
Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification

Abstract
1. Introduction
2. Methodology
2.1. SVM Framework and Notation
2.2. Conformal Transformation and Adaptive Kernel Machine
2.3. Adaptive Kernel Machine for Multi-Class Cases
2.4. Specification of Functions
2.5. Data-Adaptive SVM Algorithm for Multi-Class Case
- The magnification will be almost constant along the separating surface for each boundary;
- The magnification will be largest where the contours are closest locally. (See more details in the Appendices.)
| Algorithm 1. Multi-class data adaptive kernel scaling support vector machine (SVM). |
| Input: |
| 1: A regular SVM classifier is trained with an ordinary Gaussian radial basis kernel function; |
| 2: Based on the spatial information of these support vectors, the conformal transformation is constructed, and the original kernel function is updated; |
| 3: A new round of SVM optimization problems is conducted with the updated kernel function, and the boundaries for different classes are found; |
| 4: The predicted class labels for instances are determined by majority voting. |
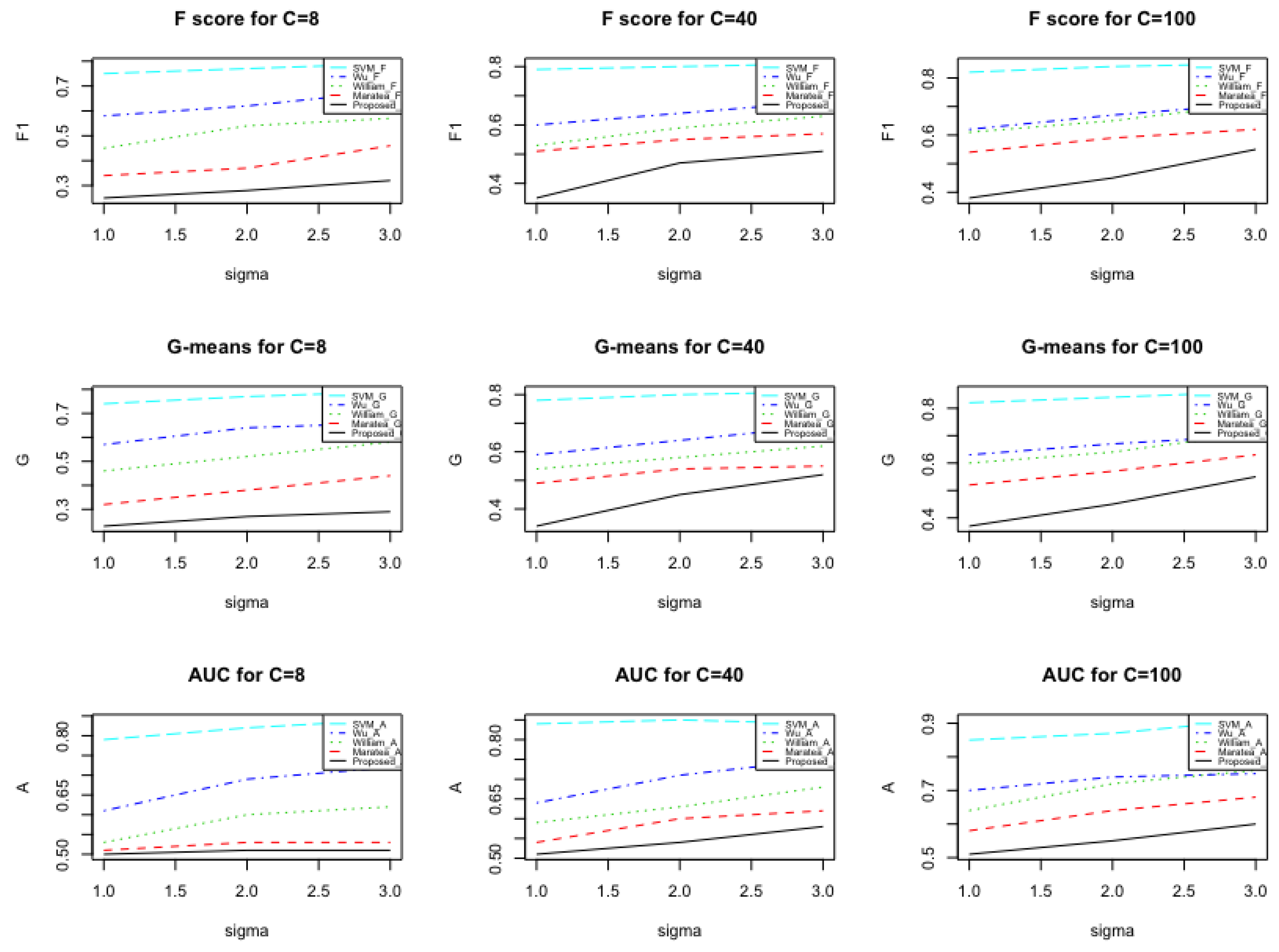
3. Numerical Investigation
3.1. Simulation Study
3.2. A Real Prostate Caner MRI Dataset
- Atrophy: As means literally (non-cancer);
- EPE: Prostatic intraepithelial neoplasia (non-cancer);
- PIN: Prostatic intraepithelial neoplasia (non-cancer);
- G3: Tumour focus that is all Gleason 3 (cancer);
- G4: Tumour focus that is all Gleason 4 (cancer);
- G3+4: Tumour focus all predominately G3 with intermingled G4 (cancer);
- G4+3: Tumour focus all predominately G4 with intermingled G3 (cancer);
- G4+5: Tumour focus all predominately G4 with intermingled G5 (cancer);
- OtherProstate: Prostate tissue that does not fall into the other categories (non-cancer).
4. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Lemmas and Theorems
Appendix A.1. Proof of Lemma 1
References
- Liu, X.; He, W. Adaptive kernel scaling support vector machine with application to a prostate cancer image study. J. Appl. Stat. 2021, 1–20. [Google Scholar] [CrossRef]
- Crammer, K.; Singer, Y. On the algorithmic implementation of multiclass kernel-based vector machines. J. Mach. Learn. Res. 2001, 2, 265–292. [Google Scholar]
- Maratea, A.; Petrosino, A. Asymmetric Kernel scaling for imbalanced data classification. Fuzzy Log. Appl. 2011, 196–203. [Google Scholar] [CrossRef]
- Zhang, Z.; Gao, G.; Shi, Y. Credit risk evaluation using multi-criteria optimization classifier with kernel, fuzzification and penalty factors. Eur. J. Oper. Res. 2014, 237, 335–348. [Google Scholar] [CrossRef]
- Vapnik, V.N.; Vapnik, V. Statistical Learning Theory; Wiley: New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- Kreßel, U.H.G. Pairwise classification and support vector machines. In Advances in Kernel Methods; MIT Press: Cambridge, MA, USA, 1999; pp. 255–268. [Google Scholar]
- Suykens, J.A.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Suykens, J.A.; Vandewalle, J. Multiclass least squares support vector machines. In Proceedings of the International Joint Conference on Neural Networks, IJCNN’99, Washington, DC, USA, 10–16 July 1999; Volume 2, pp. 900–903. [Google Scholar]
- Xia, X.L.C.; Li, K. A sparse multi-class least-squares support vector machine. In Proceedings of the IEEE International Symposium on Industrial Electronics, Cambridge, UK, 30 June–2 July 2008; pp. 1230–1235. [Google Scholar]
- Fung, G.M.; Mangasarian, O.L. Multicategory proximal support vector machine classifiers. Mach. Learn. 2005, 59, 77–97. [Google Scholar] [CrossRef]
- Fung, G.M.; Mangasarian, O. Proximal support vector machine classifiers. Mach. Learn. 2002, 1, 21. [Google Scholar]
- Zhang, Y.; Fu, P.; Liu, W.; Chen, G. Imbalanced data classification based on scaling kernel-based support vector machine. Neural Comput. Appl. 2014, 25, 927–935. [Google Scholar] [CrossRef]
- He, X.; Wang, Z.; Jin, C.; Zheng, Y.; Xue, X. A simplified multi-class support vector machine with reduced dual optimization. Pattern Recognit. Lett. 2012, 33, 71–82. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.; Japkowicz, N.; Kolcz, A. Special Issue on Learning from Imbalanced Datasets, Sigkdd Explorations; ACM SIGKDD: New York, NY, USA, 2004; Volume 6, pp. 1–6. [Google Scholar]
- Daskalaki, S.; Kopanas, I.; Avouris, N. Evaluation of classifiers for an uneven class distribution problem. Appl. Artif. Intell. 2006, 20, 381–417. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special issue on learning from imbalanced data sets. ACM Sigkdd Explor. Newsl. 2004, 6, 1–6. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V.; Krasser, S. SVMs modeling for highly imbalanced classification. Syst. Man Cybern. Part B Cybern. IEEE Trans. 2009, 39, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Shen, X. On L1-norm multiclass support vector machines. J. Am. Stat. Assoc. 2007, 102, 583–594. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2001; Volume 1. [Google Scholar]
