
Markov Chain K-Means Cluster Models and Their Use for Companies’ Credit Quality and Default Probability Estimation


Abstract
1. Introduction
2. Literature Review
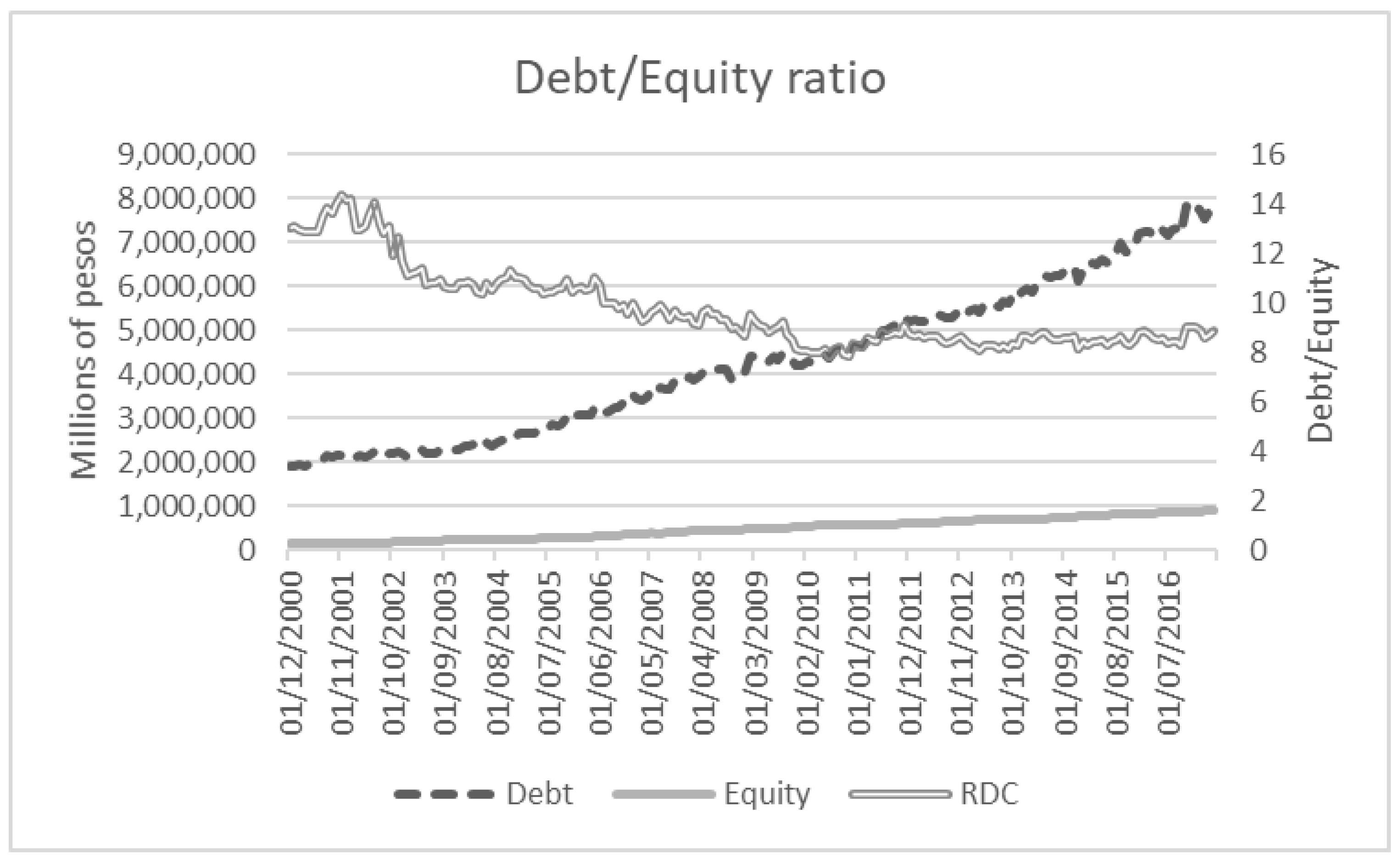
3. The Financial Sector
4. Methodology
4.1. Company Grouping or Clustering
4.2. Markov Chains
5. Results
6. Discussion & Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Minsky, H.P. The Financial Instability Hypothesis 4. The Jerome Levy Economics Institute Working Paper No. 74. 1992. Available online: https://ssrn.com/abstract=161024 (accessed on 4 March 2021). [CrossRef]
- Minsky, H.P. Can “it” happen again? A reprise. Challenge 1982, 25, 5–13. [Google Scholar] [CrossRef]
- Dickinson, V. Cash Flow Patterns as a Proxy for Firm Life Cycle. Account. Rev. 2011, 86, 1969–1994. [Google Scholar] [CrossRef]
- Merton, R.C. On the pricing of corporate debt: The risk structure of interest rates. J. Financ. 1974, 29, 449–470. [Google Scholar]
- Aparicio, C.; Gutiérrez, J.; Jaramillo, M.; Moreno, H. Indicadores Alternativos de Riesgo de Crédito en el Perú: Matrices de Transición Crediticia Condicionadas al Ciclo Económico. Superintendencia de Banca, Seguros y Administradoras Privadas de Fondos de Pensiones 2003. pp. 1–17. Available online: https://www.sbs.gob.pe/Portals/0/jer/ddt_ano2013/SBS-DT-001-2013.pdf (accessed on 4 March 2021).
