Grysiewicz, R.A.; Thomas, K.; Pandey, D.K. Epidemiology of ischemic and hemorrhagic stroke: Incidence, prevalence, mortality, and risk factors. Neurol. Clin. 2008, 26, 871–895. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Sawan, M. Trends and challenges of wearable multimodal technologies for stroke risk prediction. Sensors 2021, 21, 460. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stroke | No Stroke | |||
|---|---|---|---|---|
| Average | SD | Average | SD | |
| 2008 (155/162) | ||||
| Systolic Blood Pressure (mmHg) * | 143 | 21.75 | 140.5 | 18.31 |
| Diastolic Blood Pressure (mmHg) * | 79.5 | 11.60 | 79 | 9.98 |
| Total Cholesterol (mmol/L) * | 3.71 | 1.34 | 3.22 | 1.26 |
| High-Density Lipoprotein Cholesterol (mmol/L) * | 1.16 | 0.34 | 1.06 | 0.35 |
| Red Cell Count (1012/L) | 5.68 | 2.73 | 5.95 | 2.76 |
| Platelet Count (109/L) | 248.48 | 156.93 | 250.97 | 138.59 |
| 2011 (61/162) | ||||
| Systolic Blood Pressure (mmHg) * | 134.5 | 16.85 | 138 | 19.63 |
| Diastolic Blood Pressure (mmHg) * | 83.5 | 11.38 | 83 | 11.20 |
| Total Cholesterol (mmol/L) * | 4.36 | 1.00 | 4.14 | 0.92 |
| High-Density Lipoprotein Cholesterol (mmol/L) * | 1.35 | 0.40 | 1.22 | 0.34 |
| Red Cell Count (1012/L) | 4.36 | 1.54 | 4.91 | 1.65 |
| Platelet Count (109/L) | 167.79 | 83.78 | 219.28 | 97.48 |
| 2014 (12/162) | ||||
| Systolic Blood Pressure (mmHg) * | 138 | 26.13 | 143 | 22.35 |
| Diastolic Blood Pressure (mmHg) * | 75.5 | 9.46 | 81.5 | 12.61 |
| Total Cholesterol (mmol/L) * | 4.99 | 1.11 | 4.70 | 0.99 |
| High-Density Lipoprotein Cholesterol (mmol/L) * | 1.41 | 0.50 | 1.367 | 0.39 |
| Red Cell Count (1012/L) | 4.19 | 0.86 | 4.34 | 0.80 |
| Platelet Count (109/L) | 152.78 | 66.31 | 195.50 | 60.26 |
| Abbreviations in Equations (10)–(21) | Stroke | No stroke | |
|---|---|---|---|
| Mean (SD) | Mean (SD) | ||
| 2008 (155/162) | |||
| Sex * | sex | Female: 77, Male: 78 | Female: 73, Male: 89 |
| Age * | age | 79.2 (11.96) | 76.3 (10.41) |
| Provenience * | prov | South: 97, North: 58 | South: 98, North: 64 |
| Residence Location * | residenc | City: 0, Town: 23, Rural: 132 | City: 5, Town: 30, Rural: 127 |
| Diabetes History * | diabetes | No: 149, Yes: 6 | No: 159, Yes: 3 |
| Smoke (number per day) * | smoke | 2.8 (5.60) | 3.7 (10.41) |
| Erythrocyte Hematocrit (%) | hct | 45.41 (15.48) | 45.60 (12.99) |
| Blood Urea Nitrogen (mmol/L) | bun | 6.19 (1.82) | 6.20 (1.79) |
| Hemoglobin (g/L) | hgb | 135.2 (23.25) | 140 (22.34) |
| Housework | house | 1: 90, 2: 17, 3: 3, 4: 10, 5: 35 | 1: 120, 2: 8, 3: 10, 4: 3, 5: 21 |
| MMSE | MMSE | 0: 70, 1: 42, 2: 25, 3: 18 | 0: 92, 1: 50, 2: 12, 3: 8 |
| Hypertension History | hypertension | No: 128, Yes: 27 | No: 150, Yes: 12 |
| Fruit Consumption | fruit | 1: 7, 2: 35, 3: 67, 4: 46 | 1: 16, 2: 59, 3: 66, 4: 21 |
| Glucose (mmol/L) | glu | 5.65 (2.32) | 5.26 (1.80) |
| 2011 (61/162) | |||
| Sex * | sex | Female: 45, Male: 16 | Female: 73, Male: 89 |
| Age * | age | 80.4 (11) | 79.3 (10.41) |
| Provenience * | prov | South: 45, North: 16 | South: 98, North: 64 |
| Residence Location * | residenc | City: 0, Town: 7, Rural: 54 | City: 5, Town: 30, Rural: 127 |
| Diabetes History * | diabetes | No: 58, Yes: 3 | No: 152, Yes: 10 |
| Smoke (number per day) * | smoke | 1.48 (4.41) | 3.01 (6.77) |
| Erythrocyte Hematocrit (%) | hct | 40.09 (7.62) | 42.07 (10.92) |
| Blood Urea Nitrogen (mmol/L) | bun | 6.86 (1.71) | 6.48 (1.70) |
| Hemoglobin (g/L) | hgb | 133 (21.72) | 136.2 (25.64) |
| Housework | house | 1: 32, 2: 4, 3: 2, 4: 5, 5: 18 | 1: 105, 2: 19, 3: 3, 4: 6, 5: 29 |
| MMSE | MMSE | 0: 43, 1: 7, 2: 5, 3: 6 | 0: 114, 1: 30, 2: 12, 3: 6 |
| Hypertension History | hypertension | No: 37, Yes: 24 | No: 112, Yes: 50 |