- Wu, S.; Amari, S.I. Conformal transformation of kernel functions: A data-dependent way to improve support vector machine classifiers. Neural Process Lett. 2002, 15, 59–67. [Google Scholar] [CrossRef]
- Williams, P.; Li, S.; Feng, J.; Wu, S. Scaling the kernel function to improve performance of the support vector machine. In Advances in Neural Networks–ISNN 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 831–836. [Google Scholar]
- Maratea, A.; Petrosino, A.; Manzo, M. Adjusted F-measure and kernel scaling for imbalanced data learning. Inf. Sci. 2014, 257, 331–341. [Google Scholar] [CrossRef]
- Fawcett, T. ROC graphs: Notes and practical considerations for researchers. Mach. Learn. 2004, 31, 1–38. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| SVM | Wu [22] | William [23] | Maratea [24] | Our Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | G | A | F | G | A | F | G | A | F | G | A | F | G | A | ||||||
| 8 | 0.1 | 0.39 | 0.38 | 0.52 | 0.43 | 0.43 | 0.54 | 0.59 | 0.59 | 0.61 | 0.71 | 0.70 | 0.75 | 0.78 | 0.79 | 0.80 | ||||
| 8 | 0.5 | 0.43 | 0.42 | 0.55 | 0.47 | 0.46 | 0.56 | 0.66 | 0.66 | 0.69 | 0.75 | 0.75 | 0.78 | 0.81 | 0.81 | 0.83 | ||||
| 8 | 5.0 | 0.47 | 0.46 | 0.56 | 0.53 | 0.52 | 0.59 | 0.68 | 0.68 | 0.72 | 0.78 | 0.77 | 0.81 | 0.84 | 0.83 | 0.85 | ||||
| 40 | 0.1 | 0.45 | 0.45 | 0.55 | 0.44 | 0.43 | 0.54 | 0.61 | 0.61 | 0.66 | 0.73 | 0.72 | 0.75 | 0.81 | 0.81 | 0.85 | ||||
| 40 | 0.5 | 0.53 | 0.52 | 0.57 | 0.51 | 0.50 | 0.55 | 0.67 | 0.67 | 0.71 | 0.75 | 0.75 | 0.78 | 0.84 | 0.83 | 0.88 | ||||
| 40 | 5.0 | 0.56 | 0.55 | 0.59 | 0.62 | 0.62 | 0.67 | 0.71 | 0.72 | 0.78 | 0.78 | 0.78 | 0.81 | 0.86 | 0.86 | 0.88 | ||||
| 100 | 0.1 | 0.52 | 0.51 | 0.57 | 0.61 | 0.59 | 0.62 | 0.64 | 0.63 | 0.68 | 0.78 | 0.79 | 0.81 | 0.84 | 0.85 | 0.88 | ||||
| 100 | 0.5 | 0.60 | 0.58 | 0.62 | 0.67 | 0.65 | 0.69 | 0.77 | 0.67 | 0.76 | 0.79 | 0.80 | 0.83 | 0.86 | 0.86 | 0.90 | ||||
| 100 | 5.0 | 0.69 | 0.66 | 0.71 | 0.71 | 0.70 | 0.73 | 0.79 | 0.72 | 0.80 | 0.81 | 0.82 | 0.84 | 0.88 | 0.88 | 0.92 | ||||
| SVM | Wu [22] | William [23] | Maratea [24] | Our Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | G | A | F | G | A | F | G | A | F | G | A | F | G | A | ||||||
| 8 | 0.1 | 0.29 | 0.30 | 0.51 | 0.40 | 0.40 | 0.52 | 0.49 | 0.49 | 0.55 | 0.62 | 0.60 | 0.63 | 0.77 | 0.76 | 0.80 | ||||
| 8 | 0.5 | 0.32 | 0.32 | 0.51 | 0.42 | 0.42 | 0.55 | 0.58 | 0.57 | 0.63 | 0.66 | 0.65 | 0.71 | 0.78 | 0.78 | 0.82 | ||||
| 8 | 5.0 | 0.36 | 0.36 | 0.52 | 0.48 | 0.49 | 0.55 | 0.61 | 0.60 | 0.67 | 0.71 | 0.72 | 0.77 | 0.80 | 0.80 | 0.84 | ||||