- Támara-Ayús, A.; Aristizábal, R.; Velásquez, E. Matrices de transición en el análisis del riesgo crediticio como elemento fundamental en el cálculo de la pérdida esperada en una institución financiera colombiana. Rev. Ing. Univ. Medellín 2012, 11, 105–114. [Google Scholar]
- McCulloch, R.E.; Tsay, R.S. Statistical analysis of economic time series via Markov switching models. J. Time Ser. Anal. 1994, 15, 523–539. [Google Scholar] [CrossRef]
- Peña, E.L. Matrices de Transicion del Credito en Nicaragua; Banco Central de Nicaragua: Managua, Nicaragua, 2013. Available online: https://www.bcn.gob.ni/estadisticas/estudios/2014/DT-31_Matrices_de_Transicion_del_Credito_en_Nicaragua.pdf (accessed on 4 March 2021).
- Hamilton, J.D. A new approach to the economic analysis of nonstationary time series and the business cycle. Econ. J. Econom. Soc. 1989, 57, 357–384. Available online: https://www.jstor.org/stable/1912559 (accessed on 4 March 2021). [CrossRef]
- Gaitán, M.M.; Flores, M.M. Riesgo Crediticio Bancario: Análisis de la Cartera de Crédito del Banco MGM, SA, Mediante El empleo de Modelos de Transición con Cadenas de MARKOV en el Periodo Terminado 2015. Ph.D. Thesis, Universidad Nacional Autónoma de Nicaragua, Managua, Nicaragua, 2 September 2017. Available online: https://core.ac.uk/download/pdf/94852394.pdf (accessed on 4 March 2021).
- Porras, E.R.; Anchundia, S.; Vieira, M. Competencia, Rivalidad y Entrada del Capital Extranjero en la Banca Venezolana. Observatorio de la Economía Latinoamericana. 2002. Available online: http://www.eumed.net/cursecon/ecolat (accessed on 4 March 2021).
- Yu, F.H.; Lu, J.; Gu, J.W.; Ching, W.K. Modeling Credit Risk with Hidden Markov Default Intensity. Comput. Econ. 2018, 54, 1213–1229. [Google Scholar] [CrossRef]
- Pfeuffer, M.; Reis, G.D. Capturing Model Risk and Rating Momentum in the Estimation of Probabilities of Default and Credit Rating Migrations. arXiv 2018, arXiv:1809.09889. [Google Scholar]
- Leung, K.S.; Kwok, Y.K. Counterparty risk for credit default swaps: Markov chain interacting intensities model with stochastic intensity. Asia-Pac. Financ. Mark. 2009, 16, 169. [Google Scholar] [CrossRef]
- Córdova, J.F.; Molina, E.C.; Navarrete, P. Lógica difusa y el riesgo financiero. Una propuesta de clasificación de riesgo financiero al sector cooperativo. Contad. Y Adm. 2017, 62, 1670–1686. [Google Scholar] [CrossRef]
- García, J.C.; Bolívar, H.R.; Vázquez, F.A. Actualización del modelo de riesgo crediticio, una necesidad para la banca revolvente en México. Rev. Finanzas Y Politica Econ. 2016, 8, 17–30. [Google Scholar] [CrossRef]
- Kavitha, K. Clustering loan applicants based on risk percentage using K-means clustering. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2016, 66, 162–166. [Google Scholar]
- Zhu, S.; Chan, J.; Bright, D. Applying Machine Learning for Troubleshooting Credit Exposure and xVA Profiles (16 June 2019). Available online: https://ssrn.com/abstract=3404863 (accessed on 4 March 2021).