| Fruit Consumption | fruit | 1: 5, 2: 12, 3: 31, 4: 13 | 1: 9, 2: 44, 3: 73, 4: 36 |
| Glucose (mmol/L) | glu | 4.32 (3.78) | 4.40 (1.56) |
| 2014 (12/162) | |||
| Sex * | sex | Female: 7, Male: 5 | Female: 73, Male: 89 |
| Age * | age | 80.5 (6.87) | 82.3 (10.41) |
| Provenience * | prov | South: 9, North: 3 | South: 98, North: 64 |
| Residence Location * | residenc | City: 0, Town: 1, Rural: 11 | City: 5, Town: 30, Rural: 127 |
| Diabetes History * | diabetes | No: 10, Yes: 2 | No: 136, Yes: 26 |
| Smoke (number per day) * | smoke | 0.83 (2.89) | 2.82 (6.91) |
| Erythrocyte Hematocrit (%) | hct | 39.7 (8.31) | 40.18 (6.68) |
| Blood Urea Nitrogen (mmol/L) | bun | 6.48 (1.94) | 6.15 (1.67) |
| Hemoglobin (g/L) | hgb | 130.8 (25.56) | 132.3 (19.20) |
| Housework | house | 1: 11, 2: 0, 3: 0, 4: 0, 5: 1 | 1: 100, 2: 13, 3: 3, 4: 4, 5: 42 |
| MMSE | MMSE | 0: 9, 1: 2, 2: 1, 3: 0 | 0: 115, 1: 25, 2: 11, 3: 11 |
| Hypertension History | hypertension | No: 8, Yes: 4 | No: 92, Yes: 70 |
| Fruit Consumption | fruit | 1: 2, 2: 5, 3: 5, 4: 0 | 1: 12, 2: 56, 3: 65, 4: 29 |
| Glucose (mmol/L) | glu | 5.094 (0.78) | 5.34 (1.46) |
| AUC/ C-Index | Youden’s J Statistic | Sensitivity | Specificity | Threshold | ||
|---|---|---|---|---|---|---|
| Our Model | One Measurement Obtained in 2008 | 0.741 | 0.398 | 0.766 | 0.632 | 0.242 |
| Two Measurements Obtained in 2008 and 2011 | 0.876 | 0.595 | 0.796 | 0.799 | 0.182 | |
| Three Measurements Obtained in 2008, 2011, and 2014 | 0.926 | 0.757 | 0.917 | 0.840 | 0.107 | |
| Cox Proportional Hazard Model | One Measurement Obtained in 2008 | 0.716 | NA | NA | NA | NA |
| One Measurement Obtained in 2011 | 0.749 | NA | NA | NA | NA | |
| One Measurement Obtained in 2014 | 0.833 | NA | NA | NA | NA |
| Models | Risk of Stroke | Prediction Horizon | ||
|---|---|---|---|---|
| 2008 | 2011 | 2014 | ||
| Our Model | 13.75% Low-risk | 30.43% High-risk | 63.87% High-risk | 3 Years |
| QStroke [38] | 2.60% | 3.60% | 4.80% | 3 Years |
| PREDICT [39] | 7.30% | 8.30% | 8.30% | 5 Years |
| China-PAR [26] | 7.90% Medium-risk | 8.90% Medium-risk | 11.2% High-risk | 10 Years |
| Framingham [40] | 13.70% Medium-risk | 21.5% High-risk | 24.8% High-risk | 10 Years |
| Pooled Cohort Equations [25] | 28.70% | 40.30% | 50.10% | 10 Years |
| UCLA [41] | 7.60% Low-risk | 11.10% Low-risk | 22.80% Low-risk | 10 Years |
| Model | C-Index/AUC | 95% CI | |
|---|---|---|---|
| Our Model | 0.741–0.926 | ||
| QStroke | Male | 0.71 | [0.69,0.73] |
| Female | 0.65 | [0.62,0.67] | |
| PREDICT | 0.73 | [0.72–0.73] | |
| China-PAR | Male | 0.794 | [0.775,0.814] |
| Female | 0.811 | [0.787,0.835] | |
| Framingham | Male | 0.763 | [0.746,0.790] |
| Female | 0.793 | [0.772,0.814] | |
| Pooled Cohort Equation | 0.713–0.814 | ||
| Year | Status | C-Index | |
|---|---|---|---|
| China-PAR Model | Framingham Study | ||
| 2008 | (155/162) | 0.522 | 0.552 |
| 2011 | (61/162) | 0.514 | 0.538 |
| 2014 | (12/162) | 0.617 | 0.584 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, W.; Chen, Y.-H.; Sawan, M. Longitudinal Data to Enhance Dynamic Stroke Risk Prediction. Healthcare 2022, 10, 2134. https://doi.org/10.3390/healthcare10112134
Zheng W, Chen Y-H, Sawan M. Longitudinal Data to Enhance Dynamic Stroke Risk Prediction. Healthcare. 2022; 10(11):2134. https://doi.org/10.3390/healthcare10112134
Chicago/Turabian StyleZheng, Wenyao, Yun-Hsuan Chen, and Mohamad Sawan. 2022. "Longitudinal Data to Enhance Dynamic Stroke Risk Prediction" Healthcare 10, no. 11: 2134. https://doi.org/10.3390/healthcare10112134
APA StyleZheng, W., Chen, Y.-H., & Sawan, M. (2022). Longitudinal Data to Enhance Dynamic Stroke Risk Prediction. Healthcare, 10(11), 2134. https://doi.org/10.3390/healthcare10112134