| 40 | 0.1 | 0.40 | 0.40 | 0.54 | 0.54 | 0.53 | 0.57 | 0.57 | 0.58 | 0.62 | 0.65 | 0.66 | 0.71 | 0.80 | 0.80 | 0.83 | ||||
| 40 | 0.5 | 0.50 | 0.42 | 0.52 | 0.59 | 0.58 | 0.64 | 0.65 | 0.64 | 0.69 | 0.68 | 0.67 | 0.73 | 0.81 | 0.80 | 0.85 | ||||
| 40 | 5.0 | 0.56 | 0.56 | 0.61 | 0.62 | 0.60 | 0.64 | 0.68 | 0.66 | 0.72 | 0.72 | 0.73 | 0.77 | 0.82 | 0.82 | 0.88 | ||||
| 100 | 0.1 | 0.42 | 0.39 | 0.54 | 0.57 | 0.55 | 0.61 | 0.65 | 0.64 | 0.69 | 0.66 | 0.68 | 0.75 | 0.84 | 0.83 | 0.88 | ||||
| 100 | 0.5 | 0.52 | 0.50 | 0.59 | 0.63 | 0.65 | 0.71 | 0.70 | 0.69 | 0.75 | 0.71 | 0.72 | 0.77 | 0.85 | 0.84 | 0.89 | ||||
| 100 | 5.0 | 0.59 | 0.61 | 0.66 | 0.68 | 0.70 | 0.74 | 0.75 | 0.76 | 0.79 | 0.75 | 0.74 | 0.81 | 0.86 | 0.87 | 0.91 | ||||
| SVM | Wu [22] | William [23] | Maratea [24] | Our Method | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F | G | A | F | G | A | F | G | A | F | G | A | F | G | A | ||||||
| 8 | 0.1 | 0.25 | 0.23 | 0.50 | 0.34 | 0.32 | 0.51 | 0.45 | 0.46 | 0.53 | 0.58 | 0.57 | 0.61 | 0.75 | 0.74 | 0.79 | ||||
| 8 | 0.5 | 0.28 | 0.27 | 0.51 | 0.37 | 0.38 | 0.53 | 0.54 | 0.52 | 0.60 | 0.62 | 0.64 | 0.69 | 0.77 | 0.77 | 0.82 | ||||
| 8 | 5.0 | 0.32 | 0.29 | 0.51 | 0.46 | 0.44 | 0.53 | 0.57 | 0.58 | 0.62 | 0.68 | 0.66 | 0.72 | 0.79 | 0.79 | 0.84 | ||||
| 40 | 0.1 | 0.35 | 0.34 | 0.51 | 0.51 | 0.49 | 0.54 | 0.53 | 0.54 | 0.59 | 0.60 | 0.59 | 0.64 | 0.79 | 0.78 | 0.84 | ||||
| 40 | 0.5 | 0.47 | 0.45 | 0.54 | 0.55 | 0.54 | 0.60 | 0.59 | 0.58 | 0.63 | 0.64 | 0.64 | 0.71 | 0.80 | 0.80 | 0.85 | ||||
| 40 | 5.0 | 0.51 | 0.52 | 0.58 | 0.57 | 0.55 | 0.62 | 0.63 | 0.62 | 0.68 | 0.68 | 0.69 | 0.75 | 0.81 | 0.81 | 0.84 | ||||
| 100 | 0.1 | 0.38 | 0.37 | 0.51 | 0.54 | 0.52 | 0.58 | 0.61 | 0.60 | 0.64 | 0.62 | 0.63 | 0.70 | 0.82 | 0.82 | 0.85 | ||||
| 100 | 0.5 | 0.45 | 0.45 | 0.55 | 0.59 | 0.57 | 0.64 | 0.65 | 0.64 | 0.72 | 0.67 | 0.67 | 0.74 | 0.84 | 0.84 | 0.87 | ||||
| 100 | 5.0 | 0.55 | 0.55 | 0.60 | 0.62 | 0.63 | 0.68 | 0.71 | 0.71 | 0.76 | 0.71 | 0.70 | 0.75 | 0.85 | 0.86 | 0.91 | ||||
| Methods | Error(%) | SV(%) | F-Score | G-Means |
|---|---|---|---|---|
| Proposed | ||||
| Amari | ||||
| William | ||||
| CS | ||||
| simSVM | ||||
| 1vs1 | ||||
| 1vsA |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, J.; Liu, X.; He, W. Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification. Mathematics 2021, 9, 936. https://doi.org/10.3390/math9090936
Shao J, Liu X, He W. Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification. Mathematics. 2021; 9(9):936. https://doi.org/10.3390/math9090936
Chicago/Turabian StyleShao, Jianli, Xin Liu, and Wenqing He. 2021. "Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification" Mathematics 9, no. 9: 936. https://doi.org/10.3390/math9090936
APA StyleShao, J., Liu, X., & He, W. (2021). Kernel Based Data-Adaptive Support Vector Machines for Multi-Class Classification. Mathematics, 9(9), 936. https://doi.org/10.3390/math9090936