- Wahyudin, I.; Djatna, T.; Kusuma, W.A. Cluster Analysis for SME Risk Analysis Documents Based on Pillar K-Means. Telecommun. Comput. Electron. Control. 2016, 14, 674–683. [Google Scholar] [CrossRef][Green Version]
- Ayús, A.L.; Peña, A.M.; Álvarez, Y.C. El análisis factorial y el análisis discriminante en la estimación de la pérdida esperada para una institución financiera. Rev. Cienc. Estrateg. 2017, 25, 425–440. [Google Scholar]
- Lagunas, P.S.; Ramírez, P.J. Expectativas para operaciones financieras en los sectores vulnerables mediante Matrices de Transición. Rev. Mex. Econ. Y Finanzas 2017, 12, 71–101. [Google Scholar] [CrossRef]
- Ferreira, J. Inestabilidad financiera y los ciclos económicos: La contribución de Hyman Minsky. In Modelos Macroeconómicos de Crecimiento y de Fluctuaciones Cíclicas; Ferreira, J., Ed.; Universidad Autónoma Metropolitana: Mexico City, Mexico, 1995; pp. 113–123. [Google Scholar]
- Angeles, C.G.; Ortiz, J. Dos Crisis Económicas Recientes en México: Causas y Perspectivas. Available online: https://www.researchgate.net/publication/267220509 (accessed on 26 October 2018).
- Rodríguez, N.A.; Venegas, M.F. Liquidez y apalancamiento de la banca comercial en México. Anal. Econ. 2012, 27, 73–96. [Google Scholar]
- Berger, A.N.; Udell, G.F. The economics of small business finance: The roles of private equity and debt markets in the financial growth cycle. J. Bank. Financ. 1998, 22, 613–673. [Google Scholar] [CrossRef]
- Bencivenga, V.R.; Smith, B.D. D. Financial intermediation and endogenous growth. Rev. Econ. Stud. 1991, 58, 195–209. [Google Scholar] [CrossRef]
- Adrian, T.; Shin, H.S. Liquidity, monetary policy, and financial cycles. Curr. Issues Econ. Financ. 2008, 14, 1–7. Available online: https://ssrn.com/abstract=1090550 (accessed on 4 March 2021).
- Claessens, S.; Kose, M.A.; Terrones, M.E. How do business and financial cycles interact? J. Int. Econ. 2019, 87, 178–190. [Google Scholar] [CrossRef]
- Terreno, D.D.; Sattler, S.A.; Pérez, J.O. Las etapas del ciclo de vida de la empresa por los patrones del estado de flujo de efectivo y el riesgo de insolvencia empresarial. Rev. Dep. Acad. Cienc. Adm. 2017, 12, 22–37. [Google Scholar]
- Tudela, M.; Young, G. A Merton-model approach to assessing the default risk of UK public companies. Int. J. Theor. Appl. Financ. 2005, 8, 737–761. [Google Scholar] [CrossRef]
- Dar, A.A.; Anuradha, N.; Qadir, S. Estimating probabilities of default of different firms and the statistical tests. J. Glob. Entrep. Res. 2019, 9, 27. [Google Scholar] [CrossRef]
- Afik, Z.; Arad, O.; Galil, K. Using Merton model for default prediction: An empirical assessment of selected alternatives. J. Empir. Financ. 2016, 35, 43–67. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Berkhin, P. A survey of clustering data mining techniques. In Grouping Multidimensional Data; Springer: Heidelberg/Berlin, Germany, 2006; pp. 25–71. [Google Scholar] [CrossRef]
- Maechler, M.; Rousseeuw, P.; Struyf, A.; Hubert, M.; Hornik, K. Cluster: Cluster Analysis Basics and Extensions. R Package Version 2.0.7-1 2018, 1, 56. [Google Scholar]
- Leonard, K.; Peter, J.R. Finding groups in data: An introduction to cluster analysis. Probability and Mathematical Statistics. In Applied Probability and Statistics; Wiley Series; John Wiley & Sons: Hoboken, NJ, USA, 1990. [Google Scholar]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A k-means clustering algorithm. J. R. Stat. Soc. Ser. C 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Ledolter, J. Data Mining and Business Analytics with R; John Wiley Sons Inc.: Iowa City, IA, USA, 2013. [Google Scholar]
- Caballero, M.E.; Rivero, V.M.; Uribe, G.; Velarde, C. Cadenas de Markov. Un Enfoque Elemental; Series Textos; Aportaciones Matemáticas: Ciudad de México, Mexico, 2017. [Google Scholar]
- Norris, J.R. Introduction. In Markov Chains; Cambridge University Press: Cambridge, UK, 1998; pp. xiii–xvi. [Google Scholar]
- Venegas, M.F. Riesgos Financieros y Economicos/Financial and Economical Risks: Productos Derivados Y Decisiones Economicas Bajo Incertidumbre; Cengage Learning: México City, Mexico, 2008. [Google Scholar]
- Bolívar-Cimé, A.; Notario, C.; Pérez, A. Modelos de Markov para la trayectoria académica de estudiantes de la UJAT. Misc. Mat. 2016, 62, 29–43. Available online: https://miscelaneamatematica.org/welcome/default/download/tbl_articulos.pdf2.8c525e9a283566e3.363230332e706466.pdf (accessed on 4 March 2021).
- FitchRatings. Estudio Sobre Transición e Incumplimiento de Calificaciones Nacionales de Fitch México 2018. Available online: https://www.fitchratings.com/research/es/structured-finance/transition-study-fitch-national-ratings-mexico-2018-28-03-2019 (accessed on 4 March 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (%) Annual | AAA (mex) | AA (mex) | A (mex) | BB (mex) | BB (mex) | B (mex) | CCC (mex) | CC (mex) | C (mex) | D (mex) |
|---|---|---|---|---|---|---|---|---|---|---|
| AAA (mex) | 96.0 | 0.6 | 0.3 | |||||||
| AA (mex) | 4.5 | 88.4 | 2.5 | 0.3 | 0.3 | 0.3 | 0.3 | |||
| A (mex) | 0.5 | 3.9 | 88.2 | 2.7 | 0.3 | 0.2 | 0.6 | |||
| BB (mex) | 0.2 | 8.4 | 80.7 | 2.7 | 0.2 | 1.2 | ||||
| BB (mex) | 1.0 | 8.1 | 72.2 | 1.0 | 1.0 | 2.0 | ||||
| B (mex) | 2.3 | 13.6 | 59.1 | 9.1 | 2.3 | 2.3 | ||||
| CCC (mex) | 6.3 | 31.3 | 31.3 | 6.3 | 12.5 | |||||
| CC (mex) | 25.0 | 25.0 | ||||||||
| C (mex) | 33.3 | 66.7 |
| # | Company | Rating | Agency | Calculated Probability |
|---|---|---|---|---|
| 1 | Boeing Co Com (Chicago, IL, USA) | BBB- | Fitch | 0% |
| 2 | Embraer ON (São José dos Campos, São Paulo, Brazil) | BB+ | Fitch | 0% |
| 3 | Exxon Mobil Corp Com (Irving, TX, USA) | AA | S&P | 2% |
| 4 | AT&T Inc Com (Whitacre Tower, Dallas, TX, USA) | A- | Fitch | 1% |
| 5 | Chevron Corp Com (San Ramon, CA, USA) | AA | S&P | 2% |
| 6 | Verizon Comm Inc Com (New York City, NY, USA) | A- | Fitch | 1% |
| 7 | Amazon.Com, Inc Com (Seattle, Washington, DC, USA) | A+ | Fitch | 1% |
| 8 | Walmart Inc Com (Bentonville, AR, USA) | AA | Fitch | 2% |
| 9 | Unitedhealth Group Inc Com (Minnetonka, MN, USA) | A | Fitch | 1% |
| 10 | Comcast Corp Com A (Philadelphia, PA, USA) | A- | Fitch | 1% |
| 11 | Johnson & Johnson Com (New Brunswick, NJ, USA) | AAA | Fitch | 1% |
| 12 | Intel Corp Com (Santa Clara, CA, USA) | A+ | Fitch | 1% |
| 13 | Procter & Gamble Co Com (Cincinnati, ON, USA) | BBB | Fitch | 0% |
| 14 | Pfizer Inc Com (New York, NY 10017, USA) | A- | Fitch | 1% |
| 15 | General Motors Company Com (Detroit, MI, USA) | BBB- | Fitch | 0% |
| 16 | Intl Business Machines Corp Com (Armonk, NY, USA) | A+ | Fitch | 1% |
| 17 | Walt Disney Co Com (Burbank, CA, USA) | A- | Fitch | 1% |
| 18 | Cisco Systems, Inc Com (San Jose, CA, USA) | |||
| 19 | Fomento Econ Mex UBD (Monterrey, Mexico) | A | Fitch | 1% |
| 20 | Cemex CPO (Monterrey, Mexico) | BB | S&P | 0% |
| 21 | Alfa A (Monterrey, Mexico) | BBB- | Fitch | 0% |
| 22 | America Movil L (Mexico City, Mexico) | AAA | Fitch | 1% |
| 23 | Elektra Gpo. (Mexico City, Mexico) | A | Fitch | 1% |
| 24 | CCR SA ON (São Paulo, Brazil) | AA+ | Fitch | 2% |
| 25 | Cemig ON (Belo Horizonte, MG, Brazil) | BB- | Fitch | 0% |
| 26 | Sid Nacional ON (São Paulo, Brazil) | B- | S&P | 0% |
| 27 | CPFL Energia ON (Campinas, Brazil) | AAA | Fitch | 1% |
| 28 | Gerdau PN (Porto Alegre, RS, Brazil) | BBB- | Fitch | 0% |
| 29 | Empresas Cmpc S.A. Ord (Santiago, Chile) | BBB | Fitch | 0% |
| 30 | Empresas Copec S.A. Ord (Santiago, Chile) | BBB | Fitch | 0% |
| 31 | Enel Americas S.A. Ord (Santiago, Chile) | A- | Fitch | 1% |
| 32 | Enel Generacion Chile S.A. Ord (Santiago, Chile) | A- | Fitch | 1% |
| 33 | Buenaventura C1 (San Isidro, Perú) | BB+ | Fitch | 0% |
| 34 | BRF SA ON (Itajaí, Santa Catarina, Brazil) | BB | Fitch | 0% |
| 35 | Ambev S/A ON (São Paulo, Brazil) | BBB | S&P | 0% |
| Company | Q4 | Q1 | Q2 | Q3 | Q4 | Q1 | Q4 | Q1 | Q2 | Q3 | Q4 | Q1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| -2018 | -2019 | -2019 | -2019 | -2019 | -2020 | -2018 | -2019 | -2019 | -2019 | -2019 | -2020 | |
| BRF SA ON (Itajaí, Santa Catarina, Brazil) | −1 | −1 | 0 | 1 | −1 | −1 | 0% | 0% | 65% | 88% | 20% | 17% |
| Ambev S/A ON (São Paulo, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 5% | 0% | 0% |
| Exxon Mobil Corp Com (Irving, TX, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| AT&T Inc Com (Whitacre Tower, Dallas, TX, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Chevron Corp Com (San Ramon, CA, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Verizon Comm Inc Com (New York City, NY, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Amazon.Com, Inc Com (Seattle, Washington, DC, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Walmart Inc Com (Bentonville, AR, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Unitedhealth Group Inc Com (Minnetonka, MN, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Comcast Corp Com A (Philadelphia, PA, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Johnson & Johnson Com (New Brunswick, NJ, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Intel Corp Com (Santa Clara, CA, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Procter & Gamble Co Com (Cincinnati, ON, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Pfizer Inc Com (New York, NY 10017, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| General Motors Company Com (Detroit, MI, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Intl Business Machines Corp Com (Armonk, NY, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Walt Disney Co Com (Burbank, CA, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Cisco Systems, Inc Com (San Jose, CA, USA) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Fomento Econ Mex UBD (Monterrey, Mexico) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Cemex CPO (Monterrey, Mexico) | −1 | 0 | 0 | −1 | −1 | −1 | 1% | 25% | 60% | 16% | 14% | 3% |
| Alfa A (Monterrey, Mexico) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| America Movil L (Mexico City, Mexico) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Elektra Gpo (Mexico City, Mexico) | 1 | −1 | −1 | 1 | 0 | −1 | 100% | 0% | 0% | 100% | 32% | 0% |
| Cemig ON (Belo Horizonte, MG, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Sid Nacional ON (São Paulo, Brazil) | 0 | −1 | −1 | −1 | −1 | −1 | 2% | 0% | 0% | 0% | 0% | 0% |
| CPFL Energia ON (Campinas, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Embraer ON (São José dos Campos, São Paulo, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 2% |
| Gerdau PN (Porto Alegre, RS, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 4% | 0% | 0% | 0% | 0% |
| Empresas Cmpc S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Empresas Copec S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Enel Americas S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Enel Generacion Chile S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| Buenaventura C1 (San Isidro, Perú) | −1 | −1 | 0 | 0 | −1 | −1 | 0% | 1% | 62% | 16% | 19% | 0% |
| Boeing Co Com (Chicago, IL, USA) | 1 | 1 | 1 | 1 | 1 | 1 | 100% | 100% | 100% | 100% | 100% | 100% |
| CCR SA ON (São Paulo, Brazil) | −1 | −1 | −1 | −1 | −1 | −1 | 0% | 0% | 0% | 0% | 0% | 0% |
| 1 | 0 | −1 | |
|---|---|---|---|
| 1 | 0.75 | 0.25 | 0 |
| 0 | 0 | 0.5 | 0.5 |
| −1 | 0.0344 | 0 | 0.9655 |
| Company | Q3 | Q4 | Q1 | Q3 | Q4 | Q1 |
|---|---|---|---|---|---|---|
| -2019 | -2019 | -2020 | -2019 | -2019 | -2020 | |
| Boeing Co Com (Chicago, IL, USA) | 1 | 1 | 1 | 2.570504494 | 2.233507057 | 1.43531255 |
| Embraer ON (São José dos Campos, São Paulo, Brazil) | −1 | −1 | −1 | 0.898896071 | 0.888065486 | 0.501569282 |
| Exxon Mobil Corp Com (Irving, TX, USA) | −1 | −1 | −1 | 3.686010408 | 3.489752209 | 3.055181343 |
| AT&T Inc Com (Whitacre Tower, Dallas, TX, USA) | −1 | −1 | −1 | 1.240510776 | 1.227069878 | 1.064776635 |
| Chevron Corp Com (San Ramon, CA, USA) | −1 | −1 | −1 | 3.602881718 | 3.581614816 | 3.244899774 |
| Verizon Comm Inc Com (New York City, NY, USA) | −1 | −1 | −1 | 1.808870621 | 1.760786898 | 1.724445429 |
| Amazon.Com, Inc Com (Seattle, Washington, DC, USA) | −1 | −1 | −1 | 7.738432004 | 7.586699588 | 9.474626187 |
| Walmart Inc Com (Bentonville, AR, USA) | −1 | −1 | −1 | 4.591543813 | 4.684393948 | 4.816751716 |
| Unitedhealth Group Inc Com (Minnetonka, MN, USA) | −1 | −1 | −1 | 3.773413778 | 4.012850064 | 3.770474019 |
| Comcast Corp Com A (Philadelphia, PA, USA) | −1 | −1 | −1 | 1.809844627 | 1.747225324 | 1.611141332 |
| Johnson & Johnson Com (New Brunswick, NJ, USA) | −1 | −1 | −1 | 4.972185446 | 5.378295088 | 5.673101051 |
| Intel Corp Com (Santa Clara, CA, USA) | −1 | −1 | −1 | 5.227025032 | 5.872670718 | 4.724158649 |
| Procter & Gamble Co Com (Cincinnati, OH, USA) | −1 | −1 | −1 | 6.063299178 | 6.142447306 | 5.463732498 |
| Pfizer Inc Com (New York, NY 10017, USA) | −1 | −1 | −1 | 2.90145047 | 2.85006229 | 3.019380193 |
| General Motors Company Com (Detroit, MI, USA) | −1 | −1 | −1 | 1.059018867 | 0.970756385 | 0.859555422 |
| Intl Business Machines Corp Com (Armonk, NY, USA) | −1 | −1 | −1 | 2.491670635 | 2.517623184 | 2.371848396 |
| Walt Disney Co Com (Burbank, CA, USA) | −1 | −1 | −1 | 2.971125915 | 2.967232846 | 2.366680775 |
| Cisco Systems, Inc Com (San Jose, CA, USA) | −1 | −1 | −1 | 4.320716755 | 4.433723659 | 4.063902584 |
| Fomento Econ Mex UBD (Monterrey, Mexico) | −1 | −1 | −1 | 11.18952678 | 11.021056 | 7.94217879 |
| Cemex CPO (Monterrey, Mexico) | −1 | −1 | −1 | 1.417641949 | 1.464219447 | 0.997691805 |
| Alfa A (Monterrey, Mexico) | −1 | −1 | −1 | 1.564214225 | 1.582884514 | 1.176101053 |
| America Movil L (Mexico City, Mexico) | −1 | −1 | −1 | 1.563825184 | 1.585347478 | 1.338311027 |
| Elektra Gpo (Mexico City, Mexico) | 1 | 0 | −1 | 1.988999187 | 1.987660035 | 15.21261735 |
| CCR SA ON (São Paulo, Brazil) | −1 | −1 | −1 | 1.898926374 | 1.7351045 | 1.392020105 |
| Cemig ON (Belo Horizonte, MG, Brazil) | −1 | −1 | −1 | 1.316805993 | 1.327685596 | 1.015047328 |
| Sid Nacional ON (São Paulo, Brazil) | −1 | −1 | −1 | 0.66058143 | 0.653956514 | 0.523369495 |
| CPFL Energia ON (Campinas, Brazil) | −1 | −1 | −1 | 2.023567102 | 2.207687855 | 1.804125106 |
| Gerdau PN (Porto Alegre, RS, Brazil) | −1 | −1 | −1 | 1.204286126 | 1.261666239 | 0.954862088 |
| Empresas Cmpc S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | 1.954458606 | 1.904796194 | 1.660744623 |
| Empresas Copec S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | 2.524339455 | 2.45181136 | 2.10348955 |
| Enel Americas S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | 0.842415216 | 0.754965233 | 0.801867622 |
| Enel Generacion Chile S.A. Ord (Santiago, Chile) | −1 | −1 | −1 | 1.108866147 | 1.006618261 | 0.928291146 |
| Buenaventura C1 (San Isidro, Perú) | 0 | −1 | −1 | 1.672448948 | 1.395253837 | 1.054983844 |
| BRF SA ON (Itajaí, Santa Catarina, Brazil) | 1 | −1 | −1 | 1.523005691 | 1.512703362 | 1.138336218 |
| Ambev S/A ON (São Paulo, Brazil) | −1 | −1 | −1 | 9.344636071 | 7.834986815 | 4.914414625 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gavira-Durón, N.; Gutierrez-Vargas, O.; Cruz-Aké, S. Markov Chain K-Means Cluster Models and Their Use for Companies’ Credit Quality and Default Probability Estimation. Mathematics 2021, 9, 879. https://doi.org/10.3390/math9080879
Gavira-Durón N, Gutierrez-Vargas O, Cruz-Aké S. Markov Chain K-Means Cluster Models and Their Use for Companies’ Credit Quality and Default Probability Estimation. Mathematics. 2021; 9(8):879. https://doi.org/10.3390/math9080879
Chicago/Turabian StyleGavira-Durón, Nora, Octavio Gutierrez-Vargas, and Salvador Cruz-Aké. 2021. "Markov Chain K-Means Cluster Models and Their Use for Companies’ Credit Quality and Default Probability Estimation" Mathematics 9, no. 8: 879. https://doi.org/10.3390/math9080879
APA StyleGavira-Durón, N., Gutierrez-Vargas, O., & Cruz-Aké, S. (2021). Markov Chain K-Means Cluster Models and Their Use for Companies’ Credit Quality and Default Probability Estimation. Mathematics, 9(8), 879. https://doi.org/10.3390/math9080879